
Abstract
Against the backdrop of rapidly expanding urban structures, land policies in many countries have been adapted to contain and redirect growth to existing urban structures. However, obstacles remain to measure the effects of policies. In the meantime, geoinformation technologies have given rise to a wide range of approaches to measure and describe urban form. Nevertheless, its application for the assessment of land policy has a high, but not yet fully exploited, potential. It is thus the aim of this research to address and investigate the options of spatial analysis and machine learning in particular to analyse urban form from a land policy perspective. To do so, we develop urban metrics informed by urban planning and land readjustment policies of two countries describing urban form on different spatial levels. We therefore formulate hypotheses on causal relations between policy and form. Based on the metrics, we apply the random forest algorithm to classify the building stock of the region. We then extract the residential areas, those with single-family houses, as this is where the effects of the policy are considered most visible. In a next step, we use random forest to predict the nationality of a building. Through variable importance measures, we identify and discuss urban morphological differences between the two countries and test the hypotheses on effects of land policies. We develop and test the approach for the French-German city-region of Strasbourg using OpenStreetMap data. We identify significant differences in the building coverage ratios, which tend to be higher in Germany. This can be linked to differences in planning regulations. Furthermore, German residential areas appear to be more diverse in urban form. Differences in land readjustment policies have proven to be plausible here, as French policies favour strong actors that develop residential areas more uniformly. In Germany, policies favour fragmented ownership-oriented development of residential areas. The metrics and the applied algorithm for building classification have proven to be robust in terms of data heterogeneity and have shown high levels of accuracy. They could also be successfully used for tracing causal relations.
Introduction
Urban development is facing substantial challenges, as climate and environmental urgencies need to be addressed. Subsequently, much research has been conducted on identifying determinants of urbanisation (Colsaet et al., 2018; Siedentop, 2018) and on developing policies that promote more sustainable modes of urbanisation, such as reduction of land take and densification (Béchet et al., 2017; Gerber et al., 2018). In France and Germany in particular, demands for sustainable development have led to dynamics in land policies, while challenges of adapting complex and intertwined institutional settings that regulate land use have become apparent (Delattre and Napoléone, 2016; Jehling et al., 2018; Kretschmer et al., 2015). Here, institutionalist approaches to analyse these settings are of increasing interest, as they set urban development in the context of public policies and private property rights (Gerber et al., 2018). These approaches could establish first links between the interplay of public and private actors and resulting urban morphologies (Buitelaar and Segeren, 2011; Harbers and Tennekes, 2016). The influence of specific institutional settings on urban morphology of urban form is shown by Harbers and Tennekes (2016) through a comparative qualitative study across national systems. They compare differences in urban form at the building level to draw conclusions about the effects of land policies. They further focus on single-family house residential areas, as they are considered to reflect planning regulations clearer than historic and mixed use urban areas (Tennekes et al., 2015). Also research in planning theory explores the link between rationalities in planning systems and their impact on urban form, i.e. urban design (Hartmann and Jehling, 2019).
Against this backdrop, comparative quantitative approaches appear to be promising in order to gain further insights into the links between urban form and national land policies. Addressing urban form at the building level, where public policies and private interests interact and then analysing the “emergent” urban structures (Barthélemy, 2016), could open up new ways for land policy assessment. However, while quantitative studies exist that address the effects of specific land policies on urban form at the building level (Jehling et al., 2018, 2020; Koomen et al., 2018), their application to national comparisons is challenging due to different underlying official data sets. In particular, due to the different geometric and semantic representation schemes, the buildings are often not comparable. With regard to the comparative analysis of urban form and policy, various strands of research explore causes and effects through modelling approaches (Cortinovis et al., 2019; Li et al., 2013; Verstegen et al., 2016). These studies are, however, most often based on land use information and are therewith above the granular level of buildings and thus the level of urban morphology.
To fill this gap, data-driven approaches that quantitatively express morphological characteristics in urban form through urban metrics at the building level (Vanderhaegen and Canters, 2017) become of interest here. Buildings are like streets, urban blocks and plots the main elements of urban form that structure cities (Oliveira, 2016) and have a long-standing role in analysing urban morphology (Conzen, 1960). Urban metrics serve as the basis for mapping urban forms and functions. On one hand, they allow us to discover new urban typologies, whose individual entities (types) are characterised by certain morphological features by applying clustering techniques (Berghauser Pont et al., 2019; Gil et al., 2012). On the other hand, urban metrics can be used to distinguish between specific urban types by means of supervised classification approaches (Barr et al., 2004; Meinel et al., 2009; Steiniger et al., 2008; Wurm et al., 2016). With the increasing availability of data, machine learning techniques are becoming more widely used to process large areas very effectively. In particular, the random forest algorithm (Breiman, 2001) has proven to be suitable for classifying building footprints by geometrical, topological or spectral features (Droin et al., 2020; Du et al., 2015; Hecht et al., 2019; Lu et al., 2014). It further allows us to measure the variable importance for data exploration and understanding (Strobl et al., 2007; Verikas et al., 2011). However, using classification approaches beyond national systems for comparative research remains challenging. Trained classifiers, even within a country, are only transferable to a limited extent due to regional differences in the building cultures and histories (Hecht et al., 2015; Steiniger et al., 2008). National differences in morphology require training data that covers all areas considered. In addition, differences in the building data used, e.g. geometric detail or minimum mapping unit, can have an impact on the results. Additional context information on the level of building groups (Du et al., 2016; Wu et al., 2018) could be helpful here to develop a robust comparative approach.
It is thus the aim of this research to make use of the capabilities of machine learning to analyse urban form at the building level across national boundaries and explore their feasibility in identifying the effects of land policies through comparison. As argued above, this research will focus on residential areas to reduce the complexity of influential factors. To further account for the high complexity in urban development and the challenge to cope with indeterminacy in social systems (Rohlfing, 2012), we develop a theoretical basis that allows us to draw on casual effects between land policy and the development of residential areas. Taking the example of the Strasbourg city-region, which spans across the French-German border, this research aims at answering the following questions: Which land policies are considered key in developing residential areas in France and Germany and what is their expected effect on urban form? Which national characteristics of urban form become visible by applying a data-driven classification approach? Does the comparison of characteristics allow for tracing back effects of national land policies?
Land policies for developing residential areas in France and Germany
From a land policy perspective, urban form emerges through the interplay of public and private interests (Buitelaar and Segeren, 2011). Policies and their application by public actors through (planning) instruments are constraining or enabling the use of private property. Consequently, actors’ interests and societal norms also influence how the instruments are used (Gerber et al., 2018). In terms of causal inference (Rohlfing, 2012), urban form is considered to be the result of this interplay of interests (Jehling et al., 2020). We consider two instruments to be of particular importance. These are public land use planning, which is considered a key driver of urbanisation (Colsaet et al., 2018; Kretschmer et al., 2015; Siedentop, 2009) and land management, which is the interface between public interests and private property. It is applied to adapt property rights (parcels of land) to planning by acquiring land or land readjustment (Hartmann and Spit, 2015).
Instruments of land use planning
In France, the Plan Local d’Urbanisme (PLU) is key for defining urban form (Herrmann, 2017). Since its introduction in 2000, it is applied on municipal and inter-municipal level to steer urbanisation. Municipalities that are part of a communautés urbaines or métropoles mutually develop a PLU. The PLU sets the legal basis for granting building permits (Geppert, 2014). Its regulation is directly binding for public and private property owners. In accordance with higher tier planning, the plan divides the municipal area into zones of different land uses, which are defined by the building code (Code de l’Urbanisme, 2020). For current and planned urbanization, it sets the land use (préciser l’affectation des sols) and determines the urban form through regulations such as building coverage or limitations for buildable land on a plot (e.g. l’implantation du bâti and coefficient d’emprise au sols) (Direction générale des Finances publiques and Direction générale des Collectivités locales, 2017.
In Germany, municipalities are required to deploy land use plans. Land use planning consists of a two-tier system, which was established in the 1960s (Söfker, 2018). A preliminary land use plan for the whole municipal area sets the current and planned land use (Flächennutzungsplan). It is also applied for inter-municipal planning in urban agglomerations. With a second-tier local land use plan (Bebauungsplan), municipalities set detailed regulations. This tier is then binding for land owners and relevant for building permissions (Jehling et al., 2020). The local land use plan defines the use and the building coverage (Art und Maß der baulichen Nutzung) and designated buildable land. This is done based on the national building regulation (Baunutzungsverordnung), which defines land use categories with respective limits for the building coverage ratio (Grundflächenzahl). Within this limit, municipalities are free to redefine the building coverage ratio.
In comparison, land use planning instruments are applied by municipalities, who decide on urban form through zoning and standards for building coverage. As we look at a functional interlinked cross-border region with comparable socio-economic standards, we hypothesise that urban form subsequently does not show significant differences between Germany and France.
Instruments of land management
In France, residential development is dominated by public or private developers (Oxley et al., 2009). The most common instruments are joined development zones (zones d’aménagement collective, ZAC), which is a specific form of public-private partnership for land management. The public actor himself or – by concession – a further actor conducts the development. This includes the relevant studies, the construction works, the acquiring and reselling of land, and the public infrastructure. The parcellation of land (lotification) is a central part of the process (Olei, 2020; Oxley et al., 2009). The urban form is thus largely seen as a result of a negotiation between municipality and developer (lotissuer) (Herrmann, 2017). Instruments of owner-based land readjustment exist as well (association fonciere urbaine) but only play a minor role (Kerger, 2017). Owner-based piecemeal and small-scale development happens to a limited extent in rural and suburban contexts (Guelton, 2018).
In Germany, land management through the formal instrument of land readjustment (Umlegung) is the most prominent (Hartmann and Spit, 2015). This instrument allows for co-operation between land owners and the municipality in adapting plots to a planned development. The key characteristic is that the procedure retains the existing ownership structure and that municipalities are not required to buy and resell land. All plots of land of an area are included in the process, rearranged and then redistributed after land is taken for public needs (Erbguth and Wagner, 2005; Markstein, 2004). Thus, residential areas are developed by a heterogeneous group of actors. In practice, municipalities and private actors also cooperate, using an instrument for public-private partnership (Städtebaulicher Vertrag) through which land is acquired, subdivided and resold. In some cases municipalities also opt to develop land themselves (Erbguth and Wagner, 2005; Hartmann and Spit, 2015).
In comparison, practices of land management show a clear difference. We hypothesise that due to the resulting more heterogeneous structure of property rights during the development, also the urban form of residential areas is more heterogeneous in Germany than in France.
Method and data
The method consists of three main steps (Figure 1). The first step is to define and compute urban metrics for quantifying morphological characteristics based on pre-processed input data. Second, we identify residential single-family housing (SFH) areas by classifying buildings using a supervised learning approach, particularly the random forest algorithm. Third, random forest is used as an analytical tool to analyse the building stock within residential areas and to compare French and German urban form.
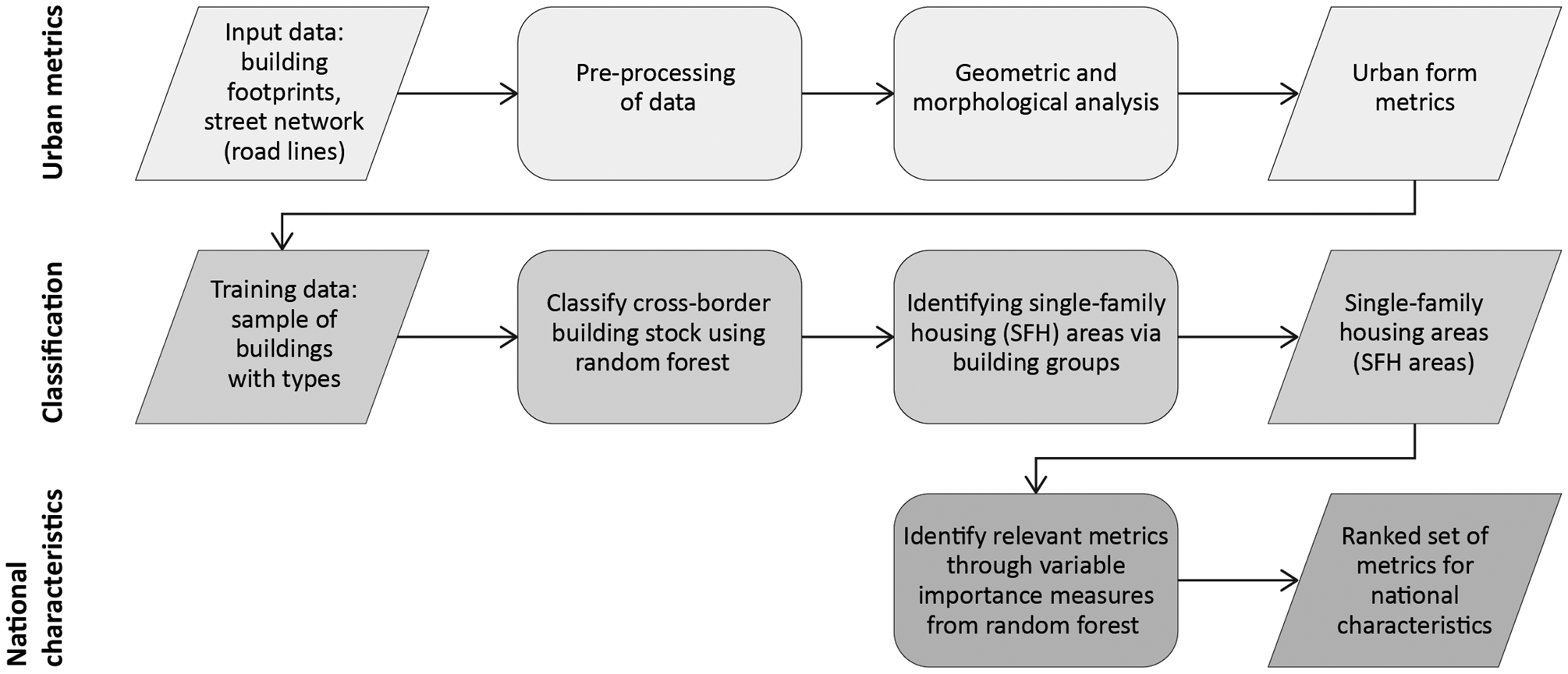
Workflow implementing the method (steps in grey scale).
Urban metrics
To discuss the assumed effects of land use policies and planning on urban form, i.e. “the physical components of urban space” (Fleischmann et al., 2020: 3), we require morphological information on different spatial and contextual levels. Vanderhaegen and Canters (2017) describe patch-based, profile-based and building-based metrics for built-up areas. While the patch-based metrics are important for describing the urban context, their comparative application across national systems is often hampered by different mapping standards. To be able to represent the urban context, grouping of adjacent buildings through graph-based algorithms has proven to be helpful (Zhang et al., 2012). Based on this proximity relationship between buildings, a minimal spanning tree (MST) is generated that spatially groups neighbouring buildings (Caruso et al., 2017; Cetinkaya et al., 2015; Wu et al., 2018). Following Caruso et al. (2017), the centroids are retrieved from building polygons and then used to generate the MST. Constraints for generating building groups are streets so that each entity represents an urban block. Furthermore, a cut-off distance of 70 m between buildings is set. Finally, geometrical and topological properties are derived for different spatial levels (Figure 2).
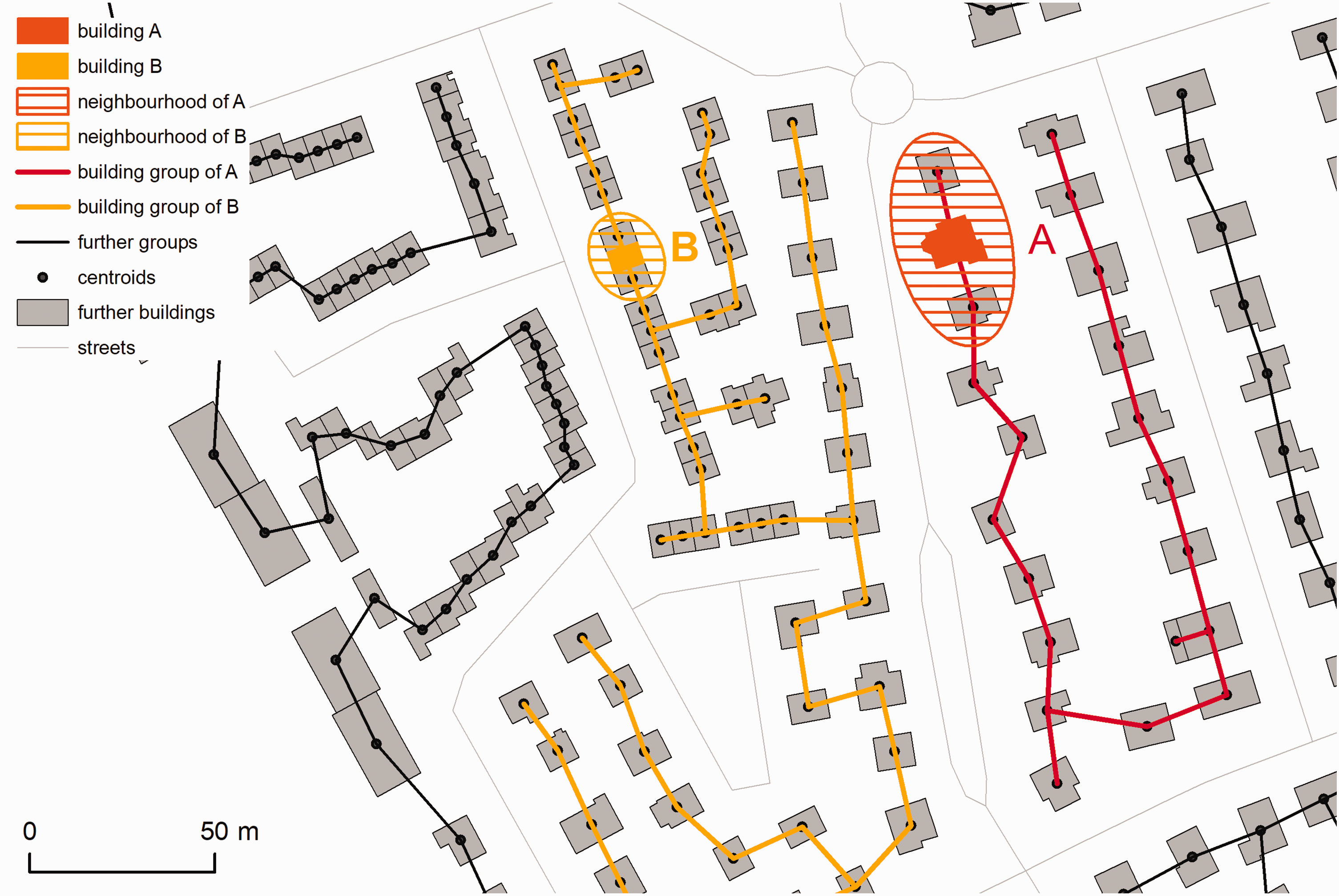
Urban form metrics on building, neighbourhood and group levels. The example highlights a detached house (building A) and a terraced house (building B). Neighbourhood is defined by first order direct neighbourhood of detached (A) or adjacent buildings (B) within a MST. All buildings within a MST form a building group. (source: authors' work; data © OSM contributors)
Inspired by further approaches (Hecht et al., 2015; Steiniger et al., 2008; Vanderhaegen and Canters, 2017), a number of characteristics are defined, which can relate to different spatial levels, particularly individual buildings, the (immediate) neighbourhood and the building groups (see Figure 2). The resulting urban metrics are listed in Table 1, which also shows how they express the land policy perspective (chapter 2). The variables for building style on neighbourhood level and the metrics on building group level (range and medium values) are considered helpful to cover structural heterogeneity.
Urban metrics as input for identifying single-family housing (SFH) areas and analysing national characteristics of urban form.
Identifying single-family housing areas
The aim of this step is to derive residential areas with single-family housing (SFH areas). The starting point for this is the classification of the building footprints that allows for identifying residential buildings, i.e. single-family houses. To realize this, we apply a supervised classification approach, particularly the random forest (RF) algorithm. RF is an ensemble classifier developed by Breiman (2001). In the context of building footprint classification, RF outperforms other machine learning classifiers in terms of the generalization ability and computational efficiency (see Hecht, 2014). Based on a given training sample, a large of number of individual trees (so-called random forest) are constructed by a random bootstrap selection of the training data. We use the RF implementation in KNIME Analytics Platform version 3.5.2 (Berthold et al., 2008; Fillbrunn et al., 2017), which uses a C4.5 algorithm to generate decision trees capable of using numerical and nominal attributes (Wu et al., 2008).
Supervised building classification requires a training data set of buildings with known type information. In order to collect this training data for the French–German region, a set of building groups is selected across the region (Figure S1, supplementary material). According to a defined building typology (Table S2, supplementary material), we assign each sample building polygon to a type by visual interpretation of aerial photographs and street views. The used typology differentiates between detached, semi-detached and terraced houses and further urban structures (Hecht et al., 2015; Jehling et al., 2018). In the process, the typology is adapted to encompass the variety of buildings in both countries.
In a next step, a random forest model is trained and then applied to the total building stock (number of trees is 500, split criterion is information gain ratio (Wu et al., 2008)). Metrics on all spatial levels are applied as variables (refer to Table 1). A validation is carried out through 10-fold spatial block cross-validation (Valavi et al., 2019) to minimize spatial autocorrelation (Brenning, 2012), while ensuring that the folds contain all types of buildings. After validation, the regional building stock is then classified by applying a RF model using the entire training data set. All building groups (see ‘Urban metrics’ section) with a predominant share of single-family houses, which we set as a share of over 90% by number, are then considered to represent residential areas, i.e. single-family housing areas (SFH areas).
Analysing national characteristics in urban form
To analyse the characteristics of urban form of the obtained SFH areas, their structural heterogeneity is of interest. We add Shannon's Evenness Index to the set of urban metrics (Table 1). The index has its origin in ecology but is often used for spatial pattern analysis for quantifying landscape structures (McGarigal and Marks, 1995; Martellozzo and Clarke, 2011). It expresses the observed level of diversity. Maximum diversity is achieved when all types are evenly distributed.
Based on the extended set of metrics, we again use the capabilities of the RF algorithm. We define the nationality as a binary classification problem with target classes representing nationality and train a RF model using urban metrics on group level (Table 1) to predict whether a building is German or French. Through the variable importance measure provided by the RF algorithm itself, we identify those variables that are most relevant for explaining differences between the German and French part of the region. We use a frequency-based measure (number of times a variable is used to split a tree) (Strobl et al., 2007). For the validation of the RF model, we perform a 10-fold spatial cross-validation using blocks. We use Welch’s t-test to determine whether the obtained mean values of the variables differ significantly between the two countries.
For validation, the classification results are spatially visualised to assess the model with regard to spatial patterns or variation of accuracy. Based on the causal relations assumed in ‘Land policies for developing residential areas in France and Germany’ section, we then discuss effects between land policy and urban form. To do so, we interpret the variables according to their importance.
Study area, data and pre-processing
We test the approach for the French–German city-region of Strasbourg. The cross-border region offers the opportunity to analyse urban form across national boundaries, while limiting topographic influences due to its location in the plains of the upper Rhine valley. To cover a wide range of urban densities and patterns within a functional region, a delimitation of 40 minutes car travel time isochrones around the city centre of Strasbourg is applied.
The data for the regional building stock and the street network (Table S1) are retrieved using the OpenStreetMap Overpass API (Padgham et al., 2017). While the data have the advantage of being available and freely accessible beyond national borders, data quality aspects need to be considered. Studies have shown that the data quality of OSM features such as streets (Barrington-Leigh and Millard-Ball, 2017) and buildings (Fan et al., 2014) is very good for cities but may be different in rural areas in terms of completeness (Hecht et al., 2013). Since we are investigating a large region with urban and rural areas, some geometrical details in OSM may be missing in some areas. It is therefore particularly important to take the aspect of heterogeneous modelling of the buildings into account by applying a pre-processing step. For this purpose, minor individual structures of ≤20 sqm, such as small building annexes, are eliminated. Separately represented building parts of ≤40 sqm are then merged with the polygon of the main building.
Results
In the following, we present the results of the classification of the regional building stock and the identification of single-family housing (SFH) areas as well as the results of the comparative analysis of residential urban form in France and Germany.
Identification of the single-family housing areas
Building footprint classification
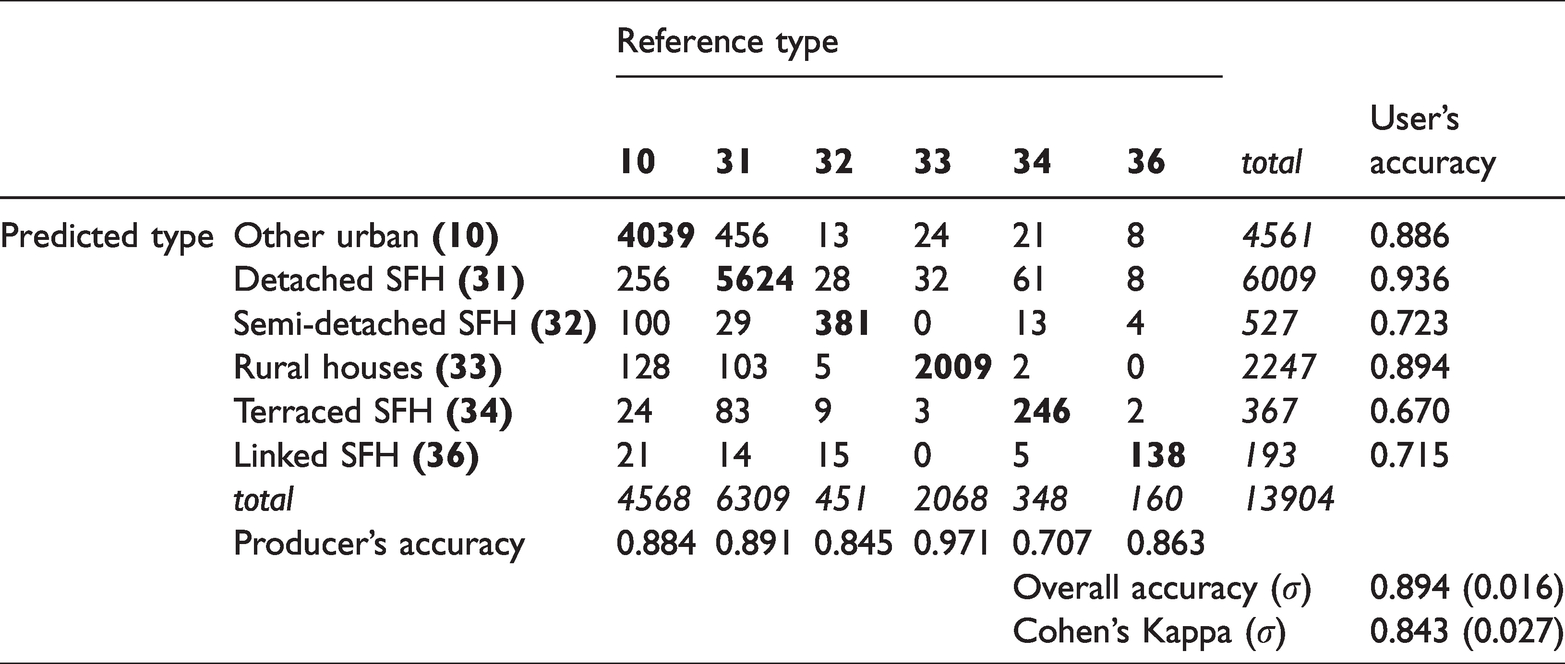
For describing the classification accuracy, we use the confusion matrix with producer’s and user’s accuracy, as well as total overall accuracy and Cohen’s kappa coefficient. Table 2 shows high accuracies for the classes: Rural houses (33) and Detached SFH (31) and only minor classification errors for the classes Semi-detached SFH (32), Terraced SFH (34) and Linked SFH (36). The overall accuracy of 0.894 with a standard deviation (σ) of 0.016 and a Cohen’s Kappa of 0.843 (σ = 0.027) shows the high quality of the model. The class-specific assessment also shows high values for producer’s and user’s accuracy, keeping in mind that we reduce spatial autocorrelation through block cross-validation. We conclude that this classification model for identifying residential buildings is suitable as a basis for further comparative analysis.
Confusion matrix and accuracy measures of building classification.
Single-family housing areas for cross-border analysis
The classified building stock is used to determine the residential areas (SFH areas) by analysing the class composition for each building group (see ‘Identifying single-family housing areas’ section). Figure S2 gives examples of these derived SFH areas in France and Germany. Statistics for the residential building stock and residential SFH areas for the entire region (Table S3) reveal that the proportions do not show large differences. Detached SFH (31) are the most frequently occurring class in both France (41%) and Germany (45%), followed by other urban buildings (10) and rural housing (33). While Germany has a higher proportion of semi-detached SFH (32) with a share of 3% compared to France with 1%, terraced SFH are more common in France.
French and German characteristics
The RF model predicting the national context of the SFH areas has the following results. The overall accuracy of 0.837 can be considered good, while a Cohen’s kappa coefficient of 0.583 shows a moderate agreement. Figure 3 gives insights into the spatial variation of the accuracy of the model, indicating if a building was predicted correctly as German or French. The block-based mapping of overall accuracy shows differences between the countries France and Germany suggesting that German buildings tend to be more often predicted as French buildings than vice versa (see confusion matrix, Table S4). Differences within countries are less clearly noticeable, but overall accuracy tends to be higher in rural areas with smaller residential areas (e.g. in the north-west) and lower in urban areas (centre). Steeper terrain in the German south-east of the region probably affects the accuracy of the model.
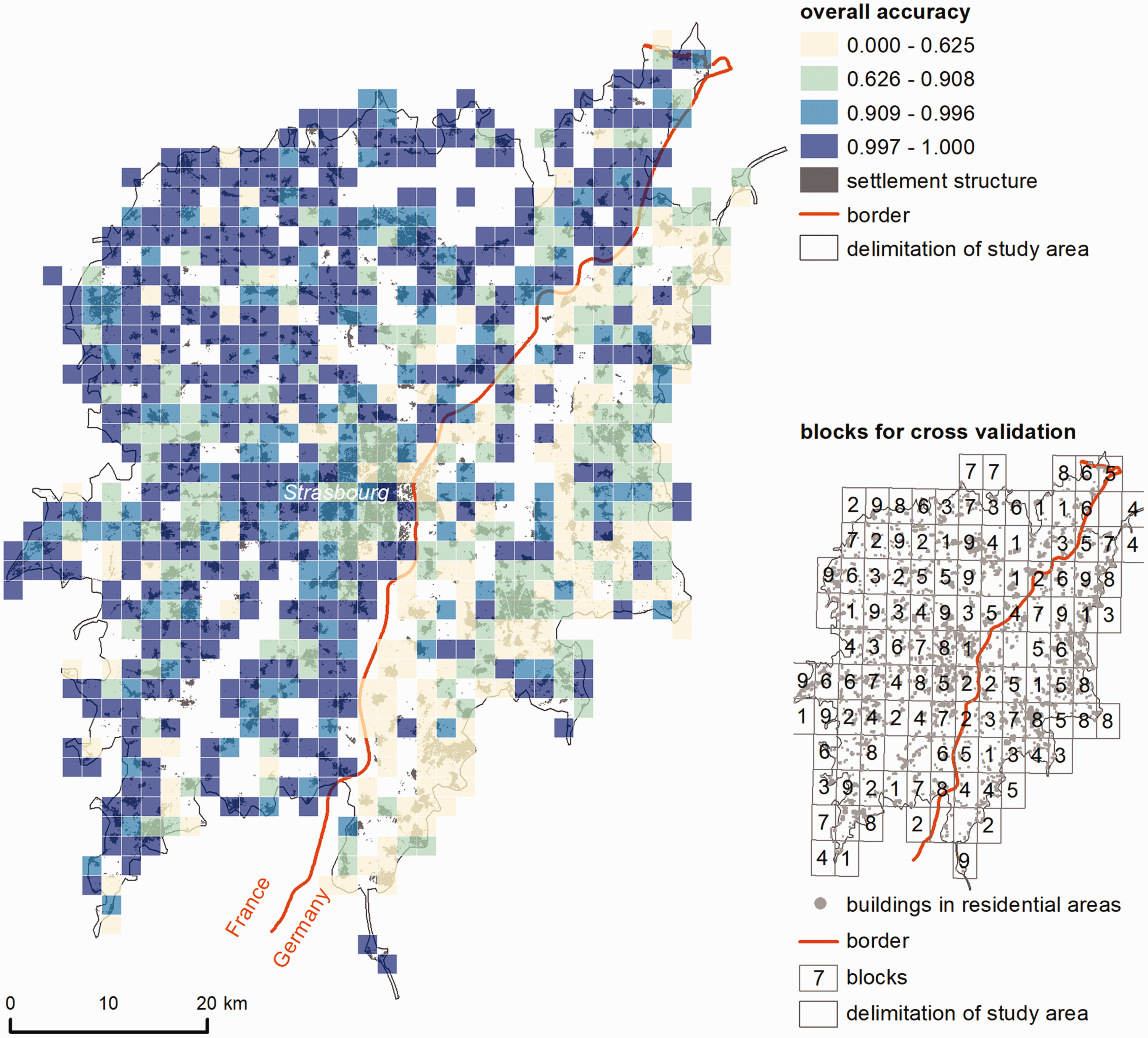
Overall accuracy of predicted national context of buildings within residential SFH areas in the Strasbourg region (source: authors’ work; data © OSM contributors).
Figure 4 gives the distribution of the variables sorted by their importance for the classification by the RF model (see Table S5). Only variables on building group level (m_ and r_ suffixes as well as the evenness index) are considered (Table S4 for the ranking of all variables). The medium building footprint size (m_footprint) and medium building coverage ratio (m_build_coverage) are the most important for the model. The distribution of the two variables shows a higher interquartile range and median for the residential single-family houses in Germany. The third most important variable is r_separation, which gives the range of how far buildings are separated within a building group. The range of the building footprint size within the building groups (r_footprint) is higher in Germany. Evenness, i.e. diversity in building types within groups, is of a low importance. While the median values are close to each other here, German building groups show a higher interquartile range compared to the French ones. Applying Welch's t-tests shows that the distributions of the standardized scores of all variables differ significantly (each with p < 0.01).
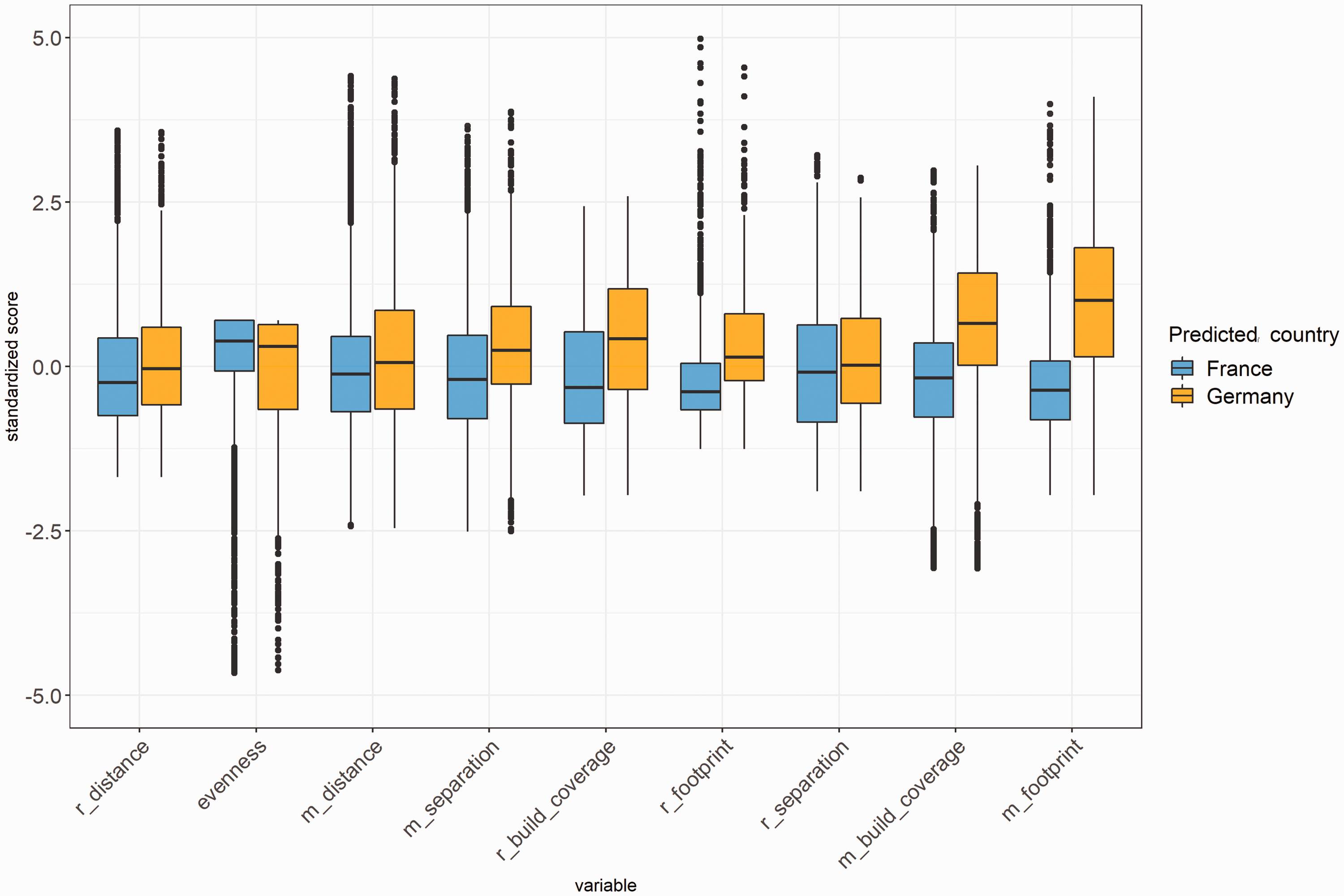
Distribution of standardized scores of variables that explain national differences, ranked by importance (from low to high) (source: authors’ work).
Discussion
Tracing effects of land policies
The analytical results and tests showed that the urban form of SFH areas in the German and French parts reveal the national context. However, the moderate values of the validation results also made clear that other effects on urban form need to be taken into account. Visualization of accuracies showed that location within the region could have an impact. Here, additional metrics describing the spatial location of the SFH areas within the region could be helpful to control for rural and urban differences in the building structure (Jehling et al., 2018), such as different densities.
Based on assumed relations between national land policies and urban form, the results allow for a further interpretation. With regard to the effects of land use planning, we hypothesised that a similar institutional setting and regulatory framework for zoning lead to similarities in urban form. However, differences in urban form become apparent. The mean building footprint size (m_footprint) and the mean building coverage ratio (m_build_coverage) of single-family houses are substantially higher in Germany. The larger interquartile ranges of the two measures for Germany also suggest a higher variability between SFH areas in Germany compared to France. German building regulation, thus, seems to give municipalities more range in decisions on urban form, while also requiring higher densities. French municipalities, in contrast, appear to apply stricter regulations, but also plan for lower urban densities.
To further scrutinize these differences, more knowledge on the agency of municipalities in applying the instrument is required. A possible path for further analysis could be the role of regional planning in Germany for the high variability that requires municipalities to plan in accordance with assigned functional roles. In France, the role of inter-municipal competition in the context of a private developer-driven residential market (Herrmann, 2017) asks for further research on the lower densities.
For the effects of the instrument of land management, we hypothesised that according to differences in the instruments for land management and the subsequent more heterogeneous structure of actors, the resulting urban form within SFH areas is more heterogeneous in Germany than in France. The range of distances between buildings (r_separation) indicates that the inner structure of French residential areas is slightly more homogeneous (lower median) than German residential areas. In terms of the range, building footprint sizes and building coverage, French residential areas are clearly more homogeneous. The diversity of building types (evenness) played only a minor role, although German residential areas are characterised by a higher diversity. This suggests that practices of land management in France and Germany (Guelton, 2018; Hartmann and Spit, 2015) lead to different outcomes in urban form. However, more empirical knowledge on the application of these practices is required to better sustain this argument and establish causal relations.
Reflections on the approach
We made use of OpenStreetMap data, as it is a highly detailed and cross-border data set beyond country-specific mapping conventions of national mapping and cadastral agencies. Moreover, these data are available free of charge worldwide. The data may have limitations, e.g. incompleteness of buildings in rural areas (Hecht et al., 2013), but recent studies show that data accuracy has improved over time (Brovelli and Zamboni, 2018). It is the nature of OpenStreetMap that no data model is predefined and no strict mapping rules (only recommendations) are given by the community. Accordingly, buildings should be mapped as individual buildings, the outline of building blocks or other complex arrangements of properties. However, this freedom means that the building representation is not the same everywhere, depending on which form of modelling the contributor prefers, and can even vary within a city or region (Hecht et al., 2013). While we considered this in the selection of metrics, the sample data for this particular cross-border region showed no substantial inconsistencies in building representation.
Regarding the use of a data-driven approach for building classification (Hecht et al., 2019; Jehling et al., 2018), we could demonstrate its successful application to enrich comparative research on land use policies. We could show that it proved to be valuable for discussing assumed effects of land policies on urban form (Tennekes et al., 2015; Gerber et al., 2018). The applied supervised machine learning approach requires a sufficiently large amount of training data; however, these data can be collected with little manual effort. The application for identifying German and French characteristics allowed us to identify the most relevant variables. The results encourage us to further test the approach in other contexts for which no explicit boundaries are given, such as for distinguishing between areas of similar planning cultures or topographically caused influences on urban form.
After testing the approach for a cross-border region, the options for transferability of our approach to cover national levels, such as France and Germany as a whole, should be seen with caution. While the focus on residential areas is meant to limit influencing factors beyond land policies, the variety of urban form and policies within a country and across different landscapes might be still too high. Transferring the approach to other cross-border regions in Europe appears more promising, as the chosen input data guarantees good applicability.
With our approach, we are able to confirm hypotheses about a specific urban form, which we have derived from a priori knowledge on available instruments of land policies. However, it is not a proof of causality, since we only consider the outcome (urban form) and not the processes of the policy instruments in a model, as for example Verstegen et al. (2016) show. Taken the complexity of the application of instruments and the challenges to infer causal relations, we argue that further research should address actors’ agency and interests empirically (Jehling et al., 2019). This should also be sustained by a more elaborated theoretical framework (Rohlfing, 2012).
Conclusion and outlook
We presented a data-driven approach to identify residential areas as a basis for analysing effects of national land policies on urban form and tested it for the French–German city-region of Strasbourg. The approach enables a classification of a cross-border building stock using OpenStreetMap data according to a predefined typology, which serves as a consistent basis for comparative analysis. We take a land policy perspective to establish a theoretical basis that allows us to develop hypotheses on the causal links between policy and urban form. We identified instruments of land use planning and land management as being key for developing residential areas. Due to their characteristics, we expected that land use planning does not lead to significant differences between residential areas in Germany and France. Land management, however, should lead to residential form that is more heterogeneous in Germany than in France. To test these links, we analysed urban form characteristics using machine learning (random forest) for classification. First, we were able to satisfactorily identify residential single-family housing areas across national borders. Second, we identified significant differences in urban form between the two countries. The mean building footprint size as well as the mean building coverage ratio showed the highest importance in explaining these. A comparison of the statistical distributions of the variables thus contradicts our hypothesis on land use planning and supports the hypothesis on land management, that residential form is more heterogeneous in Germany compared to France. While this allowed for developing a consistent argumentation from land policy to urban form, the results also revealed the need to further combine quantitative urban analytics and qualitative empirical research on instruments to establish more robust causal relations.
Supplemental Material
sj-pdf-1-epb-10.1177_2399808321995818 - Supplemental material for Do land policies make a difference? A data-driven approach to trace effects on urban form in France and Germany
Supplemental material, sj-pdf-1-epb-10.1177_2399808321995818 for Do land policies make a difference? A data-driven approach to trace effects on urban form in France and Germany by Mathias Jehling and Robert Hecht in EPB: Urban Analytics and City Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.