
Abstract
Stakeholder feedback is essential for policymakers to evaluate and develop effective policies, but traditional qualitative analysis methods are often labor-intensive and time-consuming. This study investigates the use of Large Language Models (LLMs) like GPT-4 Turbo (GPT-4) with human expertise to analyze stakeholder interviews regarding K–12 education policy in a U.S. state. The research employed a mixed-methods approach where human experts developed a codebook and iterative prompts for GPT-4 to conduct thematic and sentiment analysis. Results demonstrated that GPT-4’s thematic coding achieved 78% agreement with human coding at detailed levels and 96% alignment for broader themes, exceeding traditional Natural Language Processing methods by over 25%. GPT-4 also produced sentiment analysis results more closely aligned with a human expert’s judgment. Our qualitative comparisons between human and GPT-4 analysis results highlight the complementary roles of human expertise and LLMs in enhancing efficiency, validity, and interpretability of educational policy research.
Keywords
P
The rapid advancement of natural language processing (NLP) techniques—from traditional rule-based and statistical models to deep learning-based models, such as large language models (LLMs)—is enabling time-efficient comprehension of contents and sentiments in large text corpora. Traditional NLP approaches, including methods like Structural Topic Model (STM), have found favor in social sciences and policy studies for uncovering latent themes in extensive collections of texts, such as political speeches, news articles, and social media content (Blei et al., 2003; DiMaggio et al., 2013; Gao et al., 2023). Policy researchers are also interested in gauging stakeholders’ satisfaction about a given policy, perceived intended and unintended consequences, and areas for further improvement. Lexical-based sentiment analysis has been a popular tool for exploring public reactions expressed on social media or other platforms (Abdulaziz et al., 2021; Das et al., 2021).
Recent advances in LLMs have demonstrated impressive abilities to capture textual nuances. Researchers across various fields are examining the performance of LLMs, like OpenAI’s GPT-4, in content and sentiment analysis tasks (e.g., Chew et al., 2023; Wang, Xie et al., 2023), noting that model performance varies across different domains and tasks. However few studies have focused on these tools within the context of educational policy analysis. LLMs have been critiqued for algorithmic bias (Benjamin, 2019). Biases related to demographic factors, such as race and ethnicity, gender, and geographic location, are particularly problematic in the educational field which emphasizes equity (Baker & Hawn, 2022). Thus, it is crucial for education policy researchers to explore how to adapt LLMs for their domain-specific needs, while maximizing their benefits. Furthermore, despite the popularity of proprietary deep learning-based models among behavior and social science researchers, given the “black box” nature of these models, researchers must remain cautious of their limitations when employing these tools to make high-stakes decisions in the public policy arena (Shlezinger et al., 2023; Tang et al., 2024; Wulff et al., 2024). Before deploying LLMs in policy analysis, it is incumbent upon us to investigate: To what extent can policymakers and researchers rely on LLMs to analyze stakeholder feedback and opinions in high-stakes, context-dependent decision-making?
This paper is part of a broader study examining policies and programs that advance or hinder educational equity in Washington State’s K–12 public school system. The research was conducted in 2022, when public education was simultaneously managing post-pandemic recovery and implementing school finance reforms (SFRs) that stemmed from legislative statutes enacted in 2018–2019 following the McCleary v. State (2012) court decision, mandating changes in educational funding. For this study, educational equity is defined as the reduction of disparities in learning opportunities and outcomes for students from racial-ethnic minority groups and those from low-income backgrounds. To understand the impact of these concurrent changes, the project gathered perspectives through interviews with a diverse group of stakeholders, including state legislators, state-level policymakers, school district administrators, teacher union representatives, teachers, policy advocates, and community leaders. The study leverages cross-district variations to examine how these systemic changes affected educational equity across Washington State. Our study, guided by two sets of research questions, seeks to understand and enhance the application and performance of computer-assisted textual analysis techniques in educational policy studies:
Substantive Research Questions (SRQs)
What are the key themes that Washington stakeholders voiced about the K–12 public school system?
Which themes did stakeholders recognize as advancing educational equity (positive)? Conversely, which areas were mentioned as needing improvement or that hinder (negative) educational equity?
Methodological Research Questions (MRQs)
How accurate and valid are GPT-4 labels of key themes when compared to human experts’ labels and traditional topic modeling results?
How accurate and valid are GPT-4 sentiment classifications when compared to human experts’ and lexicon-based sentiment analysis?
This study employs multiple analytical approaches, combining human coding with NLP methods including GPT-4, STM, and lexical-based analysis. For SRQ 1, we developed a Resource Equity framework and expert-derived codebook to analyze stakeholder discussions on topics such as data accessibility, governance, and diversity, revealing that theme prominence correlates with stakeholders’ professional roles. SRQ 2 examines sentiment patterns regarding educational policies, highlighting areas needing improvement, while acknowledging progress in multilingual education and student support systems.
Our methodological analysis (MRQ 1) shows that GPT-4 achieved 77% alignment with human-coded themes, outperforming STM while offering unique insights despite occasional challenges with overlapping themes. For MRQ 2, GPT-4’s sentiment analysis demonstrated strong alignment with human coding, although both machine-led approaches faced challenges with nuanced expressions of dissatisfaction.
In the following sections, we discuss previous studies that employed computer-assisted methods approaches for semantic discovery and coding. We outline the conceptual framework that informed the formation of our codebook, ensuring that the coding process yields results relevant to the policy issue of interest. After describing the data collection and analysis process, we summarize our findings and discuss both policy and methodological implications.
Related Work
Automated content analysis methods have made it possible to discover latent themes and understand underlying sentiments in stakeholders’ narratives about given policies by systematically analyzing large text collections. Yet, the complexity of human language and domain-specific contexts suggest that automated content analysis cannot simply replace the nuanced and close reading provided by humans. The outputs of automated text analysis may be incomplete or misleading. Therefore, as the current technology stands, automatic methods should be thought of as amplifying and supplementing careful human analysis (Grimmer & Stewart, 2013). In this section, we review related prior work in GPT, traditional NLP approaches in textual analysis, their performance and limitations, and the unique contributions of our work.
GPT and Textual Data Analysis
Recent studies have investigated using GPT models for thematic and sentiment analysis of text data. These models demonstrate capability in identifying and labeling latent themes and sentiments in text, enabling automated qualitative analysis through deductive coding (Azungah, 2018), which involves either applying codebooks developed by GPT or those created through human–GPT collaboration for text interpretation (Chew et al., 2023; Dai et al., 2023).
Sentiment analysis has also been performed using GPT. Studies of social media posts and website reviews have shown that GPT-3.5 is capable of understanding sentiment and capturing tones—including sarcasm—and has substantially increased accuracy compared to widely used lexical-based methods (Belal et al., 2023; Kheiri & Karimi, 2023).
However, GPT models tend to focus on certain aspects of the input text, resulting in errors and biases that can be problematic if these biases and errors systematically correlate with people’s characteristics, such as gender, education, race and ethnicity, and socioeconomic status (Ashwin et al., 2025). If such biases are introduced during the human–AI collaboration involved in codebook development, they may compromise the validity of subsequent analyses. While prior work has shown that codebooks developed through human–GPT collaboration can achieve quality comparable to those created solely by humans, and substantially outperform GPT-only approaches (Barany et al., 2024), other studies have found that human raters who co-develop codebooks with GPT tend to evaluate passages more similarly to the model than those who were not involved in LLM-assisted codebook construction (Dai et al., 2023). This alignment suggests a potential source of bias. Notably, using a human-developed codebook in conjunction with a GPT coder has been shown to mitigate such effects (Xiao et al., 2023). Therefore, in our study, to minimize potential bias stemming from the “black-box” nature of large language models, we chose to rely on multiple rounds of human expertise without LLM assistance for codebook development.
Furthermore, LLMs like GPT may not possess all domain-specific knowledge, and their performance varies based on the structure and size of the codebook and the type of code. Inter-rater reliability varies depending on the length and complexity of passages analyzed, and the number of codes applied (Chew et al., 2023; Savelka, 2023). These weaknesses present risks for deploying GPT’s rapid text processing capabilities in less studied fields to produce impactful results, which underscores the importance of validating the methods before applying them to inform policy making in areas like K–12 public education.
Since the release of OpenAI’s latest models—GPT-4 and GPT-4 Turbo—multiple studies have documented significant improvements in performance and functionality compared to previous versions (GPT-3, GPT-3.5, GPT-3.5-turbo; Huang et al., 2023; Lyu et al., 2023; Sprenkamp et al., 2023). Researchers are examining the advantages and limitations of GPT-4 Turbo for deductive coding by testing various prompt types (Liu et al., 2024), finding substantial variability in inter-rater reliability across domains. Research indicates that GPT models’ performance is intricately linked to prompt design and phrasing (Cheng et al., 2023; Wang, Liang et al., 2023; Zhao et al., 2021). Systematically designed prompts that specify instructions and tasks for GPT can lead to more accurate and focused responses, reducing randomness, oversimplification, and overlooked information, particularly in expertise-rich content. Carefully designed prompts may even mitigate some of the model’s biases (Gao et al., 2023).
Studies on how to enhance information processing using LLMs are proliferating with unprecedented speed. This paper contributes to the current literature by expanding the investigation to a rarely studied yet high-stakes field. Methodologically, this study demonstrates a comprehensive procedure for applying GPT-4 to facilitate qualitative textual analysis, aiming to minimize latent bias and attempt to bridge inherent field-specific knowledge gaps of the model through a grounded development of the codebook by established conceptual frameworks and domain expertise in prompt designs.
Traditional NLP
Topic modeling for thematic analysis
In the realm of traditional NLP, topic modeling—like Latent Dirichlet Allocation (LDA) and STM (Structural Topic Model)—have emerged as a popular tool for the discovery stage of text analysis by extracting latent themes from texts (Jelodar et al., 2020; Leeson et al., 2019). Compared to LLMs, topic modeling maintains advantages in terms of transparency and interpretability, in addition to having well-documented operating procedures. The literature has documented a variety of strategies for validating unsupervised textual analysis results. These strategies often involve: (a) comparing the results with human expert coding of the same data, (b) juxtaposing the results with alternative data sources concerning the same phenomena, and (c) predicting criterion measures.
Researchers have used topic modeling to analyze a senator’s self-presentation to their constituents (Grimmer, 2013), and to analyze school reform documents (Sun et al., 2019). In both cases comparisons of machine-derived codes compared favorably to human coding methods. Other work compared grounded theory—an interpretive qualitative method widely used in social science (Glaser et al., 1968)—and topic modeling, finding a mix of similar and complementary insights (Baumer et al., 2017).
In our study, we initially employed human qualitative coding combined with STM topic discovery. The outcomes from the STM were then used to inform the development of the final version of the codebook. This process included examining highly representative documents within topics and extracting high-frequency keywords. Additionally, we assessed the overlapping of STM’s topic labels between the results of human coding, and conducted a comparative performance analysis for STM and GPT-4.
Lexical-based sentiment analysis
Lexical models represent one of the major approaches for sentiment analysis, with NLTK VADER being a popular lexical-based algorithm (Hutto & Gilbert, 2014). A recent study that applied seven sentiment analysis tools—Stanford, SVC, TextBlob, Henry, Loughran-McDonald, Logistic Regression, and VADER—to process social media posts and news articles found that VADER was still capable of outperforming the others (Das et al., 2021). Nonetheless, like other rule-based classifiers, VADER exhibits a weaker ability to recognize underlying tones and sarcasm in the absence of non-textual content such as emojis or social media tags (Gosavi, 2022; Nguyen et al., 2021).
The Conceptual Framework: Resource Equity Policy
Drawing on prior research in educational equity policy (Alliance For Resource Equity, 2023), we conceptualize a Resource Equity framework that includes six essential components of educational policies that influence equitable student learning experiences and outcomes in schools (Figure 1). The “inner circle” of policy strategies that are most proximate to students and have direct impacts on student learning includes: (1) the diversity and qualifications of school staff (teachers and other adults) who have close interactions with students in schools (Gershenson et al., 2022; Holt & Gershenson, 2019); (2) the curriculum and instruction that enable teachers and students to actively engage with rigorous and culturally relevant learning content (Bonilla et al., 2021; LDee et al., 2017; Long et al., 2012); and (3) other types of student support and intervention programs, such as mental health and social work services, multi-tiered support systems, summer school, and tutoring, which directly support students outside and around the classroom (Cipriano et al., 2023; Fryer et al., 2020; Guryan et al., 2023).

Resources Equity Framework Situated in a Data-Informed Iterative Improvement Cycle.
The “outer circle” of support includes (4) school finance that allocates resources to schools to support the offering of educational services (Jackson et al., 2016; Morgan, 2022), (5) school governance, leadership and community partnership that determine school decision-making structure and power dynamics among stakeholders (Gates et al., 2019; Wu & Shen, 2022), (6) the data and evidence that either enable or constrain the design, implementation, and evaluation of all the previous five components, as well as evidence-based accountability for effective and equitable use of educational resources (Dixon, 2024; Grabarek & Kallemeyn, 2020), and (7) system supports and interventions that include system-level reforms to better support students with academic and social-emotional needs, such as whole school improvement efforts (Borman et al., 2016; Dixon, 2024; Schueler et al., 2017). In addition, we acknowledge (8) the culture, climate, and local contexts that constitute the environment for student and family experiences inside and outside of the school building (Belton & Brinkmann, 2024; Bryk et al., 2010; Demirtas-Zorbaz et al., 2021).
Policy and practices pertaining to each component at each level of the school system and across the hierarchy of schooling systems are embedded within a continuous cycle of improvement. In this iterative improvement cycle, it is critical to strategically incorporate stakeholder voices from diverse racial backgrounds, professional experiences, and geographic locations in the state.
Data and Sample
Data Collection: Interview Process
The data for this study comprise 24 interviews with diverse educational policy stakeholders. Our purposeful sampling strategy was designed to maximize representation based on the following criteria (Maxwell, 2004; Patton, 1990): (a) the level within public school systems, including classrooms, schools, districts, and the state; (b) geographic locations within the state, including urban, suburb, and tribal schools; (c) roles of interviewees, spanning system actors at various levels of educational systems and three branches of the government at the state level, as well as non-system actors such as community organization leaders, advocates, lobbyists, teacher union representatives, and philanthropic organizational leaders; and (d) characteristics of students and local communities in terms of race/ethnicity, socioeconomic status, language, and homeless populations.
The interviewees were categorized into three primary professional groups: policymakers and administrators (state legislators, state-level policymakers, and school district administrators), educators (teachers and those in coaching or mentoring roles), and non-profit sector participants along with advocates (including teacher union representatives, policy advocates, and community leaders). Interviews were conducted virtually via Zoom, each lasting 45 to 60 minutes.
We intentionally designed the semi-structured interview questions to be broad, facilitating the emergence of a wide range of topics or deeper insights (Bhattacharya, 2017; see Appendix A1 in the online supplemental material for the interview protocol). Interviewees were requested to provide examples of current state and local policies that they believed most significantly enhance or limit racial and economic equity in Washington State’s K–12 public education system. We further explored their reasoning and the mechanisms they proposed. Additionally, we solicited their perspectives on access to reliable data and evidence to support policy development and implementation, as well as their suggestions for iterative policy improvement at the state and local levels.
Preprocessing Interview Data
Audio recordings were transcribed into text with filler words like “um” and “you know” removed. Given the complexity and nuanced nature of our coding categories, which exceeded those of previous studies (e.g., Liu et al., 2022), we divided the interview transcripts into paragraph-length documents to enable more precise coding analysis. This preprocessing step resulted in approximately 1,400 distinct documents for analysis. Each paragraph in our analysis represents a complete thought, which may comprise one or several sentences. To maintain coding objectivity, we stored identifying information (such as interviewees’ job roles and locations) separately from the text documents. Additionally, we randomly reorder the paragraphs to eliminate potential bias from sequential patterns or content similarity between adjacent texts, ensuring each paragraph’s coding remains an independent decision.
Method: Human–Computer Interactive Learning
Our methods incorporate multi-stage interactions between human and computer to conduct both qualitative and quantitative analysis to examine these four research questions. Figure 2 summarizes the key aspects of the overall workflow.

Workflow Diagram.
Codebook Development
First round of human qualitative coding for initial codebook development
Three qualitative researchers, all with education policy research knowledge and extensive experience working in K–12 schools, participated in the first round of coding to familiarize themselves with the interview data and to generate an initial codebook. The team employed a grounded theory approach, iteratively developing a codebook informed by the Resource Equity framework as stated in the Conceptual Framework section. This initial codebook was then used by three expert coders to code the interview data and conduct qualitative analysis for another study within the larger project, which confirmed the content validity of our conceptual framework. This initial codebook also served as the baseline for development of the final codebook used by human and machine thematic coding.
Topic modeling
Concurrent with the first round of human qualitative coding, we employed STM 1 to uncover themes and patterns through latent semantic analysis of word and phrase probability distributions. The analytical process, including the selection of the optimal number of topics, topic labeling, and cross-validation, adhered to established practice guidelines (Grimmer et al., 2022, Ch. 13; detailed information on topic modeling analysis can be found in Appendix B). The topics were labeled in accordance with the Resource Equity framework. To manually validate the themes identified by the topic modeling, we developed rubrics as detailed in Appendix A2. This validation involved scrutinizing 20 documents with the highest top proportions and the 10 most frequently occurring words to interpret the topics’ meaning and coherence. Out of 30 topics identified, 25 were deemed both theoretically coherent and practically relevant to the policy interests within the context of Washington State.
Code refinement and final codebook development
Subsequently, we integrated the themes from both the human-developed initial codebook and the STM findings to construct the final codebook. The initial codebook was refined with the help of STM, which provided more structured code labels and identified high-frequency keywords for the child codes. The finalized codebook contained eight broad parent codes that reflect the major themes from the stakeholder interviews and are aligned with our conceptual framework, thereby guarding the content validity of the text analysis by ensuring its results encompass the concepts pertinent to the policy issue of interest. These parent codes include (1) culture, climate, and environment; (2) curriculum and instruction; (3) data, evidence, and accountability; (4) governance, leadership, and community partnership; (5) school finance; (6) staffing resources; (7) student supports and interventions; and (8) system supports and interventions. Within these parent codes, we identified 28 child codes to represent specific topics discussed in the interviews. The final codebook (see Appendix A3) lists parent and child code labels, descriptions, and keywords.
We opted for topic modeling over LLMs in the final codebook development for several reasons. First, to avoid the potential biases inherent in LLM algorithms during the inductive coding phase (Benjamin, 2019), we sought to establish a baseline using the human-developed codebook for subsequent automatic analysis. Second, the topic classification and labeling with STM preceded the final refinements to the codebook; hence, subsequent changes to the codebook did not affect the STM outcomes. In contrast, if we incorporated GPT-informed codes into the codebook, those codes would be used for GPT-4 labeling and might have unduly favored it in thematic analysis. Furthermore, the straightforward interpretability of STM facilitated dimensionality reduction of unstructured text data, allowing for model improvement through parameter adjustments. Although STM’s simplicity might overlook subtleties that LLMs could capture, our human coders compensated for this with their nuanced understanding and domain-specific reasoning. Conversely, LLMs could introduce unnecessary complexity or biases at this stage of pattern discovery, making STM a more appropriate choice for supporting discovery without adding undue complexity.
Thematic Annotation
Human thematic coding as ground truth
To ensure the validity and consistency of the human annotation as the benchmark for evaluating machine-generated results, we conducted two rounds of qualitative coding, involving coders without a machine learning background. Once a codebook was developed, two doctoral research assistants were trained to annotate the entire interview dataset. Both coders had substantial training in educational policy in Washington State and did not participate in the codebook development process. They were introduced to use the codebook to identify up to three most salient themes for each paragraph, from child codes. If no appropriate child code was applicable, they were to select the most fitting parent codes.
During the training phase, both coders independently annotated a shared set of 50 paragraphs. They achieved consensus on over 75% of the coding, with any inconsistencies resolved through discussions aimed at reaching consent for final code selections. Having attained a stable inter-rater reliability, they coded the entire corpus and reported no cases of paragraphs containing more than three themes. The second round of human annotation served as verification. Authors, who were familiar with the interview data and the codebook, reviewed and revised the coders’ annotations to increase alignment with the codebook. This process yielded 0–3 codes for each unit of analysis, with 12% at the parent code level and 88% at the child code level. The codes identified by human coders were later used to compare with the topics assigned by the machine for each document.
We used human annotations to address substantial research questions. For SRQ 1, we analyzed the frequency of topic appearance during the interviews and further summarized the themes by stakeholders’ job roles. We hypothesized that teachers and teacher mentors would discuss topics such as staffing resources, recruitment, retention, and professional development more frequently due to their direct experiences and relevant knowledge. District and state administrators were expected to focus on issues like school finance and resource allocation, whereas non-profit organizations would likely emphasize the involvement of parents and communities in policymaking. If the analysis confirmed our hypotheses, it would add credibility to the human versus machine annotation comparison.
GPT-4 2 thematic annotation
To achieve optimal results from GPT-4, we developed multiple prompts, adjusting for the number of steps, examples, and instructions. We conducted several rounds of prompt testing using different parameters, manually reviewing the outcomes and the logic of the responses.
Prompt designs
Building on recent studies in prompt engineering, we designed and tested both zero-shot and chain-of-thought (CoT) prompts to reflect our double-layered codebook structure (Kojima et al., 2023; Liu et al., 2022; Wei et al., 2022). The instructions for GPT-4 mirrored those given to human coders, with the additions of study context and GPT’s role to bridge the information gap between GPT-4 and the coders. For all prompt variations, GPT-4 was specifically instructed to consider the context of the Washington State K–12 public school system. After extensive testing, we found that CoT prompts yielded a higher alignment with human annotations (54% for zero-shot vs. 77% for CoT), consistent with findings that CoT prompts enhance GPT’s performance (Kojima et al., 2023; Wei et al., 2022).
GPT analysis settings
GPT-4 was set to a temperature of 0.5. GPT temperature is a setting that controls the randomness of responses, ranging from 0 to 1 with a higher temperature allowing for more varied and creative outputs, while a lower temperature results in more predictable and conservative answers. Previous studies employing GPT for semantic annotation often selected a temperature of 0 to ensure reproducibility and low randomness (e.g., Chew et al., 2023; Dai et al., 2023; Xiao et al., 2023), albeit at the cost of limiting GPT’s exploratory capabilities. A recent study in automatic qualitative coding educational themes exploring different temperature settings reported better consistency and interpretability using T = 0.5 (De Paoli, 2024). To fully utilize LLM’s interpretative capacity while addressing concerns about inconsistent results at higher temperature, we employed three strategies: providing GPT with detailed task descriptions, verifying reproducibility on a subset of 50 randomly sampled paragraphs, and evaluating the randomness by comparing agreement rates with those calculated from shuffled labels. Our tests showed that over 96% of CoT results were reproducible and the shuffled agreement rates dropped substantially from 77.89% to 17.89%, indicating that the GPT labels were paragraph-specific rather than randomly assigned or “hallucinated.”
We refined the prompt instructions and tested them on randomly sampled data. Upon reviewing the codes and reasoning from the prompt variants, we selected the CoT prompt format as detailed in Appendix D1. Along with the prompt, we sent the OpenAI API calling GPT-4 model the entire codebook (codebook text replaced {codebook}) and one paragraph at a time (input paragraph replaced “TEXTGOHERE”). Since the OpenAI API does not have memory for prior exchanges, each API call for coding a given paragraph is stateless and independent, which allows for controlled generation conditions. To facilitate GPT-4’s step-by-step thinking, we also divided the coding task into three parts. First, in the educational context, behaving as a policy researcher, GPT-4 identified three most salient broad themes for each paragraph only using information in the “Parent” code column of the codebook
{“Theme 1”: “Accountability system”,
“Theme 2”: “Instructional programs”,
“Theme 3”: “Teacher union, salary, workforce”,
“Reasoning”: “The paragraph discusses the need for accountability in ensuring equal delivery of instruction across different regions (north and south side), which corresponds to the ‘Accountability system’ theme. It also mentions the delivery of instruction, which fits the ‘Instructional programs’ theme. Finally, the speaker refers to potential solutions that the union might not accept, which relates to the ‘Teacher union, salary, workforce’ theme.”}
Topic modeling thematic analysis
The STM results, including topic proportions and topic labels, were obtained prior to the finalization of the codebook (see section Method/Codebook Development/Topic Modeling). To be consistent with the structure of human and GPT-4 coding, we assigned the three highest topic proportions labels as the topic modeling codes to each paragraph. These codes are at child code labels as the STM did not directly assign parent codes. Because our topic modeling only produced 25 valid labels that could be matched to child codes in the final codebook, three child codes 3 from the codebook did not appear in the STM results.
Parent and child code level analysis
The codebook’s hierarchical structure led to an evaluation of machine performance at both broad (parent code) and specific (child code) theme levels. This involved standardizing annotation outputs, mapping child codes to parent codes, and removing duplicates, resulting in 0–3 codes at each level per paragraph. The methodological research questions were addressed by analyzing outcomes using both child and parent codes, where “original” labels refer to unmodified human or machine-assigned codes, and “parent codes” refer to all parent-level codes including those mapped from their child codes.
Sentiment Annotation
Human sentiment annotation
Authors conducted sentiment annotations and labeled the sentiment expressed in each paragraph as “Positive,” “Neutral,” or “Negative.” To ensure objectivity and content validity, we closely followed established definitions. “Positive” labels were assigned when interviewees expressed satisfaction with a policy or practice, demonstrated improvement from past practices, or identified policies or practices that have enhanced or have the potential to enhance educational equity. Conversely, “Negative” labels were used when interviewees expressed dissatisfaction, identified issues or challenges, or demanded improvements. When a paragraph merely describes the fact without expressing either “Positive” or “Negative,” we code it “Neutral.” After establishing common understanding of the definitions, the authors coded the interviews independently and then cross-verified each other’s coding. To maintain consistency throughout the coding process, we reached consensus through discussing any paragraph that we were unsure of or that had differential coding or understanding. Specific child codes in the codebook, such as “Progressive funding” and “Tests and inconsistent standards for college readiness and student success,” were recognized as inherently carrying sentiment in the context of studying policies advancing educational equity. Hence, we hypothesized a lower frequency of negative labels for “Progressive funding” and a higher occurrence of negative labels associated with “Tests and inconsistent standards for college readiness and students’ success” in the sentiment analysis results. This hypothesis serves as a validity check for the human sentiment analysis results.
GPT-4 sentiment annotation
The prompt for GPT-4 was carefully designed to reflect the task performed by the human coding, following the same guidelines (see Appendix D3). GPT-4 received and coded one paragraph at a time. The output included a sentiment label and a brief reasoning for assigning that label. Here is an example output:
{“Sentiment”: “Negative”,
“Reasoning”: “The interviewee expresses dissatisfaction with the tendency for teachers to delay teaching linear equations until February, resulting in a three-month gap in the curriculum. They believe that kids could learn them anytime with proper scaffolding, implying that the current practice is not effective or efficient. This statement highlights a problem or challenge in the educational system, warranting a negative sentiment classification.”}
Lexical-based sentiment analysis
We utilized the nltk.sentiment.vader package in Python for lexical-based sentiment analysis. This tool is one of the commonly used, best-performing lexical-based tools for sentiment analysis (Abdulaziz et al., 2021; Belal et al., 2023; Das et al., 2021). The interview text was input into the pre-computed algorithm, which then associated words with sentiment scores and compounded the overall sentiment scores for paragraphs, taking into account negations and intensifiers. These compound sentiment scores, ranging from -1 (most negative) to +1 (most positive), were then classified into “Positive,” “Negative,” and “Neutral” sentiment labels based on default cutoffs. 4 These cutoffs were designed to be generally effective across various texts, as determined through extensive testing and validation by the developers of the tool.
Comparing GPT and Traditional NLP to Human Coding
We applied semantic analysis to explore the underlying themes and sentiments in the interview data and discovered unique patterns that aligned with the interviewees’ job roles and responsibilities. The patterns were consistent with our hypotheses, which were derived from education policy literature and authors’ understanding of Washington State policy contexts. These findings cast credibility to the human annotation serving as the baseline for assessing the validity of computer-assisted analysis results.
To examine the validity of GPT-4’s thematic and sentiment analysis in the context of Washington State K–12 public education, we conducted systematic evaluations across multiple dimensions. We assessed thematic agreement using overlap metrics, such as the hit rate that calculates the proportion of GPT-4-identified codes matching to human-assigned codes out of the total number of human codes (Mathis et al., 2024; Xu et al., 2025). We further compared GPT-4’s coding with human coding results using confusion metrics. To ensure that a high overlap between GPT-4 and human codes was not due to overgeneralization or randomness, we also calculated a shuffled hit rate by randomly shuffling GPT-4 labels. A significantly lower shuffled hit rate would indicate meaningful, non-random coding.
Next, we evaluated topic-level alignment between machine and human codings using bootstrapped reliability measures to address class imbalance in the data 5 (Gwet, 2016) and cosine similarity based on TF-IDF to capture text-level similarity (Grimmer et al., 2022, Chapter 7). To adapt binary classification measures for our multi-label classification scenario, we applied one-hot encoding (Dahouda & Joe, 2021), assigning a value of 1 if a paragraph was associated with a given code, and 0 otherwise. Using 1,000 bootstrapped iterations—sampling with replacement to generate datasets of the same size (n = 100)—we computed Cohen’s κ to account for chance agreement (Cohen, 1960), along with 95% confidence intervals for each code by comparing human and machine annotations. Additionally, we calculated accuracy (the percentage of correct annotations) and AUC values, which assess a classifier’s ability to distinguish between classes and have been shown to be effective evaluation metrics in educational research contexts (Bowers & Zhou, 2019; Çorbacıoğlu & Aksel, 2023; Gilardi et al., 2023). Together, these diagnostic measures provided a comprehensive evaluation of the construct and criterion validity of GPT-4 for text analysis within our domain context.
Results
This section presents the key findings organized by each research question.
SRQ 1. What Are the Key Themes That Washington Stakeholders Voiced About the K–12 Public School System?
Human-annotated code frequencies (original labels) revealed the primary areas of the Washington K–12 public school system as highlighted by stakeholders during their interviews. Table 1 shows stakeholders’ extensive focus on data related topics, such as data collection and access, and use of data to help practitioners improve practices and inform policy making. This also includes issues of data sharing, reporting, transparency, and quality (“Data access, analysis, reporting, use, quality and transparency”). Beyond data-related concerns, inclusive governance in the K–12 public education system is one of the central topics, with four of the top five frequent themes related to it. Stakeholders emphasized the importance of meaningful engagement, such as building relationships and centering voices of the marginalized youth and families (“Coalition and relationship”) and collaborating with their communities (“Community”). In addition to bringing marginalized communities actively into the conversation, they also advocated for increasing representation of these communities in leadership roles (“Leadership in diversity”) to enhance diversity, inclusivity, and anti-racism in the system. Given that the interviews were situated in the context of the K–12 public school system, it was not surprising that “Governance, leadership, and community partnership” emerged as a salient topic.
Human Label Frequency

Note. All parent code frequencies were measured for original labels rather than converted parent codes from child codes. Parent codes indicated by * were not directly assigned to a paragraph by human coders.
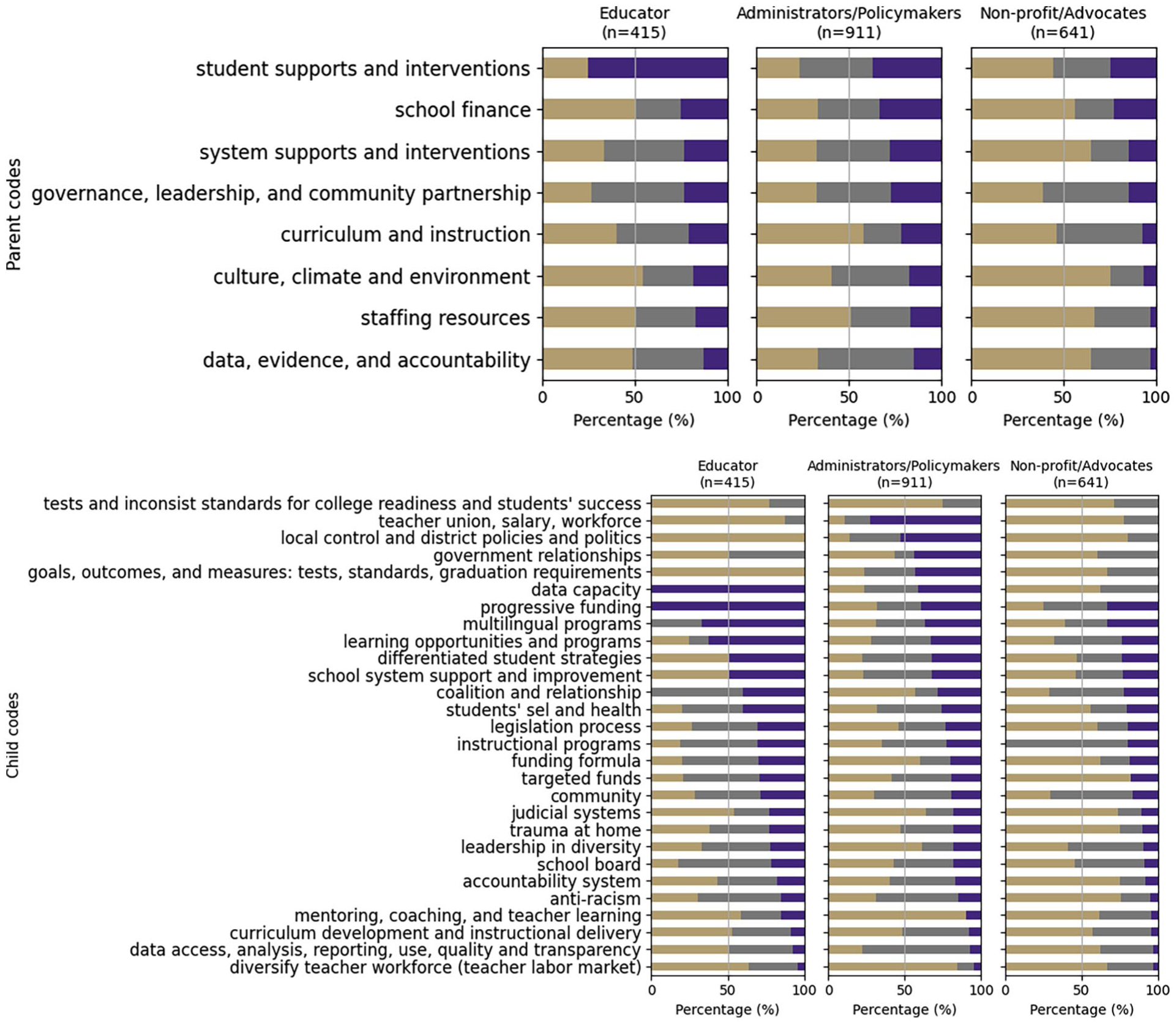
When we disaggregated our analysis by stakeholders’ job roles, 6 we developed a more nuanced understanding of the themes. As illustrated in Figure 3, the human annotation results largely indicated the same patterns of thematic distribution among the three types of stakeholders’ job roles: administrators and policymakers, educators, and non-profit advocates. These three types of stakeholders did voice unique concerns related to their daily work, expertise, and lived experience. For example, educators—including teachers and their mentors—concentrated more on “Staff resources,” such as teacher education for diversifying the teacher workforce (“Diversifying the teacher workforce and teacher labor market”), and “Student supports and interventions,” including learning opportunities in schools and access to curriculum programs (“Learning opportunities and programs”). Administrators and policymakers discussed “School finance” related themes, including “Targeted funds,” “Progressive funding” practices, “Funding formula” revisions, along with their work around bills and legislative process for educational policies (“Legislation process”). Nonprofit advocates highlighted governance and community relationships.

Human Labeled Theme Frequency by Stakeholders’ Job Roles.
SRQ 2. Which Themes did Stakeholders Recognize as Advancing Educational Equity (Positive)? Conversely, Which Areas Were Mentioned as Needing Improvement or Hindering (Negative) Educational Equity?
The study found that very few areas in the Washington state K–12 public education system received a majority of positive sentiment, which might highlight a need for improvement across many aspects of the system. Figure 4 illustrates the proportion of positive, negative, or neutral sentiments that Washington state K–12 public education stakeholders expressed within each topic area, as delineated by child or parent codes.
Human Labeled Sentiment by Stakeholders’ Job Roles.
A larger proportion of positive sentiment was expressed about progressive funding. Additionally, stakeholders commonly acknowledged the efforts and preliminary positive results in student support and interventions, particularly appreciating the reform of multilingual programs. The reform switched previously adopted late-exit programs, which focused on transitioning ELL students from home languages to English, to the multilingualism programs that committed to honor students’ cultural and linguistic heritage. As a local administrator illustrated: I think the thing that we have been able to do in that shifting, in that transition, is really clarify our commitment to bilingualism. And especially for our families who are second language [speakers], around that is your heritage language, that is the language of your ancestors. That is what connects us to who we are and the generations who came before us, and how important that is.
Such transitions demonstrated WA’s K–12 system’s commitment to equitable learning opportunities, differentiated support for students with diverse needs, and culturally responsive program design.
Stakeholders also pinpointed persistent issues such as inadequate student social-emotional learning and health support, attributed to lack of funding and insufficient staff resources—issues that became pronounced during the remote learning mode of the COVID-19 pandemic. A representative from a statewide nonprofit organization indicated the dire state of student mental health resources: “It is important to note the lack of necessary mental health resources for students around the state . . . and COVID-19 has raised the impact that the mental health crisis have been having on our students due to the lack of resources available.”
In addition to staff resources, the state’s data, evidence, and accountability system was critiqued for several commonly recognized concerns. Many stakeholders spoke positively about the volume of data collected and available within the state data system. However, they highlighted a distinction between data collection and data accessibility, critiquing the system’s complexity for creating barriers to those lacking data capacity and network connections. Furthermore, inconsistent standards and outcome measures, coupled with an absent accountability system, led to confusion and gaps in feedback loops across various aspects of the system. For instance, this lack of clarity adversely affected educators’ ability to deliver an equitable curriculum, as one stakeholder noted: “There should be some accountability that a kid on the north side is going to get the same delivery of instruction as on that south side. And I think that is still a gray area for schools.” Additionally, the absence of unified standards and accountability posed challenges in monitoring funding allocations for state administrators, with one commenting, “When you are looking at funding, we have put in almost $10 billion in the last 10 years, but there is really no accountability system to that. We still have 23 different accounting systems that feed into Office of Superintendent of Public Instruction [OSPI], and then they have to figure it out.”
Stakeholders’ attention to various areas reflected their roles and responsibilities, leading to divergent perceptions of the same issues. Compared to their counterparts in other roles, stakeholders from non-profit organizations and advocacy groups expressed general dissatisfaction with the current practices and policies, and called for improvements in numerous areas. This dissatisfaction often stemmed from the system’s inequitable treatment of marginalized students, families, and communities. A non-profit representative shared her observation of racial stratification within the system, recounting an instance where Black parents moving into a White community faced discouraging and demeaning challenges. She recalled a parent–teacher conference where the question posed to the parents was a telling one: “What makes you qualify?” She stressed that “we cannot just ask Black and brown people to enter spaces like that without some pretty intense incentive.”
These barriers impacted not only community and family access to the system but also influenced decisions related to the recruitment and retention of teachers of color. This caught the attention of state administrators aiming to diversify the teacher workforce and of representatives of teachers of color. Institutional and systemic racism led to a situation where, as an administrator acknowledged, There are very few teachers that stay for longer than 5 years. And a lot of them are exhausted. And a lot of the folks that we talk to, they leave because they do not want to be in the racial trauma of being in the school building, educating our kids and trying to decolonize the educational curriculum at the same time.
Educators recognized the limitations of policies concerning teacher unions, salaries, and the workforce. They also articulated a need for policies and practices to be designed and implemented with the aim of supporting students’ academic and social-emotional learning. Furthermore, practitioners suggested that the goals of such policies should be evaluated during implementation, rather than simply requiring compliance under the umbrella of local district control or complex government relationships. As one educator put it, I know that a couple of years ago the district came out with an equity policy. I think what is very interesting is how that actually plays out in leadership in classrooms. It felt like a very formal or not formal, but just like a checkbox. We did the thing, we wrote the thing we are going to abide by these policies that are very vague and not very specific.
MRQ 1. How Accurate and Valid are GPT-4 Labels of Key Themes When Compared to Human Experts’ Labels and Traditional Topic Modeling Results?
Evaluation for GPT-4 thematic analysis
To evaluate the overlap between machine and human coding, we calculated hit rates, which measured the percentage of machine-labeled themes that corresponded with human-labeled themes. Table 2 illustrates that, on average, approximately 78% of GPT-4 annotated child codes matched those annotated by humans for each paragraph. Given that up to three child codes were assigned to each paragraph, these results indicate a significant overlap at child code level about detailed themes, with GPT-4 and human coders identifying at least two identical themes per paragraph. The STM approach also demonstrated a high rate of overlap, aligning with human annotations for more than half of the child codes. Hit rates for both computer-assisted methods increased when comparing the broad themes (parent codes). In particular, GPT-4 parent code labels nearly fully cover the human experts’ coded parent codes.
Agreement Metrics and Evaluation Metrics for Thematic Analysis
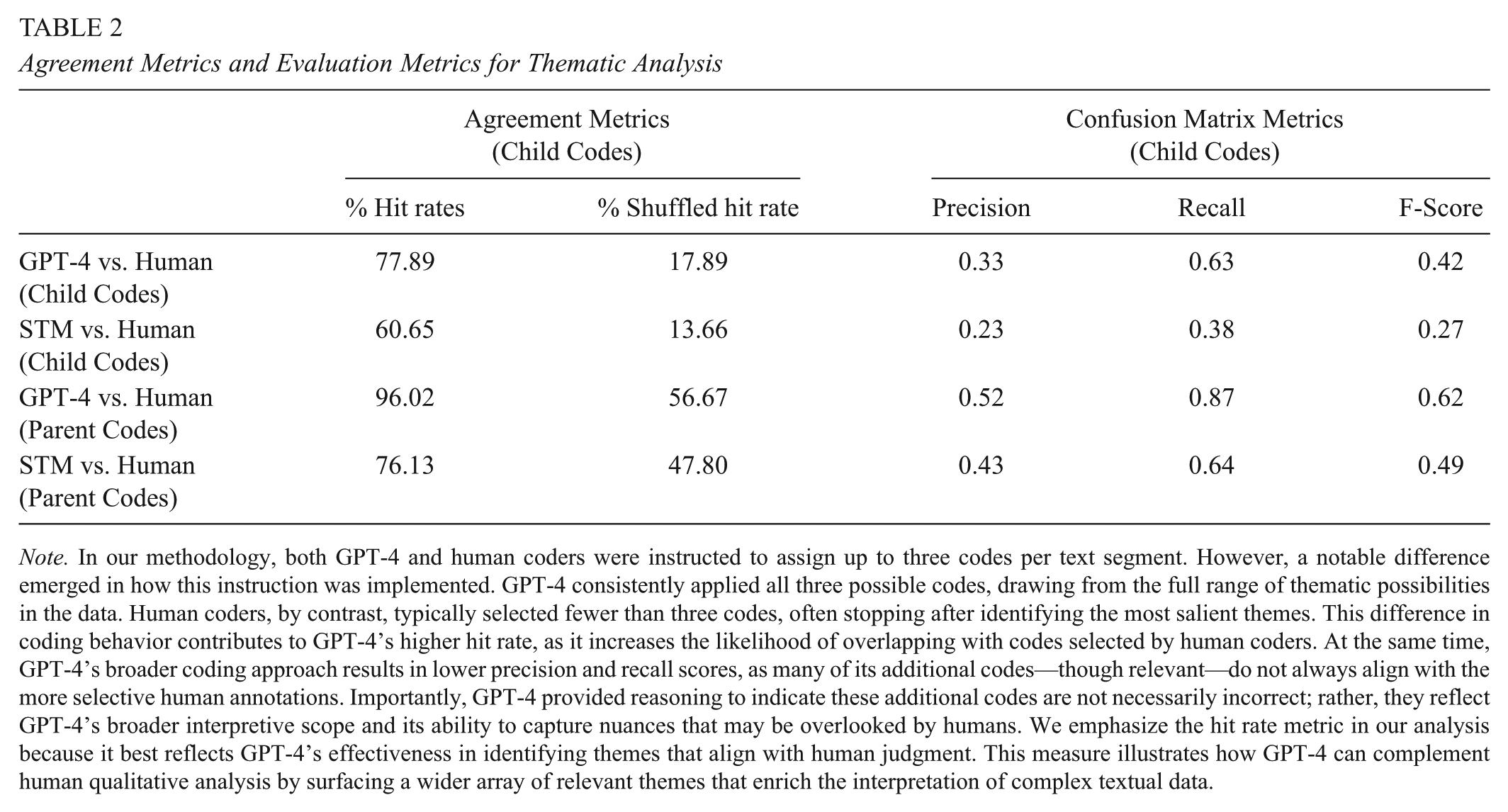
Note. In our methodology, both GPT-4 and human coders were instructed to assign up to three codes per text segment. However, a notable difference emerged in how this instruction was implemented. GPT-4 consistently applied all three possible codes, drawing from the full range of thematic possibilities in the data. Human coders, by contrast, typically selected fewer than three codes, often stopping after identifying the most salient themes. This difference in coding behavior contributes to GPT-4’s higher hit rate, as it increases the likelihood of overlapping with codes selected by human coders. At the same time, GPT-4’s broader coding approach results in lower precision and recall scores, as many of its additional codes—though relevant—do not always align with the more selective human annotations. Importantly, GPT-4 provided reasoning to indicate these additional codes are not necessarily incorrect; rather, they reflect GPT-4’s broader interpretive scope and its ability to capture nuances that may be overlooked by humans. We emphasize the hit rate metric in our analysis because it best reflects GPT-4’s effectiveness in identifying themes that align with human judgment. This measure illustrates how GPT-4 can complement human qualitative analysis by surfacing a wider array of relevant themes that enrich the interpretation of complex textual data.
To address potential random matches in GPT-4 outputs when the temperature setting is higher than 0, we calculated shuffled hit rates by comparing machine annotations for a paragraph with human annotations from another randomly selected paragraph. As shown in Column 3 of Table 2, the decrease in shuffled hit rates suggest that both GPT-4 and STM were capable of discerning paragraph content and assigning labels based on specific content. To test the robustness of our evaluation to different evaluation metrics, we also calculated Szymkiewicz-Simpson coefficients, Sørensen-Dice coefficients, and Jaccard similarity indices. The results of these measures, presented in Appendix C Table C1, are consistent with our findings in Table 2, that GPT-4 surpassed STM in accuracy for both child and parent level annotations.
Furthermore, we assessed GPT-4’s annotation performance using measures derived from the confusion matrix. Notably, at both the child and parent code levels, GPT-4 and STM exhibited high recall rates compared to precision. This implies that themes identified by human coders were likely to be recognized by the machines, but not all themes suggested by the machines were confirmed by the human coders. The relatively low precision could result from the different output formats in that human coders could choose between zero to three labels per paragraph flexibly; in contrast, the algorithms constrained the STM to always assign three themes and GPT-4 7 to identify three salient themes in most cases. Therefore, machine annotations naturally included more labels, leading to an increase in false positives. Nevertheless, the high recall rates confirmed claims from agreement metrics, illustrating that GPT-4 was adept at capturing human-identified themes and outperformed STM in this respect. Additionally, the low precision might indicate that GPT-4 was able to uncover nuances in text analysis that had not been detected by human coders.
Performance varied across thematic contents. As indicated in Table 3, GPT-4 generally outperformed STM on average, at individual parent code level, and for the majority of child codes (see Appendix C, Figures C2–C5). The average Cohen’s κ at the child level was comparable to deductive coding using an expert-informed codebook in linguistics (Xiao et al., 2023) and was better than deductive coding using a GPT-informed codebook for an open-access dataset (Dai et al., 2023).
Bootstrapped Performance Metrics

Note. This table presents the overall evaluation metrics. We also provide code-wise evaluation metrics in Appendix C (Figures C6–C9), which illustrate variations in performance across different topics. These figures highlight differences in GPT-4’s alignment with human coding depending on the thematic category.
Our parent-level statistics showed better performance. When comparing GPT-4 to human annotations for each code, Cohen’s κ exceeded 0.4 for five parent codes and surpassed 0.7 for two parent themes “Staffing resources” and “School finance.” Although Cohen’s κ for STM and human annotations for child codes ranged between 0–0.5, the agreement on the theme of “Data access, analysis, reporting, use, quality, and transparency” exceeded 0.6, outperforming the agreement between GPT-4 and human for this theme. For the remaining child codes, GPT-4 demonstrated higher concordance with human annotations than STM, especially for themes such as “Multilingual programs,” “Diverse teacher workforce (teacher labor market),” and “Teacher union, salary, and workforce.” Similar patterns were observed in the codewise AUC, which measures a machine’s ability to differentiate true positives from false positives for a theme and is unaffected by data imbalance (see Appendix C, Figures C6–C9).
In Appendix C10–C12 we present comparisons of human and machine coding at the text level and find high cosine similarities for both GPT-4 and STM. Summarizing all the evaluations, it appears that GPT-4 is capable of identifying themes from context-rich interview data, despite the complexity of the tasks posed by the hierarchical structure of our codebook and the large number of codes. GPT-4 recognized the same themes that were identified by human coders and also picked up on themes that were not selected by human coders. These deviations could potentially enrich the human interpretation of the text, adding nuance to the semantic analysis. However, agreement varied significantly across different themes. In general, GPT-4 performed better at identifying broader themes (parent codes) than more specific themes 8 (child codes), and was more adept at recognizing less domain-specific themes than more domain-specific ones. 9 Across both child and parent code levels, GPT-4 substantially outperformed STM on average, although STM might be more suitable for certain specific themes.
Qualitative review for differences between GPT-4 and human thematic analyses
For thematic analysis using GPT-4, we categorized themes by stakeholders’ job roles and summarized the findings. Unlike the uniform patterns of topic distribution among these three types of stakeholders’ job roles revealed by human coding as shown in Figure 3, the GPT-4 results presented in Figure 5 displayed a distinct topic distribution for educators. Specifically, educators focused extensively on themes such as “Anti-racism” and “Trauma at home” within the “Culture, climate, and environment” category, as well as on “Community,” “Student supports,” and “School supports.” These prevalent themes were consistent with our hypothesized focal areas based on educators’ daily responsibilities, which further cast confidence in the utility of GPT-4 coding.

GPT-4 Labeled Theme Frequency by Stakeholders’ Job Roles.
However, the theme “Local control and district policies and politics” was notably absent from educators’ narratives. Considering that the parent category of this child theme remained a significant topic among educators, we propose three potential explanations for this omission. First, the informal expertise that human coders utilized during coding may not have been fully captured in the child code description in the codebook. Second, the definition of this child code, which encompassed district-level decision-making and engagement with partners, as well as accountability and compliance under local control, might have been too nuanced for the LLM to discern, particularly in differentiating it from other child codes under the same parent category. Third, the plethora of codes provided may have overwhelmed GPT-4, preventing it from consistently attending to all codes. For instance, one educator’s statement clearly fell under this code and its definition but was not accurately labeled by GPT-4: In terms of local policies, something that can be limiting is the emphasis on compliance. I was a teacher in the district, and then I left for several years, and then I came back as a professional-development specialist around English learners.
Moreover, compared to the frequency of human coding, GPT-4 identified the “Culture, climate, and environment” category more frequently. Given that our interviews focused centrally on the evidence for equity in Washington K–12 public education, it is not surprising that themes such as “Anti-racism” were prominent in the discussions. GPT-4 seemed to detect nuances that had been overlooked by human coders. For example, one interviewee discussed changes in student demographics in programs for highly capable and gifted students, hinting at increased opportunities for non-White-middle-class students. GPT-4 recognized the inherent anti-racism tone in this statement. Nonetheless, GPT-4 also tended to overgeneralize broader themes because it lacked the ability to prioritize themes selectively, as human coders do by choosing fewer than three themes. Additionally, GPT-4 struggled to distinguish between codes with overlapping meanings under the same parent categories, resulting in some instances where themes human coders identified as “Progressive funding” were labeled as “Targeted funding” by GPT-4, inflating the latter’s frequency.
In conclusion, GPT-4 demonstrated proficiency in identifying underlying themes in our interview data. The results also suggest that human coders and LLMs can be complementary, with humans providing the priority, specificity, and expertise needed for detailed analysis and judgment, while GPT-4 uncovers embedded meanings that may be overlooked by human analysis.
MRQ 2. How Accurate and Valid are GPT-4 Sentiment Classifications When Compared to Human Experts’ and Lexicon-Based Sentiment Analysis?
Evaluation for sentiment analysis
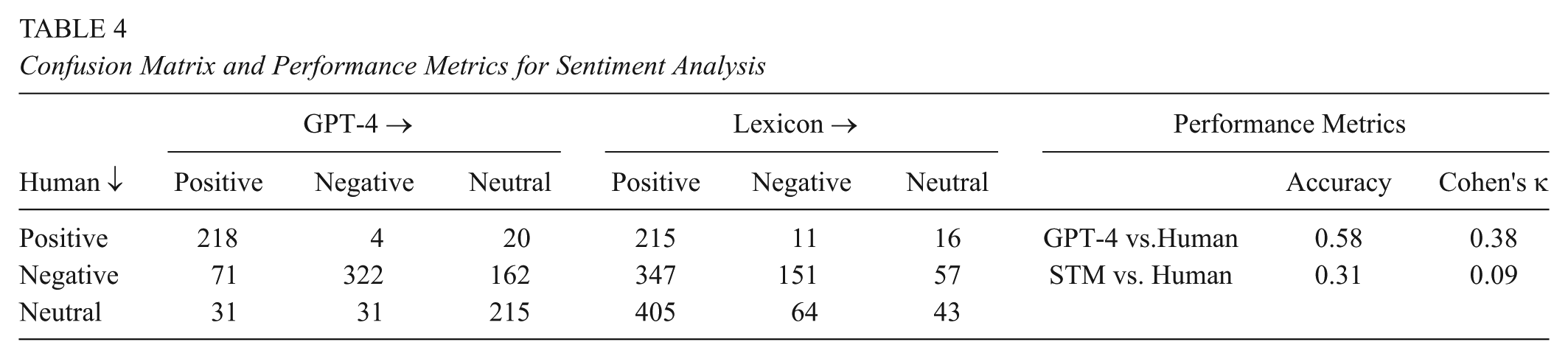
The confusion matrices in Table 4 indicate that GPT-4 aligned more closely with human sentiment labels than the lexical-based VADER. VADER notably overstated the positive sentiment in the text. Although the default settings of VADER, which were used, had been tested and validated by its developers for a variety of contexts, they may not have adapted well to the domain-specific language in educational policy, and failed to identify the underlying dissatisfactory sentiments embedded in stakeholders’ descriptions of programs and policies. Evidently, GPT-4 performed better at identifying the sentiment, aligning with human judgment in 58% of the corpus, especially for “understanding” the expressions of satisfaction, the potential for enhancing equity, and compliments on improvements. However, GPT-4 tended to overestimate sentiment. A significant divergence was observed between human perceptions and GPT-4 classifications when distinguishing “Negative” sentiment from “Neutral,” which impeded the machine’s overall performance. Humans might be more adept at detecting challenges and demands for improvement that were conveyed in the narratives. The inter-rater reliability between human coder and GPT-4 was moderate as measured by Cohen’s κ in the last column of Table 4. Cohen’s κ for sentiment analysis showed variability in previous studies, with agreement levels differing even among human coders. For example, Takala et al. (2014) reported that some pairwise agreement varied from 0.62 to 0.90 and Cohen’s κ varied from 0.41 to 0.80 between experienced human annotators using the three-category sentiments on a common set of economy news stories.
Confusion Matrix and Performance Metrics for Sentiment Analysis
Qualitative review for differences between GPT-4 and human sentiment analysis
Similar to the findings from thematic analysis, the agreement between GPT-4 and humans varied by theme. Figure 6 suggests that areas with more direct connections to equity tended to have higher agreement levels, as stakeholders could more clearly articulate their opinions on whether a given practice or policy was equity-enhancing or limiting. The more explicit illustrations resulted in easier sentiment capture by the machine.

Percentage of GPT-4 Sentiment Annotation That Agrees With Human Annotation, by Themes.
GPT-4 struggled to distinguish mixed feelings, leaning toward neutral rather than negative. For instance, an educator’s statement on learning standards was as follows: I do not even know where I stand, really, on common core standards. I like the idea of standards. I think that does help deliver a more equitable curriculum to students. but I think they are still fuzzy enough that it just simply does not happen. I know it does not happen.”
Human coders labeled the sentiment as “Negative,” noting the gap between intent and implementation expressed in the statement. In contrast, GPT-4 recognized the mixed emotions but gave a “Neutral” classification with an annotation: While they like the idea of standards and believe it can deliver a more equitable curriculum, they also mention that the standards are still fuzzy and not effectively implemented. The statement does not clearly lean towards a positive or negative sentiment, making it neutral.
Although the analyses from human coders and GPT-4 were similar, human coders utilizing their domain knowledge could discern the underlying negative emphasis by understanding the logic in the paragraph.
In conclusion, while human coders are better at logical reasoning for differentiating more nuanced sentiment intensity, GPT-4 also has its unique advantage of independent evaluation for each paragraph and uncovering implicit emotions, particularly in descriptive narratives. These distinct capabilities suggest that human and GPT-4 can complement each other in sentiment analysis to combine domain expertise with fresh perspectives.
Discussion and Limitations
This is one of the first studies to examine the potential of LLMs—represented by GPT-4—to facilitate highly domain-specific and context-dependent textual data analysis to facilitate high-stake decision-making. Our dual substance and methodological inquiries in this study have several implications for both educational policy for advancing racial and economic equity, and the potential promises and pitfalls of using LLMs.
Different stakeholder groups—educators, administrators and policymakers, and non-profit advocates—showed unique thematic focuses in the realm of educational policy. This diversity in thematic emphasis reflects the unique perspectives and priorities of each group. Educators predominantly concentrated on diversifying the teacher workforce and enhancing student supports, underscoring a direct engagement with the educational process. School administrators and policymakers, on the other hand, were more concerned with school finance and legislative processes, indicating a focus on the structural and regulatory aspects of education. Non-profit representatives brought attention to governance and community issues, highlighting the broader social context in which education operates. The varied thematic focuses suggest the need for a multi-faceted approach to educational policy analysis that takes into account the diverse priorities and perspectives of all stakeholders involved.
Our findings in sentiment analysis show that positive sentiments were predominantly directed towards “Progressive funding” and reforms in student support, particularly highlighting the value of “Multilingual programs” in preserving students’ cultural and linguistic heritage. This positive outlook underscores a growing recognition of the importance of cultural inclusivity in education. Conversely, the analysis also identified significant challenges, especially in areas like social-emotional and mental health support, which have been further exacerbated by the COVID-19 pandemic. Another notable concern raised in the analysis is the need for policymakers to prioritize diverse voices in decision-making processes. This includes balancing resource allocation, enhancing inclusivity, and extending community engagement to address the unique needs and perspectives of various groups within the education system.
Methodologically, GPT-4 demonstrates the large potential of LLMs to assist with analyzing large corpora of data to facilitate domain-specific decision-making in educational policy, especially in recognizing broader themes (parent codes). Besides its excellent performance in identifying themes with clear focal points, like “Multilingual programs” and “Data access, analysis, reporting, and use,” GPT-4 was capable of capturing nuances within broader themes like “Legislation process.” Compared to traditional NLP approaches, such as STM for thematic analysis and lexical-based sentiment analysis, LLMs have performed exceedingly well in various aspects.
GPT-4 can complement human expertise in that (a) it can discover nuances overlooked by human coders and (b) keep objective and consistent coding schema without being biased by human’s implicit and unconscious influence from their lived experiences, prior knowledge, or cognitive tiredness during the coding. For example, GPT-4 captured nuances in stakeholder discussions about equity related to themes of “Anti-racism” and “Trauma at home,” which were not initially picked up by human coders. This observation is consistent with prior research (De Paoli, 2024; Liang et al., 2024)
Additionally, LLMs offer a significant advantage in terms of time efficiency. Human qualitative coding can be labor-intensive; in the initial round, three expert coders devoted approximately 720 total hours over 3 months to complete all coding tasks. This process is also susceptible to the conceptual and subjective biases of the researchers. Collaboration with computational tools markedly reduces the time required for coding. In the subsequent round of human coding with an NLP-informed codebook, two research assistants completed the coding in a combined total of 42 hours. Including codebook development, the second stage took approximately 60 hours, a mere fraction of the time spent in the first stage. The use of LLM, specifically GPT-4, further decreased the time required, completing the coding in just 6 hours and introducing new insights into thematic discovery. Therefore, while recognizing the strengths and limitations of LLMs, a synergistic approach between LLMs and human expertise in textual analysis can enhance both efficiency and accuracy.
However, the performance of LLMs is sensitive to the nature of prompts, varying with domain intensity and the clarity of code descriptions (Liu et al., 2024). Prompts that incorporate extensive domain knowledge can help bridge the information gaps evident in current LLMs. The content validity of LLMs in aiding domain-specific data analysis relies on integrating domain knowledge into prompt development, which includes the codebook being incorporated into the prompt. Although humans’ domain knowledge and lived experience may lead to bias and inconsistent implementation of coding schema, they ensure and verify the validity of LLMs and serve as an invaluable form of informal expertise that enriches LLMs’ judgment.
Moreover, human experts are adept at capturing subtleties that LLMs may overlook. GPT-4 showed a tendency to overgeneralize themes, lacking the selective prioritization that human experts exhibit. Notably, GPT-4 performed well in identifying broader themes (parent codes) with an F1 score of 62%, which is higher than previous studies using similar technologies. However, its performance was less effective at the more specific child code level, struggling to differentiate between closely related sub-themes within the same broader categories. This issue suggests the need for more detailed descriptions in the codebook or prompts to improve LLMs’ precision. We recommend future work to explicitly direct the model to consider all available options before producing results, add more iterations with examples, or conduct multiple analyses on subsets of the data or codebook (e.g., identify the top layer [parent codes] then bottom layer [child codes]).
Despite our efforts to integrate AI and human coding approaches, several limitations warrant consideration. (1) This study is limited by its scope, focusing on participants within a single state. For larger-scale studies involving broader geographic areas and more participant roles, such as students and families from more diverse backgrounds, algorithmic biases in LLMs may have more significant impacts, which needs to be addressed when applying automated qualitative analysis. (2) While the AI-computer partnership offers flexibility in theme granularity through codebook adjustments, this adaptability may introduce inconsistency in analysis. For example, more specific codebooks may add more challenges to LLM coding. (3) Additionally, questions remain about the optimal LLM selection and parameter settings. We call for evaluation on different models’ performance for specific domain applications to ensure analytical rigor in the future study. Furthermore, we encourage a deeper conversation around the broader implications of adopting LLMs, particularly concerning the use of copyrighted content and the environmental impact of large-scale model deployment.
Conclusion
This study explored the potential of LLMs as a tool for uncovering themes and sentiments embedded in the narratives from stakeholders in Washington K–12 public education. Stakeholders emphasized the critical importance of inclusive governance, data transparency, and community partnerships within the Washington K–12 public school system, highlighting the need for stronger representation of marginalized voices. While they acknowledged some progress—such as reforms in multilingual education and progressive funding—concerns remained around insufficient student support, limited accountability systems, and persistent racial and systemic inequities across policy, practice, and leadership. The thematic and sentiment analyses have demonstrated GPT-4’s potential in educational policy studies to analyze stakeholders’ lived experiences and inform policymaking. Despite these promising results, LLMs are not yet capable of performing such analyses independently. Human domain-specific expertise remains crucial throughout the process for guidance and as a quality checker, since the risks—such as neglect, difficulty in making fine distinctions, and a tendency for overgeneralization—still need to be addressed. Policymakers and researchers should be cognizant of the limitations of LLMs as analytical tools, especially in terms of capturing the specificities of domain-specific meanings. Therefore, a balanced approach that combines the efficient thematic analysis capabilities of LLMs with the nuanced understanding of human coders can lead to more comprehensive and inclusive educational policy analysis that attends the varied needs and priorities of all stakeholders.
Supplemental Material
sj-docx-1-ero-10.1177_23328584251374595 – Supplemental material for From Voices to Validity: Leveraging Large Language Models (LLMs) for Textual Analysis of Policy Stakeholder Interviews
Supplemental material, sj-docx-1-ero-10.1177_23328584251374595 for From Voices to Validity: Leveraging Large Language Models (LLMs) for Textual Analysis of Policy Stakeholder Interviews by Alex Liu and Min Sun in AERA Open
Footnotes
Author Contributions
Liu and Dr. Sun assume equal authorship.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is supported by Ballmer Group, William T. Grant Foundation (Grant No. 190735), and the National Science Foundation (Grant No. 2055062). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the funders.
Notes
Authors
ALEX LIU is a PhD candidate in the College of Education at the University of Washington, Seattle, WA, USA; email:
Dr. MIN SUN is a professor in the College of Education at the University of Washington, Seattle, WA, USA, and Director of the AmplifyLearn AI Center; email:
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.