
Abstract
Information regarding sound-source spatial location provides several speech-perception benefits, including auditory spatial cues for perceptual talker separation and localization cues to face the talker to obtain visual speech information. These benefits have typically been examined separately. A real-time processing algorithm for sound-localization degradation (LocDeg) was used to investigate how spatial-hearing benefits interact in a multitalker environment. Normal-hearing adults performed auditory-only and auditory-visual sentence recognition with target speech and maskers presented from loudspeakers at −90°, −36°, 36°, or 90° azimuths. For auditory-visual conditions, one target and three masking talker videos (always spatially separated) were rendered virtually in rectangular windows at these locations on a head-mounted display. Auditory-only conditions presented blank windows at these locations. Auditory target speech (always spatially aligned with the target video) was presented in co-located speech-shaped noise (experiment 1) or with three co-located or spatially separated auditory interfering talkers corresponding to the masker videos (experiment 2). In the co-located conditions, the LocDeg algorithm did not affect auditory-only performance but reduced target orientation accuracy, reducing auditory-visual benefit. In the multitalker environment, two spatial-hearing benefits were observed: perceptually separating competing speech based on auditory spatial differences and orienting to the target talker to obtain visual speech cues. These two benefits were additive, and both were diminished by the LocDeg algorithm. Although visual cues always improved performance when the target was accurately localized, there was no strong evidence that they provided additional assistance in perceptually separating co-located competing speech. These results highlight the importance of sound localization in everyday communication.
Keywords
Introduction
Information regarding the spatial locations of sound sources can benefit speech understanding in complex multisensory environments in at least three ways. First, a listener can take advantage of the acoustic differences between concurrent spatially separated speech waveforms to perceptually separate the talkers to better attend to the target talker (Freyman et al., 2001; Sheffield et al., 2019). Second, accurate sound localization can allow a listener to turn and face the active talker to benefit from the visual cues from the talker's face (van Hoesel, 2015) that provide mainly phonetic information regarding the target speech. Third, in a multitalker environment, correct orientation to the target talker can also provide visual cues to facilitate the perceptual separation of concurrent talkers (Helfer & Freyman, 2005). These advantages have been documented in different environments and populations, but little is known about how they interact in complex environments with multiple talkers. Furthermore, little is known about how these advantages might be compromised when localization cues are degraded by hearing impairment (Best et al., 2011; Buchholz & Best, 2020; Lorenzi et al., 1999) or by assistive (Best et al., 2010; Denk et al., 2019; Van den Bogaert et al., 2011) or hearing-protection devices (Brown et al., 2015; Brungart et al., 2004; Simpson et al., 2005).
Research in auditory-only environments with spatially separated concurrent talkers has shown that listeners benefit from spatial-auditory perceptual-separation cues: spatial differences help listeners determine that sound sources arise from different locations, allowing them to hear the voices as distinct objects and better attend to the target speech (Freyman et al., 2001; Sheffield et al., 2019). Horizontal sound localization uses predominantly interaural time-difference (ITD) and interaural level-difference (ILD) cues that arise naturally because of the locations of the ears on the head. Providing intact ITD and ILD cues improves speech-recognition thresholds in multitalker environments, but only when the target and interfering talkers are spatially separated (Culling et al., 2004).
Listeners may also use spatial audio cues to orient toward the talker of interest, both to signal their interest in the conversation and to obtain visual speech cues. However, horizontal sound localization degrades with bilateral or unilateral hearing loss (Best et al., 2011; Brimijoin et al., 2010, 2012; Firszt et al., 2017; Lorenzi et al., 1999). Brimijoin et al. (2010) found that listeners with hearing impairment oriented their head to face a sound source more slowly and less accurately than listeners with normal-hearing thresholds. Hearing impairment and other factors that impair sound localization are likely to limit access to the visual speech cues that listeners obtain from orienting toward the target talker. For example, bilateral cochlear-implant (CI) users are able to orient toward the target talker to obtain speech-recognition benefit from visual cues when using both CIs but not when using just one (Dorman et al., 2020; van Hoesel, 2015), presumably because two CIs provide access to binaural cues for sound localization that are not available with a unilateral CI (Gifford et al., 2014; Litovsky et al., 2009; Potts & Litovsky, 2014).
In challenging multitalker listening conditions, listeners are required to perceptually separate concurrent voices using any cues available, including the visual and auditory-spatial cues that are the focus here. Visual information obtained from the talker's face could involve two different types of benefit. We define visual speech cues as the information deduced from facial movements, especially the mouth, that facilitate the identification of the content of the speech, especially phonetic information regarding consonants (e.g., /b/ vs. /g/) or vowels (e.g., /a/ vs. /u/). Such a benefit is likely to be available in any type of noisy listening situation. We define visual perceptual-separation cues as those cues that listeners take advantage of to differentiate which parts of the overall auditory signal are attributable to the target or masker, thus allowing the listener to better attend to the target speech and ignore concurrent interfering speech (Driver, 1996; Maddox et al., 2015). Previous investigations of localization-based orientation to the target talker to take advantage of visual speech cues have only examined conditions involving noise maskers (Dorman et al., 2020; van Hoesel, 2015) where visual speech cues likely dominate. In a multitalker environment, listeners might also take advantage of visual perceptual-separation cues. Helfer and Freyman (2005) found that normal-hearing listeners obtained a larger auditory-visual (AV) benefit for an interfering-talker than for a noise-masker condition. One possible interpretation of this result is that with interfering talkers, listeners benefitted from both visual speech cues and visual source-separation cues, whereas with a noise masker, the target speech and noise masker were already perceptually distinguishable, and listeners only benefitted from visual speech cues. In the current study, the relative contributions of visual speech cues, visual perceptual-separation cues, and auditory perceptual-separation cues were examined by comparing AV benefit or the benefits of target-masker spatial separation for conditions involving noise or interfering-talker maskers.
This study employed a real-time wearable processor that systematically degrades sound localization through signal processing—termed the Localization Degradation (LocDeg) algorithm (Sheffield et al., 2019)—to examine how sound localization ability affects both perceptual talker separation and access to visual cues in a simulated multitalker conversation. The LocDeg algorithm is specifically designed to assess the impact of sound localization on performance separately from any advantages that binaural hearing may provide for signal detection in the presence of a noise masker. This is accomplished primarily by swapping alternating channels between the left and right ears to distort the perception of auditory space but leave within-channel binaural benefits intact. Sheffield et al. (2019) found that the LocDeg algorithm negatively affected localization accuracy as it was designed to do. Also as designed, the algorithm had little effect on speech understanding in conditions where perceived spatial differences are thought to be unimportant, including conditions with co-located interfering speech, or a co-located or spatially separated noise masker. However, the LocDeg algorithm reduced speech understanding for conditions involving spatially separated competing talkers, consistent with the idea that listeners rely on perceived spatial differences to perceptually separate target and interfering speech (Freyman et al., 2001). Thus, the LocDeg algorithm allows for a specific assessment of the role of the perception of differences in auditory space in speech-perception tasks, apart from other advantages that rely on binaural-difference cues for enhanced signal detection in noise.
The goals of this study were two-fold: (1) to examine the interaction between the primary spatial-perception benefits for speech understanding in multitalker environments—auditory-spatial perceptual-separation cues, visual speech cues or visual perceptual-separation cues gained by turning to face the target talker and (2) to characterize the degree of localization accuracy required to support these benefits. To accomplish these goals, speech recognition performance in a simulated multitalker environment was measured as a function of auditory localization accuracy both with and without visual cues. Parametric titration of localization accuracy was carried out using the LocDeg algorithm. Experiment 1 examined a simple condition involving a single co-located speech-shaped noise masker, where localization cues were not expected to benefit auditory-only performance (Sheffield et al., 2019) but were expected to provide access to visual cues for speech understanding. Experiment 2 examined a more complex condition involving three acoustically co-located or spatially separated interfering talkers.
General Methods
This study used a mixed-reality paradigm where auditory stimuli were presented from a loudspeaker array and visual stimuli were presented via a head-mounted display. The visual stimuli consisted of four square windows arranged horizontally in virtual space, each potentially displaying a video of the target talker or a video of the same talker speaking a different incorrect sentence. The video windows were spatially synchronized with the loudspeaker array using a head-tracking device to inform the rendering processes. The participant's task was to (1) listen for the cue word spoken by the target talker to determine the physical location of the target speech and accompanying video, (2) turn to orient to the target talker, and (3) report the words heard in the sentence via a graphical user interface. Word-identification performance and localization accuracy were measured as a function of the degree of LocDeg and the various study variables which varied by experiment (auditory-only versus AV, target-to-masker ratio [TMR], masker type).
Stimuli: Speech recognition in noise was tested using a modified AV version of the Oldenburg Sentence Test (OST) (Kollmeier & Wesselkamp, 1997; see Sheffield et al., 2020, for details regarding the auditory stimuli). The OST involves a closed set of sentences with five words in each sentence and ten options for each word, in the form: <Name > <Verb > <Number > <Adjective > , for example, “Peter kept two cheap spoons.” The AV recordings consisted of two male and two female talkers each speaking 500 sentences (different for each talker) for a total of 2,000 from the matrix of 100,000 possible sentences. The usage of each word in the matrix was approximately equal.
AV stimuli were recorded by Sensimetrics Corporation (Malden, MA). Talkers were recorded in a small, roughly 10′×15′ studio (Sound Mirror, Jamaica Plain, MA). Talkers were seated in front of a green screen and they were lit with three incandescent soft box lights. Video was captured at full HD 1920 × 1080 pixel resolution with a Canon 5D Mark III SLR/Video camera. Blue gradation was keyed in post recordings to match earlier laser disc recordings used in research at Walter Reed National Military Medical Center. Video was captured at 29.97fps (30fps) in h.264 format. Audio and video were synchronized using Final Cut (Apple, Cupertino, CA) and exported unedited. Each AV segment was then edited to remove errors using FFmpeg and a custom MATLAB (Mathworks, Natick, MA) script to simplify the task of editing the thousands of short segments. An example of a video can be viewed at https://www.sens.com/products/stevi-speech-test-video-corpus/#structured-sentences. The audio was recorded separately from the video with a clapboard to synchronize the audio to the video post recordings. Audio was recorded on a Pyramix DSD Recorder (Merging Technologies, Puidoux, Switzerland). All recordings were saved as 24-bit 48 KHz pulse-code modulation wav files for post-production editing. Audio recordings were captured from a small diameter condenser microphone at approximately 1.5 feet and at 45° from the side of the talker. Final video and audio were stored in .mov files as well as separate audio-only .wav files.
LocDeg Algorithm: Localization ability was temporarily impaired using a real-time processing algorithm (LocDeg) custom built by Sensimetrics, Inc. (Malden, MA) (Sheffield et al., 2019). The rationale of the algorithm was that localization and a true rendering of auditory space rely on an accurate relation between all interaural cues and the source location, and should therefore be impaired by the algorithm, while binaural detection only relies on different interaural cues for the signal and masker and should therefore be unaffected by the algorithm. When speech is masked by spatially separated noise—for example, if the target speech is in the front and the noise is diffuse—the binaural system is able to take advantage of the differences in interaural correlation between the target (correlated at the two ears) and the masker (uncorrelated at the two ears) to effectively improve the internal TMR within a given frequency band (Durlach, 1963). The LocDeg algorithm was designed to keep these within-channel signal-detection cues intact, which is accomplished primarily by mixing alternating channels between the left and right ears. At the same time, this alternate-channel mixing resulted in a distorted spatial image of the azimuthal sound location. A more detailed description of the LocDeg algorithm and basic sound localization and auditory-only speech recognition performance with the system can be found in Sheffield et al. (2019).
The LocDeg algorithm was implemented using a system with binaural microphones mounted to ER2 insert earphones (Etymotic Research, Elk Grove Village, IL) at the entrance of the participant's ear canal. The incoming sound signals from the two ears were processed and then presented through the earphones. The signals to the left and right ears were passed through identical bandpass filterbanks numbered sequentially. The even channels were left intact in each ear while the odd channels were mixed across the ears with a variable gain parameter (MixGain) that reflected the relative mixing level of the signals from the two ears. For the conditions tested in the current study, this allowed for a graded change from very little mixing (MixGain = −20 dB), to equal mixing (0 dB), to nearly complete swapping (+20 dB). A total of up to five LocDeg conditions were tested in each experiment. For the least degraded condition (MixGain = −20 dB), Sheffield et al. (2019) reported an average overall azimuthal error of 7° for continuous 10-s bursts of noise from a set of 41 loudspeakers spanning 360° in azimuth and −45° to 90° in elevation in a group of normal-hearing listeners, which is comparable to open-ear performance (Romigh et al., 2015). The other four LocDeg conditions produced azimuthal errors of 13° (MixGain = −5 dB), 18° (0 dB), 30° (5 dB), and 42° (20 dB). The five LocDeg conditions tested in the current study were referred to by these azimuthal error values.
The output of the LocDeg system was calibrated to have the same overall level and spectrum as an open ear using a Knowles Electronic Manikin for Acoustic Research (GRAS, Holte, Denmark). The level of the system at the eardrum was not measured in individual participants. The LocDeg processing was completed within the unit worn on the participant's head. The processing condition, however, was chosen by connecting the system to a computer with custom software provided by Sensimetrics and storing the selected settings in the device. The latency of the LocDeg algorithm was 45 ms with no effect of condition on the delay. Although this delay was substantial, participants did not report asynchrony between the audio and visual stimuli and this delay is well within the temporal binding window for audiovisual speech of normal-hearing listeners (e.g., Hillock-Dunn et al., 2016). The insert earphones provided greater than 30 dB of attenuation at all frequencies for direct sound, which is similar to previous research with ER2 earphones (Munro & Agnew, 1999). This attenuation resulted in the processed sound presented by the system being at much greater levels than the direct sound.
Equipment and facilities: Videos were presented on an HMZ-T3W-H head-mounted display (Sony, Minato, Tokyo, Japan) with two-dimensional rendering. This allowed the video presentation to be perceptually co-located with the accompanying auditory target sentence, rather than on a monitor adjacent to the loudspeakers. It also allowed direct control of the participant's visual field. The four video rectangles were presented on a black background, and each was co-located with the loudspeaker target locations and dynamically adapted to the orientation of the participant in real-time based on the head-tracking data. To increase the similarity between the auditory-only and AV localization tasks, blank rectangles with no videos were presented at each target loudspeaker location in the auditory-only condition, thus providing a visual representation of the loudspeaker locations. The head-mounted display presented a visual field of 36° azimuth and the video rectangles were 18° wide. Thus, participants had to face the target location with <18° of error to see the center of the target talker's face. Although the visual field was smaller than that available with open eyes, the smaller visual field was used to limit visual cues for target-talker localization and increase video size for viewing visual speech-recognition cues. This was not expected to have a meaningful impact on the results because AV speech-perception benefits are known to decrease in the visual periphery (Paré et al., 2003). The vertical field of view was 17.3° and the video rectangles were 16° tall, such that some blank space was visible above and below the target videos. No dynamic rendering was applied in response to head movement in the vertical dimension. Instead of presenting only a single video of the target talker's face, which would have enabled the participant to simply scan the visual scene until they found the talker, visual masker videos were presented from the three incorrect target locations on each trial (van Hoesel, 2015). The masker videos were of the same talker as the target but producing different OST sentences.
Testing was conducted in the Spatial Hearing Laboratory in the Audiology and Speech Pathology Center at the Walter Reed National Military Medical Center in Bethesda, MD. This facility consists of a sound-treated double-walled booth (2.7 m×2.6 m×2.0 m) containing 26 loudspeakers mounted in a 300° arc that surrounds the participant at a radius of 1 m. The loudspeakers in the arc are arranged in three rows of elevation. Only four loudspeakers at 0° elevation and −90°, −36°, 36°, or 90° azimuths were used for the current study. The self-powered speakers in the array (MM-4XP, Meyer Sound, Berkeley, CA) were equalized by placing an ER-7C probe microphone (Etymotic Research, Elk Grove, IL) at the center of the array, measuring the frequency response from each speaker location, and generating a 512-point finite impulse response filter to match each speaker response to the frequency responses of the median speaker in the array. Participants were fitted with the LocDeg headset and head-mounted display after entering the room. Thus, they had seen the location of the loudspeakers and the rest of the room before beginning testing but could not see them during testing. Participants were not directed, however, to the four possible locations of target talkers and their corresponding loudspeakers until after the headset was in place. All signal generation and processing were accomplished in MATLAB (version 7.1) on a personal computer workstation.
Procedure: Target-talker localization and speech-recognition performance were evaluated for target auditory OST sentences randomly presented from one of the four possible loudspeaker locations. Each trial was initiated by the participant orienting toward the center of the array (0° azimuth). Participants were cued to the position and identity of the target talker by two auditory-only repetitions of the name (i.e., the first word) in the target sentence (e.g., “Thomas, Thomas”). The idea was this would be analogous to a social situation where the talker is attempting to capture the participant's attention, although in this case the name did not correspond to the participant's actual name. This provided approximately 1.66 s of auditory-cue time for each trial before the target OST sentence and maskers began. Because the name was provided as the localization cue, speech-recognition performance was evaluated for only the last four words of each target sentence.
Participants were instructed to turn and face the target talker as quickly and accurately as possible for each trial, but they were permitted to continue attempting to orient to the target throughout the entire trial. A head-tracking system (InterSense Inertial Motion Tracking System, Billerica, MA) was used to monitor head position throughout each trial. Head tracking was used for two purposes: (1) to assess target-talker localization behavior and (2) to render the virtual visual environment by shifting the positions of the target and interfering talker videos on the head-mounted display. Following the sentence presentation, participants were instructed to orient back to the center where a graphical user interface was displayed to allow for a response. The participant then used a mouse to select the all five words of the target sentence from a grid of OST word options presented on the head-mounted display following each trial. All 10 options for each of the five words were presented simultaneously, in five columns from left to right in a visual grid, to collect participant responses. In cases where the participant found it difficult to respond on their own using a mouse, the response was given verbally, and the experimenter clicked the virtual buttons on a separate monitor.
Experiment 1: Co-Located Noise Masker
Methods
Stimuli: Figure 1 illustrates the task for experiment 1. This experiment used the OST stimuli described above as target stimuli. The masker was speech-shaped noise with a random phase spectrum and an amplitude spectrum equal to the average of all 2000 sentences produced by the four talkers. The target sentences were presented with the co-located speech-shaped noise at −10 and −15 dB TMRs in both auditory-only and AV modalities. The target stimulus was always presented at 60 dB sound pressure level and the masker level adjusted to create the desired TMR. These TMRs were chosen so that auditory-only performance was well above chance but below ceiling levels to allow for the observation of benefit from visual speech cues. Each participant was tested in the AV and auditory-only modalities using five LocDeg conditions described above (7°, 13°, 18°, 30°, and 42°). In the AV conditions, one talker video was presented at each loudspeaker azimuth—one at the target location matching the target auditory sentence, and three at other locations speaking different OST sentences that did not match any audio in the trial. The same target talker was displayed at all four video locations. This was done to reduce the likelihood of the participant turning to the correct video by learning the identity of the target talker, and to match the situation in experiment 2 (see below) where the auditory target speech was masked by sentences produced by the same talker.

Illustration of the task for experiment 1 (co-located speech-shaped noise masker). The four faces represent four physical loudspeaker locations (−90°, −36°, 36°, and 90°) and the corresponding video presentation locations on the head-mounted display. The same face represents the fact that the same talker was used for all four videos. The cartoon images are for illustrative purposes only; the actual stimuli included video of a real talker. The target sentence location is bordered in green while video masker locations are bordered in red. In the auditory-visual conditions, there were always four videos presented (one at each of the four possible target speech locations), each with the same talker speaking a different sentence. In experiment 1, the audio masker was a speech-shaped noise, and therefore uncorrelated with the masker videos. In the audio-only conditions, no visual faces were present, and the possible speaker locations were indicated visually by an empty black rectangle. T = auditory target sentence, which was preceded by a cue in the form of the first word of the target sentence (a person's name) repeated twice in the absence of the masker, which had an onset after the second cue repetition. HMD = head-mounted display; M = speech-shaped noise masker.
Each participant also completed a visual-only condition with no target auditory sentence presented, but with all other experiment procedures identical to the AV conditions including the auditory presentation of the name cue for localization, the masker videos, and the auditory masker. The initial auditory cue was retained to ensure that participants could correctly locate the video for visual speech recognition and the noise masker was retained to compare visual-only speech recognition to AV speech recognition in the same environment. The visual-only condition was tested in only the mildest LocDeg condition (7°).
Each subject completed one trial for each combination of TMR (−10 and −15 dB), modality (AV and auditory-only), LocDeg condition (five conditions), target loudspeaker (four locations), and target talker (four talkers), for a total of 320 trials. Testing was completed in blocks of eight trials with LocDeg condition and modality held fixed throughout the block. The TMR, target loudspeaker, and target talker varied randomly within each block. Two additional blocks of eight trials each were completed for the visual-only condition. The order of the modality and LocDeg simulator blocks varied randomly for each participant. No feedback was given for localization or speech recognition accuracy and participants were provided with 16 trials of training before testing began.
Participants: Participants consisted of 10 adults (seven female and three male) with normal hearing thresholds in both ears (≤20 dB HL at octave frequencies between 125 and 8000 Hz), a mean age of 36.2 and an age range of 22 to 60 years.
Analyses: For most analyses, data were averaged across the four target talkers and four target loudspeaker locations. Although there was only one trial for a given target talker and target loudspeaker for each combination of the other conditions (TMR, modality, and LocDeg condition), there were a total of 16 trials when averaged in this way. AV benefit was defined as the difference between auditory-only and AV performance. Speech-recognition data were analyzed using a repeated-measures binomial logistic regression with LocDeg condition, modality, and TMR as within-subject factors. The visual-only condition was not included in the logistic regression as it was only tested in one LocDeg condition and was not repeated for all the combinations of the other experimental parameters.
The head-tracking data were analyzed as a proxy for sound-localization performance to assess the relationship between the localization and AV speech perception. Localization accuracy was defined as the percentage of the time during the target-sentence presentation that participants were oriented within 18° azimuth of the target loudspeaker location, such that they had access to visual speech information. Localization accuracy was analyzed this way to account both for differences in final head orientation accuracy and for the time it took participants to search for the target loudspeaker. Localization accuracy was analyzed with a repeated-measures binomial logistic regression with the same within-subject factors as for the speech-recognition data. All post hoc tests were completed using Bonferroni corrections, with reported p-values multiplied by the number of comparisons.
Results
Speech recognition
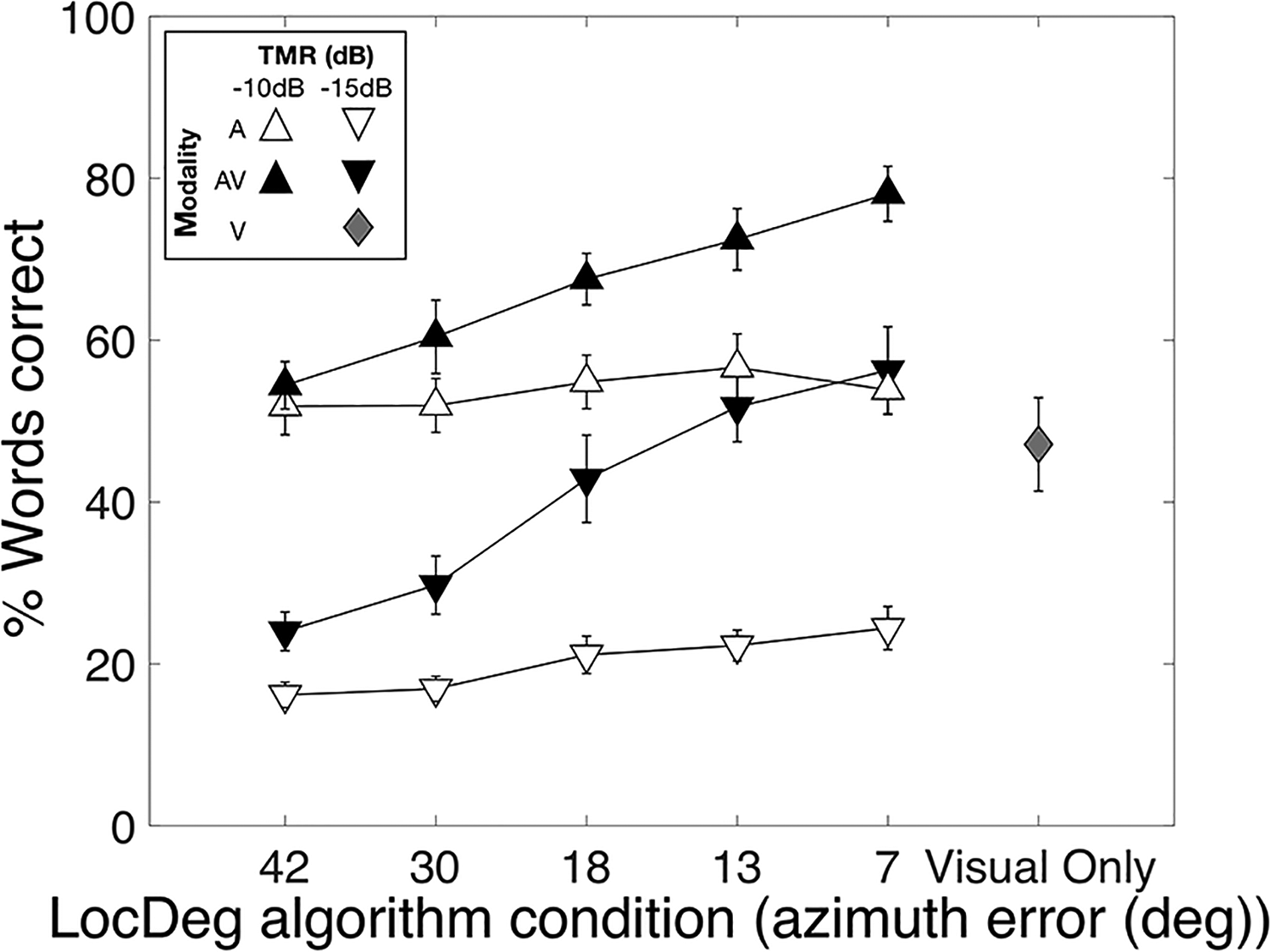
Results of experiment 1 showing word-identification performance for co-located speech in noise as a function of the LocDeg condition. The LocDeg conditions on the x-axis are identified in terms of the azimuthal error in degrees, as reported by Sheffield et al. (2019), for noise-burst localization in a large array of speakers. Symbol colors represent target stimulus modality: A = auditory only (white), AV = auditory-visual (black), V = visual-only (gray). Symbol shapes represent the target-to-masker ratio (TMR) conditions. Error bars represent one standard error of the mean across subjects.
The numbers along the x-axis represent the mean azimuthal localization error for LocDeg conditions. The TMR conditions are represented by triangle direction (up and down) while the modality conditions are represented by color (black and white). There were significant effects of LocDeg condition [χ²(4) = 102.1, p < .0001], TMR [χ²(1) = 754.8, p < .0001], and modality [χ²(1) = 95.0, p < .0001] with better performance in the AV modality in almost all conditions. Importantly, there was also an interaction between LocDeg condition and modality [χ²(4)= 42.1, p < .0001]. Post hoc paired comparisons on this interaction revealed that the mean auditory-only performance did not significantly increase across LocDeg conditions. In contrast, AV performance increased by approximately 30 percentage points from the most severe (42°) to the mildest (7°) LocDeg condition (p < .001).
There was also a significant interaction between modality and TMR [χ²(1) = 44.0, p < .0001]. Mean AV benefit across all LocDeg conditions was larger (p < .0001) at −15 dB (21 percentage points) than at −10 dB (13 percentage points). There was also a significant interaction between LocDeg condition and TMR [χ²(4) = 26.3, p < .0001]. At −10 dB, performance in the mildest LocDeg condition (7°) was only 12 percentage points better than in the most severe (42°) LocDeg condition (p < .0001, Bonferroni corrected). In contrast, at −15 dB TMR performance in the mildest LocDeg condition (7°) was significantly better than performance at the three most severe LocDeg conditions (p-value range: < .0001–.024, Bonferroni corrected), with a 19 percentage-point difference between the mildest (7°) and most severe (42°) cases. Overall, these post hoc analyses indicate that sound-localization accuracy significantly impacted target-talker localization and access to visual cues for AV benefit and that its effects were greater at a poorer TMR. Finally, although visual-only performance for these closed-set stimuli was very good with a mean word recognition near 50%, it was not as good as AV performance at −15 dB TMR in the mildest LocDeg condition (p < .0001). This suggests that participants combined information across modalities when they were able to access visual cues.
Target-talker localization: The speech-perception results described above show that the degree of AV benefit was related to the degree of spatial-cue degradation caused by the LocDeg algorithm. While these data indirectly demonstrate the relationship between these speech-perception benefits and localization ability based on previously published localization data using the LocDeg algorithm (Sheffield et al., 2019), a more direct comparison can be made from the current data set by estimating localization accuracy from head-tracking data.
Figure 3 plots mean head orientation over the course of a trial for each target loudspeaker with data averaged across modalities and participants. The different LocDeg conditions are represented by different symbols. The error bars in the upper panels and the curves in the lower panels represent the overall standard deviation (the root-mean-square of the within-subject standard deviations) of the head orientation at a given point in time. Larger values indicate more variability in subjects’ head orientation for a given condition. On average, the data show that more degradation caused participants to less accurately turn to face the target loudspeaker and with more variability. For the conditions with the least degradation (7°, 13°, and to some extent 18°), participants tended to accurately localize the position of the target loudspeaker, and standard deviations were small. For the two conditions with the most severe degradation, participants tended to orient, on average, closer to the center (0° azimuth), and standard deviations were large.
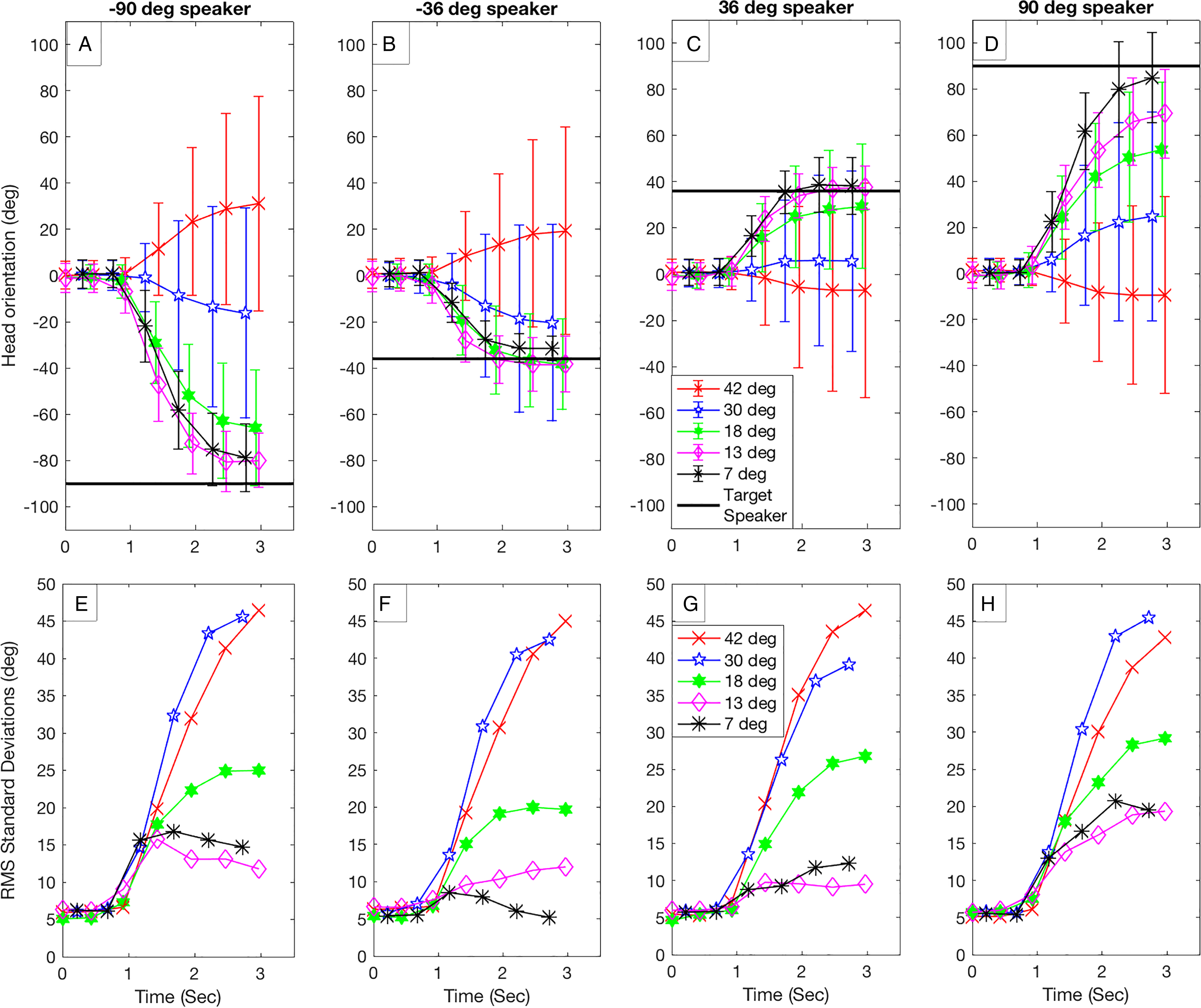
(A)–(D) Mean head orientation as a function of the timepoint during the trial, with each target loudspeaker represented by a different panel. The azimuthal location of each target loudspeaker is noted with a black horizontal line. Each curve (identified by a color and symbol) represents a different LocDeg condition, labeled in terms of the mean absolute error in localizing a short-duration noise in Sheffield et al. (2019). Time zero represents the beginning of the trial just before the onset of the auditory cue (name repeated twice), with the target sentence beginning at approximately 1.75 s. Error bars represent the root-mean-square (RMS) of the within-subject standard deviations, providing a quantification of the degree of variability in the data for a given subject. (E)–(H) The RMS standard deviations (error bars in the top panels) are replotted as curves.
For the most severe LocDeg condition, participants on average turned away from the target loudspeaker. This average trend is consistent with the bias toward the opposite hemisphere that was noted by Sheffield et al. (2019), and which might reflect the fixed interaural phase difference applied to the stimulus to produce the perception of a diffuse sound for sound sources near the midline. There was also some asymmetry in this effect, with a somewhat larger bias for a source location to the left of center. However, this bias and asymmetry were small compared to the very large standard deviation in responses for the two most severely degraded conditions. Thus, these data suggest that the primary effects of the LocDeg algorithm were to reduce the accuracy and increase the variability in localization behavior.
AV benefit and performance should be related to the proportion of time during the sentences that participants had access to the target talker's visual cues. Thus, target-talker localization was analyzed with a variable that included both time and accuracy. “Visual-access time” was defined as the proportion of time during the sentences that a participant was oriented within 18° of the target loudspeaker, such that the participant would have had access to the correct visual speech cues in the AV condition. Figure 4 plots the visual access time as a function of LocDeg condition, with the data averaged across target loudspeakers. The data are jittered on the x-axis to avoid overlap of the symbols. The average visual access time increased from approximately 20% to 90% from the most severe (42°) to mildest (7°) LocDeg condition, with little effect of modality or TMR. A repeated-measures binomial logistic regression confirmed the significant main effect of LocDeg condition [χ²(4) = 94.3, p < .0001], with no significant effects of modality [χ²(1) = 0.55, p = .459] or TMR [χ²(1) = 2.19, p = .139]. Post hoc paired comparisons on the main effect of LocDeg condition revealed significant differences in visual access time between all LocDeg conditions (p < .0001) except for the two mildest conditions (p = .079), which might have been limited by ceiling effects.

Mean percentage of the target sentence duration that participants were facing the correct target video, and therefore had access to correct visual cues, as a function of LocDeg condition (x-axis). Percentages were averaged across target loudspeaker locations. Error bars represent one standard error of the mean across subjects. The data were jittered on the x-axis to avoid overlap of the symbols. TMR = target-to-masker ratio.
The regression analysis also revealed significant two-way interactions between modality and TMR [χ²(1) = 32.3, p < .0001] and between LocDeg condition and TMR [χ²(4) = 11.4, p = .022], and a significant three-way interaction between LocDeg condition, modality, and TMR [χ²(4) = 20.2, p < .0001]. However, paired comparisons of TMR and modality within each LocDeg condition revealed no significant effects, suggesting no clear differences in localization accuracy due to any parameter other than LocDeg condition.
Speech recognition and target-talker localization interaction: It is possible that localization deficits influenced the benefit obtained from visual cues even when the target talker was correctly localized. For example, with poor localization, participants might have felt less certain of their ability to localize a correct talker and placed less emphasis on the visual cues they were seeing. To evaluate this possibility, we examined speech-recognition performance for only those trials where participants faced the target talker for more than 90% of the sentence presentation. This was the case for an average of fewer than 10 trials per participant for the most severe LocDeg condition (42°) and more than 70 trials in the mildest LocDeg condition (7°).
Figure 5 1 plots mean speech-recognition performance as a function of LocDeg condition for only correctly localized trials. LocDeg condition, TMR and modality were included in the binomial regression model as fixed-effects variables. There were significant main effects of modality [χ²(1)= 91.7, p < .0001], reflecting the AV benefit, and TMR [χ²(1)= 162.4, p < .0001], reflecting better performance at the better TMR. The interaction between the modality (white versus black symbols) and TMR was also significant [χ²(1)= 25.9, p < .0001] with larger AV benefit at the poorer TMR. Most importantly, the effects of LocDeg condition were minimal when examining only correctly localized trials. The three-way interaction [χ²(4)= 9.4, p = .051] and the two-way interaction between LocDeg condition and modality [χ²(4)= 8,4, p = .076] just failed to reach significance. These two-way and three-way interactions were further examined using paired comparisons between LocDeg conditions and TMRs with AV benefit representing changing in modality. There was one significant paired comparison of the AV benefit between the second most severe LocDeg condition (30°) and the second mildest LocDeg condition (13°) (p = .012) for the −15 dB TMR. All other paired comparisons of the three-way interaction were not significant (p-value range: .266–1.0). The main effect of LocDeg condition [χ²(4)= 1.6, p = .809] and the interaction between LocDeg condition and TMR [χ²(4)= 4.5, p = .342] were not significant.

Mean speech recognition performance as a function of LocDeg condition (x-axis). Only the correctly localized trials for each participant were included. Results were averaged across all target loudspeaker locations. Symbol colors represent target stimulus modality: A = auditory only (white), AV = auditory-visual (black). Symbol shapes represent the target-to-masker ratio (TMR) conditions. Error bars represent one standard error of the mean across subjects.
Interim Discussion
The main finding of experiment 1 was the interaction between LocDeg condition and modality for word recognition (see Figure 2). Specifically, AV benefit was largest for LocDeg conditions where localization was best. This increase in AV benefit is likely because of the ability to localize the target video to obtain visual speech cues: reducing the degree of degradation resulted in a higher chance of observing the target video for most of the duration of the sentence (Figure 4). This interpretation was reinforced by an analysis of only those trials where the target video was correctly localized (Figure 5), where the AV benefit was similar for all LocDeg conditions.
Experiment 2: Co-Located or Spatially Separated Interfering Talkers
Rationale
Experiment 2 examined a more complex condition involving three interfering talkers that were either acoustically co-located with the target talker or spatially separated from one another and the target talker. This allowed an examination of the interaction between the primary benefits of localization for speech communication: spatial-auditory perceptual-separation cues and access to visual information.
Methods
This experiment used the same mixed-reality paradigm where auditory stimuli were presented from a loudspeaker array and visual stimuli were presented via a head-mounted display. The participant's task was the same and word-identification performance and localization accuracy (in terms of visual access time) were measured as a function of the degree of localization degradation. The main difference was that here, the auditory maskers were interfering talkers, presented either co-located with or spatially separated from the target talker.
Participants: Experiment 2 included 10 adult (four female and six male) participants with a mean age of 24.3 and a range of 22 to 41 years. Three of these participants had also participated in experiment 1. All participants had normal pure-tone air-conduction thresholds ≤20 dB HL at octave frequencies between 125 and 8000 Hz in both ears.
Stimuli: The same OST audio and video materials used in experiment 1 were used for this experiment. Experiment 2, however, used three randomly chosen OST sentences spoken by the same talker as the target sentence for the maskers, with none of the words in the masker sentences matching those in the target sentence. OST sentences by the same talker were used as maskers to minimize the availability of vocal-quality cues (mean fundamental frequency, timbre), thus making it difficult to perceptually separate competing talkers (Brungart, 2001) in the absence of spatial-auditory or visual perceptual-separation cues.
To reduce testing time, only three LocDeg conditions were used (7°, 18°, and 42°) because experiment 1 showed steady linear changes in performance across the five LocDeg conditions. The visual masker videos in experiment 2 matched the three interfering auditory sentences. In the co-located condition, the auditory and visual interferers were not spatially linked; that is, the visual stimuli were spatially separated but the auditory stimuli were not. However, in the spatially separated condition the auditory and visual stimuli for each talker were spatially linked, simulating a real multitalker environment.
Procedure: Figure 6 illustrates the task for experiment 2 for co-located (Figure 6A) and spatially separated (Figure 6B) conditions. The trials and settings were identical to experiment 1 except for the masker differences and the spatial separation of auditory target and maskers for some trials. All LocDeg conditions were tested at a 0-dB TMR (defined as the relative level between the target and any one of the concurrent interfering maskers) in both auditory-only and AV modalities in both spatial conditions. Additionally, only the mildest LocDeg condition (i.e., 7°) was also tested at a −10 dB TMR due to ceiling effects at the 0 dB TMR in the AV modality. The −10 dB TMR was added a priori following pilot testing before any of the participants included in the study were tested, due to observed ceiling effects. The visual-only condition was completed in the 7° LocDeg condition for both co-located and spatially separated conditions. As in experiment 1, the visual-only condition included the auditory maskers and auditory localization cue (name repeated twice), but not the full auditory target sentence.

Illustration of the task for experiment 2 with interfering talkers. The four faces represent four physical loudspeaker locations (−90°, −36°, 36°, and 90°) and the corresponding video presentation locations on the head-mounted display. The same face represents the fact that the same talker was used for all four videos. The target sentence location is bordered in green while video masker locations are bordered in red. In the auditory-visual conditions, there were always four videos presented (one at each of the four possible target speech locations), each with the same talker speaking a different sentence. The audio maskers were three interfering talkers that corresponded to the three video maskers. The masker videos were always spatially separated from the target video. The auditory maskers could be (A) co-located with the target, in which case they did not match the masker video locations or (B) spatially separated from the target, in which case they matched the masker video locations. In the auditory-only conditions, no visual faces were present, and the possible speaker locations were indicated visually by an empty black rectangle. T = auditory target sentence, which was preceded by a cue in the form of the first word of the target sentence (a person's name) repeated twice in the absence of a masker. M1, M2, M3 = maskers, three concurrent sentences spoken by the same talker as the target. HMD = head-mounted display.
Each subject completed one trial for each combination of modality (AV and auditory-only), LocDeg condition (three conditions), spatial condition (co-located or spatially separated), target loudspeaker (four locations), and target talker (four talkers) at a 0-dB TMR. In addition, 32 trials (one trial for each combination of modality, target loudspeaker, and target talker) were presented for the mildest LocDeg condition (7°) at a −10 dB TMR in the spatially separated case to control for ceiling effects. Two additional blocks of 16 trials each were completed for the visual-only modality with spatially separated and co-located auditory maskers. LocDeg condition, modality, and TMR were held fixed throughout each block while the spatial condition, the target loudspeaker, and the target talker varied randomly. Testing for experiment 2 was completed in blocks of 16 trials, for a total of 256 trials. The order of the blocks varied randomly for each participant. No feedback was given for localization or speech recognition accuracy and participants were provided with 32 trials of training before testing began.
Analyses: Data were averaged across the four target talkers and four target loudspeaker locations, for a total of 16 trials for each combination of TMR, modality, and LocDeg condition. There were two primary spatial-perception cues that could be affected by the LocDeg algorithm. First, participants could take advantage of localization cues to turn to face the target talker to benefit from visual speech cues. Second, acoustic differences between spatially separated concurrent talkers could be used to better attend to the target talker. Experiment 2 assessed the interaction between these two cues by testing how the LocDeg algorithm affected the AV and spatial benefits for speech understanding. AV benefit was defined as the difference between auditory-only and AV performance. Auditory spatial release from masking (SRM) was defined as the difference between performance in the co-located and spatially separated conditions. Speech-recognition data were analyzed using repeated-measures binomial logistic regression with LocDeg condition, modality, and spatial configuration as within-subject factors. The visual-only conditions and −10 dB TMR were not included in the logistic regression as they were only tested in one LocDeg condition. Finally, the head-tracking data were analyzed to evaluate visual access time as in experiment 1. All post hoc tests were completed using Bonferroni corrections by multiplying p-values by the number of paired comparisons examined.
Results
Speech recognition: Figure 7 shows the data from experiment 2, plotting mean speech-recognition performance in the presence of interfering talkers as a function of LocDeg condition for the co-located (Figure 7A) and spatially separated conditions (Figure 7B), with data averaged across the four target talkers and four target-loudspeaker locations. The TMR conditions are represented by triangle direction (up and down) while the modality conditions are represented by color (black, white, and gray). Mean visual-only (gray) speech recognition in the co-located condition (29%) was poorer than in experiment 1 [47%; t(9) = 2.3, p = .0496], presumably because of the presence of auditory interfering talkers instead of stationary noise. Additionally, visual-only speech recognition was similar (p = .60) in the co-located (29%) and spatially separated conditions (35%).

Results of experiment 2 showing word-identification performance for target speech in the presence of interfering talkers for which the audio was either (A) co-located or (B) spatially separated from the target, as a function of the LocDeg condition. The LocDeg conditions on the x-axis are identified in terms of the azimuthal error in degrees, as reported by Sheffield et al. (2019), for noise-burst localization in a large array of speakers. Symbol colors represent target stimulus modality: A = auditory only (white), AV = auditory-visual (black), V = visual-only (gray). Symbol shapes represent the target-to-masker ratio (TMR) conditions. Error bars represent one standard error of the mean across subjects.
Figure 7 shows the expected main effects of LocDeg condition [χ²(2) = 423.6, p < .0001] and modality [χ²(1) = 26.8, p < .0001] with better performance in the AV modality in most conditions, as well as a main effect of spatial condition [χ²(1) = 400.0, p < .0001] with generally better performance in the spatially separated condition. More important for the purpose of this study, all two-way and the three-way interactions were also significant (p-value range: < .0001–.001). The significant three-way interaction [χ²(2) = 14.2, p = .001] indicates a complex relationship between LocDeg condition, modality, and spatial condition. Paired comparisons explored these interactions to answer two questions: (1) How did the effect of LocDeg condition on AV benefit differ between spatial conditions? (2) How did the effect of LocDeg condition on SRM differ between auditory-only and AV modalities?
AV benefit was examined using paired comparisons of auditory-only and AV speech recognition for all six combinations of LocDeg condition and spatial condition. A seventh comparison was also included for the one condition tested at an TMR of −10 dB (7° LocDeg, spatially separated) to control for ceiling effects. For both spatial conditions, significant AV benefit was obtained for the two milder LocDeg conditions (18° and 7°; p-value range: < .0001–.002) but not the most severe LocDeg condition (42°; p-value range: .052–.06). The magnitude of the AV benefit for the mildest LocDeg condition (7°) was smaller for spatially separated (10.2 percentage points; Figure 7B) than for co-located maskers (36.3 percentage points; Figure 7A; p = .005). This might be ascribed to a ceiling effect because auditory-only performance was very high in the spatially separated condition. However, a similar trend was observed for the moderate (18°) LocDeg condition (AV benefit = 10.8 percentage points for spatially separated and 22.0 percentage points for co-located maskers; p = .033) and here, auditory-only performance was lower and ceiling effects therefore less likely. It should be noted that the data shown in Figure 7 include both correctly localized trials, where visual cues would have been available, and incorrectly localized trials, where the participant was not looking at the correct face. The magnitude of the AV benefit might reflect a complex interaction between these types of trials. These possibilities will be addressed below (see “Combined Results of Experiments 1 and 2” regarding ceiling effects and “Speech recognition and target-talker localization interaction” regarding the availability of visual cues). In summary, the data show that better sound localization resulted in increased AV benefit for speech recognition in the presence of interfering talkers, and this effect was larger for co-located than spatially separated conditions.
For the auditory-only modality (open symbols), there was significant SRM for all three LocDeg conditions (p-value range: < .0001–.05) that increased significantly from 6 to 62 percentage points between the most severe (42°) and mildest (7°) LocDeg conditions [t(9) = 34.8, p < .0001; compare Figure 7A and 7B]. A similar pattern was found in the AV modality (closed symbols), albeit at a smaller magnitude, with significant SRM in all LocDeg conditions (p-value range: < .0001–.002) increasing significantly from 7 to 34 percentage points between the most severe (42°) and mildest (7°) LocDeg conditions (p = .0005). However, like the AV benefit described above, this difference might be partially ascribed to a ceiling effect, which will be addressed below.
Target-talker localization: Like in experiment 1 (Figure 3), more degradation in the LocDeg condition caused participants to less accurately turn to face the target loudspeaker. Thus, head movement is not shown for experiment 2. However, experiment 2 produced a somewhat different pattern of results when the head-tracking and speech-understanding data were evaluated in terms of the visual access time.
Figure 8 plots target-talker visual access time for experiment 2 as a function of LocDeg condition. As was the case for experiment 1, visual access time increased systematically from approximately 15% to 95% from the most severe (42°) and mildest (7°) LocDeg conditions. A repeated-measures binomial logistic regression with LocDeg condition, spatial condition, and modality revealed significant main effects for both LocDeg condition [χ²(2) = 206.1, p < .0001] and modality [χ²(1) = 7.5, p = .006], with more visual access time in the AV modality and milder LocDeg conditions. Neither the main effect of spatial condition [χ²(1) = .17, p = .677] nor any interactions were significant [p-value range: .181–.627]. Post hoc paired comparisons on the main effect of LocDeg condition revealed significant differences in target-talker localization between all three LocDeg conditions (p < .0001). One possible interpretation of the main effect of modality, which was not observed in experiment 1, is that when interfering talkers were present, subjects might have tried harder to find the target-talker video to aid speech recognition than in the auditory-only condition, although this effect was small.

Mean percentage of the time during the target sentence that participants were looking at the correct target video (i.e., they had access to correct visual cues) as a function of LocDeg condition (x-axis). Percentages were averaged across target loudspeaker locations and only included the 0 dB target-to-masker ratio. Symbol colors represent target stimulus modality: A = auditory only (white), AV = auditory-visual (black). Symbol shapes represent the spatial configurations. Error bars represent one standard error of the mean across subjects.
Speech recognition and target-talker localization interaction: Figure 9A1 plots mean speech-recognition performance as a function of LocDeg condition for only correctly localized trials (i.e., trials where the participant faced the target talker for more than 90% of the sentence presentation). LocDeg condition, spatial condition, and modality were included in the model as fixed-effects variables. When considering only correctly localized trials, performance was mostly unaffected by the LocDeg algorithm in the co-located conditions (circles), like in experiment 1 (Figure 5). In contrast, the LocDeg algorithm had a large effect on performance for spatially separated interfering talkers (squares). There was a significant main effect of modality [χ²(1) = 70.9, p < .0001] reflecting the AV benefit. The interaction between LocDeg condition (x-axis) and modality (white vs. black symbols) was also significant [χ²(2) = 9.6, p = .008] suggesting that the magnitude of the AV benefit was affected somewhat by LocDeg condition. However, differences in AV benefit between LocDeg conditions were less than 10 percentage points for either spatial configuration and not significant (p-value range: .203–.977). Most importantly, the interaction between the LocDeg condition and spatial condition that was observed when all trials were included (Figure 7) remained significant when only the correctly localized conditions were included [χ²(2) = 55.1, p < .0001]. This indicates that the LocDeg algorithm reduced performance in the spatially separated condition for both auditory-only and AV modalities regardless of whether the participant successfully oriented to the target video, but it had no effect on performance in the co-located condition. This replicates the auditory-only pattern of results in Sheffield et al. (2019) and therefore likely reflects the effects of the LocDeg algorithm on auditory spatial separation cues (see Discussion section). Lastly, neither the three-way interaction between spatial condition, modality and LocDeg condition nor the two-way interaction between modality and spatial condition for interfering talkers were significant (p-value range: .067–.838), indicating that the AV benefit was similar in both spatial conditions. In other words, when considering only the correctly localized trials, there was no significant decrease in AV benefit in the spatially separated condition, in contrast to what was observed for the 7° and 18° LocDeg conditions in Figure 7.

Mean speech recognition performance as a function of LocDeg condition, modality, and spatial configuration (A) for only correctly localized trials, where the listener was facing toward the target talker for at least 90% of the trial duration and (B) for only incorrectly localized trials, where the listener was facing toward the target talker for less than 10% of the trial duration. Results for co-located or spatially separated interfering talkers at a 0 dB target-to-masker ratio were averaged across all target loudspeakers. Symbol colors represent target stimulus modality: A = auditory only (white), AV = auditory-visual (black). Symbol shapes represent the spatial configurations. Error bars represent one standard error of the mean across subjects.
To investigate the effect on performance when participants incorrectly localized the target talker, Figure 9B plots mean speech-recognition performance as a function of LocDeg condition for only those trials where a participant faced the target video <10% of the time (note that trials where a participant faced the target video 10–90% of the time were excluded from both Figure 9A and 9B). The data for the 7° LocDeg condition are excluded from Figure 9B because there were very few incorrectly localized trials for this case. Here, there were no significant two-way or three-way interactions involving LocDeg condition, spatial condition, and modality (p-value range: .164–.640), nor was there a significant main effect of LocDeg condition [χ²(1) = 3.2, p = .74]. There was a significant main effect of spatial condition [χ²(1) = 12.1, p = .0005], with better performance in the spatially separated condition, as expected. There was also a significant main effect of modality [χ²(1) = 25.7, p < .0001]: surprisingly, AV performance was worse than for the auditory-only condition. In other words, there was visual interference, whereby looking at the wrong talker reduced performance relative to the auditory-only case. While there was no significant interaction, this effect was most prominent in the 18° spatially separated condition. This might explain why overall AV benefit was diminished in the spatially separated 18° LocDeg condition in Figure 7B: overall AV benefit included a combination of correctly localized trials where AV benefit was large (Figure 9A), and incorrectly localized trials where the incorrect visual signal caused interference (Figure 9B).
Combined Results of Experiments 1 and 2
Certain combinations of conditions from both experiments allowed us to examine more directly the extent to which participants benefited from visual cues for source separation (Figure 10). The possible influence of visual perceptual-separation cues was examined using paired comparisons of specific conditions, modeled after the analyses of Helfer and Freyman (2005).
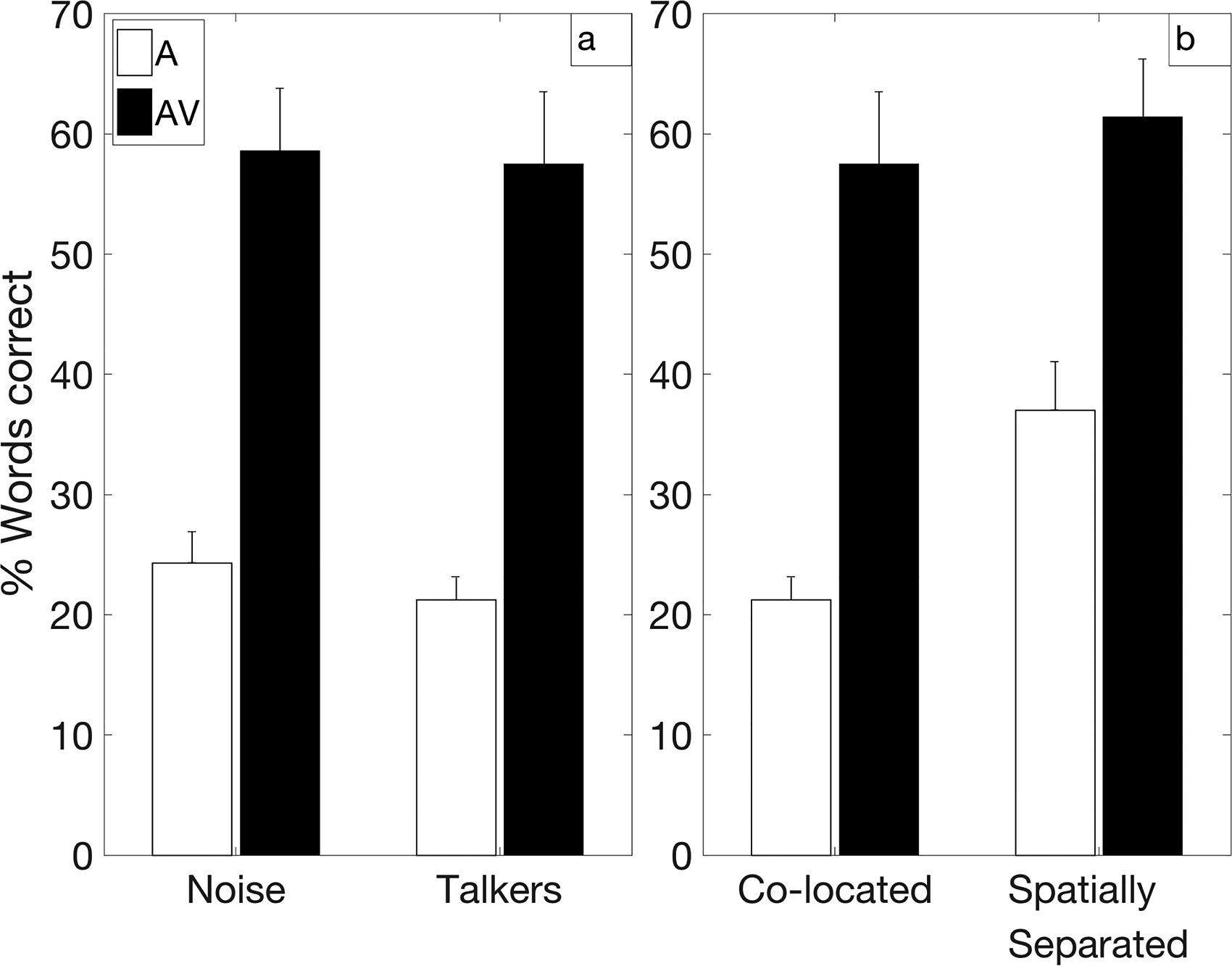
Mean speech recognition results for the auditory-only and AV modalities in selected conditions from Figures 2 and 7 chosen to yield comparable percentage-correct performance in the AV condition. To examine the possible benefits from visual perceptual-separation cues, (A) compares the AV benefit for a noise masker (−15 dB TMR) from experiment 1 (Figure 2) versus interfering talkers (0 dB TMR) from experiment 2 (Figure 7) in a co-located condition, and (B) compares the benefit for co-located interfering talkers (0 dB target-to-masker ratio, TMR) from experiment 2 (Figure 7) versus spatially separated interfering talkers (−10 dB TMR) from experiment 2 (Figure 7). Error bars represent one standard error of the mean across subjects. A = auditory-only, AV = auditory-visual.
Figure 10A compares the AV benefit for co-located stationary noise (−15 dB TMR; Figure 2) to that for co-located interfering talkers (0 dB TMR; Figure 7A) in the mildest LocDeg condition (7°). Under the assumption that the video of the target talker's face provided the same magnitude of benefit from visual speech cues for both masker conditions, this comparison should reveal the additional benefit provided by visual perceptual-separation cues in the interfering-talker case. These two combinations of masker type and TMR were chosen because they yielded approximately the same AV performance. The mean AV benefit was not significantly different for the two conditions [p = .76; noise = 34 percentage points, interfering talkers = 36 percentage points]. Therefore, this comparison did not show evidence of a significant benefit from visual perceptual-separation cues in the interfering-talker case.
Figure 10B compares the AV benefit for co-located interfering talkers (0 dB TMR; Figure 7A) to that for spatially separated interfering talkers (−10 dB TMR; Figure 7B) in the mildest LocDeg condition (7°). Here, the assumption was that any visual perceptual-separation benefit would be reduced in the spatially separated condition where spatial-auditory perception-separation cues would be available. Thus, this comparison should establish a lower bound for the extent to which visual perceptual-separation cues provided a benefit in the co-located condition. Again, these two combinations of spatial condition and TMR were chosen because they yielded approximately the same AV performance. AV benefit was slightly smaller in the spatially separated condition (mean = 24.4 percentage points) than in the co-located condition (mean = 36.3 percentage points), but this difference did not reach statistical significance (p = .058). Thus, there was only a nonsignificant trend suggesting that participants benefitted from visual perceptual-separation cues in the case of co-located interfering talkers.
Interim Discussion
Experiment 2 showed a clear interaction between modality, spatial condition, and LocDeg condition for speech recognition. When there was no spatial separation between the target and interfering speech, the AV benefit increased as localization ability improved (Figure 7A). This was consistent with the speech-in-noise condition in experiment 1 and suggests that the increased AV benefit is simply explained by the increase in access to the target video (Figure 8). In the case of spatially separated target and interfering speech (Figure 7B), the results were more complex. Both auditory-only and AV performance improved as localization ability improved, suggesting that, consistent with Sheffield et al. (2019), there was an inability to use auditory spatial cues to perceptually separate the target and interfering speech in the most severe LocDeg conditions. Furthermore, the magnitude of the AV benefit became smaller as localization ability improved. While some of this trend was likely ascribable to ceiling effects, another possible contributing factor was interference caused by looking at the wrong talker video (Figure 9B) on some trials.
General Discussion
Localization and speech perception are often considered separately, but they are closely related in a multitalker environment. Spatial hearing can provide up to three benefits for speech perception in a multitalker environment. First, visual speech cues such as those found in previous studies can be gained by localizing a target talker (Dorman et al., 2020; van Hoesel, 2015). Second, spatial auditory source-separation cues allow participants to perceptually separate each talker and attend to the target (Sheffield et al., 2019). Third, visual cues can also facilitate the perceptual separation of concurrent talkers (Helfer & Freyman, 2005). Previous studies have demonstrated that all three benefits can occur, but it is unknown how they combine.
The main findings of the study were three-fold. First, good spatial perception allowed participants to localize the target speech to turn and face the target talker and benefit from visual speech cues. Second, good spatial perception also allowed participants to make use of auditory binaural information to perceptually separate concurrent talkers based on spatial differences. Third, we did not find strong evidence that availability of visual information provided benefits for perceptually separating target and masker speech. The following sections will discuss these findings and their relationship to previous literature. Then, clinical implications of the study findings are considered, followed by a discussion of study limitations.
Localization Provides Access to Visual Cues
Both experiments 1 and 2 provided strong evidence that localization ability grants listeners access to visual cues across different experimental conditions (Figures 2 and 7). In the conditions where localization ability was best and participants therefore had the most reliable access to visual cues, AV performance was reliably better than both visual-only and auditory-only performance, meaning that participants were reliably integrating information from both modalities. This replicates in a normal-hearing population previous findings for bilateral CI listeners (Dorman et al., 2020; van Hoesel, 2015). The importance of localization for AV benefit is further demonstrated by the effects of visual access time derived from head-tracking data (Figures 4 and 8). AV benefit increased with increased visual access time as sound localization improved. When examining only correctly localized trials, participants obtained similar AV benefit no matter their spatial hearing abilities (Figures 5 and 9A). As expected, these results show that if listeners can localize a target talker to gain access to visual cues they will obtain AV benefit. The head-movement and localization accuracy data (Figures 3, 4, and 8) demonstrate that more accurate localization allowed participants to find target talkers with less error, consistent with their improved AV benefit. Furthermore, poor localization sometimes resulted in the participant orienting toward the wrong video, which not only failed to provide AV cues, but in some cases also caused interference (i.e., poorer than auditory-only performance, Figure 9B). In summary, these results indicate that better sound localization helps listeners locate target talkers more accurately, giving them larger AV benefit in both multitalker environments and single-talker environments in background noise.
Localization Provides Access to Auditory Source-Separation Cues
Accurate perception of auditory space also gives access to auditory source-separation cues in multitalker environments. In experiment 2, auditory-only spatially separated performance improved as the LocDeg algorithm provided better localization ability (Figure 7B). This replicates previous findings from Sheffield et al. (2019) and Freyman et al. (2001) showing that a perceived spatial difference can help to separate concurrent talkers even in the absence of a binaural detection advantage. Importantly, the current study showed that auditory source-separation cues and the localization-based AV speech-perception advantage were additive: in the spatially separated condition in experiment 2, adding visual cues (comparing AV versus auditory-only) provided an additional benefit beyond the source separation advantage provided by the availability of auditory spatial cues (Figure 7B). Examining only correctly localized trials (Figure 9A) provided further evidence that auditory source-separation and AV cues were additive. Even when only considering the trials that were correctly localized, participants obtained both auditory source-separation and AV benefit in the spatially separated multitalker environment.
Visual Perceptual-Separation Cues
Previous research has suggested that a visual stimulus that is co-modulated with a target acoustic signal can increase signal detection and perceptual separation from competing acoustic signals. In some cases where lip reading information has been shown to produce very large benefits for the speech understanding in competing-talker scenarios (e.g., Wightman et al., 2006), it is unclear how much of this benefit is attributable to target-speech cues provide by the visual signal versus the facilitation of object formation and perceptual separation. Several studies have explicitly controlled for these two effects, pointing to a role for visually facilitated source separation. For example, Maddox et al. (2015) found that a visual stimulus that was co-modulated with task-irrelevant amplitude modulation applied to a speech token improved speech identification performance. Devergie et al. (2011) found that congruent lip movements promoted the perceptual separation of speech streams, making it more difficult for listeners to perceive a string of sequential vowels with alternating fundamental frequencies as a single stream. Fleming et al. (2021) found that visual cues improved performance in a competing-speech task, but only when the video of the target talker's face was spatially aligned with auditory target.
In contrast to these results from the literature, the current study did not find strong evidence that participants used visual cues to facilitate perceptual talker separation. One analysis that examined the possible role of visual perceptual-separation cues was to compare the AV benefit measured between experiments 1 and 2 (Figure 10A). Experiment 1 had a co-located background of stationary speech-shaped noise which would have been easily distinguishable from the target, while experiment 2 had a co-located background of same-talker competing speech, where the target and maskers would have been difficult to perceptually separate based on auditory cues alone. Thus, visual cues in experiment 1 should mainly provide speech information, such as phonemic cues, and should not be needed to facilitate perceptual separation. In experiment 2 with multiple talkers, the visual cues could theoretically be used to facilitate the perceptual separation of talkers in addition to providing speech-perception cues. If it is assumed that the magnitude of the improvement from visual speech cues was the same for a noise masker as it was for interfering talker maskers, this comparison should reveal any benefit from visual perceptual-separation cues. There was no significant difference in the AV benefit measured in the two experiments, therefore suggesting no visual-based perceptual separation of talkers in the co-located condition.
The interpretation of Figure 10A that visual perceptual-separation was absent assumes that the interfering-talker and noise-masker conditions involved equal-magnitude benefits from visual speech cues. It is possible that this assumption was erroneous. For example, there might have been a larger visual speech-cue benefit with a noise masker, where more of the acoustic speech cues were rendered inaudible by noise, than with interfering talkers, where performance might have been more limited by uncertainty about which parts of the audible speech mixture were the target. If this was the case, it is possible that the interfering-talker condition could have included additional perceptual-separation benefit that offset a reduced amount of visual speech-cue benefit, yielding no difference between masker conditions in the total amount of AV benefit. However, Helfer and Freyman (2005) found a larger AV benefit for co-located interfering talkers than for a co-located noise masker, in contrast to the current results, and the interpretation that their data show a visual perceptual-separation benefit relies on the same assumption.
There are at least three important differences between the current study and the Helfer and Freyman (2005) study that might explain these divergent results. First, the interfering speech in the current study had the same five-word sentence structure as the target speech, whereas the interfering talkers in Helfer and Freyman (2005) produced speech unrelated to the target speech. The close time alignment of the target and interfering speech might have reduced any possible perceptual-separation benefit. Brungart et al. (2005) also used target and interfering sentences with the same sentence structure and found that presenting co-located auditory target and masker speech did not improve performance over a visual-only condition, meaning that participants were not able to determine which of the concurrent voices accompanied the video. Second, any visual benefit, including a perceptual-separation benefit, might have been reduced by auditory-on-visual interference. Note that visual-only performance was substantially poorer when auditory interfering voices were present (Figure 7A, gray diamond, 29% correct) than when only auditory masking noise was present (Figure 2, gray diamond, 47% correct). With the common sentence structures of target and interfering speech, similar interference might have occurred even when the auditory target speech was included in the mixture. Third, Helfer and Freyman (2005) tested a range of TMR conditions, and the difference between the AV benefit for co-located noise versus speech maskers was most obvious when the comparison was made in terms of the TMR required for a given fixed performance level, rather than in percentage points at a fixed TMR. The current study was only able to evaluate the AV benefit in terms of percentage points, and for this type of comparison the results were more similar to those of Helfer and Freyman (2005).
A second analysis compared the magnitude of the AV benefit between the co-located and spatially separated interfering-talker conditions. This comparison assumed that any visual perceptual-separation benefit in the co-located condition would be reduced in the spatially separated condition where auditory perceptual-separation cues would have been available. There was a trend toward reduced AV benefit in the spatially separated condition (24.4 percentage points) relative to the co-located condition (36.3 percentage points) that just failed to reach significance (Figure 10B). Because this was not the primary question posed, the study was not powered to observe this difference between differences, and it is possible that a significant effect would have been observed with a larger sample. Furthermore, Helfer and Freyman (2005) found that the magnitude of the AV benefit varied considerably as a function of TMR. For example, the AV benefit in the case of co-located interfering talkers became larger with decreasing (more negative) TMR. Yuan et al. (2021) also found that magnitude and significance of the AV benefit depends on TMR. Extrapolating this effect to the current study, a larger difference in AV benefit might have been observed if both conditions were tested at the same TMR. Thus, we cannot rule out the possibility that visual cues provided a source-separation benefit in the case of co-located interfering talkers. Overall, it should be noted that Bernstein and Grant (2009) cautioned that differences in TMR can confound comparisons of the magnitude of the fluctuating masker benefit (stationary vs. modulated noise). TMR confounds likely play a similar role in comparisons of AV benefit between conditions, complicating the interpretation in terms of visual source-separation effects.
Clinical Implications
Another goal of the study was to examine how accurate sound localization needs to be to obtain the benefits for speech perception in a multitalker environment. The LocDeg algorithm allowed us to titrate sound localization accuracy and examine its effects on visual and auditory-segregation benefits. In the multitalker environment for this study, participants did not gain either of these benefits in the most severe LocDeg condition, which produced 42° of azimuthal error in a traditional sound localization experiment. In the moderate LocDeg condition (18° of azimuthal error), however, participants obtained significant benefits from visual cues as well as auditory segregation cues. These results suggest that these benefits require sound localization accuracy better than 42° of azimuthal error. It is important to note that this calculation is based on experiments using a head-mounted display with a limited visual field, and previous research suggests that listeners may take advantage of visual cues for stimuli located up to 60° away from gaze fixation (Paré et al., 2003). Thus, it is possible that with a broader visual field, visual cues might be obtained even with localization error of 42° or poorer. Additionally, multitalker environments with a different number of talkers that are closer or farther apart could give different results.
The effects of poor sound localization on visual and auditory cues for speech perception in a multitalker environment have important real-world and clinical implications. Individuals with hearing loss have poorer sound localization than those with normal hearing (e.g., Brimijoin et al., 2010; Lorenzi et al., 1999). These deficits range from mild in individuals with symmetrical milder degrees of hearing loss to worse than our greatest degree of simulated binaural hearing impairment (>42° mean azimuthal error) in unilateral CI users (Firszt et al., 2017; Gifford et al., 2014). The current results predict that individuals with mild (<20° mean azimuthal error) sound localization difficulties should be able to orient to talkers in a multitalker conversation and obtain benefit from visual speech cues, but they might not gain the same auditory SRM benefits that those with normal binaural hearing obtain. In contrast, the results suggest that individuals with more severe sound localization difficulties, such as those with CIs and severe hearing losses, will struggle both to locate target talkers quickly for visual speech cues as well as gain auditory SRM benefits (e.g., Baltzell et al., 2020; Buchholz & Best, 2020; Dorman et al., 2020; van Hoesel, 2015). Previous research also shows that hearing aids and hearing protective devices do not improve and often degrade sound localization (Best et al., 2010; Brown et al., 2015; Denk et al., 2019; Simpson et al., 2005; Van den Bogaert et al., 2011). The results of this study stress the importance of assessing and optimizing sound localization abilities particularly in individuals with hearing loss. Accurate sound localization is important for more than just safety or situational awareness and has large additive impacts on speech perception in multitalker environments. Hearing rehabilitation devices such as hearing aids and CIs could provide benefits in these environments with sound localization cues. For example, Bernstein et al. (2022) found that individuals with single-sided deafness can benefit from cochlear implantation to improve their sound localization even in an environment with multiple competing sound sources.
Study Limitations
There were several important limitations to this study. First, the participants had less than three seconds to locate the target talkers and gain access to visual cues because of the length of the target sentences. Thus, this multitalker environment simulated a fast-moving conversation. Many conversations are slower moving with longer monologues, which likely allow any listener to eventually find the target talker. Those individuals will continue, however, to have significant difficulty with auditory perceptual separation of talkers, decreasing their overall speech perception in a multitalker conversation. Two previous studies examined the time it took listeners to identify the congruent video with an auditory stimulus when presented with two or more simultaneous videos (Alsius & Soto-Faraco, 2011; Stacey et al., 2014). In both studies, listeners required two to four seconds to identify the congruent video even with all the videos present in their field of vision. Additionally, Stacey et al. (2014) found that listeners required even more time to find the congruent video with a distorted auditory stimulus. The participants in the current study did not have time to search through every video to find the correct video. Head-tracking data (Figure 3) confirmed this, as participants typically turned to one location after the auditory cue and remained at that location for the duration of the target sentence, despite being instructed that they could continue to search for the target location.
A second limitation was that the interfering talkers were the same person as the target talker, removing visual cues which would generally be available to locate the correct target talker, such as a talker's perceived gender. We used the same talker for target and interfering videos deliberately to make it difficult to perceptually separate the target speech in the absence of spatial-auditory or visual perceptual-separation cues. In a typical multitalker environment, listeners can use memory of voice cues to aid in the search for a target talker. For example, in a group conversation, perception of a woman's voice could cue a listener to seek a congruent visual target (here, a talker perceived as female) rather than an incongruent target (a talker perceived as male). More realistic environments with different talkers, genders, and azimuthal locations might result in smaller effects of sound localization on AV speech recognition. On the other hand, in the case of CI listeners, auditory cues for talker identification would be degraded. Therefore, localization cues might be relatively important for finding the target talker even in a natural conversation.
A third limitation was the restricted visual field, which was smaller than the visual field of someone with typical vision. The visual field was restricted to also limit visual cues for target-talker localization. The average human visual field is roughly 210° azimuth, but with only the center 114° of that being binocular. Furthermore, the foveal region is only 5° azimuth, and pattern recognition including the identification of facial movements and expression decreases outside the foveal region and toward peripheral vision (Calvo et al., 2014; Howard & Rogers, 1995; Paré et al., 2003; Strasburger et al., 2011). It is possible that target-talker localization would have been faster had multiple videos (talkers) been viewed simultaneously in a larger visual field, similar to Alsius and Soto-Faraco (2011) and Stacey et al. (2014), but listeners would likely still have to turn toward to target talker to benefit from visual speech cues in a better range of their visual field.
A last more minor limitation to the study was that individuals wore the head-mounted display and responded with the right hand using a mouse for the task. The head-mounted display allowed direct control of an individual's visual field and allowed the video presentation to be perceptually co-located with the accompanying auditory presentation, rather than on a monitor adjacent to the loudspeakers. The head-mounted display and binaural distortion simulator on the participants’ heads as well as the right-handed mouse response might have affected physical movement patterns.
Conclusions
Sound localization provides several possible benefits for speech communication. It helps listeners orient toward an active talker and obtain benefits from visual speech cues and visual perceptual-separation cues, and it also provides auditory spatial cues to perceptually separate talkers. These benefits are all potentially present in multitalker communication. The results of this study suggest that these different benefits each contribute to performance under certain conditions, and that when present they are mostly additive. This study demonstrates the importance of sound localization in multitalker environments indicating that it should be prioritized in treatment of individuals who struggle in such environments.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the U.S. Department of Defense Medical Research And Development Program (grant number DM130007).