
Abstract
Online recruitment platforms are increasingly used for experimental research. Crowdsourcing is associated with numerous benefits but also notable constraints, including lack of control over participants’ environment and engagement. In the context of auditory experiments, these limitations may be particularly detrimental to threshold-based tasks that require effortful listening. Here, we ask whether incorporating a performance-based monetary bonus improves speech reception performance of online participants. In two experiments, participants performed an adaptive matrix-type speech-in-noise task (where listeners select two key words out of closed sets). In Experiment 1, our results revealed worse performance in online (N = 49) compared with in-lab (N = 81) groups. Specifically, relative to the in-lab cohort, significantly fewer participants in the online group achieved very low thresholds. In Experiment 2 (N = 200), we show that a monetary reward improved listeners’ thresholds to levels similar to those observed in the lab setting. Overall, the results suggest that providing a small performance-based bonus increases participants’ task engagement, facilitating a more accurate estimation of auditory ability under challenging listening conditions.
There is a growing interest in remote testing, both in the context of basic research (Anwyl-Irvine et al., 2020; Backx et al., 2020; Hartshorne et al., 2019; Shapiro et al., 2020) and clinical screening (Paglialonga et al., 2020; Sevier et al., 2019; Shafiro et al., 2020; Sheikh Rashid et al., 2017; Swanepoel & Clark, 2019; Swanepoel et al., 2019; Watson et al., 2012). The ability to conduct experiments online facilitates rapid data acquisition and provides access to a larger and more diverse subject pool than that available for lab-based investigations (Casey et al., 2017). However, in contrast to the lab setting, online experiments are associated with a lack of control over participants’ equipment, environment, and engagement (Chandler & Paolacci, 2017; Clifford & Jerit, 2014). These limitations may be particularly detrimental to auditory assessments that often rely on highly controlled stimulus delivery and necessitate focused engagement from the participant (e.g., Harrison & Müllensiefen, 2018).
Tasks that require effortful listening (e.g., when trying to estimate performance at threshold, or the just noticeable difference in a particular acoustic feature) may be particularly susceptible to issues related to task engagement (including attention, motivation, and commitment). In laboratories or clinics, engagement is controlled by creating a “sterile environment” that isolates the participants from potential sources of distraction (e.g., their mobile phone, software notifications, doorbell, housemates, etc.). Compliance and motivation are promoted through face-to-face interaction with the experimenter (Guéguen & Pascual, 2000; Karakostas & Zizzo, 2016). To understand how these factors affect data obtained from online participants, in this series of experiments, we investigated how performance on one version of widely used auditory speech-in-noise perception tasks differs between in-lab and online settings and whether monetary reward may be used as a mean to encourage participant engagement.
We used an adaptive speech-in-noise task based on target materials similar to the Coordinate Response Measure (CRM) corpus of Bolia et al. (2000). The CRM measures the ability to identify two keywords (color and number words) in a spoken target sentence always cued by a so-called call sign. Participants are instructed to attend to the target sentence while ignoring a masker. The CRM is part of a family of adaptive speech reception in noise tests (see also digit-in-noise test commonly used in audiology practice; De Sousa et al., 2019). These paradigms have been shown to be powerful tests of listening in complex environments because of their sensitivity to small intelligibility changes in highly noisy backgrounds, their applicability to testing with different maskers, and their relative independence from semantic/syntactic cues (Brungart, 2001; De Sousa et al., 2020; Eddins & Liu, 2012; Humes et al., 2017). Accumulating work demonstrates that speech reception thresholds (SRTs) estimated with an adaptive CRM task correlate with audiometric thresholds and with age (de Kerangal et al., 2020; Schoof & Rosen, 2014; Venezia et al., 2020), rendering it a potentially efficient proxy of hearing ability (Semeraro et al., 2017). An additional advantage is that the task relies on manipulating the relative intensity of the target and the masker, and performance is largely independent of overall level over a reasonable range. Outcomes are therefore less affected by calibration of equipment compared with other tasks that rely on absolute sound level. These considerations make the CRM, as well as other similar speech-in-noise tasks (De Sousa et al., 2019, 2020), particularly attractive for estimating auditory abilities in online settings.
We first asked whether performance among young listeners recruited “blindly” online is consistent with that observed in the highly controlled laboratory setting. Results suggested poorer performance by online listeners. We hypothesized that reduced performance in the online compared with the in-lab sample may reflect a lack of task engagement or motivation among the online cohort. Therefore, building on existing evidence that monetary reward can improve performance in tasks that involve executive or perceptual functions (Libera & Chelazzi, 2006; Plain et al., 2020; Shen & Chun, 2011), we asked whether incorporating a performance-based monetary bonus in a group of online participants could improve speech reception performance relative to an online group that does not receive a bonus. Our results revealed that a monetary bonus improved listeners’ threshold and that the resulting SRT distribution was similar to that observed in the lab setting. Overall, the results confirm that providing a small performance-based bonus increases participant task engagement (i.e., the readiness to exert effort and/or allocate sufficient attention to the task), facilitating a more accurate estimation of auditory ability.
Experiment 1
Methods
Participants
Two participant groups ranging in age between 25 and 32 years were tested. An in-lab group (data pooled from de Kerangal et al., 2020 and an additional unpublished study) comprised 81 participants (59 females, mean age 25 ± 3 years) who completed the task as part of a test battery. An age-matched online group of 49 participants (35 females, mean age 26 ± 3 years) was recruited and compensated via the Prolific crowdsourcing platform. All listeners were young, native speakers of British English and reported no known hearing problems. The online sample was not formally tested for hearing problems. We assumed that this cohort of young listeners would exhibit a similar hearing profile to the aged-matched in-lab participants. Experimental procedures were approved by the research ethics committee of University College London, and informed consent was obtained from each participant.
Stimuli and Procedure
An SRT for each participant was obtained using target sentences introduced by Messaoud-Galusi et al. (2011)—the Children’s Coordinate Response Measure (CCRM), which is a modified version of the CRM corpus described by Bolia et al. (2000). The modifications were made to be able to embed the materials in the task as a straightforward command, and using call signs (here the animal name) that would be more appropriate for use with children, without precluding the use of the material in adults, nor changing the essential properties of the corpus. Note that the CCRM as used here is likely to be at least as difficult as the original CRM (both requiring the identification of a color and a number), but here there are six colors rather than four. On each trial, participants heard a target sentence of the form “show the dog where the [color] [number] is.” The number was a digit from 1 to 9, excluding the number 7 (due to its bisyllabic phonetic structure, which would make it easier to identify). The colors were black, white, pink, blue, green, or red. Thus, there were a total of 48 combinations (6 colors × 8 numbers). Participants were instructed to press on the correct combination of color and number on a visual interface showing an image of a dog and a list of the digits in the different colors.
The target sentences were spoken by a single female native speaker of Standard Southern British English that was presented simultaneously with a two male-speaker babble that the participants were instructed to ignore. Each talker in the babble was recorded reading two five- to six-sentence passages that were concatenated together once passages were edited to delete pauses of more than 100 ms. The two talkers were then digitally mixed together at equal levels, with random sections of the appropriate duration from this 30-s long masker chosen for each trial.
The overall level of the mixture (target speaker + babble background) was kept fixed, with only the ratio between the target and masker changing on each trial. The signal-to-noise ratio (SNR) between the babble and the target speaker was initially set to 20 dB and was adjusted using a one-up one-down adaptive procedure, tracking the 50% correct threshold (Levitt, 1971). Initial steps were of 9 dB SNR, decreasing by 2 dB following the first two reversals and then fixed at a step size of 3 dB SNR for all subsequent trials. The procedure terminated after 7 reversals or after a total of 25 trials (the latter was never reached). The SRT for one run was calculated as the mean of the SNRs in the last four reversals. Each participant performed the test in four consecutive runs of approximately 2 min each. To allow a stable measure of a listener’s threshold, the SNR was averaged over the last four reversals within each run and then across the last three runs (Run 1 was used as practice). In all individual runs, a stable threshold was achieved within <20 trials. The in-lab data for this experiment are drawn from de Kerangal et al. (2020), and it was therefore important to use the parameters used in that study. de Kerangal et al. demonstrated that this parameter set produces reliable thresholds and yields the expected difference in SRT between young and old adults and a correlation between SRT and audiometric measures.
The in-lab test was conducted in a double-walled soundproof booth (IAC, Winchester). The task was implemented in MATLAB using a calibrated sound delivery system. Sounds were presented with a Roland Tri-capture 24-bit 96 kHz soundcard over headphones (Sennheiser HD 595) at a comfortable listening level of 70 dB sound pressure level (SPL).
For online testing, the task was implemented in JavaScript, and the Gorilla Experiment Builder platform (www.gorilla.sc) was used to host the experiment (Anwyl-Irvine et al., 2020). Participants were recruited and prescreened by the Prolific platform. Otherwise, the same stimuli and test heuristics were used as in the in-lab settings. As is common practice in online auditory experiments, participants were screened for headphone use. We used a strict version of the approach introduced and validated by Milne et al (2020) which yields a 7% false positive rate. In brief, this test uses a combination of Huggins pitch stimuli (Cramer & Huggins, 1958) which are only detectable when L and R channels are presented separately to each ear, and a pair of tones (f1 = 1800–2500 Hz; f2 = f1 + 30 Hz) presented binaurally that sound smooth when listening dichotically or to each channel alone but contain a beat when the channels are mixed (Oster, 1973). Together, these probes allow us to identify those participants who are listening dichotically through separate L and R channels (i.e., using headphones) from those listening over a single channel or over speakers. The test was validated in a large group of normal-hearing listeners. For full details, information about validation, and the links to experience the task, see Milne et al. (2020).
The CCRM task took approximately 10 min to complete. It began with a volume calibration to make sure that stimuli were presented at an appropriate level. A target sentence without a masker was used for this purpose. Participants were instructed to play the sound and adjust the volume to as high a level as possible without it being uncomfortable.
At the end of the experiment, participants completed a short questionnaire about their listening environment and equipment. We encouraged honest reports by stressing that “your answers will not affect your payment but will help us to get the best quality data.” In particular, participants were asked about how much background noise they experienced during the experiment (0 = not at all, 10 = a lot). This measure was used as a potential exclusion criterion to make sure that group differences in performance were not explained by mere differences in environmental noise. The experiment was piloted to take about 15 min. We thus set the base-pay rate to £2, corresponding to an hourly wage of £8.
We have made our implementation openly available and ready for use via Gorilla (https://gorilla.sc/openmaterials/171870).
Statistical Analysis
We used the two-sample Kolmogorov–Smirnov (KS) test (Conover, 1998) to ascertain the existence of a statistically significant difference between the (unknown) distributions of the two groups of interest. The KS test is a commonly used nonparametric test of the equality of continuous unidimensional probability distributions, based on the maximum distance between the cumulative distributions of the two samples. Analyses were conducted in the R environment Version 0.99.320.
Results
Figure 1 shows the probability density function (Panel A) and the cumulative distribution function (Panel B) of the SRT obtained from the in-lab (mean SRT = –16.2 dB, SD = 2.08) and online groups (mean SRT = –15.1 dB, SD = 2.21; mean difference in-lab—online = –1.1 dB). A KS test indicated a significant difference between the two distributions (D = .347, p = .001). The maximal difference occurred at –16.9 dB, which was reached by 47% of the in-lab group and only by the 12% of the online group. Despite the low level of background noise reported by the online sample (1.77 ± 2.51 from a range of 0 to 10), we repeated the analysis by excluding those participants who reported a high level of noise (≥ 5; final sample N = 42). The difference between groups was unaltered (D = .350, p = .002).

A: Probability density distributions of the in-lab (gray) and online (blue) groups. B: Cumulative distribution of the in-lab and online groups. The black dashed line indicates the SRT at which the greatest distance between the two distributions was observed. Overall, the data pattern is consistent with a rightward shift (toward higher SRTs) of the online distribution.
The overall pattern of results demonstrates that, relative to the in-lab cohort, fewer people in the online group achieved very low thresholds, suggesting that online testing may provide a less accurate measure of listeners’ speech-in-noise detection performance. The differences between the online and in-lab groups may arise due to a poorer control of participants’ listening environment and/or motivation.
Experiment 2
Methods
Participants
Two hundred young, normal-hearing listeners ranging in age from 22 to 30 years (128 females, mean age 26 ± 2.5) were recruited online as described in Experiment 1. They were randomly assigned to one of two experimental groups. All participants received a fair base payment for the time spent on the experiment (Prolific recommends £8 per hour; 2 for 15 min). One group (N = 100, 62 females) additionally received a performance-based monetary bonus (up to £5) on top of the base pay (
Stimuli and Procedure
The procedure was similar to that described for Experiment 1. The BONUS+ and BONUS– groups received identical instructions and feedback. Encouraging language was used to maximize participant motivation. After each run, the achieved threshold was displayed, and participants were challenged to try to “beat their score” in the next run. The BONUS+ group was additionally informed that each threshold was linked to a monetary bonus. They were told that at the end of the experiment, they would receive the bonus (up to £5) associated with the best threshold reached (e.g., if they reached thresholds –10, –15, –17, –10 over the runs, they were paid a bonus linked to threshold –17). At the end of each run, participants were shown the current threshold and the bonus, but also the bonus they could receive if they improve their threshold in the following run. The bonus was preassigned to SNR values from –1 to –28 (in steps of 1) through an exponential function so that improvements at lower, more difficult thresholds were rewarded more than improvements at levels expected to be easily reached by young normal-hearing listeners. As in Experiment 1, following the main task, participants answered a set of questions about their listening environment. They were also asked to answer on a scale from 0 to 10 (0 = not at all, 10 = a lot) how motivated they were in performing the task, and how engaging they found the task to be.
The base pay was set to £2 (for 15 min) for all participants. The average obtainable bonus for the BONUS+ group was £2 (range £0–5), therefore allowing them to double their pay. The BONUS+ group was only informed of the bonus at the instructions stage. To avoid bias in the selection process, participants were unaware of the possibility of being assigned to one or the other group when they signed up to the study.
Results
Both the BONUS+ and BONUS– groups reported a similar level of environmental noise (BONUS+ = 1.87 ± 2.75; BONUS– =1.44 ± 2.27; t-test: t(2,198) = 1.203, p = .230). However, to focus on the effect of bonus on performance, we excluded those participants who reported a level of noise ≥ 5 (on a scale from 0 to 10) resulting in the exclusion of ∼15 participants from each group (final numbers: BONUS+ N = 84; BONUS– N = 90). Figure 2 shows the probability density function (Panel A) and the cumulative distribution function (Panel B) of the SRT obtained for the BONUS+ (mean SRT = –16.1 dB, SD = 2.54) and BONUS– (mean SRT = –15.1 dB, SD = 2.33) groups. Data from the in-lab group (see Experiment 1) are also provided as a benchmark.
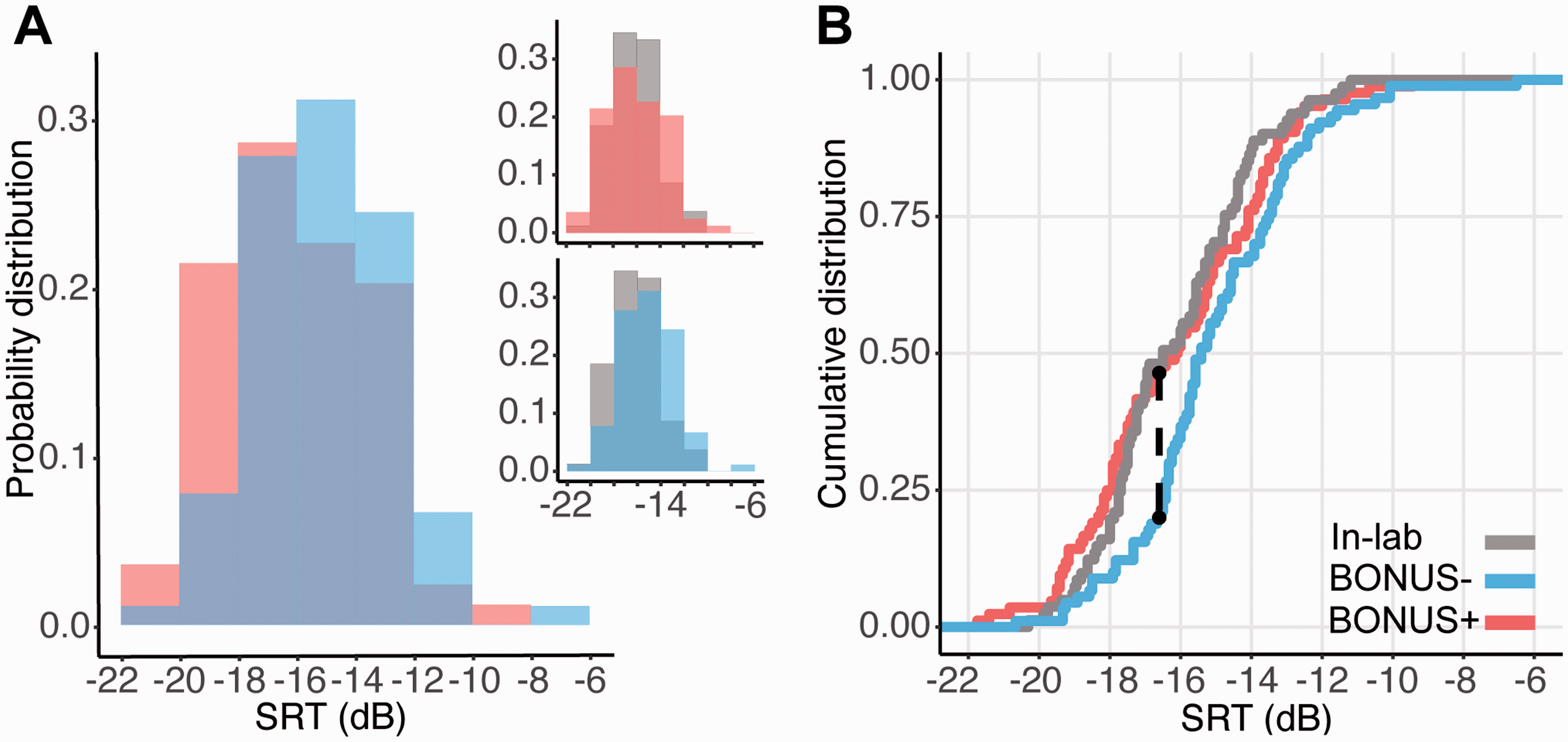
A: Probability density distributions (relative proportion) of the online BONUS+ (pink) versus the BONUS– (blue) groups. The insets show the probability density distributions of the BONUS+ (top) and the BONUS– (bottom) groups against the in-lab sample. B: Cumulative distribution of the BONUS+ and BONUS– groups. The data from the in-lab (gray) are plotted as benchmark. The black dashed line indicates the SRT at which the greatest distance between the BONUS+ and BONUS– distributions is observed. Overall, the data pattern is consistent with a leftward shift (toward better SRTs) of the BONUS+ relative to the BONUS– groups.
KS tests indicated a significant difference between the BONUS+ versus BONUS– distributions (D = .276, p = .003), revealing better performance in the BONUS+ compared with the BONUS– group. The maximum difference occurred at –16.6 dB, which was reached by 47% of the BONUS+ and only by the 21% of the BONUS– group. The comparison of these two distributions with the in-lab distribution indeed showed that the BONUS+ performance was similar to the in-lab one (D = .127, p = .519), whilst the BONUS– was different (D = .304, p = .001). The results thus indicate that the provision of a bonus increased the proportion of high-performing participants in the online group to the levels exhibited by the in-lab cohort.
In an additional analysis, we compared the in-lab group with the online data pooled from the online group of Experiment 1 and the BONUS– group of Experiment 2 (for a total of N = 132, excluding participants who reported a level of background noise ≥ 5; note all results hold even without excluding participants based on noise reports). A KS test confirmed that online performance in the absence of an additional bonus is worse than that obtained in-lab (D = .318, p < .001), in line with what was observed in Experiment 1.
Consistent with the interpretation that offering a bonus increased motivation, the BONUS+ group reported higher ratings of task engagement (BONUS+ = 9.1 ± 1.2; BONUS– = 8.4 ± 1.5; from range of 0–10; t(2,98) = 2.68, p = .009) and motivation (BONUS+ = 9.2 ± 1.12; BONUS– = 8.4 ± 1.3; from range of 0 to 10; t(2,98) = 3.212, p = .002) compared with the BONUS– group.
Discussion
We report two main findings. First, we showed that the SRT of blindly recruited online participants was poorer than that observed among an age-matched control group in the lab setting. Second, we demonstrated that the provision of a small performance-based monetary bonus improved online listeners’ speech-in-noise performance to levels similar to those observed in the lab setting.
The results from Experiment 1 revealed that the distribution of the SRT in the online group differed from that obtained from the in-lab cohort: In the lab, 47% of listeners achieved an SRT below ∼ –17 dB. In contrast, within the online cohort, only 12% of participants reached that threshold. This discrepancy is relevant to consider when using remote testing to build normative data, or to accurately estimate hearing loss across the population.
In Experiment 2, we showed that a performance-based monetary bonus increased the proportion of highly performing participants up to levels similar to those observed in the lab. This suggests that the difference in performance between the online and in-lab groups observed in Experiment 1 is not mainly driven by constraints to the sound environment but rather associated with reduced task engagement among the online participants.
With the blooming of online experiments, it is important to understand how we can improve the quality of data obtained in remote auditory assessments (Leensen et al., 2011; Milne et al., 2020; Slote & Strand, 2016). Our finding that reward increased the proportion of participants who achieved low SRTs demonstrates that participant attention, motivation, and commitment are important factors to consider when auditory tests involving effortful listening are conducted online.
Higher task engagement in the in-lab than in the online population probably results from several factors that characterize the laboratory experience: the authority of the experimenter, the absence of temptation/distractions, the effort taken to come to the lab, and so forth. All these factors are likely to make in-lab participants already quite motivated. Similar considerations may apply to certain online testing situations. For example, participants in remote clinical assessments are likely to be highly intrinsically motivated to do their best, as revealed by studies reporting similar results between testing in the clinic and at home (de Graaff et al., 2018; Whitton et al., 2016). However, in many cases, online participants are unsupervised and anonymous, and often mainly motivated by financial incentives (Buhrmester et al., 2011; Litman et al., 2015). In a recent in-house survey conducted by Prolific.co, approximately 50% of the surveyed users stated that the amount of pay is the factor that most motivates them to take part in a study (https://prolific2.typeform.com/report/PoUZHEmk/ttebnlTEllbRvdcg). Therefore, a monetary bonus is an efficient method for increasing task engagement. This consideration is also supported by the fact that the BONUS+ group in Experiment 2 reported higher ratings of task engagement and motivation compared with the BONUS– group.
Previous studies suggest that performance on many crowdsourcing tasks does not differ, and sometimes even exceeds that measured in the lab (Hauser & Schwarz, 2016, but see Harrison & Müllensiefen, 2018; Slote & Strand, 2016). In addition, a monetary incentive (amount of pay) does not always affect performance (van den Berg et al., 2019): For example, previous studies reported no modulatory effects of amount of monetary incentive on the quality of online performance in tasks such as speech transcription (Marge et al., 2010). Internal consistency in psychological surveys and attention in following instructions were also unaffected by different levels of payment (Buhrmester et al., 2011, but see Litman et al., 2015). However, the impact of incentive may depend on the kind of task under investigation. Financial incentives may have little effect on performance when the task is too easy or when return on effort is low, for example, when it is hard to improve performance (Camerer & Hogarth, 1999). Our finding that reward influences performance in the CCRM task is possibly linked to the fact that the return on effort is high: The task relies on attention to fine perceptual details, and increasing effort has the potential to lead to a notable improvement in performance.
The effect of incentives on performance may also be nuanced by how the reward is operationalized, in particular whether it is fixed or adaptive. For example, recent studies using demanding auditory tasks and where reward was fixed at a high or low value have reported no effect of reward on behavioral measures such as accuracy or response time (Koelewijn et al., 2018, 2021; Richter, 2016; see also Carolan et al., 2021). In contrast, Shen and Chun (2011), using a range of executive and perceptual tasks, demonstrated that reward can encourage participants to perform better when it is progressively increased from trial to trial, but not when the same high reward level is maintained. Furthermore, the effect of reward in Shen and Chun (2011) appeared to persist even when the ultimate outcome was success in a competition (e.g., a monetary reward assigned to the top 10% participants based on performance) rather than money itself (e.g., performance-based earning with no competition). Therefore, particularly in experiments that require many trials, a competitive setting may be a more effective incentive than a small (a few cents) reward per trial.
The present study relied on the data from Experiment 1 to adjust the bonus growth rate. It is important to acknowledge, however, that paying a bonus based on performance may disadvantage certain participants (e.g., hearing impaired individuals in the present case) in that the maximum bonus amount will not be equally achievable by all participants despite comparable effort to perform the task. Online settings, where the researcher has no contact with the participants, make it particularly difficult to determine whether poor performance (associated with a low bonus) is due to inability to perform well (e.g., due to hearing impairment), poor understanding of instructions, or lack of engagement with the task. To mitigate this ethical concern, a fair base pay for the time spent on participation in the experiment is therefore critical.
Conclusions
How reward might motivate performance is an empirical question and a long-standing object of debate. Accumulating evidence suggests that reward does seem to matter particularly in tasks where performance depends on effortful engagement (Camerer & Hogarth, 1999). The CCRM task used here is analogous to many threshold-based tasks commonly used in auditory research. The observed effect of bonus on performance should thus generalize to other auditory tasks, helping to motivate participants to exert the extra bit of effort that is needed when the task becomes just doable.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by a BBSRC grant (BB/P003745/1) to M. C. and the NIHR UCLH BRC Deafness and Hearing Problems Theme.