
Abstract
Preference for noise reduction (NR) strength differs between individuals. The purpose of this study was (1) to investigate whether hearing loss influences this preference, (2) to find the number of distinct settings required to classify participants in similar groups based on their preference for NR strength, and (3) to estimate the number of paired comparisons needed to predict to which preference group a participant belongs. A paired comparison paradigm was used in which participants listened to pairs of speech-in-noise stimuli processed by NR with 10 different strength settings. Participants indicated their preferred sound sample. The 30 participants were divided into three groups according to hearing status (normal hearing, mild hearing loss, and moderate hearing loss). The results showed that (1) participants with moderate hearing loss preferred stronger NR than participants with normal hearing; (2) cluster analysis based solely on the preference for NR strength showed that the data could be described well by dividing the participants into three preference clusters; (3) the appropriate cluster membership could be found with 15 paired comparisons. We conclude that on average, a higher hearing loss is related to a preference for stronger NR, at least for our NR algorithm and our participants. The results show that it might be possible to use a limited set of pre-set NR strengths that can be chosen clinically. For our NR one might use three settings: no NR, intermediate NR, and strong NR. Paired comparisons might be used to find the optimal one of the three settings.
Keywords
Introduction
Nowadays nearly all commercially available hearing aids contain a single-channel noise reduction (NR) algorithm. The goal of such an algorithm is to improve patient satisfaction when listening in a noisy background. NR algorithms in hearing aids have been shown to increase listening comfort at equal speech intelligibility (Chong & Jenstad, 2018). Commercially available hearing aids usually have the option of turning NR on or off or they contain a few (e.g., 3 or 5) factory default pre-sets that range from no NR, via intermediate to strong NR. Unfortunately, these default settings are mostly not documented well. NR algorithms are complex in that they depend on many parameters that can influence sound quality (e.g., maximum amount of gain reduction, the gain as a function of signal-to-noise ratio (SNR), noise tracking time constants, speech tracking time constants, and number of channels). Additionally, there are many different NR implementations (Hoetink et al., 2009) and hearing aid manufacturers have their own (scarcely documented) implementations that vary over their different product lines. Since specific prescription rules are not (yet) available, it is not known which NR setting is appropriate for an individual patient. Furthermore, it is not known how many distinct options of a certain NR parameter a device should offer in order to meet the needs of the individual listeners.
Preference for NR settings varies between individuals (Brons, Houben et al., 2014; Kubiak et al., 2022; Nelson et al., 2018; Völker et al., 2018; Wong et al., 2018). It is not clear how hearing impairment influences the preference for NR, as previous research showed inconsistent results. For instance, Kim et al. (2015) and Luts et al. (2010) did not find an effect of hearing impairment on preference for signals processed by NR. On the other hand, Sang et al. (2015) did find a difference in preference ratings for NR between normal hearing (NH) and hearing-impaired (HI) participants. In their paired comparison set-up, both NH and HI participants preferred NR over no NR, but the HI participants gave a better rating for the stimuli with active NR than the NH participants. The authors concluded that the lower preference score for NH listeners occurred because they are more affected by distortion caused by NR.
The studies described above all investigated differences in preference for NR turned on or off between NH and HI listeners. They did not investigate if NH and HI listeners differ in which setting of the NR algorithm was preferred. Neher (2014) used a coherence-based binaural NR algorithm to study preferences for NR strength. He found that strong NR (maximum attenuation was 30 dB) was more preferred by HI listeners with larger pure-tone average (PTA) than by listeners with a smaller PTA. In contrast, Arehart et al. (2015) concluded that the degree of hearing loss was not a significant factor in explaining the differences in quality ratings for different attenuation values of a binary-mask noise suppression technique. Brons, Dreschler et al. (2014) also found no significant difference between NH and HI listeners in the NR strength that they preferred. However, they did find that detection thresholds for distortion caused by NR were higher for HI participants than for NH participants. This higher detection threshold for distortions did not carry over to a significant difference in preference for NR strength. The authors’ interpretation was that HI listeners seem to tolerate fewer audible distortions than NH listeners do.
In a previous paper, different settings of a single parameter (the maximum gain reduction) were compared to investigate the preferences of NH listeners for NR strength in a laboratory experiment (Houben et al., 2011a). That work showed that, for the NR algorithm used, NH participants differed in their preferences for NR strength, if measured with enough repeats. This finding suggests that there is a relevant individual component of preferences for NR settings, although several repeats in an in-situ laboratory study might be required to reveal this. Subsequent research seems to confirm the finding that there are stable personal preferences for NR settings (Kubiak et al., 2022). However, it remains unclear if the amount of hearing loss is a determining factor for preferred NR strength.
Here we focus on NR strength, defined as the maximum gain reduction of an NR algorithm. Based on the literature we hypothesized that both NH and HI participants would have a large spread in preferences for NR strength. We further hypothesized that groups of NH and HI participants would differ in their preferred strength of NR. The direction of the preference difference is unknown. On the one hand, HI listeners might be less sensitive to signal distortions (Brons, Dreschler et al., 2014), and might thus accept stronger NR due to a larger positive effect of reduced noise. On the other hand, once signal distortions are audible, HI listeners might be less resilient to those distortions because the hearing loss itself can be regarded as a cause of signal distortion (interpretation of Brons, Dreschler et al., 2014).
Using hearing aid-based NR, we investigated if preferences for NR strength differ between NH and HI listeners for speech in babble noise. To achieve good sensitivity we used a paired comparison design and analyzed the data with a statistical model that was specifically developed for this task by Houben et al. (2011a). This model, the quadratic utility logistic (QUL) model, is described in more detail below. We also explored the range of preferences for NR strength between individuals, irrespective of hearing status. By using cluster analysis of the paired comparisons data, we aimed to find the optimal number of distinct NR strength settings for groups of participants with similar individual preferences. Finally, we estimated the number of paired comparisons required to adequately predict an individual's preference for NR strength. This was intended to provide valuable information for fine-tuning NR algorithms in clinical practice.
The following research questions were formulated:
Research Question 1: Do preferences for NR strength differ between NH and HI listeners?
Research Question 2: How many distinct settings are required to classify participants into similar groups based on their preferences for NR strength?
Research Question 3: How many paired comparisons are required to find the preferred NR strength for an individual?
Methods
Participants
Approval by the Medical Ethical Committee of AMC was obtained on 24 April 2008 (MEC 08/082). Participants were recruited from the patients of the Audiological Centre of the AMC and had to sign an informed consent prior to participation.
There were three groups of 10 participants in the study. The audiometric data are given in Appendix A. Two additional participants quit the experiment early stating that they did not hear any difference between the stimuli. Although their incomplete data sets were not used for analysis, their audiometric data are included in Appendix A for completeness.
The included number of participants was based on a power calculation with data from NH listeners from a previous study (Houben et al., 2011a). In that study, mean preference for NR strength was 7.5 dB with standard deviation of ±1.8 dB. If we assume the same measurement variance for our groups of participants, at least eight participants are required in each participant group to detect a difference in preference of 2.5 dB (between-participant design α = 0.05, β = 80, two-sided).
The audiometric inclusion criteria for the three hearing loss categories were as follows:
- NH: all hearing thresholds (octave frequencies ranging from 0.25 to 8 kHz) equal to or better than 20 dB hearing loss (HL) for both ears. - Mild to moderate HI (HI-mild): hearing loss exceeding that of NH while the PTA hearing loss at 1, 2, 4 kHz (PTA1, 2, 4 kHz) of at least one ear was equal to or better than 40 dB HL. - Moderate to profound HI (HI-moderate): hearing loss exceeding HI-mild (i.e., PTA1, 2, 4 kHz of both ears worse than 40 dB HL.
The asymmetry of the hearing loss was small, see Appendix A. The mean value of the maximum asymmetry (=maximum difference between left and right air conduction threshold at each frequency from 250 to 8000 Hz) was 16 dB with a standard deviation of 10 dB. The mean PTA1, 2, 4 Hz difference between the ears was 6 dB HL with a standard deviation of 6 dB HL. Hearing loss of the participants was sensorineural, there were no significant conductive losses.
The speech reception threshold (SRT) for consonant–vowel–consonant (CVC) words in quiet was also measured. The SRT is the sound pressure level at which the participant correctly repeated 50% of the phonemes. For the first five NH participants, no SRT measurement is available due to a measurement mistake. The mean age (with standard deviation) of the three groups was 47 ± 12 years, 61 ± 15 years, and 67 ± 7.5 years, for NH, HI-mild, and HI-moderate, respectively.
Stimuli
The unprocessed stimuli were recordings of four sentences spoken by a female, taken from the VU-98 sentence materials (Versfeld et al., 2000). During the development of this Dutch speech-in-noise test, the sentences were optimized to have near-equal intelligibility in stationary noise (Versfeld et al., 2000). The sentences are, however, not homogenized for perceived listening comfort. Therefore, from these materials, four sentences (#49, 52, 58, 63) were selected to minimize possible differences in subjective preferences between different sentences. Sentence selection was done based on perceived listening comfort. The sentences were embedded in babble noise of which the long-term spectrum was matched to that of speech of the sentence materials. The sentences were rated for perceived listening comfort by three expert listeners. Perceived listening comfort was used rather than sound quality to avoid the (explicit or implicit) reference that plays a role when judging sound quality. Perceived listening comfort was rated on a 5-point scale ranging from not comfortable to very comfortable. The four sentences were selected to have equal scores and average listening comfort.
NR processing was done using a low-latency single-microphone NR algorithm (SNRA), implemented in Matlab. This algorithm has been used before to measure individual preferences for the strength of NR (Houben et al., 2011a, 2011b, 2013). The algorithm uses modulation-based spectral subtraction and has low complexity and low latency (Appleby & Groth, 2011; Groth & Nelson, 2005; Kates, 2017; Rosenstrauch, 2011). A detailed description of the algorithm can be found in Houben et al. (2011a, 2011b, 2013). Here, the algorithm is briefly described.
The incoming speech signal is first split into a signal and an analysis path. For the signal path, all filtering and processing is done in the time domain, and for the analysis path, this is done in the frequency domain (Groth & Nelson, 2005). The two paths are each analyzed with a 17-band frequency-warped filter bank (Kates & Arehart, 2005). The advantage of a frequency-warped filter bank over a conventional filter bank is that it has a non-uniform frequency representation very close to that of the auditory system.
The SNR is estimated for each frequency band using the estimation of the noise and speech signal (Rosenstrauch, 2011). During intervals in which no speech is detected, the input signal is used to calculate a noise estimate. The estimation of the speech signal is based on spectral and temporal characteristics of speech, using samples of the input signal of about 1 ms. The gain is calculated in the analysis path using the estimated SNR and Wiener optimal filtering theory (Smith, 2002), with a threshold for gain depth (=Gmin). This threshold was used to limit the strength of the NR. The calculated gain was subsequently applied to the signal in the signal path. The variable under investigation, the threshold for gain depth (Gmin), limits the maximum gain reduction that is applied by the SNRA to Gmin. Higher values of Gmin led to more gain reduction. The variable Gmin can be applied independently from the NR algorithm since it does not alter the gain function but only applies a threshold of maximum gain reduction. In the literature on spectral subtraction, this limit is also known as “spectral floor” (Berouti et al., 1979; Loizou, 2007).
Figure 1 shows the estimated realized gain of our algorithm as function of the estimated input SNR. The processed sentences were analyzed based on the four sentences that were chosen for this experiment. These sentences were placed one after another and processed by the NR algorithm in loops such that at least 60 s of the processed output file could be removed to stabilize the algorithm. The gain that was applied by the algorithm was calculated by comparing the processed (output) signal to the input signal for separate time-frequency bins (window length was 512 samples, with a sample frequency of 16 kHz). Note that due to estimation errors, the maximum gain in this plot can be larger than Gmin.

Calculated gain function for some values of Gmin used. The gain was calculated by comparing the processed and unprocessed sound signals for one sound file which consists of all four sentences concatenated. The striped vertical line at +5 dB indicates the long-term average SNR of the stimuli.
By removing the estimated noise, the loudness of the speech-in-noise signal is inevitably affected. To correct for this, NR algorithms commonly apply a correction that restores the overall gain. Our algorithm restores the gain by matching the Root mean square (RMS) of the output signal to that of the input. The correction is thus done on the overall speech-in-noise signal.
Experimental Design
At the start of the visit, hearing status was checked for each participant by means of pure-tone audiometry. Following audiometry, they participated in a paired comparison listening test which is explained in the next two paragraphs.
A between-participants design was used, the three hearing loss groups each containing 10 participants. The main experimental parameter was Gmin, which is explained in the previous section. Ten values of Gmin were used (0, 4, 6, 7, 8, 9, 10, 12, 16, 18 dB), each of which was compared to all the others, leading to 10 × 9 unique comparisons (including AB, BA to prevent bias in the presenting order). Each comparison was done twice (test and retest, without a pause in between) leading to 180 paired comparisons per participant. This value was a trade-off between measurement accuracy (more runs are better) and total time required to do the experiment (less is better). On average, a session took about 1.5 h.
In each trial, participants had to listen to two successive processed speech-in-noise stimuli and choose which they preferred. The participants were asked the following question “Imagine that you will have to listen to these signals all day. Which sound would you prefer for prolonged listening?” The question was intentionally stated in a broad context. The reason is that we were primarily interested in general preference and not in perceived specific signal qualities such as “speech quality” or “amount of background noise.” Before commencing with the paired comparisons listening test, a training session was performed with 20 paired comparisons with similar stimuli. The data obtained during the training session were discarded.
The experimental set-up consisted of a Focusrite Saffire Pro 10 audio interface and a Presonus HP40 headphone buffer with Sennheiser HDA200 headphones. All stimuli were presented bilaterally with an input SNR of +5 dB. This value was chosen because it is representative of real-life situations, which is shown in a field study by Wu et al. (2018) who found that most realistic SNRs were between 2 and 14 dB. We chose a lower value of this range such that it is sufficiently challenging for both the listener and the NR algorithm and in line with research by Houben et al. (2013). The nominal speech level was 70 dB Sound pressure level (SPL), and the noise level was 65 dB SPL. For the participants in the HI-mild and HI-moderate groups, the sound signals were amplified according to the National Acoustics Laboratories-Revised Profound (NAL-RP) fitting rule (Dillon, 2001). The sound signals for the left and right ear received the same NAL-RP amplification, based on the ear with the smallest hearing loss. This approach was possible because the asymmetry in the hearing loss was small; see Appendix A.
Statistical Analysis
The QUL Statistical Model
The dichotomous paired comparison data were analyzed with the QUL model developed by Houben et al. (2011a, 2011b) for NR preference. Briefly, the model is based on the assumption of a trade-off between speech distortion caused by the NR algorithm and the amount of residual background noise. The model takes this trade-off into account for individual listeners by combining a quadratic utility model with Logistic regression. The QUL model estimates the value of Gmin that corresponds to the participant's highest preference (
Response Feature Analysis
The QUL model was applied to the data for each individual participant. The obtained individual optimal values were subsequently analyzed to investigate possible differences between the three participant groups. This approach is known as response feature analysis (Dupont, 2009). With response feature analysis, multiple individual responses are reduced to features that capture the attribute of interest. Subsequently, this response measure was analyzed in a fixed-effects one-way analysis. Response feature analysis has the advantage that the results are clearly interpretable. Another advantage is that the use of a single value per individual (i.e.,
The QUL model was implemented in R and the one-way between-participants analysis was done in Matlab with the standard Kolmogorov–Smirnov and Kruskal–Wallis tests. The correlation between the preferred individual Gmin levels and hearing loss was calculated using Spearman correlation (standard Matlab function `corr`). Hierarchical cluster analysis was done with R function “hclust” using the Ward criterion (method = “ward.D”). The distances between win counts were calculated using R function “dist” using the Manhattan (L1) distance metric (method = “manhattan”). We chose hierarchical clustering over alternatives like k-means clustering, as this hierarchical clustering gives insights into clustering quality for different numbers of clusters. We chose Ward's minimum within-cluster variance as method, as this method “tends to find same-size, spherical clusters” (Everitt et al., 2011). Because we wanted to divide the participants into roughly equal groups, Ward's method was the best choice. However, Ward's method is sensitive to outliers thus we used the Manhattan (L1) distance as metric, as this distance is more robust against outliers.
Results
Paired comparison data can be displayed graphically by expressing the results as win counts: the number of times each Gmin was chosen over its alternatives. Figure 2 shows the win counts for each participant. Figure 2 also shows the fits from the QUL model (blue curves). The model fits represent the preference of the participant as a function of NR strength. The error bars in the model fits show the pointwise standard errors in the model predictions for the Gmin levels used. Note that the model shows the trends for the vast majority of listeners, although there are occasional exceptions, like participant HI-mild4. The calculated preferred value of Gmin for each participant (

Win counts (as fraction of the total) and model fits obtained from the QUL model for each participant. Win counts are shown in brown and are connected by brown line segments for clarity. QUL fits are shown in blue. The first row shows data for the NH participants, the second row for the HI-mild participants, and the bottom row for the HI-moderate participants. The participants in each row are ordered by increasing value of
Response Feature Analysis
The first research question was to find out whether preference for NR strength differs between NH and HI listeners. To answer this, a response feature analysis of the data of the three participant groups was performed. Figure 3 shows box plots of

Box plot of
Because the analysis of variance (ANOVA) assumption of normality of the residuals was not met (a Kolmogorov–Smirnov test gave p < .001), we analyzed the data with a non-parametric Kruskal–Wallis test with hearing loss category as the main effect. Prior to this analysis, we checked for homoscedasticity with Bartlet's test for equal variances. The effect was not significant (Bartlett's statistic = 0.06; p = .97), indicating that the variances were not different for the three hearing loss categories, and that a Kruskal–Wallis test could be used.
The Kruskal–Wallis test gave a significant effect of hearing loss (χ2 = 6.2; p < .05). Post hoc testing (Bonferroni corrected with α = 0.05 and n = 3) showed that the mean ranks of the NH and HI-moderate groups differed significantly (p < .05).
Correlation Between Hearing Loss and Age
To investigate the effect of hearing loss on the preference for NR strength, Figure 4 (left panel) shows a scatterplot of

Scatter plot of
Because a Kolmogorov–Smirnov test showed that both PTA1, 2, 4 kHz and
We investigated the relation between age and hearing loss, and between age and
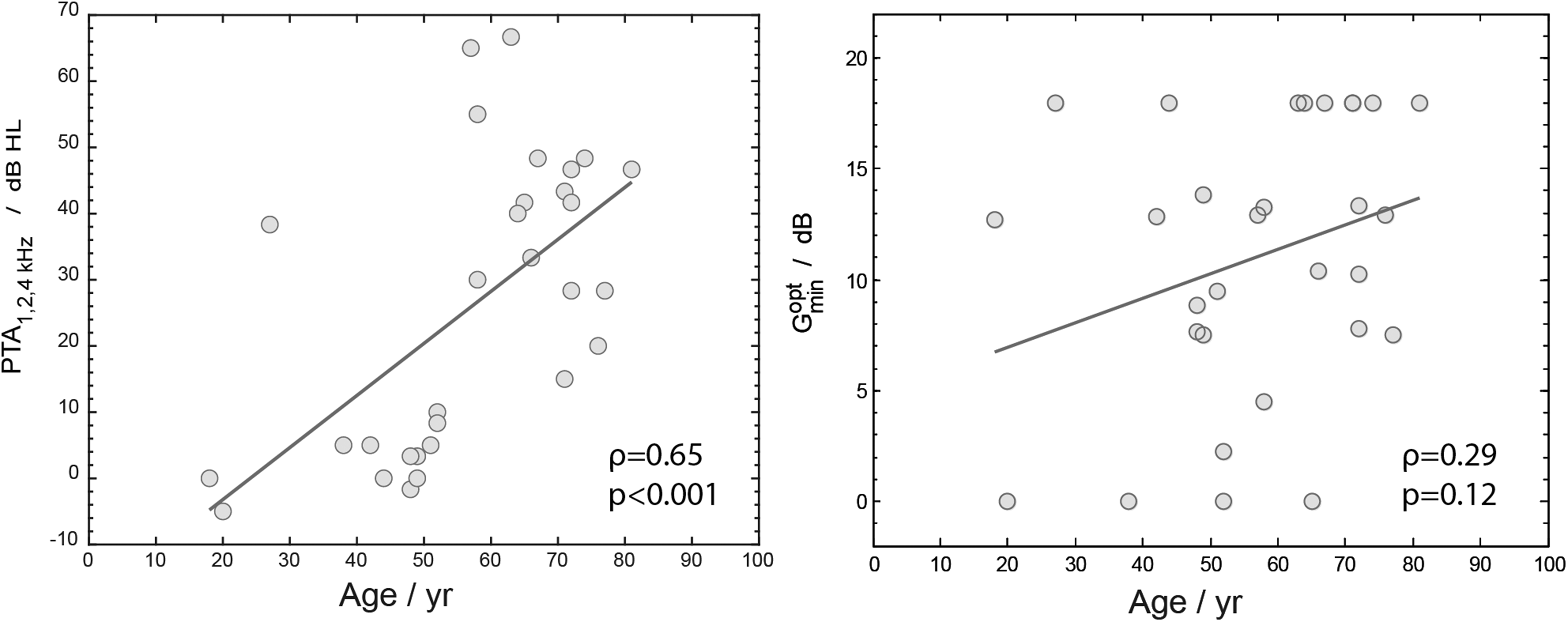
The left panel shows a scatter plot of PTA1, 2, 4 kHz against age. The right panel shows a scatter plot of
Data-Driven Analysis of Preference
The second research question was to define the required number of distinct NR settings to be able to classify our participants into similar groups based on their NR preference. To answer this question a cluster analysis was performed. Figure 6 shows the results of the hierarchical cluster analysis The dendrogram is shown on the left. The horizontal distance on the dendrogram represents the calculated Manhattan (L1) distance between the merged clusters.

Hierarchical cluster analysis of the win-count data. The different gray scales represent the win counts (white is low, black is high).
From left to right, the dendrogram shows the possible different levels with different numbers of clusters starting with two clusters in the first level and finishing with 30 separate clusters, one for each participant (see James et al., 2013 for a tutorial on hierarchical clustering and dendrograms). In the dendrogram, we can distinguish two stable clusterings: one with two clusters and one with three clusters. Stable clusterings are those that persist over a large horizontal range in the dendrogram. The clustering with two clusters has one group with six participants that prefer no NR and one group with 24 participants that prefer some non-zero level of NR. This clustering supports the choice that some hearing aid manufacturers make: NR is either on or off. The other stable clustering is one with three clusters. This clustering consists of the same group of six participants that prefer no NR and separates the remaining 24 participants into 9 and 15 participants that differ in the strength of NR they prefer. The next (unstable) clustering with five clusters does not provide us with additional insight. We focus on the clustering with three clustering for the rest of this manuscript. For each of these three clusters, the middle part of Figure 6 shows the win-count data for each participant. The different gray scales represent the win counts (white is low, black is high). Participant identity is indicated at the right of the figure. The clusters can be interpreted as one group that prefers zero NR (coded orange in Figure 6), one group that prefers an intermediate level of NR (light blue in Figure 6), and one group that prefers a high level of NR (green in Figure 6).
The average win-count data for each of the identified relevant clusters with respect to Gmin gives us information on the differences in preferences between the different clusters throughout the range of Gmin. Figure 7 shows the average win-count data (with standard deviation). Note that these data were derived directly from the participants’ answers, without information on the hearing loss or hearing loss group.

Cluster analysis: win count for each of the three clusters is calculated by averaging the win counts of each of the participants in a cluster. Error bars denote the standard deviation across participants.
The preference in Cluster 1 (shown in orange) is for low Gmin (with mean
The last question addressed is how many paired comparisons are needed to place a participant in one of the three preference clusters. As 180 paired comparisons (the number we used in this study) is too many for clinical practice, only Gmin levels of 0, 7, 8, 9, 10, and 18 dB were used in a simulation study. These Gmin levels coincide approximately with the
Subsequently, a resampling procedure was used on these paired comparisons, simulating a listening experiment where pairs were presented in random order. In resampling, each paired comparison is equally likely to be picked and each pair can be picked only once: uniform sampling without replacement. Note that this resampling is an average-case scenario: one could easily improve on this by adaptive sampling, where one uses previous responses to update the sampling strategy. For example, after a participant has indicated 6 times a preference for Gmin = 0 dB over Gmin = 18 dB one is unlikely to get new information by asking the participant a seventh or eighth time (as is done in the resampling procedure.
Getting back to the resampling procedure, 5–40 pairs were sampled (in Step 5) from the 40 paired comparisons selected previously and the Euclidian distance was calculated between the win counts of the sample and the mean win counts of each cluster as shown in Figure 7. Lastly, the cluster with the shortest Euclidean distance from the sample was picked. This simulation was run 500 times to estimate how often the sample ended up in the correct cluster (i.e., the cluster assigned to the participant based on all 180 paired comparisons).
The results of this simulation are shown in Figure 8. For nearly all participants in the first and third cluster, after 20 paired comparisons a probability of >80% of choosing the correct cluster was reached. In the middle cluster participants NH4, NH5, NH6, HI-mild2, HI-mild9, HI-mod3, HI-mod7, and HI-mod8 needed more paired comparisons to reach a probability of >80% or did not reach this percentage at all. Apparently, a significant fraction of participants in this cluster needs a wider range in Gmin to adequately estimate the actual preference. This results in more comparisons than the Gmin range in our simulation. We have no explanation for why the probability of choosing the correct cluster of HI-mild7, which belongs to the third cluster, was significantly lower in comparison to the other participants in this cluster.

Probability of selecting the correct cluster (green, blue, or orange) for each participant based on a random subset of the paired-comparison data. Data shown represent resampling from paired comparisons between three distinct groups based on Gmin (0 dB, 7, 8, 9, 10 dB, and 18 dB). The color coding represents the cluster the participants were assigned to by the cluster analysis (see Figure 5). The horizontal blue lines indicate a probability of 0.5.
Discussion
Q1: Does Preference for NR Strength Differ Between NH and HI Listeners?
In line with our hypothesis, there was a significant difference in mean preference between NH participants and HI participants with moderate hearing loss. On average, the participants with moderate hearing loss preferred stronger NR than the NH participants did. Also, there was a moderate positive correlation between PTA1, 2, 4 kHz and
The effect of age was explored by calculating the Spearman correlation between age and
Houben et al. (2011b) studied preferences for NR strength in a similar experiment. The average value of
The direction of preference (those with more severe hearing loss are likely to prefer stronger NR) is in line with the hypothesis that HI listeners are less sensitive to signal distortions (Brons, Dreschler, et al., 2014). Neher and Wagener (2016) also found that HI listeners preferred stronger NR. The average
We found a significant effect of hearing loss on preferred NR strength, although the effect size was only moderate (ρ = 0.46). This could be explained by the large individual differences in preferences (see Figure 3). Thus, there is substantial variation in preference irrespective of hearing status. Other individual traits might underlie this large spread of preferences for NR strength. Houben et al. (2011b) also found a large spread of preferences for NR strength for both NH participants and HI participants, with standard deviations of 3.6 dB and 4.0 dB, respectively. Several studies have investigated individual factors in relation to personal preferences for signal processing features in hearing aids (Neher & Wagener, 2016; Perry et al., 2019; Recker et al., 2020; Sugiyama et al., 2022). Unfortunately, for NR strength preference most of the investigated personal traits or factors were not predictive, including the acceptable noise level (ANL; Neher & Wagener, 2016; Recker et al., 2020), self-reported sound personality traits (Neher & Wagener, 2016), and the detection threshold for signal distortions (Brons, Dreschler et al., 2014; Neher & Wagener, 2016). On the other hand, Neher (2014) cautiously concluded that lower working memory might be related to preference for stronger NR. Individual preferences for NR settings, and thus NR strength, are complex and not easily predicted by subjective or objective measures.
A possible and promising explanation for the spread of preference is the individual trade-off between noise tolerance and distortion tolerance. Several researchers have used this trade-off theory to explain individual differences in preferences for NR settings (Brons, Houben, et al., 2014; Houben et al., 2013; Luts et al., 2010; Neher & Wagener, 2016; Reinten et al., 2019; Rohdenburg et al., 2005; Völker et al., 2018). Sugiyama et al. (2022) assessed individual differences in tolerance for signal distortion and residual noise using a single-channel speech enhancement algorithm. They found that their participants (N = 32) could be divided into two equal groups: those who are sensitive to distortions and those who are sensitive to noise. Kubiak et al. (2022) also found stable responses for participants (N = 30) who were classified either as “noise-haters” or “distortion-haters” in complex listening situations with different maskers. In the results shown in Figure 2, there are some participants of whom we can expect an individual trade-off to be made. For instance, the preference curve of NH1 peaks in the middle of our range of NR strengths suggesting this participant prefers an equal balance between speech distortion and noise attenuation. The preference curve of NH8 strongly suggests a preference for as much noise attenuation as possible in spite of the inevitable speech distortions, and vice versa for NH2. HI-mild9, however, which shares a similar
Q2: How Many Distinct Settings Are Required to Classify Participants Into Similar Groups of NR Strength Preference?
The results of the cluster analysis showed that for our NR algorithm, the participants could be divided into three groups with similar preferences. The
In the results of the cluster analysis, we can see that there was a trend for those with more severe hearing loss to belong to a cluster with a higher preferred NR strength, which is in line with our results for Q1. Most NH participants fell in Cluster 1 (low NR strength) or 2 (intermediate NR strength). HI-mild and HI-moderate participants fell more in Clusters 2 or 3 (high strength) than in Cluster 1. This suggests that most HI participants should be fitted with a device with NR active. However, the categorization of a participant in a cluster was not clear-cut because all three clusters contained one or more participants for the HI-moderate group. So there are, at least some, moderately HI participants who prefer no NR. These results reinforce earlier findings that the amount of hearing loss cannot reliably predict the preference for NR strength for an individual (Arehart et al., 2015; Brons, Dreschler et al., 2014). Therefore, instead of selecting the NR strength based on the audiogram, one could attempt to measure the preference with a short preference measurement.
Q3: How Many Paired Comparisons Are Required to Find the Optimal Setting for an Individual?
If one could a priori categorize a participant into one of the three clusters in a reliable way, one could optimize the NR for that individual. Paired comparisons have been used for many decades to evaluate preferences for hearing aid features (Byrne, 1994; Neuman et al., 1995; Zerlin, 1962), and are often used for measurement of user preference for NR settings (Brons, Houben, et al., 2014; Marzinzik & Kollmeier, 2003; Smeds et al., 2010). In this study, we have used a complete set of two alternative forced-choice paired comparisons analyzed with the QUL model. There are other methods of paired comparison testing such as offering a “tie” option or offering more alternatives in one comparison, as are there other statistical methods and models (i.e., the Bradley–Terry–Luce model or the Elimination by Aspects model) to analyze paired comparison data (Cattelan, 2012; Tsukida & Gupta, 2011). In clinical practice, however, paired comparisons are not routinely used for hearing aid fitting and fine-tuning (Amlani & Schafer, 2009). In a survey of 251 audiologists, Anderson et al. (2018) found that the vast majority of the respondents used default settings of the manufacturer (58%) or their own expertise (38%) for fitting an NR feature in a hearing aid. An understandable reason for not using paired comparisons is that they take considerable time, which is not feasible in clinical practice. Therefore, we investigated whether the optimal level of NR strength can be found with a small subset of paired comparisons.
Figure 8 shows for each participant the probability of choosing the correct cluster against the number of paired comparisons. For five participants (e.g., NH4), the probability did not reach 50%. This implies that for these participants a higher probability, if possible, would require more comparisons, or a wider range of included NR strengths. The majority of these participants are in the middle cluster. However, for most of the participants in the first and third clusters, the probability of choosing the correct cluster was close to 100% after approximately 10–20 paired comparisons. Such a measurement should take about 5–10 min. For a clinical setting, we suggest using a limited set (e.g., 15 comparisons, or only the comparisons of the
Although the NR algorithm used in this study is comparable to NR systems used in modern hearing aids, the optimal NR strength levels from this experiment apply only to the limited conditions tested in this study. Moreover, this study did not account for the effects of other non-linear processing, such as amplitude compression. We do not know if preferences for NR strengths differ at other input SNRs. However, since the chosen input SNR of +5 dB is representative of real-life scenario this limitation does not influence the conclusions of this work.
It is important to discuss other possible effects of our signal processing that might contribute to the differences in preference for NR strength. It is currently not known if or how the chosen hearing aid fitting rule (i.e., the amplification strategy to compensate for hearing loss) influences the preference for NR. To achieve results that are relevant to H users, one needs to use fitting rules. Fitting rules are used in hearing aids to prescribe individual, frequency-dependent amplification to compensate for the personal hearing loss. Research on preference with HI participants is thus complicated by the individual frequency-dependent hearing loss. The combination of the hearing loss with the chosen frequency-dependent fitting rule will determine the amount of spectral coloring relative to participants without hearing loss. Note that even without the use of frequency-dependent amplification there is some spectral coloring relative to NH (e.g., high frequencies can be attenuated by age-related hearing loss). We chose to apply the linear NAL-RP filter because it resembles the commonly used NAL fitting rule and it avoids the known complicated interactions with non-linear amplification (Brons et al., 2015). To what extent our choice of fitting rule (NAL-RP) has influenced the preference results is unknown. More specifically it is known that listeners might prefer less gain than prescribed by the NAL-RP fitting rule (e.g., Humes et al., 2000, 2001). This “too harsh” sound might have influenced the preference. However, due to the RMS correction that effect seems limited because overall the NR acts on all frequencies (the noise was spectrally matched to the speech).
Conclusions
The results showed that preferred NR strength in hearing aids was moderately correlated with the degree of hearing loss. An individual with more severe hearing loss is likely to prefer stronger NR. However, there was large variation in preference for NR strength. Therefore, choosing NR strength based on the audiogram alone can result in suboptimal hearing aid fitting. For the conditions tested in this study, three distinct settings of NR strength sufficed to adequately accommodate individual preference. Thus it might be possible to use a limited set of pre-set NR strengths that can be chosen clinically. For most participants, the appropriate setting could be found with about 15 paired comparisons. For clinical practice, we advise using hearing status as a (first) guess to select the NR strength and then measuring individual preferences by using a limited number of paired comparisons.
Footnotes
Acknowledgements
The authors would like to thank Professor Bert de Vries for his help with the NR algorithm.
Data Availability Statement
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Appendix A
Age, air conduction thresholds (dB HL) for each frequency and ear, PTA1, 2, 4 kHz and SRT values for all participants.