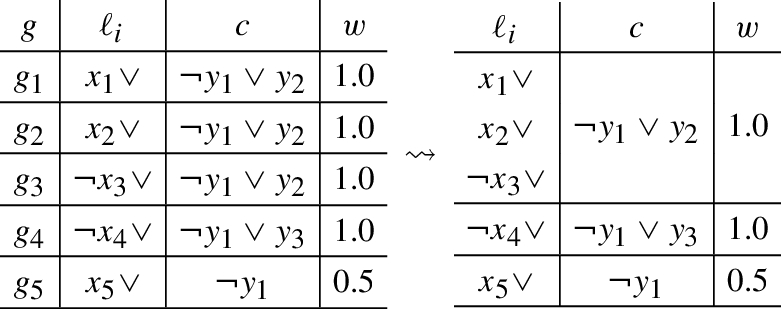We present an infrastructure for probabilistic reasoning with ontologies based on our Markov logic engine RockIt. Markov logic is a template language that combines first-order logic with log-linear graphical models. We show how to translate OWL-EL as well as RDF schema to Markov logic and how to use RockIt for applying MAP inference on the given set of formulas. The resulting system is an infrastructure for log linear logics that can be used for probabilistic reasoning with both extended OWL-EL and RDF schema. We describe our system and illustrate its benefits by presenting experimental results for two types of applications. These are ontology matching and knowledge base verification, with a special focus on temporal reasoning. Moreover, we illustrate two further use cases which are Activity Recognition and Root Cause Analysis. Our infrastructure has been applied to these use cases in the context of a cooperation with industry partners. The experiments indicate that our system, which is based on a well-founded probabilistic semantics, is capable of solving relevant problems as good as or better than state of the art systems that have specifically been designed for the respective problem. Moreover, the heterogeneity of the presented uses cases illustrates the wide applicability of our infrastructure.
Originally, the idea of the Semantic Web was built on formal ontologies and logical reasoning leading to the development of description logic-based ontology languages, in particular the Web Ontology Language OWL. The advantages of logical reasoning on the web has been argued by many researchers in terms of verifying information models and extending query results to implicit information. While in particular, the development of light-weight ontology languages and the use of database techniques for ontology-based data access has given another boost to the use of logical models (e.g. [7]), it has also become more and more clear that logical reasoning alone is not enough for many Semantic Web applications. In particular, use cases that require a combined processing of structured and unstructured data (i.e. free text) can often not be adequately handled by logical methods alone. On the other hand, abandoning logical reasoning and completely relying on machine learning techniques for handling unstructured data seems like throwing out the child with the bathwater. Therefore, research on the (Semantic) Web has focused on methods that combine structured representations with statistical inference. One possible approach is the extension of machine learning methods to complex structural features [11], the other is to extend logical reasoning in Semantic Web languages towards statistical inference. In this paper, we present a software infrastructure that implements the second way – an extension of logical reasoning in Semantic Web languages with statistical inference [32]. In particular, we focus on the task of computing the most probable consistent ontology from a set of possibly inconsistent axioms some of which are not certain and have a weight attached that can be used to resolve inconsistencies given a probabilistic interpretation. This corresponds to the maximum a posteriori (MAP) inference in statistical relational models as opposed to marginal inference, which aims at computing the probability of a certain assertion given evidence in terms of a knowledge base. Our approach is based on an encoding of description logics into Markov logic networks that enables reasoning about description logics that support consequence-driven reasoning.
Related work The extension of web languages towards statistical inference has been addressed by a number of researchers leading to various extensions of the OWL language with notions of probability using different approaches including non-monotonic reasoning, probabilistic logic programming, Bayesian networks and Markov logic. The probabilistic description logic [31] is an expressive description logic that combines conditional probabilities about concepts and statements expressing uncertain knowledge about instances. The logic supports probabilistic knowledge base consistency checking and lexicographic entailment. Both are probabilistic versions of non-monotonic reasoning where consistency can be achieved by preferring more specific assertions over less specific ones and calculating upper and lower bounds for the probabilities of the resulting statements. The corresponding methods have been implemented in the PRONTO system [27]. Riguzzi and others adapt the semantics of probabilistic logic programs as introduced in [12] to description logics defining the DISPONTE approach for probabilistic ontologies. DISPONTE can answer queries over probabilistic ontologies using binary decision diagrams. The corresponding methods have been implemented in the BUNDLE reasoner [5,41]. Both reasoners have been integrated into the Pellet description logic system. DISPONTE clearly aims at computing probabilistic query answers which corresponds to marginal inference rather than MAP inference. PR-OWL [9,10] is a language based on the multi-entity Bayesian network (MEBN) logic [29]. MEBNs specify a first-order language for modeling probabilistic knowledge bases as parametrized fragments of Bayesian networks. PR-OWL adds new elements to the OWL standard which enables to create MEBNs as part of an ontological model and thus supporting probabilistic reasoning, although providing only a limited integration of logical and probabilistic reasoning. Parts of the PR-OWL language were implemented in the tool UNBBAYES-MEBN [8] which provides a GUI and a translation of MEBN to classical Bayesian networks. Based on the translation to Bayesian networks, PR-OWL can in principle compute both MAP and marginal inference. To the best of our knowledge, INCERTO1
https://code.google.com/p/incerto/.
is the only reasoner which uses Markov logic for probabilistic description logics. It directly translates the description logic axioms to Markov logic so that concepts correspond to unary predicates, roles correspond to binary predicates, and individuals to constants. The description logic axioms are translated to first-order logic formulas. The objective of INCERTO is to learn the weights of axioms through the analysis of individuals. Furthermore, they provide exact and approximate marginal inference. However, computing the most probable coherent ontology is not supported. Due to the direct translation of the logical model into Markov logic and the implicit closed world assumption introduced on the Markov logic level, it is unclear whether the system can guarantee complete reasoning with respect to the description logic used.
In this paper, we first provide a comprehensive overview of our Markov logic engine RockIt, which to be best of our knowledge currently is the most performant and scalable Markov logic reasoner with respect to MAP inference. We give a brief introduction to Markov logic as an underlying formalism and explain how RockIt computes the most probable model by an efficient encoding of the problem as a linear integer program (see Section 3). After providing some details about the optimized implementation of RockIt, we introduce the notion of log-linear logics which provides the formal foundation for a sound and complete encoding of description logics and related formalisms into Markov logic, and describe two concrete logics that corresponds to probabilistic versions of OWL-EL and RDFS (see Section 4). We then present successful applications of the approach to relevant Semantic Web problems, in particular knowledge base verification and ontology matching (see Section 5). Furthermore, we demonstrate the impact of the system in two real-world use cases in Section 6. We close with a discussion of the benefits and limitations of our infrastructure in Section 7.
System architecture
We present a software architecture (see Fig. 1) that bundles a series of systems which enable probabilistic reasoning in the context of the Semantic Web. The system is available at http://executor.informatik.uni-mannheim.de/. The core of the presented system is the RockIt Markov logic engine. It is specialized for executing maximum a posteriori (MAP) inference in Markov Logic Networks. For this purpose, it takes advantage of a database (MySQL) and an integer linear program solver (Gurobi) (see Section 3). Based on this core system, we provide interfaces for specific probabilistic reasoning tasks. In particular, the “Semantic Web Interface” supports probabilistic reasoning for OWL-EL and RDFS (see Section 4). The web interface has the purpose to bundle different reasoning interfaces and to make them available in a convenient way, i.e., through a user interface and an API.
Overview of the system architecture.
The reasoners are made available by a web interface that allows executing different tasks. Hence, they can be used without installing them on a local machine which would involve setting up a database management system as well as an integer linear program solver. We offer a web site and REST interfaces to access the services. The web site provides a description, usage examples of the different reasoners and forms to upload files and to initiate the reasoning process. Additionally, the REST interfaces support the most important features and allow developers of other applications to use our services and to integrate them in their systems. As the infrastructure can be accessed by multiple users at the same time, we implemented a waiting line that ensures that the system processes at most one reasoning task at a time. This is necessary as it decreases the chance of overloading but it also makes the runtimes comparable.
The system creates a unique identification key for each added process that can be used to identify a specific process in the process database. For each process we keep track of relevant statistics and useful information. Therefore, we record the time and the date when a process was added to the waiting list, when the execution was started and when it terminated. Moreover, we store the input information which includes the selected reasoning method as well as the chosen parameter settings and input files (see Fig. 2). We also present the console output of the underlying reasoning system during the execution in real-time which helps to keep track of the execution of a process.
View of a terminated process.
The web interface is written in Python and uses the web application framework “Pylons”.2
Its internal architecture allows integrating other (reasoning) system. In fact, it is possible to add any system that is compatible with the Linux distribution Debian.
The RockIt engine
The foundation of our system is the RockIt reasoning engine [37], a state of the art reasoning engine for Markov logic networks. RockIt is specialized on performing maximum a posteriori (MAP) inference. Each MAP query corresponds to an optimization problem with linear constraints and a linear objective function and, hence, RockIt formulates and solves the problem as an instance of integer linear programming (ILP). This is done in several iterations where the novel cutting plane aggregation approach (CPA) is tightly integrated with cutting plane inference (CPI) which is a meta-algorithm operating between the grounding algorithm and the ILP solver [40]. Instead of immediately adding one constraint for each concrete instantiation of a general formula to the ILP formulation, the ILP is initially formulated so as to enforce the given evidence to hold in any solution. Based on the solution of this more compact ILP one determines the violated constraints, adds these to the ILP, and resolves. This process is repeated until no constraints are violated by an intermediate solution. In the following, we provide a brief introduction to Markov logic as well as RockIt’s approach to efficient maximum a posteriori (MAP) inference.
Markov logic
Markov logic is a first-order template language combining first-order logic with log-linear graphical models. We first review function-free first-order logic [16]. Here, a term is either a constant or a variable. An atom consists of a predicate of arity n followed by n terms . A literal ℓ is an atom a or its negation . A clause is a disjunction of literals. The variables in clauses are always assumed to be universally quantified. The Herbrand base is the set of all possible ground (instantiated) atoms. A ground atom is an atom where every variable is replaced by a concrete value. Every subset of the Herbrand base is a Herbrand interpretation.
A Markov logic network is a finite set of pairs , , where each is a clause in function-free first-order logic and [39]. Together with a finite set of constants it defines the ground Markov logic network with one binary variable for each grounding of predicates occurring in and one feature for each grounding of formulas in with feature weight . Hence, a Markov logic network defines a log-linear probability distribution over Herbrand interpretations (possible worlds)
where is the number of satisfied groundings of clause in the possible world x and Z is a normalization constant.
In order to answer a MAP query given evidence , one has to solve the maximization problem
where the maximization is performed over possible worlds (Herbrand interpretations) x compatible with the evidence.
ILP formulation of Markov logic networks
Since we are employing cutting plane inference (CPI), RockIt retrieves in each iteration the ground clauses violated by the current solution. Hence, in each iteration of the algorithm, RockIt maintains a set of ground clauses that have to be translated to an ILP instance. RockIt associates one binary ILP variable with each ground atom ℓ occurring in some . For a ground clause let be the set of ground atoms occurring unnegated in g and be the set of ground atoms occurring negated in g. Now, we encode the given evidence by introducing linear constraints of the form or depending on whether the evidence sets the corresponding ground atom ℓ to false or true. For every ground clause with weight , , we add a novel binary variable and the following constraint to the ILP:
Please note that if any of the ground atoms ℓ in the ground clause is set to false (true) by the given evidence, we do not include it in the linear constraint.
For every g with weight , , we add a novel binary variable and the following constraint to the ILP:
For every g with weight , that is, a hard clause, we add the following linear constraint to the ILP:
Finally, the objective of the ILP is:
where we sum over weighted ground clauses only, is the weight of g, and is the binary variable previously associated with ground clause g. We compute a MAP state by solving the ILP whose solution corresponds one-to-one to a MAP state x where if the corresponding ILP variable is 1 and otherwise.
Constraint aggregation
The ILP defined in the previous section can be simplified by aggregating groups of similar constraints. The resulting ILP has fewer variables, fewer constraints, and its context-specific symmetries are more exposed to the ILP solver’s symmetry detection heuristics. We present the general idea implemented in RockIt and illustrate it by an example. Formal details can be found in [37].
First we define which subsets G of can be aggregated to a single constraint.
Letbe a set of n weighted ground clauses and let c be a ground clause. We say that G can be aggregated with respect to c if (a) all ground clauses in G have the same weight and (b) for every,, we have thatwhereis a (unnegated or negated) literal for each i,.
A set of ground clauses that can be aggregated
Table 1 illustrates an example. The subset can be aggregated with respect to , while and can be aggregated only as singleton sets, which does not yield in an advantage over the standard way of generating the ILP. The standard way of translating , and , ignoring the possibility of an aggregation, would result into the following ILP.
Note that , , and are binary variables within this ILP. By using instead of that a single integer variable z, all ground clauses in G can be taken into account as a whole within the following ILP.
This translation follows a general pattern for positive weights and a similar pattern for negative weights. As a result of this simplification the number of constraints can be reduced significantly resulting in a notably improved runtime behavior of the system. The general approach is called cutting plane aggregation (CPA).
RockIt parallelizes constraint finding, constraint aggregation, and ILP solving.
Implementation
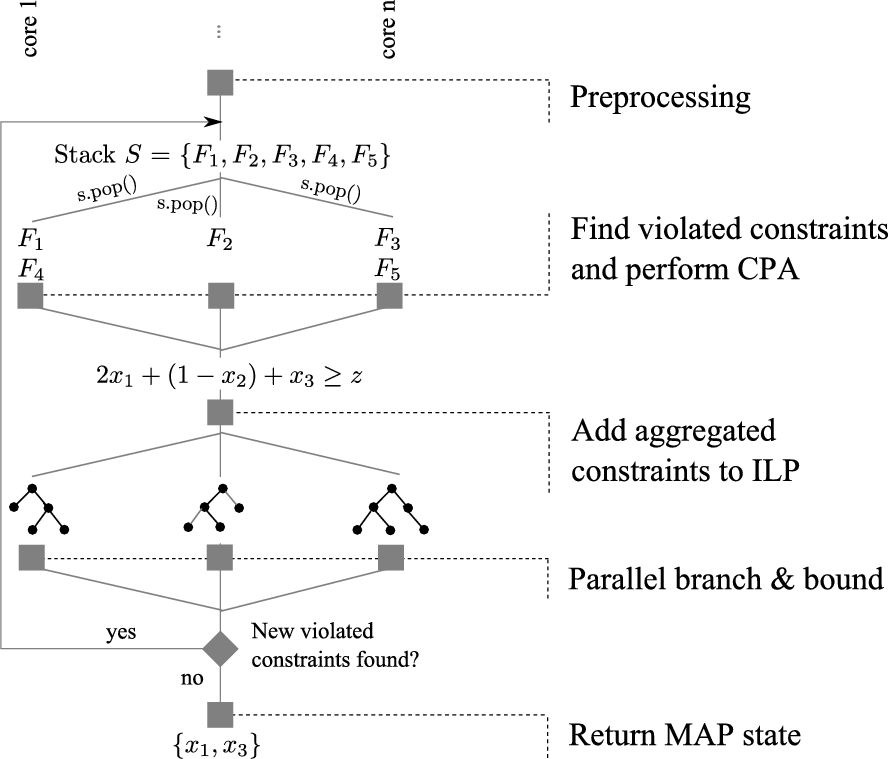
Figure 3 depicts the computational pipeline of the system. After pre-processing the input MLN and loading it into the relational database system, RockIt performs CPI iterations until no new violated constraints are found. The violated constraints are computed with joins in the relational database system where each table stores the predicate groundings of the intermediate solutions. In each CPI iteration, RockIt performs CPA on the violated constraints. We can parallelize the aggregation steps by processing each first-order formula in a separate thread. To this end, each first-order formula is initially placed on a stack S. RockIt creates one thread per available core and, when idle, makes each of the threads (i) pop a first-order formula from the stack S, (ii) compute the formula’s violated groundings, and (iii) perform CPA on these groundings. The aggregated groundings are compiled into ILP constraints and added to the ILP formulation. When the stack S is empty and all threads idle we solve the current ILP in parallel, obtain a solution, and begin the next CPI iteration.
There are different possible strategies for finding the ground clauses c that minimize the number of counting constraints per first-order formula which is required for CPA. This problem can be solved optimally, however, we implemented a greedy algorithm that only estimates the optimal aggregation scheme, since experiments showed that optimal algorithms dominate the ILP solving itself. The algorithm stores, for each first-order clause, the violated groundings of the form in a table with n columns where each column represents one literal position of the clause. For each column k, RockIt computes the set of distinct rows of the table that results from the projection onto the columns . Let . The clause groundings are then aggregated with respect to the rows in .
RockIt employs MySQL’s in-memory tables for the computation of violated constraints and the aggregation. Most tables are hash indexed to facilitate highly efficient join processing. We use Gurobi3
http://www.gurobi.com/.
as RockIt’s internal ILP solver due to its ability to parallelize its branch, bound, and cut algorithm, its remarkable performance on standard ILP benchmarks [28], and its symmetry detection heuristics.
We have tested the efficiency of RockIt and compared it against other state of the art Markov Logic solvers on several benchmarks. These benchmarks stem from different applications like Entity Resolution, Information Extraction and Protein Interaction. The Protein Interaction dataset, which is the largest dataset, has 40,234,321 ground clauses. In most testcases RockIt was able to generate the correct results in a few seconds. For the Protein Interaction dataset RockIt required 13 seconds, while the other systems were 30 times slower or failed completely to generate any results. The details of this evaluation are available in Section 6 in [36].
The Semantic Web interface
The RockIt system introduced in the previous section is a generic Markov logic engine that does not directly target languages relevant for the Semantic Web community. In this section we show how Semantic Web languages, in particular description logics and RDF Schema based formalisms, can be transformed to Markov logic while preserving their original semantics. This translation approach, to which we refer as log-linear logics, makes the power of the RockIt system available for Semantic Web applications.
Log-linear logics
Log-linear (description) logics have been introduced by Niepert and others as a framework for encoding non-trivial logics into probabilistic reasoning using the notion of log-linear models [35]. A log-linear logic knowledge base consists of a deterministic knowledge base and an uncertain knowledge base . contains axioms in some logic that supports a valid entailment relation and notion of contradiction . The uncertain knowledge base is defined as where c is also an axiom in and is a real-valued weight assigned to c. represents definite knowledge about the world, whereas contains axioms for which only a degree of confidence is available. The certain knowledge base is assumed to be non-contradictory, i.e. . The semantics of a log-linear logic is based on joint probability distributions over the uncertain knowledge base. In particular, the weights of the axioms in determine a log-linear probability distribution in a similar way as it is the case for Markov logic models introduced earlier.
For a given log-linear knowledge base and some (certain) knowledge base over the same signature, the probability of is defined as
where Z is the normalization constant of the log-linear probability distribution P.
The notion of a log-linear logic provides a means for interfacing Semantic Web languages with the RockIt engine in the following way:
We define a Markov logic predicate for each type of axiom supported by the language. For this purpose, the axioms in the knowledge base typically have to be normalized in an appropriate way.
We encode the entailment relation using Markov logic rules over the predicates representing the different axiom types.
We define the notion of contradiction by adding a set of first order rules that results into an inconsistent set of first-order formulas whenever, with respect to the semantics of , a logically undesired behavior occurs.
This approach naturally limits the applicability of the framework to languages that can be normalized to a finite set of axiom types and whose entailment relation can be modeled using Markov logic rules. In Semantic Web research such languages have been studied in connection with the notion of consequence-driven reasoning [26], providing us with a set of possible languages we can extend towards probabilistic reasoning. In the following, we discuss two of these languages that we have implemented in our infrastructure.
The OWL-EL interface
Computing the MAP state for a log-linear knowledge base that contains OWL-EL axioms requires first to map the different axioms to a first-order representation. As it has been shown that any OWL-EL knowledge-base can be normalized into an equivalent knowledge base that only contains 6 types of axioms, we can map it into Markov logic predicates using the following set of mapping rules.
The first-order predicates in this listing are typed, meaning that r, s, , , are role names, , basic concept descriptions, and D basic concept descriptions or the bottom concept. Note that axioms involving complex concept descriptions can be transformed into a normalized representation by applying a finite set of normalization rules introducing new concept and role names [3].
The translation of and results in unweighted (hard) and weighted first order formulas. The hard formulas are used, together with the completion rules described in the following paragraph, to decide whether for a potential MAP state we have and . To our knowledge there exists no commonly accepted proposal related to adding weights or probabilities to OWL axioms. In our implementation we are using annotation properties to add weights to axioms.
The completion rules of the formalism, in this case OWL-EL, which corresponds to the description logics , are listed in Table 2. By adding these rules as constraints to the Markov logic formalization, we are able to support complete reasoning mechanisms for , i.e., we re-define by adding the respective reasoning rules as first-order formulas in our Markov logic formalization. Given a concrete reasoning problem, the resulting MAP state will always contain the most probably non contradictory subset of that entails the previously known axioms .
Completion rules for OWL-EL
Note that rule does not belong to the completion rules for . This rule takes the notion of incoherence into account. An incoherent ontology is an ontology that contains an unsatisfiable concept, i.e., a concept that is subsumed by ⊥. Usually, an unsatisfiable concept indicates that the ontology contains a contradictory set of axioms. An incoherent ontology is not necessarily inconsistent, Thus, we added rule which allows us to extend the notion of contradiction from inconsistency to incoherence.
For more technical details on applying the principle of log-linear logic to OWL-EL, we refer the reader to [35]. The reasoner that we have implemented following the described approach is called ELog.4
While the OWL-EL interface was mainly designed for terminological reasoning, the focus of the RDFS interface is rather on reasoning tasks related to the A-Box. A RDF [20] knowledge base contains statements of the form . Such statements can be seen as the only axiom type present in an RDF Schema knowledge base. Thus, we only need to define one general first-order logic predicate to which all RDF statements can be transformed:
We decided to use this modeling as it is flexible and covers all possible RDF statements. In order to attach weights to RDF statements, we rely in our implementation on the concept of reification and annotation properties. Our system relies on the RDF(S) entailment rules [6] as a standard rule set. Using the predicate , we define the entailment relation by mapping the RDF(S) entailment rules to first-order formulas. For instance, we state the rule rdfs11 which expresses the transitivity of the property rdfs:subclassOf as follows:
We define formulas for the other RDF(S) completion rules in the same way. Moreover, it is possible to extend the basic set of completion rules by defining additional rules and constraints in order to cover a wide range of application scenarios. In particular, pure RDF Schema reasoning does not have a notion of contradiction. We therefore introduce notions of contradiction by adding special rules. For example, if one might want the reasoner to cover the semantics of the property owl:disjointWith, the rule set can be extended:
This is only one of the required rules to cover the semantics of owl:disjointWith. Our formalism can be extended by such rules depending on the requirements of a specific use case. By executing the MAP inference, the reasoner determines for each potential MAP state if and holds. Thereby, the system resolves not only the detected inconsistencies but is also able to infer new facts. Hence, the MAP state corresponds to the most probable consistent subset of facts and all assertions that can be entailed from that subset.
We adapted our reasoning system to the special case of probabilistic temporal reasoning. Additionally to adding weights to RDF statements, it is possible to assign a temporal interval, which consists of a start point and end point, resulting in statements of the form . The interval expresses the validity time of a fact [18,19]. Considering the temporal relations of events, it is possible to extend the set of constraints in order to detect inconsistencies. For this purpose, the reasoning system incorporates the temporal predicates (e.g. before, during, …) of Allen’s interval algebra [1] that can be used to express such constraints. The proposed approach is implemented by the reasoner T-RDFS-Log.5
In [38] we have applied the OWL-EL interface to improve automatically generated ontology alignments, while in [23] we have shown how to use the methods available via the RDF schema interface to debug a probabilistic temporal knowledge base. Within the following two sections we summarize these applications and the experimental results to illustrate the general applicability of our framework.
Ontology matching
Ontology matching is concerned with the task of constructing an alignment between two ontologies and . An alignment is a set of mappings usually interpreted as equivalence axioms between concepts and properties of and . Most matching systems annotate mappings with a confidence value that expresses the trust in the correctness of the generated mapping. Thus, we have a perfect setting for applying ELog: The alignment can be interpreted as a set of uncertain, weighted equivalence axioms , while comprises the certain axioms .
Some of the concepts in or might become unsatisfiable due to the axioms of . is called an incoherent alignment if this happens. The following is an example for an incoherent alignment.
In this example the concepts and are unsatisfiable in the merged ontology. There are several possible ways to resolve this incoherence by removing different subsets from . Applying the formalism introduced in Section 4.2 results in computing the coherent subset as MAP state. The alignment is thus the must probable alignment given the information available in and .
Several systems and algorithms have been developed to deal with the problem of debugging incoherent alignments. We present experiments comparing our generic approach to two of these system which are LogMap [25] and Alcomo [34]. LogMap is a matching system that consists beside other components of an algorithm for generating (nearly) coherent alignments. Alcomo is a system that has specifically been developed for the purpose of debugging ontology alignments. It can be used with different settings that differ with respect to completeness and runtime efficiency.
We have used the testcases of the well known OAEI conference track together with the alignments submitted by the OAEI 2013 participants [17]. We merged these alignments (details can be found in [38]) and conducted experiments for different thresholds. For low thresholds the input alignments were large and highly incoherent while high thresholds resulted in precise and small input alignments. We applied our generic approach as well as LogMap and Alcomo (in two settings) to these alignments. The results of our experiments are depicted in Fig. 4.
Mapping quality and runtime for different debugging approaches.
On the left side of the figure we have shown the F-measure of the debugged alignments for different input thresholds. ELog achieves for all thresholds the best f-measure. In some cases the results of the other systems are similar, however, ELog outperforms the other systems with respect to the threshold range that results into the best f-measure. Only Alcomo (optimal setting) can achieve the same result in one case. ELog can debug the given alignments in acceptable time (see right side of the figure), however, Alcomo (greedy setting) and LogMap are significantly faster for large input alignments. This is mainly related to the fact that both systems do not solve the underlying optimization problem, but generate an approximate solution by applying a greedy algorithm. This explains also why both algorithms generate results that are slightly worse compared to the results of ELog. Only Alcomo in the optimal setting, using a search tree to find the optimal solution, is an exception. However, Alcomo (optimal setting) does not terminate for larger testcases. More details related to the scalability of our approach can be found in [36]. We conclude that our generic approach can be applied successfully to the problem of alignment debugging and, even more, outperforms existing systems that have specifically been designed for the given problem.
Knowledge base verification
Knowledge base verification is concerned with the task of identifying erroneous statements in a knowledge base. In the context of a probabilistic knowledge base, this scenario is essentially an optimization problem. This means that a reasoner must identify the most probable consistent subset of facts given a set of constraints. This corresponds to the computation of the MAP state. The following example illustrates a inconsistent knowledge base :
For this knowledge base, we define the following constraint set :
Given the constraint set , it is possible to detect inconsistencies in . causes a clash between the facts and while causes a clash between the facts and . Hence, has to be removed in order to obtain a consistent knowledge base despite having the highest weight of all facts.
Different approaches have been proposed to solve such problems. In [2,4] OWL 2.0 is extended in order to enable temporal reasoning for supporting temporal queries. The authors define SWRL rules that are compatible with a reasoner that supports DL-safe rules in order to detect inconsistencies. However, their system can only detect if a knowledge base is consistent but cannot resolve the existing conflicts. [13,14,45] proposed different approaches to resolve temporal conflicts at query time. In particular, they define temporal constraint as Datalog rules. However, these approaches do not incorporate terminological knowledge while resolving the conflicts and do also not support weighted constraints.
Contrary to this, our reasoner T-RDFS-Log (see Section 4.3) is well-suited for verifying probabilistic temporal knowledge bases as it allows extending a standard rule set, i.e., the RDFS entailment rules, by defining domain-specific constraints. Hence, it is a flexible system that can be adapted to many domains. Based on rules and constraints, the reasoner is able to cleanse a knowledge base by removing the statements that do not belong to the MAP state.
In [23] we have evaluated this application scenario in an artificial setting that is based on DBPedia [30] data. Therefore, we extracted over 150k facts (RDF triples) describing entities of the domain of academics. For this domain, we define a set of specific constraints that are used to detect and to resolve inconsistencies in the knowledge base. We also generate erroneous facts and add them to the knowledge base in order to investigate the influence of the percentage of wrong statements in the knowledge base on the precision of our application. Hence, we create multiple datasets whose recall is 1.0 while its precision depends on the number of added statements. In order to obtain a probabilistic knowledge base, we assign to all statements a random weight in the range from 0.0 to 1.0. The results of the experiments indicate that our approach is able to remove erroneous statements with a high precision. Table 3 shows that the F-measure of the knowledge base increases independently of the share of added erroneous statements which is depicted in the column . The precision of the debugging process is ≈80% while the recall is ≈65% which means the at least 4 out of 5 are proper removals while more than half of the wrong statements get detected and removed.
Precision (P), Recall (R) and F-measure (F) for the repaired dataset. We apply the RDFS reasoner to the input datasets that contain different fractions of erroneous statements. The reasoner removes those statements with a high precision as the loss of recall is reasonable with respect to the gain of precision
Input
Repaired Dataset
ΔF
P
P
R
F
0.99
1.00
1.00
1.00
0.002
0.91
0.97
0.98
0.97
0.022
0.80
0.92
0.96
0.94
0.050
0.67
0.84
0.93
0.88
0.084
0.57
0.78
0.90
0.83
0.106
0.50
0.72
0.87
0.79
0.119
With respect to the runtime, we measured that it takes ≈7 minutes for the initial dataset (150k facts, precision = 1.0) and minutes for the largest extended dataset (300k facts, precision = 0.5) to determine the consistent subset. We executed our experiments on a virtual machine running Ubuntu 12.04 that has access to two threads of the CPU (2.4 GHz) and 16 GB RAM. Hence, T-RDFS-Log is capable to verify knowledge bases by exploiting terminological knowledge and temporal relations of events.
Impact
By presenting the applications and experiments of the previous sections we illustrated the benefits of our infrastructure in the context of data integration problems. Our infrastructure has been applied in two further scenarios that require the combination of an ontological representations and efficient probabilistic reasoning. These two tasks are activity recognition and root cause analysis. We give a brief summary in the following two sections.
Activity recognition
In [21,22] Helaoui et al. identified the acquisition and modeling of rich and heterogeneous context data as a major challenge of ubiquitous computing. This includes also the identification of ongoing human activities at different degrees of granularity. To tackle the challenge of identifying activities at different levels (from atomic gestures over manipulative gestures and simple activities up to complex activities) the authors use log-linear description logics (DLs) in a multilevel activity recognition framework.
The approach was applied to a real-life dataset collected in highly rich networked sensor environment. This dataset is part of the EU research project Activity and Context Recognition with Opportunistic Sensor Configuration. In a smart room simulating a studio flat, a total of 72 sensors with 10 modalities are deployed in 15 wireless and wired networked sensor systems in the environment [33]. Several users participated in a naturalistic collection process of a morning routine.
Core activities and their dependencies as shown in [22].
Obviously the sensor data gathered are closely related to the manipulative gestures (e.g. Open Fridge or Fetch Salami), while it is hard to derive complex activities (e.g., Clean Up or Sandwich Time). For that reason Helaoui et al. defined a probabilistic ontology do describe the inter-dependencies between the activities and other relevant context features in the appropriate way. Some of the core elements of this ontology are shown in Fig. 5. The following two weighted axioms are examples from this ontology.
The second axiom, e.g., says that FetchMilk is an activity that is a manipulative gesture performed by an actor who performs (at the same time) the atomic gesture MoveMilk. Note that MoveMilk, in turn, is defined via the measurement of sensor data that might be related to the movement of the milk carton. With the help of the whole ontology it is thus possible to derive also higher level activities from given sensor data. The simultaneity of the activities is implicitly taken into account by reasoning over time windows. Note that many of these axioms are weighted ( and are the weights in our example), which means the these axioms will be contained in . The weights can be specified by domain experts or can be learned from training data. Our infrastructure does not yet contain a learning component as official core component. For that reason Helaoui et al. added the weight manually based on expert judgments.
With this application of our infrastructure to activity recognition, which was motivated by a cooperation with an industry partner, Helaoui et al. proposed a tightly-coupled hybrid system for human activity recognition that unites both symbolic and probabilistic reasoning. The experimental results validate the viability of this approach to address multilevel activities for user independent scenarios. Depending on the granularity level of the activities a F-measure between 70% and 90% has been achieved. The benefits of the proposed approach are manifold. Unlike the majority of related works, it supports the inherent uncertain nature of human activities without sacrificing the advantages of ontological modeling and reasoning. These advantages include the ability of integrating rich background knowledge and the simultaneous recognition of coarse and fine-grained activities. The use of a standard description formalism enhances the portability and reusability of the proposed system, and supports the representation of heterogeneous and uncertain context data.
Risk assessment and root cause analysis
Risk Assessment and Root Cause Analysis are two important aspects of IT management in modern infrastructures. Risk Assessment identifies the impact of potential threats (e.g. power failure, or hacker attack), whereas Root Cause Analysis finds the underlying source of the observed symptoms of a problem (e.g. failing e-mail deliveries, inaccessible websites, or unresponsive accounting systems). Today’s IT infrastructures are getting increasingly complex with diverse explicit and implicit dependencies. A high availability and short response times to failures are crucial [24]. Therefore, identifying the impact of a threat or the source of a failure or outage as fast as possible is important to achieve a high service level [15].
In the context of an industry project we integrated our system as a module in an application for IT infrastructure management. Therein a general ontology for IT infrastructure captures the dependencies between components and threats affecting them. An example for such a dependency graph is depicted in Fig. 6 which shows an Email service relying on two redundant servers, each connected to its own router, and an access point providing WiFi, depending on one of those routers. Using an ontology to model IT infrastructure and risk for example has the benefit of easily defining threats that are common for types of components, e.g. mean time between failure (MTBF) for a specific brand of hard disks.
Example for a small dependency network. Solid arrows indicate specific dependencies, dashed arrows symbolize generic dependencies and the dotted line represents a redundancy.
In [43,44] it was demonstrated how the system can be used to assess the general impact of a threat on the availability of components. After adding threats to the modeled dependency graph, the user can run an inference step that propagates the impact of all threats through all dependencies and calculates availability for every single component. In an extension, the MLN is also used to check the modeled infrastructure for inconsistencies. For example threats like “fire” can be categorized to have a local influence and thus if one component is affected by it, all components in its vicinity should also be checked for it.
Furthermore, we proposed and implemented an approach for root cause analysis in [42]. The approach extends the MLN with generic rules for abductive reasoning, which is not inherently supported by the standard inference for MLN. Abduction aims to find an explanation for a given observation in the light of some background knowledge, i.e. an ontology in our case. In root cause analysis, the explanation corresponds to the root cause (it will be a component that is offline or an active threat in the MAP state), the observation of the failure of a component, and the background knowledge of the dependency graph extended by potential risks. The dependency graph is encoded in , while risks and their probabilities are encoded in . Observations are added as deterministic facts to .
We developed a dialog-based system, using our infrastructure as reasoning component, which supports a sequence of interactions between our system and an administrative user (Fig. 7). Note that a fully automatic workflow would be desirable, however, not every information can be retrieved directly and sometimes manual investigation of log files or on the status of components is necessary.
Process flow for our approach on root cause analysis. Rectangles denote automated processes. Trapezoids require manual interaction by an administrative user.
In its normal state, without any hard evidence about availabilities or unavailabilities, all components are assumed to be available. Thus, when calculating the MAP state, it contains all components as available. When a problem occurs the user is required to provide observations as evidence for the MLN (1). These observations include any certain information about available and unavailable components. For example, the user can enter that printing over the network is not possible, although the network is functional as browsing the internet still works. This results in hard evidence for the printing service being unavailable and network services and hardware required for internet access being available.
Our approach extends the Markov Logic Network with the new evidence (2) and uses RockIt to run inference on it (3). The calculated state contains the evidence provided by the user (this must be always fulfilled), components being unavailable due to a direct or indirect dependency on components observed as not available, and (at least) one root cause that explains the unavailabilities. Components which are not affected by specified observations or the calculated root cause are listed as available.
The application was evaluated in multiple business use cases and proven to generate valuable insights about the infrastructure in general and the nature of incidents. It proved to be especially useful when the reasons for the failure are not obvious to the administrator that is in charge of resolving the problem. Thus, the applications is most beneficial in IT infrastructures, where competences are scattered over the members of different organizational units.
Conclusions
We presented an infrastructure for probabilistic reasoning about Semantic Web data. The infrastructure is based on the state of the art Markov logic engine RockIt that supports very efficient MAP inference. We presented the RockIt system and showed how the concept of log-linear logics can be used to translate Semantic Web data into Markov logic and use RockIt to solve relevant problems on the web. We also demonstrated the benefits of specific probabilistic extensions of Semantic Web languages. In particular a temporal extension of RDFS as well as the EL fragment of the Web Ontology language for verifying extracted information from the web and for matching heterogeneous web ontologies. The reasoning infrastructure presented is available for download6
https://code.google.com/p/rockit/.
and can also be accessed through a web interface that we provide for testing and smaller reasoning problems.7
http://executor.informatik.uni-mannheim.de/.
We have already used the infrastructure for the experiments described in the paper. Moreover, we also presented two further uses cases illustrating the impact and the wide applicability of our infrastructure. However, there is still a lot of potential for improving the system. First of all, we have only experimented with a restricted set of logical languages that do not fully exploit all possibilities of the concept of log-linear logics. There is a need for a more systematic investigation of the concept of log-linear logics and their possible use in the context of Semantic Web applications and beyond.
So far, our infrastructure only provides efficient reasoning support for MAP inference. Other important problems, in particular marginal inference and weight learning are only supported to a limited extent. While MAP inference can be used to solve a number of important problems, the restriction to this particular kind of reasoning limits the applicability of the infrastructure. In particular, there is a lack of support for answering probabilistic queries over Semantic Web data. We will address these limitations in future work.
References
1.
J.F.Allen, Maintaining knowledge about temporal intervals, Communications of the ACM, P.J.Denning, ed., 26 (November 1983), 832–843, ACM, New York, NY, USA. doi:10.1145/182.358434.
2.
E.Anagnostopoulos, S.Batsakis and E.G.M.Petrakis, CHRONOS: A reasoning engine for qualitative temporal information in OWL, Procedia Computer Science, J.Watada, L.C.Jain, R.J.Howlett, N.Mukai and K.Asakura, eds, 22 (2013), 70–77, Elsevier, Philadelphia, Pennsylvania, USA. doi:10.1016/j.procs.2013.09.082.
3.
F.Baader, S.Brandt and C.Lutz, Pushing the EL envelope, in: Proc. of the 19th International Joint Conference on Artificial Intelligence (IJCAI), L.P.Kaelbling and A.Saffiotti, eds, Morgan Kaufmann, Palo Alto, CA, USA, 2005, pp. 364–369, http://www.ijcai.org/papers/0372.pdf.
4.
S.Batsakis, K.Stravoskoufos and E.G.M.Petrakis, Temporal reasoning for supporting temporal queries in OWL 2.0, in: Knowledge-Based and Intelligent Information and Engineering Systems, A.König, A.Dengel, K.Hinkelmann, K.Kise, R.J.Howlett and L.C.Jain, eds, Lecture Notes in Computer Science, Vol. 6881, Springer, Berlin, Heidelberg, Germany, 2011, pp. 558–567, ISBN 978-3-642-23850-5. doi:10.1007/978-3-642-23851-2_57.
5.
E.Bellodi, E.Lamma, F.Riguzzi and S.Albani, A distribution semantics for probabilistic ontologies, in: Proc. of the 7th International Workshop on Uncertainty Reasoning for the Semantic Web (URSW 2011), F.Bobillo, R.Carvalho, P.C.G.da Costa, C.d’Amato, N.Fanizzi, K.B.Laskey, K.J.Laskey, T.Lukasiewicz, T.Martin, M.Nickles and M.Pool, eds, CEUR Workshop Proceedings, Vol. 778, RWTH Aachen, Germany, 2011, pp. 75–86, urn:nbn:de:0074-778-5.
6.
D.Brickley and R.Guha, RDF vocabulary description language 1.0: RDF schema, W3C, February 2004, http://www.w3.org/TR/2004/REC-rdf-schema-20040210/.
7.
D.Calvanese, G.De Giacomo, D.Lembo, M.Lenzerini, A.Poggi, M.Rodriguez-Muro and R.Rosati, Ontologies and databases: The DL-Lite approach, in: Reasoning Web, Semantic Technologies for Information Systems, S.Tessaris, E.Franconi, T.Eiter, C.Gutierrez, S.Handschuh, M.-C.Rousset and R.A.Schmidt, eds, Lecture Notes in Computer Science, Vol. 5689, Springer, Berlin, Heidelberg, Germany, 2009, pp. 255–356, ISBN 978-3-642-03753-5. doi:10.1007/978-3-642-03754-2_7.
8.
P.Cesar, G.da Costa, M.Ladeira, R.N.Carvalho, K.B.Laskey, L.L.Santos and S.Matsumoto, A first-order Bayesian tool for probabilistic ontologies, in: Proc. of the Twenty-First International Florida Artificial Intelligence Research Society Conference, Palo Alto, California, USA, D.C.Wilson and H.C.Lane, eds, AAAI Press, Palo Alto, CA, USA, 2008, pp. 631–636.
9.
P.Cesar, G.da Costa and K.B.Laskey, PR-OWL: A framework for probabilistic ontologies, in: Proc. of the 2006 Conference on Formal Ontology in Information Systems: Proceedings of the Fourth International Conference (FOIS 2006), B.Bennett and C.Fellbaum, eds, Frontiers in Artificial Intelligence and Applications, Vol. 150, IOS Press, Amsterdam, The Netherlands, 2006, pp. 237–249, ISBN 1-58603-685-8, http://dl.acm.org/citation.cfm?id=1566079.1566107.
10.
P.C.G.Costa, Bayesian semantics for the Semantic Web, PhD thesis, School of Science, George Mason University, Fairfax County, Virginia, USA, 2005.
11.
C.d’Amato, N.Fanizzi, M.Grobelnik, A.Lawrynowicz and V.Svatek, Inductive reasoning and machine learning for the Semantic Web, Semantic Web Journal, C.d’Amato, ed., 5 (2014), 3–4, IOS Press, Amsterdam, The Netherlands. doi:10.3233/SW-130103.
12.
L.De Raedt, A.Kimmig and H.Toivonen, ProbLog: A probabilistic prolog and its application in link discovery, in: Proc. of the 20th International Joint Conference on Artificial Intelligence IJCAI 2007, AAAI Press, Palo Alto, CA, USA, 2007, pp. 2462–2467, www.ijcai.org/papers07/Papers/IJCAI07-397.pdf.
13.
M.Dylla, I.Miliaraki and M.Theobald, A temporal-probabilistic database model for information extraction, in: Proc. of the VLDB Endowment, C.Koch and M.Böhlen, eds, Vol. 6, ACM, New York, USA, 2013, pp. 1810–1821. doi:10.14778/2556549.2556564.
14.
M.Dylla, M.Sozio and M.Theobald, Resolving temporal conflicts in inconsistent rdf knowledge bases, in: 14. GI-Fachtagung Datenbanksysteme für Business, Technologie und Web (BTW 2011), T.Härder, W.Lehner, B.Mitschang, H.Schöning and H.Schwarz, eds, Lecture Notes in Informatics, Vol. 180, Bonner Köllen Verlag, Bonn, Germany, 2011, pp. 474–493, http://dbis.eprints.uni-ulm.de/1227/.
15.
Ernst & Young, Managing IT risk in a fast-changing environment, Technical report, Ernst & Young, 2013, http://www.ey.com/Publication/vwLUAssets/Managing_IT_risk_in_a_fast_changing_environment/$FILE/IT_Risk_Management_Survey.pdf.
16.
M.R.Genesereth and N.J.Nilsson, Logical Foundations of Artificial Intelligence, Morgan Kaufmann, Palo Alto, CA, USA, 1988, ISBN 978-0-934613-31-6.
17.
B.C.Grau, Z.Dragisic, K.Eckert, J.Euzenat, A.Ferrara, R.Granada, V.Ivanova, E.Jiménez-Ruiz, A.O.Kempf, P.Lambrix, A.Nikolov, H.Paulheim, D.Ritze, F.Scharffe, P.Shvaiko, C.T.dos Santos and O.Zamazal, Results of the ontology alignment evaluation initiative 2013, in: Proc. of the 8th International Workshop on Ontology Matching, P.Shvaiko, J.Euzenat, K.Srinivas, M.Mao and E.Jiménez-Ruiz, eds, RWTH Aachen, Germany, 2013, pp. 61–100.
18.
C.Gutierrez, C.Hurtado and A.Vaisman, Temporal RDF, in: The Semantic Web: Research and Applications, J.E.A.Gómez-Pérez, ed., Lecture Notes in Computer Science, Vol. 3532, Springer, Berlin, Heidelberg, Germany, 2005, pp. 93–107, ISBN 978-3-540-26124-7. doi:10.1007/11431053_7.
19.
C.Gutierrez, C.A.Hurtado and A.Vaisman, Introducing time into RDF, in: IEEE Transactions on Knowledge and Data Engineering, X.Wu and C.Faloutsos, eds, Vol. 19, IEEE Computer Society, New York, NY, USA, 2007, pp. 207–218. doi:10.1109/TKDE.2007.34.
R.Helaoui, D.Riboni, M.Niepert, C.Bettini and H.Stuckenschmidt, Towards activity recognition using probabilistic description logics, in: Activity Context Representation: Techniques and Languages, AAAI Technical Report WS-12-05, Vol. 12, AAAI Workshops, Toronto, Canada, 2012, pp. 26–31.
22.
R.Helaoui, D.Riboni and H.Stuckenschmidt, A probabilistic ontological framework for the recognition of multilevel human activities, in: Proc. of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, UbiComp’13, F.Mattern, S.Santini, J.F.Canny, M.Langheinrich and J.Rekimoto, eds, ACM, New York, NY, USA, 2013, pp. 345–354, ISBN 978-1-4503-1770-2. doi:10.1145/2493432.2493501.
23.
J.Huber, C.Meilicke and H.Stuckenschmidt, Applying Markov logic for debugging probabilistic temporal knowledge bases, in: Proc. of the 4th Workshop on Automated Knowledge Base Construction (AKBC), ACM, New York, NY, USA, 2014.
24.
IBM X-Force, Mid-year trend and risk report, 2013, Technical report, IBM X-Force, 2013.
25.
E.Jiménez-Ruiz and B.C.Grau, Logmap: Logic-based and scalable ontology matching, in: The Semantic Web – ISWC 2011, L.Aroyo, C.Welty, H.Alani, J.Taylor, A.Bernstein, L.Kagal, N.Noy and E.Blomqvist, eds, Lecture Notes in Computer Science, Vol. 7031, Springer, Heidelberg, Dordrecht, London, New York, 2011, pp. 273–288. doi:10.1007/978-3-642-25073-6.
26.
Y.Kazakov, Consequence-driven reasoning for horn SHIQ ontologies, in: Proc. of the 21st International Joint Conference on Artificial Intelligence, IJCAI 2009, Pasadena, California, USA, AAAI Press, Palo Alto, CA, USA, 2009, pp. 2040–2045.
27.
P.Klinov, Practical reasoning in probabilistic description logic, PhD thesis, School of Computer Science, The University of Manchester, Manchester, UK, 2011.
T.Lukasiewicz and U.Straccia, Managing uncertainty and vagueness in description logics for the Semantic Web, Web Semantics: Science, Services and Agents on the World Wide Web6 (2008), 291–308, Elsevier, Amsterdam, The Netherlands. doi:10.1016/j.websem.2008.04.001.
33.
P.Lukowicz, G.Pirkl, D.Bannach, F.Wagner, A.Calatroni, K.Förster, T.Holleczek, M.Rossi, D.Roggen, G.Trösteret al., Recording a complex, multi modal activity data set for context recognition, in: 23rd International Conference on Architecture of Computing Systems (ARCS), IEEE, 2010, pp. 1–6.
34.
C.Meilicke, Alignment incoherence in ontology matching, PhD thesis, School of Business Informatics and Mathematics, University of Mannheim, Germany, 2011.
35.
M.Niepert, J.Noessner and H.Stuckenschmidt, Log-linear description logics, in: Proc. of the Twenty-Second International Joint Conference on Artificial Intelligence (IJCAI 11), Barcelona, Spain, T.Walsh, ed., AAAI Press, Menlo Park, CA, USA, 2011, pp. 2153–2158. doi:10.5591/978-1-57735-516-8/IJCAI11-359.
36.
J.Noessner, Efficient maximum a-posteriori inference in Markov logic and application in description logics, PhD thesis, School of Business Informatics and Mathematics, University of Mannheim, Germany, 2014.
37.
J.Noessner, M.Niepert and H.Stuckenschmidt, Rockit: Exploiting parallelism and symmetry for map inference in statistical relational models, in: Proc. of the 27th Conference on Artificial Intelligence (AAAI), AAAI Press, Palo Alto, CA, USA, 2013, http://www.aaai.org/ocs/index.php/AAAI/AAAI13/paper/view/6240.
38.
J.Noessner, H.Stuckenschmidt, C.Meilicke and M.Niepert, Completeness and optimality in ontology alignment debugging, in: Proc. of the 9th International Workshop on Ontology Matching, P.Shvaiko, J.Euzenat, M.Mao, E.Jiménez-Ruiz, J.Li and A.Ngonga, eds, Vol. 1317, RWTH Aachen, Germany, 2014, pp. 25–36.
39.
M.Richardson and P.Domingos, Markov logic networks, in: Machine Learning, H.Blockeel, D.Jensen and S.Kramer, eds, Vol. 62, Springer, 2006, pp. 107–136. doi:10.1007/s10994-006-5833-1.
40.
S.Riedel, Improving the accuracy and efficiency of map inference for Markov logic, in: Proc. of the 24th Conference in Uncertainty in Artificial Intelligence, D.McAllester and P.Myllymaki, eds, AUAI Press, Corvallis, Oregon, 2008, pp. 468–475, ISBN 0-9749039-4-9.
41.
F.Riguzzi, E.Bellodi, E.Lamma and R.Z.Bundle, A reasoner for probabilistic ontologies, in: Reasoning and Rule Systems – 7th International Conference, RR 2013, Mannheim, Germany, W.Faber and D.Lembo, eds, Lecture Notes in Computer Science, Vol. 7994, Springer, Heidelberg, Dordrecht, London, New York, 2013, pp. 183–197. doi:10.1007/978-3-642-39666-3_14.
42.
J.Schoenfisch, J.von Stülpnagel, J.Ortmann, C.Meilicke and H.Stuckenschmidt, Using abduction in Markov logic networks for root cause analysis, CoRR (2015), 1511.05719.
43.
J.von Stülpnagel and W.Chen, Risk assessment and risk-driven testing, in: Risk Assessment Risk-Driven Testing, F.Seehusen, M.Felderer, J.Großmann and M.-F.Wendland, eds, Lecture Notes in Computer Science, Vol. 9488, 2015, pp. 34–48, ISBN 978-3-319-26415-8. doi:10.1007/978-3-319-26416-5.
44.
J.von Stülpnagel, J.Ortmann and J.Schoenfisch, IT risk management with Markov logic networks, in: Proc. of the 26th International Conference on Advanced Information Systems Engineering, M.Jarke, J.Mylopoulos, C.Quix, C.Rolland, Y.Manolopoulos, H.Mouratidis and J.Horkoff, eds, Lecture Notes in Computer Science, Vol. 8484, Springer, Cham, Heidelberg, New York, Dordrecht, London, 2014, pp. 301–315. doi:10.1007/978-3-319-07881-6_21.
45.
Y.Wang, M.Yahya and M.Theobald, Time-aware reasoning in uncertain knowledge bases, in: Proc. of the Fourth International VLDB Workshop on Management of Uncertain Data (MUD 2010), A.de Keijzer and M.van Keulen, eds, CTIT Workshop Proceedings Series, Vol. WP10-04, Centre for Telematics and Information Technology (CTIT), University of Twente, The Netherlands, 2010, pp. 51–65.