
Abstract
Technology options for children with limited hearing unilaterally that improve the signal-to-noise ratio are expected to improve speech recognition and also reduce listening effort in challenging listening situations, although previous studies have not confirmed this. Employing behavioral and subjective indices of listening effort, this study aimed to evaluate the effects of two intervention options, remote microphone system (RMS) and contralateral routing of signal (CROS) system, in school-aged children with limited hearing unilaterally. Nineteen children (aged 7–12 years) with limited hearing unilaterally completed a digit triplet recognition task in three loudspeaker conditions: midline, monaural direct, and monaural indirect with three intervention options: unaided, RMS, and CROS system. Verbal response times were interpreted as a behavioral measure of listening effort. Participants provided subjective ratings immediately following behavioral measures. The RMS significantly improved digit triplet recognition across loudspeaker conditions and reduced verbal response times in the midline and indirect conditions. The CROS system improved speech recognition and listening effort only in the indirect condition. Subjective ratings analyses revealed that significantly more participants indicated that the remote microphone made it easier for them to listen and to stay motivated. Behavioral and subjective indices of listening effort indicated that an RMS provided the most consistent benefit for speech recognition and listening effort for children with limited unilateral hearing. RMSs could therefore be a beneficial technology option in classrooms for children with limited hearing unilaterally.
Approximately 2.5% to 3% of school-aged children are reported to present with unilateral hearing loss (UHL) with an increase in prevalence of up to 14% in adolescents (Bess et al., 1998; Shargorodsky et al., 2010). There is mounting evidence that these children have a greater risk of poorer speech, language and cognitive outcomes compared with normal hearing peers (Ead et al., 2013; Lieu, 2013), in addition to more behavioral problems (Lieu, 2004) and academic difficulties (Bess et al., 1986; Lieu, 2004; Oyler et al., 1988). The risks can even be more prominent for children with unaidable UHL (Bess et al., 1986; Culbertson & Gilbert, 1986; Lieu et al., 2013), defined as greater than severe unilateral sensorineural hearing loss and/or poor word recognition. Unaidable UHL has been referred to as “single-sided deafness” or “limited useable hearing unilaterally” (LUHU; Oosthuizen et al., under review; Picou et al., 2020a, 2020b, 2019b). The term LUHU will be used hereafter to refer to the specific population under study. Compared with children with milder UHL, children with LUHU are at greater risk of poorer speech recognition performance (Bess et al., 1986; Lieu et al., 2013) and an increased need for academic assistance (Culbertson & Gilbert, 1986; Lieu et al., 2013). More recently, results from a previous study also indicated that children with LUHU experience significantly more listening effort in indirect, noisy listening situations relative to their peers with normal hearing bilaterally (Oosthuizen et al., under review).
Listening Effort
Listening effort is defined as “the deliberate allocation of mental resources to overcome obstacles in goal pursuit when carrying out a task that involves listening to understand speech” (Pichora-Fuller et al., 2016, p. 11S). The FUEL (Framework for Understanding Effortful Listening; Pichora-Fuller et al., 2016) and the ELU model (Ease of Language Understanding; Rönnberg et al., 2008, 2013) clearly describe that cognitive demand is a key factor to listening effort. Several factors can increase the cognitive demand of a listening task, for example, the hearing ability of a listener (e.g., the presence of hearing loss) and task demands (e.g., presence of noise or reverberation in the listening situation). Furthermore, the listener’s motivation to achieve the goal of understanding what is said as well as to complete a listening task also affects listening effort. Speech understanding and listening effort are related, yet distinct concepts as people with hearing loss often complain that listening is tiring and effortful even when speech is audible, and words are recognized correctly (Pichora-Fuller et al., 2016). Furthermore, some factors affect listening effort and not speech recognition (e.g., digital noise reduction; Sarampalis et al., 2009) or affect recognition but not listening effort (e.g., reverberation; Picou et al., 2019a). Therefore, examining listening effort in addition to speech understanding can be of clinical importance, especially for school-aged children.
Recent evidence suggests that school-aged children spend 70% to 80% of their time in school listening in the presence of background noise (Crukley et al., 2011; Ricketts et al., 2017). Based on the FUEL and ELU models, increased listening effort is expected with increased background noise, as reflected in numerous previous studies in adults (Desjardins & Doherty, 2013; Picou et al., 2013, 2017; Picou & Ricketts, 2014; Sarampalis et al., 2009; Tun et al., 2009) and children (Gustafson et al., 2014; Howard et al., 2010; Lewis et al., 2016; McGarrigle et al., 2019; Picou et al., 2017, 2019a). Within the context of the FUEL and ELU model, it can be expected that intervention options that reduce cognitive demand while maintaining or improving speech recognition performance may be anticipated to also reduce the listening effort experienced in situations with high task demands. Given the increased academic difficulties that children with LUHU might experience together with the detrimental effects that listening effort and the resultant fatigue can have on academic performance and quality of life (Bess & Hornsby, 2014a, 2014b), it is important to examine the efficacy that intervention options for children with LUHU might have on reducing the listening effort experienced in classroom situations.
Nonsurgical Intervention Options for Children With LUHU
Current nonsurgical intervention options for children with LUHU include preferential seating alone or in combination with either a remote microphone system (RMS) or contralateral routing of signal (CROS) system. RMS refers to a wireless system that converts audio signals from a remotely placed microphone into radio or digital signals and transmits them via frequency modulation (FM) or digital modulation to a receiver near the listener (Bagatto et al., 2019). Remote receiver options include a personal ear-level RMS, a classroom audio distribution system (single or multiple loudspeakers), or a personal desktop loudspeaker. RMSs improve the signal-to-noise ratio (SNR) for the listener by overcoming noise, distance, and reverberation because a microphone (transmitter) is close to the mouth of a talker (Thibodeau, 2014; Wolfe et al., 2016). Current guidelines state that RMSs are the preferred choice of intervention recommended for school-aged children with LUHU in classrooms as they offer the most consistent speech recognition benefits (e.g., American Academy of Audiology, 2013).
In a CROS system, which includes two ear-level devices, sound is transmitted from the ear with limited useable hearing to the ear with better hearing. The purpose of CROS fittings is to reroute indirect speech to the ear with better hearing. However, CROS can be detrimental with direct speech and indirect noise; the CROS would enable the presentation of interfering noise to the ear with normal hearing when the noise would previously have been reduced due to head shadow effects. Therefore, CROS aids have not previously been recommended for young children (McKay et al., 2008).
These recommendations are based in part on work by Kenworthy et al. (1990), who evaluated speech recognition in noise for six children (8–12 years of age) with moderate to profound UHL. The authors evaluated three interventions (none, CROS, RMS) used in three listening configurations: monaural direct (speech presented at 45° relative to ear with normal hearing; noise presented at 45° relative to ear with UHL), monaural indirect (speech presented at 45° relative to ear with UHL; noise presented at 45° relative to ear with normal hearing), and midline signal (speech presented at 0°; noise presented at 135°, 180°, 225° relative to midline). The remote microphone was always placed near the speech loudspeaker. Results revealed RMS benefits for improved speech recognition in noise in the midline and indirect loudspeaker conditions, and CROS benefits only in the indirect condition. CROS detriments were evident in the midline and direct loudspeaker conditions. The consistent benefits of RMS use were confirmed by Updike (1994), whose findings also support RMS benefits for children with UHL and whose work also informed current recommendations for management of UHL.
However, as Kenworthy et al. (1990) and Updike (1994) focused on speech recognition performance, the effect of nonsurgical intervention options on listening effort for children with LUHU is less clear. In the adult and pediatric populations, listening effort is often measured by means of behavioral methodologies involving a timed response, for example, speed of speech repetition, also known as verbal response time (VRT; Gagne et al., 2017). Cowan et al. (2003) suggested that increases in VRTs in nonword recognition tasks reflect an increase in the amount of time that children need to process a signal, with longer VRTs reflecting greater processing effort. Previous studies employing VRTs in the pediatric population support the use of such a single-task paradigm as a listening effort measure for school-aged children (Gustafson et al., 2014; Houben et al., 2013; Lewis et al., 2016; McGarrigle et al., 2019; Oosthuizen et al., 2020; Pals et al., 2015; Prodi et al., 2019).
Subjective ratings have also been used in a few studies to evaluate listening effort, primarily by means of study-specific questionnaires (e.g., Gustafson et al., 2014; Picou et al., 2019a). Emerging evidence suggests results of behavioral and subjective indices might reflect different aspects of listening effort, especially in children (Gustafson et al., 2014; Hicks & Tharpe, 2002; Picou et al., 2019a). However, recent evidence suggests that self-report measures of listening effort can be used in school-aged children to document perceived listening effort (Oosthuizen et al., under review). Moreover, considering subjective ratings of the effect that specific intervention options for children with LUHU might have on their listening effort would be of value for child-specific management plans. Considerations of how intervention options affect the child’s motivation to sustain listening can be included because motivation also affects experienced listening effort (Peelle, 2018; Pichora-Fuller et al., 2016).
Purpose
The purpose of this study was to evaluate the effects of RMS and CROS on speech recognition and listening effort in three different loudspeaker conditions reflecting listening situations that can be encountered in the classroom scenario, namely midline, monaural direct, and monaural indirect. Employing a single-task paradigm and listening scenarios with similar loudspeaker configurations as Kenworthy et al. (1990), this study has the potential to replicate earlier findings on the effects of RMS and CROS on speech recognition and to extend these findings to listening effort. A second purpose of this study was to explore subjective ratings of RMS and/or CROS benefits in terms of ease of listening and listening motivation. As the three loudspeaker conditions followed a similar configuration to previous laboratory studies (Kenworthy et al., 1990), the investigators expected that listening with the RMS would result in improved digit triplet recognition relative to the unaided condition and listening with a CROS system. A decrease in VRTs also was expected (i.e., less listening effort) when participants listened with the RMS in comparison to the CROS condition. It was further hypothesized that the CROS benefit for speech recognition and listening effort mainly would be evident in the indirect loudspeaker condition, based on the findings of Kenworthy et al. (1990).
Materials and Methods
Participants
Nineteen school-aged children with LUHU, from diverse language backgrounds, participated in the study (M = 9.9 years, SD = 1.7, range 7–12 years). All participants had normal middle ear function, verified by tympanometry measures and normal otoscopic examination findings on the day of testing. Participants presented with normal hearing sensitivity in one ear (≤15 dB HL for octave frequencies from 250 to 8000 Hz) and a severe-profound sensorineural UHL in the opposite ear. Hearing loss was characterized by air conduction thresholds greater than 70 dB HL from 250 to 8000 Hz; an average air-bone gap no greater than 10 dB at 1000, 2000, and 4000 Hz; and poor phonetically balanced monosyllabic word recognition at a comfortable presentation level (<70%) in the impaired ear (Madell et al., 2011). No participant had other otologic or cognitive disorders, as reported by parents/guardians. Participants had typical speech, language, and motor development as confirmed by parental report. Table 1 summarizes the demographic information of study participants. Children participated in this study as part of a larger protocol, the remainder of which is published elsewhere (Oosthuizen et al., under review). Institutional review board approval was granted for this study by the Research Ethics Committee of the Faculty of Humanities, University of Pretoria.
Participants’ Demographic Information.

Note. Participant ID 8 was deemed unreliable during testing, and his data were not included in analyses. For participants wearing a CI, the sound processor was removed during data collection.
LUHU = limited usable hearing unilaterally; RMS = remote microphone system; HA = hearing aid; CI = cochlear implant; CROS = contralateral routing of signal hearing aid; OM = otitis media.
Behavioral Listening Effort: VRT
The listening effort measure was a behavioral methodology involving a timed response, namely a single-task paradigm of VRT. This paradigm was used previously in studies of listening effort with school-aged children with normal hearing (Oosthuizen et al., 2020) as well as school-aged children with LUHU (Oosthuizen et al., under review). Outcomes from this single-task paradigm include both speech recognition performance and VRTs. The speech stimuli consisted of digit triplets from the South African English digits-in-noise hearing test (Potgieter et al., 2016, 2018). The recognition probabilities of all the digits are equalized so that a potential difference in recognition probabilities is eliminated (Smits, 2016). Therefore, mono- and bisyllabic digits (0–9) were used in the triplets. In comparison to the use of open-set word or sentence recognition stimuli, digit triplets from an English-based digits-in-noise test present several advantages, for example, digits-in-noise stimuli are low in linguistic demands. Second, the speech material is presented in a closed set, including only digits between 0 and 9 (Kaandorp et al., 2016; Potgieter et al., 2018). Third, English digits are mostly familiar and often used by speakers of other languages (Branford & Claughton, 2002), making it a more appropriate choice of stimuli for use in a multilingual population. In addition, as evidenced by Oosthuizen et al. (2020), performance on single- and dual-task measures of listening effort was unaffected by language background of school-age children using these stimuli. As multilingualism is a universal reality in classrooms, both native and nonnative speakers of English were included in this study.
Participants were instructed to listen to and repeat digit triplets presented in noise. Participants were encouraged to guess if they were unsure of the digit triplet that was presented. Digit triplets were presented at 60 dB(A), and noise was presented at 72 dB(A) for a –12 dB SNR. The noise was steady-state noise with the same long-term average spectrum as the South African English digits-in-noise hearing test (Potgieter et al., 2016, 2018). The SNR was chosen based on pilot testing with naïve participants to target digit triplet recognition performance levels between 50% and 80% correct in a midline loudspeaker condition. In addition, the background noise level reflects possible noise levels that might be encountered in classrooms. Noise levels in occupied classrooms range from 56 to 76 dB(A) (Shield & Dockrell, 2004) and often exceed 70 dB(A) in South African primary school classrooms (Van Tonder et al., 2015). With moderate-level speech (60 dBA), the resultant SNRs would range from +4 to –16 dB (Shield & Dockrell, 2004; Van Tonder et al., 2015).
Participants’ verbal responses were recorded by a head-worn microphone and saved by a custom software program (MATLAB R2015a). The experimenter scored the verbal responses of the digit triplets and calculated a percent correct digit triplet recognition score for each participant in each condition. VRTs were calculated as the time elapsed from the offset of the digit triplet to the onset of the participant’s verbal response in the MATLAB software. Subjective checks of all recordings were done to identify occurrences of speech fillers such as “umm” and “uh,” stutters, and nonspeech sounds (e.g., breathing, yawns) that occurred before a digit triplet was spoken as well for trials with self-corrections. In these cases, fillers and false starts were removed. The verbal response onset time was marked as the onset of the self-corrected, second utterance.
Subjective Ratings
Directly after completion of a listening effort task in each condition with either the personal RMS or the CROS system, participants provided subjective ratings. The following questions were asked: (a) “Did the remote microphone system (FM system)/hearing aids (CROS system) make it easier for you to listen when it was noisy?” (ease of listening); (b) “Did the remote microphone system (FM system)/hearing aids (CROS system) help you to keep trying?” (motivation to complete listening task). Participants answered the two questions on a questionnaire by marking their subjective opinion on a binary (yes/no) emoji scale—(1) yes = big smile, thumb up; (2) no = big frown, thumb down. The questions were typed on a piece of paper with the emoji options scale below each one. No questions were asked after unaided conditions.
Test Conditions
Three loudspeaker configurations, displayed in Figure 1, were used during testing. In the midline condition, the digit triplets were played through the loudspeaker directly in front of the participant (0°), and identical noise was routed synchronously from the audiometer to the two loudspeakers placed at 90° and 270° azimuths. In the monaural direct listening condition, the digit triplets were presented through the loudspeaker that was at 90° azimuth to the participant’s ear with normal hearing, and noise was presented through a second loudspeaker positioned perpendicular to the participant’s ear with hearing loss. In the monaural indirect listening condition, speech was presented through a loudspeaker directed at 90° azimuth toward the ear with hearing loss of the participant, and noise was directed through a loudspeaker positioned directly toward the ear with normal hearing.

Schematic Diagram Representing Loudspeaker Locations in the Midline, Monaural Direct, and Monaural Indirect Configurations. Black loudspeakers indicate noise loudspeakers. White loudspeakers indicate speech loudspeakers. The LUHU ear is indicated by an “X.”
In each of the three loudspeaker conditions, participants performed the single-task paradigm in three intervention conditions, namely unaided, with the use of a digital ear-level, personal RMS and a CROS hearing aid. Participants with a cochlear implant removed their speech processor during all conditions. The remote microphone was always placed at the single-coned loudspeaker of interest, as displayed by a rectangle labelled “remote mic” in Figure 1.
Intervention Options
Prior to data collection, fitting and verification procedures for the RMS and CROS hearing aid were conducted on each participant. A digital ear-level, personal RMS receiver (Phonak Roger™ Focus) was fitted on the normal hearing ear of each participant. Acoustic coupling was a standard slim tube and a small, nonoccluding, noncustom eartip. Slim tube length was measured and changed accordingly for each participant. The ear-level RMS receiver was paired to a remote microphone (Phonak Roger™ Touchscreen). Real-ear measurements were conducted on the Audioscan Verifit Real Ear System (Audioscan, Dorchester, Ontario) as recommended by the American Academy of Audiology (2011) and Schafer et al. (2014) to verify that estimated uncomfortable loudness levels (UCLs) were not exceeded and prescriptive targets were met. During these measurements, the remote microphone was placed in the test box, and the real-ear microphone was placed in the participant’s ear. Specifically, the maximum power output (MPO) stimulus was selected on the Verifit. The examiner visually compared the MPO (based on the default volume setting) with the estimated UCL from the desired sensation level (DSL) v5.0 software (Scollie et al., 2005) to ensure that the MPO did not exceed predicted UCL levels. Next, the output from the RMS receiver was compared with DSL v5.0 targets (Scollie et al., 2005) using the Verifit’s “standard speech signal” presented in the test box at an intensity appropriate for a chest-level transmitter microphone (i.e., 84 dB sound pressure level [SPL]) to ensure that the output from the child’s ear met the DSL v5.0 prescriptive targets at 1000, 2000, and 4000 Hz. If volume adjustments were done, the MPO measurement was repeated at the volume adjusted level.
Subsequently, a CROS hearing aid (Phonak CROS B-312) was fitted to the ear with the severe-profound sensorineural hearing loss with a helix hook for stability and retention. A receiver hearing aid (Phonak Sky B70-M, open fitting) was fitted to the normal hearing ear of each participant. Acoustic coupling was a standard slim tube and a small, nonoccluding, noncustom eartip. Slim tube length was measured and changed accordingly for each participant. The automatic features in the receiver hearing aid were deactivated, including automatic program selection, digital noise reduction, and wind noise reduction. The microphone was set to mild, fixed-directional. The CROS microphone was set to be a “real-ear” microphone. Real-ear measurements were conducted on the Audioscan Verifit Real Ear System (Audioscan, Dorchester, Ontario) prior to data collection to ensure that the receiver hearing aid of the CROS system was acoustically appropriate for each participant’s individual hearing thresholds. The CROS receiver hearing aid output in the participant’s ear, at octave frequencies, was compared with DSL (Scollie et al., 2005) v5.0 targets using the Verifit’s “standard speech signal” (the carrot passage) presented at 65 dB SPL.
Furthermore, real-ear unaided responses were measured and compared with real-ear occluded responses with the ear-level RMS receiver and the CROS receiver hearing aid turned off to ensure that there was minimal insertion loss. Because the ear-level RMS receiver and the receiver hearing aid of the CROS system were fitted to a normal hearing ear, it is important that use of such a device does not degrade environmental hearing.
Test Environment
Listening effort measures were conducted in a double-walled, sound-attenuating audiometric test booth (2.13 m × 2.03 m × 2.43 m). Three loudspeakers (GSI 90 dB) were located at 0°, 90°, and 270° at 1 m from the participant, who was seated at a school desk. Handprints were placed on the desk’s surface showing participants where to place their hands during testing to help eliminate possible noise from hand movements. Furthermore, participants were instructed to keep their head still and face forward for the duration of the testing. Digit triplets were presented through custom programming of MATLAB software, routed to an audiometer (GSI AudioStar Pro) and to a loudspeaker. Noise files were stored on the audiometer and selected from the internal files. The noise was routed from the audiometer to loudspeaker(s). Output levels for digit triplets and digit noise were measured by means of a sound level meter to ensure the correct output level in the sound field.
Procedures
Before data collection commenced, informed consent was obtained from each participant’s parent/guardian, and assent was obtained from the participants. Standard audiometric procedures confirmed normal hearing in one ear and a severe-profound sensorineural hearing loss in the opposite ear. After fitting and verification procedures, training rounds were conducted to ensure that the participants understood the listening task. Training rounds consisted of VRT tasks in quiet and in noise. Training lists (containing 10 digit triplets) were not repeated during the experimental testing. After the training rounds, participants were prepared to start with data collection testing. A single list with 20 digit triplets was used in each loudspeaker and intervention condition. Twenty-five lists consisting of 20 digit triplets each were created to ensure no repetition of a digit triplet list in the various test conditions. The order of the loudspeaker conditions (midline, monaural direct, monaural indirect), intervention conditions (unaided, RMS, CROS hearing aid), and digit triplet lists was randomized across participants. Directly after each digit triplet list was presented when listening in either the RMS or the CROS condition, participants completed a short questionnaire with the two binary rating questions.
Data Analysis
During testing, one participant (ID 8 = 9-year-old male) was noticeably distracted. As a result, his results were deemed unreliable, and his data were excluded from the study in general. Prior to analysis, digit triplet recognition data were converted to rationalized arcsine units (rau) to normalize the variance near the extremes with the equations found in Studebaker (1985). This transformation was necessary due to excellent digit triplet recognition performance by many participants with the RMS in all loudspeaker conditions. VRTs were taken as the measure of listening effort. As suggested by Hsu et al. (2017), VRT data from both correct and incorrect digit triplet recognition trials were included as it would result in better representation of the varying levels of listening effort that children might experience in real-life, noisy classroom situations. However, there were some exceptions. VRTs for verbal responses not containing digits (e.g., “I don’t know/I didn’t hear”) were excluded from analysis (a total of 93 VRTs from 9 participants). In addition, VRTs were included in the analysis only if they were within ±2.5 standard deviations of the mean VRT for the participant in a given digit triplet list as in previous studies of response time in children (Ratcliff, 1993). A total of 96 VRTs were eliminated in this process. In total, 189 of 3240 VRTs were excluded for all participants and conditions (5.8%).
Data were analyzed separately for each outcome (digit triplet recognition, VRTs) using repeated measures analysis of variance (RM-ANOVA) with two within-participant factors, Loudspeaker (midline, direct, indirect) and Intervention (unaided, RM, CROS). Significant interactions were explored using follow-up ANOVAs and multiple pairwise comparisons controlling for familywise error rate with Bonferroni adjustments for the number of comparisons (Dunn, 1961). Greenhouse–Geisser corrections for sphericity violations were used when necessary. Data for VRTs were normally distributed as assessed by Shapiro Wilk’s test of normality on the studentized residuals with significance values corrected for the number of comparisons within a paradigm. Data for the digit triplet recognition performance violated the assumption of normality due to expected excellent performance in some conditions (e.g., digit triplet recognition with the RMS in the direct loudspeaker condition). Data for digit triplet recognition had one outlier. Repeated measures ANOVA were rerun with and without the outlier included in the analysis. Analyses resulted in similar significant results, and it was therefore decided to include the outlier in the digit triplet recognition analyses. Despite nonnormal distributions for digit triplet recognition in some conditions, ANOVAs were used because they are considered to be robust to deviations from normality (Maxwell & Delaney, 2004). Subjective ratings were analyzed using nonparametric, exact McNemar’s tests as the data were dichotomous in nature. All analyses were completed in SPSS (IBM Corporation, v 26).
Results
Digit Triplet Recognition
Mean digit triplet recognition scores (rau) for the different intervention conditions (unaided, RMS, CROS) across the different loudspeaker configurations are displayed in Figure 2. Analysis revealed significant main effects of Loudspeaker, F(2, 16) = 101.63, p < .001, ηp2 = 0.93, and Intervention, F(2, 16) = 159.25, p < .001, ηp2 = 0.95, as well as a significant two-way interaction of Loudspeaker × Intervention, F(4, 14) = 60.68, p < .001, ηp2 = 0.94. Consequently, the significant interaction was explored using separate RM-ANOVAs for each Loudspeaker with a single within-participant factor (Intervention). Results are displayed in Table 2. Taken together, these data indicate the RMS significantly improved digit triplet recognition in all loudspeaker configurations, whereas the CROS significantly improved recognition only in the indirect condition and significantly impaired recognition in the direct condition.

Mean Digit Triplet Recognition Scores (rau) for the Different Intervention Conditions (Unaided, RMS, CROS) Across the Different Loudspeaker Configurations.Vertical bars indicate standard deviation.
Results of Pairwise Comparisons of Digit Triplet Recognition Performance (rau) in Different Loudspeaker Conditions for Different Intervention Options.

Note. Significant differences are indicated by
Verbal Response Times
Figure 3 displays the mean VRTs for the different intervention options (unaided, RMS, CROS) for each loudspeaker configuration. Analysis revealed significant main effects of Loudspeaker, F(2, 16) = 14.43, p < .001, ηp2 = 0.64, and Intervention, F(2, 16) = 40.20, p < .001, ηp2 = 0.83, as well as a significant two-way interaction of Loudspeaker × Intervention, F(4, 14) = 12.07, p < .001, ηp2 = 0.78. Consequently, the significant interaction was explored using separate RM-ANOVAs for each Loudspeaker with a single within-participant factor (Intervention). Results are displayed in Table 3. Collectively, the data reveal that RMS significantly reduced VRTs in the midline and indirect loudspeaker conditions. A significant effect of the CROS to reduce VRTs was only evident in the indirect loudspeaker configuration.
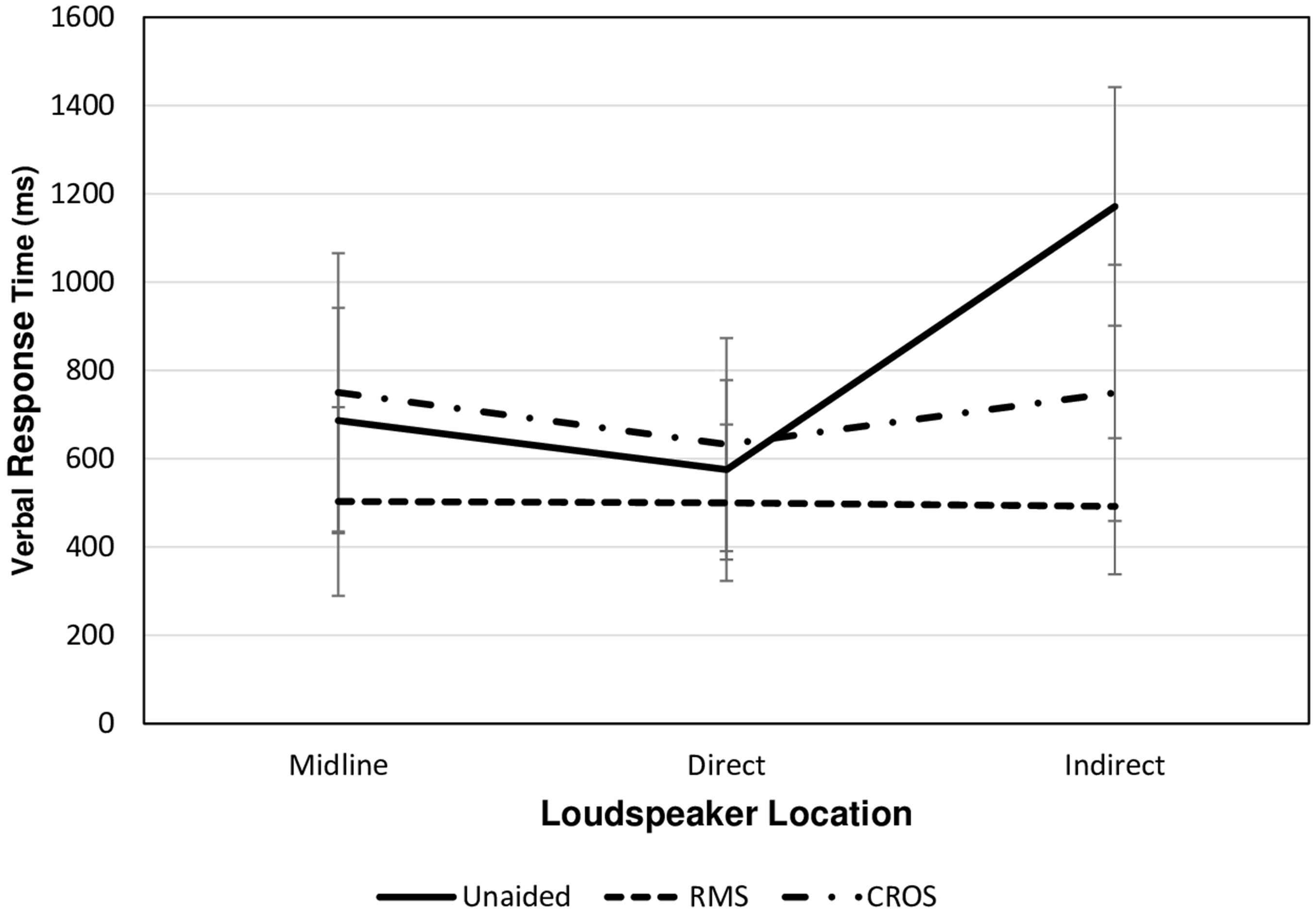
Mean Verbal Response Times for the Different Intervention Options (Unaided, RMS, CROS) for Each Loudspeaker Configuration. Vertical bars indicate standard deviation.
Results of Pairwise Comparisons of Verbal Response Times (ms) in Different Loudspeaker Conditions for Different Intervention Options.

Note. Significant differences are indicated by
Subjective Ratings
An exact McNemar’s test was run for the two subjective questions: (a) ease of listening and (b) motivation in each loudspeaker configuration. Results are displayed in Table 4. For Question (a), analysis revealed that significantly more participants indicated that the use of an RMS made listening easier in the midline and monaural indirect conditions. In the direct loudspeaker condition, no significant difference was found between the two intervention options in question regarding ease of listening. Similar to the findings of Question (a), results for Question (b) showed that in the midline and monaural indirect loudspeaker conditions, participants indicated the use of an RMS significantly improved their motivation to listen compared with the use of a CROS system. In the monaural direct condition, results indicate no significant difference between the effect of the RMS and the CROS system on participants’ motivation to complete the listening task.
Results of the McNemar’s Tests of the Subjective Ratings for Each Question in Each Loudspeaker Condition.
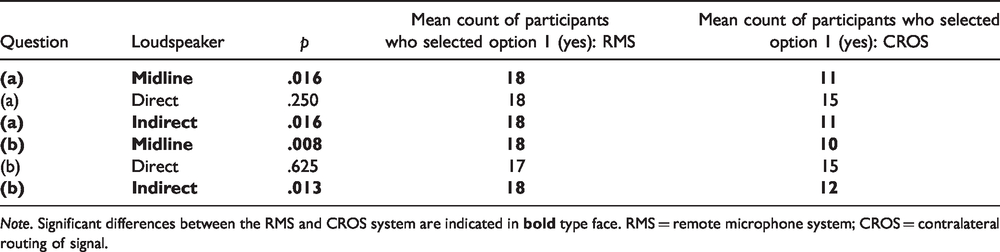
Note. Significant differences between the RMS and CROS system are indicated in
Discussion
This study aimed to evaluate the effects of an RMS and CROS systems on digit triplet recognition and listening effort in school-aged children with LUHU in a number of different listening conditions that might be encountered in a classroom (i.e., midline signal, monaural direct, and monaural indirect). Existing research has not yet demonstrated whether the use of a personal, ear-level RMS and/or a CROS system can reduce listening effort for children with LUHU. A second objective of this study was to explore subjective ratings of RMS and/or CROS benefits in terms of listening ease and motivation to complete a listening task. Results for each outcome will be discussed separately.
Effect of RMS and CROS Intervention Options: Digit Triplet Recognition
As expected, results suggest that the use of a personal RMS significantly improved digit triplet recognition in noise for all three loudspeaker conditions relative to the unaided condition. Specifically, 94%, 56%, and 100% of participants demonstrated digit triplet recognition benefit with the RMS relative to unaided listening in the midline, direct, and indirect loudspeaker conditions, respectively (see Online Appendix for intervention benefit scores for each participant). These findings are consistent with results of previous laboratory studies with similar loudspeaker configurations which indicated that RMS provided the most consistent speech-in-noise recognition benefits (Kenworthy et al., 1990; Updike, 1994). Also consistent with earlier work, the CROS system impaired digit triplet recognition in the direct condition and improved it in the indirect condition. The CROS benefits in the indirect condition and the detriments in the direct condition were evident for 100% and 94% of participants, respectively (see Online Appendix).
Combined, it can be concluded that the findings for speech recognition from Kenworthy et al. (1990) generalized to the results from a larger pool of multilingual participants in the current study, indicating that the use of RMS and/or CROS intervention options can be beneficial to support speech recognition in noise for children with LUHU in different listening situations.
Effect of RMS and CROS Intervention Options on Listening Effort: VRTs
Children with LUHU experience increased listening effort relative to their peers with normal hearing in indirect listening (Oosthuizen et al., under review). To alleviate this increased listening effort, the FUEL and ELU models suggest audibility needs to be increased. Therefore, intervention options that are able to improve the SNR for the listener and thus improve audibility have the potential to reduce listening effort. For children with LUHU, an RMS could improve audibility by overcoming noise, distance, or reverberation; a CROS system could improve audibility by overcoming the consequences of the head shadow for the ear with hearing loss.
Results of this study indicate that the use of both intervention options of the RMS and the CROS hearing aid had a significant effect on reducing VRTs during the indirect loudspeaker condition when compared with the unaided condition. Specifically, 100% and 89% of participants demonstrated a benefit in terms of listening effort (i.e., faster VRTs) relative to the unaided condition with the RMS and CROS, respectively (see Online Appendix). In addition, the mean VRT achieved with the RMS in the indirect condition (492 ms) in this study is less than the mean VRTs from peers with normal hearing in an indirect condition (556 ms) reported in a recent study by the authors (Oosthuizen et al., under review). This suggests that the use of an RMS has the potential to effectively alleviate the significantly increased listening effort experienced by children with LUHU in an indirect, noisy condition.
The benefit of the RMS to reduce listening effort relative to the unaided condition is also evident in the midline loudspeaker condition. Specifically, with the RMS, 72% of participants had VRTs that were 182 ms faster on average compared with the unaided condition in the midline loudspeaker condition. In the direct loudspeaker condition, listening with the RMS and CROS system did not result in significant reduction of VRTs compared with the unaided condition.
When comparing the effect of RMS to a CROS system to reduce listening effort (i.e., faster VRTs), results revealed that VRTs were faster with the RMS compared with the CROS in all three loudspeaker conditions. Specifically, 89% of participants had reduced VRTs by an average of 247 ms compared with the CROS system in the midline condition. In the direct condition, listening with a personal RMS resulted in significantly less listening effort as indicated by shorter VRTs for 89% of participants compared with listening with a CROS system (M difference = –133 ms). In the indirect condition, 89% of participants had VRTs that were significantly faster with the use of a personal RMS compared with the CROS (M difference = –258 ms).
Effect of RMS and CROS Intervention Options on Listening Effort: Subjective Ratings
From the FUEL model (Pichora-Fuller et al., 2016), it is clear that an individual’s motivation also affects listening effort. If a listener has little motivation to understand what they are hearing, increasing cognitive demands may result in little or no change in effort. However, if an intervention option can increase a listener’s motivation to continue listening, even if the listening situation poses a high cognitive demand with increased listening effort, it might help the listener to maintain the effort and complete the listening task (e.g., continue listening and participating in discussions in a noisy classroom situation and not disengage). Consistent with the findings of digit triplet recognition and VRTs, results of the subjective measures indicate that the RMS yielded consistent benefits in terms of (a) ease of listening and (b) motivation to complete the listening task for most participants in this study. However, results could have been influenced by the fact that only two participants were experienced CROS users and that more than half of participants had experience listening with an RMS, whether personal or in combination with another intervention option. Furthermore, the findings might be limited by a social desirability response bias (King & Bruner, 2000). That is, participants want to give researchers answers that they think are desirable. As participants were informed of the purpose of the study before testing commenced, and as the minority had experience with CROS, it is possible they wanted to increase their social appropriateness by indicating in the subjective ratings that the RMS was more beneficial. Therefore, future studies should take into consideration potential social desirability response biases (King & Bruner, 2000). Considering subjective measures in the pediatric population is important toward implementing child-specific and responsive management plans. However, more research is needed in this area to develop reliable and valid subjective listening effort questionnaires.
Future Directions
Several aspects of this study may limit generalizability of the findings. First, results may be limited by the specific, laboratory test conditions used during this study with relatively directional noise sources. The digit noise that was used was steady state and speech-shaped. It did not contain temporal modulations or informational masking, both of which might affect listening effort (Desjardins & Doherty, 2013; Koelewijn et al., 2014). Such laboratory setups do not reflect typical contemporary classrooms that have primarily diffuse noise (Crukley et al., 2011; Ricketts et al., 2017). This might have underestimated the possible benefits of a CROS system; results of recent work with unilateral cochlear implants and CROS systems indicated that the limitations of CROS systems can be larger with directional noise than diffuse noise (Taal et al., 2016).
Furthermore, the noise levels used do not represent all classroom environments. Although the chosen –12 dB SNR employed in this study falls within the range of +15 to –17 dB SNRs often encountered in classrooms (Bradley & Sato, 2008; Crandell & Smaldino, 2000; Larsen & Blair, 2008; Markides, 1986; Pearsons et al., 1977; Sato & Bradley, 2008), future studies can consider examining the effect of RMS and CROS systems on listening effort at more typical classroom SNRs ranging from –5 to +5 dB (e.g., American Academy of Audiology, 2011; Howard et al., 2010; Schafer et al., 2014).
The use of digit triplets as speech stimuli may pose several advantages compared with using open-set word or sentence recognition stimuli (as described earlier under the section Behavioral Listening Effort: VRT). These advantages make the choice of digit triplets as speech stimuli more applicable for use in a multilingual population, which is typical of school-aged children in South Africa. However, the closed-set nature of these specific stimuli does not replicate classroom listening demands where children are expected to listen to and comprehend instructions rather than just identification and repetition of digits.
In addition, in the current study, the remote microphone was always placed near the talker (loudspeaker) of interest, similar to the setup used by Kenworthy et al. (1990). This might overestimate the benefits of an RMS for speech recognition in a classroom environment. Modern classroom situations are characterized by multiple talkers of interest speaking simultaneously (e.g., oral group reading) or in quick succession (e.g., question and answer sessions; Ricketts et al., 2010, 2017). This may result in a remote microphone that is not always near the talker of interest. In these situations, the remote microphone is more likely to remain with a single talker (e.g., the teacher) who is not always the talker of primary interest (e.g., during group discussions). The test setup is used in recent studies by Picou et al. (2019b, 2020a); the authors controlled for the aforementioned factors by using diffuse noise and dynamic talker locations, but with a single location for the remote microphone. The results suggested that CROS has the potential to improve speech recognition in dynamic, classroom listening situations, more than what was found in the current study and previous studies (e.g., Kenworthy et al., 1990; Updike, 1994). Future work can focus on using such a test setup that resembles a multitude of realistic classroom situations to determine the effect that an RMS or CROS system has on the listening effort experienced by children with LUHU in everyday learning environments.
Related, participants in the study by Picou et al. (2020a) were allowed to move their heads to face the loudspeakers, whereas participants in the current study were explicitly instructed to keep their heads still and face the front loudspeaker. Consequently, the limitation of head turning in the current study, and in the study by Kenworthy et al. (1990), could have reduced participants’ abilities to manage their listening environment to help improve speech recognition, especially with the use of a CROS system. However, head orientation was not directly measured in this study or in the studies by Picou et al. and thus warrants future research.
Finally, only nonsurgical intervention options were considered in this study. However, bone-anchored implants and cochlear implants can be intervention options for children with LUHU. Bone-anchored implants have the potential to improve speech recognition in monaural indirect listening scenarios by rerouting signals to overcome the head shadow (Bosman et al., 2003; Hol et al., 2005). A cochlear implant might offer children with LUHU the potential for bilateral hearing (Bernstein et al., 2017) and improved speech recognition in noise (Arndt et al., 2015; Hassepass et al., 2013). Therefore, future studies can consider examining the effect of bone-anchored hearing devices and cochlear implants on listening effort in children with LUHU. Related, digital noise reduction technology has been found to effectively reduce listening effort in children (Gustafson et al., 2014). As the digit noise used in this study was steady-state noise, the digital noise reduction was deactivated to prevent possible interference of the digital noise reduction technology with processing of the speech signal in noise. Hence, determining the effect of activated digital noise reduction technology in the receiver hearing aid use of a CROS system on listening effort in children with LUHU might be explored in future studies. Also, the combination of a CROS hearing aid system together with an RMS (RM receiver coupled to the CROS hearing aid system) can be considered in future studies concerning listening effort in school-aged children with LUHU. However, recommendations for intervention options must consider individual factors such as the location of the seat of the child with LUHU, the classroom configuration, and whether peers, the teacher, or everyone in the classroom are talkers of interest (Picou et al., 2020b). Exploring the effect of all the intervention options for children with LUHU on listening effort, in addition to speech-in-noise recognition improvement, may support recommendations for the type of intervention options for school-aged children with LUHU.
Conclusions
As children with LUHU are at risk for decreased speech recognition and increased listening effort in noisy conditions, this study aimed to investigate the effect of two intervention options on speech recognition and listening effort for this population. Digit triplet recognition results with the RMS and CROS replicated the extant literature and indicated that when the microphone was placed near the loudspeaker of interest, the RMS provided the most consistent benefit, with significant positive effects in all loudspeaker conditions (midline, direct, indirect). A significant benefit of the CROS system relative to unaided digit triplet recognition was evident only in an indirect loudspeaker condition. VRT results suggest that the use of a personal RMS effectively alleviated the increased listening effort experienced by children with LUHU in midline and indirect loudspeaker conditions. Conversely, relative to unaided listening, the CROS reduced listening effort only in an indirect condition. The self-report questionnaires can be useful to determine perceived benefit of intervention options for lessening listening effort in school-aged children. Reducing listening effort by means of intervention options may enable children with LUHU to achieve successful participation in academic and social situations.
Footnotes
Acknowledgments
The authors would like to thank the Eduplex Audiology Department for assistance in participant recruitment and use of facilities during data collection as well the Carel du Toit Centre for their assistance in recruiting of participants. The authors also thank the Eduplex Training Institute and Professor Stefan Launer for support during the project.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: D. W. S. is a member of the Phonak Pediatric Research Advisory Board.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research project was funded by Sonova, AG.
Supplemental Material
Supplemental material for this article is available online.