
Abstract
Purpose
This study examines the use of Google's advanced large language models and the LangChain library for developing a chat counseling system for cataract disease.
Methods
The proposed system integrates a manually constructed cataract disease information repository with Google Generative artificial intelligence (AI) models, while LangChain is used to simplify the development and deployment of the conversational pipeline. The effectiveness of the system is evaluated using the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) score, a standard metric for assessing the quality of generated responses.
Results
Preliminary evaluation demonstrates an encouraging trend, indicating that the proposed system is suitable for building innovative and responsive counseling tools for cataract education.
Conclusion
The findings suggest that combining Google Generative AI models with LangChain and a curated cataract information repository can support the development of practical conversational systems in the domain of cataract disease.
Introduction
Context and motivation
GenAI refers to a family of artificial intelligence (AI) technologies capable of generating new information in a human-like way, using knowledge acquired from large datasets within specific domains. The main goal of GenAI is to understand and interpret data to create unique content that is coherent and contextual, and in many cases could be mistaken for human-created content. 1 GenAI, as the entity, utilizes Gemini Pro, a language model from Google AI, across various functions such as text generation, machine translation, question–answering, and factual topic summarization. This multifaceted application spans various fields like content creation, query answering, online translation, and summarizing of intricate topics. 2 However, existing large language model (LLM) applications like ChatGPT, Claude 2, or Google's Bard are limited in terms of factual accuracy, desired outcomes specificity, scalability in processing large data sets, and automated and sequential analysis. 3
The task of the Gemini Pro is the application of the question–answering capability in the field of cataract diseases by addressing the questions. The Gemini Pro was equipped with Cataract disease information, which was manually compiled and integrated to create a straightforward question–answering tool, customized for the public. The increasingly information-saturated web with numerous online platforms is an issue that information seekers face when looking for targeted answers to specific questions.
Scientific contribution
The main scientific contributions may be summarized as follows:
− Development of a Conversational AI System: The authors have created a chat counseling system for cataract illness education that makes use of Google's sophisticated LLMs and LangChain. This system is a clever and adaptable teaching tool since it is made to respond to user inquiries with helpful responses. − Integration of a Cataract Illness Information Repository: The manual compilation and integration of Google Generative AI models with a comprehensive cataract illness information repository constitutes a noteworthy contribution. This enables precise and customized answers to customer inquiries concerning cataract illness. − Use of sophisticated Language modeling techniques: To produce responses that are both coherent and contextually relevant, the study makes use of sophisticated language modeling techniques. This includes the construction of vector representations from the cataract disease repository, enhancing the system's ability to understand and respond to queries effectively. − Empirical Evaluation Using Recall-Oriented Understudy for Gisting Evaluation (ROUGE) Score: The effectiveness of the conversational AI system is measured using the ROUGE score, a standard metric in automatic summarization tasks. This empirical evaluation helps validate the performance and suitability of the proposed system for educational purposes. − Novel Methodological Approach: The authors propose a novel methodology for transforming a manually curated cataract disease repository into vector representations. This approach involves segmenting the information into manageable chunks and employing the Facebook AI Similarity Search (FAISS) library and Google Generative AI Embeddings for data processing.
These contributions collectively enhance the understanding of how advanced language models can be effectively utilized in medical information systems, particularly for the education and management of cataract disease.
Composition of the article
The article is structured into five main sections to comprehensively explore the integration of Google's LLMs and LangChain in cataract disease education through conversational AI. The Introduction sets the stage by discussing the current landscape of generative AI technologies and their limitations, particularly in medical information delivery. The Literature Review follows, summarizing existing research on AI applications in eye diseases and identifying gaps in the current methodologies. In the Proposed Work section, the development of a vector representation from a cataract disease repository and its application in generating AI responses is detailed. The Results and Discussions section evaluates the effectiveness of the model using the ROUGE score and discusses the outcomes. Finally, the Conclusion summarizes the findings, reaffirms the value of the proposed system, and suggests future avenues for research and development. Each section builds upon the last to present a detailed exploration of using AI to improve public health education regarding cataract disease.
Literature review
Current research
Most eye disease research is based on machine learning and deep learning approaches.4,5 Commonly, machine learning techniques are tried first, and then deep learning approaches. For example, a group of researchers 6 developed a computer-assisted cataract classification system using fundus images. The feature extraction was done using wavelet transforms and sketch-based techniques, which was then followed by cataract detection and grading using a multi-class discriminant analysis algorithm. Results showed that CCRs reached up to 90% for wavelet-based features and 77% for sketch-derived features. The other study 7 used the K-nearest neighbor classifier, obtaining high accuracy by joining the spatial features such as dissimilarity, contrast, and uniformity. By employing statistical texture analysis and artificial neural networks in, 5 the authors proposed a competitive system for cataract detection and achieved 94. 5% average precision in separating normal fundus images and cataract-affected ones. 8
On the other hand, the scientists worked out an in-vivo Automatic Nuclear Cataract Detection and Classification System 9 aimed at feature extraction from the ocular cup and intervertebral disc areas. For this, they used datasets such as DRISHTI and RIM-ONE V3 of fundus images. The other research 10 integrated machine learning and ultrasound technologies to generate the automatic detection and classification of the Nuclear Cataract system. Applying the support vector machine classification, researchers 11 classified the fundus images as cataract or no cataract, reaching a specificity of 93. 33% with RBF network-based grading severity. The convolutional neural networks (CNN) model was also designed for automatic glaucoma classification by transfer learning on DRISHTI and RIM-ONE V3 datasets. 12 Finally, an Android smartphone-based cataract detection method that utilizes a single-layer perceptron approach with an 85% classification accuracy is proposed in. 13
In the authors’ study, 14 they analyzed five different architectures of ImageNet-pretrained networks—Xception, ResNet50, VGG19, VGG16, and Inceptionv3 for the task of glaucoma detection. The relevant neuro-architecture does not require any feature extraction or for the ONH geometric structure estimate to be done, and scores 0.8. 3.54, 0.8041, 0.8575, and 7.739, individually. Among the various machine learning techniques, deep learning stands out due to its capability to learn the most important features automatically before incorporating them in the model. This diminishes the reliance on manually designed features, rendering them more adaptable across diverse medical imaging modalities. 15
In a separate investigation, slit lamp images were utilized to develop a deep learning-based approach for assessing the severity of nuclear cataracts. A local filter (CNN) was constructed by amalgamating image patches fed into a convolutional neural network. Subsequently, additional higher order features were extracted using a set of recursive neural networks. 16 Employing feature maps from the architectures’ concatenated layers, a deep CNN (DCNN) was devised for cataract detection and grading. This method demonstrated rapid and accurate performance, achieving 93.52% accuracy for cataract detection and 86.69% for grading. 17
Furthermore, in their research, 18 the authors proposed a classifier model trained on the ResNet architecture alongside an automatic cataract detection system utilizing DCNNs.
While a considerable amount of AI research was dedicated to cataract diseases, much of it has focused on future predictions. Recent works have emphasized the broader impact of generative AI and LLMs in healthcare applications such as patient engagement, diagnosis, and data-driven personalization. 19 In parallel, educational environments have increasingly adopted LLMs like ChatGPT and GPT-4 to support personalized and scalable learning systems, demonstrating their value in knowledge dissemination and human–AI interaction. Although there has been significant progress in generative AI endeavours20–22 and the utilization of LLMs23,24 in the medical and healthcare sectors, there remains a research gap specifically concerning targeted, factual, and interactive question–answering related to cataract disease using conversational AI systems, despite the promising advancements in LLMs and generative AI technologies.
Research gap
Although conversational AI has gained traction in broader healthcare contexts, its application to specific medical conditions—particularly cataract disease—remains underexplored. Despite significant advancements in generative AI and its applications in medical domains, the research on utilizing such technologies for specific diseases like cataracts remains sparse. A notable research gap is identified in the application of conversational AI to provide targeted and precise information about cataract disease. While current LLMs are widely employed in text production, machine translation, and summarization, their ability to immediately respond to user inquiries in the medical domain—particularly ophthalmology—has not yet been adequately investigated.
Furthermore, as prior research has shown, there are several AI-driven cataract diagnosis tools and classification systems; however, these tools are mostly centered on image processing and feature extraction, with minimal attention to conversational, text-based interfaces for public education. Unlike diagnostic models, which require medical imaging and professional interpretation, our system focuses on delivering accessible, AI-driven responses to general users’ questions—making it a distinctive contribution to non-clinical, educational support in ophthalmology.
There is a need to develop a conversational system that is both instructive and responsive and that makes use of LLMs to improve public awareness of cataract illness. This gap justifies the contributions made by the present study, which aims to bridge this divide by implementing a conversational AI that integrates a structured cataract disease information repository with Google Generative AI models to facilitate precise and accessible communication about cataract disease.
Proposed work
This study introduces a novel and domain-relevant integration of LangChain, Google Generative AI (Gemini Pro), and FAISS to construct an intelligent educational chatbot tailored to cataract disease. The proposed model comprises two primary components: firstly, the construction of a vector representation derived from the provided cataract disease repository, and secondly, the utilization of this vector to generate responses to given queries.
The selection of LangChain, Google Generative AI (Gemini Pro), and FAISS was based on their proven effectiveness in developing robust, scalable, and context-aware conversational systems. While numerous LLMs and vector databases exist, our pilot study specifically evaluated this stack for the following reasons:
− Google Generative AI (Gemini Pro): Selected for its advanced core language processing capabilities, including high factual accuracy in question–answering and summarization tasks. It offers a sophisticated balance between response coherence and medical relevance, which is critical for specialized domains like cataract education. − LangChain: This language library was utilized to simplify the orchestration of the LLM pipeline. It facilitates the seamless integration of a manually curated disease repository with the generative model, enabling structured data processing and deployment. − FAISS: Chosen for its high-performance vector representation and similarity search capabilities. It allows for efficient retrieval of the most relevant information from the cataract repository, ensuring that the AI's responses are grounded in the provided factual context.
Ethical scope and safety-by-design considerations
This study did not involve human participants, user interaction experiments, or the collection of any personal or clinical data. All evaluations were conducted using a manually constructed question–answer dataset derived from publicly available educational materials.
Accordingly, the work represents a technical feasibility and methodological evaluation of a conversational pipeline rather than a clinical study.
The system was explicitly designed with basic safety constraints appropriate for educational medical tools. Responses are grounded in retrieved content from the curated repository, and when relevant evidence is not retrieved, the model is instructed to return “Answer is not available in the context” rather than generate unsupported content.
The system is also framed as informational only, and the manuscript clarifies that outputs should not be interpreted as medical advice.
Vector of cataract information with Google Generative AI
The comprehensive methodology detailing the creation and retention of the vector is depicted in Figure 1.
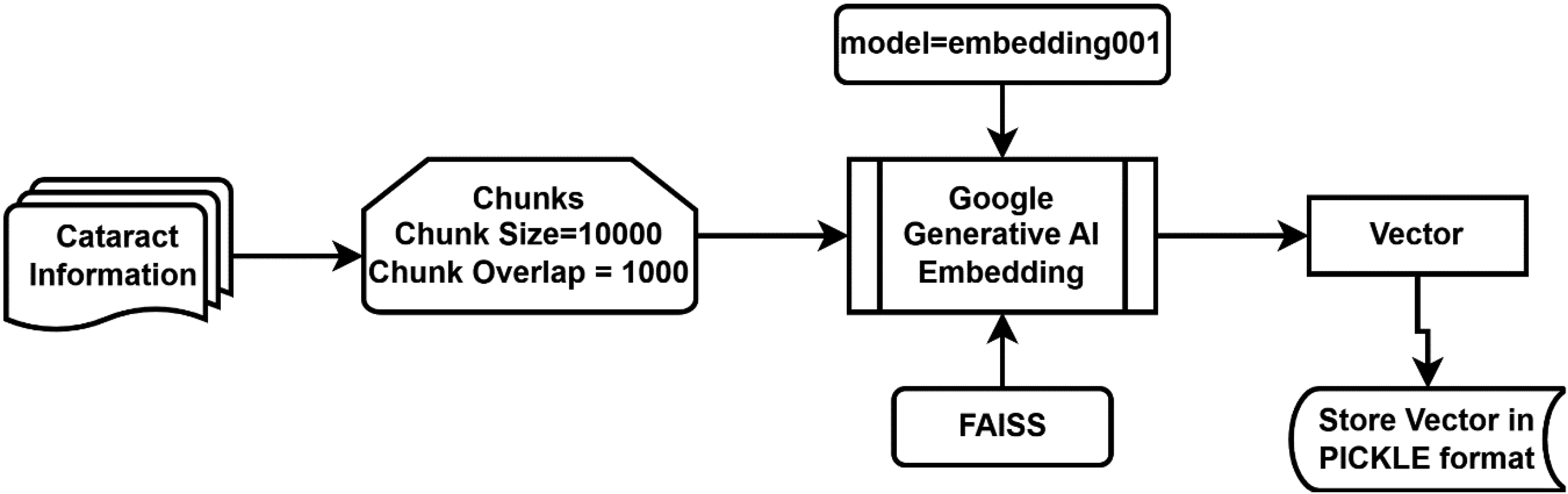
Vector creation from cataract disease repository.
A self-generated PDF repository on cataract disease, encompassing details about symptoms, causes, risk factors, prognosis, diagnosis, prevention, and treatment, was compiled from the source. 25 The cataract-related data was segmented into chunks of size 1000, with a chunk overlap of 1000, using LangChain's RecursiveCharacterTextSplitter as illustrated in Eq. 1 and Eq. 2, which represent function call syntax rather than mathematical equations. This configuration was selected to preserve contextual integrity in medically dense passages and to reduce retrieval failures caused by splitting clinically linked statements across chunk boundaries. Because the system relies on FAISS similarity search to retrieve supporting evidence before the LLM generates an answer, maintaining continuity between adjacent segments is essential for keeping responses grounded in the repository and mitigating hallucinations.
# Phyton code for Eq 1
# Split raw repository text into chunks
chunks_cataract_repository = splitter.split_text (cataract_repository_text)
The calculation for the splitter is as follows:
# Configure the text splitter (character-based, with overlap)
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=10000,
chunk_overlap=1000
)
The “RecursiveCharacterTextSplitter” is made available through the “langchain.text_splitter” module. LangChain, a framework crafted to streamline the development of applications utilizing LLMs, serves as an integration framework tailored for language models. Its functionalities align extensively with the broader spectrum of language models, encompassing tasks such as document analysis and summarization, chatbot development, and code analysis. 26 In this pipeline, the splitter directly impacts the retrieval stage: well-formed chunks increase the likelihood that the similarity_search step retrieves all medically relevant statements needed to support an answer.
The “VectorCatarct” derived from the segmented chunks can be acquired through the utilization of Eq-3 and Eq-4. These equations employ the “from_texts” function of the FAISS library, made accessible by “langchain.” Here, “chunksCataractRepository” is derived from Eq-1, while “EmbeddedVector” is computed in Eq-4.
# Create embeddings object (Google Generative AI embeddings)
from langchain_google_genai import GoogleGenerativeAIEmbeddings
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001”)
# Build the FAISS vector store from chunked texts
from langchain.vectorstores import FAISS
vector_cataract = FAISS.from_texts(
texts = chunks_cataract_repository,
embedding = embeddings
)
For the vectorization process, we utilized the models/embedding-001 model from Google Generative AI Embeddings. This model transforms the text chunks into high-dimensional vectors, which are then indexed using the FAISS library. The similarity search is conducted by calculating the distance between the user's query vector and the stored document vectors, allowing the system to retrieve the most relevant contextually related chunks for any given inquiry. We enabled allow_dangerous_deserialization = True during the loading of the FAISS index to facilitate seamless local data retrieval.
“GoogleGenerativeAIEmbeddings” is part of the Google AI SDK. It allows developers to use advanced generative models like Gemini to build AI-driven features and applications. This SDK facilitates various use cases, including text generation from text-only input, text-and-images input for multimodal generation (specifically for Gemini), building multi-turn conversations (chat), and embedding. In this context, we utilize the “embedding001” model for embedding purposes. Google Generative AI Embeddings is also accessible through “langchain.”
FAISS is a library developed by Facebook, specifically tailored for efficient similarity search and clustering of dense vectors. Widely employed in machine learning and information retrieval applications, FAISS significantly enhances the performance of such tasks. 27
Getting answers about cataract disease using model chat-Google-Generative-AI
The comprehensive procedure for obtaining the requested answer is illustrated in Figure 2.
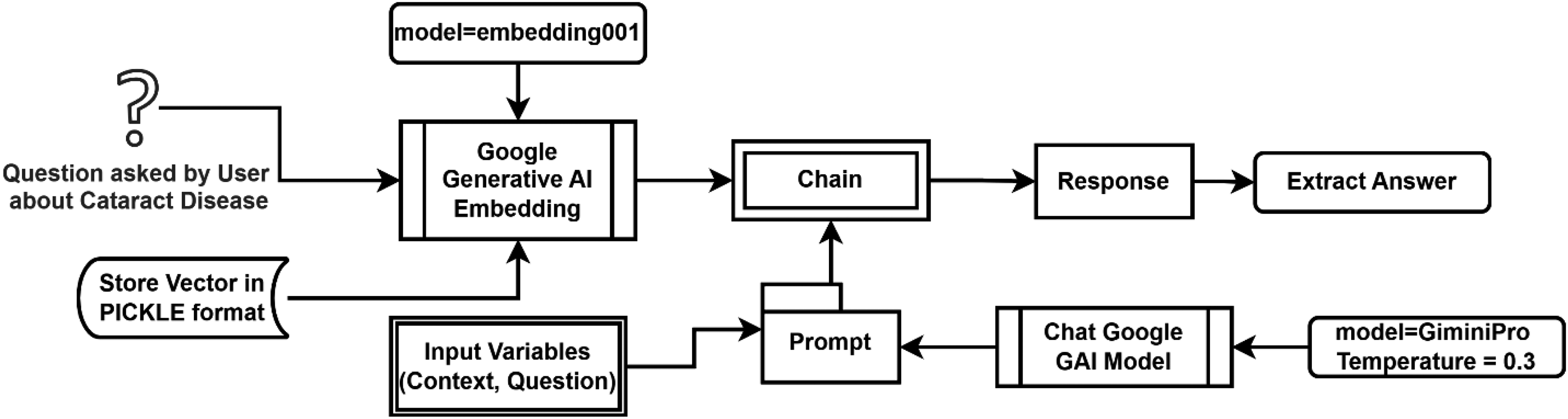
Procedure for getting answers about cataract disease using model chat-Google-Generative-AI.
A “promptCataract,” as computed in the context of a language model, constitutes a collection of directives or input furnished by a user to direct the model's response, facilitating comprehension of the context and generation of pertinent and coherent language-based output. This output may include answering questions, completing sentences, or participating in a conversation. The constructor of its object comprises two parameters: the template and input variables. In the proposed methodology, the template utilized includes “context” and “question” as input variables. The creation of a “promptCataract” is represented as follows in Eq. 5 below:
# Define the prompt template with context + question
from langchain.prompts import PromptTemplate
prompt_cataract = PromptTemplate(
input_variables = [“context”, “question”],
template=(
“You are an educational assistant for cataract disease.\n”
“Answer the question using ONLY the provided context.\n”
“If the answer is not in the context, say: ‘Answer is not available in the context’.\n\n”
“Context:\n{context}\n\n”
“Question:\n{question}\n\n”
“Answer:”
)
)
The “PromptTemplate” class is a component made accessible through “langchain,” utilized for structuring prompts.
The retrieved context is passed to the Gemini Pro model (gemini-pro). To ensure the responses are grounded in the provided medical context and to minimize hallucinations, we set the model's temperature to 0.3, prioritizing deterministic and factual outputs over creative ones. The interaction is governed by a specific PromptTemplate, visually depicted in Figure 3.

Conceptual structure of the prompt template and hallucination-control mechanism used in the proposed retrieval-augmented conversational system.
This prompt explicitly constrains the model to the provided CataractInfo repository. We utilized the load_qa_chain with a “stuff” chain type, which consolidates all retrieved document chunks into a single prompt for the LLM.”
# Initialize Gemini Pro with a low temperature for grounded responses
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(
model="gemini-pro”,
temperature=0.3
)
The employed model is “gemini-pro” with a temperature setting of 0.3, sourced from “ChatGoogleGenerativeAI” as specified in Eq-7 below. “ChatGoogleGenerativeAI” is likewise made available through “langchain.”
# Load a QA chain (stuff = concatenate retrieved chunks into a single prompt)
from langchain.chains.question_answering import load_qa_chain
cataract_chain = load_qa_chain(
llm = llm,
chain_type="stuff”,
prompt = prompt_cataract
)
The temperature parameter influences the model's variability in response generation. Higher values (closer to 1) lead to less predictable outputs, whereas lower values (closer to 0) yield more deterministic responses. Adjusting the temperature parameter according to the specific needs of the task is recommended. 3 For short-answer scenarios like ours, a lower temperature (e.g. 0.3) is preferable to ensure more deterministic outputs, aligning with our choice for this setting.
The temperature parameter in LLMs controls the randomness and creativity of the output, ranging from 0 (completely deterministic) to 1 (highly creative). For this pilot study, a temperature of 0.3 was empirically determined to be optimal. While a temperature of 0.1 or 0.2 was considered, these lower values occasionally led to overly repetitive phrasing and a failure to synthesize complex information from the multiple document chunks retrieved. Conversely, settings above 0.5 introduced a higher risk of “hallucination” or the inclusion of irrelevant medical advice not present in our verified repository. A value of 0.3 was selected as it provided the best balance: ensuring high deterministic accuracy required for clinical information while maintaining enough linguistic flexibility to generate coherent and natural-sounding explanations for the public.
Now, if a user poses a question, the text of which is depicted in Eq. 8 below:
# Example user question
question = “What are the primary symptoms of cataracts?”
All configurations pertinent to the cataract repository are now stored in vector formats. These vectors are subsequently loaded into a new vector named “loadVector,” as described in Eq. 9 below, to facilitate obtaining responses from this repository.
# (Optional) Persist/load FAISS index if you saved it locally
# vector_cataract.save_local(“faiss_cataract_index”)
load_vector = FAISS.load_local(
“faiss_cataract_index”,
embeddings,
allow_dangerous_deserialization = True
)
# Retrieve top-k relevant chunks by similarity search
docs = load_vector.similarity_search(question, k = 4)
# Generate the final answer using retrieved context
response = cataract_chain.run(
input_documents = docs,
question = question
)
print(response)
The response delineated in Eq. 11 constitutes the answer to the “Question” as presented in Eq-8. A straightforward interface, encompassing all underlying processing, is illustrated in Figure 4. Here, users simply input their questions regarding Cataract Disease and receive responses in a user-friendly manner.

User interface for getting the response to a given question about cataract disease.
Results
To assess the efficacy of the implemented model available on GitHub, 29 we systematically generate a comprehensive array of inquiries about each designated term, including symptoms, causes, risk factors, prognosis, diagnosis, prevention, and treatment, as sourced from reference. 25 Presented herein is an excerpt exemplifying the “Diagnosis” term.
“Diagnosis: There are many reasons why your vision may get worse as you grow older. Because of this, other possible causes need to be ruled out before cataracts can be diagnosed. Your eye doctor (ophthalmologist) will first ask you about your symptoms and your general medical history. You will have a few eye tests done to find out how much your eyesight is affected and what might be causing the symptoms. The lens of the eye is examined using a slit lamp (a microscope with a light). The doctor looks at the eye through the microscope with the help of a line – or slit – of light that shines onto your eye. This makes it possible to take a close look at the lens and the other parts of the eye, like the vitreous body and the retina. This examination is not painful. To look at the back of the eye, doctors usually use medication to dilate (widen) your pupils. The pupils stay dilated for a few hours. During this time, it is difficult to focus properly, and you will be more sensitive to light and glare. For this reason, you shouldn't drive a car for the next 4 to 5 h. This effect can last longer in some people. If you're not sure whether your eyes have returned to normal, it's better not to drive.”
To create a meaningful testbed, the complete Cataract Information Repository—comprising a manually constructed dataset of 70 question–answer pairs—was utilized. These queries were strategically distributed across clinical thematic areas: Introduction/Prevalence (10), Symptoms (10), Causes and Risk Factors (10), Diagnosis (10), Prevention (5), and Treatment (25). While Table 1 illustrates 10 specific entries under the “Diagnosis” category to demonstrate the evaluation framework. The aforementioned content is a segment of the Cataract Information Repository, wherein a collection of potential questions and corresponding answers is delineated in Table 1.
Designed question–answer from “Diagnosis” term.

Due to the absence of a standardized, publicly available conversational dataset specifically for cataract education, we manually constructed a comprehensive testbed. This involved two distinct phases:
− Repository Creation (Training phase): We compiled a domain-specific knowledge base by aggregating factual medical data from diverse reputable resources into a primary PDF repository. This repository serves as the system's “ground truth” for retrieval. − Manual Question Formulation (Testing phase): To ensure a rigorous evaluation, we manually developed 70 “unseen” questions that were not directly present as a Q&A list in the original sources. These questions were designed to mimic real-world public inquiries, ranging from simple factual lookups to complex clinical scenarios requiring detailed explanations.
The evaluation was conducted using a dataset of 70 representative question–answer pairs spanning seven medical categories: symptoms, causes, risk factors, diagnosis, prognosis, prevention, and treatment. This dataset was manually derived from publicly available cataract education materials and is available upon request.
Testing of the model
The evaluation utilized these 70 manually prepared questions to test the model's ability to retrieve information and generate best-in-class, detailed explanations. By using “unseen” questions—those the model had not encountered in a structured Q&A format—we were able to accurately assess the chatbot's effectiveness in providing factual, coherent, and highly relevant responses based solely on the integrated medical repository. Table 2 presents a comparative overview of actual and predicted answers for the 10-question sample from the “Diagnosis” category. This comparison highlights the chatbot's ability to extract semantically faithful responses from the vectorized cataract information base.
Actual and predicted answer.

Rouge scores
ROUGE Score serves as a prevalent metric for gauging the quality of automatic summaries. It involves a comparison between a system-generated answer and the actual answer, thereby evaluating the system's proficiency in encapsulating essential information from the source text. 30
The ROUGE Score, comprising ROUGE-1, ROUGE-2, and ROUGE-L, stands as a crucial metric for appraising the caliber of generated responses. It scrutinizes the extent to which system-generated answers correspond with actual answers, thus providing an indication of the fidelity in capturing pivotal information from the original text. Table 3 details the ROUGE-1, ROUGE-2, and ROUGE-L scores for the actual and predicted answer pairs shown in Table 2. These scores quantitatively assess lexical overlap and semantic consistency, providing insight into the chatbot's summarization and matching accuracy.
ROUGE-1, ROUGE-2, and ROUGE-L scores of actual and predicted answers of sample data.

ROUGE-N
The intersection of n and n-grams that exist in the summary and reference summaries serves as the foundation of ROUGE- N, an essential component of the extensive ROUGE framework. ROUGE- 1 examines individual words (unigrams), whereas ROUGE- 2 examines consecutive word pairs(bigrams), despite challenges posed by sparsity. The processing includes computing Precision and Recall metrics, matching n-grams, and calculating the F1 Rating. The last ROUGE-N evaluation is based on averaging F1 ratings across all references.
Rouge-1
Figure 5 shows that the proposed model's ROUGE-1- 1 score achieved the highest accuracy, recall, and F1 score for both genuine and predicted answers in relation to cataract disease. This metric measures the frequency with which the model's predicted responses correspond to the actual responses “individual words (units).”

Precision, recall, and F1-score of Rouge-1.
Rouge-2
Figure 6 depicts that, as per the ROUGE-2 score, the proposed model achieved an average precision, recall, and F1 score concerning actual and predicted answers. This metric assesses the concurrence of bigrams (pairs of consecutive words) between the predicted answers and actual answers. Essentially, it evaluates how frequently the model generates responses containing not only identical individual words (unigrams) as the reference answers but also those words arranged in the same sequential order (bigrams). However, it's noteworthy that although we primarily generated short answers, the model occasionally produced slightly longer responses, leading to fewer points at a score of 1. Nonetheless, the predicted answers were found to be accurate.

Precision, recall, and F1-score of Rouge-2.
ROUGE-L
ROUGE-L is tailored to compute the longest common subsequence (LCS) between the model-generated answer and the actual answer. This metric emphasizes the model's recall, reflecting the extent to which the predicted answer encapsulates the actual answer. Figure 7 illustrates that the proposed model attained superior ROUGE-L scores, as evidenced by F1-Graph predominantly surpassing 0.
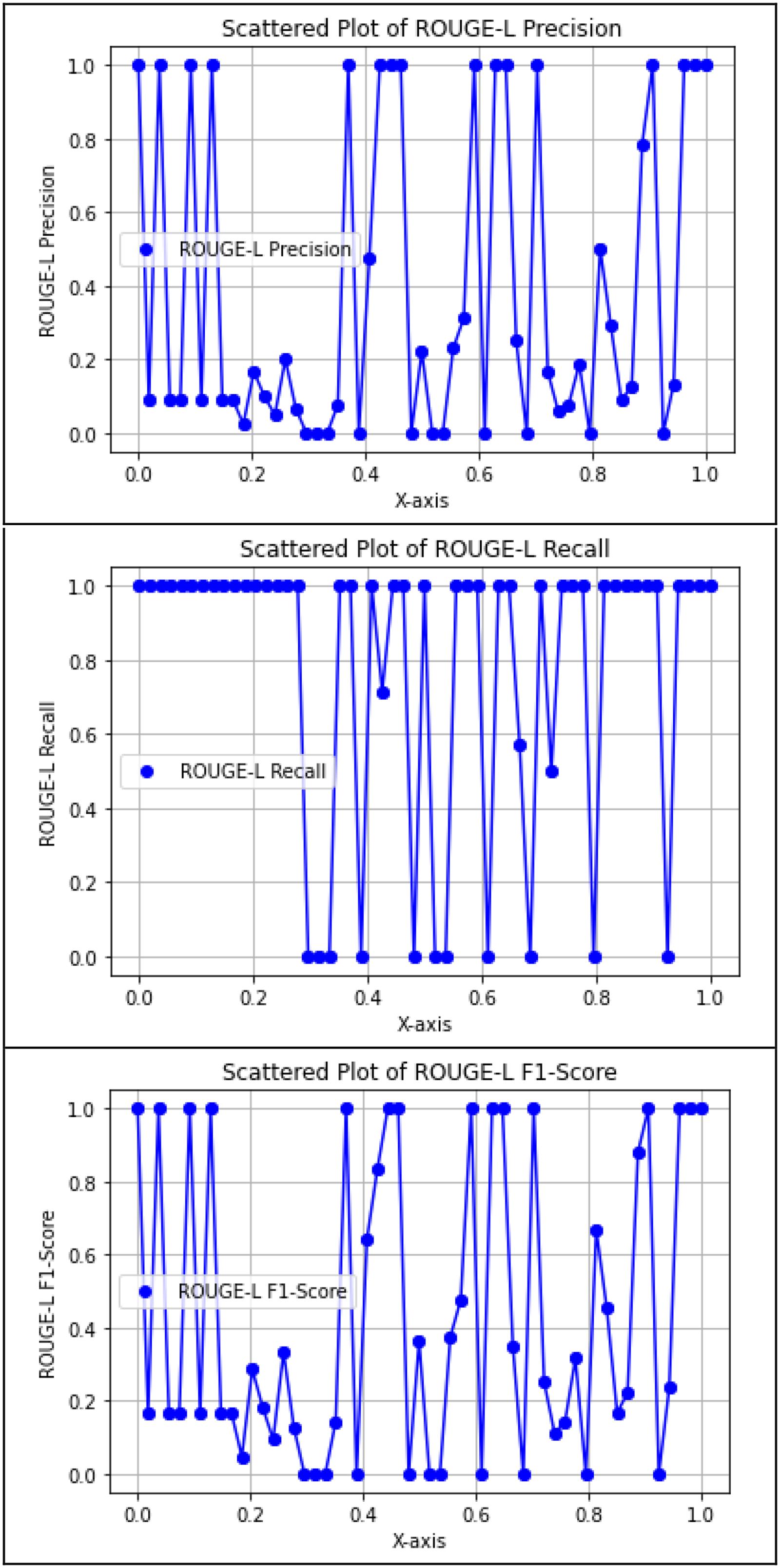
Precision, recall, and F1-score of Rouge-L.
Empirical analysis
To empirically evaluate the proposed model's effectiveness in comprehending and responding to inquiries regarding cataract disease, a rigorous assessment was conducted. The assessment encompassed several key aspects.
Data collection and preparation
As a first step, we accumulated trustworthy information from a reliable source to develop a collection that is mostly specialized for different aspects of cataract diseases (like symptoms, causes, diagnoses, and treatment). Together, this set of evidence is what we built our education and assessment programs on. To make this wealth of information noticeable, we statically embodied the cataract disease repository in smaller, more ordered chunks through a special text-splitting algorithm. Finally, we leveraged the FAISS library to convert these small chunks into matrix inputs, whereas Google Generative AI provided the embedding service. The goal of this method was to arrange the necessary data in a fashion that was both well-organized and efficient enough to query.
Response generation
The proposed type was assigned the role of generating replies to customer questions concerning cataract disease on the vector representations constructed. The difference was in the application of state-of-the-art language modeling techniques, especially the Gemini-pro model, which is a part of the Google-Generative AI framework. We assessed the performance of the model on the task of query interpretation in context and generating clear and informative answers.
Comparison with actual answers
The model's responses were routinely compared to actual responses from the customized collection. In order to evaluate the model's accuracy and importance in providing information on cataract disease, this comparison served as a benchmark.
ROUGE score analysis
The convenience of ROUGE-type scores like ROUGE 1, ROUGE 2, or ROUGE L is are significant measure for statistical evaluation. In addition to the scores, the evaluation showed a clearly demarcated threshold where there was a close correlation between the scores obtained by the model-generated responses and the actual scoring of the human candidates; thus, the evaluation served as a fair measure of how well this technique performed in terms of capturing critically important data.
Discussion of findings
Finally, a thorough discussion of the experimental research's findings was held about the proposed model's advantages and disadvantages. A complex understanding of the model's capabilities, possible improvements, and implications for future research and application in the field of medical information retrieval and comprehension was made possible by this discussion.
Through this experimental analysis, the proposed model's ability to address inquiries relating to cataract disease was analyzed in a robust, evidence-based manner.
While ROUGE-1 scores were generally high due to effective unigram matching, ROUGE-2 scores were comparatively lower. This is expected in generative models that produce syntactically correct but non-identical phrasing. The model often captured the correct medical information but used alternative expressions or reordered terms, leading to fewer exact bigram matches. For instance, “Avoid driving” and “It is better not to drive” convey the same message but share minimal bigram overlap.
In real-world educational settings, this variation is acceptable—sometimes even desirable—as it improves conversational fluency. However, it poses a challenge for automated evaluation metrics like ROUGE-2, which are sensitive to surface-form differences. Therefore, while ROUGE-2 helps flag sequence mismatch, human evaluation or semantic similarity scoring (e.g. BERTScore) may be better suited for deployment validation.
BERTScore and SentenceTransformer-based semantic similarity
SentenceTransformer-based semantic similarity
A semantic evaluation was conducted on all 70 question–answer pairs using BERTScore and SentenceTransformer-based semantic similarity. BERTScore evaluates contextual token-level alignment, whereas Sentence-BERT cosine similarity captures sentence-level semantic relatedness, making both metrics suitable for open-ended answer generation. The proposed model achieved a mean BERTScore-F1 of 0.340 with a 95% confidence interval of [0.228, 0.452], and a mean semantic similarity score of 0.482 with a 95% confidence interval of [0.388, 0.576]. As illustrated in Figures 8 9, the observed variability across questions reflects differences in answer completeness, phrasing, and specificity. Overall, these results indicate moderate but consistent semantic alignment between generated and reference answers, demonstrating that the model captures the underlying contextual meaning of responses beyond surface-level lexical overlap. For retrieval evaluation, metrics such as Recall@5 and Mean Reciprocal Rank were computed using FAISS. Failure cases (e.g. SNO 4 and 8 in Table 2) were analyzed via chunk inspection, revealing that certain relevant content was either missing or insufficiently represented in the vector index. A fallback mechanism has been implemented to handle such cases and improve robustness. Overall, the results indicate moderate but consistent semantic alignment between generated and reference answers, demonstrating that the model captures the underlying contextual meaning beyond surface-level lexical overlap.

BERTScore F1 for all questions.

Semantic similarity for all questions.
In the context of hallucination control, these semantic metrics complement ROUGE by assessing meaning preservation when the model produces faithful paraphrases, while retrieval metrics help explain when abstentions occur due to missing or weakly retrieved evidence.
Baseline comparison context
To contextualize our reported evaluation outcomes, we summarize (i) our task-specific semantic evaluation on the 70 cataract question–answer pairs and (ii) published ROUGE/BERTScore values reported in the literature for multiple general-purpose generative AI systems evaluated on a document summarization benchmark. 31 Importantly, the latter is included only as external contextual evidence, because it does not correspond to a cataract-domain dataset, nor to a RAG setting, and therefore should not be interpreted as a direct baseline comparison with our system.
Instead, this comparison is intended to illustrate how ROUGE and BERTScore are commonly reported in multi-system evaluations, and to position our task-specific semantic results within a broader evaluation landscape.
Table 4 deliberately separates our cataract-domain evaluation from literature-reported results obtained on a different task (document summarization) and under different experimental conditions. As such, these values are not used to claim superiority or direct comparative performance, but rather to provide contextual grounding on how ROUGE and BERTScore behave across large-scale generative models.
Contextual comparison between our task-specific evaluation and literature-reported benchmarks.

QA: quality assurance; RAG: retrieval-augmented generation.
A rigorous baseline comparison for this study would require computing ROUGE and BERTScore on the same cataract quality assurance (QA) dataset, under identical prompting conditions, for alternative systems such as zero-shot Gemini Pro, ChatGPT-4o, and a LangChain pipeline without FAISS. This task-specific baseline evaluation is therefore explicitly identified as a priority direction for future work.
Discussion
Interpretation of QA performance and retrieval-grounded behavior
Table 2 evidently demonstrates a high degree of concordance between the predicted answers generated by the model and the actual answers.
Overall, the chatbot demonstrated strong factual alignment with the curated repository. Of the 10 sample questions from the “Diagnosis” category, seven were answered with high semantic accuracy, as reflected in the overlapping phrasing of the predicted answers. However, two questions (SNO 4 and 8) lacked direct responses, likely due to token-level limitations or chunk segmentation within the embedding space. These misses highlight an opportunity for future optimization of the chunking method or prompt context expansion.
The use of full-sentence generation by Gemini Pro sometimes led to longer or paraphrased responses. For example, “Avoid driving” was generated as “It is better not to drive"—semantically correct, but with a lower lexical overlap, which is reflected in slightly lower ROUGE precision and F1 scores in Table 3.
Importantly, this behavior also reflects an explicit hallucination-control mechanism in our pipeline: when the retrieved context does not contain a sufficiently relevant span to support a factual answer, the model is prompted to refrain from fabrication and instead returns “The answer is not available in the context” (Table 2, SNO 4 and 8).
Because responses are generated from retrieved chunks of the Cataract Information Repository rather than unconstrained generation, hallucinations are reduced by design: the model is context-grounded, and unsupported content is suppressed rather than invented.
Interpretation of ROUGE behavior and semantic metrics
The ROUGE-1 scores show the highest alignment between actual and predicted answers, indicating that the model reliably captured unigrams (individual keywords), which is critical in medical question–answering. ROUGE-2 scores, while slightly lower, still demonstrate acceptable bigram alignment in most cases, but highlight that sequential coherence varies depending on the phrasing in the repository. ROUGE-L scores suggest the model effectively captured the LCSs when answers were phrased similarly. These differences reflect a trade-off between semantic accuracy and syntactic fidelity—a key consideration when evaluating generative AI models using extractive metrics.
From a safety perspective, this trade-off is also relevant to hallucination analysis: the system may generate fluent paraphrases, but the retrieval-grounded context and prompt constraints are intended to prevent the introduction of unsupported medical statements.
Practical relevance and deployment considerations
In addition, because hallucinations are a recognized risk in LLM-based medical dialogue, we emphasize that our evaluation includes observing abstentions (“not available in the context”) as a safety-preserving outcome when retrieval fails, rather than rewarding potentially fabricated content.
Linking performance to practical outcomes and deployment considerations. The evaluation metrics reported in this section are primarily designed to quantify answer fidelity with respect to the curated repository, rather than to measure real-world patient comprehension or clinical impact. Nevertheless, higher lexical and semantic alignment (as reflected by ROUGE, BERTScore, and semantic similarity) is practically relevant in educational deployments because it indicates that generated responses remain consistent with verified source content, which supports clarity, user trust, and safety. In this context, the abstention behavior (“Answer is not available in the context”) should be interpreted as a conservative safety outcome when evidence is insufficient. For future deployment, a staged roadmap is appropriate: (i) integration into a user-friendly web/mobile interface for cataract education, (ii) controlled pilot testing with non-expert users using structured feedback and A/B testing of prompt and retrieval settings, and (iii) subsequent clinical-facing evaluations with appropriate ethics oversight and involvement of domain experts to assess comprehension, usability, and safety before broader adoption.
Quality gaps and improvement directions
Although the chatbot achieved generally high semantic fidelity, several quality criteria were not fully satisfied. For instance, two questions in the evaluation sample (SNO 4 and 8) returned “Answer is not available in the context,” despite the relevant answer being present in the original repository. This suggests that either (i) the chunk containing the relevant answer was not retrieved due to limitations in the FAISS vector similarity match, or (ii) the model was unable to interpret the query with sufficient specificity to extract the answer contextually. Furthermore, when predicted responses were phrased differently—e.g. “It is better not to drive” vs. “Avoid driving”—they passed the human check but underperformed on lexical evaluation due to ROUGE's extractive design.
From the hallucination perspective, this abstention behavior is intentional: the system is designed to avoid producing unsupported medical statements when the retrieved evidence is insufficient, even if this leads to a lower ROUGE score for those items.
To address these issues in future development, we identify three key strategies:
− Refining chunk segmentation to reduce overlap and ensure that each concept is appropriately indexed in the vector store. − Enhancing the prompt template to reinforce context relevance and constrain the model toward concise factual outputs. − Tuning generation parameters (e.g. lower temperature or use of stop sequences) to prevent unnecessary paraphrasing and boost alignment with original answer phrasing.
These adjustments will directly contribute to more reliable retrieval and consistent quality, especially under quantitative evaluation frameworks.
Temperature sensitivity and hallucination risk
Table 5 provides a comparative analysis of the generative model's performance under varying temperature parameters to illustrate the rationale behind the final system configuration. The table presents side-by-side examples of the model's response to a standard clinical inquiry, such as symptoms of cataract disease, across three distinct temperature levels: 0.1, 0.3, and 0.7. At the lower end of the spectrum (0.1), the model demonstrates a highly deterministic but “robotic” output, which often results in repetitive phrasing and a failure to naturally synthesize the detailed information retrieved from the cataract repository. Conversely, at a higher temperature (0.7), the model's increased “creativity” poses a significant risk of medical hallucination, where it may introduce descriptive metaphors or clinical advice not explicitly found in the verified source text. As demonstrated in the table, the selected temperature of 0.3 provides the optimal balance; it maintains high factual fidelity by staying strictly within the provided context while ensuring the response is phrased with the linguistic fluidity necessary for an effective patient counseling system.
Comparison of Gemini pro outputs at different temperature settings.

This temperature comparison is included to explicitly address hallucination sensitivity: higher temperatures can increase the risk of introducing unsupported content, whereas the selected setting prioritizes grounded, deterministic outputs for medical education.
Conclusion
Recapitulation
In this study, we investigated the application of Google's advanced LLMs and LangChain, an open-source development library, in developing a conversational counseling system for cataract disease. By leveraging Google Generative AI models and LangChain's framework, we devised a system capable of providing informative responses to user queries regarding cataract disease. Our approach involved manually curating a repository of cataract disease information and integrating it with Google Generative AI models to facilitate question–answering.
Our initial findings indicate promising accuracy and contextual coherence, as evaluated using the ROUGE score, a metric commonly employed in automatic summarization tasks. The proposed model demonstrates the potential for developing informative and accessible counseling systems for cataract disease. By leveraging advanced language modeling techniques and structured data representation, our model effectively comprehends user queries and generates coherent and contextually relevant responses.
In addition to the empirical evaluation, we proposed a novel methodology for constructing a vector representation of cataract disease information and generating responses to user queries. This methodology involves segmenting the cataract disease repository into manageable chunks and transforming them into vector representations using the FAISS library and GoogleGenerativeAIEmbeddings. By employing advanced language modeling techniques within the Model Chat-Google-Generative-AI framework, our model generates responses tailored to user queries, thereby enhancing accessibility to pertinent medical knowledge.
There is still a research gap concerning cataract disease, even with the notable advancements in massive language models and generative AI. By putting forth a novel strategy that blends sophisticated language modeling with carefully chosen domain-specific data, our study fills this gap. Using empirical analysis, we assessed our model's ability to understand and address queries related to cataract disease, highlighting both its strengths and areas requiring refinement.
Future work
For future development of this conversational AI system, several enhancements and expansions are proposed:
− Incorporation of multilingual capabilities to serve a broader global population and increase linguistic inclusivity. − Expansion of medical information sources to increase accuracy and maintain relevance with evolving medical standards. − Integration with real-time medical databases or health records to allow personalization of responses based on up-to-date information and patient context. − Development of a user-friendly interface for deployment across web and mobile platforms, supporting broader public access and usability. − Conducting Large-Scale User Studies: To validate the system's practical viability, we plan to carry out real-world usability studies involving both non-expert users and domain professionals. These studies will assess the tool's accuracy, clarity, and educational effectiveness in real-time interactions and will provide feedback for refining both content delivery and system design. − Exploration of advanced AI techniques, such as reinforcement learning and personalization models, to dynamically adapt responses and improve user satisfaction. − Incorporation of human evaluation methods: To complement ROUGE-based analysis, future studies should involve domain experts who can assess the chatbot's responses in terms of factual correctness, medical relevance, and language fluency. This qualitative validation is essential to ensure responsible deployment in real-world public health education. − Task-specific baseline evaluation: Future work will compute ROUGE and BERTScore on the same cataract QA test set for (i) a zero-shot LLM setting without retrieval, (ii) ChatGPT-4o, and (iii) a LangChain pipeline without FAISS, and will report a comparative table under identical prompting and evaluation conditions. − User-centered readability and comprehension evaluation: Future studies will include formal readability assessment of generated answers (to ensure suitability for non-expert audiences) and structured comprehension testing with lay users to measure whether responses are understandable and actionable in an educational setting. − User satisfaction and usability measurement: Future work will incorporate validated usability and satisfaction instruments (e.g. questionnaire-based feedback) to evaluate perceived usefulness, trust, and overall user experience, and to guide iterative improvement of response style and interface design. − Response tailoring for non-expert users: Future iterations will explore response adaptation strategies (e.g. simpler vocabulary, shorter sentences, and progressive disclosure of details) to better align generated explanations with varying health-literacy levels and patient-facing needs.
By pursuing these directions, the system can evolve into a highly scalable and impactful platform for public health education in ophthalmology and beyond.
Footnotes
Acknowledgment
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2026R235), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Ethical considerations
While the proposed system is designed for educational purposes, it is critical to recognize the ethical implications of using conversational AI in the medical domain. Users may misinterpret generated content as professional advice, especially when responses appear confident or precise.
To mitigate this risk, the system should prominently display a disclaimer stating that all outputs are informational and do not substitute for medical diagnosis or treatment. Moreover, to prevent inadvertent misinformation, future iterations must include content validation pipelines and may benefit from human oversight in sensitive information domains.
Data privacy is also essential. Even though the current implementation does not retain user input, future expansions involving patient context or health records must comply with strict privacy regulations (e.g. HIPAA, GDPR). Adhering to ethical AI development guidelines ensures that the tool remains trustworthy, transparent, and safe for public deployment.
Consent to publish
Not applicable.
Consent to participate
Not applicable because the data is publicly available.
Author contribution
SMS and TM perform the original writing part, software, and methodology; MAK and TM perform rewriting, investigation, design methodology, and conceptualization; TS, NSN, HH, AAR and TM perform the related work part and manage results and discussions; TS, AAR and TM perform related work part and manage results and discussion; FA, TM, and MAK perform rewriting, design methodology, and visualization; SMS and MUT performs rewriting, design methodology, and visualization.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Conflict of interest
Not Applicable.
Data availability
The data used to support the findings of this study are available from the corresponding authors upon request.
Clinical trial number
Not applicable.