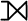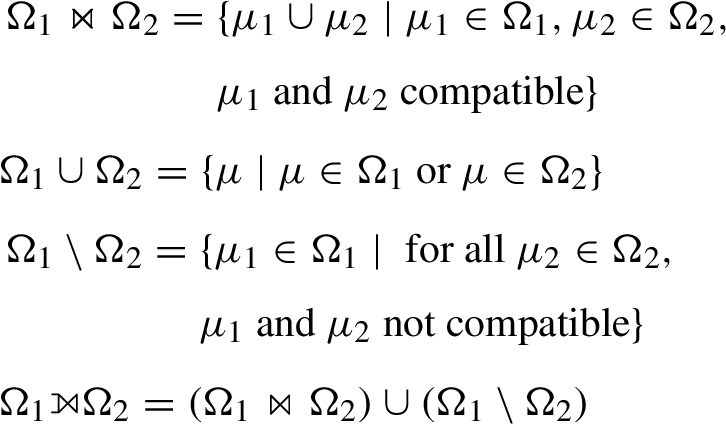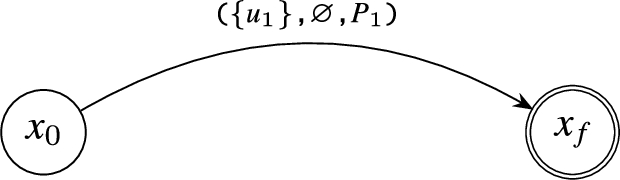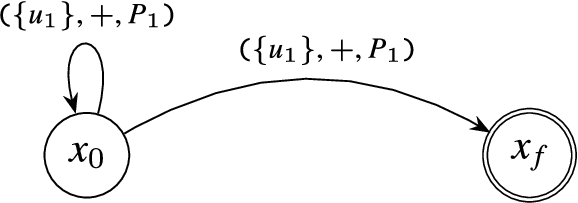The field of Complex Event Processing (CEP) deals with the techniques and tools developed to efficiently process pattern-based queries over data streams. The Semantic Web, through its standards and technologies, is in constant pursuit to provide solutions for such paradigm while employing the RDF data model. The integration of Semantic Web technologies in this context can handle the heterogeneity, integration and interpretation of data streams at the semantic level. In this paper, we propose and implement a new query language, called SPAseq, that extends SPARQL with new Semantic Complex Event Processing (SCEP) operators that can be evaluated over RDF graph-based events. The novelties of SPAseq include (i) the separation of general graph pattern matching constructs and temporal operators; (ii) the support for RDF graph-based events and multiple RDF graph streams; (iii) the expressibility of temporal operators such as Kleene+, conjunction, disjunction and event selection strategies; and (iv) the operators to integrate background information and streaming RDF graph streams. Hence, SPAseq enjoys good expressiveness compared with the existing solutions. Furthermore, we provide an efficient implementation of SPAseq using a non-deterministic automata (NFA) model for an efficient evaluation of the SPAseq queries. We provide the syntax and semantics of SPAseq and based on this, we show how it can be implemented in an efficient manner. Moreover, we also present an experimental evaluation of its performance, showing that it improves over state-of-the-art approaches.
Stream processing has become an important paradigm for processing data at high speed and large scale, where query operators such as selection, aggregation, filtering of data are performed in a streaming fashion [1,33]. Complex Event Processing (CEP) systems, however, provide a different view and additional operators for streaming applications: each data item within a data stream is considered as an event and predefined temporal patterns are used to generate actions to the systems, people and devices. CEP systems have demonstrated utility in a variety of applications including financial trading, security monitoring, healthcare, social and sensor network analysis [21,45,59]. In general, CEP denotes algorithmic methods for making sense of events by deriving higher-level knowledge, or complex events from lower-level events in a timely fashion [21,42]. CEP applications commonly involve three requirements [3,21,42,46]:
complex predicates (filtering, correlation);
temporal, order and sequential patterns; and
transforming event(s) into more complex structures.
The past several years have seen a large number of CEP systems and query languages being developed by both academic and industrial worlds [3,7,8,13,15,26,45,46]. Following the trend of using RDF as a unified data model for integrating diverse data sources across heterogeneous domains, there is a great interest in using RDF data model for the CEP. This results in a new field of the Semantic CEP (SCEP) [7,43]. The use of RDF as an input data model provides the following attributes [14,34]. First, it offers a unified data model (directed labelled graphs). Second, it allows building upon countless domain knowledge formalisations, in the form of vocabularies, thesauri and ontologies. Third, RDF-based data integration systems benefit from the reasoning capabilities offered by the Semantic Web technologies to reason upon the context of detected events. Fourth, it makes it possible to leverage the huge knowledge base represented by the Web of Data, thereby opening up opportunities to discover related data sets, enrich data, and create added value by mashing up all this information.
The design of an efficient SCEP system requires carefully marrying the temporal operators with the RDF data model and the additional characteristic of event enrichment. Even though SCEP can be evolved from the common practice of stitching heterogeneous techniques and systems, a well organised query language is a vital part of SCEP: it not only allows users to specify known queries or patterns of events in an intuitive way, but also to showcase the expected answers of a query while hiding the implementation details.
While there does not exist a standard language for expressing continuous queries over RDF streams, a few options have been proposed. In particular, a first strand of research focuses on extending the scope of SPARQL to enable the stateless continuous evaluation of RDF triple streams called RDF Stream Processing (RSP) languages. These query languages include CQELS [40], C-SPARQL [12], SPARQLStream [16]: they are used to match query-defined graph patterns, aggregates and filtering operators against RDF triple streams, i.e. a sequence of RDF triples , each associated with a timestamp τ. Most of these languages do not provide any explicit temporal pattern matching operator and thus cannot be classified under the SCEP languages.
The second strand of research focused on SCEP languages to extend SPARQL with stateful operators, where few options have been proposed [6,24,50]. EP-SPARQL [6] – with its expressive language and framework – is the primary player in this field with other works focusing on a subset of operators and functionalities. EP-SPARQL extends SPARQL with sequence constructs that allow temporal ordering over triple streams and its semantics are derived from the ETALIS language [7]. Although EP-SPARQL is a pioneering work in the field of SCEP, it suffers from drawbacks such as mixing of sequence and graph pattern matching operators, single triple stream model, lack of explicit Kleene+, and event selection operators.
Considering these shortcomings, our contribution in this paper is twofold. First, we present a novel query language and system, called SPAseq, to enable complex event processing over multiple streams using the RDF graph model. Second, we present an efficient framework to process SPAseq queries. SPAseq covers the aforementioned shortcomings of existing languages and systems, and provides a unified language for SCEP over RDF graph streams, while introducing expressive explicit temporal operators. The use of explicit operators lets the users specify complex queries at high level and enables the appropriate implementation details and optimisations at the domain specific level. The main features of the SPAseq query language are summarised as follows:
One of the most important features of SPAseq is that it clearly separates the query components for describing temporal patterns over RDF graph events, from specifying the graph pattern matching over each RDF graph event. This results in language reusability and expressiveness. This separation distinguishes SPAseq from other SCEP query languages.
It provides an RDF graph stream model to support streaming of graphs instead of triples. This allows to structure more complex events in a stream. Furthermore, it provides event processing over multiple RDF graph streams, while following the SPARQL specification of named datasets [17].
It is equipped with expressive temporal operators such as Kleene+, disjunction, conjunction and event selection strategies over events from multiple streams.
It provides explicit operators to join background knowledge base and RDF graph streams.
These features stem from the general specifications described by the W3C RSP community group [20] and the use cases for the CEP [3,10,15,27,47,52].
As our second contribution, we provide an executional framework for SPAseq using a non-deterministic finite automata (NFA) model called . Although a large number of techniques exist to process temporal operators [7,13,45], the NFA model offers higher expressiveness required for SPAseq. Hence, leveraging the automata-based techniques, SPAseq queries are compiled over equivalent NFAs: the compiled NFA is processed to incrementally produce the partial matches before a full match of the query is produced. Moreover, we employ various optimisation techniques on top of our system. It includes indexing and partitioning of incoming streams; pushing the stateful predicates and query windows; and lazy evaluation of the disjunction and conjunction operators.
Our main contributions are summarised as follows:
We present SPAseq, a novel SCEP language, including a full description of its syntax and semantics.
We provide the detailed semantics of SPAseq and its main operators.
We provide the NFA-based framework to efficiently compile and evaluate SPAseq queries.
We provide system and operator-level optimisation strategies for SPAseq queries.
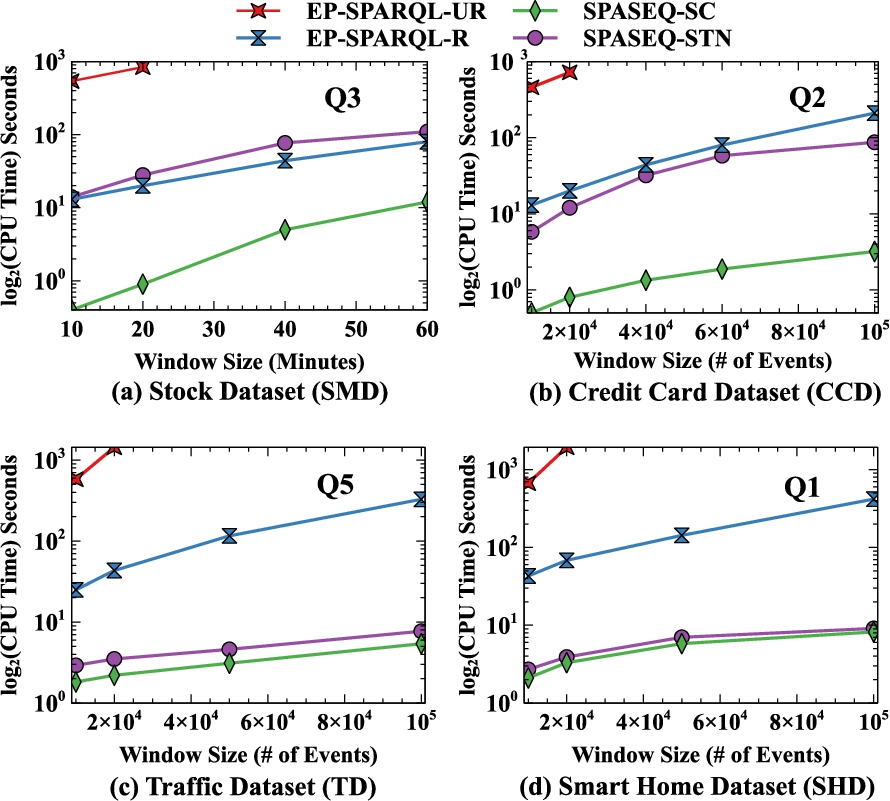
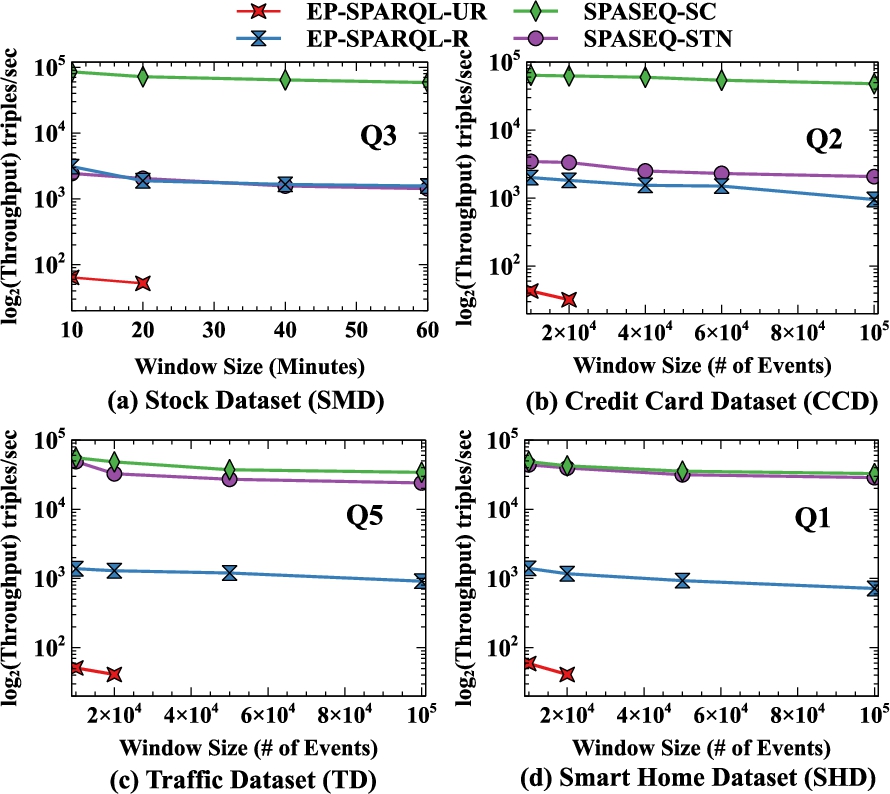
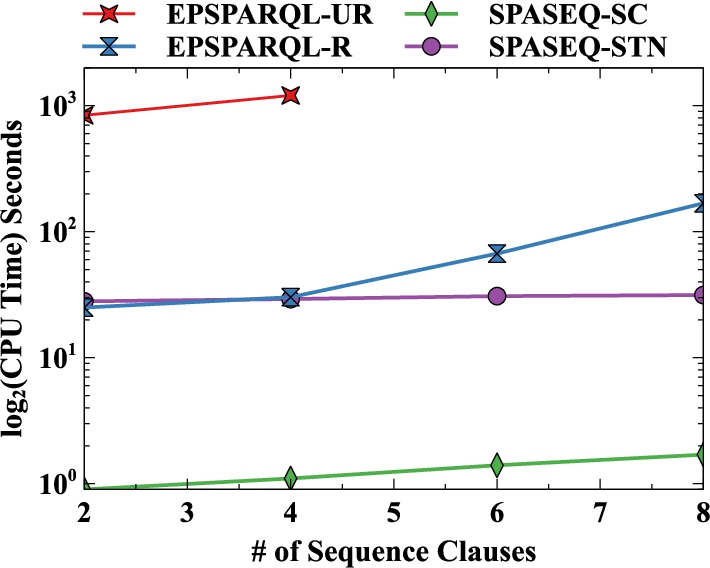
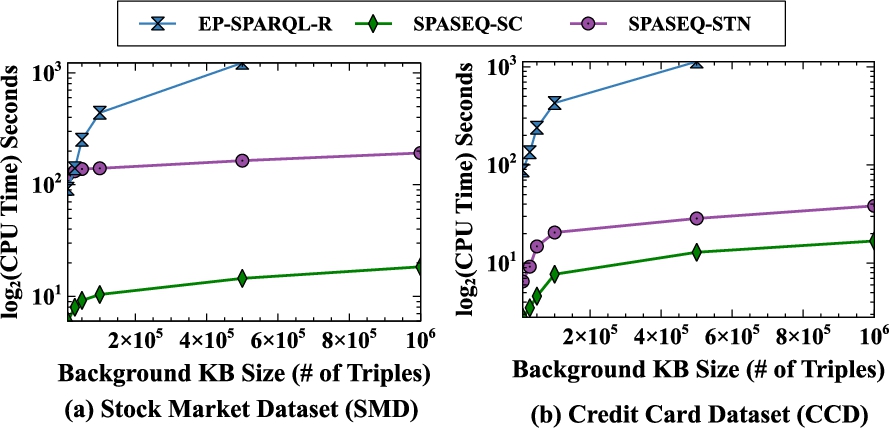
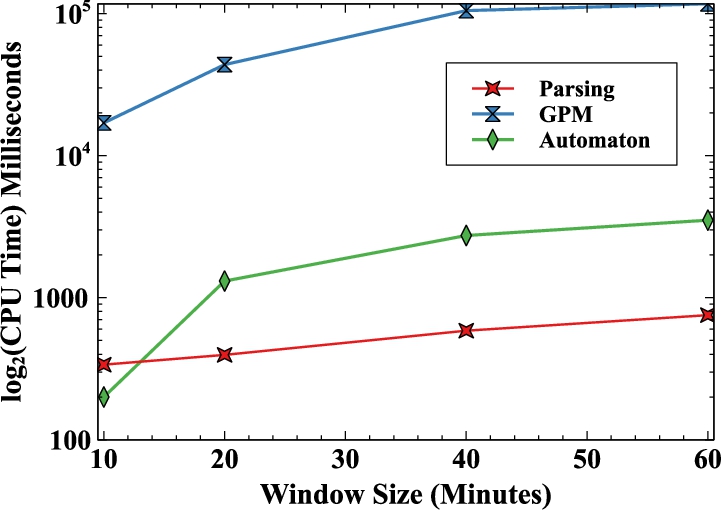
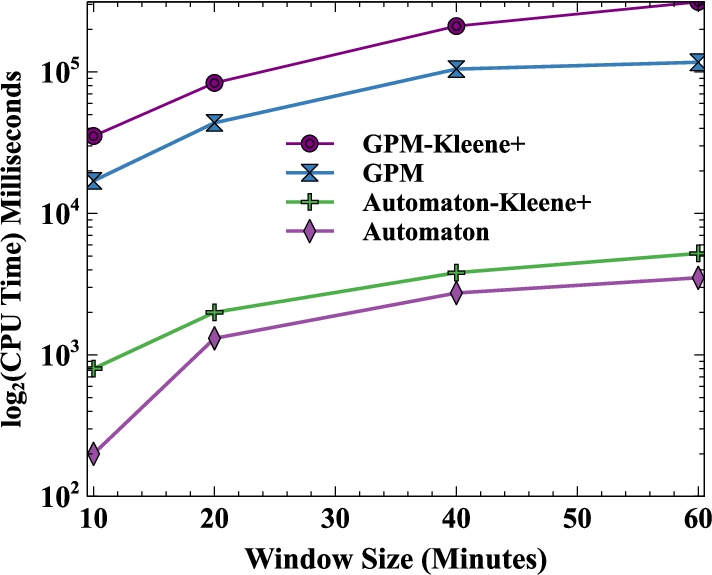
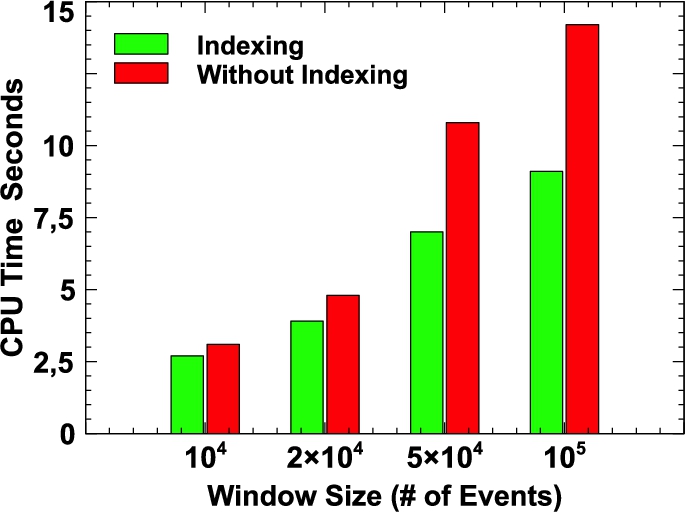
Using real-world and synthetic datasets, we demonstrate the effectiveness of our optimisation strategies and our experimental evaluations show that they outperform existing systems for the same use cases and datasets.
The rest of the paper is structured as follows. Section 2 presents the motivational examples to showcase the requirements for a SCEP language. Section 3 reviews the related work. Section 4 presents the data model and syntax of SPAseq. Section 5 presents the semantics of the SPAseq language. Section 6 presents the details about the compilation of SPAseq queries onto the model, the evaluation of automata and the design of the SPAseq query engine. Section 7 presents the optimisations techniques used for the SPAseq query engine. Section 8 provides experimental evaluations of the SPAseq query engine. Section 9 concludes the paper.
Motivational examples and requirements
In the following, we use various use cases to show the kind of expressiveness and flexibility needed for a SCEP query language. These use cases are illustrative to showcase how a SCEP can be applicable over provided RDF graph streams.
(Smart Grid Monitoring).
A smart grid monitoring application processes events from multiple distributed streams with the aim to notify the users of an online service to take a decision to improve the power usage when a defined pattern is detected [30,41]. An example of it is to notify the user to switch to a renewable power source instead of fuel-based power source, if the system observes the following pattern: (A) the price of electricity generated by a fuel-based power source is greater than a certain threshold; (B) weather conditions are favourable for renewable energy production (one or more events); and (C) the price of storage source attached to the renewable power source is less than the fuel-based power source. Moreover, a background knowledge base (KB) containing information about the homes’ addresses, owners and measurement units, etc., can be used to further enrich the matched events.
(Trajectory Classification).
Trajectory classification uses the sequence of objects movement (trajectories) to determine their types [27,44]. For instance, finding the fishing boat by discovering the trajectory of a boat over some time interval. An example pattern to determine the trajectory of fishing boats represents the following pattern: A: vessel leaves the harbour, B: vessel travels by keeping steady speed and direction (one or more events), C: vessel arrives at the fishing area and stops. The information about the owner of the vessels, shipping company a vessel is operating under, address of the fishing area, etc., can be used from a background KB to enrich the matched events.
(Fraud Management).
Fraud management has become a central aspect in today’s world, and it covers a large variety of domains. The goal in credit card fraud management is to detect fraud within 25 milliseconds, in order to prevent financial loss [10]. An important pattern in this context is to detect the “Big after Small” fraudulent transaction [4,10]. That is, an attacker withdraws one or a series of small amounts from a credit card after withdrawing a large sum of money. The SCEP query in this context detects the following pattern: (A) the withdrawn amount gradually increases; (B) until it is considerably less than the earlier withdrawn (one or more events). Furthermore, a background KB containing the cards’ owner names, issuing banks, etc., can further enrich the context of the matched events.
(Stock Market Analytics).
A stock market analytics platform processes financial transactions to detect the patterns that signify the emergence of profit opportunities [3,15,52]. Examples of such pattern are head-and-shoulders [11], V-shaped [3,45], and W-shaped [47] patterns. From the set of these patterns, the head and shoulder pattern is defined as follows: A the left shoulder (increase in the stock price) that is formed by an uptrend; B detect the head being a peak higher than the left shoulder (one or more events); C the right shoulder that shows an increase but fails to take out the peak value of the head. Moreover, background KB containing the company related information, such as address, CEO, type, etc., can be joined with the matched events to extract the contextual information.
(Traffic Management).
With the growing popularity of Internet of Things (IoT) technologies, more and more cities are leaning towards the initiative of smart cities to provide robust traffic management [5,55]. A key use case in this context is to be proactive against the traffic jams due to an accident or a social event. Hence taking actions to keep the traffic jams as local as possible and stop its effect propagation to the main roads of the city [55]. A query for such use case would be: A If a road segment is congested followed by B (at least) one of its connected road segments is also congested then traffic should be directed to other directions. The information about the road segments’ congestion is gathered from a set of streams, each from a sensor located at a road segment. Further contextual information such as the exact location of the sensors, the type of the road, etc., can be extracted from an static background KB.
Using the aforementioned use cases, we identify the set of requirements for a SCEP.
RDF graph-based events
All the use cases discussed above provide events that contain multiple observations and hence require an RDF graph-based event model instead of RDF triples. This allows to structure more complex events in a stream, as opposed to plain triples. For instance, a weather event requires multiple triples to describe the current weather conditions such as temperature, humidity, wind speed, etc. Another reason to provide RDF graph-based events is the flexibility in timestamping, i.e. using source or system timestamp. This can only be possible if timestamps can be attached to an event structure. That cannot be achieved with plain triples [20,24].
Multiple streams
The integration of multiple streams is essential in UC 1, 2 and 5. For instance, UC 1 detects patterns over events coming from a fuel-based power stream, a weather stream and a power-storage stream, while in UC 5 we employ multiple streams each for a road segment. Although one could merge all the streams together before processing, this would introduce the practical problems as described for RDF reification [17], where a pure triple data model is not adequate enough to represent meta-information about the RDF data [17,18]. In SPARQL, the RDF reification problem is addressed with the introduction of named graphs[17]. Furthermore, named graphs enforce the blank node scoping rules [35] with the global assumption that blank nodes cannot be shared between named graphs. Considering this, the SCEP should allow the definition of multiple named streams to provide the scope on the graph-based events. A similar approach is used in the existing RSP query languages, such as CQELS and C-SPARQL, and this can be achieved by extending the FROM NAMED clause of SPARQL.
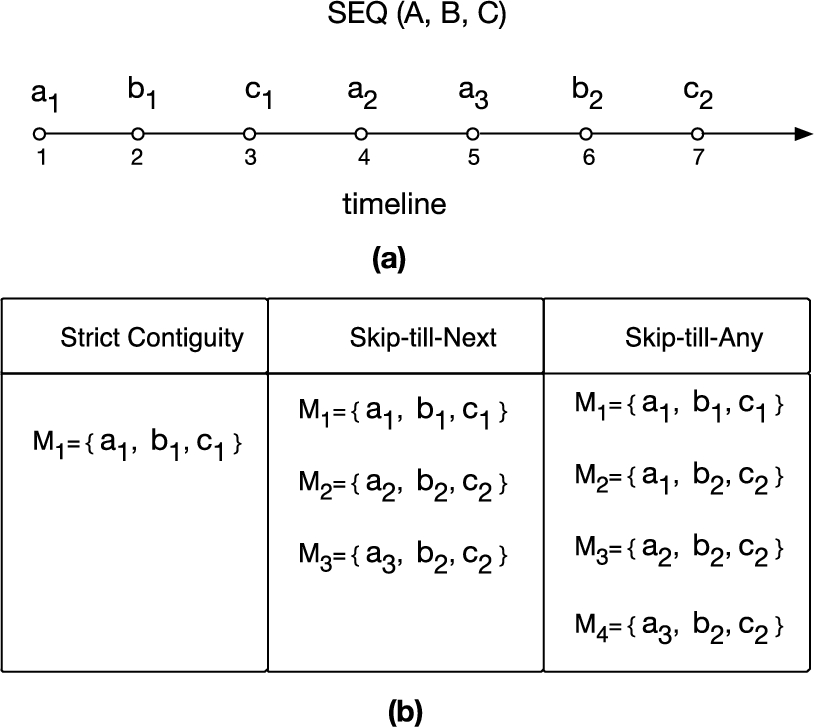
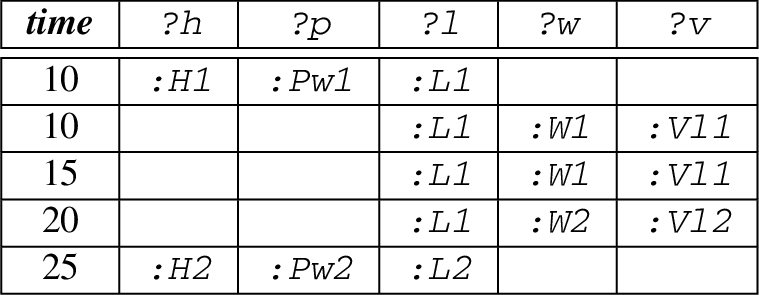
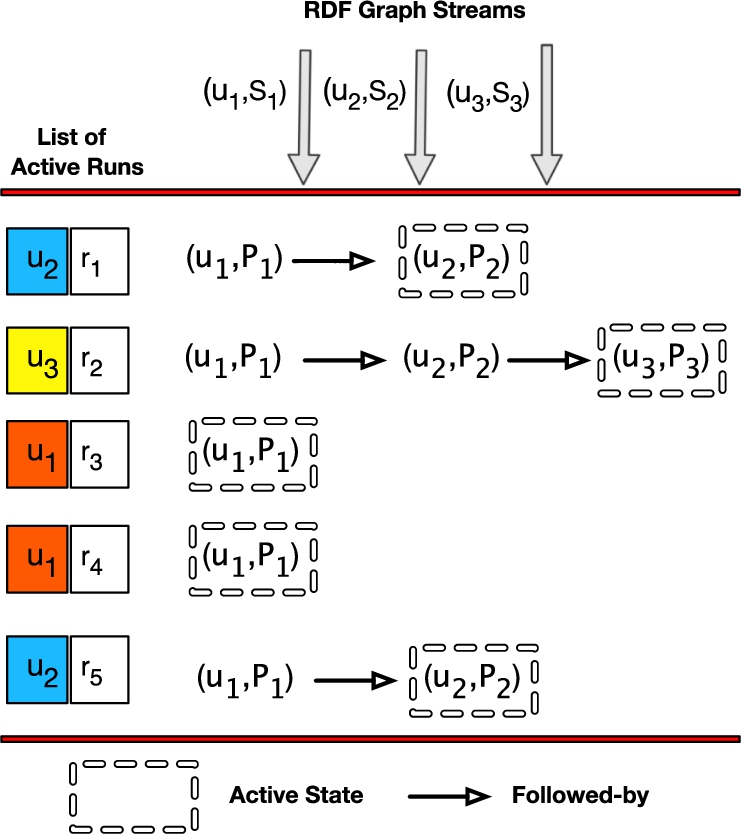
(a) Pattern to be matched and the input stream, (b) the table showcase all the set of matches that can be extracted from the input stream using different event selection strategies.
Expressive temporal operators
The main aim of an SCEP language is to provide temporal operators on top of standard SPARQL graph pattern matching constructs. Thus, the list of temporal operators introduced for the CEP over relational models [2,46,59] should be supported in a SCEP language. The two main operators, apart from the traditional sequence operator, that are required in all the aforementioned use cases are Kleene+ and event selection strategies. They are described as follows.
Kleene+ operator This is a widely used operator in the CEP languages [3,25,45]. It is used to extract finite yet unbounded number of events with a particular property from the input streams. Most, if not all, of the aforementioned use cases cannot be expressed to its core without this operator. For example, UC 1 requires Kleene+ to select one or more events that represent favourable weather conditions; UC 2 requires Kleene+ on activity events of the vessels; UC 3 requires one or more lower withdrawn amounts using Kleene+.
Event selection strategies In general, the sequence temporal patterns between events detect the occurrence of an event followed-by another. However, a deeper look reveals that it can represent various different circumstances using different event selection strategies [25,59]. Event selection strategies determine how the selected events for a pattern follow each other, hence mixing the relevant and irrelevant events from the input streams [25]. The three main event selection strategies described in the CEP literature [3,52,59] are strict contiguity, skip-till-next and skip-till-any. The first selection strategy states that the events for a match should be contiguous in the input stream, the second relaxes this by skipping the irrelevant events until the next relevant event arrives, while the third one selects all the possible patterns by skipping both relevant and irrelevant events. Figure 1(a) shows the input stream and the pattern to be matched, while the table in Fig. 1(b) shows all the matches for the pattern for each event selection strategy. Note how having the same sequence pattern but different event selection strategies results in diverse outputted matches. The importance of these operators can also be inferred from the aforementioned use cases. For instance, in UC 1, weather-related events generally repeat the observed values and can be skipped to find the most relevant event to be matched; in UC 4, we need to select the relevant events by ignoring local price fluctuations to preserve opportunities of detecting longer and thus more reliable patterns. Providing event selection strategies at the query level would enable the users to determine the semantic differences between them and tailor their usage according to the targeted use cases [24]. Furthermore, these operators are also described at the query level for most of the CEP languages [3,25].
Separation of query constructs
A SCEP query language has to express graph patterns to match events’ content and temporal operators to determine the temporal relations between events. Hence, a separation of these two orthogonal constructs would enable language reusability and ease in implementation. This way, constructs for graph patterns can be borrowed directly from SPARQL, and temporal operators from the CEP works. For example, in UC 1, the price and weather conditions for events can be matched using the constructs from SPARQL 1.1, while the sequencing and Kleene+ operators can be used to determine the defined sequences.
Background knowledge base
One of the main properties of the SCEP is to provide an extra knowledge about the situation of interest. Since the streams traditionally do not include the static information, such information can be used as a background KB. Hence a SCEP query language should provide operators to directly enrich events through background KB. For example, in UC 1, user profiles and detailed information about the power sources; in UC 2, detailed information about the shipping vessels; in UC 4, detailed information about the company whose stock events are in question, etc. The operators for the background KB at the query-level also provide the control over which background information is required for a query, i.e. joining only the relevant information. For the same reason, existing RSP solutions [12,40] provide such operators at the query-level.
In this section, we pointed out various general requirements of a SCEP query language. In the next section, using them as a yardstick, we outline the limitations of existing languages.
Related work
Existing languages for RDF stream processing systems differ from each other in a wide range of aspects, which include the executional semantics, data models and targeted use cases. In this section, we adopt the same classification criteria as used in [43], and divide the systems into two classes: RDF Stream Processing (RSP) systems, and Semantic Complex Event Processing (SCEP) systems. Their details are discussed as follows.
RDF stream processing (RSP) systems
The standardisation of the RSP is still an ongoing debate and the W3C RSP community group [20] is an important initiative in this context. Most of the RSP systems [12,16,39,40] inherit the processing model of Data Stream Management Systems (DSMSs), but consider a semantically annotated data model, namely RDF triple streams. Query languages for these systems are inspired from CQL [9], where a continuous query is composed from three classes of operators, namely stream-to-relation (S2R), relation-to-relation (R2R), and relation-to-stream (R2S) operators. C-SPARQL [12] and CQELS [40] are among the first contributions, and often cited as a reference in this field. They support timestamped RDF triples and queries are continuously updated with the arrival of new triples. The query languages for both systems extend SPARQL with operators such as FROM STREAM and WINDOW to select the operational streams, and the most recent triples within sliding windows. They also support the integration of background KB to further enrich the incoming RDF triples. Unlike the aforementioned systems, recently, we proposed a system called SPECTRA [31] to process RDF graph streams. It provides various system and operator level optimisations and continuously processes the standard SPARQL queries over RDF graph streams.
All the aforementioned systems and various others [16,39] are mainly developed as real-time monitoring systems: the states of the events are not stored to implement temporal pattern matching among a set of events. For the same reason, their query languages do not provide any operators for temporal pattern matching. Although, the sequence-based query is partially supported in C-SPARQL through a timestamp function in Filter, the query construction is not intuitive and the validity of results cannot be determined due to the missing semantics for such sequence pattern matching.
Semantic CEP systems
Semantic CEP (SCEP) systems are inspired from the classical rule-based CEP systems, i.e. by integrating high-level knowledge representation and background KB. To the best of our knowledge, EP-SPARQL is the only system that provides a unified language and executional framework for processing semantically enriched events with the temporal ordering. Hence, it is the most relevant work w.r.t ours. EP-SPARQL extends SPARQL 1.0 with a set of four binary temporal operators: SEQ, EQUALS, OPTIONAL-SEQ, and EQUALS-OPTIONAL. Using these operators, complex events in EP-SPARQL are defined as basic graph patterns. Since this technique is similar to the UNION and OPTIONAL operators in SPARQL, events are not first class citizens.
Although EP-SPARQL is a pioneering work in the field of SCEP, it lacks various important features. These limitations are discussed as follows:
Triple-based Events: EP-SPARQL only supports triples as events annotated with time-intervals. This restricts to structure more complex events as discussed before.
Single Stream: EP-SPARQL data model is based on a single stream model and all the triples within a defined window are merged into a default graph and then queried for matches. Hence the meta-information of triples, such as the source and occurring time, cannot be captured. Furthermore, it raises several questions about the treatment of blank nodes: being part of the RDF specification, blank nodes are now a core aspect of Semantic Web technology and they are featured in several W3C standards, a wide range of tools, and hundreds of datasets across the Web [35].
Temporal Operators: EP-SPARQL only supports a small subset of temporal operators. Operators such as Kleene+ or event selection strategies are not supported. These operators are, however, important for many use cases as discussed before. Moreover, the conjunction and disjunction operators in EP-SPARQL are inspired from SPARQL ( and ). These operators do not provide the nesting over a set of events as described for CEP systems [2,45]. This leads to a design where the semantics of temporal operators and SPARQL graph patterns are mixed, hence it can be devious to extend it and construct advanced event processing patterns [58].
Enriching Events with Background Knowledge Base: The static background KB is used to extract further implicit information from events. As a query language, EP-SPARQL does not provide any explicit operator to join graph patterns defined on an external knowledge and incoming RDF events. It, however, employs Prolog rules or RDFS rules within an ETALIS engine. This results in expensive reasoning process for each incoming event and the user is not able to select only the specific required information [43].
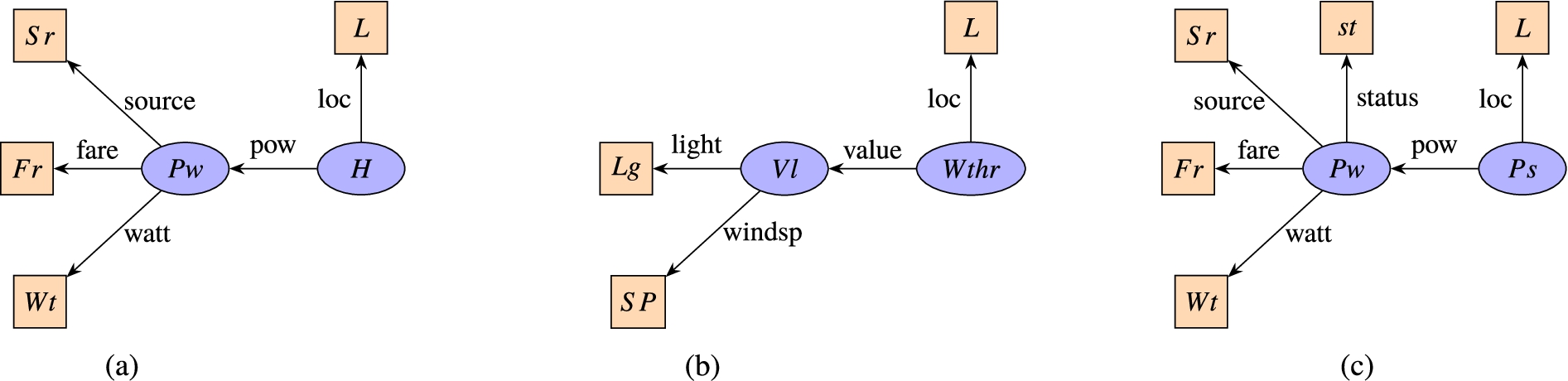
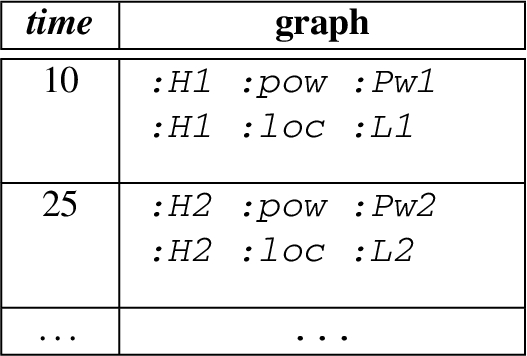
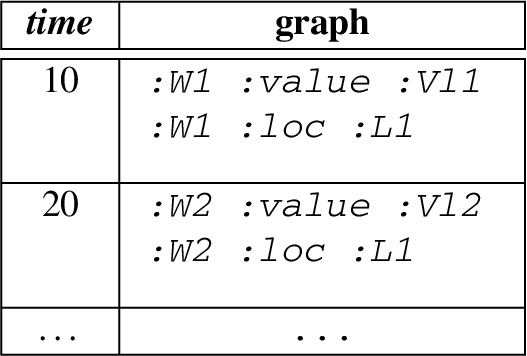
Structure of the Events from three Named Streams, (a) Power Event, (b) Weather Event, (c) Power Storage Event.
Apart from EP-SPARQL, recently, some other works also provide the intuition of SCEP. Some of these works are presented mainly for the purpose of theoretical analysis instead of practical implementation, while others take an approach for transforming queries over ontologies into relational ones, via ontology-based data access (OBDA) with temporal reasoning. Table 1 shows the properties of these systems. STARQL [49] uses the OBDA technique to determine ABox sequencing with a sorted first order logic on top of them. It provides a simple formalism/mapping to SQL for sequence operators and all the other operators (such as Kleene+, conjunction, disjunction, event selection strategies) are not part of its framework. Furthermore, it is not a freely available system and it does not provide operators for explicitly referencing different points in time [50]. CQELS recently proposed in [23] the integration of sequence and path negation operators inspired from EP-SPARQL. However, its sequence clause is evaluated over a single stream and its syntax and semantics does not include event selection strategies. RSEP-QL [24] is a reference model to capture the behaviour of existing RSP solutions and to capture the semantics of EP-SPARQL’s sequence operator. It is based on the RDF graph model; however, its main focus is to capture the event selection strategies and other complex operators are currently not supported. It defines the semantics of the three main event selection strategies supported by the ETALIS engine. It includes recent, chronological and unrestricted. The recent selection strategy can be mapped to the strict contiguity, while chronological and unrestricted are different variations of the skip-till-next strategy. However, due to the time-interval semantics these selection strategies cannot be directly mapped to ours.
The SPAseq query language
Considering the shortcomings of existing languages, we propose a new language called SPAseq. The design of SPAseq is based on the following main principles: (1) support of an RDF graph stream model; (2) clear separation between the temporal and RDF graph operators; (3) adequate expressive power, i.e. not only based on core SPARQL constructs but also including general purpose temporal operators (inspired from the common CEP operators); (4) genericity, i.e. independent of the underlying evaluation techniques; (5) compositionality, i.e. the output of a query can be used as an input for another one. Hence SPAseq provides all the required features as discussed in Section 2.
The most important feature of SPAseq is that it clearly separates the query components for describing temporal patterns over RDF graph events, from specifying the graph pattern matching over each RDF graph event. This enables SPAseq to employ expressive temporal operators, such as Kleene+, disjunction, conjunction and event selection strategies over RDF graph-based events from multiple streams. In the following, we start with the data model over which SPAseq queries are processed and then provide the details regarding its syntax and semantics.
Data model
In this section, we introduce the structural data model of SPAseq that captures the concept of RDF graph events: this serves as the basis of our query language. We use the RDF data model [22] to model an event. That is, we assume three pairwise disjoint and infinite sets of IRIs (), blank nodes (), and literals (). An RDF triple is a tuple and an RDF graph is a set of RDF triples. Based on this, the concepts of RDF graph event and stream are defined as follows.
An RDF graph event is a pair where G is an RDF graph, and τ is an associated timestamp that belongs to a one-dimensional, totally ordered metric space.
We do not make explicit what timestamps are because one may rely on, e.g., UNIX epoch, which is a discrete representation of time, while others could use xsd:dateTime which is arbitrarily precise.
In our setting, streams are sets of RDF graph events defined as follows:
An RDF graph event stream is a possibly infinite set of RDF graph events such that, for any given timestamps τ and , there is a finite amount of events occurring between them, and there is at most one single graph associated with any given timestamp.
An RDF graph event stream can be seen as a sequence of chronologically ordered RDF graphs marked with timestamps. The constraints ensure that it is always possible to determine what unique event immediately precedes or succeeds a given timestamp. Without the first restriction, it would be possible to define a stream where there is no event immediately succeeding 0. In order to handle multiple streams, we identify each using an IRI and group them in a data model we call RDF streamset.
A named stream is a pair where u is an IRI, called the stream name, and is an RDF graph event stream. An RDF graph streamset Σ is a set of named streams such that stream names appear only once.
In the rest of the paper, we simply use the terms graph for RDF graph, event for RDF graph event, stream for RDF graph stream, and streamset for RDF graph streamset.
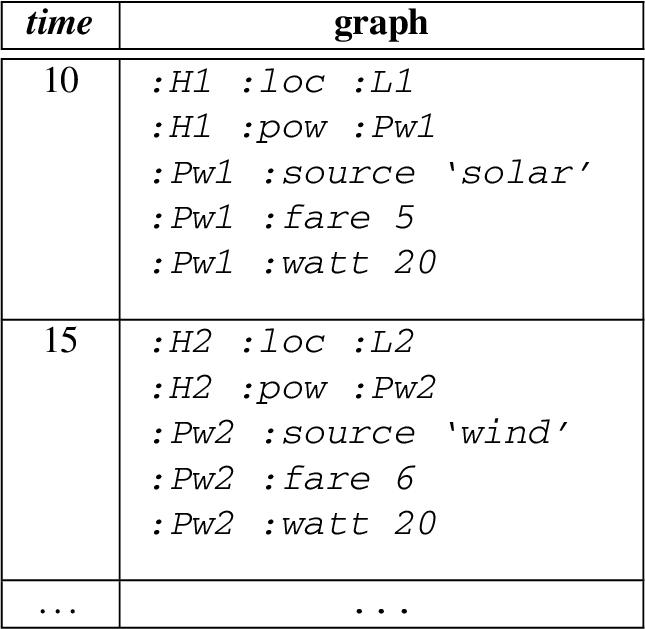
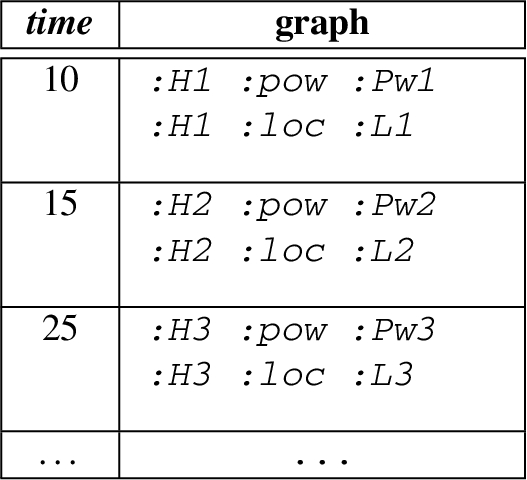
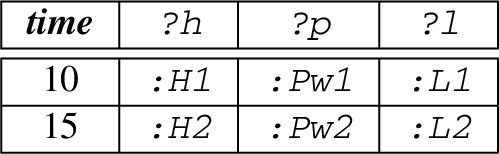
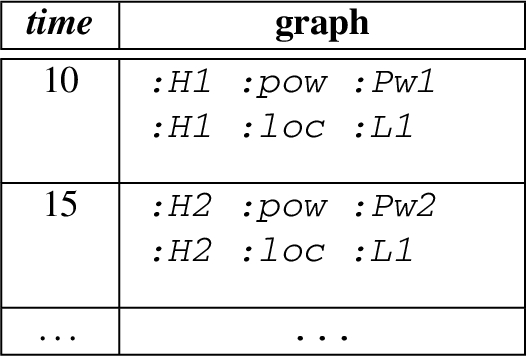
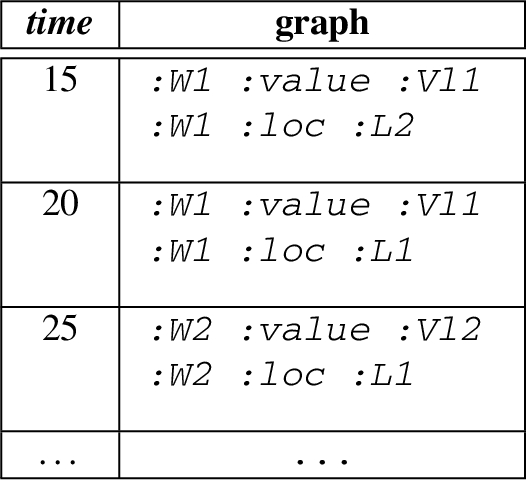
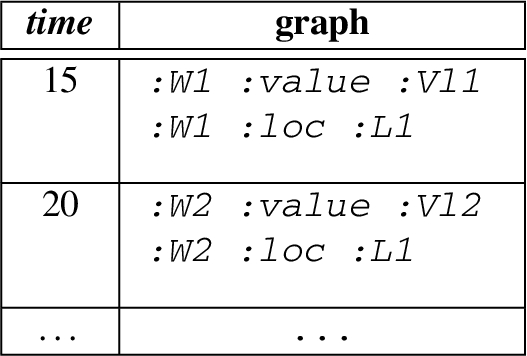
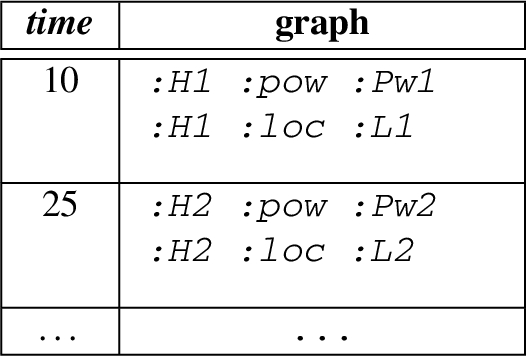
Recall UC1, here we extend it with our data model using three named streams. The first named stream provides the events about the power-related sources from a house, the second named stream provides the weather-related events for house, and the third named stream provides the power storage-related events. Figure 2 illustrates the general structure of the events from each source. An exemplary content of a named stream is describe as follow:
Note that the above table describe the named stream in an informative way, in practice RDF 1.1 Trig or an Nqaud format is used to represent such streams.
Syntax of SPAseq
This section defines the abstract syntax of SPAseq, where SPAseq queries are meant to be evaluated over a streamset, and each query is built from the two main components: graph pattern matching expression (GPM) for specifying the SPARQL graph patterns over events; and sequence expression for selecting the sequence of a set of GPM expressions. For this discussion, we assume that the reader is familiar with the definition and the algebraic formalisation of SPARQL introduced in [51]. In particular, we rely on the notion of SPARQL graph pattern by considering operators , , , , and .
The syntax of a SPAseq SELECT query is a tuple , where is a set of variables, ω is a duration, and is a sequence expression defined according to the following grammar:
where u is an IRI, P is a SPARQL graph pattern, is called a graph pattern matching expression (GPM), and is a SPARQL graph pattern defined for a static RDF graph, i.e. an external knowledge-base.
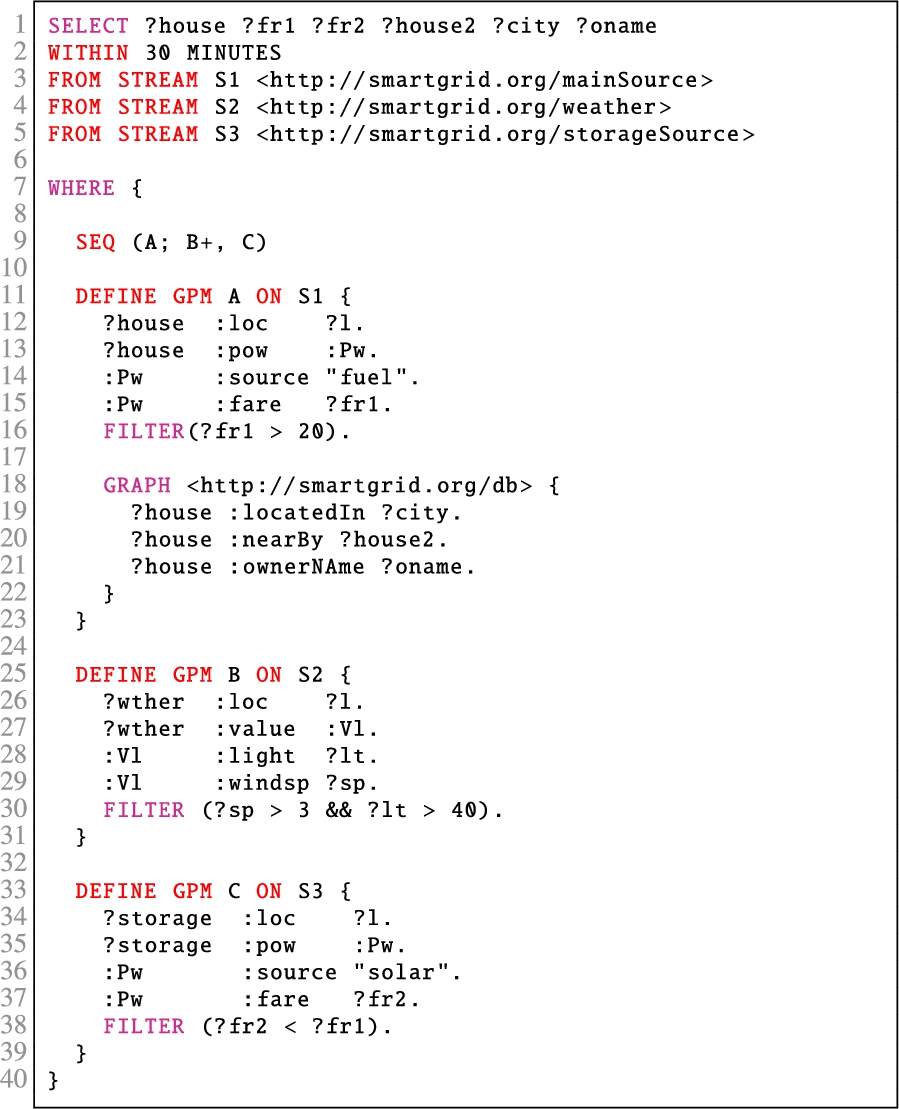
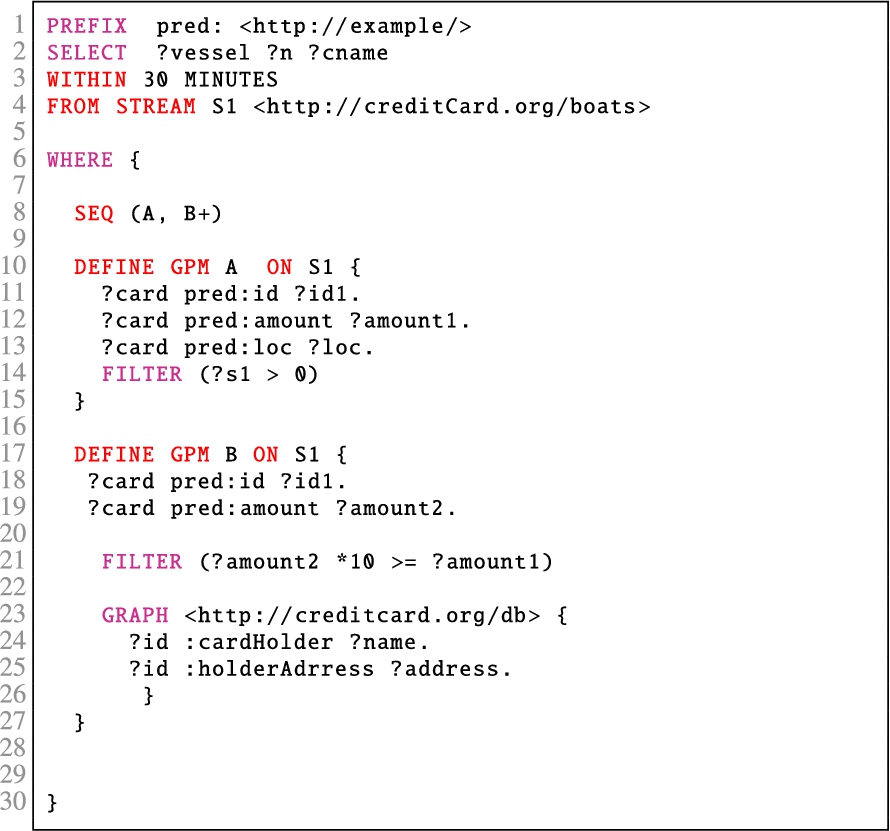
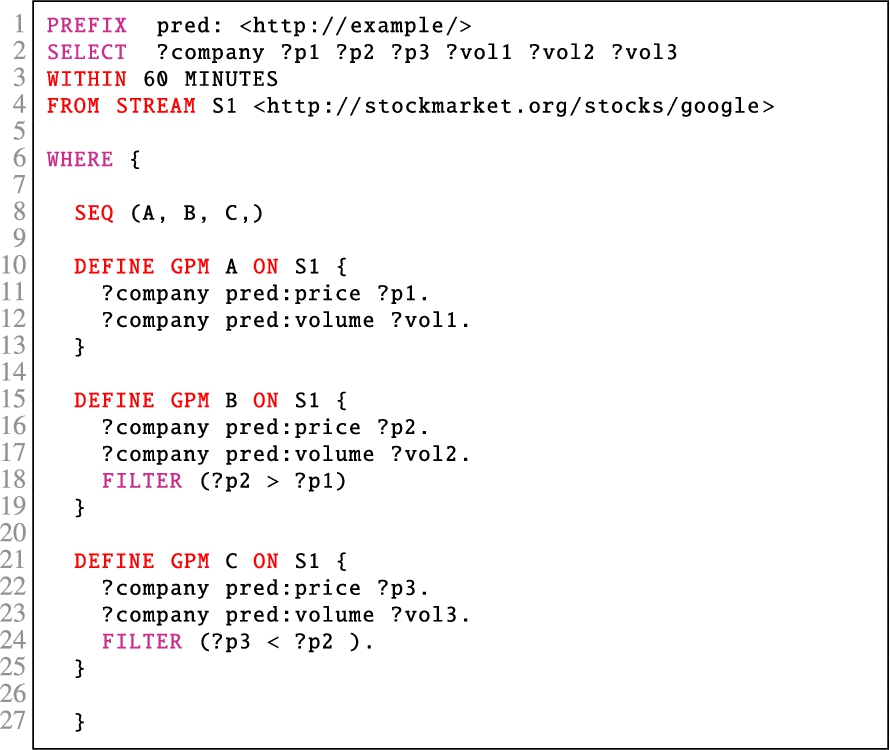
The concrete syntax of SPAseq is illustrated in Query 1 which includes syntactic sugar that is close to SPARQL. It contains three GPM expressions each identified with a name (A, B, and C), which allows one to concisely refer to GPMs and to the named streams. These names are employed by the sequence expression to apply various temporal operators. The sequence expression in Query 1 is presented at line 9; the streams are described at lines 3–5; the GPM expressions on these streams start at lines 11, 19 and 27.
One of the main properties of the SPAseq language is depicted in Query 1, i.e. the separation of sequence and GPM expressions. Herein, we first study how the sequence expression interacts with the graph pattern to enable temporal ordering between matched events. We start with the brief description of unary operator (), the event selection strategies () and binary operators (). The details of these operators are covered during the description of their semantics in Section 5. Furthermore, we also present the Graph operator for the SPAseq query language.
SPAseq unary operators
The sequence expression in SPAseq is used to determine the sequence between the events matched to the graph pattern P. The symbol corresponds to the Kleene+ operator. It determines the occurrence of one or more events of the same kind. This means a series of events can be matched using this operator.
SPAseq event selection strategies
The event selection strategies overload the sequence operator with the constraints to define how to select the relevant events from an input stream, while mixing relevant and irrelevant events (as described in Section 2.3). The symbols are binary operators which describe the interpretations of the sequence between events. That is, ‘,’ represents strict contiguity, ‘;’ represents skip-till-next, ‘:’ represents skip-till-any.
SPAseq binary operators
Conjunction and disjunction defined over the event streams constitute the binary operators. In SPAseq, these operators are introduced within the sequence expression through symbols () and () respectively. They provide the intuitive way of determining if a set of events happen at the same time (conjunction) or at least one event among the set of events happens (disjunction).
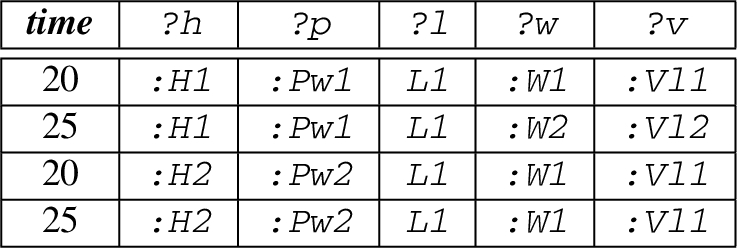
Consider the SPAseq Query 1, which illustrates the UC
1
. The sequence expression SEQ(A; B+, C) illustrates that the query returns a match: if an event of type A defined on a stream S1 matches the GPM expression A followed-by one or more events (using skip-till-next operator (‘;’) and (‘+’)) from stream S2 that match the GPM expression B, and finally immediately followed-by (using strict contiguity operator (‘,’)) an event from stream S3 that matches the GPM expression C. Notice that a GPM expression mainly utilises SPARQL graph patterns for the evaluation of each event.
SPAseqgraph, window and stream operator
The combination of streaming information in the form of RDF graph streams and other information from the static knowledge base can lead to novel semantics and information rich SCEP. The Graph operator in SPAseq is designed to take advantage of static information available in the form of an RDF graph. Thus, a graph pattern defined over the static RDF graph is first evaluated and then the results are matched with the incoming stream . This leads to a SCEP system, where detailed information regarding a context can be revealed with the help of already available static datasets. For instance, consider the SPAseq Query 1, where we use static background KB about the house owners, their neighbours and city to have better understanding of the matched events.
In SPAseq, the sequence expression is defined over a streamset. Thus, we use the FROM STREAM clause to define a set of streams. For instance, in Query 1 we use three streams identified as S1, S2 and S3 (lines 3–5). These stream names are used within the defined GPM expressions. Furthermore, since the sequence over a set of events is constrainted by the temporal window, we use the WITHIN clause to define the temporal windows (line 2 in Query 1). In SPAseq, windows can be defined in seconds, minutes and hours. For instance, in Query 1 we use a 60 MINUTES window.
In this section, we presented the syntax of SPAseq query language with a query for the UC 1. The queries for the remaining use cases are described in Appendix A. Using the defined syntax, we present the semantics of SPAseq in the proceeding section.
Formal semantics of SPAseq
To formally define the semantics of SPAseq queries, we reuse concepts from the semantics of SPARQL as defined in [51]. A mapping is a partial function from a set of variables to RDF terms (). The domain of a mapping μ, denoted , is the set of variables that have an image via μ. We say that two mappings μ and are compatible if they agree on all shared variables, i.e. if for all . For a graph pattern P, we denote by the set of variables appearing in P and is the graph pattern obtained by replacing each variable by whenever defined.
We repeat the definitions of join (⋈), union (∪), minus (∖), left outer-join ()and evaluation of graph patterns as in [51].
Let and be sets of mappings:
Let t be a triple pattern, P, , graph patterns and G an RDF graph, then the evaluation is recursively defined as follows:
In this section, we define the semantics of SPAseq in a bottom-up manner, where we start with the semantics of GPM expressions by integrating the temporal aspects of events and streams. Note that, for the sake of brevity, we show the evaluation of GPM expressions over a streamset and the aspects of evaluating Graph operator (over RDF dataset) within GPM expressions are discussed later. This will aid us in highlighting the decisions we took to define the semantics of SPAseq operators.
Evaluation of graph pattern matching expressions
In SPAseq, Graph Pattern Matching expressions are evaluated against a streamset over a finite time interval that “tumbles” as time passes. Consequently, we constrain the evaluation function to a temporal boundary (i.e. a window), with a start time () and an end time (). In addition, we use the notation to select a stream of name u from a streamset, such that
In order to define the evaluation of a GPM expression, we introduce a pair which represents a set of mappings annotated with a timestamp τ of the matched event. The evaluation of a GPM expression is defined as follows.
The evaluation of a GPM expression over the streamset Σ for the time boundaries [] is:
The evaluation of the GPM expression over an event within a streamset results in a pair In the absence of a match, no results are returned for the considered timestamp.
Consider a GPM expression and a power-related named stream with events as follows:
The evaluation of over Σ for the time boundaries [5,15], i.e. , is described as follows:
Notice that since the end time of the window is restricted at , only the events at and are included in the result. The event at is outside the window and thus is not included in the results.
In order to define the semantics of sequence expressions, we use the notion of BOp expressions from Definition 4 for conjunction and disjunction operators. A BOp expression does not contain Kleene+ or event selection operators.
Evaluation of binary operators
Herein, we define the semantics of binary operators provided for SPAseq, i.e. conjunction and disjunction of events.
Given two BOp expressions the evaluation of the conjunction operator over the streamset Σ and for the time boundaries is defined as follows:
The conjunction operator detects the presence of two or more events that match the defined GPM expressions and occur at the same time, i.e. containing the same timestamps.
Consider the following, a GPM expression and a power-related named stream as follows:
Now consider a GPM expression and a weather-related named stream as follows:
The evaluation of the conjunction operator over the aforementioned GPM expressions and named streams () for the time boundaries will result in the following sets of mappings.
We now define the disjunction operator. It detects the occurrence of events that match to a GPM expression within the set of defined ones.
Given two BOp expressions and , the evaluation of the disjunction operator over the streamset Σ and for the time boundaries is defined as follows:
Consider the two GPM expressions and , and the two named streams and from Example 4. Then the evaluation of the disjunction sequence operator for the sequence expression , and for the time boundaries is as follows:
Notice that the disjunction operator may generate several sets of mappings for the same timestamp, as we can see at time 10 in the example.
Evaluation of event selection operators
Herein we present the semantics of the three event selection strategies namely strict contiguity, skip-till-next and skip-till-any.
Let σ be a sequence with a set of GPM expressions and binary/unary operators. The evaluation of the skip-till-any operator is defined as follows:
Given a sequence σ and a BOp expression Ψ, the evaluation of the skip-till-any (‘:’) sequence operator over a streamset Σ for the time boundaries is defined as follows:
From the above definition, the evaluation of the skip-till-any operator is simply the join between the mapping sets from σ and the GPM expression. Its evaluation is explained in the following example.
Consider the following, a GPM expression and a power-related named stream as follows:
A GPM expression as follows:
and a weather-related named stream as follows:
Then for the evaluation of the skip-till-any operator on these GPM expressions for the time boundaries , i.e. , we have the mappings as given below.
Notice that there are four matches sequences: both the first and seconds events (at and ) from the power-related named stream matched with both events ( and ) in the weather-related named stream. This is due to the skip-till-any operator and all the possible combinations of matches are produced.
The following definition shows the evaluation of the skip-till-next operator.
Given a sequence σ and an BOp expression Ψ, the evaluation of the skip-till-next (‘;’) sequence operator over a streamset Σ for the time boundaries is defined as follows:
Consider the GPM expressions , and the streams from Example 6. Then for the evaluation of the skip-till-next operator on these GPM expressions for the time boundaries , i.e. , we have the mappings as given below.
Due to the skip-till-next operator, there are only two matches in the aforementioned example. Both events (at and ) from the power-related stream match with just one event (at ) from the weather-related stream.
We now define the semantics of the strict contiguity operator, where U is a set of stream names within a streamset Σ.
Given a sequence σ and a BOp expression Ψ, the evaluation of the strict contiguity (‘,’) sequence operator over a streamset Σ for the time boundaries is defined as follows:
The semantics of the strict contiguity operator follows the semantics of the skip-till-next operator, however with one important difference: the contiguity between the matched events. That is, an event is contiguous to another, only if there can be no other events between the two selected ones.
Consider the GPM expressions and the named streams defined in Example 6. Then the evaluation of the strict contiguity operator described as , for time boundaries , will result in a single sequence match with the following mappings.
This is due to the strict ordering of the strict contiguity operator. That is, for first event (at ) in power-related stream, there is no immediately followed-by event in the weather-related stream.
Evaluation of Kleene+ operator
We now move towards the definitions of the unary operator, namely Kleene+. We first define its semantics in a standalone manner and then recursively define it with the help of sequence σ.
The evaluation of the standalone Kleene+ operator over the streamset Σ and for the time boundaries is defined using auxiliary constructs for integers as follows:
The Kleene+ operator groups all the matched events with the defined GPM expression. Notice that the evaluation will not only match the longest sequence of matching patterns, but will also provide results for the shorter sequences (using the skip-till-next operator (‘;’). The case of the Kleene+ operator with sequence σ using additional skip-till-next and strict contiguity is defined as follows:
Let ∙ denote any of ‘,’, ‘;’, or ‘:’. Given a sequence expression σ, the evaluation of the Kleene+ operator in a sequence over the streamset Σ and for the time boundaries are defined as follows:
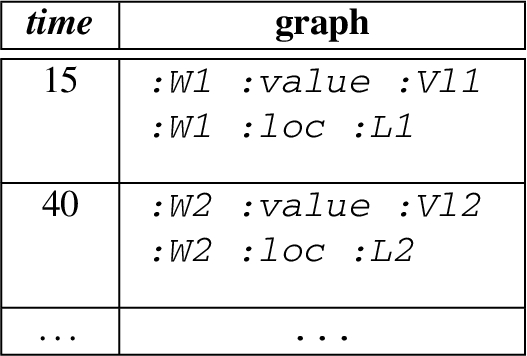
Consider the following, a GPM expression and a power-related named stream as follows:
A GPM expression
and a weather-related named stream as follows:
The evaluation of the sequence with the Kleene+ and skip-till-next operators for the time boundaries is as follows:
Notice that the Kleene+ operator collects one or more matches for from the weather-related named stream.
The graph operator
The Graph operator within GPM expressions allows one to query both background KB and streams. In the previous sections, we omitted this construct because it needlessly makes the notations cumbersome: it would require adding an RDF dataset (in addition to a streamset) as a parameter of the evaluation function.
However, for completeness, we present the definition of the evaluation of the Graph operator. Now similarly to the Definition 7, we use a function to select an RDF graph of name u from an RDF dataset D, such that:
Let D be an external RDF dataset and be a graph pattern. Let be the GPM expression defined over the streamset Σ, and be the time boundaries. The evaluation of the GPM expression and the Graph operator is defined as follows:
Consider the same GPM expression and power-related named stream presented in Example 9. Now consider a graph pattern defined over an external RDF graph D as follows:
The evaluation of the GPM expression and the Graph operator is as follows:
Evaluation of SPAseq queries
In the previous sections, we outline the semantics of temporal operators and Graph operator of the SPAseq query language. Herein, to sum it up, we present the evaluation of complete SPAseqSELECT queries.
Let Ω be a mapping set, be the standard SPARQL projection on the set of variables , and ω be the duration of the window. The evaluation of SPAseqSELECT query issued at time t, over the streamset Σ is defined as follows:
where
The evaluation of the SPAseq queries follows a push-based semantics, i.e. results are produced as soon as the sequence expression matches to the set of events within the streamset. Thus, the resulting set of mappings takes the shape of a stream of mappings, where the order within the mappings depends on the underlying executional framework. Note that the definition of is the intended one. It could be possible to define a continuous version of the query evaluation but we want to stay agnostic to how the solutions are provided. For instance, the evaluation could be performed on a static file with time series, possibly including future previsions; or the solutions could be provided in bulks every ω time units. Moreover, according to Definition 16, SPAseq uses tumbling windows. This choice of windows is inspired from the classical CEP works and it is a specific design choice of SPAseq. This enable us to focus on the other important aspects of the language and borrow existing techniques for windows. However, one could extend it for sliding windows without changing the core semantics of SPAseq.
Recall the two GPM expressions from Example 6, and . Now consider the power-related and weather-related named streams , respectively as follows:
Then the evaluation of a SPAseq query
with the skip-till-next operator at time over the streamset Σ, i.e. , can be described as follows:
In this section, we presented the detailed semantics of SPAseq operators. Based on this, we also present some details how SPAseq can be extended for operators such as negation and optional. Such details can be referred from Appendix B. The implementation details of SPAseq operators are provided in the proceeding section.
Implementing the SPAseq query engine
In this section, we move from the theory to the practical implementation of the SPAseq query engine. We first present the model that is utilised to compile SPAseq queries, and then provide details regarding the various system’s blocks and optimisations used for the SPAseq query engine.
In general, for a CEP system, the set of defined temporal operators are evaluated in a progressive way against the incoming events. That is, before a composite or complex event is detected through a full pattern match, partial matches of the query patterns emerge with time. These partial matches require to be taken into account, primarily within in-memory caches, since they express the potential for an imminent full match. There exists a wide spectrum of approaches to track the state of partial matches, and to determine the occurrence of a complex event. In summary, these approaches include rule-based techniques [7] that mostly represent a set of rules in a prolog like language, tree structures [28,45] where the pattern are parsed as join trees, graph-based representations [29,52] to merge all the rules within a single structure, and finally Finite State Machine representations, in particular Non-deterministic Finite Automata (NFA) [3,60]. The choice of these representations is motivated not only by their expressiveness measures, but also on the performance metrics that each approach tries to enhance. For instance, ETALIS [7], a rule-based engine, mostly focuses on how the complex rules are mapped and executed as Prolog objects and rules, while SASE+ [3,59], Zstream [45] and lazy evaluation [38] of NFAs focus on query-rewriting, predicate-related optimisations and memory management techniques.
Due to the separation of constructs, SPAseq queries can be easily mapped to various different models. For instance, a query tree can be constructed from a SPAseq query, where the GPM expression are mapped at the leaves of the tree and the matched results are propagated to the root of the tree to extract a full match. However, considering the following points, we opt to use an NFA-based compilation and execution model for SPAseq queries: (i) given the semantic similarity of SPAseq’s sequence expressions to the regular expressions, NFA would appear to be the natural choice; (ii) NFAs are expressive enough to capture all the complex patterns in SPAseq; (iii) NFAs retain many attractive computational properties of Finite State Automata (FSA) on words, hence, by translating SPAseq queries into NFAs, we can exploit several existing optimisation techniques [3,60].
In addition to the NFA-based model, we use various optimisation techniques to evaluate GPM expressions proposed by our system SPECTRA [31]: since SPAseq employs an RDF graph model, it not only requires the efficient management of temporal operators, but also the efficient evaluation of graph patterns. In the following, we first describe the model for SPAseq, and later present how SPAseq queries are compiled and evaluated using . The optimisation techniques for the execution of SPAseq queries are provided in Section 7.
The model for SPAseq
We extend the standard NFA model [25,36] in three ways. First, given that SPAseq matches events with GPM expressions, we associate each automaton edge with a predicate, and for an incoming event, this edge is traversed iff the GPM expression is satisfied by this event. Second, in order to handle statefulness between GPM expressions (shared variables), we store in each automaton instance the mappings of those events that have contributed to the state transition of this instance. Third, we map all the SPAseq operators (conjunction, disjunction, Kleene+, event selection strategies, etc.) on the NFA model: in the existing works [3,15], the mapping for the NFA model are only shown for a subsets of these operators and all the operators are not mapped onto a single model. We call such an automaton model as and it is defined as follows:
An automaton is a tuple , where
X: a set of states;
E: a set of directed edges connecting states;
Θ: is a set of state-transition predicates, where each , is a tuple; U is a set of stream names, is a temporal operator, and P is a graph pattern;
φ: is a labelling function that maps each edge to the corresponding state-transition predicate;
: is an initial or starting state;
: is a final state or acceptation state.
We define three types of states: initial (), ordinary (x) and final () states. These state types are analogous to the ones used in the traditional NFA models to implement the operators such as sequence, Kleene+, etc. Each state, except the final state, has at least one forward edge. Note that, we use a structure to store the set of mappings Ω corresponding to the state-transition predicate and the automaton instance . Hence, when an event makes an automaton instance traverse an edge, the mappings in that event are properly referenced.
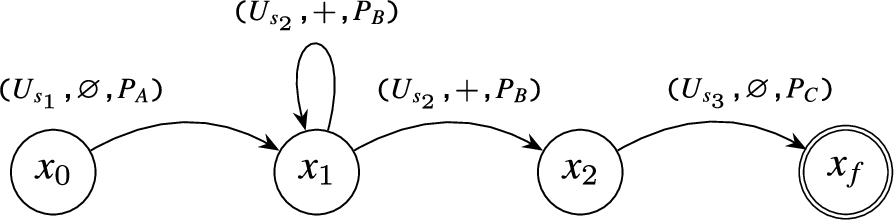
Figure 3 shows the compiled for the SPAseq Query 1 with the sequence expression SEQ(A,B+,C). It contains four states, each having a set of edges labelled with the state-transition predicates. The state-transition predicate (U, op, P) consists of three parameters: graph pattern P for the events with stream names (U); op describes the type of operator mapped to an edge, for instance edges of state contain the Kleene+ operator. The description of mapping from the SPAseq Query 1 to the in Fig. 3 is as follows:
The SPAseq Query 1 contains the sequence expression , which produces one initial state, two ordinary states and a final state.
State has one edge with state-transition predicate (called as GPM A in Query 1) (, ∅, ), where = and is the graph pattern. Since the sequence expression in Query 1 only contains the immediately followed-by operator, the can simply transit to the next state on matching the state-transition predicate.
State maps GPM B with Kleene+. Therefore, it has two edges each with a state-transition predicate (, +, ), one with the destination state , and other with itself as destination () to consume one or more same kind of events; where and is the graph pattern.
State has one edge, which is used to transit to the next state if an event matches the defined state-transition predicate (, ∅, ); where and is the graph pattern.
Compiled for SPAseq Query 1 with SEQ(A,B+,C) expression.
State-transition predicates are used to determine the action taken by a state to transit to another. For instance, in Fig. 3 the state transits to , if (1) the incoming event is from the defined stream name , (2) the evaluation of the graph pattern does not produce an empty set. Furthermore, the event selection strategy also determines if there is a followed-by or immediately followed-by relation between the processed events. Note that, in the presence of the Kleene+ operator, will exhibit a non-deterministic behaviour, since the state-transition predicates will not be mutually exclusive.
Considering the vocabulary from existing NFA works [3,60], we say that each instance of an or a partial match is called a run. A run depicts the partial matches of defined patterns, and contains the set of selected events. Each run has a current active state. A run whose final state has reached is a matched run, hence denoting that all the defined patterns are matched with the set of selected events. We call the output of the matched run as a query match.
Compilation of SPAseq queries
As discussed earlier, the two main components of the SPAseq language are sequence and GPM expressions. Due to the separation of these components, one can provide multiple different techniques to compile and process them. The compilation process of graph patterns using the traditional relational operators (e.g., selection, projection, cartesian product, join, etc.) within each GPM expression is borrowed from our earlier work [31]. Herein, we focus on the sequence expression and show how the temporal operators are mapped onto the .
The sequence expression sorts the execution of GPM expressions according to its entries. Moreover, the temporal operators determine the occurrence criteria of such GPM matches and the event selection strategies are utilised to select the relevant events. These constraints or properties are mapped on the through the compiled state-transition predicates, while the window constraints are computed during the evaluation of each automaton run.
Let and be two GPM expressions, the compilation of SPAseq temporal operators onto an automaton is described as follows.
Simple GPM expression: The for a simple GPM expression with a sequence expression forms a state which transits to the next one with the match of the GPM expression mapped at the state’s edge. The automaton for a GPM expression is presented in Fig. 4.
Example of Compilation of the GPM Expression ().
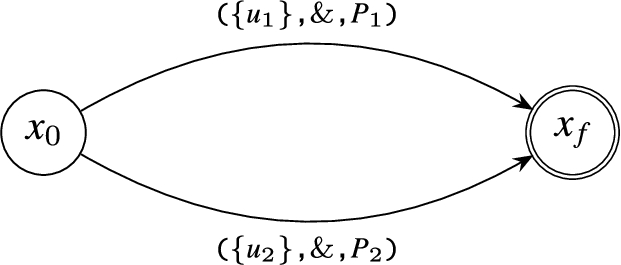
Kleene+: The Kleene+ operator selects a set of events if they match to the defined GPM expression. Its automaton is constructed using two edges with one edge having the same source and destination state. Thus, it can detect one or more consecutive events. The corresponding for () is illustrated in Fig. 5.
Example of Compilation of the Kleene+ Operator ().
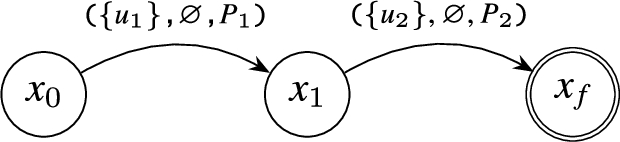
Strict Contiguity Operator: The construction of for this operator is similar to the compilation of a simple GPM expression, where a single edge for the corresponding state – having different source and destination states – is constructed. The corresponding automaton for () is illustrated in Fig. 6.
Example of Compilation of the Strict Contiguity Operator ().
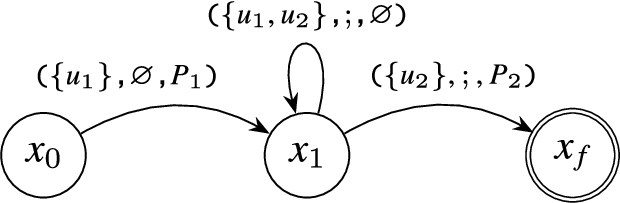
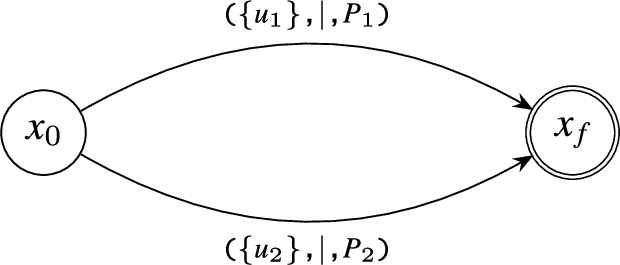
Skip-Till-Next and Skip-Till-Any Operators: These operators require the irrelevant events to be skipped. Thus, two different edges emanate from the corresponding state. One has the same source and destination states: this transition matches any kind of event. The second edge is destined for the next state with the defined state-transition predicate. Note that the construction of both of these selection strategies is the same with the difference how they are evaluated at the run time. The corresponding automaton for () is presented in Fig. 7, where is the set of stream names.
Example of Compilation of the skip-till-next (or skip-till-any) operator ().
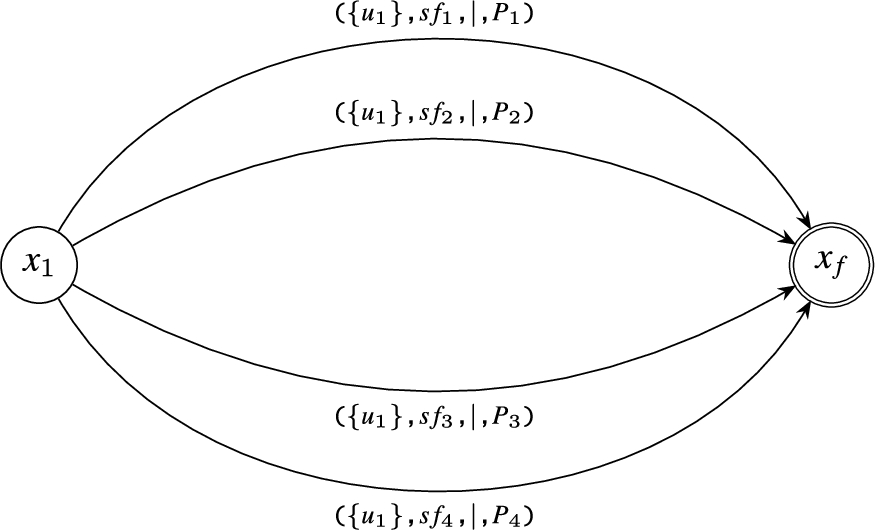
Conjunction Operator: This operator detects the simultaneous occurrence of two or more events. Thus, there are two edges for the conjunction state, each destined for the same destination state. The automaton for () is illustrated in Fig. 8, where the conjunction state has multiple edges, each having different state-transition predicates.
Example of Compilation of the Conjunction Operator ().
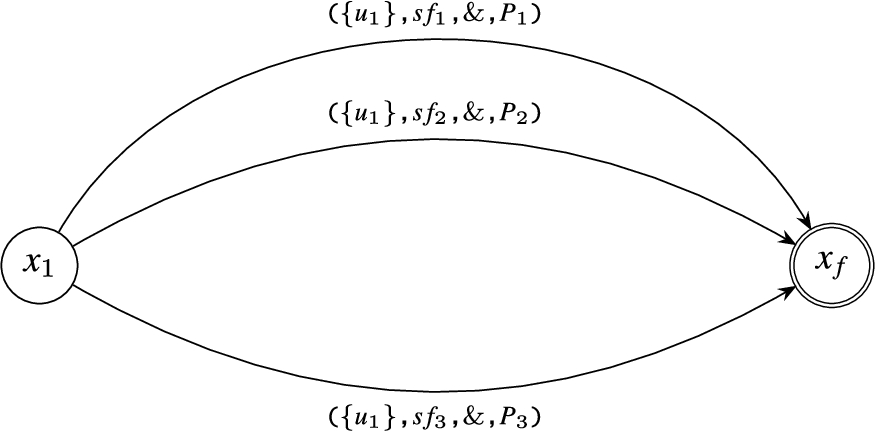
Disjunction operator: This operator forms a similar automaton structure as that of conjunction operator, however with the difference of how it is executed for an active run. That is, only one edge has to be matched with the incoming event. The automaton for () is illustrated in Fig. 9.
Example of Compilation of the Disjunction Operator ().
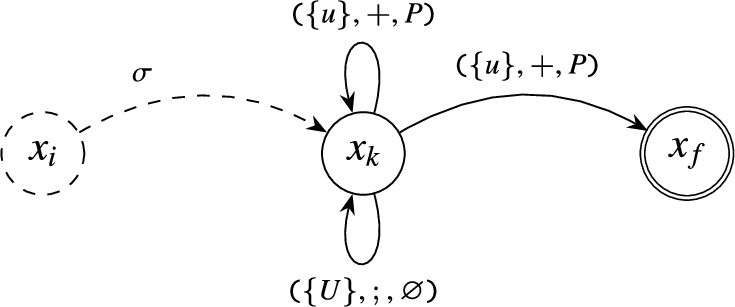
In the aforementioned discussion, we show the compilation of SPAseq operators independently. For the full SPAseq query, these operators can be combined together to form a complex automaton. In order to show this, let σ be a sequence with a set of GPM expression and binary/unary operators. The compilation of sequence expression with the additional skip-till-next and Kleene+ operators is presented in Fig. 10. Notice from Fig. 10 how the concatenating process is simply the mapping of the last state of sequence σ onto the initial state of the GPM expression .
Example of Compilation of the Sequence Expression .
To conclude, this section presented the mapping of SPAseq queries onto equivalent automata. In the next section, we show how automata are executed while considering the window constraints defined within a query.
Evaluation of automaton
The compiled automaton represents the model that a matched sequence should follow. Thus, in order to match a set of events emanating from a streamset, a set of runs is initiated at run-time. This set of runs contains partially matched sequences and a run that reaches to its final state represents a matched sequence. When a new event enters the evaluator, it can result in several actions to be taken by the system. We describe them as follows:
New runs can be created, or new runs are duplicated (cloned) from the existing ones in order to cater the Kleene+ operator, thus registering multiple matches.
If the newly arrived events match with state-transition predicates (θ) of the active states, existing runs transit from one active state to another.
Existing runs can be deleted, either because the arrival of a new event invalidates the constraints defined in the model such as event selection strategies, conjunction, etc. or the selected events in those runs are outside the defined window.
These conditions can be generalised into an algorithm that (i) keeps track of the set of active runs (), (ii) starts a new run or deletes the obsolete ones, (iii) chooses the right event for the state-transition predicates , (iv) calls the GPM evaluator to match an event with the graph pattern (P) which is provided in the state-transition predicate (θ), and (v) keeps track of the mappings of matched events with a structure .
Processing streamset with
ProcessEvent with
Algorithm 1 presents the initialisation process of various data structures and how a streamset Σ is processed against the automaton . The initialised data structures include (i) a list of currently active runs (), where each run stores partial matches; (ii) a history cache to store the mappings of matched events; (iii) an edge-timestamp map to store the mapping of events and their timestamps that are matched at a conjunction operator’s state (lines 1–3). The algorithm selects the initial state and final state of automaton , and the stream name u of the event to be processed (lines 5–6). This information along-with the initialised structures is passed to the ProcessEvent function (see Algorithm 2), where each incoming event is matched with the active automaton’s runs.
In Algorithm 2, we present the general execution of SPAseq operators with the arrival of an event. Algorithm 2 begins by iterating over the list of active runs. The list of active runs is used to determine if (i) the existing runs are expired or not, i.e. their initialisation time is outside the window boundary, and hence to be deleted (lines 2–5); (ii) the active state of the active run can be matched with the newly arrived event (lines 9–16). The algorithm starts by comparing the initialising time of the run r under evaluation and the defined time window. The run r is deleted if its outside the defined window (line 3). The algorithm then extracts the current active state of the run, and according to the mapped operators it selects the appropriate function for the corresponding operator. In the end, the algorithm checks if the incoming event can start a new run or not (lines 19–22). That is, it matches the initial state’s () edge of the automaton with the incoming event using the Gpm function (line 22).1
Herein, for sake of brevity, we only show the simple option where the complex operators are not mapped at the initial state. However, in practice, it is implemented using the function for the defined operator at the initial state.
In case of a match and if the event is from the same stream the edge is waiting for (), it initiates a new run of the automaton with the active state , i.e. it proceeds to the next state (line 23). This new run is then added to the list of active runs (line 24).
The aforementioned general algorithm gives an overall view of how SPAseq queries are executed. To keep the discussion brief, the evaluation details of SPAseq temporal operators are provided in Appendix C. Note that, herein, we only provide the implementation of strict contiguity and skip-till-next event selection strategies, since skip-till-any operator results in a exponential time complexity [60] and may not be suitable for some real-world applications. The optimised implementation of the skip-till-any operator will be the subject of discussion for our future endeavours.
Design of the SPAseq query engine
Having provided the details of compiling the SPAseq queries onto automata and their evaluation strategies, herein we provide an overview of the system architecture of SPAseq query engine.
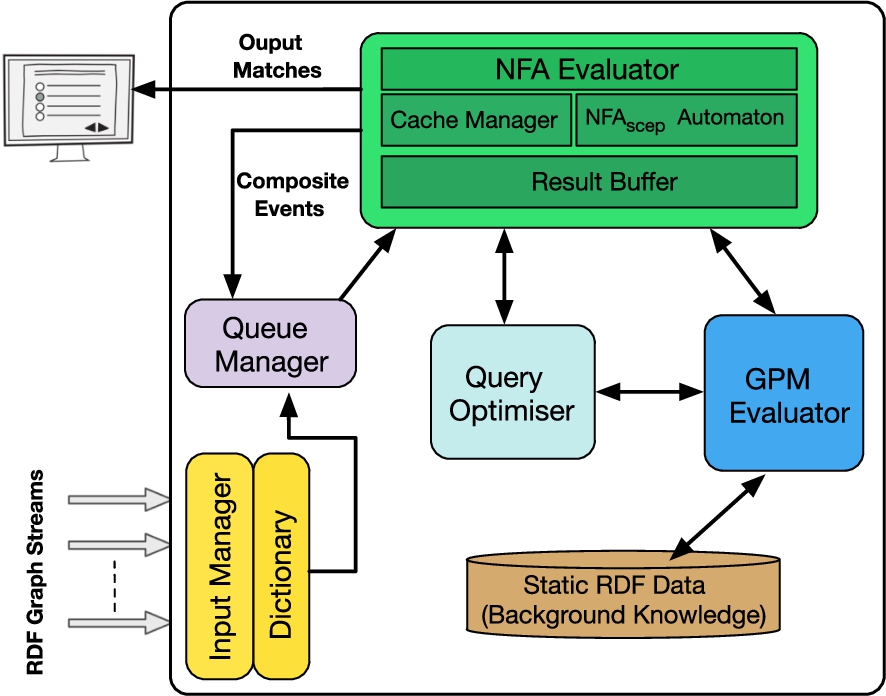
Architecture of the SPAseq Query Engine.
Figure 11 shows the architecture of the SPAseq query engine. Its main components are input manager, queue manager, query optimiser, NFA evaluator, and an RDF graph processor in GPM evaluator. In the following, we briefly discuss these components.
The queue and input managers do their usual job of feeding the required data into the NFA evaluator. Since our system employs streamsets, there are multiple buffers to queue the data from a set of streams. Moreover, the newly constructed events for SPAseq queries can also be fed back to the queue manager for further processing. The incoming data from streams are first mapped to the numeric IDs using dictionary encoding.2
Dictionary encoding is a usual process employed by a variety of RDF-based systems [19,48]. It reduces the memory footprints by replacing strings with short numeric IDs, and also increases the system performance by using numeric comparisons instead of costly string comparisons.
The input manager also utilises an efficient parser3
We employ the performance intensive NxParser, which is a non-validating parser for the Nx format, where x = Triples, Quads, or any other number.
NxParser: https://github.com/nxparser/nxparser, last accessed: November, 2017.
to parse the RDF formatted data into the internal format of the system.
At the heart of SPAseq query engine, the GPM evaluator uses the GPM expressions, events, cache history and edge-timestamp mappings (see Appendix C) to match the defined graph pattern with the incoming events. We employ our SPECTRA GPM engine [31] for this task. SPECTRA is a main memory graph pattern processor but uses specialised data structures and indexing techniques suitable for the optimised evaluation of RDF graph events. We employ two main operators of SPECTRA for SPAseq and they are described as follow:
The SummaryGraph operator enables the system to avoid storing all the triples within an event by exploiting the structure of the graph patterns. That is, the graph pattern P is used to prune all the triples within an event that do not match the subjects, predicates or objects defined in P. The pruned set of triples within an event, called Summary Graph, are materialised into a set of vertically partitioned tables called views. Each view, a two-column table () stores all the triples for each unique predicate in a summarised event.
The QueryProcessor employs the set of views to implement multi-join operations using incremental indexing. That is, for each view a sibling list is used to incrementally determine the set of joined subject/objects that belong to a specific branch within a graph. This results in an incremental solution, where the creation and maintenance of the indexes are the by-product of the join executions between views, not of updates within a defined window.
The use of specialised indexing techniques and data structures enables SPECTRA to outperform existing RSP systems up to an order of magnitude [31]. Thus, employing such optimisations also aids the evaluation of GPM expressions in SPAseq. Furthermore, the evaluated events can also be enriched using the static RDF data, where such data are loaded into the memory using the vertically partitioned tables.
Next comes the NFA evaluator of SPAseq. It contains the compiled automata and employs the GPM evaluator to compute the GPM expressions mapped on the state-transition predicates. Its subcomponent, the cache manager stores the mappings of matched events and mappings for the conjunction operator, i.e. cache history () and conjunction edge-timestamp map (). Finally, the query optimiser employs various techniques to reduce the load for GPM evaluator and the number of active runs. The detailed description of query optimiser is presented in the proceeding section.
Query optimisations
The two main resources in question for processing CEP queries are CPU usage, and system memory. As discussed in Section 6, many different strategies have been proposed to find an optimal way of utilising CPU and memory in CEP systems. One of the main benefits of using an NFA model as an underlying execution framework is that we can take advantage of the rich literature on such techniques. These optimisation techniques can be borrowed into the design of SCEP, while customising them for RDF graph streams. In this section, we describe how such techniques are applicable for SCEP, and also propose new ones considering the query processing over a streamset. First, we review the evaluation complexity for the main operators of the SPAseq query language.
Evaluation complexity of
The evaluation complexity of provides a quantitative measure to establish the cost of various SPAseq operators. Herein, we first describe the cost of temporal operators in terms of the GPM evaluation function, and later provide the upper bound of time-complexity in terms of number of active runs.
Incoming events are matched to the GPM expressions mapped on the state’s edges and such evaluation decides if a state can transit to the next one. Given n number of events in a streamset, the cost of comparing a graph pattern P with n number of events within a window for the unary operators and event selection strategies is described as follows:
where represents the cost of matching a graph pattern P with a RDF graph-based event . For a BGP = from Theorem 1 in [51]. Now we extend this cost to include the cost of the binary operators (BOp). Given n events and k BOp operators, the cost function is extended as follows:
Notice that due to the k number of BOp operator, each event in worst case scenario has to be matched with all the defined GPM expressions for the BOp operators.
Prior works analysing the complexity of NFA evaluation often consider the number of runs or partial matches created by an operator and employ upper bounds on its expected value [3,60]: since each event has to traverse the list of partial matches to find the complete matches. We adopt the same approach for analysing the complexity of evaluation. Given an and streamset, for each incoming event the system has to check all the active runs to determine if the newly arrived event results in (i) state transition from the current active state to the next one, (ii) duplication of a new run, (iii) deletion of the active run. Query operators that result in creating new runs or those which increase the number of active runs are considered to be the most expensive ones. In order to simplify the analysis, we make the following assumptions:
We ignore the cost of evaluating a GPM expression over each event, i.e the Eval function.
We ignore the selectivity measures of the state-transition predicates, i.e. the events that are not matched are either skipped or result in deleting a run of an automaton. Hence, our focus is on the worst-case behaviour.
Based on this, let us consider that there are n number of events with a window and a new event arrives at a current active state of a run, where the active state may contain the following set of operators: strict contiguity, skip-till-next, Kleene+, conjunction and disjunction.
The upper bound of evaluation complexity of event selection strategies, i.e. strict contiguity and skip-till-next, is linear-time, where n is the total number of runs generated for the n input events within a window.
None of the operators described in Theorem 1 duplicate runs from the existing ones. Each has only one GPM expression to be matched with the incoming events. Let us consider the case of event selection operators. Given a sequence expression (op), where , mapped to states and . With the arrival of an event at τ, where an event selection operator is mapped at state , it can result in the following actions: (i) the run will transit to the next state, (ii) the event will be skipped due to skip-till-next operator, and (iii) the run will be deleted. Since we are considering the worst-case behaviour, let us dismiss the situations (ii) (iii). In situation (i) there be will no extra run created for the above mentioned operators, and each incoming event will be matched to only one GPM expression. Thus the evaluation cost remains linear and for n number of events there can be only n runs. □
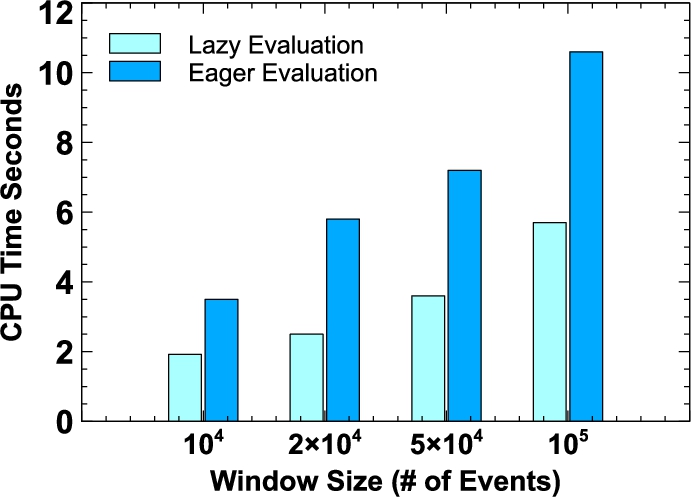
Although the upper bound of the operators described in Theorem 1 has the same evaluation complexity, there exists discrepancies when considering the real-world scenarios [60]. Due to the skipping nature of skip-till-next operator, the life-span of its runs can be longer on a streamset. In particular, those runs that do not produce matches, and instead loop around a state by ignoring incoming events until the defined window expires. On the contrary, the expected duration of a run is shorter for the strict contiguity operator, since a run fails immediately when it reads an event that violates its requirements. Such difference in their evaluation cost is visible in our experimental analysis (Section 8).
The case of conjunction and disjunction operators is slightly different, and therefore has a different upper case bound. That is, for each conjunction/disjunction operator: (i) more than one edge has different source and destination states with distinct GPM expressions, (ii) the edges do not have an ϵ-transition. Thus, in worst case each incoming event has to match to the complete set of state-transition predicates. Hence, for k such edges of a conjunction/disjunction operator, and n events within a window, we can provide the upper bound on the complexity of these operators as follows:
The upper bound of evaluation complexity of conjunction and disjunction is, where n is the total number of events within a window and k is number of GPM expressions mapped to the edges of a state.
For the conjunction and disjunction operators no new runs are initiated from old ones. If an event arrives at active state x, it either matches to the set of edges defined and moves to the next state, or it stays at the current active states and waits for new events (in case of the conjunction operator). However, for both operators, each incoming event can end up traversing the whole set of k mapped edges. Thus, even if the number of active runs remains the same, each event may have to be matched with a number of GPM expressions mapped at the state’s edges. For k such edges and n events, in worst case the cost will be . □
The upper bound of evaluation complexity of each Kleene+ operator is quadratic-timefor n events within a window.
Consider the following sequence expression , which is mapped onto the state with the Kleene+ operator. Let us consider that is an active state. If an event arrives at time τ, and if it matches the GPM expression of the state-transition predicate, it will duplicate the current active run and append the duplicated one to the list of active runs. Thus, for each newly matched event at a Kleene+ state, a new run is added to the active list, and for n such events, there will be in total runs to be generated considering all the events are matched to the GPM expression of the state , i.e. worst case behaviour. □
The Kleene+ operator is the most expensive in the lot, in terms of number of active runs. Based on the observations in Theorems 1, 2 and 3, we adopt some of the optimisation strategies previously proposed, and also propose some new ones. We divide these techniques into two classes from the view point of operators and system: local, and global levels. Local-level optimisation techniques are targeted at the specific operators considering their attributes, while the global-level optimisation are for all the operators, and are implemented at the system level. In the following section, we present these techniques in details.
Global query optimisations
The evaluation of an automaton is driven by the state-transition predicates being satisfied (or not) for an incoming event. The number of active runs of an automaton, and the number of state-transition predicates that each run could potentially traverse can be very large. Therefore, the aim of global optimisation is to reduce the total number of active runs by (i) deleting, as soon as possible, the runs that cannot produce matches, and (ii) indexing the runs to collect the smaller number of runs that are actually affected by an event.
Pushing windows and stateful predicates
Pushing the defined windows and stateful predicates are usually employed by the CEP systems to evict, as soon as possible, the events that are outside the window or cannot produce matches for the defined predicates [3,45]. Hence, we employ the same technique of window pushing to efficiently delete runs that are outside the time window. In Algorithm 2 (lines 3–5), we push the window check before iterating over the active runs list. For the stateful predicates, we customised our GPM evaluator. That is, we use the expression in the GPM construct to first determine if the incoming event can match the defined mapping without first evaluating the initiating the complete GPM process. This results in pruning the irrelevant events and reducing the load over the GPM evaluator. As an example of this, consider the SPAseq Query 1. Its GPM expressions share the stateful variables of location (?l) and electricity fare (?fr). Pushing these two joins, we can easily ignore the events that would not contain the expected mappings of these variables, and consequently the system does not have to process the complete GPM expressions (GPM B and C) for such events.
Indexing runs by stream names
SPAseq queries are evaluated over a streamset, where the edges from each state contain the stream name which is used to match the graph patterns. Therefore, each active state waits for a specific type of event from a specific stream, and later invokes the GPM evaluator. This means we can use such property of streamset to extract the set of runs, from active run list, that can be affected by the incoming event. Based on this, we index each run by the stream name of its active state (see Fig. 12). More precisely, the index takes the stream name as a key and the corresponding run as the value. These indexes are simple hash tables, and for each incoming event it essentially returns a set of runs that can be affected by the incoming event. These indices proved to be a useful feature for processing events from a streamset. Note that the naive implementation using a single list of runs would be inefficient in this case: each incoming event would iterate over all the active runs, and initiate the matching process for each of them.
Partitioning Runs by Stream Names.
Figure 12 shows a set of streams employed by a set of active runs. The active runs , are waiting for an event from stream with name , the active run is waiting for an event from stream with name , and active runs and are waiting for the events from the stream with name . Hence these runs are evaluated only for the events coming from the desired stream.
Memory management
The memory requirements usually grow in proportion to the input stream size or the matched results [60]. For our system, the three main data structures that require tweaking are the cache manager, the result buffer and the indexed active run list. In this context, our first step is to use the buy bulk design principle. That is, we allocate memory at once or infrequently for resizing. This complies to the fact that the dynamic memory allocation is typically faster when allocation is performed in bulk, instead of multiple small requests of the same total size. Second, since the cache manager and the result buffer are indexed with the dynamically generated run ids, we use the expired runs – which either are complete or not – to locate the exact expired runs to be deleted. These runs are added to a pool: when a new run is created, we try to recycle the memory from such pool. This limits the initialisation of new runs and reduces the load over the garbage collector [3]. Note that we use hash-based indexing for all the data structures, which means the position of expired runs can be found in theoretically constant time.
Local query optimisation
Local query optimisation is devised for the conjunction and disjunction operators, where the chief problem is how to select the GPM expression from a set of edges and how to reduce the load on the GPM evaluator. The knowledge of the runs affected by an incoming event is not sufficient, we also have to determine which edge these runs will traverse. These issues are not catered by the existing NFA models since they (i) work on single stream mode; (ii) most of them do not provide the evaluation techniques for disjunction and conjunction operators.
To better illustrate the problem, let us start by examining the sequence expression ( | | | ) for the disjunction operator. Figure 13 shows the related automaton. Now consider an input stream , and an event at time arrives at the state . The basic sequential way of processing would be to first match with then , and finally with : since all the graph patterns are waiting for an event from the stream . Now the question is how to choose the less costly graph pattern to be selected first by the state, such that if it matches the automaton moves to the next state, hence complying to the optional operator.
Compilation of Disjunction Operator for ( | | | ).
The optimal way of processing the disjunction operator would be to sort the graph patterns according to their cost, and select the cheapest one for the first round of evaluation. That is, if is the cost of matching a graph pattern with an event , then we require a sorted list such that . The question is how to determine the cost of GPM evaluation. There can be two different ways to it.
Use the selective measures and structure of the graph patterns. That is, how much the GraphSummary operator be handy for them (see Section 6.4).
Adaptively gather the statistics about the cost of matching a specific graph pattern, and sort the graph pattern accordingly.
Let us focus on the first approach. As according to Theorem 1 in [32], the cost of matching a graph pattern and an event is directly proportional to each of their sizes. That is, if there are more triple patterns , then there will be more join operations on different vertically-partitioned views: this can give us a fair bit of idea about the costly graph patterns. Furthermore, due to the presence of filters, the GraphSummary operator can prune most of unnecessary triples, and consequently reduce the cost of the GPM operation. Following this reasoning, we keep a sorted set of graph patterns within the state which mapped the conjunction/disjunction operator, each associated with a stream name . This set is sorted by checking the number of triple patterns, and the selectivity of subjects, predicates and objects within a graph pattern during the query compilation [31]. The state can utilise this set to first inspect the less costly graph patterns for the incoming events. This can lead to a less costly disjunction operator with few calls to the GPM evaluator.
The second approach is based on the statistics measures. That is, the system during its life-span observes which graph pattern has been utilised successfully in the past and is less costly compared with others. This approach can be built on top of the technique discussed above. Herein, the implementation of such optimisation technique is considered as future work.
Compilation of Conjunction Operator for ( & & ).
The conjunction operator, however, contains an additional challenge on top of the one discussed above. To illustrate this, let us consider a sequence expression ( & & ) for the conjunction operator. Figure 14 shows the automaton for it. Hence, for the state to proceed to the next state, it has to successfully match all the defined state-transition predicates, such that events satisfying them should occur at the same time. Thus, if an event arrives and matches to one of the state-transition predicate, the automaton buffers its result, timestamp, and waits for the remaining events. Now consider a situation, where events and arrive at and match with the GPM expressions and respectively. Then the automaton waits for an event to satisfy GPM expression . Now consider an event arrives at . It results into two constraints to be examined (i) if , and (ii) if matches with the GPM expression . Here, if any of the above mentioned constraints would not match, then it means the run has to be deleted and all the previous GPM evaluations were useless: the process of matching an event with a graph pattern is expensive and it stresses the CPU utilisation.
Our approach to address this issue is to employ a lazy evaluation technique. Conceptually, it delays the evaluation of graph patterns until it gets enough evidence that these matches would not be useless. Its steps are described as follow:
Buffer the events from streams until the number of events with the same timestamps is equal to the number of edges (with distinct GPM expressions) going out from the state that maps conjunction operator.
After the conformity of the above constraint, choose graph patterns according to their costs (as discussed for disjunction operator).
The main idea underlying our lazy evaluation strategy is to avoid unnecessary high cost of the GPM, and to start the GPM process when it is probable enough that it would return the desired results. The idea of lazy batch-based processing is the reminiscent of work [45] on buffering the events and processing them as batches. To keep the discussion brief, the detailed algorithm for our lazy evaluation is described in Appendix D.
In this section, we presented various strategies to optimise the evaluation of SPAseq temporal operators. In the next section, we present the quantitative analysis of the SPAseq operators and the effect of our optimisation strategies.
Experimental evaluation
In this section, we present the experimental evaluation that examines (i) the comparative analysis against state-of-the-art systems, (ii) the complexity of various SPAseq temporal operators, and (iii) the effect of various optimisation strategies. We first describe our experimental setup, and later we analyse the system performance in the form of questions.
Experimental setup
Datasets We used four real-world datasets and their associated queries for our experimental evaluation.
The stock market dataset (SMD) is a real-world dataset [52,56] from the New York Stock Exchange. It contains 225k transaction records of 10 companies in 1 sector during 12 hours. Each event in the dataset carries company, sector, and transaction identifiers, volume, price, time stamp, and type (sell or buy). We replicate this dataset 10 times with adjusted company, sector, and transaction identifiers such that the resulting data set contains transactions for 110 companies in 11 sectors. No other attributes except identifiers were changed in the replicas compared to the original. This dataset is then mapped to RDF N-Triples format, where each attribute of the stock event is mapped as a triple and a whole event (set of triples) refer to an RDF graph.
The UMass smart home dataset (SHD) [
37
] is a real-world dataset and provides power measurements that include heterogeneous sensory information, i.e. power-related events for power sources, weather-related events from sensors (i.e. thermostat) and events for renewable energy sources. We use a smart grid ontology [30] to map the raw eventual data into N-Triples format for three different streams: the power stream (), the power storage stream () and the weather stream (). In total the dataset contains around 30 million triples, 8 million events.
The credit card dataset (CCD) is a real dataset of credit card transactions [4,10]. In this dataset, each event is a transaction accompanied by several arguments, such as the time of the transaction, the card ID, the amount of money spent, etc. The total number of transactions in this summary dataset was around 1.5 million. We mapped the dataset to the RDF N-Triples format, where each attribute of the transaction is mapped as a triple and a whole transaction refer to an RDF graph.
The traffic dataset (TD) is a real traffic dataset gathered from sensors deployed within the city of Aarhus, Denmark [5]. Traffic data are collected by observing the vehicle count between two points over a duration of time. The dataset includes the average vehicle speed, vehicle count, estimated travel time and congestion level between the two points set over each segment of road. The dataset is then mapped to the sensor network ontology as provided by the CityBench [5].
Queries We evaluate the workload of four main queries and their variations for the above mentioned datasets. That is, the queries for the UC
1
(SHD dataset and Q1 from Section 4), UC
3
(CCD dataset and Q2 from Appendix A) UC
4
(SMD dataset and Q3 and Q4 from Appendix A) and UC
5
(TD dataset and Q5 from Appendix A). The properties of these queries are described as follows: Q1 uses the multistreams and provides a sequence using three GPM clauses with stateless or constant filters; Q2 provides a sequence over two GPM clauses using stateful or variable filters; Q3 and Q4 employ three to seven GPM clauses for V-shaped and head-and-shoulder patterns with stateful filters; Q5 uses multistreams and provides a sequence with conjunction over three GPM clauses using stateless or constant filters.
Credit Card Fraud Detection, Big after Small: SPAseq query.
Head and Shoulders Pattern: SPAseq query.
V-Shaped Pattern: SPAseq query.
Traffic Management: SPAseq query.
Methodology To show the efficiency of our approach, we compare our system with EP-SPARQL. EP-SPARQL is the only system which provide a SCEP language and its implementation. SPAseq and EP-SPARQL differ w.r.t. each other in terms of semantics and data model. Hence, they may produce different results for the same query. Therefore, the aim of our comparative analysis is to employ the same use case, its queries and dataset to measure the performance differences between the two. This strategy is mostly utilised by the information retrieval systems [54]. Although EP-SPARQL doe not provide any event selection strategies at the query level, its underlying system ETALIS provides various event selection strategies. We use the recent (EPSPARQL-R) and unrestricted (EPSPARQL-UR) strategy from ETALIS for our experiments, where the recent strategy can be mapped to the strict congruity (SPAseq-SC) and unrestricted to skip-till-next (SPAseq-STN). Note that we also use C-SPARQL for our set of experiments. Although C-SPARQL provides a time function to allow simple sequences over the RDF triple streams, it does not perform well on the selected datasets and queries, and takes several hours to process windows of moderate sizes. Hence, the results could not fit properly in our charts and are not included. Note that the GPM process of SPAseq is based on our previous work called SPECTRA [31]. The readers are encouraged to refer to our previous work for the detailed comparison between the GPM of SPECTRA and other RSP systems. Moreover, for multiple streams, we use events from the streams in the order defined within the queries. This enables us to get the maximum number of matches and compare systems under heavy workloads. For all the sets of experiments, we use time and event-based windows. For the time window, we use the event’s source timestamps. We measured two common metrics [3,52,53,60] for the CEP system, namely average CPU time over the windows and average throughput. Average CPU time is measured in seconds and milliseconds as the sum of total elapsed time in all windows divided by the number of windows. Average throughput is the number of triples processed per second averaged over all the processed windows. We execute each experiment three times and report their average results here.
Average CPU Time comparison of SPAseq (Strict Contiguity (SC) and Skip-Till-Next (STN)) with EP-SPARQL (Recent (R) and Unrestricted (UR)) over the four selected datasets (SMD, CCD, TD and SHD).
Results and analysis
We start our analysis by first providing the comparative analysis with the existing SCEP systems for the same datasets and use cases.
Comparative analysis
Question 1 How does theSPAseqengine perform w.r.t. the EP-SPARQL engine?
Figure 15 and 16 showcase the CPU time and throughput respectively of both SPAseq and EP-SPARQL for the two event selection strategies over the four selected datasets using various window sizes. From Fig. 15 and 16, SPAseq using the SC and STN event selection strategies outperforms EP-SPARQL for R and UR event selection strategies in terms of CPU time and throughput measures. The details of these results are as follows.
Average Throughput comparison (triples/second) of SPAseq (Strict Contiguity (SC) and Skip-Till-Next (STN)) with EP-SPARQL (Recent (R) and Unrestricted (UR)) over the four selected datasets (SMD, CCD, TD and SHD).
EP-SPARQL. In general, EP-SPARQL uses a Prolog wrapper based on the event driven backward chaining rules (EDBC), and schedules the execution via a declarative language using backward reasoning. This first results in an overhead of object mappings. Second, each time a new consequent of a rule is matched, the entire rule set is searched to see what else can be concluded. Hence resulting in high computation costs. The CPU time of both EP-SPARQL-R and EP-SPARQL-UR grows with the size of the window. However, since EP-SPARQL-R provides a strict sequence over the incoming events, only the most recent rules are selected to produce the matches. This results in less computation cost compared with EP-SPARQL-UR: EP-SPARQL-UR skips the irrelevant events and a broad set of rules is selected and processed. Hence, EP-SPARQL-UR results in a considerable high computational cost for each incoming event. Hence the CPU time for EP-SPARQL-UR increases quadratically (subsequently throughput decreases) with the increase in the window size. The same effect can be seen in Fig. 16, when comparing the throughput measures of EP-SPARQL-R and EP-SPARQL-UR. Furthermore, the CPU costs for both EP-SPARQL-R and EP-SPARQL-UR have similar measures for all the datasets and queries. This is because of evaluating the backward chaining rules, where the defined constant filters in the queries are not taken into account beforehand and the system does not prune the irrelevant rules before starting the complete rule matching procedure. Moreover, EP-SPARQL uses a goal-based memory management technique, i.e. periodic pruning of expired goals using alarm predicates, which is expensive for large window sizes.
SPAseq. The CPU time of SPAseq-SC and SPAseq-STN also increases (subsequently the throughput decreases) with the increase of the window size. However, it performs much better than its counterpart. The reasons are as follows. SPAseq employs the model with various optimisation strategies to reduce the cost of evaluating GPM and the state-transition predicates. It utilises efficient “right-on-time” garbage collection for the deceased runs, and optimisations such as pushing temporal windows and stateful joins, and incremental indexing from SPECTRA – SPAseq’s underlying GPM engine – reduce the average computation overheads and life-span of an active run. Due to these optimisation strategies, SPAseq has different CPU cost for different datasets and queries. For the CCD and SMD queries (Q2 and Q3), the initial state (GPM expression) has variable or stateful filters. Hence, each incoming event can potentially start a new run or a partial match. This results in a large number of runs to be evaluated for each incoming event. This effect, however, is not evident for SPAseq-SC, since it expects a strict sequence of events and it deletes runs as soon as the incoming events violate it. For the SPAseq-STN, events that are not matched are skipped and the runs life-times are much longer, hence the size of total active runs. This means, for each incoming event, the system has to go through a larger list of runs to be matched. This behaviour of event selection strategies is in line with our theoretical analysis in Section 7. For the SHD and TD queries (Q1 and Q5), the initial state (GPM expression) has static or stateless filters. Hence, only specific events can start a new run. This results in a small number of active runs to be produced and processed for an incoming event. For the same reason, for both TC and SMD datasets, both SPAseq-SC and SPAseq-STN have similar CPU costs and throughput. From Fig. 15(c), we can also see that the conjunction operator of SPAseq performs much better than EP-SPARQL for the two event selection strategies. This is due to the lazy evaluation of the conjunction operator, where the GPM process is started only when we have enough events that can produce a match. In summary, on all the datasets, SPAseq-SC is two orders of magnitude less costly that EP-SPARQL-R, and SPAseq-STN is two to three orders of magnitude less costly than EP-SPARQL-UR.
Comparison of SPAseq (Strict Contiguity (SC) and Skip-Till-Next (STN)) with EP-SPARQL (Recent (R) and Unrestricted (UR)) by increasing the number of sequence clause for SMD dataset and queries over a window of 40 minutes.
To further consolidate our comparison analysis, we showcase the performance of both systems by increasing the number of sequence clauses over windows of size 40 minutes. We use the SMD dataset and create a set of queries (extensions of Q3 and Q4), since SMD is much costly than other datasets and queries. From Fig. 17, the CPU cost of both EP-SPARQL-R and EP-SPARQL-UR increases with the number of sequence clauses. However, the cost of SPAseq-SC and SPAseq-STN provides similar measures. This is due to the fact that the CPU cost of SPAseq depends on the number of active runs, since they result in large number of GPM evaluation operations. Increasing the number of sequences would not increase the number of active runs but the active life of runs. Hence, increasing the number of sequences does not increase the CPU cost drastically compared with EP-SPARQL. For EP-SPARQL, increasing the number of sequence clauses results in more complex backward chain reasoning for incoming event; hence the increase in the CPU cost.
Comparison of EP-SPARQL and SPAseq over the background KB using SMD and CCD datasets and queries.
Question 2 How does EP-SPARQL andSPAseqperform using the background KB?
To analyse the CPU cost by using the background KB, we use the SMD and CCD datasets and their respective queries. We generated the simulated background KB for these datasets. The background KB of SMD contains information about the company name, address, URL, phone number, while the background KB of CCD contains information about the cardholder name, issuing bank, bank address and type of the card. We increase the size of the background KB from 10K to 1M triples. We do not use show the CPU time for EP-SPARQL-UR for this set of experiments, since it does not perform well with the integration of background KB.
Figure 18 shows the performance comparison of both systems. From Fig. 18, the CPU cost of EP-SPARQL-R increases quadratically with the increase in the number of triples for background KB. The reasons are as follows. EP-SPARQL bases its reasoning process on the ETALIS engine, where the background KB is used to map the complete set of inference rules before starting the event processing. With the arrival of a new event, not only the defined sequences are matched, but also all the inference rules are triggered at the same time. Hence, EP-SPARQL spends considerable amount of time on matching the events with a large set of rules, even for the events that would not produce matches. SPAseq, on the other hand, employs an optimised way of processing background information due to its separation of the query constructs. That is, the evaluation of sequence clauses in a SPAseq query is separated from the evaluation of the background KB. Hence, triples from the background KB are joined only when the BGP defined in the query is matched with the incoming event. That is, the background KB is materialised only once by considering the patterns defined on the background KB, and only the events that match with the defined BGP are matched with the materialised background KB. Hence, unnecessary computation costs are saved. Furthermore, we employ the optimised indexing techniques from the SPECTRA [31] – our underlying RDF processing engine – for an efficient computation of the background KB and incoming events. For these reasons, the CPU cost of SPAseq increases in a sub-linear manner by increasing the number of triples in the background KB. The results from this set of experiments also highlights the importance of providing explicit constructs for the background KB, rather than using it at the implementation level.
General analysis of the SPAseq query engine
In this section, we present the general analysis of SPAseq’s query evaluation strategies and the cost of its temporal operators. We start by describing the cost of its internal operations.
Question 3 What is the cost of various operations for theSPAseqengine?
The analysis of the cost of various SPAseq operations would aid us in discovering the bottlenecks of the systems. For this set of experiments we use the SMD dataset and query Q3, since it is the most expensive from our previous analysis.
Cost analysis (in milliseconds) of various SPAseq operations using the SMD and STN event selection strategy.
Figure 19, shows the cost of three main operations of the SPAseq query engine, namely parsing time, GPM evaluation time and automaton evaluation time. The parsing time is the time to parse the incoming set of triples in N3 form to the internal representation of the SPAseq engine. The GPM evaluation time is the total time to match each incoming event with the defined GPM expressions mapped at the automaton states. The automaton evaluation time determines the time to (i) create new automaton runs, and (ii) transit from one state to another. From Fig. 19, it is evident the GPM evaluation is the most expensive operation compared with parsing and automaton evaluation. However, this is expected since the RDF data model – which requires GPM – provides much more expressiveness than the traditional relational data model and is at the backbone of the Semantic Web. The cost of the automaton evaluation is the standard one since we need to create new runs to start a new partial match, and we proceed to the next state to produce the full matches. The parsing time is proportional to the number of parsed events and is quite less than the other operations. Note that the parsing time can be reduced by parsing the simple text-based triples – as used by many RSP systems and EP-SPARQL – than the standard full URI-based triples in N3 form.
The cost of SPAseq operations shows us that optimising the GPM evaluation has a direct effect on the overall cost of a SCEP system. Since we use SPECTRA [31] as our underlying GPM engine – which outperforms existing RSP systems – the SPAseq engine provides an optimised performance. Next, we determine the effect of our optimisation strategy on the performance of the SPAseq engine.
Question 3 How does the cost of a simple sequence clause compare with the cost of the Kleene+ Operator?
Cost analysis (in milliseconds) of various SPAseq operations for Kleene+ operator and simple sequence operators using the SMD and STN event selection strategy.
In this set of experiments, we compare the CPU cost of GPM and automaton evaluation for the Kleene+ operator and simple sequence clause using SMD and its respective queries. We do not compare the parsing time since it is the same for both queries. From Fig. 20, we can see that Kleene+ operator results in an increase of the GPM and automaton evaluation costs’. This is because the number of runs generated for a query with a simple sequence clause is relatively proportional to the number of events that result in starting a new run from its initial state . However, the same is not the case with the Kleene+ operator. If an event matches to the Kleene+ operator, the system duplicates an additional run and adds it to the active runs list; hence to match the one or more relations over event streams. This means, following the same intuition from earlier, each newly arrived event has to process a large number of active runs. This results in an extra cost for the Kleene+ operator to process an event. Nevertheless, our system provides good performance measures for the expressive operators such as the Kleene+. The experimental cost of the Kleene+ operator is in line with our theoretical analysis in Section 7.
Question 4 How does the strategy for indexing runs by stream names affect the performance of the system?
Analysis of the cost of indexing runs by stream names using SHD dataset and its query.
In order to determine the effectiveness of indexing runs by stream names, we employ the SHD and Q1 for UC
1
with STN event selection strategy, since it is costly compared with the SC strategy. Recall from Section 7.2, we index runs by stream name, thus when an event arrives, only the runs whose active state is waiting for such an event are used. Consequently, it reduces the overhead of going through the whole list of available active runs. Figure 21 shows the results of our evaluation with variable window sizes. According to the results, the performance differences between the indexed and non-indexed approach is not evident at smaller windows with less number of events. This is due to the fact that small numbers of runs are produced/remain active for the smaller windows, hence indexing of runs does not results in a comparatively smaller set of runs to be probed for each event. However, the effectiveness of the indexing technique becomes quite clear with the increase in the window size. That is, a large number of runs is produced with a smaller set of them waiting for an event from a specific stream.
Question 4 How does the lazy evaluation affect the performance of the conjunction operator?
Analysis of eager and lazy evaluation strategies for conjunction operator using TD dataset and its query.
For this set of experiments, we employ the TC dataset and its respective query Q5 with conjunction operator and STN event selection strategy. Figure 22 shows the results of the conjunction operator with lazy and eager evaluation strategies. Recall from Section 7.3, lazy evaluation delays the computation of all the state-transition predicates until the number of the events with the same timestamp is equal to the number of state-transition predicates. As shown in Fig. 22, the lazy evaluation strategy performs much better on smaller windows and relatively better on larger ones: the eager evaluation results in a larger number of useless calls to the GPM evaluator, while lazy evaluation performs a batch-based call to the GPM evaluator. Thus, with lazy evaluation, a set of events is evaluated against a set of GPM expressions, only if all the buffered events (for a conjunction state) has the same timestamp. For the smaller window, if the number of buffered events is not equal to the number of edges from a conjunction state, the GPM evaluator is not invoked. Hence, with the expiration of the window, the runs are deleted without matching events and without using the additional resources. Contrary to this, the eager evaluation strategy calls the GPM evaluator for each incoming event and a large number of such calls proved to be useless for smaller windows.
Conclusion
In this paper, we presented the syntax, semantics and implementation of a SCEP query language called SPAseq. We provided the motivation behind SPAseq and pointed out various qualitative differences between other SCEP languages. Such analysis showcased the usability and expressivity of the SPAseq query language. During the design phase of our language, we carefully consulted existing CEP techniques and the lessons learned. Thus, a suitable compromise between the expressiveness of a SCEP language and how it can be implemented in an effective way is made possible. We also proposed an model to map the SPAseq operators and showed how they can be evaluated over a streamset. Furthermore, we also provided multiple optimisation techniques to evaluate SPAseq operators in an optimised manner. Lastly, while utilising real-world datasets we showcased the usability and performance of SPAseq query engine. Our future endeavours include: extension of the language with new operators, a through semantic comparative analysis with the EP-SPARQL, further optimisation strategies for the Kleene+ operator and the evaluation of the SPAseq operators in a distributed environment. We believe that SPAseq can ignite the SCEP research community and will open the doors for the new insights and optimisation techniques in this field.
Acknowledgement
This work was partly support by grant ANR-14-CE24-0029 from Agence Nationale de la Recherche for project OpenSensingCity.
Footnotes
SPAseq by examples
In this section, we provide the SPAseq queries for the use cases described in Section 2.
A note on the extension of SPAseq
As discussed earlier, the design of SPAseq encouraged the extensibility of the language with new operators. Herein, we present two operators and discuss how they can be integrated into the SPAseq query model and their effects on the semantics of SPAseq.
Evaluation of SPASEQ operators
Herein, we present the details how SPAseq operators are evaluated using the model.
Local query optimisations of disjunction and conjunction operators
Algorithm 10 shows the lazy evaluation of the conjunction operator and it extends Algorithm 5. It employs an event buffer to cache the set of events having the same timestamps. The algorithm first takes the set of edges E for an active state and timestamp τ of the newly arrived event (lines 1–2). It then checks if there exists any previously buffered event in . If so it checks their timestamp and the timestamp τ of the newly arrived event (line 5). If the timestamps do not match it deletes the run under evaluation while removing all the previously buffered events in (lines 4–7). Otherwise it adds the event in the event buffer , which is later used to evaluate the unmatched edges (line 10). At this stage, the algorithm prunes the edge set E with the edges that have already been matched – using the mapping structure (line 11) (as described in Algorithm 5). If the number of unmatched edges in E is equal to the number of buffered event , it starts the matching process using the lazy evaluation strategy. Before starting the matching process, it first sorts the edges according to the selectivity of the graph patterns in state-transition predicates, hence using the low cost edges first (line 13). The algorithm then iterates over the sorted edges E and the buffered events set to match the selected edge (lines 12–22). If an edge matches the buffered event , its mapping is added into and the matched event is removed from the buffer (lines 18–19). In the end, the algorithm has to determine if all the edges of the active states are matched and should it transit to the next state or not. Therefore, it examines the number of actual edges of the state and the number of them that have already been matched (line 25). If all the edges are matched the run transits to the next state. Otherwise, it waits at the same state to receive more events having the same timestamps (line 28).
References
1.
D.J.Abadi, D.Carney, U.Çetintemel, M.Cherniack, C.Convey, S.Lee, M.Stonebraker, N.Tatbul and S.Zdonik, Aurora: A new model and architecture for data stream management, The VLDB Journal12(2) (2003), 120–139. doi:10.1007/s00778-003-0095-z.
2.
R.Adaikkalavan and S.Chakravarthy, SnoopIB: Interval-based event specification and detection for active databases, Data Knowl. Eng.59(1) (2006), 139–165. doi:10.1016/j.datak.2005.07.009.
3.
J.Agrawal, Y.Diao, D.Gyllstrom and N.Immerman, Efficient pattern matching over event streams, in: Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, SIGMOD ’08, ACM, New York, NY, USA, 2008, pp. 147–160. doi:10.1145/1376616.1376634.
4.
E.Alevizos, A.Artikis and G.Paliouras, Event forecasting with pattern Markov chains, in: Proceedings of the 11th ACM International Conference on Distributed and Event-Based Systems, DEBS ’17, ACM, New York, NY, USA, 2017, pp. 146–157. doi:10.1145/3093742.3093920.
5.
M.I.Ali, F.Gao and A.Mileo, CityBench: A Configurable Benchmark to Evaluate RSP Engines Using Smart City Datasets, Springer International Publishing, Cham, 2015, pp. 374–389.
6.
D.Anicic, P.Fodor, S.Rudolph and N.Stojanovic, EP-SPARQL: A unified language for event processing and stream reasoning, in: Proceedings of the 20th International Conference on World Wide Web, WWW ’11, ACM, New York, NY, USA, 2011, pp. 635–644.
7.
D.Anicic, S.Rudolph, P.Fodor and N.Stojanovic, Stream reasoning and complex event processing in ETALIS, Semant. web3(4) (2012), 397–407.
8.
Apache Flink. Available at: https://flink.apache.org/.
9.
A.Arasu, S.Babu and J.Widom, The CQL continuous query language: Semantic foundations and query execution, The VLDB Journal15(2) (2006), 121–142. doi:10.1007/s00778-004-0147-z.
10.
A.Artikis, N.Katzouris, I.Correia, C.Baber, N.Morar, I.Skarbovsky, F.Fournier and G.Paliouras, A prototype for credit card fraud management: Industry paper, in: Proceedings of the 11th ACM International Conference on Distributed and Event-Based Systems, DEBS ’17, ACM, New York, NY, USA, 2017, pp. 249–260. doi:10.1145/3093742.3093912.
11.
C.Balkesen, N.Dindar, M.Wetter and N.Tatbul, RIP: Run-based intra-query parallelism for scalable complex event processing, in: Proceedings of the 7th ACM International Conference on Distributed Event-Based Systems, DEBS ’13, ACM, New York, NY, USA, 2013, pp. 3–14. doi:10.1145/2488222.2488257.
12.
D.F.Barbieri, D.Braga, S.Ceri, E.D.Valle and M.Grossniklaus, Querying RDF streams with C-SPARQL, SIGMOD Rec.39(1) (2010), 20–26. doi:10.1145/1860702.1860705.
13.
T.Bernhardt and A.Vasseur, ESPER-complex event processing, in: Online Article, 2010.
14.
C.Bizer, T.Heath and T.Berners-Lee, Linked data – the story so far, International Journal on Semantic Web and Information Systems5(3) (2009), 1–22. doi:10.4018/jswis.2009081901.
15.
L.Brenna, A.Demers, J.Gehrke, M.Hong, J.Ossher, B.Panda, M.Riedewald, M.Thatte and W.White, Cayuga: A high-performance event processing engine, in: Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, SIGMOD ’07, ACM, New York, NY, USA, 2007, pp. 1100–1102. doi:10.1145/1247480.1247620.
16.
J.-P.Calbimonte, O.Corcho and A.J.G.Gray, Enabling ontology-based access to streaming data sources, in: Proceedings of the 9th International Semantic Web Conference on the Semantic Web – Volume Part I, ISWC’10, Springer-Verlag, Berlin, Heidelberg, 2010, pp. 96–111.
17.
J.J.Carroll, C.Bizer, P.Hayes and P.Stickler, Named graphs, provenance and trust, in: Proceedings of the 14th International Conference on World Wide Web, WWW ’05, ACM, New York, NY, USA, 2005, pp. 613–622. doi:10.1145/1060745.1060835.
18.
J.J.Carroll, C.Bizer, P.Hayes and P.Stickler, Named graphs, in: Web Semantics: Science, Services and Agents on the World Wide Web, Vol. 3, 2005, pp. 247–267, World Wide Web Conference Semantic Web Track.
19.
J.J.Carroll, I.Dickinson, C.Dollin, D.Reynolds, A.Seaborne and K.Wilkinson, Jena: Implementing the semantic web recommendations, in: Proceedings of the 13th International World Wide Web Conference on Alternate Track Papers &Amp; Posters, WWW Alt. ’04, ACM, New York, NY, USA, 2004, pp. 74–83. doi:10.1145/1013367.1013381.
20.
O.Corcho, D.Dell’Aglio, E.D.Valle, S.Gao, A.J.G.Gray, D.Le-Phuoc, R.Keskisärkkä, A.Llaves, A.Mileo, B.Ortner, A.Paschke, M.Solanki, R.Stühmer, K.Teymourian, P.Wetz, D.Anicic and J.-P.Calbimonte, W3C Community Group, Latest version available as http://streamreasoning.github.io/RSP-QL/RSP_Requirements_Design_Document/#.
21.
G.Cugola and A.Margara, Processing flows of information: From data stream to complex event processing, ACM Comput. Surv.44(3) (2012), 15:1–15:62. doi:10.1145/2187671.2187677.
22.
R.Cyganiak, D.Wood and M.Lanthaler, RDF 1.1 Concepts and Abstract Syntax, Technical report, W3C, 2014.
23.
M.Dao-Tran and D.Le Phuoc, Towards enriching CQELS with complex event processing and path navigation, in: Proceedings of the 1st Workshop on High-Level Declarative Stream Processing Co-Located with the 38th German AI Conference (KI 2015), Dresden, Germany, September 22, 2015, 2015, pp. 2–14.
24.
D.Dell’Aglio, M.Dao-Tran, J.Calbimonte, D.Le Phuoc and E.D.Valle, A query model to capture event pattern matching in RDF stream processing query languages, in: Proceedings of Knowledge Engineering and Knowledge Management – 20th International Conference, EKAW 2016, Bologna, Italy, November 19–23, 2016, 2016, pp. 145–162.
25.
Y.Diao and N.Immerman, Sase+: An agile language for kleene closure over event streams, UMASS Technical Report, 2007.
26.
Drool Fusion. Available at: http://www.drools.org/, Accessed: 2016-06-03.
27.
I.Flouris, N.Giatrakos, A.Deligiannakis, M.Garofalakis, M.Kamp and M.Mock, Issues in complex event processing, J. Syst. Softw.127(C) (2017), 217–236. doi:10.1016/j.jss.2016.06.011.
28.
C.L.Forgy, Expert Systems. Chapter Rete: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem, IEEE Computer Society Press, Los Alamitos, CA, USA, 1990, pp. 324–341.
29.
S.Gatziu and K.R.Dittrich, Detecting composite events in active database systems using petri nets, in: Proceedings Fourth International Workshop on Research Issues in Data Engineering, 1994, Active Database Systems, 1994, pp. 2–9. doi:10.1109/RIDE.1994.282859.
30.
S.Gillani, F.Laforest and G.Picard, A generic ontology for prosumer-oriented smart grid, in: EDBT/ICDT Workshops, CEUR Workshop Proceedings, Vol. 1133, 2014, pp. 134–139. Available at: CEUR-WS.org.
31.
S.Gillani, G.Picard and F.Laforest, Spectra: Continuous query processing for rdf graph streams over sliding windows, in: Proceedings of the 28th International Conference on Scientific and Statistical Database Management, SSDBM ’16, ACM, New York, NY, USA, 2016, pp. 17:1–17:12.
32.
S.Gillani, G.Picard and F.Laforest, Continuous graph pattern matching over knowledge graph streams, in: Proceedings of the 10th ACM International Conference on Distributed and Event-Based Systems, DEBS ’16, ACM, New York, NY, USA, 2016, pp. 214–225.
33.
L.Golab and M.T.Özsu, Issues in data stream management, SIGMOD Rec.32(2) (2003), 5–14. doi:10.1145/776985.776986.
34.
T.Heath and C.Bizer, Linked Data: Evolving the Web into a global data space (1st edn), in: Synthesis Lectures on the Semantic Web: Theory and Technology, Morgan and Claypool, 2011.
35.
A.Hogan, M.Arenas, A.Mallea and A.Polleres, Everything you always wanted to know about blank nodes, Web Semantics: Science, Services and Agents on the World Wide Web27–28 (2014), 42–69. Semantic Web Challenge 2013.
36.
J.E.Hopcroft, R.Motwani and J.D.Ullman, Introduction to Automata Theory, Languages, and Computation, 3rd edn, Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 2006.
37.
D.Irwin, E.Cecchet, P.Shenoy, S.Barker, A.Mishra and J.Albrecht, Smart: An open data set and tools for enabling research in sustainable homes, in: Proceedings of the 2012 Workshop on Data Mining Applications in Sustainability (SustKDD 2012), 2012.
38.
I.Kolchinsky, I.Sharfman and A.Schuster, Lazy evaluation methods for detecting complex events, in: Proceedings of the 9th ACM International Conference on Distributed Event-Based Systems, DEBS ’15, ACM, New York, NY, USA, 2015, pp. 34–45. doi:10.1145/2675743.2771832.
39.
S.Komazec, D.Cerri and D.Fensel, Sparkwave: Continuous schema-enhanced pattern matching over rdf data streams, in: Proceedings of the 6th ACM International Conference on Distributed Event-Based Systems, DEBS ’12, ACM, New York, NY, USA, 2012, pp. 58–68. doi:10.1145/2335484.2335491.
40.
D.Le-Phuoc, M.Dao-Tran, J.X.Parreira and M.Hauswirth, A native and adaptive approach for unified processing of linked streams and linked data, in: Proceedings of the 10th International Conference on the Semantic Web – Volume Part I, ISWC’11, Springer-Verlag, Berlin, Heidelberg, 2011, pp. 370–388.
41.
G.Liu, W.Zhu, C.Saunders, F.Gao and Y.Yu, Real-time complex event processing and analytics for smart grid, Procedia Computer Science61(Supplement C) (2015), 113–119. Complex Adaptive Systems San Jose, CA November 2-4, 2015.
42.
D.Luckham, The power of events: An introduction to complex event processing in distributed enterprise systems, in: Rule Representation, Interchange and Reasoning on the Web, Springer, Berlin, Heidelberg, 2008, pp. 3–3. doi:10.1007/978-3-540-88808-6_2.
43.
A.Margara, J.Urbani, F.van Harmelen and H.Bal, Streaming the Web: Reasoning over dynamic data, Web Semantics: Science, Services and Agents on the World Wide Web25 (2014), 24–44.
44.
N.Mehdiyev, J.Krumeich, D.Enke, D.Werth and P.Loos, Determination of rule patterns in complex event processing using machine learning techniques, Procedia Computer Science61(Supplement C) (2015), 395–401. Complex Adaptive Systems San Jose, CA November 2–4, 2015.
45.
Y.Mei and S.Madden, ZStream: A cost-based query processor for adaptively detecting composite events, in: Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, SIGMOD ’09, ACM, New York, NY, USA, 2009, pp. 193–206.
46.
B.Mozafari, K.Zeng, L.D’antoni and C.Zaniolo, High-performance complex event processing over hierarchical data, ACM Trans. Database Syst.38(4) (2013), 21:1–21:39. doi:10.1145/2536779.
47.
B.Mozafari, K.Zeng and C.Zaniolo, From regular expressions to nested words: Unifying languages and query execution for relational and XML sequences, Proc. VLDB Endow.3(1–2) (2010), 150–161.
48.
T.Neumann and G.Weikum, The RDF-3X engine for scalable management of rdf data, The VLDB Journal19(1) (2010), 91–113. doi:10.1007/s00778-009-0165-y.
49.
Ö.L.Özçep, R.Möller and C.Neuenstadt, A stream-temporal query language for ontology based data access, in: KI 2014: Advances in Artificial Intelligence, C.Lutz and M.Thielscher, eds, Springer International Publishing, Cham, 2014, pp. 183–194.
50.
Ö.L.Özcep, V.Thost and J.Holste, On implementing temporal query answering in DL-lite (extended abstract), in: Proceedings of the 28th International Workshop on Description Logics, Athens, Greece, June 7–10, 2015, D.Calvanese and B.Konev, eds, CEUR Workshop Proceedings, Vol. 1350, CEUR-WS.org, 2015.
51.
J.Pérez, M.Arenas and C.Gutierrez, Semantics and complexity of SPARQL, ACM Trans. Database Syst.34(3) (2009), 16:1–16:45.
52.
O.Poppe, C.Lei, S.Ahmed and E.A.Rundensteiner, Complete event trend detection in high-rate event streams, in: Proceedings of the 2017 ACM International Conference on Management of Data, SIGMOD ’17, ACM, New York, NY, USA, 2017, pp. 109–124. doi:10.1145/3035918.3035947.
53.
M.Ray, C.Lei and E.A.Rundensteiner, Scalable pattern sharing on event streams, in: Proceedings of the 2016 International Conference on Management of Data, SIGMOD ’16, ACM, New York, NY, USA, 2016, pp. 495–510. doi:10.1145/2882903.2882947.
54.
M.Sanderson and J.Zobel, Information retrieval system evaluation: Effort, sensitivity, and reliability, in: Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’05, ACM, New York, NY, USA, 2005, pp. 162–169. doi:10.1145/1076034.1076064.
55.
C.Song, T.Ge, C.Chen and J.Wang, Event pattern matching over graph streams, Proc. VLDB Endow.8(4) (2014), 413–424. doi:10.14778/2735496.2735504.
56.
Stock Trace Dataset. Available at: http://davis.wpi.edu/datasets/Stock_Trace_Data/.
R.Tommasini, P.Bonte, E.D.Valle, E.Mannens, F.de Turck and F.Ongenae, Towards Ontology-Based Event Processing, Springer International Publishing, Cham, 2017, pp. 115–127.
59.
E.Wu, Y.Diao and S.Rizvi, High-performance complex event processing over streams, in: Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, SIGMOD ’06, ACM, New York, NY, USA, 2006, pp. 407–418. doi:10.1145/1142473.1142520.
60.
H.Zhang, Y.Diao and N.Immerman, On complexity and optimization of expensive queries in complex event processing, in: Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, SIGMOD ’14, ACM, New York, NY, USA, 2014, pp. 217–228.