
Abstract
This study measured electroencephalographic activity in the alpha band, often associated with task difficulty, to physiologically validate self-reported effort ratings from older hearing-impaired listeners performing the Repeat-Recall Test (RRT)—an integrative multipart assessment of speech-in-noise performance, context use, and auditory working memory. Following a single-blind within-subjects design, 16 older listeners (mean age = 71 years, SD = 13, 9 female) with a moderate-to-severe degree of bilateral sensorineural hearing loss performed the RRT while wearing hearing aids at four fixed signal-to-noise ratios (SNRs) of −5, 0, 5, and 10 dB. Performance and subjective ratings of listening effort were assessed for complementary versions of the RRT materials with high/low availability of semantic context. Listeners were also tested with a version of the RRT that omitted the memory (i.e., recall) component. As expected, results showed alpha power to decrease significantly with increasing SNR from 0 through 10 dB. When tested with high context sentences, alpha was significantly higher in conditions where listeners had to recall the sentence materials compared to conditions where the recall requirement was omitted. When tested with low context sentences, alpha power was relatively high irrespective of the memory component. Within-subjects, alpha power was related to listening effort ratings collected across the different RRT conditions. Overall, these results suggest that the multipart demands of the RRT modulate both neural and behavioral measures of listening effort in directions consistent with the expected/designed difficulty of the RRT conditions.
Introduction
The last decade has produced major collaborative efforts evidencing a need to update our approach to hearing health. Common to both the Ease of Language Understanding model (Rönnberg, 2003; Rönnberg et al., 2019; 2013; 2008) and the Framework for Understanding Effortful Listening (FUEL; Pichora-Fuller et al., 2016) is an appreciation for how listeners’ hearing losses and cognitive resources interact to influence the effort they experience when trying to understand speech in adverse listening environments. Indeed, a common complaint from listeners with a hearing loss—that listening to speech feels effortful and cognitively demanding—may find some support in measurable neurophysiological signals where it has otherwise been difficult to show conclusively by comparing normal hearing and hearing loss groups on subjective ratings at fixed intelligibility levels or with behavioral measurements of reaction time in dual-task paradigms (for a review, see: Ohlenforst et al., 2017). The FUEL model further considers how listening difficulty might affect listeners’ motivations to expend effort in conditions where there is little hope of successful understanding (Pichora-Fuller et al., 2016). Related declines in willingness to engage with communication, and with social activities in general, are particularly concerning considering recent suggestions that hearing loss is the largest modifiable risk factor for developing dementia later in life (Livingston et al., 2020).
While there is some agreement in operationalizing “cognitive resources” through measures of working memory capacity (WMC), how to best conceptualize listening effort, let alone measure it, is still contested (e.g., Alhanbali et al., 2019; Francis & Love, 2020; McGarrigle et al., 2014). Perhaps partly for this reason, there is a reluctance to incorporate surveys of listening effort into clinical assessments of speech-in-noise performance. Instead, it is commonly assumed that listeners will exert as much effort as needed to perform the assessment, and no more, so long as the task is not too difficult, nor too easy, and optimal performance is considered a worthwhile goal (Gendolla & Richter, 2010). Differences in speech-in-noise performance are then interpreted to directly reflect differences in the effort required of the listening conditions. However, both behavioral and physiological approaches to quantifying listening effort have shown such measures as separable from task performance (Francis & Love, 2020). Intuitively, one can appreciate how two similarly good measures of speech intelligibility (e.g., 80% correct) may result in disparate experiences of effort depending on factors such as the cognitive capacity of the listener, the properties of the background noise, and/or the listener's motivation to understand the speech. If intelligibility is the only outcome of concern, then our assessments might miss otherwise meaningful insight into the nature of our patients’ speech processing difficulties.
With this in mind, we recently developed and introduced a novel speech-in-noise assessment called the Repeat-Recall Test (RRT; Kuk et al., 2020, 2021; Slugocki et al., 2018). The RRT is designed to be a clinically friendly tool that integrates tests of speech-in-noise intelligibility with measures of auditory WMC, and surveys of listening effort and willingness to engage with communication. By design, different conditions and configurations of the RRT are differentially demanding of listeners’ hearing and cognitive abilities. For example, the RRT assesses sentence-level speech-in-noise recognition over signal-to-noise ratios (SNRs) that range from very challenging to easy (e.g., 0–15 dB, in 5 dB steps), encompassing SNRs that are considered realistic for everyday communication (Smeds et al., 2015; Wu et al., 2018). Listeners may also be asked to remember what was heard for later recall. Recall performance is not only used to derive estimates of auditory WMC but places additional demand on listeners’ cognitive resources during the primary speech-in-noise task. In addition, RRT speech materials comprise complementary sets of sentences that are either semantically meaningful (high context) or rearranged to be syntactically valid but semantically meaningless (low context) which allows clinicians and researchers to study the facilitative role of context on listeners’ speech-in-noise abilities.
The integrative nature of the RRT presents an opportunity to study how individuals’ cognitive abilities interact with the demands of the RRT's listening conditions (SNRs, context availability, recall, etc.) to affect both speech-in-noise performance and the effort experienced by listeners in achieving said performance. Indeed, the unique properties of the RRT have already been leveraged to reveal the benefit of a hearing aid (HA) noise reduction (NR) system through lower ratings of listening effort, despite no effect on speech intelligibility, and to show that listeners with good versus poor WMCs, as defined by the RRT's recall component, differ in how strongly they benefit from a directional microphone system (Kuk et al., 2020).
For ease of use, the RRT relies on self-reported ratings of listening effort provided by listeners after each RRT trial. Self-reports have great clinical value, in that they are easy to collect and directly reflect a listener's experience (i.e., conscious awareness) of effort. However, these ratings may also be biased by listeners’ internal states and retrospective expectations about how they should have performed under the test conditions (Francis & Love, 2020). It would be beneficial to the development and interpretation of the RRT if the test's subjective listening effort ratings could be validated/disambiguated using a more objective measure of actual exerted effort under the different RRT conditions. For example, dual-task measures get closer to measuring exerted effort by loading capacity-limited cognitive systems, such as WMC, which are also thought to be involved in speech processing (for a review, see: Gagne et al., 2017). However, these measures largely assume that listeners are always optimizing performance for the primary speech task and cannot determine if listeners reallocate their cognitive resources between primary and secondary tasks during testing.
Physiological measures of listening effort are also numerous and include electrical skin conductance, heart rate and heart rate variability, blood pressure, pupil dilation (e.g., Koelewijn et al., 2012; Mackersie & Calderon-Moultrie, 2016; Mackersie et al., 2015; Zekveld et al., 2010), and activity in the alpha-band of the electroencephalogram (EEG; Strauß et al., 2014). Neural activity in the alpha-band (8–12 Hz), particularly as measured over posterior electrode sites (i.e., occipitoparietal lobes), has been speculated to reflect a type of domain general neural support system that functionally inhibits or “gates” information flow/processing in brain areas that are not relevant to a particular task (Jensen & Mazaheri, 2010; Klimesch et al., 2007; Weisz et al., 2011). In this capacity, posterior alpha power has been observed to increase with the difficulty of speech-in-noise tests (McMahon et al., 2016; Petersen et al., 2015; Ryan et al., 2022), or decrease with the availability of greater spectral and temporal detail in speech sounds (Obleser & Weisz, 2012). These findings, among others (e.g., Dimitrijevic et al., 2017, 2019), have led to suggestions that synchronization in alpha activity over posterior electrodes can be used as a proxy for estimating exerted listening effort in real time (Strauß et al., 2014). Relevant to the RRT, alpha-band activity has also been observed to increase with memory load (Obleser et al., 2012), though the scalp topography of alpha activity may shift toward frontal electrode sites when reflecting the maintenance of memory contents as working memory is updated (Manza et al., 2014). Using alpha power as a proxy for effort is particularly appealing in studies of listeners with hearing loss given reports that alpha activity can be reliably recorded from the outer ear (i.e., ear-EEG; Ala et al., 2022; Mikkelsen et al., 2015) using dry electrodes as might one day be used on HAs.
The current study measured alpha-band power as a physiological real-time proxy for listening effort in the different conditions of the RRT to examine the relative influence of SNR, context availability, and memory load in older adults with a hearing loss tested in the aided mode. The primary goal of the study was to validate subjective listening effort ratings as measured during the RRT by linking them to underlying neurophysiological dynamics suggestive of exerted effort. We formed four specific hypotheses regarding how we expected the different RRT conditions to modulate both effort ratings and alpha-band power. First, we hypothesized that increasing levels of background noise (i.e., decreasing SNRs) would be associated with greater alpha-band power over posterior electrode sites. Based on the results of Ryan et al. (2022) in younger normal hearing listeners, and predictions made by the FUEL model (Pichora-Fuller et al., 2016) the relationship between posterior alpha and SNR was expected to be nonmonotonic—i.e., maximal at moderately challenging SNRs (e.g., 0, and 5 dB) and lower at positive SNRs (e.g., 10 dB), where listening should be easy, and/or at very challenging SNRs (e.g., −5 dB), where listeners may lose the motivation to continue expending effort in order to understand the speech. Second, we hypothesized that the availability of semantic context (i.e., high versus low context speech materials) would have a facilitative role on speech understanding and thus be associated with a reduction in posterior alpha. Third, we hypothesized that active maintenance of the RRT materials in conditions where listeners were told that recall would be tested would increase alpha activity compared to conditions where recall was not required. Fourth, we hypothesized that listeners subjective ratings of listening effort would be related to their alpha-band activity across the different RRT conditions.
Materials and Methods
Participants
Sixteen mostly older adults (mean age = 71 years, SD = 13, range = 38–84 years, 9 female) with a moderate-to-severe degree of sensorineural hearing loss participated in the current study. Participants’ hearing thresholds were assessed with audiometric headphones (Telephonics, TDH-50P) using the standard Hughson-Westlake method (i.e., up 5, down 10 dB). Four-frequency (0.5, 1, 2, and 4 kHz) pure-tone averages (PTA4 s) were 52.7 and 49.1 dB HL (SD = 11.3, range = 31.2–68.8) for the left and right ears, respectively. The loss was symmetrical within 15 dB in all but three participants across frequencies. The asymmetry of the remaining three participants did not exceed 20 dB at any three contiguous frequencies (Figure 1). Thirteen participants were experienced HA wearers (average duration of use = 24.5 years, SD = 12.6, range = 8–50). Daily HA usage ranged from 4 to 16 h per day, with an average usage of 11.3 h per day. Only three experienced HA wearers used their own HAs for less than 10 h per day. Overall satisfaction for participants’ own HAs in noisy conditions averaged 3 (out of 5, i.e., acceptable or neutral) as assessed by a subset of questions from the MarkeTrak questionnaire (Kochkin, 2010). The three nonwearers had participated in HA studies, previously. All participants were native speakers of US English and passed cognitive screening (average score = 27.3, range = 24–30) on the Montreal Cognitive Assessment (MoCA; Nasreddine et al., 2005) at a criterion of ≥23 (Carson et al., 2017). Participants gave their written informed consent and were remunerated financially in accordance with a protocol approved by an external, independent Institutional Review Board (Salus IRB).

Individual pure-tone thresholds (thin lines) for the left (blue lines) and right (red lines) ears of 16 older adult listeners with a hearing loss. The average pure-tone threshold in each ear is plotted in a thicker line and noted with solid Xs and open circles for the left and right ears, respectively.
Hearing Aids
All listeners were tested in the bilateral aided mode with Signia AX receiver-in-canal HAs. These multichannel WDRC HAs use both input and output compression with ratios typically below 4:1 and adaptive release times. The study aids were programmed using the latest version of Signia Connexx fitting software (version 9.4.0.255). Participants were fit according to the NAL-NL2 formula at 100% prescription gain for instant-fit closed ear domes. Hearing aid output was verified via coupler measurement (Verifit2, AudioScan). The HAs were tested in a standard omnidirectional microphone mode without compensation for the pinna effect. Two simultaneously operating NR algorithms were enabled. The first NR algorithm reduces gain in channels where the dominant signal is relatively unmodulated. The second NR algorithm uses a fast-acting adaptive Wiener filter that tracks the signal envelope to calculate SNR and update filter coefficients within each channel. The two NR systems operate continuously based on overall input levels and SNRs. Additional advanced features, other than feedback cancellation, were disabled. None of the participants had any prior experience wearing the study aids. Although there was no formal acclimatization period, participants wore the study aids while the experimenter conducted the MoCA, explained the study tasks, and fit the EEG cap. The total time between being fit with the study aid and the start of data collection was approximately 1 h. When asked, no participants expressed concerns regarding the sound of the study aids.
Repeat-Recall Test—Stimuli
The RRT draws speech materials from five sets of thematically related passages. Each theme comprises seven passages of six sentences. Each sentence contains three to four target words (mostly nouns, adjectives, and verbs) so that 20 target words are scored for every passage. Speech materials are designed with complementary high context (e.g., “The tart pie had too much lemon;”) and low context passages (e.g., “The tart chef had too many countries.”) where target words in the six sentences of a given high context passage have been rearranged across the six sentences of a complementary low context passage to produce sentences that are syntactically correct but semantically meaningless. As such, the RRT speech corpus comprises 420 unique sentences (i.e., 5 themes * 7 passages * 2 contexts * 6 sentences = 420 unique sentences). For a detailed description of the rationale behind the RRT's speech corpus, see Kuk et al. (2021).
Repeat-Recall Test—Procedure
The study followed a single-blind within-subjects design. Participants were tested in a single two-hour session at the ORCA-USA office. All testing took place in a double-walled sound-treated booth (Industrial Acoustics, Bronx, NY; internal dimensions: 3 × 3 × 2 m, W × L × H) with listeners seated on a comfortable chair in the middle of the booth.
Prior to testing, listeners were instructed on performing the RRT using a standardized script. After instruction, a practice RRT trial was administered using a dedicated low context passage presented at an SNR of 10 dB. The RRT speech materials were presented at a fixed conversational level of 65 dB SPL from a single KRK ST6 loudspeaker (±2 dB from 62 Hz to 20 kHz) located directly in front (0° azimuth) and continuous speech-shaped noise was simultaneously presented from the back (135° and 225° azimuth) using two identical model KRK ST6 loudspeakers. The level of the noise was varied to produce each of four SNRs (−5, 0, 5, and 10 dB) as verified by separate measurement of speech and noise using a Quest Technologies Model 1800 sound-level meter. Loudspeakers were driven by the output of a Niles SI-1230 (Nortek Security & Control LLC) power amplifier that received input from a Focusrite 18i20 sound card (Focusrite PLC) connected to a PC (Windows 10) running the RRT software. Prior to every experiment session, the output level of each loudspeaker channel was calibrated using the Quest sound-level meter.
Each trial of the RRT involved four stages that were guided by the RRT software. In the repeat stage, listeners were presented with a sequence of six prerecorded sentences in noise at one fixed SNR. Listeners were tasked with repeating each sentence as it was heard and committing the content of the sentences to memory. The experimenter scored target words in each sentence for correct repetition. After the final sentence, and a brief retention period (15 s), listeners were prompted to begin the recall stage where they were to recall as much sentence content as possible, verbatim. Only those target words that had been repeated correctly during the repeat phase were eligible for scoring during the recall phase. Listeners then rated how effortful they found the listening situation on a 10-point Likert-type scale, with “1” representing minimal effort, “5” representing moderate effort, and “10” representing very effortful listening. Specifically, listeners were instructed to “indicate how effortful it was to hear in the background noise” (Table 1). Lastly, listeners provided an estimate of how much time (in minutes) they would be willing to try to spend listening to the talker under the specific test conditions (i.e., tolerable time). The noise stimulus alone was presented for 20 s prior to each RRT trial so that the HA processing could stabilize.
The RRT Instructional Script Read to Each Listener Prior to Testing.

Testing proper was executed in two blocks, where one block included the recall stage, and the other block omitted the recall stage. Each block assessed listener performance for both high and low context RRT passages at each of four fixed SNRs (−5, 0, 5, and 10 dB). Each combination of conditions was tested using a single RRT passage of six sentences. All four SNRs were first tested using low context passages to minimize any learning/carryover effects that may have resulted from first testing with semantically meaningful (i.e., high context) sentences. The order of SNRs was fully counterbalanced across participants. High context passages were then tested across the same four SNRs following the same SNR order that was used to test low context passages for a given participant. Unique complementary high and low context passages (i.e., same target words) were used to assess each SNR. Hence, four unique passages related to a single theme, each with complementary high/low context versions of six sentences (i.e., 48 sentences), were selected from the RRT speech corpus for each participant. The selection of four passages within a theme was randomized per participant, whereas the choice of theme was balanced across participants to the extent possible (i.e., four out of five themes were tested across three unique participants, and the remaining theme was tested across four unique participants). The average duration of the RRT sentences used in the current experiment was 2.3 s (SD = 0.3, range = 1.3–3.3). The same passages were used to test each participant in the no recall block. The order of RRT blocks (i.e., with recall and no recall) was fully counterbalanced across participants. Participants were informed and understood whether a particular block was going to be tested with or without the memory component before the test block.
Listeners were instructed to refrain from closing their eyes (except for blinking) while performing the RRT to control for the well-known dominance of alpha activity in the EEG during eyes-closed resting conditions and relative attenuation during visual stimulation (e.g., Barry et al., 2007; Volavka et al., 1967). To facilitate an eyes-open state, listeners were instructed to focus their gaze on a touchscreen computer monitor (17” Planar PT 1700 MU) placed on a small table directly in front at a 45° downward angle in the median plane. The position of the monitor did not obstruct a direct line between the loudspeaker and the listener's ears. The RRT software presented visual prompts on this monitor that would alert listeners to respond according to the RRT phase (e.g., “Repeat,” “Wait,” “Recall,” “Listening Effort,” “Tolerable Time”).
Electroencephalography
During RRT testing, listeners’ EEGs were recorded using 19 Ag/AgCl sintered electrodes embedded in an elastic cap (g.GAMMAcap, g.tec medical engineering GmbH). The electrodes were positioned at Fp1, Fp2, Fz, F3, F4, F7, F8, Cz, C3, C4, T7, T8, Pz, P3, P4, P7, P8, O1, and O2 according to the 10–20 system. The EEG signals were amplified and then digitized at a rate of 19.2 kHz using a g.USBAMP (g.tec) biosignal amplifier. Digitized signals from the amplifier were routed to a PC (Windows 10) via a USB interface and recorded using g.RECORDER (g.tec) acquisition software. Electrode channels were referenced online to physically linked bilateral earlobe electrodes with a forehead electrode serving as ground. To reduce impedance, electrode sites were prepared with a mild exfoliating paste (LemonPrep Gel, Mavidon), and the electrodes wells were filled with a conductive saline gel (SignaGel, Parker Laboratories, Inc.). Electrode impedances averaged 27.9 kΩ (±23.7 SD) across all participants and electrode sites. Square wave triggers sent to the biosignal amplifier denoted the timing of RRT sentences in the EEG acquisition software. Triggers were time-aligned and embedded with the RRT materials in eight-channel audio files. Different triggers (i.e., separate audio channels) were used to denote RRT sentence onsets and offsets. Recordings lasted approximately 25 min for the with recall block and 15 min for the no recall block. Total experiment time, including participant intake, instruction/practice on the RRT, electrode set-up/clean-up, and debriefing amounted to just under 2 h.
Analysis
Listener RRT performance was analyzed in R using separate linear mixed effects (LME) models as fit using the lme4 package (Bates et al., 2015) for each of the RRT outcome measures: repeat (i.e., speech-in-noise intelligibility), recall (i.e., memory), subjective listening effort, and tolerable time (i.e., noise acceptance). Models assessing repeat, subjective listening effort, and tolerable time each examined the fixed effects of SNR (−5, 0, 5, and 10 dB), context (high and low), and RRT version (no recall and with recall). The model assessing recall only examined the fixed effects of SNR and context. All models coded participants as random effects with unique intercepts. Prior to analysis, repeat and recall data were transformed into Rationalized Arcsine Units (Studebaker, 1985) to help linearize the proportional data near floor/ceiling performance. In addition, tolerable time data were log-transformed to account for the positive skew of listener responses.
Listener EEG data were processed offline in MATAB using the EEGLAB toolbox (Delorme & Makeig, 2004). First, the EEG was resampled at 250 Hz. Next, the continuous EEG was high-pass filtered at 1 Hz using a noncasual Butterworth filter (4th order, 24 dB/octave) to remove drift. Filtered data were then cleaned of line noise using the CleanLine plugin (Mullen, 2012). Additional artifacts were removed using Artifact Subspace Reconstruction (Kothe & Makeig, 2013) as implemented in the clean_rawdata plugin (Miyakoshi, 2023), where bad data regions were defined as those exceeding five standard deviations of the mean (i.e., burst criterion), before low-pass filtering (4th order noncasual Butterworth, 24 dB/octave) at 30 Hz. Epochs were cut from 0 to 8.5 s after sentence onset and rejected if they contained large artifactual activity exceeding ±100 μV. The average number of epochs surviving this artifact rejection was 93.2 out of 96 total epochs across all conditions (SD = 3.6, range = 86–96). A detailed summary of the number of surviving epochs per level of each condition is provided in Table 2. An additional “baseline” epoch was defined from −10 to 0 s relative to the onset of the first sentence of a given RRT trial/passage (i.e., sequence of six sentences). Cleaned data from each condition were analyzed at each electrode using the pspectrum function in MATLAB to generate short-term power spectrum estimates. Time-frequency data for all epochs were then baseline corrected in the frequency domain by subtracting the corresponding baseline spectrum (i.e., unique baseline for each combination of participant, electrode, and RRT condition). Alpha-band activity was defined as the maximum absolute power between 8 and 12 Hz at each time point in the time-frequency transformed data. Time traces of alpha power were cut from the beginning of each RRT sentence until 5 s after sentence onset to accommodate lagging alpha responses observed visually in time-frequency plots that may have been related to active sentence reconstruction (Rönnberg, 2003; Rönnberg et al., 2013). Alpha power values in these windows were then averaged across sentences for each combination of test conditions.
Descriptive Statistics for the Number of Sentences/Epochs of the Continuous EEG That Survived Simple Threshold-Based Artifact Rejection at a Criterion of ±100 μV.

The limited trial count (i.e., six sentences) collected at each unique combination of conditions precluded analyzing all possible interactions in this fully crossed design. Hence, an LME model was used to only evaluate the fixed effects of the different RRT conditions (i.e., SNR, Context, and RRT version), as well as the possible two-way interaction of Context and RRT version, on the average of alpha-band activity calculated across posterior electrodes (Pz, P3, P4, P7, P8, O1, and O2). In this way, each level of SNR would reflect data collected across 24 sentences as would each level of the possible two-way interaction of Context and RRT version. This model coded participants as random effects with unique intercepts.
A final LME model assessed the relationship between the fixed effect of alpha-band power (predictor variable) and subjective ratings of listening effort (dependent variable) measured during the RRT. To address the ceiling/floor effects observed in ratings of listening effort, data were limited to those measured at SNRs of 5 and 10 dB. Given that effort is observed to correlate with SNR, we also included SNR as a fixed effect in this model. To ensure this did not introduce multicollinearity, we computed variance inflation factors (VIFs) for each fixed effects term and determined that all VIFs were below 1.5, where VIFs of 5 are typically considered to signal highly correlated variables. As our interest was primarily in determining whether alpha power was related to listening effort ratings within listeners, our model coded participants as random effects with unique intercepts. This LME model formulation could be interpreted as a linear multilevel model analogue to the “repeated measures correlation” described by Bland and Altman (1995). The model was not intended to explore whether alpha power might account for variance in listening effort scores beyond that introduced by the RRT conditions, but rather to show that the RRT conditions affected both alpha and listening effort scores similarly across conditions within individual listeners.
For all tests, residual plots were visually inspected to ensure no obvious deviations from normality or homoscedasticity. P values were obtained by Wald tests (Type II SS) of linear hypotheses using the Chi-square statistic as implemented in the car package for R (Fox & Weisberg, 2019). Post hoc analysis of significant fixed effects and interactions were conducted using the emmeans package (Lenth et al., 2021) in R with significance levels Tukey adjusted for multiple comparisons. Summarized data reviewed below are available upon request.
Results
Repeat-Recall Test Outcome Measures
Listener performance-intensity (P-I) functions for the different RRT outcome measures are shown in Figure 2. In general, the P-I functions measured using RRT with recall followed those reported previously by Kuk et al. (2020) for older listeners with a hearing loss tested under similar conditions (i.e., speech-front, continuous noise back with HAs set in the omnidirectional microphone mode). The LME model results for each of RRT outcome measures are summarized in Table 3. Significant effects related to SNR and Context also replicate Kuk et al. (2020) where all outcome measures were observed to improve with increasing SNR and with the availability of semantic context. Significant interactions of SNR and context observed for repeat, listening effort, and tolerable time outcomes, further reflect stronger facilitative effects of context at better SNRs (i.e., >5 dB) and floor effects at the lowest SNR. New to this study, our analyses found that RRT version (no/with recall) had a significant effect on subjective ratings of listening effort and tolerable time. In general, listeners rated the same test conditions as more effortful and less tolerable when recall was assessed. On the other hand, RRT version did not significantly affect listeners’ repeat performance. Together, these results suggest that listeners were sensitive to the extra demand placed upon them by the memory (i.e., recall) component, even if it did not interfere with their performance on the primary speech-in-noise task.

Performance-intensity functions of the different RRT outcome measures across four fixed SNRs. Points represent performance/rating means and error bars represent within-subjects 95% confidence intervals of the means. Data are shown as measured using low context (dashed/open) and high context (solid) speech materials in no recall (black) and with recall (yellow) versions of the RRT.
Summary of LME Models Assessing Fixed Effects and Interactions on Four Different RRT Outcome Measures.

n.s. = not significant, * p < .05, ** p < .01, *** p < .001.
Alpha-Band Power
Tracings of alpha-band power, averaged across sentences and participants, are plotted as a function of time in Figure 3 for each combination of RRT conditions. Horizontal grey bars in each panel of Figure 3 define the window over which alpha power was averaged for all analyses that follow.

Time traces of alpha-band power plotted across 8.5 s trial epochs. Tracings are plotted as measured at different test SNRs (panels) using low context (dashed) and high context (solid) speech materials in no recall (black) and with recall (yellow) versions of the RRT. In each panel, vertical dashed lines denote sentence onset at 0 s and horizontal grey bars define the window over which alpha power was averaged for analysis.
Our first hypothesis was that alpha-band power would be affected by SNR. We further expected this relationship would be nonmonotonic where alpha-band power would be highest at moderately challenging SNRs (0/5 dB) and decrease at easier (10 dB) and more difficult (−5 dB) SNRs. As predicted, the LME model analysis revealed that alpha-band power was significantly affected by SNR (Figure 4, left; Table 4). However, contrary to predictions made based on the FUEL model, post hoc tests revealed a monotonic relationship between SNR and alpha-band power where alpha-band power decreased significantly from SNR = 0 dB through SNR = 10 dB but was equally high at SNRs of −5 and 0 dB. Hence, whereas more favorable SNRs appeared to disengage processes contributing to power in the alpha-band, no such disengagement was observed at the least favorable SNR where average listener intelligibility was near 0%.
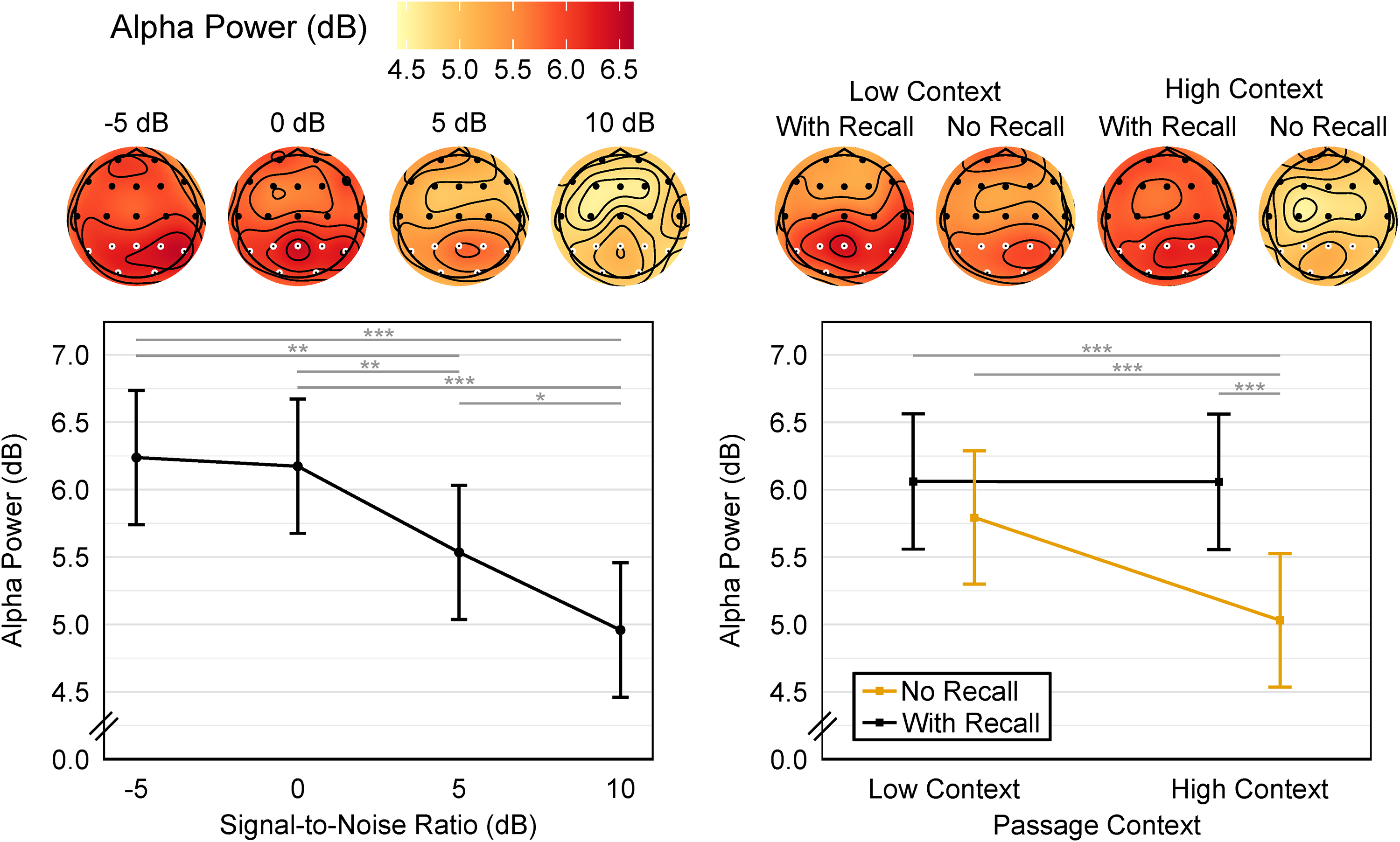
Summary of alpha-band dynamics measured as listeners performed the RRT. TOP: Scalp topography of alpha-band power relative to baseline summarized across different RRT conditions. Posterior electrodes used for statistical analysis are highlighted in white. BOTTOM: Estimated marginal means exploring the significant fixed effect of SNR (right panel) and the significant two-way interaction of Context × RRT version (right panel) on alpha-band power measured at posterior electrodes. Error bars represent 95% confidence intervals around each estimated marginal mean. Asterisks denote significant contrasts Tukey adjusted for multiple comparisons, * p < .05, ** p < .05, *** p < .001.
Summary of LME Model Assessing Fixed Effects and Interactions on Alpha-Band Power.

* p < .05, ** p < .01, *** p < .001.
Our second and third hypotheses were that alpha-band power would be greater for low than high context sentences and for with recall than no recall conditions, respectively. Here, the results of the LME model analysis revealed that the availability of semantic context affected alpha power differently depending on whether participants had to store the sentences in memory for the recall task as captured by the two-way interaction of Context and RRT version (Figure 4, right; Table 4). Specifically, in the no recall condition, alpha-band power was significantly lower when listeners were tested with high context compared to low context sentences. In the with recall condition, alpha-band power was equally high for both high and low context sentences. Alpha-band power was also significantly lower in no recall compared to with recall conditions, but only when listeners were tested with high context sentences. These results are in partial agreement with our second and third hypotheses but add nuance suggesting that the facilitative effect of context on reducing effort may be negated when listeners must actively maintain the RRT materials in memory.
Lastly, our fourth hypothesis predicted that participants’ subjective ratings of listening effort provided during the RRT would be positively related to their alpha-band power measured across different RRT conditions. Here, a final LME model restricted to favorable SNRs (i.e., 5 and 10 dB) where listeners did not consistently rate their effort at near maximum, confirmed that the relationship between RRT listening effort ratings and alpha-band power was indeed significant (χ2(1) = 8.73, p = .003) after controlling for the significant fixed effect of SNR (χ2(1) = 36.33, p < .001). This result, displayed graphically in Figure 5, suggests that listeners performing the RRT were able to reliably rate their experience of listening effort in a manner reflecting neurophysiological changes that mostly followed the difficulty of different RRT conditions. Interestingly, Figure 5 (left) also shows that the nature of this relationship was somewhat listener dependent. Although most (n = 12) individuals exhibited positive associations between alpha power and ratings of listening effort, as suggested by the LME model, a subset of listeners (S02, S04, and S13) exhibited a negative relationship, and one listener (S10) showed virtually no relationship. Unfortunately, the relatively small sample size of our study precluded exploring what factor(s) might have explained the difference between these groups of listeners.

LEFT: Scatterplots comparing individual listeners’ alpha power relative to their subjective ratings of listening effort as measured across different conditions of the RRT after partialling out the effect of SNR. Colored lines represent least-squares fits of the individual listener data and the solid black line represents the significant LME relationship bewteen alpha power and listening effort assessed within-listeners after controlling for the effects of SNR. The shaded region represents the 95% confidence interval of that linear relationship. RIGHT: Scatterplot representing the same data from all listeners with different colors representing data from different individual listeners.
Discussion
General
The primary goal of the current study was to assess whether different conditions of the RRT dynamically modulate alpha-band activity in older (aided) adults with a hearing loss in a way that would validate the RRT's subjective listening effort ratings. Based on previous studies, we hypothesized that the three major components by which the RRT is designed to increase the difficulty of the listening task—i.e., decreasing SNR, limiting semantic context, and requiring later recall of the test materials—would each be associated with increased posterior alpha-band power and that these changes in alpha power would mirror changes in listeners’ subjective ratings of listening effort. As expected, alpha power and subjective ratings of listening effort were both significantly affected by SNR, but the relationships between either behavioral (RRT listening effort ratings) or physiological (alpha-band power) indices of listening effort and SNR were observed to be monotonic over the range of SNRs tested. Notably, both behavioral and neurophysiological measures behaved similarly across SNRs, plateauing at the most challenging SNRs of −5 and 0 dB and decreasing significantly with increase SNR from 0 through 10 dB. In addition, the availability of semantic context affected alpha power differently based on whether listeners were required to later recall the sentence materials. Here, we had hypothesized overall alpha-band power would be lower for high context than for low context sentences, but this was only observed when listeners were told that later recall would not be required. Similarly, we had expected overall alpha-band power to be lower when recall was omitted, but this was only observed when listeners were tested with high context speech materials. An interaction between context and the memory requirement was notably absent for behavioral ratings of listening effort measured during the RRT. Critical to this study, the significant relationship between alpha-band power and RRT ratings of listening effort observed within listeners suggests that the effortfulness experienced and reported by these listeners across different conditions of the RRT is largely supported by neural signatures of exerted listening effort. As such, the RRT appears to be a useful tool for investigating how a listeners’ experience of effort is affected by each of the test's components.
Comparison to Other Studies
The results of the current study contribute to the existing literature supporting synchronization of alpha-band activity in the EEG as a neural signature of effortful listening (Dimitrijevic et al., 2017, 2019; McMahon et al., 2016; Paul et al., 2021; Ryan et al., 2022; Strauß et al., 2014). The results also further extend the evidence supporting alpha as a proxy of listening effort in older aided adults (e.g., Petersen et al., 2015) to the processing of sentence-level speech. While it was expected that alpha power would be reduced at the least favorable SNRs, where extreme difficulty might cause participants to disengage with the task, the relationship between alpha-band power and SNR was instead unexpectedly monotonic over the range of test SNRs. Although inconsistent with predictions made by the FUEL model (Pichora-Fuller et al., 2016) and with reports from Ryan et al. (2022) in younger normal hearing listeners, the results of the current study are internally consistent with listeners’ subjective ratings of listening effort measured by the RRT. Part of the discrepancy between the current study and Ryan et al. (2022), with respect to the relationship between alpha power and SNR, might be related to the choice of speech materials. Ryan et al. (2022) used a simple monosyllabic test (i.e., Words-In-Noise; Wilson, 2003) where listeners could use the carrier phrase (“say the word__”) to quickly evaluate whether the noise was likely to obfuscate the target word and then adjust expended effort accordingly. In contrast, the current study used sentence-level materials and tested each SNR over six consecutive sentences meaning that listeners may have stayed more motivated to listen for any possible words that were intelligible through the noise. Indeed, using sentence-level speech materials (i.e., Bamford–Kowal–Bench/Australian Version; Bench et al., 1979) across a range of SNRs similar to those of the current study, McMahon et al. (2016) found parietal alpha increased monotonically with decreasing SNR in younger normal hearing listeners. This suggests that choice of speech materials should be carefully considered for their effects on listeners’ motivations to expend effort during speech-in-noise assessments. Future work might individualize the range of SNRs tested according to the performance and/or effort ratings of different listeners to examine whether a nonmonotonic trend could also be observed when listeners are tested with the sentence-level RRT materials.
Interestingly, the extent to which semantic context influenced alpha-band activity depended on whether listeners were tested with or without the RRT's recall component. In the no recall conditions, alpha synchronization was reduced for high context as compared to low context sentences, as might be expected by the facilitative role of semantic context in supporting speech understanding (McMahon et al., 2016; Holmes et al., 2018; Ryan et al., 2022; Winn, 2016). However, Hunter (2020) observed the opposite effect in younger normal hearing listeners. Specifically, materials drawn from the revised version of the Speech Perception in Noise (SPIN-R) test (Bilger et al., 1984) with unpredictable sentence final words were associated with greater event-related alpha desynchronization (i.e., greater decrease in alpha relative to baseline) compared to SPIN-R materials where the sentence final word was predictable. Part of this discrepancy might be explained by differences in the precise nature of the “context” under manipulation. While the context effect in Hunter (2020) relied on a semantic violation in the final word, the context effect in the RRT was present throughout the test sentence. Hence, in Hunter (2020), alpha-band power that was already elevated due to task demands may have been disrupted due to the surprising semantic mismatch, whereas listeners performing the RRT could leverage context through the entire test sentence thus leading to reduced effort and reduced alpha-band power.
On the other hand, alpha-band power was equally elevated for high and low context sentences when listeners were explicitly instructed that they would later be required to recall the test materials. In this case, we speculate that availability of semantic context may have influenced how listeners allocated cognitive resources to each of the repeat and recall tasks. If we consider reduced alpha-band power for high versus low context sentences in no recall conditions to suggest that the encoding of predictable sentences is less cognitively demanding, then significantly elevated alpha-band power for high context sentences in with recall conditions might suggest listeners are leveraging spare cognitive resources in support of recall performance. Elaboration of semantically meaningful high context sentences is one strategy through which listeners could attempt to improve the maintenance of target words in memory (e.g., Anderson, 1983; Riggs et al., 1993). Speaking to the connection between alpha-band power and rehearsal, Meeuwissen et al. (2011) observed that stronger alpha activity (i.e., greater raw spectral power) predicted successful long-term memorization of three-word sequences when listeners were explicitly encouraged to make sentences of the three words to aid with remembering their order. Indeed, the semantic context afforded by high context sentences would be conducive to the use of advanced storage/maintenance strategies, such as chunking (Miller, 1956) or story-based mnemonics (Hill et al., 1990; 1991), which may have further motivated listeners to exert the effort required to improve recall performance. Conversely, attempting to memorize speech materials that are highly unpredictable could be demoralizing, especially as required over the duration of a six-sentence RRT trial. As such, most of the effort exerted for processing low context sentences would be devoted to the repeat task rather than the recall task. Still, it is curious that a similar interaction of context and recall was not observed in behavioral measures of listening effort or tolerable time collected during the RRT. Though listeners were instructed to base their ratings on “how effortful it was to hear with the background noise,” these ratings were still independently affected by context and the inclusion/omission of the recall requirement. One possible explanation is that the increased alpha-band power observed for memorization of high context sentences, and that reported by Meeuwissen et al. (2011), is separate from the expression of alpha that is associated with the experience of listening effort. Again, such results underscore the need to consider the nature of speech materials used to investigate alpha-band dynamics as they relate to cognitive effort.
Whereas our overall results were consistent with reports of alpha synchronization increasing with decreasing SNR (McMahon et al., 2016; Ryan et al., 2022; Strauß et al., 2014), and hence with an increase in implied listening effort, analysis of the relationship between alpha-band power and RRT ratings of listening effort suggested the possible existence of two subgroups of listeners. The larger (n = 12) subgroup exhibited the expected positive relationship between alpha-band power and ratings of listening effort (Dimitrijevic et al., 2019; Paul et al., 2021; Ryan et al., 2022). The smaller subgroup (n = 4) exhibited a much weaker or negative relationship between the neural and subjective measures of effort. Although our limited sample size precludes determining which, if any, individual factors might separate the two groups, we can speculate on at least two possibilities. First, it is possible that the two groups of listeners approached their ratings of listening effort differently. For example, one can interpret effort as that required of the task or that invested into the task. Whereas ratings of required effort tend to show a close relation to objective task difficulty, ratings of invested effort are less consistent (e.g., Mulert et al., 2007). Second, given that the negative relationship between alpha power and effort ratings was generally weaker in the smaller subgroup, it is possible that these listeners simply did not exhibit much measurable alpha modulation in response to the changing demands of the RRT. Perhaps, these listeners show little alpha modulation in general, or else they found the entire limited set of test conditions too difficult such that both alpha power and effort ratings stayed near maximum across the conditions. Future studies assessing the RRT at more positive SNRs might be useful in addressing this second possibility. Additional studies may also attempt to specifically recruit listeners who show opposite relationships between alpha-band power and reported listening effort ratings to better understand the factors that determine the direction of this relationship in the two groups.
Implications for the RRT
The results of the present study further support the use of the RRT as a tool for assessing speech-in-noise difficulties and listening effort across a range of challenging listening conditions. Moreover, discrepancies between intelligibility (i.e., repeat) performance and subjective ratings of listening effort highlight the value of evaluating speech-in-noise abilities using an assessment sensitive to the potential influence of central factors. For example, although the inclusion/omission of the recall component did not affect listener performance on the primary speech intelligibility (i.e., repeat) task, listeners did exhibit increased alpha synchronization while listening to sentences if they were required to commit sentence materials to memory for later recall, though this effect was strongest for high context sentences. Subjective ratings of listening effort and tolerable time measured by the RRT further suggest that listeners experienced this extra cognitive demand despite being instructed to base their ratings solely on how difficult it was to hear the speech. In this way, listening effort ratings could be used along with recall scores to differentiate between listeners with generally better/poorer cognitive capacities who may find achieving the same speech-in-noise performance scores differentially demanding (e.g., Kuk et al., 2020).
Limitations and Future Directions
As stated above, the goal of this study was to measure alpha-band power as a means of validating/contextualizing the effort experienced by listeners performing the RRT. This required analysis of EEG data recorded while administering the RRT as would be done in a clinical setting. Although the full RRT can be completed rather quickly (∼25 min) considering the amount of information it provides (i.e., full high/low context P-I functions across realistic SNRs for repeat/recall performance and subjective ratings of listening effort and tolerable time), the test bases this information on performance across a single RRT passage of six sentences. For behavioral performance, the average of 40 monosyllabic words (with 20 of those being unique target words) has been shown to have good test–retest reliability (Slugocki et al., 2018), but this falls short of the monosyllabic word counts used by other studies (e.g., 100 trials per condition in Dimitrijevic et al., 2019) for comparing alpha-band power across conditions. The test time required to match an equivalent monosyllabic word count would likely be too long for listeners to remain fully engaged with the difficult conditions of the RRT. The RRT speech materials are also limited in quantity. Increasing the number of repetitions for each combination of conditions would mean that listeners would be exposed to the same test materials multiple times which may have led to familiarization with the test materials and possibly impacted the difficulty exerted/experienced on any given condition. As such, we restricted our analysis of these data to focus on the main effect(s) of three possible determiners of task difficulty in the RRT (i.e., SNR, context availability, and recall requirement [RRT version]) as well as the possible two-way interaction of context and recall. In this way, each level of SNR comprised activity recorded over 24 RRT sentences (∼160 monosyllabic words, 80 target words) as did each crossed level of context and RRT version. Unfortunately, this restriction limited our ability to gain insight into more complex interactions between the three main effects. For example, the inclusion/omission of the recall requirement may have impacted the monotonicity of alpha-band power's relationship with SNR. Later studies may focus on a smaller range SNRs, or else limit the test to a single context and/or recall condition, in order to accommodate the larger trail counts necessary to explore these possible interactions.
As we did not test at more positive SNRs, we cannot ascertain how much further alpha-band power might have been reduced in conditions which are more realistic to everyday communication (i.e., ≥80% intelligibility; Smeds et al., 2015; Wu et al., 2018). Average listening effort data measured by the RRT in the current study did not approach the lowest anchor, whereas previous studies (e.g., Kuk et al., 2020) have observed lower effort ratings under more favorable conditions. One positive interpretation of this result is that listeners did not simply scale their listening effort ratings according to the range of background noise levels tested, which bodes well for the RRT's ability to measure listeners’ actual experience of effort. However, given that the availability of semantic context appeared to have stronger effects on subjective listening effort ratings at the most positive SNR of 10 dB, our study conditions may have missed potential facilitative effects of semantic context on listeners’ alpha-band activity at SNRs that would support greater low context intelligibility performance. Of course, it is possible that hearing loss itself, even if corrected with HAs, and/or the age of the listeners who participated in the current study would always make listening feel somewhat effortful in all but the quietest conditions (Ohlenforst et al., 2017). Future studies might use dense-array EEG to better localize the sources of alpha activity modulated by the RRT and compare older normal hearing and aided hearing-impaired listeners across conditions extending to more positive SNRs. Such studies could reveal the performance levels and/or test conditions required to maximally ameliorate alpha/effortful listening in the two groups.
We must also acknowledge that our choice to use the same HAs for all participants in the study (which had instant-fit closed dome ear tips) may have caused some listeners to contend with listening to sound that deviated from that of their everyday HAs or their preference for listening unaided. During the 1-h preparation for the experiment proper (i.e., fitting, task explanation, and EEG cap setup), participants were asked explicitly by the experimenter whether the study devices “sounded ok” with attention directed to the quality of the experimenter's voice and that of their own. Although no participant expressed concerns regarding the sound of the study aids, the effect of testing in controlled conditions (i.e., same study aid) compared to more ecologically valid conditions (i.e., participants’ own devices or unaided) is worth considering. Our choice to use common study aids helped to ensure that HA output matched prescribed NAL-NL2 gain targets, that the HA settings would not be changed during testing by the action of a HA classifier, and that certain listeners’ HAs would not be providing strong directionality which would negate the expected difficulty of the task where speech was presented from the front and noise was presented from the back. Individualizing the SNR space and/or speech input level according to the behavior of participant's own devices could be one way for future work to assess the impact of device unfamiliarity on perceived listening effort and alpha. Such a study may be particularly relevant to better understanding the negative/positive reactions that some listeners have when being fitted with new HAs.
Conclusion
In older adult listeners with a hearing loss tested in the aided mode, neural activity in the alpha-band mostly followed the expected difficulty of test conditions comprised in the RRT as they pertain to the effort demanded of inhibiting distracting noise while processing speech with high/low availability of semantic context and retaining said speech content in auditory memory. The RRT may be a useful tool for researchers and clinicians to better understand how a listeners’ experience of effort is affected by each of the test's components.
Footnotes
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: All authors are employees of WS Audiology.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.