
Abstract
Speech and music both play fundamental roles in daily life. Speech is important for communication while music is important for relaxation and social interaction. Both speech and music have a large dynamic range. This does not pose problems for listeners with normal hearing. However, for hearing-impaired listeners, elevated hearing thresholds may result in low-level portions of sound being inaudible. Hearing aids with frequency-dependent amplification and amplitude compression can partly compensate for this problem. However, the gain required for low-level portions of sound to compensate for the hearing loss can be larger than the maximum stable gain of a hearing aid, leading to acoustic feedback. Feedback control is used to avoid such instability, but this can lead to artifacts, especially when the gain is only just below the maximum stable gain. We previously proposed a deep-learning method called DeepMFC for controlling feedback and reducing artifacts and showed that when the sound source was speech DeepMFC performed much better than traditional approaches. However, its performance using music as the sound source was not assessed and the way in which it led to improved performance for speech was not determined. The present paper reveals how DeepMFC addresses feedback problems and evaluates DeepMFC using speech and music as sound sources with both objective and subjective measures. DeepMFC achieved good performance for both speech and music when it was trained with matched training materials. When combined with an adaptive feedback canceller it provided over 13 dB of additional stable gain for hearing-impaired listeners.
Introduction
Speech and music are two types of sounds that have been widely used in studies of auditory perception (Fastl & Zwicker, 2007; Darwin, 2009; Roederer, 2009; Moore, 2013). Speech provides a natural and effective means of communication while music enhances social interactions, brings pleasure, and conveys emotions. Both speech and music perception are important for hearing-impaired people, but devices such as hearing aids are designed primarily to improve speech perception, with less focus on music perception.
Both speech and music are highly non-stationary and have a large dynamic range. The level of speech ranges from about 30 dB sound pressure level (SPL) for a whisper to about 85 dB SPL for a shouted voice, the level of normal conversation being about 60 dB SPL (Zhang & Hansen, 2007; Moore et al., 2008). The level of live music can be as low as 30 dB SPL while the peak levels can reach 115–120 dB SPL, depending on the type of instruments and on whether amplification is used (Hockley et al., 2012; Chasin & Hockley, 2014; Moore, 2022). Speech and music also differ in many other ways. One is that speech often contains silent pauses, typically before and after stop consonants (Brady, 1965), while music can contain long passages without any pauses. A second is that speech can be recursively predicted, as shown by a well-known speech production model (Atal & Schroeder, 1970; Saito et al., 1970; Makhoul, 1975; Quatieri, 2006), while music usually cannot be modeled in this way. A third is that music often contains components that are stable over tens or hundreds of milliseconds, while the fundamental frequency of voiced speech usually changes rapidly over time. These different characteristics of speech and music make it difficult to develop a unified approach to signal processing in hearing aids.
It is common to use different strategies when processing speech and music for both normal-hearing (NH) and hearing-impaired listeners. Noise suppression based on time-frequency analysis is often used to reduce noise and improve speech quality for NH and hearing-impaired listeners and to improve speech intelligibility for hearing-impaired listeners (Zheng, Zhang, et al., 2022). It would be useful to reduce noise when listening to music in noisy situations such as in a car, bus, or train. However, single-channel noise suppression methods such as spectral subtraction generally rely on the estimation of the noise characteristics during pauses in the speech, and the lack of pauses in much music makes this approach problematic. Dynamic range compression for hearing aids may also need to depend on the type of sound, because of differences between speech and music in characteristics such as dynamic range, frequency range, and spectral shape (Chasin & Russo, 2004; Kirchberger & Russo, 2016; Moore, 2022).
The paper focuses on another aspect of signal processing that is used in hearing aids, namely acoustic feedback cancellation. A hearing aid is a closed-loop system because of the acoustic transfer function
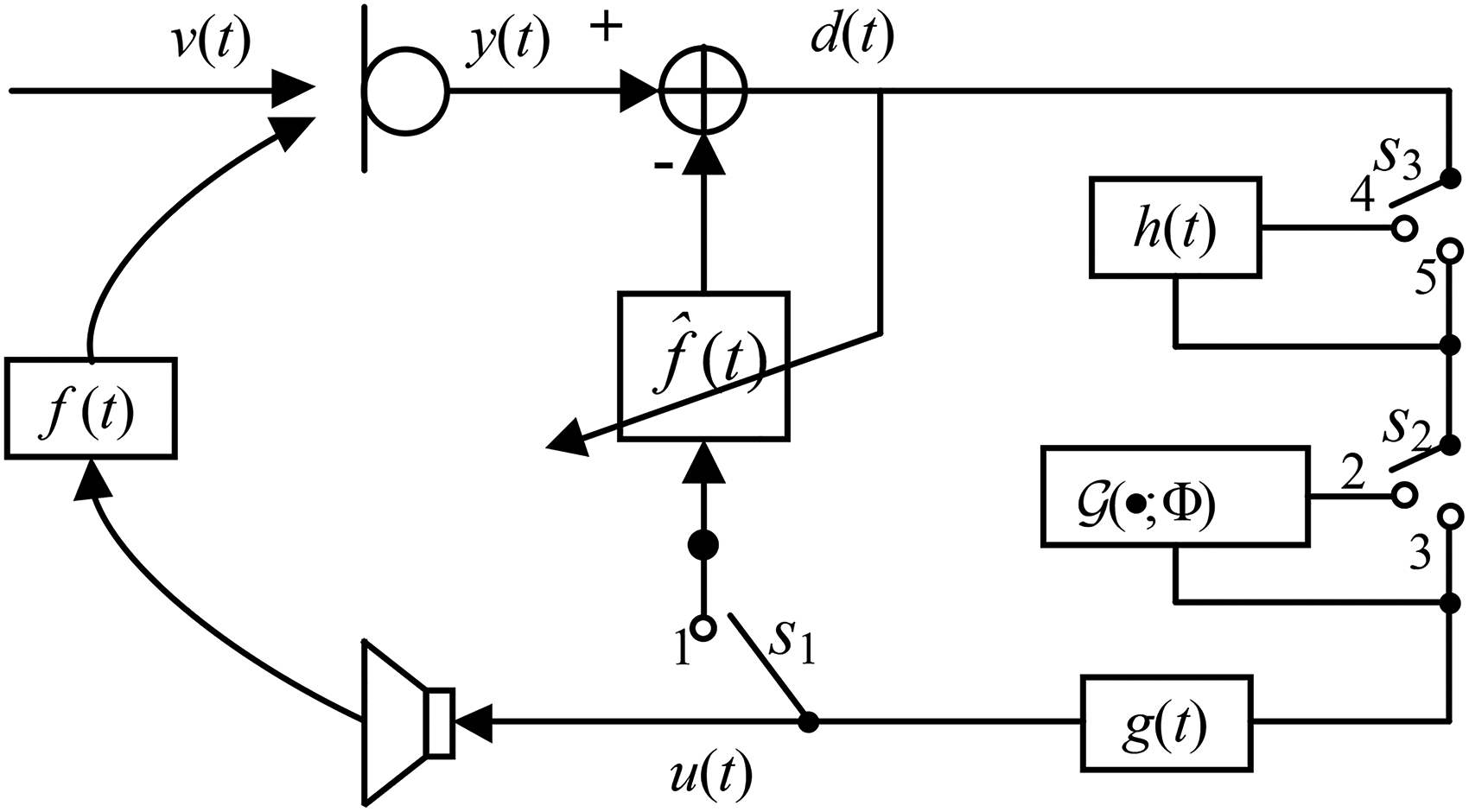
Signal flowchart of a hearing aid. There are three interlinked switches,
Different types of approaches often have different underlying assumptions, and the performance of a given approach may be poor when the assumptions are not satisfied or are poorly approximated. When Schroeder (1964) theoretically and experimentally studied the additional stable gain (ASG; the amount by which the gain can be increased before instability occurs) provided by FS, the intended application was in public address systems, for which it was assumed that feedback was caused only by the reverberant sound field. However, for hearing aids, the direct sound from the receiver to the microphone and early reflections from nearby surfaces are usually dominant. Because FS does not require any assumptions about the type of sound source, it works for both speech and music, although music quality may be somewhat degraded because annoying beats are often produced when open-fit hearing aids are used and the sound reaching the eardrum is a mixture of sound leaking through the open fitting and sound produced by the hearing aid (Moore, 2016).
For AFC, it is often assumed that the feedback path between the receiver and microphone is time-invariant or only slowly time-varying (Bustamante et al., 1989; Kates, 1991; Guo et al., 2012). When the feedback path changes rapidly, for example, when the hearing-aid user moves close to a reflecting surface, it takes some time to track this change and howling may occur during the convergence stage. Although the convergence rate can be improved by properly choosing the step size when recursively updating the filter coefficients of the AFC (Rotaru et al., 2012), instability may still occur for a short time.
AFC systems suffer from bias in the estimation of the feedback signal when the sound source is spectrally colored (Kates, 1991; Hellgren, 2002; Spriet et al., 2005; Guo et al., 2012). This is especially serious when the sound source is music, since the AFC may cancel steady tones instead of removing the feedback signal. However, speech is also a spectrally colored signal, leading to problems with estimation bias. To deal with this, speech can be spectrally flattened (whitened) with a time-varying low-order infinite impulse response filter, using a speech-production model (Quatieri, 2006). This approach called the prediction error method (PEM) was combined with an AFC method (PEM–AFC) by Spriet et al. (2005). When the sound source was speech, PEM–AFC performed much better than AFC approaches without whitening, in terms of convergence rate, estimation bias, and the amount of ASG. However, as demonstrated by Guo et al. (2013), PEM–AFC did not outperform AFC approaches without whitening when the sound source was music. This may be because music cannot be whitened using the prediction error method of Spriet et al. (2005).
Gain-control-based feedback suppression approaches (Patronis, 1978; Foley, 1989; Waterschoot & Moonen, 2010) detect howling components in the first stage and gain reduction is then applied to subbands containing howling components. The performance of gain-control approaches depends on the accuracy of howling detection (Waterschoot & Moonen, 2010). This leads to problems with music, since the tonal components in music may be identified as howling components, resulting in gain reductions at many frequencies and a degradation of sound quality.
A deep-learning framework for feedback control called DeepMFC was recently proposed by Zheng, Wang et al. (2022). DeepMFC was primarily intended to reduce the artifacts associated with feedback reduction when a system was working with a gain just below the maximum stable gain, a state referred to as a marginally stable gain. These artifacts include spectral coloration, whereby the gain is higher than desired at frequencies where the gain is only slightly below the maximum stable gain, and short whistles occurring when the feedback path changes. However, DeepMFC also increased the maximum stable gain. Unlike the above-mentioned approaches, DeepMFC is data-driven. DeepMFC was shown to outperform non-data-driven approaches in terms of objective and subjective measures when the sound source was speech. In DeepMFC, the complex spectrum of the microphone signal is mapped directly to the complex spectrum of the receiver signal using a pre-trained deep complex neural network denoted
This paper had three purposes. The first was to evaluate DeepMFC in simulated closed-loop systems with measured feedback paths for both music and speech using different models trained with different materials and using both objective and subjective measures. The second was to estimate the ASG provided by DeepMFC using the hearing-aid speech quality index version 2 (HASQI-V2) proposed by Kates & Arehart (2014) and the hearing-aid audio quality index (HAAQI) proposed by Kates & Arehart (2016). The third purpose was to clarify the way in which DeepMFC works.
Methods
DeepMFC Models
Zheng, Wang et al. (2022) proposed a data-driven feedback control approach, called DeepMFC. Using both objective metrics and listening tests DeepMFC was shown to perform better than several effective and representative approaches, including FS, AFC, and PEM–AFC, when training was done using speech in background noise and the sound source for testing was speech in quiet or in noise. For the present paper, a DeepMFC model with the same architecture as in Zheng, Wang et al. (2022) was retrained, because we found that performance was improved when the length of the simulated feedback paths was increased from about 3 ms to about 15 ms. The model that was re-trained with speech is denoted DeepMFC(1). In total, 10,000 feedback paths with lengths randomly selected from 200 to 300 samples for the sampling rate of 16 kHz were simulated. When training DeepMFC(1), the WSJ0-SI84 speech corpus (Paul & Baker, 1992) was used. In total, 40,000 utterances spoken by 76 speakers were randomly selected and each utterance was mixed with a noise clip randomly chosen from the DNS-Challenge data set (Reddy et al., 2021) at a signal-to-noise ratio randomly selected from 5, 10, 15, and 20 dB. Each noisy mixture was used together with one randomly selected simulated feedback path to generate the closed-loop receiver signal when the closed-loop system performed in marginal stable gain states (Zheng, Wang, et al., 2022). The corresponding open-loop receiver signal with the same clean utterance as the sound source was generated and paired with the closed-loop receiver signal. Note that the training target was clean speech. Thus, DeepMFC(1) was intended both to control feedback and to reduce noise. In total, 40,000 paired speech signals were included in the speech training data set. The paired speech validation data set was generated using 2400 utterances spoken by the same speakers as for the training data set. For both the speech training and validation data sets, the duration of each utterance was cut to 4 s. Note that DeepMFC(1) becomes a deep noise reduction (DeepNR) model when each noisy mixture is used as the receiver signal and paired with its corresponding clean speech to create the training data set. Zheng, Wang et al. (2022) showed that DeepNR performed worse than DeepMFC(1) in handling feedback. Although DeepNR suppressed howling components, it did not solve the coloration problem effectively. Thus DeepNR will not be discussed further in this paper.
A second DeepMFC model, denoted DeepMFC(2), was trained to control feedback when the sound source was music. For this purpose, the sound sources used for the training and validation data sets were taken from the synthesized Lakh data set, denoted Slakh, provided by Manilow et al. (2019). Slakh was designed for the evaluation of music source separation approaches, and its first version, Slakh2100, had 2100 instrumental pieces with a total duration of about 145 hours. In total, 80,000 clips randomly cut from Slakh2100 were used as the source signals for training. One simulated feedback path was randomly selected and used together with each clip to generate the closed-loop receiver signal. The corresponding open-loop receiver signal with the same music clip was generated and paired with the closed-loop receiver signal. In total, 80,000 paired clips were included in the music training data set. The paired music validation data set was generated in the same way as the paired music training data set, using 2400 clips randomly cut from Slakh2100. For both the training and validation data sets, each music clip was cut to 4 s.
A third DeepMFC model, denoted DeepMFC(3), was trained to appropriately process either speech or music. While DeepMFC(1) was primarily intended for feedback control, it also had the effect of reducing background noise. As denoising may seriously degrade music quality, only clean speech
Comparison Control Approaches, Stimuli, and Procedure
Feedback Control Approaches
In addition to the three DeepMFC models, three more traditional feedback-control methods, FS, PEM–AFC, and their combination, denoted FS+PEM–AFC, were implemented and evaluated. As demonstrated by Zheng, Wang et al. (2022), performance was improved when DeepMFC was combined with PEM–AFC when the gain margin in decibels was set to be negative. For completeness, we also evaluated the combination of two traditional approaches and DeepMFC, specifically FS+DeepMFC and PEM–AFC+DeepMFC. In summary, the following 10 feedback-control approaches, including five single-stage and five two-stage approaches were used and compared:
FS: the approach proposed by Schroeder (1964) was used with a frequency shift of 10 Hz. PEM–AFC: the approach proposed by Spriet et al. (2005) was used. The fixed step size of the normalized least mean square algorithm for updating the feedback path was set to 0.005. To improve its performance for music, when estimating the feedback path a time-invariant high-pass 3-tap finite impulse response (FIR) filter was applied to the output signal of PEM–AFC DeepMFC(1): this model was expected to give the best performance when the source was speech, because it suppresses noise and reduces feedback problems simultaneously. DeepMFC(2): this model was expected to give better performance than DeepMFC(1) when the source was music. DeepMFC(3): this model was expected to give moderate performance for both speech and music. PEM–AFC+FS: the output signal from PEM–AFC was further processed using FS. As shown by Guo et al. (2013) and Zheng, Wang et al. (2022), FS improved the performance of PEM–AFC when the gain margin in decibels was negative. FS+DeepMFC(1): after performing FS the signal was further processed using DeepMFC(1) when the source was speech. While DeepMFC(1) was not trained using signals with FS, it has been shown that DeepMFC is robust to both linear and non-linear processing of the signal (Zheng, Wang, et al., 2022). PEM–AFC+DeepMFC(1): after performing PEM–AFC, the signal was further processed using DeepMFC(1) when the source was speech. FS+DeepMFC(3): after performing FS the signal was further processed using DeepMFC(3) when the source was music. Note that DeepMFC(2) was not used. Although preliminary experiments showed that it achieved better performance than DeepMFC(1) for music, DeepMFC(2) gave worse performance than DeepMFC(3) for music. This may have occurred because Slahk2100 (Manilow et al., 2019) contains only instrumental pieces, while the test materials contained both musical instruments and singing voices. PEM–AFC+DeepMFC(3): the output from PEM–AFC was further processed using DeepMFC(3) when the source was music.
All the above-mentioned approaches were run using the simulated closed-loop system shown in Figure 1. By changing the status of the three switches, one or various combinations of feedback control approaches could be implemented. When
Stimulus Generation
When training all DeepMFC models, only simulated feedback paths were used. The simulation method was the same as described by Zheng, Wang et al. (2022). When testing the various feedback-control approaches, only feedback paths measured using a hearing aid (Lee et al., 2017) 4 were used in the simulated closed-loop system. In this way, the feedback paths used for testing were unseen during training. The length of each measured feedback path was 263 samples using a sampling rate of 16 kHz.
It is well known that better performance of deep-learning approaches is often achieved when the source for the test,
With the measured feedback paths and different types of sound sources, the feedback-control approaches were run one by one in the closed-loop systems and the receiver signals were recorded for objective and subjective measures. To measure performance with different prescribed gains, the value
For each approach,
Objective Quality Assessment
Objective quality measures often give inconsistent results when applied to speech and music signals (Torcoli et al., 2021). For that reason, separate measures are needed for speech and music. The wideband PESQ metric proposed by Rix et al. (2001) is often used to evaluate the quality of unprocessed and processed speech signals for NH listeners, because PESQ scores are usually highly correlated with subjective scores for speech quality for these listeners. Note that PESQ was originally designed to measure speech quality in the context of speech coding, but it has since been used to assess the influence of more types of distortions, including noise (Hu & Loizou, 2007), reverberation (Naylor & Gaubitch, 2010), and acoustic feedback (Schepker et al., 2020). However, the PESQ metric is not designed to take into account the effects of hearing loss or of hearing-aid signal processing. Here, in addition to PESQ, the HASQI-V2 (Kates & Arehart, 2014) was used to evaluate speech quality, while the HAAQI (Kates & Arehart, 2016) was used to evaluate music quality. HAAQI scores are more highly correlated than HASQI-V2 scores with subjective ratings of music sound quality (Kates & Arehart, 2016).
The HASQI-V2 and HAAQI metrics can be used to simulate both NH and hearing loss. Both require the audiometric thresholds of the simulated listener to be entered. If the audiometric thresholds are specified as 0 dB hearing level (HL) at all frequencies, the metrics use a model of auditory processing to give estimates of sound quality for listeners with NH. If some of the audiometric thresholds are specified as
Only mild and moderate hearing losses were simulated. Bisgaard et al. (2010) divided standard audiograms into two groups: a flat and moderately sloping group, and a steeply sloping group. The first group included seven audiograms characterizing different degrees of hearing loss, while the second group had three audiograms with different degrees of hearing loss. Here, two standard audiograms
Audiometric thresholds in decibels hearing level (dB HL) for the two standard audiograms

For each approach and each type of source, an average score for each objective quality measure was calculated across all clips for a specific value of the gain margin, giving 33 average scores for speech and 33 average scores for music.
Subjective Quality Assessment
Paired comparisons were used to estimate subjective preference scores. This was done separately for speech and music signals. Fifteen participants with self-assessed NH were tested. Their ages ranged from 20 to 52 years. All were native Chinese speakers. Since the experiment involved listening to stimuli presented at safe sound levels, in accordance with local regulations, no ethical approval was required.
For speech, the conditions that were compared were: unprocessed, PEM–AFC, DeepMFC(1), and PEM–AFC+DeepMFC(1), giving six pairs. For music, the conditions that were compared were: unprocessed, PEM–AFC, DeepMFC(3), and PEM–AFC+DeepMFC(3), again giving six pairs. Gain margins of 0,
Stimuli were presented diotically via headphones (Sennheiser HD202, Wedemark, Germany). The levels of all stimuli were adjusted to give the same peak level, and the overall level was adjusted separately for each participant until it was judged to be at the most comfortable level. Each participant was asked to compare all six pairs of approaches using a gain margin of 0 dB. For the negative gain margins, only conditions that did not lead to instability were tested. Thus, three pairs of approaches (PEM–AFC versus DeepMFC, PEM–AFC versus PEM–AFC+DeepMFC, and DeepMFC versus PEM–AFC+DeepMFC) were compared using a gain margin of
Each participant was presented with five pairs of utterances for each pair of approaches and each gain margin and selected one of the three options after the presentation of each pair: first better, second better, or equal. The order of presentation of the approaches within a pair was random. When approach A was selected as the better one, one point was assigned to approach A, and zero to approach B, and vice versa. When equal was selected, “equal” was assigned one point. The points were summed for each approach and the total was divided by 75 and multiplied by 100 to obtain a preference score as a percentage.
Results
Speech Quality for Simulated NH Listeners
Figures 2 and 3 show the PESQ and HASQI-V2 scores, respectively, assuming NH listeners for HASQI-V2. Among the feedback-control approaches, only AFC-based approaches explicitly estimate the feedback path. When the feedback path is simulated and time-invariant, as here, the ASG in decibels resulting from the use of AFC can be computed by subtracting the maximum stable gain without AFC from that with AFC. For other types of feedback-control approaches, the ASG is more difficult to determine, because the maximum stable gain with feedback control cannot be computed directly. To estimate the ASG of the different feedback-control approaches, the gains giving a PESQ score
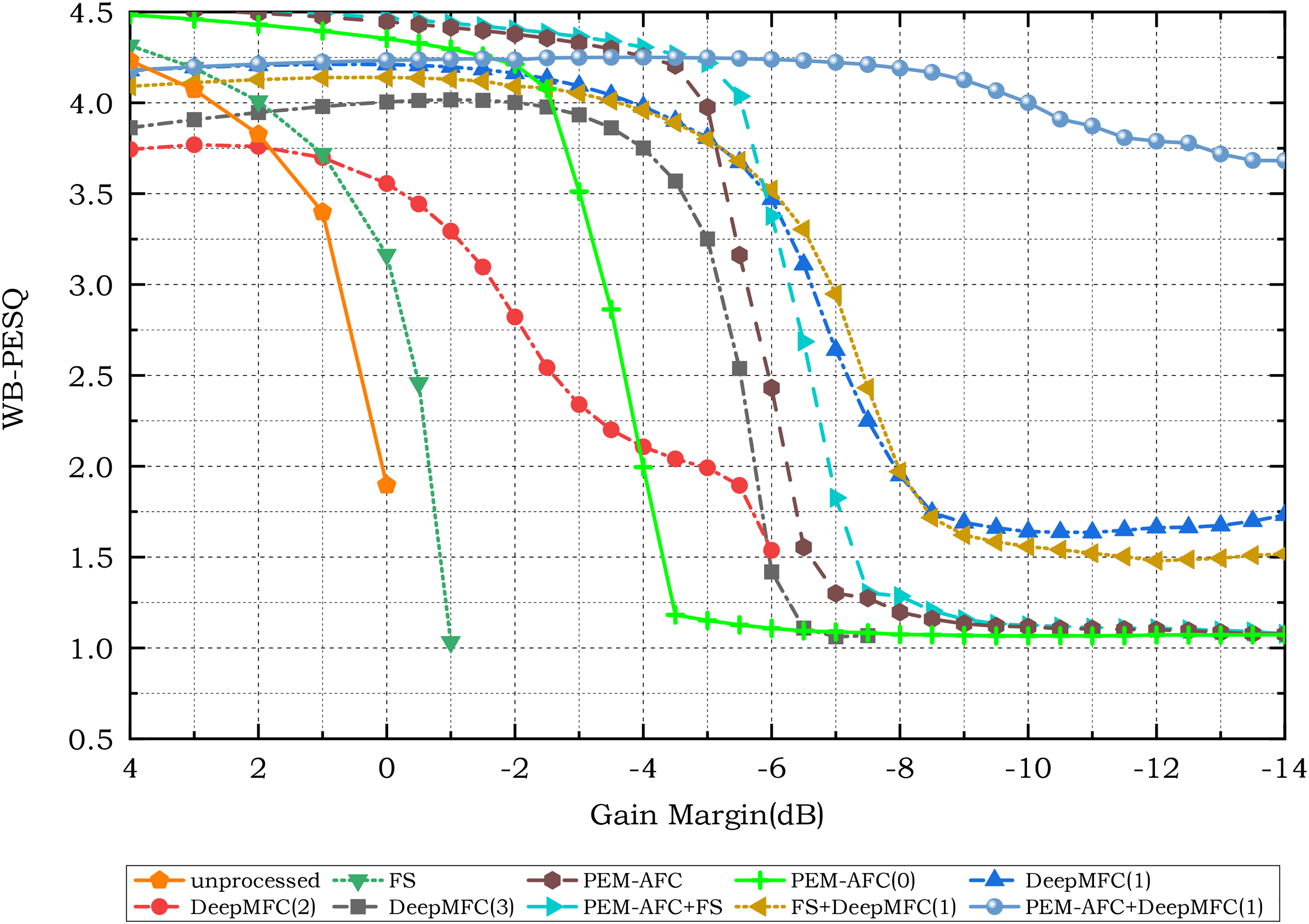
Wideband perceptual evaluation of speech quality (WB-PESQ) scores for unprocessed and processed speech using different feedback-control approaches.
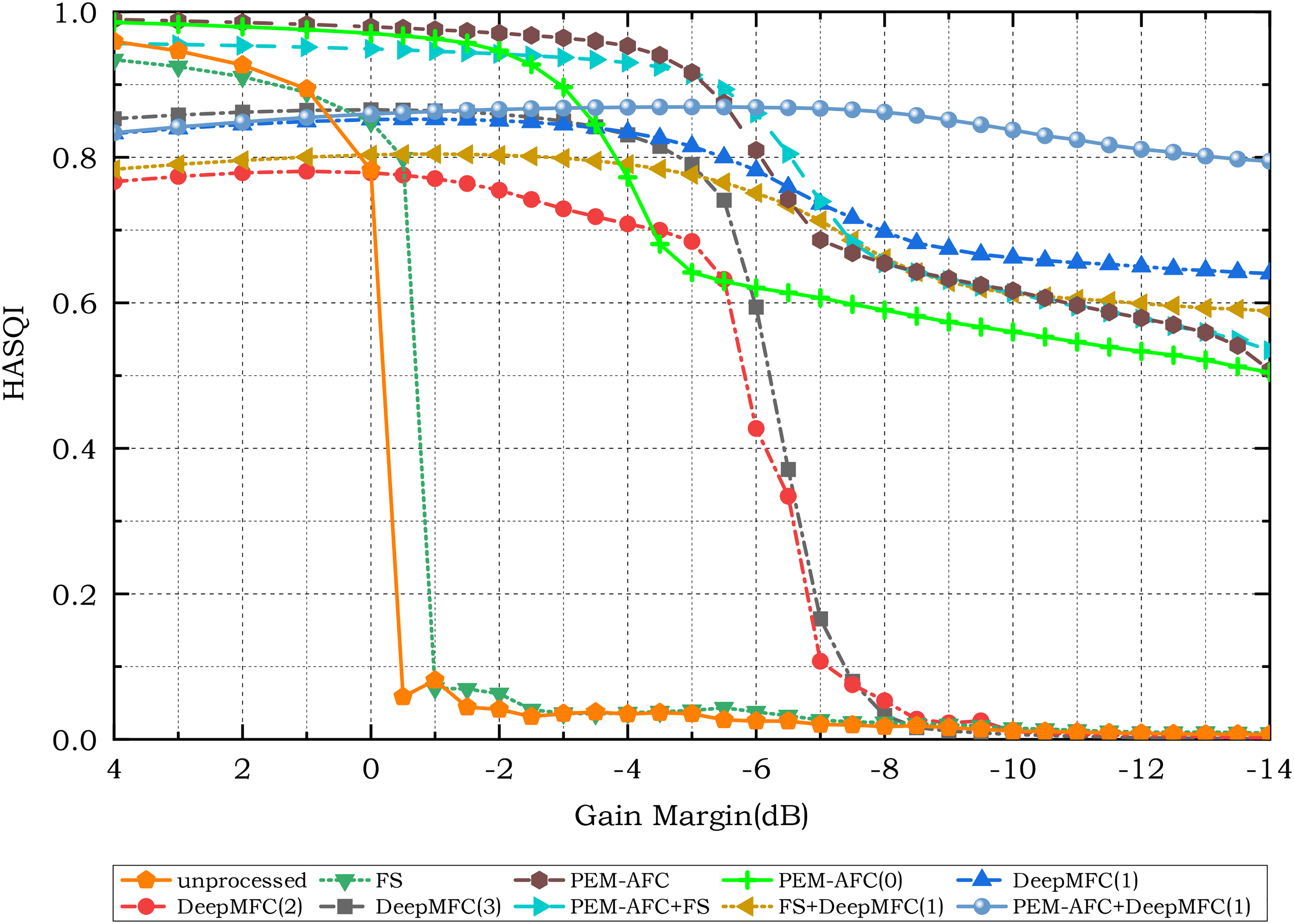
Hearing-aid speech quality index version 2 (HASQI-V2) scores for unprocessed and processed speech using different feedback-control approaches, assuming normal-hearing listeners.
Estimated ASG (in dB) of the feedback-control approaches using the HASQI-V2 score for speech. The estimated ASG using the WB-PESQ score is shown in brackets for the simulated NH listeners.

ASG: additional stable gain; HASQI-V2: hearing-aid speech quality index version 2; WB-PESQ: wideband perceptual evaluation of speech quality; NH: normal hearing; FS: frequency shifting; PEM: prediction error method; AFC: adaptive feedback cancellation.
Without any feedback control, both WB-PESQ and HASQI-V2 scores worsened dramatically when the gain margin in decibels changed from positive to negative values, because the system became unstable and howling occurred. With FS alone, the ASG was about 0 dB 6 , consistent with the theoretical analysis of Zheng et al. (2016) and the experimental results of Berdahl & Harris (2010). For PEM–AFC, which was initialized by averaging several measured feedback paths, the ASG was about 6 dB, which is 2 to 3 dB higher than the ASG for PEM–AFC(0). This indicates that appropriate initialization of the AFC is important. The combination of FS and PEM–AFC improved the ASG relative to PEM–AFC alone, but the improvement was <1 dB.
Of the three versions of DeepMFC, DeepMFC(2) performed the most poorly; the HASQI-V2 score was lower than the criterion value of 0.8 for all gain margins. This indicates that using only music clips for training was not sufficient to give substantial ASG for speech. The combination of FS and DeepMFC(1) did not markedly affect the ASG, while the combination of PEM–AFC and DeepMFC(1) yielded the highest ASG of 13 to 14 dB. DeepMFC(1) yielded the highest ASG among the individual feedback control approaches.
Speech Quality for Simulated Hearing-Impaired Listeners
Figures 4 and 5 show the HASQI-V2 scores for simulated hearing-impaired listeners with mild (N2) and moderate (N3) hearing loss, respectively. The same threshold as used for the simulated NH listeners, 0.8, was used to determine the maximum stable gain of the different feedback-control approaches for the simulated hearing-impaired listeners. Comparison of Figures 4 and 5 with Figure 3 shows that for almost all of the feedback-control approaches the maximum stable gain increased with increasing hearing loss, as can also be seen from Table 2. For example, the maximum stable gain for DeepMFC(1) increased from 6 dB for the simulated NH listeners to 8.5 dB for the listeners with simulated mild hearing loss (N2) and to over 14 dB for the listeners with simulated moderate hearing loss (N3). For the latter, DeepMFC(1) alone performed very well, and combining it with PEM–AFC led to only slightly higher HASQI-V2 scores. In contrast, for both the simulated NH listeners and simulated listeners with mild hearing loss, the combination of PEM–AFC and DeepMFC(1) led to a much higher maximum stable gain than for either method alone. The finding that HASQI scores were higher for simulated hearing-impaired listeners than for simulated NH listeners is consistent with the results presented by Kates & Arehart (2022). As explained by Kates & Arehart (2022), these higher scores may have occurred because the simulated hearing-impaired listeners were less sensitive than the simulated NH listeners to signal degradations such as increased gain at certain frequencies (coloration), owing to the simulated reduced frequency selectivity of the former. Also, for the simulated hearing-impaired listeners, some distortion spectral components would have had levels below the hearing threshold, and thus would not be perceived (Tan & Moore, 2008).

Hearing-aid speech quality index version 2 (HASQI-V2) scores for unprocessed and processed speech using different feedback-control approaches, assuming hearing-impaired listeners with mild hearing loss (N2).
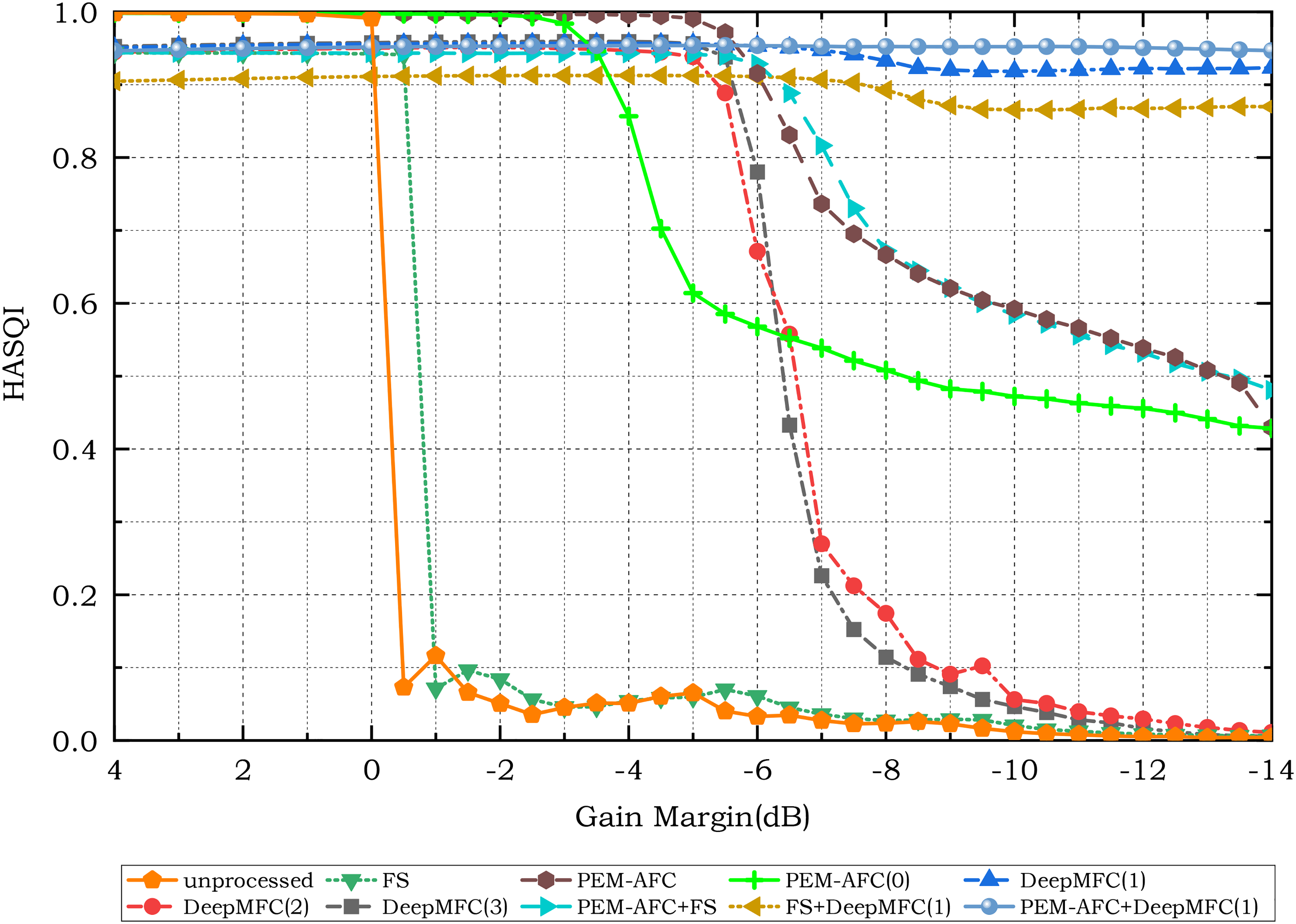
Hearing-aid speech quality index version 2 (HASQI-V2) scores for unprocessed and processed speech using different feedback-control approaches, assuming hearing-impaired listeners with moderate hearing loss (N3).
Music Quality for Simulated NH Listeners
Figure 6 shows the HAAQI scores for simulated NH listeners for the unprocessed and processed music signals using the different feedback control approaches. HAAQI scores were generally lower than HASQI scores and so a lower criterion, 0.6, was chosen as the threshold indicating the maximum stable gain for each approach. Informal listening tests confirmed that music quality was relatively high when the HAAQI score was above 0.6. Table 3 shows the estimated ASG in decibels of each feedback-control approach for music. When the HAAQI score was <0.6 for all gain margins, the estimated ASG is not shown.

Hearing-aid audio quality index (HAAQI) scores for unprocessed and processed music signals using different feedback control approaches for simulated normal-hearing listeners.
As Table 2 but for music.

NH: normal hearing; FS: frequency shifting; PEM: prediction error method; AFC: adaptive feedback cancellation.
Of the single approaches, PEM–AFC achieved the highest ASG (about 10 dB), and its combination with DeepMFC(3) gave nearly the same ASG. PEM–AFC(0) yielded much poorer HAAQI scores than PEM–AFC, the ASG of PEM–AFC(0) being only about 7 dB. This again shows the importance of initialization. With initialization based on measured feedback paths, PEM–AFC converged rapidly, while if all adaptive filter coefficients were initially set to 0, PEM–AFC converged slowly and instability occurred at the beginning of the adaptation period or when the feedback path changed. For DeepMFC(2) and DeepMFC(3), the ASG was about 5 dB. DeepMFC(3) performed only slightly better than DeepMFC(2). DeepMFC(1) performed the most poorly among the three deep-learning approaches, and it failed to increase the maximum stable gain. More seriously, DeepMFC(1) degraded HAAQI scores markedly even when the closed-loop system worked in a stable state. This confirms the importance of using matched training and testing conditions 7 for deep learning-based approaches. FS yielded an ASG <1 dB for music, consistent with the result for speech.
Music Quality for Simulated Hearing-Impaired Listeners
Figures 7 and 8 show the HAAQI scores for the simulated listeners with mild and moderate hearing loss, respectively. DeepMFC(1) yielded the lowest HAAQI scores when the gain margin was high, indicating that it degraded sound quality. This again confirms the importance of using music for training when the source for evaluation is music rather than speech. As can be seen in Table 3, the highest ASG values were obtained with PEM–AFC and the combination of PEM–AFC and DeepMFC(3). HAAQI scores for PEM–AFC were higher for the simulated hearing-impaired listeners than for the simulated NH listeners. The ASG for PEM–AFC(0) was about 3 dB smaller than that for PEM–AFC. DeepMFC(2) and DeepMFC(3) yielded ASGs of 6 to 7 dB for the N2 and N3 listeners. FS gave a small ASG value of 0.5 dB.
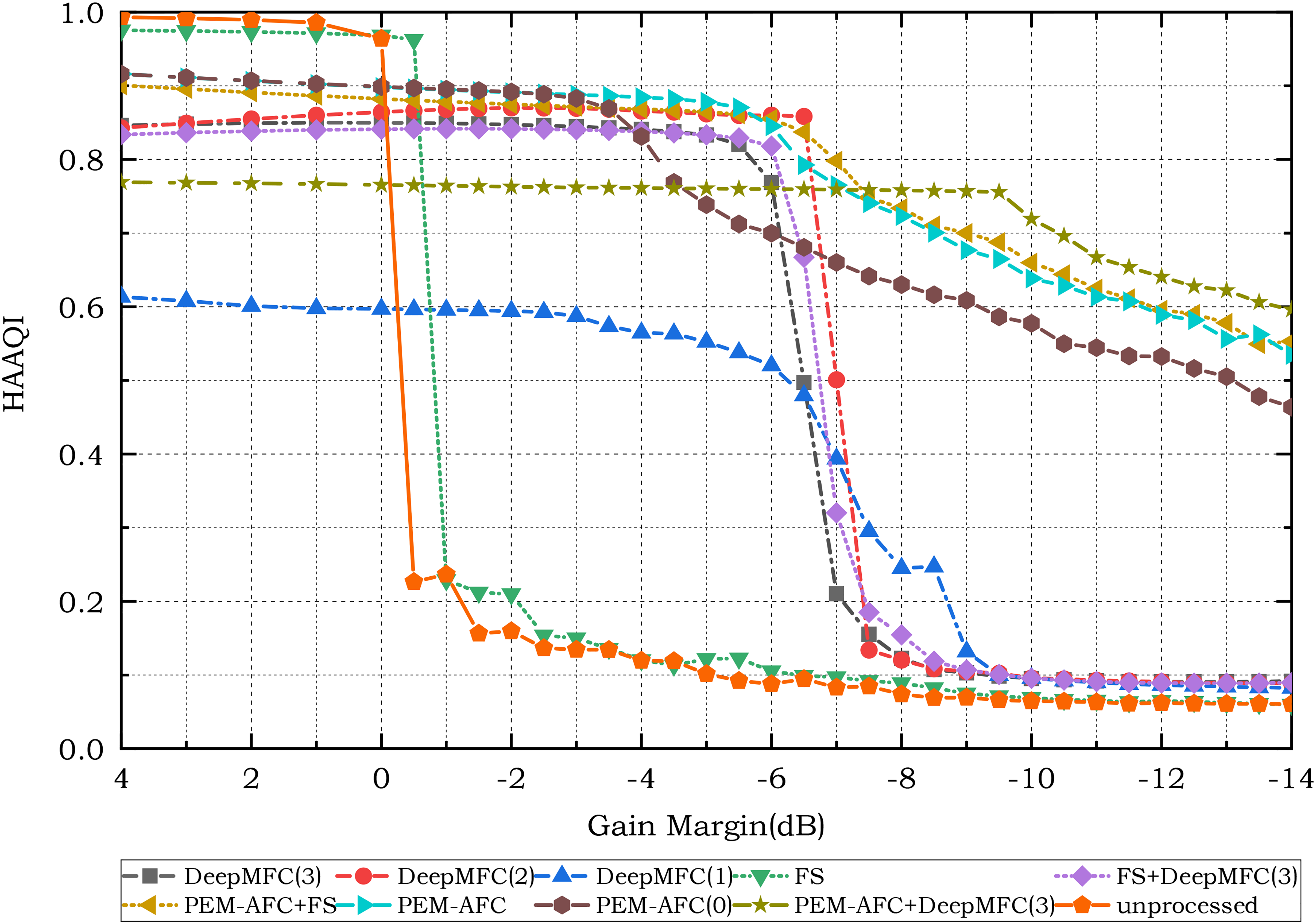
Hearing-aid audio quality index (HAAQI) scores for unprocessed and processed music signals using different feedback control approaches for simulated listeners with mild hearing loss.
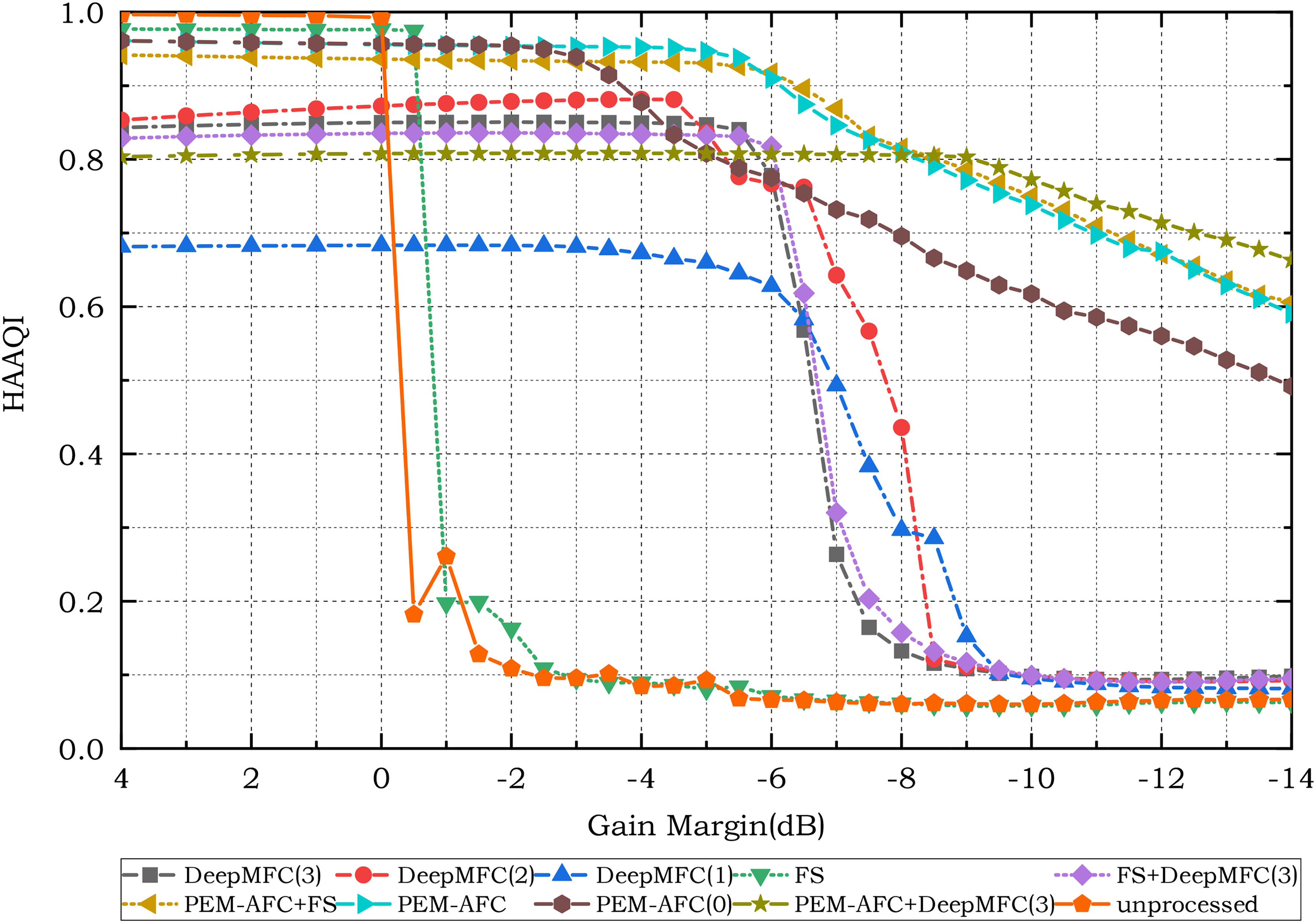
Hearing-aid audio quality index (HAAQI) scores for unprocessed and processed music signals using different feedback control approaches for simulated listeners with moderate hearing loss.
Comparison of Figure 6 with Figures 7 and 8 shows that HAAQI scores for unprocessed music differed for simulated NH and hearing-impaired listeners. When the gain margin was reduced from 4 dB to 0 dB, the HAAQI scores remained above 0.95 for the simulated hearing-impaired listeners, while the scores decreased from slightly over 0.9 to below 0.8 for the simulated NH listeners. The higher HAAQI scores for the simulated hearing-impaired listeners shown in Figures 7 and 8 are consistent with the HASQI scores in Figures 4 and 5. These higher scores probably occurred for the same reasons as discussed earlier, namely reduced sensitivity of hearing-impaired listeners to signal degradations.
Results of the Listening Test for Speech
Table 4 presents the results of the listening test for speech. When the gain margin was set to 0 dB, both PEM–AFC and DeepMFC(1) were clearly preferred over the unprocessed signals. DeepMFC(1) was preferred over PEM–AFC, and the difference was small but significant (
Subjective preference scores for speech.

PEM: prediction error method; AFC: adaptive feedback cancellation.
For the gain margin of
Results of the Listening Test for Music
Table 5 shows the results of the listening test for music. For the gain margin of 0 dB, PEM–AFC was preferred over DeepMFC(3) (
As Table 4 but for music.

PEM: prediction error method; AFC: adaptive feedback cancellation.
Characterization of How DeepMFC Works for Speech and Music
With the speech signals, DeepMFC(1) performed very well for all types of simulated listeners regardless of the degree of hearing loss and it also performed well in the subjecti6ve listening test. The ASG of DeepMFC(1) was up to 14 dB when 0.8 was used as the threshold HASQI-V2 score indicating that the maximum stable gain was reached. With the music signals, DeepMFC(2) and DeepMFC(3) yielded smaller ASG values, despite the fact that these two models were trained using music (together with speech for DeepMFC(3)). This probably happened because the well-defined spectro-temporal structure of speech allows deep-learning approaches to map the complex spectrum of the input directly to the complex spectrum of the output (Zheng, Wang, et al., 2022), while the spectro-temporal structure of music varies markedly depending on the instruments being played, the manner of playing, and the type of music, and this makes it more difficult for deep-learning approaches to learn and perform the appropriate mapping. This is especially the case when the number of parameters of a deep-learning model is limited, as it would be for many practical applications using resource-limited devices 8 , such as hearing aids. The number of parameters needed for satisfactory mapping is probably much greater for music than for speech (Défossez et al., 2019).
To elucidate the way in which DeepMFC handles feedback, both speech and music were used as the source in a simulated closed-loop system whose feedback path was selected from the measured feedback paths. The time-domain loop transfer function (LTF) and the loop gain response (LGR) are plotted in Figure 9(a) and (b), respectively, for a gain margin (without processing) of

Illustration of how DeepMFC implemented feedback control when the gain margin was
Figure 10 shows spectrograms of speech and music before and after processing using DeepMFC when the gain margin was

Spectrograms of speech and music when the gain margin was
To further illustrate the behavior of DeepMFC with marginally stable systems, Figure 11 is the same as Figure 9, except that the closed-loop system worked with a gain margin of 0.5 dB. Comparing Figure 11(a) with Figure 9(a), it can be seen that the magnitude of the LTF for the gain margin 0.5 dB is lower than for the gain margin
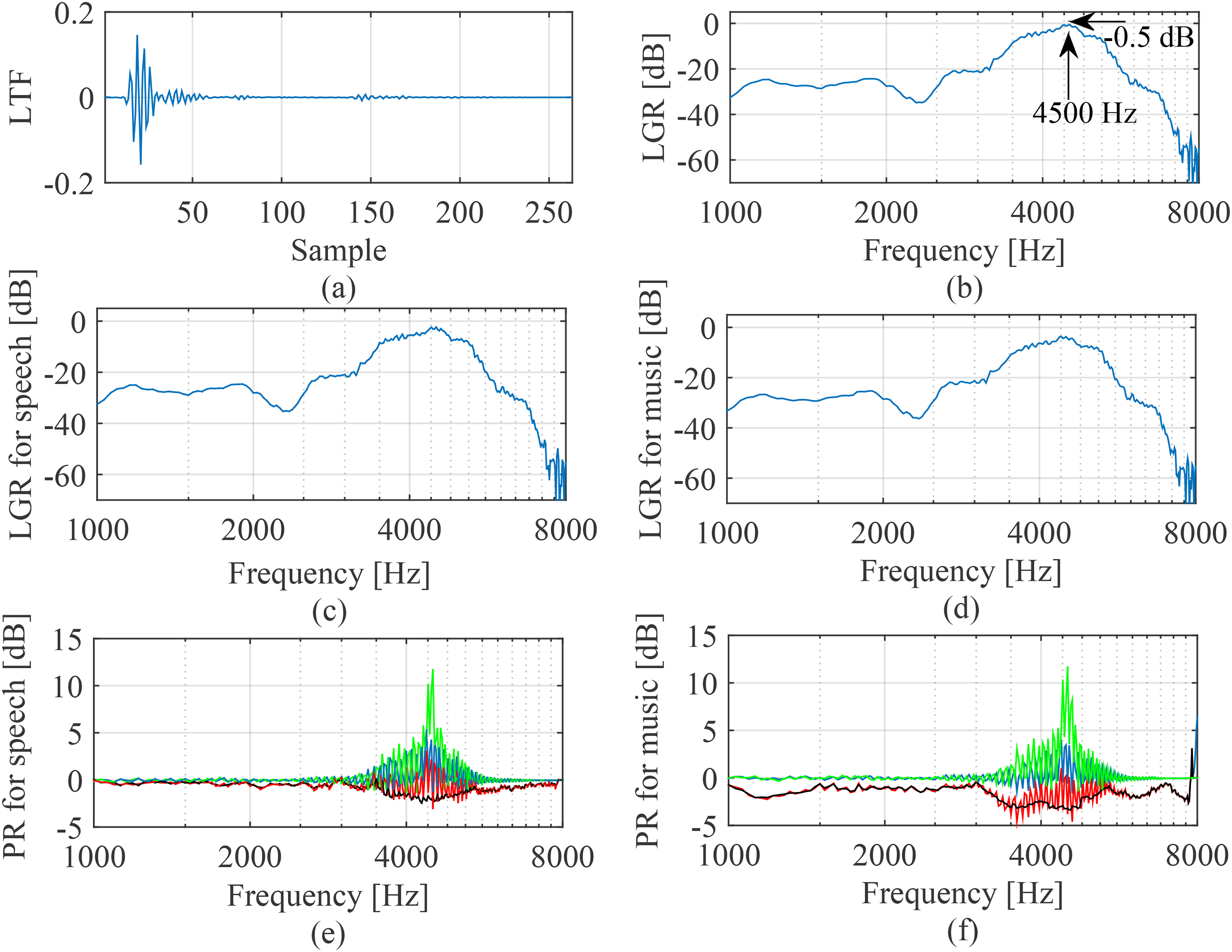
Illustration of how DeepMFC implemented feedback control when the gain margin was 0.5 dB. (a) Time-domain LTF; (b) LGR without DeepMFC; (c) LGR for speech with DeepMFC(1); (d) LGR for music with DeepMFC(3); (e) PR for speech; (f) PR for music. For (e) and (f) the PR is between: the input and output signals – black; the input and target signals – blue; the output and target signals – red. For completeness, the PR between the unprocessed signal and the target signal at the receiver is also plotted in (e) and (f) using green. LTF: loop transfer function; LGR: loop gain response; PR: power ratio.
Conclusions and Future Prospects
This paper evaluated the performance of three versions of DeepMFC in handling feedback, using both speech and music as the sources. When the source was music and the gain margin was set to 0 dB or
This paper also helped to clarify the way in which DeepMFC handles feedback. When a closed-loop system works at a marginally stable gain, DeepMFC can reduce the excess gain that occurs for frequencies where the loop gains are just below 0 dB. By comparing the PR between the input and output signals of DeepMFC, it was shown that DeepMFC suppressed the excess gain frame by frame. When a closed-loop system without feedback control worked with a gain margin of
In this paper, the forward path was simplified as having a uniform linear gain, and all simulations were carried out under this condition. Although this simplified model of the forward path is commonly used in evaluating the performance of feedback control methods (Hellgren, 2002; Spriet et al., 2005; Lee et al., 2017), the frequency response of the forward path for a hearing aid is rarely uniform (Moore et al., 2010; Dillon, 2012) and often changes over time because of hearing-aid processing such as noise suppression and multichannel dynamic range compression (Moore, 1987; Kates, 2008; May et al., 2018). The influence of frequency-gain characteristics and hearing-aid processing on the performance of DeepMFC needs to be assessed. When the frequency-gain characteristics and hearing-aid processing are known in advance, their effects on the target sound at the receiver can be simulated. Better performance may be achieved when these effects are taken into account in generating the training data set for DeepMFC.
This paper evaluated the performance of DeepMFC only for speech and music sound sources. However, a hearing aid should also provide good perception of environmental sounds (Pichora-Fuller & Singh, 2006). There is a need to assess how well DeepMFC works when the hearing aid input includes a wide range of environmental sounds. Li et al. (2021) showed that for noise suppression and dereverberation tasks, speech and other types of sounds were processed appropriately when these other sounds were included as training targets in addition to speech. It will be interesting to assess whether DeepMFC can be trained to reduce the deleterious effects of acoustic feedback without introducing significant distortion for other types of sounds.
Footnotes
Acknowledgements
We thank two reviewers and the Editor-in-Chief Dr. Andrew Oxenham for very helpful and insightful comments on an earlier version of this paper.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Key R