
Abstract
To address policy challenges such as climate change or pandemics effectively, policymakers require insights into the views of the general public. However, traditional large-scale quantitative methods like surveys and aggregated social media analytics lack nuance, while qualitative approaches such as interviews are labor intensive and thus limited to small samples. We discuss how artificial intelligence tools known as large language models (LLMs) could be leveraged to surface the detailed views of large numbers of citizens on policy issues. In particular, we showcase an LLM-supported method designed to provide both quantitative and qualitative insights from large samples of respondents who provide free-text responses to open-ended questions. We propose that such approaches could help policymakers efficiently integrate citizens’ input into their decision-making processes and give them timely, nuanced insights that complement those produced by established methods of obtaining large-scale public input.
Understanding citizens’ perspectives on societal challenges, such as climate change, artificial intelligence (AI), and pandemics, is crucial for the successful design, implementation, and adoption of public policies.1–6 In the COVID-19 pandemic, for instance, a better understanding of citizens’ views and needs along with more effective communication could have strengthened public trust in such institutions as governments and health organizations.7–11 This enhanced trust, in turn, might have attenuated the impact of misinformation and thereby led to higher vaccination rates and wider adoption of preventive measures.9,10,12 In general, awareness of citizens’ perspectives on policy challenges and the measures proposed to address them can help policymakers align their decisions with public needs and expectations,9–11 potentially facilitating more timely and appropriate responses. Policymakers and the public alike could thus benefit from having methods to (a) elicit citizens’ perspectives on a large scale and (b) analyze these perspectives quickly and with sufficient nuance.
Although quantitative methods such as surveys and polls13,14 can collect opinions from large samples, they use closed-form questions—ones that have preset answers—which require pollsters to have a good idea in advance of likely responses. 15 And more open-ended approaches that analyze large collections of text (such as social media postings or text messages) to identify broad themes and patterns16,17 can likewise fail to capture nuance. Conversely, nuanced qualitative approaches18–22 that provide more in-depth insights through open-ended questions and conversations (for example, interviews) allow for detailed and varied responses and have the potential to uncover new and unexpected insights. However, those approaches are labor intensive, which limits their use to small samples of people or would require considerable time and resources when applied to large samples.
Today’s digital society offers new opportunities for simplifying and accelerating the collection of citizens’ perspectives at scale23–26 because recently emerged AI tools—particularly large language models (LLMs)—can quickly analyze vast numbers of open-ended responses from citizens and capture nuance. In the sidebar, “A Brief History: LLMs as Research Tools in the Behavioral, Cognitive, and Social Sciences,” we describe some key technological advances that gave rise to and underlie LLMs, and we note that LLMs have been applied to such policy-related tasks as gleaning citizen sentiments from online social postings and forums. Below, we propose that LLM-based approaches can be more broadly applied to other text sources relevant to policymaking, such as transcripts of brainstorming sessions, 27,28 and that LLMs could potentially provide valuable, fresh insights into how citizens perceive policy issues. However, this proposal raises important questions: How can such policy perspectives be elicited, and what could policymakers expect to learn from those responses? To answer those questions and highlight the potential of using LLM-driven methods29–32 to enhance policymaking, we describe an approach we applied in a recent study.33,34 We also discuss how such approaches might complement established methods of eliciting the public’s opinions and help policymakers to efficiently integrate citizens’ insights into their decision-making processes.
An Approach to Surfacing Citizens’ Policy Perspectives at Scale
Our study showcasing the potential of an LLM-based approach featured a brainstorming task that elicited citizens’ ideas on policy issues.33,34 In the study, conducted online, 300 U.K. citizens (quota matched to reflect the U.K.’s demographics in age, gender, and ethnicity) were asked to generate up to five ideas for each of five policy problems derived from the United Nations’ sustainable development goals 35 —a set of objectives for meeting global challenges. For example, they were asked, “How could we improve vaccination rates in rural environments?” and “How could we reduce stress levels in our society?” They had three minutes to brainstorm per problem. Below, we focus on the vaccination responses; for details on the responses to the other questions, see Reference 33.
The task aimed to capture respondents’ first thoughts—that is, those that were immediately accessible and relevant when they brought the issue to mind. Respondents generated ideas such as “free bus to vaccination center” and “reminding people of the negative effects if not taken.” We then used an LLM to clean out ambiguity and extract specific elements—units of information we refer to as concepts—from their responses, such as “transport subsidy” or “vaccination center.” See Figure 1 for a schematic depiction of how the LLM extracted concepts from the respondents’ answers.

Example of an LLM method for surfacing citizens’ policy perspectives, Step 1
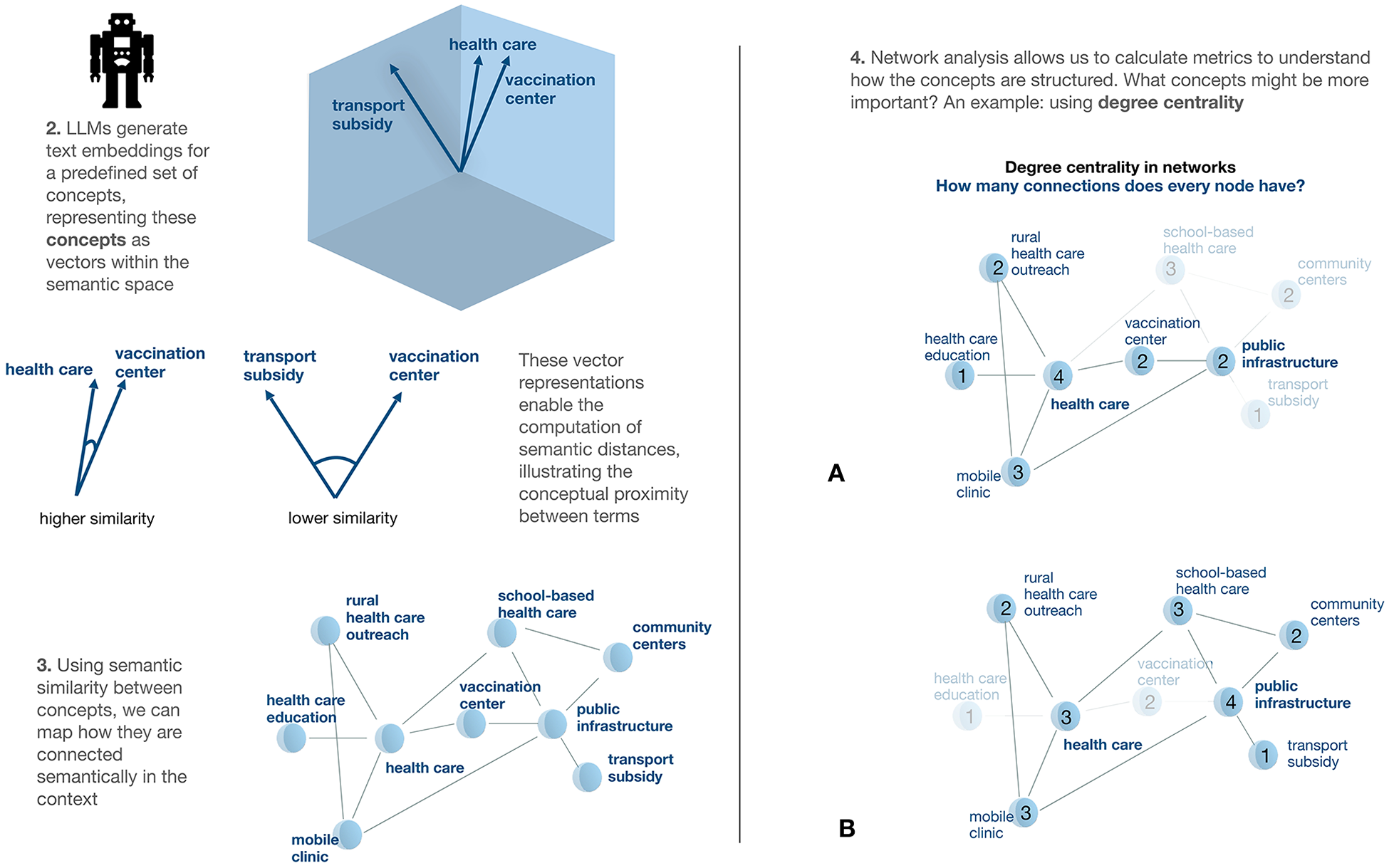
Example of an LLM method for surfacing citizens’ policy perspectives, Steps 2–4
LLMs can reveal which unique concepts are mentioned by a group of respondents as a whole or by subgroups (such as younger versus older citizens). Extraction of these concepts makes it possible to apply other analyses that provide deeper insights into the importance of the mentioned concepts. For instance, network analyses can clarify how the concepts link to one another and indicate whether and to what extent the ideas of different subgroups overlap. For example, do younger and older adults think of similar things when asked about vaccination? What about rural and urban citizens?
In particular, to obtain information that goes beyond concept frequencies, investigators can use the LLMs’ outputs to construct data representations known as semantic networks 36 that depict how closely the meanings of multiple concepts are related to one another (see the left panel of Figure 2). Semantic networks have been applied to study cognitive processes, 36 casting light on such processes as how people recall information37–39 and connect concepts,25,40,41 revealing how individual differences might affect these processes. 42 In the policy realm, one way that the importance of a given concept to a given group of people can be assessed is by measuring its centrality, or connectedness to other concepts. For example, one can examine the degree centrality of a concept by counting the number of connections between it and others.
The right panel of Figure 2 illustrates the kind of centrality data that might appear in a survey like ours. After participants have been asked about ways to increase vaccination rates in rural environments, a degree centrality measure might indicate that the concept “health care” was more central to the thinking of one subgroup (A) when it pondered the vaccination problem whereas the concept “public infrastructure” was more central to Subgroup B.
Going beyond frequency measures to examine centrality also provides finer-grained insights, such as revealing when concepts that do not necessarily receive the most mentions can nonetheless be implicitly important to respondents. The strength of the influence of such concepts is somewhat akin to that of a person on social media who is not the most popular or visible individual but has significant influence because of interacting with many different groups. 43 Measures of centrality could provide insights or inform hypotheses about which concepts most influence the perspectives of different groups of citizens on policy issues and thus which concepts might need to be targeted to produce the most effective policy measures or communication campaigns for those different groups.
For example, in our study, we compared the answers of rural and urban subgroups to the question, “How could we increase vaccination rates in rural environments?” (see Figure 3). Although the rural citizens explicitly mentioned the concepts “vaccination” and “vaccination education” more frequently than the urban citizens did, it was the urban citizens for whom those concepts were most central (that is, those concepts were connected to a larger number of other concepts within that subgroup’s ideas on the question). Conversely, the concepts “education” and “public awareness” were mentioned more frequently by urban respondents but were more central to the ideas of rural respondents.
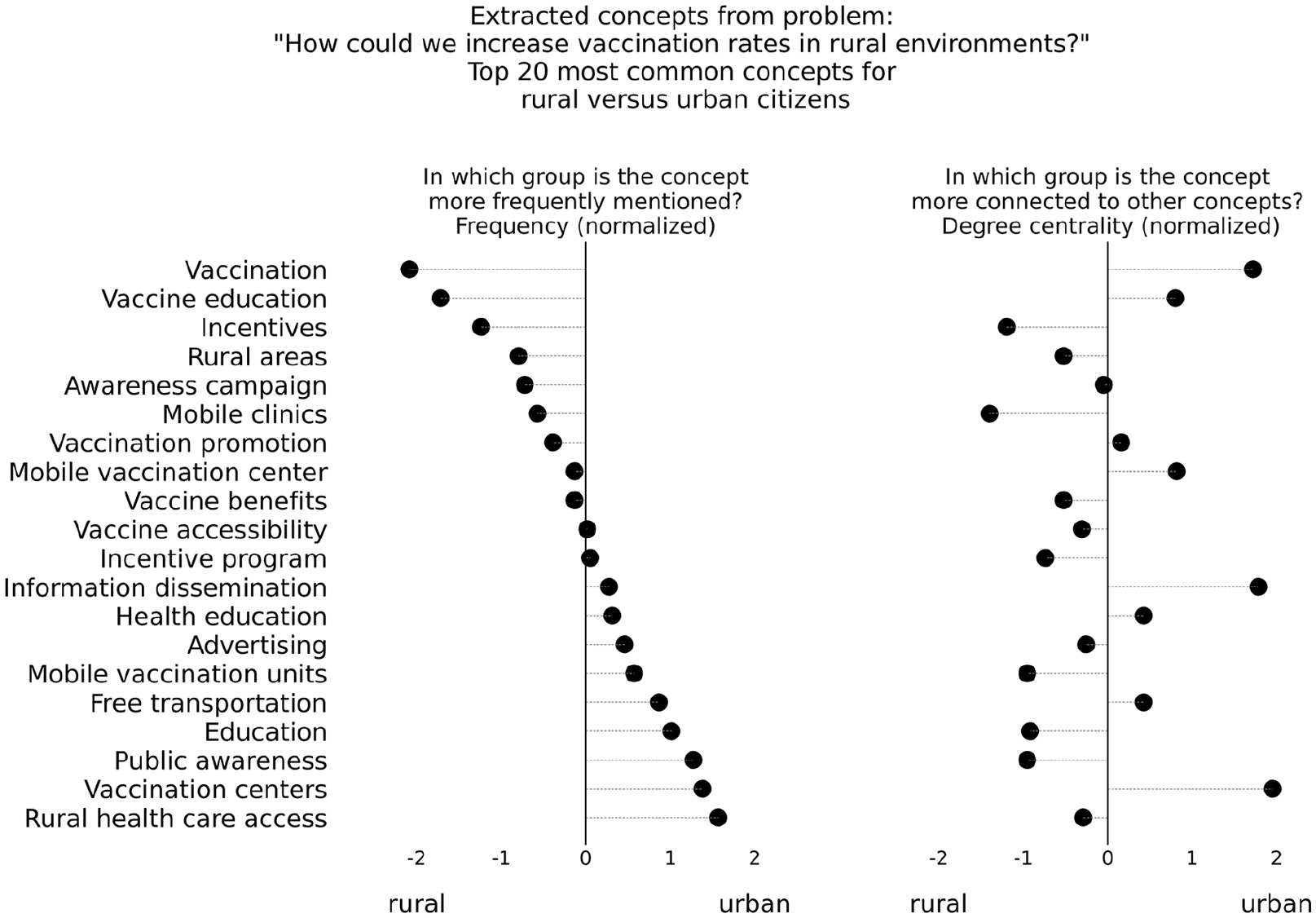
How measures of centrality add insights not provided by frequency measures alone
The use of network analysis can be extended in various ways and to various problems. It can, for instance, be applied to different subsets of a larger population (say, to subpopulations divided by age, gender, or political leaning). Or, depending on the goal, other metrics can be applied.36,44,45 For example, the overall distance between concepts in the network (the average path length) reveals how interconnected ideas are or how easily relationships between distant concepts can be bridged. Similarly, if concepts tend to cluster (a feature reflected by a metric called a clustering coefficient), this pattern indicates the presence of overarching topics that encompass related concepts in meaning. For example, concepts such as “mandatory school immunizations,” “workplace vaccine mandates,” and “international travel vaccination requirements” could appear close together under a broader heading that might be called vaccination requirements and mandates. (See References 46 and 47 for examples of how the findings of network analyses have provided insights into how to change people’s beliefs about genetically modified foods and the importance of childhood vaccines.)
Implications for Policymakers
Citizens’ perspectives may not always suggest ready-to-implement solutions, but they can reveal new and viable paths for addressing societal challenges.3,48–52 In our study, respondents did not necessarily directly say use schools as vaccination centers to improve vaccination rates in rural areas, but the idea of using existing public infrastructure did emerge from our analysis of their perceptions of the problem. Although the insights we derived from this approach do not conclusively provide solutions, they highlight potentially promising and sometimes surprising avenues for further quantitative and qualitative investigations.
The promise is evident in the finding that the concept “vaccination education” was more central to the thinking of urban citizens, whereas “education” and “public awareness” were more central to the thinking of rural citizens. This difference could indicate differing interpretations of the concept “education” in the context of vaccination. If so, understanding of this nuance could help guide the development of tailored communication strategies that resonate more effectively with each group. For instance, a broad health campaign in rural areas might focus on general health education, highlighting the importance of preventive care, regular check-ups, nutrition, and hygiene. Vaccinations could be framed as part of maintaining overall health, rather than treated as an isolated issue. Such insights may help policymakers to not only use traditional methods for understanding citizens’ views more effectively (say, by helping the policymakers identify new closed-form survey items that directly capture such perspectives) but also to develop more effective data collection methods and better informed public health interventions.
Going forward, the approach could be applied to a variety of text inputs beyond those explored here, including interviews, focus groups, social media posts, forum discussions, and messaging applications—potentially providing a valuable new tool for computational social science. 53 It could also complement established citizen participation methods—for example, enriching citizen panels 2,22,54,55 with prepanel brainstorming and near-live processing of session transcripts to streamline discussions and the generation of useful insights.
LLM-based approaches like the one presented here offer other advantages as well. One is their potential to be integrated into existing policymaking processes, significantly accelerating the cycle of consultation, analysis, and policy design. In contrast to established qualitative and quantitative approaches, they yield timely yet nuanced and granular insights at scale. For instance, consider one way policymakers might have revised the approach the Dutch government took when designing its COVID-19 exit strategy. 9 Using a closed-form survey, it solicited input on eight proposals for the relaxation of lockdown measures from 30,000 citizens. Instead, in advance of generating the survey, they might have elicited brainstorming proposals from the public, along with their views on the pros and cons. These insights could then have identified additional proposals and questions to be included in the survey and could have potentially led to the adoption of a different, not yet considered proposal.
Furthermore, LLMs provide powerful out-of-the-box capabilities for extracting concepts from open-ended responses and constructing semantic networks across diverse domains56,57 without requiring the LLM to first be customized to the task at hand (that is, without necessarily training or tuning it on additional data). Instead, using a process called prompt engineering,58,59 analysts can adjust the instructions given to the LLM. (See Figure 1 for an example of the prompt used in our study.) The ease of using “off-the-shelf” LLMs should enable policymakers to integrate the perspectives of large numbers of citizens into their work much more quickly than has been true in the past.
Challenges and Future Research
Establishing the validity of LLM-based approaches to policymaking and mitigating potential risks are key challenges and priorities for future research. It is critical to systematically assess the reliability, accuracy, and representativeness of methods like the one discussed here. In particular, research needs to examine the quality of the extracted insights, ensuring that they accurately reflect the raw text inputs and the perspectives of different demographic groups without perpetuating biases ingrained in the models through biases in the training data.56,57,60–62 Human validation of insights derived through such LLM-based approaches is essential in this process.20,63,64
Future research should also compare LLM-based insights derived from different data collection approaches (such as brainstorming,27,28 group deliberations, 65 polls, and qualitative interviews), examining the relative strengths and weaknesses of the available approaches for different policy goals and settings. This comparison would yield actionable guidance for both policy researchers and practitioners about when to use which approach—and why. Research should further explore synergies between our proposed approach and other possible uses of LLMs in policy contexts,66,67 including using LLMs to scope likely reactions to behavioral interventions (see References 32 and 68 through 70 for examples of how LLMs can be used to simulate and study human behavior), design conversational agents that can better engage with citizens, 71 and enhance the productivity of discussions about controversial topics. 72 The semantic networks generated by our approach could potentially be used to empirically ground such LLM-based approaches, similarly to how curated databases of documents can ground other uses of LLMs. 73
Incorporating LLMs into policymaking would require adhering to best practices in terms of ensuring transparency,74,75 mitigating errors,62,76 using culturally relevant training data,77,78 conducting regular bias audits,61,79,80 and prioritizing the use of truly open-source LLMs,81,82 whose inner workings are more transparent than those of proprietary technologies. These efforts should be conducted within a robust regulatory framework, akin to those applied in the medical field. 83 This framework should align with ongoing regulatory initiatives 84 that aim to ensure fairness, transparency, and accountability in the application of LLMs to policymaking.74,78
Conclusion
LLM-based methods offer tremendous potential benefits for policymaking and society at large but also present significant risks. To maximize the benefits and minimize the risks, researchers would be wise to invest time now in exploring how and when methods such as the one presented here could be safely integrated into behaviorally informed policymaking processes.85-87
A Brief History: LLMs as Research Tools in the Behavioral, Cognitive, & Social Sciences
Large language models (LLMs) represent the most advanced form of natural language processing (NLP) models available today. Broadly, NLP involves using mathematical and computational approaches to extract meaning from text, including everyday written or spoken text. Applied to large collections of text, these methods can, for instance, classify their contents by categories, 88 extract information on specific entities 89 or broad topics, 90 and identify arguments91,92 and sentiments. 93 Below, we present a brief history of NLP from its early years to the introduction of LLMs, 94 highlighting its connections to the behavioral, cognitive, and social sciences.
Early NLP (1950s–1980s) relied on rule-based methods to analyze sentence structure. However, because language depends heavily on context, these approaches often struggled to capture nuanced meaning. 95 In the 1990s, statistical methods to better address meaning in text (in other words, semantics)—particularly, latent semantic analysis (LSA) 96 —were introduced to analyze large collections of text. Semantic analyses identify relationships between words based on how often they appear in similar contexts, and they enabled investigators to gain a more sophisticated understanding of language patterns. 97 Their advent kickstarted a wave of research in psychology and cognitive science that used semantic analysis to study cognition 98 —for example, assessing people’s knowledge 99 or comprehension 100 of topics or determining whether texts were coherent. 101
The subsequent integration of machine learning techniques into NLP in the early 2010s significantly advanced the tasks that semantic analyses could accomplish, most prominently through the development of word embedding approaches, such as word2vec 102 and gloVe, 103 that capture the meaning of text by going beyond simple word co-occurrence statistics and broad patterns across documents to focus on the immediate context in which words appear. Word embeddings have been extensively used in social sciences and psychology—for example, to identify implicit biases, 104 understand how people mentally represent risk, 42 and analyze honesty in political discourse. 105 They have also enriched the usefulness of tools like psychology-informed dictionaries 106 (such as the Linguistic Inquiry and Word Count, or LIWC 107 ), by attending to the meanings and context of words rather than just their presence or absence and thus provide deeper insights than do standard dictionary-based approaches that rely only on word lists or word frequency counts.
NLP technology took another leap forward with the introduction of transformers, 108 such as BERT, 109 which have revolutionized text representation by more effectively capturing the contexts in which words are embedded and the relationships between words. Through a so-called attention mechanism, 108 transformers can focus on relevant words in a text even if the words are far apart.
Transformers have enhanced the ability of AI models to generalize across tasks—that is, to perform tasks they have not been explicitly trained for. This includes identifying similar topics or sentiments across large-scale text corpora. As a result, transformers have enabled applications such as conducting personality assessments, 110 identifying suicide risk, 111 and recognizing antivaccination attitudes. 112
LLMs are essentially built on large-scale transformers that are trained on vast amounts of data and have greater capabilities than the original transformers had—including the ability to provide more accurate, more context-aware text processing and to generate human-like text. 113 Notable examples include generative pretrained transformers—the foundation of ChatGPT—as well as Gemini, Llama, Qwen, Mistral, Claude, Grok, DeepSeek, and others. LLMs’ capabilities surpass those of earlier NLP approaches by dynamically adapting to context; enabling nuanced language representation; and offering researchers powerful tools29,32 for studying cognitive processes,114,115 mapping mental representations, 116 and advancing psychological measurement and experimentation.31,117 They have been used, for example, in the study of everyday choices, 118 risk preferences, 119 and narratives.115,120 LLMs have also been applied to policy-related tasks such as making public affairs documents transparent to citizens, 121 identifying issues important to citizens, 122 and gauging sentiments 123 evident in citizens’ social media posts and discussions in online forums. 124
For a fuller description of how NLP has been used in the behavioral sciences, see Reference 125.
Key Points for Policymakers
Existing LLM models could be used to identify the views of large numbers of citizens and distinguish between the opinions and priorities of different subgroups.
Such information could enable policymakers to quickly assess the views of many citizens before surveys or interventions are designed, thus producing more meaningful outcomes.
An application of the method to transcripts from brainstorming sessions about ways to solve policy problems, such as the low uptake of vaccinations, has demonstrated the technique’s ability to provide nuanced insights into the views of multiple subgroups.
Policy researchers and practitioners should further explore the potential benefits and risks of the approach.
Footnotes
Author Note
We thank Susannah Goss for editing the manuscript and Christoph Abels, Samuel Aeschbach, Caedyn Stinson, and Mubashir Sultan from the Adaptive Rationality Center at Max Planck Institute for Human Development for their feedback.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: E. L.-L. and S. M. H. were funded by the Deutsche Forschungsgemeinschaft (DFG)—Project number 458366841 (POLTOOLS—Assisting behavioural science and evidence-based policy making using online machine tools).