
Abstract
Status inequality is a matter both of the distribution of persons to status positions (men and women, highly educated and poorly educated, young and old) and of the value of those positions relative to one another. The authors’ work focuses on the second issue. The authors propose a stochastic model for how status value can be measured on a ratio scale from data on how occupancy of macro-status positions influences the micro-status orderings of actors that arise in task groups. The model is tested on three available data sets by estimating parameters and assessing goodness of fit.
Introduction
A great deal of research in social psychology documents the impact of macro-status differences (such as actors’ having different profiles on gender, race, and/or educational attainment) on properties of interaction in micro contexts such as task groups and committees. Such work presumes that large differences in status value have greater impact than small differences but does not develop this point into a way of meaningfully measuring the relative status value of different profiles on macro-status characteristics such as gender, race, and educational attainment. This is just one example of a wider problem of linking macro and micro levels of research.
In this article, we propose a model that bridges this divide. Its key assumption is the stochastic nature of how macro-status differences in position translate into differences in actors’ positions in micro-status orders in actual interaction. For example, in juries, college tenure and promotion committees, and ad hoc project teams, relative strangers come together to accomplish a task. When they do, status hierarchies emerge, as indicated by patterns of deference. For sociology, who defers to whom in a group’s interaction is a central problem, and much research documents that patterns of deference are related to individual standing on general status dimensions external to the context of group interaction. Although generally, those occupying higher external status positions (white-collar job holders on juries, full professors on tenure and promotion committees, persons with advanced degrees on project teams) tend to receive more deference, the connection is not perfect. In some groups, deference is given to someone who ranks low on the external dimension, while those who rank high are found at the bottom of the power and prestige hierarchy. It may be tempting to look for special circumstances in which such reversals occur. For the model proposed in this article, however, such anomalies are valuable clues to the relative value of macro-status positions measured on a ratio scale. They are systematic outcomes of how position in the micro-status orders of actual interaction is determined stochastically by differences in status value of the external macro-status positions.
The ability to measure key constructs is a hallmark of science. Measurement issues have plagued sociology from the start. 1 In the present context, how differences in the prestige or status value of positions in society arise, how they are maintained, and how they change are among the fundamental theoretical problems of sociology. But the precision with which the field can address these questions is limited by existing methods for measuring stability and change in the status value of positions. To take a specific example, the sociological understanding of changes over time in the relative value of gender statuses in American society is limited by our lack of a precise quantitative concept of status value (as applied to gender). That status inequality advantaging men over women has persisted through profound shifts in economic organization and in women’s labor force participation cannot be denied (Ridgeway 2011). Yet there has been no way to calibrate just how much persistence there has been and how much change might be yet in store.
Thus, we want to provide a precise measurement basis for the concept of status value, and we do so by modeling how status value affects initial conditions for micro-social processes, in particular interaction in task groups. Heretofore, most research has assumed that there is an unproblematic relationship between the differential evaluation of the characteristics or positions of people in a society or in an organization and the evaluations held by concrete individuals in a situated interaction situation, at least when they are unacquainted. In other words, in studying such situations, sociologists have assumed that there is an isomorphism of macro or global ranking and micro or local ranking as an initial condition of social interaction. It is this assumption that we abandon. As we explain in detail later, we take a stochastic approach to status value. We assume that evaluative choice or selection is a probabilistic phenomenon and apply a probabilistic theory of ranking that draws on a classic theory proposed by Luce (1959). One implication of Luce’s axiom of choice is fundamental to our approach: if choices are made over a set of alternatives in accord with the axiom, there exists a value function at a ratio level over the domain of alternatives (e.g., such as different macro-status positions like occupations). We apply this theory to the evaluative milieu of social interaction. It implies that a set of status values for different macro-status positions occupied by actors yields a probability distribution over the concrete (micro, local) status evaluations that are part of the conditions of interaction in the group. An important consequence of this probabilistic view is that it predicts the extent to which rank reversals can and do occur, that is, the extent to which higher and lower macro-status actors exchange relative ranks in a realized set of micro-status orders.
As to the situations of interaction to which the model is applied, they concern deference and hence status evaluations as documented in studies of differential participation in group problem solving. We present tests using three different discussion group data sets that record participation rates (which we use as our indicator of the micro-status order). One of these data sets has gender as the differentiating characteristic, while another uses an experimentally created differentiating characteristic. Such variation allows us to observe how different kinds of macro-status positions, through differences in relative status value of high and low positions on these characteristics, affect actors’ locations in micro-status orders as revealed by participation ranks. Moreover, these data also allow us to test the model’s predictions about rank reversals. We conclude with a discussion of the current limitations of our research, its implications for related research, and new directions of inquiry opened up by the ability to more precisely calibrate the relative status value of macro-status positions.
Deference and Interaction
In one of its accepted meanings, the notion of deference refers to “an attribution of superiority” to the other in an interaction (Shils 1968). The bases for deference, as discussed by Shils (1968), include a large number of what he called “macro-social” properties: occupation, wealth, style of life, proximity to centers of power, and educational attainment, to name a few. In this article, we use the term macro-status to refer to any such macro-social property that is a basis for deference, that is, an attribution of superiority (or inferiority).
To specify the problem, let us consider the example of occupation. National prestige rankings provide a convenient example of macro-status. But how widely shared is such a ranking? We know that it is constructed out of considerable variation among respondents and so is based on averaging. How then do differences in such occupational macro-status enter into situations of direct interaction? Surely, it is not safe to assume that people in such situations will all regard one another in terms of some consensual ranking corresponding to the national prestige ranking. So how then can we link the macro-status construct to social situations in which the underlying macro-social properties are part of the initial conditions? In particular, how can we use the solution to this problem in the context of theoretical models that make use of a mechanism involving deference to explain differential participation rates in group interaction?
How micro-status orders structure group interaction has been the topic of much previous research and formal modeling on the basis of a fertile idea attributable to Horvath (1965). His model proposes that an opportunity to speak moves down a micro-status hierarchy: members implicitly defer to the top person, who may or may not take the opportunity to speak; if not, members defer to the second-rank person, and if that person does not speak, the process continues with the opportunity passing down the status order until, if the lowest ranking person does not take the opportunity, it moves back to the top. As Horvath shows, the mathematics of this process yield a formula for the differential rates of participation in a group.
Horvath’s (1965) model has been the starting point for a variety of subsequent models linking status to participation rates. Tsai (1977), for instance, applied the model to natural groups of discussants, and Nowakowska (1978) developed the work of Horvath and Tsai further. These models, however, treat the initial conditions of ranking of members—the micro-status order—as directly reflecting, in a deterministic manner, the macro-status ordering. For instance, men are assumed to have higher status than women in the given group. The only question is how this status difference manifests itself in differential rates of participation in group discussion. Skvoretz (1988) also used variants of Horvath’s idea in his comprehensive model development exploring a variety of different models for participation distributions. Later work by Skvoretz and Fararo (1996) introduced a stochastic element and incorporated key insights and mechanisms from expectation states theorists (Fişek, Berger, and Norman 1991), but, like the earlier work, it elides the question of the relative status value of the macro-status positions.
More recent related work includes an empirical analysis of task group discussion by Gibson (2003, 2008) and theoretical modeling of micro-status orders in small groups by Lynn, Podolny, and Tao (2009) and Manzo and Baldassarri (2015) that built on the work of Gould (2002). Gibson analyzed meetings of managerial groups with 4 to 25 attendees. He focused on the micro-structure of conversational exchange through the concept of participation shifts. Participation shifts (P-shifts) refer to how specific individuals are recruited to the conversational roles of speaker, target (addressed recipient), and unaddressed recipient from one speaking turn to another. For example, one extremely common P-shift (among 13 possibilities) is represented as AB-BA, in which A addresses B, and in the following turn, B addresses A. Relative to this level of analysis, Horvath-based models ignore the nuances of conversational exchange in favor of an aggregated measure of sheer volume of participation as an indicator of rank in the group.
The theoretical models of hierarchy development in groups formulate the problem as an allocation of deference from group members to one another that results in some members receiving a greater amount of deference from others than they give to others. Such members have, by definition, higher rank in the group hierarchy than those who receive less than they give. Deference allocation is sensitive to (1) the perceived (exogenous) quality of one’s fellow group members (those of higher perceived quality are given more deference, all else equal), (2) pairwise balance in deference given and deference received, and (3) endogenous social influence of other group members on the perceived quality of one another. It was originally argued by Gould (2002) and Lynn et al. (2009) that these “micro-level mechanisms of social influence and reciprocity and deferential gestures,” in Manzo and Baldassarri’s (2015) terms, explained two group-level regularities about status hierarchy development. The first regularity is increasing deference inequality over time, accompanied by an increasing disconnection between quality and micro-rank in the deference order (i.e., reversals of relative quality and relative rank). The second regularity is the expectation that greater concern for reciprocity would dampen both growth trends (increasing inequality and increasing disconnection). However, the agent-based models of Manzo and Baldassarri show that these claims are either in error or, at best, limited to narrow windows of specific parameter values rather than holding more generally. If we equate the concept of quality in this line of research with the notion of macro-status, the model we propose is simpler in that it omits the micro-mechanisms of social influence on quality perceptions and concern with reciprocal balance. At that same time, it allows for disconnection between macro-status (exogenous) and micro-rank in a group’s status order so that those with lower macro-status (lower quality) may have higher micro-rank in terms of deference order. Furthermore, and unlike the deference exchange models, the observed probability of such reversals yields a way of measuring status values of different macro-status positions, as we now explain. 2
A Stochastic Approach to Status Value
Our approach may be called “stochastic interactionism.” It is based on the idea that when faced with a set of situational alternatives of social orientation, groups stochastically select among those alternatives, with the alternatives weighted by an agreed-upon set of values or scores that apply in all contexts in which such orientations are relevant. In this article, we apply this idea to the construction of a model for the measurement of status value in situations in which such status values are germane. The mathematical framework for our stochastic model assumes that the values of the states of a macro-status (such as occupation, education, or gender) satisfy a theory of choice (selection) proposed by Luce (1959). Luce’s theory implies that if the selection process satisfies a particular axiom, called Luce’s axiom of choice, there exists a ratio-level scale of values over the domain of evaluation such that each alternative has a defined point on that scale.
More specifically, our probabilistic framework for the measurement of status values and for the operation of such values in social interaction is grounded in this simple but powerful axiom, which can be formally stated as follows: let T be a set of alternatives, S a subset of T, and x an alternative in S. Let PT (x) be the probability that an individual chooses x when the set T is presented. Similarly, let PS (x) be the probability that x is chosen when the set S is presented. Let PT (S) be the probability that an alternative in set S is chosen when the set T is presented. The axiom of choice states, 3

One way to grasp what is being assumed is to think of a menu T with S as a part of T and x as an item in part S. Then one can see that the axiom of choice is the equivalent of the assumption that the probability that x is selected from part S of menu T is the same as the probability of choosing x when S is the (complete) menu. In symbols,

This equivalence holds because with the conditional probability on the left replacing the right side in the axiom (equation 1), the expression is no more than an identity of probability theory. Yet there is real empirical content to the axiom: an invariance of choice behavior is assumed between these two empirically distinct situations.
Luce proved that the axiom of choice implies that there exists a real valued function v, unique up to multiplication by a positive constant, such that for any finite subset of T,

This formula says that the probability that x is chosen from the set of situated alternatives S is given by the value of x divided by the sum of the values of all the alternatives in S. Because the values are unique up to multiplication by a positive constant, we have a ratio scale for the values v(x). Note that if S is limited to a pair of alternatives, the denominator is simply the sum of the two values:

Luce (1977) reviewed research on the choice axiom, including an earlier measurement study in sociology relevant in the present context, so we provide a brief sketch (details are found in Skvoretz, Windell, and Fararo 1974). These authors used as alternatives nine occupations from the National Opinion Research Center’s (NORC) well-known 1963 occupational prestige study (Hodge, Siegel, and Rossi 1964). Subjects, 79 male undergraduate engineering majors, were asked, for each pair of occupations in a list of pairs, to “choose that occupation which, in general, you accord a higher social standing.” Because the choice patterns generally obeyed Luce’s axiom, each occupation could be assigned a “prestige” (status value) on a ratio scale. The results are presented in Table 1, which is reproduced from Table 11.13.1 in Fararo (1973:334). 4 Table 1 includes the corresponding NORC prestige scores for comparison. The measurement based on Luce’s axiom produces an intuitively appealing ordering of the occupations, absent in the NORC measurements, into two broad categories, the first five professional titles and the lower four clerical or working-class titles. Because the values lie on a ratio scale, comparisons such as author of novels having about 6 times as much prestige as carpenter are valid, whereas such comparisons would not be valid on the basis of the NORC values (which are ordinal at best).
Occupational Prestige Status Values.

Source: Adapted from Fararo (1973:334).
Note: NORC = National Opinion Research Center.
We assume that the axiom of choice applies to situations of social interaction, not just to measurement tasks. That is, we assume that in situations of group interaction in which the question of deference arises, groups use the agreed-upon status values attached to actors’ profiles on various macro-status positions (such as occupation) to construct a micro-understanding of who defers to whom. But because of the probabilistic nature of the underlying choice situation, a particular ordering is not guaranteed on any given occasion, only that some orderings are more probable than others. To illustrate, consider a two-person group in which we have as an initial condition that it consists of an author of novels (x) and a carpenter (y) who are unacquainted with each other. According to Table 1, the author of novels has a higher macro-status position than the carpenter. A deterministic interpretation of this difference would immediately imply an isomorphic micro-status position difference, namely, the author of novels ranks higher in the interaction situation than the carpenter, so the latter defers to the former; in practical terms, the former participates more in group interaction, his or her ideas are more positively evaluated, and he or she has more influence over any group decisions.
In one stochastic interpretation that assumes that the decisions by individuals on the deference order are independent, we assume that both individuals hold the status values given in Table 1 for the two occupations and choose who ranks higher in the micro-situation in accordance with equation 3. So the author of novels ranks self above other with probability
Because the status values lie on a ratio scale, they can be multiplied by any constant without altering their empirical interpretation, so we can take the higher macro-status value and divide both values by it. For instance, if
Micro-condition Probabilities for the Two-person Case.
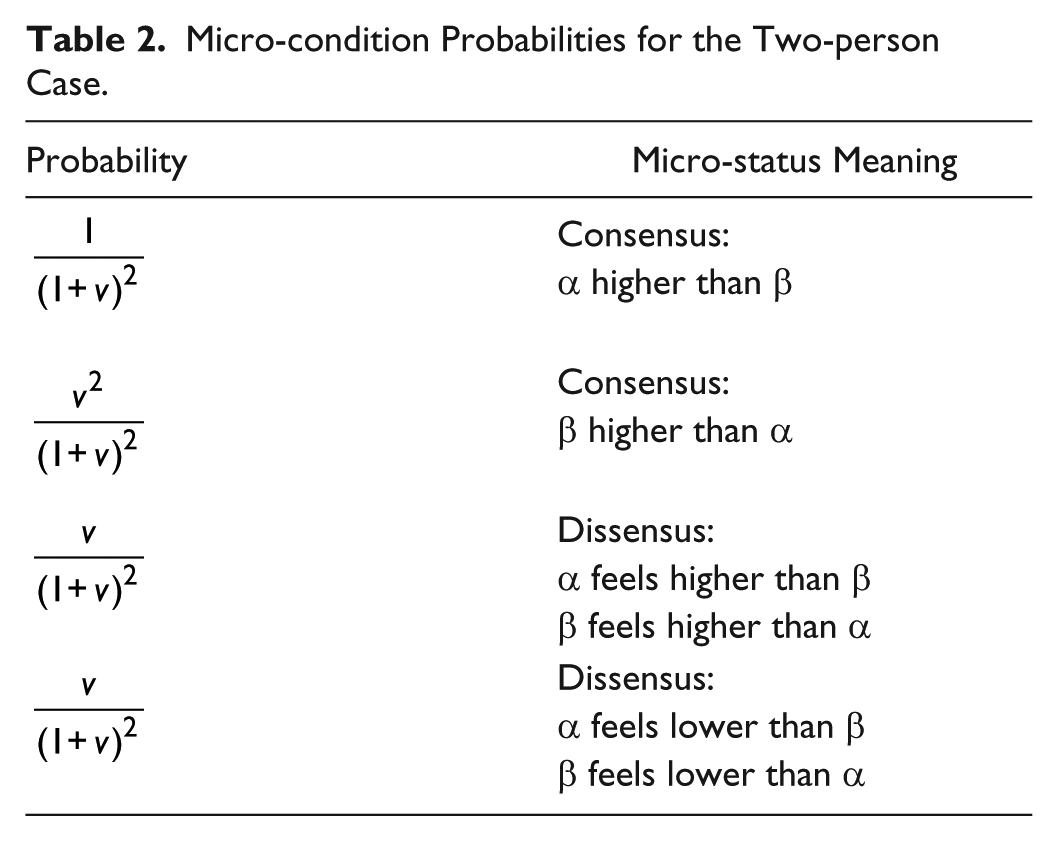
The Stochastic Determination of a Micro-status Ranking
There are many ways to deal with cases in which consensus on a micro-status order is not generated, and the selection of an appropriate way may depend on the context of application. In relation to this point and with an eye toward our application of the axiom of choice framework to task-oriented group interaction, we note that an important scope condition for such interaction in status characteristic theory (Wagner and Berger 2002) is collective orientation: all members are oriented to the group’s doing the best it can rather than do doing well for themselves individually. Discordant micro-status rankings clearly interfere with smooth joint action, so it is in the group’s collective interest to avoid dissensus. 5
Thus, rather than assuming that group members choose a ranking independently, the consequences of which are illustrated in Table 2, we assume an implied collective (group) selection of the situational status order. The macro-status values held by the actors stochastically generate that situational ranking. Thus, the group makes a stochastic transition to a uniform situational ranking (micro-status order) but not necessarily one in which actors of higher macro-status are also higher in the situated micro-status order. It makes this transition as if the group as a collective entity “selects” a ranking of its members on the basis of the status values of the positions they occupy. This key assumption of the model produces a weighted probability distribution over possible micro-status orderings or rankings. 6
In the illustration of the two person group, the probability that the ranking of α over β in which the first actor’s position is H (high) and the second actor’s position is L (low) is selected by the group is given simply by
Micro Distributions for Three Different Values of v.

Two points should be made about this assumption. First, although our illustrations and later applications are with reference to groups in which actors occupy only two possible status positions, conventionally denoted H and L, the assumption is quite general and can accommodate k different positions, each of which has a different status value. The limitation is driven by the research context we use to test the model’s predictions. 7 Second, the assumption that the group selects a ranking is a shorthand gloss on the process by which such a selection could occur through the initial stages of concrete interaction. That is, one can think of the group selecting a micro-ranking through an interaction process that leads to a particular order with a certain probability depending on the values of the macro-status positions occupied by its members. We return to this point in the discussion section when we consider how such status values can be insinuated into an existing stochastic process model for task group interaction proposed by Skvoretz and Fararo (1996) and motivated by expectation states theory.
To apply this framework to n-person groups in which persons occupy either of two positions, say H and L, on a given macro-status characteristic, we invoke another aspect of Luce’s choice theory, his ranking postulate, to define the probability of a particular ranking (Fararo 1973:Chap. 11; Luce 1959:72). This postulate states that a ranking is produced top down by drawing an actor from the initial group of n with probability equal to the value of the actor’s position on the macro-status characteristic divided by the sum of the macro-status position values of all n actors, then by repeating this draw for the remaining n – 1 actors and so on until all n actors are ranked. 8
Formally, let σ denote a ranking of the set T of actors, and let

and

For example, the probability in a six-person group with
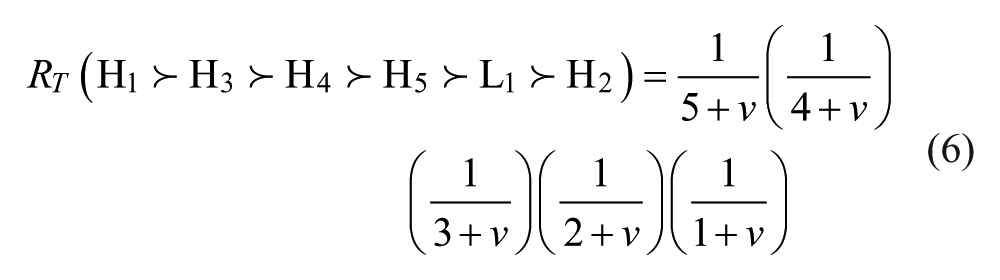
by repeated application of the ranking postulate.
The micro-status order is determined directly by these probabilities because it is as if the group as a whole selects a ranking for the micro-order. Therefore, the probability that the micro-status order is a particular ranking σ k is simply

The model has an unexpected empirical consequence. Smith-Lovin, Skvoretz, and Hudson (1986) used a standard correlation coefficient for ordinal variables, “gamma,” to assess the relationship between macro-status and micro-status, as indicated by participation rank, reporting an average value for gamma of .33 in a set of six-person mixed-status groups. The formula for gamma is typically expressed in terms of

The following theorem expresses the unexpected empirical consequence of the model.
Correlation Theorem. For all groups of size n divided into nH actors occupying macro-status position H and nL actors occupying macro-status position L, the expected gamma correlation between macro-status and micro-status rank depends only on v, the relative value of macro-status L, and is given as follows:

The equality holds for all values of group size n and mixtures of H and L macro-status positions. (See Appendix A for the proof.)
The model implies that as the relative value of the low macro-status position increases, the expected value of gamma decreases at a decreasing rate (as can be seen from the theorem’s formula by differentiation and by inspection of Figure 1).

E[Gamma] as a Function of v.
Tests of the Model
We turn now to tests of the model. Three questions arise at once: How can we identify the ranking that constitutes the micro-status order? How can we estimate status values from such observables? How can we test the consequences of the above formulation, given we have estimates of the status values?
As discussed earlier, in studies of participation in task groups, the idea that participation is organized by a hierarchy dates back to the early work of Horvath (1965), who postulated a process model of shifting action opportunities. In the context of a two-person group, the process works as follows: if α ranks first in the micro-status order, then α gets the first opportunity and takes it with probability r; should α not take it, β gets the opportunity and takes it with probability r; should β not take it, it goes back to α, and the process cycles back and forth. Thus, if α ranks first, then α speaks first (i.e., takes the opportunity in a small time interval) with probability

and with the complementary probability, β finally takes the opportunity. If β ranks first in the micro-status order, then the same result holds, except that p1 specifies β’s participation chances. The process is governed by the parameter r, which must be estimated from participation data. The important point for our immediate purpose is the fact that regardless of the exact value of r, higher rank in the underlying micro-status hierarchy translates into greater expected participation. Thus, we can use the participation ordering to identify the micro-status ranking that obtains in a particular group. But the use of the participation ordering is well justified to the extent that the observed participation distributions fit the Horvath model with specific values of r estimated. Consequently, we have two analytical tasks: first, use the observed rankings to estimate the stochastic model by which macro-status affects micro-status, and second, and subsidiary to the first, demonstrate that the micro-ordering inferred from the observed rankings provides good fits to the participation distributions.
The model specifies probabilities that particular micro-status orders will occur in groups of mixed macro-status positions using Luce’s ranking postulate and the hypothesis that a concordant ranking emerges quickly under the scope conditions constraining the group. Participation differentials identify the ranking in a group. We use the observed frequencies with which various such rankings emerge to estimate the value v of the lower of the two positions. Quite separately, the actual participation frequencies are then used to estimate the Horvath parameter r.
We apply this analysis to three data sets, two of which have been previously analyzed in the literature on small groups. The first data set is from Smith-Lovin et al. (1986). They reported participation distributions in mixed and homogenous gender groups of six members, composed of unacquainted undergraduates (race homogenous). Skvoretz (1988) used these data to evaluate several different models, one of which was the pure Horvath model. However, none of the models evaluated proposed a testable mechanism for the probability that a particular ranking of high- and low-status actors (in this group, men and women) occurs. Only the 22 groups of mixed-status composition are relevant to testing our model. The remaining 9 groups are homogenous and so offer no evidence on the relative values of the states of the macro-status presumed to be activated in these groups, namely, gender.
The second data set is reported in Skvoretz, Webster, and Whitmeyer (1999). The participation distributions are from four-person groups of undergraduates, either all men or all women, in which status differences derive from natural differences in year in school and grade point average. Mixed-status groups contain both first-year and fourth-year students. In addition, the first-year students, who are instructed separately from the fourth-year students, are told that the fourth-year students are high achievers, while they themselves are average. The fourth-year students are told that their first-year partners are low achievers but that they themselves are average. Of the 51 groups with usable measures, 35 are mixed-status groups and so provide evidence on the relative value of the macro-status, here year in school consolidated with academic achievement.
The final data set consists of 77 six-person groups, all of mixed-status composition. These data were collected at a southeastern university from 1998 to 2000 (Skvoretz 2012). Groups are homogeneous in race and gender: there are 16 groups composed of black women, 6 groups composed of black men, 36 groups composed of white women, and 21 groups composed of white men. Status composition varies from one high-status and five low-status actors to five high-status and one low-status actor. Status was entirely artificial and created by how individuals supposedly scored on a test of “meaning insight” administered prior to group discussion (Berger 2007; Berger and Fişek 1970). Students assigned to high status are told that they scored extremely high on this test (in the top 10 percent), while students assigned to low status are told that they scored about average for a student population. This information is communicated to the group as a whole just prior to discussion. We note that questionnaires administered after the report of scores checked for success of the manipulation and that there were two additional groups (for a total of 79) not used because recording quality made speaker identification too difficult.
Quite clearly, the first two data sets involve differentiating characteristics that most would recognize as macro-social properties: gender, year in college, and academic achievement. These characteristics are naturally occurring distinctions that are understood to have meaning and implications for social interaction well beyond the confines of the laboratory. In contrast, it seems odd to call “meaning insight ability” a macro-social property, because, if it has any effect, it is intentionally limited to the experimental situation; indeed, debriefing is required as part of the institutional review board–approved protocol to ensure that the manipulation is understood by participants to involve an entirely fictional ability. Nevertheless, in the context of the third set of experiments, this property functions as would a true macro-social property, namely, to differentiate members of a task group on a characteristic external to any micro-status order that emerges in group discussion and hence available for use in forming expectations about who is to defer to whom.
Thus, in all, we have data from 134 discussion groups of mixed-status composition. Of this total, 99 are six-person groups and 35 are four-person groups. The status distinction also varies from completely natural, the gender characteristic in the oldest 22 groups and year in school and grade point average in the 35 four-person groups, to completely artificial in the most recent data from the 77 six-person groups. The actual topic for discussion also varies. In the mixed-gender groups, participants are asked to create a problem for discussion by later groups meeting several criteria. In the other data sets, participants are asked to discuss 15 items in terms of usefulness to survival in a hostile environment and arrive at an agreed-upon ranking: a so-called survival task. In all three experiments, groups are incentivized by a “bonus” to arrive at what experts judged to be the best ideas or rankings.
Estimation of the relative status value of the lower ranking state of the macro-status characteristic is by maximum likelihood. For a group of size n, there are n! possible rankings of the n actors, each of which has an associated probability depending on the positions of the actors on the macro-status differentiating them. Let σ denote one of these rankings, let

Estimation uses the optimize routine in R (R Development Core Team 2012).
Assessment of the model compares the improvement in fit over a baseline model that assumes that there is no difference between the values of the higher and lower positions of the macro-status, that is, the null hypothesis that v = 1. The results are found in Table 4.
Model Estimation and Fit.

Note: A model that estimates a single parameter for all groups yields an estimate of v = .629 and a fit value of 1,504.583. Estimation of three parameters, one for each set of groups, yields an overall fit value of 1,497.245, for a difference of 7.338 (df = 2), an improvement in fit significant at the .05 level. A model that estimates two parameters, one for the first two sets of groups and separate one for the third set, has a fit value of 1,497.771 for a difference over the one parameter model of 6.812 (df = 1), an improvement in fit significant at the .01 level. This model is, therefore, the preferred model, and in that case, the estimate of v for the first two sets of groups is .443 and for the third set it is .772.
In all cases the null hypothesis can be rejected. The strongest status effect is found in the four-person groups and the weakest status effect in the six-person groups, in which the status distinction is entirely artificial. The most parsimonious specification uses two parameter values: one for the two sets of groups that use natural status distinctions and one for the set of groups that uses the artificial status distinction. The difference between the two sets means that actors of high macro-status position are more certain to attain high rank in the micro-status order in the four-person and six-person groups that are differentiated by naturally occurring distinctions and least certain to attain high rank in the micro-status order in the six-person groups differentiated by a totally artificial and experimentally manipulated status distinction.
The relative value of the high macro-status position in the four-person groups is 2.5 times the value of the low micro-status position (i.e., a ratio of 1 to .394). In the mixed-gender six-person groups, the relative value of high macro-status position is 2.0 times the value of the low macro-status position. In the mixed–meaning insight groups, the relative value of the high macro-status position is only 1.3 times the value of the low macro-status position. These interpretations can be made because the values of the macro-status positions lie on a ratio scale. The artificially created status distinction on meaning insight ability is not as important a driver of deference as the naturally occurring distinctions of gender, year in college, and academic achievement.
So far, the analysis of the participation data simply uses the information about the micro-status rankings to estimate the relative status value of the macro-positions. To fit the actual distributions of participation requires another estimation step, namely, estimation of the Horvath parameter r. The results of this estimation, also done by maximum likelihood methods, are found in Table 5.
Estimation and Fit for the Horvath Participation Model.

Note: A model that estimates a single parameter for all groups yields an estimate of r = .242 and a fit value of 183,467.200. Estimation of three parameters, one for each set of groups, yields an overall fit value of 183,347.800 for a difference of 119.400 (df = 2), a significant improvement in fit at the .001 level. The three parameter model fits significantly better (p < .050) than any model that equates parameters in two of three groups.
Although not anticipated, Table 5 shows that the three sets of groups differ significantly in the value of the Horvath parameter, which is the probability that the top-ranking actor takes a chance to participate, the complement of which is that he or she does not and the chance passes to the second-ranking actor. The pattern of difference follows relative status value, with the most unequal distributions being found in the mixed-gender groups and the four-person groups and the least unequal in the mixed–meaning insight groups. In this estimation, there is no simpler model that would fit the data equally well as the note to the table indicates. (Appendix B presents an analysis of the participation model in each group separately and shows that there are proportionally many more successful fits in the mixed-gender and four-person groups than in the meaning insight groups.)
That the model significantly improves fit overall and that it fits many of the groups well in an absolute sense are important to the overall idea of using micro-status orders to estimate the differential value of macro-status positions. It supports the inference that the micro-orders are meaningful data points from which to estimate macro-status values because taking these orders into account provides statistically significant leverage over the explanation of observed participation differentials.
Now that we have satisfied ourselves that using the rankings is acceptable, we return to a further assessment of the stochastic model for the rankings. It would be desirable to have an independent evaluation of the model’s fit. The usual way to accomplish such a task uses the fitted model to predict additional properties of the ranking data. Here we introduce one such property, namely, the number of macro-status position reversals in the observed rankings. That is, we count up the number of pairs in which an actor in a low macro-status position has a higher rank in the micro-status ordering than an actor in a high macro-status position. The maximum number of such reversals possible depends of course on mix of macro-status positions in a particular group. For instance, in a group of three H and three L actors, there are nine possible reversals (if the top three positions in the micro-status order are taken by the L occupants) whereas in a group of one H and five L actors, the maximum is five. Table 6 compares the observed and expected frequencies of reversals in each of the three data sets and assesses fit by a simple χ2 statistic. In all three data sets, the null hypothesis, namely, that observed frequencies are fit by the predicted scores, cannot be rejected at the .050 level. Thus, additional confirmation is provided to the overall idea that in these groups, micro-status orders can be accounted for by groups stochastically selecting among a set of ranking alternatives weighted by an agreed upon set of values for the macro-status positions (H or L) occupied by group members.
Observed versus Predicted Distribution of Reversals.

Finally, Figure 2 comprehensively summarizes these observed and predicted distributions relative to one another. It shows that the cumulative distribution of number of reversals depends on the status value difference between the H and L positions in a set of groups. The greater the status value difference, the more shifted to the left (toward smaller numbers of status reversals) is a cumulative proportion curve. The shift is clearest for the two data sets of six-person groups.

Larger Differences in Macro-status Value Produce Fewer Macro-status Reversals in Micro-status Orders.
The four-person groups have a smaller maximum number of reversals that could be observed, but were the curves for these groups to be scaled to that maximum, they would still lie above and to the left of the curves for the six-person groups. Within a particular set of groups, the figure also shows how well observed and expected cumulative proportions track each other.
Summary and Discussion
In this article, we link occupancy of macro-status positions to rank in micro-status orders via probabilistic models that also supply a ratio scale measure of the relative status value of the macro-positions. Rank in a micro-status order is identified with rank in the distribution of participation in collectively oriented task group discussion. The distribution of participation is modeled by a probabilistic process first proposed by Horvath (1965). The simple model linking macro-status to rank in micro-status orders assumes that a ranking is determined as if the discussion group as a whole draws from the set of possible rankings, with each alternative having a defined probability based on the relative value of the macro-status positions. Looked at from the bottom up, the Horvath model presupposes a ranking of members that controls the taking of opportunities to speak and thereby generates a distribution of overall participation in discussion such that the higher ranking members participate more (because of the mechanism governing getting and taking chances to speak). We derive that presupposed ranking from Luce’s choice and ranking postulates under the interpretation that evaluative selections are being made among states of a given macrosocial property. This derivation is a front end to the Horvath process model but does not involve any change in the process, for example, no bystander effects (but see our following discussion).
The model implies that on occasion, the local status order in a small group will differ considerably from what might be expected from the ordering of the macro-status positions of the actors. For example, consider a group composed of four H and two L actors, with v = .330 being the relative status value of the lower status position (so the H position has exactly three times the status value of the L position). A local ranking in which the two L actors occupy the top two positions has probability equal to .011 or one sixth less frequent than expected by chance (.067). Within the confines of the model, no further guidance is possible as to the circumstances under which such a highly unusual ordering could be observed. Such a rare outcome is inevitable but only stochastically. Quite possibly there are factors outside of the model’s current scope that could enhance the chances of observing a rare outcome; for instance, a second macro-status dimension, orthogonal to the first, could be activated in the situation and contribute to the high local context standing of the actors occupying the L position on the first dimension. Clearly, then, extension of the simple model to multiple characteristic situations would be in order.
Put more discursively, the following points sum up our analysis. First, Luce’s axiom of choice provides us with a general mathematical foundation for the measurement of macro-status value as a ratio-level construct. As a direct logical consequence of the meaning of the v scale and its role in ranking, the initial status condition of social interaction is interpretable as a probabilistically generated ranking of the actors on the basis of the states they occupy on a macro-social characteristic they bring to the situation (e.g., gender). Second, according to our model, this ranking “controls” the Horvath process of participation distribution in the situation. For instance, the highest ranking actor has the greatest chance of receiving and taking opportunities to speak. Third, once the model is applied to a set of relevant data on participation, the fact that the probabilistically generated ranking controls the Horvath process justifies the use of participation rate in order to identify which micro-status ranking is realized in a particular group. The term micro-status refers to this identification: in one sense, the deference pattern of participation (summarized in the rates) is the micro-status aspect of the situation, and in another sense, that aspect resides in the initial ranking that control the process. Through the use of the ranking postulate and its linkage to the Horvath process, there is a systematic linkage to the macro-status construct. Fourth, the data also enable us to estimate both the parameter r of the Horvath process and the macro-status parameter v, the value of the lower of two macro-positions differentiating group members. Fifth, and finally, we can derive a prediction about the distribution of rank reversals and use the degrees of freedom remaining after the estimation of parameters to test the model by comparing the predicted and observed number of reversals in the three data sets.
We may note some additional directions for further work. First, there is extension of the models to macro-social properties that have more than two states. Currently the macro-social properties are binary because that is all that is needed to coordinate with relevant data sets. Further development would deal with more differentiated macro-social characteristics, such as occupation, levels of education, or wealth. In principle, our application of Luce’s axiom and his ranking postulate applies to such cases as shown in Table 1, in which we report results of an early measurement study of occupational prestige.
Second, the scope condition that the group be collectively oriented provides the justification for the model’s assumption that status conflicts are adjudicated quickly and an agreed-upon micro-status order obtained. Although reasonable as a first approximation, it would desirable if the assumption could be anchored in a formal understanding of the group’s interaction in a way that clarified how the group’s act of selection could be accomplished. In the spirit of this remark, we note the Markov-chain model of Skvoretz and Fararo (1996), in which a group’s micro-status order is represented as a network of precedence ties that accumulate over time as a result of interaction. Three mechanisms are postulated by which such ties can form: an initiator effect, a bystander effect, and a status activation effect. The third effect, represented by a probability denoted η, modifies the first two effects. It amplifies the chance that a precedence tie forms from the initiator of an interaction to the target (or from a bystander to the target) when the initiator (or bystander) has a higher macro-status position than the target. It also depresses the chance that such a tie forms from initiator (or bystander) to target when the initiator (or bystander) has a lower macro-status position than the target. It is reasonable to suggest that the strength of the status activation effect depends on the relative status value of the high and low positions. In that case, we have a micro-mechanism by which the group, through interaction, “selects” a ranking of its members that favors occupants of the high macro-status position but does not guarantee their ascendancy in the micro-status order. To go even further, it could be asserted that the status value of the lower position, v, and the probability of status activation, η, are related by the simple equation

The stipulation leads to intuitively sensible interpretations: when the relative status value of the lower position equals that of the higher position—so there is no status value difference – the activation probability is zero, whereas if the relative status value is at its minimum, zero, the macro-status dimension is sure to be activated whenever there is a status difference in favor of the initiator or bystander. Fully developing the integration of the Markov-chain model with the ideas proposed in this paper seems to be a fruitful direction for future work. 9
In closing, the reader may wonder whether it is worth the effort to undertake the research necessary to establish the relative status value of the states of some macro-status property such as gender. Do we really need the precise measurements our approach offers? Much understanding of status inequality and its changes can be achieved in the absence of precise measurement, as Ridgeway’s (2011) analysis of gender inequality shows. Furthermore, the basis of our measurement approach rests on experiments in which the effects of some natural (non-ictional) macro-status property such as gender show up in the micro-status rankings of persons differentiated by the property in group discussion. Is it reasonable to suppose such measurements can be generalized beyond that context?
To respond to the first point, we note that although much can be accomplished in the absence of precise measurement, the more we understand the phenomena of status inequality and the deeper our comprehension of the mechanisms that sustain or change it, the more important it becomes to have precise measurements of any impact or intervention proposed to alter existing status inequalities. Absent good measurement, success or failure is more in the eye of the beholder than in the actual performance of the beheld. As for the second point, it is unlikely that the point estimates can be widely generalized beyond the context used to make those estimates. However, were we to find generational differences in those estimates, it is reasonable to suppose that such differences would signify important and pervasive social change that has penetrated throughout the social order from which the subjects of the experiments have been drawn. The measurements would then form one benchmark calibrating the amount of social change that has occurred.
One could imagine other benchmarks, an exercise that ironically highlights an advantage of the method in this article. For instance, another approach would be to elicit responses to suitable items from a random sample of a society-wide population, leading to direct status value estimates. In the case of gender, however, there would be a potential problem of contamination by social acceptability response bias. By contrast, the indirect method used in this paper has the advantage of arising in interaction situations in which the manifestation of differential evaluation occurs without conscious awareness.
Footnotes
Appendix A: Proof of the Correlation Theorem
Appendix B: Fit of Horvath Model to Individual Groups

| Group | Macro-status Position Mix | Estimate of r | Pearson’s χ2 | p |
|---|---|---|---|---|
| Gender six-person | 1H/5L | .374 | 1.240 | .871 |
| 1H/5L | .333 | 17.730 |
|
|
| 1H/5L | .351 | 5.430 | .246 | |
| 1H/5L | .317 | 19.330 |
|
|
| 1H/5L | .366 | 7.440 | .115 | |
| 2H/4L | .205 | 6.860 | .143 | |
| 2H/4L | .299 | 10.800 | .029 | |
| 2H/4L | .354 | 13.620 |
|
|
| 2H/4L | .281 | 10.210 | .037 | |
| 2H/4L | .188 | 1.720 | .787 | |
| 3H/3L | .169 | 0.480 | .975 | |
| 3H/3L | .287 | 8.870 | .064 | |
| 3H/3L | .252 | 1.990 | .738 | |
| 3H/3L | .329 | 5.520 | .238 | |
| 4H/2L | .302 | 5.240 | .264 | |
| 4H/2L | .451 | 13.630 |
|
|
| 4H/2L | .179 | 4.450 | .349 | |
| 4H/2L | .388 | 5.210 | .266 | |
| 4H/2L | .332 | 12.080 | .017 | |
| 5H/1L | .396 | 6.990 | .136 | |
| 5H/1L | .280 | 1.910 | .752 | |
| 5H/1L | .231 | 2.080 | .721 | |
| Year in school/academic achievement four-person | 1H/3L | .387 | 8.830 | .012 |
| 1H/3L | .248 | 1.420 | .492 | |
| 1H/3L | .285 | 14.340 |
|
|
| 1H/3L | .313 | 5.610 | .064 | |
| 1H/3L | .261 | 10.320 |
|
|
| 1H/3L | .213 | 1.070 | .586 | |
| 1H/3L | .273 | 6.150 | .462 | |
| 1H/3L | .197 | 0.230 | .891 | |
| 1H/3L | .267 | 0.930 | .628 | |
| 1H/3L | .144 | 2.220 | .330 | |
| 1H/3L | .163 | 1.100 | .577 | |
| 1H/3L | .192 | 5.960 | .051 | |
| 1H/3L | .370 | 2.870 | .238 | |
| 1H/3L | .397 | 7.040 | .030 | |
| 1H/3L | .388 | 0.610 | .737 | |
| 1H/3L | .136 | 0.120 | .942 | |
| 1H/3L | .483 | 9.950 |
|
|
| 1H/3L | .183 | 0.370 | .831 | |
| 2H/2L | .220 | 1.600 | .449 | |
| 2H/2L | .324 | 10.290 |
|
|
| 2H/2L | .236 | 1.140 | .566 | |
| 2H/2L | .347 | 15.790 |
|
|
| 2H/2L | .485 | 7.040 | .030 | |
| 2H/2L | .390 | 34.780 |
|
|
| 2H/2L | .275 | 0.310 | .856 | |
| 2H/2L | .274 | 5.180 | .075 | |
| 2H/2L | .349 | 3.680 | .159 | |
| 2H/2L | .434 | 5.020 | .081 | |
| 2H/2L | .258 | 8.130 | .017 | |
| 2H/2L | .177 | 4.700 | .095 | |
| 2H/2L | .273 | 5.050 | .080 | |
| 2H/2L | .283 | 5.920 | .052 | |
| 2H/2L | .089 | 1.020 | .600 | |
| 2H/2L | .256 | 10.110 |
|
|
| 2H/2L | .271 | 2.590 | .274 | |
| Meaning insight six-person | 1H/5L | .258 | 8.860 | .065 |
| 1H/5L | .259 | 0.330 | .988 | |
| 1H/5L | .155 | 1.960 | .744 | |
| 1H/5L | .224 | 8.180 | .085 | |
| 1H/5L | .238 | 13.700 |
|
|
| 1H/5L | .159 | 5.350 | .254 | |
| 1H/5L | .383 | 9.300 | .054 | |
| 1H/5L | .229 | 16.750 |
|
|
| 1H/5L | .316 | 19.410 |
|
|
| 1H/5L | .277 | 16.250 |
|
|
| 1H/5L | .161 | 6.190 | .185 | |
| 1H/5L | .218 | 1.620 | .805 | |
| 1H/5L | .247 | 0.720 | .949 | |
| 1H/5L | .281 | 2.000 | .736 | |
| 1H/5L | .289 | 52.120 |
|
|
| 1H/5L | .306 | 13.600 |
|
|
| 2H/4L | .200 | 4.450 | .349 | |
| 2H/4L | .253 | 4.860 | .302 | |
| 2H/4L | .192 | 18.030 |
|
|
| 2H/4L | .254 | 40.790 |
|
|
| 2H/4L | .292 | 39.620 |
|
|
| 2H/4L | .251 | 21.940 |
|
|
| 2H/4L | .202 | 26.240 |
|
|
| 2H/4L | .273 | 11.270 | .024 | |
| 2H/4L | .213 | 80.390 |
|
|
| 2H/4L | .121 | 8.560 | .073 | |
| 2H/4L | .255 | 14.850 |
|
|
| 2H/4L | .155 | 1.930 | .749 | |
| 2H/4L | .205 | 53.000 |
|
|
| 2H/4L | .280 | .890 | .925 | |
| 2H/4L | .395 | 35.980 |
|
|
| 3H/3L | .289 | 24.370 |
|
|
| 3H/3L | .366 | 13.210 | .010 | |
| 3H/3L | .229 | 5.040 | .283 | |
| 3H/3L | .207 | 14.070 |
|
|
| 3H/3L | .173 | 53.960 |
|
|
| 3H/3L | .174 | 11.650 | .020 | |
| 3H/3L | .209 | 24.700 |
|
|
| 3H/3L | .262 | 20.080 |
|
|
| 3H/3L | .264 | 48.700 |
|
|
| 3H/3L | .186 | 9.830 | .043 | |
| 3H/3L | .264 | 12.170 | .016 | |
| 3H/3L | .277 | 2.050 | .729 | |
| 3H/3L | .164 | 3.510 | .477 | |
| 3H/3L | .237 | 2.100 | .718 | |
| 3H/3L | .191 | 9.930 | .042 | |
| 4H/2L | .147 | 3.900 | .419 | |
| 4H/2L | .269 | 27.970 |
|
|
| 4H/2L | .195 | 5.180 | .269 | |
| 4H/2L | .269 | 95.660 |
|
|
| 4H/2L | .157 | 5.750 | .218 | |
| 4H/2L | .170 | 14.310 |
|
|
| 4H/2L | .242 | 34.600 |
|
|
| 4H/2L | .148 | 3.260 | .516 | |
| 4H/2L | .249 | 12.470 | .014 | |
| 4H/2L | .182 | 2.810 | .590 | |
| 4H/2L | .291 | 2.040 | .728 | |
| 4H/2L | .281 | 3.200 | .525 | |
| 4H/2L | .137 | 1.320 | .859 | |
| 4H/2L | .151 | 3.680 | .457 | |
| 4H/2L | .213 | 6.690 | .153 | |
| 5H/1L | .256 | 5.950 | .203 | |
| 5H/1L | .455 | 8.770 | .067 | |
| 5H/1L | .352 | 51.150 |
|
|
| 5H/1L | .162 | 1.950 | .744 | |
| 5H/1L | .143 | 1.730 | .785 | |
| 5H/1L | .331 | 1.640 | .802 | |
| 5H/1L | .208 | 19.480 |
|
|
| 5H/1L | .182 | 0.670 | .955 | |
| 5H/1L | .305 | 12.110 | .017 | |
| 5H/1L | .349 | 6.683 | .156 | |
| 5H/1L | .229 | 87.610 |
|
|
| 5H/1L | .227 | 58.840 |
|
|
| 5H/1L | .322 | 20.090 |
|
|
| 5H/1L | .236 | 19.450 |
|
|
| 5H/1L | .321 | 5.520 | .238 | |
| 5H/1L | .231 | 9.300 | .054 |
Note: Boldface p values indicate Pearson’s χ2 scores that would occur with probability less than .010 if the Horvath model with one estimated parameter were correct. The test has 2 degrees of freedom in the four-person groups and 4 degrees of freedom in the six-person groups. The hypothesis that the Horvath model as estimated fits the data cannot be rejected in 18 of 22 gender mixed groups (81 percent), in 28 of 35 year in school/academic achievement mixed groups (80 percent), and in 46 of 77 (60 percent) meaning insight mixed groups at the .010 level.