
Abstract
Speech recognition in rooms requires the temporal integration of reflections which arrive with a certain delay after the direct sound. It is commonly assumed that there is a certain temporal window of about 50–100 ms, during which reflections can be integrated with the direct sound, while later reflections are detrimental to speech intelligibility. This concept was challenged in a recent study by employing binaural room impulse responses (RIRs) with systematically varied interaural phase differences (IPDs) and amplitude of the direct sound and a variable number of reflections delayed by up to 200 ms. When amplitude or IPD favored late RIR components, normal-hearing (NH) listeners appeared to be capable of focusing on these components rather than on the precedent direct sound, which contrasted with the common concept of considering early RIR components as useful and late components as detrimental. The present study investigated speech intelligibility in the same conditions in hearing-impaired (HI) listeners. The data indicate that HI listeners were generally less able to “ignore” the direct sound than NH listeners, when the most useful information was confined to late RIR components. Some HI listeners showed a remarkable inability to integrate across multiple reflections and to optimally “shift” their temporal integration window, which was quite dissimilar to NH listeners. This effect was most pronounced in conditions requiring spatial and temporal integration and could provide new challenges for individual prediction models of binaural speech intelligibility.
Introduction
Speech signals arriving at the listener’s ears in real listening scenarios consist of the direct sound, the “early” reflections within the first 50–100 ms after the direct sound, as well as later reflections that ultimately fuse to the late reverberation. It is generally agreed that early reflections are beneficial, that is, that they can be integrated (at least partially) with the direct sound causing an improvement of speech recognition (e.g., Lochner & Burger, 1964; Bradley et al., 2003; Arweiler & Buchholz, 2011; Warzybok et al., 2013). In contrast, late reflections cannot be integrated with the direct sound and can be detrimental for speech intelligibility (e.g., Steeneken & Houtgast, 1980; George et al., 2010; Rennies et al., 2011; Hochmuth et al., 2015). The concept of separating early (assumed useful) and late (assumed detrimental) reflections is the basis for standard room acoustical measures such as the clarity or definition measure. In a previous study (Rennies et al., 2019), we investigated how the integration of speech reflections depended on their amplitude, their delay relative to the direct sound as well as on the binaural information contained in them (such as the interaural phase differences, IPDs) in listeners with normal hearing. In this article, we extend this study by testing a group of listeners with sensorineural hearing loss.
Many studies have investigated the temporal integration of speech reflections and reverberation. For very short reflection delays, some studies found the same improvement in speech intelligibility irrespective of whether the speech energy was added as reflection(s) or to the direct sound, which indicates that the reflection could be perfectly integrated with the direct sound. The temporal window for perfect integration was reported to be between 25 and 50 ms (Lochner & Burger, 1964; Nábělek & Robinette, 1978; Bradley et al., 2003; Warzybok et al., 2013; Leclère et al., 2015; Rennies et al., 2019). In contrast, other studies found that adding speech energy as early reflections was less beneficial than adding the same energy as direct sound (Parizet & Polack, 1992; Soulodre et al., 1989; Arweiler & Buchholz, 2011), that is, the temporal integration of early reflections was less than perfect even at very short delays. This would also be in line with predictions of the Speech Transmission Index (STI). The STI is based on the average of the modulation transfer function across modulation frequencies, which continuously decreases as the delay of a single reflection increases (IEC, 2003; Rennies et al., 2014; Roettges et al., 2022).
Only few studies explicitly investigated the interaction between temporal integration of speech reflections and binaural processing. Arweiler & Buchholz (2011) measured speech recognition thresholds (SRTs, i.e., the signal-to-noise ratios (SNRs) required to achieve 50% speech intelligibility) in diffuse noise. They varied the SNR by either increasing the direct sound energy or the energy of 20 early reflections (all within 55 ms after the direct sound), which were presented from their original azimuth and elevation (the direct sound was presented from the front). As control conditions, Arweiler & Buchholz (2011) also presented all reflections from the frontal loudspeaker (i.e., co-located with the direct sound) and, in addition, included monaural presentation. The main findings were that an increase in direct-speech energy was more beneficial than an equivalent increase in reflection energy, and that this difference was smaller when all reflections were presented from the front. Arweiler & Buchholz (2011) concluded that temporal integration of early reflections was facilitated when they arrived from the same direction as the direct sound. In addition, they found that SRTs were lower in binaural than in monaural listening conditions due to spatial unmasking in the presence of the diffuse masker. This SRT benefit was the same for frontal and spatially distributed early reflections and, hence, Arweiler & Buchholz (2011) argued that the binaural system could not integrate early reflections more efficiently than the monaural system and that, therefore, temporal and binaural processing was independent.
Warzybok et al. (2013) confirmed this finding for conditions with frontal direct sound and a single, equally strong frontal reflection. In comparison to a reference condition with co-located noise, they found SRTs to decrease by a constant amount of about 4 and 8 dB when using diffuse noise or lateral noise, respectively, independently of the delay of the reflection. However, this was no longer the case when the reflection was not co-located with the direct sound: When the reflection delay was short (
The present study explored if and to what degree these effects are also present in listeners with hearing loss. If hearing impairment would simply affect the level and spectral shape of the internally perceived sound by these listeners, we would expect no difference to the findings in normal-hearing (NH) listeners if an appropriate frequency-dependent amplification is applied. However, even above threshold and/or after appropriate amplification, it is well known that sensorineural hearing loss affects binaural processing capabilities resulting in, forexample, reduced sensitivity to interaural time differences (e.g., Neher et al., 2011; King et al., 2014; Füllgrabe & Moore, 2017), binaural pitch perception (e.g., Santurette & Dau, 2012), binaural masking level differences (e.g., Hall & Harvey, 1985), or binaural intelligibility level differences (e.g., Goverts & Houtgast, 2010). Some authors attribute this specific binaural impairment to a separate factor in modelling individual effects of speech intelligibility (e.g., Kollmeier & Kiessling, 2018) and found (at least slightly) improved prediction accuracy when including individually adjusted binaural processing errors in their models (e.g., Brand et al., 2018, also in Vicente et al., 2021, to account for level-dependent effects of binaural unmasking). In contrast, the majority of other studies reported good prediction accuracy of binaural speech intelligibility for hearing-impaired (HI) listeners without including a specific binaural impairment factor (e.g., Beutelmann et al., 2010; Schädler et al., 2018; Kubiak et al., 2020; Vicente et al., 2020; Lavandier et al., 2021). Hence, a direct comparison between the performance of NH and HI listeners with a sensorineural hearing loss in an ecologically relevant task, that is, speech recognition in a noisy and reverberant environment, could shed some light on the yet unresolved issue of a specific binaural hearing impairment. To this end, a group of HI listeners was measured under spatio-temporal conditions that exactly matched those tested in our earlier study with NH listeners. This allowed us to address the following research questions:
A: Can the tested HI listeners make use of early reflections with or without additional binaural information in the same way as NH listeners? B: Are they also capable of “ignoring” the direct sound if the late parts of the BRIR contain more relevant information due to their energy or IPD cues? And can they flexibly “shift” their temporal integration window as observed for NH listeners? C: Can the tested HI listeners cope with having to integrate across multiple reflections? D: Can interindividual variability in performance in complex spatio-temporal conditions be predicted by average hearing loss, low-frequency hearing thresholds (assumed most relevant for IPD-processing), or general speech recognition performance in less complex conditions for the present group of HI listeners?
Methods
Listeners
Fourteen native German listeners (five female, nine male) between 45 and 84 years of age participated in this study. The majority was older than 70 years at the time of their participation. Their audiometric details are summarized in Table 1, and average air-conduction audiograms across ears are shown in Figure 1. All listeners had post-lingual, mild to moderate, symmetrical, sloping, hearing loss with differences in pure-tone average (PTA

Average Air-Conduction Audiograms Across Ears for all 14 Listeners. Each line represents one listener. The three listeners with the worst speech recognition thresholds (SRTs) in the reference condition (#1–3) are indicated by open symbols with dash-dotted lines; the three best listeners (#12–14) by filled triangles and dashed lines. The remaining listeners are indicated by gray solid lines.
Air-Conduction Audiograms for Left (L) and Right (R) Ears of all Listeners Together With PTA

Stimuli and Conditions
As in the previous study with NH listeners, SRTs were measured using a matrix sentence test. The target speech was uttered by a male talker and consisted of sentences taken from the Oldenburg sentence test (Wagener et al., 1999), for example, “Peter kauft acht nasse Steine.” [“Peter buys eight wet stones”]. These sentences always have the fixed five-word structure name-verb-numeral-adjective-object. For each word group ten alternatives are available, which can be randomly combined to produce syntactically correct, but semantically unpredictable sentences. The test material consists of 100 such sentences, which are combined with lists of 20 sentences. The sentences as well as their combinations to obtain lists have been optimized to produce highly homogeneous SRTs (see Wagener et al., 1999). Due to the lack of semantic predictability, memorizing any of the 100 sentences is not likely (i.e., each sentence appears to the listeners as one of the 10
The desired combinations of speech components (direct sound, D, and one or several reflections, R) and noise (N) were generated exactly as in our previous study, that is, the target speech was convolved with artificial binaural room impulse responses (BRIRs). The BRIRs were created based on the BRIR for frontal sound incidence in anechoic conditions (i.e., without reflections) employed by Warzybok et al. (2013). This BRIR had been simulated with the CATT Acoustic software v8.0a (CATT, Gothenburg, Sweden) by using an omnidirectional source in an anechoic room and modeling the receiver as a head-and-torso simulator (KEMAR; G.R.A.S., Sound & Vibration, Holte, Denmark) at a distance of 5 m from the source. This BRIR comprising only direct sound was used as the basic component to create new BRIRs by introducing identical copies at specific delays to produce the desired reflections, resulting in BRIRs with between 1 (direct sound only) and 10 components (direct sound plus nine reflections). The delay
Note that, as in the previous study, the overall speech level was always calculated including all speech components. This means that, for speech stimuli with at least one reflection, the absolute level of the direct sound was reduced at a given overall speech level, because the energy was spread across the BRIR components. This reduction of the direct sound level depended on reflection amplitude and the number of reflections (cf. Table 2 in Rennies et al., 2019). For example, when a single reflection with the same amplitude as the direct sound was added to the direct sound (as in Exp. I to III), each component was decreased by about 3 dB to obtain the same overall speech level. For more than one reflection added (as in Exp. VI to IX), the level of each component decreased accordingly by up to about 10 dB for the largest number of reflections employed in this study.
The present study comprised a subset of the conditions measured by Rennies et al. (2019). Altogether, 22 different conditions were created with different parameter variations. For the sake of clarity, these conditions are combined and discussed as nine experiments below, where some conditions served as anchor points for several experiments (e.g., the “direct sound-only” condition and the conditions with nine reflections were included as reference points in several experiments as described in the following, that is, some data points are re-plotted in the several experiments). During the measurements, all conditions were pooled and randomized for each subject (see below). Table 2 summarizes the different combinations of BRIR components, the reflection delays relative to the direct sound, their amplitude amplification factor
Overview of Measurement Conditions. The Second and Third Columns Indicate the IPD of the Direct Sound (D) and Noise (N), Respectively, While the Remaining Columns Indicate the Properties of the Reflection(s).

Calibration and Equipment
The masker level was always fixed at a 65 dB sound pressure level (SPL, as in Warzybok et al., 2013; Rennies et al., 2019) and the speech level was adjusted to converge to the SRT. All stimuli were generated and controlled using Matlab (Natick, MA, USA). The AFC-Matlab framework of Ewert (2013) was used to measure SRTs. The digital output was D/A converted via an RME Fireface UC (ASIO) sound card (RME, Chemnitz, Germany), amplified using a Tucker-Davis HB7 headphone amplifier (Tucker-Davis Technologies, Alachua, FL, USA), and delivered to the listeners via HD650 headphones (Sennheiser, Wedemark, Germany) in a sound-attenuated booth. The setup was calibrated for SPL using a Brüel and Kjær (B&K, Nærum, Denmark) 4153 artificial ear, a B&K 4143 1/2 in. microphone, a B&K 2669 preamplifier, and a B&K 2610 measuring amplifier. The right ear served as a reference point for the calibration, but the level of the two ears was always the same. The actual output levels differed for each subject due to the individual NAL-RP amplification.
Procedure
The SRT measurements were conducted using an open-set response format, that is, listeners repeated the words they had recognized after each sentence and an experimenter marked with the correct words on a graphical user interface (not visible for the subjects), then the next sentence was played. This was contrary to the closed-set response format employed by Rennies et al. (2019) in which the listeners selected the recognized words on a touchscreen displaying the entire 50-word matrix. The open-set format was chosen because, in our experience, this is less tiring for elderly listeners. Two initial training SRTs were measured using lists of 20 sentences of the original matrix test (i.e., without BRIR convolution) to familiarize the listeners with the speech material and the task to reduce training effects typical for matrix sentence test (Kollmeier et al., 2015). Subsequently, the experimental conditions were measured, each with a new random list of 20 sentences. The initial SNR of each adaptive track was 0 dB. The SNRs of the subsequent sentence presentations varied adaptively, that is, the step size of the speech level depended on the number of correctly understood words and decreased exponentially after each reversal of the presentation level using the procedure described by Brand & Kollmeier (2002) to converge to the SRT. The maximum initial step size in case all five words of the first sentence were recognized correctly or incorrectly was
Results and Discussion
Experiment I: Baseline Performance
The purpose of Exp. I was to assess listener performance in comparatively simple conditions not involving any reflections. The left panel of Figure 2 shows SRTs measured for HI listeners. Data of NH listeners are shown in the right panel for comparison. Squares and error bars represent the mean values and interindividual standard deviations. Other symbols show individual data, where the three worst HI listeners in the D

SRTs of Exp. I (left panel). Black squares and error bars indicate the interindividual mean values and standard deviations. The small symbols indicate individual data. The three listeners with the worst SRTs in the reference conditions (#1–3) are indicated by open symbols; the three best listeners (#12–14) by filled triangles. The remaining listeners are indicated by gray crosses. The corresponding data of NH listeners (Rennies et al., 2019) are shown in the right panel together with a schematic sketch of the BRIR envelope, which consisted only of direct sound in this experiment (see inset). The asterisk indicates that the NH data were shifted vertically to account for systematic differences between the data sets, see “Stimuli and Conditions.” SRTs = speech recognition thresholds; NH = normal-hearing; BRIR = binaural room impulse responses.
The difference in SRTs between HI and NH listeners was larger in the dichotic conditions (about 2.8 dB for the D
Experiments II and III: Integration of a Single Reflection
Exp. II explored temporal integration of a single speech reflection (same amplitude as the direct sound) in diotic conditions. SRTs for reflection delays between 10 and 200 ms are shown in the top left panel of Figure 3. Symbols and line styles are the same as in the previous figures. Comparison data of NH listeners is again shown in the corresponding right panel. In general, SRTs increased with increasing reflection delay as observed for NH listeners. The ANOVA indicated that the effect of reflection delay was significant (F[1.517,20.426]=81.995, p<.001,

SRTs Measured in Exp. II (top left) and III (bottom left). Individual and mean data are represented as in Figures 1 and 2. The corresponding data of NH listeners (Rennies et al., 2019) are shown in the right panels together with a schematic sketch of the BRIR envelope, which consisted of direct sound and a single reflection with varying delay (see inset). The asterisk indicates that the NH data were shifted vertically to account for systematic differences between the data sets, see “Stimuli and Conditions.” SRTs = speech recognition thresholds; NH = normal-hearing; BRIR = binaural room impulse responses.
Exp. III employed the same reflection delays, but here the reflection had a
Experiments IV and V: Effects of Reflection Amplitude
Experiments IV and V explored the role of reflection amplitude for a fixed delay of 200 ms. SRTs as a function of the amplitude amplification factor

SRTs Measured in Exp. IV (top left) and V (bottom left). Individual and mean data are represented as in the previous figures. The corresponding data of NH listeners (Rennies et al., 2019) are shown in the right panels together with a schematic sketch of the BRIR envelope, which consisted of direct sound and a single reflection with varying relative amplitudes at constant overall speech level (see inset). The asterisk indicates that the NH data were shifted vertically to account for systematic differences between the data sets, see “Stimuli and Conditions.” SRTs = speech recognition thresholds; NH = normal-hearing; BRIR = binaural room impulse responses.
SRTs resulting from the same variations in amplification factor, but with a
Experiments VI and VII: Integration of an Increasing Number of Early Reflections
Experiments VI to IX explored the HI listeners’ capability to integrate more than one reflection. In these experiments, the reflections always had the same amplitude as the direct sound, and the level of all components was adjusted so that the overall level was always the same independent of the number of BRIR components. During these experiments, some listeners were not able to complete the SRT measurement for higher numbers of reflections. In other words, they consistently failed to correctly repeat more than two out of the five words of a sentence even at an SNR of +20 dB, which caused the adaptive procedure to abort the track to avoid too high speech levels of more than 85 dB SPL plus individual NAL-RP amplification. Because of these huge interindividual differences, the subsequent experiments were not statistically analyzed on a group level. Instead, the conditions provoking these differences are discussed in detail for the different listeners.
In Exp. VI, diotic stimuli were used and an increasing number of reflections (starting with the lowest delay) was added to the direct sound (thereby decreasing the relative energy of each BRIR component). SRTs are shown in the top panels of Figure 5. For one reflection (delay 10 ms) and five reflections (i.e., with a maximum reflection delay of 100 ms, see Table 2), SRTs of HI listeners monotonically increased as observed for NH listeners. The average increase for five reflections relative to the direct sound-only condition was only slightly larger (4.3 dB vs. 3.5 dB), and the SRT of the worst HI listener (0.6 dB) was only slightly higher than the SRT of the worst NH listener (
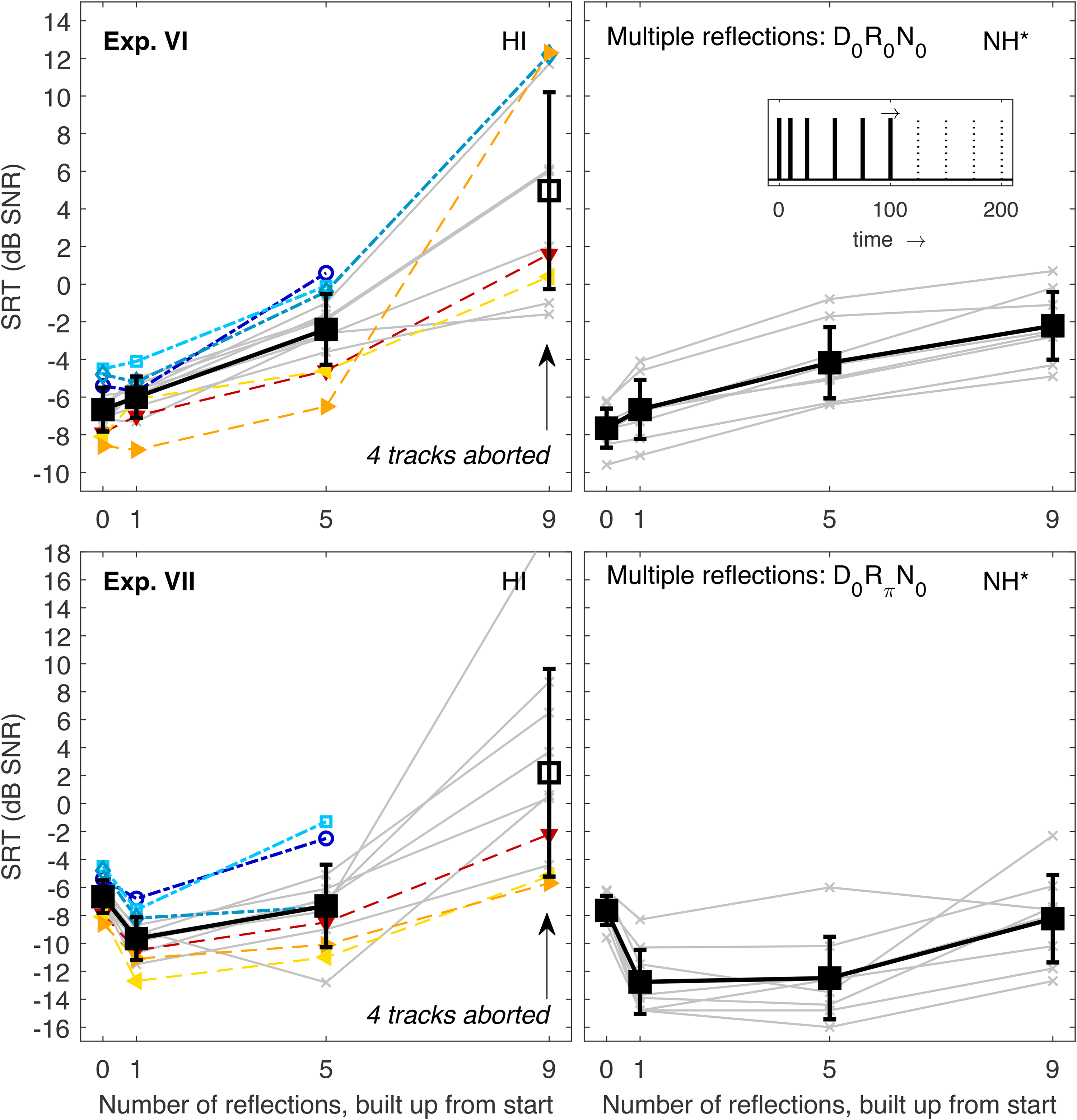
SRTs Measured in Exp. VI (top left) and VII (bottom left). Individual and mean data are represented as in the previous figures with the exception that the mean SRTs could not be measured for all listeners in the most difficult conditions. Unfilled black squares indicate mean values that were computed across a smaller number of listeners. These conditions are also marked by labelled arrows indicating the number of unmeasurable tracks. The corresponding data of NH listeners (Rennies et al., 2019) are shown in the right panels together with a schematic sketch of the BRIR envelope, which consisted of direct sound and multiple reflections built up from the front (see inset). The asterisk indicates that the NH data were shifted vertically to account for systematic differences between the data sets, see “Stimuli and Conditions.” SRTs = speech recognition thresholds; NH = normal-hearing; BRIR = binaural room impulse responses.
Exp. VII (bottom panels of Figure 5) used the same BRIRs, but here reflections had a
Experiments VIII and IX: Integration of an Increasing Number of Late Reflections
The final two experiments also employed multiple reflections spread across the same 200-ms window, but here the reflections were gradually added starting with the longest delay. SRTs for diotic stimuli (Exp. VIII) are shown in the top panels of Figure 6. Note that the last data point (nine reflections) is the same as the last data point of Exp. VI because in both cases all nine reflections were included. Similarly, the data points for one reflection were taken from Exp. 2 (Figure 3, top left, last data points). In general, the trend from direct sound-only to one and five reflections was similar to the monotonic SRT increase observed for NH, with a slightly stronger increase for HI listeners (7.0 dB vs. 5.6 dB). The data for nine reflections were already discussed above: where NH listeners had a moderate further SRT increase from five to nine reflections, some HI listeners struggled heavily, and four SRTs could not be measured at all (#1, 2, 4, and 6).

SRTs Measured in Exp. VIII (top left) and IX (bottom left). Individual and mean data are represented as in the previous figures. Data points for which SRTs could not be measured for all listeners are indicated by arrows. The corresponding data of NH listeners (Rennies et al., 2019) are shown in the right panels together with a schematic sketch of the BRIR envelope, which consisted of direct sound and multiple reflections built up from the end (see inset). The asterisk indicates that the NH data were shifted vertically to account for systematic differences between the data sets, see “Stimuli and conditions.” SRTs = speech recognition thresholds; NH = normal-hearing; BRIR = binaural room impulse responses.
Data of Exp. IX are shown in the bottom panels of Figure 6. Reflections were also gradually added starting from the longest delay, but here the reflections had a
When the number of reflections was increased to seven (i.e., when five more reflections with shorter delays down to 50 ms were added), many HI listeners had difficulties performing the task: for eight out of 14 listeners no SRTs could be measured (#1–4, 6, and 9–11). Even listeners who had shown very good SRTs in the other experiments and in the conditions with fewer reflections in this experiment had very strong SRT increases for seven reflections. For example, listeners #12 and 13 had SRTs that were 16.4 and 26.9 dB higher, respectively, for seven reflections than for two reflections (see downwards- and left-pointing triangles). The best HI listener (#14, right-pointing triangles) had an increase of 5.3 dB, while the average increase for NH listeners was 2.6 dB. Interestingly, SRTs improved for most HI listeners when two more reflections with short delays (10 and 25 ms) were added. Here, “only” four listeners could not perform the task (#1, 2, 3, and 9). For the two “otherwise good” listeners whose SRTs had increased strongly from two to seven reflections (downwards- and left-pointing triangles), SRTs dropped considerably by 20.1 and 8.5 dB, respectively.
It appears that the condition with seven reflections was particularly difficult for many HI listeners. This conditions consisted of the diotic direct sound and seven reflections with
Clearly, NH listeners did not show any sign of comparable difficulties. Their behavior was consistent with the assumption that they were able to focus on the reflections which carried an IPD-advantage in all conditions. If they had always focused on the direct sound, their SRTs would have been higher by about 10 dB for nine reflections than for direct sound-only because of the reduced relative energetic contribution of the direct sound in the normalized BRIR (cf. Table 2 in Rennies et al., 2019). In fact, SRTs were slightly lower for nine reflections than for direct sound only, suggesting a small binaural benefit. This benefit was much smaller than for D
General Discussion and Conclusions
With respect to the research questions outlined in the introduction, the following conclusions can be drawn from the data:
A: The present group of HI listeners can make use of early reflections similarly to NH listeners, but a larger spread in performance is generally observed. B: The same HI listeners are in general less able to “ignore” the direct sound and to optimally “shift” their temporal integration window than NH listeners. C: Some HI listeners show a remarkable inability to integrate across multiple reflections, which is quite dissimilar to NH listeners. This effect is most pronounced in conditions requiring spatial and temporal integration. D: Only some of the observed interindividual variability observed in the present group of HI listeners can be well predicted by audiogram-derived measures. In contrast, speech performance in less complex conditions was often found to be highly correlated to performance in complex conditions.
The present group of HI listeners had normal or close-to-normal aided SRTs in the D
The observation that some subjects performed generally better than others across different conditions was also reported for speech recognition tasks with more complex maskers than the stationary noise employed here. For example, Kidd et al. (2019) measured SRTs of a target talker in the presence of two interfering talkers. They manipulated the target-to-masker similarity/dissimilarity by introducing sex differences between target and maskers, spatial separation between target and maskers, and time-reversal of the maskers (making them unintelligible). Using the same audibility-loss compensation as in the present study (linear NAL-RP prescription), Kidd et al. (2019) found considerable interindividual differences in SRTs in all conditions. Interestingly, the ranking of individuals across conditions was very similar (see their Figure 7), even though exploiting the different unmasking cues likely relies on very different processing strategies like identifying differences in fundamental frequency and vocal tract length (for sex differences), binaural processing (for spatial separation), and negation of masker intelligibility (for time-reversed maskers). Kidd et al. (2019) hence argued that the performance of the relatively poor subjects “appears to be a reflection of a more general problem affecting multiple abilities rather than being strongly related to reduced resolution of any specific cue per se.” This is in line with the notion that no specific and distinct binaural impairment factor can be singled out—as discussed in the introduction—but instead a general suprathreshold processing deficit causes variations across hearing-impaired subjects, such as the “D-component” (for “distortion”) proposed by Plomp (1978). Such a “D-component” was employed in recent modelling approaches by Kollmeier et al. (2016) and Hülsmeier et al. (2021) as an individual jitter of the internal stimulus representation, which could be interpreted as an individual factor to describe the capacity to process the available information (beyond what is lost by limited or only partly restored audibility). Again, it should be emphasized that the present sample size is too small to draw conclusions about the general HI population, especially since many individual traits and basic psychoacoustic performance metrics were not measured. Running prediction models and systematically varying different types of processing deficits (such as audibility, binaural processing, or the “D-component”) could help to better understand the reasons underlying the observed interindividual variability. Likewise, extensions of the present study with NH and HI listener groups matched in age and/or cognitive performance could shed more light on the role and interactions of age, cognitive factors, and increased hearing thresholds in speech intelligibility in spatio-temporal integration tasks. Similarly, the role of audibility should be investigated in more detail, e.g., by also measuring SRTs in unaided HI listeners or by employing different amplification schemes. Nevertheless, despite the small sample size and the unknown hearing loss etiologies the results of the present study suggest that a consistent performance ranking of individual HI listeners across conditions can also be observed for less complex maskers without any impact of “informational masking” (IM). IM occurs when interferers share perceptual attributes with the target that can draw attention away from the target, lead to explicit confusion of masker and target words, or generally cause uncertainty in the observer (e.g., see review in Kidd & Colburn, 2017). Based on the concept of “generally good/bad” subjects, one could speculate that subjects who struggle with, for example, spatio-temporal integration of reflections would also be poor performers in speech-on-speech masking conditions. However, this remains to be shown in future studies.
The largest performance differences between listeners in the present study were observed in conditions with multiple reflections, especially when the BRIR components spread over a period of 200 ms. In these conditions, some HI listeners failed to reach 50% speech recognition at an SNR of +20 dB (at which point the employed adaptive procedure aborted the track). Listeners with unmeasurable SRTs were often the same across the different experiments and conditions, and most frequently included listeners #1, 2, and 3, that is, the listeners with the worst SRTs in the baseline condition. However, the relatively consistent ranking of HI listeners was not as obvious as in conditions with fewer reflections. For example, one of the generally best performers had the worst (measurable) SRT in Exp. VIII. While this may have been a random outlier, this seems an unlikely explanation for the data measured in Exp. IX: Here, SRTs could not be measured for more than half of the HI listeners in one condition. Remarkably, this condition also revealed that otherwise very good HI listeners had considerably increased SRTs, while they had shown normal SRTs in all other conditions of the present study. Further research is needed to investigate in more depth what makes this condition stand out, for example, if a particular combination of stimulus parameters can be identified to measure a threshold at which major difficulties arise even for generally good listeners. Furthermore, these data may be a challenge for the majority of existing models which do not include a specific binaural impairment factor, but instead focus on audibility as the main driver of reduced performance (see section “Introduction”) or a more general suprathreshold deficit factor. It seems unlikely that such models could explain the specific difficulties of some listeners which arise in conditions with multiple reflections, especially when diotic direct sound was combined with
From a clinical perspective, it would be interesting to compare the performance in conditions like the ones tested here with basic psychoacoustic performance measures, measures of cognitive function, aspects such as hearing-aid satisfaction in aided real-life listening conditions, or more generally to include such conditions in auditory profiling (see, e.g., Sanchez-Lopez et al., 2020; Iliadou et al., 2022; Saak et al., 2022). It is possible that a systematic manipulation of spatio-temporal integration demands in laboratory settings can help to magnify interindividual performance differences and hence to identify listeners with specific difficulties in their everyday life, thus supporting the diagnostics and fitting processes of hearing devices.
Data will be made available upon request.
Footnotes
Acknowledgements
We thank the Hörzentrum Oldenburg for their support with the subject acquisition and Julia Thomas for her support with the data collection.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Klaus Tschira Foundation (grant number GSO/KT 06) and the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) Projektnummer 352015383—SFB 1330 A1.