
Abstract
Localization of sound sources in sagittal planes significantly relies on monaural spectral cues. These cues are primarily derived from the direction-specific filtering of the pinnae. The contribution of specific frequency regions to the cue evaluation has not been fully clarified. To this end, we analyzed how different spectral weighting schemes contribute to the explanatory power of a sagittal-plane localization model in response to wideband, flat-spectrum stimuli. Each weighting scheme emphasized the contribution of spectral cues within well-defined frequency bands, enabling us to assess their impact on the predictions of individual patterns of localization responses. By means of Bayesian model selection, we compared five model variants representing various spectral weights. Our results indicate a preference for the weighting schemes emphasizing the contribution of frequencies above 8 kHz, suggesting that, in the auditory system, spectral cue evaluation is upweighted in that frequency region. While various potential explanations are discussed, we conclude that special attention should be put on this high-frequency region in spatial-audio applications aiming at the best localization performance.
Keywords
Introduction
Monaural spectral cues allow humans to localize a broadband sound source within a sagittal plane (Middlebrooks, 1999b; Van Wanrooij & Van Opstal, 2004). These cues originate from the direction-dependent filtering of the torso, the head, and mainly the pinnae (Shaw, 1974), which is usually described by the head-related transfer functions (HRTFs) and emphasized at frequencies above 700 Hz (Algazi et al., 2001; Baumgartner et al., 2014). The auditory system is sensitive to these spectral differences due to its tonotopic organization (Von Békésy & Wever, 1960), but the exact mechanisms describing the extraction of spectral cues from this sound representation are still not fully clarified. Neurophysiological measurements of the dorsal cochlear nucleus in cats showed sensitivity to positive spectral gradients (PSGs) of the sound that could be central to sagittal-plane localization (Reiss & Young, 2005). This finding, combined with computational considerations (Zakarauskas & Cynader, 1993), led to the integration of PSG extraction in a sagittal-plane sound-localization model, which markedly improved the quality of the prediction of human behavioral data (Baumgartner et al., 2014). The PSG profiles emphasize local features such as spectral peaks and notches, while reducing the influence of macroscopic spectral characteristics such as spectral tilt (Macpherson & Sabin, 2013). However, further research is needed to understand the relative contribution of monaural cues on sound source localization.
The relative contribution of monaural cues in various frequency regions may be estimated from the acoustic filtering of the pinna. This pinna filtering provides crucial spatial information because it varies with the polar angle,
The contribution of monaural cues has also been studied from a purely perceptual point of view (Langendijk & Bronkhorst, 2002; Zhang & Hartmann, 2010). In a battery of perceptual tests, Zhang & Hartmann (2010) systematically modified the spectral content of stimuli, for example, by flattening certain frequency regions, in a front-back discrimination task (DT). They found that the contribution of each frequency region is extremely individual even in a simple front-back DT, suggesting that listeners might have developed individual localization strategies, the origin of which remained unclear. Ahrens and Brimijoin (2019) conducted a study in which listeners were asked to indicate whether a target stimulus was below or above a reference stimulus, both of which consisted of a combination of simultaneously presented narrowband noises. For reference, all the narrowband noises were filtered by the HRTF corresponding to a single direction. For the targets, each narrowband noise was filtered with the HRTF corresponding to a random direction. The relative contribution of a spectral region to the perceived direction was then computed from the relation between the subject responses and the direction of the targets in each frequency band. The results suggested an emphasized contribution of the frequency region around 6 kHz. However, the large variation across subjects indicates that the contribution of this frequency region was strongly individual.
Understanding which frequency ranges contribute more to the process of sound localization is essential for spatial-audio applications, such as hearing aids or virtual-reality audio systems. In order to shed light on the spectral contribution of spatial cues, we compared the effect of five spectral weighting schemes on the performance of an auditory model at predicting sound localization of wideband, flat-spectrum targets. The sound localization model, originally introduced by Baumgartner et al. (2014) and modified here, aims at predicting the probability distribution of spatial responses of a listener to a target stimulus. We hypothesized that the studied modification of spectral weighting schemes would affect the model-estimated distributions, even for wideband, flat-spectrum stimuli, which are considered easy to localize compared to band-limited or other nonflat-spectrum stimuli. In turn, the attempt to identify listeners’ spectral weighting functions via model fitting assumes that the distribution of listeners’ responses to these easy-to-localize stimuli is sensitive to the weighting function they employ. Accordingly, we hypothesized that there is a spectral weighting scheme that would best predict the observed response distribution of a listener in the actual localization experiment. The results of our comparison might help to determine which frequency ranges need to be accurately delivered to the listener in spatial-audio applications.
Methods
Five spectral weighting schemes were compared by analyzing their impact on the predictions of sagittal-plane response distributions. The predictions used the sagittal-plane localization model from Baumgartner et al. (2014), modified to accommodate the spectral weighting schemes. Each model variant was reparametrized to guarantee a fair comparison across spectral weighting schemes. The prediction quality of the five model variants was compared to actual localization data from various studies by means of Bayesian statistics. For each model variant, we report the goodness of fit.
Actual Localization Data and Directional Transfer Functions
We used the localization responses from Goupell et al. (2010); Majdak et al. (2010); Majdak et al. (2013a); and Majdak et al. (2013b). These were obtained in experiments with normal-hearing human listeners localizing virtual sound sources, generated by convolving a 500-ms white-noise burst with the listeners’ individual directional transfer functions (DTFs; i.e., HRTFs with the direction-independent characteristics removed for each ear; Middlebrooks, 1999b). These DTFs are available in the Auditory Modeling Toolbox (AMT; Majdak et al., 2022) as accompanying data for the model implementation for Baumgartner et al. (2014). The localization responses were given using a manual-pointing method, that is, the listener pointed with a pointer in the hand toward the perceived sound direction (Haber et al., 1993; Majdak et al., 2010). In order to reduce a potential misalignment between the actual pointer direction and targeted response direction, a visual cursor presented via a head-mounted display in a virtual environment showed the actual pointing direction during the whole response procedure. With that visual information, any misalignment could have been corrected by the listener before confirming the direction with a click. The responses were collected after procedural training, in which a visual target had to be hit with a root-mean-squared error of 2° measured in three consecutive trials. The procedural training aimed at reducing the misalignment between the perceived and the reported direction. For further methodology details, see the corresponding studies.
The pooled data set comprised 23 humans (14 female, 9 male; between 19 and 46 years; all audiometrically normal hearing) and is summarized in Table 1 by means of two localization metrics. The first metric is the quadrant error rate (QE, in %), which measures the rate of nonlocal responses, that is, with an absolute angular disparity between target and response polar angles (PE) larger than 90°. The second metric is the local PE (in degrees), which captures both the accuracy and the precision of the local responses, that is, with an absolute PE smaller than or equal to 90°, by computing the polar root-mean-square error (Middlebrooks, 1999a). These metrics were also used in Baumgartner et al. (2014) for the same experimental data to parameterize and validate the model and are available in the AMT (Majdak et al., 2022).
Localization Metrics of the Actual Localization Responses Used in Our Study.

ID: Listeners’ identifier; N: Number of trials; QE: Quadrant error rate (in %); PE: Local polar error (in degrees). Median plane comprises data from lateral range: −10° <
Sagittal-Plane Localization Model
We based our work on a sagittal-plane sound-localization model (Baumgartner et al., 2014), which infers the probability distribution of the listener's polar angle responses by comparing the spectral cues derived from the target sound to internally stored cue templates. In that model, the cues are derived from the listener's DTFs. To extract the monaural cues of the target and the template, first, the incoming sound is processed by a peripheral auditory model that computes the spectral magnitude profile 
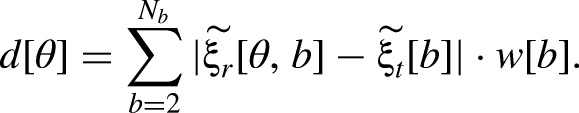
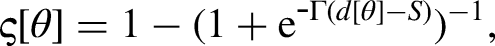
As in Baumgartner et al. (2014),
To illustrate the effect of the model parameters

Effect of the parameters
Model Variants: Weighting Schemes
We defined five model variants that differ by their spectral weighting scheme. Three weighting schemes were previously used or proposed by others and two schemes are proposed here. The weighting schemes are shown in Figure 2.

Spectral weighting schemes. NR: notch region; DT: discrimination task; LP: low-passed; SV: spatial variance calculated at group level for sagittal planes at various lateral angles
The first scheme previously proposed was taken from the original sagittal-plane localization model (Baumgartner et al., 2014), which assumes a flat spectral weighting. We refer to this scheme as the “Flat” scheme.
The second scheme was proposed by Zonooz et al. (2019). It emphasizes the frequency region where the main spectral notch changes with elevation and has a high weighting around 8 kHz. Thus, we refer to this scheme as the “NR” scheme.
The third scheme was derived from an elevation DT (Ahrens & Brimijoin, 2019), and it emphasizes frequencies around 6 kHz. Thus, we refer to this scheme as the “DT” scheme.
The fourth scheme was based on the potential effect of acoustic spatial variance (SV) on localization. We refer to this scheme as the “SV” scheme. It assumes that the frequency bands with larger SV in magnitude across polar angles provide more spatial information than those with a lower variance. To this end, we define the SV 

The schemes Flat, NR, DT, and LP were defined at the group level. For the scheme SV, subject-level information was available. We calculated the SV weights both at the subject and the group level in order to test whether the subject-level scheme helps to explain individual differences in localization behavior. While the subject-level scheme assumes that the contribution of each frequency band to sound-localization performance depends on the idiosyncratic localization cues of the listener, the group-level weights are the same for all subjects and were computed by averaging over the subject-level weights:
To decide whether the group- or subject-level weights should be used in the main analysis, a preselection process was performed in which we compared the predictions on these two types of weights. This comparison was done for median-plane localization data only.
Parameter Estimation
Three model parameters were fitted: the degree of selectivity
In Baumgartner et al. (2014), the parameter fitting was conducted by minimizing a cost function that combines the two-error metrics QE and PE. Yet those two metrics aggregate the listener's response behavior in a coarse manner. To make use of each listener's entire response pattern and fit all three parameters at the subject level, we here applied a fitting strategy based on likelihood maximization. The likelihood function was computed by using response probabilities provided by the model and the listener's directional responses recorded during the localization experiments.
The likelihood function 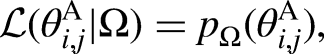

The likelihood function optimization was performed using the Bayesian adaptive direct search algorithm (BADS; Acerbi & Ma, 2017). BADS alternates between a series of fast local optimization steps and a systematic slower exploration of a mesh grid defined on the parameter space. The model parameter ranges were defined as: 0.1 <
To check for differences in the optimized parameter values across conditions, a one-way analysis of variance test was conducted for each parameter (significance level:
Model Variant Selection
Bayesian model selection was used to identify the model variant best predicting individual responses. Since the number of trials per listener differs across subjects (see Table 1), we used the Bayesian information criterion (BIC) as statistical metric. The BIC corrects the optimized likelihood depending on the number of samples and the number of fitted parameters, and, for each model variant and subject, the BIC resulted as:
In order to select which model variant best described measured data at the group level, we relied on a Bayesian selection method (Rigoux et al., 2014; Stephan et al., 2009). In contrast to the assumption of a single model best describing all subjects, this approach treats model variants as random effects that can vary across subjects by accounting for individual differences, offering a more flexible representation of the listeners’ pool. This method computes the protected exceedance probability (PXP) at the group level, that is, the corrected probability of preferring a model variant over the alternatives. The correction can be achieved with the computation of the Bayesian Omnibus Risk (BOR) quantifying the posterior probability that model frequencies are all equal. Thus, the per-listener PXP for each model variant was obtained by computing the posterior probability distribution p of the variants based on model evidence which informed which model best describes the individual response patterns:
The model selection was performed separately for the median plane only, that is,
It was not clear whether the SV scheme should be defined at a group- or at a subject level. To address this question, a preselection was conducted to determine whether the SV scheme should be defined with the subject- or the group-level weights of the following analyses.
Goodness of Fit
An analysis of the goodness of fit aimed at assessing the absolute performance of each model variant and at complementing the model variant selection by means of an intuitive metric of the benefit obtained by each of the model variants. For that, the coefficient of determination R2 was computed from log-likelihoods as in Nagelkerke (1991):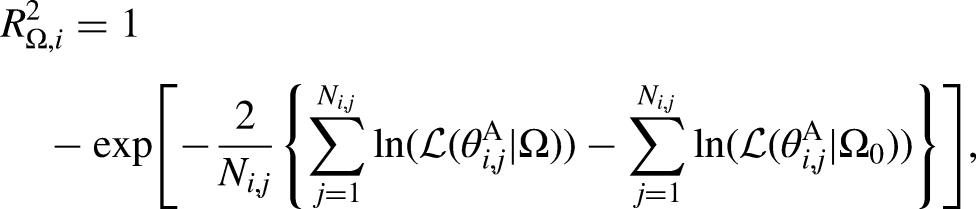

Results
Parameter Fits
The statistics of the parameters across subjects is shown in Figure 3. Note that only the subjects for which all parameters could be optimized (i.e., for all the weighting schemes) are included. For the Flat scheme, the optimization failed twice:

Statistics of the optimized model parameters for each of the model variants across subjects. The subjects with parameter fit not converging within predefined bounds (y-axis limits) were excluded. For SV, group-level (GL) and subject-level (SL) schemes were considered. The S parameter is dimensionless. The “x” symbols represent individual data.
Only the
Effect of the Spectral Weighting Schemes and Parameters on the PMVs
The effect of the spectral weighting schemes on the PMVs for the example listener NH12 is shown in Figure 4. Panel (a) shows the distance metric for each model variant and the target located at the frontal direction (i.e.,

Examples of the effect of the spectral weighting schemes on the probability mass vectors (PMVs). Panel (a) shows the model's internal distance values for a target located at
Preselection of the SV Scheme: Group vs. Subject Level
The preselection analysis resulted in a PXP = 0.66 in favor of the group-level SV, that is, the probability of group-level SV being better at describing the data than the subject-level SV was 0.66. However, the probability of selecting the wrong model, BOR, was 0.64, which was considered too high to conclude that one model variant is better than the other one. Figure 5 shows the results of this inconclusive comparison: the responses of some listeners were better explained by individual weights and of others by group-level weights.

Protected exceedance probabilities (PXPs) of a model variant being best at describing the actual responses in the localization task. Results of the pre-selection of two model variants with the SV scheme are shown: that one with weights calculated at the group level (GL) and that one at the subject level (SL).
Despite this inconsistency, in order to enable a fairer comparison with the weighting schemes available at the group level only, the group-level SV scheme was selected for further analyses. This also enabled us to reinclude all the listeners for which the parameters have been optimized within the plausible boundaries for the group-level SV scheme.
Model Selection
The PXPs for the model variants applied on the median-plane data only, which is the region for which the parameter values were optimized, are shown in Figure 6(a). The SV scheme was the most often preferred scheme (12 out of 17 subjects) as supported by the high group-level PXP of 0.96 and low BOR of 0.01. For two subjects, NR was the preferred scheme; for three subjects, DT was the preferred scheme.

Protected exceedance probabilities (PXPs) of a model variant being best at describing the actual responses in the localization task. Results of the comparison of five model variants: Flat, NR: notch region, DT: discrimination task, SV: spatial variance, and LP: low-passed. Panel (a) shows the results of analyzing the median plane; panel (b) shows the results of analyzing the lateral sagittal planes (
The PXPs for the various model variants in the lateral sagittal planes, that is,
For a joint analysis across all lateral angles, Figure 6(c) shows the PXPs obtained from predictions done for targets located on the median and lateral sagittal planes. This combined model selection showed a clear preference for the NR scheme for 12 out of 17 subjects, with a group-level PXP of 0.96 and a low BOR (smaller than 0.01). For four subjects, the SV was the preferred scheme. For one subject, the DT was the preferred scheme.
Goodness of Fit
The
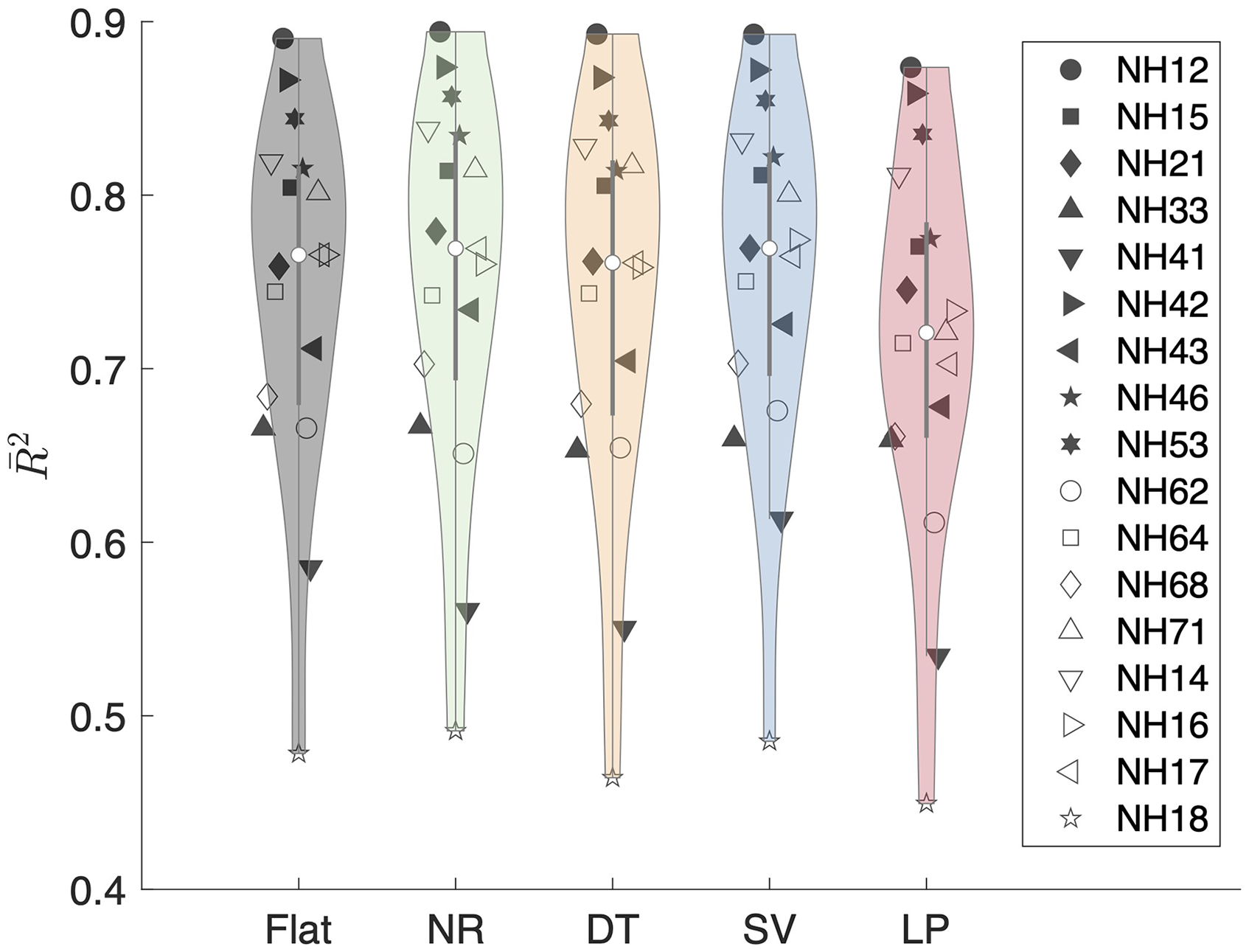
Nagelkerke's corrected
However,
Interestingly, there was no clear pattern of interaction between
Actual vs. Predicted Localization Patterns
Figure 8 shows the effect of the weighting schemes on the model PMVs in the median plane for the listeners NH12 (highest

Examples of predicted probability mass vectors (PMVs; encoded by brightness) obtained from the five model variants (in rows) for the responses of three listeners (in columns: NH21, NH41, and NH18). Actual responses are shown as red open circles.
For NH16, the different spectral weighting schemes produced largely similar PMVs, with precision remaining relatively constant along with the entire median plane. However, particularly for upper rear target angles, the PMVs obtained with the SV scheme seem to best (though still only partially) capture the consistent bias toward upper frontal responses.
For NH18, the response pattern shows a high front-back confusion rate in the ranges −30° <
Discussion
A model-based comparison of spectral weighting schemes showed a consistent yet small benefit in emphasizing the contribution of spectral cues at higher frequencies for sagittal-plane sound localization of wideband, flat-spectrum targets. The best predictions were obtained when the contribution of the spectral cues was emphasized at higher frequencies. Emphasizing the contribution of the main NR (around 8 kHz) provides the best predictions, with those emphasizing the largest SV (around 11 kHz) being the second-best choice.
Weighting Schemes
Our results show that weighting schemes emphasizing the contribution of spectral cues at higher frequencies outperform the flat spectral weighting used in Baumgartner et al. (2014). These results suggest that listeners have an increased sensitivity to spectral localization cues at higher frequencies, being in accordance with results from Zonooz et al. (2019) and Van Opstal et al. (2017). Thus, special attention should be put on accurately reproducing the high-frequency region of spectral-shape cues that listeners seem to upweight in their spatial perceptual evaluation. It is worth mentioning that only young adults with normal-hearing participated in this study, and our results might not generalize for other population groups such as older listeners or listeners suffering from hearing loss in high frequencies.
The SV scheme yielded best predictions for 5 out of 17 subjects only. For the majority, namely 12 out of 17 subjects, best predictions were achieved by the NR scheme, that is, by emphasizing the contribution of the main notch. The corresponding frequency range covers the region of a monotonic increase in the main notch center frequency with the elevation angle. It thus appears to be particularly useful for estimating source elevation (Van Opstal et al., 2017; Zonooz et al., 2019). In the particular case of the median plane (region where the model parameters were optimized), the most preferred weighting was the SV scheme. That SV scheme has largest weights around 11 kHz, which falls under a frequency region that was found to provide useful information for elevation perception in Van Opstal et al. (2017).
The increase in sensitivity of specific spectral regions can be interpreted as optimization of perceptual inference in response to specific acoustic conditions (Keating et al., 2013). Such optimization mechanisms have been shown for the binaural weighting of spectral cues, where the contribution of each ear depends on the interaural cues (Li et al., 2020; Macpherson & Sabin, 2007; Morimoto, 2001). Similarly, a reweighting of localization cues seems to be required to maintain a stable perception of the auditory space (Kumpik et al., 2010). When listeners are exposed to abnormal conditions that persist over time, such as unilateral earplugging (Kumpik et al., 2010) or deliberate altered localization cues (Klingel & Laback, 2022), their localization performance improves by adapting to using the most reliably available cues. Therefore, such adaptation mechanism may also exist for the integration of spectral cues by relying on the most informative frequency regions, for example, the main NR (Zonooz et al., 2019) or based on the SV. However, if the optimization of perceptual inference was responsible for the spectral weights, one could expect that the subject-level SV scheme should have outperformed the group-level SV scheme. Unfortunately, this is not clear from our results. It is possible that the individual schemes are susceptible to containing outliers (i.e., atypical values for specific listeners found within specific frequency bands), and pooling across subjects helped to average those out.
The analysis of the goodness of fit showed similar performance across model variants, indicating that the benefit of selecting among spectral weighting schemes is rather subtle. The small differences in
Interindividual Differences
Our results show interindividual differences both in the goodness of fit and the model selection results. While all tested model variants seem to capture reasonably well the response patterns for some listeners, they showed a poor fit for others. These differences could be related to the listeners' localization abilities and/or their strategies to perform the task. As shown in Majdak et al. (2014), nonacoustic factors, that is, factors that are related to perceptual abilities and not to the HRTF itself, seem to play an important role. Certain errors are not properly captured by the model. This concerns particular biases in the response patterns (e.g., see Figure 8, in which the response pattern for NH18 presents a bias toward the horizontal plane that is not captured by the PMVs). Further steps could account for biases in the model, for example, as in Barumerli et al. (2023), but our conclusions regarding weighting schemes seem not to be compromised by this inability to model such responses.
Our model selection results show an improvement in the predictions when the high-frequency region is emphasized, but there are inter-individual differences in which model best describes a listener's response pattern. The origin of these differences is unclear. They may be related to acoustic factors, that is, features that have an impact on the HRTFs, such as pinnae size (Best et al., 2005; Zhang & Hartmann, 2010). However, these could also have a non-acoustic origin, for example, some listeners may focus more on the NR, while others may better exploit the available SV.
The result of the subject- vs. group-level SV was inconclusive. We hypothesized that listeners may learn to exploit frequency bands with higher spectral variance in their HRTF. While adaptation to HRTFs is a long-life process (Mendonça, 2014), it remains unclear whether listeners learn to take advantage of the specific frequency bands at which their HRTFs present larger spectral variance for localization tasks.
Limitations and Future Directions
We were not able to fit parameters for the data in 12 (out of 138) cases, that is, combinations of subjects and model variants. Two of those cases were related to a missing convergence for the parameter S, six are due to
In this study, the model parameters were considered constant across all sagittal planes. This might be a simplification because the model parameters may vary along with some dimensions. For example, it might be that the sensorimotor scatter changes with the lateral angle or even differ between left and right. In future modeling approaches, it might be interesting to investigate such dependencies, their effect on the predicted localization performance, and their contribution to the spectral weighting schemes.
We focused on wideband flat-spectrum stimuli, which is a specific case for which localization performance is usually accurate. Under such conditions, listeners know the frequency content of the stimulus a priori, which may influence the cues they exploit in the task. In everyday listening situations, spectral-weighting schemes may change depending on the task and the spectral content of the target. The latter may be a crucial aspect because the frequency bands with a low signal-to-noise ratio may be ignored by the auditory system in the process of sound-source localization. Previous studies varied systematically the frequency content of the stimuli to find which frequency regions are necessary for accurate localization or how the performance drops when the bandwidth is limited (Hebrank & Wright, 1974; Langendijk & Bronkhorst, 2002; Zhang & Hartmann, 2010). While such studies are of great value to understand which frequency regions need to be delivered to the listener, conclusions about the contribution of each specific frequency region within a broadband stimulus remain quite speculative. This and our methodology could be combined in the future to understand how the contribution of each specific frequency region depends on the frequency content of the stimulus.
Further studies should assess the generalizability of our findings to stimuli with limited bandwidth and spectral variations, for example, by simultaneously presenting two (or more) competing sounds with limited non-overlapping bandwidths and analyzing which frequency regions—emphasized by each spectral weighting scheme—dominate the localization responses. This would complement our data by extending the scope of the study from Ahrens & Brimijoin (2019). Moreover, the spectral content of the stimuli could be systematically varied over trials to understand to which extent the contribution of each frequency range depends on prior knowledge.
Taken together, our results suggest that an increase in the perceptual weight of frequency regions with systematic changes in spectral cues is relevant for accurate modeling of sagittal-plane sound localization. Thus, further development in HRTF individualization procedures need to be particularly accurate in this frequency region.
Supplemental Material
sj-docx-1-tia-10.1177_23312165251317027 - Supplemental material for Spectral Weighting of Monaural Cues for Auditory Localization in Sagittal Planes
Supplemental material, sj-docx-1-tia-10.1177_23312165251317027 for Spectral Weighting of Monaural Cues for Auditory Localization in Sagittal Planes by Pedro Lladó, Piotr Majdak, Roberto Barumerli and Robert Baumgartner in Trends in Hearing
Footnotes
Acknowledgments
The authors thank David Meijer for his assistance with the data analysis. This study received funding from the European Union's Horizon 2020 research and innovation funding programme (grant no. 101017743, project “SONICOM”–Transforming auditory-based social interaction and communication in AR/VR), from the Austrian Science Fund (FWF; grant no. ZK66, project Dynamates) and from the UK Research and Innovation fund (UKRI; grant no. EP/X032981/1, project Challenges in Immersive Audio Technology).
Data Availability
The localization data are available in the AMT version 1.5 as data_goupell2010, data_majdak2010, and data_majdak2013. The original model is also available in that AMT version as baumgartner2014. The model's extensions by means of customizable spectral weights will be available in the upcoming AMT version. The code to reproduce our results will be included as exp_llado2025 in that version of the AMT as well.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the UK Research and Innovation, Austrian Science Fund, European Union’s Horizon 2020, (grant number EP/X032981/1, 10.55776/ZK66, 101017743).
Supplemental Material
Supplemental Material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.