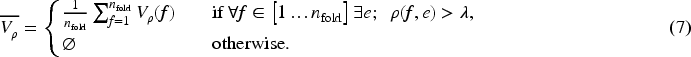The choice made for representing the inputs and outputs of generative pretrained language models (PLMs) can impact their fine-tuning on a new task. This article focuses on the fine-tuning and linearization process to generate facts extracted from text. On a restricted relation extraction (RE) task, we challenged five encoder–decoder models, including BART, T5, CodeT5, FlanT5, and PileT5 by fine-tuning them on 13 linearization variations, including RDF standard syntaxes and variations thereof. Our benchmark covers the validity of the produced triples, the model’s performance, the training behavior, and the resources needed. We show these PLMs can learn some syntaxes more easily than others, and we identify a promising “Turtle Light” syntax supporting the quick and robust learning of the RE task.
Relation extraction (RE)—the task of retrieving relations from unstructured text—has been drastically improved recently by two main changes: (1) the construction of massive corpora aligning texts and facts from knowledge graphs (KGs), using distant supervision (Smirnova & Cudré-Mauroux, 2018), for example, Wikipedia articles with the corresponding Wikidata (Huguet Cabot & Navigli, 2021; Yao et al., 2019) or DBpedia (Elsahar et al., 2018; Gardent et al., 2017) subgraphs, and (2) the availability of pretrained language models (PLMs) that can be used or adapted to solve a vast number of natural language processing tasks.
However, large KGs such as Wikidata and DBpedia may be affected by several quality issues: they could contain wrong facts, could store inconsistent data, be incomplete, or outdated (Hofer et al., 2023; Shenoy et al., 2022; Zaveri et al., 2013, 2018). In this context, extracting information from Wikipedia to fill the gaps in KGs is critical, as neither DBpedia nor Wikidata directly relies on the text of the articles. Aside from that, large language models (LLMs), exclusively relying on decoder-only Transformer architectures, demonstrated interesting few-shot capacities. Nonetheless, they only marginally outperform fine-tuned encoder–decoder-based models on the RE task, at the cost of significant engineering expenses, including integrating RAG (Retrieval-Augmented Generation) systems, prompt design for the few-shot strategy, and higher adaptation costs incurred during fine-tuning. Moreover, a structured extraction task requires the use of structured constraint approaches. These approaches actually require an additional cost at the inference step, which is not suitable in a knowledge-intensive context. A promising research direction is to design frugal models allowing adaptability and fine-grained quality control. Encoder–decoder models can solve extraction as a translation task, offering the option to produce linearized graphs from natural language directly. In this approach, the production of triples in the RDF (Resource Description Framework) syntax allows for the direct integration of the produced triples into the Semantic Web ecosystem. The usage of constraints, e.g., with SHACL (Shapes Constraint Language) or ShEx (Shape Expressions), can help formalize both the extraction/learning set target and the validation of the produced output.
However, to the best of our knowledge, no study has been proposed to analyze the impact of the choice of the encoder–decoder models and the selection of a specific RDF syntax model to perform RE directly from Wikipedia articles.
Pattern-Based RE. Formally, let be a dual base, where is a set of Wikipedia articles and is the set of the corresponding KGs. Our goal is to learn a pattern-based extractor leveraging generative PLM:
: , where is an input text, is a set of SHACL shapes, and is an RDF graph implied by and valid against . We refer to this task as pattern-based RE, as illustrated in Figure 1.
Pattern-based relation extraction process.
Encoder–decoder models could be easily adapted to solve a seqToseq task, but variations in prompts and output formats can affect their performance. In this paper, we focus on RE for the most common datatype properties of DBpedia resources of type dbo:Person. In this specific yet frequent setup, we challenged encoder–decoder models trained on various RDF syntaxes.
Research Question:How does the choice of a linearization syntax impact the generation of RDF triples representing datatype properties for different pretrained language models?
We have presented initial experiments to answer this question in Ringwald et al. (2025a), where we already challenged BART and T5 on a set of 12 syntaxes. In this paper, we extend our analysis by considering three additional encoder–decoder models (FlanT5, CodeT5, and PileT5), and one additional RDF syntax (Turtle Ultra Light). Moreover, we better define the meta-metrics we proposed, which leads us to new insights about the training behavior of the models we fine-tuned. The produced material is made open and reusable under an open license: the extension of the 12ShadesofRDF GitHub repository1 as well as the complete experimental results.2
The paper is organized as follows. After reviewing the related works (Section 2), we present our method to extract RDF from text with an application to Wikipedia (Section 3). We then report on the experiments and evaluations we carried out (Section 4) before discussing the results (Section 5).
Related Works
Generative Language Models for RE. Before investing in generative PLMs, the research community focused on systems built on top of encoder-only PLMs (derived from BERT; Devlin et al., 2019), where relations were decoded by design in a discriminative manner (Nayak et al., 2021). Since 2021, generative PLMs have gained interest after demonstrating their ability to solve complex tasks in an end-to-end design. The solutions based on pretrained generative transformer models rely either on encoder–decoder or decoder-only models:
Decoder-only models have interesting generalization properties when scaled, which paved the way for many model proposals better known today as Large language models (LLMs). The Text2KGBench (Mihindukulasooriya et al., 2023) proposes to benchmark LLMs in the context of ontology-driven RE, which is closely related to our pattern-based design, demonstrating the difficulties of such models in dealing with more domain-focused RE. More globally, in the classical context of RE tasks, they have shown a small margin of improvement using few-shot learning, which requires a lot of engineering (Efeoglu & Paschke, 2024; Li et al., 2024; Wadhwa et al., 2023; Zhang et al., 2023). When it comes to adapting them to a specific context using fine-tuning LLMs, it requires considerable resources. Parameter-efficient fine-tuning approaches (Ding et al., 2023) allow the adaptation of large models by reducing this cost, but do not necessarily perform as well as encoder–decoder fine-tuned models (Gallardo et al., 2024; Hussam Ghanem, 2024; Lehmann et al., 2024; Li et al., 2025).
The usage of LLMs is debated today (Grangier et al., 2024; Lu et al., 2024; Wang et al., 2024), as they are costly to train, slow at the inference stage, and hard to adapt to a specialized domain (Kandpal et al., 2023). Moreover, they are also not particularly adept at handling hallucinations and structured output, and they raise essential sovereignty issues when used via the APIs via few-shot prompting. Nonetheless, their capacity to understand patterns and generate reliable natural language content gives them a strategic place in intermediary steps such as data-augmentation to later learn smaller, specialized models (Patel et al., 2024). This was also experimented in the context of RE (Josifoski et al., 2023; Šakota & West, 2025).
RDF-Syntaxes for RE. Globally, generative pretrained models may be adapted to respect a given syntax implicitly from the examples submitted during training (Ye et al., 2022). The question of the structure of the output was initially referred to as “Answer Engineering” (Liu et al., 2023), but in the domain of graph extraction, the community refers to it as the “linearization process,” that is, the transformation of a graph structure into a raw sequence of tokens. This allows using a generative model pretrained on natural language texts (Jin et al., 2023).
The two main solutions found in the literature to represent graphs are:
sequence of tagged elements (Ke et al., 2021), for example, with tags in .
Huguet Cabot and Navigli (2021) and Josifoski et al. (2023) proposed a triple linearization method (subject-collapsed) where triples sharing the same subject are grouped to avoid repetition. In this benchmark, we will also consider the syntaxes recommended by the W3C to serialize RDF triples, namely:
RDF/XML, a historical syntax with the verbosity of XML.
N-Triples, an easy-to-parse line-based format.
Turtle, a lighter and easier-to-read syntax supporting the use of qualified names for compacting URIs, and integrating shortcuts for the writing of triples sharing the same subject or predicate.3
JSON-LD, relying on the popular JSON format.
And variations of the list, tags, and Turtle syntaxes.
Few research works have proposed RDF-generated content with language models. To illustrate it, a recent dedicated survey (Regino et al., 2025) only covers one model explicitly generating RDF triples, where a majority of the analyzed models follow the tags or the list syntaxes presented above. Still, the research interest in producing more complex structured output with language models has grown, notably to perform information extraction (Dagdelen et al., 2024; Liu et al., 2024a, 2024b). These works mainly focus on the usage of LLMs to benchmark a data-extraction task with the JSON syntax, and sometimes other syntaxes such as XML. Other research also demonstrates the potential of constrained generation with a grammar (Geng et al., 2023), which is reliable on simple syntaxes but expensive on complex ones. The Semantic Web community also proposed research directions using LLMs to assist KG engineering. For instance, Meyer et al. (2024) conducted an extended benchmark focused on graph understanding and generation tasks based on the Turtle syntax (Frey et al., 2023). The approach was extended to other W3C languages such as SPARQL (Meyer et al., 2025) or RML (Hofer et al., 2024). However, few initiatives have been proposed to rigorously compare and benchmark smaller and frugal models to produce RDF syntaxes as we do in this extended paper.
Positioning. In this article, we propose a benchmark that focuses solely on encoder–decoder based PTMs (Pre-trained Models), which offer an interesting performance/cost balance and may be adapted to a variety of output syntaxes via fine-tuning. The goal is to determine the optimal model and syntax for extracting relations most effectively and at minimal cost, while maintaining the highest expressivity.
Methodological Framework
Overview of the Approach
Our method is depicted in Figure 2. Our pipeline takes as input a DBpedia dump4 from which we extract a subset containing specifically targeted triples. This subset is then filtered to check that the values of the selected DBpedia triples are mentioned in the corresponding Wikipedia abstracts (step 1.1) and comply with a predetermined SHACL shape (step 1.2) presented in Section 3.3. The selected triples are then ordered (step 2.1) and the URIs are URL-encoded and cleaned (step 2.2). The resulting dataset is then linearized (step 3) into 13 distinct syntaxes presented in Section 3.4. The obtained corpora are finally split into five independent folds (step 4). These subsets are used to fine-tune five small language models (SLMs) (step 5) presented in Section 3.5. The fine-tuning configuration of the experiment is described in Section 4. The evaluation of the RE (step 6) is conducted at the end of the training step with the computation of the metrics detailed in Section 4.2.
Overview of our pipeline: from dataset construction to relation extraction evaluation.
Task Definition: A Relation Extraction Focused on a Maximal Target Shape
Dual Base Definition
We start by formally defining the RE task introduced in our previous work (Ringwald et al., 2025a). It relies on a training set built from the dual base defined from the set of Wikipedia abstracts associated with the set of DBpedia graphs describing () the same resources :
SHACL-Constrained Training Set
To ensure the quality of the training set, we consider the subset of where all the graphs are valid against a SHACL shape . We call this shape maximal, as it matches the largest pattern to be extracted. We note this validation, and the corresponding subset:
Finally, to reduce the noise in entailed by the mismatch between DBpedia graphs and Wikipedia abstracts, we focus only on the couples where the abstract entails the paired graph , that is, the triples of that can effectively be extracted from the paired abstract . We note it and we denote the dataset by :
Baseline Extraction Model
is used to train a model expected to predict, from an abstract , a graph valid against . We denote by this original model, and baseline:
Dataset and Ground Truth
Our experiment focuses on a simplified RE task to better analyze the impact of the syntax. To avoid any entity linking step related to object properties, we limit our experiment to datatype properties with number, string, and date values. This is a good starting point because language model hallucinations generally affect these literal values (Ji et al., 2023). Moreover, until now, the proposed generative models mostly focus on object properties, allowing for constrained decoding (Josifoski et al., 2022) that cannot be envisaged in the case of datatype properties.
We consider the DBpedia subgraphs describing instances of one of the most represented DBpedia classes (), dbo:Person, and their corresponding Wikipedia abstracts (). The descriptions of instances of this class also include the highest number of datatype properties. We focus on seven datatype properties that are most likely to be found in the abstracts describing dbo:Person instances: rdfs:label, dbo:alias, dbo:birthName, dbo:birthDate, dbo:deathDate, dbo:birthYear, and dbo:deathYear, as illustrated in Figure 3 using ShapeVOWL visualizations.
Visual representation of in ShapeVOWL of SHACL shape targeting class dbo:Person.
Several works mention the noise caused by the massive alignment of facts with text (Smirnova & Cudré-Mauroux, 2018), which also impacts T-Rex or REBEL (Li et al., 2025). More specifically, two problems are pointed out: the values in a triple do not necessarily appear in the corresponding text, and conversely, the facts in the text may not have counterpart triples in the knowledge base. To solve those issues, we first considered a maximal SHACL shape () targeting class dbo:Person (Figure 4) and specifying which property is mandatory and which one is optional, and we only keep the graphs valid against this shape ( described in equation (2)). In a second step, we keep only the triples whose values can be found in the Wikipedia abstract of a given entity ( described in equation (3)). When applying these two preprocessing steps to a random sample of 1,000 entities, we found that 80% of the triples have values that can be found in the corresponding Wikipedia abstract, but only 45% of the entities have a graph description valid against the shape.
Linearization in Turtle syntax of the SHACL shape targeting class dbo:Person.
Our pipeline includes two additional preprocessing steps:
Triples ordering: Mihindukulasooriya et al. (2022); Wu and Chen (2020) and Möller and Usbeck (2025) demonstrated the positive impact of typing the entity in the context of the RE task. Therefore, asking a model to first type the main subject of our graphs could be a good idea. However, RDFlib5 does not guarantee the same order of triples for every syntax. So, we implemented a triple-ordering step, which enforces the first triple to be the type of the subject, as illustrated in Figure 5.
URI encoding: the Turtle syntax uses tokens that can be found in URIs (dots and parentheses), but their usage is forbidden in local names. We had to encode them systematically. In DBpedia, the Turtle output of URIs containing these special characters is written without prefixes and wrapped into brackets, for example, <https://dbpedia.org/resource/Tom_Nichols_(footballer)>. Therefore, we rewrite this URI as dbr:Tom_Nichols_%28footballer%29.
Example of reordered triples.
Our ground truth is randomly sampled from and will later be sampled and split into , , and . contains 6,000 entities described by 28M triples. The seven datatype properties we are focusing on are associated with 13,832 distinct values. Table 1 shows the frequency of each property defined as the number of occurrences of a property divided by the number of entities described in , and its variability defined as the number of distinct values for a property divided by the number of occurrences of the property. The frequencies reported in this table show that all the graphs in the dataset contain an occurrence of properties rdf:type, dbo:birthYear, and rdfs:label (which is in line with the shape we defined), and they highlight the low representation of properties dbo:alias and dbo:birthName. The reported variabilities highlight the historical bias of the data: the low variability of properties dbo:birthYear and dbo:deathYear means that the entity descriptions in the dataset target some specific historical period. All the combinations of properties identified in are described in Table 2. Interestingly, a low number of property combinations are represented in the dataset: there are 18 combinations of properties among 127 possible combinations of seven properties, and their frequencies indicate a long-tail distribution. The four most instantiated graph patterns are shown in Figure 6.
Top four graph patterns represented in our training set: (a) graph pattern 1, (b) graph pattern 2, (c) graph pattern 3, and (d) graph pattern 4.
Datatype Properties Statistics of the Ground Truth .
Property Combinations Observed in the Ground Truth .
prop_pattern
label
birthYear
birthDate
deathYear
deathDate
alias
birthName
No. of Prop.
freq (%)
pattern1
✓
✓
✓
3
64.43
pattern2
✓
✓
✓
✓
✓
5
25.47
pattern3
✓
✓
✓
✓
✓
✓
6
3.67
pattern4
✓
✓
✓
✓
4
2.85
pattern5
✓
✓
✓
✓
4
0.80
pattern6
✓
✓
2
0.72
pattern7
✓
✓
✓
✓
4
0.62
pattern8
✓
✓
✓
✓
✓
✓
6
0.40
pattern9
✓
✓
✓
✓
4
0.37
pattern10
✓
✓
✓
✓
4
0.17
pattern11
✓
✓
✓
✓
✓
5
0.10
pattern12
✓
✓
✓
✓
✓
5
0.10
pattern13
✓
✓
✓
3
0.10
pattern14
✓
✓
✓
✓
✓
5
0.03
pattern15
✓
✓
✓
✓
✓
5
0.03
pattern16
✓
✓
✓
✓
4
0.03
pattern17
✓
✓
✓
✓
4
0.02
pattern18
✓
✓
✓
3
0.02
RDF Syntaxes and Alternative Linearizations
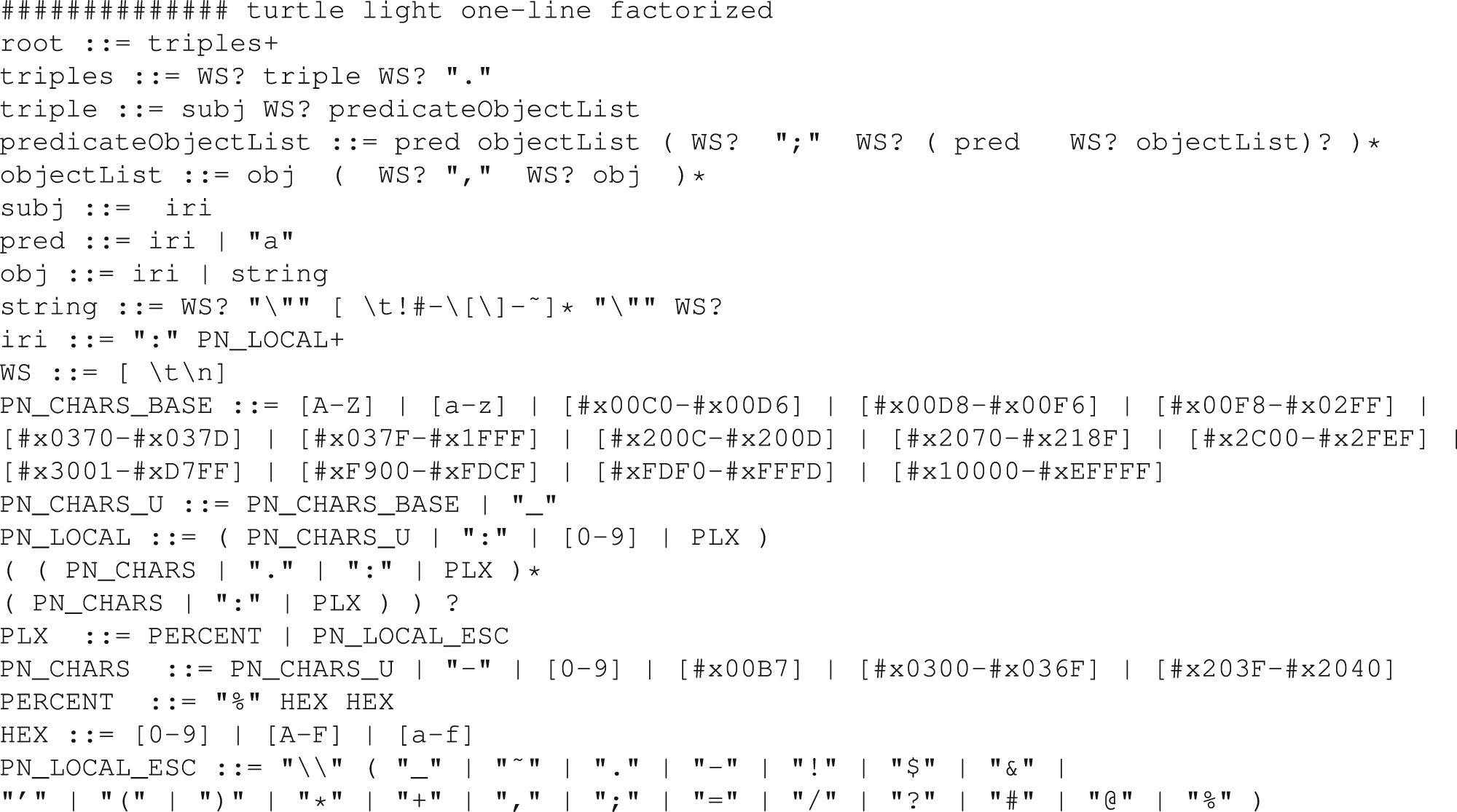
Our benchmark considers 13 syntaxes belonging to three distinct categories. The first category includes the syntaxes classically found in the literature (Figure 7): (a) the List (noted ) and (b) the Tags (noted ), and (c/d) their factorized variations (noted ). As underlined by Huguet Cabot and Navigli (2021) and Josifoski et al. (2023), factorization enables avoiding the repetition of subjects or predicates. It is naturally integrated into Turtle, JSON-LD, and RDF-XML, and we also integrated it into the List and Tags syntaxes (noted ). The second category includes the four W3C RDF syntaxes (Figure 8): (a) XML-RDF (noted ), (b) N-Triples (noted ), (c) Turtle (noted ), and (d) JSON-LD (noted ). The third category includes additional syntaxes we propose: Turtle Light (noted ) is a simplified Turtle syntax where namespaces, prefixes, and datatypes are considered as already defined. Turtle Light comes with several variations (Figure 9): one with subject factorization, one with single-line writing (noted ) to evaluate the impact of the line break.6 Another variation combines factorization and single-line writing. In addition to these 12 syntaxes considered in our initial experiments, we introduced an Ultra Light Turtle syntax (noted ) which is based on the factorized, inlined Turtle Light where we remove the “:” characters in the qualified names.
Linearization proposed by the literature applied on a graph describing Nelson Mandela: (a) list syntax, (b) tag syntax, (c) list syntax factorized. and (d) tag factorized.
Linearization proposed by the W3C applied on a graph describing Nelson Mandela: (a) RDF-XML, (b) N-Triples, (c) Turtle syntax, and (d) JSON-LD.
Turtle Light variations proposed andapplied on a graph describing Nelson Mandela: (a) Turtle Light syntax, (b) Turtle Light syntax on one line, (c) Turtle Light syntax factorized, and (d) Turtle Light syntax on one line and factorized, and (e) Turtle Ultra Light.
Finally, we consider the use of vocabulary extension (noted ), which is a common practice, notably used for QA SPARQL query generation, which consists of extending the tokenizer vocabulary (Banerjee et al., 2023; Reyd & Zouaq, 2023). This ensures that syntax-related tokens will not be considered as unknown by the tokenizer, and allows the model to learn a vector representation of these tokens during the fine-tuning process, for example, the representation of the comma in Turtle code replacing the representation of the comma from the pretrained embedding space. For each W3C syntax, we added all the tokens specified in its recommendation.
Benchmarking Frugal Encoder–Decoders
In our initial experiments described in Ringwald et al. (2025a), we focused on the two encoder–decoder models traditionally used in the literature (see Section 2), namely BART (noted ) and . We extended our benchmark by integrating three other T5-based models: FlanT5 (Chung et al., 2022) noted , PileT5 (Sutawika et al., 2024) noted , and CodeT5 (Wang et al., 2021) noted . These models follow the encoder–decoder transformer architecture. Table 3 summarizes their main differences. We can see from this table several differences: first, the number of pretraining objectives: all of them are pretrained using token masking, whereas CodeT5 and BART were also pretrained, along with other objectives. CodeT5 was, for example, pretrained on task-specific code context: (1) identifier prediction, and (2) identifier tagging on both unimodal and bimodal data (so from code to natural language and vice versa). BART, in this case, was trained to better deal with noisy text via pretraining using (1) token deletion, (2) text-infilling, (3) sentence permutation, and (4) document rotation. In addition, the T5 family of models is pretrained to solve and gain an initial understanding of specific tasks using prefix tuning in the case of T5 and CodeT5, and using Instruction tuning in the cases of FlanT5 and PileT5.
Encoder–Decoder Model Specificities.
Model
Pretraining Objective
Prefix Tuning
Instruct. Tuning
Pretraining Dataset
Tokenizer
Nb Params
Max Input Len.
Max Output Len.
BART
Token masking + 4 other obj.
–
–
BookCorpus + Wikipedia 2019
BPE
140M
1,024
1,024
T5
Token masking
✓
–
C4
SentencePiece
220M
512
512
CodeT5
Token masking + 2 other obj.
✓
–
CodeSearchNet
Byte-Level BPE
220M
512
256
FlanT5
Token masking
✓
✓
C4 + Muffin + F0-SF + CoT + NaturalInstructionsV2
SentencePiece
248M
1,024
256
PileT5
Token Masking
✓
✓
The Pile
LLaMA Tokenizer
248M
512
512
We limited our experiments to pretrained models in their “base” versions counting between 140M and 248M parameters, which is frugal compared to decoder-only LLMs that count billions of parameters (Minaee et al., 2024). Concerning the datasets used for pretraining, we can underline that all of them use different corpora, and not all of them are open and available, while this is the case for BART. However, unlike larger LLMs, these models were not pretrained directly on KG data from Wikidata or DBpedia. But all of them were trained at least on a complete Wikipedia dump from 2019 (for BART, T5, and FlanT5) or 2020 (for PileT5). In contrast, the training dataset for CodeT5 is limited to coding tasks and does not include Wikipedia pages.
Each model uses different tokenizers and has different context sizes related to the specific input/output lengths on which they were pretrained. For this reason, the input and generation lengths must be adapted to these constraints to avoid generation degradation or early truncation. Concerning the input size, our models are not impacted by the truncation of text fitting the input length, since all the values targeted by our shape are generally expressed at the beginning of the abstract. Figure 10 illustrates the effect of the tokenization of each model tested on the same Turtle graph. We can see from that example that T5-base is the model using the highest number of tokens to represent the sequence, while CodeT5 is the model representing the sequence with the lowest number of tokens. We also see that BART is generally representing words starting with an uppercase as a unique unit of meaning, while the T5 models tokenize the uppercased letter separately from the rest of the word.
Tokenization comparison of the same Turtle graph.
Table 4 shows the longest size (in the number of tokens) of the sequences that each model has to generate according to the ground truth , depending on the targeted RDF syntax. Starred values () indicate that the longest sequence contained in exceeds the maximum output length of the pretrained model. In practice, the encoder–decoder models can produce sequences longer than the maximal output length, but then they are more prone to generation degeneration.
Maximum Number of Tokens Generated Over the Ground Truth , Depending on the Chosen Syntax and Tokenizer.
Code
Syntax
B
T5
541
583*
610*
583*
566*
479
514
498
514*
481*
-
646
411
488
411*
469*
392
285
316
285*
320*
286
312
289
312*
284*
307
274
310
274*
314*
229
265
273
265*
259*
303
225
270
225
255
152
137
171
137
164
146
127
153
127
142
121
127
140
127
135
78
97
99
97
104
92
85
100
85
104
Note. Underlined values indicate the highest number of tokens obtained for a given model, while the bold values indicate the lowest number of tokens. Values marked with an asterisk (*) denote sequences that exceed the maximum limit defined by the corresponding language model.
This highlights potential issues with CodeT5 and FlanT5, whose maximum output length (256) is exceeded for seven syntaxes. This table also reveals the fact that light syntaxes allow to divide the output context length by five, compared to complex syntaxes (N-triples, XML, or JSON): for instance, to represent seven datatype properties, BART with one-line, factorized Turtle Light () requires 121 tokens while BART with JSON () requires 541 tokens. From that observation, we can estimate that with the factorized, one-line Turtle Light syntax, we can generate a graph of almost 60 properties while JSON hardly reaches 14 properties.
In the following sections, we use the notations introduced above to name each possible configuration. For instance, a BART model trained on Turtle Light syntax, with factorization and multilines will be written , and a CodeT5 model trained on lists with a vocabulary will be written .
Experimental Setup
Fine-Tuning Details
Our code7 is based on a fork of REBEL8 , which we extended and adapted to our task. It is published under an open license. For each standard RDF syntax, we developed a specific parser and integrated the metrics we present below.
Data Split. We follow a fivefold cross-validation based on 5,000 examples sampled from and then used to build rotating splits of 4,000 training examples () and 1,000 test examples (). In addition, 250 disjoint examples also sampled from are used for the evaluation ().
Configuration. The BART model was fine-tuned using the inverse square root scheduler with an initial learning rate of 0.00005. For T5, we used the Adafactor scheduler with an initial learning rate of 0.001. Both models were fine-tuned with 1,000 warm-up steps and configured with an early stop mode with patience of five steps. For FlanT5, CodeT5, and PileT5, we used the same configuration as for T5. Models were trained on a single GPU, Tesla V100-SXM2-32GB for BART and NVIDIA A100 80GB PCIe for T5 models (able to manage bf16).
Handling of Tokenization Inconsistencies. T5 and BART tokenizers can duplicate or delete spaces before or after special tokens (Banerjee et al., 2022; Sun et al., 2023). For this reason, we controlled token consistency during the evaluation with a typographic checker and cleaner. This is applied to the learning examples and to the predicted output when both are compared.
Fine-Tuning Prompts. We used two different prompts to fine-tune the tested models:
for BART: “$entity_URI : $Abstract”;
for the T5 models’ family (T5, PileT5, CodeT5, and Flan-T5):
“Translate English to $Syntax: [$entity_URI] $Abstract,”
where $Abstract is a Wikipedia abstract, $Syntax is the targeted RDF syntax, and $entity_URI the URI of the entity in DBpedia.
Evaluation Metrics
The first stage of this experiment is to evaluate the ability of the model to produce a given syntax without generating any parsing errors. This is measured by the rate of Parsed Triples . We also introduce the rate of Correct Subject : the choice of the URI for the subject of a generated triple depends on the ability of the model to copy from the input the targeted entity URI. In addition, we define the rate of SHACL-validated triples :
Nonparsable triples are evaluated by computing the Levenshtein edit distance between the generated RDF code and the targeted one . The result is the number of editions needed to transform into .
By contrast, when the graphs produced are parsable, it is possible to evaluate them with respect to the RE task. Traditionally, RE focuses on precision (), recall (), score, or top@k metrics. But as underlined in Harbecke et al. (2022), these metrics are generally computed at the micro level, that is, they are computed on all the expected and produced triples without taking into account the variable distribution of the properties. As a result, these metrics can hardly account for the performance of a model on underrepresented properties, as the micro metrics are dominated by the results obtained for much more frequent properties. In our context, we observed that the property distribution is unbalanced. Therefore, we propose to also compute the macro measures (, , ) which average the metrics recorded on each property, thus equally representing the performances for each property. These metrics follow the Strict Mode evaluation (Taillé et al., 2020), comparing predicted and ground-truth values and verifying their strict equality. The strict evaluation-based metrics are not the most appropriate to evaluate datatype properties with values of type xsd:String, where we may accept semantically close values. For this reason, we also compute the BLEU score (Papineni et al., 2002): the closer is to 1, the greater the similarity between string values. As our experimental framework is trained on 10-fold for each configuration, all the metrics computed are averaged and noted with an overlined, for instance, is the average of over the folds (Table 5).
Impact of Context Variations on BART and T5 Performances.
Model
Test Set
Baseline
98.86
78.22
1.00
1.00
1.00
78.22
ReOrder
98.65
80.23
1.00
1.00
1.00
80.23
MaskedEntities
90.72
72.48
1.00
0.00
1.00
0.00
NoEntity
97.39
74.42
1.00
0.00
1.00
0.00
Baseline
88.56
68.84
0.90
0.89
0.90
49.57
ReOrder
88.68
73.67
0.90
0.88
0.90
52.34
MaskedEntities
84.27
66.21
0.90
0.00
0.90
0.00
NoEntities
86.93
67.89
0.90
0.00
0.90
0.00
NoInstruct
70.44
54.78
0.70
0.00
0.70
0.00
We define a global grade that will allow us to compare the overall performances of our configurations. It combines the performance of the model in terms of parsability, SHACL validity and subject validity on one side, and in terms of macro on the other side: .
Finally, we also monitored the training time (in min) and the carbon footprint9 (emissions of CO-equivalents in g) for training a model.
To assess the training process itself based on the cross-entropy loss objective, we define three meta-metrics from a metric of interest : the velocity , the stability , and the divergence . In our case, we will use these meta-metrics to compare and follow the behaviors of the and the , consequently . All meta-metrics consider a specific state of the training called saturation which is reached when the metric reaches a threshold . The metrics of interest are computed for a fold and an epoch , noted . Let us now detail the computation of each of the meta-metrics:
(1) The velocity is the number of epochs needed to reach the first saturation () on a given fold by a metric :
Interpretation: A velocity close to indicates that the model saturates at the early stage of the training. Conversely, a velocity close to the number of epochs recorded by the whole training process indicates a late model saturation. Aggregation: The average velocity on all the folds is computed as follows:
(2.1) The broken steps set: To define the stability, we first define the set of the for a given fold . During a fold , a step is considered as broken if the metric is smaller than the defined saturation threshold:
(2.2) The stability is the ratio of the number of epochs during which a metric remains stable after the first saturation:
Interpretation: During the training, if the metric of interest rarely falls below the saturation threshold, then the stability will be close to 1; conversely, if it often falls below the threshold, the stability will be close to 0.
Aggregation: The average stability on the folds is computed as follows:
(3) The divergence indicates if the final value of the metric is lower than the saturation threshold:
Interpretation: The divergence is equal to 1 if the measure recorded at the end of the training is under the saturation threshold. Inversely, the divergence is equal to 0 if the training completes with a value higher than the saturation threshold.
Aggregation: We compute the sum on all the folds of each , and note it as :
To illustrate the principle of these meta-metrics, Figure 11 shows the behavior of a given metric observed at a given fold and computed at each epoch . In this example, the training took epochs; , that is, reaches the saturation threshold of 0.9 at the seventh epoch; , with two broken steps (circled in the figure) during the training process; , that is, the model is not diverging at the end of the training process, as .
Example behavior of a metric during the training of a model on given fold during 23 epochs.
Results and Discussions: Best Models and Syntaxes
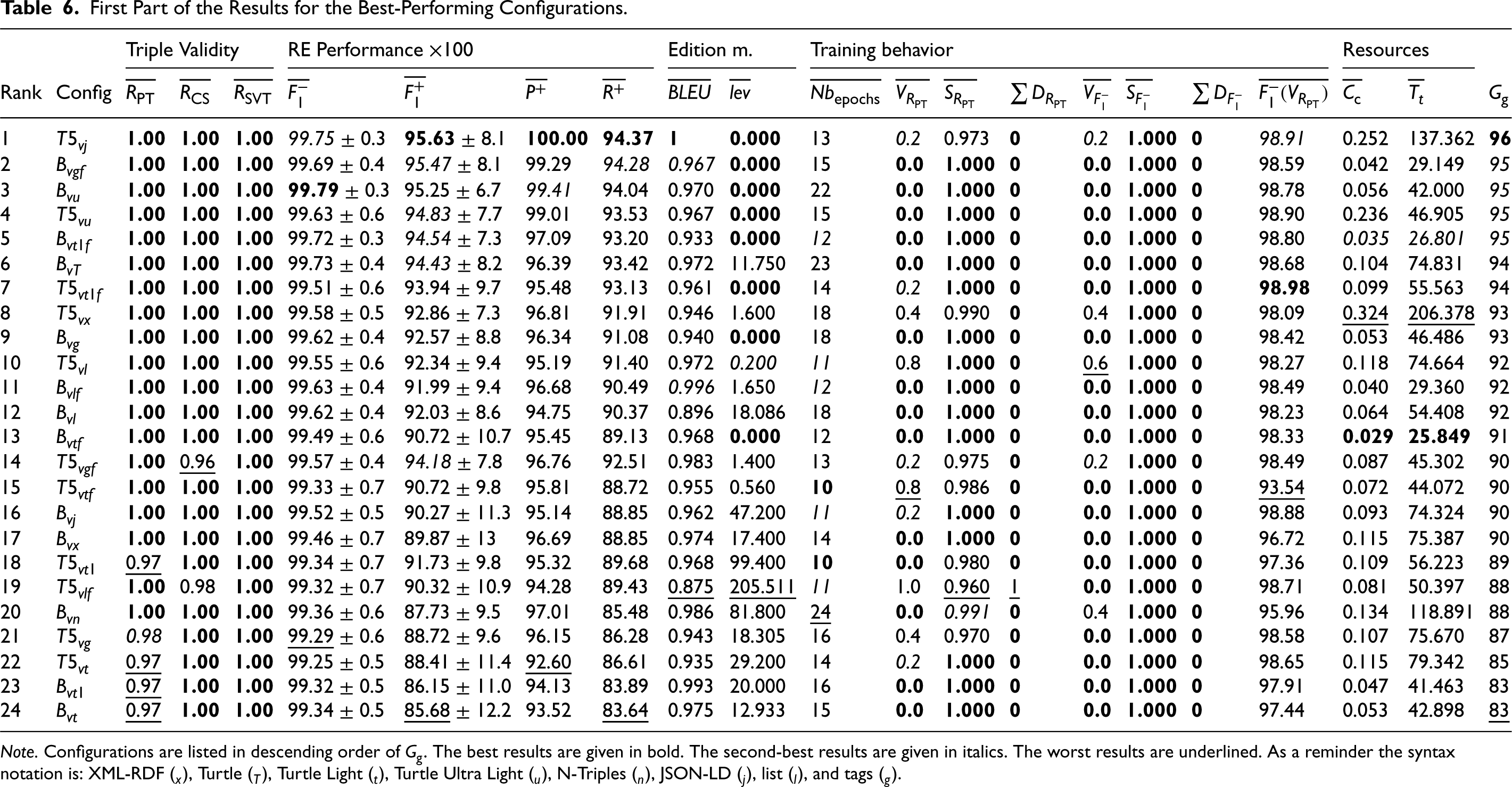
Tables 6 to 8 compile the results obtained following the experimental framework described in the previous sections, ranked by global grade . Table 6 gathers all the models that can effectively generate valid triples; it includes the models based on BART and T5. Table 7 gathers models with lower performances, mostly based on CodeT5, but also some models based on PileT5 and FlanT5. Table 8 gathers the worst models; these are based on FlanT5 and PileT5. RE metrics are computed on valid triples and, in that respect, the best models have a , , and close to 0.95. This is a good result since the macro metrics are generally less optimistic and more informative than the micro ones, with which every configuration seems to reach an almost perfect extraction. From that point of view, is the best model, closely followed by , , , , , , and . It is more difficult to discuss the good performances of , , and in regard to their low triple validity scores.
First Part of the Results for the Best-Performing Configurations.
Triple Validity
RE Performance
Edition m.
Training behavior
Resources
Rank
Config
1
1.00
1.00
1.00
99.75 0.3
95.63 8.1
100.00
94.37
1
0.000
13
0.2
0.973
0
0.2
1.000
0
98.91
0.252
137.362
96
2
1.00
1.00
1.00
99.69 0.4
95.47 8.1
99.29
94.28
0.967
0.000
15
0.0
1.000
0
0.0
1.000
0
98.59
0.042
29.149
95
3
1.00
1.00
1.00
99.79 0.3
95.25 6.7
99.41
94.04
0.970
0.000
22
0.0
1.000
0
0.0
1.000
0
98.78
0.056
42.000
95
4
1.00
1.00
1.00
99.63 0.6
94.83 7.7
99.01
93.53
0.967
0.000
15
0.0
1.000
0
0.0
1.000
0
98.90
0.236
46.905
95
5
1.00
1.00
1.00
99.72 0.3
94.54 7.3
97.09
93.20
0.933
0.000
12
0.0
1.000
0
0.0
1.000
0
98.80
0.035
26.801
95
6
1.00
1.00
1.00
99.73 0.4
94.43 8.2
96.39
93.42
0.972
11.750
23
0.0
1.000
0
0.0
1.000
0
98.68
0.104
74.831
94
7
1.00
1.00
1.00
99.51 0.6
93.94 9.7
95.48
93.13
0.961
0.000
14
0.2
1.000
0
0.0
1.000
0
98.98
0.099
55.563
94
8
1.00
1.00
1.00
99.58 0.5
92.86 7.3
96.81
91.91
0.946
1.600
18
0.4
0.990
0
0.4
1.000
0
98.09
0.324
206.378
93
9
1.00
1.00
1.00
99.62 0.4
92.57 8.8
96.34
91.08
0.940
0.000
18
0.0
1.000
0
0.0
1.000
0
98.42
0.053
46.486
93
10
1.00
1.00
1.00
99.55 0.6
92.34 9.4
95.19
91.40
0.972
0.200
11
0.8
1.000
0
0.6
1.000
0
98.27
0.118
74.664
92
11
1.00
1.00
1.00
99.63 0.4
91.99 9.4
96.68
90.49
0.996
1.650
12
0.0
1.000
0
0.0
1.000
0
98.49
0.040
29.360
92
12
1.00
1.00
1.00
99.62 0.4
92.03 8.6
94.75
90.37
0.896
18.086
18
0.0
1.000
0
0.0
1.000
0
98.23
0.064
54.408
92
13
1.00
1.00
1.00
99.49 0.6
90.72 10.7
95.45
89.13
0.968
0.000
12
0.0
1.000
0
0.0
1.000
0
98.33
0.029
25.849
91
14
1.00
0.96
1.00
99.57 0.4
94.18 7.8
96.76
92.51
0.983
1.400
13
0.2
0.975
0
0.2
1.000
0
98.49
0.087
45.302
90
15
1.00
1.00
1.00
99.33 0.7
90.72 9.8
95.81
88.72
0.955
0.560
10
0.8
0.986
0
0.0
1.000
0
93.54
0.072
44.072
90
16
1.00
1.00
1.00
99.52 0.5
90.27 11.3
95.14
88.85
0.962
47.200
11
0.2
1.000
0
0.0
1.000
0
98.88
0.093
74.324
90
17
1.00
1.00
1.00
99.46 0.7
89.87 13
96.69
88.85
0.974
17.400
14
0.0
1.000
0
0.0
1.000
0
96.72
0.115
75.387
90
18
0.97
1.00
1.00
99.34 0.7
91.73 9.8
95.32
89.68
0.968
99.400
10
0.0
0.980
0
0.0
1.000
0
97.36
0.109
56.223
89
19
1.00
0.98
1.00
99.32 0.7
90.32 10.9
94.28
89.43
0.875
205.511
11
1.0
0.960
1
0.0
1.000
0
98.71
0.081
50.397
88
20
1.00
1.00
1.00
99.36 0.6
87.73 9.5
97.01
85.48
0.986
81.800
24
0.0
0.991
0
0.4
1.000
0
95.96
0.134
118.891
88
21
0.98
1.00
1.00
99.29 0.6
88.72 9.6
96.15
86.28
0.943
18.305
16
0.4
0.970
0
0.0
1.000
0
98.58
0.107
75.670
87
22
0.97
1.00
1.00
99.25 0.5
88.41 11.4
92.60
86.61
0.935
29.200
14
0.2
1.000
0
0.0
1.000
0
98.65
0.115
79.342
85
23
0.97
1.00
1.00
99.32 0.5
86.15 11.0
94.13
83.89
0.993
20.000
16
0.0
1.000
0
0.0
1.000
0
97.91
0.047
41.463
83
24
0.97
1.00
1.00
99.34 0.5
85.68 12.2
93.52
83.64
0.975
12.933
15
0.0
1.000
0
0.0
1.000
0
97.44
0.053
42.898
83
Note. Configurations are listed in descending order of . The best results are given in bold. The second-best results are given in italics. The worst results are underlined. As a reminder the syntax notation is: XML-RDF (), Turtle (), Turtle Light (), Turtle Ultra Light (), N-Triples (), JSON-LD (), list (), and tags ().
Second Part of the Results for the Best-Performing Configurations.
Triple Validity
RE Performance
Edition m.
Training Behavior
Resources
Rank
Config
25
1.00
0.98
1.00
98.82 0.8
83.47 9.7
87.99
82.15
0.877
269.573
12
1.6
0.923
0
0.2
1.000
0
97.68
0.135
80.982
82
26
1.00
0.98
1.00
98.51 0.4
83.18 7.9
91.51
81.64
0.929
19.789
14
0.2
0.913
0
0.0
1.000
0
98.14
0.082
55.403
81
27
0.97
0.99
1.00
98.55 0.8
83.21 9.1
89.41
81.25
0.930
47.107
17
0.6
0.949
1
0.0
1.000
0
94.19
0.138
89.753
79
28
0.97
0.98
1.00
98.29 0.4
82.02 7.9
89.42
78.81
0.927
122.218
15
0.0
0.900
0
0.0
1.000
0
94.70
0.131
77.993
78
29
0.94
0.97
1.00
98.60 0.6
83.68 7.4
92.13
81.59
0.881
80,844.715
19
0.2
0.741
2
0.0
1.000
0
96.77
0.101
73.919
77
30
0.82
1.00
1.00
99.38 0.8
93.15 10.3
95.55
91.93
0.968
810.135
15
0.8
0.620
2
0.4
1.000
0
98.62
0.221
139.095
76
31
0.96
0.95
1.00
97.66 1.8
80.41 11.2
85.87
80.08
0.911
208.583
13
1.2
0.925
1
0.0
1.000
0
95.11
0.083
54.966
73
32
0.75
0.99
1.00
99.39 0.4
90.61 7.9
97.98
88.17
0.972
137.233
13
1.6
0.747
2
0.2
1.000
0
97.68
0.250
159.895
67
33
0.82
0.99
1.00
98.51 0.8
78.92 7.8
86.83
76.55
0.977
40.978
17
0.2
0.813
2
0.0
1.000
0
97.26
0.174
90.203
64
34
0.84
0.99
1.00
98.41 0.4
74.54 7.9
84.07
73.27
0.949
421.512
12
1.8
0.857
2
1.0
1.000
0
97.96
0.220
139.832
62
35
0.70
0.99
1.00
98.58 0.8
81.41 8.4
87.09
79.85
0.926
71.099
17
2.6
0.65
3
0.0
1.000
0
97.73
0.119
83.253
56
36
0.61
0.97
1.00
97.12 1.9
77.73 7.8
85.89
76.72
0.882
287,087.870
11
0.0
1.000
0
0.079
44.384
47
37
0.92
0.41
0.99
98.84 0.8
87.83 8.9
91.33
86.54
0.927
77.72
16
0.2
0.89
1
0.0
1.000
0
97.66
0.109
57.632
32
38
0.59
1.00
1.00
59.60 54.4
52.11 47.7
60.00
49.64
17.800
14
0.174
132.535
31
39
0.39
1.00
1.00
79.27 0.9
72.61 13.8
76.25
71.24
33.056
10
0.0
1.000
0
0.159
77.297
28
40
0.33
1.00
1.00
59.67 0.6
53.78 7.4
55.72
52.95
66.548
14
0.2
0.74
2
0.0
1.000
0
98.77
0.115
69.921
18
41
0.94
0.251
0.77
88.49 10.0
85.59 8.9
96.40
79.16
0.970
7042933
12
0.0
0.89
1
0.0
1.000
0
96.07
0.083
42.996
15
42
0.26
0.97
1.00
59.59 54.4
43.92 44.3
46.08
42.85
18.316
18
0.205
168.913
11
43
0.04
0.99
1.00
97.19 4.1
79.29 12.9
81.01
79.36
0.983
67.679
18
0.4
1.000
0
0.279
241.861
3
44
0.59
0.00
0.87
93.32 7.6
90.29 7.2
97.37
87.00
0.972
69.29
18
0.0
1.000
0
0.122
76.741
0
45
0.02
1.00
1.00
79.84 44.6
61.59 39.8
62.86
60.86
55.849
16
2.6
1.000
0
0.109
71.955
0
46
0.00
1.00
1.00
39.51 54.1
31.28 43.1
31.14
31.43
21.812
11
0.113
69.022
0
47
0.00
1.00
1.00
20.00 44.7
8.57 19.2
8.57
8.57
23.183
13
0.088
73.299
0
Note. Configurations are listed in descending order of . The best results are given in bold. The second-best results are given in italics. The worst results are underlined. As a reminder the syntax notation is: XML-RDF (), Turtle (), Turtle Light (), Turtle Ultra Light (), N-Triples (), JSON-LD (), list (), and tags ().
Third Part of the Results for the Best-Performing Configurations.
Triple Validity
RE Performance
Edition m.
Training Behavior
Resources
Rank
Config
48
0.29
0.00
0.00
79.68 54.1
72.56 43.1
74.07
71.54
12.462
11
0.087
59.423
0
49
0.26
0.00
0.00
59.43 54.3
51.66 47.8
52.96
51.78
25.253
13
0.080
55.165
0
50
0.17
0.00
0.00
39.92 54.7
39.51 54.1
39.95
39.16
47.084
13
0.067
45.982
0
51
0.15
0.00
0.00
59.67 54.5
40.58 37.6
42.78
40.29
28.467
15
0.6
1.000
0
0.154
100.197
0
52
0.01
0.00
0.00
39.63 54.3
29.28 40.1
31.35
28.75
24.247
14
0.089
61.239
0
53
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
384.492
13
0.250
164.578
0
54
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
21.538
15
0.124
77.378
0
55
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
107.384
12
0.137
114.290
0
56
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
17.443
14
0.189
108.608
0
57
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
79.172
14
0.403
200.460
0
58
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
20.584
14
0.109
62.134
0
59
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
310.462
17
0.270
186.559
0
60
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
118.134
17
0.183
89.052
0
61
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
195.167
12
0.217
114.521
0
62
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
97.534
15
0.122
83.726
0
63
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
97.423
13
0.263
160.633
0
64
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
18.166
16
0.169
107.316
0
65
0.00
0.00
0.00
0.00 0.0
0.00 0.0
0.00
0.00
77.319
11
0.160
115.238
0
Note. The best results given are in bold. The second-best results are given in italics. The worst results are underlined. As a reminder the syntax notation is: XML-RDF (), Turtle (), Turtle Light (), Turtle Ultra Light (), N-Triples (), JSON-LD (), list (), and tags ().
The bar charts in Figures 12 and 13 put in perspective the averaged metrics obtained relatively to the metric, by plotting the stacked over and at the scale of the bar. Figure 12 confirms the performances of and , as well as the relatively good results of . On the other hand, and are far behind the others. From the point of view of the syntax and as shown in Figure 13, we can see the robustness of Turtle Ultra Light which has a high and a high , notably because this syntax is correctly handled by every model, even by and . We can also observe a poor performance of the models on W3C syntaxes and a good performance of the tag and list syntaxes globally. Concerning TurtleLight, it seems necessary to apply the variations we proposed (the factorization and the one-line writing) on this syntax to be able to perform well in terms of both and .
Averaged model performances of relative to .
Averaged syntax performances of relative to .
With respect to the details, and starting with the triple validity metrics, almost every configuration related to BART and T5 produces triples that could be parsed () with the exception of struggling to produce the Turtle and N-Triples syntaxes. Concerning CodeT5, only the Turtle (basic, the Light, and Ultra Light versions) and the list-based syntaxes are nearly perfectly parsed. The capacity of CodeT5 to deal with Turtle is peculiar to our context and could be explained by a syntax close to a code structure, with the definition of the prefixes at the top and the data content written after it. FlanT5 and PileT5 can approximately generate triples only in the simplest syntaxes. Among them, Turtle Ultra Light is the one recording the better for FlanT5 (0.95) as well as for PileT5 (0.59).
Considering the Levenshtein distance () computed on the triples with parsing errors, we observe the ability of some models to extract close to perfect triples, particularly BART. Moreover, many models record negligible distances () and in these cases, the parsing mainly fails because of forgotten or misplaced tokens that break the syntax. In contrast, high values of the also allow us to identify models producing triples that are far from well-formed. We identified that these high values are generally related to the generation of incomplete, truncated, or empty sequences as in , , , , and at a higher level , , and . Some typical errors illustrating it are reported in Figure 14.
Examples of parsing errors accounted. (a) generated triple with a missing “/” token on the closing <rdf:Description> element, (b) triples with a missing “<rel>” starting tokens, (c) triples with a missing “@prefix” declaration, and (d) triples with a repeated “Cara_Grzesk” pattern.
Regarding the rate of SHACL-validated triples (), all the configurations that lead to parsed triples almost perfectly fit the defined maximal SHACL shape. Moreover, the fact that all the scores are close to 1 in Tables 6 to 8 is a sign that the subject URI given in the prompt is easily copied by the model in all the configurations. But we can point out some exceptions: the Turtle Ultra Light syntax for which FlanT5 and PileT5 fail to properly write the subject URI, forgetting, for example, the prefix token “:” or struggling to produce sequences containing special characters, for example, produces “” instead of “,” as well as only “” instead of “.”
The BLEU scores are generally above 0.9, which shows the global ability of the models to predict the right values when the graphs produced are parsed. In particular, for , , meaning that the model always perfectly predicts string values of datatype properties. , , and perform less well on that specific aspect.
The training behavior meta-metrics all depend on the saturation of a given metric. Consequently, we cannot evaluate many of the PileT5 and FlanT5 configurations that never reached saturation on both considered metrics ( being an exception here). Conversely, BART and T5 configurations always saturate both and metrics. Some CodeT5 configurations have difficulties saturating on both and , for example, , , and .
The average velocity values and demonstrate that all the BART and T5 configurations saturate at the first epoch, except for . We checked the value of the at the epoch where saturates (noted in Tables 6 to 8), and we observed that all models saturating the also record high values, which means that learning the syntax is the main challenge when it comes to learn an RDF-extractor. Moreover, we observe that the BART models generally saturate both and early, followed by the T5 models. From the syntax point of view, TurtleLight written on one line saturates earlier than other syntaxes. The factorization of list and tag syntaxes leads to earlier saturation, which is particularly noteworthy in the case of the tag syntax configurations. Regarding the W3C syntaxes, there is a clear difference between JSON and XML on the one hand, which have a close to 0, and Turtle and N-Triples on the other hand, which have a close to 1. This gap could be due to the pretraining of the language models we used, which are more likely to have seen JSON and XML that are common on the web. The average stability and divergence values show that all the saturating models are stable from the point of view () and never diverge (). Only the and meta-metrics reveal differences in the performances of the models. These metrics are correlated in the sense that an unstable model always diverges. We see that BART models never diverge, while many configurations of T5 diverge.
The resource metrics (time and CO) also show important discrepancies between models, which could be explained by the verbosity of some syntaxes, and the ability of a model to learn a given syntax without divergence. As shown in Figure 15, T5 models are greedier than BART models, and simple syntaxes are thriftier than RDF ones. Model training CO footprint (radius) vary from 0.029 g for , to 0.324 g for . It is also interesting to see that the Turtle Ultra Light syntax, despite conciseness and good overall results, finally requires more training and, consequently, more resources.
Best performing model (BART and T5) configurations against ( axis), ( axis) and (radius).
To sum up, our experiments show that the quality of the generated RDF triples depends on both the choice of the model and of the syntax. In terms of models, BART generally writes syntactically better triples than T5, while T5 needs fewer training epochs but requires more resources. Interestingly, CodeT5 is in the third place without being pretrained on Wikipedia data. FlanT5 and PileT5 are unable to solve our task.
In terms of syntaxes, factorization applied on the list, tags, and Turtle Light syntaxes positively impact the models’ performance, except on . The one-line variation improves the quality of Turtle Light variations, and the best configuration combines factorization and one-line writing. In the end, (BART with Turtle Light, factorization, one-line) offers good performances at a low cost with a standard and human-readable syntax.
Evaluation of Specific Model Capacities
Two potential solutions can be considered to address the syntactic errors produced by our models. (1) The first relies on the use of constrained decoding guided by an Extended Backus–Naur Form (EBNF) grammar. As demonstrated by Geng et al. (2023), grammar-based decoding can constrain a model to generate outputs that strictly follow a predefined syntax, thereby reducing structural errors. Their work shows that constrained generation can be effectively applied at inference time in the context of LLMs; however, it remains to be verified whether similar benefits can be achieved for small language models (SLMs).
(2) The second solution exploits the capabilities of the CodeT5 model, which was pretrained on code understanding and correction tasks (Wang et al., 2021). This family of models could be leveraged to automatically correct malformed textual sequences that deviate from a target syntax.
Constrained Decoding Based on Grammar
Following discussions with the maintainers of the transformers-CFG library10 and building on the work of Geng et al. (2023), we extended this package to support the BART and T5 models. To evaluate the effectiveness and potential of constrained decoding, we reused our fine-tuned model and adapted the EBNF grammar defined by the W3C11 to manage the proposed Turtle Light syntax, including both its one-line and factorized forms (Figure 16).
However, none of our tests yielded conclusive results. In practice, constrained decoding led to a substantial increase in inference time, requiring on average approximately 250 ms per token on a personal computer, which is about six times slower than unconstrained decoding. Moreover, the generated outputs were often incomplete and syntactically incorrect, indicating that grammar-constrained decoding could not be effectively applied within our experimental context (Figure 17).
Example of broken sequence generated using the EBNF grammar. EBNF = Extended Backus–Naur Form.
CodeT5 Coding Capacities
The CodeT5 model was pretrained to perform multiple code-related tasks: (1) code summarization, (2) code generation, (3) code refinement and correction, (4) code vulnerability detection (defect detection), and (5) code translation (Wang et al., 2021). In our case, the code refinement capability is of particular interest, as it can help correct syntactic errors within the generated outputs. It may also assist in fixing minor encoding inconsistencies that often penalize models from the T5 family.
Using the Pretrained CodeT5 Directly. A straightforward approach is to employ the general pretrained CodeT5 model to automatically fix common syntactic or encoding errors observed in our generated outputs. To evaluate this potential, we tested CodeT5 on a recurrent error made by T5-family models when generating Turtle graphs—specifically, the omission of the @prefix declaration. We used the following “Refine:” prompt to instruct CodeT5 to correct such cases. This preliminary example showed that the pretrained CodeT5 model is not capable of handling RDF data or understanding the specific syntactic conventions of Turtle. As a result, it was unable to correct even simple structural errors such as missing declarations (Figure 18).
Example of CodeT5 Refine sequence fixing.
Using the Fine-Tuned CodeT5 Model. We hypothesized that a fine-tuned model, denoted as , could potentially manage such cases within the Turtle Light syntax. To evaluate this hypothesis, we reused the same refinement prompt and tested the model on four artificially corrupted versions of an original triple. Each corrupted instance represented a different type of syntactic distortion—such as omitted prefixes, misplaced delimiters, invalid datatype annotations, and missing brackets—allowing us to assess the model’s ability to restore the valid graph given in the prompt. The fine-tuned model appeared capable of correcting two of the syntactic errors illustrated in Figures 19 and 20. However, this improvement came at a high cost: a noticeable reduction in the number of triples successfully produced. Regarding the date format, the model indeed generated a syntactically valid correction, but it altered the original value, thereby compromising the factual integrity of the triple (Figure 21). Finally, when instructed to infer the year properties from a complete date—as shown in Figure 22—the model succeeded only in generating the birthYear property, while omitting the corresponding deathYear.
Example of Refine on a missing dot broken sequence.
Example of Refine applied on a missing “:” broken sequence.
Example of Refine on malformed date.
Example of Refine on sequence missing the year properties.
Robustness of the Models to Prompt Noise
To further evaluate the contextual sensitivity of our models, we investigated how variations in prompt design and input structure affect RE performance.
Sensitivity to Sentences Order in Abstracts. Both BART and T5 fine-tuned models demonstrate a strong capacity to extract factual knowledge from reordered abstracts. The BART model, in particular, shows near-perfect robustness to sentence reordering, achieving almost identical performance across the baseline and reordered test sets.
Impact of Entity URIs in the Prompt. A recurrent limitation observed in both models concerns their inability to infer entity URIs autonomously, even when the extracted relations are correct. By comparing the MaskedEntity and NoEntity configurations, we observe that omitting the entity entirely yields better performance than masking it. This suggests that explicit masking introduces noise into the encoding process, whereas the absence of the entity allows the model to generalize more effectively.
Impact of Explicit Instructions in T5. Although the T5 model was fine-tuned to produce triples directly from Wikipedia abstracts, the presence of an explicit instruction prompt (e.g., Extract RDF triples from the following abstract:”) remains essential for high-quality extraction. When this instruction was removed, performance degraded sharply, as shown in the “NoInstruct” configuration.
Discussion
Our benchmark first demonstrated that all encoders–decoders are highly sensitive to the choice of a syntax for the RE task. Moreover, we observed that the choice of the model itself is crucial in terms of performance. BART is supposed to be trained on plain text, where the T5 family models were all trained on noisier sources, potentially containing XML or JSON input data. These specificities related to the pretraining corpora help explain why T5 is better at handling JSON and XML than BART, but these good performances come at a higher training cost for T5. In that context, we showed that the closer the syntax is to natural language, the easier it is for a pretrained model to learn it.
Many hypotheses can be drawn to explain these discrepancies. (1) BART was pretrained on a larger set of basic subtasks, which may encourage the flexibility of the model. (2) The multitask learning design of the T5 family enables the resolution of high-level objectives. However, all of these predefined tasks expect short or natural language answers that are far from being structured, which may, in our context, penalize these models.
Considering the supplementary experiment we conducted on the usage of grammar-based constrained generation, we showed that this solution does not significantly help encoder–decoder-based models to generate well-formed output. First, the constrained generation incurs a significant cost at inference time, and the actual library developed struggles to handle complex grammars. Aside from this, the experiments conducted with CodeT5 showed that the model’s refinement capacities are limited when used directly. Nonetheless, these results are encouraging since the models are producing parsable triples and can still be further fine-tuned using explicit examples of refinement.
Of course, one potential explanation for the good results of T5 and BART may be a memorization effect. In a recent work (Ringwald et al., 2025b), we tested this hypothesis. We fine-tuned BART models using only facts that were already seen during the model’s pretraining, that is, those existing in the 2021 Wikipedia dumps. We then tested it on two sets of datasets: one comprising Wikipedia pages published before 2021 and the other comprising new Wikipedia pages published after this date. Our results showed no significant difference between these two configurations, which allows us to refute the memorization hypothesis today.
Conclusion: BART and a Turtle Light Go a Long Way
In this article, we evaluated the impact of the choice of a syntax on the fine-tuning of SLMs for the generation of RDF triples, focusing on extracting datatype properties from text. We demonstrated the ability of the BART and T5 models to solve the RE task compared to CodeT5, PileT5, and FlanT5. To do so, we proposed several metrics that allowed us to characterize the behaviors of the given training configuration. Our results show that syntax understanding is the main challenge language models face when they are fine-tuned to solve an RE task: all the configurations able to generate well-written graphs also highly perform in terms of . Moreover, the choice of the syntax also has a significant impact on the performance of the extraction, as well as on the resources needed to learn it (time and CO footprint). Basic syntaxes (list and tags) are generally easily learned but lead to average performances. While learning W3C RDF syntaxes is more resource-consuming, and the RDF potential (managing ontologies, datatypes) must generally be paid for at a higher cost in terms of resources. The best-performing configuration (T5 with JSON) outperforms the others at the cost of 2 h of training on an A100 GPU and a 0.250 g CO footprint. An interesting compromise is the use of simplified standard syntaxes (as the Turtle Light syntaxes proposed in this work) that are robust and quick to learn. However, despite its simplicity, we also show that the Turtle Ultra Light syntax (Turtle variation omitting the prefixes and their declarations) could be costly to learn. For all these reasons, the fine-tuning of BART models using the inline factorized Turtle Light () is a good tradeoff between efficiency and frugality.
Beyond syntax optimization, we evaluated the capacity of models to handle and repair syntactic errors. Constrained decoding using EBNF grammars, although theoretically promising, proved impractical in our context due to a sixfold increase in inference time and incomplete outputs. In contrast, experiments with the CodeT5 model and its fine-tuned variant () showed partial success in correcting malformed triples within the Turtle Light syntax, demonstrating potential for integrating code-oriented pretraining into graph refinement tasks. However, these approaches also revealed a trade-off between syntactic correction and semantic fidelity: models can repair structure but occasionally corrupt values or omit facts.
Finally, our study of contextual robustness emphasized the prompt sensitivity of the models analyzed. Both BART and T5 remained stable under reordered textual inputs, confirming limited order sensitivity. However, entity masking and missing led to degraded results, underlying some limitations related to the fine-tuning models since they could not generalize enough to be able to guess the subject of the graph, when conditioned to use it from the prompt to compose the output. Moreover, we saw that the instruction also has an important impact on the T5 model, underlying the importance of defining a new instruction for a new task, but also to refer to the right instruction when the model is used for inference.
In future work, we will focus on systematizing the task proposed at a Knowledge base scale, notably by extending our proposal to Shape, containing both data and object properties.
Footnotes
ORCID iDs
Fabien Gandon
Catherine Faron
Franck Michel
Hanna Abi Akl
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
References
1.
BanerjeeD.NairP.UsbeckR.BiemannC. (2023). The role of output vocabulary in T2T LMs for SPARQL semantic parsing. In A. Rogers, J. Boyd-Graber, & N. Okazaki (Eds.), Findings of the Association for Computational Linguistics: ACL 2023 (pp. 12219–12228). Toronto, Canada: Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-acl.774
2.
BanerjeeD.NairP. A.KaurJ. N.UsbeckR.BiemannC. (2022). Modern baselines for SPARQL semantic parsing. In Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval, SIGIR ’22 (pp. 2260–2265). New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3477495.3531841
DagdelenJ.DunnA.LeeS.WalkerN.RosenA. S.CederG.PerssonK. A.JainA. (2024). Structured information extraction from scientific text with large language models. Nature Communications, 15(1), 1418. https://doi.org/10.1038/s41467-024-45563-x
5.
DevlinJ.ChangM. W.LeeK.ToutanovaK. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In J. Burstein, C. Doran, & T. Solorio (Eds.), Proceedings of the 2019 conference of the North American chapter of the Association for Computational Linguistics: Human language technologies (Vol. 1) (Long and Short Papers) (pp. 4171–4186). Minneapolis, MN: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1423
6.
DingN.QinY.YangG.WeiF.YangZ.SuY.HuS.ChenY.ChanC. M.ChenW.YiJ.ZhaoW.WangX.LiuZ.ZhengH. T.ChenJ.LiuY.TangJ.LiJ.SunM. (2023). Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence, 5(3), 220–235. https://doi.org/10.1038/s42256-023-00626-4
ElsaharH.VougiouklisP.RemaciA.GravierC.HareJ.SimperlE.LaforestF. (2018). T-REx: A large scale alignment of natural language with knowledge base triples. In LREC2018. Miyazaki, Japan: European Language Resources Association (ELRA). https://aclanthology.org/L18-1544
9.
FreyJ.MeyerL. P.ArndtN.BreiF.BulertK. (2023). Benchmarking the abilities of large language models for RDF knowledge graph creation and comprehension: How well do LLMs speak turtle? ArXiv abs/2309.17122. https://api.semanticscholar.org/CorpusID:263310661
10.
GallardoA. P.ConsoliS.CeresaM.HulsmanR.BertoliniL. (2024). On constructing biomedical text-to-graph systems with large language models. In S. Tiwari, N. Mihindukulasooriya, F. Osborne, D. Kontokostas, J. D’Souza, M. Kejriwal, M.A. Pellegrino, A. Rula, J. E. L. Gayo, M. Cochez, & M. Alam (Eds.), Joint proceedings of the 3rd international workshop on knowledge graph generation from text (TEXT2KG) and Data Quality meets Machine Learning and knowledge graphs (DQMLKG) co-located with the Extended Semantic Web Conference (ESWC 2024), Hersonissos, Greece, May 26–30, 2024, CEUR Workshop Proceedings (Vol. 3747, p. 12). CEUR-WS.org. https://ceur-ws.org/Vol-3747/text2kg_paper10.pdf
11.
GardentC.ShimorinaA.NarayanS.Perez-BeltrachiniL. (2017). Creating training corpora for NLG micro-planners. In Proceedings of the 55th annual meeting of the Association for Computational Linguistics (Vol. 1, Long Papers) (pp. 179–188). Vancouver, Canada: ACL. https://doi.org/10.18653/v1/p17-1017
12.
GengS.JosifoskiM.PeyrardM.WestR. (2023). Grammar-constrained decoding for structured NLP tasks without finetuning. In H. Bouamor, J. Pino, & K. Bali (Eds.), Proceedings of the 2023 conference on empirical methods in natural language processing. Singapore: Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.emnlp-main.674
13.
GrangierD.KatharopoulosA.AblinP.HannunA. (2024). Need a small specialized language model? Plan early! https://arxiv.org/abs/2402.01093
14.
HarbeckeD.ChenY.HennigL.AltC. (2022). Why only micro-F1? Class weighting of measures for relation classification. In T. Shavrina, V. Mikhailov, V. Malykh, E. Artemova, O. Serikov, & V. Protasov (Eds.), Proceedings of NLP power! The first workshop on efficient benchmarking in NLP (pp. 32–41). Dublin, Ireland: Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.nlppower-1.4
15.
HoferM.FreyJ.RahmE. (2024). Towards self-configuring knowledge graph construction pipelines using LLMs—A case study with RML. In D. Chaves-Fraga, A. Dimou, A. Iglesias-Molina, U. Serles, & D. V. Assche (Eds.), Proceedings of the 5th international workshop on knowledge graph construction co-located with 21st Extended Semantic Web Conference (ESWC 2024), Hersonissos, Greece, May 27, 2024, CEUR Workshop Proceedings (Vol. 3718). CEUR-WS.org. https://ceur-ws.org/Vol-3718/paper6.pdf
Huguet CabotP. L.NavigliR. (2021). REBEL: Relation extraction by end-to-end language generation. In M. F. Moens, X. Huang, L. Specia, & S. W. T. Yih (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2021 (pp. 2370–2381). Punta Cana, Dominican Republic: Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.findings-emnlp.204
JiZ.LeeN.FrieskeR.YuT.SuD.XuY.IshiiE.BangY. J.MadottoA.FungP. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), 1–38. https://doi.org/10.1145/3571730
20.
JinB.LiuG.HanC.JiangM.JiH.HanJ. (2023). Large language models on graphs: A comprehensive survey. ArXiv:2312.02783 [cs]. http://arxiv.org/abs/2312.02783
21.
JosifoskiM.De CaoN.PeyrardM.PetroniF.WestR. (2022). GenIE: Generative information extraction. In M. Carpuat, M. C. de Marneffe, & I. V. Meza Ruiz (Eds.), Proceedings of the 2022 conference of the North American chapter of the Association for Computational Linguistics: Human language technologies (pp. 4626–4643). Seattle, USA: Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.naacl-main.342
22.
JosifoskiM.SakotaM.PeyrardM.WestR. (2023). Exploiting asymmetry for synthetic training data generation: SynthIE and the case of information extraction. In H. Bouamor, J. Pino, & K. Bali (Eds.), Proceedings of the 2023 conference on empirical methods in natural language processing (pp. 1555–1574). Singapore: Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.emnlp-main.96
23.
KandpalN.DengH.RobertsA.WallaceE.RaffelC. (2023). Large language models struggle to learn long-tail knowledge. In Proceedings of the 40th international conference on machine learning, ICML’23. JMLR.org.
24.
KeP.JiH.RanY.CuiX.WangL.SongL.ZhuX.HuangM. (2021). JointGT: Graph-text joint representation learning for text generation from knowledge graphs. In C. Zong, F. Xia, W. Li, & R. Navigli (Eds.), Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 (pp. 2526–2538). Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.findings-acl.223
25.
LehmannJ.MeloniA.MottaE.OsborneF.RecuperoD. R.SalatinoA. A.VahdatiS. (2024). Large language models for scientific question answering: An extensive analysis of the SCIQA benchmark. In A. Meroño Peñuela, A. Dimou, R. Troncy, O. Hartig, M. Acosta, M. Alam, H. Paulheim, & P. Lisena (Eds.), The semantic web (pp. 199–217). Cham: Springer Nature Switzerland.
26.
LewisM.LiuY.GoyalN.GhazvininejadM.MohamedA.LevyO.StoyanovV.ZettlemoyerL. (2019). BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. ArXiv:1910.13461 [cs, stat]. https://doi.org/10.48550/arXiv.1910.13461; http://arxiv.org/abs/1910.13461
27.
LiG.WangP.KeW.GuoY.JiK.ShangZ.LiuJ.XuZ. (2024). Recall, retrieve and reason: Towards better in-context relation extraction. In K. Larson (Ed.), Proceedings of the thirty-third international joint conference on artificial intelligence, IJCAI-24 (pp. 6368–6376). International Joint Conferences on Artificial Intelligence Organization. https://doi.org/10.24963/ijcai.2024/704
28.
LiX.PolatF.GrothP. (2025). Do instruction-tuned large language models help with relation extraction? In S. Razniewski, J. C. Kalo, S. Singhania, & J. Z. Pan (Eds.), Joint proceedings of the 1st workshop on knowledge base construction from pre-trained language models (KBC-LM) and the 2nd challenge on language models for knowledge base construction (LM-KBC), CEUR Workshop Proceedings (Vol. 3577). CEUR. https://ceur-ws.org/Vol-3577/##paper4
29.
LiuM. X.LiuF.FiannacaA. J.KooT.DixonL.TerryM.CaiC. J. (2024a). “We need structured output”: Towards user-centered constraints on large language model output. In Extended abstracts of the chi conference on human factors in computing systems, CHI EA ’24. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3613905.3650756
30.
LiuP.YuanW.FuJ.JiangZ.HayashiH.NeubigG. (2023). Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9), 195:1–195:35. https://doi.org/10.1145/3560815
31.
LiuY.LiD.WangK.XiongZ.ShiF.WangJ.LiB.HangB. (2024b). Are LLMs good at structured outputs? A benchmark for evaluating structured output capabilities in LLMs. Information Processing & Management, 61(5), 103809. https://doi.org/10.1016/j.ipm.2024.103809
32.
LuY.LiuQ.DaiD.XiaoX.LinH.HanX.SunL.WuH. (2022). Unified structure generation for universal information extraction. In MuresanS.NakovP.VillavicencioA. (Eds.), Proceedings of the 60th annual meeting of the Association for Computational Linguistics (Vol. 1, Long Papers, pp. 5755–5772). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.acl-long.395
33.
LuZ.LiX.CaiD.YiR.LiuF.ZhangX.LaneN. D.XuM. (2024). Small language models: Survey, measurements, and insights. https://arxiv.org/abs/2409.15790
34.
MeyerL.-P.FreyJ.BreiF.ArndtN. (2025). Assessing SPARQL capabilities of Large Language Models. arXiv 2409.05925. https://arxiv.org/abs/2409.05925
35.
MeyerL. P.StadlerC.FreyJ.RadtkeN.JunghannsK.MeissnerR.DziwisG.BulertK.MartinM. (2024). LLM-assisted knowledge graph engineering: Experiments with ChatGPT. In C. Zinke-Wehlmann & J. Friedrich (Eds.), First working conference on artificial intelligence development for a resilient and sustainable tomorrow (pp. 103–115). Wiesbaden: Springer Fachmedien Wiesbaden. https://doi.org/10.1007/978-3-658-43705-3_8
36.
MihindukulasooriyaN.SavaM.RossielloG.ChowdhuryM. F. M.YachbesI.GidhA.DuckwitzJ.NisarK.SantosM.GliozzoA. (2022). Knowledge graph induction enabling recommending and trend analysis: A corporate research community use case. In The Semantic Web—ISWC 2022: 21st international semantic web conference, Virtual Event, October 23–27, 2022, Proceedings (pp. 827–844). Berlin, Heidelberg: Springer-Verlag. https://doi.org/10.1007/978-3-031-19433-7_47
37.
MihindukulasooriyaN.TiwariS.EnguixC. F.LataK. (2023). Text2kgbench: A benchmark for ontology-driven knowledge graph generation from text. https://arxiv.org/abs/2308.02357
38.
MinaeeS.MikolovT.NikzadN.ChenaghluM.SocherR.AmatriainX.GaoJ. (2024). Large language models: A survey.
39.
MöllerC.UsbeckR. (2025). Analyzing the influence of knowledge graph information on relation extraction. Springer Nature.
40.
NayakT.MajumderN.GoyalP.PoriaS. (2021). Deep neural approaches to relation triplets extraction: A comprehensive survey. Cognitive Computation, 13, 1215–1232. 10.1007/s12559-021-09917-7
41.
PaoliniG.AthiwaratkunB.KroneJ.MaJ.AchilleA.dos SantosR.AnubhaiC. N.XiangB.SoattoS. (2021). Structured prediction as translation between augmented natural languages. In 9th International conference on learning representations, ICLR 2021.
42.
PapineniK.RoukosS.WardT.ZhuW. J. (2002). BLEU: A method for automatic evaluation of machine translation. In P. Isabelle, E. Charniak, & D. Lin (Eds.), Proceedings of the 40th annual meeting of the Association for Computational Linguistics (pp. 311–318). Philadelphia, PA, USA: Association for Computational Linguistics. https://doi.org/10.3115/1073083.1073135
43.
PatelA.RaffelC.Callison-BurchC. (2024). DataDreamer: A tool for synthetic data generation and reproducible LLM workflows. In L. W. Ku, A. Martins, & V. Srikumar (Eds.), Proceedings of the 62nd annual meeting of the Association for Computational Linguistics (Vol. 1, Long Papers) (pp. 3781–3799). Bangkok, Thailand: Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.acl-long.208
44.
RaffelC.ShazeerN.RobertsA.LeeK.NarangS.MatenaM.ZhouY.LiW.LiuP. J. (2023). Exploring the limits of transfer learning with a unified text-to-text transformer. ArXiv:1910.10683 [cs, stat]. http://arxiv.org/abs/1910.10683
45.
ReginoA. G.RossanezA.da Silva TorresR.dos ReisJ. C. (2025). A systematic literature review on RDF triple generation from natural language text. Semantic Web Journal.
46.
ReydS.ZouaqA. (2023). Assessing the generalization capabilities of neural machine translation models for SPARQL query generation. In T. R. Payne, V. Presutti, G. Qi, M. Poveda-Villalón, G. Stoilos, L. Hollink, Z. Kaoudi, G. Cheng, & J. Li (Eds.), The Semantic Web—ISWC 2023—22nd international semantic web conference, Athens, Greece, November 6–10, 2023, Proceedings, Part I, Lecture Notes in Computer Science (Vol. 14265, pp. 484–501). Springer. https://doi.org/10.1007/978-3-031-47240-4_26
47.
RingwaldC.GandonF.FaronC.MichelF.AklH. A. (2025a). 12 shades of RDF: Impact of syntaxes on data extraction with language models. In A. Meroño Peñuela, O. Corcho, P. Groth, E. Simperl, V. Tamma, A. G. Nuzzolese, M. Poveda-Villalón, M. Sabou, V. Presutti, I. Celino, A. Revenko, J. Raad, B. Sartini, & P. Lisena (Eds.), The Semantic Web: ESWC 2024 satellite events (pp. 81–91). Cham: Springer Nature Switzerland.
48.
RingwaldC.GandonF.FaronC.MichelF.AklH. A. (2025b). Overcoming the generalization limits of SLM finetuning for shape-based extraction of datatype and object properties. In KCAP 2025—The thirteenth international conference on knowledge capture-10—Association for Computing Machinery. Dayton: OH, USA: ACM. https://hal.science/hal-05285428. Accepted at KCAP2025—Preprint version not updated with reviews.
49.
ŠakotaM.WestR. (2025). Combining constrained and unconstrained decoding via boosting: BoostCD and its application to information extraction. https://arxiv.org/abs/2506.14901
TailléB.GuigueV.ScoutheetenG.GallinariP. (2020). Let’s stop incorrect comparisons in end-to-end relation extraction! In B. Webber, T. Cohn, Y. He, & Y. Liu (Eds.), Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) (pp. 3689–3701). Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.emnlp-main.301
55.
WadhwaS.AmirS.WallaceB. (2023). Revisiting relation extraction in the era of large language models. In A. Rogers, J. Boyd-Graber, & N. Okazaki (Eds.), Proceedings of the 61st annual meeting of the Association for Computational Linguistics (Vol. 1, Long Papers) (pp. 15566–15589). Toronto, Canada: Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.acl-long.868
56.
WangC.LiuX.ChenZ.HongH.TangJ.SongD. (2022). DeepStruct: Pretraining of language models for structure prediction. In S. Muresan, P. Nakov, & A. Villavicencio (Eds.), Findings of the Association for Computational Linguistics: ACL 2022 (pp. 803–823). Dublin, Ireland: Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.findings-acl.67
57.
WangF.ZhangZ.ZhangX.WuZ.MoT.LuQ.WangW.LiR.XuJ.TangX.HeQ.MaY.HuangM.WangS. (2024). A comprehensive survey of small language models in the era of large language models: Techniques, enhancements, applications, collaboration with LLMs, and trustworthiness. https://arxiv.org/abs/2411.03350
58.
WangY.WangW.JotyS.HoiS. C. H. (2021). CodeT5: Identifier-aware unified pre-trained encoder–decoder models for code understanding and generation. https://arxiv.org/abs/2109.00859
59.
WuC.ChenL. (2020). Utber: Utilizing fine-grained entity types to relation extraction with distant supervision. In 2020 IEEE International conference on smart data services (SMDS) (pp. 63–71). https://doi.org/10.1109/SMDS49396.2020.00015
60.
YaoY.YeD.LiP.HanX.LinY.LiuZ.LiuZ.HuangL.ZhouJ.SunM. (2019). DocRED: A large-scale document-level relation extraction dataset. In Proceedings of the 57th annual meeting of the ACL (pp. 764–777). Florence, Italy: ACL. https://doi.org/10.18653/v1/p19-1074
ZaveriA.KontokostasD.HellmannS.UmbrichJ.FärberM.BartschererF.MenneC.RettingerA.ZaveriA.KontokostasD.HellmannS.UmbrichJ. (2018). Linked data quality of DBpedia, Freebase, OpenCyc, Wikidata, and YAGO. Semantic web, 9(1), 77–129. https://doi.org/10.3233/SW-170275
63.
ZaveriA.KontokostasD.SherifM. A.BühmannL.MorseyM.AuerS.LehmannJ. (2013). User-driven quality evaluation of DBpedia. In Proceedings of the 9th international conference on semantic systems, I-SEMANTICS ’13 (pp. 97–104). New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/2506182.2506195
64.
ZhangB.ReklosI.JainN.PeñuelaA. M.SimperlE. (2023). Using large language models for knowledge engineering (LLMKE): A case study on Wikidata. https://arxiv.org/abs/2309.08491

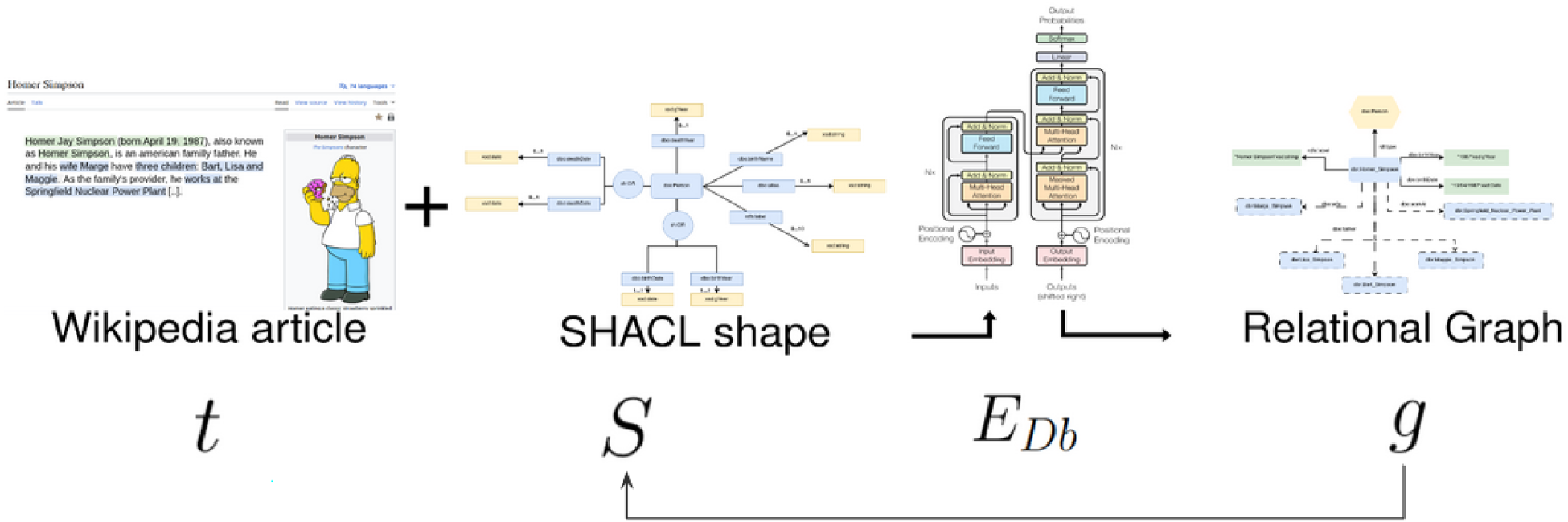
 12ShadesofRDF GitHub repository
1
as well as the complete experimental results.
2
12ShadesofRDF GitHub repository
1
as well as the complete experimental results.
2