
Abstract
Due to an increased competition for volunteers, nonprofit organizations have intensified efforts to recruit members as volunteers. But how to effectively persuade members to volunteer using visual communication? Research suggests that images are most persuasive when they demand something from the viewer. A demand is expressed through the depiction of a person who directly gazes at the viewer, whereas an offer is expressed through the depiction of a face with an averted gaze. Demands and offers can also be expressed verbally. A verbal demand is articulated through commands, whereas a verbal offer is conveyed through statements. This study examines whether NPOs should address their members using demands or offers and whether correspondence between image and text increases persuasion. An experiment among 205 members of a Swiss NPO finds that direct gaze images are most effective. However, image-text matching increases persuasion for campaigns that feature an averted gaze image.
Nonprofit organizations (NPOs) are witnessing increasing difficulties to recruit volunteers (Cao, 2018). This is due to a consistent downward trend in volunteering that has led to a heightened competition for volunteers (Randle et al., 2013; Septianto et al., 2018). In face of this development, mobilizing their members is key for many NPOs to survive over the long haul. But how to persuade members to volunteer?
Accumulated research in the field of visual advertising suggests that campaigns are more persuasive when they include images that demand something from the viewer compared to images that offer things (Brownlow, 1992; Kreysa et al., 2016; Manesi et al., 2016). A demand is expressed through the depiction of a person who directly gazes at the recipient, whereas an offer is expressed through the depiction of a face with an averted gaze (Kress & van Leeuwen, 2006). What is missing from current knowledge, however, is how such images should be combined with verbal text. Is it advisable to pair a visual demand with a verbal demand which comes in the form of a command (e.g., “Go to our website and join our program!”)? Does image-text matching increase persuasion? Or is it better to combine a visual demand with a verbal offer which comes in the form of a statement (e.g., “You can go to our website and join our program.”)?
The present study addresses this question with the aim of better understanding how to increase volunteering among members of nonprofit organizations. We therefore conduct a 2 (offer: averted gaze vs. demand: direct gaze) × 2 (offer: statement vs. demand: command) experiment among 205 members of a Swiss nonprofit organization. Focusing on visual and verbal offers, this research project explores the interplay between visual image and verbal text. The term “visual image” includes all types of photographs but excludes other forms of visual communication such as charts, cartoons, or drawings (Meyer et al., 2018). Verbal text refers to all kinds of written documents (Meyer et al., 2018). In the sections that follow, we will outline the theoretical foundations underlying this study, namely the concept of image act (Kress & van Leeuwen, 2006) and the concept of speech act (Halliday, 1985).
Theoretical Background
Image Act (Offer vs. Demand)
The concept of image act is rooted in social semiotics and describes the way that visual images—respectively the persons shown in the image—establish a relationship with the viewer (Macken-Horarik, 2004; Valentini et al., 2018). According to Kress and van Leeuwen (2006), image acts can take the form of an offer or a demand. A visual offer is articulated when the person depicted in the image does not gaze at the viewer directly and, by doing so, offers themself as an object for the viewer’s contemplation (Kress & van Leeuwen, 2006; Valentini et al., 2018). An averted gaze suggests disengagement and does not encourage an interaction with the viewer (Macken-Horarik, 2004). A visual demand is achieved when the person in the image directly gazes at the viewer and, by doing so, demands some kind of response from the viewer (Kress & van Leeuwen, 2006; Valentini et al., 2018). The direct gaze creates a vector that connects the represented person with the viewer (Macken-Horarik, 2004). Through this direct gaze, the person depicted in the image explicitly acknowledges the viewer and addresses him or her “with a visual ‘you’” (Kress & van Leeuwen, 2006, p. 117).
Direct gaze is associated with different functions relevant to interpersonal communication and persuasion (Guyer et al., 2019; Tyler et al., 2021). Specifically, it has been linked to social affiliation, social control, and attention orientation. In terms of social affiliation, direct gaze is conceptualized as a salient signal of closeness and social engagement, whereas averted gaze is described as a signal of lacking social closeness, interest, and social engagement (Ewing et al., 2010; Valentini et al., 2018). In line with this idea, previous research has shown that direct gaze leads to more favorable evaluations of a speaker’s personal traits (Kleinke, 1986). Speakers who direct their gaze at their audience are rated as more honest and credible (Hemsley & Doob, 1978), competent (Brooks et al., 1986), and attractive (Ewing et al., 2010), and trustworthy (Kreysa et al., 2016) than speakers who do not directly gaze at their audience.
Direct gaze also performs a social control function. It has been argued that direct gaze elicits a feeling of being watched and, by doing so, triggers concerns for one’s own reputation and increases motivation to engage in prosocial behaviors including helping, donating, or volunteering (Manesi et al., 2016). People strive for social approval and seek to make a good impression on others. When they believe they are being monitored by others, people tend to behave more prosocial (van Bommel et al., 2012). Moreover, in the absence of anonymity, people often act more prosocial to avoid social penalties and social exclusion (Boyd et al., 2010). Combined evidence from three experimental studies lends support to the idea that direct gaze is a powerful cue to exert social control (Manesi et al., 2016). Comparing direct gaze images with averted gaze images and eyes closed images, the study showed that people are more inclined to help others when the veil of anonymity has been removed and they feel that they are being watched.
Finally, direct gaze has been associated with an attention-orienting function. Exposure to faces with direct gaze is theorized to be more engaging and arousing than exposure to faces with averted gaze (Baberini et al., 2015). Direct eye contact conveys to recipients that they are the object of another’s attention. This arguably makes recipients alert to the speaker and leads to enhanced perceptual processing, for instance in terms of more accurate assessment of the speaker’s physical appearance or of his or her intentions (Adams & Kleck, 2005). Previous research indicates that more attention is allocated to faces with direct gaze and that this effect takes place automatically (Hoehl & Striano, 2010). The orienting function of eye gaze, however, seems to go at the expense of verbal information processing (Casado-Aranda et al., 2020). Research points toward a distraction effect in the sense that faces with direct gaze are so captivating that recipients pay considerably less attention to the accompanying verbal text (Straub, 2008). Wang et al. (2018) showed that a smiling face with a direct gaze enhances emotional arousal, while at the same time decreasing the depth of processing of the verbal text. Similarly, Sajjacholapunt and Ball (2014) examined the effects of direct versus averted gaze in online banner advertisements. The study found that direct gaze leads to significantly longer dwell times on the model’s face but also to substantially less engagement with the advertising text (measured in terms of dwell time per word) and to decreased memorability of the advertising text.
Despite the negative influence on verbal information processing, accumulated evidence lends evidence to the idea that direct gaze images are more persuasive than averted gaze images. However, the persuasive advantage of direct gaze over averted gaze seems to be contingent upon people’s prior attitude toward the message advocacy. When people disagree with the message advocacy, averted gaze has shown to be more persuasive than direct gaze (Chen et al., 2013). As to the present study, it is reasonable to assume that nonprofit members are generally supportive of the message advocacy. Thus, we would expect that direct gaze images (i.e., visual demands) are more effective in promoting volunteering.
Hypothesis 1: Visual demands (i.e., direct gaze images) are more persuasive than visual offers (i.e., averted gaze images) among nonprofit members.
Having presented the concept of image act, we now focus on the corresponding verbal concept, that is, the concept of speech act.
Speech Acts (Offer vs. Demand)
The concept of speech act is used in Systemic Functional Linguistics to refer to different speech roles (demand vs. offer) and commodities (information vs. goods and services). The combination of these speech roles and commodities produces four basic speech acts (Halliday, 1985). Speech acts can: (1) offer information through statements realized as declaratives (e.g., “Our dog is called Barry.”), (2) offer goods and services through different moods such as the modulated interrogative (e.g., “Would you like a cup of tea?”), (3) demand information through questions realized as interrogatives (e.g., “What is your favorite color?”), and (4) demand goods and services through commands realized as imperatives (e.g., Wear your jacket!; Kress & van Leeuwen, 2006; Macken-Horarik, 2004).
The concept of speech acts is considered the verbal counterpart to the concept of image act, although the latter is essentially more limited (Kress & van Leeuwen, 2006; Macken-Horarik, 2004). Images can express offers or demands, but they lack the ability to specify whether these offers or demands refer to “information” or “goods and services.” Thus, for reasons of comparability, the present study will only consider the offer/demand dimension when examining speech acts. When referring to offer speech acts, we will focus on statements expressed as declaratives. When referring to demand speech acts, we will focus on commands expressed as imperatives. We will not consider questions because the distinction between modulated interrogatives (offer) and genuine interrogatives (demand) is not always clear-cut.
Although the concepts are related, speech acts perform different persuasive functions than image acts. Specifically, commands are associated with communicative explicitness and transparency. Commands can be used to communicate requests in an explicit manner, thereby rendering the speaker’s intentions more transparent than statements (Jovanovic & van Leeuwen, 2018; Kress & van Leeuwen, 2006). For instance, the sentence “Go to our website and register now as a volunteer!” requires less guesswork regarding the speaker’s intentions than the sentence “You can go to our website and register as a volunteer.” Although commands may guide the recipients toward certain conclusions, previous research suggests that they are less persuasive than statements.
According to the theory of psychological reactance and politeness theory, people have an innate need for freedom and want to be unimpeded in their decision-making (Brehm & Brehm, 1981; Brown & Levinson, 1987). When people feel threatened in their freedom to choose, they resist persuasion. Although any attempt to persuade can be considered a threat to freedom, verbal messages vary in the extent to which they are perceived as threatening (Jenkins & Dragojevic, 2011). Explicit persuasive messages, including commands, impose a specific choice upon the recipient and, by doing so, are more likely to be seen as a threat to freedom (Blum-Kulka, 1987; Martin et al., 2003; O’Keefe, 1997; Shen & Bigsby, 2014). We would expect nonprofit members to be especially prone to perceiving commands as a threat to freedom. Being addressed with commands may make them feel not just pushed toward certain choices but also disrespected and instrumentalized. It is thus straightforward to assume that the use of commands decreases persuasion in volunteer recruiting campaigns.
Hypothesis 2: Verbal offers (i.e., statements) are more persuasive than verbal demands (i.e., commands) among nonprofit members.
Over the last years, persuasion research has begun to pay increasing attention to the interplay between image and text (Kergoat et al., 2017; To & Patrick, 2021; Xue & Muralidharan, 2015). This interest is motivated by the idea that the visual and verbal elements in a persuasive message interact with each other and, by doing so, influence persuasion (Geise & Baden, 2015). In the following, we therefore turn to the persuasive interplay between image act and speech act.
Combining Image Acts and Speech Acts
Image-text matching is a principle that is often invoked to guide message design. The principle holds that correspondence between image and verbal text increases a message’s persuasiveness (Seo & Dillard, 2019a, 2019b). Correspondence means that image and text reinforce each other in terms of a high visual-verbal redundancy (Geise & Baden, 2015).
Two explanations have been proposed for the effects of image-text matching: First, correspondence between image and text is argued to increase processing fluency, which subsequently leads to greater persuasion. In order to evaluate the message and its advocacy, recipients face the task of integrating the meanings conveyed visually and verbally into one coherent whole (van Rompay et al., 2010). According to processing fluency theories, the ease at which the visual and verbal meanings can be integrated into an overall impression influences the persuasiveness of the message. The more easily a message can be processed, the more positively it is assessed and the more persuasive it is (Reber et al., 2004; van Rompay et al., 2010).
The second view explains the persuasiveness of image-text matching as a function of reduced ambiguity. Matching is associated with certainty, that is a state that is subjectively comfortable and that leads to more intense emotional responses and to more favorable cognitions (Mitchell, 1986). This amplifying effect of image-text matching on emotional and cognitive responses is theorized to result in greater persuasion (Seo & Dillard, 2019a). Research lends partial support to this explanation. In two experimental studies on sustainable packaging, Magnier and Schoormans (2015) found that incongruence between the visual appearance of the packaging and the verbal sustainability claims led to a decrease in people’s affective attitudes and purchase intentions, but only among consumers with low environmental concern. Other studies examined whether the persuasive effects of verbal message frames (gain vs. loss) could be amplified by the presence of a matching image (positive vs. negative valence; Seo & Dillard, 2019a; Seo et al., 2013). The findings were complex and yielded mixed effects on emotions, cognitions, and persuasion. Seo and Dillard (2019a) therefore call for further refinements to the principle of image-text matching.
The present study tests the idea that image-text matching increases persuasion, but only for campaigns with low attention-grabbing images. An image is considered attention-grabbing when it includes features that are so captivating that the viewers instantly focus on them and spend a disproportionate amount of time to engage with them (Carlson et al., 2020). In a multimodal message, high attention-grabbing images may distract recipients’ attention away from the verbal portions of the message and, by doing so, make recipients less sensitive to whether the text matches the image or not. In contrast, low attention-grabbing images may lead recipients to allocate their attention more evenly between image and text. This more equal distribution of attention between image and text may make recipients more sensitive to visual-verbal correspondence (Kergoat et al., 2017).
Contemporary research suggests that gaze direction is a visual feature that varies in the extent to which it grabs viewers’ attention. While direct gaze images have been associated with an attention-orienting function, averted gaze images have shown to be less captivating and to lead recipients to dwell significantly longer on the verbal message elements (Sajjacholapunt & Ball, 2014; Wang et al., 2018). We therefore conceive direct gaze images as high-attention grabbing images and averted gaze images as low-attention grabbing images. Arguing that the image-text matching increases persuasion for low attention-grabbing images, we would expect the principle to apply to averted gaze images, but not necessarily to direct gaze images. Specifically, we assume that averted gaze images (visual offer) are more persuasive when combined with a statement (verbal offer) as compared to a command (verbal demand). This leads us to the following hypothesis:
Hypothesis 3: There is an interaction effect between image act and speech act, such that visual offers (i.e., averted gaze images) are more persuasive when paired with a matching verbal appeal (i.e., statement) as compared to a mismatching verbal appeal (i.e., command).
Persuasion
According to the theory of reasoned action (TRA), persuasion unfolds in a multi-step process in which attitudes are antecedents to behavioral outcomes (Yzer, 2012). One way to influence people’s behavior is therefore to influence their attitudes toward that behavior (O’Keefe, 2016). The idea of persuasion as a “sequence of linked changes” (Seo et al., 2013, p. 567) provides a compelling explanation for why persuasion research has often failed to find significant message effects on behavioral outcomes. Because behavioral outcomes are at the end of the persuasion process, they are less sensitive to variations in message features than earlier outcomes including attitudes (Seo et al., 2013). Thus, the present study conceptualizes persuasion as a sequence, in which attitudes precede behavioral outcomes. In line with prior research, we use behavioral intention as a proxy for actual behavior (Yzer, 2012). Figure 1 summarizes the presumed persuasion process and illustrates the expectation that:
Hypothesis 4: Attitude toward the advocacy mediates message effects of image act and speech act on behavioral intentions.
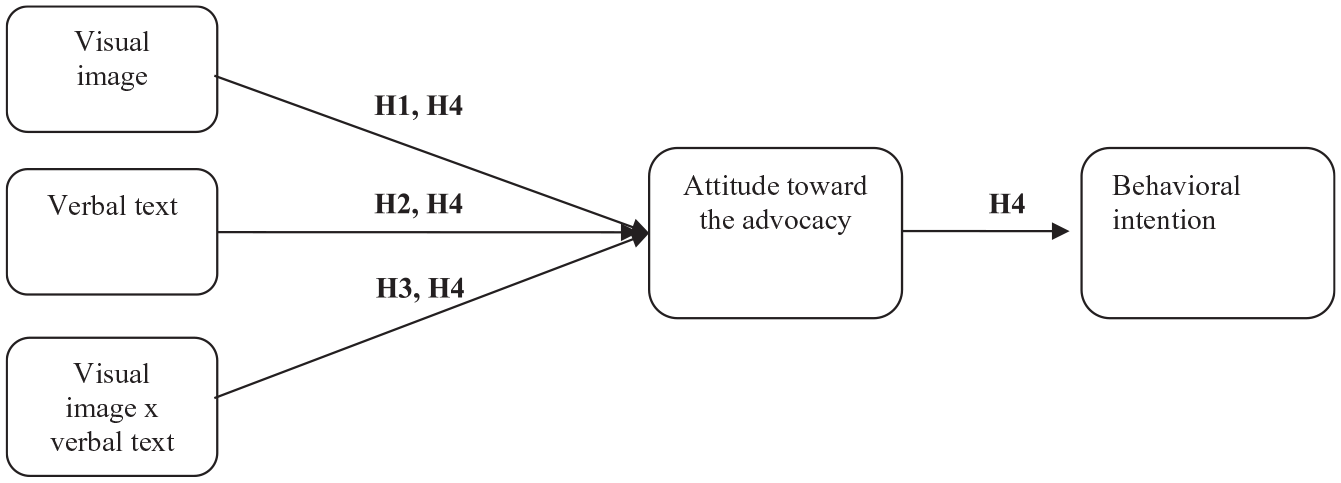
Conceptual model of the hypotheses.
Methods
Design
We conducted a 2 (visual image: offer vs. demand) × 2 (verbal text: offer vs. demand) factorial online experiment. Visual image and verbal text were between-subjects factors. That means, each participant saw one out of four messages that varied in terms of visual image and verbal text. The messages advocated volunteering at a Swiss nonprofit organization and were inserted in a web survey. About 10 minutes were required to complete the entire web survey.
Topic and Stimuli
In cooperation with the Swiss Red Cross (SRC), we developed a fictitious Facebook campaign aimed at recruiting volunteers. The Swiss Red Cross of the Canton of Berne 1 (i.e., regional unit of the SRC) was the message source of the fictitious campaign. The campaign consisted of a short text promoting volunteering at the SRC and an accompanying image. Manipulation occurred in the image and in the text (Figure 2). To vary the type of image act, we made a photoshoot with a female employee of the SRC. For the visual offer, we selected a photo in which the employee looks to the right and thus does not gaze at the viewer (i.e., averted gaze image). For the visual demand, we selected a photo in which the employee looks frontally into the camera and thus directly gazes at the viewer (i.e., direct gaze image). Image components such as the distance between the depicted person and the viewer, camera angle, facial expression, color, or brightness were carefully controlled to minimize potential confounding factors.

Experimental treatments.
The verbal offer was realized with a statement: “You can do something purposeful—as a volunteer at the SRC of the Canton of Berne. □ As a volunteer at the SRC of the Canton of Berne, you can get to know interesting people, explore new lifeworlds and experience a lot of gratitude.  www.srk-bern.ch/freiwillige”
www.srk-bern.ch/freiwillige”
The verbal demand was realized with a command: “Do something purposeful—as a volunteer at the SRC of the Canton of Berne! □ Get to know interesting people, explore new lifeworlds and experience a lot of gratitude as a volunteer at the SRC of the Canton of Berne! www.srk-bern.ch/freiwillige.”
The final version of the stimuli was developed in an iterative process including feedback from communication scholars and discussion rounds with the SRC of the Canton of Berne. In a first round, we focused on the visual images of the campaign and discussed whether we should use stock photos or do a photo shoot with an employee of the SRC. We opted for the latter to ensure that the campaign looks as realistic as possible (stock photos often look staged). We also decided to portray a female employee to reflect the fact that the majority of volunteers at the SRC of the Canton of Berne are women. In a second round, we defined the principles guiding the development of the verbal stimuli. For the verbal offer, we decided to use sentences with “can” and to put a full stop at the end of each sentence. For the verbal demand, we agreed to use sentences with imperatives and to put an exclamation mark at the end of each sentence.
Participants
Members of the SRC of the Canton of Berne were contacted via email newsletter and invited to participate in the online experiment. The e-mail newsletter had been sent out to 2,890 members. A total of 205 members of the SRC completed the study. Participants did not receive a reward for their participation. Twenty-one cases had been identified as extreme outliers (>2.5 SD above or below the mean) and had therefore been removed from the data set, resulting in a final N of 184. The sample included 118 females (64.1%) and 66 males (35.9%). Participants were classified into seven age categories, with 1 (0.5%) being younger than 20 years, 7 being between 21 and 30 years (3.8%), 14 being between 31 and 40 years (7.6%), 27 being between 41 and 50 years (14.7), 44 being between 51 and 60 (23.9%), 54 being between 61 and 70 years (29.3%), and 37 being older than 70 years (20.1%). About 179 participants reported their nationality as Swiss (97.3%), 7 as European (3.8%), 1 as British (0.5%), 1 as Russian (0.5%), and 3 as Brazilian (0.5%). Multiple answers were possible for the nationality question, which resulted in the total exceeding 100%.
Procedure
The experiment took place between January 31 and February 14 in 2020 (i.e., the survey remained open for 15 days). When clicking on the link to the online experiment, participants were first informed about the study procedure and asked to give their consent to participate in the experiment. They were subsequently directed to a web survey that consisted of three parts: (1) sociodemographic information (age, sex, nationality, and education) and (2) a screenshot of a Facebook ad campaign (each participant only saw one out of four ads) which was followed by questions about their reactions to the campaign (attitude toward the advocacy and behavioral intentions), as well as (3) questions related to prior experiences with volunteering and to the SRC’s efforts to recruit volunteers.
Measures
Attitude toward the advocacy
Attitude toward the advocacy was measured based on three 7-point scale items (1 = strongly disagree; 7 = strongly agree; M = 5.9, SD = 0.98). The items were adopted from Seo et al. (2013) and included the following statements: “I support what the message was trying to accomplish,” “I agree with the position advocated in the message,” and “I am favorable toward the main point of the message” (α = .90).
Behavioral intentions
Three 7-point items ranging from 1 (strongly disagree) to 7 (strongly agree) were used to measure participants’ volunteering intentions (M = 3.4, SD = 1.59). The items were taken from Seo et al. (2013): “I intend to act in ways that are compatible with the position advocated by the message,” “I plan to act in ways that are consistent with the position advocated by the message,” and “I am going to make an effort to do what the message asked me to do” (α = .93).
Controls
Several sociodemographic variables (age, sex, nationality, education) were obtained. Participants were further asked to indicate whether they have any prior volunteering experiences (M = 0.84, SD = 0.37) 2 and whether they have known that the SRC of the Canton of Berne was recruiting volunteers (M = 0.80, SD = 0.4). 3
Statistical Power
Assuming α = .05 and N = 184, power to detect a small main or interaction effect equal to a partial η2 of .02 was .49, power to detect a medium main or interaction effect equal to a partial η2 of .06 was .92, and power to detect a large main or interaction effect equal to a partial η2 of .14 was .99. The study thus has adequate power to discover medium to large effects.
Results
In H1 we proposed that visual demands (i.e., direct gaze images) would be more persuasive than visual offers (i.e., averted gaze images). In contrast, H2 postulated that verbal offers (i.e., statements) would be more persuasive than verbal demands (i.e., commands). We also expected that image-text matching would increase the persuasiveness of ads with averted gaze images. H3 led us to expect an interaction effect, such that the use of a verbal offer (i.e., a statement) would be more persuasive for ads with an averted gaze image as compared to a verbal demand (i.e., a command). In order to test these hypotheses, an ANCOVA was performed. The independent variables were visual image and verbal text. The dependent variable was attitude toward the advocacy. The control variables included participants’ sex and age as well as their prior volunteering experiences and their knowledge of the organization’s efforts to recruit volunteers. Table 1 reports the means and the standard deviations of attitude toward the advocacy across all experimental conditions.
Means and Standard Deviations of Attitude Toward the Advocacy by Experimental Condition.
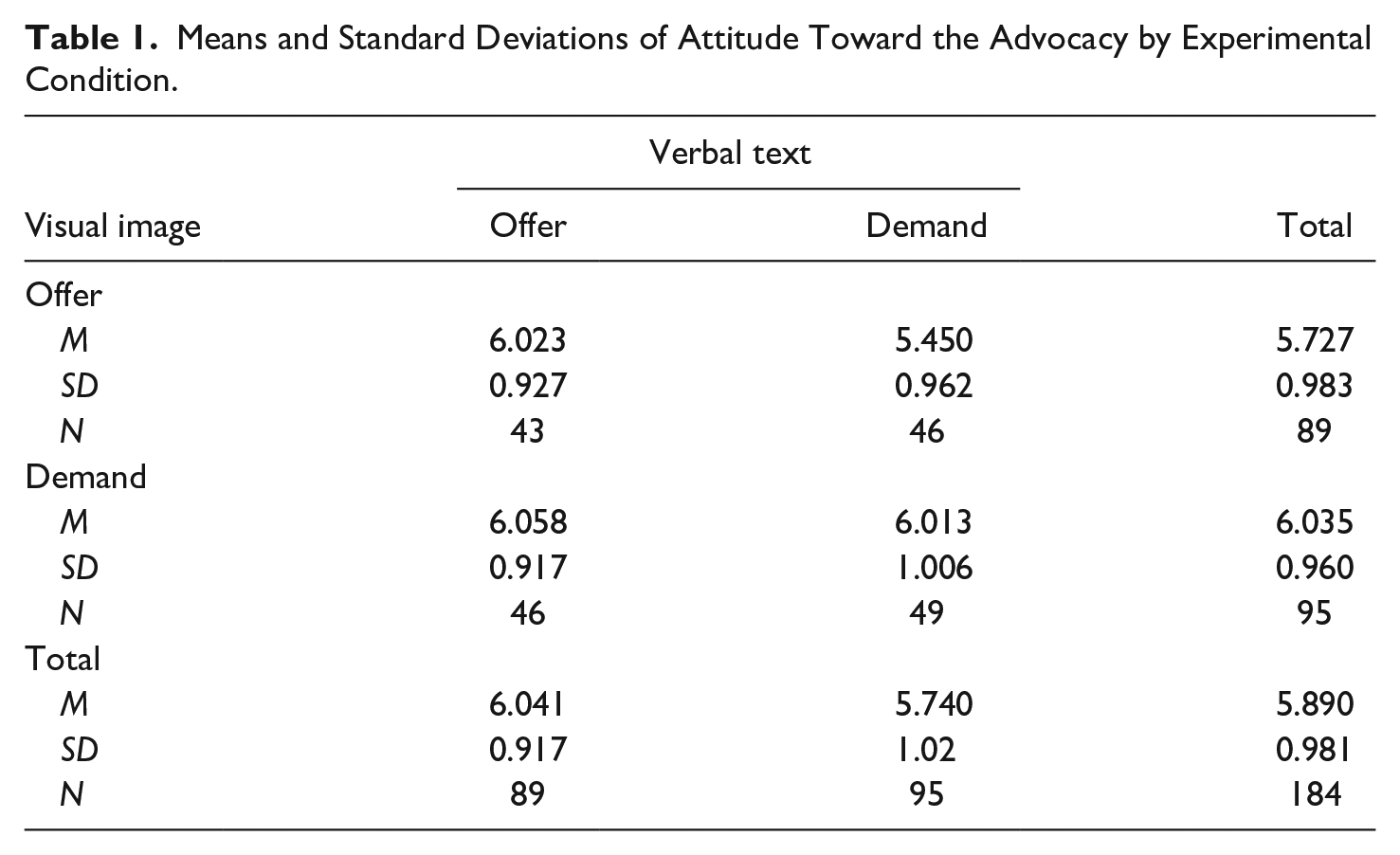
The effect for visual image on attitude toward the advocacy approached significance F(1, 176) = 3.707, p = .056, partial η2 = .021, with the direct gaze image (M = 6.035, SD = 0.960) being slightly more persuasive than the averted gaze image (M = 5.727, SD = 0.983). Thus, the results lend support to H1, indicating that visual demands are more persuasive than visual offers.
The analysis revealed a significant main effect for verbal text F(1, 176) = 4.682, p = .032, partial η2 = .026, indicating that statements (M = 6.041, SD = 0.917) are more effective in improving participants’ attitude toward the advocacy than commands (M = 5.740, SD = 1.02). Thus, H2 was fully supported, suggesting that verbal offers are more persuasive than verbal demands.
The analysis showed a significant interaction effect between visual image and verbal text on attitude toward the advocacy, F(1, 176) = 3.946, p = .049, partial η2 = .022. To qualify the nature of this interaction, a simple effects analysis using Fisher’s Least Significance Difference Test (LSD) was conducted (Figure 3). The results indicate that the averted gaze image was significantly more persuasive when paired with a statement than with a command, F(1, 176) = 8.364, p = .004, partial η2 = .045. However, no such effect was found for the direct gaze image: When the ad included an image with a direct gaze, the statement and the command seemed to be equally persuasive, F(1, 176) = .015, p = .904, partial η2 = .000. Overall, the data support hypothesis 3.
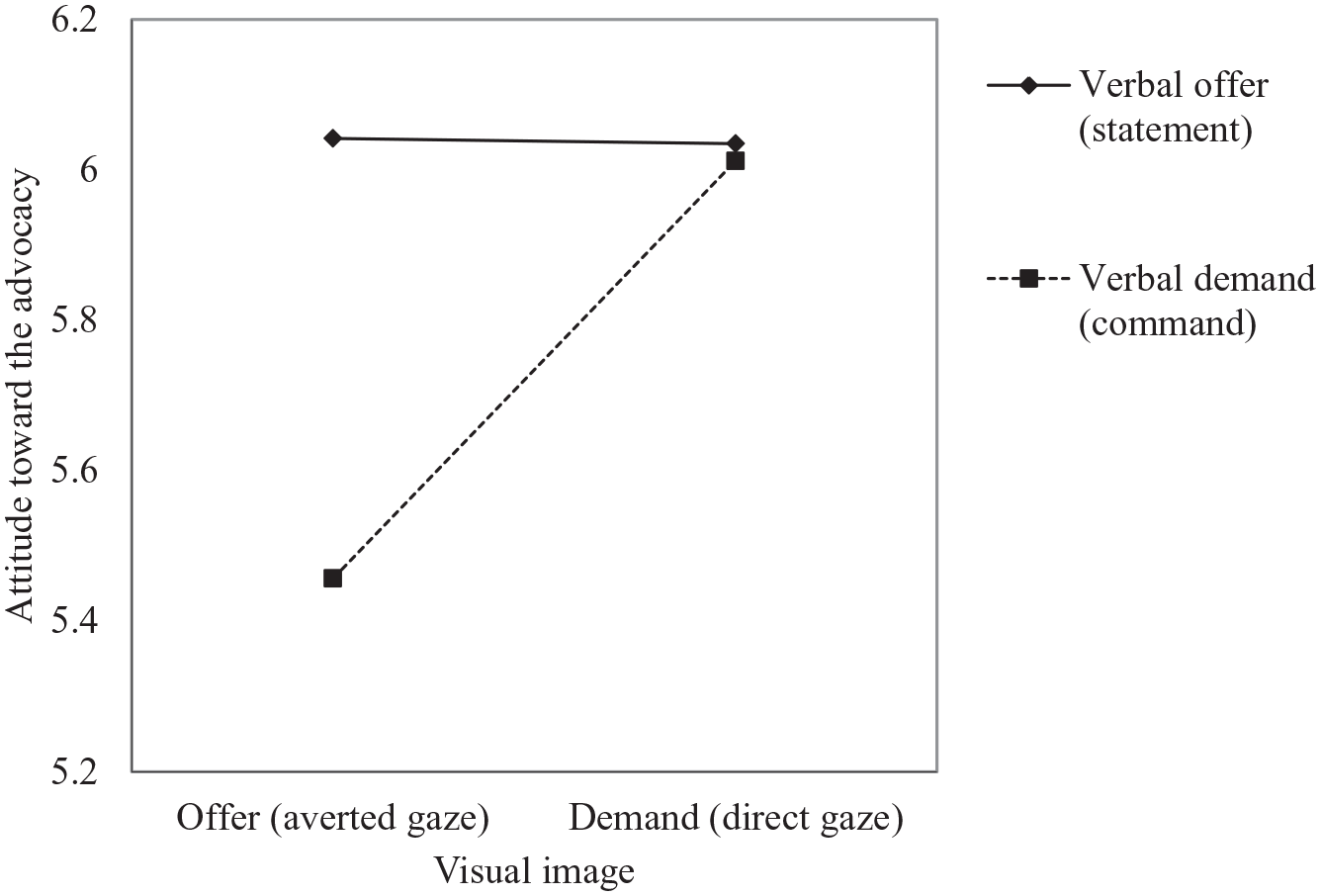
Interaction between visual image and verbal text on attitude toward the advocacy.
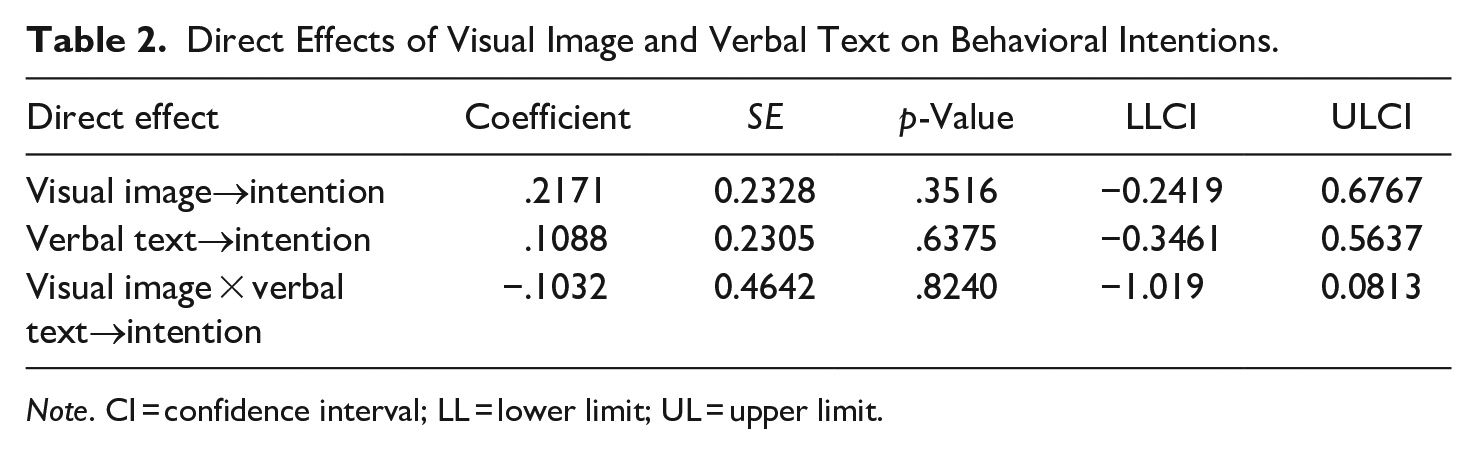
H4 maintained that the effects of visual image and verbal text on participants’ intentions to volunteer would be mediated by attitude toward the advocacy. A series of mediation analyses was conducted using Hayes’ PROCESS macro in SPSS. Analysis 1 included visual image as the independent variable (Mediation model 4), Model 2 included verbal text as the independent variable (Mediation model 4), and Analysis 3 included visual image as the independent variable and visual text as the moderator variable (Moderated mediation model 8). All analyses controlled for sex, age, prior volunteering experience, and knowledge of the SRC’s effort to recruit volunteers. As indicated in Table 2, no direct message effects were found on behavioral intentions: Neither visual image (coefficient = .217, p = .352, 95% CI [−0.2419, 0.6767]), nor verbal text (coefficient = .109, p = .638, 95% CI [−0.3461, 0.5637]), nor the interaction between visual image and verbal text (coefficient = −.103, p = .824, 95% CI [−1.019, 0.0813]) yielded a significant direct effect on people’s intention to volunteer at the SRC. However, significant indirect effects were obtained in all three analyses (Table 3). An indirect effect was found between visual image and behavioral intentions through attitude (coefficient = .121, 95% BCI [0.002, 0.2591]) as well as between verbal text and behavioral intentions through attitude (coefficient = −.134, 95% BCI [−0.3069, −0.0077]). Moreover, the results showed a significant index for moderated mediation (coefficient = .245, 95% BCI [0.0099, 0.5585]). Overall, the data support the idea that attitude toward the advocacy mediates the message effects of visual image and verbal text on behavioral intention. This leads us to accept H4.
Direct Effects of Visual Image and Verbal Text on Behavioral Intentions.
Note. CI = confidence interval; LL = lower limit; UL = upper limit.
Indirect Effects of Visual Image and Verbal Text on Behavioral Intentions Via Attitude Toward the Advocacy.
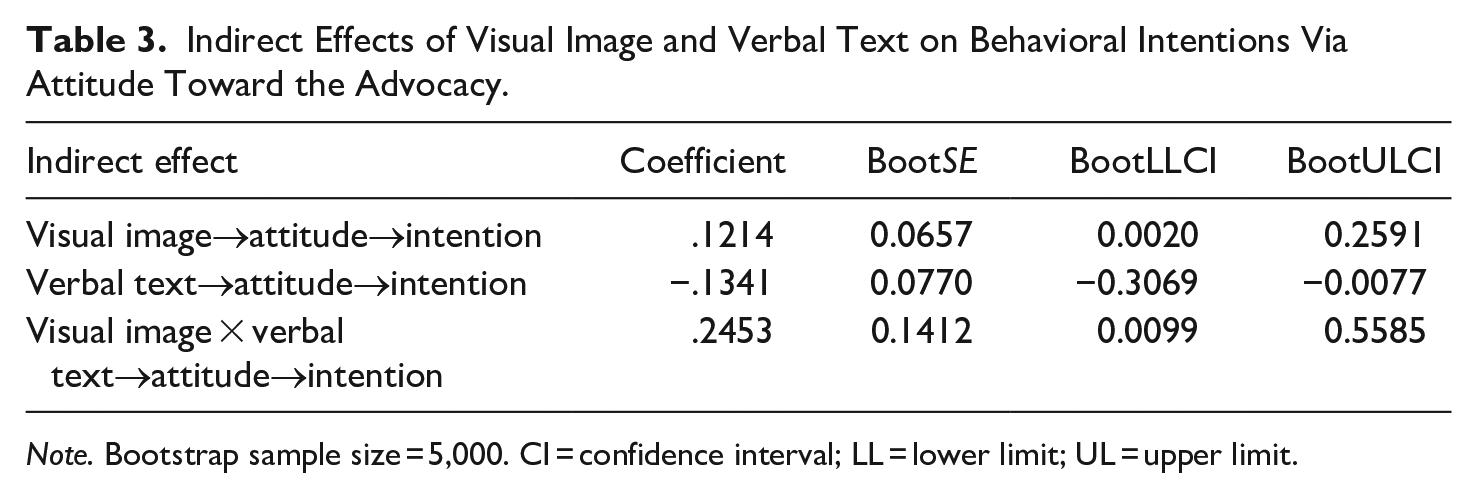
Note. Bootstrap sample size = 5,000. CI = confidence interval; LL = lower limit; UL = upper limit.
Discussion
Nonprofit organizations are confronted with an increasing competition for volunteers. In face of this development, mobilizing their own members becomes key for many of these organizations. This study was motivated by the aim to better understand how to combine visual and verbal appeals to increase volunteering among nonprofit members. We thereby focused on image acts (demand: direct gaze vs. offer: averted gaze) and speech acts (demand: command vs. offer: statement). The results lend support to the idea that correspondence between image and text only matters when the campaign includes low-attention grabbing images in the form of averted gaze images.
Visual Offer (Averted Gaze) Versus Visual Demand (Direct Gaze)
The concept of image act captures the relationship that is established between the depicted person and the viewer (Kress & van Leeuwen, 2006). We differentiated between two types of image acts: visual offers (averted gaze images) and visual demands (direct gaze images). Associating direct gaze with social affiliation, social control, and attention orientation, we anticipated that demand images would be more effective than offer images. The data confirmed this effect. However, the difference was only marginally significant. This may have to do with the type of behavior that was promoted: volunteering, that is a prosocial behavior. Previous research on prosocial advertising campaigns suggests that averted gaze images may also fulfil a social control function. A face that looks away may evoke considerations about belongingness and social evaluation (Manesi et al., 2016). Wirth et al. (2010) demonstrated that exposure to pictures of a face with an averted gaze (as compared to pictures of a face with a direct gaze) led to greater feelings of social exclusion, negative emotions, and lower self-esteem. Hence, by eliciting fears of negative social evaluation and rejection, averted gaze images may motivate people to engage in prosocial behaviors including volunteering (Manesi et al., 2016). Given these explanations, we encourage research to further investigate the mechanisms underlying the persuasive effects of image acts in volunteer recruitment campaigns.
Verbal Offer (Statement) Versus Verbal Demand (Command)
Kress and van Leeuwen (2006) relate images acts to a concept that is known as speech act. Verbal text can offer things through statements (e.g., “You can register on our website”). Moreover, verbal text can demand things through commands (“Register now on our website!”). In line with reactance theory and politeness theory (Brehm & Brehm, 1981; Brown & Levinson, 1987), we found statements to be significantly more persuasive than commands. This indicates that people are more persuaded by campaigns that give them the freedom to derive their own conclusions instead of pushing them toward certain choices.
Combining Image Acts and Speech Acts
A central purpose of this study was to examine the interplay between image acts and speech acts. We tested the idea that image-text matching would increase persuasion, but only for campaigns that include an averted gaze image. Our data supported this assumption. The results showed that participants found the averted gaze image significantly more persuasive when it was paired with a statement. No such effect was found for the direct gaze image: When the ad included an image with a direct gaze, nonprofit members rated the statement and the command as equally persuasive.
These findings align with previous research, indicating that image-text matching does not generally increase persuasion, but does so under certain conditions (Seo & Dillard, 2019a, 2019b; Seo et al., 2013). One of the key theoretical contributions of this study is that it identifies such a boundary condition. Based on our research, we propose the following amended rule for image-text matching: Image-text matching only leads to greater persuasion for persuasive campaigns that include low-attention grabbing images (e.g., averted gaze images). Despite the obvious utility of such a heuristic, further research is needed to validate the refined rule in contexts beyond volunteer recruitment campaigns. Moreover, future studies could examine the refined image-text-matching rule with other types of attention-grabbing images such as emotionally-evocative images (e.g., pictures of people with a neutral facial expression vs. pictures of people with an angry or happy facial expression) or shocking images (e.g., factual pictures vs. exaggerated, disturbing pictures).
Persuasion Process
In line with the theory of reasoned action (Fishbein & Ajzen, 2005), we conceptualized persuasion as a sequence of linked changes. The data revealed the expected pattern, indicating that people’s attitude toward volunteering mediates the effects of image act and speech act on their intentions to volunteer. Although this finding is not novel, it replicates an established effect and, by doing so, underscores the veracity of the other findings from our study.
Practical Implications
The present study yields implications as to how nonprofit organizations should address their members to effectively promote volunteering. The findings show that nonprofit members respond differently to volunteer recruitment campaigns depending on whether they are demanded to volunteer or whether they are offered the possibility to do so. When looking separately at the visual and the verbal mode, the study indicates that nonprofit organizations should use direct gaze images (i.e., visual demands) and statements (i.e., verbal offers). Moreover, our research project offers guidance as to how to combine image acts and speech acts to promote volunteering. When the campaign includes a direct gaze image, nonprofit organizations can use statements or commands. However, pairing averted gaze images with commands should be avoided as it considerably decreases the campaign’s persuasiveness. These results fall in line with prior research, indicating that visual images serve as “entrance stimuli” (Brantner et al., 2011, p. 526) into a campaign. Depending on how much attention the image absorbs, correspondence between the verbal and visual elements plays a more or less important role for persuasion (Sajjacholapunt & Ball, 2014). This has an important implication for the design of volunteer recruitment campaigns. If nonprofit organizations use attention-grabbing images (such as direct gaze images), there is an increased risk that verbal message elements will be overlooked by the recipients. Thus, to make sure that verbal message elements are given sufficient attention, nonprofit organizations may want to increase the salience of the verbal elements, for instance, by visually highlighting them (e.g., by using big and bold font sizes, using different colors; Bateman, 2014).
Limitations
Although this study is the first to examine the interplay between image and text in volunteer recruitment campaigns, it is not without limitations.
First, one of the strengths of the study can be simultaneously considered one of its most significant weaknesses. Study participants were members of the Swiss Red Cross. On the one hand, this strengthens the external validity of our findings and offers nonprofit organizations robust guidance on how to effectively mobilize their own members. On the other hand, our focus on members of a nonprofit organization may limit our ability to generalize our findings to a broader population. Nonprofit members likely have a favorable attitude toward that nonprofit organization and may therefore be generally supportive of its campaigns. Favorable attitudes presumably influence information processing, in that they decrease resistance to persuasive attempts (Rucker et al., 2014). This lower resistance may lead people with a positive prior attitude to be more receptive and open to persuasive messages. In line with this assumption, previous studies found that positive prior attitudes toward a nonprofit organization increase donation intentions (Lwin & Phau, 2014; Song & Kim, 2020). Although speculative, the greater baseline support of people with positive prior attitudes may affect the magnitude of the effects measured (Bünzli, 2022). When people are already favorably inclined toward an advocacy, variations in message strategies may produce relatively smaller effects (i.e., smaller effect sizes). In contrast, variations in message strategies may engender relatively bigger effects among people with less favorable prior attitudes (i.e., bigger effect sizes). For the present study this could mean, for example, that mismatching an averted gaze image with a verbal appeal would decrease persuasion even more among non-members. Alternatively, prior attitudes may also influence the direction of the effects measured. A study by Jäger and Eisend (2013) suggests that humorous appeals reduce intentions to driving after drinking alcohol or disobeying speed limits among people with less favorable prior attitudes toward these behaviors, whereas fear appeals are more effective among people with favorable prior attitudes. Similarly, averted gaze images seem to be more effective than direct gaze images among people who disagree with the message advocacy (Chen et al., 2013). With regard to the interplay between visual and verbal offers, however, we would expect that the refined image-text matching principle equally applies to people with less favorable prior attitudes (i.e., we would expect that prior attitude does not change the direction of effects). Correspondence between image and text has shown to increase persuasion because it decreases the cognitive load required to process a message. Hence, the mechanism by which image-text matching works is not contingent upon subjective views toward an organization. To test these assumptions and see if the interplay between visual and verbal appeals is influenced by prior attitudes, we encourage future research to replicate the study using a broader sampling strategy. Specifically, we recommend that the sample includes both members and non-members of a nonprofit organization.
A second limitation of the study concerns the fact that we measured self-reported intentions to volunteer instead of actual behavior. While it is common to utilize intention as a proxy for actual behavior (Yzer, 2012), future studies might want to capture actual volunteering behaviors and check to what extent favorable attitudes toward volunteering and intentions translate into volunteering. Third, attitudes and intentions were measured immediately after message exposure. This reduces our ability to make predictions about the long-term impact of presenting recipients with different (combinations of) image acts and speech acts.
Conclusion and Outlook
In modern persuasive communication, visual image and verbal text mostly occur together. A thorough understanding of persuasion therefore requires considering the combined effects of visual and verbal stimuli. Toward this end, the present study investigated the interplay between image act (offer: averted gaze vs. demand: direct gaze) and speech act (offer: statement vs. demand: command). An experimental study among 205 members of a Swiss nonprofit organization indicates that image-text matching increases persuasion, but only for campaigns that feature an averted gaze image. Moreover, the study showed that the message effects of image acts and speech acts on nonprofit members’ intention to volunteer are mediated by their attitude toward volunteering. In terms of practical implications, the study suggests that nonprofit organizations should pay close attention to the way they combine image and text in their volunteer recruiting campaigns. Averted gaze images should be paired with verbal appeals that emphasize the possibility of volunteering (e.g., sentences that use terms such as “can” and end with a full stop). Combining averted gaze images with verbal appeals that express a command (i.e., sentences that use imperatives and exclamation marks) has shown to significantly decrease persuasion.
The findings lend support to the idea that images are often the first thing people focus on when looking at a campaign message and that this affects subsequent verbal message processing (Gulliver et al., 2020; Sajjacholapunt & Ball, 2014). We therefore recommend future research to further explore interaction effects between gaze direction and verbal text. Beyond attention orientation, direct gaze images have also been associated with social control because they may evoke a feeling of being watched (Manesi et al., 2016). It is thus possible that direct gaze images, in combination with certain emotional appeals, may backfire and decrease persuasion. Imagine a volunteer recruiting campaign emphasizing that the audience has a moral obligation to help others in need (guilt appeal). When feeling watched and controlled, people may perceive such appeals as obtrusive or even threatening. A similar effect may occur with anger appeals or fear appeals.
Strikingly, previous research has linked direct gaze with both social control as well as social affiliation (Ewing et al., 2010; Valentini et al., 2018). We encourage future researchers to investigate the conditions under which direct gaze is interpreted as a sign of control versus a sign of personal closeness, and how this affects verbal message processing. We suspect that the facial expression of the photo model plays an important role. A direct gaze from a happy-looking person may elicit perceptions of social affiliation, whereas a direct gaze from an angry-looking person may evoke perceptions of social control. It would be interesting to see how perceptions of affiliation compared to perceptions of control influence viewers’ responses to commonly used verbal message elements such as gain-loss frames (e.g., describing blood donation as a way to either “save a life” or “prevent a death”; Chou & Murnighan, 2013). Under an affiliation perspective, gain frames might be more effective because people may experience a greater motivation to maximize the benefits for themselves and others and, therefore, may be focusing on the advantages of complying with the message. Under a control perspective, loss frames might be more persuasive because people may be more concerned about preventing potential sanctions and, as a result, may exhibit a stronger tendency to avoid losses.
Overall, the present study examines whether NPOs should use demands or offers in their volunteer recruiting campaigns and whether correspondence between image and text increases persuasion. By doing so, it makes an important theoretical contribution to our understanding of how visual image and verbal text work together in modern campaigns. We believe that our study provides a valuable starting point for further research. Since the image-text matching rule tested in this study refers to a general principle of multimodal persuasion, we would expect to see similar effects in other campaign contexts such as health advocacy or commercial marketing. In terms of practical implications, our study offers much-needed guidelines for nonprofit organizations on how to best combine image and text to persuade their target audiences to volunteer.
Footnotes
Author Note
We confirm that this work is original and has not been published elsewhere, nor is it currently under review at another journal.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.