
Abstract
Frequency-domain monaural speech enhancement has been extensively studied for over 60 years, and a great number of methods have been proposed and applied to many devices. In the last decade, monaural speech enhancement has made tremendous progress with the advent and development of deep learning, and performance using such methods has been greatly improved relative to traditional methods. This survey paper first provides a comprehensive overview of traditional and deep-learning methods for monaural speech enhancement in the frequency domain. The fundamental assumptions of each approach are then summarized and analyzed to clarify their limitations and advantages. A comprehensive evaluation of some typical methods was conducted using the WSJ + Deep Noise Suppression (DNS) challenge and Voice Bank + DEMAND datasets to give an intuitive and unified comparison. The benefits of monaural speech enhancement methods using objective metrics relevant for normal-hearing and hearing-impaired listeners were evaluated. The objective test results showed that compression of the input features was important for simulated normal-hearing listeners but not for simulated hearing-impaired listeners. Potential future research and development topics in monaural speech enhancement are suggested.
Keywords
Introduction
The aim of monaural speech enhancement is to extract clean speech or to improve the speech-to-background ratio by removing noise and reverberation from a noisy-reverberant speech signal captured by a microphone (Lim, 1983; Benesty et al., 2006; Martin et al., 2008; Naylor & Gaubitch, 2010; Loizou, 2013). This is especially important for improving speech quality and/or intelligibility for digital speech communication devices, such as hearing aids and other assistive listening devices (Dillon, 2012; Popelka et al., 2016), audio-visual conference equipment, smartphones, and true wireless earphones. It is also important for automatic speech recognition systems (Hansen, 1996; Li et al., 2014), such as smart home appliances, in-car voice assistants, and speech transcription services. It should be noted that it is not always necessary to reconstruct the time-domain speech signal for the purpose of automatic speech recognition; enhancement of extracted features often leads to improve speech recognition performance (Schuller et al., 2009; Krueger & Haeb-Umbach, 2010). The present paper focuses on monaural speech enhancement for human hearing rather than for machine hearing, where the time-domain waveform of the clean speech needs to be reconstructed.
Both time- and frequency-domain methods of monaural speech enhancement have been proposed and widely studied. For the former, the clean speech is estimated directly in the time domain without (short-term) spectral analysis and synthesis (Lee & Jung, 2000; Benesty & Chen, 2011; Luo & Mesgarani, 2018; Macartney & Weyde, 2018; Pandey & Wang, 2018, 2019b; Hao et al., 2019; Pandey & Wang, 2019a; Von Neumann et al., 2020; Zucatelli & Coelho, 2021; Pandey & Wang, 2022). For the latter, the short-term complex spectrum of the clean speech is estimated, the spectrum is converted back to a time-domain signal, and this process is repeated for a series of overlapping frames (time segments) to reconstruct the complete time-domain signal, using the overlap-add method (Allen, 1977; Boll, 1979; Ephraim & Malah, 1984; Griffin & Lim, 1984; Loizou, 2013; Wang & Chen, 2018). There are some hybrid methods, in which the appropriate gain for each of several frequency sub-bands is estimated in a first stage, and a time-domain enhancement filter is designed in a second stage to partially remove the noise and reverberation (Vary, 2006; Löllmann & Vary, 2007; Zheng et al., 2022). Among these methods, frequency-domain methods have been the most extensively studied, for the following reasons. First, short-term spectral analysis and synthesis can be efficiently performed by the fast Fourier transform (FFT) algorithm, although the Fourier decomposition may not be optimal for speech enhancement (Johnson et al., 2007; Benesty et al., 2009). Second, the spectral magnitude and phase of the speech are decoupled, and thus one can process the spectral magnitude alone or optimize the spectral magnitude and the phase step by step or jointly depending the hardware resources and the desired performance (Paliwal et al., 2011; Gerkmann et al., 2015; Li et al., 2022a). Third, the human ear works as a frequency analyzer (Plomp, 1964). In particular, different places on the basilar membrane within the cochlea respond to different frequency ranges in sound (Moore, 2013). Hence, it seems very natural to enhance speech in a way that mimics the operation of the normal healthy ear. Fourth, speech is sparse in the frequency domain, which facilitates removal of nonspeech components, while it is not sparse in the time domain (He et al., 2007). Fifth, frequency-domain methods can readily be used in combination with special applications, such as frequency-dependent amplification to compensate for hearing loss (Kates, 2008). Finally, frequency-domain monaural speech enhancement methods usually achieve higher objective and subjective scores than time-domain methods (Hu et al., 2020; Li et al., 2021a, 2021), although this may in part be the case because more effort has been put into frequency-domain methods than into time-domain methods. For the above reasons, this paper reviews only frequency-domain monaural speech enhancement methods, which have been extensively studied over the 60 years since Schroeder (1965, 1968) first proposed a noise suppression method using an analog implementation.
In the last ten years, monaural speech enhancement has made great progress with the development of deep learning methods (Hochreiter & Schmidhuber, 1997; Hinton & Salakhutdinov, 2006; LeCun et al., 2015). A large number of deep-learning-based frequency-domain methods have been proposed (Wang et al., 2014; Xu et al., 2014b, 2015), and they have been shown to surpass traditional frequency-domain methods in challenging conditions such as at low speech-to-noise ratios (SNRs), in high reverberation, and when the noise is nonstationary. Deep-learning methods can be categorized into two types: spectral magnitude-only enhancement and complex spectrum enhancement. The former estimate only the spectral magnitude of the clean speech. The noisy phase is used to reconstruct the time-domain speech signal. The latter estimate the real and imaginary parts of the complex spectrum of the clean speech directly, which has the potential to further improve speech quality. In general, deep-learning methods have much more computational complexity and greater storage requirements than traditional frequency-domain methods. Although many researchers have proposed ways of reducing the number of parameters and the complexity (Tan & Wang, 2021), it is still challenging to implement advanced deep-learning-based methods in resource-limited devices such as hearing aids. In contrast, traditional frequency-domain speech enhancement methods have been extensively applied in devices such as digital hearing aids, smartphones, and audio-visual communication systems. However, it is becoming more feasible to implement deep-learning methods in such devices because of the development of low-resource deep-learning methods in combination with increases in computing performance and memory capacity of signal-processing chips.
The purposes of this paper are fourfold. Firstly, the paper provides an overview of both traditional and deep-learning frequency-domain monaural speech enhancement methods that have been proposed over the last six decades. Although many review papers and books have been published on traditional methods (Loizou, 2013; Gerkmann et al., 2015) or deep-learning methods (Wang & Chen, 2018), the reviews do not give a deep insight into the advantages and disadvantages of the two categories of methods. The second purpose is to clearly reveal the fundamental assumptions underlying the different methods and the consequences of these in practical applications. The third purpose is to compare the objective performance of the two types of methods using the same speech corpus and noise corpus. To our knowledge, such a comprehensive evaluation has not been reported before. Finally, challenges for the future are formulated and some potential research topics are outlined.
The remainder of this paper is organized as follows. Firstly, the processing stages in frequency-domain monaural speech enhancement are formulated, and different estimation targets are presented. After that, traditional methods are described, including a complete flowchart of these methods and a review of each key module. Deep learning-based methods are then presented, and the reasons why deep-learning methods surpass traditional methods are discussed. The two types of methods are evaluated using a common set of objective measures. Finally, future research topics in monaural speech enhancement are discussed.
Signal Model and Problem Formulation
For monaural speech enhancement, only a single sensor, such as a microphone, is used to pick up a sound. Thus, the signal can be represented as

With the short-time Fourier transform (STFT), the time-frequency (T-F) representation of Equation (1) can be written as


This paper focuses on reviewing and evaluating monaural speech denoising methods. It should be noted that many speech denoising methods have been extended to perform speech dereverberation (Lebart et al., 2001), based on the assumption that late reverberant speech components are uncorrelated with the direct and early-reflected speech components (see Braun et al., 2018, and references therein). This assumption is reasonable when the speech rate is reasonably rapid, so that a given speech sound at the microphone has been completed before the late reverberation from that sound arrives at the microphone. The assumption may also be reasonable if the impulse response h(t) changes over time, as pointed out by Elko et al. (2003).
Without sound reflections,


For frequency-domain monaural speech enhancement methods, the goal is to estimate the complex spectrum of the clean speech from
There are many ways to obtain
Recent studies have confirmed that it is important to minimize the phase difference between the estimated speech and the clean speech (Paliwal et al., 2011), and phase processing for speech enhancement has attracted considerable attention in the last decade (Gerkmann, 2014; Krawczyk & Gerkmann, 2014; Gerkmann et al., 2015). Because it is difficult if not impossible to estimate the phase of the clean speech at low SNRs, traditional methods of phase processing do not greatly improve speech quality. For deep-learning speech enhancement methods, it has been shown that performance can be improved in terms of both objective and subjective metrics if the clean speech phase can be estimated before reconstructing the estimated time-domain speech signal (Williamson et al., 2016; Fu et al., 2017; Williamson & Wang, 2017; Tan & Wang, 2019, 2020; Yin et al., 2020).
In recent years, many direct methods have been proposed, where the magnitude of
Traditional Methods
This section reviews statistical signal-processing-based methods for monaural speech enhancement. These methods are usually based on the assumption that the speech and noise are independent, and that the speech or noise follows a specific distribution, such as Gaussian (McAulay & Malpass, 1980; Ephraim & Malah, 1984, 1985), Gamma (Martin, 2002), Laplacian (Chen & Loizou, 2007), or Super-Gaussian (Breithaupt & Martin, 2003). Hendriks et al. (2007) and McCallum & Guillemin (2013) assumed that speech was a combined stochastic-deterministic signal instead of a completely stochastic signal. Note that a great number of traditional methods do not make use of any stochastic model (Boll, 1979; Berouti et al., 1979; Gülzow et al., 2003; Li et al., 2008; Loizou, 2013). Rather, they are heuristic (rule-based) or the speech is assumed to be a deterministic signal. For example, spectral subtraction, for which the estimated spectrum of the noise is subtracted from the spectrum of the speech-plus-noise, is a typical heuristic method, and although it is not a perfect solution for monaural speech enhancement, it has been widely used in practical applications. For all of these traditional methods, five key modules are often used, namely estimation of: noise, a priori SNR, speech-presence probability, spectral gain, and phase. The a priori SNR is the true short-term power ratio between each spectral component of the clean speech and the noise. It can be contrasted with the a posteriori SNR, which is the short-term power ratio between each spectral component of the observed noisy speech and noise.
Figure 1 shows a flow diagram of typical traditional frequency-domain speech enhancement methods. In this figure, both a spectral magnitude enhancement module and a phase-processing module are included. Note that all five modules are not necessarily used in all traditional methods. For example, when Boll (1979) proposed spectral subtraction, which involves subtraction of the estimated noise spectrum from the speech+noise spectrum for each time-frequency bin, he used only two modules, noise estimation and spectral gain estimation. The estimate of the noise power spectral density (PSD) was updated based on segments estimated to contain only noise, via a voice activity detector (VAD). Ephraim & Malah (1984) proposed the decision-directed method to estimate the a priori SNR, and Cappé (1994) analyzed its importance in suppressing the well-known “musical noise” artifact. McAulay & Malpass (1980) first introduced a two-state model (
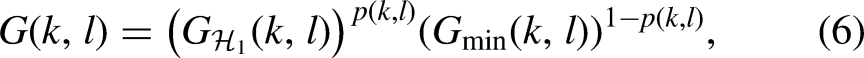
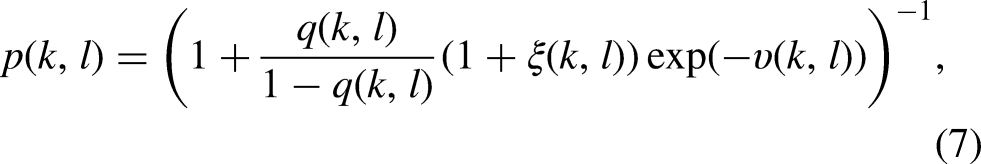


A flow-process diagram of traditional methods.
In the following five sections, the five modules are each overviewed. Then, the valid and invalid assumptions of traditional methods are described and limitations of the methods are discussed.
Noise Estimation
The noise-estimation module plays an important role for almost all traditional frequency-domain speech enhancement methods. Its performance has a direct effect on both noise reduction and speech distortion. When the noise PSD is underestimated, the amount of noise reduction is reduced, leading to speech-amplification distortion (Loizou & Kim, 2011). 1 This can explain why traditional methods do not improve the intelligibility of speech in nonstationary noises for normal-hearing listeners (Loizou & Kim, 2011), although they can improve the quality of speech in quasi-stationary noises for both hearing-impaired and normal-hearing listeners (Sang et al., 2014, 2015). In contrast, when the noise PSD is overestimated, this results in speech-attenuation distortion, even though the amount of noise reduction increases. Because of the importance of estimation of the noise PSD, many types of noise PSD estimators have been proposed.
In early work on this topic, noise estimation was based on the use of a VAD (Lim et al., 1978; Boll, 1979; McAulay & Malpass, 1980; Ephraim & Malah, 1984, 1985). This exploits the fact that speech usually contains brief pauses, for example before or after a stop consonant. With this approach, each time frame was categorized into one of two states: speech absent and speech present. The noise PSD was updated in speech-absent frames and the estimate was maintained across subsequent speech-present frames. This is represented by

There are two drawbacks of this VAD-based noise PSD estimator. Firstly, noise-estimation accuracy depends strongly on the performance of the VAD. Misclassification of speech-present frames as speech-absent frames leads to overestimation of the noise, resulting in speech attenuation distortion. Unfortunately, this misclassification problem cannot be avoided when the SNR is low (Sohn et al., 1999; Tan et al., 2020), especially when the noise is nonstationary. Secondly, since the noise PSD is not updated during frames classified as speech present, the sparsity of speech in the T-F domain is not fully exploited. This sparsity is readily apparent in spectrograms of clean speech from a single talker (Darwin, 2009); there are many T-F regions with very low energy.
If the noise PSD is estimated via use of a VAD, this implicitly assumes that the noise is quasi-stationary and that its PSD changes slowly over time. To avoid use of a VAD, one more assumption is necessary, namely that the PSD of each speech-plus-noise T-F bin is always larger than or equal to the noise PSD for the corresponding T-F bin, i.e.,


Cohen (2003) proposed an improved minima-controlled recursive averaging method for noise estimation. In this method, the noise PSD is first roughly estimated using the minimum statistics method, and the SPP is then estimated to control the smoothing factor used in estimating the noise PSD. This can be written as
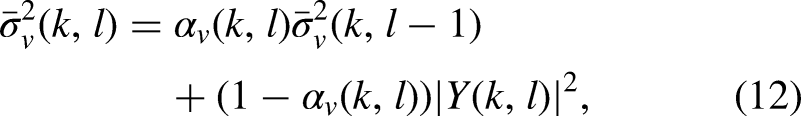
Hendriks et al. (2010) and Gerkmann & Hendriks (2012) suggested estimating the noise PSD based on the minimum mean-square error (MMSE) criterion
2
of the noise magnitude-squared STFT coefficients. The estimated noise PSD can then be calculated from the conditional expectation of
Although many researchers have attempted to improve noise-estimation accuracy when the noise is nonstationary (Cohen, 2003; Rangachari & Loizou, 2006; Hendriks et al., 2010; Gerkmann & Hendriks, 2012; Zhang et al., 2019), this remains a challenging task for highly nonstationary noises, such as babble noise, siren noise, and wind noise. As mentioned above, the performance degradation of traditional noise PSD estimators when the noise is nonstationary limits the performance of traditional methods. As a result, data-driven methods have been proposed to improve noise-tracking performance (Erkelens & Heusdens, 2008; Li et al., 2019; Liu et al., 2021).
A Priori SNR estimation
Before Cappé (1994) analyzed the operation of the decision-directed method in reducing musical-noise artifacts without sacrificing the quality of speech, the importance of the a priori SNR in speech enhancement had not been appreciated, although the maximum-likelihood method for estimation of the a priori SNR had been proposed a long time previously (Boll, 1979; McAulay & Malpass, 1980; Ephraim & Malah, 1984). Maximum likelihood and decision-directed estimation of the a priori SNR can be, respectively, given by
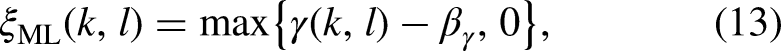


There are two drawbacks of the decision-directed method, as pointed out by Cohen (2005) and Plapous et al. (2006). Firstly, a delay of one frame is needed to track the a priori SNR at speech onsets, leading to speech distortion. Secondly, a delay of one frame is needed to track the a posteriori SNR at speech offsets (Cohen, 2005). By taking into account the correlation between adjacent speech frames, Cohen (2005) proposed causal and noncausal methods for a priori SNR estimation. The causal method can solve the first problem of the decision-directed method, reducing speech distortion, while the noncausal method can solve the two above-mentioned problems simultaneously at the expense of three additional frames delay. Plapous et al. (2004, 2006) proposed a two-stage SNR estimator, solving the two drawbacks of the decision-directed method simultaneously without introducing further algorithmic delay. The two-stage SNR estimator is given by

Except for the maximum-likelihood method, the above-mentioned methods for estimating the a priori SNR only exploit the correlation over time for each frequency bin, while the correlation over frequency is ignored. Breithaupt et al. (2008) exploited the latter to develop a novel a priori SNR estimator by selectively smoothing the maximum-likehood estimate of the speech power in the cepstral domain. This SNR estimator surpassed the decision-directed method in both stationary and nonstationary noise scenarios. With this new method, the residual noise sounded more natural than for the decision-directed method and the musical-noise problem was reduced.
All of the above-mentioned a priori SNR estimators need to make an initial estimate of the a posteriori SNR. If the a posteriori SNR is overestimated due to underestimation of the noise PSD, this often leads to an overestimate of the a priori SNR. There are two ways of solving this problem. One is to improve the accuracy of the noise PSD estimate using data-driven methods (Erkelens & Heusdens, 2008; Li et al., 2019; Liu et al., 2021). The other is to estimate the a priori SNR directly using data-driven methods without estimating the noise PSD (Nicolson & Paliwal, 2019, 2020; Zhang et al., 2020). Strictly speaking, these data-driven methods should not be classified as traditional methods, but since they can be used for parameter estimation, they are still mentioned in this section.
Speech Presence Probability Estimation
As shown in Equation (7), the SPP depends on three parameters: the a posteriori SNR,
The a priori probability of speech absence is defined as

After estimating
Spectral Gain Estimation
Spectral gain estimation methods can be categorized into three groups: deterministic, stochastic, and stochastic-deterministic. In the following, each of these three groups is reviewed.
Deterministic Methods
The first group derives the spectral gain under the assumption that the speech and noise are independent of each other and that
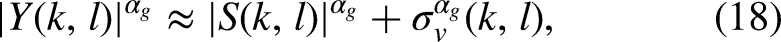


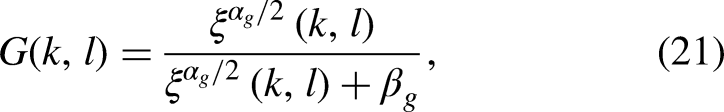
When the spectral gain is determined only by the a posteriori SNR, as in Equation (20), the musical noise problem arises. There are many ways to reduce this problem. One is to increase the value of
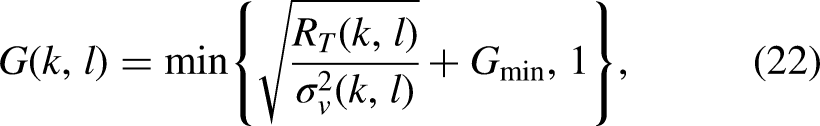
Equation (18) is only an approximation and the two cross terms,
Stochastic Methods
McAulay & Malpass (1980) assumed that the speech and noise are two statistically independent Gaussian random processes and used a maximum-likelihood method to estimate the speech spectrum. Based on modeling the real and imaginary parts of the speech and noise complex spectra as statistically independent Gaussian random variables, Ephraim & Malah (1984) derived the MMSE short-time spectral amplitude (MMSE-STSA) estimator. Its spectral gain under the condition of speech presence is given by
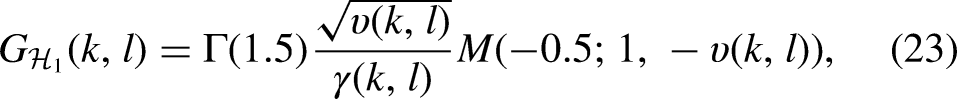





Loizou (2005) proposed a group of perceptually motivated Bayesian estimators of the STSA based on some perceptually related quantity that is to be minimized, such as the Itakura-Saito divergence (Itakura & Satio, 1968), weighted likelihood-ratio distortion, and weighted square estimation error. They showed that the best performance in terms of a specific objective measure was achieved if that same objective measure was chosen as the quantity to be minimized.
Although the Gaussian statistical model has been widely used for modeling speech and noise, it is well accepted that speech is non-Gaussian (Martin, 2002; Breithaupt & Martin, 2003; Cohen, 2005; Chen & Loizou, 2007) and that different types of noise follow different distributions (Davis et al., 2006). It is sometimes reasonable to assume that the noise has a Gaussian distribution, but a non-Gaussian statistical model may be more appropriate for speech. Using different statistical models of the speech, different MMSE-STSA estimators have been derived and have been shown to improve speech enhancement performance when compared with use of a Gaussian statistical model. In addition to modeling the speech and noise with the same statistical model, Martin (2002) derived two novel MMSE-STSA estimators using different distributions for the speech and noise. Both estimators were based on a Gamma distribution for the speech, but one was based on a Gaussian noise model and the other on a Laplacian noise model. Modeling both speech and noise with non-Gaussian statistical models led to increases in the amount of noise reduction, but only a marginal objective performance improvement was found.
Deterministic-stochastic Methods
In one well known speech-production model (Quatieri, 2006), speech can be linearly predicted as follows


Hendriks et al. (2007) proposed an MMSE-STSA estimator based on a stochastic-deterministic speech model. The estimated speech spectrum was a linear combination of the noisy spectrum filtered by a Wiener filter and the expectation of the noisy spectrum, where the linear combination factor was determined by the uncertainty of the speech presence. McCallum & Guillemin (2013) also proposed a stochastic-deterministic MMSE-STSA estimator that explicitly exploited the periodic structure of speech.
Evaluations using objective measures of speech quality/intelligibility have demonstrated the superiority of MMSE-STSA estimators based on stochastic-deterministic speech models over those based on stochastic models (Hendriks et al., 2007; McCallum & Guillemin, 2013). However, this superiority is marginal. Informal listening tests also show only a marginal benefit of stochastic-deterministic speech models (McCallum & Guillemin, 2013).
Some Remarks
All of the above-mentioned spectral gain estimation methods need to estimate the noise PSD. Some do this using only the a posteriori SNR or a priori SNR, while others use both types of SNR. Because the gain functions discussed above are all real and non-negative, they extract clean speech nonlinearly, especially when oversubtraction (
Phase Processing
Wang & Lim (1982) were among the first to consider whether or not phase estimation is necessary. They concluded that the phase was unimportant for monaural enhancement of speech in white Gaussian noise. Based on this finding, phase estimation was ignored for a long time. In any case, it is extremely difficult to estimate the phase of the clean speech directly from the noisy speech, especially when the SNR is low.
Instead of modifying the STSA of the noisy spectrum, Wojcicki et al. (2008) described a method of changing the noisy phase spectrum. This changed phase spectrum was combined with the noisy amplitude spectrum to reconstruct the complex spectrum of the enhanced speech. This also suppressed noise and preserved the speech, and Wojcicki et al. (2008) showed that changing the noisy phase spectrum outperformed the spectral subtraction method proposed by Boll (1979) and the MMSE-STSA estimator proposed by Ephraim & Malah (1984) in mean PESQ scores. Paliwal et al. (2011) conducted four experiments to assess the importance of phase estimation. They concluded that using the clean speech phase spectrum can greatly improve speech quality when using mismatched analysis windows for the spectral amplitude and phase estimation. In such approaches, windows with low dynamic range, such as Dolph-Chebyshev windows, are used for phase estimation and Hanning/Hamming windows are commonly used for spectral amplitude estimation. When the MMSE-STSA estimator was implemented with the phase spectrum compensation (PSC) method incorporated, better performance was found than when modifying only the amplitude spectrum or only the phase spectrum (Paliwal et al., 2011).
Gerkmann et al. (2015) give a comprehensive overview of phase-processing-based monaural speech enhancement methods. Interested readers are referred to that paper for details.
Only a few researchers have proposed enhancing speech in the complex-spectrum domain, based on the assumption that the real and imaginary parts of the complex spectrum are statistically independent (Martin, 2005; Erkelens et al., 2007; Zhang & Zhao, 2013; Schwerin & Paliwal, 2014). As stated by Parchami et al. (2016), this assumption is an alternative to the assumption that the magnitude and phase of the complex spectrum are independent; the assumptions are not the same (Martin, 2005). Without some sort of independence assumption, a closed-form estimator for speech enhancement cannot be derived. For deep-learning methods, such assumptions are not necessary, and the magnitude and phase or the real and imaginary parts of complex spectrum are often jointly optimized. We return to this issue later.
Discussion
For most traditional frequency-domain speech enhancement methods, there are four underlying assumptions. The first is that the speech and noise are statistically independent. The second is that the noise is much more stationary than the speech. The third is that each T-F bin is statistically independent of other bins when deriving the spectral gain function under a specific statistical model. The last is that the speech phase is not as important as the speech spectral amplitude. While the first assumption is reasonable, the other three are not, and this constrains the application scenarios and limits the performance of methods based on these assumptions.
The second assumption is fundamental to most existing noise PSD estimators, such as the VAD (Boll, 1979), minimum statistics (Martin, 2001), and MMSE (Gerkmann & Hendriks, 2012) methods. Without this assumption, the noise PSD cannot be estimated using noise-only segments or represented by the minimum value of the noisy PSDs of several past frames. This assumption also limits the application scenarios, and most noise PSD estimators only work well for quasi-stationary noises. The noise PSD is often underestimated for highly nonstationary noises, such as babble noise (Loizou & Kim, 2011), siren noise (Sherratt et al., 1999), and transient noises (Talmon et al., 2011). To improve the performance of speech enhancement in highly nonstationary noise scenarios, each highly nonstationary noise needs a specially designed method. To the best of our knowledge, a common framework for handling all types of highly nonstationary noise does not exist for traditional methods. It is highly desirable to be able to reduce both stationary and nonstationary noises using a unified framework.
The third assumption ignores the fact that the speech spectrogram has clear structure over time and frequency, as shown in Figure 2(

Time-domain clean speech and noisy speech, and their corresponding magnitude and phase spectrograms. (
The last assumption has had a significant impact on the progress of research on frequency-domain monaural speech enhancement. Most traditional methods do not take into account the importance of phase estimation in improving speech quality. As shown in Figure 2(
The unstructured nature of speech phase using typical analysis methods makes it difficult to estimate the phase of the clean speech directly from noisy observations. To tackle this problem, two-stage traditional methods have been proposed. In the first stage, the spectral amplitude of the clean speech is estimated. Iterative approaches for phase estimation are then applied to reconstruct the time-domain signal (Griffin & Lim, 1984). The spectral amplitude has been estimated using the MMSE-STSA estimator, and the phase has been separately estimated using a PSC algorithm (Wojcicki et al., 2008; Paliwal et al., 2011). Wojcicki et al. (2008) and Paliwal et al. (2011) showed that use of the PSC algorithm alone can suppress noise, and that higher PESQ scores were achieved when the PSC algorithm was combined with other speech enhancement methods such as MMST-STSA. Mowlaee & Saeidi (2013) proposed a method for joint optimization of spectral amplitude and phase in an iterative manner. This method can be regarded as an iterative version of two-stage traditional methods. Pruša et al. (2017) proposed a noniterative method, namely phase gradient heap iteration (PGHI), for phase reconstruction from the STFT magnitude. PGHI is based on the simple relationship between the partial derivatives of the phase and log-spectral magnitude when a Gaussian window is used when computing the STFT coefficients (Portnoff, 1979). This method was computationally efficient, and achieved competitive performance when compared with many state-of-the-art algorithms. As described earlier, a higher PESQ score can be achieved when both spectral amplitude and phase are estimated. Unfortunately, because the spectral amplitude of clean speech is not estimated accurately using traditional methods, the accuracy of the phase estimation is limited, which in turn limits the contribution of phase estimation in improving speech quality.
As discussed above, the use of the last three assumptions largely explains why traditional methods do not work well in nonstationary noise scenarios. The performance degradation in low SNR environments can largely be explained by use of the third assumption. Because each T-F spectral amplitude bin is assumed to be independent of other bins, the SNR for each T-F bin is the only physical quantity used to determine whether or not that T-F bin contains speech. It is difficult to estimate the a priori SNR in low SNR environments. Most methods are biased towards underestimation in order to reduce musical noise. Without exploiting the structure of clean speech in time and frequency, the low SNR T-F bins containing speech cannot be recovered. In the next section, deep learning methods are reviewed. These methods implicitly relax the unrealistic assumptions, thus improving speech enhancement performance.
Before deep learning methods became the most popular methods for speech enhancement, researchers proposed many methods for solving the problems of traditional methods, including nonnegative matrix factorization (NMF) (Lee & Seung, 1999; Wilson et al., 2008; Mohammadiha et al., 2013; Sun et al., 2015) and K-means singular value decomposition (K-SVD) (Aharon et al., 2006), which is a method for factoring a matrix. For supervised NMF approaches, the speech and noise basis matrices 5 are respectively learned from the speech and noise datasets in a first stage. The noisy NMF coefficients are then obtained from the noisy speech magnitude and the two basis matrices. Finally, speech denoising is performed using the two basis matrices and their corresponding coefficients (Mohammadiha et al., 2013). For unsupervised NMF approaches, the noise basis matrix is learned from the noisy speech directly without use of the noise dataset. Mohammadiha et al. (2013), using objective assessment metrics, showed that both supervised and unsupervised approaches outperformed traditional methods such as Wiener filtering and the MMSE estimator of speech discrete-time Fourier transform coefficients based on a generalized Gamma distribution (Erkelens et al., 2007). For K-SVD-based approaches, noise dictionaries are trained using K-SVD, and they are then applied to speech denoising (Aharon et al., 2006). K-SVD-based approaches often work better than traditional methods in terms of noise attenuation.
Shallow neural networks (Tamura, 1989) and codebook-based methods were applied to speech denoising some time ago (Zavarehei et al., 2007; Suhadi et al., 2011). For example, Zavarehei et al. (2007) proposed pretraining the harmonic-noise model (HNM) codebook using a dataset comprising only clean speech. A codebook-mapping algorithm was then developed to create the estimated clean speech with the pretrained HNM codebook. However, while these methods improved speech enhancement in some specific scenarios, their ability to generalize to other scenarios, such as different types of background noise, was limited. This limitation mainly comes from the limited modeling ability of these methods due to the limited maximum number of dictionaries/basis matrices or the limited number of hidden layers and the difficulty of training a model with the limited computational resources and limited storage available at that time. Moreover, training models with greater numbers of hidden layers and more hidden units per layer was challenging before an effective initialization method was proposed by Hinton & Salakhutdinov (2006). In the next section, we review deep learning methods to clarify how these problems have been alleviated.
Deep Learning Methods
Over the last 15 years, deep learning methods have become pervasive, and they have been successfully applied to computer vision (He et al., 2016; Krizhevsky et al., 2017; Huang et al., 2017), speech processing (Yu & Deng, 2011; Hinton et al., 2012; Dahl et al., 2012; Abdel-Hamid et al., 2014), and other practical applications because of their powerful high-dimensional nonlinear modeling capability. About ten years ago, deep learning was extended to monaural speech enhancement. Many effective network architectures were proposed for denoising (Wang & Wang, 2012, 2013) and dereverberation (Han et al., 2014). Figure 3 shows a flow-chart of typical deep learning-based frequency-domain methods. These methods involve two stages: training and testing. For the training stage, there are four modules: feature extraction, network architecture, learning target, and loss function. For the testing stage, there are also four modules. The feature extraction and network architecture modules are the same as for the training stage. The target spectrum reconstruction and time-domain speech reconstruction modules are used to generate the processed time-domain speech signal. The last two modules of the testing stage are straightforward to realize. Therefore, in the following, only the four modules of the training phase are reviewed and discussed.

A generic flow-process diagram of deep learning methods.
Feature Extraction
Feature extraction is the first step for deep learning methods. A good feature set can improve the discrimination of speech from noise. Chen et al. (2014) extracted a range of acoustic features from speech in noise at low SNRs and evaluated their influence on the classification of T-F bins as speech-dominated or noise-dominated. Classification accuracy was assessed in terms of hits (the proportion of correctly identified speech-dominated T-F bins) and false alarms (the proportion of noise-dominated T-F bins that were incorrectly classified as speech dominated). It was concluded that features derived using a gammatone filterbank, which is intended to represent the frequency analysis that takes place in the human auditory system (Moore, 2013), achieved better performance than other types of features, such as perceptual linear prediction (PLP) (Hermansky, 1990), power normalized cepstral coefficients (Kim & Stern, 2016), and Gabor filterbank features. Delfarah & Wang (2017) evaluated several acoustic features of speech in noise, including the amplitude modulation spectrogram as used by Kim et al. (2009), the relative spectral transform-PLP (RASTA) as used by Hermansky & Morgan (1994), gammatone frequency cepstral coefficients, Mel-Frequency Cepstral Coefficients (MFCCs) as used by Xu et al. (2017), log-amplitude spectral features (LOG-AMP) as used by Han et al. (2015), and fundamental-frequency-based features as used by Hu (2006), using the short-time objective intelligibility (STOI) score as the objective performance metric. The time required to extract each feature was also determined. Gammatone-domain features led to higher STOI scores than LOG-AMP, log-mel filterbank features and MFCC. However, the gammatone-domain features required more extraction time than the other features. Perhaps because of this, gammatone-domain features have not been used as widely as MFCC and LOG-AMP features for applications in resource-limited devices and real-time systems.
Various easily extracted features of noisy speech have been used in deep neural network (DNN) models designed to extract clean speech from noisy speech, including the LOG-AMP, the log-power spectrum (Xu et al., 2014b, 2015), spectral amplitudes (Tan & Wang, 2018) and the spectral amplitudes raised to a power less than 1 (Zhao et al., 2020), which represents a form of amplitude compression. The cube-root of the spectral amplitudes generally led to the best performance, perhaps because taking the cube-root reduces the dynamic range of the speech, facilitating the training process (Luo et al., 2022). Tan & Wang (2020) extracted the real and imaginary parts of the complex spectrum of noisy speech as input features. The mapping targets were the corresponding real and imaginary parts of the complex spectrum of the clean speech. Better performance was achieved than with networks that only mapped spectral magnitudes, because of the implicit phase recovery (Tan & Wang, 2020). It was also shown that compression of the complex spectrum improved speech dereverberation performance based on both objective metric scores and subjective preference scores (Li et al., 2021d). Better performance with compression in the joint denoising and dereveberation task was shown in the 3rd deep noise suppression (DNS) Challenge (Li et al., 2021a).
Extraction of STFT-domain features is computationally efficient, so their computational load is often small relative to the load of the DNN itself. However, the number of features increases with increasing frame length, and fine frequency resolution, which facilitates the discrimination of speech and noise, requires a large frame length. It is generally accepted that the frequency resolution of the human auditory system can be characterized using the ERB-Number frequency scale, for which the bandwidths of the auditory filters in Hz increase with increasing center frequency (Moore, 2013). The Bark scale (Fastl & Zwicker, 2007) has similar properties, but differs from the ERB-Number scale in resolution at low frequencies. These psychoacoustically based scales have been applied to reduce the number of STFT-domain features. For example, Valin (2018) extracted 22 Bark-frequency cepstral coefficients (BFCCs), the first and second derivatives of the first six BFCCs, and the strength of the dominant periodicity for the first six bands, which is related to the fundamental frequency (F0), and used them as input features for real-time speech enhancement. This reduced the number of features per frame from 481 for the STSAs (when the sampling rate was 48,000 Hz and the window length was 20 ms) to 42. Valin (2018) also computed and used at input features the period (1/F0) and a spectral nonstationary metric that measured the spectrum variation over time. To improve performance, Valin et al. (2020) used 70 input features. To extract these features, the audible frequency range was split into 34 bands based roughly on the ERB-number scale, and the magnitude of each band for the third future frame and the pitch correlation of each band for the current frame were computed and used to obtain 68 input features. The other two input features were the period (1/F0) and an estimate of the correlation of the period across frames. The computational load was about 40 million floating point operations per second when 42 features per frame were used (Valin, 2018) and about 800 million multiply-accumulate operations per second (Valin et al., 2020) when 70 features were used. Valin et al. (2020) showed that the quality of the enhanced speech was significantly improved in terms of mean opinion score (MOS) and PESQ when compared with the previous work by Valin (2018).
Another advantage of using perceptually based features occurs when full-band 6 speech is to be enhanced. For full-band speech, the number of the input features increases markedly when features are extracted on a linear frequency scale, resulting in much greater computational complexity. The number of input features can be reduced by extracting them on a logarithmic frequency scale, or by using ERB-based or Bark-based filter banks to extract input features (Schröter et al., 2022).
F0-based features have been widely used in computational auditory scene analysis to separate speech from simultaneous talkers, but their effectiveness in enhancing speech in noise is poor at low SNRs because of inaccurate estimation of F0-based features (Wang & Chen, 2018). Furthermore, as shown by Delfarah & Wang (2017), the extraction of F0-based features with a 64-channel gammatone filterbank followed by F0 estimation for each channel takes longer than the extraction of other features. Some researchers have used F0 information only implicitly. For example, Valin (2018) extracted the correlation of F0 estimates over time for the first six bands as supplementary features. Wang et al. (2022) extracted F0 information as an additional feature for predicting a mask as a postprocessing filter, further suppressing residual noise between harmonics of voiced speech and reducing speech distortion.
Comparison of the effectiveness of input features is often conducted using a specific DNN. A specific feature set may yield improved performance when used with a given DNN but may not with another DNN. In recent years, the importance of magnitude compression and phase has been confirmed using several different DNNs (Williamson & Wang, 2017; Zhao et al., 2020; Tan & Wang, 2020). As a result, the compressed complex spectrum has become popular. There are many benefits of magnitude compression in practical applications (Li et al., 2021d). The first is that while noisy speech is typically quantized with 16-bit resolution, only 8 bits are needed to represent the compressed magnitude if the compression exponent is 0.5. This leads to reduced computational complexity and memory requirements, which are important for practical applications of DNNs. The second benefit is that speech distortion and noise reduction can be better balanced when compared with the raw magnitude without compression, resulting in improving speech quality. This may be the case because compression reduces the dynamic range of the magnitude values, facilitating the training process (Luo et al., 2022). Compression of the magnitude of the noisy spectrum can be expressed by:


Network Architecture
Early DNN-based speech enhancement methods operated in the T-F domain by enhancing the magnitude spectrum but leaving the phase spectrum unaltered. These methods focussed on capturing information in changes over time and in patterns across frequency. To capture information related to changes over time, Xu et al. (2014b) concatenated up to 11 frames and used the concatenated frames as input features to a fully connected DNN in which each node of the previous layer was connected to all nodes of the current layer. However, the use of such long features increases the number of input features and limits the generalization capabilities of fully connected DNNs. Recurrent neural networks (RNNs), which are naturally suitable for temporal modeling, were then proposed for speech enhancement. The main difference between fully connected DNNs and RNNs is that although both have connections between nodes, only the latter allow the output from some nodes to influence subsequent input on the same nodes. Returning to the speech production model specified by Equation (29), each time sample of speech can be recursively estimated from its previous
Recently, deep learning-based speech enhancement has benefited immensely from the use of convolutional neural networks (CNNs), which were inspired from biology and first proposed by Fukushima (1980) and developed extensively by LeCun et al. (1989). For CNNs, at least one convolutional layer is included in the architecture, performing a dot product of a convolution kernel with the input of this layer. The number of parameters of CNNs is markedly lower than for fully connected DNNs, although this does not necessarily reduce computational complexity. Park & Lee (2017) utilized a convolutional encoder-decoder network for spectral mapping, achieving comparable performance to an RNN-based model, while having many fewer trainable parameters. Convolutional recurrent networks (CRNs) that combine CNNs and RNNs or LSTMs into one model were first proposed by Pinheiro & Collobert (2014), and they have become one of the most popular architectures for image and speech processing, because they combine the feature-extraction capability of CNNs and the temporal modeling capability of RNNs or LSTMs. Naithani et al. (2017) developed a CRN by successively stacking convolutional layers, LSTM layers and fullyconnected layers. Takahashi et al. (2018) developed a CRN that combines convolutional layers and recurrent layers at multiple scales. The two CRN models proposed by Naithani et al. (2017) and Takahashi et al. (2018) achieved higher signal-to-distortion ratios (SDRs) than the simple combination of CNN and RNN models.
The approaches described above enhanced the noisy speech only in the magnitude domain. However, considerable improvements in both objective and subjective measures of speech quality can be achieved by recovering the phase of the clean speech (Paliwal et al., 2011). To this end, Williamson et al. (2016) employed stacked fully connected layers to estimate a complex ideal ratio mask (cIRM), which is applied to the real and imaginary parts of the spectrum to recover the magnitude and phase of the clean speech (the definition of cIRM is presented later). Subsequently, Fu et al. (2017) proposed a CNN for estimating the real and imaginary parts of the clean complex spectrum from the noisy features. Tan & Wang (2019) first applied CRNs to complex spectrum mapping-based speech enhancement, an approach they called GCRN. Two CRNs were used to separately estimate the real and imaginary parts of the clean complex spectrum and a gate mechanism was employed for both the encoder and decoder. The RNN utilized in GCRN did not effectively model extremely long sequences because of the problem of vanishing gradients and exploding gradients. These refer to situations where the error that is to be minimized changes hardly at all with changes in model parameters (vanishing gradients) or changes considerably with small changes in model parameters (exploding gradients). Vanishing gradients prevent tuning of the model parameters, while exploding gradients cause very large changes in the model parameters, resulting in the training being unstable and divergent. To deal with this, Le et al. (2021) proposed DPCRN, in which the RNN was replaced by a dual-path RNN. This dual-path RNN contained an intra-chunk RNN that was used to model the spectrum of a single time frame over frequency and an inter-chunk RNN that was used to model the variation of the spectrum over time.
Although the above-mentioned networks generated the complex spectrum of the clean speech or the cIRM, they themselves applied real-valued multiplication and addition operations. Choi et al. (2019) first introduced complex convolutional layers into the real-valued U-Net, which is a convolutional network architecture, proposed by Ronneberger et al. (2015) for speech enhancement. State-of-the-art performance was achieved in terms of many objective metrics, such as CSIG, CBAK and COVL (Hu & Loizou, 2008). Hu et al. (2020) proposed a complex CRN, called DCCRN, and reported significant performance improvements in both objective metric scores and subjective listening scores over the LSTM and CRN models, as well as over the baseline model (NSNet) provided by the DNS Challenge organizer (Xia et al., 2020). The DCCRN model was ranked first in the first DNS Challenge organized by Microsoft (Reddy et al., 2020).
Recently, approaches that decompose the speech enhancement task into several progressive tasks have been developed. These are called progressive task-oriented training approaches. The processing in earlier stages can improve the optimization of later stages. Experiments conducted using the Voice Bank + DEMAND dataset showed a large objective improvement relative to earlier methods without progressive learning, such as MMSE-GAN (Soni et al., 2018). Gao et al. (2016) first introduced the progressive learning concept into speech enhancement. They decomposed the mapping from noisy to clean speech into multiple stages so as to increase the SNR progressively. Inspired by Gao et al. (2016), a subband decomposition-based progressive learning framework was proposed by Li et al. (2021e). The progressive learning approaches proposed by Gao et al. (2016) and Li et al. (2021e) improved PESQ and STOI scores for SNR values
A related but somewhat different approach is to break down the speech-enhancement task into separate goals, and to optimize these goals sequentially or in parallel. For example, Yin et al. (2020) proposed a network called PHASEN for recovering magnitude and phase in a parallel processing topology. Fu et al. (2022) proposed Uformer, in which a U-Net based dilated complex-and-real dual-path conformer network was designed to improve performance in the complex-valued and magnitude domains simultaneously. Some other networks use a sequential processing structure to decompose the speech-enhancement task. For example, Strake et al. (2019) used a first task of noise suppression and a second task of restoring the parts of the speech that had been removed during noise suppression. A similar task-splitting method was used by Hao et al. (2020), who called the two tasks “masking and inpainting”.
Another task-decoupling approach is to enhance spectral magnitude in the frequency domain in a first stage and then to further reduce noise in the time domain. For example, Westhausen & Meyer (2020) combined two signal transformation methods, i.e., the STFT and a learnable analysis/synthesis method, achieving competitive results in the Interspeech2020 DNS-Challenge (Reddy et al., 2021). Note that this learnable analysis/synthesis method was introduced for feature extraction with a data-driven approach; the idea had already been proposed by Luo & Mesgarani (2019) for speech separation. This decoupling method was independently proposed by Du et al. (2020). These authors designed a cascade framework including a Mel-domain denoising autoencoder 8 for magnitude recovery and a generative vocoder for waveform synthesis. The denoising autoencoder was first proposed by Vincent et al. (2008) for image processing to improve the robustness of feature extraction. It is often used to extract features for model training. Using the denoising autoencoder for speech enhancement led to improved model generalizability across different noisy conditions (Lu et al., 2013; Yu et al., 2020). Many other autoencoders have been introduced and applied to speech enhancement (Leglaive et al., 2018, 2020; Bie et al., 2022).
Different from the above decoupling approaches, Li et al. (2021b) proposed a complex spectral refinement network. A magnitude spectral estimation network was used to recover phase implicitly. This framework, called SDDNet, achieved state-of-the-art performance in the ICASSP2021 DNS-Challenge. Subsequently, Wang et al. (2021) pointed out that the estimated spectral magnitude and phase are related, and showed that it is better to estimate the spectral magnitude and the residual complex spectral component. It can be inferred that estimating spectral magnitudes first and then recovering phase is not necessarily the best choice. Wang et al. (2022) introduced a magnitude refinement module after estimation of the complex spectrum of the clean speech. Li et al. (2022b) and Fu et al. (2022) adopted parallel structures to optimize both the complex spectrum and the magnitude. Other examples of decoupling-style frameworks include decomposing the speech-enhancement task into noise estimation and speech recovery, and performing these tasks using parallel and serial structures, respectively. Zheng et al. (2021), and Liu et al. (2021) decomposed the speech enhancement process into two stages: in the first, the magnitude of the noise was estimated and used as a priori information for the second stage, which estimated the complex spectrum of the clean speech. Zhang et al. (2021) proposed a dual-branch framework for spectrum and waveform modeling. All of the above-mentioned decoupling methods achieved better performance in terms of PESQ and STOI or Extended STOI (ESTOI) scores than methods mapping learning targets directly.
Training Target
The training target plays an important role in deep learning methods. A well-defined training target is important for obtaining good speech intelligibility and quality. The training target should be suitable for supervised learning. Many training targets have been developed in the T-F domain. They can be divided into two main groups i.e., masking-based and mapping-based.
One masking-based target is the ideal binary mask (IBM) (Wang & Wang, 2013). For each T-F bin, the value of the IBM is either 1 or 0. A value of 1 means that the estimated SNR for this bin is larger than a predefined threshold value, while a value of 0 means that the estimated SNR is smaller than this threshold. The IBM is applied to the T-F matrix for that frame, effectively selecting the T-F bins that are to be preserved. The IBM can be expressed as






For mapping-based targets, a spectral representation of the clean speech is mapped directly using a pretrained deep-learning model. In much early work, mapping-based supervised speech-enhancement methods focussed on mapping from the noisy magnitude spectrum to the clean magnitude spectrum while leaving the phase unaltered. Because the dynamic range of the magnitude is large, the log-power spectrum was initially proposed as the mapping target (Xu et al., 2015, 2014b). However, Zhao et al. (2020) showed that power compression of the magnitude led to better performance than logarithmic compression. More recently, motivated by the fact that appropriate use of phase information could notably improve speech quality, especially at low SNRs (Paliwal et al., 2011), complex-valued spectrum mapping has become mainstream. Li et al. (2021d) proposed combining the noisy phase with the power-compressed magnitude. The compressed complex spectrum
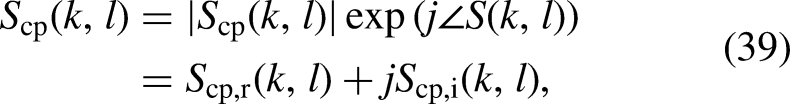
Some researchers have used mapping targets in addition to the spectrum or mask (Xu et al., 2017; Fang et al., 2023). Xu et al. (2017) proposed a DNN that learned the magnitude spectrum as the primary target and MFCC as the secondary target. The additional MFCC estimation imposed constraints that were not applicable in the prediction of the magnitude spectrum alone, improving the prediction performance of the primary target. Fang et al. (2023) proposed a framework for jointly modeling random uncertainties and uncertainties due to insufficient training data for deep-learning-based Wiener filter estimation for speech enhancement. The involvement of modeling uncertainties increased the robustness of the estimator, and it was shown that this method preserved more speech at the cost of decreasing the amount of noise reduction slightly.
Loss Function
For deep-learning approaches, the loss function, also known as the cost function, evaluates how well a model is currently performing on a specific dataset, and tunes the model parameters based on the gradient of performance with respect to these parameters (Yu & Deng, 2011; Hinton et al., 2012). The training loss function is one of the key components for deep learning methods, and it is commonly used to assess how well the trained model fits the training data. An appropriate loss function can lead to a good balance between performance on the one hand and storage memory and/or computational complexity on the other hand. The commonly used loss functions for speech enhancement can be divided into three categories: frequency-domain, time-domain, and perceptually motivated.
In the frequency domain, early work used a neural network to map the IBM, and used binary cross entropy to supervise the model training. As mentioned above, for each T-F bin the value of the IBM is either 1 or 0, and thus this binary cross entropy measures the dissimilarity between the predicted and true labels of a dataset. Later, with the increasing complexity of training targets, the speech-enhancement task began to be regarded as an approximation or regression problem rather than a classification problem, and commonly used loss functions were the Kullback-Leibler divergence proposed by Kullback (1997), the Itakura-Saito distance proposed by Itakura & Satio (1968), and the MSE. Liu et al. (2014) showed that both the Kullback-Leibler divergence and the Itakura-Saito distance led to worse performance than the MSE, and since then the MSE has become a very popular loss function for monaural speech enhancement. The models are often trained by minimizing the MSE between the magnitude/complex spectrum of the clean speech and the estimated spectrum, a method denoted signal approximation (SA), rather than by minimizing the MSE between the true mask and the estimated mask (Huang et al., 2014; Weninger et al., 2014; Wang & Chen, 2018). Better objective metric scores have been obtained with SA (Weninger et al., 2014) than when the MSE between the estimated mask and the true one was minimized, provided that the same network architecture was used. Spectral magnitude-based MSE (Weninger et al., 2015), phase-sensitive MSE (Erdogan et al., 2015) and complex spectrum-based MSE (Fu et al., 2017) have all been proposed. The spectral magnitude-based MSE and complex spectrum-based MSE loss functions can be expressed as:
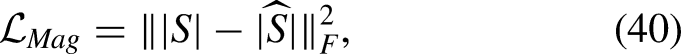


The mean absolute error (MAE) between the estimated and clean speech magnitudes (Qi et al., 2020) has also been explored as a complex spectral distance metric, based on the assumption that the real and imaginary parts of each STFT bin follow a Laplacian distribution rather than a Gaussian distribution (Braun & Tashev, 2021). Tu et al. (2018) used a log-spectral MSE loss function for magnitude estimation, because human perception of auditory magnitudes roughly corresponds to a logarithmic scale. More recently, a power-law-compressed spectral MSE loss function (Yin et al., 2020) has been shown to be effective in denoising. This method can be formulated as:
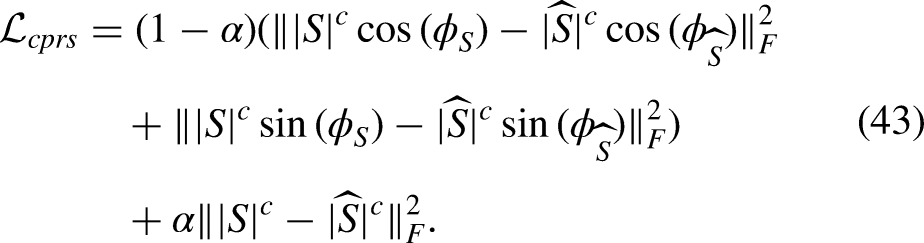
Perceptually motivated loss functions have been developed to optimize DNNs based on objective metrics such as PESQ, cepstral distance, and STOI (Zhao et al., 2019). As described earlier, when used singly, these loss functions generally achieve better performance when assessed with the metric used for optimization (Fu et al., 2020), but not for other metrics, while combining these loss functions often results in improvement of multiple objective metric scores simultaneously (Fu et al., 2017).
For deep learning approaches, “overfitting” can occur when the number of training parameters is too large relative to the size of the training dataset. When this happens, performance evaluated using the training dataset is much better than performance evaluated using an independent but similar dataset. Overfitting can be avoided by stopping the training early (Wang & Chen, 2018). In addition, a learnable loss mix-up approach, in which two loss functions were combined together with a learnable parameter, has been proposed to improve the generalization of DNN-based speech-enhancement models (Chang et al., 2021). The purpose of introducing the learnable parameter was to automatically optimize the weighting factor of the two loss functions with the training dataset in the training stage.
Discussion
As described above, unrealistic assumptions limit the performance of traditional frequency-domain monaural speech enhancement methods. In contrast, deep learning methods do not depend on any specific assumptions about the properties of the speech or noise. For example, it is well known that deep learning methods can handle nonstationary noises better than traditional methods, because the former are not based on assumptions about the statistics of the noise, while the latter are often based on the assumption that the noise is stationary or quasi-stationary. Also, deep learning methods can utilize speech contextual information and the speech spectral structure to reconstruct clean speech or to separate speech from noise. The earliest deep learning speech enhancement methods estimated only the spectral magnitude of the clean speech, ignoring the importance of speech phase for speech quality and speech intelligibility. This was done because it was thought that speech phase is unstructured, and thus cannot be learned or mapped by deep learning methods. However, the real and imaginary parts of the complex spectrum both have structure.
The speech phase can be implicitly recovered in two ways: one is to estimate the cIRM (Williamson et al., 2016) and the other is to estimate the real and imaginary parts of the complex speech spectrum (Wang & Chen, 2018). Note that these two ways have some similarities: the former often maps the cIRM directly and uses the MSE between the true and estimated cIRM as the loss function (Williamson et al., 2016), while the latter often maps the real and imaginary parts of the complex speech spectrum and uses the MSE between the true and estimated complex spectrum as the loss function. The loss function is often based on the distance between the mapped target and the true one. For example, Tan & Wang (2020) used the MSE between the true and estimated complex spectrum as the loss function for training, while the mapped target was the cIRM. However, this is not a mandatory requirement. For example, Choi et al. (2019) proposed mapping the cIRM, but a time-domain loss function that considers both the speech prediction error and noise prediction error, namely the weighted SDR, was used to train the model.
Although most deep learning methods train models using parallel noisy and clean speech, this is not always necessary. Some researchers have trained models using nonparallel noisy and clean data and achieved moderate performance in terms of both objective and subjective measures (Xiang & Bao, 2020; Xiang et al., 2020; Yu et al., 2022; Bie et al., 2022), although performance did not surpass that of models trained with a large amount of parallel data. Deep learning methods trained without parallel data are often referred to as unsupervised methods, while those trained with parallel data are referred to as supervised methods. Bie et al. (2022) categorized unsupervised methods into two types, noise-dependent and noise-agnostic. The latter methods require only clean speech, and thus in principle they can handle any type of noise (Bando et al., 2018; Bie et al., 2022), while the former methods also require noisy speech or noise although the noisy and clean speech signals are not necessarily parallel. Unsupervised noise-agnostic methods (Bando et al., 2018; Bie et al., 2022) learn the characteristics of the clean speech from the clean speech dataset in the training stage, and the noise signal is only modeled in the test stage. Some NMF methods also learn the speech basis matrix using clean speech and the noise basis matrix is estimated in the denoising stage using information from the speech basis matrix (Mohammadiha et al., 2013).
One interesting question is: what information do deep learning methods use to learn the mapping from noisy to clean speech. It is nearly always the case that the speech and noise have different T-F characteristics, so these differences can be used to distinguish speech from noise or to estimate the SNR for each bin. For monaural speech enhancement, important differences are: the noise is often more stationary than the speech; the speech has a more sparse spectral structure than the noise; in voiced segments, the F0 does not change rapidly, resulting in a correlation over time, and the harmonic structure shows a patterning in frequency; and voiced and unvoiced segments tend to alternate, unvoiced segments having most of their energy at mid and high frequencies and voiced segments having most of their energy at low and mid frequencies. These differences are presumably exploited by deep-learning methods.
Environmental noise can be roughly divided into four categories: industrial, construction, traffic, and noise resulting from social activities (Han et al., 2018). These noise types have different T-F characteristics, and, unlike speech, noise cannot be treated in a unified way and described by a simple model. Hence, it is relatively difficult for DNNs to learn the characteristics of noise. However, when speech is mixed with noise, if the speech can be reconstructed from its corresponding noisy version, the noise can then be estimated by subtracting the estimated complex spectrum of the speech from that for the noisy speech. This information can in turn be used to improve the speech enhancement process.
Zhang et al. (2020) estimated the a priori SNR using the Deep Xi model proposed by Nicolson & Paliwal (2019). The noise PSD was then estimated using the MMSE-based approach proposed by Gerkmann & Hendriks (2012). Xu et al. (2014a) have shown the benefits of noise-aware training for DNN-based speech enhancement. In the noise-aware training, information about the noise, such as its short-term spectrum, is used to provide supplementary features. This leads to better mapping of the clean speech spectrum. Liu et al. (2021) and Liu et al. (2022) further showed that estimating the noise spectrum in a first stage improved the performance of single and multimicrophone denoising and dereverberation methods.
A special case is when the background sound is competing speech from one or more talkers. In this case, the problem reduces to speech separation, which is outside the scope of this paper. However, speech from more than one talker often occurs in social interactions, and this is challenging for speech enhancement. A recent study showed that a DNN designed for single-talker speech enhancement performed poorly when it was required that speech from two talkers was to be preserved simultaneously in noisy and reverberant environments (Zheng et al., 2023). This happened because the speech from two talkers is very different from the speech of a single talker. For example, for two overlapping voiced segments there are two simultaneous F0s, and the spectral pattern is much more complex than for a single talker. Increasing the number of talkers generally results in worse performance of DNN-based methods. It seems that most current DNN methods are mainly applicable to single-talker situations. To reduce speech distortion for multiple desired speakers, the training dataset should contain multiple simultaneous talkers and the mixed speech should be regarded as the target when training the DNN (Zheng et al., 2023).
Traditional and deep learning methods differ in several ways in how they reconstruct clean speech. Firstly, the estimated short-term SNR for each T-F bin determines the IRM for mask-based deep learning methods, while the a priori SNR is the key parameter determining the gain function for traditional methods. For the latter, “musical noise” is a serious problem due to the large variability in the estimate of the spectrum for a given frame when time-averaging or frequency-averaging are not used. If the short-term SNR instead of the expected SNR can be accurately estimated for each T-F bin, “musical noise” can be largely eliminated. Unfortunately, it is extremely difficult if not impossible to estimate the short-term SNR using traditional methods, making it difficult to achieve a good balance between the suppression of “musical noise” and the reduction of speech distortion. A second difference between traditional and deep learning methods is that traditional methods estimate the spectral magnitude and phase to reconstruct the time-domain speech signal, while most deep-learning methods estimate the real and imaginary parts of the complex clean speech or estimate the spectral magnitude in a first stage and then estimate the residual complex component of the clean speech in a second stage. In other words, deep learning methods often recover the phase implicitly and indirectly, while traditional methods estimate the phase explicitly and directly. Note that phase reconstruction from the STFT magnitude using DNN approaches has been proposed by Oyamada et al. (2018), Masuyama et al. (2019), Takamichi et al. (2020), Masuyama et al. (2021), and Peer et al. (2022). The effectiveness of DNN-based phase reconstruction has been shown by the reconstruction of clean speech/audio phase without knowledge of the phase spectrogram. However, although DNN-based phase reconstruction has been applied to speech separation (Wang et al., 2018), only a few researchers have explicitly estimated the clean speech phase for the purpose of enhancing speech in noise (Peer & Gerkmann, 2022).
Finally, while deep learning methods suffer less from the musical noise problem than traditional methods, the former can introduce artificial noise components that degrade speech quality. This artificial noise needs to be suppressed to achieve good speech perceptual quality. Li et al. (2021a) showed that a low-complexity spectral subtraction method used in a postprocessing stage to suppress the artificial noise improved subjective preference scores, although PESQ scores were somewhat decreased. It is interesting that DNSMOS scores (Reddy et al., 2021) correctly reflected subjective preference scores, supporting the effectiveness of DNSMOS in estimating subjective speech quality.
Hybrid Methods
As mentioned above, traditional methods cannot suppress nonstationary noise completely because the noise PSD cannot be accurately tracked, especially when the noise PSD increases rapidly or fluctuates strongly over time. One straightforward way to alleviate this problem is to improve noise tracking using data-driven methods (Erkelens & Heusdens, 2008). Another way is to jointly estimate the speech PSD and the noise PSD, so that Wiener-type filtering can be applied to the noisy speech (Zavarehei et al., 2007; Suhadi et al., 2011; Mohammadiha et al., 2013). Although nonstationary noise is better removed using these methods, the speech distortion for low SNR T-F bins still occurs, thus limiting the quality of speech recovery.
Although traditional and deep-learning methods are quite different, the latter have been considerably influenced by the former. Also, there are some hybrid methods for which key parameters extracted using traditional methods are mapped using DNN methods. For example, mapping the a priori SNR using the Deep Xi DNN proposed by Nicolson & Paliwal (2019, 2020) and integrating it into the MMSE-STSA estimator led to good speech quality. Another approach is to combine DNNs with NMF (see Bando et al., 2018, Bie et al., 2022, and references therein). The results showed better performance in terms of objective metrics than for both supervised and unsupervised noise-dependent models for unseen noise scenarios. A complete survey of hybrid models is outside the scope of this paper.
Evaluation of Different Methods
Datasets
To evaluate the performance of the different types of speech enhancement methods, we used two datasets, namely WSJ + DNS and Voice Bank + Demand (Valentini-Botinhao et al., 2016). The WSJ + DNS training dataset was generated using the WSJ0-SI84 and Interspeech 2020 DNS-Challenge noise datasets. They contain 150,000 mixtures of speech and noise together with the corresponding clean speech, amounting to about 300 hours in total. The clean utterances were selected from the WSJ0-SI84 dataset (Paul & Baker, 1992), which comprises 7138 utterances spoken by 83 speakers (42 males and 41 females). 5428 and 957 utterances spoken by 77 speakers were selected for model training and model validation, respectively. 150 utterances spoken by the remaining 6 speakers (3 males and 3 females) were used for testing. This was done to assess the generalization capability of the models for different speakers. The noise clips, which include about 20,000 noise types, were selected from the noise set of the Interspeech 2020 DNS-Challenge dataset (Reddy et al., 2021). Their total duration was about 55 hours. To create a training mixture, a randomly selected training utterance was mixed with a randomly cut segment from the noises at a given SNR. The SNR range for training was
Voice Bank + Demand includes 11,572 utterances for training. 824 utterances were used for testing. The clean speech set was a selection of 30 speakers taken from the Voice Bank corpus (Veaux et al., 2013): 28 speakers were used for training and the remaining 2 speakers were used for testing. To create the noisy training set, 40 conditions were used: 10 types of noise (2 artificial noises and 8 noises taken from the Demand database (Thiemann et al., 2013)), each mixed with clean speech at SNRs of 15, 10, 5, and 0 dB. There were about 10 sentences in each condition for each training speaker. For the test set, 20 conditions were used: 5 types of noise (all from the Demand database) with 4 SNRs (17.5, 12.5, 7.5, and 2.5 dB). There were about 20 sentences in each condition for each test speaker. Note that the test set was totally unseen because it used different speakers, noises, and SNRs from the training set.
Parameter Values
All of the utterances were sampled at 16 kHz. For all of the models except the four models marked with asterisks in tables, the window duration and hop size were 20 ms and 10 ms, respectively, and thus the FFT length was 320. Pytorch was used to train the models, based on the Adam optimizer (
Methods Evaluated
The DNNs that were evaluated can be categorized into three groups: magnitude-spectrum based, complex-spectrum based, and decoupling style. For each group, the STFT spectrum or compressed spectrum of the noisy speech were used as the input features, and the training targets were the corresponding STFT spectrum or compressed spectrum of the clean speech. For all models, spectral MSE loss functions were utilized. All of the models were consistent with the best configurations reported by the authors of those models.
For completeness, six representative traditional methods were evaluated, including the MMSE-STSA estimator (Ephraim & Malah, 1984), the MMSE-LSA estimator (Ephraim & Malah, 1985), the
Two hybrid methods were chosen, namely DeepXi-LSA and DeepXi-STSA. These are denoted group 2.
DeepXi-LSA: The a priori SNR is estimated using the Deep Xi framework proposed by Nicolson & Paliwal (2019), and the a posteriori SNR is computed as the estimated a priori SNR plus one. With the estimated a priori SNR and a posteriori SNR, the spectral gain can be computed using Equation (24). DeepXi-STSA: As for DeepXi-LSA, the a priori SNR and a posteriori SNR are estimated, and the spectral gain is then computed using Equation (23). Note that DeepXi-LSA and DeepXi-STSA use the same network architecture to estimate the a priori SNR. The only difference is in the method of determining spectral gain from the estimated a priori SNR and a posteriori SNR. The window duration and hop size of DeepXi-LSA and DeepXI-STSA were set to 32 ms and 16 ms, respectively, so as to be consistent with the parameter settings of the model proposed by Nicolson & Paliwal (2019). LSTM: the LSTM-based model contains four LSTM layers, each with 1024 units. The output layer is a 161-unit fully connected layer. The input and output are the noisy and estimated clean speech magnitudes, respectively. FullSubNet: FullSubNet is a full-band and sub-band fusion model, which was ranked 11th in the ICASSP 2021 DNS-Challenge. Full-band and sub-band refer to models that input full-band and sub-band noisy spectral features and output full-band and sub-band speech targets, respectively. The window duration and hop size were set to 32 ms and 16 ms, respectively, so as to be consistent with the parameter settings of the model proposed by Hao et al. (2021). CRN: CRN contains an encoder and a decoder with two LSTM layers. The input and output are the magnitude of the noisy and estimated speech, respectively. GCRN: GCRN is a complex spectral mapping network based on CRN, where both the spectral magnitude and phase are estimated. GCRN comprises one encoder and two decoders, and both the real and imaginary components of the clean speech complex spectrum are estimated. DPCRN: DPCRN was ranked second in the Interspeech 2021 DNS-Challenge. The RNNs in the CRN were replaced by dual-path RNN modules, where the intra-chunk RNNs were used to model the spectral pattern of a single frame and the inter-chunk RNNs were used to model the inter-dependence of successive frames. Uformer: Uformer is a U-Net based dilated complex and real dual-path conformer network, which processes speech in both complex and magnitude domains. The window duration and hop size were set to 25 ms and 10 ms, respectively, and the FFT length was 512, so as to be consistent with the parameter settings of the model proposed by Fu et al. (2022). DCCRN: DCCRN was ranked first in the Interspeech 2020 DNS-Challenge. Both convolutional encoder-decoder and LSTM structures are handled by complex-valued operations. The window duration and hop size were set to 32 ms and 8 ms, respectively, so as to be consistent with the parameter settings of the model proposed by Hu et al. (2020). DCCRN(SNR): DCCRN(SNR) has the same network architecture, input features and learning targets as DCCRN. The only difference is in their loss functions. DCCRN(SNR) used the SNR loss instead of the MSE loss. The SNR loss was used because initial evaluations showed that a DCCRN model trained using the MSE loss performed much worse than a DCCRN model trained with the SNR loss for the Voice Bank + DEMAND dataset, although the two models had comparable performance for the WSJ + DNS dataset. CTSNet: CTSNet is a two-stage pipeline that initially generates a coarse estimate of the magnitude spectrum and then predicts a complex residual component that is used to refine the coarse estimate. CTSNet was ranked first in the ICASSP 2021 DNS-Challenge. GaGNet: GaGNet is an improved version of CTSNet. It uses a parallel structure for coarse magnitude and refined complex spectrum estimation, enabling bifurcate and joint optimization to estimate the complex spectrum of the clean speech. TaylorSENet: TaylorSENet is a decoupling-style framework based on Taylor’s approximation theory. The complex target spectrum is reconstructed by the superimposition of 0th-order and higher-order network estimations following Taylor’s formula.
For magnitude-spectrum mapping DNNs, three one-stage causal models were selected and denoted group 3, namely LSTM (Sun et al., 2017), FullSubNet (Hao et al., 2021), and CRN (Tan & Wang, 2018):
Five single-stage complex spectrum mapping DNN-based causal models were chosen as group 4, namely GCRN (Tan & Wang, 2020), DPCRN (Le et al., 2021), Uformer (Fu et al., 2022), and DCCRN (Hu et al., 2020):
Three decoupling-style multi-stage causal frameworks were chosen as group 5: i.e., CTSNet (Li et al., 2021b), G2Net (Li et al., 2022b), and TaylorSENet (Li et al., 2022a):
The models listed above were chosen to be representative of a wide range of models of different types. They were not chosen because they gave the best performance for a given type of processing. The models were trained and evaluated using the same datasets and using the same evaluation metrics, thus allowing a fair comparison across methods for both simulated normal-hearing and simulated hearing-impaired listeners. This allowed a fair assessment of the improvement achieved by each advance in signal-processing method.
Evaluation Metrics
Four objective metrics were chosen to estimate speech quality for normal-hearing listeners, namely PESQ (Rix et al., 2001), the extended STOI (ESTOI) (Jensen & Taal, 2016), the SDR (Vincent et al., 2007), and DNSMOS (Reddy et al., 2021). Note that the first three metrics are intrusive, requiring knowledge of the clean speech to compute their scores. The DNSMOS is nonintrusive, and it is used to evaluate and rank different DNS methods. Its predictions correspond well with MOS values (Reddy et al., 2021). The hearing-aid speech quality index (HASQI) version 2 proposed by Kates & Arehart (2014) and hearing-aid speech perception index (HASPI) version 2 proposed by Kates & Arehart (2021) were chosen as two objective measures to evaluate speech quality and intelligibility, respectively, for both normal-hearing listeners and hearing-impaired listeners.
PESQ scores are usually highly correlated with human estimates of speech quality. Both the narrow-band version and the wideband version recommended in ITU-T P.862 were used, and the two versions are denoted NB-PESQ and WB-PESQ, respectively. Note that NB-PESQ uses the raw scores provided by P.862 directly, while WB-PESQ maps raw scores to the MOS-listening quality objective (MOS-LQO) domain. NB-PESQ scores and WB-PESQ scores therefore have different ranges. NB-PESQ scores range from
The ESTOI is another measure that is widely used to evaluate speech intelligibility. Its value ranges from 0 to 1 (Jensen & Taal, 2016; Zhao et al., 2018). Only raw ESTOI scores are provided in this paper. In other words, we did not map the ESTOI scores to intelligibility because the parameters of this mapping depend on many factors, such as the test material and the test paradigm (Jensen & Taal, 2016).
The SDR is a time-domain metric that is widely used in blind speech separation and can also be applied for speech quality evaluation. DNSMOS is a robust speech quality metric serving as a proxy for subjective scores, which consists of three sub-metrics, i.e., DNS-OVL, DNS-SIG, and DNS-BAK, evaluating overall signal quality, signal distortion, and background distortion, respectively. The values of the three DNSMOS metrics range from 1 to 5. For all these metrics, a higher score indicates better performance.
The HASQI and HASPI can be used to evaluate speech quality and speech intelligibility, respectively, for both simulated normal-hearing and hearing-impaired listeners when the audiometric thresholds of the simulated listener are given (Kates & Arehart, 2014, 2021). The two metrics use a model of the auditory periphery. For normal-hearing listeners, the audiometric thresholds were set to 0 dB HL at all frequencies required by HASQI and HASPI (250, 500, 1000, 2000, 4000, and 6000 Hz). For hearing-impaired listeners, the audiometric thresholds were specified as greater than 0 dB HL and the auditory model was modified so as to take into account some of the typical consequences of hearing loss, such as reduced frequency selectivity (Glasberg & Moore, 1986) and reduced compression in the cochlea (Moore et al., 1996). In this paper, only mild and moderate hearing losses were considered. Bisgaard et al. (2010) divided standard audiograms into two groups: A flat and moderately sloping group, and a steeply sloping group. The first group included seven audiograms characterizing different degrees of hearing loss, while the second group had three audiograms with different degrees of hearing loss. Here, two standard audiograms, N2 and N3, with mild and moderate sloping hearing losses, respectively, were used, as shown in Figure 4. Both the HASQI and HASPI provide the option of applying frequency-dependent gain to compensate for the reduced audibility produced by the hearing loss, based on the NAL-R method (Byrne & Dillon, 1986). That option was used here. The software packages for calculating HASQI and HASPI scores were used with the default setting that a signal with a root-mean-square (RMS) value of 1 has a level of 65 dB SPL. In all tests, each signal was normalized to have an RMS value of 1, so the effective input level was 65 dB SPL. The NAL-R recommended gains are suitable for this level. The values of the HASQI and HASPI, expressed as a percentage, range from 0% to 100%, where higher scores indicate better performance.

Standard audiograms for two of the audiograms defined by Bisgaard et al. (2010): Norm: normal, N2: mild sensorineural loss, N3: moderate sensorineural loss.
Results and Analysis
Results for the WSJ + DNS Dataset
Simulated Normal-hearing Listeners
Tables 1–6 give the results for the five groups of speech enhancement methods. Several observations can be made. First, all deep-learning methods and hybrid methods achieved much better performance than traditional methods, regardless of whether or not the input feature, magnitude or complex spectrum, was compressed. Second, almost all deep-learning methods performed better when the compressed input features were used. Third, when the phase was implicitly estimated by deep-learning methods, better performance was achieved than when only spectral magnitudes were processed, and this gap became larger when compressed input features were used. Fourth, when the magnitude was mapped in the first stage and the residual complex spectrum of the clean speech was recovered in the second stage, performance was further improved. Fifth, a more recent method did not always work better than earlier ones when the input feature changed from the compressed complex spectrum to the uncompressed complex spectrum. For example, TaylorSENet worked better than CTSNet when the input features were compressed, while CTSNet worked better than TaylorSENet when no compression was applied. A similar effect was observed for GCRN and DCCRN; their performance was comparable when the input features were uncompressed, but DCCRN performed better when the input features were compressed.
Scores for the objective measures WB-PESQ and NB-PESQ for the different methods using the WSJ + DNS dataset.

For all deep learning methods, the uncompressed spectrum was used. Bold font indicates the best average score in each group. DNS = deep noise suppression; SNR = speech-to-noise ratio; MMSE = minimum mean-square error; LSA = log-spectral amplitude; STSA = short-time spectral amplitude; MSS = magnitude spectral subtraction; PSS = power spectral subtraction; LSTM = long short-term memory; CRN = convolutional recurrent network.
Scores for the objective measures ESTOI and SDR for the different methods using the WSJ + DNS dataset.

For all deep learning methods, the uncompressed spectrum was used. Bold font indicates the best average score in each group. SDR = signal-to-distortion ratio; MMSE = minimum mean-square error; LSA = log-spectral amplitude; STSA = short-time spectral amplitude; MSS = magnitude spectral subtraction; PSS = power spectral subtraction; LSTM = long short-term memory; CRN = convolutional recurrent network.
As Table 1 but using the compressed spectrum as input features for all deep learning methods.
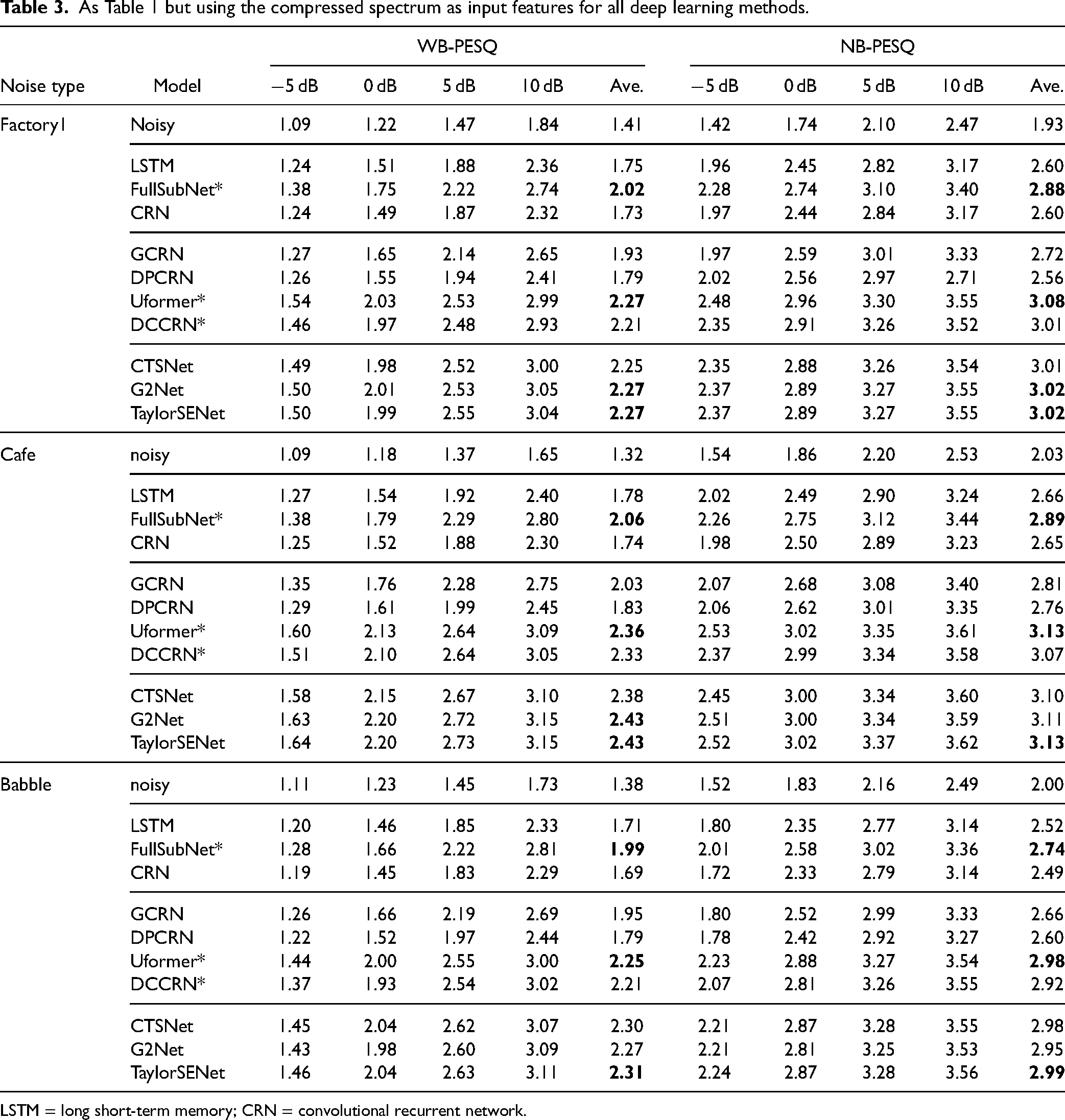
LSTM = long short-term memory; CRN = convolutional recurrent network.
As Table 2 but using the compressed spectrum as input features for all deep learning methods.

LSTM = long short-term memory; CRN = convolutional recurrent network.
As Table 1 but using DNS-MOS as the evaluation metric.

DNS = deep noise suppression; MOS = deep noise suppression; MMSE = minimum mean-square error; LSA = log-spectral amplitude; MSS = magnitude spectral subtraction; PSS = power spectral subtraction.
As Table 3 but using DNS-MOS as the evaluation metric.

DNS = deep noise suppression; MOS = deep noise suppression; LSTM = long short-term memory; CRN = convolutional recurrent network.
Hybrid methods obtained comparable performance to single-stage deep learning based magnitude-only mapping methods in terms of PESQ, ESTOI, and SDR scores, confirming that the a priori SNR is a key parameter for magnitude estimation in the speech-enhancement task. The hybrid methods performed more poorly than the deep-learning methods of groups 2, futher confirming the importance of phase recovery for speech enhancement. As can be seen from Table 5, hybrid methods yielded much lower DNS-MOS scores than the deep-learning methods of groups 3–5, especially for low-SNR scenarios. On the other hand, the hybrid methods worked better for relatively high SNR scenarios, and this finding was confirmed by the objective test results using the Voice Bank + DEMAND dataset, as described below. The poorer performance of hybrid methods for low-SNR scenarios may have occurred because speech distortion is inevitable using traditional spectral gain functions when many bins have low a priori SNR values.
The HASQI scores for simulated normal-hearing listeners denoted by “Normal” and shown in Tables 7 and 8 were consistent with the scores in Tables 1–6. Also, the HASPI scores for simulated normal-hearing listeners shown in Tables 9 and 10 were consistent with the HASQI scores for simulated normal-hearing listeners. Over the SNR range from
As Table 1 but using HASQI (%) as the evaluation metric. The HASQI scores for simulated normal-hearing and hearing-impaired listeners are included for completeness.
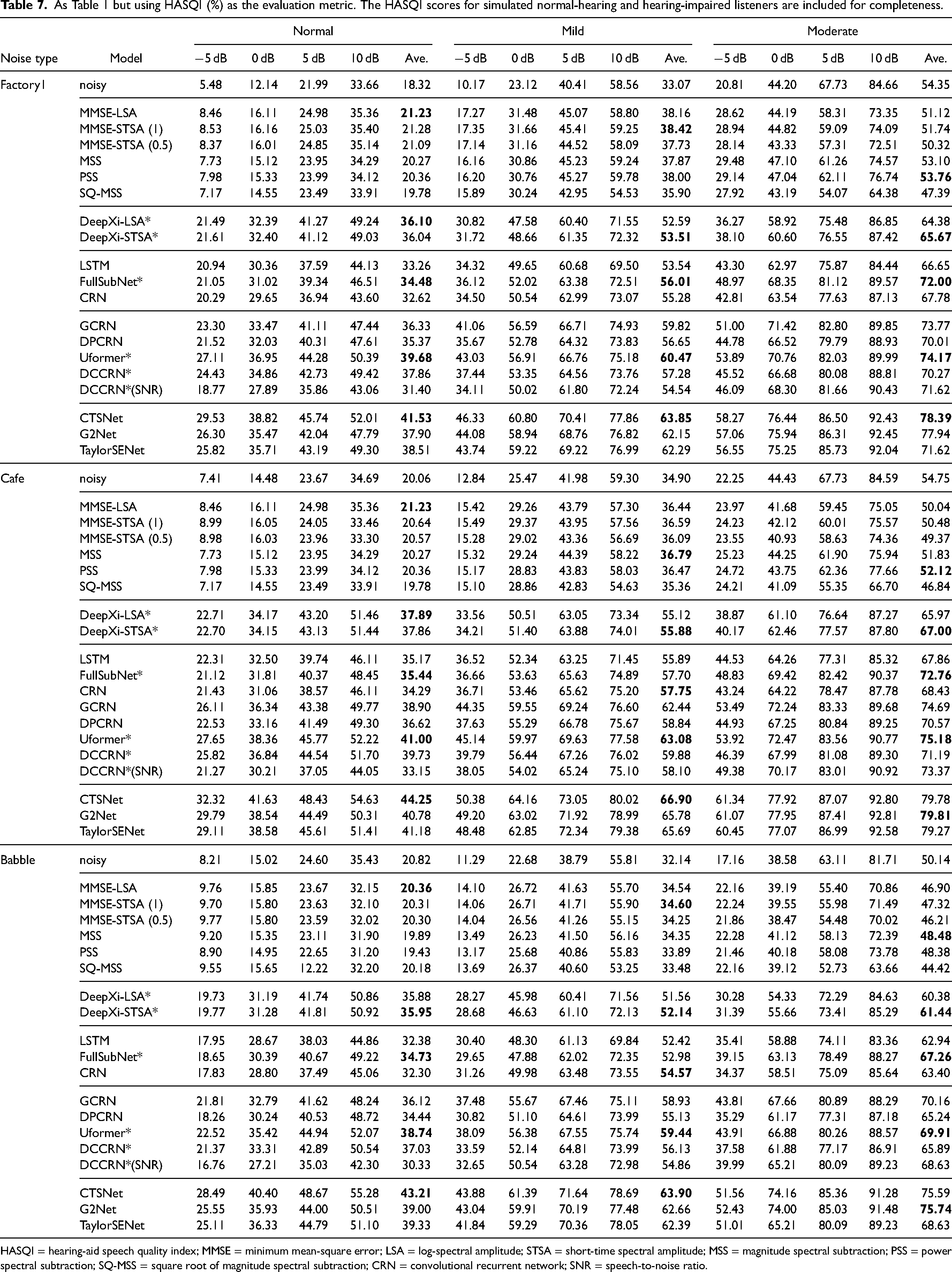
HASQI = hearing-aid speech quality index; MMSE = minimum mean-square error; LSA = log-spectral amplitude; STSA = short-time spectral amplitude; MSS = magnitude spectral subtraction; PSS = power spectral subtraction; SQ-MSS = square root of magnitude spectral subtraction; CRN = convolutional recurrent network; SNR = speech-to-noise ratio.
As Table 3 but using HASQI (%) as the evaluation metric.
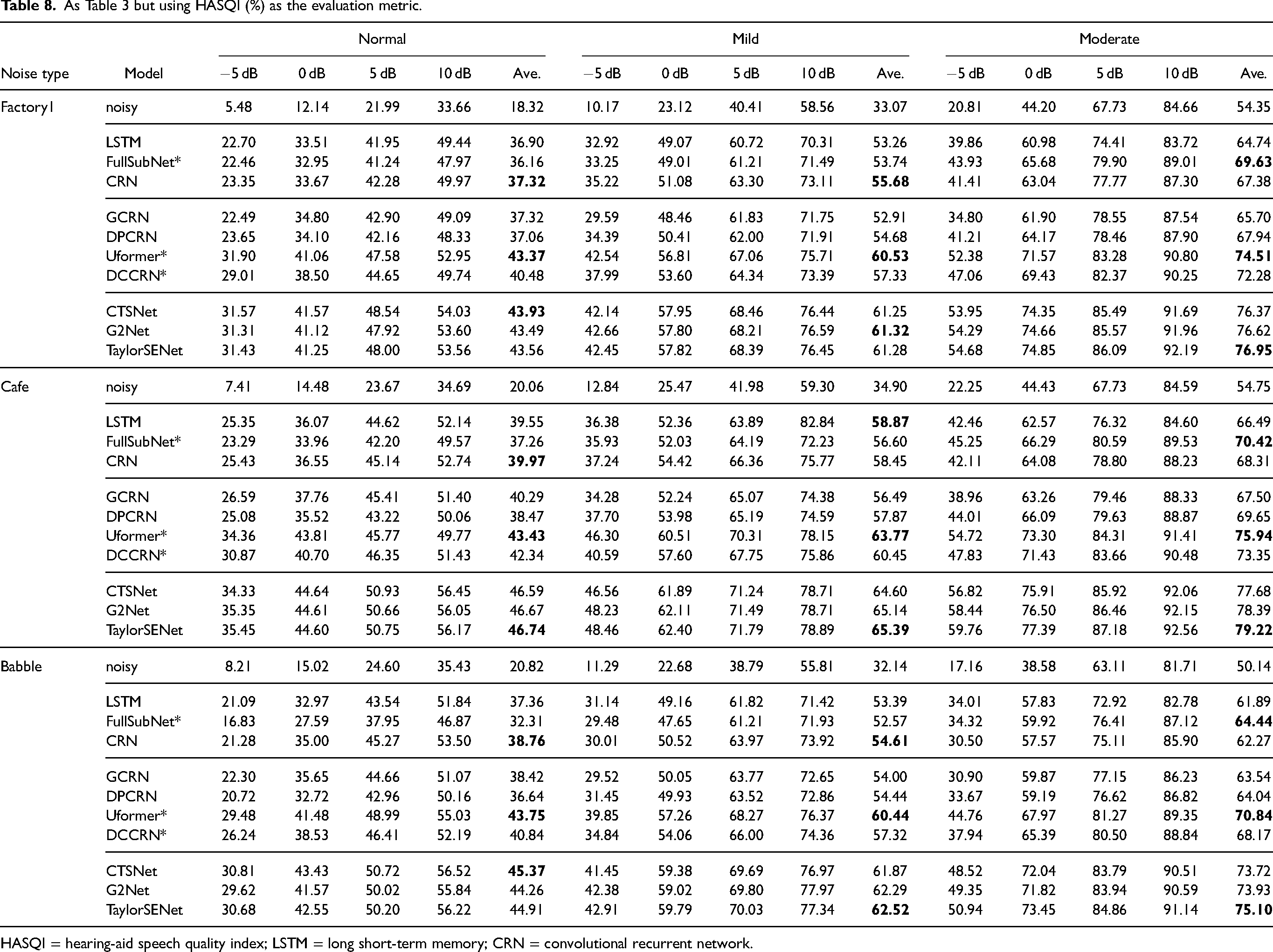
HASQI = hearing-aid speech quality index; LSTM = long short-term memory; CRN = convolutional recurrent network.
As Table 1 but using HASPI (%) as the evaluation metric.

HASPI = hearing-aid speech perception index; MMSE = minimum mean-square error; LSA = log-spectral amplitude; STSA = short-time spectral amplitude; MSS = magnitude spectral subtraction; PSS = power spectral subtraction; CRN = convolutional recurrent network; SNR = speech-to-noise ratio.
As Table 3 but using HASPI (%) as the evaluation metric.

HASPI = hearing-aid speech perception index; LSTM = long short-term memory; CRN = convolutional recurrent network.
Simulated Hearing-impaired Listeners
Tables 7 and 8 present the HASQI scores for the different methods for all three simulated listener groups. The results differ in some interesting ways from those for the simulated normal-hearing listeners. First, MSS and SQ-MSS achieved better performance than MMSE-LSA. Second, all deep-learning methods gave lower or comparable HASQI scores when the input features were compressed than when they were not, which is opposite to the results for the simulated normal-hearing listeners. Third, for all of the single-stage deep-learning methods, the HASQI scores were not improved when the phase was also implicitly estimated, in contrast to the metrics for simulated normal-hearing listeners. Fourth, the most recently proposed methods did not always achieve the best performance. Fifth, for relatively high SNRs, the HASQI score for the enhanced speech was sometimes lower than that for the noisy speech, especially for the traditional methods. For the deep-learning methods, the benefit of speech enhancement reduced dramatically for high SNRs and only a small improvement was obtained when the SNR was 10 dB. Finally, the HASQI scores increased with increasing hearing loss, perhaps because the speech degradation produced by signal processing has a smaller perceptual effect for listeners with more severe hearing loss (Kates & Arehart, 2022).
Tables 9 and 10 present the HASPI scores for listeners with simulated mild and moderate hearing losses, denoted “Mild” and “Moderate,” respectively. In contrast to the HASQI scores, the HASPI scores decreased with increasing hearing loss, probably because the simulated hearing loss itself leads to poorer speech intelligibility. When the input SNR was lower than 5 dB, deep learning methods improved the HASPI score in most cases, but this was not the case when the input SNR was 10 dB. Moreover, as was the case for the HASQI scores for the simulated hearing-impaired listeners, compression of the input features did not improve HASPI scores, perhaps because the reduction of speech distortion and residual noise gained by compression of the input features was not audible for the simulated hearing-impaired listeners.
Results for Voice Bank + DEMAND Dataset
Simulated Normal-hearing Listeners
Tables 11 and 12 give the results for the five groups of speech enhancement methods. Several observations can be made. First, all metric scores were relatively high and most were above the corresponding metric scores for the noisy speech signals at 10 dB SNR in the WSJ + DNS dataset. Second, when the input features were not compressed, NB-PESQ scores were sometimes lower for the deep-learning methods than for the conventional methods, while the other metric scores were much higher. Third, when the input features were compressed, the performance gap between conventional methods and deep-learning methods became larger. Fourth, estimating the phase implicitly did not improve all of the metric scores for the single-stage deep-learning methods, while performance improved markedly when decoupling-style deep-learning methods were used. Fifth, the performance of DCCRN was strongly influenced by the loss function for relatively high SNRs. When the MSE was used as the loss function, the PESQ, ESTOI, DNS-SIG scores for the enhanced speech signals were sometimes lower than those for the unprocessed noisy speech signals. However, when the SNR was used as the loss function for DCCRN, denoted DCCRN(SNR), scores markedly improved, except for the SDR. Finally, hybrid methods yielded the second-highest scores in terms of NB-PESQ, WB-PESQ, and ESTOI when the input features for the deep-learning methods were uncompressed. Because the SNR in the Voice Bank + DEMAND dataset is relatively high, the competitive performance of hybrid methods for this dataset further confirms that these methods may be more suitable for relatively high SNR scenarios.
Objective test results using the Voice Bank + DEMAND dataset when the input feature was uncompressed.
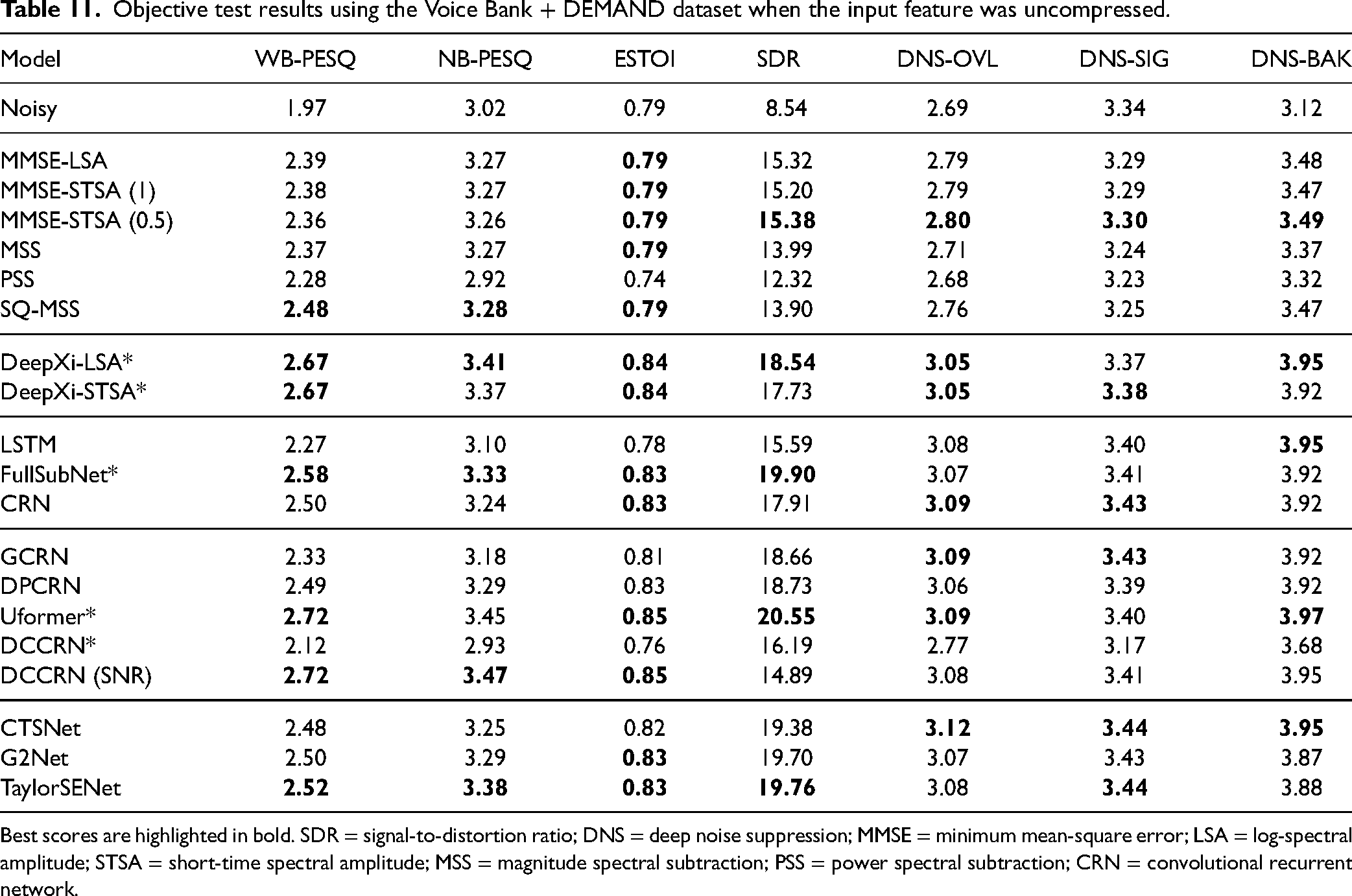
Best scores are highlighted in bold. SDR = signal-to-distortion ratio; DNS = deep noise suppression; MMSE = minimum mean-square error; LSA = log-spectral amplitude; STSA = short-time spectral amplitude; MSS = magnitude spectral subtraction; PSS = power spectral subtraction; CRN = convolutional recurrent network.
As Table 11 but for the compressed input feature.

SDR = signal-to-distortion ratio; DNS = deep noise suppression; LSTM = long short-term memory; CRN = convolutional recurrent network.
The HASQI and HASPI scores for simulated normal-hearing listeners denoted by “Normal” are shown in Table 13. The deep learning methods only slightly increased the HASQI and HASPI scores when the input features were not compressed, and the HASQI scores were increased by only about 10% when the input features were compressed. The small benefit for the HASQI scores partly reflects the fact that the HASPI scores for the unprocessed noisy speech were high, e.g. 97.1% for the simulated normal-hearing listeners. The results in Table 13 confirm that compression of the input features is important for deep learning methods when the enhanced speech is intended for normal-hearing listeners.
Values of the HASQI (%)/HASPI (%) for the different methods using the Voice Bank + DEMAND dataset.

For all deep-learning methods, both the uncompressed spectrum and the compressed spectrum were used. Bold font indicates the best average score in each group. HASQI = hearing-aid speech quality index; HASPI = hearing-aid speech perception index; MMSE = minimum mean-square error; LSA = log-spectral amplitude; STSA = short-time spectral amplitude; LSTM = long short-term memory; CRN = convolutional recurrent network; SNR = speech-to-noise ratio.
Simulated Hearing-impaired Listeners
The HASQI and HASPI scores for two types of simulated hearing-impaired listeners are also presented in Table 13. All of the traditional methods yielded lower (worse) HASQI and HASPI scores than for the unprocessed noisy speech. For all deep-learning methods, the HASQI and HASPI scores for the enhanced speech signals were similar to or only slightly higher than those for unprocessed signals. These negative findings for speech quality for the simulated hearing-impaired listeners could be a result of the relatively high SNR of the noisy speech in the Voice Bank + DEMAND dataset, which is probably, on average, above 10 dB, as inferred from the metric scores for the noisy speech signals. The performance of DCCRN depended on the loss function, better performance being obtained when the SNR was used as the loss function.
With increasing hearing loss, speech quality increased, while speech intelligibility decreased, consistent with the results for the WSJ + DNS dataset. Although speech quality was somewhat improved by deep-learning methods, speech intelligibility was only marginally improved, partly because intelligibility was relatively high for the noisy speech in the Voiced Band + DEMAND dataset. However, for simulated hearing-impaired listeners with moderate loss, although the HASPI score was only 64.7% for the unprocessed noisy speech, deep learning methods still did not markedly improve intelligibility, indicating some limitation of deep learning methods. Because speech intelligibility was at least not decreased, removing noise may increase the acceptable noise level, and hearing-impaired listeners may then be more willing to wear hearing aids (Nabelek et al., 2006).
Discussion
Based on the metrics for simulated normal-hearing listeners, most deep-learning methods and hybrid methods gave better speech quality than traditional methods, even when the SNR was relatively high. Deep-learning methods gave markedly better performance with compressed input features than with uncompressed input features. The decoupling-style deep-learning methods performed best among the three groups of deep-learning methods, indicating that it is important to optimize the magnitude and phase separately. With decoupling, interaction effects between the magnitude and the phase can be avoided, thus improving estimation accuracy for both magnitude and phase. It might be expected that decoupling-style deep-learning methods would require more parameters and more computational resources than single-stage methods. Fortunately, this is not the case. To demonstrate this, Table 14 presents the model size and number of multiply-accumulate operations (MACs) in GMAC per second for each deep-learning method and the hybrid methods (Because DeepXi-LSA and DeepXi-STSA use the same network architecture, only a single model size and computational complexity are shown for this csae). For traditional methods, the model size and number of MACs are less than 5 K and 10 million MACs, respectively. It is clear that better performance does not necessarily require greater storage and computation. For example, the hybrid method has the second smallest model size, but it yielded good performance for relatively high SNRs.
Comparisons in terms of model size (in million) and MACs (in GMAC per second).

LSTM = long short-term memory; CRN = convolutional recurrent network.
Based on the metrics for the simulated hearing-impaired listeners, there was no benefit of using compressed input features; most of the deep-learning methods gave higher HASQI scores using the uncompressed features than using the compressed features. When the SNR was relatively low, e.g.,
Conclusions and Future Prospects
This paper has reviewed many representative frequency-domain monaural speech enhancement methods proposed over the last six decades. Traditional methods are often not data-driven and often rely on specific statistical models of the speech and noise and/or a deterministic model of the speech. Early researchers in this area often assumed a model, derived a method based on this model, and then evaluated the proposed method by simulation or experiment. Traditional methods usually did not estimate the complex spectrum of the clean speech in a single stage; even for the simplest traditional method, the noise PSD had to be estimated in an initial stage. In contrast, deep-learning methods are usually data-driven and their performance depends on the training dataset, the input features provided, the learning target, and the deep-learning network architecture. Deep learning methods do not require the assumption of a statistical signal model. Note that a given deep-learning architecture may yield significantly different performance when trained using different datasets and schemes. A disadvantage of deep-learning methods is their “black box” nature. It is hard to understand in detail how a DNN achieves its results, and it can be hard to interpret performance changes produced by changing the architecture of the DNN. From a theoretical viewpoint, it is important to open the black boxes to allow understanding of the mechanisms underlying better performance. This may in turn lead to better methods.
As demonstrated in the evaluations presented in this paper, deep-learning speech enhancement methods 10 can yield much better performance than traditional methods. However their storage and computational requirements are much higher than for traditional methods, which limits their application in low-resource devices, such as hearing aids and cochlear implants. Moreover, a majority of deep-learning speech enhancement methods are noncausal and their algorithmic delay covers a wide range; some of them are even sentence based. Although many researchers have developed frame-wise deep-learning speech enhancement methods, the algorithmic delay is still larger than 30 ms in most cases. This delay is small enough for some applications, such as audio-visual conferences, smart home devices, and smartphones, but it is too long for hearing-assistance devices (Stone & Moore, 1999; Stone et al., 2008) and on-site sound reinforcement systems. For hearing aids it is generally believed that the delay should be as small as possible, and some hearing aids have delays as small as 0.5 ms. It is still challenging to reduce the delay to below 4 ms without affecting performance, although some researchers have tried to solve this problem (Vary, 2006; Schröter et al., 2022; Zheng et al., 2022). Tammen & Doclo (2021) proposed a deep multiframe approach to reduce the delay for hearing aids, and this approach was further extended for binaural noise reduction (Tammen & Doclo, 2022). From the application perspective, future work should concentrate on reducing the complexity, storage, and latency of deep-learning methods to facilitate their application in hearing aids and cochlear implants.
For multitalker scenarios, all deep-learning methods show reduced performance. Although training deep-learning models with multitalker speech signals can reduce the performance degradation, this problem is far from being solved.
Finally, subjective listening tests using both normal-hearing and hearing-impaired listeners are needed to fully evaluate the benefits of deep-learning methods for speech intelligibility and speech quality, and to evaluate the disturbing effects of the remaining background noise.
Footnotes
Acknowledgments
We thank three reviewers and the associate editor Torsten Dau for very helpful and insightful comments on an earlier version of this paper.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research & Development (R&D) Program of China (2021YFB3201702).