
Abstract
Individuals regularly experience Hearing Difficulty Moments in everyday conversation. Identifying Hearing Difficulty Moments has particular significance in the field of hearing assistive technology where timely interventions are key for real-time hearing assistance. In this article, we propose and compare machine learning solutions for the temporal detection of segments containing Hearing Difficulty Moments in conversational audio. We show that audio language models, through their multimodal reasoning capabilities, can achieve state-of-the-art results for this task, significantly outperforming a simple automatic speech recognition (ASR) hotword heuristic and a more conventional fine-tuning approach with Wav2Vec, an audio-only input architecture that is state-of-the-art for ASR.
Introduction
A central purpose of speech-intelligibility assessments used during hearing-device fitting is to predict how well a listener will understand speech and experience benefit in their daily life. However, performance on clinical and laboratory measures frequently diverges from how individuals report hearing and coping in real-world conversational interactions (Cord et al., 2004; Pronk et al., 2018; Walden & Walden, 2004; Working Group on Speech Understanding and Aging, 1988; Wu et al., 2018). Increasing evidence suggests that conventional assessments tend to overestimate real-world performance (Badajoz-Davila & Buchholz, 2021; Cord et al., 2007; Miles et al., 2022, 2020), giving the impression of adequate outcomes even when listeners may still be experiencing substantial communication challenges. Such overestimation can obscure the need for further rehabilitation or device optimization and, in turn, may contribute to dissatisfaction with hearing devices (Cord et al., 2007).
Given these limitations in predicting real-world outcomes, there is increasing interest in approaches that move beyond controlled test assessments to capture speech understanding and device benefit in everyday environments. An emerging line of research has focused on naturally occurring conversational adaptations such as changes in vocal effort levels, speech timing, the temporal dynamics of turn-taking, and interpersonal distance—during conversations under different acoustic and hearing conditions (Beechey et al., 2020; Hadley et al., 2019; Hadley & Ward, 2021; Petersen, 2024, 2025; Petersen & Parker, 2024; Slomianka et al., 2025; Sørensen et al., 2024; Weisser & Buchholz, 2019; Weisser et al., 2021). Complementing this is research that examines interactional units of talk—that is, the conversational moves and signals that listeners and talkers use to manage intersubjectivity in real time. Recent conversational-interaction studies have shown that units of talk such as other-initiated repairs (e.g., “what?” and “huh?”) and listener back-channels (e.g., “mm” and “yeah”) vary systematically with hearing loss, background noise, and/or hearing-aid amplification (Miles et al., 2023; Petersen et al., 2023). These interactional cues therefore offer a metric for assessing speech understanding and hearing-aid benefit as conversations unfold in the real-world, in real time.
Here, we focus on Hearing Difficulty Moments, those conversational events in which a listener publicly signals emerging trouble in perceiving a prior turn by initiating other-initiated repair. These repair initiations are well-described interactional practices that disrupt the progressivity of talk (Dingemanse et al., 2015; Schegloff et al., 1977). Although other-initiated repairs can arise from both perceptual trouble (e.g., difficulty hearing or mishearing the prior turn) and understanding trouble (e.g., ambiguity about referents or intent), our analyses focus specifically on the subset of other-initiated repairs that signal perceptual trouble, which is the operational definition we refer to as Hearing Difficulty Moments.
The signaling of Hearing Difficulty Moments, in particular, is a meaningful metric for people who are hard of hearing. These frequent moments and repeated trouble-source turns are commonly reported as sources of frustration and relational strain for communication partners of people who are hard of hearing (Scarinci et al., 2008; Schulz et al., 2017). Reducing these moments is a core aim of hearing-device algorithms: that is, improve speech intelligibility so that listeners experience fewer Hearing Difficulty Moments during conversation. Detecting when Hearing Difficulty Moments occur in natural dialogue provides a vital biometric feedback loop for evaluating device performance. We propose that future intelligent hearing devices can utilize these detections as a triggering signal for proactive intervention. A truly intelligent hearing device will not only use these cues to improve intelligibility but, in doing so, will establish an adaptive pathway to respond proactively, mitigating emerging difficulty and optimizing the listening experience in real time. This study focuses only on the upstream detection task which would enable such workflows in future.
Detecting such moments of hearing difficulty in conversation requires methods capable of identifying the specific interactional units of talk through which listeners signal trouble. These units correspond to well-defined dialogue acts, such as signal-nonunderstanding and clarification requests, which makes them amenable to computational modeling. Dialogue-act prediction in human–human conversation has been modeled using text-based approaches, from Bayesian and support vector models to convolutional neural networks (Fernandez & Picard, 2003; Khanpour et al., 2016; Lee & Dernoncourt, 2016; Stolcke et al., 2000)—with some studies incorporating audio or multimodal input (Miah et al., 2023; Ortega & Vu, 2018; Shriberg et al., 1998). However, while the interactional practices of other-initiated repair are extensively documented in conversation-analytic literature (Dingemanse et al., 2015; Schegloff et al., 1977), few computational studies have attempted to automatically detect these dialogue acts in natural human–human conversation. What limited work does exist is almost exclusively situated within spoken dialogue systems, where the emphasis is on detecting nonunderstanding in human–machine interactions (Alghamdi et al., 2024).
Taken together, the evidence highlights a gap in current hearing assessment tools: no existing method to detect moments of hearing difficulty directly from natural conversation using speech signals. Developing such a capability would offer a more ecologically grounded way to characterize communication difficulty and to assess hearing-device benefit as it is experienced in daily life. Here, we investigate whether these moments can be automatically detected from audio-only recordings of human–human dialogue.
Dataset
Our dataset for identifying Hearing Difficulty Moments in conversational audio comprises 1,199 long conversations sourced from the Switchboard Dialog Act Corpus (SWDA) (Jurafsky et al., 1997) and Meeting Recorder Dialog Act Corpus (MRDA) (Shriberg et al., 2004) datasets. Combined, the dataset is segmented into over 327,000 short utterances (typically a few seconds long), containing different speakers (there is some overlap between speakers with MRDA) and different topics. The audio data is standardized to single-channel (mono) and uses a sample rate of 16 kHz. In this single-stream format, the models process the interaction between both interlocutors as a single acoustic event, focusing on identifying the listener’s overt repair initiation following a speaker’s turn.
Each utterance from MRDA and SWDA has already been assigned a human-annotated act tag (e.g., “Statement” or “Question”). The two datasets use slightly different schemes for annotation, which are mapped to the commonly used DAMSL (Dialog Act Markup in Several Layers) annotation scheme (Core & Allen, 2001).
In this study, Hearing Difficulty Moments were drawn from existing “signal-nonunderstanding” dialogue-act labels from the Switchboard and MRDA corpora. Crucially, under the DAMSL scheme, these labels do not merely map to isolated lexical tokens (e.g., the words “huh?,” “what?,” or “sorry?”), but rather encompass the entire temporal span of the dialogue act functioning as an other-initiated repair. The original corpus annotators identified the start and end timestamps for these events based on the acoustic boundaries (vocal onset and offset) of the speaker’s turn. Consequently, the durations associated with these events capture the full acoustic profile of the turn, beginning with the initial vocal onset (such as audible intakes of breath or preparatory ‘‘uh” vocalizations) and extending through the repair initiation itself. By using acoustic boundaries rather than just text-alignment boundaries, the model is exposed to the prosodic characteristics of the phonated repair, such as its pitch contour and intensity, relative to the immediate preceding silence or overlapping speech from the prior turn. This ensures that the model processes the repair as a continuous acoustic event, capturing the transition from the listener’s silence to their overt signal of difficulty. From the 522 such instances in the combined datasets, we retained a subset (n = 298) in which the initiating utterance plausibly reflected perceptual difficulty with the acoustic signal (e.g., low signal-to-noise ratio, overlapping speech, reduced audibility or signal quality in the preceding turn), rather than linguistic or pragmatic nonunderstanding with intact audibility (e.g., requests for clarification of content, referential ambiguity, or unfamiliar concepts). This refinement was performed by a single trained coder using audio–transcript pairs. While this refinement step introduces additional subjectivity beyond the original corpus annotations, we treat this operationalization as a conservative proxy for Hearing Difficulty Moments.
To prevent data leakage, all utterances from a single conversation are grouped together, belonging entirely to either the training or test set.
To sample positive Hearing Difficulty Moments in the time domain, we construct examples that provide a reasonable amount of context before a Hearing Difficulty Moment takes place.
To capture the relevant acoustic context, we opted for a four-second audio segment. Although Hearing Difficulty Moments themselves are brief when overtly signaled, the interactional and perceptual processes that give rise to these moments unfold during the preceding speaker’s turn, as listeners project turn endings and prepare responses prior to turn completion (de Ruiter et al., 2006; Levinson & Torreira, 2015; Stivers et al., 2009). Work on conversational interaction in noise suggests that some interactional adaptations associated with challenging communication conditions emerge over multi-second timescales in natural dialogue (Miles et al., 2023). A multi-second context window may therefore provide sufficient temporal scope to capture the interactional cues that precede the onset of Hearing Difficulty Moments. The chosen window length is also consistent with common practice in sound-event classification pipelines (Salamon et al., 2014), facilitating comparison with prior audio-only modeling approaches. We note that this window length is a design choice rather than a theoretically fixed boundary, and future work should systematically evaluate sensitivity to shorter and longer temporal contexts. The Hearing Difficulty Moments in our dataset are much shorter than that, with a mean length of 473 ms. The histogram of these events can be seen in Figure 1.
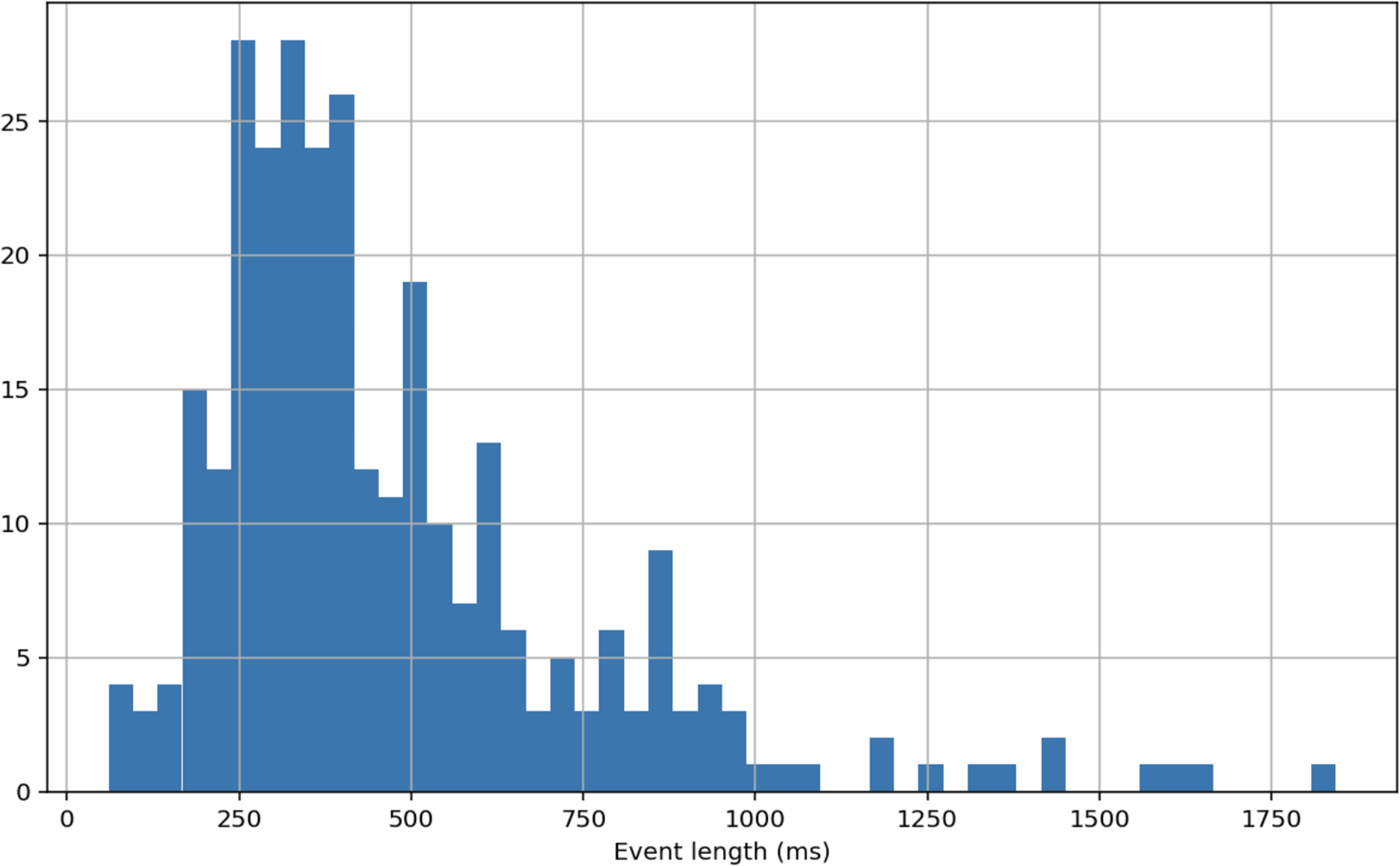
Histogram of lengths of Hearing Difficulty Moments in the dataset. The longest event is 1,843 ms in duration and the shortest event is 60 ms in duration. The illustration uses 50 bins which are each
For positive observations, we extract a four-second context window preceding a sampled detection point
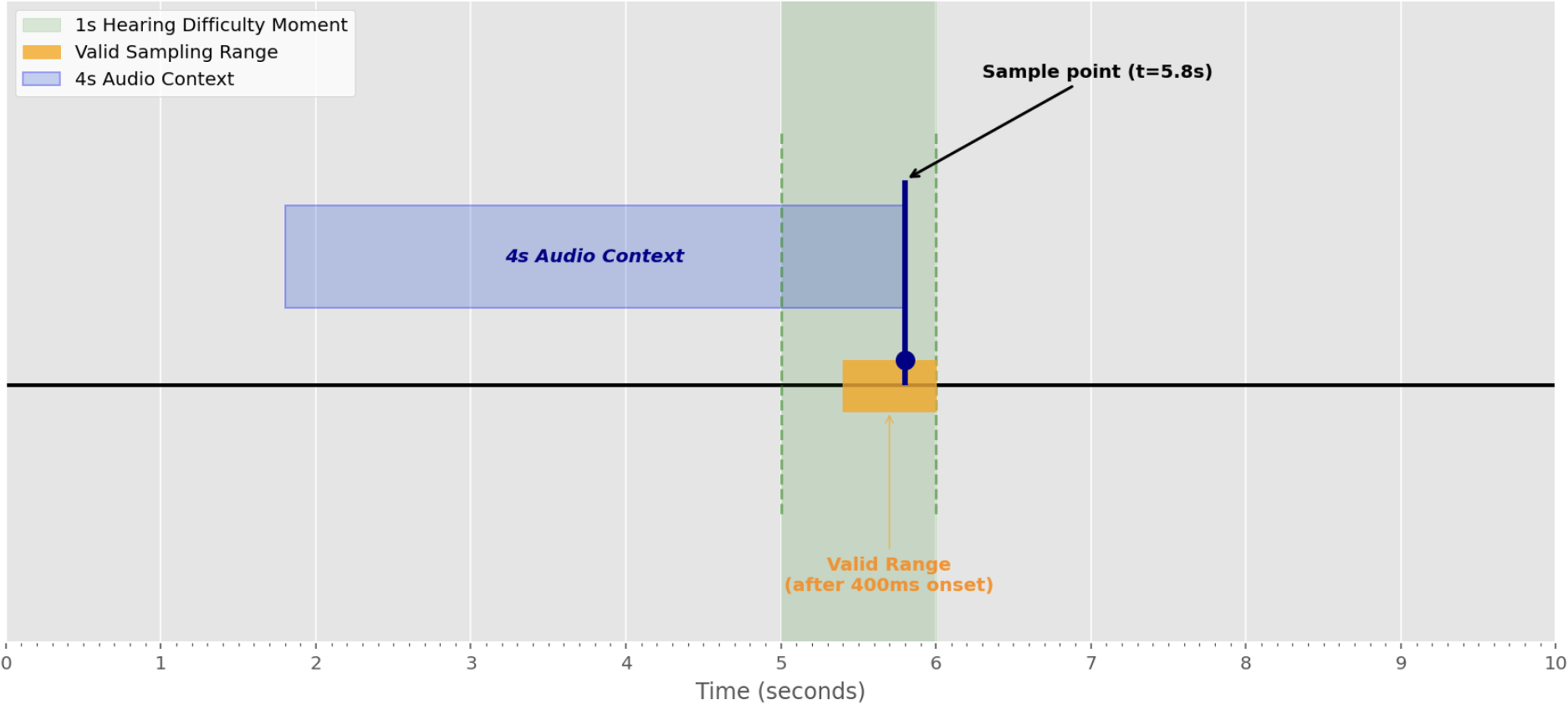
Sampling strategy for a long (1,000 ms) Hearing Difficulty Moment. To ensure sufficient acoustic evidence is available to the model, the 4-second context window is anchored at a randomly sampled point (

Sampling strategy for a short (200 ms) Hearing Difficulty Moment. Because the event duration is <400 ms, the sample point (
Methods
This research focuses on the detection of a subject’s level of hearing difficulty at a specific time
We evaluate an automatic speech recognition (ASR) Hotword Heuristic solution, a Wav2Vec supervised fine-tuning model and audio language models (prompting and fine-tuning) as classifiers for this task.
ASR Hotword Heuristic (Baseline)
We include a simple lexical baseline based on the presence of short repair-initiating expressions in ASR transcripts. The first part uses Chirp 2, a specific implementation from Google’s broader Universal Speech Model (USM) family of state-of-the-art speech models (Zhang et al., 2023), to transcribe the audio. For the second part, we search the transcripts for a dictionary of hotwords (“what,” “pardon,” “huh,” “sorry,” “excuse me,” and “repeat”). These forms draw on commonly attested English formats for other-initiated repair described in the conversation-analytic literature (Dingemanse et al., 2015; Kendrick, 2015; Schegloff et al., 1977) but are not intended to constitute a comprehensive inventory of repair practices.
We recognize that lexical forms such as “what” and “excuse me” are polyfunctional and can serve a range of interactional functions beyond perceptual difficulty (e.g., as surprise tokens, backchannels, or contact-initiation). This hotword approach is therefore not presented as a validated operationalization of Hearing Difficulty Moments, but as a deliberately coarse lexical heuristic included to provide a lower-bound baseline for comparison with audio-based models that incorporate nonlexical acoustic cues.
Wav2Vec 2.0 Transfer Learning
Wav2Vec 2.0 (Baevski et al., 2020) is a popular speech recognition model published by Meta. It is trained in a self-supervised manner, learning from unlabeled audio and is then fine-tuned on labeled transcriptions. The model achieves state-of-the-art results with limited labeled data and is relatively cheap from a computational point of view, especially compared to competitors such as Whisper. Whisper is additionally less suitable for our task since it is primarily fine-tuned and optimized for general ASR tasks and transcription, limiting its sensitivity to nonverbal cues.
We use the wav2vec2-base-960h model as a base model. It has
We replace the final layer of the Wav2Vec2.0 model with a standard two-layer deep neural network classification head. The entire model is then trained using a learning rate of 1
To enhance performance, a probabilistic data augmentation process is implemented during training. Each time a training example is sampled, Gaussian noise (amplitude uniformly sampled between 0.001 and 0.015), time stretching (with a fixed rate for all samples, uniformly sampled between 0.8 and 1.25), and pitch shifting (uniformly sampling between
Prompted Audio Language Model
To implement this classification task using the multimodal Gemini 1.5 Pro model, we repurpose the “P” and “N” tokens as our predicted classes. Specifically, the model is prompted as shown in Figure 4 with detailed instructions to analyze the audio signal for classification. These instructions draw on well-established acoustic correlates of the Lombard effect, such as increased fundamental frequency, shifted energy, and increased vowel duration (Brumm & Zollinger, 2011; Junqua, 1993).

The system prompt provided to the Gemini 1.5 Pro model for identifying Hearing Difficulty Moments.
While the ASR Hotword Heuristic described earlier uses a rigid, exhaustively defined, list of formulaic phrases for exact string matching, here we provide in the prompt a set of explicitly nonexhaustive, illustrative ‘‘seeds” designed to trigger Gemini’s semantic reasoning so that it can generalize beyond merely the presence of specific keywords.
Given that perceived hearing difficulty varies by individual, we also explicitly mention this subjectivity within the prompt. This further encourages generalization on this task beyond fixed criteria, taking full advantage of Gemini’s reasoning strengths.
The prompt details both semantic and nonsemantic information about a Hearing Difficulty Moment which the model is encouraged to pay attention to to inform its prediction and includes both a textual preamble describing the task along with the target audio, which are ultimately processed as tokens by the language model in an interleaved way. The target audio itself is provided without any explicit transcription step. In the few-shot case, we present an equal number of (randomly drawn) positive and negative examples along with the corresponding ground truth label (Audio: [audio_tokens], Label: P
The next-token log probabilities of the “P” and “N” tokens are then retrieved to compute a relative confidence signal for the positive class. This method can yield a signal at each token step which predicts the probability of a Hearing Difficulty Moment at that point in the conversation. At 0-shot, each inference takes an average of 2 s, which compared to 4 s of audio corresponds to a real-time factor (RTF) of 0.5. At 10-shot, the RTF is 1. As shown in Figure 5, this approach can be used to generate a continuous signal for a single example in a single fold. A threshold of 0.97 was found to maximize the F1 score. The red shaded areas represent two distinct, brief ground truth Hearing Difficulty Moments and the green line is the output probability of the “P” token obtained over multiple 4s windows of audio sampled every 1,000 ms. The green shaded area represents the period of time for which this method would predict a positive label. A lag can be observed from the beginning of the first ground truth event until the method begins predicting a positive label since the model becomes more confident as more information comes into context. Additionally, the method is not sensitive enough to stop predicting a positive label in between the two distinct ground truth events since the two events are <4 s apart. In this case, this method predicts a single prolonged episode of hearing difficulty.
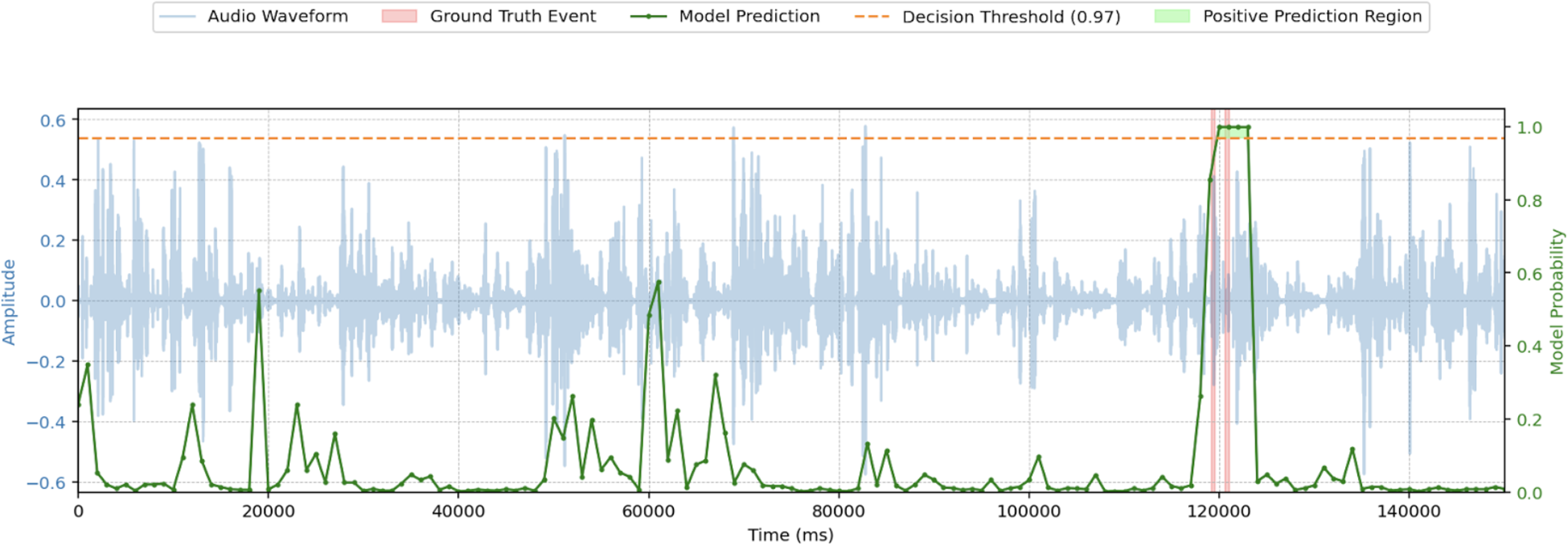
Example of continuous output from the Gemini 1.5 Pro 10-shot prompting method from a single example in a single fold.
In an alternative approach, the audio modality is withheld as input, and a Chirp 2 text transcript is provided instead to Gemini 1.5 Pro (Gemini Team, Google, 2024) in a 0-shot configuration along with a slightly modified prompt to remove references to nonsemantic audio cues and to draw attention to the “transcript” rather than to the “audio.” This variation allows for observation of the uplift provided by the additional audio modality in this context.
LoRA Fine-Tuned Audio Language Model
Low-Rank Adaptation (LoRA) (Hu et al., 2021) fine-tuning is a technique to efficiently adapt large pre-trained language models to specific tasks. Instead of fine-tuning all the model’s parameters, LoRA freezes the original weights and introduces a pair of low-rank matrices to represent the changes. During training, only these smaller matrices are updated. This method significantly reduces the number of trainable parameters, leading to faster training and lower memory usage compared to full fine-tuning, while still achieving comparable or even better performance, particularly when using all available examples.
To ensure a viable path toward successful fine-tuning and production deployment, we utilized the Gemini 2.0 Flash model (Hassabis & Pichai, 2024) instead of the much larger Gemini 1.5 Pro model. This model offers a balance between state-of-the-art performance and reduced computational overhead (and costs) necessary for iterative fine-tuning and inference.
The Gemini 2.0 Flash model is fine-tuned over 14 epochs with a learning rate multiplier of 0.5, starting at an original learning rate of 1
Evaluation
Monte Carlo Cross-Validation
We have a limited number of positive examples (298) and an abundance of negative examples.
We employ Monte Carlo cross-validation with five train/test splits. Each split randomly divides the conversations, allocating 80% for training and 20% for testing. As conversations may contain multiple positive events, the number of positive samples can vary between training and testing sets across different splits. For each positive instance, 10 random negative instances are sampled from conversations within the same split, resulting in a 10:1 negative to positive ratio.
Monte Carlo cross-validation helps mitigate variance arising from a single train/test split on our small dataset (e.g., simple examples in the test set). This approach is also beneficial for increasing the diversity of negative samples, as we randomly resample them for each split, unlike standard k-fold cross-validation which maintains a fixed set of both positive and negative examples.
Results
The results of each method are detailed in Table 1. We also include details about random and minority-class (positive) guessing methods to establish the floor performance for this task. To establish statistical significance of the performance between methods, we compared the models with a one-tailed Student’s
Comparison of F1-Scores Across Different Approaches.

Abbreviations: ASR = automatic speech recognition; LoRA = low-rank adaptation; MCCV = Monte Carlo cross-validation.
The ASR hotword heuristic served as a baseline comparison. The fine-tuned Wav2Vec classifier, representing a state-of-the-art ASR model, significantly outperformed that baseline, as anticipated. Remarkably, Gemini 1.5 Pro, in a zero-shot configuration without any historical examples of the task, achieved approximate performance parity with the Wav2Vec solution, based solely on the descriptive prompt provided. When prompted with just two randomly drawn examples (one positive and one negative), Gemini 1.5 Pro is already able to identify many of these Hearing Difficulty Moments, showing a clear uplift over the Wav2Vec solution (F1-score: 0.76) with an F1-score of 0.85. At 10-shot prompting (five positive and five negative), Gemini 1.5 Pro shows a further performance uplift, reaching an F1-score of 0.87. The uplift of the 10-shot prompting method versus the Wav2Vec solution is further illustrated in Figure 6 which shows the respective precision–recall curves from a single fold.
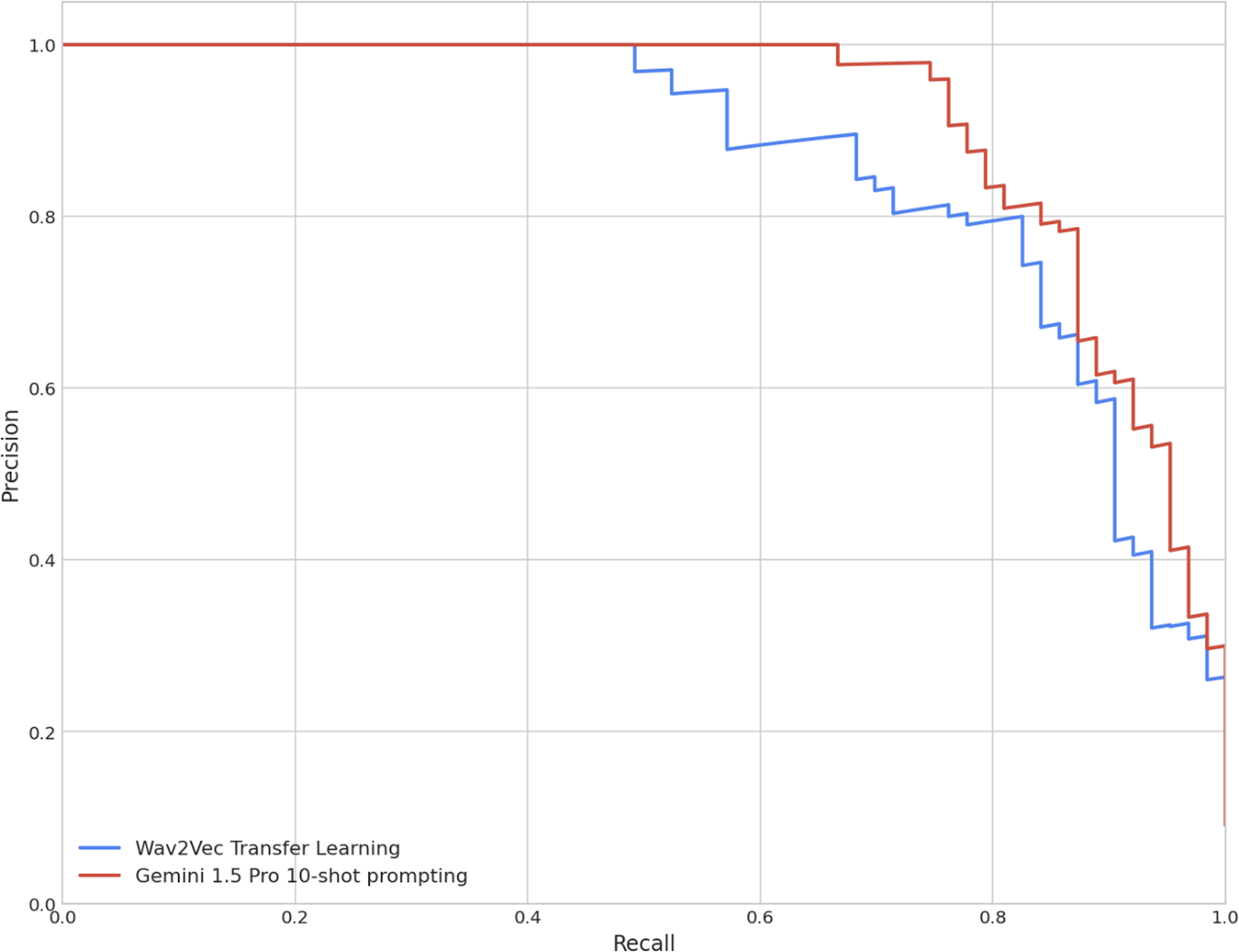
Precision–recall curves compared from a single fold for Wav2Vec and Gemini 1.5 Pro 10-shot prompting methods.
When Gemini 1.5 Pro was prompted without the audio tokens, relying solely on the Chirp 2 text transcript for information, a significant degradation in performance was observed. This approach had no observable uplift over the ASR hotword heuristic baseline.
Discussion
Dialogue-act annotation can be subjective and challenging, and prior work has noted variability in coder agreement depending on task and tag set complexity (Stolcke et al., 2000). We therefore treat the dialogue-act labels used here as a form of “silver-standard” ground truth rather than error-free targets. Our analyses rely on the original “signal-nonunderstanding” annotations provided with the published corpora, and our subsequent refinement to isolate Hearing Difficulty Moments was performed by a single coder. This additional refinement step introduces further subjective judgment in distinguishing perceptual difficulty attributable to the acoustic signal from linguistic or pragmatic nonunderstanding, and likely contributes label noise to the training data. We acknowledge that residual ambiguity in the original labels introduces noise, which remains a limitation of the present study. While this operationalization provides a practical starting point for modeling Hearing Difficulty Moments from conversational audio, future work should employ purpose-built annotation protocols with multiple independent raters, formal reliability assessment, and larger, more diverse datasets to more rigorously characterize Hearing Difficulty Moments (including a broader range of repair types and nonovert indicators of difficulty).
As expected, the ASR Hotword Heuristic performed poorly relative to the audio-based models, potentially reflecting the polyfunctionality of repair initiators and the limitations of lexical-only detection for isolating Hearing Difficulty Moments.
Leveraging audio language models for nuanced audio-classification tasks requires audio reasoning capabilities that extend well beyond those of conventional ASR systems. Here, we established a Hearing Difficulty Moment detection task and showed that audio language models can achieve state-of-the-art performance. For the smaller model (Gemini 2.0 Flash), fine-tuning yielded performance comparable to a fine-tuned state-of-the-art ASR model. For the larger model (Gemini 1.5 Pro), fine-tuning becomes impractical; instead, few-shot prompting provides a cost-effective and highly performant alternative. We hypothesize that this uplift in performance reflects the cross-modality reasoning capabilities of audio language models in combination with their scale. The marked performance difference between audio-based and text-only prompting further indicates that nonsemantic acoustic cues play a critical role in identifying these moments. While lexical cues (e.g., ‘‘what?”) identify the intent of a repair, they are often ambiguous; the same words can signal a request for information rather than hearing trouble. We hypothesize that Gemini outperforms the Wav2Vec and text-only baselines because it integrates these lexical triggers with prosodic features to resolve this ambiguity. Unlike Wav2Vec, which is optimized for phoneme recognition, or text-only models, which lack acoustic context, the audio language model’s multimodal reasoning allows it to verify that the lexical repair initiation is grounded in a genuine perceptual struggle.
The training data in this study comprised a 1:10 positive-to-negative label ratio, whereas in real conversational settings these events are likely to be orders of magnitude rarer. For example, “signal-non-understanding” acts occur approximately once every 1,000 utterances in the Switchboard corpus (Stolcke et al., 2000). Such imbalance would likely increase false positives in deployment. Future work could, therefore, adopt a more continuous evaluation framework that better reflects real-world serving distributions and moves beyond the discrete segment-classification strategy used here. In parallel, given the scarcity of positive labels, it may be valuable to investigate whether reinforcement-learning formulations offer advantages over the supervised learning approach employed in this study.
Given the nature of the training examples used in this study, we expect the methods described here to generalize well to a variety of conversational settings. While SWDA consists of dyadic telephone conversations, MRDA contains multiparty meeting interactions. Despite the different interactional structures, ranging from two-party to multi-party exchanges, both datasets generally feature relatively clean audio and predictable turn-taking. These characteristics provide a plausible basis for generalization to structured real-world interactions (e.g., clinical consultations or small group meetings). However, because the training data contain limited variability in environmental noise, speaker movement, prolonged silences, or out-of-conversation dynamics, the models may face limitations in ambient or “always-on” scenarios where multiple speakers, spontaneous activity, and fluctuating acoustic conditions are common. Integration of Voice Activity Detection (VAD)-based heuristics may help mitigate these challenges in future work. VAD identifies the portions of an audio signal that contain speech, thereby providing a clear segmentation cue by indicating the precise start and end points of spoken segments, which greatly reduces the amount of required downstream processing.
Furthermore, it is important to distinguish between the internal, cognitive state of hearing difficulty and the public interactional act of a ‘‘repair initiation.” Our task is fundamentally event detection. The models identify the overt, public signal that communication trouble has occurred, which serves as an observable proxy for the internal experience of hearing difficulty. Additionally, because our current approach utilizes a single-stream mono audio format containing both interlocutors, the models detect the occurrence of these events within the dialogue but cannot inherently determine which speaker is experiencing the difficulty. This presents a practical consideration for real-world hearing-aid applications, where the system may primarily or exclusively have access to the device wearer’s own microphone. Future research must determine if a user’s repair initiations remain detectable and discriminative when the interlocutor’s preceding turn is significantly attenuated or absent from the model’s input.
Prolonged silences and out-of-conversation dynamics play an important role in real-world conversational audio but are largely absent from the training examples used here. In everyday settings, people routinely pause for extended periods, shift attention away from the interaction, talk while moving through space, or engage in side activities that result in long stretches of low-energy audio, incidental noise, microphone-handling sounds, or other background conversations. These dynamics influence the acoustic context in which Hearing Difficulty Moments occur and may affect the reliability of automatic detection, particularly in always-on or passive-listening scenarios. By contrast, the SWDA and MRDA corpora consist of structured telephone and meeting recordings, where conversations start and end cleanly, speakers remain engaged throughout, and long silences or off-task behaviors are minimal or removed during segmentation. As a result, the models trained here have limited exposure to these naturally occurring fluctuations in conversational engagement and ambient sound, which may reduce robustness when deployed in noisier, less predictable environments. Our future research includes testing the robustness of these models in a wide variety of settings to determine the limits of generalization in real-world exchanges.
Outlook
In this study, we capture Hearing Difficulty Moments solely through overt verbal signals. However, listeners frequently signal trouble perceiving a prior turn nonverbally as well, for example, through brief “freeze looks” or eyebrow movements that can serve as repair initiations (Hömke et al., 2025; Manrique, 2016). Recent work using variation-modeling approaches has demonstrated that individuals’ facial expressions can be associated with underlying hearing loss (Yin et al., 2024), underscoring the potential value of multimodal data for understanding real-world communication challenges. Similar to how video-based methods can reveal moment-to-moment difficulty, our findings show that audio-only recordings can reliably track the occurrence of Hearing Difficulty Moments in natural conversation. While detection is the focus of this work, its primary clinical value lies in its application to assistive technologies. This opens opportunities for passive monitoring of how often individuals encounter such moments in daily life and, as an aspirational future application, for optimizing hearing-aid processing by dynamically prioritizing speech information when the user exhibits signs of difficulty. Future work may also explore multimodal extensions of this task, combining audio with video-derived behavioral cues to improve detection accuracy and open new avenues for modeling the fine-grained dynamics of real-world communication difficulty.
In the present work, we restrict prediction to hearing difficulty at time
Our evaluation focuses on predictive performance without considering constraints such as real-time latency or computational efficiency. In particular, deploying audio language model solutions on edge devices remains challenging due to model size. Future work will investigate model-distillation approaches to transfer knowledge from large models into smaller, edge-deployable systems.
Finally, while this initial study demonstrates the promise of using audio language models for specialized audio-classification tasks, it also reflects the limitations of relying on closed-weight models. Future work within this research program will prioritize the use of open-weight models where possible to support transparency, reproducibility, and wider adoption of the methods.
The work also opens several promising avenues for further research. Extending the prediction task to incorporate varied temporal contexts, multimodal behavioral cues, and more flexible formulations of the detection problem may enhance the ecological validity and performance of future hearing systems. Exploring these directions will deepen our understanding of how communication difficulty unfolds in real time and support the development of tools and technologies that better reflect the complexity of real-world conversation to ultimately ease listening for people who use hearing devices.
Conclusion
We demonstrated that Hearing Difficulty Moments can be automatically identified from audio alone using contemporary audio language model approaches. By formalizing these moments and evaluating multiple modeling strategies, we show that subtle, real-world indicators of listening difficulty can be captured without relying on controlled laboratory speech or explicit behavioral tasks. These findings establish a foundation for scalable, passive methods to track communication difficulty in daily life. By providing a reliable method for identifying these moments, we highlight the potential for next-generation adaptive hearing technologies that can use these signals to trigger real-time adjustments, ultimately easing the listening burden for people in challenging acoustic environments.
Footnotes
Acknowledgments
We thank Brooke Luthy from Macquarie University for her assistance with the final manuscript preparation.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Australian Future Hearing Initiative, a collaboration formed under Google’s Digital Future Initiative in partnership with Macquarie University.
Declaration of Conflicting Interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on request.