
Abstract
Over the past decades, different types of auditory models have been developed to study the functioning of normal and impaired auditory processing. Several models can simulate frequency-dependent sensorineural hearing loss (SNHL) and can in this way be used to develop personalized audio-signal processing for hearing aids. However, to determine individualized SNHL profiles, we rely on indirect and noninvasive markers of cochlear and auditory-nerve (AN) damage. Our progressive knowledge of the functional aspects of different SNHL subtypes stresses the importance of incorporating them into the simulated SNHL profile, but has at the same time complicated the task of accomplishing this on the basis of noninvasive markers. In particular, different auditory-evoked potential (AEP) types can show a different sensitivity to outer-hair-cell (OHC), inner-hair-cell (IHC), or AN damage, but it is not clear which AEP-derived metric is best suited to develop personalized auditory models. This study investigates how simulated and recorded AEPs can be used to derive individual AN- or OHC-damage patterns and personalize auditory processing models. First, we individualized the cochlear model parameters using common methods of frequency-specific OHC-damage quantification, after which we simulated AEPs for different degrees of AN damage. Using a classification technique, we determined the recorded AEP metric that best predicted the simulated individualized cochlear synaptopathy profiles. We cross-validated our method using the data set at hand, but also applied the trained classifier to recorded AEPs from a new cohort to illustrate the generalizability of the method.
Keywords
Auditory-evoked potentials (AEPs) are widely adopted as markers of sensorineural hearing loss (SNHL) in clinical and research settings. In research animals, auditory brainstem response (ABR) or envelope-following response (EFR) amplitudes can be used to quantify auditory-nerve (AN) fiber damage, that is, cochlear synaptopathy (CS; Furman et al., 2013; Kujawa & Liberman, 2009; Sergeyenko et al., 2013; Shaheen et al., 2015). However, applying the same AEP markers for CS diagnosis in humans has yielded mixed success, since AEP amplitudes can be affected by (a) other coexisting SNHL aspects such as outer-hair-cell (OHC) damage (Chen et al., 2008; Don & Eggermont, 1978; Garrett & Verhulst, 2019; Gorga et al., 1985; Herdman & Stapells, 2003; Keshishzadeh et al., 2020; Verhulst et al., 2016) and (b) subject-specific factors such as age, gender, and head size (Hickox et al., 2017; Mitchell et al., 1989; Trune et al., 1988). Moreover, the sensitivity of AEPs to different degrees of OHC loss and CS is unclear, and a direct quantification of AN fiber damage through histopathology is impossible in live humans (Bharadwaj et al., 2014). These problems hinder the study of the specific impact of OHC damage and CS on recorded AEPs and render an AEP-based quantification of AN fiber damage difficult in listeners with mixed hearing pathologies. However, this last step is crucial when developing personalized models of auditory processing for use within numerical closed-loop hearing restoration systems.
Even though several auditory models incorporate sources of SNHL (e.g., Ewert & Dau, 2000; Ewert et al., 2013; Heinz et al., 2001; Jepsen & Dau, 2011; Jepsen et al., 2008; Rohdenburg et al., 2005; Verhulst et al., 2018; Zilany & Bruce, 2006), methods to individualize the AN-damage pattern on the basis of recorded AEP metrics are nonexistent. Here, we investigate the potential of common AEP markers to individualize the frequency-specific AN-damage profile of personalized auditory models with or without other co-occurring aspects of SNHL. Specifically, we present a combined experimental-modeling method in which (a) individual cochlear-gain-loss (CGL) parameters are extracted from either the audiogram or distortion-product otoacoustic emissions (DPOAEs) and (b) a feature set of recorded AEP metrics is compared to simulated AEP metrics to derive periphery models with different CS profiles. Using a classifier that was trained on simulated AEPs for different SNHL profiles, we selected the individual AN profile that best explained the recorded AEP features from a test subject. We tested this method on 35 participants, which were separated into groups of young normal-hearing (yNH), older normal-hearing (oNH), and older hearing-impaired (oHI) listeners (Garrett et al., 2020). Validation of our method to predict individual AN-damage profile from recorded AEPs was performed on data from a new cohort.
Before we describe the classification method in detail, we summarize which AEP markers are promising to include. Among the hitherto proposed AEP-derived metrics of AN damage, the ABR wave-I is known to degrade as a consequence of CS in subjects with intact sensory hair cells (Kujawa & Liberman, 2009; Parthasarathy & Kujawa, 2018); however, this metric is highly variable in humans (Plack et al., 2016; Stamper & Johnson, 2015) when the contribution of between-subject variability sources such as head size or tissue resistance are not considered (Prendergast et al., 2018). Even though we can assume that any hearing deficit reflecting on the ABR wave-I would travel through the auditory pathway to reflect on the ABR wave-V as well, homeostatic gain changes between AN fibers and inferior colliculus (IC) may affect the wave-V amplitude (Chambers et al., 2016; Henry & Abrams, 2018; Möhrle et al., 2016; Schaette & McAlpine, 2011) and hence its diagnostic power for CS diagnosis. Another AEP marker, the EFR amplitude, which reflects the strength of a phase-locked AEP response to an amplitude-modulated (AM) stimulus, was shown to degrade as a consequence of CS in mice histological studies (Parthasarathy & Kujawa, 2018; Shaheen et al., 2015) and as a consequence of age in human listeners (Goossens et al., 2016; Vasilkov et al., 2021). EFRs offer a more robust measure of the AN fiber population than the ABR wave-I, when recorded in the same animals (Parthasarathy & Kujawa, 2018; Plack et al., 2016; Shaheen et al., 2015). However, similar to the ABR wave-V, EFR generators have latencies associated with IC processing (Purcell et al., 2004), thus differences in central auditory processing may reflect on the EFR magnitude to mask individual synaptopathy differences (Chambers et al., 2016; Möhrle et al., 2016; Parthasarathy et al., 2019a, 2019b). To address these issues, relative EFR and ABR metrics were proposed in several studies to cancel out subject-specific factors and isolate the CS component of SNHL in listeners with coexisting OHC-loss: ABR wave-I amplitude growth as a function of stimulus intensity (Furman et al., 2013), ABR wave-I–V latency difference (Coats & Martin, 1977; Elberling & Parbo, 1987; Watson, 1996), the wave-V and I amplitude ratio (Gu et al., 2012; Hickox & Liberman, 2014; Schaette & McAlpine, 2011), EFR amplitude slope as a function of modulation depth (Bharadwaj & Shinn-Cunningham, 2014; Guest et al., 2018), the derived-band EFR (Keshishzadeh et al., 2020), or the combined use of the ABR wave-V and EFR (Vasilkov & Verhulst, 2019). Although these relative metrics are promising, it is not known how OHC loss and CS differentially impact AEPs. Recent modeling approaches have shown promise to design EFR stimuli which are maximally sensitive to CS in the presence of OHC damage (Vasilkov et al., 2021), but conclusive histopathological evidence is to date not available. To make use of the listed metrics to build personalized hearing profiles for a broad population with various SNHL etiologies, two requirements need to be fulfilled. We need to (a) use AEP markers that are maximally sensitive to the CS aspect of SNHL and (b) combine them with a sensitive marker of OHC deficits to individualize the OHC and CS aspects of SNHL. We thus considered various AEP markers (a total of 13) encompassing spectral magnitudes, time-domain peaks, latencies and relative metrics, and combinations thereof, to identify which markers best predict the simulated individualized CS profiles and can be used for reliable auditory profiling.
Experimental Design
ABR, EFR, and OHC-damage markers were derived from recordings of two experimental setups in different locations. These recordings were used for development and validation of the proposed method, respectively.
Participants
The dataset that was used to develop the auditory profiling method included recordings from a total of 43 subjects. They were recruited into three groups: 15 young normal-hearing (yNH: 24.53 ± 2.26 years, 8 female), 16 older normal-hearing (oNH: 64.25 ± 1.88 years, 8 female) and 12 older hearing-impaired (oHI: 65.33 ± 1.87 years, 7 female) groups. Two oNH subjects were omitted from our study due to nonidentifiable ABR waveforms. The hearing thresholds of the participants were assessed at 12 standard audiometric frequencies between 0.125 and 10 kHz (Auritec AT900, Hamburg, Germany audiometer). AEP stimuli were presented monaurally to the ear with the best 4 kHz threshold. Audiometric thresholds were below 20 dB-HL at all measured frequencies in the yNH group and below 25 dB-HL for frequencies up to 4 kHz in the oNH group. The oHI listeners had sloping high-frequency audiograms with 4-kHz thresholds above 25 dB-HL (Figure 1A). The AEP recordings were conducted in an electrically and acoustically shielded booth, while subjects were sitting in a comfortable chair and watching silent movies.

Measured audiograms and DPOAE thresholds. A: Audiograms. B: DPOAE thresholds (DPTHs) of the participants in the first experiment.A: Audiograms. B: DPOAE thresholds (DPTHs) of the participants in the first experiment. DPOAE = distortion-product otoacoustic emission; yNH = young normal-hearing; oNH = older normal-hearing; oHI = older hearing-impaired.
The second experiment, which was used to validate our method on a new cohort, had 19 yNH subjects, aged between 18 and 25 years (21.6 ± 2.27 years, 12 female). Volunteers with a history of hearing pathology or ear surgery were excluded based on a recruitment questionnaire. Audiograms were measured in a double-wall sound-attenuating booth, using an Interacoustics Equinox Interacoustics audiometer. All participants had audiometric thresholds below 25 dB-HL within the measured frequency range, that is, 0.125 to 10 kHz, and the best ear was determined on the basis of their audiogram and tympanogram. The experiment protocol included AEP measurements with a maximum duration of 3 hours, and we only considered one AEP metric for validation purposes in the present study. AEP recordings were conducted in a quiet room while subjects were seated in a comfortable chair and watching muted movies. To minimize the noise intrusion level, both ears were covered with earmuffs and all electrical devices other than the measurement equipment (Intelligent Hearing Systems) were turned off and unplugged.
Participants of both experiments were informed about the experimental procedure according to the ethical guidelines at Oldenburg University (first experiment) or Ghent University Hospital (UZ-Gent, second experiment) and were paid for their participation. A written informed consent was obtained from all participants.
Distortion Product Otoacoustic Emission
In the first experiment, distortion product otoacoustic emissions (DPOAEs) were acquired and analyzed using a custom-made MATLAB software (Mauermann, 2013). Stimuli were delivered through ER-2 earphones coupled to the ER-10B+ microphone system (Etymotic Research) using a primary frequency sweeping procedure at a fixed
EEG Measurements
ABR and EFR stimuli were generated in MATLAB and digitized with a sampling rate of 48 kHz for the first data set. Afterwards, they were delivered monaurally through a Fireface UCX external sound card (RME) and a TDT-HB7 headphone driver connected to a shielded ER-2 earphone. The electroencephalogram (EEG) signals were recorded with a sampling frequency of 16384 Hz via a 64-channel Biosemi EEG system using an equidistantly-spaced electrode cap. All active electrodes were placed in the cap using highly conductive gel. The common-mode-sense (CMS) and driven-right-leg (DRL) electrodes were attached to the fronto-central midline and the tip of the nose, respectively. A comprehensive explanation of the experimental configuration can be found in Garrett and Verhulst (2019).
AEPs of the validation experiment were recorded using the SmartEP continuous acquisition module (SEPCAM) of the Universal Smart Box (Intelligent Hearing System, Miami, FL, USA). EFR stimuli were generated in MATLAB using a sampling rate of 20-kHz and stored in a “.wav” format. AEP stimuli were presented monaurally through a shielded ER-2 earphone (Etymotic Research) and AEPs were recorded at a sampling frequency of 10 kHz via Ambu Neuroline 720 snap electrodes connected to vertex, nasion, and both earlobes. The electrodes were placed after a skin preparation procedure using NuPrep gel. The skin-electrode impedance was kept below 3 kΩ during the recordings.
EFR Stimuli
We recorded EFRs in response to a 400-ms-long stimuli consisting of a 4-kHz pure-tone carrier and a 120-Hz rectangular-wave modulator with 25% duty cycle (i.e., the RAM25 in Vasilkov et al., 2021). The stimulus waveform is visualized in the inset of Figure 2B and we considered a modulation depth of 95%. Stimuli were presented 1,000 times (500 times in either positive or negative polarity) and had a root-mean-square (RMS) of 68.18 dB-SPL. The calibration of the stimulus was performed to have the same peak-to-peak amplitude as a 70-dB-SPL sinusoidal amplitude modulated (SAM) 4-kHz pure-tone. The Cz channel recording was re-referenced to the average of the ear-lobe electrodes and 400-ms epochs were extracted relative to the stimulus onset. The mean amplitude of each epoch was subtracted to correct for the baseline-drift. See Vasilkov et al. (2021) for further details on the frequency-domain bootstrapping and noise-floor estimation method. The noise-floor corrected spectral magnitudes (


Comparison of Exemplary NH and HI RAM-EFRs and ABRs. A: RAM-EFR of a yNH subject (yNH15) and the corresponding noise-floor (NF). Arrows specified by
Figure 2A depicts a typical NH RAM-EFR spectrum and corresponding noise-floor. The arrows show the derived peak-to-noise-floor magnitudes at the modulation frequency and following harmonics. The energy of EFR peak is reduced for the oHI subject shown in the Panel B.
The RAM stimulus in the second experiment (i.e., the validation database) was a 110-Hz 95% modulated 4-kHz pure tone. The 500-ms stimulus was presented 1,000 times with alternating polarity (500 each) and had a 70 dB-SPL level. The acquired AEPs were initially saved in “.EEG.F” format on SEPCAM and were afterwards converted to “.mat” format using the custom-made “sep-cam2mat” MATLAB function for offline analysis. EFRs recorded from the vertex electrode were rereferenced to the ipsilateral earlobe electrode and filtered between 30 and 1500 Hz using an 800th order Blackman-window based finite-impulse-response (FIR) filter. Epoching was applied to the steady state part of the response, that is, 100 to 500 ms of the response relative to the stimulus onset. The baseline drift was corrected by subtracting the mean of each epoch, afterwards 200 epochs with the highest peak-to-trough values were rejected. The amplitudes of the remained epochs did not exceed 100 µV. A frequency-domain bootstrapping approach was adopted to estimate the noise-floor and to remove it from the averaged trials using the method proposed in Zhu et al. (2013). To this end, we calculated the fast Fourier Transform (FFT) of 800 epochs to generate 400 mean spectra by randomly sampling the 800 epochs with replacement (keeping an equal number of polarities in the draw). Averaging the resampled spectra yielded the i-th mean-EFR spectrum (

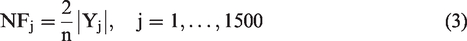
In Equation 3,
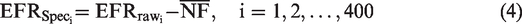
The peaks of the
Auditory Brainstem Responses
ABRs were recorded to 80-µs-long alternating polarity clicks presented at 70 and 100 dB-peSPL. Stimuli were presented through the setup explained in Garrett et al. (2019) and repeated 3,000 times with a rate of 10 Hz using a uniformly distributed random interstimulus interval of 100 ms ± 10 ms. Cz-channel recordings were rereferenced to the contralateral earlobe electrode and filtered between 100 and 1500 Hz. Moreover, 25 ms-long epochs, that is, −5 to 20-ms relative to the stimulus onset, were extracted and corresponding mean values were subtracted to perform a baseline correction. Then, each positive polarity epoch was averaged with the following negative epoch and 100 paired-averages with the highest peak-to-trough values were rejected. The remaining pair-averaged epochs had amplitudes below 25 µV. To include ABR variability in our analysis and to estimate the ABR noise floor, we applied the bootstrapping approach of Zhu et al. (2013), in the time domain. In addition, 2,000 and 4,500 epochs were drawn for the signal and noise-floor estimation, respectively. Half of the noise-floor-estimation epochs (i.e., 2,250 pair-averaged drawn epochs with replacement) were multiplied by −1 before final averaging. Finally, the estimated noise-floor mean was subtracted from the 2,000 averaged epochs to yield mean noie-floor-corrected ABR waveforms. ABR wave-I and -V peak and trough amplitudes and corresponding latencies were determined by visual inspection from the mean ABR waveform and were confirmed by an audiologist. Figure 2 (Panels C and D) compares ABR waveforms of a yNH and oHI subject from the cohort and indicates the identified ABR peaks and latencies. To extract peak latencies and amplitudes from the bootstrapped data, wave maxima and minima were detected in 1, 1.8, 0.5, and 1.5 ms intervals around the wave-
We used a total of 13 ABR and EFR markers in the development phase and one EFR marker in the validation phase. Table 1 details the definition of each metric and lists the corresponding abbreviations used in this paper. The last column defines the variability metric associated with each marker, which were obtained from the earlier described bootstrapping procedure. To determine the measurement variability of ABR growth-slopes, we applied error propagation to account for the standard deviations of two different measures from the same listener, for example, ABR-70 and ABR-100. In this case, the bootstrapped metrics were drawn from the 95% confidence interval of a normal distribution characterized by the mean of the metric and its bootstrapped standard deviation. The bootstrapping technique described in this section, provided a tool to estimate the variability of AEP-derived metrics and to incorporate them in the proposed classification approach. Obtained standard deviations from bootstrapping can be used to measure the CS-profiling prediction robustness of the study participants.
Extracted AEP-Metrics Definitions and Corresponding Standard Deviations.

Note. EFR = envelope-following response; ABR = auditory brainstem response. In the last column,
Individualized Auditory Periphery Model
To simulate individualized SNHL profiles that would match the histopathology of the study participants, we used a computational model of the auditory periphery (Osses & Verhulst, 2019; Verhulst et al., 2018). In the first step, we personalized the cochlear model parameters on the basis of OHC markers of SNHL (audiogram or DPTH). Afterwards, we simulated AEPs for different degrees of CS and compared the simulations to the recordings to develop and test our auditory profiling method. Figure 3 schematizes the auditory model individualization.

Auditory Model Individualization. The block diagram on the left depicts the different stages of the employed auditory periphery model (Verhulst et al., 2018). Experimentally measured audiometric thresholds were inserted to the transmission-line cochlear model to adjust BM admittance function poles. The box on top-right corner shows the nonuniform AN population distribution across the CF for simulated different degrees of CS profiles. The profile without CS is shown in dark brown (indicated with N) and higher degrees of CS are shown according to the color map. HSR = high-spontaneous-rate; MSR = medium-spontaneous-rate; LSR = low-spontaneous-rate; EFR = envelope-following response; FFT = fast Fourier Transform; CS = cochlear synaptopathy; AN = auditory nerve; DPOAE = distortion-product otoacoustic emission.
Cochlear Model Individualization
Measured audiograms and DPTHs were used independently to determine the individual CGL parameters (in dB-HL) of the cochlear transmission-line (TL) model, shown in pink in Figure 3. In our approach, CGL determines the double pole of the cochlear admittance through the gain and tuning of the cochlear filters (Verhulst et al., 2012). We thus model the consequence of OHC damage or presbycusis without specifically accounting for damage of the stereocilia or sensory cells.
From here on, mAudTH and sAudTH refer to measured and simulated audiometric thresholds, respectively. Likewise, mDPTH and sDPTH stand for measured and simulated DPOAE thresholds.
Audiogram-Based Cochlear Filter Pole-Setting
Here, we translated the frequency-specific audiometric dB-HL (Figure 1A) into cochlear filter gain loss. These values were translated into double-pole values of the cochlear admittance function across CF (see Verhulst et al., 2016).
Specifically, at a CF corresponding to a measured audiometric frequency (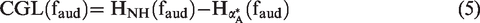
We employed the predicted pole functions to simulate individual audiograms and to evaluate the prediction error. To this end, individualized AN excitation patterns (ANEP) were simulated in response to 500-ms pure tones presented at audiogram frequencies (

Figure 4A shows grand-averaged mAudTHs and sAudTHs across the yNH, oNH, and oHI groups. In addition, Figure 4C compares the sAudTH (dashed lines) and mAudTH (solid lines) of an example yNH and oHI subject. Note that simulating CGLs greater than 35 dB-HL is impossible in our cochlear model, which has a maximal applicable cochlear mechanical gain of 35 dB. In the last step, we estimated the absolute prediction error as follows


A Comparison Between the Measured and Simulated AudTHs and DPTHs. The average (solid) and standard deviation (shaded area) of the measured (gray) and simulated (red) AudTHs and DPTHs are shown in Panels A and B, respectively. A comparison between sAudTH and mAudTH of a yNH and oHI listener is shown in Panel C. Panel D compares the sDPTH (dotted) and mDPTH (solid) of the same yNH and oHI listeners (Panel C). Frequency-specific group-averaged absolute prediction errors of AudTH and DPTH are shown in Panels E and F, respectively (yNH: blue, oNH: black, oHI: orange). DPTH = DPOAE threshold; yNH = young normal-hearing; oNH = older normal-hearing; oHI = older hearing-impaired.
Figure 4E compares the mean absolute errors on a group-level basis. The elevated error of the oHI group at high frequencies is due to the model limitation in simulating gain losses greater than 35 dB-HL.
DPTH-Based Cochlear Filter Pole Setting
Implementing DPTH-based cochlear model individualization was complicated by the fewer DPTHs we had available, that is, four frequencies, compared to 12 AudTHs. Hence, a simple interpolation to determine poles between the measured frequencies, yielded large prediction errors. In addition, the longitudinal filter coupling and associated gain propagation along the cochlear partition complicated matters. To tackle these issues, we trained a machine-learning algorithm to map DPTHs via cochlear travelling waves to corresponding cochlear filter pole functions across CF. Once trained, we need only a few measured DPTHs to make a relatively accurate prediction of individual pole values. Figure 5 illustrates the complete procedure.

Neural Network-Based Cochlear Model Individualization Using Measured and Simulated DPTHs. A: Random cochlear filter poles are generated and corresponding DPTHs are simulated using TL model (sDPTH). B: The normalized sDPTH (
First, we constructed the training data (Figure 5A) using 26 sets of random cochlear filter pole functions. Each set contained 1001 CF-dependent poles and random pole values lay between 0.036 and 0.302, covering the pole values associated with both NH and HI profiles. In addition, three reference pole functions were included as part of the training:
The architecture of the designed neural network is shown in Figure 5B and consists of an input layer of four neurons, two hidden layers of 150 neurons and an output layer of 1001 neurons. A standard sigmoid activation function (i.e., between 0 and 1) was applied to the hidden layers. A customized sigmoid activation function (between 0.036 and 0.302) was employed in the output layer to yield the desired range of the cochlear model pole functions. An ADAM optimizer with a learning rate of 0.001 was applied to minimize the mean-square-error (MSE) of the learning algorithm. The method was developed in Python using Keras library and Tensorflow backend.
The trained neural network was employed to predict individualized pole functions given DPTHs of the experimental cohort (Figure 5C). Prior to the prediction, mDPTHs needed to be preprocessed to determine a suitable experimental range of DPTHs for the mapping. Among the 41 subjects, six subjects (yNH: three, oNH: two, and oHI: one) without complete mDPTH values at all measured frequencies were dropped. In each of the three recruited groups, the 99% confidence interval around the frequency-specific group means were specified and mDPTH values that either exceeded or fell below of those intervals were set to extremum values. Then, mDPTHs were mapped to the range of the sDPTH associated with reference 



Finally, the prediction error was calculated as in Equation 13, and the absolute mean error for each group is shown in Figure 4F.

The developed machine-learning approach can be used to personalize cochlear model parameters based on an objective measure of OHC damage (DPTH) and predict individual CS profiles. CS profiling can be compared for either the DPTH or AudTH-based cochlear model individualization method, and when no DPTHs are available, the standard audiogram-based method can be adopted.
Simulating CS Profiles
We employed the AudTH- and DPTH-based individualized CGL models to simulate EFRs and ABRs for different CS profiles. To introduce CS, the simulated normal-hearing AN fiber populations, the N CS profile in Figure 3, was reduced in a CF-specific manner. Five additional CS profiles were simulated by proportionally lowering the number of different AN types, starting from low- and medium-spontaneous-rate (LSR and MSR) fibers in profile A to the most severe AN loss in E that only kept 7.69% of the high-spontaneous-rate (HSR) fiber population. The table in Figure 3 details the AN fiber numbers and types considered for each of the six simulated CS profiles. IHC-related dysfunctions were not considered in this study, given that low degrees of CS do not cause IHC damage (Furman et al., 2013; Kujawa & Liberman, 2009; Shaheen et al., 2015). However, removing all AN fibers from an IHC in the model would functionally correspond to IHC damage. The CF dependence of the AN population was considered in two steps: (a) Following the CF-dependent AN distribution observed in rhesus monkey (Keshishzadeh et al., 2020; Valero et al., 2017), we applied a nonuniform NH AN fiber population. (b) CF-specific AN-damage profiles were simulated. The former was achieved by mapping the counted CF-dependent AN fibers population in the rhesus monkey (Valero et al., 2017) to the human cochlea, using a distribution of
For every subject we simulated AEPs for each CS profile, after we personalized the cochlear models using either the AudTH-or DPTH-based method. The stimuli adopted for these simulations were identical to those adopted experimentally, but were digitized using a sampling rate of 100 kHz, rather than 48 kHz. Simulated instantaneous firing rates from the AN, cochlear nucleus (CN), and IC model stages, namely, ABR wave-I, III, and V, respectively, were added up to simulate EFRs (Figure 3). RAM-EFR magnitudes were calculated using Equation 1.
To simulate ABRs, 80-µs clicks were presented to the model with a continuous sequence of 50 repetitions of alternating polarities (100 in total) and a rate of 10 Hz. Sequential stimulus presentation was adopted to account for the adaptation properties of AN fibers. Individual ABR wave-I and V latencies and amplitudes were extracted by averaging the peak-to-trough values of the response to the last, that is, 50th, positive and negative clicks. The simulated ABR wave-I and V latencies were, respectively, shifted by 1 and 3 ms to match latencies of recorded ABRs. These values were determined to match the measured yNH group-mean ABR wave-I and V latencies (at 100 dB-peSPL) with the grand-average individualized ABR simulations across the yNH group. Given that simulated ABR latencies were not impacted by CS, the applied latency shifts will not confound the CS prediction.
Individual Synaptopathy Profile Predictions
In previous sections, cochlear model parameters of the subjects were determined using either AudTH- or DPTH-based methods and 13 personalized AEP-derived metrics were simulated for six CS profiles of each experiment participant. Here, we develop a classification approach, forward-backward classification, to predict the simulated CS profile that best matches recorded individual AEP metrics and determine the AEP metric that gives the most accurate segregation of simulated individualized CS profiles. This step was implemented separately for either of the cochlear individualization methods. After excluding eight subjects from the cohort (six without complete DPTHs and two with undetectable ABRs), we developed our individual SNHL-profiling method on data from 35 subjects (yNH: 12, oNH: 12, and oHI: 11).
Before classification, we first normalized the 13 AEP metrics (Table 1) derived from measured (M) and simulated six CS profiles per individual (S). The normalized S and M were calculated using Equations 14 and 15.

S is the matrix of simulated AEP metrics and contains 210 rows (35 subjects with 6 CS profiles) and 13 columns, the number of derived AEP metrics. 
In Equation 15, M refers to the matrix of measured AEP metrics with a dimension of 35 × 13. We created 8,191 feature-sets using all possible combinations of 13 metrics (
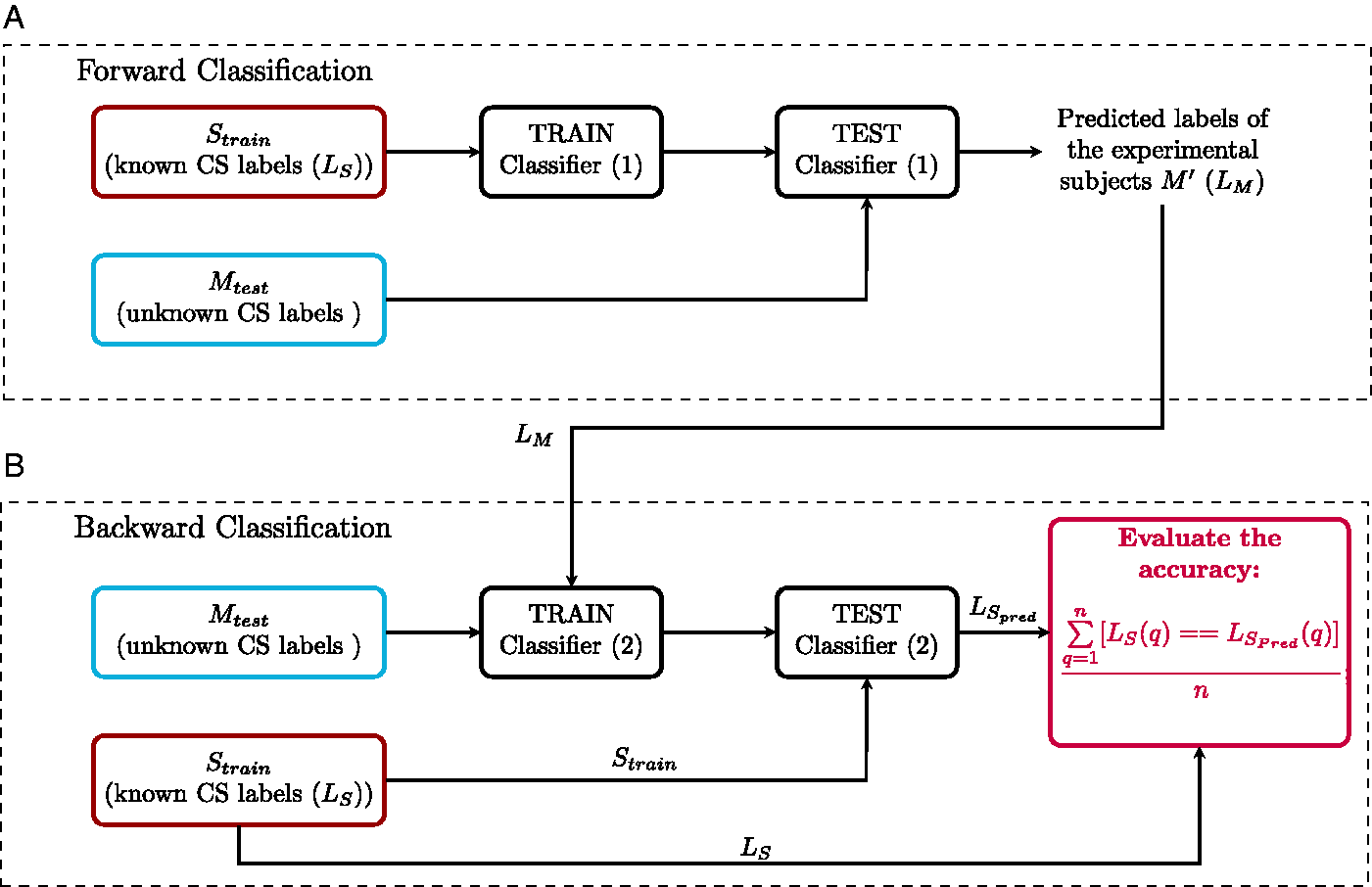
The Forward-Backward Classification Method. A: Forward classification: Classifier (1) is trained with individualized simulated AEP-derived metrics (
Results
We applied forward-backward classification for each of the cochlear model individualization methods (AudTH and DPTH) and calculated the prediction accuracy of all feature-sets in
Combination of AEP-Derived Metrics
To determine the best combination of metrics for CS profiling, the forward-backward classification was performed on the mean AEP-derived metrics of experiment participants and corresponding classification accuracy was reported as
Combination of Metrics With the Highest Mean Accuracy (

Note. EFR = envelope-following response. The standard deviations of obtained accuracies are shown in
Combination of Metrics With the Highest Mean Accuracy (

Note. EFR = envelope-following response. The standard deviations of obtained accuracies are shown in
Prediction Variability
The impact of subject-specific factors and measurement noise reflect on inter- and within-subject variability of the AEP recordings and can have an impact on the accuracy of the classification method. To measure this effect, the forward-backward classification was repeated, this time by extracting metrics from the bootstrapped average trials, rather than from the mean of trials. This resulted in distributions for each specific metric and each subject, with standard deviations as given by the last column of Table 1. Then, 100 samples were randomly drawn from the distribution of each metric. Thus, for every feature-set in Tables 2 and 3, the corresponding metrics samples were combined to yield 100 variations of each feature-set. Afterwards, the CS profile prediction was repeated 100 times with each feature-set for each subject, and prediction accuracy was assessed in every repetition. Lastly, the standard deviation of the calculated accuracies (
For the best predictor metric (RAM-EFR),

Confusion Tables at Subgroup and Group-Levels for Both AudTH and DPTH-Based Cochlear Model Individualization Methods. The tables summarize the accuracy of classifier (2) in Figure 6B for subgroups as well as all groups together. AudTH = audiometric thresholds; DPTH = DPOAE threshold.
CS Profile Prediction Based on Individualized Classifiers
Table 4 lists the predicted individual CS profiles from the RAM-EFR metric (best prediction accuracy) for both AudTH- and DPTH-based cochlear individualization methods. The reported profiles are the output of the forward classification step, that is,
Predicted Individuals CS Profiles Obtained From AudTH and DPTH-Based Cochlear Individualization Methods, Based on RAM-EFR Metric.

Columns
Thus far, the reported individualized CS profiles for RAM-EFR were predicted by training a single classifier with simulated individualized CS profiles of the whole experimental cohort. This has drawbacks for individual profiling in a clinical context, because it would be ideal if the profiling could be performed using only recordings from the tested individual. Hence, to establish more accurate predictions of the individual CS degrees, we took one step further and designed individualized classifiers, which were trained and tested with the RAM-EFR metric of the same listener. If
To provide a demonstration of the implemented method, and to show to which extent the model simulations imitate the experimental measurements, we compare simulated and measured AEPs of a yNH subject in Figure 8. Panel A depicts simulated RAM-EFR spectra for the different considered CS profiles. Based on the experimental RAM-EFR (Panel D) and forward classification, we predicted that this subject had a “N” CS profile, that is, no AN damage. The CGL parameters of the individualized model were adjusted based on DPTHs of the same yNH listener. Panels B and C depict the simulated personalized ABR waveforms for the predicted “N” CS degree. Experimental ABR waveforms to 70 and 100 dB-peSPL clicks are shown in Panels (E) and (F), respectively. Details regarding the value of extracted metrics from the measurements and simulations are provided in a table at the bottom of Figure 8. Even though our classifier did not consider ABR metrics, the applied personalized OHC and AN profiles predicted

A Comparison Between Simulated and Measured AEPs for a yNH Subject (yNH15). This subject was predicted to have a normal (N) CS profile, that is, without CS. A: Simulated RAM-EFR spectra for six CS profiles. The sum of the drawn arrows yields the RAM-EFR magnitude metric. B: Simulated ABR wave-I to 70 and 100 dB-peSPL clicks. Waveforms were shifted by 1 ms to match the experimental data. C: Simulated ABR wave-V to 70 and 100 dB-peSPL clicks. Waveforms were shifted by 3 ms to match the experimental data. The specified arrows in (B) and (C) indicate the extracted metrics. D: Measured RAM-EFR of the same listener (yNH15). Shown arrows, indicate the peak-to-noisefloor values. Akin to (A), the measured RAM-EFR metric was calculated by summing the arrow amplitudes. E: Measured ABR waveform to 70 dB-peSPL clicks. F: Measured ABR waveform to 100 dB-peSPL clicks. Arrows in (E) and (F) determine the extracted metrics. The shown simulated waveforms were predicted based on the DPTH-based cochlear individualization method. The table shows the exact value of EFR and ABR metrics derived from recordings and predicted CS-profile, “N,” of the same listener. EFR = envelope-following response; ABR = auditory brainstem response; CS = cochlear synaptopathy.
Method Validation
To validate the proposed method and its generalizability to other cohorts and other measurement equipment, we applied the developed classifier in backward classification step to RAM-EFRs recorded in a second experiment. Figure 9 schematizes the implementation of the validation method. Considering the different experimental setup and recording location of the second experiment, the measured RAM-EFRs of both experiments were scaled between zero and one, prior to classification. Given that only yNH listeners participated in the second experiment, we employed the smallest RAM-EFR magnitude recorded from oHI listeners (as part of another study) recorded with the same setup as the second experiment to scale the RAM-EFRs. The scaled RAM-EFRs of the first experiment were used to train the classifier (1) in Figure 6 and afterwards, the trained classifier was tested with the scaled RAM-EFRs of the second experiment. The predicted CS profiles are illustrated as a bar-plot in Figure 9. Moreover, 84.21% of the 19 yNH participants of the second experiment were classified as N, that is, without CS, and the rest were predicted to have mild CS. These predictions show that a classifier designed on our cohort can be applied to other cohorts to predict individual CS degrees based on the RAM-EFR. In line with expectations, the classifier predicted that most yNH subjects were synaptopathy free.

Implementation of the Validation Method. Measured RAM-EFRs (M) with predicted labels in Figure 6 (
Discussion
By combining experimental ABR and EFR measurements with a modeling approach, we were able to develop a classifier that can assign one out of six CS profiles to listeners with mixed SNHL pathologies. The classifier considered 8,191 feature sets, of which our forward-backward classification method identified that the RAM-EFR metric yielded the best performance in both AudTH- and DPTH-based cochlear individualization methods. We tested both a group and individually based method and showed that our method can generalize to other cohorts and measurement setups. Taken together, we have high hopes that this method can find its way to clinical hearing diagnostics, since a single AEP metric is required to yield a CS-profile prediction, given the audiogram or at least four DPTHs.
Implications for RAM-EFR-Based Synaptopathy Profiling Prediction
On the one hand, predicting the CS degree from AEP metrics is controversial in listeners with coexisting OHC deficits and on the other, validation of the predicted CS profiles with temporal bone histology is impossible in humans. Without these means, models of the human auditory periphery and AEP generators can provide a tool to bridge this experimental gap. The similarity between predicted AEP degradations for a known CS profile and experimental AEP degradations can be used to predict the CS profile of individuals. In a previous study, we tested the potential of the derived-band EFR as a CS predictor in NH listeners using a fuzzy c-means clustering method and validated our CS predictions using an another AEP-derived metric (wave-V amplitude growth slope) recorded from the same listener. We evaluated the method based on the percent of subjects that were predicted and validated to have the same CS profile, that is, 61% (Keshishzadeh & Verhulst, 2019). However, the performance of this method is easily impacted by the characteristics of the adopted predictor and validation metrics, for example, different generator sources, degree of sensitivity to subtypes of SNHL, and tonotopic susceptibility.
The interdisciplinary approach we took in this study tackled this validation issue by proposing a forward-backward classification approach and applying the trained classifier to AEPs from a new cohort to test its generalizability. Moreover, we were able to determine the most accurate AEP-derived metric for CS degree prediction, given a range of 13 possible AEP-derived metrics. Among the considered AEP-based metrics and combinations thereof, we found that the RAM-EFR magnitude showed the best performance in segregating simulated individual CS profiles. At the same time, RAM-EFR metric was involved in all feature sets that yielded the highest
The Effect of Cochlear Model Individualization Method on Predicting Cochlear Synaptopathy Profiles
In this study, we determined the CGL model parameters using either measured audiometric or DPOAE thresholds and assessed the classifier performance of each method in the backward classification step. Comparing the resulting
It is noteworthy that the DPTH-based cochlear individualization was implemented using DPTHs from only four frequencies (0.8–4 kHz), whereas the AudTH-based method considered audiometric thresholds measured at 12 frequencies (0.125–10 kHz). This difference may have resulted in less accurate CGL model parameters for the DPTH-based method, despite a better performance of forward-backward classification. In future implementations of this method, we intend to incorporate more frequencies in the DPTH measurements, especially at higher frequency regions. Employing DP-grams instead of DPTHs is another option, as these require a shorter measurement time. In both cases, we suggest to include lower stimulus levels as well, given that noise-induced OHC deficits can be identified earlier at lower stimulus levels (Bramhall et al., 2019).
Method Limitations
The proposed method for AEP-based CS profiling relies on the interactive use of recordings and model simulations. Hence, shortcomings in either aspect could have caused performance limitations of the method. The following sub-sections summarize a number of these limitations:
Experimental Limitations
(a) ABRs in humans are recorded using vertex electrodes placed on the scalp, which yields smaller and more variable wave-I amplitudes than when they are recorded in animals using subdermal electrodes. The measured ABR
Model Limitations
(a) The adopted computational model of the auditory periphery allows for OHC deficit simulation on a CF-dependent basis, but not for CGLs above 35 dB, since the maximum possible BM filter gain is 35 dB in the model (Verhulst et al., 2018). This constraint led to elevated absolute prediction errors for high-frequency audiometric thresholds in the oHI (above 4 kHz) and oNH (above 8 kHz) groups (Figure 4E). The increased absolute errors were mainly observed for the audiometric threshold predictions, since DPTHs were only measured for frequencies up to 4 kHz. Thus, the individualized hard-coded OHC-loss component for the oHI group might lead to similar and less accurate CS profile prediction for oHI participants with audiometric losses greater than 35 dB-HL. (b) In the adopted method, we hard-coded the CGL using the individual hearing thresholds and related the remaining AEP alterations to CS. An alternative way would be to run the model iteratively and simultaneously optimize both CGL and CS profile parameters on the basis of the experimental data to obtain the best OHC-loss and CS profiles. However, we did not further explore this route due to the high computational cost of running the adopted TL cochlear model in an iterative optimization procedure.
Conclusion
In this study, we proposed an integrated modeling and experimental approach to build personalized auditory models and predict the AN-damage profile of listeners with mixed SNHL profiles. To develop individualized cochlear models, we implemented two different methods on the basis of measured AudTHs and DPTHs. Next, we developed a classification-based approach to predict individual CS profiles and determined which AEP metric (or combinations thereof) yielded the highest prediction accuracy. Afterwards, we evaluated the implemented CGL and CS-profile individualization methods on the development data set as well as on a new cohort. Our study suggests that a DPTH-based cochlear model individualization approach combined with a RAM-EFR recording predicts individual CS profiles most accurately among the 8,191 possible combinations of 13 AEP markers. In addition, we tested the applicability of the proposed method by applying the trained classifier to the recorded RAM-EFRs of a new cohort of yNH listeners. The classifier predicted that these listeners mostly had mild forms of CS, which supports that our method is generalizable to other recording setups and cohorts. Training the classifier again on larger cohorts may further increase the generalizability of the method. We hope that this method, or variations thereof, can be used in a clinical diagnostic context, as the number of needed AEP recordings to yield an individual CS-profile is small (i.e., 10–15 min). Individualized models of SNHL are an important step for the development of hearing aid algorithms that compensate for both the OHC- and AN-damage aspects of SNHL.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by European Research Council under the Horizon 2020 Research and Innovation Programme, grant agreement no. 678120 RobSpear (S. K. and S. V.) and DFG Cluster of Excellence EXC 1077 1 Hearing4all (M. G. and S. V.).