
Abstract
Auditory learning is essential for adapting to continuously changing acoustic environments. This adaptive capability, however, may be impacted by age-related declines in sensory and cognitive functions, potentially limiting learning efficiency and generalization in older adults. This study investigated auditory learning and generalization in 24 older (65–82 years) and 24 younger (18–34 years) adults through voice discrimination (VD) training. Participants were divided into training (12 older, 12 younger adults) and control groups (12 older, 12 younger adults). Trained participants completed five sessions: Two testing sessions assessing VD performance using a 2-down 1-up adaptive procedure with F0-only, formant-only, and combined F0 + formant cues, and three training sessions focusing exclusively on VD with F0 cues. Control groups participated only in the two testing sessions, with no intermediate training. Results revealed significant training-induced improvements in VD with F0 cues for both younger and older adults, with comparable learning efficiency and gains across groups. However, generalization to the formant-only cue was observed only in younger adults, suggesting limited learning transfer in older adults. Additionally, VD training did not improve performance in the combined F0 + formant condition beyond control group improvements, underscoring the specificity of perceptual learning. These findings provide novel insights into auditory learning in older adults, showing that while they retain the ability for significant auditory skill acquisition, age-related declines in perceptual flexibility may limit broader generalization. This study highlights the importance of designing targeted auditory interventions for older adults, considering their specific limitations in generalizing learning gains across different acoustic cues.
Keywords
Introduction
Auditory-perceptual learning allows listeners to adjust to difficult listening conditions (e.g., to understand fast-rate speech, speech amid background noise, and competing talkers), using an interplay between top-down (cognitive) and bottom-up (sensory) processes (Bieber & Gordon-Salant, 2021; Davis & Johnsrude, 2007; Samuel, 2011; Samuel & Kraljic, 2009). With age, the sensory and cognitive processes mediating perceptual learning deteriorate (Anderson & Karawani, 2020; Harada et al., 2013; Jayakody et al., 2018; Pichora-Fuller & Singh, 2006; Schneider, 2011). Accordingly, the process of learning and the ability to generalize the learning gains to new conditions and tasks may be significantly impaired with increasing age. One way to explore the learning capacity of older adults is via auditory training. However, findings from the literature addressing the efficacy of learning following auditory training for older adult listeners are limited and highly varied (Bieber & Gordon-Salant, 2021). The present study sought to compare the learning and generalization characteristics of older adults to younger adults, using auditory training with a basic psychoacoustic task of voice discrimination (VD). Such a comparison may help infer how age could influence the neural processes undergoing reorganization after training (Ahissar et al., 2009; Censor, 2013; Karni, 1996; Karni & Sagi, 1993) and bear significance to the latent potential for enhancing functioning in advanced aging.
Perceptual skill learning is defined as a long-lasting improvement in the ability to respond to the environment and extract information from a given stimulus, due to experience (Gibson, 1963; Goldstone, 1998). One constraint on perceptual learning is that the training-induced gains may become more specific to the trained task and/or conditions as training progresses (Zaltz et al., 2020), suggesting that both the magnitude and the nature of changes in neural encoding of an auditory task evolve progressively throughout the learning process (Ahissar et al., 2009; Ahissar & Hochstein, 2004). Furthermore, the learning specificity was suggested to be affected by the similarity, or overlap in brain representation, between the trained and untrained stimuli or tasks, with better generalization of the learning-gains to untrained tasks or conditions that share the same neural circuits as the trained task (Amitay et al., 2014; Hesseg et al., 2016). Exploring the extent of generalization may therefore serve as a possible probe into the neural processes undergoing reorganization following training.
Understanding how perceptual learning interacts with age-related changes in peripheral and central auditory abilities is critical, as aging is associated with declines in auditory functions that extend beyond reduced hearing sensitivity (as measured by audiometry). These include deficits in the temporal and spectral processing of the auditory input (Goupell et al., 2017; Moore & Peters, 1992; Schvartz-Leyzac & Chatterjee, 2015) that may influence both the learning process and the extent of generalization. In terms of temporal processing, electrophysiological studies reveal significant age-related declines in temporal precision, particularly within the auditory brainstem (Anderson et al., 2011; Purcell et al., 2004). These deficits are thought to stem from diminished phase-locking (Anderson et al., 2021) and decreased auditory nerve synchrony (Anderson et al., 2012). Such temporal impairments may contribute to the poorer F0 discrimination observed in older adults, who require approximately twice the F0 difference to perform at levels comparable to younger listeners when tested with harmonic complex tones and synthetic vowels (Moore & Peters, 1992; Vongpaisal & Pichora-Fuller, 2007). In terms of spectral processing, broadened auditory filters—likely due to reduced outer hair cell function (Tun et al., 2012)—have been associated with the poorer speech-in-noise performance observed in older adults, even among those with normal audiometry (Nambi et al., 2016). Furthermore, age-related changes in the spiral ganglion and auditory nerve can further contribute to spectral resolution deficits, particularly in more advanced stages of age-related hearing loss (Schmiedt, 2010). Additionally, aging negatively affects top-down, cognitive abilities in the domains of working memory, attention, and inhibition (Craik & Salthouse, 2000; Schneider & Pichora-Fuller, 2000). Such declines may adversely impact the capacity for perceptual learning.
The literature regarding age effects on auditory perceptual learning is both limited and inconsistent (Bieber & Gordon-Salant, 2021). For example, listeners aged 65–87 showed rapid plateauing during implicit training on accented speech, with improvements ceasing after the first block (Adank & Janse, 2010). In contrast, substantial learning gains have been observed in older adults when engaging in explicit training paradigms that provided trial-by-trial feedback. Examples include gap detection training in individuals aged 60–80 (Kishon-Rabin et al., 2013), time-compressed speech (TCS) training in those aged 65–91 (Manheim et al., 2018), combined training on speech-in-noise, TCS, and competing speakers in individuals aged 60–72 (Karawani et al., 2015), and speech-in-noise training in participants aged 61–79 (Humes et al., 2014).
Additionally, evidence regarding the effect of age on the transfer of learning to new stimuli or conditions is varied, ranging from extensive (Fostick et al., 2020; Sabin et al., 2013) to restricted generalization (Manheim et al., 2018; Peelle & Wingfield, 2005). For example, older adults aged 56–82 displayed broad generalization of learning gains after undergoing spectral modulation detection training, exhibiting superior transfer to an untrained spectral modulation frequency compared to the young control group (Sabin et al., 2013). Conversely, following TCS training, older adults showed poorer generalization to untrained compression ratios (65–78 year olds, Peelle & Wingfield, 2005) or untrained sentences (65–91 years old, Manheim et al., 2018) compared to their younger counterparts. Manheim et al. (2018) proposed that older adults rely more on higher-level representations of training material, such as the semantic meaning of sentences, than lower-level representations like the acoustic structure. Consequently, they exhibit decreased generalization of the learning-gains to untrained material that solely shares acoustic properties with the trained material compared to younger adults. One way to explore whether this reduced generalization is a general characteristic of older adults or depends on task complexity is to employ a training protocol focused on a basic discrimination task, such as VD, rather than a speech perception task like TCS. This approach allows for the assessment of learning generalization in a task that emphasizes fundamental psychoacoustic processing.
VD holds significant importance in differentiating speakers within a multi-talker environment, a skill linked to improved speech perception amid background noise (Bronkhorst, 2015; Vestergaard et al., 2009). This task involves discriminating between auditory stimuli (e.g., words or sentences) based on variations in fundamental frequency (F0), influenced by vocal cord characteristics like length, mass, and vibration rate, and formant frequencies shaped by the vocal tract length of the speaker (Darwin et al., 2003; Mackersie et al., 2011; Schvartz-Leyzac & Chatterjee, 2015; Skuk & Schweinberger, 2013; Vestergaard et al., 2009, 2011). These acoustic cues convey crucial information about the speaker, encompassing attributes such as age, gender, and individual characteristics (Başkent & Gaudrain, 2016; Shultz, 2015; Skuk & Schweinberger, 2013; Smith et al., 2007; Smith & Patterson, 2005). Research indicates that efficient F0 coding relies largely on processing the temporal envelope and/or temporal fine-structure cues of the signal, while formant coding predominantly involves the place-based coding of spectral energy peaks (Carlyon & Shackleton, 1994; Fant, 1960; Fu et al., 2004; Lieberman & Blumstein, 1988; Oxenham, 2008; Xu & Pfingst, 2008). Considering the temporal and spectral processing demands for effective F0 and formant perception, it is not surprising that a growing body of research indicates older adults exhibit poorer abilities in F0 discrimination (across various age groups, Anderson et al., 2021; Anderson & Karawani, 2020; Moore & Peters, 1992; Souza et al., 2011; Vongpaisal & Pichora-Fuller, 2007), vowel identification based on formant changes (60–81 years old, Chintanpalli et al., 2016, pp. 65–78 years old, Goupell et al., 2017, pp. 65–83 years, Vongpaisal & Pichora-Fuller, 2007), and VD based on either F0 or formant cues, compared to younger groups (65–78 years, Zaltz & Kishon-Rabin, 2022).
Although no study has yet attempted to enhance VD performance in older adults through training, findings from studies with young adults suggest that voice training can significantly improve performance across various tasks, such as explicit voice identification, implicit voice familiarity, and VD tasks (Kreitewolf et al., 2017; Nygaard et al., 1994; Yonan & Sommers, 2000; Zaltz, 2024). For example, two training sessions focused on VD using either F0 or formant cues resulted in significant improvements in performance (Zaltz, 2024). Similarly, two-session voice identification or familiarization training with sentence stimuli significantly enhanced both VD and voice recognition (Yonan & Sommers, 2000). Notably, even brief training protocols can yield measurable benefits in young adults. For instance, a 10-min voice training session improved speech intelligibility for speech produced by the trained voice (Holmes et al., 2021). However, in some cases, the effects of voice training have been reported to remain highly specific to the trained task and stimuli. Yonan and Sommers (2000) found that sentence-based voice training enhanced sentence recognition for the trained voice but did not improve the recognition of isolated words. Similarly, Biçer et al. (2023) demonstrated that while a 30-min audiobook listening protocol reduced pupil dilation when listening to the trained voices, indicating reduced listening effort, it did not improve VD with the same voices. Additionally, Zaltz (2024) recently reported that VD improvements did not generalize to the same trained VD task when using untrained voice cues. The limited generalization in young adults raises concerns about whether older adults would be able to generalize their learning gains following VD training, assuming they demonstrate improvement.
The present study aims to advance our understanding of the constraints that influence auditory learning and generalization in older adulthood, using VD training that is focused on F0 information. To this end, two groups of participants, young adults and older adults underwent three-session VD training based on F0 cues. The extent of generalization of the learning gains was assessed to a different acoustic cue (formants) and to combined F0 + formant cues. Performance in these conditions was assessed by comparing it with control groups of young and older adults that did not undergo any training. The hypothesis suggested that while older adults would generally demonstrate lower VD compared to young adults (Zaltz & Kishon-Rabin, 2022), they would also benefit from training (Humes et al., 2014; Karawani et al., 2015; Kishon-Rabin et al., 2013; Manheim et al., 2018). However, poorer generalization of the learning gains to untrained conditions was expected, reflecting differences in the neural circuits engaged in learning at varying ages (Amitay et al., 2014; Hesseg et al., 2016).
Materials and Methods
Participants
Forty-eight participants took part in the study. Twenty-four young adults aged 18–34 years were divided into training (mean age of 28.58 years ± 4.10, n = 12) and control groups (mean age of 23.09 years ± 3.17, n = 12), and 24 older adults, aged 65–82 years were divided into training (mean age of 72.67 years ± 6.36, n = 12) and control groups (mean age of 73.18 years ± 5.18, n = 12). None of the participants had prior experience with similar psychoacoustic tasks, nor did they have any documented history of ear disease. Additionally, all participants had completed a minimum of 12 years of formal education. The young adults exhibited normal pure-tone air conduction thresholds in both ears, registering pure-tone air conduction thresholds of ≤20 dB HL across octave frequencies from 250 to 8,000 Hz (ANSI, 2018). The older adults displayed pure-tone air conduction thresholds that were equal to or superior to the 50th percentile for their age group (Engdahl et al., 2005). Table 1 presents the mean pure-tone thresholds across the tested frequencies for the training and control groups of older participants, while Figure 1 provides detailed audiograms. Overall, hearing thresholds ranged from normal to mild hearing loss (up to 40 dB HL) at 2,000 Hz, minimal to moderately severe loss (25–70 dB HL) at 4,000 Hz, and mild to severe loss (35–90 dB HL) at 8000 Hz. Some variation was observed between the training and control groups, with statistically significant differences at 500 and 2000 Hz. None of the older adults had utilized a hearing aid. Each older adult demonstrated cognitive abilities within the normal range (Mini-Mental State Examination [MMSE] score ≥ 25, based on the English version [Folstein et al., 1975]), maintained independent living, and reported leading an active lifestyle. Informed consent was obtained from all participants. The study received approval from the Institutional Review Board of Tel Aviv University (approval number: 0007524-2).

Mean (thick lines and symbols) and Individual (thin Lines and Symbols) Hearing Thresholds Across Octave Frequencies Ranging from 250 to 8000 Hz for the Right (red circle) and left (blue cross) Ears for the Older Adults (n = 24).
Mean Pure-Tone Thresholds (in dB) Across Octave Frequencies for Training and Control Groups (Mean of two Ears), and Results of Multivariate Analysis.

Note. * = p < .05, ** = p < .005.
VD Test
Stimuli
The specific VD test utilized in this study was previously described (Zaltz, 2023, 2024). In summary, the test involved 82 single-syllable CVC words from the Hebrew version of the Arthur Boothroyd (HAB) test (Kishon-Rabin et al., 2004). The words were recorded by a female native speaker in a soundproof room using an AT-892-TH microphone and Sound-Forge software (version 7.0). The recordings utilized stereo channels at a sampling rate of 44,100 Hz and a 16-bit quantization level. Ensuring consistent intensity levels across all stimuli, amplitudes were normalized to −16 dB RMS. The words were altered within a 14-point stimulus continuum, adjusting either F0 solely, formant frequencies solely, or both F0 and formants. This continuum followed an exponential progression in √2 steps, ranging from a change of −0.127 semitone to −8 semitones, mirroring techniques in previous papers (Levin & Zaltz, 2023; Zaltz, 2023; Zaltz et al., 2018, 2020; Zaltz & Kishon-Rabin, 2022). Specifically, the mean F0 was adjusted in increments of 0, −0.127, −0.18, −0.26, −0.36, −0.51, −0.72, −1.02, −1.44, −2.02, −2.86, −4.02, −5.67, and −8 semitones from the original stimulus's mean F0. This manipulation was carried out using the PSOLA algorithm (Moulines & Charpentier, 1990) for pitch extraction and modification. For instance, if a word had a mean F0 of 175.62 Hz, lowering the F0 transitioned the comparison word exponentially from 174.33 to 110.35 Hz in √2 steps. When manipulating formant frequencies, adjustments ranged exponentially from a ratio of 0.99 (the smallest change from the original frequencies) to 0.63 (the most significant change), necessitating resampling the stimulus to compress the frequency axis. This compression was achieved using factors akin to the F0 change, followed by the application of the PSOLA algorithm to restore the original pitch and duration.
VD Threshold Assessment
The study employed the three-interval three-alternative forced-choice (3I3AFC) method to evaluate VD difference limens (DLs) based on F0, formants, or their combination. Each trial displayed two unprocessed reference stimuli alongside one manipulated comparison stimulus, timed with a 300-millisecond interstimulus interval. A corresponding square on the PC monitor signaled each stimulus presentation. Participants were directed to select the stimulus they perceived as “sounding different” by clicking the respective square using a computer mouse. The initial comparison stimulus underwent the most significant manipulation, with F0 lowered by eight semitones and formants adjusted by a ratio of 0.63. An adaptive tracking procedure, following a two-down, one-up pattern, was utilized to establish DLs corresponding to a 70.7% detection threshold on the psychometric function (Levitt, 1971). The difference between reference and comparison stimuli was successively halved until the first reversal, then adjusted using a √2 factor until the sixth reversal. Just noticeable differences were calculated as the average of the last four reversals, following a protocol documented in prior studies (Levin & Zaltz, 2023; Zaltz, 2023; Zaltz et al., 2018, 2020; Zaltz & Kishon-Rabin, 2022). Participants were not limited by time constraints in making their selections. Throughout the VD assessment, no feedback was provided regarding participants’ responses. However, during training sessions, visual feedback was provided: The selected square on the PC monitor would illuminate in green for correct responses and in red for incorrect ones. Each VD block lasted around 3–4 min. Before formal testing, participants engaged in a short familiarization task with 5–10 trials featuring the greatest difference between the reference and comparison stimuli to confirm their understanding of the task.
Study Design
The trained participants completed a series of five sessions, two testing sessions and three training sessions, with 1–3 days between each consecutive session (Figure 2). The testing sessions were the first and last (fifth) sessions. They involved six VD blocks: two with F0-only cues, two with formant-only cues, and two combining F0 + formant cues. The order of VD cues was counterbalanced among participants. Additionally, during the first testing session, all participants underwent a bilateral air-conduction threshold hearing test across octave frequencies ranging from 250 to 8000 Hz (ANSI, 2018), and only the older adults underwent cognitive screening using the Hebrew version of the MMSE (Folstein et al., 1975). This assessment consists of 11 questions and covers various mental functions. A score of 25 points or more indicated cognitive abilities within the normal range. Overall, the first session lasted approximately 90 min, while the fifth session lasted about 45 min, with short breaks provided as needed.
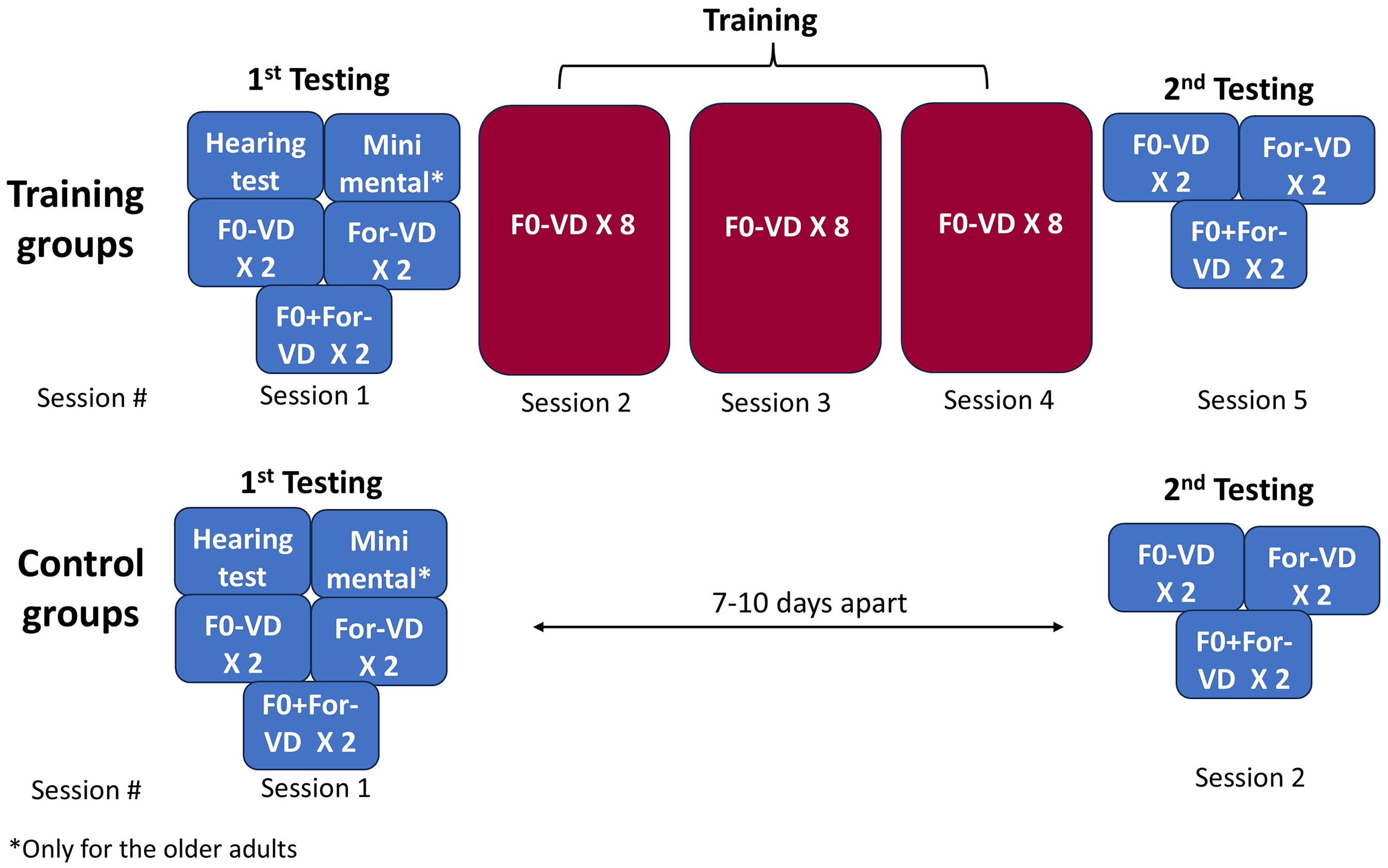
Study Design Outlining the Sessions Conducted by the Training and Control Groups, Each Including 12 Young Adults and 12 older Adults Training Groups Underwent Five Sessions (two testing and three training sessions), Separated by 1–3 days. Control groups Participated in two Testing Sessions only, with Sessions Spaced 7–10 days Apart. Note. VD = Voice Discrimination, F0 = Fundamental Frequency, For = Formants.
Sessions 2–4 were dedicated to training, consisting of eight VD blocks using F0-only cues, with each session lasting approximately 60 min.
The control groups completed only two testing sessions, spaced 7–10 days apart. These sessions were identical to the first and fifth session of the training groups.
Apparatus and Data Analysis
The study was conducted in a sound-treated, single-walled room. Stimuli were delivered using the internal soundcard of a laptop personal computer through a GSI-61 audiometer to both ears via TDH-49 headphones. The individual mean pure-tone air conduction thresholds at 500, 1,000, 2,000, and 4,000 (PTA4) were calculated for each ear. These values served as a baseline to establish presentation levels for the VD task, and stimuli were presented at 35 dB sensation level (SL) above the individual PTA4, aiming to approximate a balanced SL across young and older participants. Pearson correlation coefficients showed no significant correlations between PTA4 and VD performance (mean of the two blocks) for either acoustic cue during the first testing session, in both age groups (p > .05).
Statistical analyses were carried out using SPSS-28 software (IBM Corp, Armonk, NY). All VD data underwent logarithmic transformation before being entered into analyses, following the approach used in previous studies (El Boghdady et al., 2019; Koelewijn et al., 2021, 2023; Zaltz, 2024). Two multilevel models (MLMs) for repeated measures were employed. The first MLM was used to assess learning, with a three-level structure: blocks (level 1) nested within sessions (level 2), and further within participants (level 3). Session and block were modeled as linear trends, and age group as a between-participant factor. Power was determined using G*Power (Faul et al., 2007). Based on previous studies reporting medium to large effect sizes for similar interactions (Anderson et al., 2022; Karawani et al., 2015; Manheim et al., 2018), we adopted a conservative estimate of Cohen's f = 0.25 with α < 0.05. The hypothesized age group * session * block interaction had a power of 0.99 in our sample.
The second MLM was utilized to assess generalization, with a five-level structure: Blocks (level 1) nested within sessions (level 2) and cue type (level 3), further nested within participants (level 4). Session, cue type and block were treated as within-person variables, and age group and group as between-participant factors. All variables were effect-coded so that lower-order terms (e.g., main effects) were not biased due to the inclusion of higher-order terms (e.g., interactions). Using the same power estimation approach, the hypothesized 2 * 2 * 2 * 3 interaction (group, age group, session, and cue type) had a power of 0.98 in our sample.
Results
Learning
Averaged F0-based VD thresholds for the training groups during the training sessions are detailed in Appendix 1, Table 1. A full model summary of the statistical analysis employed to assess learning is shown in Table 2. Results revealed a significant effect for age-group, signifying better thresholds among younger participants. In addition, there was a significant linear effect for session and block, indicating between-session (Figure 3A) and within-session learning (Figure 3B). No significant interactions were observed, suggesting comparable learning trajectories between the groups.

Mean Voice Discrimination Thresholds (± Standard error) Based on Fundamental Frequency (F0) Cues for the Young (n = 12) and Older (n = 12) Training Groups, Showing a Significant Effect for (A) Training Sessions (collapsed across training blocks), and (B) Training Blocks (collapsed across training sessions).
A Model Summary of the Three-Level Multilevel Model (MLM) Employed to Assess Learning.

Generalization
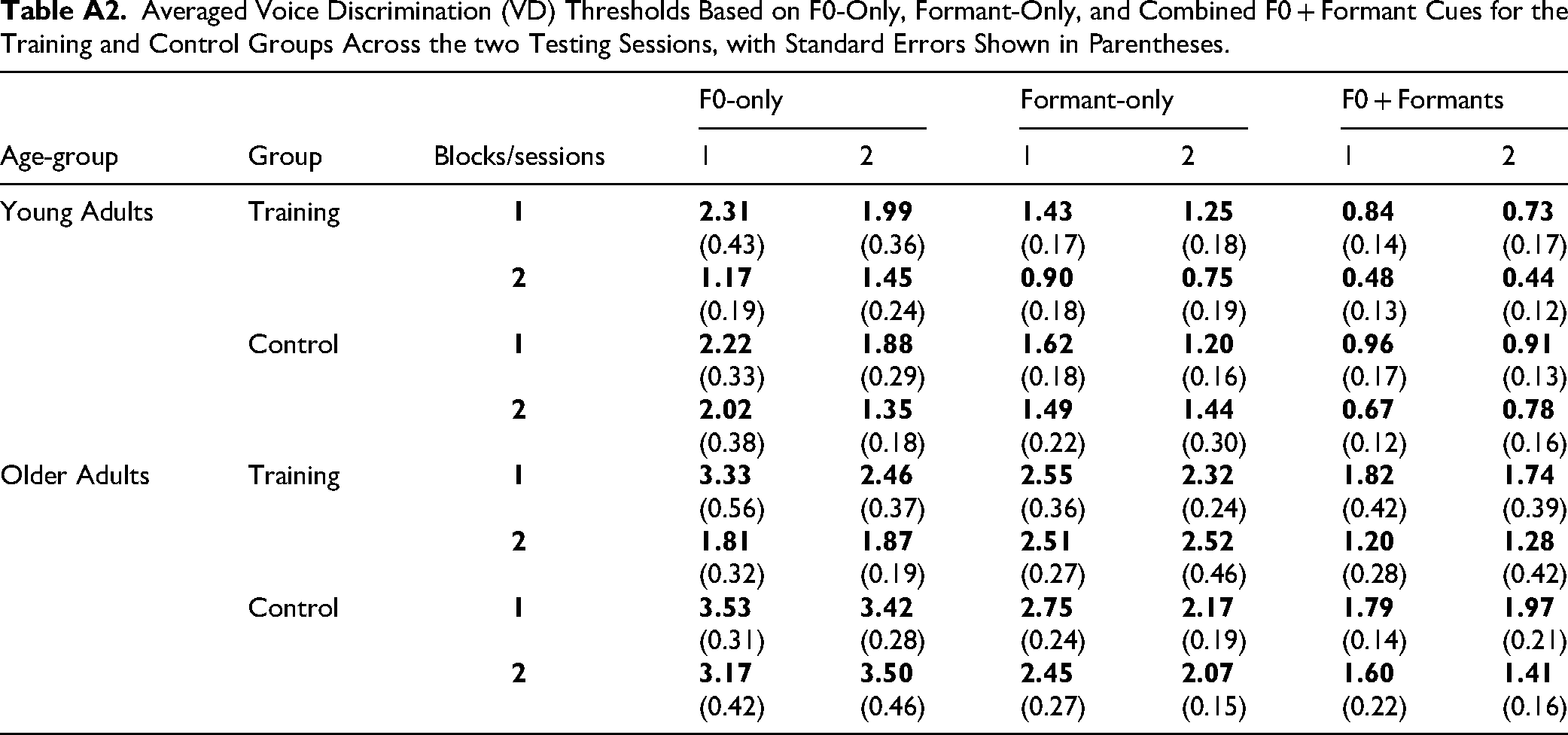
Averaged VD thresholds based on either F0-only, formant-only or combined cues during the first and second testing sessions are outlined for the trained and control groups in Appendix 1, Table 2. A full model summary of the statistical analysis employed to assess generalization is shown in Table 3.
A Full Model Summary of the Five-Level Multilevel Model (MLM) Employed to Assess Generalization.
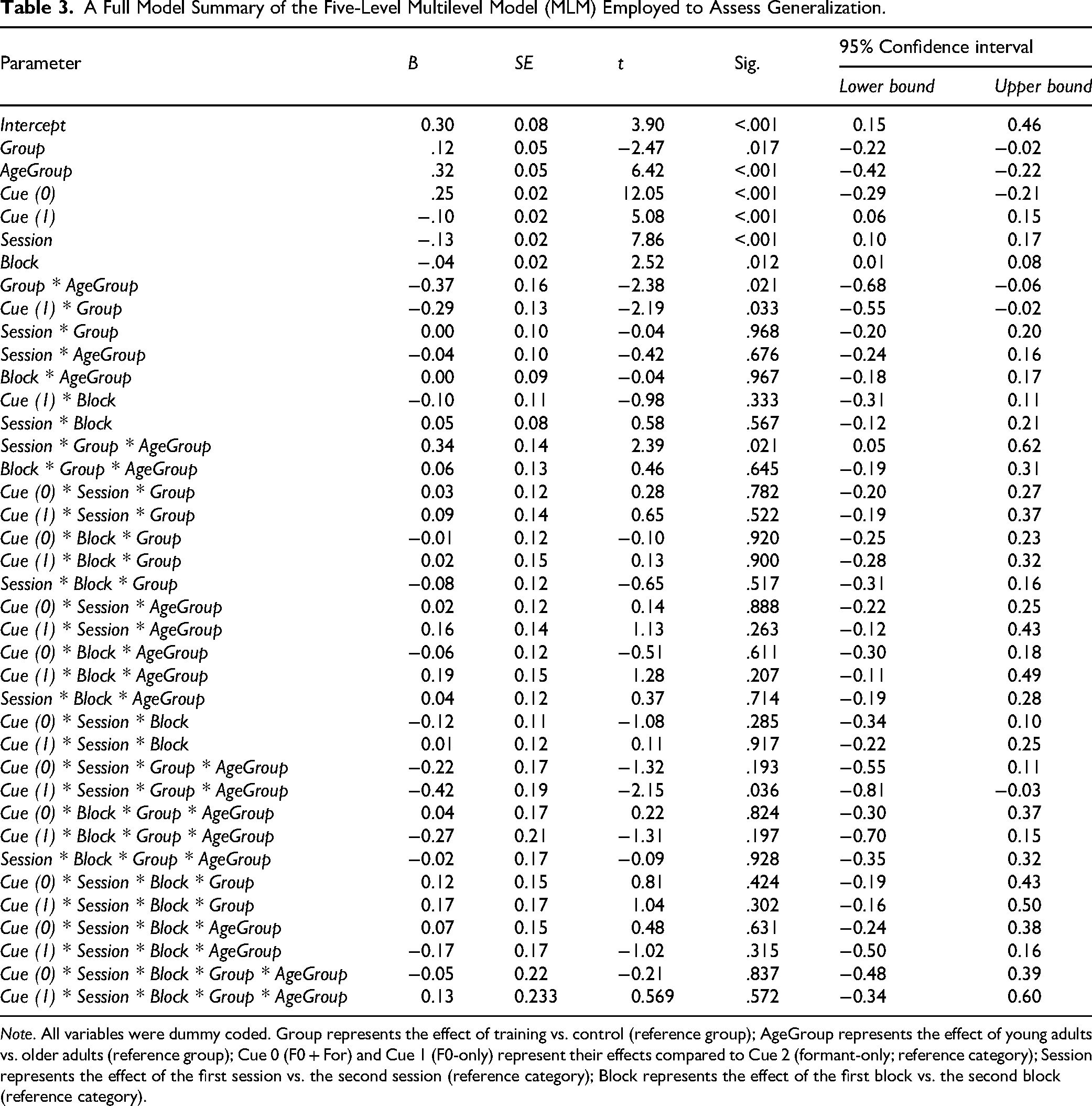
Note. All variables were dummy coded. Group represents the effect of training vs. control (reference group); AgeGroup represents the effect of young adults vs. older adults (reference group); Cue 0 (F0 + For) and Cue 1 (F0-only) represent their effects compared to Cue 2 (formant-only; reference category); Session represents the effect of the first session vs. the second session (reference category); Block represents the effect of the first block vs. the second block (reference category).
The results revealed a significant block effect, with no significant block interactions (p > .05), indicating rapid improvement between the first and second block across groups and cue types. A significant group * age-group * cue type * session interaction was observed. To further examine this effect, we analyzed conditional interactions separately for each cue type. For the F0-only (Figure 4A), the analysis revealed a significant effect for age-group [B = 0.12, SE = 0.03, p < .001], with older adults performing worse. A significant effect was also found for session [B = −.07, SE = 0.01, p < .001], along with a significant session * group interaction [B = 0.03, SE = 0.01, p = .007], indicating significant improvement from the first to the second testing sessions only for the training groups [B = −0.09, SE = 0.02, p < .001]. No other interactions reached significance (p > .05), suggesting a similar magnitude of improvement in the F0-only condition for both young and older adults. Furthermore, visual inspection of the data suggested no significant difference between the F0 performance of the young training group in the first testing session and that of the older adults training group in the second testing session. To statistically assess this, a Bayesian analysis was conducted on the F0 performance scores from these two sessions. A Bayes Factor (BF01) of 3 or higher indicates that the null hypothesis (H0) is favored over the alternative hypothesis (H1), with BF01 = 3 corresponding to a 5% criterion in hypothesis testing. The analysis yielded a BF01 = 3.35, supporting the no-difference hypothesis. This suggests that three training sessions were sufficient for the older adults to reach the VD performance level of the young adults at their naïve baseline.

Mean Voice Discrimination Thresholds (± Standard error) Based on (A) Fundamental Frequency (F0) Cues, (B) Formant Cues, and (C) Combined F0 + formant Cues, Shown Separately for the Training (n = 24) and Control (n = 24) groups, as well as for Young (n = 12 per group) and Older Adults (n = 12 per group), Across the two Testing Sessions.
For the formant-only (Figure 4B), the analysis revealed significant effects for age-group [B = 0.16, SE = 0.02, p < .001] and session [B = −0.04, SE = 0.02, p = .008]. Significant interactions were found for group * session [B = 0.03, SE = 0.03, p = .036] age-group * session [B = 0.04, SE = 0.02, p = .024] and group * age-group * session [B = −0.04, SE = 0.02, p = .009]. We further broke down the tripled interaction using conditional interaction analysis. Results revealed significant improvement between the first and second testing sessions only for the young adults who received training [B = −0.10, SE = 0.03, p < .001].
For the F0 + formant (Figure 4C), the analysis revealed significant effects for group [B = 0.08, SE = 0.03, p = .027], with poorer thresholds in the control groups; for age-group [B = 0.19, SE = 0.03, p < .001], with worse performance among older adults; and for session [B = −0.09, SE = 0.02, p < .001], showing significant improvements between the first and second testing sessions. No interactions reached significance (p > .05), indicating a similar magnitude of improvement in the F0 + formant condition, across both the training and control groups and both age groups.
Discussion
The objective of the present study was to enhance our understanding of the constraints influencing auditory learning and generalization in the elderly population. This was achieved by employing a basic psychoacoustic task of VD. Young and older adults underwent a three-session VD training regimen focused on F0 cues. The study assessed the efficiency of learning by examining the time course of learning both within and between sessions, as well as the extent to which the acquired learning generalized across different voice cues. The principal findings can be summarized as follows: (a) Although older adults exhibited poorer hearing thresholds and inferior VD performance compared to young adults, both groups demonstrated substantial improvements in VD based on F0 cues following training. Furthermore, no statistically significant differences were found in the learning trajectories or overall gains between the two age groups, indicating similar learning efficiency; (b) despite similar learning gains with the trained VD condition (F0-based), only the younger training group showed significant improvements in the formant-based VD condition following training, suggesting greater generalization of the learning gains in younger compared to older adults; (c) learning gains for VD based on combined F0 + formant cues did not differ between the training and control groups, indicating no added advantage of single-cue training for combined-cue VD. This result reveals limitations in the generalization for both young and older adults.
Our finding that, as a group, the older adults exhibited poorer VD thresholds based on F0-only, formant-only or combined F0 + formant cues compared to the young adults aligns with previous research demonstrating age-related impairments in F0 and formant perception (Anderson et al., 2021; Chintanpalli et al., 2016; Goupell et al., 2017; Souza et al., 2011; Vongpaisal & Pichora-Fuller, 2007) as well as inferior VD performance based on these cues in older populations (Zaltz & Kishon-Rabin, 2022). This outcome may be influenced by the potential confounding effect of hearing sensitivity in the older adult group. While their hearing thresholds generally aligned with typical age-related patterns, a notable prevalence of high-frequency hearing loss was observed, with some individuals exhibiting thresholds in the moderately severe to severe range. Such age-related hearing loss (presbycusis) is associated with impaired auditory processing, including reduced spectral resolution due to outer hair cell loss, broadened auditory filters, strial dysfunction, or cochlear synaptopathy, and/or decreased temporal resolution from reduced neural synchrony (Anderson & Karawani, 2020). Previous research suggests that effective F0 and formant frequency coding relies on efficient utilization of both temporal and spectral information (Fu et al., 2004; Oxenham, 2008; Xu & Pfingst, 2008). Therefore, deficits in spectro-temporal processing, such as impairments in periodicity and fine-structure perception (Souza et al., 2011), may account for the reduced VD performance observed in older adults. Alternatively, the poorer VD performance in older adults may partly reflect age-related declines in cognitive abilities, such as working memory and executive control (Harada et al., 2013; Mitchell et al., 2000) which may be critical for attending to the relevant acoustic cue for VD and retaining this information long enough to facilitate decision-making. However, all older adults in the current study passed the MMSE screening. Furthermore, if cognitive decline played a major role, it would also be expected to affect learning. Yet, in the present study, older and younger adults demonstrated comparable learning outcomes, making this explanation less likely.
Notably, although older adults exhibited poor hearing thresholds and overall VD performance, training with VD based on F0-only cues led to significant improvements, with both the time course and magnitude of their learning closely matching those of the young adults. The lack of significant differences in learning trajectories and overall gains between the two groups suggests that the fundamental mechanisms supporting auditory skill learning remain intact in older adults. This aligns with previous studies showing that older adults can benefit from auditory training despite initially lower performance relative to younger adults (Humes et al., 2014; Kishon-Rabin et al., 2013; Manheim et al., 2018). These findings support the notion that auditory perceptual learning is achievable even as sensory and cognitive capacities decline with age (Anderson & Karawani, 2020; Jayakody et al., 2018), provided that training is appropriately structured.
Moreover, the rapid improvements in VD performance observed across cues in older adults between the first and second blocks of the initial and final testing sessions, mirroring the young adults’ rapid learning, suggest preserved adaptation mechanisms. Similar rapid learning effects have been documented in young adults during speech perception tasks involving degraded speech (e.g., noise-vocoded or accented speech [Banai et al., 2022; Borrie et al., 2012; Davis et al., 2005; Gordon-Salant et al., 2010]), as well as in a VD task (Zaltz, 2024). While aging may negatively affect rapid learning for some types of complex speech, such as TCS (Manheim et al., 2018), studies have shown that older adults with hearing impairments exhibit comparable rapid learning effects to younger adults following repeated exposure to stimuli that are less acoustically demanding, such as accented speech (Gordon-Salant et al., 2010). Fast learning is thought to arise from top-down tuning and adaptation processes that facilitate effective task-solving strategies and reduce response bias (Hauptmann et al., 2005; Hauptmann & Karni, 2002), with recent evidence also suggesting involvement of early stages of perceptual learning (Banai et al., 2022). These mechanisms were suggested to contribute to enhanced speech understanding in difficult listening situations, allowing listeners to quickly adapt to changing acoustic environments (Banai et al., 2022). The current findings, indicating rapid VD improvements in older adults, suggest that brief, voice-targeted training has the potential to enhance the perception of basic acoustic features, which may, in turn, support better performance in challenging listening environments, such as noisy settings, for older adults.
Our finding that three VD training sessions with F0 cues were sufficient for older adults to “close the gap” and reach the naive performance level of the younger group further underscores the efficiency of auditory skill learning in this age group. Similarly, Kishon-Rabin et al. reported that four training sessions were enough for older adults to achieve gap detection performance comparable to the initial (naïve) performance of young adults (Kishon-Rabin et al., 2013). The fact that just a few sessions can bridge the performance gap across various psychoacoustic tasks suggests that the observed age-related differences may primarily result from declines in higher-order cognitive processes, such as auditory attention and decision-making, which are most impacted in the initial phases of learning (Censor, 2013; Karni, 1996). In line with this reasoning, the three-day training in the present study may have enhanced focused attention, enabling better processing of the most informative neural channels, reducing internal noise (Jones et al., 2013), and helping establish efficient task-specific routines (Karni, 1996; Ortiz & Wright, 2010; Wright & Zhang, 2009). However, it is also possible that, alongside these top-down “task learning” processes, lower-level neural changes may have taken place (Hawkey et al., 2004), improving fine-temporal coding deficits associated with aging and, consequently, enhancing F0 perception in older adults. Further research, incorporating a broader range of psychoacoustic tasks, is needed to determine if these age-related “gaps” can consistently be closed within a few training sessions, as suggested by our findings. Such evidence could have significant implications for developing clinical interventions and training protocols aimed at enhancing auditory skills in older populations.
While the study confirmed that both groups showed significant learning gains with the F0-only cues, significant improvement with formant-only cues was observed only in the young training group, indicating a broader scope of learning transfer compared to older participants. A review of the literature reveals that only a limited number of studies have evaluated the generalization of auditory training effects to untrained stimuli in older versus younger adults (Bieber & Gordon-Salant, 2021). Among these, studies on TCS learning show that older adults exhibit less generalization compared to younger adults, with performance improvements confined to the specific compression ratio (Peelle & Wingfield, 2005) and sentence content (Manheim et al., 2018; Peelle & Wingfield, 2005) used during training. Other studies found that all listener groups showed limited but comparable generalization of learning for non-native speech (Bieber & Gordon-Salant, 2017), while no generalization of the learning-gains was observed following noise-vocoded speech training, across groups (Sheldon et al., 2008). Manheim et al. (2018) suggested that older adults may prioritize higher-level semantic information over lower-level acoustic details during auditory processing, which could limit their ability to generalize learning. However, the present findings indicate that even in a basic VD task that requires listeners to focus on acoustic features rather than linguistic content, older adults show a reduced generalization compared to younger adults. This suggests that the difficulty may not stem from a focus on semantic information but rather from age-related declines in perceptual flexibility and auditory processing. Older adults may struggle to adapt to new or altered acoustic patterns due to inefficient auditory processing or declines in cognitive functions such as auditory attention and working memory. These challenges likely hinder their ability to shift focus and adjust perceptual strategies when confronted with different acoustic cues, thereby limiting their capacity to generalize learning effectively. Future studies should test this theory by examining the role of auditory attention and flexibility in learning generalization across various acoustic tasks in older adults.
Interestingly, VD training using the F0-only cue did not significantly improve VD performance when combining F0 and formant cues for either young or older adults, beyond the gains observed in the control groups, which are likely due to rapid learning mechanisms (Banai et al., 2022; Gordon-Salant et al., 2010; Holmes et al., 2021). This result is consistent with a recent study that found no generalization to combined cues after two sessions of VD training with either F0-only or formant-only cues in young adults (Zaltz, 2024). A possible explanation for this outcome may be the distinct processing mechanisms involved for each acoustic cue in VD. Specifically, formant coding primarily relies on spectral processing, while F0 coding depends mainly on temporal processing (Fu et al., 2004; Oxenham, 2008; Xu & Pfingst, 2008). Therefore, in a VD task using both formant and F0 cues, an integration of these coding mechanisms is required. Although this task may benefit from cue redundancy, as indicated by the better performance with combined cues compared to individual ones across groups, it also demands higher-level integration beyond basic sensory processing. The lack of generalization to the combined-cue condition suggests that the neural adaptations resulting from single-cue training may not extend to the complex processing required for integrating multiple acoustic cues (Ahissar & Hochstein, 2004; Irvine, 2018). This finding underscores the specificity of perceptual learning and implies that to facilitate generalization, training protocols may need to incorporate multiple cues or conditions simultaneously, irrespective of age.
Limitations and Future Directions
One limitation of this study is its focus on F0-based training without incorporating variability in the training materials. This protocol was chosen to minimize potential interference from interleaved or consecutive training involving additional conditions (Banai et al., 2010; Maidment et al., 2015), but it may have limited the extent of generalization achieved. Future studies could explore a more varied training approach, alternating between different voice cues (e.g., F0, formants) or introducing varied listening environments, such as background noise, to determine whether such strategies might promote broader learning generalization without compromising the learning timeline. Additionally, incorporating neurophysiological measures, such as auditory-evoked potentials, could offer valuable insights into the neural changes underlying both the successes and limitations in generalization. Finally, caution is warranted in interpreting these results due to the relatively small cohort used in the present study and the differences in hearing sensitivity between the two older adult groups. Future research should aim to replicate these findings while ensuring that hearing thresholds are matched between training and control groups. Additionally, employing a larger sample size and including a broader range of age groups and populations, such as older adults who use hearing aids, would further enhance the applicability and generalizability of the current study's implications.
Conclusions
The novel findings of the present study carry significant implications for the potential of auditory training in older adults with age-related hearing loss. Although older adults showed similar learning efficiency to young adults in the trained condition—VD based on F0 cues, their limited ability to generalize this learning to an untrained voice cue suggests constraints likely associated with age-related declines in processing flexibility (Harada et al., 2013; Schneider, 2011). The present study's results align with the previous suggestions that older adults’ neural reorganization following training may be more constrained to the specific conditions experienced during the training process (Manheim et al., 2018; Peelle & Wingfield, 2005). However, as neural mechanisms were not directly assessed in this study, this interpretation should be approached with caution. Further research is needed to develop training protocols that facilitate broader generalization, especially for older populations, to maximize the potential benefits of auditory training in enhancing speech perception abilities in complex listening environments. Additionally, given the varying degrees of hearing impairment among the older adults in this study, future research should explore whether auditory training outcomes differ based on hearing profile and whether individuals with more severe hearing loss may derive distinct benefits or require tailored intervention approaches.
Footnotes
Acknowledgments
We would like to express our sincere gratitude to Prof. Yaniv Kanat-Maymon for his invaluable assistance with the statistical analysis in this study. We also extend our heartfelt thanks to all the participants for their time and commitment, which made this study possible.
Ethical Considerations
The study received approval from Tel Aviv University Review Board (approval number: 0007524–2).
Author Contributions
Conceptualization, methodology, formal analysis, supervision, writing—original draft, writing—review &editing: Y.Z. Investigation, data curing, formal analysis & writing—review &editing: N. S. All authors have read and agreed to the published version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are publicly available on the Open Science Framework (OSF) (Zaltz, 2025).
Informed Consent
Informed written consent was obtained from all participants.
Appendix
Averaged Voice Discrimination (VD) Thresholds Based on F0-Only, Formant-Only, and Combined F0 + Formant Cues for the Training and Control Groups Across the two Testing Sessions, with Standard Errors Shown in Parentheses.
| F0-only | Formant-only | F0 + Formants | ||||||
|---|---|---|---|---|---|---|---|---|
| Age-group | Group | Blocks/sessions | 1 | 2 | 1 | 2 | 1 | 2 |
| Young Adults | Training |
|
(0.43) |
(0.36) |
(0.17) |
(0.18) |
(0.14) |
(0.17) |
|
|
(0.19) |
(0.24) |
(0.18) |
(0.19) |
(0.13) |
(0.12) |
||
| Control |
|
(0.33) |
(0.29) |
(0.18) |
(0.16) |
(0.17) |
(0.13) |
|
|
|
(0.38) |
(0.18) |
(0.22) |
(0.30) |
(0.12) |
(0.16) |
||
| Older Adults | Training |
|
(0.56) |
(0.37) |
(0.36) |
(0.24) |
(0.42) |
(0.39) |
|
|
(0.32) |
(0.19) |
(0.27) |
(0.46) |
(0.28) |
(0.42) |
||
| Control |
|
(0.31) |
(0.28) |
(0.24) |
(0.19) |
(0.14) |
(0.21) |
|
|
|
(0.42) |
(0.46) |
(0.27) |
(0.15) |
(0.22) |
(0.16) |
||