
Abstract
Masters swimming is a swimming program for adults, featuring both individual and group events. In individual events each swimmer competes against other swimmers in the same age category, whereas in group events any four swimmers can form a relay, and the age category of the relay is given by the sum of the ages of its participants. Setting up relays in masters swimming may be harder than for professional or junior swimming, in which swimmers compete against other athletes in the same age category. In this work, an integer programming model is presented in order to optimize the assembly of relays in masters swimming, and a scheme is implemented to present the results in a friendly format for the coach. These models are applied to data from a team in Buenos Aires City, Argentina.
Introduction
Masters swimming is a swimming program organized by clubs or federations, for adults. This type of swimming is aimed at those who stopped competing due to their age, for people who started practicing the sports at midlife, and in general for those who think that it is never too late to play sports (i-Natación, 2023). The first formal competitions were held in the 1970s and 1980s in Australia, Canada, Great Britain, New Zealand, USA, Japan, Germany, and Italy (Federación Internacional de Natación, 2023). Like many other initiatives, it did not take long to reach the rest of the world with increasing success. The categories in this modality are divided into age groups with a five year span, starting at 25 years old. There is also a category called “pre-masters”, for swimmers between 20 and 24 years old.
Master swimming has individual and group events. In individual competitions, each swimmer competes against other athletes in the same age category, i.e., within a range of five years. In group events, though, it is not mandatory to assemble groups of four people in the same age category, since this would impose too strong a constraint given the wide age range of swimmers. Instead, any four people can form a relay, and the category to which they belong will be given by the sum of the ages of the participanting swimmers, as follows:
Pre-masters can only form relays among themselves (i.e., the relay category spans from 80 to 99 years old) and cannot participate in relays of other categories. Due to these facts, swimmers in this category are not considered in this work. Each tournament usually consists of the following swimming events:
In Events 1 and 4, relays are composed by four women. In Events 2 and 5, relays are composed by four men. Finally, in Events 3 and 6, relays are composed by two men and two women. In Events 1 to 3 all swimmers perform freestyle swimming, whereas in Events 4 to 6 each swimmer performs a different style (backstroke, breaststroke, butterfly, and freestyle, in this order).
Due to these rules, setting up relays in masters swimming may be a nontrivial task compared to professional swimming (where athletes are not grouped into categories given by age) and to minor swimming (in which categories span a two-year range and relays are composed by people from the same age category). In this work we tackle this issue, by seeking to automatically optimize the assembly of relays prior to a competition, as a tool for assisting the coach’s decisions. Usually, the coach performs this task by hand, having previously registered the swimming times for each athlete and each swimming style on a spreadsheet. This is performed by trying different options and manually calculating the time that would result from each combination the coach comes up with. Clearly, if the team is large, it is not possible to test all possible options by hand.
Due to these reasons, in this work we propose an integer programming model for optimizing the design of relays prior to a tournament, by taking into account the available swimmers, their age and their best times at each swimming style, and the available events to be performed, in order to maximize the overall chances of winning trophies for the participating team. As we shall show in the next sections, the proposed approach is computationally effective and allows to find optimal configurations (with respect to the criteria to be defined in the next sections) within reasonable running times.
The remainder of this work is organized as follows. Section “Literature review” reviews similar works in the existing literature. Section “Proposed integer programming model” proposes an integer-programming based approach for optimizing the assembly of relays, and Section “Experimental results” reports our computational experience with this machinery. Finally, Section “Concluding remarks” closes the paper with concluding remarks and lines for future research.
Literature review
The literature contains previous experience applying combinatorial optimization techniques to different problems related to the assembly of swimming teams.
In Nowak M. and Pollock (2006) high school swimming is considered, in particular when two teams face each other. It is assumed that the opponent’s times are known, and with those times a model is run that estimates the composition of the relays in the opposing team. This is then used to run the final model in order to design the participating relay. The related work (Bailey and Nowak, 2018) also deals with high school swimming and two opposing teams, and is a generalization of Nowak M. and Pollock (2006). The user has to propose different scenarios for the opposing team’s setup, so that the model can then decide the best setup for its own team, depending on each possible scenario.
In Mancini (2018) masters swimming is considered, but only one age category is analyzed (women from 25 to 29 years old). Therefore, the proposed scheme is analogous to high school swimming. Multiple teams face each other, and the times and setup of the opposing teams are estimated based on previous tournaments. In the similar work Hannan and McKeown (1979), the user must specify the swimming times of the opposing team, and which athletes he/she believes the opposing team is going to present in each event. In all four cases, the aim is to decide in which individual and relay events (only individual events in Hannan and McKeown, 1979 and Mancini, 2018) each swimmer has to participate in order to maximize the points obtained by the team, taking into account the results of the competing teams.
Finally, in Masedu and Angelozzi (2006) only relays are optimized. All athletes are assumed to swim the same style, and age and gender are not mentioned. Different times are considered depending on the starting place, which is more applicable to athletics than to swimming. As a side remark, these models can be applied both to swimming and athletics due to their similarities, although the consideration of swimming styles does not apply in athletics.
Proposed integer programming model
The objective of this work is to propose a computational machinery in order to optimize the assembly of the relays for a team prior to a competition. The motivations for the coach may not always be the same, namely the aim could be to get as many podiums (i.e., top-three finishes) as possible or to set a national/continental record. In the former case as many competitive relays as possible should be assembled, whereas in the latter case just a single competitive relay may be assembled.
In any case, the notion of “competitive relay” is set up against the expected time for the category, which in turn is calculated as a function of the existing record for the corresponding age category and the expected competitiveness of the category. Indeed, assembling the fastest possible relay may not be a good strategy if the age category for the resulting relay is already too competitive and, therefore, the opposing teams are fast (hence the assembled team is less likely to be among the first three teams), or the existing record is too low. If this is the case, maybe slower relays could have more chances in the competition or at setting a record, since the existing record for the corresponding age category or the available competition is not too strong. Due to these facts, we propose to assemble the relays by optimizing the difference between the relay’s time to the corresponding national/continental record plus a certain additional time aiming to capture the competitiveness of the category (more details are provided in the sequel). As a general rule, Category 1 (i.e., the “youngest” category) and Categories 5 and 6 (i.e., the “oldest” categories) usually have a smaller number of participating relays than Categories 2–4 since it is difficult to assemble a relay within the corresponding age ranges, due to the lack of many young/senior swimmers. Hence, a relatively slow relay could have better chances in Categories 1, 5, or 6, compared to a comparatively similar relay in Categories 2–4.
We consider each event, each pool size (25 or 50 meters), and each type of record (national or continental) individually, thus getting 24 total problems to be solved. We seek a “global solution” by setting up many competitive relays, although the fastest relay may not be identified by this solution. We solve a different problem for each event since, with the exception of some tournaments, swimmers who can participate at each event do not overlap, due to the fact that the first day the competitions for women and men are held, whereas mixed relays compete in the second day.
We could also be interested in finding the best relay for each event, pool size, and type of record, i.e., finding a single relay, the one with the shortest distance to the target time for the resulting age category. The obtained solution will not necessarily be the fastest relay since records depend on the age category and, in general, the higher the category, the greater the record time. This solution provides the best attainable relay, and may be an interesting reference for the coach. There may be a preference to set a record in one category rather than another (for example, it may be that in the category with the highest chances of breaking a record, the current record is already held by the club, and it is therefore preferable to aim for a record in a new category). Once the best relay to be submitted has been identified, the global model can be run again with the remaining swimmers.
Tackling these problems involves solving one or several combinatorial optimization problems, i.e., problems asking the best solution with respect to a certain objective function over a set of solutions defined by combinatorial considerations (Korte and Vygen, 2012). For each event, pool size, and type of record, we propose to solve this combinatorial optimization problem with the following integer programming formulation. Let For For For For each category For each age category Finally, for each age category
Some comments on the parameters are in order. The random variable representing the time for each swimmer and each category is in general not known and, furthermore, evolves with the swimmers’ age and training (Alshdokhi et al., 2020; Costa et al., 2011). Furthermore, this random variable corresponds to the swimmer’s performance in competitions (and not in trainings), since the preparation for a competition implies that the times set during a competition are better than times recorded during trainings. Due to these facts, we usually have very few data points in order to estimate the parameters of this random variable. Although there are long-term studies enabling to have a general idea of these distributions (Born et al., 2022; Post et al., 2020), this task will have a certain amount of uncertainty associated with the lack of data for amateur swimmers.
Another parameter that is subject to an educated guess is the competitiveness of each age category. Although in general we expect Categories 2–4 to be more competitive due to a larger number of participating relays, in general the number and strength of the rival relays is difficult to estimate. We would like to “normalize” in some sense the distance to the record of the corresponding age category in order to capture the fact that a small distance to the record in a very competitive category will not be as good as a relatively larger distance to the record in a less competitive category. Since we will solve the problem with an integer programming formulation, we propose to consider
In order to obtain the expected time of a relay, the mean times of the four swimmers in the relay are added and then 1.5 seconds are subtracted from this figure. This corresponds to half a second for each swimmer from second to last, accounting for a shortened reaction time. Indeed, except for the first swimmer of the relay whose reaction time is the same as that of an individual race, for the swimmers who follow the reaction time is lower since the start can be anticipated by watching the previous swimmer arriving to the start/stop mark. We use the sum of the standard deviations of the random variables for the swimmers/style in the relays as a measure of the risk associated with each relay. Although this expression does not represent the standard deviation of the random variable representing the sum of the times for the swimmers in the relay, it provides a conservative upper bound on the dispersion and can be readily used in an integer programming formulation since it is a linear expression on the decision variables.
The model includes two sets of binary variables. For each swimmer
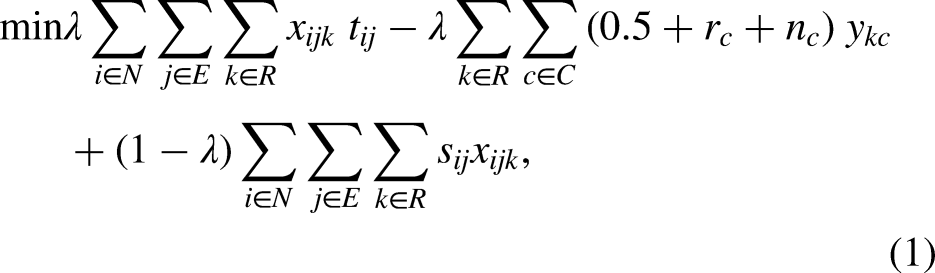
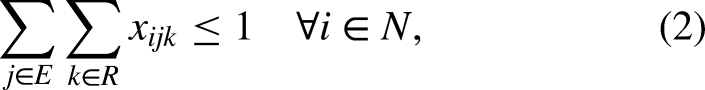
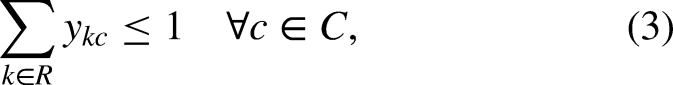
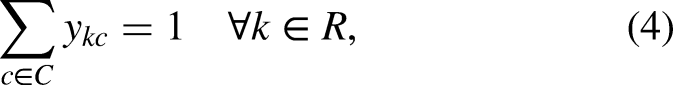
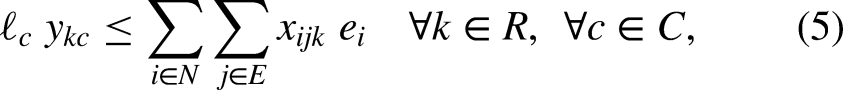
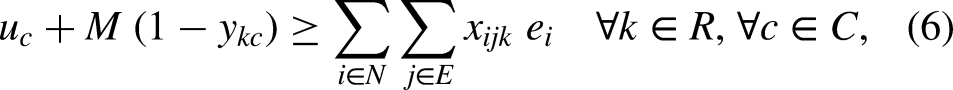
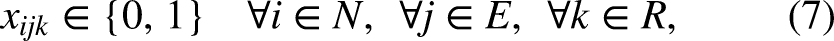
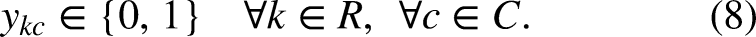
Constraints (2) request that there be no more than one relay and one swimming style per swimmer. Constraints (3) ask that there be no more than one relay per category, while constraints (4) ensure that each relay is in exactly one category. Constraints (5)-(6) bind the variables, in such a way that
The formulation (1)-(8) is appended with additional constraints for the different executions of the model. For Events 1 to 3 (corresponding to freestyle competitions), all four swimmers must use the freestyle style, i,e.,
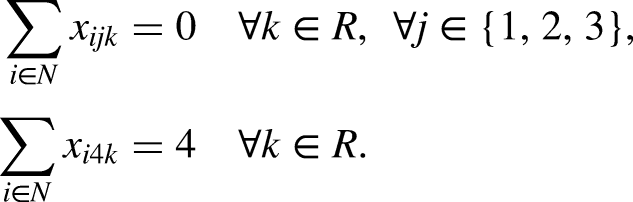
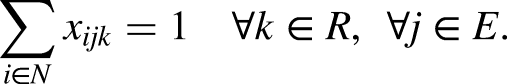
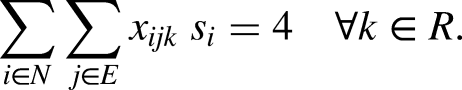
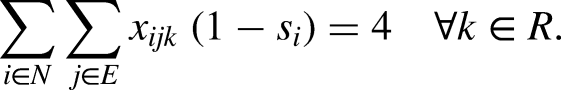
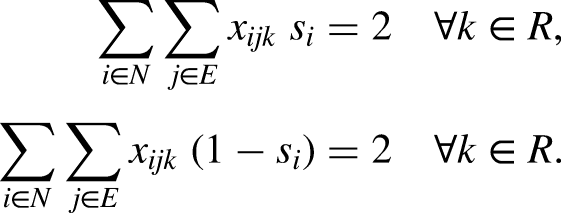
If we need to search for the single best relay, we can run the model by setting
Experimental results
We present in this section our experimental results with the models introduced in the previous section, with the objective of evaluating their solvability with state-of-the-art integer programming solvers. We also report the application of this machinery to real data from a team in Buenos Aires City, Argentina.
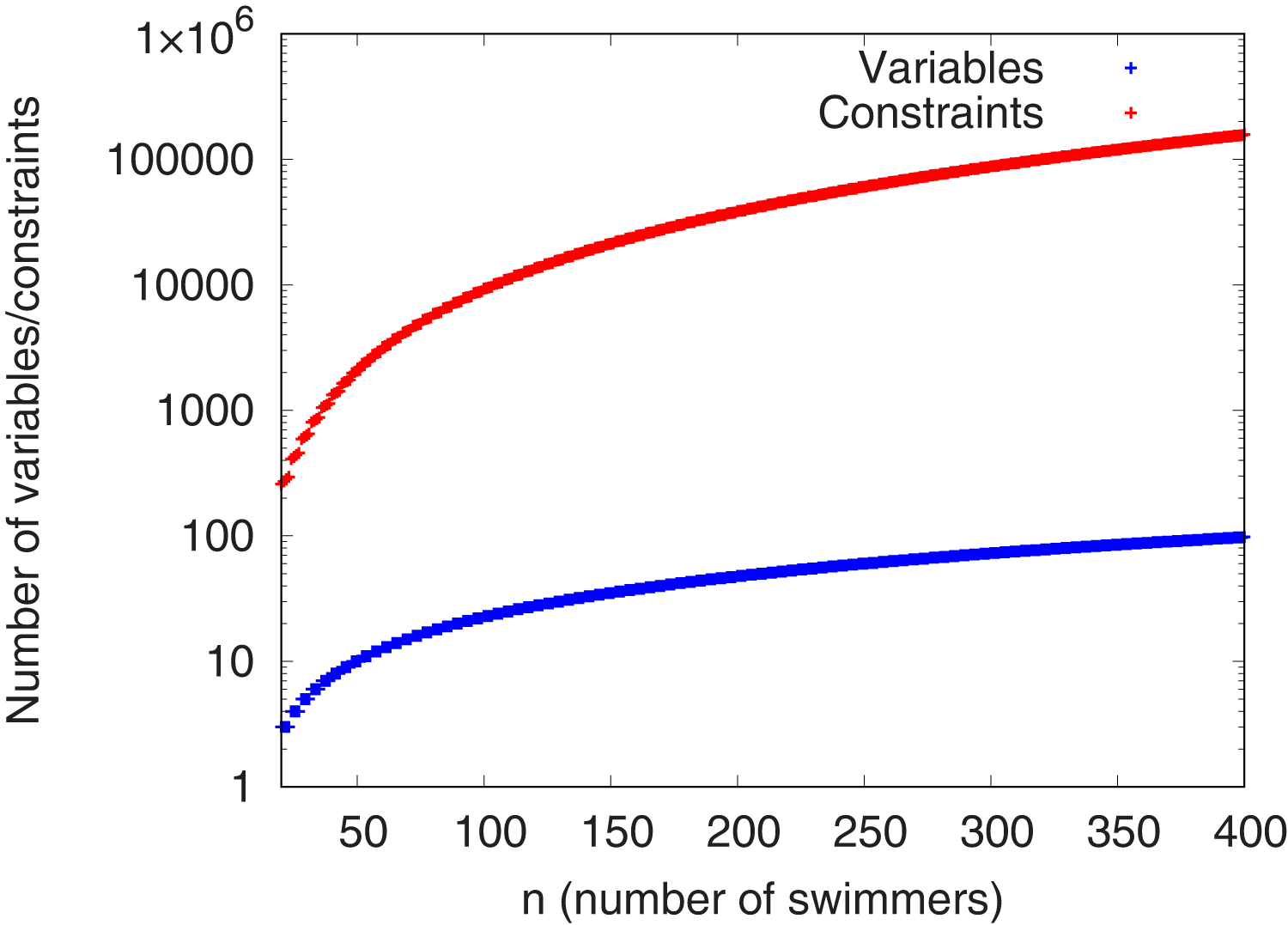
Depending on their structure and size, integer programming models may be difficult to solve by computational means. To this end, we implemented the models presented in Section “Proposed integer programming model” with the ZIMPL modeling language (Koch, 2004). Figure 1 reports the number of variables and constraints for the formulation (1)-(8) considering mixed medley relays, which is the most difficult instance from a computational point of view. The model has over 10.000 variables for
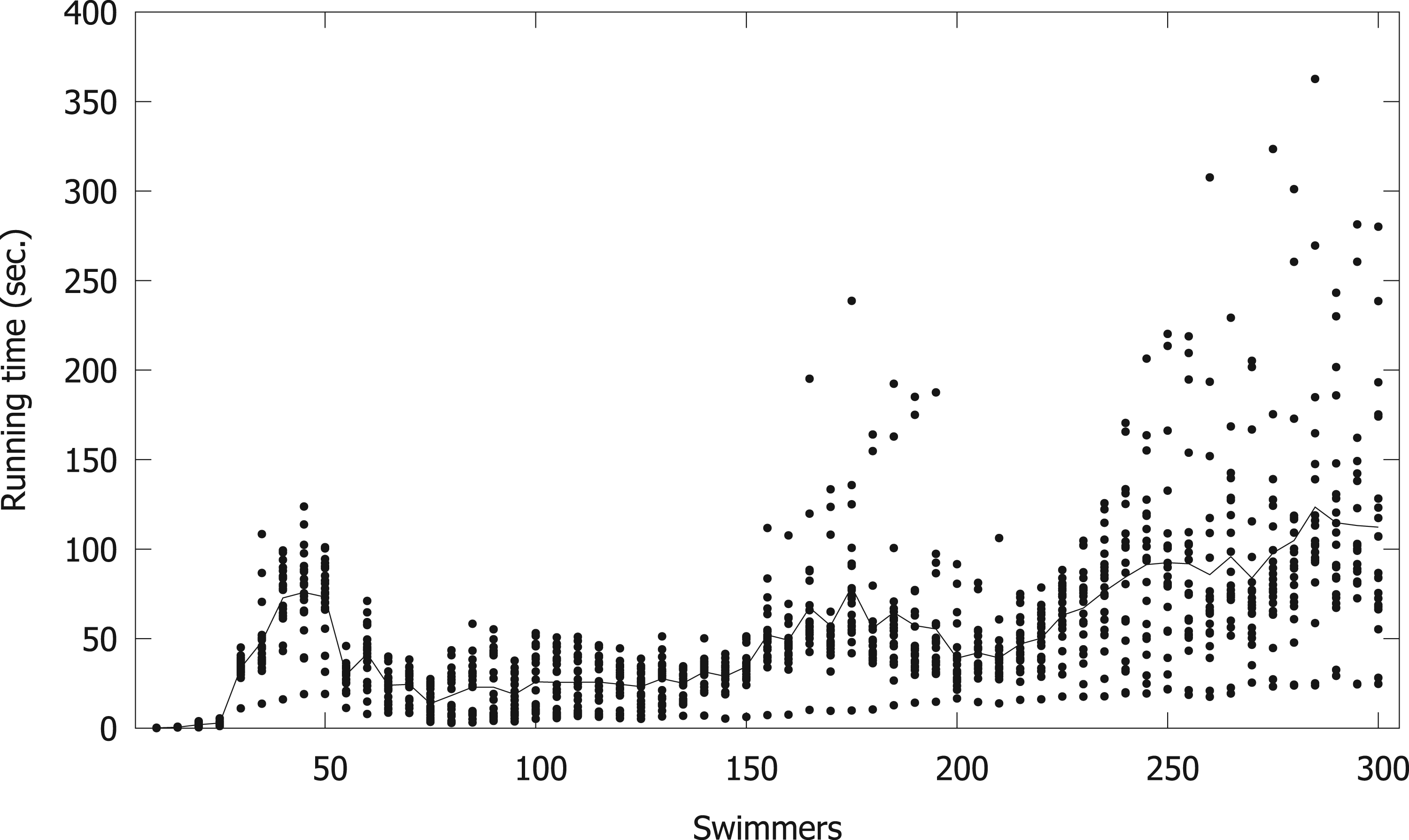
These observations may cast doubt on the possibility of effectively solving these instances with an integer programming solver. To evaluate this situation, we try to solve this model with the SCIP integer programming solver (Bolusani et al., 2024), which is the best-performing open-source integer programming solver at the time of writing this work. Figure 2 reports the running time to optimality of randomly-generated instances with increasing numbers of swimmers and a deterministic objective function, i.e., we take
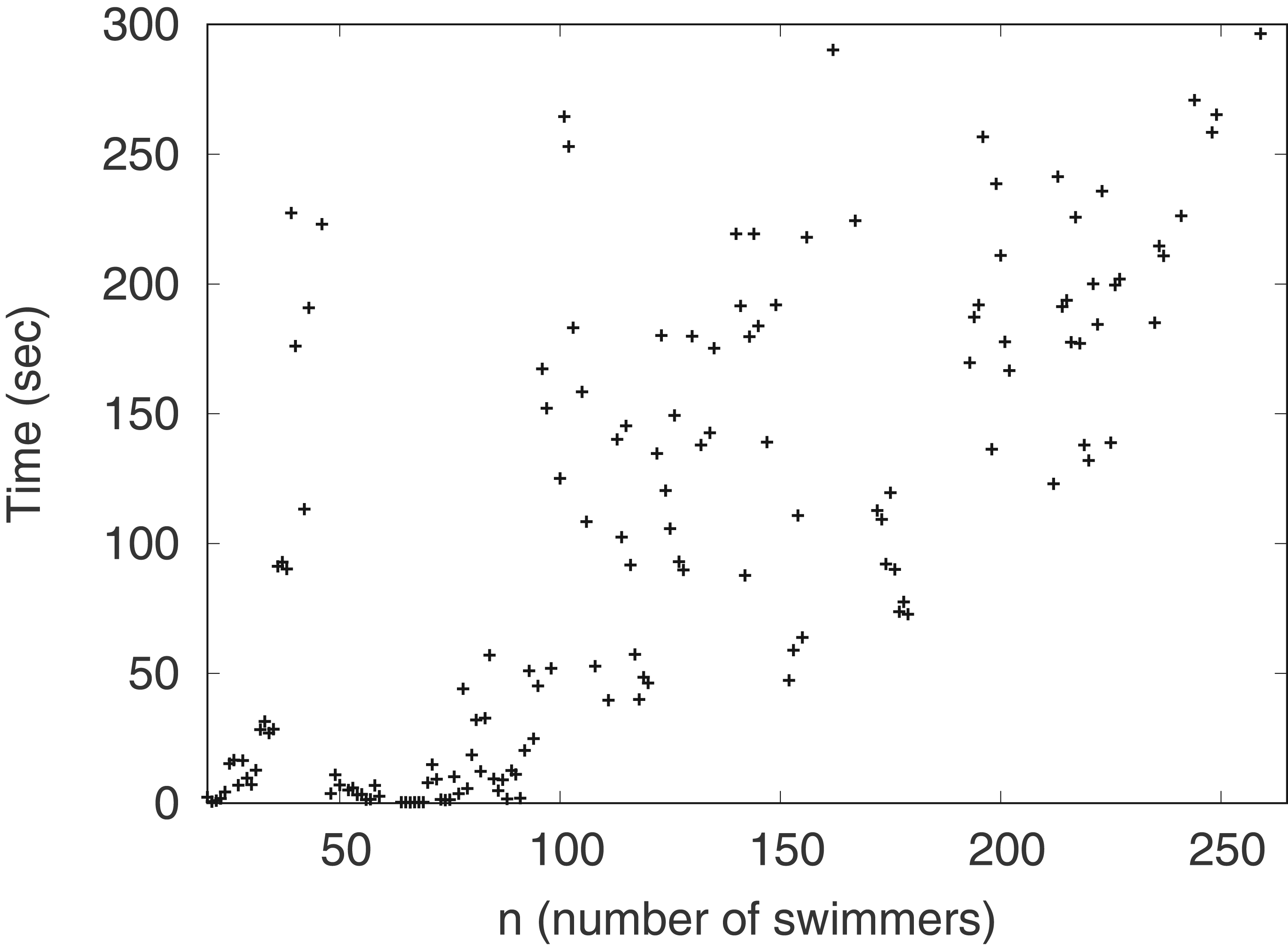
Time (in seconds) needed by the SCIP integer programming solver to solve randomly-generated instances with optimality, as a function on the number of swimmers.
We now explore the interplay between the two objectives (setting up fast relays with respect to the normalized records and minimizing the risk associated with the relays). To this end, we have constructed synthetic instances with reasonable times and standard deviations for each swimmer, according to his/her age. Figures 3 and 4 report the performance of SCIP over instances between 10 and 300 swimmers, taking
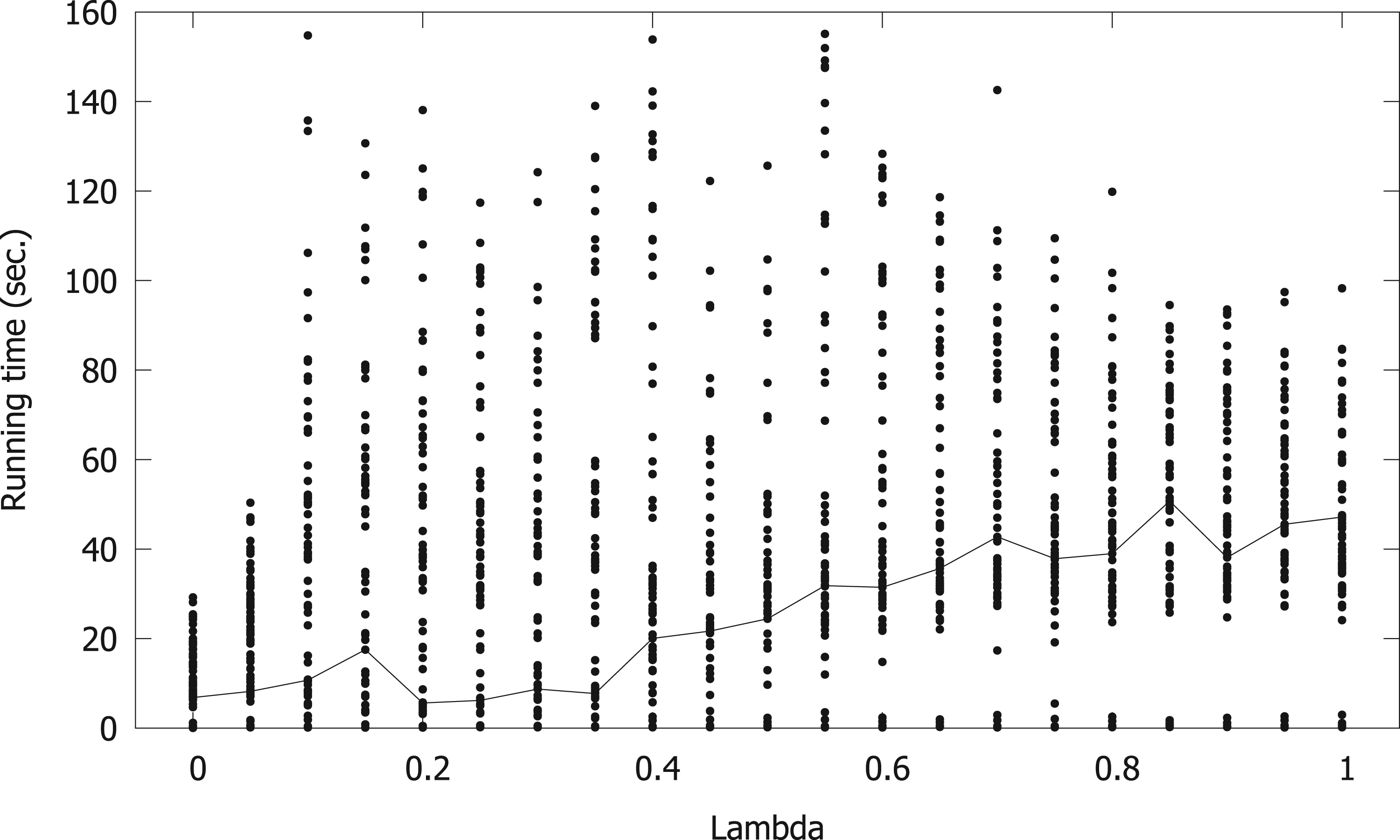
Average time as a function of the risk aversion parameter
Average time as a function of the number
Figure 5 reports the solution quality for a representative 50-swimmer instance, showing a typical behavior when performance and risk interplay. As the risk aversion factor
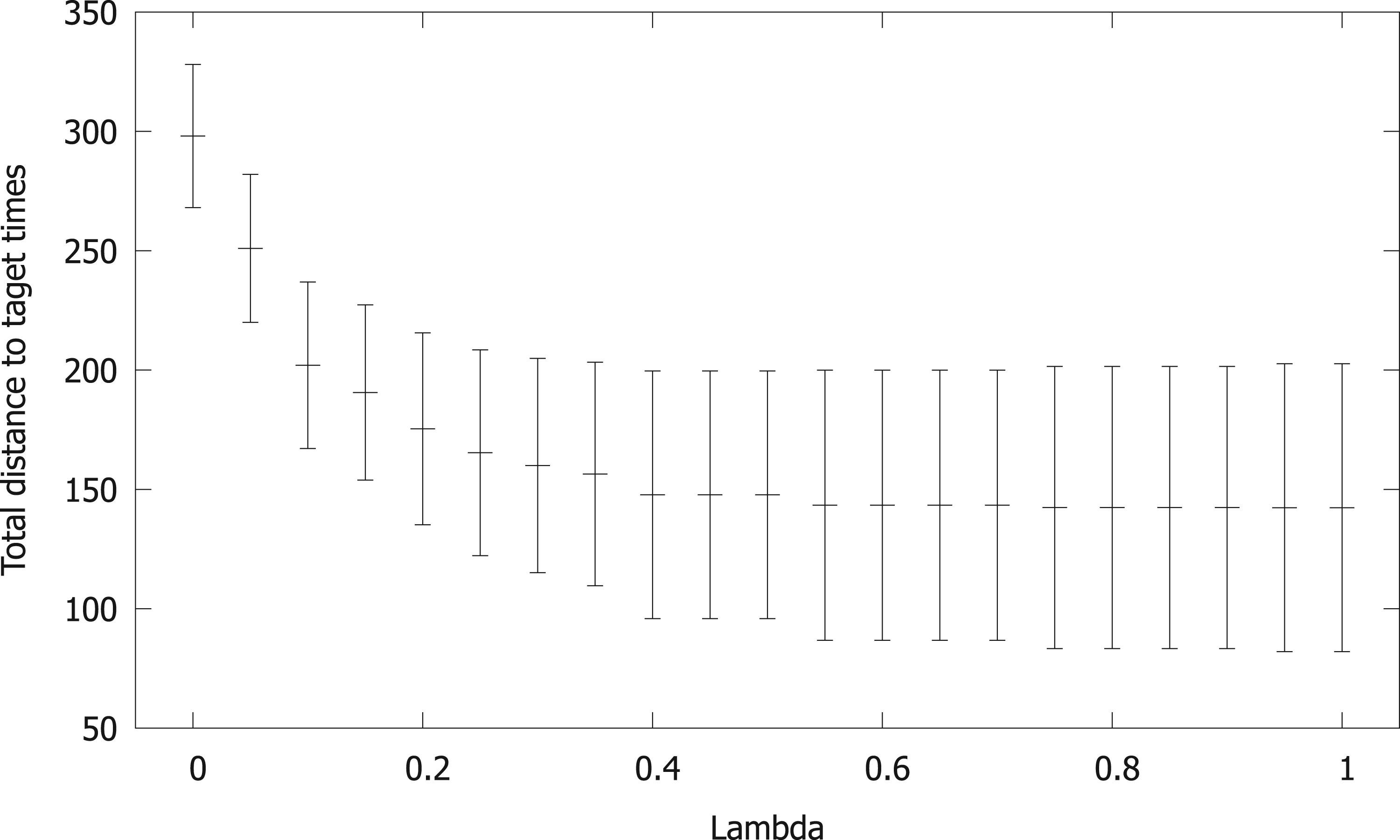
Sum of the distances to the target times, plus/minus the sum of the standard deviations, as a function of
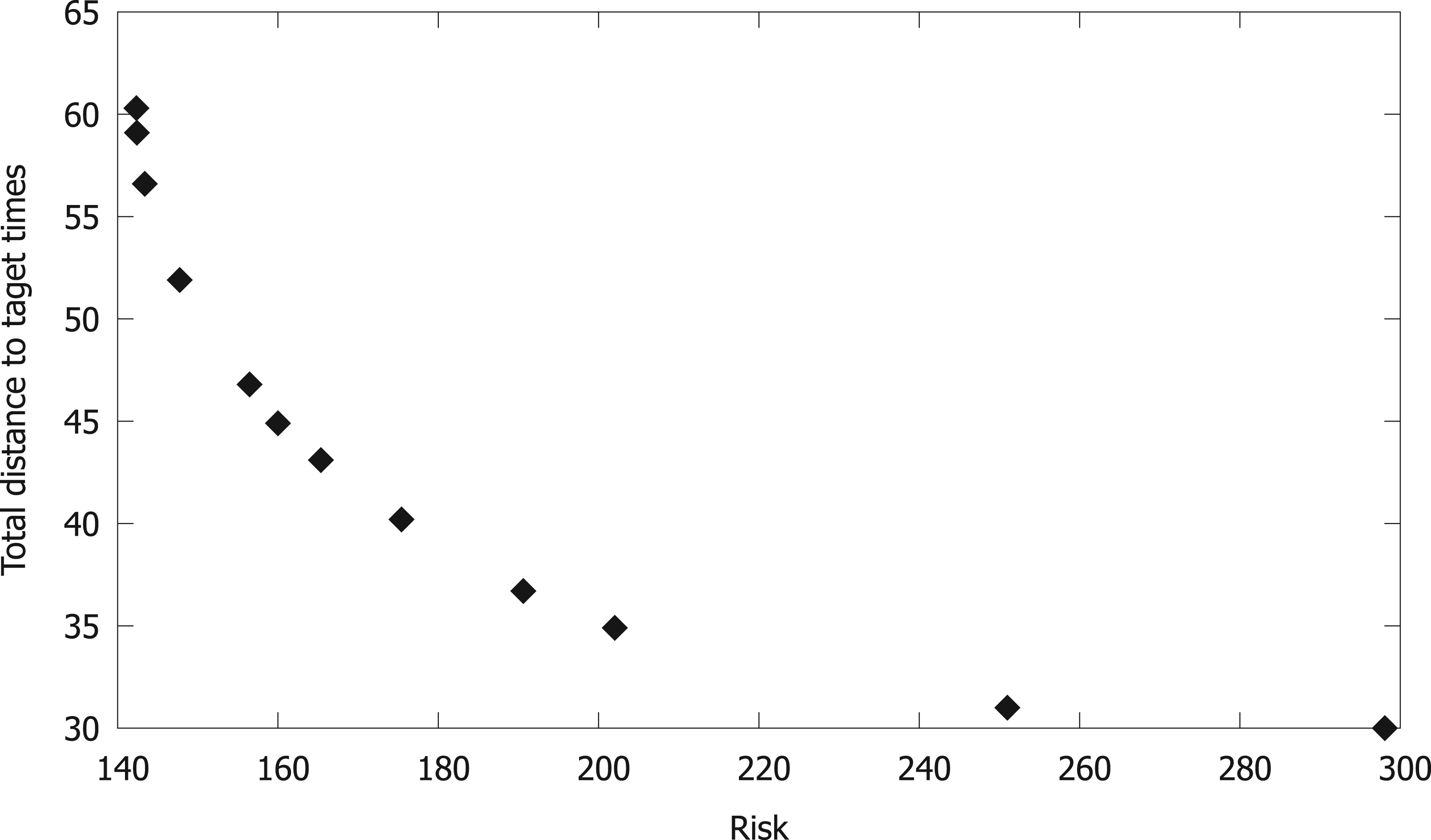
Pareto front for a representative 50-swimmer synthetic instance.
We close this section with the application of this machinery to a team in Buenos Aires City, Argentina. The team is composed by 36 swimmers (11 women and 25 men), aged between 24 and 84 years old. The times for each swimmer and each style were taken from tournaments held between 2021 and 2025 in 25- and 50-meter swimming pools (Confederación Argentina de Deportes Acuáticos, Cadda, 2023; Federación de Natación Buenos Aires, FeNaBA, 2023; Torneo Master Open, 2023). Times are taken from individual events and from the first swimmer at each relay, which are official times. As a reference, the average 50m backstroke time is 38.90 seconds, the average breaststroke time is 43.01 seconds, the average butterfly time is 34.31 seconds, and the average freestyle time is 33.11 seconds. The best 50m time is given by 25.33 seconds in freestyle for a 37-year old swimmer.
The data availability is limited in this case, and we have between one and seven measurements for each swimmer and each style. For swimmers with more than four measurements, the dataset appears consistent with a normal distribution. Descriptive statistics reveal slight skewness and moderate platykurtosis, both within reasonable bounds for normality. A Shapiro-Wilk test for normality yields no evidence against the null hypothesis of normality. Additionally, the Q-Q plots for these datasets show that the sample quantiles align closely with the theoretical quantiles of a normal distribution. Taken together, these results suggest that the data are well approximated by a normal distribution.
Figure 7 depicts the standard deviation of swimming times for swimmers with more than four measurements, showing no clear correlation between age and dispersion in swimming times. Also, it is remarkable to note that swimming times have a relatively small variability, especially considering that these swimmers are not professional athletes. It must be noted that these measurements are exclusively taken on competitions (where the performance is expected to peak), and no times taken in trainings are taken into account.
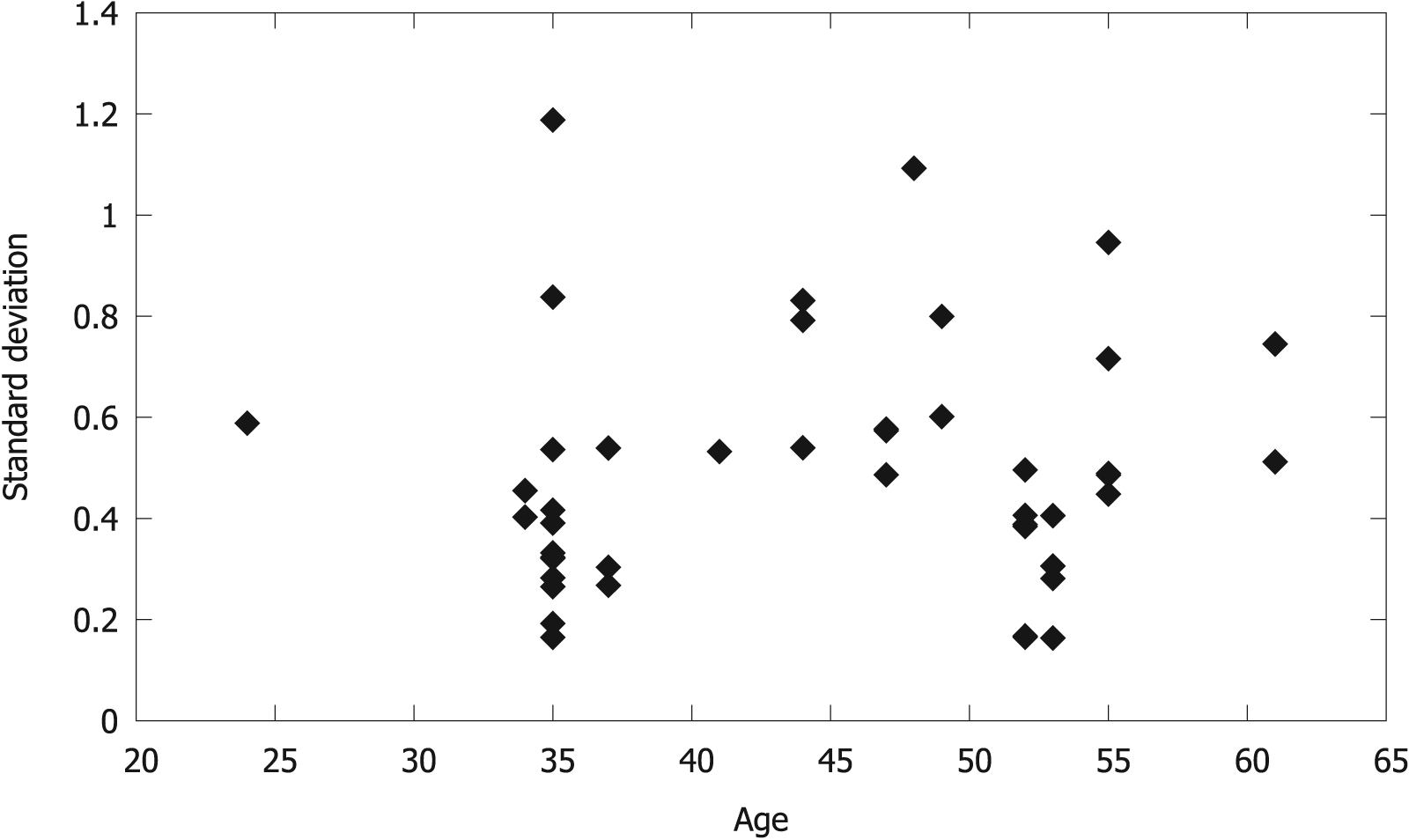
Standard deviation of swimming times as a function of swimmer age for swimmers with more than four measurements.
If we only have measurements for a certain swimmer and style for one pool size, the missing data is completed with the following approximation. If we have the average time for a 50-meter pool, we take half a second to complete the time for the short pool. Conversely, if we have the time for a 25-meter pool, we add half a second to obtain the time for a 50-meter pool. This estimation is based on the fact that an athlete usually swims faster in a 25-meter pool, since the return helps to propel him/her off again. When a swimmer does not have a registered time for a style in either the long pool or the short pool, we specify a time of 1000 seconds, which is extremely high. This way, the model will not choose a swimmer with a style with such a high time, although this may happen in order to complete a relay when no one else is available.
The Argentine records by category, both for long pool and short pool, were obtained from the Argentine Confederation of Aquatic Sports (Confederación Argentina de Deportes Acuáticos, Cadda, 2023), whereas the South American records by category were obtained from the Brazilian Association of Swimming Masters (Asociação Brasileira de Másters de Natação, 2023). As a reference, the Argentine record for mixed 4
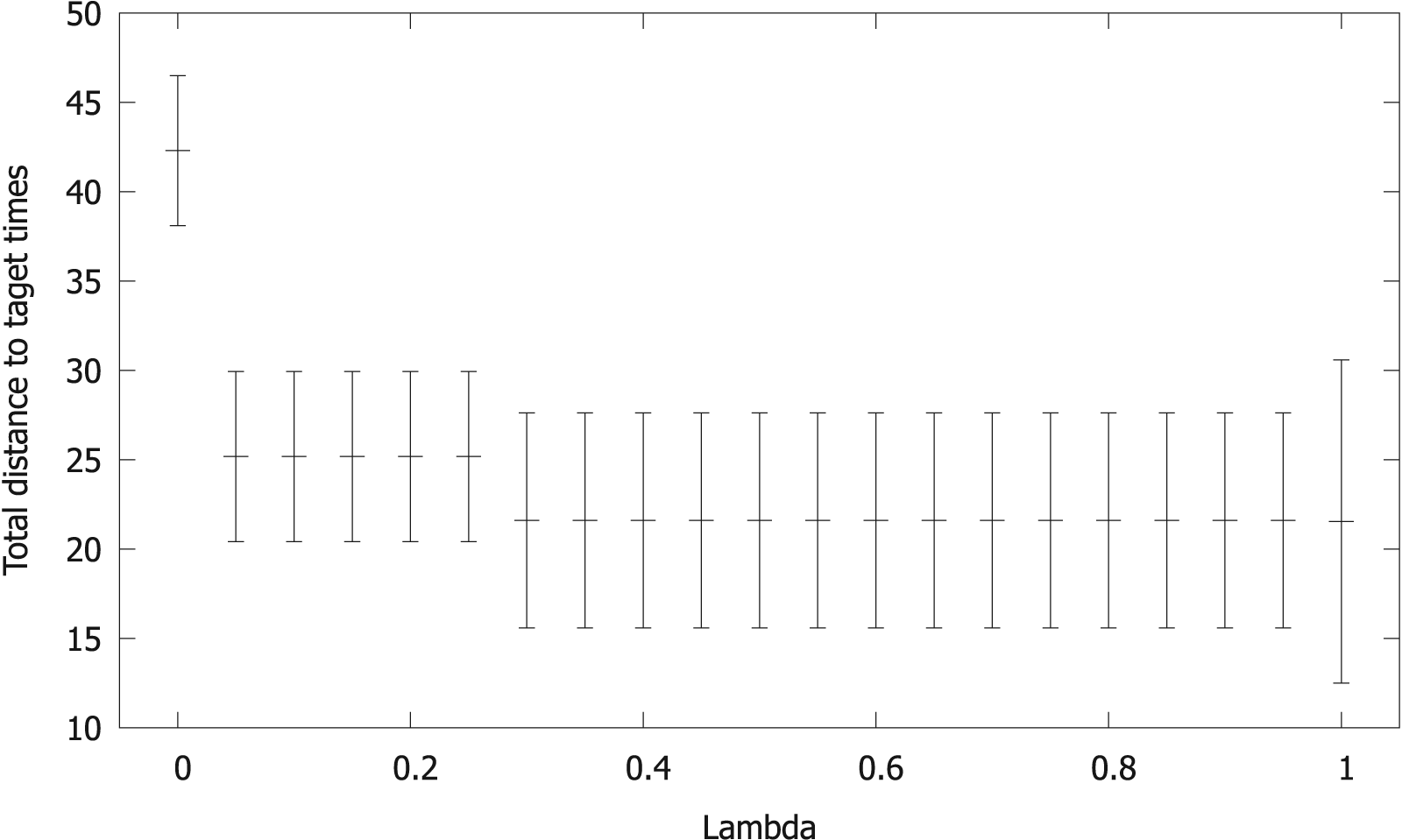
Sum of the distances to the target times, plus/minus the sum of the standard deviations, as a function of
Once the models are solved, an R Markdown is implemented that exports the results into an .HTML file. In this step, the data provided by SCIP are taken and presented in a readable format for users, in addition to adding complementary information to make decisions, including times, records, time differences, and styles of each swimmer. Then, in a back-and-forth with the coach, he/she can fix a certain number of relays or propose alternative relays. The swimmers involved in these fixed relays are taken out from the imput data and the optimization is performed again with the remaining swimmers. This way, the coach can fix some decisions and the model will optimize around these decisions for the remaining athletes.
This implementation has been used to put together relays for some tournaments since 2023, although the initial implementation resorted to a deterministic model, which is equivalent to setting
Concluding remarks
In this work we have proposed a computational tool based on combinatorial optimization techniques for designing swimming relays prior to a masters competition. The aim is not to provide a definitive solution but rather to provide various options, so the coach can choose among them according to the strategy that he/she believes is best for the tournament. Manually performing this task can be challenging as the number of swimmers increases, and the greatest help is given in the mixed 4
This tool has been in use since 2023 by a swimming coach and a swimmer who assists him in setting up the relays. We collect their thoughts below, translated from Spanish. We have the best information to make better decisions. We can save a lot of time in assembling the relays. We have a tool that gives us the assembly of the relays. In general, master swimmers do not know all the options there are to assemble or why some swimmers are left out of a relay. It is the best tool for a coach to design unbiased relays.
From a technical point of view, it would be interesting to explore whether the integer programming formulation presented in this work can be reinforced in order to solve with optimality instances with larger numbers of swimmers. This may involve studying this formulation in order to find valid inequalities (Aardal and van Hoesel, 1996; Aardal and Van Hoesel, 1999) and/or designing decomposition schemes for tackling these large instances (Nemhauser and Wolsey, 1988). The statement of an integer programming formulation considering both times to the record (normalized with respect to the expected competitiveness of the age category) and the risk associated with the relay involves some compromises. It would be interesting to explore whether such a normalization can be achieved by taking the relative time to the record (thus generating a nonlinear objective function), and whether the standard deviation of the complete relay can be incorporated to the risk term, instead of the upper bound used in this work. These issues may make the optimization problem quite challenging from a computational point of view.
Footnotes
Acknowledgements
We would like to take this opportunity to express our gratitude towards the anonymous reviewer for his/her suggestions, which greatly helped to broaden the scope of this manuscript.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and publication of this article.