
Abstract
Given the increasing use of app books with young children, research is needed to inform their selection and design. Although broad guidelines exist, more fine-grained guidance is needed. To address this need, we explored the relations among app books’ digital affordances, readers’ behaviors with these affordances during both buddy and individual reading sessions, and their individual outcomes. Fifty-three kindergarteners (ages 5.05–6.46 years; M = 5.60, SD = 0.42) read 12 app books twice each across 24 buddy reading sessions and four app books once each across four individual reading sessions, and their comprehension was assessed after each individual reading session. Multivariate, mixed response analysis found that (a) when a greater number of minimum hotspots were available per page, retelling was better; and (b) availability of word hotspots was linked to better critical thinking/inference outcomes. Implications include choosing app books with affordances that this study showed support particular reading outcomes, in alignment with instructional goals.
Analysis of Previous Interactive Digital Text Research With Young Children
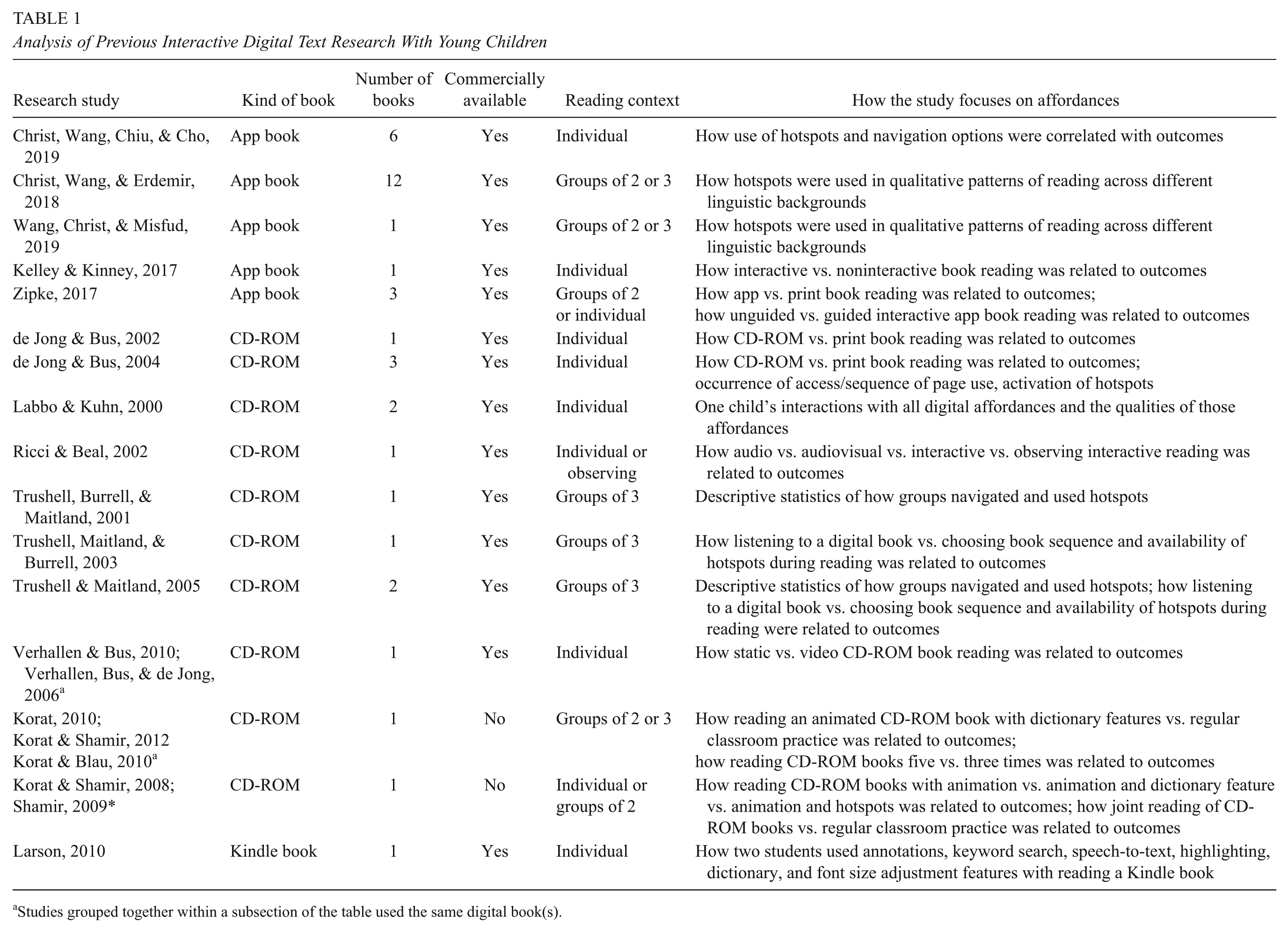
Studies grouped together within a subsection of the table used the same digital book(s).
Week-by-Week Design Overview of the Study

We address these limitations in our study by (a) focusing on interactive app books; (b) exploring the relations among affordances, reading behaviors, and reading outcomes; (c) exploring these relations across two contexts—buddy reading and individual reading; and (d) including all affordance variables available in the books in one analysis. The goal of this within-subjects exploratory study is to identify the relations between affordances, behaviors, and outcomes to better inform how to select and design books with affordances that promote desired reading behaviors and outcomes. This aim is guided by the following research question: How are app book affordances related to young children’s reading behaviors (during buddy reading and individual reading) and comprehension outcomes with interactive app books?
Theoretical Perspectives
This study is informed by Rosenblatt’s (1982, 1985) transactional theory of reading, which posits a framework that considers how readers, texts, and contexts dynamically and recursively transact to construct meaning. Although this theory was developed before interactive digital texts were available, we believe that it aptly applies to reading these, as well. Further, new literacies perspectives offer insights into the unique meaning-making pathways offered in interactive digital texts, such as the multitude of choices about how readers will transact with many more modes of meaning (e.g., sound, animation, interactive hotspots) as compared to printed paper books, which results in much more dynamic and complex transactions (Kress, 2003). Interactive digital texts are underscored by user control (Trushell, Burrell, & Maitland, 2001) of multiple affordances that necessitate user processing savvy (Lefever-Davis & Pearman, 2005), including young children knowing what affordances to ignore and not use (Christ et al., 2019). Because emergent literacy is conceptualized as “strategies the child uses to comprehend” (Harris & Hodges, 1995, p. 71), throughout this article, we refer to children’s transactions (i.e., behaviors) with app books as reading (i.e., often emergent reading) and their outcomes as reading comprehension (i.e., the outcomes of having used strategies to comprehend). It is important to note that the children in this study were not decoding printed words conventionally (i.e., word recognition) at the beginning of the study, as they were emergent readers. Instead, they were constructing meaning using the multimodal affordances (e.g., text reading aloud, animated hotspots). However, some children likely became early beginning readers across the school year.
To illustrate how the transactional theory of reading and new literacies perspectives are applied to emergent readers’ engagement with app books, consider the following example of Karen (all names are pseudonyms) from our study in this video: http://bit.ly/2naxs9h. The video shows the affordances of the app book But Not the Hippopotamus, such as reading aloud the various modes available in the book (e.g., “Read Myself”). Karen chooses “Megan Reads It,” a mode that reads all of the text to her when she turns each page. This mode selection, a reading behavior that reflects a transaction between reader and text, affects meaning-making and comprehension outcomes (Christ et al., 2019).
Additionally, listening to the text read aloud (e.g., “A frog and a hog cavort in the bog . . .”) potentially supports Karen’s choice to press the frog and hog hotspots, which in turn activate animation of them cavorting (a word used in the story’s text). This behavior is important, because activating hotspots improves children’s vocabulary learning (Christ et al., 2019). Further, because Karen is reading the app book independently, she cannot rely on any support from another reader who might help her choose or use the affordances effectively. When children engage in app book reading with a same-aged peer (i.e., buddy reading), they have the potential support of another child to improve their transactional behaviors with text (Christ et al., 2018; Wang et al., 2019).
Relevant Research
Given the limited research on app books, we review studies that explore the availability or use of digital affordances, such as various kinds of hotspots, animations, and reading modes, across both CD-ROM and app books to inform our study. Most previous research focuses on hotspots, which are activated by a user’s touch to generate (a) animations, (b) sound effects or music, (c) orally read words, or (d) some combination of these. Some hotspots are congruent—that is, they elaborate or extend the story line (see Unsworth & Chan, 2008, for a discussion of the ways illustrations and text elaborate and extend one another). For example, recall the video of Karen reading But Not the Hippopotamus. When she presses the frog and hog hotspots, which activates animation of them cavorting, this elaborates the meaning of the text. However, hotspots can also be incongruent—that is, they do not align with the story line. For example, in the same video, Karen moves the tree that the hippo is standing under. The tree’s movement is not aligned with the story line, so it is incongruent. Research shows that the use or availability of congruent hotspots is associated with better vocabulary, retelling, and inference outcomes in buddy and individual reading contexts (Christ et al., 2018, 2019; Korat & Shamir, 2012; Labbo & Kuhn, 2000; Shamir, 2009). In contrast, the use or availability of incongruent hotspots does not help improve comprehension outcomes in individual or buddy reading contexts (Labbo & Kuhn, 2000; Trushell et al., 2001; Trushell & Maitland, 2005). Further, when children read with buddies, they facilitate one another’s use of hotspots (Brown, 2016; Christ et al., 2018; Shamir, 2009; Wang et al., 2019).
Other research explores different digital affordances, as well. For example, research shows that reading books with automatic animations of illustration objects, which are activated immediately when the page turns, results in children’s better vocabulary, retelling, and inference outcomes, as compared to when they read static texts; and this is the case in both the buddy and individual reading contexts (Korat, 2010; Korat & Blau, 2010; Ricci & Beal, 2002; Verhallen & Bus, 2010; Verhallen, Bus, & de Jong, 2006). Additionally, young children most frequently use the “Read to Me” mode, which presents the book by reading the text aloud to them, and this mode improves their retelling outcomes as compared to using another mode (Brown, 2016; Christ et al., 2019; Trushell et al., 2003). Further, app books have other features, such as navigation options that include page-turn and menu navigation features, for which previous research has not yet investigated how their availability and use are related to young children’s comprehension outcomes.
Our study aims to extend this limited body of research on affordances in digital books for young children by focusing on how children use all the available affordances in app books across two contexts (buddy and individual) and how this is related to individual comprehension. This addresses researchers’ calls for more fine-grained analyses regarding effective digital affordance selection and design (e.g., Kucirkova, 2017; Zipke 2017).
Method
As part of a broader research project on kindergarteners’ app book reading development, this study explores how the digital affordances available in app books are related to young children’s reading behaviors in the buddy and individual reading contexts and their individual reading comprehension outcomes. The broader study design was modeled on Clay’s (1966) seminal concepts about print development research. Our broader study included 12 whole-class shared reading lessons that modeled and guided children to use digital affordances in app books effectively to support their comprehension. After each lesson, children had two opportunities to read the books used for instruction to practice applying the lesson strategies with a buddy. There were 24 buddy reading sessions in all. After every set of three lessons (i.e., a unit), each child individually read a novel app book that had similar affordances to those used during instruction in the unit and answered a research assistant’s questions based on a comprehension protocol. There were four individual reading sessions in all.
Drawing from this broader data set allowed us to explore the relations among app book affordances, reading behaviors in each of two contexts, and comprehension outcomes in an ecologically valid way. It also allowed us to investigate varied app book designs across eight publishers, all of which met the existing criteria for having affordances that support comprehension (Baxa & Christ, 2017; Brueck, 2013; Cahill et al., 2013; Morgan, 2013; Zipke, 2014). The study used a within-subjects design to reduce error related to individual participant differences. Thus, every child in the study read all the same books, engaged in the same number of buddy and individual reading sessions, and was tested on the same books in the same way at approximately the same time. Table 2 presents a week-by-week overview of the study design.
Participants
Children from four suburban classrooms in two U.S. states were invited to participate in the research. No child in these classrooms was excluded due to language or other learning needs. We included all children to provide a broad sample that reflects actual classroom populations. Of those invited, 53 kindergarteners had both parent consent and orally assented to participate. Children were ages 5.05 to 6.46 years (M = 5.60, SD = 0.42). The sample was about equal in terms of gender (52.8% girls, 47.2% boys). Several racial groups were represented: 62.3% Caucasian, 13.2% Asian, and 24.5% African American. Although most children spoke English as their first language, 20.8% spoke English as a second language.
Materials (App Books)
Twelve app books were selected for shared reading instruction and were also used after the lesson for two sessions of buddy reading. Four additional app books were selected for individual reading sessions. Selection of all app books was based on broad criteria that research suggests for selecting high-quality app books, such as choosing books that have (a) high interactivity, (b) affordances that transform children’s meaning making as compared to paper books, (c) intuitive affordances that are easy for users to figure out how to operate, (d) developmental appropriateness, and (e) good narrative/illustration quality (Baxa & Christ, 2017; Brueck, 2013; Cahill et al., 2013; Morgan, 2013; Zipke, 2014). Affordances of each app book used in the study are presented in Table 3. We chose to use commercially available app books that were suggested by online app book reviews for children in the age range of our participants. Using books that educators and parents have access to provided ecological validity for our work. This selection allowed us to investigate a variety of affordances in commercially available books that may support young children’s comprehension. This aligns with the purpose of our study, that is, to inform more fine-grained suggestions for app book selection and design that support young children’s comprehension by engaging in a comprehensive analysis of how children’s use of affordances in buddy and individual reading is related to their individual comprehension outcomes.
App Book Digital Affordances
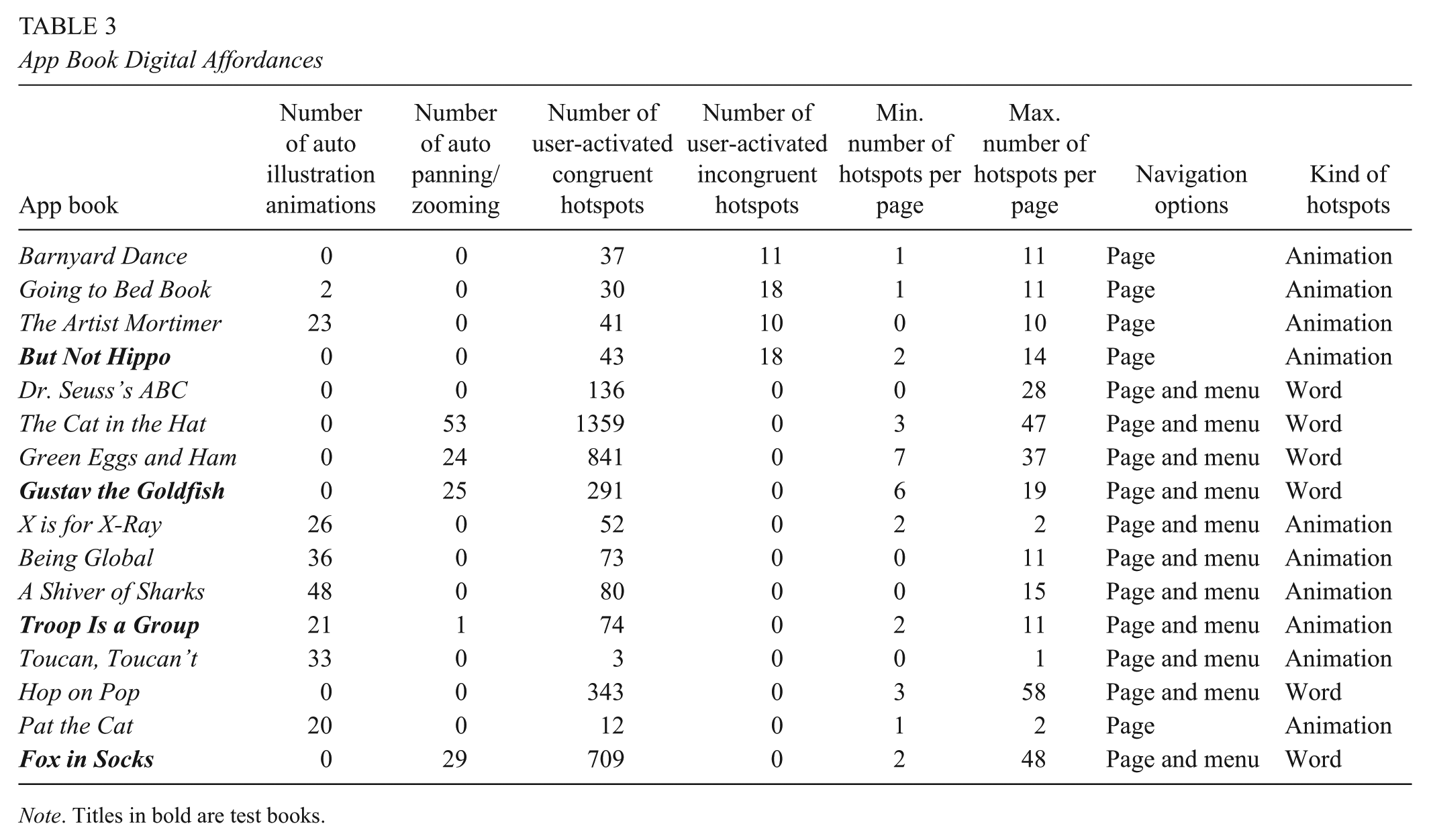
Note. Titles in bold are test books.
Data Collection
The broader study investigated app book reading across the kindergarten year, which is the first mandated year of formal schooling in the United States. Because we were unable to find any schools that were already engaged in regular app book reading instruction, we provided research assistant–implemented whole-class shared reading lessons so that we could observe children’s app book reading over time and across a variety of high-quality app books. To ensure that children had time to practice their app book reading skills, we also provided two research assistant–facilitated app book buddy reading sessions with each book that was presented in a shared reading lesson. Instruction and buddy reading sessions were organized into four units. Each unit presented three app books that shared similar features (see Table 3). At the end of each unit, every child read the same new app book individually in a quiet room alone with a research assistant. Afterward, the research assistant used the comprehension protocol for that book to ask a variety of comprehension questions (retell, inference/critical thinking, and vocabulary-meaning derivation). An overview of children’s engagement with app books across the study is presented in Table 2.
The present study included two data sources from the broader study, video recordings of buddy and individual reading sessions, which were collected from early October through mid-April. There were 24 buddy reading sessions, during which each dyad or triad of children read together (one dyad/triad reading during one session constituted an event). There were 624 video-recorded buddy reading events in all, each about 15 min, totaling about 156 hr of video data. Buddies were instructed to help each other read the app book and put the iPad in the middle so that both buddies could interact with it. Given the large number of buddy reading sessions (624), it was not possible to test comprehension after every session. Instead, comprehension was tested only after individual reading sessions.
Individual reading sessions occurred one-on-one with a research assistant in a room adjacent to the classroom in late November, early February, late March, and late April. These sessions varied considerably in length (7–32 min), given that children were allowed to spend as much or little time reading the app book as they chose. The sessions were guided by an observation protocol, which also included a comprehension assessment (see Figure 1). Each child engaged in four individual reading sessions, resulting in a total of 212 individual video-recorded reading sessions (about 53 hr of video data).

Individual comprehension assessment protocol for after reading Troop Is a Group of Monkeys.
Data Coding
Five sets of variables were coded: (a) digital affordances, (b) reading behaviors during buddy reading, (c) reading behaviors during individual reading, (d) individual reading comprehension outcomes, and (e) control variables.
Digital affordances
For each app book, first we counted the numbers of automatic animations of illustration objects across the book. Second, we determined whether an app book had any automatic zooming or panning (i.e., yes/no dichotomous variable) and then counted the number of times it occurred within each book (i.e., frequency count variable). Third we counted the number of user-activated congruent hotspots across the book. Fourth, we counted the number of user-activated incongruent hotspots across the book. Fifth, we identified the minimum number of hotspots on any page in the book. Sixth, we identified the maximum number of hotspots on any page across the book. Sixth, we noted the navigation options available in the book, that is, page-turn-only or page-turn and menu navigation. Finally, we identified what kinds of hotspots were available in the illustrations, animation or word. For animation hotspots, when the illustration was touched, it resulted in animation and also often was accompanied by sound, as well (e.g., when an octopus was pressed, it moved and squirted ink). For word hotspots, when the illustration was touched, this made the word for the object in the illustration appear and be read aloud (e.g., when a box was pressed, the word box appeared and was read aloud). (Note that word hotspots were distinct from the function that reads words aloud when pressed in the text of the story.) Affordances varied, sometimes considerably, across app books. Coding for affordances in each app book is presented in Table 3.
Reading behaviors during buddy and individual reading
Using the videos of buddy and individual reading sessions, we coded five variables: mode selection, sequential versus nonsequential progression through the book, hotspot use, use of modalities, and use of monitoring. Coding is adapted from our previous work (Christ et al., 2019; Wang et al., 2019) and is presented in Table 4. Codes for buddy reading are in column 2, and codes for individual reading are in column 3.
Reading Behaviors

Individual reading comprehension outcomes
After each individual reading session, a comprehension assessment protocol was used (see Figure 1 for the protocol used after children individually read the app book Troop Is a Group of Monkeys). Responses to the protocol were coded for four comprehension outcomes: unprompted retelling, prompted retelling, inference/critical thinking responses, and vocabulary-meaning generation. Both unprompted and prompted retellings were coded using a retelling rubric (see Figure 2, which shows the scoring for Troop is a Group of Monkeys). Inferential/critical thinking responses and vocabulary-meaning generation were coded on categorical scales, which are presented in Table 5.
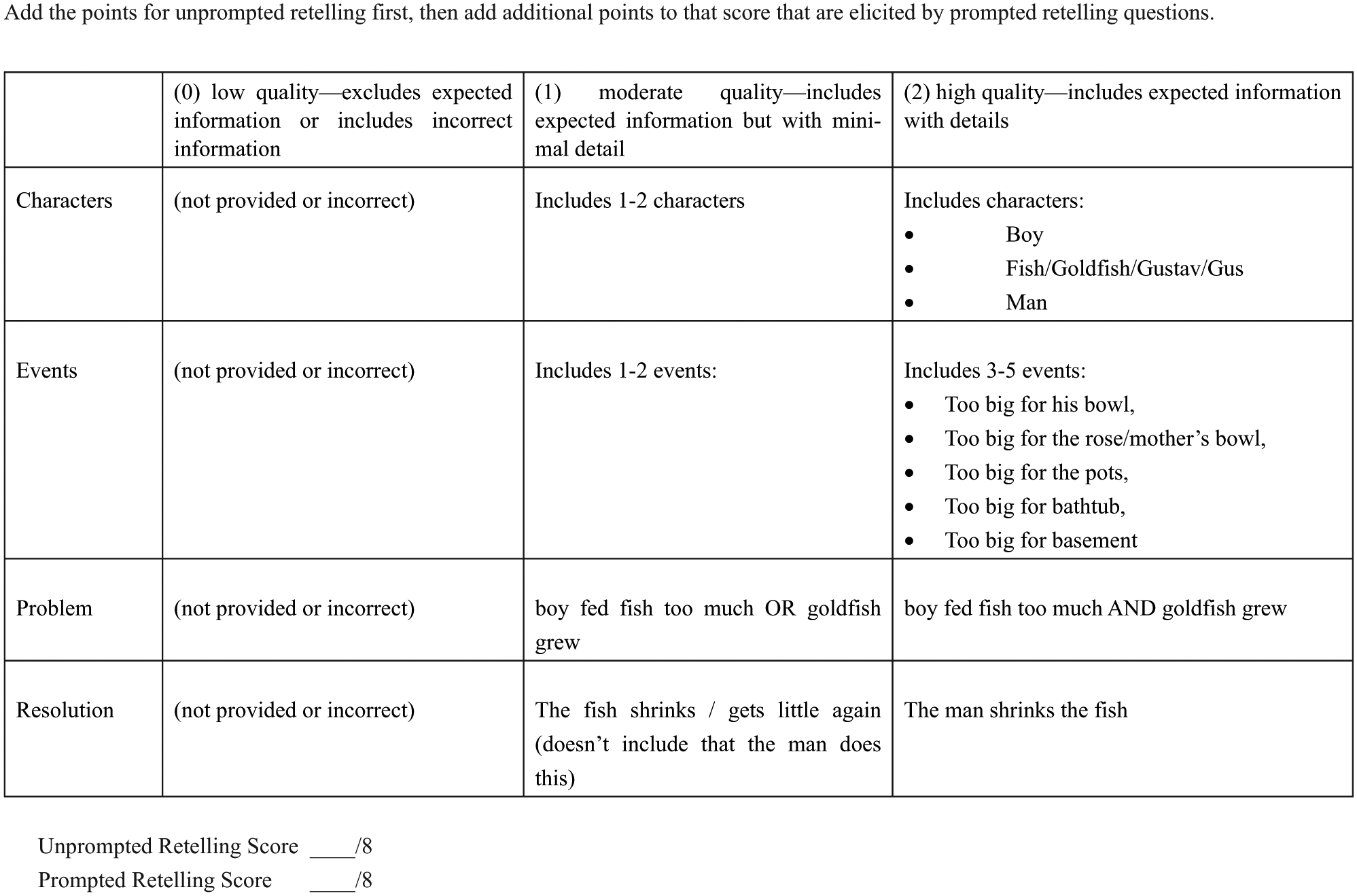
Retelling rubric for Troop Is a Group of Monkeys.
Individual Reading Outcomes

Control variables
To avoid uncontrolled variable bias, we included child variables culled from the broader study, including gender, race, language status (English as a first language or English language learner based on school records), concepts about print score at the beginning of the year, and listening comprehension with traditional printed book score at the beginning of the year. We also controlled for the location (Michigan or New York), classroom in which a child was embedded (Class 1, 2, 3, or 4), and time (i.e., the date on which the session occurred).
Coder training, process, and intercoder agreement
Rigorous coder training was undertaken, then two coders separately coded all the reading behaviors during buddy reading, reading behaviors during individual reading, and individual reading comprehension outcomes. Differences were discussed to establish consensus codes, which were used for analyses. Interrater reliability and percentage agreement were high and are presented in the last two columns of Table 6.
Summary Statistics (N = 318) and Interrater Reliability

Krippendorf’s alpha.
Percentage agreement between coders.
Data Analysis
As modeling outcomes separately via several ordinary least squares regressions ignores correlations among outcomes and can bias the results, we modeled all outcomes simultaneously to obtain unbiased results via Zellner’s method (also known as “seemingly unrelated regressions”; Kennedy, 2008) with EViews software (Lilien, Startz, Ellsworth, Noh, & Engle, 1995). Specifically, we modeled children’s comprehension outcomes (unprompted retelling, prompted retelling, inference/critical thinking responses, and vocabulary-meaning generation). We entered the variables according to time constraints, expected causal relationships, and likely importance.

The vector of outcomes,
To determine which explanatory variables were linked to the outcomes, we first entered structural explanatory variables (class, child demographics, time, digital affordances for the specific book being read on a specific day), which might affect process explanatory variables (reading behaviors during buddy reading or reading behaviors during individual reading), which in turn are entered later. Class variables capture location and class within each location: New York (vs. Michigan), New York Class 1 (vs. Class 2), and Michigan Class 1 (vs. Class 2) (
Second, we entered a vector of children’s characteristics: gender (female vs. male), race (Caucasian or Asian vs. African American), English as a first language (vs. English as a second language), concepts about print score at the beginning of the year, and listening comprehension score at the beginning of the year (
Fourth, we entered the affordances of the specific app book that a child was reading at that time before comprehension assessment for that book: whether the book had page-turn-only (vs. menu and page-turn) navigation, whether the book had word hotspots (vs. animation hotspots), the minimum number of hotspots that were available on each page of that book, the maximum number of hotspots that were available on each page of that book, total automatic animations of illustration objects in that book, whether that book had panning/zooming, the number of automatic panning/zooming occurrences in that book, total user-activated congruent hotspots in that book, and total user-activated noncongruent hotspots in that book (
Fifth, we entered percentages of children’s buddy reading behaviors: progression (percentage pressed/said all words but not sequentially, percentage predominantly used hotspots [vs. predominantly listened to text read aloud], percentage read pages sequentially and some of the text was not read aloud, percentage only part of text was read aloud, percentage read pages sequentially, percentage read pages sequentially and all of the text was read aloud), mode (percentage used “Read to Me” mode [vs. “Read Myself” mode]), hotspot use (percentage mostly took turns using hotspots and someone used hotspots on almost every page, percentage predominantly only one child pressed hotspots and did so on almost every page, percentage mostly took turns using hotspots and someone used hotspots on almost every page, percentage infrequent hotspot use [pressed hotspots on fewer than 20% of pages in an app book]), and monitoring (percentage debated about the book, percentage negotiated use of affordances in the book, percentage drew attention to the book content, percentage asked a question) (
Sixth, we entered percentages of students’ individual reading behaviors: progression (percentage books that a child read sequentially [vs. nonsequentially]), mode (percentage books for which a child selected “Read to Me” mode [vs. “Read Myself” mode], percentage pages on which child listened to text read and pressed the hotspots after the text was read, percentage pages on which child pressed hotspots simultaneously while text was being read, percentage pages on which child waited for all the text to be read aloud before turning the page), hotspot use (percentage pages on which congruent, unprompted hotspots are used; percentage pages on which incongruent, unprompted hotspots are used; percentage pages on which prompted hotspots are used; percentage pages on which use any hotspot is used multiple times), and monitoring (percentage books during which a child used a monitoring strategy).
We also tested the natural log of the behaviors and the likelihood that each behavior occurred at least once when reading a book. If multiple variations of the same variable were significant, we retained the one that accounted for the most variance.
To test whether behaviors (
An alpha level of .05 was used for all analyses. To aid reader understanding, we report how a 10% greater value of an explanatory variable beyond its mean is related to a corresponding difference in the outcome variable beyond its mean. For inference/critical thinking and vocabulary-meaning generation outcomes, we used the odds ratio (Kennedy, 2008). With 53 children, statistical power exceeded 0.85 for an effect size of 0.4 (Cohen, West, Aiken, & Cohen, 2003). Due to the low statistical power of this small sample, the likelihood that a nonsignificant result is a false negative is high, but we retain high confidence for significant results. Testing many hypotheses increases the likelihood that at least one of them incorrectly rejects a null hypothesis (false positive). To reduce their likelihood, we used the two-stage linear step-up procedure, which outperformed 13 other methods in computer simulations (Benjamini, Krieger, & Yekutieli, 2006).
Results
Interestingly, app book affordances were not linked to either the buddy reading or individual reading behaviors that we identified but rather were directly linked only to individual reading outcomes (see Figure 3, columns 1 and 4; for correlations and covariances, see Table A1 in the appendix). First, for app books with a greater minimum number of hotspots available on each page, children’s unprompted and prompted retelling outcomes were better. Specifically, when reading app books with 10% more minimum hotspots available on each page than average, students averaged 2% higher prompted and unprompted retelling scores (2% = odds ratios of 0.983 and 0.828 in Table 7, columns 2 and 3, row a). As we did not examine app books that represented a wide range of minimum numbers of hotspots available on each page, we lacked the data to calculate the optimum number. This can be examined in future studies.
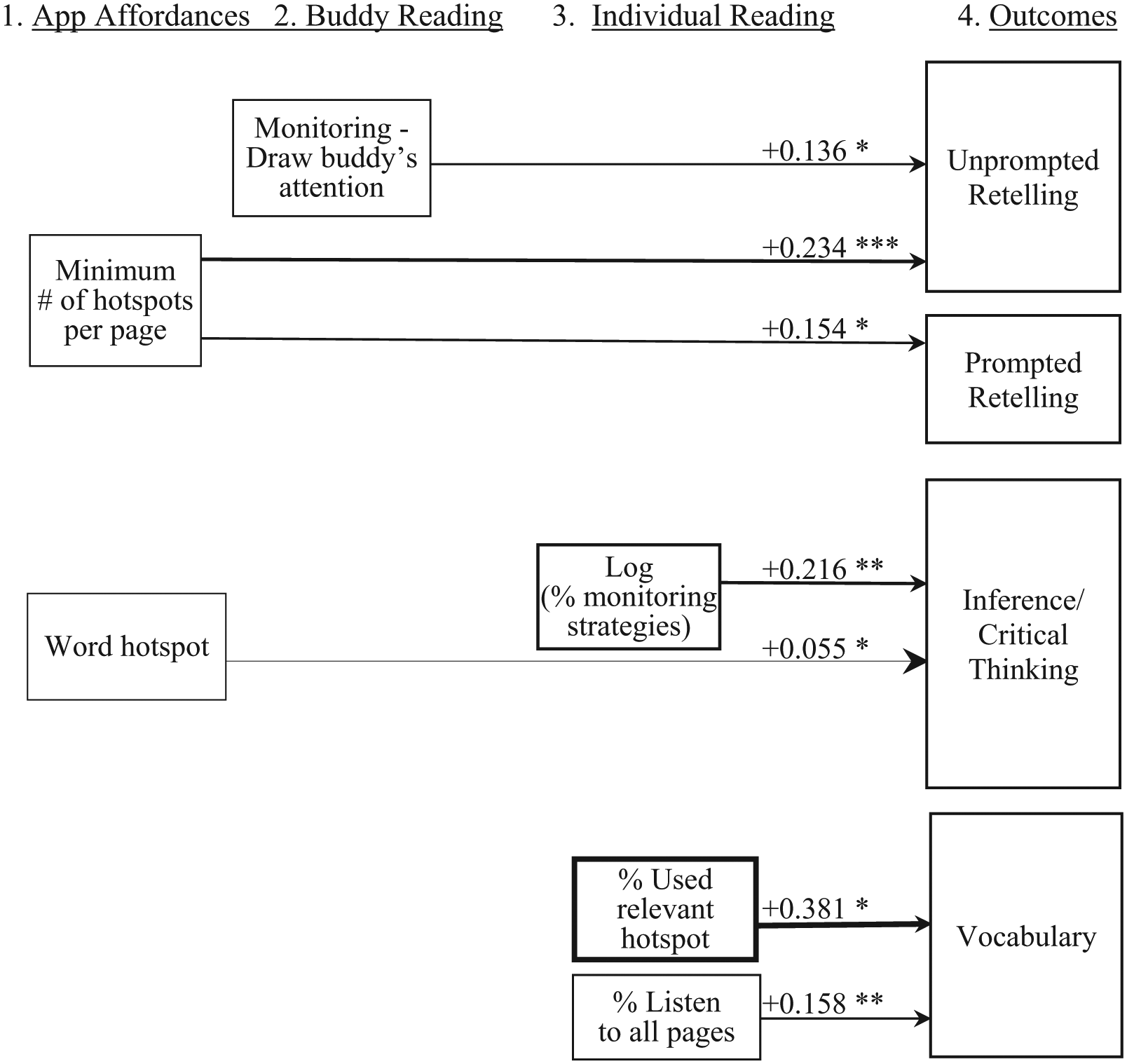
Path diagram modeling students’ unprompted retelling, prompted retelling, inference/critical thinking, and vocabulary. Thicker lines indicate larger effect sizes.
Summary of Four Final Regression Models Predicting Students’ Comprehension Outcomes

Note. Unstandardized regression coefficients shown with standard errors in parentheses. Each regression model included a constant term for each outcome.
p < .05. **p < .01. ***p < .001.
Second, when reading app books with word hotspots available, students averaged 3% higher inference/critical thinking scores (3% = odds ratio of 0.136 in Table 7, column 4, row b). Other app book affordances, including navigation options in a book, maximum number of hotspots available on each page in a book, total number of automatic animations of illustration objects in a book, whether a book had panning/zooming, total number of automatic zooming/panning occurrences in a book, total number of user-activated congruent hotspots available in a book, and total number of user-activated noncongruent hotspots available in a book, were not linked to buddy reading behaviors, individual reading behaviors, or outcomes when reading that book. Also, all mediation tests were not significant.
Finally, findings related to how buddy and individual reading behaviors were related to children’s outcomes are important (Figure 3, columns 2 to 4; Table 7, columns 4 and 5, rows c to f). However, they are not related to our research questions or hypotheses for this study. Further, these relations have been reported in our previous work (see Christ et al., 2019; Wang et al., 2019; Wang, Christ, Chiu, & Strekalova-Hughes, 2019). Therefore, these aspects of the results are not discussed.
Discussion
Our study, which explored more digital affordance variables across a greater number and variation of app books than has been done in previous research, and how these were related to young children’s reading behaviors in both buddy and individual reading contexts and individual comprehension outcomes, revealed important new findings. In this section, we discuss how each important finding extends previous research and its implications for educators, researchers, and app book designers. We also discuss the meaning of some notable nonsignificant findings. We conclude by advocating a more detailed and nuanced perspective for app book selection, which we refer to as dynamic selection.
Minimum Number of Hotspots Available on a Page
First, our findings show that a greater minimum number of hotspots available on each page is related to young children’s better retelling outcomes. This is likely due to each hotspot’s contribution to extending the possibilities for interactions that create deeper understanding or retaining that information about the story. Largely, this is because most of the hotspots in the books we selected were congruent (see Table 3). For example, in the app book Gustav the Goldfish, the minimum number of hotspots on a page is six, and all of those were congruent (see Table 3). This is the second greatest minimum number of hotspots per page across all 18 books (range = 0–7). This relatively large minimum number of hotspots per page includes hotspots for all the characters on every page on which they are included in the illustration. When any character is touched in the illustration, its printed name appears and is read aloud. This provides ample additional opportunities to process the characters’ names while reading the book, and characters’ names are one element that is scored in the retellings. Likewise, aspects of events in the book are also reinforced by the word hotspots, and the greater minimum number of hotspots provides more opportunities for reinforcement. For example, the text reads, “Gustav was bigger!” Then, when a child touches Gustav in the illustration, the word big appears and is read aloud. When Gustav is touched again, the word bigger appears and is read aloud. If touched a third time, the word bursting appears and is read aloud (these are three of 13 total hotspots on this page). Thus, the hotspots reinforce and extend the idea of Gustav getting bigger. This provides opportunities for children to better recall events from the story, which is another aspect of retelling that is scored. This finding extends earlier research that qualitatively explored how children used congruent versus incongruent hotspots and how this was related to their comprehension outcomes (e.g., de Jong & Bus, 2004; Labbo & Kuhn, 2000; Trushell et al., 2001, 2003) but did not statistically explore how a broader variety of hotspot affordance variables, including minimum/maximum numbers of hotspots, types of hotspots, and so on were related to young children’s reading outcomes in one statistical analysis to identify their relative contributions to outcomes.
Most of the hotspots in the books used in our study were congruent (see Table 3), and congruent hotspots have been shown to support positive comprehension outcomes (Christ et al., 2018, 2019; Korat & Shamir, 2012; Labbo & Kuhn, 2000; Shamir, 2009). Thus, our results should be interpreted as showing that increasing the minimum number of congruent hotspots per page would be beneficial in terms of app book selection and design. Unfortunately, we lack the data to calculate the optimum number of minimum hotspots available per page. Thus, this should be explored in future studies.
Word Hotspots
Our findings show that the availability of word hotspots (i.e., places in the illustration that when touched activate a printed word appearing and being read aloud) is related to young children’s better inference/critical thinking outcomes. This is likely due to the word hotspots providing additional text-based clues that support the inference/critical thinking process. For example, one of the inference questions about the Gustav the Goldfish story is, “What do you think the man did to get Gustav back to his regular size?” On the page that precedes Gustav being restored to his regular size, the text reads, “. . . he came right away with a lot of strange bottles tucked into his vest and a thing on his back like a medicine chest.” Then, when the child touches the illustration of the man, the words strange bottles appear and are read aloud. Likewise, when the child touches the illustration of the chest, the words medicine chest appear and are read aloud. These hotspots seem to help identify relevant text clues that can be used to infer that the man gave Gustav some medicine to shrink him back to his regular size. Again, this finding extends previous qualitative research that predominantly explored children’s use and outcomes related to congruent versus incongruent hotspots (e.g., de Jong & Bus, 2004; Labbo & Kuhn, 2000; Trushell et al., 2001, 2003; Wang et al., 2019) but not a broader variety of hotspot affordance variables within a single statistical analysis to identify their relative contributions to children’s comprehension outcomes.
For educators, this finding suggests that selection of app books with congruent word hotspots will better facilitate young children’s inference/critical thinking outcomes as compared to other affordances. In terms of design, integrating word hotspots into app books would support their being used to meet this goal.
Notable Nonsignificant Findings
Some of the digital affordance variables that we explored seem not to matter. For example, whether or not app books have page-turn-only or page-turn and menu navigation options does not relate to young children’s comprehension outcomes. Likely this is because most children in our study read sequentially, and either mode of navigation facilitates this. Likewise, neither app books’ maximum number of hotspots available on each page nor their total number of user-activated congruent hotspots available relates to young children’s comprehension outcomes. This may be because the minimum numbers are more important than the maximum numbers—that is, having enough congruent hotspots is important, but having more than that is not problematic. Again, this is likely a function of the majority of hotspots in the books we selected being congruent (see Table 3). So, the hotspots largely facilitate better comprehension (Christ et al., 2018, 2019; Korat & Shamir, 2012; Labbo & Kuhn, 2000; Shamir, 2009) rather than detract from it, as might occur with large numbers of incongruent hotspots (Labbo & Kuhn, 2000; Trushell et al., 2001; Trushell & Maitland, 2005). Thus, educators and researchers do not need to focus on these aspects of app book affordances during selection when the majority of hotspots are congruent. Further, app designers may choose to include navigation affordances and maximum numbers of hotspots for app book design aligned with the story and need not worry about the effects of too many hotspots or navigation options having a negative relation to young children’s comprehension outcomes, so long as they design congruent hotspots.
In addition, some affordances that previous research shows to be significant predictors of young children’s comprehension outcomes are not significant when included in a broader analysis, like ours. This is likely due to the relative strength of their contribution to the outcomes. For example, although automatic animations of illustration objects in digital books are related to better outcomes as compared to static paper books (Korat, 2010; Korat & Blau, 2010; Ricci & Beal, 2002; Verhallen et al., 2006; Verhallen & Bus, 2010), our findings show that when automatic animations of illustration objects are included in the same analysis with other affordances, such as interactive hotspots, their contribution to outcomes is no longer significant. Likely, this reflects how affordances provide gradations of support for comprehension—that is, automatic animations of illustration objects provide more support than static ones, and interactive animations provide more support than automatic ones. Thus, although educators and researchers might choose app books with automatic animations of illustration objects, they should be mindful to ensure that the app books also include additional affordances, such as greater minimum numbers of congruent interactive hotspots, which are significantly related to young children’s better comprehension outcomes. Likewise, app book developers may include automatic animations of illustration objects in addition to other affordances that support better outcomes but not in lieu of those.
Finally, we note that our findings do not show any connections between the availability of digital affordances and young children’s reading behaviors in particular contexts (i.e., buddy or individual reading). This may be because the buddy reading group was small (two or three children), and the iPad was always placed in the center of the table, so all children could engage in interactivity with the affordances in similar ways across buddy and individual reading. This issue warrants further exploration in the future.
Dynamic Selection of App Books
Our findings extend suggestions for app book selection, underscoring the importance of considering specific affordances to support particular outcomes. We call this dynamic app book selection. That is, although broad criteria are initially important when selecting an app book—such as choosing app books that have a developmentally appropriate high-quality narrative and illustrations and digital affordances that are interactive, transformative, and intuitive (Baxa & Christ, 2017; Brueck, 2013; Cahill et al., 2013; Morgan, 2013; Zipke, 2014)—a second critical step is also important: dynamic selection that considers how specific affordances are related to specific outcomes to inform selection of app affordances that align with desired reading outcomes. For example, our findings suggest that to facilitate retelling outcomes, educators should select a high-quality app book that contains a greater number of minimum hotspots per page. Or if the goal is to support inference/critical thinking outcomes, it is important to select a high-quality app book that has hotspots that contain important information/language related to the story, like the word hotspots did in our study. In terms of app books’ design, we suggest that integrating multiple affordances that support desirable outcomes (e.g., a greater minimum number of hotspots per page and hotspots that contain important information/language related to the story) in the same app book would provide the most flexibility in terms of its potential use to meet multiple objectives. This is the case in the app book Gustav the Goldfish.
Limitations and Future Research Directions
There are five limitations to our research, several of which suggest future research directions. First, we chose books with predominantly supportive digital affordances. Future research might explore how digital affordances available in app books link to reading behaviors and outcomes when more of a range of supportive versus nonsupportive affordances are included in the books (e.g., some books with predominantly noncongruent hotspots). Second, we chose commercially available app books. This choice aligns with most previous research in this area (see Table 1, last column) and also provides ecological validity for our findings. However, this choice meant that we did not have experimental control of books/affordances. Third, our outcome focus was limited to comprehension. Other researchers have explored other early literacy outcomes, such as word recognition (e.g., Zipke, 2017). We suggest extending research that focuses on other kinds of outcomes by using a more fine-grained analysis of how digital affordances in app books are linked those outcomes. Fourth, the children in our study were kindergarteners and emergent/beginning readers. Studies of older readers at later beginning and almost fluent reading stages might also adopt this more fine-grained approach to identifying links between digital affordances and outcomes. Fifth, given the fine-grained coding for each child in the study, we had to limit the total number of participants to make the coding task feasible. However, future studies might include a greater number of participants from across more locations and research teams to better represent the population of young app book readers.
Footnotes
Appendix
Acknowledgements
We are grateful for the support of the Spencer Foundation and the International Literacy Association’s Elva Knight grant.
Authors
TANYA CHRIST is a professor of reading and language arts at Oakland University. Her research focuses on early childhood vocabulary, comprehension, and digital literacies learning; issues of educational access and equity; and teacher education.
X. CHRISTINE WANG is an associate professor of early childhood education and the director of the Early Childhood Research Center at University at Buffalo, State University of New York. Her primary research interests include children’s learning and collaboration in technology-rich environments, young children’s science inquiry and digital literacy, and early childhood education in international contexts.
MING MING CHIU is Chair Professor of Analytics and Diversity in the Special Education and Counseling Department, and director of the Assessment Research Centre, at the Education University of Hong Kong. He invented statistics methods to analyze conversations (statistical discourse analysis) and to analyze how ideas spread through a population (multilevel diffusion analysis) and applies these methods to analyze classroom conversations, the academic achievement of over 500,000 students in 65 countries, and corruption in the music and banking industries.
EKATERINA STREKALOVA-HUGHES is an assistant professor in the Division of Teacher Education and Curriculum Studies at University of Missouri–Kansas City. Her research focuses on culturally sustaining practices and teaching for young children with refugee status and their families.