
Abstract
Speech intelligibility in challenging listening environments relies on the integration of audiovisual cues. Measuring the effectiveness of audiovisual integration in these challenging listening environments can be difficult due to the complexity of such environments. The Audiovisual True-to-Life Assessment of Auditory Rehabilitation (AVATAR) is a paradigm that was developed to provide an ecological environment to capture both the audio and visual aspects of speech intelligibility measures. Previous research has shown the benefit from audiovisual cues can be measured using behavioral (e.g., word recognition) and electrophysiological (e.g., neural tracking) measures. The current research examines, when using the AVATAR paradigm, if electrophysiological measures of speech intelligibility yield similar outcomes as behavioral measures. We hypothesized visual cues would enhance both the behavioral and electrophysiological scores as the signal-to-noise ratio (SNR) of the speech signal decreased. Twenty young (18–25 years old) participants (1 male and 19 female) with normal hearing participated in our study. For our behavioral experiment, we administered lists of sentences using an adaptive procedure to estimate a speech reception threshold (SRT). For our electrophysiological experiment, we administered 35 lists of sentences randomized across five SNR levels (silence, 0, −3, −6, and −9 dB) and two visual conditions (audio-only and audiovisual). We used a neural tracking decoder to measure the reconstruction accuracies for each participant. We observed most participants had higher reconstruction accuracies for the audiovisual condition compared to the audio-only condition in conditions with moderate to high levels of noise. We found the electrophysiological measure may correlate with the behavioral measure that shows audiovisual benefit.
Introduction
An important factor for many real-life conversational situations involving verbal communication is that listeners can see the face of the conversation partner. The benefit gained from the added visual information has been investigated using behavioral measures with speech stimuli (consisting of words or short sentences) presented by human speakers (Sumby & Pollack, 1954) or video recordings (Grant & Seitz, 2000; Le Rhun et al., 2024; Llorach et al., 2022; Ross et al., 2007).
While these materials provide more realism for an audiovisual experiment, an experimenter cannot easily combine these materials with an audiovisual environment. Previous research has made audiovisual environments (Ahrens et al., 2019; Hohmann et al., 2020; Seeber et al., 2010). Furthermore, efforts have been made to create synchronized mouth movements from a virtual speaker. These studies used deep-neural networks (DNNs) to create synthetic talking faces that provide audiovisual cues to the listener (Shan et al., 2022; Varano et al., 2022; Yu et al., 2024). These studies have found these synthetic talking faces provide an audiovisual benefit to the listener; however, the benefit provided is not as much as a natural, human speaker. While these previous research studies have paved the way for audiovisual settings, there is still a need for a combination of audiovisual environments and virtual speakers. A tool that provides a solution to this problem is the Audiovisual True-to-life Assessment of Auditory Rehabilitation (AVATAR) environment, which was developed to provide an ecological environment in which to test an individual's speech intelligibility and working memory (Devesse et al., 2018, 2020a, 2020b, 2020c). The AVATAR environment provides an ecological scenario in a controlled environment. The virtual avatars in this tool possess audiovisual speech capabilities, addressing a crucial aspect of speech, in natural settings such as a restaurant, a metro car, and a living room. The AVATAR environment has been validated using speech-in-noise assessments which showed improved speech intelligibility in noise with the addition of visual cues (Devesse et al., 2018).
Speech intelligibility tests are challenging to administer since they rely on feedback. To address this, a promising approach involves the use of electrophysiological signals recorded with neuroimaging techniques. Electrophysiological measures of hearing have long been obtained using evoked-related potentials (ERPs) which can be measured using electro-/magneto-encephalography (EEG/MEG) and repetitive or periodic stimuli (Anderson et al., 2013; McGee & Clemis, 1980; Picton et al., 2005). These measures allow us to measure hearing ability in populations that cannot be measured using standard hearing tests. One such example is measuring auditory brainstem responses in babies (Polonenko & Maddox, 2019).
While ERP research has broadened our knowledge of how the brain responds to different sounds, the neural responses to these sounds are not representative of how the brain responds to the continuous processing of sound. Short, repetitive stimuli may only capture the onset responses to speech, while extended, continuous speech may capture language processing mechanisms and other long-term processing mechanisms (Hullett et al., 2016).
For the past decade, research studies have worked on the development of electrophysiological methods to measure speech intelligibility in individuals while they listen to continuous speech (Di Liberto et al., 2015; Ding & Simon, 2012, 2013; Lalor & Foxe, 2010). These studies have shown that slow modulations in speech signals, known as the speech envelope, correlate with electrophysiological signals. This correlation has been termed neural tracking and has been shown to correlate with speech intelligibility in quiet and noisy environments (Gillis et al., 2021; Lesenfants et al., 2019; Vanthornhout et al., 2018).
Previous studies have shown that watching mouth movements while listening to a story leads to an increase in neural tracking compared to conditions where no mouth movements occur or when mouth movements that do not match the target speech are presented to the listener (Ahmed et al., 2023; Crosse et al., 2015; O'Sullivan et al., 2019, 2021; Zion Golumbic et al., 2013). Furthermore, studies that have used audiovisual speech materials of recorded humans, have shown that audiovisual benefit can be linked between behavioral measures and neural measures which allows for a better understanding of these mechanisms on an individual level (Crosse et al., 2016; Reisinger et al., 2023). While these studies have increased our knowledge of the effects of audiovisual processing of stories, these studies did not address the effects of audiovisual processing in an ecological environment such as the one provided by the AVATAR paradigm.
Our study aims to bridge the gap between behavioral and electrophysiological scores of audiovisual benefit by using an audiovisual environment in noise. To accomplish this, we use a validated behavioral procedure that can be compared to the neural tracking results we will obtain in our electrophysiological procedure. In this environment we use a single speaker in noise before moving on to multiple speakers in future studies. The choice of single speaker was also motivated by the similarity to behavioral speech audiometry. Based on previous research, we hypothesized that the behavioral and electrophysiological measures would correlate positively with each other. Furthermore, we hypothesized that the added value of mouth movements would enhance both the behavioral and electrophysiological scores as the SNR of the speech signal decreased.
Methods
Participants
Twenty young (18–25 years old) participants (1 male and 19 female) with normal hearing, language processing, and cognitive function participated in our study. We defined normal hearing as having hearing thresholds at or below 20 dB HL for the frequency range between 125 and 8000 Hz. We verified these hearing thresholds for each subject using a MADSEN Itera II. All participants were proficient in the Flemish-Dutch language. Each participant completed both the behavioral and electrophysiological tests. For each participant, these tests were conducted sequentially in this respective order.
Speech Materials
For our stimuli, we chose to use the Leuven Intelligibility Sentence Test (LIST) corpus (van Wieringen & Wouters, 2008). The corpus contains 35 lists of sentences and each list contains 10 semantically predictable sentences. The original sentences were spoken at relatively low rate of 2.5 syllables per second since the sentences were developed for persons with severe hearing impairment (van Wieringen & Wouters, 2008). For this study with young normal-hearing listeners, we sped up the rate of these sentences to 4.3 syllables per second, which corresponds to a 0.6 compression ratio. The version of the LIST was used previously in Decruy et al. (2018). Furthermore, multitalker babble noise consisting of 20 English speakers (8 male and 12 female) was used as a masker (Francart et al., 2011). We presented the stimuli at 60 dBA. The presentation level of the stimuli was calibrated at 80 dBA using a Brüel & Kjær 2250 sound level meter.
We controlled the presentation of the stimuli using a computer running the software APEX 3 (Francart et al., 2008). Using an RME Fireface UCX sound card (RME, Haimhausen, Germany) connected to the computer, the target stimuli were presented through a FOSTEX 6301B3 loudspeaker (Fostex, Tokyo, Japan) that was located directly in front of the participant at eye level and approximately a 1 meter away from them. The masker stimuli were also presented through another FOSTEX 6301B3 loudspeaker located on the ceiling of the sound booth directly above the participant. For the virtual environment of the AVATAR paradigm, we chose the restaurant scenario with a single avatar in the center of the room (see Figure 1). The virtual environment was projected on an acoustically transparent screen (1.73 × 3 m) using an Optoma EH200ST projector (Optoma, Hemel Hempstead, UK). The screen covered the location of the loudspeaker and the mouth of the virtual avatar was right in front of the driver of the loudspeaker. The avatar was controlled using the AVATAR paradigm (Devesse et al., 2018), which was created in a 3D engine software (Unity Technologies, 2017).

(A) Experimental setup of the AVATAR environment. (B) The avatar displayed on the projector screen during the experiment. For the experiment we display a single avatar in the center of a restaurant scenario. (C) Design of the behavioral experiment where a list of 10 sentences was presented to the listener. The SNR of the speech in noise would increase or decrease depending if the listener recalled the keywords correctly or incorrectly, respectively. The resulting SRT is calculated based on an average SNR level of the last five sentences plus an imaginary 11th sentence (a sentence that would have been presented if the experiment continued). (D) Design of the neural tracking experiment where 35 lists of sentences (… a collection of 10 sentences) were presented for each visual condition (audio-only and audiovisual). Therefore, the experiment presented a total of 70 lists. Each presentation was assigned 1 of 5 SNR conditions (−9, −6, −3, 0, and silence (∞)) with equal distribution across the lists (… 7 lists per visual condition and SNR condition). The visual condition for each list was randomized. We then calculated the reconstruction accuracies at each SNR level. AVATAR=Audiovisual True-to-Life Assessment of Auditory Rehabilitation; SNR= signal-to-noise ratio; SRT= speech reception threshold.
Behavioral Measures
The speech reception threshold (SRT) was determined using an adaptive procedure (Devesse et al., 2018), in which the signal-to-noise ratio (SNR) was adjusted by 2 dB steps based on correct or incorrect responses. Sentence scoring was used to determine whether a response was correct or incorrect, meaning that if any of the keywords was incorrectly recalled then the entire sentence was marked as incorrect. The starting SNR for each list was −12 dB SNR and the first sentence of each list was repeated until all keywords were correctly identified. Subsequently, the remaining sentences were presented adaptively in steps of 2 dB to determine the SRT. The adaptive procedure was designed to converge to 50% to estimate the SRT. We calculated the SRT as the average of the last five out of a total of 10 sentences, plus an 11th imaginary sentence that would have been presented if the procedure had continued. SNR adjustments were made by increasing or decreasing the level of the multitalker babble noise, while the level of the target speaker was kept constant. To examine the effect of mouth movements in this adaptive behavioral test, we administered two lists: audio-only and audiovisual. We also included an additional list for audio-only training at the beginning of the test to mitigate learning effects. For a visual overview see panel C in Figure 1.
Electrophysiological Measures
After the behavioral test, we conducted an electrophysiological test. In the electrophysiological test, we recorded brain signals with a BioSemi ActiveTwo system (Amsterdam, the Netherlands) using 64 channels and a sample rate of 8192 Hz for each recording. During this recording, we presented (at a speech intensity level of 60 dBA) all 35 lists of sentences (total duration of 23 min) twice during the experiment to ensure both visual conditions (audio-only and audiovisual) have a sufficient and equivalent amount of data for the neural tracking measures. These lists of sentences were randomized across five SNR levels (silence, 0, −3, −6, and −9 dB) and the two visual conditions. Therefore, for each experiment a total of 70 lists of sentences were presented, which provided 7 lists per visual condition and SNR condition. To randomize the SNR levels paired with the visual conditions, the Fisher-Yates shuffle algorithm was implemented in JavaScript. Each list consists of 10 individual sentences, which were concatenated with a randomly jittered silence duration in between sentences from 800 to 1200 ms. To keep the participants’ attention, at the end of each list presentation we asked them if a specific keyword occurred within the set of sentences they just heard and they answered “yes” or “no.” We did not perform further analysis of the results from this keyword task. For a visual overview see panel D in Figure 1.
Analysis
We preprocessed the electrophysiological data with MATLAB R2022b using custom scripts (The MathWorks Inc., 2022). We first high-pass filtered the data using a second-order zero-phase Butterworth filter with a 0.5 Hz cutoff. From there we epoched the raw data into trials that consisted of one presentation of an LIST, which consists of 10 sentences. There were a total of 70 trials; therefore, there were 35 trials per visual condition and 7 trials per SNR condition. Then to reduce computation time of the proceeding steps, we downsampled the data to a 256 Hz sampling rate using the built-in resample function in MATLAB. We then used a multichannel Wiener filter to remove eye blink artifacts from each trial of EEG data (Somers et al., 2018). After artifact removal, we concatenated trials with matching conditions. Then we re-referenced the EEG channels to the average reference across channels. We then band-pass filtered the data between 0.5 and 8 Hz using a zero-phase Chebyshev type II filter with 80 dB attenuation at 10% outside the passband and a pass band ripple of 1 dB.
We calculated the envelope of each LIST sentence using a gammatone filterbank followed by a power law; the details of this method are outlined in Vanthornhout et al. (2018). We then downsampled the envelope to 256 Hz to match the sample rate of the EEG data and concatenated the envelopes with matching conditions. Then we filtered the concatenated envelopes between 0.5 and 8 Hz using the same band-pass filter used for the EEG analysis. Finally, we downsampled both the EEG and envelope down to 128 Hz for reduced computation time of the neural tracking measures and then normalized both signals with z-scoring per condition.
Neural Tracking Measures
For our neural tracking measure, we used a linear decoder to reconstruct the speech envelope. To train this decoder for each condition, we used ridge regression and approximately 300 s of EEG and speech envelope data split using a fixed fold length of 60 s for K-fold cross-validation. The ridge parameter was set to the maximum value of the autocorrelation matrix of the EEG signal, which has been found to yield stable results in our lab. For the integration window, we chose 0 to 250 ms. We concatenated the reconstructed envelope in each fold together and computed a Spearman correlation with the true envelope to obtain reconstruction accuracy as a measure of neural tracking.
Linear Mixed Effect Modeling
To estimate if there was a significant effect between Spearman correlations and SNR level, we computed a linear mixed effect model using the neural tracking data, according to the following equation:

Results
Behavioral
For the behavioral results, we found that the participants obtained lower SRTs in the audiovisual conditions compared to the audio-only conditions (shown in Figure 2A). The median SRT values for each modality are −5.6 dB for audio-only and −7.3 dB for audiovisual. This absolute difference is 1.7 dB SNR. We performed a paired Wilcoxon signed rank test to assess statistical significance. The test result was below the significance level of 0.05 (W = 318.5, P = 0.001); therefore, we reject the null hypothesis that the two medians were the same. We concluded that the audiovisual had a significantly lower SRT than the audio-only.
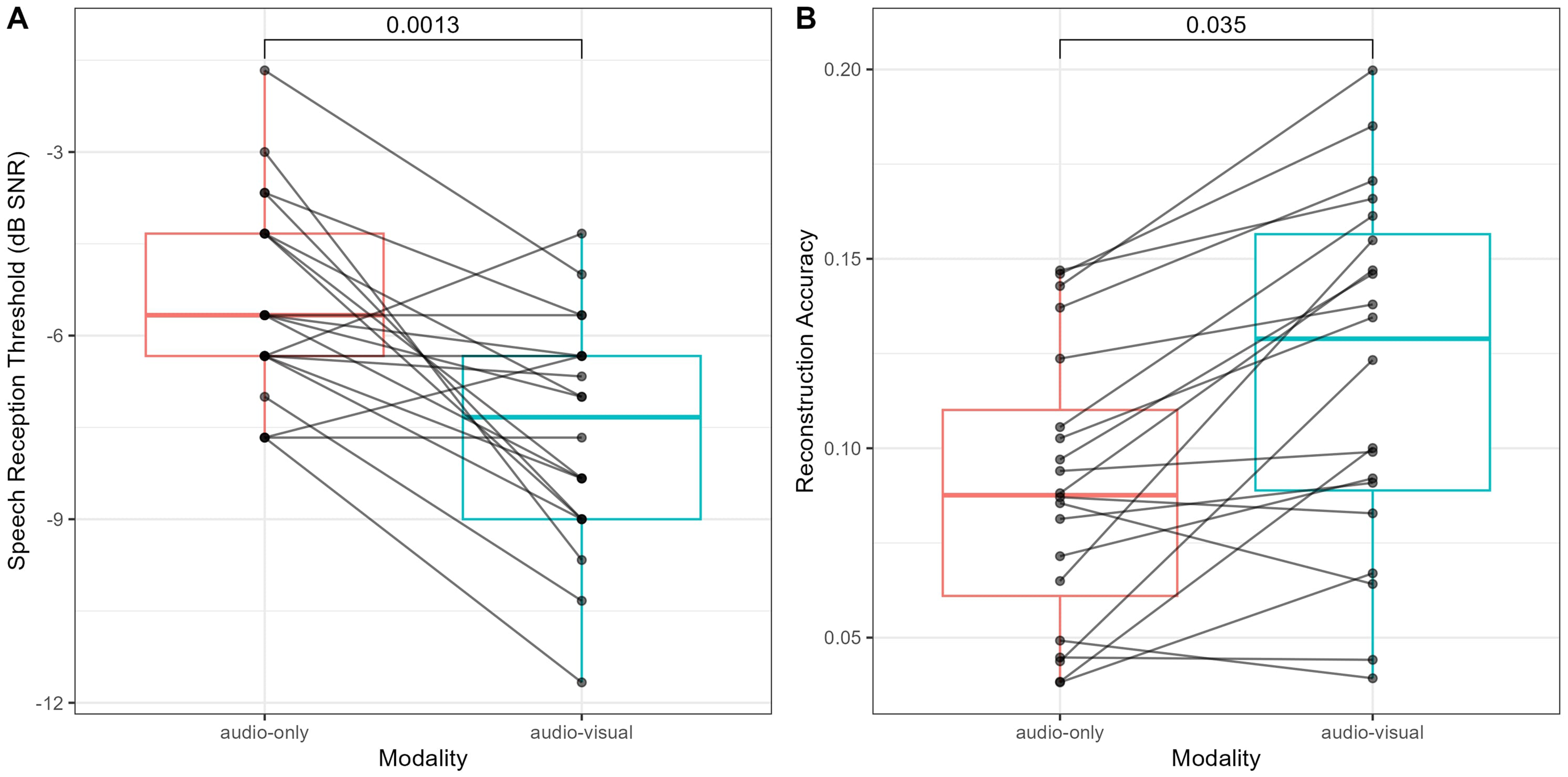
(A) SRTs of the individual participants for the audio-only and audiovisual conditions. (B) Reconstruction accuracies of the individual participants for the audio-only and audiovisual conditions, where each dot represents the average across all SNR conditions except the silence condition for each participant. Lines are drawn between visual conditions for individual subject comparisons. The P-values of the Wilcoxon signed rank tests are shown above the distributions. SNR= signal-to-noise ratio; SRT= speech reception threshold.
Electrophysiological
For the electrophysiological results, we observed that on average the participants had a higher reconstruction accuracy for the audiovisual condition than the audio-only condition in all SNR levels except the silent condition (see Figures 2B and 3A). The median reconstruction accuracies for each modality are 0.089 for audio-only and 0.120 for audiovisual. This absolute difference is 0.031. We performed a paired Wilcoxon signed rank test to assess statistical significance. The test result was below the significance level of 0.05 (W = 122, P = 0.035); therefore, we concluded that the audiovisual had a significantly lower SRT than the audio-only. To evaluate statistical significance, we used a linear mixed model and the results are shown in Figure 3B.

(A) The distributions of reconstruction accuracies for each modality across SNR levels. The lines represent individual participants. (B) The contrast results of the linear mixed effect model when comparing the difference in modality for each SNR level. The contrast is computed as audiovisual minus audio-only. SNR= signal-to-noise ratio.
An analysis of variance (ANOVA) did not yield a significant interaction effect between modality and SNR level (F value = 2.230, P-value = 0.067); however, both main effects are significant (modality: F value = 19.230, P-value = 2.019e-05; SNR: F value = 18.615, P-value = 1.019e-12). We can conclude that (1) as SNR level decreases neural tracking decreases and (2) the inclusion of lip movements leads to an increase in neural tracking. However, we cannot conclude that lip movements yield higher neural tracking as the SNR level decreases. This is visualized in Figure 3B where noise conditions have a significant difference between audiovisual and audio-only, while the silence condition does not.
Discussion
The aim of this study was to see if, in normal hearing listeners, electrophysiological measures of speech intelligibility correlated with behavioral measures in an audiovisual environment. From the results of this study, we found that the participants scored better both in behavioral and electrophysiological tests for the audiovisual condition compared to the audio-only condition. Additionally, the results show that the AVATAR environment can be used to study both behavioral and electrophysiological measures of audiovisual benefit in more ecological circumstances.
The behavioral results replicate the audiovisual benefit of approximately 2 dB that was reported in (Devesse et al., 2018). The neural tracking results show that most participants exhibit higher reconstruction accuracies when presented with an audiovisual stimulus compared to an audio-only stimulus in conditions where moderate to high levels of noise are present (0 to −9 dB SNR).
Both the behavioral and electrophysiological results show that when noise is present in the listening environment the audiovisual benefit becomes apparent. These results show the brain integrates visual information when the auditory information is degraded. This multisensory integration leading to audiovisual benefit is known as “inverse effectiveness” (Alex Meredith & Stein, 1986; Crosse et al., 2016). Further evidence for this has been found previously in listeners with normal hearing (O'Sullivan et al., 2021) and hearing-impairment (Puschmann et al., 2019). Our study substantiates this previous evidence by using multiple noise levels, but the audiovisual benefit seems to remain unchanged regardless of noise level.
For our speech feature, we decided to only use the envelope and not use higher level features (e.g., linguistic features) because the LIST sentences, while semantically predictable, are expected to not have enough context for higher level features to outperform the envelope as a feature. However, there may be more nuanced effects to find and the use of other features that target language statistics may improve the sensitivity of the measure. Previous studies have shown linguistic features enhance electrophysiological measures of speech intelligibility (Brodbeck et al., 2018; Broderick et al., 2019; Di Liberto et al., 2015; Gillis et al., 2021; O'Sullivan et al., 2021). Moreover, the results from other previous studies suggest audiovisual integration occurs at a simplified linguistic level (Crosse et al., 2016; Ding & Simon, 2013). More data from follow-up studies would be required to compute models for neural tracking from these linguistic features.
From the behavioral results we observe that −9 dB SNR is a very difficult listening condition; however, in the electrophysiological results the reconstruction accuracies are above zero. This result has also been shown in (Vanthornhout et al., 2018) in which Flemish Matrix sentences (Luts et al., 2014) were used where it is only around −11 dB SNR that the reconstruction accuracies approach zero. Furthermore, Ding and Simon (2013) has shown that audio-only speech envelope tracking is robust at low SNR levels where there is little to no speech intelligibility. Also, this robust tracking is further enhanced for audiovisual speech (Crosse et al., 2016; Zion Golumbic et al., 2013).
With regard to generating mouth movements for AVATAR, there are a few limitations. The AVATAR paradigm uses a system similar to a facial action coding system (FACS) (Sayette et al., 2001) to produce the mouth movements of the avatars (Salvi et al., 2009). Currently, the AVATAR is only programmed to display the mouth movements for the LIST sentences. A future goal would be to incorporate longer speech passages into the AVATAR paradigm and to accomplish this goal a DNN system would be required (Shan et al., 2022; Varano et al., 2022). However, recent research shows that there is no difference in the audiovisual benefit provided by an avatar with mouth movements produced by FACS or DNNs (Yu et al., 2024); therefore, we expect there would be no loss in audiovisual benefit. Whether or not this DNN system is implemented into AVATAR in the future, we believe the current AVATAR paradigm provides sufficient audiovisual benefit to be used in future studies that incorporate both behavioral and electrophysiological measures to study audiovisual effects in various challenging listening environments.
Conclusion
In conclusion, we find that the group level electrophysiological measures may correlate with the behavioral measures that show an improvement in speech intelligibility when presented with lip movements as an additional feature in speech in noise. In the future, we plan to carry out future studies using this tool with individuals with hearing impairment to further research these measures in an audiovisual environment that simulates daily life for this population.
Footnotes
Acknowledgements
The authors thank Tine Weerens for their help with the data acquisition.
Ethical Approval and Informed Consent
The medical ethics committee of the UZ Leuven/KU Leuven approved this experiment and every participant signed an informed consent form before their participation (S65640).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Financial support was provided by a PhD grant of the Research Foundation Flanders (FWO) from FWO project grant 1SF1324N.
Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability
The data cannot be made available due to privacy rights determined by our ethical approval.