
Abstract
Artificial intelligence large language models (LLMs) have been shown to replicate social and cultural biases that exist in their training data, particularly with regard to race and gender. The authors examine if LLMs hold implicit assumptions with regard to religious identities. The authors prompted multiple LLMs to generate a total of 175 religious sermons, specifying different combinations of race and religious tradition of the clergyperson. The synthetically generated sermons were fed into a readability analyzer and given several commonly used readability scores. The authors analyzed this dataset of readability scores using bivariate and multivariate analyses. LLMs generated sermon texts that varied in readability. Evangelical Protestant pastors had easier to read artificial intelligence–generated sermons, whereas Jewish rabbis and Muslim imams had more difficult to read synthetic texts. There were no significant differences in readability across ethnoracial groups; however, all prompts specifying a race/ethnicity generated more difficult to read synthetic text than those with no ethnoracial group specified. As LLMs continue to expand in accessibility and capability, it is important to continue to monitor the ways they may sustain social biases across a variety of identities and group memberships.
The use of generative large language models (LLMs), a type of artificial intelligence (AI) technology, is becoming increasingly widespread. A growing number of individuals and organizations use this new technology to generate content and perform a multitude of everyday tasks. Interest in their use for social science research has similarly expanded (Halterman 2025; Law and Roberto 2025; Stuhler, Ton, and Ollion 2025; Than et al. 2025). As the uses of LLMs grow in number, a concurrent body of research has explored how social biases are embedded in their processing and output. This study builds on this literature by assessing the readability scores of AI-generated sermons created by hypothetical clergy of varying races and religions, extending the literature into the field of religion and introducing a new measure of bias 1 in AI models.
Early work in the sociology of AI explored algorithmic bias (Liu 2021), with a number of studies establishing that social and cultural biases are embedded within the algorithms that govern everyday processes and interactions, often to the detriment of marginalized categories of people (Beer 2017; Mittelstadt et al. 2016; Noble 2018; Obermeyer et al. 2019). This work has expanded with the advent of new AI technologies, most notably in the emergence of LLMs available for widespread public use. Generative LLMs can generate novel text, images, and videos from natural language prompts, deriving their content from training on large, publicly available databases of existing information.
Much in the same way that biases in algorithms reflect assumptions built in from their creators, LLMs have been shown to replicate preexisting social biases on the basis of their training data (Benjamin 2019; Gallegos et al. 2024; Kotek, Dockum, and Sun 2023). LLMs have been shown to produce stereotyped content on the basis of race, gender, and sexuality, even when given ordinary user prompts (Acerbi and Stubbersfield 2023; Fang et al. 2024; Sheng et al. 2019). These stereotypes are particularly enhanced when intersectional identities are considered (Kirk et al. 2021; Salinas et al. 2023). Although these technologies continue to evolve, it is imperative to monitor the ways in which the biases of the data on which LLMs are trained manifest themselves in the productions of those LLMs (Alvero et al. 2024; Joyce and Cruz 2024; Joyce et al. 2021; Law and McCall 2024).
Although studies of bias in LLMs have focused mostly on race and gender, less attention has been paid to religious identities. For example, ChatGPT-3 completed prompts about Muslims with statements associating them with violence (Abid, Farooqi, and Zou 2021), even after applying mitigation techniques (Hemmatian and Varshney 2022). In another study, conditioning prompts by religious identity produced variable emotion-based content (Plaza-del-Arco et al. 2024). However, the literature on LLMs and religion remains relatively thin compared with studies of LLMs and other identities. Ample space remains to explore how LLMs construct religion in their generated content and whether those generations show differences between groups.
This gap in the literature is particularly conspicuous because religion is particularly well situated to test for existing biases in LLMs. The racialized nature of religion, especially in the American context (Emerson and Bracey 2024; Yukich and Edgell 2020) means that it is inherently intersectional. Most religions have extensive historical corpora of literature, doctrine, and other cultural artifacts that LLMs can be trained upon; further, this body of religious content is constantly replenished and extended with new content as a matter of regular practice. Examining LLM-generated religious content harnesses the inherent advantages of religion as an object of social inquiry in its growing connection with AI technologies. LLMs have already made inroads into sacred spaces through leaders experimenting with their use in crafting worship services, prayers, research, and sermons (Mannerfelt and Roitto 2025; Tan 2025). Sermons, being new creations typically made weekly by clergy in the most common monotheistic religious traditions, are especially well suited for a test of LLM-generated religious content.
In this study, we ask a selection of the most popular publicly available LLMs to produce synthetic sermons on the basis of different major religions, relying partially on the typology set by Steensland et al. (2000), varying the race of the religious leader in separate prompts. We then analyze the readability scores of these synthetically generated sermons to test for differences by race and religious tradition. Differences in readability scores by race or religion would suggest some kind of bias in the assumptions of the LLMs and the data they are trained on. Readability scores track the difficulty and complexity of texts. Many measures, in fact, are meant to be directly interpretable as grade-reading level, making for an intriguing potential measure of inherent bias in the models generating content.
This present study is an exploratory analysis of the variation in readability scores from LLM-generated religious sermons. We offer a null hypothesis that there is no variation in readability scores across religious and racial/ethnic categories. Yet if there are differences, we expect to reject this null hypothesis and find support for our alternative hypothesis.
Null hypothesis: LLMs will generate sermons with no differences in readability across religious traditions and racial/ethnic categories.
Alternative hypothesis: LLMs will generate sermons with some variation in readability across religious traditions and racial/ethnic categories.
Data and Methodology
To test these hypotheses, we use multiple chatbots based on generative LLMs to construct a dataset of artificially generated sermons. Generative LLMs are trained on broad data and capable of completing a variety of tasks. They are able to understand text input and create text output, and they are widely accessible as they are able to engage with and respond to a common vernacular through the use of chatbot interfaces and prompts (Law and Roberto 2025). We used a selection of five generative LLMs based on popularity and public accessibility: GPT-4, GPT-4o, Gemini, Claude 3 Opus, and Llama 4. We based our selection on popularity and accessibility because we are primarily interested in the generated content that would be most likely encountered by typical, nonprofessional LLM users, especially those who would use them to produce religious content; such content would have the greatest potential public reach.
ChatGPT is a chatbot owned by OpenAI, an AI research company that introduced the first generative LLM, an AI that is able to generate synthetic text on the basis of instructions provided by users, to the public in November 2022 (OpenAI 2024a). There are multiple models available for use through the ChatGPT chatbot. OpenAI introduced its flagship ChatGPT-4 in March 2023 (OpenAI 2024b). Later, in May 2024, the company announced ChatGPT-4o, which can handle images, audio, and video. Gemini is a generative LLM developed by Google and introduced in December 2023 (Google 2023). Claude is an AI chatbot and generative LLM created by Anthropic and opened to the public in March 2023 (IBM 2024). Llama is a multimodal generative LLM developed by Meta and publicly introduced in February 2023, and Llama 4 was released in April 2025 (Meta 2025). Llama is an open-source LLM; however, the Open Source Initiative has classified Llama 4 as semiopen because of its restriction of companies with more than 700 million active users per month (Samad 2025).
Each LLM-generated sermon was created by starting a new chatbot session and entering the same direct prompt: “Write a sermon that a [race] [religious leader] might give during a religious service.” We opted for a generic open-ended survey prompt as the best way to assess baseline differences in model assumptions based on religious tradition. More specific prompts—requesting specific sermon topics, for example—would almost certainly inject biases into the data, as religious traditions vary considerably in their historical interests and emphases. We constructed this according to best practices for academic prompt generation (Giray 2023) to provide enough specificity regarding the content we were seeking to generate while avoiding overfitting through constraints. We determined that sermon was understood by the models in the context of each prompted religious tradition, while homily was too specific to the Catholic religion to be broadly useful. Similarly, religious service was broad enough to be recognized for any specified religious tradition without creating conflicts within the model. The generic title of a religious leader within traditions needed to be specific (i.e., a Catholic priest vs. a Jewish rabbi) to consistently generate sermons. We created iterations of every race-religious tradition pair, including versions in which no race or religion were specified, and used them once for each LLM. The race/ethnicity categories are Asian, Black, Hispanic, White, and none specified. The categories of religious leaders are as follows: Roman Catholic priest, evangelical Protestant pastor, mainline Protestant pastor, Mormon (Latter-Day Saints) bishop, Jewish rabbi, Muslim imam, and none specified (“person”).
When no religious leader was specified, we used the word person instead (e.g., “Write a sermon that an Asian person might give during a religious service”). When we did not specify a racial group, the space was left blank (e.g., “Write a sermon that a Muslim imam might give during a religious service”). For the prompts that had neither race nor religion specified, we used the prompt “Write a sermon that a person might give during a religious service.” Sometimes, the LLM would create a bulleted outline for a potential sermon instead of a full text, and we would offer the following prompt to create the full text: “Instead of an outline, please write out the sermon.” An example sermon is presented in the Appendix.
Additionally, when we prompted the LLM to create a sermon from a Hispanic person, the original text would sometimes be in Spanish. We would then use the prompt “Please translate this to English” to get an English version. We flagged each sermon that was translated into English in our dataset. We created sermons from August 8, 2024, to April 21, 2025, with sermons generated between public model updates. In total, we created a dataset of 175 sermons (5 LLMs × 5 races × 7 religions).
We took the text of each sermon and entered it into a readability analyzer from Datayze (https://datayze.com/readability-analyzer). Readability scores assess the difficulty a reader would have understanding a particular text and measure the complexity of the written word (Wasike 2018; Williamson 2008). This analyzer calculates multiple measures of the text, including the number of sentences, words per sentence, characters per word, and percentage of difficult words. It also creates readability scores using the leading measures: the Gunning-Fog scale, Flesch-Kincaid grade level, and Fry readability grade level. Datayze has been used in previous literature to reliably generate readability scores and statistics about texts (Birkun and Gautam 2023; Olszewski et al. 2024; Riza et al. 2021; Tami-Maury et al. 2022; Van Horn 2022).
Readability is often used to assess whether texts are accessible to desired audiences, particularly in the fields of health education, communication, and research ethics (Ames 2019; Basch et al. 2019; Seidel, Hillyer, and Basch 2021; van Ballegooie and Hoang 2021). Within these fields, several studies have analyzed the readability of text created by LLMs where generating texts with accessible, approachable readability is imperative (Birkun and Gautam 2023; Fischer et al. 2021; Gencer 2024; Huang, Wei, and Huang 2024; Olszewski et al. 2024; Srinivasan et al. 2024). In this project, we applied readability as a novel way to measure potential biases that exist within the text-generating models themselves. Readability scores may correlate with stereotyped expectations regarding textual complexity and sophistication.
Dependent Measures: Readability
We used three common measures of readability: the Gunning-Fog scale, the Flesch-Kincaid grade level, and the Fry readability grade level.
The Gunning-Fog scale uses the number of syllables and sentence length to determine readability (Ginges 1958; Gunning 1969). The scale also uses the percentage of words that contain three or more syllables, which it considers “foggy” words. The measure ranges from a minimum score of 0 to a maximum score of 20. The measure is not context dependent but analyzes any text. A Gunning-Fog score of 5 is considered readable, a score of 10 is hard, 15 is difficult, and 20 is very difficult.
Flesch-Kincaid grade level is a widely used measure that assesses the reading grade level of a text using sentence length and word complexity. It indicates that the text can be read by the average student in the specified grade level (Kincaid et al. 1975). The measure was developed by the U.S. Navy, which used it for training technical manuals (Readable 2024) and uses a 0-to-18 range. It is not context dependent, but it is interpreted using grades from the U.S. educational system. For instance, a score of 8 represents an 8th grade reading level, while a score of 12 represents a 12th grade (high school senior) reading level. Scores above 12 represent collegiate-level reading, with a top score of 18.
The Fry readability grade level is a measure developed by Edward Fry and is often selected for its simplicity and accuracy (Fry 1975, 1977). It is based on a graph with two axes: the average number of syllables (x-axis) and the average number of sentences (y-axis) per 100 words. The measure is not context dependent, and any passages of text that are at least 100 words can be plotted on the graph to find the corresponding grade level. The measure ranges from 1 to 15 (https://datayze.com/readability-analyzer).
Although the minimums and maximums slightly differ for each measure, each readability score approximates the traditional school grade levels used in the United States. For instance, a 7 on each measure roughly equates to a text that an American seventh grader should be able to read. Scores greater than 12 indicate a college-level text.
Analytic Strategy
Because our goal is to see how LLM-generated texts differ on readability, we first explore univariate descriptive statistics to gain a better understanding of the overall distributions of the AI-generated data. Then, we use bivariate one-way analyses of variance (ANOVAs) and violin plots to see if specifying a religious tradition or a race/ethnicity was associated with higher or lower readability scores.
Finally, we use a multivariate robust regression to simultaneously estimate the effects of religious tradition and race/ethnicity along with the control variables of having an English translation and the LLM. We use robust regression instead of the usual ordinary least squares (OLS) regression because our data have one to two influential outliers, particularly from texts generated by the LLM Gemini (diagnostic results available upon request). OLS regression is sensitive to outliers and assumes homoscedasticity of residuals. Instead, robust regression is less sensitive to outliers because it calculates weighted residuals to reduce the influence of large errors (Andersen 2008; Huber 1973; Verardi and Croux 2009). Robust regressions first estimate an OLS regression and calculate a Cook’s distance (D) score for each observation. Using Cook’s D, which is a measure of outlier influence, the robust regression then weights each observation so that outliers have less impact on the model. For extreme outliers, the model gives the observation a weight of zero, and the observation is not used in the analysis. We note how many influential outliers have a weight of zero and are therefore not used in the analysis for each robust regression model. We use Stata 18 for all analyses and the rreg command for the robust regression (UCLA Statistical Consulting Group 2024; Verardi and Croux 2009).
Results
Descriptive Statistics
Table 1 reports the descriptive statistics for the dataset of 175 AI-generated sermons. Overall, the average number of sentences for each sermon was 32.65 (SD = 12.65), with on average 15.68 words per sentence (SD = 2.38). For each word, there was an average of 4.43 characters (SD = 0.32), and 11.79 percent (SD = 4.45 percent) of each text was categorized as “difficult” by the readability analyzer. A total of 19 generated sermons were first written in Spanish, and we had to translate them into English. Table 1 also reports how the religious traditions, race/ethnicities, and LLMs differ on core measures of the synthetic texts.
Mean (SD) for Artificial Intelligence–Generated Sermons.

Bivariate Results
Religious Traditions
To first examine how the readability measures varied between the synthetic sermons from different religious traditions, we created violin plots to visualize this relationship. Figures 1 to 3 show these distributions, and a clear pattern of variation emerges. Across all readability measures, three religious traditions stand out as having distributions further away from the mean: evangelical, Jewish, and Muslim. The distributions for synthetic sermons from evangelical Protestant pastors show easier to read texts, with very few observations close to the mean. The distributions from Jewish rabbis and Muslim imams, too, are further from the mean but in the opposite direction. These synthetic sermons are more difficult to read. Synthetic sermons not specifying a religious tradition or specifying Catholics, Latter-Day Saints, or mainline Protestants have distributions closer to the mean.

Mean Gunning-Fog score by religious tradition.

Mean Flesch-Kincaid grade level by religious tradition.
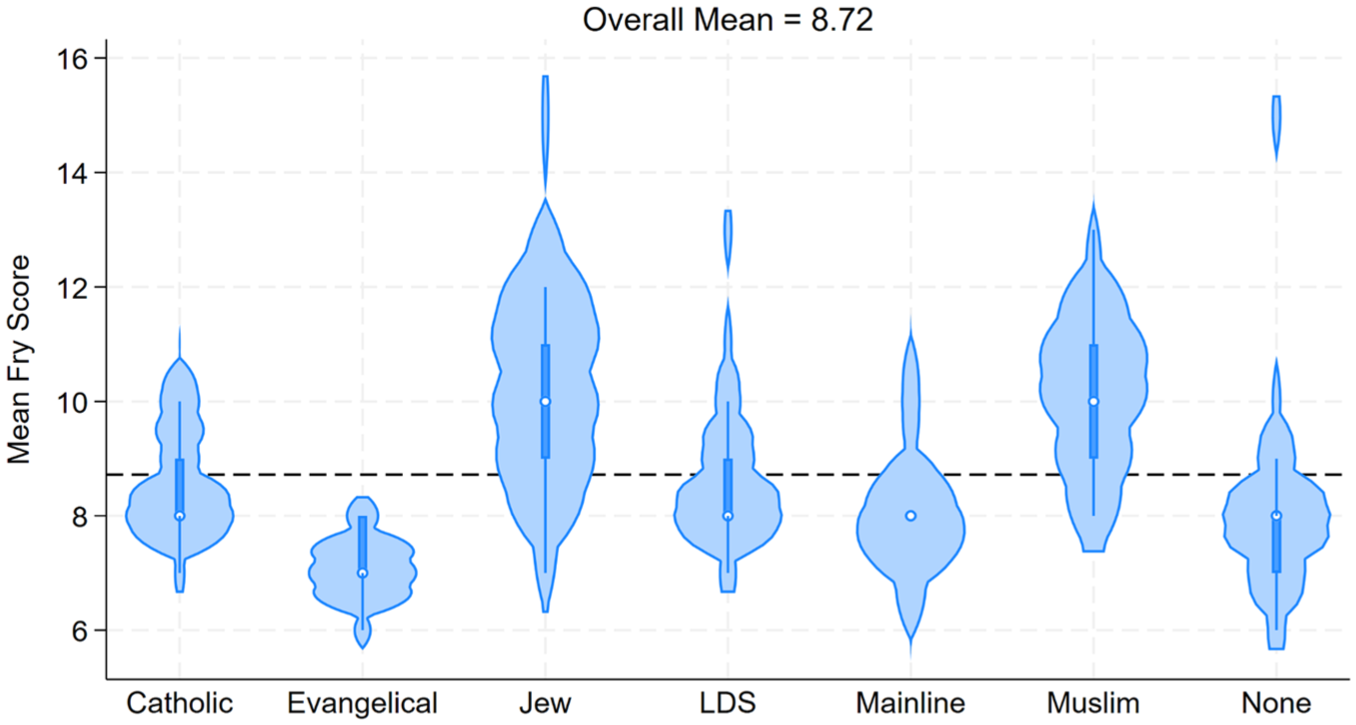
Mean Fry reading level by religious tradition.
Table 2 statistically examines this relationship between readability scores and religious traditions with means and standard deviations. As with the violin plots, the overall pattern shows that the LLM-generated sermons created from prompts specifying an evangelical Protestant pastor are easier to read, while those from Jewish rabbis or Muslim imams are more difficult to read. This offers evidence to support rejecting the null hypothesis. For instance, synthetic sermons from an evangelical Protestant pastor had lower scores on the Gunning-Fog measure (M = 9.03, SD = 1.15), indicating that the texts were easier to read than others. Synthetic sermons generated from a prompt stating a Jewish rabbi (M = 12.64, SD = 1.68) or a Muslim imam (M = 12.19, SD = 1.43) had higher Gunning-Fog scores, indicating a higher level of difficulty. The other two measures—Flesch-Kincaid and Fry reading level—also show a similar pattern, with AI-generated texts from Jewish rabbis and Muslim imams scoring higher and those from evangelical Protestant pastors scoring lower.
Analysis of Variance of Readability Scores by Religious Tradition.

Note: Post hoc (Scheffé) t test differences: C = different from Catholic; E = different from evangelical Protestant; J = different from Jewish; L = different from Latter-Day Saints; M = different from Muslim; N = different from no religion specified; P = different from mainline Protestant.
For each readability measure, the one-way ANOVA F statistic had a p value less than .01, indicating at least one of the means is different, contrary to our null hypothesis of no significant differences across religious traditions. Post hoc Scheffé tests reveal the significant differences between the two-category comparisons using two-sample t tests. Overall, AI-generated texts from evangelical Protestant pastors, Jewish rabbis, or Muslim imams had more pairwise differences, while sermons from mainline Protestant pastors, Latter-Day Saints bishops, and no religion specified had the fewest differences. For example, synthetic sermons from Jewish rabbis were significantly more difficult to read than every other religious category except Muslim in the Fry reading level. This pattern repeats itself for the Gunning-Fog and Flesch-Kincaid measures, except that the Jewish AI-generated texts are no longer different from those generated from a Latter-Day Saint bishop as well. Similarly, synthetic sermons generated by evangelical Protestant pastors were less difficult to read than those generated by Catholics, Jews, Latter-Day Saints, and Muslims.
Race/Ethnicity
When analyzing the distributions of synthetic sermons generated from prompts mentioning race/ethnicity, a different pattern emerges. Figures 4 to 6 show violin plots visualizing the distributions of readability scores by race/ethnicity. First, no racial or ethnic category’s distribution is pointedly away from the mean. Second, the category “none” (no racial or ethnic category specified) has readability scores that are easier to read (i.e., lower scores), even though its distribution still overlaps the mean scores.

Mean Gunning-Fog score by race/ethnicity.

Mean Flesch-Kincaid grade level by race/ethnicity.

Mean Fry reading level by race/ethnicity.
Table 3 statistically examines this relationship between readability scores and race/ethnicity categories using a one-way ANOVA and post hoc Scheffé tests. Similar to the violin plots, sermons generated from prompts with no racial/ethnic category specified are significantly different from those stating “Asian” on all measures of readability. Synthetic sermons given by Asian leaders are more difficult to read than sermons where no racial category is listed. For example, texts from Asian leaders have a mean Fry reading level between the 9th and 10th grades (M = 9.37, SD = 1.77), while texts with no racial/ethnic category have a reading level around the 8th grade level (M = 8.03, SD = 1.27).
Analysis of Variance of Readability Scores by Race/Ethnicity.
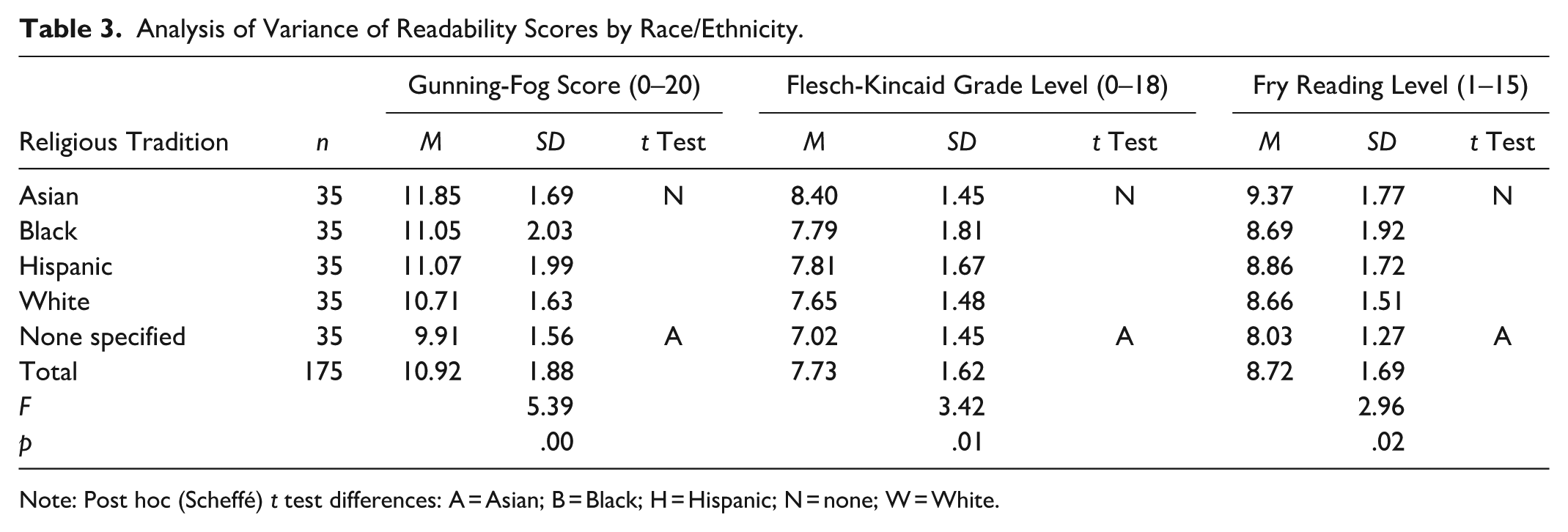
Note: Post hoc (Scheffé) t test differences: A = Asian; B = Black; H = Hispanic; N = none; W = White.
Multivariate Results
To assess the effects of religious tradition and race/ethnicity, alongside the influence of the LLM and English translation, we estimate three multivariate robust regression models including all variables. As shown in Table 4 and Figure 7, the patterns observed in the bivariate analyses persist even after controlling for LLM type and translation status. Contrary to the null hypothesis, synthetic sermons generated from prompts identifying an Evangelical Protestant pastor are less difficult to read than those with no religious affiliation specified. For all other traditions, except mainline Protestant, specifying a religious identity increases synthetic sermon text difficulty. For instance, AI-generated texts attributed to Jewish rabbis (b = 2.53) and Muslim imams (b = 2.12) score more than two grade levels higher on the Flesch-Kincaid scale. Latter-Day Saints sermons are one grade level higher (b = 1.01), and Catholic synthetic sermons are roughly three quarters of a grade higher (b = 0.79). In contrast, evangelical synthetic sermons are about one grade level easier to read than those with no religious identification (b = −0.92).
Robust Regression Predicting Reading Scores (n = 175).

p < .05. **p < .01. ***p < .001.

Robust regression coefficients predicting readability scores.
The effects of race/ethnicity mirror the findings from the bivariate analyses, too. For all three measures of readability, specifying a race/ethnicity category in the prompt creates a synthetic sermon text that is more difficult to read. For instance, using the Flesch-Kincaid measure shows that synthetic sermons from Asian leaders have more than one grade level higher in reading difficulty (b = 1.25), while those from Black, Hispanic, and White leaders are roughly three quarters of a grade level higher (b = 0.71, b = 0.88, b = 0.78, respectively). The only exception to this pattern is that AI-generated texts from Black leaders did not differ from texts without a race specified for the Fry reading level measure.
The only LLM that differed from ChatGPT-4 was Llama 4, which produced significantly easier to read texts. This is a noteworthy trend, as this is an open-source AI and less commonly used by laypeople, and therefore one would expect for the readability of its synthetic content to be more difficult than those of more widely used LLMs. It is worth examining in future studies if other synthetic content created by Llama is more readable than other LLMs, or if this pattern is more specific to synthetic sermons. Additionally, texts that were initially not in English and had to be translated by the LLM did not have higher or lower readability scores.
Conclusion
We explored the differences in synthetic sermons generated by LLMs by utilizing commonly used measures of readability. We did this by asking five different LLMs to create a sermon text. After each prompt we reset the LLMs and asked them to generate another sermon, but for a specific religious tradition and by a clergy member of a specified race. In all, we had each of the five LLMs construct 35 different sermons, which we uploaded to the Web site datayze.com, a frequently used source of calculating readability. We rejected the null hypothesis with regard to readability differences across religious traditions, as Jewish and Muslim synthetic sermons were constructed with significantly more difficult reading levels than were synthetic sermons constructed for an unspecified religious tradition. Conversely, LLMs consistently generated sermons with significantly easier reading levels for leaders in the evangelical Protestant tradition than those made for leaders from an unspecified religious tradition.
As LLMs are increasingly used across multiple fields, it is important to remain cognizant of the assumptions and potential biases embedded in the content they generate. Although LLMs are immune from interpersonal biases, they are informed by the content on the Internet, and we would expect to see variations across social groups. Although our results found readability varied by religious tradition, we observed generally consistent patterns across racial groups with the exception of Asians; when Asian religious leaders were specified AI-generated sermons were more than one grade level higher in reading level on average compared with other racial groups. It is possible that these differences reflect racialized assumptions about Asian intellectual ability or educational attainment, consistent with long-standing “model-minority” stereotypes in the American context. (Walton and Truong 2022) However, there was relatively small variation in reading levels across all other ethnoracial identities, contrary to our hypothesis, while sermons with a specified racial identity were, on average, higher than those with no specified racial identity. Future research on racial bias in AI should continue to explore the extent to which Asians may be unique as a stereotyped category compared with other racial/ethnic groups.
More research is still needed to explore the implications of these findings. This study focuses on the variation by readability. However, there are multiple ways to interpret these findings. For example, is it possible that the LLMs are implying that those listening to Jewish and Muslim sermons are more intelligent than those from Christian traditions, while evangelical Protestants are considered less intelligent? Conversely, the easier reading levels consistently associated with evangelical Protestant sermons across all LLMs could have nothing to do with assumed intelligence and merely suggest that Evangelicals are more likely to cater their sermons to a wider audience or want to distill their message to the most digestible form, an idea that resonates with previous research on the history of Evangelical leaders (Hatch 1991). As LLMs are trained on existing data, it is possible—perhaps likely—that these results reflect the religious content to which they are exposed. The extent to which that content is representative of each religious tradition is unclear. Our use of the concept of bias in this article is consistent with existing work in the literature but may be misleading when it comes to achieved statuses such as religion versus ascribed statuses such as race or sex. Furthermore, these readability scores are based on measures like word complexity and sentence length; these measurement limitations should be kept in mind, as other aspects of these AI-generated sermons, such as the interpretation of the religious content itself, may also prove to be useful in measuring group differences.
Nevertheless, assessing the readability of LLM content proved worthwhile, and we encourage other researchers to apply it as a test of implicit bias. The gendered nature of religious life is another intersection that could be explored in this manner. Alternative methods of analysis may also provide further insight into LLMs and bias, even in the dataset generated for this study. A content analysis of LLM-generated sermons could produce more nuanced results. Although our study demonstrates differences in reading levels, it is possible that LLMs inject culturally specific or stereotypical content into their sermons that are not picked by readability software. A cursory read of our dataset of AI-generated sermons suggests that “Black” synthetic sermons are disproportionately disposed to be about racial justice, while “Asian” sermons draw upon stereotypical imagery, such as lotuses or bamboo. These results demand a more systematic examination outside the scope of this study. But LLMs continue to evolve rapidly, and as their capabilities grow, so does their user base. Continually testing their generated outputs for preconceived social and cultural biases will only be more important as society increases its reliance on what these LLMs produce.
Footnotes
Appendix
Acknowledgements
We would like to thank the editors and anonymous reviewers for their helpful comments on an earlier version of this article.
Data Availability Statement
1
The use of bias in the literature on algorithms and AI typically refers to differences in group outcomes that are plausibly attributable to different assumptions about each group; we retain this language throughout but also discuss its limitations in our conclusion.