
Abstract
Auditory attention can be defined as the cognitive process that enables us to selectively focus on relevant aspects of the acoustic environment while other aspects are ignored. The remarkable ability of the auditory system to focus on one out of several speakers in a multispeaker environment has become known as the cocktail party effect. Although the neural processes underlying selective auditory attention (SAA) are not well understood, it has recently been shown that the cortical representation of a listener’s attended sound stream can be recorded noninvasively from the scalp and that stimulus reconstruction from single trial electroencephalographic (EEG) data enables the decoding of the orientation of auditory attention. The present study extends this approach by evaluating its efficacy in a naturalistic and challenging four-speaker acoustic free field environment, in which the four speakers were spatially separated and presented different but equally salient spoken messages to the listeners. Ten participants were instructed to focus SAA on a spoken prose message in one of the four loudspeakers while ignoring the remaining three streams of prose. Concurrent EEG activity recorded via 128 scalp channels was used for a stimulus reconstruction analysis. The results showed that this approach can be used to decode the orientation of SAA even in a complex and realistic acoustic setting. To confirm that the successful decoding was driven by correspondences between the recorded EEG activity and the attended speech envelopes, the analysis method was validated against randomly constructed sets of surrogate data and by correlations with behavioral data.
Keywords
Introduction
In 1953, E. C. Cherry introduced the term cocktail party effect to describe a listener’s ability to attend easily to one out of several competing and spatially separated talkers in a multitalker environment such as a noisy cocktail party (Cherry, 1953). The cognitive process that enables us to selectively focus on relevant information in our sensory environment while ignoring or suppressing concurrent irrelevant information is known as attention (Treisman, 1969). Solving the cocktail party problem involves using selective auditory attention (SAA) to focus on one of several competing sound sources. Among other things, this typically involves the auditory system’s ability to spatially direct auditory attention.
SAA relies on neural and cognitive processes that are not fully understood. However, multiple studies have revealed how specific regions of the cortex interact during auditory scene analysis and have described neural correlates of SAA (Bizley & Cohen, 2013; Fritz, Elhilali, David, & Shamma, 2007). One of the first studies of the neural correlates of SAA in humans recorded event-related potentials (ERPs) in response to separate sequences of tone pips in the left and right ears (Hillyard, Hink, Schwent, & Picton, 1973). It was found that all tone pips in the attended ear elicited enlarged N1 components (latency
The present research is aimed at investigating the effects of SAA on ongoing EEG activity during continuous, nonrepetitive stimulation in the form of natural speech (Wöstmann, Herrmann, Maess, & Obleser, 2016). Previous studies have demonstrated that it is possible to reconstruct characteristics of sensory stimulation (including speech) from recorded neural activity (Rieke, Bodnar, & Bialek, 1995; Stanley, Li, & Dan, 1999; Zion Golumbic et al., 2013), and that attended aspects of the external acoustic environment are emphasized within their cortical representations (Mesgarani & Chang, 2012). According to these findings, stimulus reconstruction should be sensitive to SAA and thus could be used to decode the direction of auditory attention from the ongoing EEG. Several recent studies have shown that stimulus reconstruction from EEG activity can indeed be used to reliably decode auditory attention (i.e., to identify the attended speech message) in a multitalker environment (Biesmans, Das, Francart, & Bertrand, 2017; O’Sullivan et al., 2012, 2017). The basic idea behind this stimulus reconstruction approach is that the brain is acting as a linear time-invariant system that maps input, that is, acoustic stimulation, to a certain output, that is, the EEG activity. Following this idea, the ongoing EEG activity being driven by ongoing stimulation could be interpreted as a linear convolution, with the instantaneous neural activity being the result of a convolution of the acoustic stimulation with an unknown (to be derived) function. This function can be considered as a filter describing the transformation of the acoustic stimulus to the EEG activity. This transformation represents a forward model, while the corresponding backward model describes the stimulus reconstruction from recorded EEG activity (Crosse, Di Liberto, Bednar, & Lalor, 2016).
The present study extends previous work by investigating the effectiveness of the stimulus reconstruction approach in a naturalistic and challenging four-speaker acoustic free field environment. In particular, this is the first study in which four speakers presenting different but equally salient spoken messages have been used to investigate the classification accuracy of the stimulus reconstruction approach. A previous study by Fuglsang, Dau, and Hjortkjaer (2017) employed eight spatially separated loudspeakers, but six of them played background noise and only two served as target loudspeakers (Fuglsang et al., 2017). In the present design, the loudspeakers were equal in relation to the task of the participant (each of the four loudspeakers served as the target speaker during the experiment), equal in relation to the presented content (each loudspeaker played its own continuous audio book), and equal in volume (all loudspeakers were identical in volume due to careful calibration). Moreover, this is the first study in which subjects were confronted with more than two spatially separated speakers of equal relevance in a free-field environment. The previous study of O’Sullivan et al. (2017) presented subjects with more than two target speakers, but all speakers were presented via one loudspeaker (O’Sullivan et al., 2017). Here, particular emphasis was placed on positioning the four loudspeakers at locations relevant to future hearing aid applications; that is, the frontal half circle—the area that is essentially covered by the microphones of hearing aids. In addition, the stimulus material was selected to offer complex as well as naturalistic sentences, that is, longer passages of classic fiction, as compared to the simple presentation of digits or short nonsense sentences as, for example, in the Oldenburger Sentence Test. The intention here was to evaluate the stimulus reconstruction approach in an environment that was as close to a real-life situation as possible, that is, in an environment having many different but relevant spatially separated speakers in a listener’s entire field of vision—as might be encountered in a cocktail party.
In sum, the present study aimed to explore the limits of the stimulus reconstruction approach in a complex and life-like acoustic environment with several spatially separated talkers of equivalent relevance. To verify that the classification accuracy of the stimulus reconstruction approach was driven by regularities within the EEG, we tested the approach against two randomly constructed sets of surrogate data and compared the classification accuracy with a set of behavioral data. The long-range goal of this research is to assess the possibility of moving stimulus reconstruction from laboratory settings into everyday situations, including the future development of advanced hearing aids.
Materials and Methods
Participants
In total, 10 subjects with no known health problems—especially no known hearing loss (tested with a pure tone audiometer) or neurophysiological diseases/impairments—took part in this study. The participants’ age ranged between 22 and 27 years (average:
Experimental Setup
A schematic of the acoustic environment used for this study can be seen in Figure 1. To achieve an acoustically controlled environment—especially to achieve as little sound reflection as possible—a cubic, acoustically controlled room was used. The dimensions of the room were 3 × 3 × 3 m. The walls and the ceiling were equipped with heavy (900 Setup of the stimulus presentation and the data acquisition: PC 1 controls the paradigm. It provides the stimulus material, that is, four different audiobooks and the trigger signal, to the audio interface. The audio interface deploys the stimulus material to the four loudspeakers (LS1–LS4) and the trigger signal to the trigger box. In addition, PC 1 is connected to the monitor and the keyboard in front of the participant—it broadcasts the instructions on the screen and receives the input from the keyboard. PC 2 handles the data acquisition. It records the data from the signal amplifier, that is, 128 channels of EEG data from scalp electrodes and the trigger signal.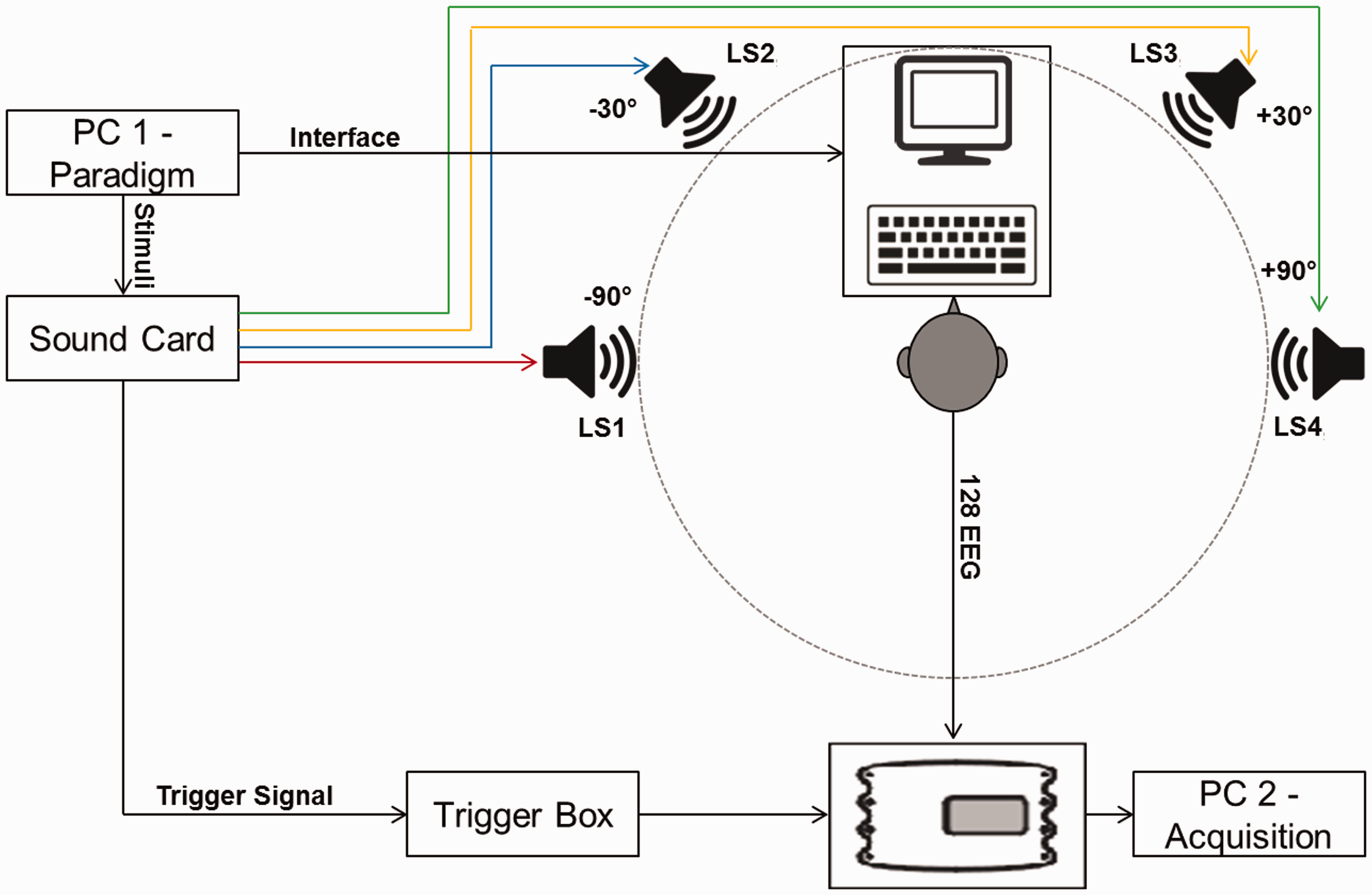
Paradigm and Stimulus Material
The paradigm was designed to simulate the cocktail party problem. The participant’s goal was to follow the spoken content of an audiobook presented by one of the four loudspeakers, while ignoring the remaining three loudspeakers that each played a different audiobook at the same time. Four different audiobooks spoken by four different professional speakers (two male and two female voices) were used to generate the acoustic environment. Each of the audio books was professionally recorded and sampled with a frequency of 44.1 kHz (Ackner & Fischbach, 2017).
LS1 ( LS2 ( LS3 ( LS4 (
Each audiobook was decomposed into 25 segments, each having a duration of 120 s. Throughout the experiment, each segment was presented in chronological order to maintain the story line. Each of the 100 segments was calibrated individually to 55 dBLA eq . A hand-held sound-level meter (type 2250, Brül & Kjær, Denmark) was used to calibrate the audiobook segments at the position of the ear. The signal to noise ratio between the different loudspeakers was thus held constant at 0 dB over the whole experiment. To control the entire paradigm, the open source toolbox Psychophysics Toolbox Version 3 (PTB-3) for Matlab (MATLAB R2013A, MathWorks, USA) was used (Brainard, 1997; Pelli, 1997).
Experimental Design
The experiment was divided into three parts—a training session, experiment 1 (E1), and experiment 2 (E2). The training session consisted of one trial. The participant was asked to sit as comfortable as possible, to rest his or her chin on the chin rest, and to listen to the audiobook presented at LS3 for 120 s while ignoring the audiobooks presented from the other three loudspeakers (LS1, LS2, and LS4). The participant was also asked to move as little as possible and to fixate his or her eyes upon the cross presented on the monitor during the presentation of the audiobooks. Shortly before the acoustic stimuli were played, three content-related questions were displayed on the screen. The subject was told that it was not necessary to keep the questions in mind because the questions were going to be displayed again after the trial with multiple choice response options. The reason for displaying the questions before the stimulus presentation was to help the participant to follow the corresponding audiobook segment. Immediately after presentation of the audiobook segment, the subject had to answer the three previewed multiple choice questions displayed on the screen by using the keyboard. The subject was asked if the training trial was clear or if there were any further questions. If there were none, the participant was told that the following trials were going to be exactly like the training trial and that it was up to him or her to control the speed of the experimental procedure, and that it was possible to take rests.
E1 consisted of eight trials (120-s segments). Each of the four loudspeakers played its individual audiobook segment, while the subject was asked to focus either on the far left or on the far right speaker, that is, LS1 or LS4, respectively. The participant was asked to focus to LS1 or to LS4 for four of the trials each—the exact order was randomized for every subject. E2 consisted of 16 trials, and the participant had to pay attention to each of the four loudspeakers for four trials each. Here, the exact order was randomized for each participant as well.
Data Acquisition
EEG was recorded from 128 active Ag/AgCl electrodes and a ground electrode. Of these, 32 EEG channels were used in the stimulus reconstruction analysis. The electrodes had been positioned using an EEG-cap (Active Electrode System, g.GAMMAsys, Guger Technologies, Austria) that followed the International 10-20-System. The impedance of each electrode was kept below 50 kΩ as recommended for active electrodes. Scalp EEG activity was amplified (g.Hiamp, Guger Technologies, Austria) and sampled at 512 Hz with reference to a ground electrode positioned at the center of the forehead (AFz). No additional online processing options such as frequency filtering were used. The signal amplifier was connected to the acquisition PC (PC 2) using USB 2.0. To control the data acquisition, a Simulink interface (MATLAB R2013A, MathWorks, USA) was used. A trigger signal indicated the onset of each experimental trial. The trigger signal was deployed to the signal amplifier via paradigm PC (PC 1), sound card, and conditioner box (g.TRIGbox, Guger Technologies, Austria). Thus, the EEG data could be analyzed in synchrony with the presentation of the target sound. In addition, PC 1 was used to record the answers to the multiple choice questions presented to the subject.
Data Processing
The acquired EEG (raw) data were imported into the software Matlab (MATLAB R2017A, MathWorks, USA). The data were stored as a N × T matrix, where N denotes the number of recorded EEG channels and T denotes the recorded data points. The first step of data processing was to rereference the recorded channels against the electrode positioned at the vertex (Cz). The next step was to band pass filter all channels (from 1 Hz to 45 Hz) using a zero phase shift finite impulse response (FIR) band pass filter of order 1000 based on a Hamming window. The filtered EEG channels were segmented into 24 blocks according to the recorded trigger signal, that is, 8 for E1 and 16 for E2. Each of those data matrices represented the preprocessed EEG data of one experimental trial: Normalized spectrogram of the recorded EEG data. The example shows subject 3 while focusing on speaker LS1 for the first time in E1. On the x-axis, the frequency is noted in Hz and on the y-axis, the magnitude. Each line represents one of the 32 EEG channels. One can clearly recognize peaks in the range of α- (8–13 Hz) and in the range of β- (13–25 Hz) activity, which is a typical pattern for EEG data.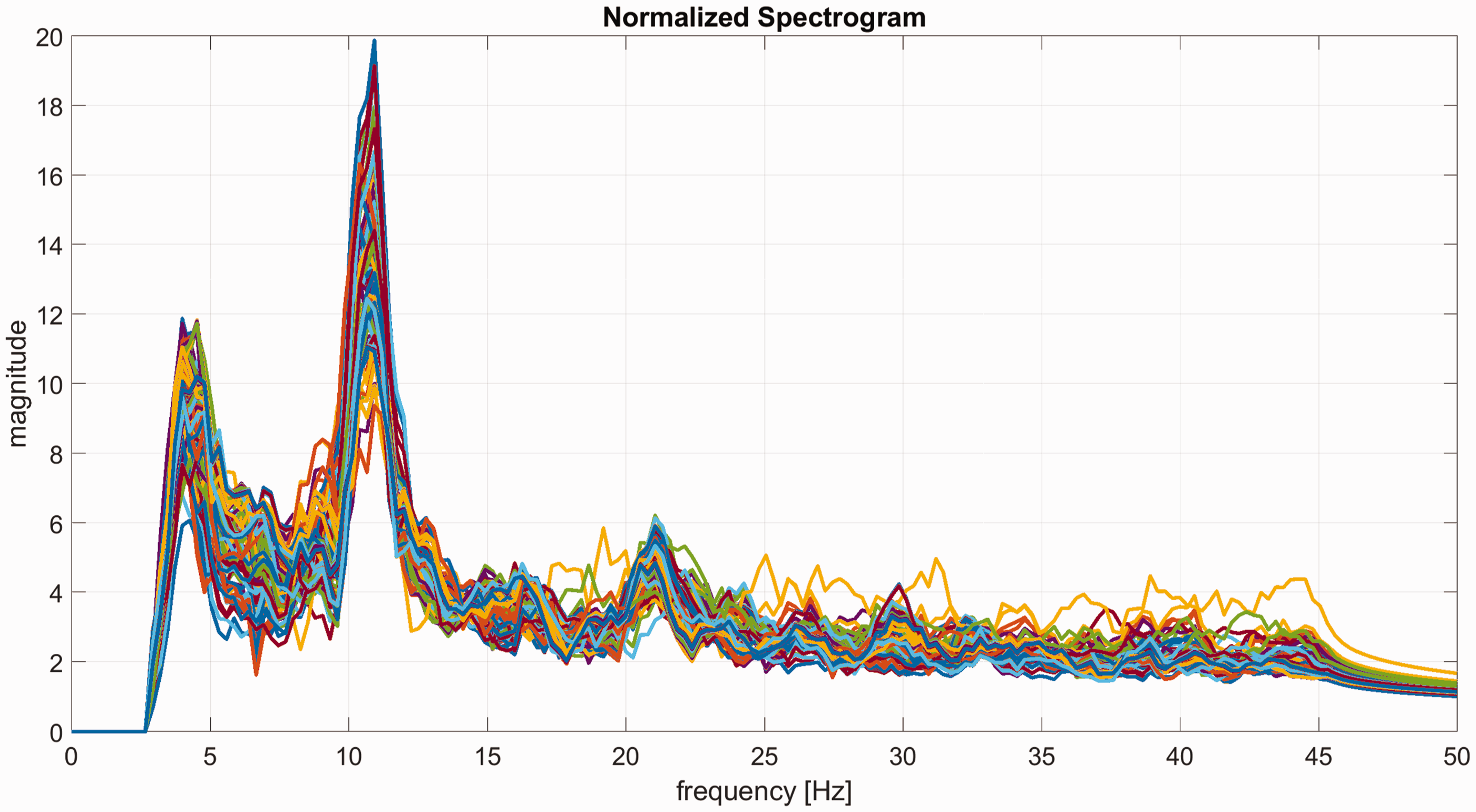
The data sets that had been categorized as analyzable were prepared for further application of the stimulus reconstruction algorithm, following the guidelines described by Crosse et al. (2016). At first, the data volume was reduced. Of the recorded 128 channels, only 32 were included into the analysis. Those 32 channels were equally distributed across the scalp according to the International 10-20-System. The next step was to filter the 32 EEG channels using a zero-phase shift FIR low-pass filter with a cut-off frequency at 15 Hz and order 1000 based on a Hamming window. In addition, the amplitudes of every EEG channel were individually scaled to 0 to 1. The EEG data sets were then downsampled to 128 Hz and segmented into subblocks of 30 s duration. This resulted in 96 matrices per participant:
The stimulus reconstruction algorithm requires the recorded EEG data together with the physical characteristics of the acoustic stimulation as input. Thus, the stimulus material had to be prepared in the same way as the EEG data, that is, having the same duration and the same sampling frequency. The first step was to calculate the broadband envelope of each audiobook segment according to the following equation:

Data Analysis
The following gives a short overview of the stimulus reconstruction approach. We refer to Crosse et al. (2016) for more detailed information.
The basic idea behind the approach is that the cortex acts like a linear time invariant system mapping input, that is, acoustic stimuli, to a certain output, that is, the EEG activity. ERPs in the EEG can be interpreted as the impulse response of the cortex to a discrete stimulation—for example, a click sound. Following that idea, the ongoing EEG activity resulting from ongoing, continuous stimulation—like real speech—can be interpreted as a linear convolution. According to this, the instantaneous neural activity r(t, n) (
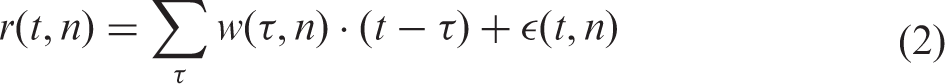
To reconstruct the speech envelope, the decoder

Here,

Here,
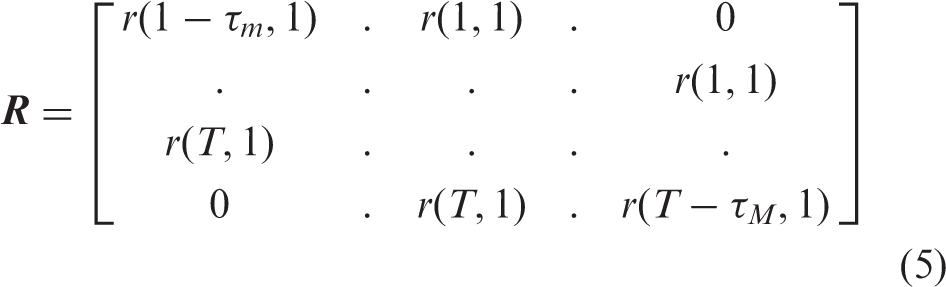
Here,
The first step of data analysis was the reconstruction of the attended speech envelopes
The calculated 95 × 11 decoders were averaged along the 95 trials to prevent over-fitting. The results were 11 averaged decoders
The second step of the data analysis involved the comparison of the reconstructed speech envelope The N − 1 preprocessed EEG data, combined with the corresponding attended speech envelopes, were used to calculate a decoder for each of the N − 1 trials and each ridge parameter. The computed decoders were averaged along the trials in order to prevent over-fitting. The averaged decoders for every ridge parameter and the unseen Nth preprocessed EEG data set were used to reconstruct the corresponding speech envelope. This procedure was repeated for N trials, that is, a leave-one-out cross-validation process. The reconstructed speech envelopes for each trial and each ridge parameter were compared to the actual attended speech envelopes using Pearson’s correlation coefficient. To define the optimal ridge parameter, the resulting correlation coefficients were averaged along the trials. The result was the set of optimal decoders for each trial. The optimal set of decoders was used to reconstruct the attended speech envelopes. The final step was to compare the reconstructed speech envelopes with the corresponding attended speech envelope and unattended speech envelopes. The resulting correlation coefficients were used to determine the attended speech envelope.

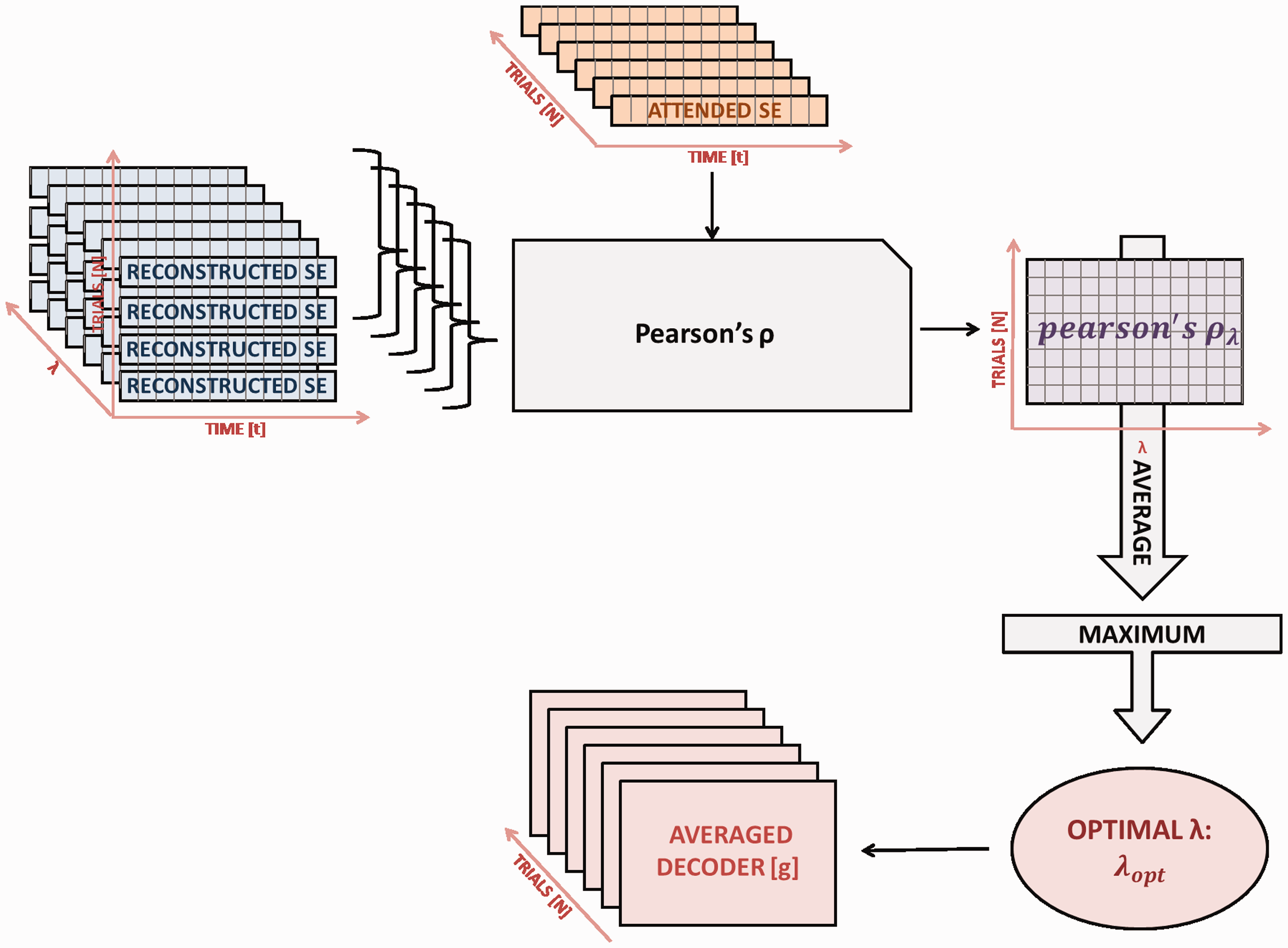

To validate this stimulus reconstruction method, the abovementioned analysis was carried out on two sets of randomized surrogate data. The first set was generated by combining the EEG data from each trial with attended speech envelopes from randomly chosen trials. The second set was generated by randomly combining the EEG data of each trial with a temporally matching speech envelope that could be either attended (25%) or unattended (75%). If our assumptions are correct, that is, that SAA specifically enhances the neural representation of the attended speech message, the total number of correct classifications for these surrogate data should be in the range of simple guessing, that is, a value around 24.
Results
After every experimental trial, the participants had to answer three content-related multiple choice questions with four possible answers so that chance level was 25%. The aim was to verify that the participants were able to follow the story line of the audiobook segments they were asked to attend to. Figure 7 shows the percentage of correctly answered multiple choice questions for each subject, which ranged between 50.0% and 94.4% with an average of Results from the content-related multiple choice questions the participants had to answer after every 120-s trial. Three questions had to be answered on each trial, so there were 72 questions in total. Each bar represents a different subject and indicates the percent correct answers. The orange line shows the mean over all subjects.
To find out whether it was possible to predict the orientation of SAA from the combination of recorded neural activity and the physical characteristics of the spoken messages, that is, the speech envelopes, in a challenging cocktail party situation, we used stimulus reconstruction and counted the number of correct and incorrect classifications. Figure 8 shows the results for every participant over each of the 24 experimental trials. Note that each trial was subdivided into four parts, resulting in 96 segments to be classified. The number of correct classifications per subject ranged between 21 and 81 with an average of 58.70 ± 18.02. The number of correct classifications of the attended message obtained using speech reconstruction. Each subject is represented by four bars—the blue bar indicates the number of correct classifications of the attended loudspeaker, and the orange, green, and red bars indicate the numbers of incorrect classifications for the three unattended loudspeakers. The purple line marks the level of guessing (25%).
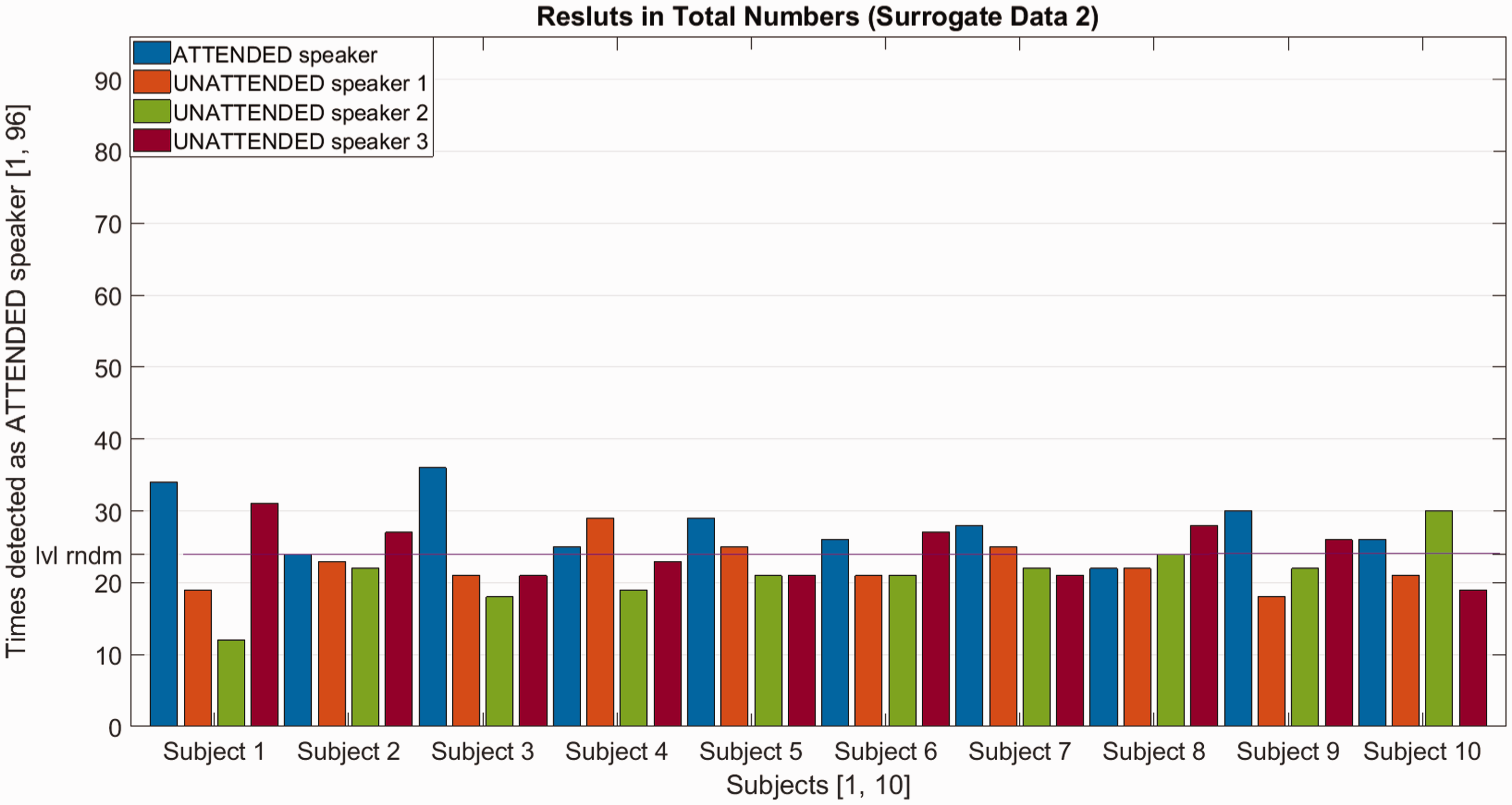
To demonstrate the validity of these classifications, the stimulus reconstruction algorithm was also applied to two sets of randomly constructed surrogate data. For the first set of surrogate data, the recorded EEG activity from each trial was matched with attended speech envelopes of randomly selected trials. In this case, the total number of correct classifications (of the attended speaker) fell within the range of 16 and 32 per subject with an average of 25.40 ± 4.67. For the second set of surrogate data, the EEG activity was combined with the speech envelopes of matching trials, but not necessarily the attended envelopes. Here, the total number of correct classifications (of the attended speaker) fell within the range of 22 and 36 per subject with an average of 28.30 ± 4.64.
To verify that the EEG-based classification accuracy was actually related to SAA, the number of correct classifications was correlated (using Pearson’s coefficient) with the number of correctly answered multiple choice questions on the content of the audiobooks. The correlation was positive (ρ = .69) and significant (p = .026).
Discussion and Future Work
The present results show that it is possible to decode the orientation of SAA in a four-speaker free field environment using stimulus reconstruction. Over all subjects, the EEG-based stimulus reconstruction algorithm correctly classified the attended loudspeaker on an average of 61.1% of the trials, well above chance level of 25%. The two best subjects showed over 80% correct classifications. These findings provide strong support for the hypothesis that the recorded EEG is mostly driven by the attended speaker compared to the unattended ones; in other words, the EEG is mostly driven by the rhythm of speech that the listener is attending. Figure 8 indicates that the classification was successful for every participant, except subject 2. A recent study also tested the stimulus reconstruction approach with several loudspeakers in free field (Fuglsang et al., 2017), but only two of the loudspeakers were used as targets of attention, while the others served as distractors. In that study, an average classification accuracy rate of 87.1% was achieved, some 37.1 percentage points above the chance level of 50%. Similarly, the present study achieved a classification accuracy of 36.1% percentage points above the chance level of 25% using four spatially separated loudspeakers having equivalent relevance to the subjects. The present results thus demonstrate for the first time that the stimulus reconstruction approach can be used effectively to determine the direction of SAA in an environment having four spatially separated loudspeakers with equal relevance to the listener.
On average, the 10 subjects were able to correctly answer 76.8% of the multiple choice questions about the content of the attended audiobook story. This indicates that the subjects were able to attend effectively to the designated spoken message and that the present paradigm is a valid simulation of the cocktail party problem. Subject 2 stands out as the participant showing the weakest performance, with less than 50% correct answers. This subject also showed the lowest number of correct classifications of the attended loudspeaker based on EEG stimulus reconstruction (see Figure 8), which in fact did not exceed the chance level. It appears that subject 2 was unique in not focusing attention effectively on the attended message.
To validate this classification process based on EEG stimulus reconstruction, two sets of surrogate data were generated. The aim of the first set of surrogate data was to verify that classification of the attended and unattended speaker would not be possible if the algorithm was fed with obviously incorrect data. In Figure 9, it can be seen that the classification was indeed not successful, that is, not significantly above chance level. The goal of the second set of surrogate data was to determine whether classification was possible if the algorithm is randomly fed with attended and unattended speech envelopes from the same experimental trial. In Figure 10, it can be seen that the classification was not successful although its performance appeared to be slightly better than with the first set of surrogate data. This slight improvement with the second set of surrogate data might be explained as follows: The probability of combining a certain trial of EEG data with the matching attended speech envelope was The number of classifications of the attended and unattended speakers for each subject using the first set of surrogate data. The number of classifications of the attended and unattended speakers for each subject using the second set of surrogate data.
Another noteworthy finding of the present study was that the number of correctly answered content questions correlated significantly (and positively) with the number of correctly classified trials. Assuming that the number of correctly answered questions depends on the listener’s attention to the designated audiobook, this would be another indication that the stimulus reconstruction approach is indeed sensitive to SAA. Based on this result, we can envisage future testing of the approach as an objective EEG-based measure of focused attention and speech intelligibility in realistic acoustic environments.
A major aim of this study was to investigate the limitations of the stimulus reconstruction approach with respect to its potential applications for improving hearing aid capabilities. For this reason, we placed the speaker locations so as to cover the frontal semicircle in the free field environment, which corresponds to the zone of hearing aid microphones. In addition, we set up a realistic and complex listening environment consisting of four equally relevant and spatially separated speakers. This type of acoustic environment is particularly relevant for the further development of hearing aids, given that people with hearing loss have greater difficulty in understanding a speaker in a multispeaker environment compared to normal hearing individuals (e.g., Bernarding, Strauss, Hannemann, Seidler, & Corona-Strauss, 2013; Pichora-Fuller & Singh, 2006). For this reason, the stimulus reconstruction approach may have important applications in the field of rehabilitation audiology: The inclusion of a hearing aid wearer’s intended targets of attention into the design of future hearing aids, that is, by means of a brain computer interface, could help to improve the quality of life of hearing-impaired people. An important advantage of the stimulus reconstruction approach in this regard is that it is based on single-trial EEG recordings and thus can provide near real-time information to the listener. The present findings suggest that the approach is robust enough to begin testing in everyday situations by using wearable EEG devices and new electrodes, such as in-ear electrodes, to help prepare the way for a new generation of hearing aids.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the German Federal Ministry of Education and Research grant (number BMBF-FZ 03FH004IX5).