
Abstract
Several segregation cues help listeners understand speech in the presence of distractor talkers, most notably differences in talker sex (i.e., differences in fundamental frequency and vocal tract length) and spatial location. It is unclear, however, how these cues work together, namely whether they show additive or even synergistic effects. Furthermore, previous research suggests better performance for target words that occur later in a sentence or sequence. We additionally investigate for which segregation cues or cue combinations this build-up occurs and whether it depends on memory effects. Twenty normal-hearing participants completed a speech-on-speech masking experiment using the OLSA (a German matrix test) speech material. We adaptively measured speech-reception thresholds for different segregation cues (differences in spatial location, fundamental frequency, and talker sex) and response conditions (which word(s) need(s) to be reported). The results show better thresholds for single-word reports, reflecting memory constraints for multiple-word reports. We also found additivity of segregation cues for multiple- but sub-additivity for single-word reports. Finally, we observed a build-up of release from speech-on-speech masking that depended on response and cue conditions, namely no build-up for multiple-word reports and continuous build-up except for the easiest condition, i.e., different sex/spatially separated maskers for single-word reports. These results shed further light on how listeners follow a target talker in the presence of competing talkers, i.e., the classical cocktail-party problem, and indicate the potential for performance improvement from enhancing segregation cues in the hearing-impaired.
Introduction
Oral communication is an essential part of life and often takes place in situations where several people are talking simultaneously. Often, the goal of the listener is to attend to a specific talker and to ignore the others. Such multi-talker situations are frequently referred to as the “cocktail-party problem” (e.g., Bronkhorst, 2015). When multiple speech signals occur simultaneously, the performance in understanding a specific signal is determined by the cumulative effects of two types of masking: “Energetic” masking occurs when the representation at the auditory periphery of two signals overlaps, e.g., when the signals contain energy in the same frequency band at the same time. Any additional masking is termed “informational” masking and occurs when similarities between the two signals or uncertainties regarding the masker make it difficult to perceptually disentangle the signals (Kidd et al., 2008; Lutfi et al., 2013). This study focuses on informational masking effects in normal-hearing listeners.
Solving the “cocktail-party problem” requires sufficient spectro-temporal information of the target speech. Even multiple interfering speech signals provide opportunities to listen to the target speech in the temporal dips of the fluctuating temporal envelope of the masker (Gaudrain & Carlyon, 2013). But successful dip listening requires perceptual cues to segregate (i.e., distinguish) the target from the interfering sources, thus enabling release from informational masking. One important segregation cue is the spatial separation in azimuth between the target and interfering speech signals, providing release from masking of up to approximately 10 dB (e.g., Kidd et al., 2010), assuming favorable acoustics and a fully intact auditory system of the recipient. Another important segregation cue is monaural source characteristics, as arising from different talker sexes (e.g., Festen & Plomp, 1990). The differences in voice characteristics between male and female talkers can be adequately modeled by differences in fundamental frequency (f0) and vocal tract length (VTL) (Atal & Hanauer, 1971).
Several studies investigated the effect of these cues (i.e., f0, VTL, and spatial location) or others (e.g., using reversed speech as a masker) in isolation or in combination on release from (informational) speech-on-speech masking (e.g., Darwin et al., 2003; Du et al., 2011; Rennies et al., 2019; Rodriguez et al., 2021; Willis et al., 2021; Xia et al., 2015; see also reviews by Bronkhorst, 2000, and Bronkhorst, 2015), but there are still open questions on how these cues interact. One question addressed in the current study is whether spatial and talker sex-based segregation cues show additive or even synergistic effects on release from speech-on-speech masking. To that end, additivity is determined by comparing the obtained performance to optimal-observer prediction. Performance equal to the prediction would indicate additive effects, performance worse than the prediction would indicate sub-additive effects, and performance exceeding the prediction would indicate super-additive or synergistic effects.
Darwin et al. (2003) tested the effect of differences in f0 and VTL on release from speech-on-speech masking and found that the effect of f0 is somewhat higher than that of VTL, but neither matched the effect of a talker of the opposite sex. Interestingly, the effect of a combination of the two cues was larger than adding the individual effects and comparable to the effect of an actual different-sex talker, meaning that changes in f0 and VTL have, together, a super-additive or synergistic effect on speech intelligibility.
Rodriguez et al. (2021) tested the effects of f0 and spatial location on participants’ ability to distinguish whether vowel triplets were spoken by the same or by different talkers (i.e., the vowels did not have to be identified). They matched the effectiveness of each cue in isolation and found that combining the two cues also led to a super-additive or synergistic effect. Du et al. (2011) investigated the effect of differences in f0 and spatial location on identifying two simultaneously presented vowels and measured cortical responses using magnetoencephalography (MEG). They found that the combined effect of both cues is best described by a simple addition of the individual effects, both on a behavioral and on a cortical level.
Other studies, however, reported sub-additive effects. Xia et al. (2015), Rennies et al. (2019), and Willis et al. (2021) investigated the effect of differences in sex and spatial location between target and distractor talkers on speech intelligibility as well as cognitive load (Xia et al., 2015) and listening effort (Rennies et al., 2019). These studies observed that the effect on speech intelligibility of presenting both cues in combination is weaker than would be expected by adding up the effects of each cue in isolation (although this was not explicitly tested statistically). Rodriguez et al. (2021) argue that this could be due to not matching the cues in effectiveness. This might be true for Experiment 1 of Xia et al. (2015), that used a small spatial separation of 15° resulting in no significant difference between the effect of talker sex and the combination of talker sex and spatial location, and for Willis et al. (2021), who used a large separation of 90° and did not observe a significant difference between the effect of spatial location and the combination of talker sex and spatial location. But neither Experiment 2 of Xia et al. (2015) using a 60° separation nor Rennies et al. (2019) using a 90° separation found significant differences between the conditions with sex difference or spatial separation in isolation. Instead, it is more likely that the differences in the results of the reported studies stem from using different-sex talkers rather than just differences in f0, since then listeners effectively have access to three main cues: f0, VTL, and spatial location. As a consequence, ceiling effects might have limited the possibility to show (super-)additivity for studies using percent-correct based analyses (e.g., Xia et al., 2015). Another difference is that the studies showing (super-) additivity for the f0 and spatial cues did not test speech-on-speech masking, as they only tested for identification of vowels (Du et al., 2011) or same/different judgements (in f0 or space) for vowel triplets (Rodriguez et al., 2021). It is, therefore, also possible that f0 and VTL show super-additivity for release from speech-on-speech masking (Darwin et al., 2003), but f0 and spatial location do not.
Therefore, this study systematically tests the effects of spatial location, f0, and talker sex on release from speech-on-speech masking. Based on the literature summarized here, we expect that combining differences in f0 and spatial location produces either additive or super-additive effects, but combining differences in talker sex and spatial location does not. Alternatively, (super-)additivity of talker sex and spatial location might be restricted to more simple tasks such as vowel identification or same/different judgements (Du et al., 2011; Rodriguez et al., 2021). Jones (2016) suggested an ideal observer might use an additive model under low cognitive demands while reverting to a simpler strategy (such as an N-look strategy focusing only on a single cue, resulting in sub-additive effects) under high demands.
Multi-talker situations are often studied with the coordinate response measure (CRM) corpus (Bolia et al., 2000). Its sentences are structured “Ready [call sign] go to [color] [number] now.” Participants are asked to attend to the talker uttering a specific call sign and then report the color and number of that sentence. Advantages of the CRM corpus include limited linguistic variation, no predictability due to context as occurring for natural sentences, and minimal impact of memory for previously presented sentences. Additionally, the call sign allows participants to follow a target sentence even if distractor sentences from the same corpus are presented simultaneously and from the same location. Here we employ a similar test for German speakers, using the speech material of a matrix test (OLSA; Wagener, Brand et al., 1999; Wagener, Hochmuth et al., 2014). The OLSA material consists of grammatically correct but random five-word sentences structured name, verb, number, adjective, noun. Each word is selected from 10 options (i.e., there are 10 names, 10 verbs, etc., to choose from). Therefore, similarly to the CRM corpus, the predictability of a single word due to context is low. However, different from the CRM corpus, each of the five words can vary between sentences instead of just the third and second last (i.e., the color and number). Therefore, it is unclear which words should be reported in order to get the most reliable estimates of masking release. Kidd, Mason, Swaminathan et al. (2016) and Kidd, Mason, Best et al. (2019) used stimuli with a sentence structure identical to the OLSA corpus and designated the first word (name) as a call sign similar to the CRM corpus. Participants were asked to repeat the full sentence, meaning that they had to recall four varying target words. In a later study, Villard and Kidd (2019) used a subset (i.e., only the name, verb, and noun) from the same speech material as their stimuli and asked participants to repeat only one target word (noun) due to their listener population. It was argued that the thresholds in these three studies are similar based on a rough comparison (Villard & Kidd, 2019), but we are not aware of a study systematically comparing the number of words that have to be reported in a speech-on-speech masking experiment. Having to report a whole sentence as opposed to a single word might add memory effects such as worse performance due to increased working memory load or the recency effect, i.e., the tendency to recall the last item(s) on a list more easily (Greene, 1986). Note that for the CRM corpus, two words are reported, while for the OLSA or similar matrix sentence tests, participants are usually asked to report the whole sentence (i.e., five words). Depending on working memory capacity and signal-to-noise ratio (SNR), participants are able to recall three to five words from a list of words presented in broadband noise (Ljung et al., 2013) and asking participants to repeat single words presented in a 12-talker babble results in speech reception thresholds (SRTs) that are 2–3 dB lower compared to repeating a full sentence (Gordon-Salant & Cole, 2016). Thus, the number of words that need to be recalled likely makes a difference. Therefore, the current study tests whether results differ if participants have to report one vs. multiple words.
Finally, words that occur later in a sentence or series of digits masked by competing speech have been reported to be more accurately reproduced, and this has been attributed to a build-up in stream segregation (e.g., Best et al., 2018; Ezzatian et al., 2012; Ruggles et al., 2011; Wang et al., 2018). While Best et al. (2018) and Ruggles et al. (2011) did observe build-up for spatially separated talkers, the only condition they tested, Ezzatian et al. (2012) only observed build-up for the more difficult co-located (same talker sex but different individuals) condition and not for the easier condition including spatial separation. It is, therefore, unclear to what extent the buildup effect depends on the absence of spatial segregation cues. Furthermore, none of the studies tested different-sex talkers or differences in f0. Therefore, we are interested in whether build-up also occurs for other conditions, including differences in f0 or talker sex. If these other conditions also show build-up, we expect the effect to be stronger for more difficult conditions (e.g., for single-cue conditions as opposed to multiple-cue conditions). Usually, this build-up is investigated by asking participants to report all key words on each trial. We additionally test if the effect can also be observed on an across-trial basis, where only one word per sentence has to be reported. Memory-based effects like the recency effect should be weaker in the single-word conditions, and it is also possible that the build-up of streaming requires active attention to the entire stream of words. However, if the single-word conditions do show temporal position effects, these are more likely due to the build-up of streaming rather than cognitive (memory-based) effects, helping to dissociate these components.
In summary, we investigate, whether previously reported (super-)additive effects of stream segregation cues depend on which cues are used, whether release from speech-on-speech masking depends on the number of words that need to be reported, and whether build-up in stream segregation is also observed if the talkers differ in f0/sex or if only a single word has to be reported on a given trial.
Methods
Participants
We tested 20 young normal-hearing (NH) participants (9 female and 11 male, age range: 18–29 years, mean: 22.6 years). They were recruited using the Vienna CogSciHub: Study Participant Platform, which uses the hroot software (Bock et al., 2014). For each participant, the pure tone average (PTA) for 500, 1,000, and 2,000 Hz was measured at both ears before starting the experiment, and participants with hearing thresholds ≥20 dB HL at any of these frequencies were excluded. All participants gave written informed consent before starting the experiment and received monetary compensation for their participation. The study was conducted in accordance with the ethics statement for human experimental research conducted at the Acoustics Research Institute of the Austrian Academy of Sciences, as approved by the Commission for Science Ethics of the Austrian Academy of Sciences on April 23, 2024.
Apparatus and Stimuli
Participants were seated in front of a touchscreen inside a double-walled, soundproof booth. The touchscreen showed buttons with all possible response options (i.e., four columns, one for the verbs, numbers, adjectives, and nouns, with 10 words each) and participants responded by tapping the respective button(s).
The stimuli were generated on a personal computer and output via a sound interface (Sonible hp-1) and a D/A converter (RMEFireface UC) and presented via headphones (Sennheiser HDA 200). We used the OLSA material recorded by the male (Wagener et al., 1999) and female (Wagener et al., 2014) talkers. The OLSA material consists of grammatically correct but random five-word sentences in German with the structure name, verb, number, adjective, noun, such as “Britta sieht zwei nasse Dosen” (“Britta sees two wet cans”). Each word is selected from 10 options (i.e., there are 10 names, 10 verbs, etc., to choose from). An additional “talker” was created by shifting the f0 of the male recordings to match the median f0 of the female recordings (197.14 Hz) using the Vocal Toolkit of the Praat software package (Boersma & Weenink, 2024). This was done to isolate the effect of f0 from other voice characteristics, differentiating male and female talkers such as VTL. On a given trial, three sentences were presented (one target and two distractor sentences). The name was used as a call sign to define the target sentence, as in previous studies using the OLSA or similar matrix sentence tests for speech-on-speech masking (Heeren et al., 2022; Kidd, Mason, Best et al., 2019; Kidd, Mason, Swaminathan et al., 2016; Pyschny et al., 2011). We chose the name “Peter” as the call sign. The male talker was used as the target talker, while, depending on the condition, distractor talkers were either male, female, or f0-shifted. It was ensured that neither distractor sentence shared a word with the target sentence and that the two distractor sentences were different. Since the original male recordings only included 12 sentences per name (i.e., call sign), we generated 93 additional male sentences with the selected call sign (“Peter”) by pasting recordings of “Peter” over the names in the other sentences using the Praat software package, resulting in 105 target sentences in total. Both authors listened to these new sentences and confirmed that they did not contain audible artifacts and sounded natural. All originally recorded as well as the f0-shifted sentences not starting with the name “Peter” were used as distractor sentences (135 sentences for the female talker, 108 sentences for the male and f0-shifted talkers).
The target talker was presented at 0° azimuth, and the distractor talkers were either co-located (i.e., also at 0° azimuth) or spatially separated at ±30°. For that purpose, the auditory stimuli were filtered (i.e., spatialized) with non-individualized HRTFs, since individualization has no or only marginal influence on azimuthal localization (e.g., Begault et al., 2001). The HRTFs were selected from the ARI HRTF database (https://sofacoustics.org/data/database/ari/). Two symmetrically arranged distractors were used to ensure that the task cannot easily be solved based on “better ear listening,” i.e., focusing on the ear that provides the better SNR. The specific spatial separation was chosen based on a pilot test revealing similar SRTs for the f0 (f0-shifted talker/co-located) and spatial (S; same talker/30° spatial separation) conditions using the methodology described here. These results agree with a previous study suggesting that for a male target talker and a target presentation level of 60 dB, the spatial and the sex cue are weighted equally strongly at approximately 20–25° (Oh et al., 2021). This match in SRTs is expected to be beneficial for demonstrating (super-)additivity of segregation cues (Rodriguez et al., 2021). Since the recordings vary in length (between 1.79 and 2.77 s for the male talker and between 2.12 and 3.01 s for the female talker), we introduced an offset with which target and distractor sentences are presented. The target sentence always started first, and Distractor 1 started 500 ms later (thus ensuring that the last target word was always masked, since the longest target sentence is 500 ms longer than the shortest distractor sentence). For Distractor 2, the offset was randomly varied between 0 and 350 ms, to ensure that the first target word (verb) was always masked as it started approximately 400 ms after the onset of the target sentences, and that participants do not learn to exploit a fixed target-distractor-offset. Note that, therefore, the first 500 ms of each sentence (i.e., approximately 100 ms of the first target word) were masked by one distractor talker only. Similarly, up to 500 ms (depending on target and distractor sentence lengths as well as Distractor 2 offset) at the end of the target sentence were only masked by one distractor talker. In these time frames, a general improvement in SNR and “better-ear listening” could have contributed to some extent.
Procedure
The experiment took approximately 2.5 hr including breaks, which participants were encouraged to take every 15–20 min. First, participants completed a hearing screening measuring the thresholds for 500, 1,000, and 2,000 Hz separately for the left and right ears. Then, participants completed two adaptive training runs with co-located speech-shaped noise (“OLSA noise”) as a masker, reporting all four target words. This was done to get participants accustomed to the materials and task, thus reducing training effects typical for matrix sentence tests, but at the same time avoiding the training of actual testing conditions. For the main experiment, participants were asked to report the target word(s) by tapping the respective button(s) on a touch screen showing the full candidate word matrix for the last four words (i.e., 10 words each for the verb, number, adjective, and noun). In conditions for which only one word needed to be reported, all other columns were faded to a light gray, and only words from the target word column could be selected. After each response, feedback on the number of correctly reported words was presented, and participants could initiate the next trial by pressing a button. The SRT for 50% intelligibility for each condition was measured using the modReference adaptive procedure described in Herbert et al. (2023), using a starting target-to-masker ratio (TMR) of +13 dB (Equation 1). TMRs are often used in speech-on-speech studies (e.g., Kidd et al., 2010) and are calculated as the ratio between the target level and each individual distractor. For two distractors, a TMR of 0 dB corresponds to an SNR of approximately −3 dB using the level of the sum of both distractors.

Herbert et al. (2023) showed that this procedure estimates SRTs with little bias and a high degree of accuracy even for very few trials. In our study, the average number of trials per adaptive run was 27.06 (range: 18–42 trials). Stimuli were presented at a comfortable level (between 60–65 dB SPL), and the TMR was adapted by increasing or decreasing the level of the target and the distractor talkers by half each. This level splitting restricts variation of the summed level of all three sentences and is potentially advantageous, particularly when testing populations with restricted dynamic range.
We tested five response conditions: A four-word condition (reporting all target words, i.e., the verb, number, adjective, and noun of each target sentence as done for the practice runs) and four single-word conditions (reporting either only the verb, only the number, only the adjective, or only the noun). These response conditions were presented in blocks, and participants were instructed before the start of each block, which word(s) they were supposed to report. The block order was randomized across participants. Within each block, there were six different cue conditions presented in randomized order: 2 (co-located vs. spatially separated) × 3 (same talker vs. different talker sex vs. f0-difference only). Therefore, participants completed 30 adaptive testing runs in total (6 cue conditions × 5 response conditions).
Analysis
We chose the analysis method Beta described by Herbert et al. (2023) to derive the SRTs. That is, we fitted psychometric functions to the adaptively collected data for each condition using the Psignifit 4 toolbox for MATLAB (Schütt et al., 2016) and calculated SRTs for 50% intelligibility. To analyze the additivity of segregation cues, we required the sensitivity index d’ for the different cue conditions at a fixed TMR. To that end, we pooled the data across response conditions (and target words for the single-word conditions) for each cue condition before fitting the psychometric functions. Based on these psychometric functions, we calculated d’ at a set TMR. That is, we read out the estimated percent correct at the set TMR from the psychometric function and then calculated d’ using the dprime.mAFC function of the R package “psyphy” (Knoblauch, 2023). The TMR was chosen as the average SRT across participants and conditions, excluding the reference (same talker/co-located) condition (which, naturally, showed a strong difference in the SRTs compared to the other cue conditions). The additivity of segregation cues was then tested by comparing the obtained performance with optimal-observer prediction assuming independent peripheral noises for the cues that are to be added (Green & Swets, 1966). Thus, the measured d’ in the two-cue f0 & S condition (f0-shifted talker/spatially separated) was compared to the predicted d’ based on the single-cue conditions (i.e., the square root of the sum of the squared d's in the f0 and S conditions). We expected the measured d’ to be larger than or equal to the predicted d’, indicating either super-additivity or additivity of the cues, respectively. Additionally, we compared the measured d’ in the three-cue f0 & VTL & S condition (different talker sex/spatially separated) to the predicted d’ based on the single-cue S condition and the two-cue f0 & VTL condition (different talker sex/co-located). Here, we expected the measured d’ to be smaller than the predicted d’, replicating the findings of Xia et al. (2015), Rennies et al. (2019), and Willis et al. (2021). To test these comparisons statistically, we ran a 2 (2- vs. 3-cue condition) × 2 (measured vs. predicted) × 2 (single- vs. four-word response condition) repeated-measures (RM) ANOVA. All statistical analyses were performed using JASP Version 0.19.3 (JASP Team, 2024).
To analyze the build-up of stream segregation, we again split the data according to the response condition. For the single-word conditions, we compared the SRTs for the verb, number, adjective, and noun using a 4 (word position) × 6 (cue condition) RM ANOVA. For the four-word condition, the presented TMR always depends on the performance of all four words combined. Nevertheless, we split the data per word, fitted psychometric functions, calculated SRTs for each word separately, and also ran a 4 (word position) × 6 (cue condition) RM ANOVA. We expected better SRTs for later word positions for the S (same talker/spatially separated) condition (replicating the findings of Best et al., 2018, and Ruggles et al., 2011). We also expected better SRTs for later word positions for the f0 (f0-shifted talker/co-located) condition, since it was matched in difficulty to the S condition and Ezzatian et al. (2012) suggested that build-up depends on the difficulty of the condition. The results then allow to show whether the newly tested f0 & S (f0-shifted talker/spatially separated) and f0 & VTL (different talker sex/co-located) conditions are difficult enough to show build-up. Lastly, we expected no difference in thresholds between word positions for the f0 & VTL & S (different talker sex/spatially separated) conditions, since we expected these three-cue conditions to be too easy to require build-up.
Finally, we pooled the data across the four single-word conditions and compared the SRTs in the single-word conditions to the SRTs in the four-word conditions using a 2 (single vs. four-word condition) × 6 (cue condition) RM ANOVA to test whether the presumably higher cognitive load in the four-word condition leads to worse SRTs.
Results
Effect of Cue Quantity and Memory Demands
Figure 1 plots the SRTs for each condition. We ran a 2 (response condition) × 6 (cue condition) RM ANOVA, yielding a significant main effect of response condition (F(1,19) = 78.82, p < .001, η2 = .058) as well as a significant main effect of cue condition (F(5,95) = 312.44, p < .001, η2 = .835), but no significant interaction (F(5,95) = 1.93, p = .097, η2 = .004). Post hoc tests revealed lower (better) SRTs for single- (M = −14.10, SD = 1.80) compared to four-word (M = −11.63, SD = 1.61) conditions (pholm < .001). They further showed no significant differences between conditions with the same number of segregation cues (i.e., S and f0 conditions: pholm = 0.627; f0 & S and f0 & VTL conditions: pholm = 0.974) and significant differences between conditions with an unequal number of segregation cues (all pholm < .004), with each additional cue leading to better SRTs.

SRT for Each Condition. SRTs Were Significantly Better for Single-Word Conditions Than for Four-Word Conditions. There Were No Significant Differences Between Conditions With the Same Number of Cues (Constant Color), but Each Additional Segregation Cue Significantly Reduced the SRT (Changing Color). Error Bars Show the Standard Error of the Mean (SEM). S = Same Talker/Spatially Separated, f0 = f0-Shifted Talker/Co-Located, f0 & S = f0-Shifted Talker/Spatially Separated, f0 & VTL = Different Talker Sex/Co-Located, f0 & VTL & S = Different Talker Sex/Spatially Separated.
Additivity
In order to maximize chances for observing super-additivity, the cues have to be matched in effectiveness (Jones, 2016). Therefore, we had conducted a pilot test to set the spatial separation to match the effect of the f0 difference. The analysis above confirmed that, also in the main experiment, the cues were appropriately matched. However, they seem to be better matched in the four-word compared to the single-word condition (see Figure 1). Therefore, we calculated d’ separately for the response conditions. Figure 2 shows the measured and predicted d's based on the individual-cue conditions using optimal-observer prediction assuming independent peripheral noises. We compared the f0 & S and the f0 & VTL & S conditions, because previous literature suggests (super-) additive effects for the cues f0 and spatial separation, but sub-additive effects for different sex and spatial separation. We ran a 2 (two- vs. three-cue condition) × 2 (measured vs. predicted) × 2 (single- vs. four-word response condition) RM ANOVA yielding significant main effects of cue condition (F(1,19) = 32.38, p < .001, η2 = .155), measurement (F(1,19) = 19.72, p < .001, η2 = .066), and response condition (F(1,19) = 23.90, p < .001, η2 = .166) as well as significant cue condition × response condition (F(1,19) = 7.37, p = .014, η2 = .025) and measurement × response condition (F(1,19) = 9.12, p = .007, η2 = .041) interactions. Additionally, there was a (non-significant) trend for a cue condition × measurement interaction (F(1,19) = 3.83, p = .065, η2 = .012). Simple main effects analyses showed that the cue condition × response condition interaction was driven by a stronger difference between response conditions for the f0 & S condition (F(1) = 41.67, pbenjamini−hochberg < .001) than for the f0 & VTL & S condition (F(1) = 4.84, pbenjamini−hochberg = .040) with larger d's in the single-word condition. The measurement × response condition interaction was driven by a non-significant effect of measurement in the four-word condition (F(1) = 0.27, pbenjamini−hochberg = .611) while there was a significant effect of measurement in the single-word condition (F(1) = 44.68, pbenjamini−hochberg < .001) with smaller values for measured compared to predicted d's. This indicates additive segregation cues in the four-word condition, but sub-additive effects in the single-word condition. To test the robustness of this analysis, we also determined d's at individualized TMRs, i.e., we calculated the mean SRT across cue condition excluding the reference for each participant individually and used the resulting TMRs to calculate d's. The individualized analysis produced the same picture as the analysis based on the group mean SRT, which is why we report the group mean analysis for simplicity here.
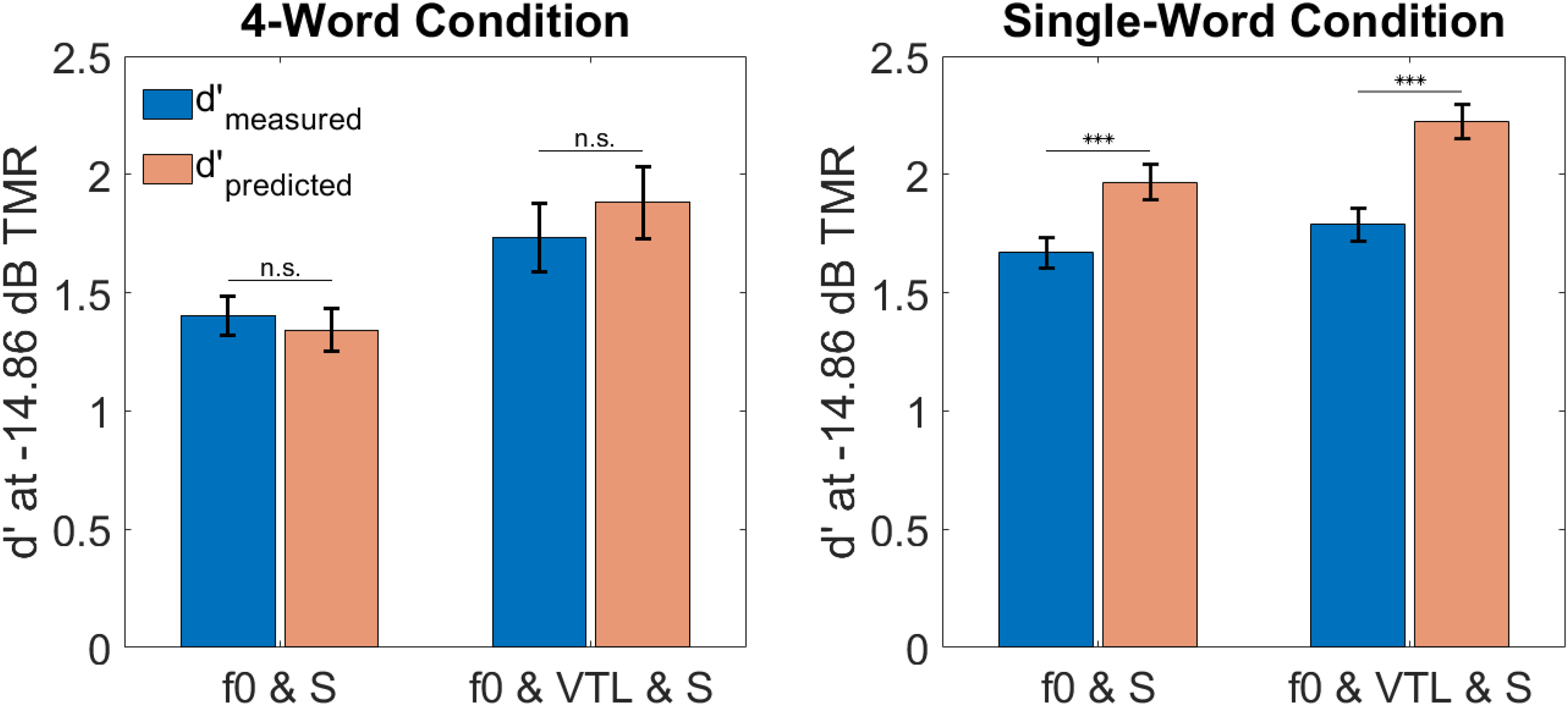
Measured and Predicted d's at a Set TMR (Chosen as the Average SRT Across Participants and Conditions Excluding the Reference Condition) Separately for the Four-Word and Single-Word Conditions. The Segregation Cues Showed Additive Effects in the Four-Word Condition, but Sub-Additive Effects in the Single-Word Conditions. Error Bars Show the SEM. f0 & S = f0-Shifted Talker/Spatially Separated, f0 & VTL & S = Different Talker Sex/Spatially Separated; p < .001 Is Denoted as ***.
Since the absence of a significant effect of measurement in the four-word conditions does not necessarily mean that the cues are indeed additive, we additionally calculated the Bayes factor (BF01) in the four-word condition, quantifying the evidence in favor of the absence of an effect, i.e., in our case, evidence in favor of cue additivity. For the f0 & S condition, the BF01 = 3.12 (error % = 0.02), indicating that the observed data are 3.12 times more likely if the segregation cues are indeed additive and thus providing just about moderate evidence for additivity. For the f0 & VTL & S condition, the BF01 = 2.67 (error % = 0.02), indicating that the observed data are 2.67 times more likely under additive effects, thus providing only anecdotal evidence.
Build-Up of Stream Segregation
Figure 3 shows the SRTs (top row) and masking release (i.e., the difference between the reference condition and the respective cue condition; bottom row) as a function of word position separately for the four-word (left column) and single-word conditions (right column). The reference condition showed a strong dependence on the word position, with SRTs being better for the verb than for other target words. This likely reflects differences in the overall SNR due to the different distractor offsets (see above). To exclude these effects, statistical analyses on the build-up of stream segregation were only performed on the masking release data (bottom row of Figure 3), as all cue conditions are equally affected by potentially varying SNRs across word positions and normalizing the thresholds using the reference condition therefore removes the bias. Since masking with only one masker could lead to “better-ear listening” in conditions with a spatial separation between the target and masker, we compared the S and f0 conditions at the verb and noun (i.e., word positions that were potentially masked by only one masker). Except for the noun in the single-word condition (which should be less affected than the verb), the S condition was not significantly better than the f0 condition, suggesting that “better-ear listening” did not systematically affect the results reported below.

SRTs (Top Row) and Masking Release (Bottom Row) as a Function of Word Position Separately for the Four-Word (Left Column) and Single-Word Conditions (Right Column). Build-Up of Stream Segregation Was Only Observed in the Masking Release Data of the Single-Word Condition (Except for the f0 & VTL & S Condition). Error Bars Show the SEM. S = Same Talker/Spatially Separated, f0 = f0-Shifted Talker/Co-Located, f0 & S = f0-Shifted Talker/Spatially Separated, f0 & VTL = Different Talker Sex/Co-Located, f0 & VTL & S = Different Talker Sex/Spatially Separated.
For the four-word condition, a 4 (word position) × 5 (cue condition) RM ANOVA yielded a significant main effect of word position (F(188,35.67) = 3.69, p < .038, η2 = .052, Greenhouse–Geisser-corrected) as well as a significant main effect of cue condition (F(4,76) = 19.75, p < .001, η2 = .221), but no significant interaction. Post hoc tests showed significant differences between the number and the adjective (pholm = .013) with more masking release for the number as well as between the adjective and the noun (pholm = .008) with less masking release for the adjective. They further showed two “groups” of cue conditions, for which there were no significant differences within-group (all pholm > .426), but significant differences between all conditions belonging to different groups across word positions (all pholm < .016). These groups were the single-cue conditions (S and f0) vs. the multiple-cue conditions (f0 & S, f0 & VTL, and f0 & VTL & S).
For the single-word condition, a 4 (word position) × 5 (cue condition) RM ANOVA yielded a significant main effect of word position (F(1.93,36.59) = 6.80, p = .003, η2 = .165, Greenhouse-Geisser-corrected), a significant main effect of cue condition (F(4,76) = 33.66, p < .001, η2 = .113), and a significant interaction (F(12,228) = 1.86, p = .041, η2 = .018). Simple main effect analyses showed that the significant word position × cue condition interaction was driven by a non-significant effect of word position for the f0 & VTL & S condition (F(3) = 2.62, pbenjamini−hochberg = .059), while the effect was significant for all other cue conditions (all pbenjamini−hochberg < .029). Simple main effect analyses also showed that there was a significant effect of cue condition at each word position (all pbenjamini−hochberg < .001). Post hoc tests yielded no significant difference between the f0 & VTL and the f0 & S condition (pholm = .916), but significant differences between all other conditions (all pholm < .010).
Response Condition Showing Best Masking Release
Since different speech-on-speech tests vary in the number of words and the word positions that need to be reported, we tested, which response condition shows the most consistent spatial and f0-based release from masking. To that end, we ran paired t-tests comparing the reference condition to the S and f0 conditions separately for each of the five response conditions and compared the resulting effect sizes. All t-tests were highly significant (all p < .001). The largest effect sizes were observed in the four-word condition with a Cohen's d of 5.21 for spatial and a Cohen's d of 5.20 for f0-based masking release. In the single-word conditions, the largest effect sizes were observed for the noun with a Cohen's d of 4.17 for spatial and a Cohen's d of 4.18 for f0-based masking release. Therefore, multiple-word reports are beneficial for showing masking release, and if single-word reports are required, the last word position should be tested.
Discussion
The present study investigated how stream segregation cues (specifically, differences in spatial location, f0, and VTL between the target and distractor talkers) interact perceptually. Specifically, we tested to what extent release from speech-on-speech masking depends on the perceptual combination of segregation cues as well as on the number of words that need to be reported per trial, which cues or cue combinations show evidence for build-up in stream segregation, and if these effects depend on memory load.
Effect of Cue Quantity and Memory Demands
We observed similar SRTs for conditions with the same number of segregation cues, while conditions with a different number of segregation cues differed significantly from one another. Adding another segregation cue always resulted in better performance, i.e., a reduction of the SRT, indicating that participants made use of all available cues. This extends the results of Rennies et al. (2019), who also investigated the effect of the number of segregation cues, but could only report trends. While we intentionally matched the efficacy of spatial separation and f0 difference (and, therefore, obtained similar SRTs in these conditions), the VTL cue was a natural occurrence, and still, the f0 & VTL (different talker gender/co-located) condition matched the f0 & S (f0-shifted talker/spatially separated) condition in effectiveness. Therefore, our results provide evidence that the number of cues seems to be of particular importance for the obtained amount of release from speech-on-speech masking.
We also compared SRTs in conditions where the whole sentence (excluding the call sign) needed to be reported to conditions where only a single word needed to be reported per trial. Thus, we manipulated attentional demands while holding the task structure constant to investigate the effects of memory load on release from speech-on-speech masking. Single-word reports led to better SRTs by, on average, 2.47 dB TMR/SNR. This improvement agrees with the results of Gordon-Salant and Cole (2016), who observed that repeating single words compared to a full sentence presented in a 12-talker babble improves thresholds by 2–3 dB SNR. To our knowledge, no previous study systematically investigated the effect of memory load operationalized by the number of to-be-reported words on release from masking with various segregation cues. We found no interaction between the number of words that needed to be reported and the cue conditions, meaning that the added memory load affected each cue condition similarly. Zekveld et al. (2014), on the other hand, observed a reduction in cognitive processing load (measured via pupil dilation) when introducing a sex difference but not when introducing a spatial separation between target and masker talkers, while behaviorally, both cues provided release from masking as in our study. Note, however, that in their study, cognitive load was not varied, but measured, and could reflect other processes than memory.
Additivity
One of the main goals of the present study was to test whether combining segregation cues produces sub-additive, additive, or even synergistic effects. We suspected that inconsistencies regarding this question among previous studies (Darwin et al., 2003; Du et al., 2011; Rennies et al., 2019; Rodriguez et al., 2021; Willis et al., 2021; Xia et al., 2015) resulted from an insufficient match in the effectiveness of the compared cues in some studies and due to differences regarding which segregation cues were studied (i.e., whether f0 or talker sex was manipulated). We hypothesized that studies comparing differences in spatial location and talker sex observed sub-additive effects because participants effectively had three cues available (f0 & VTL & S) instead of only two when comparing spatial and f0 differences. While our results do show a trend for less additivity in the f0 & VTL & S condition compared to the f0 & S condition (p = .065), it failed to reach significance. So, this hypothesis could not be confirmed.
Interestingly, we found additive effects in both cue combinations when the whole sentence (excluding the call sign) needed to be reported (four-word condition), but sub-additive effects in both cue combinations when only one word had to be reported per trial. This is surprising, given that the four-word condition requires a higher memory load and under higher load, an ideal observer might revert to an N-look strategy (i.e., focusing on a single cue to save resources, resulting in sub-additive effects), while using an additive model under low memory load (Jones, 2016). This may suggest that the added load due to keeping more words in short-term memory does not equal higher load due to a large number of cues, which does lead to sub-additive effects in the visual domain (e.g., Solomon et al., 2011). It is also possible that the processing of multiple cues is not influenced by memory resources because it is sufficiently automatized from daily experience. Under such a regime, participants may have followed the opposite strategy: Due to the single-word task being easier, they might have felt confident to be able to solve the task with minimal effort and thus focus only on a single cue. Conversely, in the more demanding four-word condition, listeners might have needed to rely on any information available and to combine it optimally. Another potential explanation for additive effects in the four-word but sub-additive effects in the single-word condition is that in the four-word condition, the segregation cues f0 and spatial separation happened to be better matched in efficacy, which generally facilitates the demonstration of (super-)additivity. However, the difference in mean SRTs between the single-cue conditions was under 1 dB even for single-word reports, and this difference is probably too small to explain the whole effect. Finally, note that these conclusions refer to the analysis of d’, following signal detection theory. When considering SRTs, for both the single- and four-word conditions, combined-cue SRTs were significantly lower (better) than single-cue SRTs. This shows that both conditions showed at least some degree of cue additivity.
Build-Up of Stream Segregation
The second focus of this study was to investigate how stream segregation builds up over time based on segregation cues and the number of words that needed to be reported. We expected to see less build-up for easier cue conditions (i.e., conditions with more segregation cues) and the four-word condition to be more affected by memory effects such as the primacy and recency effect. Interestingly, we did not observe any build-up in the SRT data, as other studies did (e.g., Best et al., 2018; Ezzatian et al., 2012; Ruggles et al., 2011; Wang et al., 2018). This appears to be due to differences in speech materials. Particularly, it may be partly attributable to the different offsets of the two masker talkers in the current study, potentially leading to less masking of the first (verb) and last (noun) word to be reported. However, when focusing just on the two words in the middle (number and adjective) for which masker offset effects are ruled out, there was no evidence for buildup either. In any case, to exclude effects of speech material and masker-offsets, we focused our analyses on the build-up of masking release.
The analysis of the build-up of masking release revealed differences between the two response conditions. When only a single word needed to be reported, continuous build-up was observed for the single- and two-cue conditions, while there was no significant build-up in the three-cue condition (f0 & VTL & S). This is consistent with Ezzatian et al. (2012), who argued that some cue conditions are too easy to require build-up, as the streams are instantly separated. The remaining cue conditions did not differ significantly among each other in their pattern of build-up. Therefore, our single-word results agree with the previous literature (Ezzatian et al., 2012; Ruggles et al., 2011; Wang et al., 2018), even though these previous studies report SRTs instead of masking release and used multiple-word/digit reports. Best et al. (2018), on the other hand, collected responses to all digits in each trial but encouraged participants to type in their response directly after each presented digit to reduce memory effects and is therefore somewhat comparable to our single-word condition (if listeners indeed made use of immediate reporting). They observed build-up up to three to four digits (on the order of two seconds) and stable performance afterwards, which is still consistent with our results, given that only four target words were tested. In summary, the build-up of masking release for the single-word condition observed in our study appears consistent with the build-up in SRTs reported in the literature.
For the four-word condition, however, no systematic build-up was observed. There were significant differences in masking release between the verb and adjective as well as between the adjective and noun, but these resulted from poorer performance (i.e., less masking release) for the adjective and not from systematically better performance for later target words. At first sight, this is surprising, given that previous studies also used multiple-word reports. However, the differences in build-up between the single- and four-word conditions in the present study appear to be primarily due to differences in the reference condition (same talker/co-located maskers) for the verb, affecting the masking release data. The single-word condition showed a strong preference for the verb in the reference condition (possibly because of a better SNR due to the masker offsets), which was not as pronounced in the four-word condition, likely because of the higher memory load. The absence of build-up in the four-word condition was the same for all cue conditions, but the cue conditions themselves differed, as expected, with respect to their masking release. Finally, even though the memory load was higher in the four-word condition (which was reflected in worse overall SRTs), there was no evidence for memory-related word position effects such as the primacy or recency effect, since the performance for the first and last words was not systematically better in the four-word compared to the single-word condition.
Limitations and Future Directions
We chose the OLSA material as it shares the advantages of the CRM corpus such as low predictability due to context, minimal impact of memory for previously presented sentences, and the potential of using a name as a call sign to define the target sentence. Additionally, each sentence is recorded as a whole to preserve a natural speech flow, and the material is well evaluated (e.g., Wagener, Brand et al., 1999; Wagener, Hochmuth et al., 2014). However, this means that the words across sentences are not time locked and the sentences vary in length. We addressed this by starting the two masker sentences with different offsets, ensuring that each target word was masked by at least one masker. Nevertheless, resulting different SNRs at each word position seem to have influenced the SRTs and thus, build-up of stream segregation was analyzed relative to the reference condition, i.e., in terms of masking release. Previous studies did not test the reference condition, thus limiting the comparability with those studies.
With respect to perceptual cue additivity, we expected to see differences between the four- and single-word conditions, whereas the specific results were somewhat surprising and should be explored in future studies. Specifically, how the task influences the integration of segregation cues is still unclear, namely, under which tasks they are combined sub- versus (super-) additively. We expected to see sub-additivity for more complex tasks, as Jones (2016) suggested an ideal observer might use an additive model under low cognitive demands while reverting to a more simple strategy (such as an N-look strategy, resulting in sub-additive effects) under high demands, and two studies showing (super-)additivity for the segregation cues under investigation here used more simple tasks, namely vowel identification or same/different judgements, instead of classical speech-on-speech paradigms (Du et al., 2011; Rodriguez et al., 2021). However, the present data showed sub-additivity for the single-word conditions requiring less memory load than the four-word condition showing additivity. This suggests that the higher load due to memory demands leads to other effects than simple reliance on a single-cue-use strategy and therefore, the exact relationship between (super-) additivity and task demands is an interesting topic to systematically test in future studies.
Conclusions
The present study shows that to compare SRTs across studies, the task (more specifically, the number of to-be-reported words) needs to be considered because reduced memory load led to better SRTs, while masking release or comparisons across segregation cues were not affected by memory load. We also found that each added segregation cue improved SRTs, but cues were only combined additively when the whole sentence (excluding the call sign) needed to be reported. Build-up of stream segregation, which was studied in terms of masking release, was found only for single-word reports. An exception was the condition with all three segregation cues, for which strong masking release occurred already for the first target word, suggesting that this condition was so easy that streams were instantly segregated. These results serve to better understand how listeners process speech in the classical cocktail-party situation and which cues or cue combinations have potential for enhancing performance in impaired populations.
Footnotes
Ethical Approval
The study was conducted in accordance with the ethics statement for human experimental research conducted at the Acoustics Research Institute of the Austrian Academy of Sciences, as approved by the Commission for Science Ethics of the Austrian Academy of Sciences on April 23, 2024.
Consent to Participate
All participants gave written informed consent before starting the experiment.
Consent for Publication
Not applicable.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Austrian Research Promotion Agency (FFG-Bridge; project SELECT; grant no. 898907).
Declaration of Conflicting Interests
The authors declare no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
The data will be made available upon request.