
Abstract
Investigations of the role of audiovisual integration in speech-in-noise perception have largely focused on the benefits provided by lipreading cues. Nonetheless, audiovisual temporal coherence can offer a complementary advantage in auditory selective attention tasks. We developed an audiovisual speech-in-noise test to assess the benefit of visually-conveyed phonetic information and visual contributions to auditory streaming. The test was a video version of the Children's Coordinate Response Measure with a noun as the second keyword (vCCRMn). The vCCRMn allowed us to measure speech reception thresholds in the presence of two competing talkers under three visual conditions: a full naturalistic video (AV), a video which was interrupted during the target word presentation (Inter), thus, providing no lipreading cues, and a static image of a talker with audio (A). In each case, the video/image could display either the target talker or one of the two competing maskers. We assessed speech reception thresholds in each visual condition in 37 young (≤35 years old) normal-hearing participants. Lipreading ability was independently assessed with the test of adult speechreading (TAS). Results showed that both target-coherent AV and Inter visual conditions offer participants a listening benefit over the static image with audio condition. Target coherent visual information provided the greatest listening advantage in the full audiovisual condition, but a robust advantage was also seen in the interrupted condition, where listeners were unable to lipread the target words. Together, our results are consistent with visual information providing multiple benefits to listening, through lipreading and enhanced auditory streaming.
Keywords
Introduction
Listening in noise is difficult, so much so that our ability to cope with interactions in noisy settings has interested researchers since Cherry (1953) defined the “cocktail party problem”. It is known that listening is not only supported by the auditory system but also by vision. Sumby and Pollack (1954), in their seminal work, demonstrated that looking at the talker's face can augment participants’ speech perception when speech is being perceived in the presence of background noise. More recent work has shown that that visual information lowers the signal-to-noise ratio (SNR) for which speech can be perceived at a fixed level of performance (Bernstein et al., 2004; Grant & Seitz, 2000), as well as increase the percentage of correct stimulus identification at fixed SNRs (Tye-Murray et al., 2007) when compared to the performance in audio-only conditions. Other advantages of audiovisual speech perception (compared to audio only), include better comprehension of stories (Arnold & Hill, 2001), more efficient shadowing of spoken passages (Reisberg et al., 1987), reduced cognitive effort to perform the auditory task at hand (Brown, 2025; Fleming & Winn, 2025), and improved ability to learn degraded speech (Wayne & Johnsrude, 2012). The “visual enhancement” of audition described in these studies is referred to as the audiovisual benefit (AV benefit).
Studies of speech-in-noise perception largely focus on contributions of lipreading, that is, the visually-conveyed phonetic information obtained from the talker's mouth movements. Growing evidence, however, demonstrates that audiovisual temporal coherence alone—that is, temporal coherence between (both naturalistic and artificial) auditory stimuli and artificial visual stimuli—can also offer listening benefits (Atilgan & Bizley, 2021; Maddox et al., 2015; Yuan et al., 2020, 2021; but see Cappelloni et al., 2023). Such benefits can be obtained using auditory stimuli coupled to disks of fluctuating size, thought to mimic the natural temporal correlations between the amplitude envelope of vocalizations and mouth opening size (Chandrasekaran et al., 2009), and are indicative of a bottom-up, language-independent process (Bizley et al., 2016). That such benefits are observed for non-speech stimuli, and when visual stimuli are, themselves, uninformative in terms of the content of the auditory stimuli they are coupled with, is evidence that they arise through enhancing auditory selective attention, either through augmenting one's ability to segregate competing sounds, or to correctly select the correct sound in a mixture. It remains unclear whether listeners simultaneously exploit both audiovisual temporal coherence and lipreading during speech perception, largely due to difficulties isolating audiovisual temporal coherence using conventional speech-in-noise tests (Lee et al., 2019). Even if both mechanisms contribute simultaneously to AV benefit, their relative contributions remain to be determined.
The aims of this study were to two-fold. Firstly, to develop a speech-in-noise test that is capable of measuring individuals’ AV benefit provided by looking at a talker's mouth when listening in noise. Secondly, to test the hypothesis that visual benefits arise through both lipreading and enhancing auditory scene analysis mechanisms.
Methods and Materials
Development of the vCCRMn Speech-in-Noise Test
Our goal was to develop a test to capture an AV benefit and to measure contributions from both lipreading and audiovisual temporal coherence mechanisms. Since visual benefits to listening are known to be most beneficial during adverse listening conditions (Helfer & Freyman, 2005), the listening task must be sufficiently hard such that visual cues do not become redundant. Moreover, while lipreading contributions are independent of the presence of sound, audiovisual temporal coherence requires sound (Bizley et al., 2016; Lee et al., 2019). Consequently, the test must be designed such that participant performance does not saturate through the use of lipreading alone, as seen in seminal audiovisual studies such as that of Sumby and Pollack (1954).
The audio-only Children's Coordinate Response Measure speech-in-noise test (CCRM; Messaoud-Galusi et al. (2011); see also (Bolia et al. (2000) and Brungart et al. (2001) for the Coordinate Response Measure, or CRM, corpus from which the CCRM was inspired) served as the basis for developing our speech-in-noise test. The CCRM was selected as a starting point due to its widespread use in research with both adults and children, as well as its clinical applicability (Bianco et al., 2021; Billings et al., 2024; Messaoud-Galusi et al., 2011; Saleh et al., 2023).
The CCRM sentences follow the template “Show the [animal] where the [colour] [number] is”, where an animal word is chosen from [dog, cat, cow, duck, pig, sheep], the colour from [black, blue, green, pink, red, white], and the number from [1, 2, 3, 4, 5, 6, 8, 9]. Thus, all animal, colour, and number words are monosyllabic. The target sentences always use the animal “dog” (i.e. “Show the dog where the [colour] [number] is”), while the remaining sentences, which feature other animals, colours, and numbers from those of the target and from each other, are used as maskers. The participants’ task is to identify the colour and number words mentioned in the target sentence.
The CCRM was adapted to include a video component, making the vCCRM. Initial pilot results revealed that the default choice of monosyllabic colours and numbers rendered the task too easy for some participants, as those target words could be identified accurately via lipreading alone. Consequently, in the new version of the vCCRM, the second key word was changed from a number to a monosyllabic noun. In designing the final set of 16 nouns, the mouth movements for the onset and offset of each noun were considered, ensuring that no noun exhibited unique mouth movements. In this way, each noun was visually confusable with at least two other nouns in the set—sharing a common beginning with one and a common ending with another. Pilot results showed that the task could not be resolved through silent lipreading alone and that the video provided the expected audiovisual benefit, making the task a promising tool for the study.
This adapted version is hereby referred to as the video version of the CCRM with nouns (or vCCRMn). Similar to the CCRM, sentences spoken in Southern British English followed the template “Show the [animal] where the [colour] [noun] is”. Animal options included [cat, cow, dog, duck, pig, sheep], colour options included [black, blue, green, pink, red, white] and noun options included [bed, bin, boat, bone, bowl, cloak, clock, coat, cone, lock, oak, oat, pear, peg, pen, pin].
Each trial of the vCCRMn comprised three simultaneously presented sentences—one target and two maskers—featuring different animal, colour, and noun combinations each. The target sentence always included the animal “dog” and was identified on this basis—there were no additional pretrial cues provided to indicate the target talker. Trials featured either a male or female target talker, with maskers that included one male and one female talker, which were different from the target and from each other. The talkers presented were randomly drawn from a pool of four possible talkers (two male and two female). A total of 2304 sentence stimuli were recorded at UCL's anechoic chamber—576 for each of the two male and two female talkers, all native speakers of Southern British English. Continuous audio was sampled at 44,100 Hz and segmented into 3 s segments, with the speech aligned to the end of the segment. Sentences were variable in duration depending on the talker, and aligning at the end ensured that the sentence onset times were variable across competing talkers, and the colour and noun words of the target were always masked by the non-target talkers. All talkers gave consent for their videos and images to be used in the test and in any subsequent publications or presentations and were paid for their time. All four recorded talkers (two male, two female) could be either target or masker talkers across all conditions of the vCCRMn.
The task included three main conditions. The naturalistic condition Audiovisual (AV) presented participants with both the video and the audio of a talker and was expected to provide AV benefits that encompass the contributions of both lipreading and audiovisual temporal coherence (see Figure 1A for an example trial of the AV condition, and Figure 1C for an example of the response panel). The Interrupted (Inter) condition differed from the AV condition in that the entire screen froze during the [colour] [noun] combination, thereby removing lipreading cues during that period. Consequently, the Inter condition was expected to eliminate any contributions of directly lipreading the target words to performance in the vCCRMn, but leave intact the cues that allowed the observed talker to be tracked through the mixture. Finally, the task included an Audio with a Static Image (A) condition, which served as a performance baseline for assessing listening benefits. Each of the three main conditions was further divided into two sub-conditions. In the target-coherent sub-condition, the voice of the target talker matched the face presented in the video, whereas in the masker-coherent sub-condition, the video presented matched one of the two masker voices (Figure 1B). This was also true for the static image with audio condition, thus also allowing us to assess potential advantages of looking at the static image of the target talker as compared to one of the two masker talkers.

The video version of the Children's Coordinate Response Measure task, using nouns (vCCRMn). (A) Example of an Audiovisual (AV) target-coherent trial. Participants were presented with the video of the talker whose voice was made the target talker voice in that trial (i.e. the talker uttering the sentence using the animal “dog”). Their task was to follow the target talker's voice and identify the colour and noun key words in it. Two masker voices uttering a sentence of the same form but featuring different animals, colours, and nouns were presented in the background. All four recorded talkers (two male, two female) could be either target or masker talkers across all conditions of the vCCRMn. (B) Example of an AV masker-coherent condition. The video presented matches the voice of one of the masker talkers, while participants are still tasked with identifying the key words of the target sentence. (C) Response panel with colour and confusable nouns set. The Interrupted video (Inter) and Audio with a Static Image (A) conditions followed the same structure.
Participants
Participants were recruited via the UCL Ear Institute and the UCL SONA subject pool. The experiment was conducted under the protocol approved by the University College London Research Ethics Committee (ref. 3866/003). Informed written consent was obtained from all participants prior to their participation. They were all compensated for their time.
A total of 37 participants (ages 19–35; Mean = 25.92, SD = 4.17), all native speakers of British English, were recruited and tested in person. The sample size was determined via a power calculation that accounted for potentially small effects of audiovisual temporal coherence on the AV benefit (Cappelloni et al., 2023; Maddox et al., 2015). Based on preliminary observations, an effect size of 0.5 was estimated, corresponding to a mean difference of 1 dB SNR between the target-coherent A and target-coherent Inter conditions, and a standard deviation of 2 dB SNR. With a Type I error probability of 0.05 and a power of 0.80, the minimum required sample size was estimated to be 33. Inclusion criteria required that participants were native speakers of British English, had normal hearing status (see Pure-tone audiometry), normal or corrected-to-normal vision (including normal colour vision), ability to maintain focus for the duration of the study, absence of neurological, psychiatric, or developmental conditions, no prior training in lipreading, no intrusive tinnitus, no language-related difficulties, no exposure to loud sounds within the 24 h preceding participation and no participation in the previous pilot versions of the vCCRMn.
Equipment and Apparatus
All testing procedures were completed inside a triple-walled Industrial Acoustics Company (IAC) soundproof booth located at the Human Labs of University College London's Ear Institute. The speech-in-noise and lipreading tests were run on a Dell Latitude laptop. Prior to testing, adjustments were made using an adjustable desk, chair, and laptop stand so that the screen was comfortably positioned at eye level. Participants wore closed-back, around-the-ear headphones (Sennheiser, HD 280 Pro Dynamic HiFi Stereo), which were tested and calibrated using an artificial ear (Bruel and Kjaer Type 4153) and a measuring amplifier (Bruel and Kjaer, 3110-003) to ensure a sound level output of 65 dB SPL (RMS normalized). Participants were instructed to maintain their eye-gaze on the task display during task testing. A camera positioned on top of the screen—connected to a computer in the experimenter's control room—was used to monitor compliance with this instruction. Communication between participants and the experimenter was maintained at all times via a microphone installed within the IAC booth.
Participants’ hearing status was assessed with a calibrated audiometer (Interacoustics, AS629, with Radioear DD450 headphones).
Test Battery
Participants carried out an array of tests during their testing session. The primary performance measure was the audiovisual speech-in-noise task vCCRMn, as detailed below. Additional measures included a pure-tone audiometry (PTA) test, completed prior to the vCCRMn and a silent lipreading test (TAS; Mohammed et al., 2006), which was run after the vCCRMn. All measures were completed within a single < 2-h testing session.
vCCRMn
The vCCRMn was implemented as described above (Development of the vCCRMn speech-in-noise test) and used an adaptive one-up one-down (1U1D) staircase procedure. This tracked participants’ speech reception threshold-fifty (SRT50)—i.e. the SNR at which a participant is expected to complete 50% of the trials successfully. The staircase maintained the same overall level across trials and adjusted both the level of target and masker sentences to adjust the SNR. Beginning with an SNR of 20 dB, staircase step sizes were 8 dB SNR until the first track reversal, then 6 dB SNR until the second, 4 dB SNR until the third, and 2 dB SNR for all subsequent reversals. The sequence was set to stop after four runs of the final step size had been concluded or when a total of thirty trials had been completed. Participant SRT50s for each run of a vCCRMn condition were estimated as the mean of the last four staircase reversals.
Participants completed three runs of each of the three main conditions of the task (AV, Inter, and A), with the conditions presented in a random order across runs. Within each run, two simultaneous staircases operated, one with target-coherent trials and one for masker-coherent trials, which were randomly intermixed and were not cued to the participant. Each run took approximately 5 minutes and yielded two threshold estimates (one for target-coherent and one for masker-coherent visual trials). Overall participant performance for each coherence type of each condition was estimated as the mean of the three thresholds (one per run) obtained for that participant. Communication between participants and the experimenter was maintained at all times via a microphone installed within the IAC booth.
Before embarking on testing, participants were given a short demonstration that included example trials from each of the six vCCRMn sub-conditions as well as example SNR changes. Following the demonstration, participants completed a five-minute practice session consisting of 8 trials. Each trial presented a randomly-selected vCCRMn condition and a randomly-selected vCCRMn sentence at 20 dB SNR, spoken by any one of the four talkers, and could be either target- or masker-coherent. Participants passed the practice session if they correctly identified the target words in at least 7 out of the 8 trials. They were given two opportunities to pass the practice session. Not passing the practice session led to the end of their participation and compensation for their time.
Pure-Tone Audiometry
Each participant's hearing was assessed via air conduction PTA, following the British Society of Audiology's guidelines (British Society of Audiology, 2018). Briefly, hearing thresholds were measured at the frequencies 1,000, 2,000, 4,000, 8,000, 500, and 250 Hz in the order listed. Hearing status was, then, determined as the mean of the better-ear scores (measured frequencies between 500 and 4,000 Hz). Participants with a PTA threshold of ≤20 dB HL were classified as having normal hearing (see also Figure 2).

Mean PTA threshold (averaged across both ears) as a function of frequency. Each line represents a participant. The thick central line depicts the mean performance across all participants.
Silent Lipreading Task
Silent lipreading ability was independently measured with the Test for Adult Speechreading (TAS). Detailed information on the test—including instructions on how to conduct the test—is available in Mohammed et al. (2006) and on the TAS webpage (https://dcalportal.org/tests/tas). Briefly, the test consists of video clips of silent speech produced by either a male or a female speaker. It includes three core tests of speechreading ability (assessing words, sentences, and short stories), and three additional subtests (minimal pairs, sentence stress, and question or statement). Participants completed all core and subtest tasks. Lipreading scores (percentage correct) on the sentence-level test were selected to represent participants’ lipreading ability, as this test revealed neither floor nor ceiling effects.
Data Analysis
Visual benefits were computed from the SRT50s for the AV condition and the Inter condition relative to the A condition. Specifically, the AV benefit was estimated using the formula:
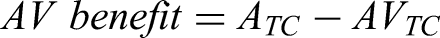
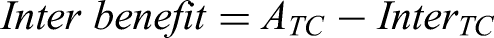
Coherence-type benefits were computed from the differences between masker- and target-coherent condition pairs. For the AV, the coherence benefit was estimated as:


Finally, the audio with static image-coherence benefit was computed as:

A 3 × 2 repeated measures ANOVA was used to examine the effects of visual condition (AV, Inter, and A), visual coherence type (Target, Masker), and their interaction on participant performance in the vCCRMn task. Post-hoc comparisons were conducted using pairwise paired t-tests with Bonferroni correction. Cohen's d and mean differences between contrasted conditions were computed measures of effect size.
Pearson correlations were performed to assess the relationship between AV benefit and Inter benefit, AV benefit and lipreading score, and Inter benefit and lipreading score. A Steiger test was performed to determine whether the correlations differed significantly. These correlational analyses were exploratory, as they were not covered by the power analysis, which focused on detecting mean differences between conditions.
All statistical analyses were conducted in R (Version 4.2.0).
Results
We developed a version of the CCRM that required that listeners report the colour and noun spoken by a target talker in the presence of two maskers, in three audiovisual conditions: full video (AV), interrupted video (Inter), and static image with audio (A).
Listeners Benefit from Visual Information in Both Audiovisual and Interrupted Video Conditions
Participants’ thresholds varied across visual stimulus conditions (Figure 3). A 3 × 2 repeated measures ANOVA yielded significant main effects for both visual condition (F(2, 210) = 7.28, p < .001) and visual coherence type (F(1, 210) = 29.89, p < .001), as well as a significant interaction between the two (F(2, 210) = 18.27, p < .001). To further explore this interaction, we conducted post hoc paired t-tests.

The effect of visual condition on speech-in-noise performance and assessment of benefits. (A) Boxplots displaying performance in each of the six vCCRMn sub-conditions. White dots depict mean performance, boxes indicate the quartiles, whiskers the distribution range, and grey dots are individual participants. Pairwise comparisons are shown as horizontal lines over the relevant conditions (* indicates p < 0.05; *** indicates p < 0.001; ns = non significant). TC = target-coherent condition; MC = masker-coherent condition. (B) Histograms of visual benefits for the AV and Inter conditions. (C) Histograms of coherence-type benefits for the AV, Inter, and A conditions. Dashed grey lines indicate zero benefit; solid coloured lines indicate the mean performance for each benefit, with colours matching the respective conditions.
These analyses showed that performance was significantly better in the AVTC condition compared to both the ATC baseline (AV benefit = 5.4 dB SNR) and the InterTC (difference = 3.5 dB SNR); performance in the InterTC condition was also significantly better than in the ATC (Inter benefit = 1.9 dB SNR) (see also Figure 3A). For both AVTC and InterTC, thresholds were significantly lower than the respective masker-coherent conditions (AV coherence benefit = 6.9 dB SNR; Inter coherence benefit = 2.3 dB SNR). Coherence type did not influence performance in the static image with audio (A) conditions. Finally, performance was significantly worse in the AV masker-coherent condition than in the audio with a static image (AV detriment = 1.45 dB SNR). Full details, including t-test statistics, p-values, and effect sizes for all comparisons, are shown in Table 1.
Summary of the Post-Hoc Paired t-Test Comparisons: The Comparisons Are Categorised by Type. Measures of Effect Size, Including Cohen's d and Mean Differences between the Conditions Being Compared, Are Also Included.

Note. Star symbols in the p-value column denote statistical significance (* indicates p < 0.05; *** indicates p < 0.001). TC = target-coherent condition; MC = masker-coherent condition.
Video Conditions Can Both Enhance and Impair Participant Performance
To more directly compare the influence of visual stimuli on listening, we calculated the visual benefits for each participant by comparing the AVTC and InterTC with the ATC condition (Figure 3B). Likewise, we visualized the effect of coherence on performance for each condition by comparing the thresholds for targets and maskers within each visual condition (Figure 3C).
The histogram representations of visual and coherence-type benefits highlight the findings outlined in Figure 3A and Table 1, and offer insights into the variance of each benefit (Figure 3B, C). AV benefit values varied from −2 to 15.5 dB SNR, with 34 out of 37 listeners scoring a positive visual benefit for AVTC. The visual benefit in InterTC varied from −5.5 to 6.5 dB SNR, with 29 out of 37 participants achieving a positive value.
The impact of coherence on performance also varied across conditions (Figure 3C): Both AV and Inter coherence benefits were substantially positive, while the A coherence benefit was approximately symmetric around zero—consistent with the non-significant performance differences between ATC and AMC conditions. The AV coherence benefit varied from 0.5 to 15 dB SNR, the Inter coherence benefit from −2.5 to 8.5 dB SNR, and A coherence benefit from −3 to 6 dB SNR.
Contributions of Streaming and Lipreading to the AV Benefit Vary Across Participants
To explore whether we could separate the contribution of lipreading the target words from streaming or other more general multisensory processes, we explored the relationship between AV and Inter benefits (Figure 4A). The correlation between the AV benefit and Inter benefit approached significance (Pearson's r = 0.31, p = 0.058), either indicating that these are independent processes, or possibly failing to reach significance due to the added variability introduced when computing benefit measures as differences between the original SRT50s.

Linear dependencies and relative contributions of audiovisual temporal coherence and lipreading score to the AV benefit. (A) Scatter plot and Pearson correlation between AV benefit and Inter benefit. (B) Scatter plot and Pearson correlation between AV benefit and Lipreading score (TAS sentences score). (C) Scatter plot and Pearson correlation between Inter benefit and Lipreading score. (D) Bar plot displaying participant-specific AV (blue) and Inter (green) benefits, with participants ranked by the magnitude of their AV benefit. The height difference between the blue and green bars indicates the additional contribution of lipreading to the overall AV benefit. Black lines in A and B = regression lines; dashed line in A = equality line.
To further understand to what extent the AV benefit reflected lipreading ability, we asked whether the independent TAS measure for silent lipreading at the sentences level correlated with either the AV or the Inter benefit. A Pearson correlation was conducted between AV benefit and Lipreading score (Figure B), revealing a small-to-moderate positive correlation (Pearson's r = 0.42, p = .009). In contrast, the Inter benefit and Lipreading scores (Figure 4C) were not significantly associated (Pearson's r = .20, p = .233), supporting the hypothesis that the benefit in the Inter condition does not emerge from lipreading, but, instead, from a separate multisensory process. However, a Steiger test comparing the correlations did not reach significance (z = 1.45, p = .15, two-tailed); thus, the current data are not sufficient to draw decisive conclusions as to whether lipreading ability predicts the benefits in the Inter condition. To examine the relative contributions of both lipreading and streaming mechanisms within the vCCRMn and within individual participants, the AV and Inter benefits were plotted for each subject (Figure 4D; blue and green bars, respectively). Within this visualization, the lipreading contribution is reflected by the difference between the height of the AV benefit and Inter benefit bars. Figure 4D clearly shows substantial inter-individual variability in the relative use of the two mechanisms, including extreme cases where individuals obtain almost all of their AV benefit using only one of the two.
Discussion
In the present study, we investigated how visual cues from a talker's face affect speech-in-noise perception in young, normal-hearing participants. To do so, we developed a novel speech-in-noise test (vCCRMn) that incorporates both auditory and visual information. This task was specifically designed to capture the AV benefit—that is, the performance improvement observed when individuals process audiovisual speech compared to audio-only speech—by quantifying contributions from both directly lipreading the target words and assisting with auditory selective attention more broadly.
Our results demonstrated that the vCCRMn reliably measured an AV benefit, as participants showed improved performance in the AV target-coherent (AVTC) condition compared to the audio with static image (ATC) condition. This finding aligns with previous studies reporting AV benefits for speech-in-noise perception (Bernstein & Grant, 2009; Grant & Bernstein, 2019; Sumby & Pollack, 1954).
Participants also performed significantly better in the Inter target-coherent (InterTC) condition compared to ATC. Because the InterTC condition did not provide lipreading cues for the target words, the observed benefit cannot be attributed to lipreading of the target words and, instead, must relate to an enhanced ability of listeners to track the target talker through the mixture. What cues allow listeners to do this remains to be determined but is likely to be a mixture of correspondence between lipreading movements and speech, and low-level temporal coherence cues that promote audiovisual binding (Bizley et al., 2016; Lee et al., 2019; Maddox et al., 2015).
Evidence in favor of the InterTC condition providing streaming cues for speaker segregation comes from the observation that the AV benefit provided by the AVTC condition was positively correlated with independently-assessed lipreading scores (TAS test), whereas the Inter benefit did not. A direct statistical comparison of the two correlations, however, did not reach significance. Notably, these correlational analyses are exploratory and statistically underpowered, as the sample size was optimized to detect mean differences between vCCRMn conditions rather than differences between correlations. Resolving this question conclusively will require a larger dataset and, ideally, the use of synthetic stimuli that eliminate lipreading cues.
Our scenes were composed of three co-located talkers, with one of the maskers being the same sex as the target talker, making segregation of the target talker from the mixture non-trivial. Audiovisual temporal coherence has been shown to confer a limited benefit when auditory scenes are simple to segregate. For example, Cappelloni et al. (2023) used only two competing artificial vowel streams—one with a male pitch, and one with a female—making the scene easy to segregate based solely on fundamental frequency. As such, talker identity conveys a strong advantage on auditory selective attention performance, aiding, however, in selection rather than segmentation. In our study, we did not find significant differences between the two static image conditions (ATC and AMC), ruling out the talker identity as a principal driver of the advantage seen in the InterTC condition. Another key difference between the study of Cappelloni et al. (2023) and studies that have demonstrated advantages of audiovisual temporal coherence (e.g., Atilgan et al., 2018; Atilgan & Bizley, 2021; Maddox et al., 2015; Yuan et al., 2020, 2021) is that the latter studies all utilized amplitude cues to link audition and vision temporally, suggesting that this may be a key driver of both synthetic and naturalistic audiovisual binding.
In the InterTC condition of the vCCRMn, we chose to remove lipreading cues by freezing the video during the colour and noun window of presentation. An alternative way to further separate articulatory correspondence and temporal coherence, utilized by Fiscella et al. (2022), could be to rotate the orientation of the face, thus, potentially disrupting lipreading while maintaining temporal coherence. Such a control would be an interesting follow-up to the work presented here, potentially revealing larger Inter benefits as temporal coherence cues might be better retained through the target word presentation period.
More broadly, further refinements to the vCCRMn may be required to ensure applicability across listener populations. While we consider the vCCRMn to be a sensitive and efficient tool for measuring audiovisual benefit in a variety of participant demographics, it should be noted that, in some dialects, the words “pin” and “pen” are homophonous. While this merger does not apply to the vCCRMn talkers, who were native speakers of Southern British English, these words would need to be removed or replaced with other, appropriate monossylabic words in versions of the test intended for dialects in which the merger is present (e.g., some American English dialects).
Beyond providing benefits to speech perception, the vCCRMn also revealed conditions under which visual information can be detrimental. We demonstrated that masker-coherent visual information can impair speech-in-noise perception, as performance in the AVMC condition was significantly worse than in the audio with a static image condition. In the AVMC condition, the audiovisual binding of the face and voice likely results in a stronger perceptual representation of the masker that makes it both harder to track the target talker through the mixture, and provides conflicting lipreading cues during the target presentation. The observation that there was no significant detriment elicited by the InterMC condition compared to audio with a static image condition, and InterMC was significantly better than AVMC suggests that lipreading during the target words is the key driver of this deficit, and in favor of the former interpretation.
As is common in studies of multisensory integration (see, e.g., Grant et al., 1998; Macleod & Summerfield, 1987; Tye-Murray et al., 2016), there was considerable inter-individual variability in the magnitude of the AV benefit measured, and in the relative benefits observed for the full video (AVTC) and interrupted (InterTC) conditions. Many participants derived some benefit in each condition, which is consistent with the interrupted condition capturing a subset of the available audiovisual benefit. However, some participants relied almost exclusively on Inter condition-derived benefits, while others not at all—with the latter, presumably, relying exclusively on lipreading-related cues for their AV benefits. This variability could have important clinical implications for populations who live with hearing loss, suggesting that personalized assessments of lipreading and audiovisual temporal coherence abilities may be valuable for designing effective rehabilitation and training programs.
Footnotes
Acknowledgments
We thank Professor Mairéad MacSweeney for helpful discussions, Gordon Mills for implementing an online version of the vCCRM that allowed us to run pilot experiments during the COVID-19 pandemic, and the vCCRMn talkers for their help with recording the vCCRMn sentence stimuli. Finally, we thank all of the participants of this study, without whom none of this work would have been possible.
Ethics
Participants were recruited via the UCL Ear Institute and the UCL SONA subject pool. The experiment was conducted under the protocol approved by the University College London Research Ethics Committee (ref. 3866/003). Informed written consent was obtained from all participants prior to their participation. They were all compensated for their time.
Funding
This work was supported in whole, or in part, by a studentship from the NIHR UCL(H) Biomedical Research Centre (Deafness and Hearing Problems Theme) and the UCL Ear Institute to L.C.A.; the Wellcome Trust/Royal Society Sir Henry Dale Fellowship Grant 098418/Z/12/A and a Wellcome Career Development Award 227480/Z/23/Z to J.K.B. and the European Research Council Consolidator award 771550 SOUNDSCENE to J.K.B.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data is freely available at the following https://doi.org/10.5522/04/31017220.v1. Code used to run the experiment is available at https://github.com/BizleyLabTeam/vCCRM_2026 (Alampounti et al., 2026).