
Abstract
Auditory training can lead to notable enhancements in specific tasks, but whether these improvements generalize to untrained tasks like speech-in-noise (SIN) recognition remains uncertain. This study examined how training conditions affect generalization. Fifty-five young adults were divided into "Trained-in-Quiet" (n = 15), "Trained-in-Noise" (n = 20), and "Control" (n = 20) groups. Participants completed two sessions. The first session involved an assessment of SIN recognition and voice discrimination (VD) with word or sentence stimuli, employing combined fundamental frequency (F0) + formant frequencies voice cues. Subsequently, only the trained groups proceeded to an interleaved training phase, encompassing six VD blocks with sentence stimuli, utilizing either F0-only or formant-only cues. The second session replicated the interleaved training for the trained groups, followed by a second assessment conducted by all three groups, identical to the first session. Results showed significant improvements in the trained task regardless of training conditions. However, VD training with a single cue did not enhance VD with both cues beyond control group improvements, suggesting limited generalization. Notably, the Trained-in-Noise group exhibited the most significant SIN recognition improvements posttraining, implying generalization across tasks that share similar acoustic conditions. Overall, findings suggest training conditions impact generalization by influencing processing levels associated with the trained task. Training in noisy conditions may prompt higher auditory and/or cognitive processing than training in quiet, potentially extending skills to tasks involving challenging listening conditions, such as SIN recognition. These insights hold significant theoretical and clinical implications, potentially advancing the development of effective auditory training protocols.
Introduction
Perceptual training can improve speech recognition in noisy environments. It involves enduring changes within the perceptual system that enhance the response to stimuli and require adjustments in internal representations based on experience (Goldstone, 1998; Herszage & Censor, 2018; Irvine, 2018). However, while studies involving auditory or cognitive training typically show significant improvements in trained tasks, evidence for generalization of the learning gains to untrained tasks, such as speech-in-noise (SIN) recognition are mixed (Henshaw & Ferguson, 2013; Jacoby & Ahissar, 2015; Lawrence et al., 2018; Simons et al., 2016). Assessing the scope of generalization could provide insight into the neural processes undergoing reorganization following training (Ahissar et al., 2009; Censor, 2013; Karni, 1996; Karni & Sagi, 1993) and bear clinical significance for developing effective training protocols (Henshaw et al., 2022). The current study sought to investigate the level of generalization achieved through two training protocols involving an auditory voice discrimination task, emphasizing critical acoustic cues for SIN recognition (Bronkhorst, 2015; Darwin et al., 2003; Vestergaard et al., 2009). One protocol operated in quiet settings, whereas the other mirrored the first but with added background noise, the latter potentially encompassing higher auditory or cognitive processing.
There is limited understanding regarding the circumstances facilitating the generalization of perceptual learning (Irvine, 2018). Various factors have been proposed to impact generalization, including the specific level of processing. This level refers to the depth or complexity of cognitive operations involved in transforming and manipulating incoming information targeted during training (e.g., lower-level auditory processing, where basic sensory information is encoded and analyzed, or higher-level cognitive processing, involving complex reasoning, decision-making, and memory retrieval, Henshaw et al., 2022; Lawrence et al., 2018; Van Wilderode et al., 2023). Other suggested factors include the extent of overlap in brain representations between the trained and untrained tasks (Amitay et al., 2014; Hesseg et al., 2016), the degree of variability within the training materials (Amitay et al., 2005; Banai & Amitay, 2012; Van Wilderode et al., 2023), the number of training sessions (Jeter et al., 2010; Korman et al., 2003; Zaltz, Goldsworthy et al., 2020), and the number of trials conducted within each session (Censor & Sagi, 2009; Molloy et al., 2012).
The accepted notion suggests that while there is no straightforward rule to predict the generalization pattern for a specific task (Wright & Zhang, 2009), generalization tends to occur when the neural changes induced by training extend beyond neurons activated solely by the training stimuli (Irvine, 2018). Accordingly, when generalization occurs, the presumption is that learning takes place in high-level neural processing, where neurons respond independently to various stimulus features. This leads to representations that respond similarly to stimuli differing in these features, allowing learning gains to transfer to untrained stimuli or tasks (Dudai et al., 2015; Pinsard et al., 2019). Conversely, if the learning gains remain specific to the trained conditions or tasks, it implies that neural changes induced by training occurred in lower-level processing and representation. This level is characterized by selectivity for fundamental input features (Ahissar & Hochstein, 1997, 2004; Ahissar et al., 2009).
Voice discrimination (VD) offers a unique task to investigate the extent of generalization following perceptual training, given its significance in enhancing speech perception in noisy environments (Bronkhorst, 2015). Among the voice cues for VD, the fundamental frequency (F0), influenced by vocal cord length, mass, and vibration rate, and formant frequencies shaped by vocal tract length, emerge as significant contributors (Başkent & Gaudrain, 2016; Darwin et al., 2003; Mackersie et al., 2011; Schvartz-Leyzac & Chatterjee, 2015; Skuk & Schweinberger, 2013; Vestergaard et al., 2009, 2011). Both cues convey substantial information about the speaker, including characteristics such as age, gender, and individual traits (Başkent & Gaudrain, 2016; Shultz, 2015; Skuk & Schweinberger, 2013; Smith et al., 2007; Smith & Patterson, 2005). Moreover, studies involving individuals with normal hearing demonstrate their strong reliance on F0 and formant frequencies for speaker discrimination (Koelewijn et al., 2021, 2023; Zaltz, Goldsworthy et al., 2020; Zaltz & Kishon-Rabin, 2022) and talker segregation (Başkent & Gaudrain, 2016; Darwin et al., 2003). Conversely, individuals facing difficulties in perceiving differences in F0 and formant frequencies, such as those with hearing impairments using cochlear implants, display reduced VD (El Boghdady et al., 2019; Gaudrain & Başkent, 2018; Zaltz et al., 2018). These limitations may potentially contribute to their struggles in listening amid noisy environments.
Research investigating the impact of auditory training on voice perception commonly utilized two approaches. Explicit approaches involve the intentional acquisition of voice information through tasks like voice identification, where listeners are asked to identify the speaker's identity based on specific voice characteristics. In contrast, implicit approaches entail an unintentional acquisition of voice information through voice familiarity training, where listeners are exposed to specific voices while focusing on linguistic content rather than voice characteristics. Both of these approaches provide evidence supporting the advantages of such training for SIN recognition (Kreitewolf et al., 2017; Nygaard et al., 1994; Yonan & Sommers, 2000). Notably, even a brief 10-min voice training session has been shown to enhance speech intelligibility (Holmes et al., 2021). However, there are some indications that the results of such training remain highly specific to the tasks that were trained (Biçer et al., 2023; Yonan & Sommers, 2000). For example, a two-session voice identification or voice familiarization training with sentence stimuli proved beneficial for identifying words within sentences but not for recognizing isolated words (Yonan & Sommers, 2000). The authors accounted for this specificity by proposing that sentence-based training directed attention toward prosodic and rhythmic features absent in isolated words. Specificity in learning gains after voice familiarization training in quiet was also reported recently by Biçer et al. (2023). In their study, the inclusion of a training protocol involving approximately 30 min of listening to an audiobook segment did not yield a significant impact on VD when the reference voice matched the trained (audiobook) voice. The authors posited that this learning specificity could be attributed to the divergence in linguistic materials between training, which involved meaningful sentences, and testing, which comprised isolated, meaningless consonant–vowel (CV) triplets. Nevertheless, a noteworthy observation was a substantial increase in pupil dilation during VD with untrained voices compared to trained voices using vocoder-degraded speech. This finding suggests a training-induced advantage for the familiar voice in terms of reduced listening effort.
The present study aimed to advance our understanding of the constraints that influence generalization following auditory training and offer new insights into how the training conditions affect generalization. To this end, two participant groups underwent a two-session VD training alternating between F0 or formant cues (interleaved training). One group received training in quiet conditions, while the other was trained in background noise, the latter requiring increased engagement of high-level auditory and/or cognitive processing (Eckert et al., 2016; Herrmann & Johnsrude, 2020). The extent of generalization of the learning gains was evaluated across several differences between the trained and untrained tasks: (a) Acoustic cues for VD: comparing a single cue (F0/formants) versus the combined use of both, (b) Stimuli: contrasting sentences with words, and (c) Training conditions: distinguishing between quiet conditions, which primarily engage low-level processing, and background noise which additionally involves higher-level auditory and/or cognitive processing. Performance in the generalization tasks was assessed by comparing it to a control group that did not undergo any training. The hypothesis posited that the interleaved training would enhance VD based on a single acoustic cue, drawing from recent findings in interleaved interaural time difference (ITD) and interaural level difference (ILD) discrimination training (Ning & Wright, 2023). However, differences were expected in the extent of generalization of the learning gains across the various tasks and conditions, highlighting the linkage between the specificity of learning and the level of processing targeted during training (Henshaw et al., 2022; Lawrence et al., 2018; Van Wilderode et al., 2023).
Materials and Methods
Participants
Fifty-five young adults (28 females and 27 males), aged 18–33 years, were recruited for this study. The participants were assigned using a semirandomized method to one of three groups: (a) The "Trained-in-Quiet" group (mean age of 24.53 years ± 3.72, n = 15); (b) The "Trained-in-Noise" group (mean age of 24.61 years ± 3.89, n = 20); and (c) The "Control" group (mean age of 24.15 years ± 3.55, n = 20). Initially, participants were assigned to one of the three groups in a sequential order (group 1–2–3–1–2…). However, due to challenges in participant recruitment and the primary focus of the study on the effect of noise on VD learning and generalization, after reaching 15 participants in each group, randomization continued exclusively between the Trained-in-Noise and Control groups.
Sample size justification: based on previous studies, the group * learning effects (described below) were assumed to be large (f = .76). A power analysis was carried out using G*Power 3.1.9.2. (Faul et al., 2007). The minimum total sample size required to detect such an effect for an ANOVA mixed design with three groups and two measurements, assuming a .01 probability of Type I error and a power of .95, is 15. Therefore, the current sample, consisting of a total of 55 participants, was adequately powered.
All participants met specific inclusion criteria, including the following: (a) bilateral pure-tone air-conduction thresholds at octave frequencies of 500–4,000 Hz were ≤20 dB hearing level (ANSI, 2018); (b) participants were native Hebrew speakers; (c) they had completed at least 12 years of education; (d) there was no history of language or learning disorders; (e) no known attention deficit disorders were present; (f) participants had less than 1 year of musical training; and (g) participants had no prior experience with psychoacoustic testing. Background information related to criteria (a)–(g) was obtained through self-reported data gathered via a comprehensive questionnaire. Participants were not compensated for their participation in the study. Informed consent was obtained from all participants.
Speech Recognition Thresholds in Noise (SRTn)
To determine the signal-to-noise ratio (SNR) for the group who VD-trained in noise and evaluate the effect of VD-training on SIN recognition across participant groups, speech recognition thresholds in noise (SRTn) were measured for all participants utilizing a sentence-in-noise test (previously described in Levin et al., 2022; Levin & Zaltz, 2023; Zaltz, 2023).
Stimuli for the SRTn Test
For the present study, a set of 96 sentences specifically developed for this purpose was employed, each consisting of three disyllabic words in Hebrew adhering to a fixed grammatical structure (noun, verb, and adjective). A preliminary assessment confirmed that these sentences utilized a straightforward vocabulary suitable for young native-speaking adults. The sentences were recorded by a female native speaker in a soundproof room, using an AT-892-TH microphone and Sound-Forge software (Version 7.0), with stereo channels at a sampling rate of 44,100 Hz and a 16-bit quantization level. To maintain uniform intensity levels across the stimuli, amplitudes were normalized to −16 dB RMS. Each SRTn assessment included approximately 20–25 sentences selected from the pool of 96 sentences. The presentation order of the sentences was pseudorandomized, ensuring that each sentence was presented only once during an assessment. The background noise utilized was a continuous, speech-shaped noise (SSN) with a long-term spectrum that matched the long-term spectrum of the speech material.
SRTn Assessment
The sentences were presented at a constant level, while the noise levels were adjusted using a two-down, one-up adaptive process to determine the SNR corresponding to 70.7% sentence recognition on the psychometric function (Levitt, 1971). The tested SNR range spanned from +3 to −12 dB. Initially, sentences were presented at an SNR of +3 dB. Listeners were instructed to verbally repeat what they heard as accurately as possible, and they were encouraged to make educated guesses if unsure. There was no time limit for their responses. Based on the listener's responses, the tester marked the correctly repeated words on the computer, and subsequently the level of the next sentence was adjusted. Correctly repeating two or three words within a sentence was considered as correct sentence recognition, whereas correctly repeating zero or only one word within a sentence was regarded as incorrect sentence recognition. The initial SNR step was calculated as the difference between the easiest and most challenging SNRs, resulting in a 15 dB step (3 − (−12) = 15 dB). This step was halved following two consecutive correct responses or one incorrect response, down to the second reversal, reducing the step size to 7.5 dB, and then further to 3.75 dB. For instance, following two correct responses at the easiest SNR (+3 dB), the SNR was reduced from 3 dB to −4.5 dB (3 − 7.5 = −4.5). If the participant continued to give two correct responses, the SNR was further reduced from −4.5 dB to −8.25 dB (−4.5 − 3.75 = −8.25). However, if the participant provided one incorrect response, the SNR was increased from −4.5 dB to −0.75 dB (−4.5 + 3.75 = −0.75). For the next reversal, the SNR step was reduced by a factor of 1.41 (√2) to 2.66 dB, and for the subsequent reversals (n = 3), the SNR step was reduced by a factor of 1.19 (∜2) to 2.23 dB. The adaptive procedure concluded after six reversals, and the Speech Recognition Threshold in noise (SRTn) was computed as the mean of the last four reversals. A similar adaptive procedure was previously employed to evaluate SRTn in children, young adults with normal hearing, and cochlear implant users (Levin et al., 2022; Levin & Zaltz, 2023; Zaltz, 2023).
Voice Discrimination (VD) Test
Stimuli for the VD Test
The VD test employed in this study was previously detailed (Zaltz, 2023). This test comprises either monosyllabic consonant–vowel–consonant words from the Hebrew version of the Arthur Boothroyd test (HAB) test (Kishon-Rabin et al., 2004) or sentences featuring three disyllabic words in Hebrew following a fixed grammatical structure (noun, verb, and adjective). All stimuli were recorded under identical conditions to those employed for the SRTn test to minimize acoustic differences between the tests. Specifically, the stimuli were recorded in the same room, by the same female speaker, using the same microphone, and at the same sampling rate and quantization level. The stimuli were modified within a 14-point stimulus continuum in either F0 alone, formant frequencies exclusively, or both F0 and formants, using the Pitch Synchronous Overlap-Add (PSOLA) algorithm (Moulines & Charpentier, 1990) implemented in the PRAAT software version 5.4.17 (copyright© 1992–2015 by Paul Boersma and David Weenink). This continuum exponentially ranged in √2 steps from a change of −0.127 semitone to a shift of −8 semitones, a technique similar to previous articles (Levin & Zaltz, 2023; Zaltz, 2023; Zaltz et al., 2018, 2020; Zaltz & Kishon-Rabin, 2022). Specifically, the mean F0 was altered by 0, −0.127, −0.18, −0.26, −0.36, −0.51, −0.72, −1.02, −1.44, −2.02, −2.86, −4.02, −5.67, and −8 semitones from the mean F0 of the original stimulus, using the PRAAT's Manipulation editor. For example, if a sentence had a mean F0 of 175.62 Hz, lowering the F0 resulted in the comparison sentence transitioning exponentially in √2 steps from 174.33 to 110.35 Hz. When manipulating the formant frequencies in this sentence, they were adjusted exponentially, ranging from a ratio of 0.99 (the smallest change from the original formant frequencies) to a ratio of 0.63 (the most significant change), using the PRAAT's Change Gender editor. The latter adjustment necessitated resampling the stimulus to compress the frequency axis using a range of factors similar to the F0 change. Following this, the PSOLA algorithm was applied to restore the original pitch and duration. Combined F0 + formant changes were performed using first the Change Gender editor and then the Manipulation editor.
VD Threshold Assessment
The three-interval three-alternative forced choice (3I3AFC) method was used to assess VD Just Noticeable Differences (JNDs) based on either F0, formants, or the combination of F0 and formant cues. Each trial involved the presentation of two reference (unprocessed) stimuli and one comparison (manipulated) stimulus, which were timed with a 300-ms interstimulus interval. A corresponding square on the PC monitor was highlighted when a stimulus was presented. Participants were instructed to select the stimulus they perceived as "sounding different" by clicking on the respective square using a computer mouse. Because these instructions focused on voice characteristics rather than linguistic content, the task was categorized as an explicit voice perception task. The initial comparison stimulus featured the most significant manipulation, with F0 lowered by eight semitones and formants adjusted by a ratio of 0.63. An adaptive tracking procedure following a two-down, one-up pattern was employed to determine difference limens (DLs) that corresponded to a 70.7% detection threshold on the psychometric function (Levitt, 1971). The difference between the reference and comparison stimuli was successively halved until the first reversal, and subsequently, it was adjusted using a √2 factor until the sixth reversal. This process resulted in an average of approximately 25 trials for each VD assessment, totaling around 75 stimuli. JNDs were calculated as the average of the last four reversals, as documented in previous studies (Levin & Zaltz, 2023; Zaltz, 2023; Zaltz et al., 2018, 2020; Zaltz & Kishon-Rabin, 2022). Participants received no feedback during the task, and there was no time restriction for making their selections.
For the group who trained in noise, VD training was carried out using the SSN employed in the SRTn test. This noise was presented at an SNR set approximately 5 dB above the individual SRTn, denoted as SRTn +5 dB. It was assumed that this SNR corresponded to over 90% speech recognition based on recent findings that established speech recognition functions for young adults with normal hearing (Sobon et al., 2019).
Study Design
Assessments
All participants underwent two assessments in two separate sessions, spaced 1–3 days apart (Figure 1). The first (baseline) assessment included a short hearing test to ensure air-conduction thresholds within the normal range bilaterally at octave frequencies of 500–4,000 Hz (ANSI, 2018). Following the hearing test, participants underwent two SRTn evaluations and four VD evaluations in quiet conditions, with combined F0 + formant cues: two with word stimuli and two with sentence stimuli. The order of tests and stimuli was balanced across participants. The mean pure-tone air-conduction thresholds at 500 Hz, 1,000 Hz, and 2,000 Hz (PTA) were individually calculated for each ear, serving as a baseline to determine the presentation level for the SRTn and VD tasks.
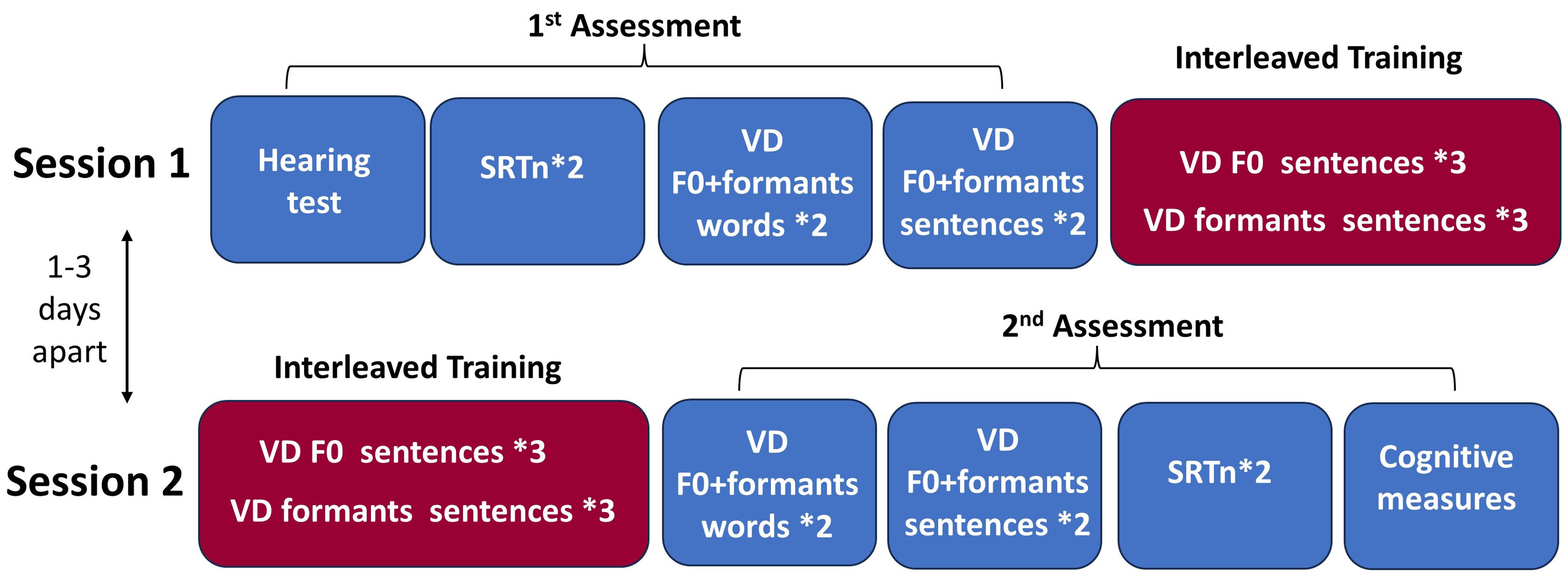
Study design. Participants are divided into three groups—Trained-in-Quiet (n = 15), Trained-in-Noise (n = 20), and Control (n = 20). Two sessions were conducted 1–3 days apart. First session: baseline (first) assessment for all groups and interleaved training phase for trained groups only. Second session: interleaved training phase for trained groups and second assessment for all three groups. Trained-in-Quiet group, trained in quiet; Trained-in-Noise group, trained amidst background noise. VD = voice discrimination, F0 = fundamental frequency, SRTn = speech recognition thresholds in noise.
The second assessment comprised two SRTn evaluations and four VD evaluations based on combined F0+ formant cues, mirroring the tasks from the first assessment.
Training
Two interleaved training phases were administered only to the trained groups. The first phase occurred immediately after the initial assessment during the first session. Subsequently, the second phase took place before the second assessment during the second session (Figure 1). Each training phase encompassed six VD evaluations utilizing sentence stimuli. These evaluations alternated between three VD tests employing F0 cues and three utilizing formant cues, following these sequences: F0–formants–F0–formants–F0–formants, F0–F0–formants–F0–F0–formants, formants–F0–formants–F0–formants–F0, and formants–formants–F0–formants–formants–F0, evenly distributed among participants. Training took place in a quiet setting for the Trained-in-Quiet group, while the Trained-in-Noise group underwent training under background noise conditions as detailed above.
Each session lasted approximately 85–100 min for the trained groups and 45–55 min for the control group, including one to three short breaks, as needed. The study received approval from the Institutional Review Board of the University.
Apparatus
The stimuli were delivered using the internal soundcard of a laptop personal computer through a GSI-61 audiometer to both ears via TDH-49 headphones. The stimuli were presented at approximately 35–40 dB sensation level (above individual PTA of each ear), to balance sensation level across participants. The testing and training sessions were conducted in a sound-treated, single-walled room. The experimenter sat alongside the participants, closely monitoring, and recording their verbal responses.
Data Analysis
Statistical analyses were carried out using SPSS-20 software (IBM Corp, Armonk, NY). A single participant from the control group had VD data deviating by over 2.5 standard deviations (SDs) from the group mean and was consequently excluded from the data analysis. Before performing the analyses of variance (ANOVAs), normality checks were conducted on the residuals of all dependent variables using one-sample Kolmogorov–Smirnov and Shapiro–Wilk tests (for a total sample size of N = 54). The results of these tests, along with a visual inspection of the residuals using Normal Q–Q plots, indicated that the residuals for the SRTn variables exhibited a normal distribution (p-values > .05). However, several residuals for the VD variables did not meet the normality assumption, specifically VD with word stimuli in the second session for both the control group and the Trained-in-Noise group, and VD with sentence stimuli in the second session for the Trained-in-Noise group. Consequently, all VD data underwent logarithmic transformation before being entered into the ANOVAs, following the approach used in previous studies (El Boghdady et al., 2018; Koelewijn et al., 2023; 2021). Subsequent analysis revealed that the residuals of the log-transformed VD data conformed to a normal distribution (p-values > .05), ensuring that all the data adhered to the assumptions required for ANOVA.
To assess learning with the trained task, repeated measures ANOVA (RM-ANOVA) was conducted on the VD thresholds obtained during the training phase. Acoustic cue (F0 only, formants only), session (1, 2), and block (1–3) were considered as within-subject variables, while training conditions (quiet, noise) served as the between-subject variable. To investigate the generalization of learning to untrained tasks compared to the control group, two additional RM-ANOVAs were performed on data collected during the two assessments. The first RM-ANOVA was performed on the average of the two VD blocks associated with each stimulus. The within-subject variables were stimulus (words, sentences) and session (1, 2) and the between-subject variable was group (Trained-in-Quiet, Trained-in-Noise, control). The second RM-ANOVA focused on the average of the two SRTn blocks, with session (1, 2) as the within-subject variable and group (Trained-in-Quiet, Trained-in-Noise, control) as the between-subject variable. All post hoc analyses were conducted using the Šidák correction for multiple comparisons.
Results
Learning
VD thresholds for the two trained groups during the training phase are detailed in Table 1. Statistical analysis revealed a significant effect for voice cue [F(1, 33) = 10.907, p = .002, ƞ2 = .254], indicating better thresholds for formant compared to F0 cues. In addition, a significant effect of the session [F(1, 33) = 13.939, p = .001, ƞ2 = .303] was observed, with better thresholds in the second session than in the first session, indicating significant learning. No significant effect was observed for the block [F(2, 33) = .177, p = .823]. Figure 2(a) illustrates VD performance for each voice cue in each session. Note that due to the absence of a significant block effect, the performance in each session is depicted as the average of the three blocks within that session. Although a visual inspection suggests better performance in quiet than in noise, the effect of training conditions was not found to be significant [F(1, 33) = 2.924, p = .068]. Furthermore, no significant interactions were detected (p > .05).

Average voice discrimination thresholds (±SE). (a) Training session data (mean of blocks 1–3 per session with each voice cue) for both training groups. (b) Assessment data (mean of two blocks per session with each task) for the training and control groups. F0 = fundamental frequency, SE = standard error.
Average Voice Discrimination Thresholds (in Semitones) in the Three Blocks Conducted During Each of the Two Training Sessions With Each Voice Cue for Both Training Groups (in Parentheses Are the Standard Deviations).

Generalization
VD thresholds for the two trained groups and the control group during the first and second assessments are outlined in Table 2 (a). Figure 2(b) visually represents the mean two blocks for each stimulus (words/sentences) in each assessment. Statistical analysis revealed a significant effect for session [F(1, 51) = 32.175, p < .001, ƞ2 = .387], with better thresholds in the second session than the first session, signifying significant learning. No significant effects were found for group [F(2, 51) = .076, p = .927] or stimulus [F(1, 51) = 1.689, p = .200], and no significant interactions were detected (p > .05).
(a) Average Voice Discrimination Thresholds (in Semitones) in the Two Blocks Conducted During Each of the Two Assessment Sessions With the Word and Sentence Stimuli, Across the Three Study Groups. (b) Average SRTn (in dB) in the Two Blocks Conducted During Each of the Two Assessment Sessions, Across the Three Study Groups (in Parentheses are the Standard Deviations).

SRTn for the two trained groups and the control group during the two assessments are detailed in Table 2(b). Statistical analysis revealed significant effects for group [F(2, 51) = 6.597, p = .003, ƞ2 = .206] and session [F(1, 51) = 79.444, p = .001, ƞ2 = .609], with a significant group × session interaction [F(2, 51) = 4.443, p = .017, ƞ2 = .148]. Follow-up ANOVAs explored this interaction, with each analysis comparing two specific groups. Results revealed significant session × group interactions for the Trained-in-Noise group versus Trained-in-Quiet and the Trained-in-Noise group versus Control [F(1, 33) = 7.940, p = .008, ƞ2 = .194; F(1, 37) = 5.236, p = .028, ƞ2 = .124, respectively]. These interactions indicated that the Trained-in-Noise group exhibited a steeper slope between sessions, reflecting greater improvement in SRTn compared to both the Trained-in-Quiet and Control groups (as illustrated in Figure 3). Notably, there was no significant interaction observed for the Trained-in-Quiet group versus Control [F(1, 32) = 1.142, p = .293], suggesting a similar magnitude of improvement between these two groups across sessions.

Average SRTn (±SE). Mean of two blocks per session for the training and control groups. SRTn = speech recognition thresholds in noise, SE = standard error.
Discussion
The primary aim of the current study was to investigate the impact of two training sessions with VD on the generalization of the learning gains to various tasks, differing in acoustic, linguistic, and cognitive demands from the trained task. This approach sought to shed light on the efficiency and limitations of auditory learning mechanisms in young adults with normal hearing. The key findings of the study are as follows: (a) Two sessions of interleaved VD training focused on a single voice cue (either F0 or formants) resulted in significant learning improvements, irrespective of the training conditions (quiet or noise). (b) Rapid learning was evident in VD utilizing combined F0 + formant cues between the first and second assessments. However, the learning gains for this task did not differ significantly between the training groups and the untrained control group. This lack of differentiation suggests no added advantage from single-cue training for combined-cue VD, indicating limited generalization. (c) Rapid learning was also observed in the SRTn task for both trained and control groups. However, the most significant enhancements were seen in the group that underwent VD training in background noise, suggesting increased generalization between tasks with challenging acoustic conditions.
The observed significant improvements in VD performance between the first and second training sessions, relying on either F0 or formant cues, align with numerous studies that have noted enhancements in pure-tone and F0 discrimination following training (Delhommeau et al., 2005; Lau et al., 2017; Menning et al., 2000; Micheyl et al., 2006; Roth et al., 2008; Wright & Sabin, 2007; Zaltz et al., 2018, 2020). These findings are also consistent with research showing significant learning gains following voice training including different tasks, such as voice identification or familiarization (Kreitewolf et al., 2017; Nygaard & Pisoni, 1998; Yonan & Sommers, 2000).
Interestingly, in the current study, significant improvements in VD between the initial and subsequent assessments were also observed for the combined F0 + formant task across both the trained and control groups, indicating rapid learning or adaptation. Rapid learning has been previously noted in studies focusing on speech perception with various forms of degraded speech, such as noise-vocoded, accented, smeared, or time-compressed speech (Banai et al., 2022; Borrie et al., 2012; Davis et al., 2005; Gordon-Salant et al., 2010). Moreover, research has shown that even as little as 10 min of voice training can lead to improvements in speech intelligibility (Holmes et al., 2021). Previous research has attributed such fast improvements to top-down tuning and adaptation processes that facilitate the formation of effective task-solving strategies and/or reduce response bias (Hauptmann et al., 2005; Hauptmann & Karni, 2002). A recent study further suggests that this rapid learning may be stimulus-specific, representing an essential initial stage of perceptual learning (Banai et al., 2022). Importantly, this study also demonstrated that rapid learning of time-compressed speech is associated with improved speech understanding in adverse listening conditions, enabling listeners to quickly adapt to continuously changing acoustic environments. The current findings of rapid improvements in VD therefore support the idea that brief exposure to tasks targeting voice characteristics may enhance speech perception in noisy environments. Future studies could explore this potential further.
It is important to note that the training approach in the present study was different from previous ones by incorporating two distinct acoustic cues: F0 and formant frequencies, in an interleaved manner. The rationale behind this approach stemmed from prior findings suggesting that increased variability in training materials could enhance generalization (Amitay et al., 2005; Banai & Amitay, 2012; Van Wilderode et al., 2023). Moreover, the alternating training between these voice cues appeared not to impede learning, as comparable improvements in VD were evident using either cue. This finding aligns with a recent study demonstrating learning for interleaved training between ITD and ILD discrimination tasks (Ning & Wright, 2023). However, it contradicts an earlier study that reported alternating training between two auditory temporal interval discrimination tasks with different standards to disrupt learning for both tasks (Banai et al., 2010). This suggests that the susceptibility of learning on a particular task to interference from training on another task may depend on the specific learning stage when the second task is introduced and the specific combination of tasks.
Despite incorporating some variability in the training material regarding voice cues, VD training with a single cue did not significantly enhance VD with both cues beyond the improvements observed in the control group, which were attributed to rapid learning mechanisms. This remained consistent for stimuli resembling the trained ones—three-word sentences—and for dissimilar stimuli like monosyllabic words. This outcome was rather surprising, especially considering that the VD training in the present study included voice familiarity training, utilizing the same voice for both training and testing. Numerous studies suggest that, in the realm of speech, acoustic similarity plays an important role in the generalization of learning (Bradlow et al., 2023; Strori et al., 2020; Tzeng et al., 2024). One possible explanation for this unexpected outcome may be linked to the distinct processing mechanisms involved with each acoustic cue for VD. Notably, formant coding predominantly engages spectral processing, while F0 coding relies on both spectral and temporal processing (Carlyon & Shackleton, 1994; Fant, 1960; Fu et al., 2004; Lieberman & Blumstein, 1988; Oxenham, 2008; Xu & Pfingst, 2008). Therefore, in a VD task utilizing both formant and F0 cues, a synthesis of these coding mechanisms is required. Thus, although this task may benefit from cue redundancy, as evidenced by the overall superior performance with combined cues compared to separate cues, it also necessitates higher-level integration beyond simple sensory processing. The limited generalization to combined cues beyond initial adaptation may suggest that the neural changes induced by single-cue training were rooted, to some extent, in lower levels of sensory processing. This rationale aligns with the notion that during training neural changes progressively shift from higher to lower processing levels, marked by specificity for fundamental features, thereby limiting generalization (Ahissar & Hochstein, 1997, 2004; Ahissar et al., 2009; Karni, 1996; Karni & Sagi, 1991). It is also supported by studies involving voice familiarization or identification training, which indicated a lack of generalization between training using meaningful sentences and subsequent testing employing isolated meaningful words (Yonan & Sommers, 2000) or meaningless CV-triplets (Biçer et al., 2023).
Notably, rapid learning was also evident in the SRTn task, across groups. However, while one might have initially speculated that both the Train-in-Noise and Train-in-Quiet groups would demonstrate significant improvements in SRTn compared to the control group, our findings revealed a more nuanced result. Specifically, only the Trained-in-Noise group, whose training conditions were identical to those utilized in the SRTn test, exhibited notable enhancements in SRTn compared to controls. Furthermore, this group surpassed the Trained-in-Quiet group in terms of SRTn improvements. This outcome suggests that SRTn performance was primarily influenced by the training conditions (noise) rather than the VD task or voice familiarization, which were shared by both the Trained-in-Quiet and Trained-in-Noise groups. A recent study revealed that only about 25%–55% of the variability in VD performance in the presence of SSN with a similar favorable SNR could be explained by VD performance levels observed in quiet environments among both children and adults (Kishon-Rabin & Zaltz, 2023). This suggests the engagement of additional processing mechanisms specifically utilized for VD in noisy conditions, beyond those utilized in quiet conditions. The Model of Listening Engagement proposes that as the listening environment becomes more intricate, for example, with added background noise, the demand on listening effort intensifies, necessitating greater involvement of cognitive functions, including working memory, inhibition, and selective attention (Herrmann & Johnsrude, 2020). Furthermore, neuroimaging studies that investigated speech recognition in challenging listening situations (such as degraded speech or background noise) consistently reveal the involvement of nonauditory neural systems. These systems support attention, performance monitoring, and optimization across various tasks (for a review see: Eckert et al., 2016). The superior SIN recognition demonstrated by the Trained-in-Noise group after training may therefore reflect improvements due to training in both low-level sensory processing of voice cues and higher-level nonauditory (cognitive) mechanisms such as focused attention on the relevant task while inhibiting background noise, particularly within this group. While the improvements at the low level remained specific to the trained task (without additional enhancement in the combined-VD task, as previously discussed), the adjustments in higher-level processing generalized, resulting in superior SIN recognition. This explanation aligns with the concept that the generalization of learning gains occurs when neural changes induced by training affect higher-level processing, where neurons respond similarly to stimuli varying in multiple features (Dudai et al., 2015; Pinsard et al., 2019). They are also in accordance with a recently introduced training approach that integrates both auditory and cognitive challenges to foster broad generalization across various auditory scenarios (Van Wilderode et al., 2023).
An alternative explanation regarding the transfer of learning improvements from the VD-in-noise task to SIN recognition proposes that the noise-based training enhanced either peripheral or central auditory processing of the speech signal, extending beyond the specific VD task. In terms of peripheral auditory processing, prior findings highlight the detrimental impact of background noise on both F0 and formant perception. Noise has been demonstrated to mask spectral information in speech signals (Brungart, 2001; Ezzatian et al., 2012), leading to poor identification of formant peaks within the speech signal's spectral envelope (Liu & Kewley-Port, 2004; Stelmachowicz et al., 1990; Swanepoel et al., 2012) and impeding VD based on formant cues (Kishon-Rabin & Zaltz, 2023). Additionally, it has been suggested to hinder the ability to exploit periodicity cues (Steinmetzger & Rosen, 2015) and decrease subcortical neural synchrony, potentially affecting phase-locking mechanisms (Dimitrijevic et al., 2013; Han et al., 2020). These effects might, in turn, impede F0 perception (Carlyon & Shackleton, 1994; Oxenham, 2008). VD training amidst noise may have improved these spectral and temporal processing mechanisms, thereby boosting VD and speech recognition, both highly dependent on F0 and formant perception. Although this rationale appears plausible, it is important to emphasize that in the current study, VD was trained at an SNR that was 5 dB higher (easier) than the individual SNR associated with 70.7% sentence recognition on the psychometric function, ensuring clear audibility of the speech signal (Abdel-Latif & Meister, 2021; Sobon et al., 2019). This approach aimed to minimize the possibility of energetic masking, thereby mitigating potential information loss due to noise at the peripheral level (Brungart, 2001).
The proposition that VD training in noise might have enhanced central auditory processing of the speech signal is supported by studies investigating SIN using auditory evoked potentials. These studies reveal that combining background noise with a speech signal typically reduces the amplitude and delays the latency peaks of N1, P2, and the mismatch negativity (MMN). This indicates that noise negatively impacts preattentive auditory processing of the speech signal, affecting sensory representation, classification, and discrimination (Gustafson et al., 2019; Kaplan-Neeman et al., 2006; Kozou et al., 2005; Martin et al., 1999; Muller-Gass et al., 2001). Furthermore, several studies detected notable alterations in evoked potential measures, encompassing changes in MMN latency, duration, and area after training involving SIN recognition tasks (Ceyhan et al., 2022; Kraus et al., 1995). Subsequent research endeavors could explore the proposition that training in VD within a noisy environment enhances central auditory processing of the speech signal, employing a combination of behavioral and physiological assessments.
Limitations and Suggestions for Future Studies
In the current study, participants were assigned to one of three study groups using a semirandomized procedure. This randomization method, resulting in uneven groups, may have introduced bias, and acted as a confounding factor, leading to differences in participants’ baseline (naïve) performance across the groups. Specifically, the Trained-in-Quiet group demonstrated superior initial SRTn performance compared to the other two groups, potentially having less to gain from the training. This limitation was partially addressed by focusing on improvements (slope of the difference between the two sessions) rather than absolute performance values. Indeed, despite initial performance differences, there was no significant difference in the magnitude of SRTn improvement between the Trained-in-Quiet and Control groups. Only the Trained-in-Noise group demonstrated greater improvement compared to both groups. However, for future studies aiming to replicate our work, researchers may consider allocating participants into groups of equal size, based on their initial performance with the task. This adjustment could further enhance the clarity of the observed training effects and strengthen the comparability of outcomes across different study groups. Additionally, VD training in the current study involved multiple JND assessments per session, with each assessment comprising a fixed number of reversals (six). However, the total number of stimuli was not predetermined to allow for a more precise determination of individual JNDs. While this flexibility may have introduced some variability in the results, future studies could consider implementing training protocols with a fixed number of stimuli to enhance consistency and comparability across participants. Finally, the SRTn assessment in the present study closely aligned with the conditions used for training the Trained-in-Noise group on VD, utilizing the same speaker and background noise. This methodological alignment enabled us to explore potential generalization across tasks that share similar acoustic environments. However, drawing broader conclusions about generalization to real-world speech perception scenarios requires further investigation and consideration.
Conclusions
The primary objective of the present study was to explore the impact of training conditions on the generalization of learning gains. The findings indicate that VD training in either quiet or background noise conditions can rapidly enhance performance. However, the generalization of learning gains following training in quiet conditions appears to be limited, suggesting that resultant neural changes may predominantly occur at a low processing level. Conversely, VD training conducted in more challenging listening conditions, such as background noise, has the potential to broaden transferability to tasks involving greater auditory or central challenges in the listening process, such as SIN recognition. This potential generalization may occur by prompting higher levels of auditory or cognitive processing. While the study exclusively examined young adults with fully developed auditory and cognitive systems, these novel insights underscore the advantages of employing auditory training tasks that engage multiple processing levels to broaden the generalization of the learning gains, offering practical benefits. Future investigations encompassing younger children, older adults with normal hearing, and individuals with auditory or cognitive impairments are necessary to evaluate whether similar patterns of generalization occur across different developmental stages and pathological conditions.
Footnotes
Acknowledgments
The author expresses gratitude to the undergraduate students from the University who assisted in data collection. Special appreciation is extended to all the subjects who participated in the study.
Data Availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author upon reasonable request.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.