
Abstract
The verbalization of structured data is a beneficial process for several applications. In the context of knowledge graphs (KGs), transforming Resource Description Framework (RDF) triples into natural language facilitates tasks such as KG documentation or alternative exploration methods for different user needs. While significant progress has been made on the English verbalization of KGs, Spanish remains an under-represented language for this task due to the lack of suitable resources. This hinders the development and evaluation of models capable of generating high-quality Spanish verbalizations. To tackle this problem, we create a Spanish adaptation of the WebNLG dataset, a benchmark consisting of over 45,000 verbalizations paired with DBpedia triple sets. To our knowledge, this is the first formal attempt to provide such a dataset in Spanish, which not only serves for data verbalization but can also potentially support the automated generation of RDF triples from text. We leverage this dataset to conduct a comprehensive evaluation of resource-efficient models for the Spanish triple-to-text task employing two different learning approaches: context learning (zero-shot, one-shot, and few-shot settings) and supervised learning through partial fine-tuning. Our results highlight the challenges of generating fluent and accurate Spanish text and demonstrate that partial fine-tuning of the evaluated models significantly improves performance.
Introduction
Knowledge graphs (KGs) contain interconnected entities and relationships, usually presented as Resource Description Framework (RDF) (World Wide Web Consortium, 2014) triples with a subject-predicate-object structure. While KGs are useful for machines, humans naturally understand and interpret plain text more intuitively than structured data, as it aligns with our ability to process language, context and nuances related to it. In the context of natural language processing (NLP), the data-to-text (D2T) task focuses on converting structured data into natural language text. Its goal is to make complex data more understandable and accessible by generating human-readable summaries or descriptions from raw structured data.
A lot of effort has been put into automating both the generation and verbalization of triples with a growing interest in the use of language models for these tasks (Lin et al., 2024). Most of these efforts only focus on the English language (Osuji et al., 2024), leaving a wide gap between said language and others. In fact, there is a notable lack of resources for other languages. Osuji et al. (2024) report that, of 90 works they studied in their review of D2T literature, 85% of them were approaches focused exclusively on English and that only two of the works, which propose multilingual approaches, feature the Spanish language, none of which tackle the triples-to-text task. This highlights the need to develop resources for other languages, such as Spanish. Over 450 million people around the world speak Spanish natively (Cervantes, 2024), which represents around 6% of the world population, without considering the population that speaks Spanish non-natively. Even though Spanish is one of the most spoken languages in the world, the resources found related to the automatic generation and verbalization of triples in this language are almost non-existent.
In this work, we present our contribution to the task of KG, specifically triples, verbalization in Spanish, focusing on the triples-to-text challenge. Spanish is a language characterized by its rich inflectional morphology and considerable flexibility in word order, which, in comparison to English, includes a more extensive verbal and nominal inflection and multiple acceptable positions for subjects and objects around the verb (Aguado-Orea et al., 2019; Moreno-Sandoval & Goñi-Menoyo, 2002). As a result, a single structured input may correspond to a broader set of equally natural verbalization options in Spanish. For example, for the triple [subject: Maria, relationship: need, object: help], English commonly allows expressions such as "Maria needs help.", "Maria requires help.", or "Maria is in need of help.” In Spanish, the same content can be rendered as "María necesita ayuda.", "María requiere ayuda.", "María precisa ayuda..", "María tiene necesidad de ayuda.", or "María está necesitada de ayuda.", among others. To tackle this task, we create a semi-supervised Spanish adaptation of the WebNLG dataset (Gardent et al., 2017), which contains the Spanish translation of the triples-verbalization pairs included in the English WebNLG. For this, we followed an automatic machine translation process which was then verified and partially manually revised through a detection process of potentially problematic cases. We also present a study of the performance of a selection of resource-efficient large language models (LLMs) on the task of translating Spanish triples to text. With this study, we aim to answer three research questions:
This article presents our adaptation of WebNLG to Spanish and the evaluation of low-resource LLM performance for the verbalization of triples in Spanish. It is structured as follows: We introduce the background related to structured D2T verbalization in Section 2, followed by the introduction to the proposed Spanish WebNLG and the methodology followed for its development in Section 3. Then, in Section 4.1, we explain the process followed to fine-tune and evaluate a selection of LLMs on the task of Spanish triples-to-text generation using our proposed dataset, followed by Section 4.2, with the presentation of the results obtained in the previous process, and Section 4.3, where we present the discussion of the findings. Finally, in Section 5, we present the conclusions extracted from the previous contributions and future work.
All the code and resources used to develop this work and the results obtained are available in GitHub 1 and Zenodo. 2
Background
Structured data verbalization, also known as data-to-text generation, is the name given to the task of generating natural language passages from structured data. Structured data can be stored in different forms, with the most common being graphs, tables, and meaningful representations (MRs) such as key-value structures or abstract meaning representation (AMR) (Banarescu et al., 2013), which is a semantic representation framework that captures the meaning of a sentence as a rooted, labeled graph of concepts and their relationships (Figure 1).

Data-to-text (D2T) generation overview.
A lot of work has been done to produce data resources to develop and evaluate data verbalization systems. In their review of the work presented in the literature related to D2T, Osuji et al. (2024) identify 63 distinct D2T datasets, mainly for table and AMR data formats. In terms of our specific task, that is, RDF-like data verbalization, specifically triples, they identify four datasets: WebNLG (Gardent et al., 2017), DART (Nan et al., 2021), T-REx (Elsahar et al., 2018), and WITA (Fu et al., 2020). WebNLG dataset (Gardent et al., 2017) stems from the WebNLG challenge (Colin et al., 2016), a shared task to generate text descriptions from structured data found in DBpedia (Mendes et al., 2012). It consists of pairs of DBPedia triples sets and texts. This dataset was originally presented as an English resource, although with time it has been adapted to other languages and, at present, 3 it also features Russian, Maltese, Irish, Breton, and Welsh (Cripwell et al., 2023) verbalization translations and partial triples translation (only the entities) for Russian, making it the only multilingual dataset of the ones named. Beyond the dataset itself, prior work has briefly addressed Spanish verbalization in the WebNLG setting. Mille et al. (2019) extend the existing rule-based FORGe generator to cover a subset of DBpedia properties in Spanish within a template- and grammar-based framework, but they do not provide a Spanish WebNLG dataset or a parallel benchmark for training and evaluating neural triple-to-text models. This, together with its variety in categories and manual supervision, is the reason we chose WebNLG to adapt to Spanish. In our case, differently from the previous adaptations, we fully translate both the triples and all the available English verbalizations for each entry in all the data splits-train, validation and test-, which results in a fully parallel dataset between English and Spanish. This enables the possibility of not only exploring Spanish triple verbalization, but also cross-lingual approaches.
Similar to WebNLG, DART (Nan et al., 2021) consists of structured data in the form of RDF triples and their corresponding textual descriptions. DART is built from multiple sources, including WikiTableQuestions (Pasupat & Liang, 2015), WikiSQL (Zhong et al., 2017), WebNLG (Gardent et al., 2017), and E2E (Novikova et al., 2017) datasets, covering diverse domains such as Wikipedia, databases, and e-commerce. On the same line, T-REx (Elsahar et al., 2018) is built from Wikipedia text and Wikidata triples. It contains millions of automatically aligned sentences with structured knowledge, making it useful for pre-training and fine-tuning language models to better understand factual knowledge and entity relationships. Lastly, WITA (Fu et al., 2020) is constructed from Wikipedia tables and their associated text, using a distant supervision approach to match table records with textual descriptions. Unlike fully supervised datasets, WITA contains partial alignments, reflecting real-world challenges in structured-to-text generation. It helps train models to generalize from imperfect data, making it useful for applications requiring robust natural language generation from structured inputs.
Regarding the language aspect of the task, as stated in Section 1, Osuji et al. (2024) report that, only 15% of the works they reviewed weren’t English-exclusive and only one of the works (Moussallem et al., 2018) focused completely on a non-English language, Brazilian Portuguese specifically, while the other 12 focus on multilingual approaches. From these 12 articles, only two (Fan & Gardent, 2020; Xu et al., 2021) incorporate Spanish to their multilingualism, both of which are based on AMR-formatted data. These numbers, in addition to the fact that the representation of non-English languages on well established datasets is quite low, reinforce our belief that more work has to be done in the multilingual aspect of the task for a wider spectrum of data formats.
Modeling Approaches for RDF Triple-to-Text Generation
As illustrated in Figure 1, the approaches proposed in the D2T research can be separated into two main blocks: rules or template-based approaches and neural approaches. The first block of approaches, template- or rule-based D2T, relies on predefined templates and handcrafted rules to convert structured data into fixed or semi-fixed textual outputs (Goldberg et al., 1994; Reiter & Dale, 1997). These systems operate by mapping data inputs to specific linguistic constructs, ensuring consistent and contextually appropriate outputs (Gatt & Krahmer, 2018). This approach offers simplicity and control over the generated text, making it particularly useful in domains where precision and reliability are essential (Gkatzia, 2016), such as weather (Boyd, 1998; Ramos-Soto et al., 2015) and triple-like health reporting data (Hallett et al., 2006). However, the rigidity of templates can limit linguistic variability and may require extensive manual effort to create and maintain, especially when scaling across diverse domains or languages. Some approaches propose the dynamization of these templates by adding control expressions and/or attribute mechanisms to better control the possible inconsistencies during the slot-filling process (Mcroy et al., 2003). Despite these challenges, template-based methods remain a viable solution for applications where the data structure is well-understood, and the desired output follows a predictable pattern (Wiseman et al., 2017).
More recently (Osuji et al., 2024), neural approaches, which leverage neural architectures to automate the verbalization process, have taken a more prominent role, moving away from traditional rule-based and modular approaches that require handcrafted features and domain-specific templates. Lin et al. (2024) propose a taxonomy of neural approaches based on two axes: neural end-to-end and modular D2T. End-to-end neural models have become the dominant approach for structured data verbalization (Liu et al., 2019; Puduppully et al., 2019; van der Lee et al., 2018; Wiseman et al., 2018; Yang et al., 2022), and more specifically triple verbalization (Chen et al., 2020; Lorandi & Belz, 2024), due to their ability to learn complex mappings between structured data and natural language text without requiring explicit intermediate steps. These models are generally based on sequence-to-sequence architectures, where an encoder processes input triples into a latent representation, and a decoder generates textual descriptions (Agarwal et al., 2021; Duong et al., 2023). Various other architectures have been introduced to different approaches, such as the use of advanced encoding techniques like graph neural networks (Lu et al., 2023). Transformer-based architectures, including BERT (Devlin et al., 2019), BART (Lewis et al., 2020), T5 (Raffel et al., 2020), and GPT-2 (Radford et al., 2019), leverage large-scale pretraining and fine-tuning to boost contextual understanding and generalization (Ma et al., 2022). Despite their advantages, neural end-to-end models often struggle with weak controllability and factual inconsistency, sometimes generating hallucinations in their output not present in the input data (Maynez et al., 2020) or presenting semantic errors (Kasner & Dusek, 2024). To mitigate these issues, modular neural approaches reintroduce intermediate processing steps to enhance interpretability and control (Moryossef et al., 2019). A common framework for triple-to-text tasks is the two-stage approach, which separates content planning from text generation. The content planning phase determines what information should be included and its structure, with models such as neural content planning (NCP) (Zhao et al., 2020) or a two-step content planning based on an encoder-then-order approach (Su et al., 2021). The text generation phase then transforms the structured content plan into fluent and coherent text while maintaining faithfulness to the input data. Other approaches introduce templates into their neural modular approaches to define initial verbalization of single triples that will later be used for sentence fusion and scoring based on neural models (Kasner & Dušek, 2020).
Evaluation of RDF Triple Verbalization
Evaluation of triple-to-text and, more broadly, D2T systems typically relies on human evaluation or automatic reference-based metrics adapted from other natural language tasks such as machine translation or summarization, most prominently BLEU (Papineni et al., 2002), alongside alternatives such as METEOR (Lavie & Agarwal, 2007), ROUGE (Lin, 2004), chrF (Popović, 2017) and more recent embedding-based metrics like BERTScore (Zhang et al., 2020), among others (Osuji et al., 2024; Puduppully et al., 2019; Zhao et al., 2020). These measures estimate the quality of a system output by comparing it to one or more reference texts, usually in terms of n-gram or token overlap. However, some studies have highlighted important limitations of some reference-based metrics, specifically BLEU, as a proxy for human judgments (Callison-Burch et al., 2006; Post, 2018; Reiter, 2018). They report that BLEU-based system rankings can diverge from human evaluations, that BLEU is often under-specified in practice with inconsistent tokenization and parameter choices, and that its correlation with real-world utility and user satisfaction is far from guaranteed, particularly for natural language generation tasks. These observations motivate the use of complementary metrics, which we also adopt in our experiments.
In general, the domain of neural D2T generation is advancing toward finding an ideal equilibrium among fluency, factual accuracy, and controllability. Although end-to-end methods produce coherent text with little human involvement, modular methods offer enhanced control and dependability, which makes them better suited for applications that demand accuracy. However, a major obstacle persists due to the scarcity of multilingual resources and methodologies, which restricts the accessibility and efficiency of D2T systems in various linguistic and cultural settings. Tackling these deficiencies is necessary to create more inclusive and universally applicable solutions.
Spanish WebNLG
WebNLG (Gardent et al., 2017) is a structured D2T generation benchmark that was initially introduced as an English D2T dataset for a challenge (Colin et al., 2016). In the last few years, it has also been adapted to other languages, specifically Russian, Maltese, Irish, Breton, and Welsh (Cripwell et al., 2023). With three major releases, we chose to work with the most recent version, specifically WebNLG v3.0. The dataset is split into training, validation, and test sets, ensuring a standardized evaluation process. It is provided in XML format, where the root element, <benchmark>, contains multiple <entries>. Each <entry> has attributes such as category, ID, shape, shape type, and triple set size. The structure of an entry consists of three key components: <originaltripleset>, which holds raw RDF triples extracted from DBpedia and wrapped in <otriple>; <modifiedtripleset>, containing the processed original triples which were revised by annotators and wrapped in <mtriple>; and <lex>, which includes human-generated natural language text (lexicalizations) with quality annotations. The dataset accommodates varying complexity, with each entry containing between one and seven triples. The training set comprises around 13.2k entries with
WebNLG English v3.0 serves as the foundation for our Spanish adaptation due to its key attributes:
A well-structured benchmark featuring a diverse set of RDF triples from DBpedia, covering a wide range of topics. The topics are varied yet presented at a sufficiently high level, making them accessible to non-native English speakers with a relatively good command of the language and general knowledge. High-quality triples and corresponding verbalizations, carefully verified by annotators and reviewers to maintain accuracy and linguistic clarity. A range of complexity levels, with datasets containing between one and seven triples per set, allowing for a thorough evaluation of model performance across different levels of difficulty. Demonstrated multilingual adaptability, as evidenced by successful extensions into other languages. An active research community and well-established evaluation frameworks that support continuous improvement and benchmarking of generated text.
In Section 3.1, we introduce the methodology followed to adapt the dataset to Spanish.
Methodology Overview
Currently, WebNLG (Cripwell et al., 2023) supports a range of languages, but the multilingualism is generally exclusive to the verbalizations, meaning that the original KG or triples must strictly be in English, limiting its applicability for multilingual scenarios. To overcome this constraint, we introduce the translation of both triples and verbalizations within WebNLG. This enhancement enables seamless processing in English, Spanish, or a combination of both, expanding the potential for multilingual natural language generation and improving adaptability across different linguistic contexts.
During the adaptation of the dataset, we maintained the original structure of the WebNLG English dataset while translating both the triples and their corresponding verbalizations into Spanish. This ensures consistency in format and allows for direct comparisons between English and translated versions. An overview of this adaptation methodology is shown in Figure 2, which outlines the procedure used to align the translated triples and verbalizations. Specifically, it illustrates the process divided into two steps: the automatic translation phase, explained in Section 3.1.1, and the manual revision and triple composition, explained in Section 3.1.2. In Section 3.2, we introduce the final structure of the dataset and some of its characteristics and limitations.

Methodology followed for the adaptation of WebNLG to Spanish, in blue the process followed for triples adaptation and in red the process followed for verbalizations adaptation.
We acknowledge that the methodology adopted here does not aim to cover the full range of possible Spanish verbalization variants. Owing to Spanish’ inflectional system and syntactic flexibility, a single structured input may correspond to many equally natural wording variants (Aguado-Orea et al., 2019; Moreno-Sandoval & Goñi-Menoyo, 2002), and generating all such variants would not be feasible. Moreover, Spanish is an official language in over 20 countries across Europe, the Americas, and Africa (Cervantes, 2024), which entails substantial national and regional variation in lexical and stylistic preferences. Rather than pursuing exhaustive coverage, our goal is to provide a fully aligned Spanish version of WebNLG with broad, practical coverage for benchmarking. We, therefore, translate all verbalizations available in the original English WebNLG entries to approximate a wide range of Spanish expressions. This initial release primarily reflects a standard Peninsular variety of Spanish, aligned with the authors’ linguistic expertize to support reliable manual revision in this first version. We recognize that Latin American lexical and stylistic variants are under-represented and acknowledge this as a limitation of the present dataset and a clear target for future, community-driven and dialect-aware expansion.
To adapt WebNLG into Spanish, we first processed the structured data and textual elements and generated automatic machine translations using DeepL 4 . DeepL is a neural machine translation service known for its high-quality machine translation, especially for European languages like Spanish (Kamaluddin et al., 2024).
For triples, which are initially presented in the format subject — relationship — object, we separated each component to handle them individually. This decomposition allowed us to translate subjects, relationships, and objects independently, avoiding potential errors from translating entire structured statements at once. We machine-translate all entities and relationships, which may introduce errors due to the lack of context during translation. These potential errors are later addressed through manual revision of all the triple instances. After extraction, given that the same entities and relationships can be present across different triples, we compiled separate sets for entities (subjects and objects) and relationships. Working on these unique sets makes it possible to ensure consistency across the whole dataset.
For entities, we combined KG information with machine translation. We queried Wikidata (Vrandečić & Krötzsch, 2014) to obtain Spanish labels and/or aliases when available, and only fell back to machine translation when such information was missing. To ensure the best possible translation quality, we applied the following priority order: (i) if a Spanish Wikidata label existed, we selected it as the translation; (ii) otherwise, if an alias was available, we used it; and (iii) if neither was found, we relied on machine translation. In total, this yielded 3,615 unique entities, of which 2,116 were translated using Wikidata labels/aliases and 1,499 via machine translation.
For relationships (properties), we relied exclusively on machine translation. This decision is motivated by the structure of WebNLG v3.0, where the triple sets used for training correspond to manually modified triples rather than the raw properties. As a result, there is no simple one-to-one mapping from these modified properties back to canonical properties, which makes property labels from the KG less reliable as a source of truth. Instead, we treated the 412 unique relationships as dataset-specific predicates and translated all of them via machine translation, followed by manual revision (see Section 3.1.2).
For verbalizations (or lexicalizations), which are natural language expressions of the triples, we extracted them as plain text and directly applied machine translation. Since these are full sentences rather than structured elements, they were translated without decomposition, ensuring fluency in the resulting Spanish text. After machine translation, we automatically detected dates in formats such as
Once the translations of entities and relationships had been manually revised (see Section 3.1.2), we performed an automatic consistency check over all verbalizations. In this pass, we verified that (i) the entities mentioned in the Spanish verbalizations matched the final, revised Spanish entities associated with the corresponding triples, and (ii) all dates still conformed to the normalized textual format described above. Whenever mismatches were found (for instance, if a verbalization still contained a previous version of an entity translation), the verbalization was automatically updated so that all entity mentions and dates were consistent with the final triple translations.
Detection of Problematic Cases and Manual Oversight
The second step of the adaptation was to manually revise the automatic translations. This step was carried out in two stages: first on entities and relationships, and then on a selected subset of verbalizations.
Regarding the triples, with a total of 3,615 unique entities and 412 unique relationships, since the numbers were manageable, we conducted a manual revision of their translations. We reviewed the selected translation for each entity and relationship and corrected any inaccurate or incomplete translations identified.
Overall, 301 entities (
Regarding the verbalizations, the dataset contains 45,031 lexicalizations, which made a complete manual revision of all of them infeasible for this first version of Spanish WebNLG. Instead, we relied on automatic detection of potentially problematic cases, followed by targeted manual revision. Our intention for future work is to enrich the dataset and to apply crowdsourcing to refine these translations at scale.
To identify potentially problematic verbalizations, we computed the cosine similarity between the embeddings of the English and Spanish verbalizations (one-to-one) using three different embedding models. We chose cosine similarity with multilingual embedding models over other metrics because it effectively captures semantic similarities across different languages, enabling accurate cross-linguistic comparison. We chose to use more than one model since the dataset contains a wide variety of topics, aiming to ensure the representativeness of the models as closely as possible. The models were selected based on the SentenceTransformers (Reimers & Gurevych, 2019) documentation on multilingual models. 5 (Reimers & Gurevych, 2020). Specifically, we used the SentenceTransformers models paraphrase-multilingual-MiniLM-L12-v2, 6 paraphrase-multilingual-mpnet-base-v2, 7 and distiluse-base-multilingual-cased-v2 8 (Reimers & Gurevych, 2019). For each verbalization, we took the maximum similarity score across all models.
We deliberately use cosine similarity not as a full evaluation metric, but as a risk-based heuristic to prioritize which MT verbalizations should be prioritised for human revision. Concretely, instead of randomly sampling from the 45,031 verbalizations, we rank English–Spanish pairs by their cross-lingual similarity and focus manual effort on those that look atypical in the embedding space. This is conceptually similar to outlier or noise detection in other NLP settings, where multilingual sentence embeddings and distance thresholds are used to flag misaligned or low-quality sentence pairs in large parallel corpora before downstream use (Kurfalı & Östling, 2019).
We focused our manual revision on verbalizations whose maximum similarity score was 0.9 or lower. To choose this value, we inspected the empirical distribution of similarity scores and observed a strongly right-skewed shape with a clear "elbow” or ‘‘knee” around 0.9, where the density of points drops sharply (Figure 3). Selecting a cut-off at such an elbow is a standard heuristic in data analysis and outlier detection (Thorndike, 1953), where it marks the transition between a dense region of typical cases and a sparse tail of atypical ones (Satopaa et al., 2011). At the same time, we needed a threshold that was operationally feasible: the selected band had to be sufficiently narrow that a complete manual revision of all retrieved cases was realistic, yet wide enough to cover a meaningful fraction of atypical verbalizations. In our data, a cutoff at 0.9 corresponds to approximately the lowest 3% of the similarity distribution, which we interpret as a high-risk band for potential translation problems. This allows us to concentrate manual effort on the most atypical English–Spanish pairs while keeping the annotation effort realistic. With this criterion, we obtained a selection of 1,239 verbalizations (around 3% of the total) for manual inspection, providing a practical compromise between expected error coverage and annotation cost.

Histogram of verbalizations similarity results.
It is important to note that this procedure does not guarantee that all problematic translations fall below the threshold, nor that all items below 0.9 are incorrect. Rather, it provides a principled way to concentrate limited human effort on those verbalizations that are statistically more likely to be problematic, instead of relying on uninformed random sampling. Although we cannot manually revise all 45,031 verbalizations, every verbalization is nevertheless subject to an automatic consistency check: entity mentions are aligned with the final, manually revised entity translations, and dates are enforced to follow the normalized textual format described above. In this way, we at least aim to guarantee global consistency of entities and dates across the dataset, even when the full wording of a verbalization has not been manually inspected. A full, crowdsourced revision of all verbalizations remains part of our future work.
The manual revision was carried out by a native Spanish speaker with advanced, formally certified proficiency in English. To ensure consistent decisions, the annotator followed a simple set of internal guidelines: a verbalization was marked as erroneous and corrected if (i) it did not fully preserve the information and context expressed in the original English verbalization, (ii) it contained clear grammatical errors in Spanish (such as agreement, conjugation, or syntactic well-formedness issues), or (iii) it exhibited inconsistent or clearly inappropriate lexical choices with respect to the intended meaning (such as mistranslations or infelicitous word choice according to the triple sets). Since all manual revisions were performed by a single annotator, inter-annotator agreement could not be measured. Instead, we relied on the internal guidelines just described to ensure consistency. Under these criteria, 406 verbalizations were identified as requiring correction, corresponding to 31.5% of the manually inspected subset and <1% of all generated verbalizations.
When creating the Spanish adaptation of WebNLG, we decided to maintain the same structure and content as the English version with the goal of having a parallel translation that enables us to not only compare results along both languages but potentially create multilingual adaptations. In Table 1, we can observe the statistics about entities and verbalizations in the Spanish adaptation. Specifically, we have a total of 16.657 entries, which are composed of 45.031 triple set-verbalization pairs. These entries are divided into three splits, following the original grouping of entries, train, validation and test, in a proportion of 80%, 10%, and 10%, respectively, which potentially enables the training and evaluation of neural models.
Entry and Verbalization Statistics for the WebNLG Datasets.
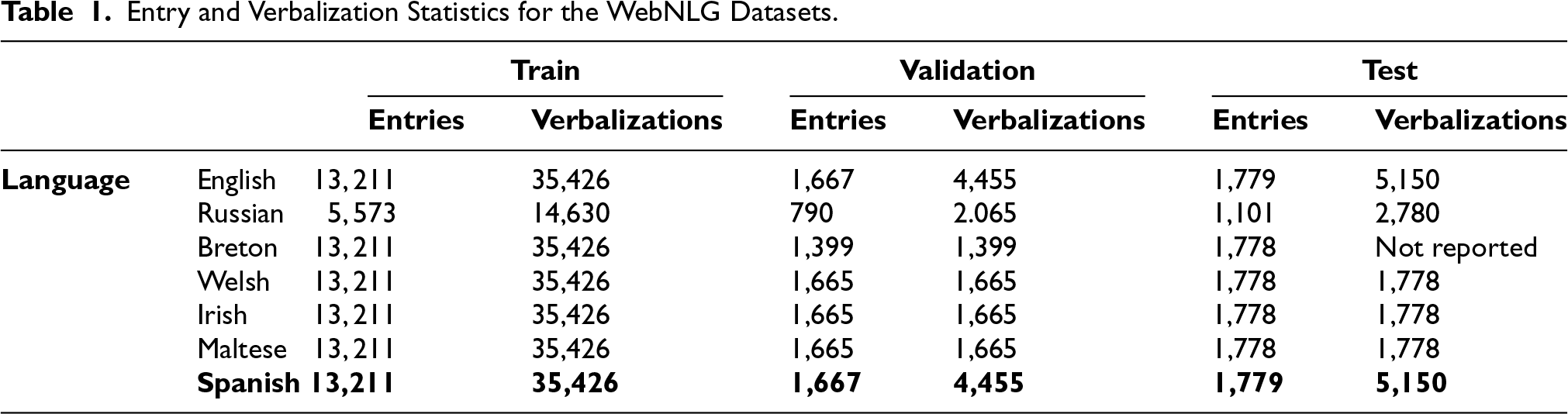
Entry and Verbalization Statistics for the WebNLG Datasets.
In terms of category and triple size, in Table 2, we illustrate the distribution of entries per splits for Spanish WebNLG, that mirrors the original English version. The dataset contains a diverse range of 19 categories, including places (Airport, City, Monument, etc.), people (Artist, Astronaut, Politician, etc.), entities (Company, Film, MusicalWork, etc.), and abstract concepts among others. The number of triples per entry varies significantly, with most entries containing between one and five triples, though some categories, such as Astronaut and University, also include larger entries with up to seven triples. In the train split, categories like Food, MeanOfTransportation, and Politician have a large number of entries, whereas others such as Monument and Company have fewer examples. The validation split follows a similar distribution pattern, but with a significantly lower number of examples per category, ensuring a representative yet smaller validation dataset. The test set, however, includes categories absent in training, such as Film and MusicalWork, which help test the model’s generalization ability. Overall, the dataset balances a variety of domains while varying the complexity of entries by the number of triples, which gives us a wider scope of evaluation.
Category and Triple Size Statistics About English and Spanish WebNLG.

Comparing the development process and nature of the data in the other available supported languages in WebNLG with our Spanish dataset, outside of English, the previously existing translations for the other languages were developed using machine translation and a posterior crowdsourcing process for verbalizations exclusively. In contrast, our Spanish WebNLG dataset includes translations for both triples and verbalizations, which adds more variability and consistency to the dataset.
To obtain the development and test data for each of the low-resource languages (Breton, Irish, Maltese, and Welsh), professional translators manually translated the English text from the WebNLG 2020 (Castro Ferreira et al., 2020) development and test sets, given both the English text and the input RDF graph. Only the first reference of each test example in the original English dataset was considered for translation, except in the case of Breton, which contains two translated references for some test items. For Russian, the WebNLG+ 2020 (Castro Ferreira et al., 2020) data was used. Although the Russian dataset includes partial triple translation—where only the DBpedia translation of entities was extracted, leaving relationships untranslated—it only contains data for nine of the 19 categories of entries: Airport, Astronaut, Building, CelestialBody, ComicsCharacter, Food, Monument, SportsTeam, and University. In all cases, the training split data is also available, with the verbalizations being generated exclusively through machine translation and thus considered "noisy" data.
In contrast, for Spanish, we translated all triples and verbalizations available in the English version of WebNLG. The translation process began with automatic generation, using Wikidata for triples, and was followed by a posterior manual revision of all triples. Additionally, we detected and manually revised potentially problematic cases for verbalizations across all data splits, further ensuring quality and variability in the dataset. This comprehensive approach ensures the full availability of all translations in the Spanish dataset, unlike the partial triple translation for Russian and the limited translation for the other languages.
Referring again to Table 1, which reports the entry and verbalization sizes for each split across languages, we can observe that, in terms of size, English and Spanish have notably more available verbalizations for the validation and test splits. This is because the developers report that only the first English verbalization for each entry was considered for translation into low-resource languages. 9 In our case, we believe that a wider availability of verbalizations can provide a more comprehensive representation of the various forms a text can take to express the triples.
Nevertheless, while Spanish WebNLG is designed to be a broadly useful benchmark, some aspects of its current release delimit its scope. First, the diversity of Spanish realizations is naturally constrained by the paraphrastic space present in the English WebNLG v3.0 dataset: we obtain our range of expressions by translating all existing English triple sets and verbalizations, which we assume are inherently coherent with each other due to their gold standard nature. This means that, although the corpus offers multiple references per triple set and a wider variety than single-reference resources, it should not be interpreted as an exhaustive sample of all possible Spanish verbalizations. Second, although all triples are manually checked and all verbalizations pass through automatic consistency filters, only a similarity-based subset of verbalizations is manually corrected by an annotator, which may leave some residual noise or annotator preference. Finally, this first release primarily reflects a standard Peninsular variety of Spanish, with more limited coverage of other regional varieties. We view a broader, crowdsourced revision and a dialect-aware expansion of the corpus as natural next steps to further strengthen the resource.
The goal of this study is to conduct a preliminary evaluation of resource-efficient LLMs for the task of Spanish triple verbalization using the Spanish WebNLG dataset presented in Section 3. Specifically, we aim to explore how context learning and fine-tuning can enhance the performance of resource-efficient LLMs in generating natural language text from Spanish triples. We aim to answer three key research questions:
This Section is structured as follows: In Section 4.1, we present the Learning Approaches and Models employed in our study. This includes an exploration of Context learning (Section 4.1.1) and its role in model performance, the methodology behind Supervised learning through Fine-tuning (Section 4.1.2), the criteria for Models’ selection (Section 4.1.3), and a description of the Evaluation metrics used to assess our models (Section 4.1.4). Section 4.2 provides a comprehensive overview of the Evaluation Results and Analysis. We first examine the Context Learning performance (4.2.1) and compare it with the results obtained from Fine-tuning performance (Section 4.2.2). Additionally, we conduct a Cross-lingual Analysis (Section 4.2.3) to evaluate the adaptability of models across different languages. Finally, we perform an Error Analysis (Section 4.2.4) to identify common failure cases and areas for improvement. To conclude, in Section 4.3, we present a Discussion of our findings, reflecting on the key takeaways and outlining potential directions for future research.
With this structure, we aim to provide a clear and comprehensive examination of the learning approaches, their effectiveness, and the insights gained from our evaluation.
Learning Approaches and Models
To answer
Even though our goal is to study the performance of the models on the Spanish task, for a better understanding of the results, we also run all the experiments presented before on the English WebNLG set, that is, the context-based learning and data-based learning of the same models. The English results allow us to gain a clearer understanding of the results in Spanish, as they serve as a comparison of the performance of the models in order to have a better understanding of whether the difficulties they may have in carrying out the task are exclusively rooted in the task itself or are also rooted in the language.
Context Learning Through Prompts
The context learning approach, sometimes referred to as prompt-based learning, enables models to generate responses based on provided prompts without modifying their internal parameters. This approach leverages contextual cues from the input text to guide the model’s behavior, allowing it to adapt dynamically to different tasks. It operates under three main settings: zero-shot (0S), one-shot (1S), and few-shot (FS).
Zero-shot learning (0S): The model generates responses without any prior examples, relying solely on its pre-trained knowledge. One-shot learning (1S): The model is given a single example to help it understand the task before generating responses. Few-shot learning (FS): The model is provided with a small number of examples to better grasp patterns and context, improving response accuracy.
In our case, we will evaluate the context learning approach using 0S, 1S, and FS (with two examples) settings. We use the same base prompt in all the tests and only add examples, in the case of 1S and FS tests. Our base prompt introduces the structured data format and instructs the model to generate fluent, grammatically correct Spanish text from given triples: En español, los datos estructurados se representan comúnmente como tripletas o triples, con el formato [sujeto, predicado, objeto]. A partir de estas tripletas, genera un texto de un solo párrafo formado por oraciones completas, gramaticalmente correctas y naturales. Genera el texto únicamente a partir de las siguientes tripletas:
As we stated previously, we also run all the experiments on the English WebNLG set using the same configuration of the experiments as the Spanish evaluation. In this case, we translated the original base prompt to English: In English, structured data is commonly represented as triples, with the format [subject, predicate, object]. Based on these triples, generate a single-paragraph text composed of complete, grammatically correct, and natural sentences. Generate the text solely from the following triples:
The full prompts used to evaluate the models are available in Appendix A.
Data-Based Learning Through Fine-Tuning
In contrast to the previous approach, the supervised learning method we used involves a partial fine-tuning approach, which adapts the model’s weights using low-rank adaptation (LoRA) (Hu et al., 2021). This method is particularly efficient for fine-tuning large models, as it introduces small, trainable low-rank matrices into the model’s architecture rather than updating all of the model’s parameters. By doing so, LoRA significantly reduces the computational cost and memory requirements, making it feasible to fine-tune large-scale models on limited hardware resources such as ours.
The fine-tuning process in our case lasts
During the fine-tuning phase, we employ the same base prompt used in the zero-shot setting of the context learning approach to ensure a fair comparison and evaluate the differences in performance under identical conditions. This consistency allows us to isolate the impact of LoRA-based fine-tuning and demonstrate its effectiveness in improving model performance without extensive computational overhead.
In this approach, we also evaluate the models with the English WebNLG. That means that we fine-tune each model twice, once with each of the following prompts:
Spanish base prompt: “En español, los datos estructurados se representan comúnmente como tripletas o triples, con el formato [sujeto, predicado, objeto]. A partir de estas tripletas, genera un texto de un solo párrafo formado por oraciones completas, gramaticalmente correctas y naturales. Genera el texto únicamente a partir de las siguientes tripletas:” English base prompt: “In English, structured data is commonly represented as triples, with the format [subject, predicate, object]. Based on these triples, generate a single-paragraph text composed of complete, grammatically correct, and natural sentences. Generate the text solely from the following triples:”
The models are fine-tuned using the train split of WebNLG (both in English and Spanish) as examples and the validation split as reference evaluation. The code and the results are available in GitHub 10 and Zenodo. 11
Model Selection
To select the LLMs to evaluate, we defined four main criteria: The models must be (non-exclusively) trained on Spanish: Models must be able to handle data in Spanish to ensure high-quality text generation in our task, as language-specific training enhances fluency, coherence, and grammatical accuracy. The models can have up to 2 billion parameters: Over time, LLMs have tended to grow larger and more resource-intensive. This means that they often become inaccessible to regular users who lack the necessary hardware to run them efficiently, as high-end GPUs and large amounts of memory are typically required. At the same time, when dealing with large amounts of data, in our task sometimes involving thousands or millions of triple sets, the resources and/or time needed to process them grow exponentially. To address this, we focus on resource-efficient models that can run efficiently (in our case, this means that it takes a few seconds to compute each answer) on a machine with an RTX 3060 Laptop GPU (6 GB VRAM) and 16 GB RAM. This generally limits us to models with up to around 2 billion parameters, ensuring practical usability without compromising too much on performance. The models must be trained for instruction-following tasks: Instruct LLMs (instruction-tuned LLMs) are language models fine-tuned to follow explicit natural language instructions. Unlike generic LLMs, which predict text based on training data patterns, these models are optimized to understand and execute user commands. They process structured prompts containing instructions, ranging from open-ended queries to specific tasks like summarization, translation, or coding. In our case, to ensure direct and well-structured outputs, the models must be trained for instruction-following tasks, eliminating the need for additional post-processing. Our goal is to generate responses that are already aligned with the given prompt, minimizing manual adjustments or corrections that could affect the evaluation results of model performance.
The models must be available in HuggingFace (Wolf et al., 2020).
Given the previous limitations, the test models selected come from two of the large open-source families of LLM, Llama 3 (Grattafiori et al., 2024) and Qwen (Team, 2024; Yang et al., 2024), and Salamandra (Gonzalez-Agirre et al., 2025), a family of LLMs created by the Barcelona Supercomputing Center 12 ) in Spain which, although it was trained with data from a wide range of European and programming languages, was mainly trained with English and Spanish data. Specifically, based on our criteria, we selected the following models 13 :
Evaluation Metrics
We evaluate the quality of the generated text using both lexical semantic similarity and efficiency metrics (Table 3), further explained along this section.
Evaluation Metrics Categorized by Type.
Evaluation Metrics Categorized by Type.

BLEU = Bilingual Evaluation Understudy; METEOR = Metric for Evaluation of Translation with Explicit ORdering; CHRf++ = Character n-gram F-score, extended version.
Information preservation metrics: These metrics assess how well the generated text retains the content of the reference text by evaluating n-gram overlap and word alignment. These metrics include: BLEU (Bilingual Evaluation Understudy) (Papineni et al., 2002): BLEU is a metric that measures the n-gram overlap between generated and reference texts. It’s calculated as a weighted geometric mean of n-gram precision, with a brevity penalty to penalize short translations. In our evaluation, we use n = 4 sequences. BLEU scores range from 0 to 1, with higher scores indicating closer matches. This metric is sensitive to exact word matches and does not account for synonyms or paraphrasing, making it less effective in evaluating texts with flexible word choices. However, as discussed in Section 2.3, BLEU is sensitive to exact word overlap and has known limitations in natural language generation, including weak correlations with human judgements in some settings (Mathur et al., 2020; Reiter, 2018). We, therefore, report BLEU alongside additional lexical and semantic similarity metrics. METEOR (Metric for Evaluation of Translation with Explicit ORdering (Lavie & Agarwal, 2007): METEOR improves upon BLEU by incorporating precision, recall, stemming, synonym matching, and word order penalties. Unlike BLEU, METEOR aligns words between the generated and reference texts and computes a harmonic mean of precision and recall. METEOR scores range from 0 to 1, with higher values indicating better alignment between the predicted and reference sentences. This metric is useful for evaluating languages with rich morphology, such as Spanish, where word forms can vary significantly.
Language fluency metrics: These metrics assess the readability and naturalness of generated text by analyzing character-level and subword-level coherence. These metrics include: CHRf++ (Character n-gram F-score, extended version) (Popović, 2017): CHRF++ calculates an F-score based on the overlap of character n-grams between the reference and generated texts. In our evaluation, we set n = 6. The CHRF++ score ranges from 0 to 1, with higher values indicating better similarity. Since this metric operates at the character level, it is more robust to minor spelling variations and inflectional changes compared to BLEU.
Semantic similarity metrics
In contrast to previous metrics, semantic similarity metrics focus on meaning rather than exact matches. These metrics compare the underlying meaning or context of the sentences, making them more robust to synonyms, paraphrasing, or other linguistic variations that don’t affect the underlying content. These metrics include, among others: Cosine Similarity: This metric computes the cosine similarity between sentence embeddings, which are high-dimensional vector representations of the sentences. Sentence embeddings capture semantic meaning beyond exact word overlap. The value ranges from 0 to 1, where 1 indicates identical meaning. For our experiments, we selected the sentence model paraphrase-multilingual-MiniLM-L12-v2
18
(Reimers & Gurevych, 2019), given that it is currently the most downloaded sentence transformers model with Spanish support.
19
We deliberately opt for a multilingual encoder rather than a Spanish-only sentence model to keep the embedding space consistent across our Spanish and English evaluations: both languages are embedded into a shared semantic space, enabling direct cross-lingual comparison. Since our goal is not to benchmark embedding models, we leave a systematic study of other encoders such as monolingual Spanish encoders for future work. BERTScore (Zhang et al., 2020): BERTScore computes contextual token-level similarities using embeddings from a pretrained BERT model. BERTScore considers precision, recall, and the F1-score for evaluating the match between the predicted and reference sentences at the semantic level taking values between 0 and 1, where the higher the value the better. For BERTScore, we use the HuggingFace (Wolf et al., 2020) "evaluate" wrapping of the metric implementation (Zhang et al., 2020), which in our case corresponds to the bert-base-multilingual-cased model (Devlin et al., 2019) with the default layer configuration.
Efficiency metric:
Efficiency metrics measure the computational cost of generating text. In our case, the efficiency metric chosen is the following: Time: This metric measures the duration required to generate a text output in seconds, with lower values indicating more efficient text generation.
This section is structured to assess the performance of the models in both context learning and fine-tuning scenarios, with a primary focus on the Spanish evaluation, based on the results presented in Table 4
Spanish Evaluation Results.
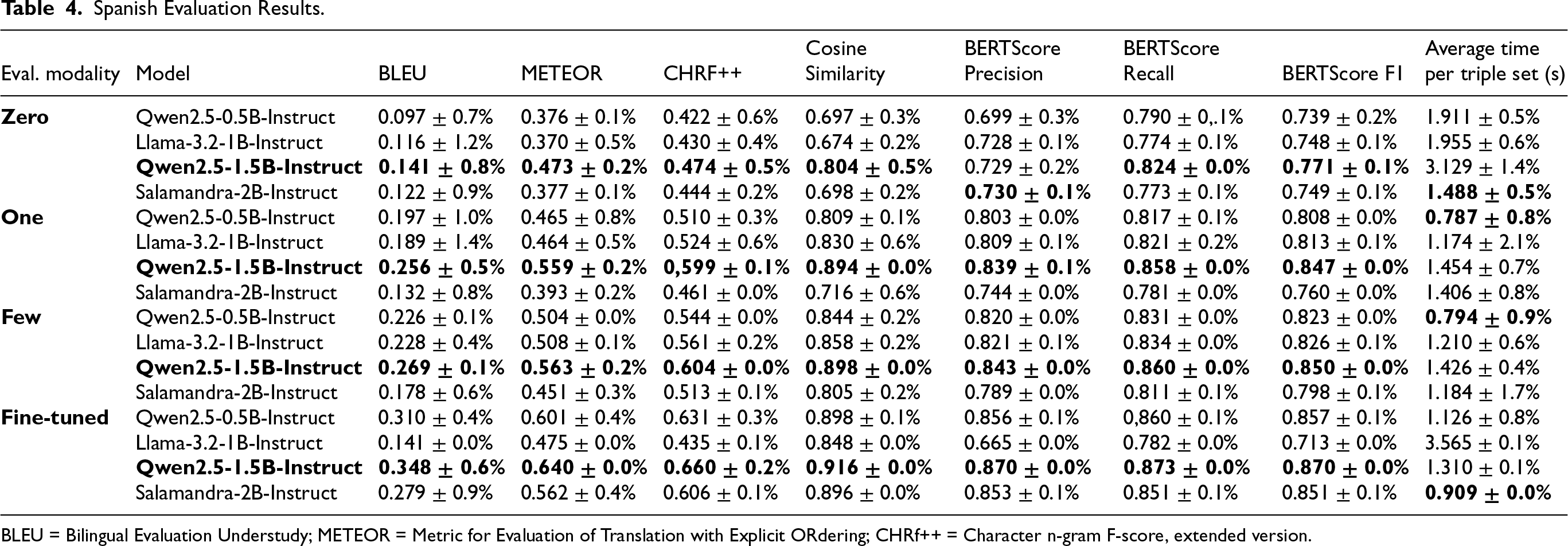
Spanish Evaluation Results.
BLEU = Bilingual Evaluation Understudy; METEOR = Metric for Evaluation of Translation with Explicit ORdering; CHRf++ = Character n-gram F-score, extended version.
The results of our experiments on Spanish triple generation using a context learning approach (Table 4 and Figure 4) reveal several insights. First, we observe a significant improvement in performance from 0S to 1S learning, with only a slight improvement from 1S to FS learning. This suggests that providing even a single example significantly enhances the model’s understanding of the task, likely due to better contextualization. Notably, this improvement is not only qualitative but also time-efficient: 1S and FS settings generally require less time for verbalization compared to 0S. This efficiency gain could be attributed to the model generating more precise outputs with less non-relevant information, as 0S often produced additional content outside the scope of the triples, which also results in nearly double the generation time in some cases. For example, when given the triple

Average Spanish context learning results by triple set size. (a) BLEU, (b) METEOR, (c) CHRF++, (d) Cosine Similarity, (e) BERTScore Precision, (f) BERTScore Recall, and (g) BERTScore F1. BLEU = Bilingual Evaluation Understudy; METEOR = Metric for Evaluation of Translation with Explicit ORdering; CHRf++ = Character n-gram F-score, extended version.
In terms of evaluation metrics, BLEU scores are notably low, with a maximum of 0.27 (on a scale of 1).
As discussed in Sections 2.3 and 4.1.4, this behavior is consistent with known limitations of BLEU, which relies on strict lexical n-gram overlap and tends to under-reward valid paraphrases and alternative surface realizations. In contrast, other lexical metrics such as METEOR and CHRf++ yield more favorable results, ranging between 0.47 and 0.6, as they are more tolerant to morphological variation and partial lexical matches. These scores suggest that, despite lexical differences from the references, the generated outputs capture more of the intended content than would be indicated by BLEU alone. Additionally, similarity-based metrics provide further evidence of the model’s effectiveness. Cosine similarity increases from 0.8 in 0S to nearly 0.9 in 1S and FS settings, indicating that the generated content is contextually closer to the reference text when examples are provided. Similarly, BERTScore metrics show consistent improvements: BERTScore recall remains stable (0.82–0.86), while precision rises from 0.73 in 0S to around 0.84 in 1S and FS, and F1 score improves from 0.77 to 0.85. These results suggest that, while 0S outputs may include unnecessary information, 0S and FS settings produce more focused and contextually aligned responses.
At the same time, if we observe the graphics from Figure 4, where the results can be seen according to triple size, we can see that, in general, the performance tends to drop with the increase of the number of triples. It can also be seen that, in general, 1S and FS (marked in blue and red in the figures) perform better than 0S (marked in green). Albeit, if we observe these results more deeply, we can see that for the 0S tests, BLEU, CHRF++, cosine similarity and BERTScore Precision, this trend is contrary; the more triples, the better the performance. This could probably be explained with the fact presented before about 0S generation, where models often produced additional content outside the scope of the triples. Logically, the more triples a set has, the longer the verbalization has to be. If the model tends to create larger and richer answers when no examples are given, it could be logical to think that the longer the ground truth, the higher the probability that the evaluation finds more similarity among the reference and generated texts. Moreover, despite our efforts to explain what triples are and clarify our goal, it’s important to recognize that we are introducing structured data to models that were generally not trained to handle such information. These models may lack domain-specific knowledge, making the prompt potentially insufficiently descriptive without examples. Consequently, this lack of context could affect the quality and accuracy of the verbalization, particularly in cases where structured data is involved.
Among the models evaluated, Qwen2.5-1.5B-Instruct consistently outperforms the others across all tests. Although less time-efficient, its competitive performance in 1S and FS settings highlights its robustness for Spanish triple generation. Surprisingly, Salamandra-2B-Instruct, which we expected to be among the better-performing models due to its Spanish-centric training (Spanish being the second most prominent language in its training data) and development by a Spanish institution, underperforms relative to the other models. This suggests that factors beyond language-specific training, such as task-specific fine-tuning, may play a more critical role in its performance.
Taken together, these findings highlight the importance of contextualization in helping models correctly interpret structured inputs such as triples, as well as the limitations of relying on a single evaluation metric. As discussed earlier, lexical-overlap measures alone may fail to reflect improvements in meaning preservation when multiple valid verbalized forms are possible, a limitation widely noted in natural language generation research (Mathur et al., 2020; Reiter, 2018). By contrast, considering both lexical and similarity-based metrics offers a clearer view of model behavior, showing that although lexical overlap may remain limited, semantic and contextual alignment improves noticeably in 1S and FS settings.
As explained in Section 4.1.2, we apply a LoRA fine-tuning to the models with our dataset, having the configuration of the LoRA training being the same for each model. LoRA is applied to attention layers because they are the most critical for learning contextual relationships while significantly reducing the number of trainable parameters, making fine-tuning more efficient. In Table 5, we can see the parameter configuration of each model. Generally, we only fine-tune between 0.2% and 0.4% of the parameters. It is notable that Salamandra-2B-Instruct has a smaller proportion of trainable parameters despite having more total parameters. Here, we have to take into account that the number of trainable parameters depends on how many attention layers the model has and their size, rather than the total parameter count. A possible explanation is that Salamandra-2B-Instruct might have fewer or smaller attention layers relative to its total size, meaning LoRA modifies a smaller portion of the model. Other architectures, like Qwen or Llama, might distribute their parameters differently, with a larger fraction dedicated to attention layers, leading to more trainable parameters under the same LoRA configuration.
Models’ Parameters Fine-Tune Configuration.

Models’ Parameters Fine-Tune Configuration.
In Table 4, we can see that when transitioning from FS learning to fine-tuning, we observe notable improvements across all metrics for Qwen2.5-0.5B-Instruct, Qwen2.5-1.5B-Instruct, and Salamandra-2B-Instruct, with the exception of time efficiency. Specifically, Qwen2.5-0.5B-Instruct experiences a slight degradation in time efficiency, while Qwen2.5-1.5B-Instruct and Salamandra-2B-Instruct show improvements. This suggests that fine-tuning enhances the models’ ability to generate more accurate and contextually appropriate text, albeit at a potential cost in computational speed for some models.
As illustrated in Figure 5, fine-tuned models exhibit greater stability in performance as the size of the triple set increases, compared to the variability seen in 0S, 1S, and FS settings. However, Llama-3.2-1B-Instruct stands out as an exception, showing a significant drop in performance relative to its FS results. This indicates that Llama-3.2-1B-Instruct may not have adapted effectively during fine-tuning, potentially due to limitations in its architecture or training dynamics. Additionally, while Qwen2.5-1.5B-Instruct and Salamandra-2B-Instruct improve in computation time, Qwen2.5-0.5B-Instruct and Llama-3.2-1B-Instruct experience degradation, with the latter taking more than double the time to generate text compared to its context learning performance.

Average Spanish fine-tuning results by triple set size. (a) Qwen2.5-0.5B-Instruct, (b) Llama-3.2-1B-Instruct, (c) Qwen2.5-1.5B-Instruct, and (d) Salamandra-2B-Instruct.
Overall, these results demonstrate that even a small-scale fine-tuning process, such as the one employed in this study, can significantly enhance the performance of models for Spanish D2T generation. Fine-tuning not only improves the stability and quality of the generated text but also highlights the importance of model-specific adaptability. While some models, like Qwen2.5-1.5B-Instruct, show rather good results in both performance and efficiency after fine-tuning, others, like Llama-3.2-1B-Instruct, may require further optimization to achieve comparable results. These findings underscore the value of fine-tuning as a practical approach for improving multilingual models, particularly for underrepresented languages.
As stated in the methodology of the evaluation, we also computed the same tests as with the Spanish WebNLG using English WebNLG. Table 6 shows the results we obtained during this evaluation for all the models for 0S, 1S, and FS setting.
English Evaluation Results.

English Evaluation Results.
BLEU = Bilingual Evaluation Understudy; METEOR = Metric for Evaluation of Translation with Explicit ORdering; CHRf++ = Character n-gram F-score, extended version.
When comparing the results for English and Spanish, it is evident that the models generally perform better with English input than with Spanish. This is expected, given that English constitutes a significant portion of the training data for most multilingual models, making them inherently more proficient in English. However, the performance gap also highlights the challenges of adapting these models to languages like Spanish, which, despite being widely spoken, may not receive the same level of representation in training datasets.
Across all context learning settings—0S, 1S, and FS—the Qwen2.5-1.5B-Instruct model consistently comes up as the best performer. This suggests that Qwen2.5-1.5B-Instruct may possess some inherent capability to generate text from triples, regardless of the input language. Its robustness in both English and Spanish settings underscores its versatility and effectiveness for structured text generation tasks, even in low-resource or 0S scenarios.
Interestingly, the Llama-3.2-1B-Instruct model presents a contrasting case. In the fine-tuning experiments, Llama-3.2-1B-Instruct struggled to adapt effectively to the Spanish triple verbalization task. However, in the English context learning results, it performs competitively, achieving the best results across all metrics including time efficiency. This discrepancy suggests that the issue may lie not in the task itself but rather in the model’s ability to learn and generalize the task specifically for Spanish. This could be attributed to differences in linguistic characteristics, training data distribution, or the model’s architectural limitations when handling Spanish compared to English.
To interpret some of the errors observed in our evaluation, it is useful to recall that English and Spanish encode grammatical information differently. English generally relies more on word order and has comparatively limited overt verbal inflection, whereas Spanish marks person and number more systematically on verbs and shows gender and number agreement within the noun phrase (Moreno-Sandoval & Goñi-Menoyo, 2002). For example, in English the verb eat shows relatively limited inflection across subjects ("I eat", "you eat", "she eats", and "we eat"), whereas in Spanish the verb exhibits richer inflectional variation ("yo como", "tú comes", "ella come", and "nosotros comemos"). Spanish also allows null (silent) subjects, since subject features are often recoverable from the verb (Ordóñez & Treviño, 1999). In addition, Spanish permits greater flexibility in the placement of subjects and objects than English, which further expands the set of grammatical realizations available for a given triple (Aguado-Orea et al., 2019). Taken together, these properties increase the likelihood that a faithful Spanish output may differ in surface form from a single reference. This is why we interpret lexical overlap metrics alongside more meaning-sensitive measures, in line with prior work showing that automatic metrics capture complementary aspects of NLG quality and are best used in combination (Mathur et al., 2020; Reiter, 2018).
In Table 7, we can see a good example of the importance of variety in evaluation metrics. 23 In the first row, we see that Qwen2.5-1.5B-Instruct predicted ‘‘La empresa MotorSport Vision tiene su sede en Fawkham.” (‘‘MotorSport Vision is based in Fawkham.”) as the verbalization, which generally would be correct, as, in this case ‘‘based” can be expressed as "se ubica"; "está", "se encuentra", "tiene su base en", and so on. If we observe the lexical results only, we can see that the BLEU value is 0.14, which is a very low performance, while METEOR and CHRF++ have a score of 0.60 and 0.63, respectively, which is not nearly as low as BLEU, but it is also not that high. On the other hand, we have that the semantic metrics, Cosine Similarity and the BERTScore scores are all above 0.91, which means that, semantically, the answer is very close to the ground truth.
Predictions Samples and Their Performance (see Footnote 23).

Predictions Samples and Their Performance (see Footnote 23).
On the other hand, in the second row of Table 7, we can see a case contrary to the previous one. We can see that, for the same triple as the previous instance, Salamandra-2B-Instruct has generated a very long text introducing Fawkham city, which is not what we were aiming for. Similarly to the first case, lexical metrics perform quite poor and the similarity metrics perform better (but nevertheless worse than previously). If we analyze the metrics more deeply, we can see that BLEU, METEOR, and CHRF++ all present results under 0.2, which was to be expected given the content of the prediction. The semantic scores give a better result, ranging between 0.48 and 0.73, which can also be expected given that, even though it is not the answer we expected, it also speaks about Fawkham, which is a relevant part of the real content of the triple.
These examples make it clear that it is necessary to rely on a range of metrics to better understand the results obtained. As noted earlier, lexical-overlap measures capture only part of text quality in data-to-text generation, particularly when a single reference is used. We, therefore, treat BLEU as one indicator among others and place additional emphasis on METEOR and CHRF++, which better accommodate stemming, character-level overlap, and inflectional variation.
The second example of Table 7 also illustrates the problem of hallucinations when the model cannot grasp the task it is asked for. In Section 4.2.1, we explained that, for 0S instances, when the model didn’t really understand the task we gave them, they tended to generate quite elaborated long texts that were somewhat related to some contents of the triples but did not reflect their meaning. This can also be an example of this case, which reinforces the idea that some sort of learning is needed when we want to execute specific tasks on general-purpose LLM, either context learning, fine tuning, transfer learning or even training them from scratch in some cases.
The results of our study demonstrate the importance of contextualizing the task and/or fine-tuning the model. We have seen that the performance greatly improves for both Spanish and English when going from 0S to 1S setting. Going one step further, small-scale fine-tuning, even with limited computational resources, significantly enhances model performance for Spanish D2T generation, as evidenced by improvements in both task-specific metrics and stability across varying triple set sizes (Figure 5). These findings underscore the practical value of fine-tuning for adapting multilingual models to underrepresented languages, where pre-trained models often lag behind their English counterparts due to disparities in training data representation.
Regarding the individual performance, model-specific performance reveals a few insights for practitioners: Qwen2.5-1.5B-Instruct emerges as the top performer across most metrics, benefiting substantially from fine-tuning and exhibiting robust cross-lingual capabilities. Similarly, Qwen2.5-0.5B-Instruct, while less efficient, delivers competitive results, positioning it as a viable option for low-resource scenarios where computational constraints prioritize smaller models.
On the other hand, Llama-3.2-1B-Instruct struggles with Spanish fine-tuning despite adequate English performance. This pattern suggests that, in our setting, pre-training language representation and model capacity may be more influential than task familiarity alone when adapting to Spanish triple-to-text generation. Finally, Salamandra-2B-Instruct, though computationally efficient, generally underperforms the other models in both Spanish and English settings.
These observations align with our multilingual and error analysis, which reinforces the necessity of language-specific adaptations. While models like Qwen2.5-1.5B-Instruct demonstrate promising cross-lingual transfer (despite a performance gap between English and Spanish), others like Llama-3.2-1B-Instruct may benefit from targeted training strategies or task-specific adaptation. The stark contrast in Llama-3.2-1B-Instruct’s performance across languages (excelling in English but faltering in Spanish) suggests that task competence alone is insufficient; successful adaptation hinges on a model’s ability to internalize language-specific structural and semantic patterns.
This study also highlights three key implications for Spanish D2T that could also be extrapolated to multilingual NLP:
Fine-tuning efficiency: Even minimal fine-tuning can help mitigate linguistic under-representation in pre-trained models, offering a cost-effective pathway to improve performance for languages like Spanish. Model selection criteria: Performance, computational cost, and language adaptability must be balanced. For Spanish-centric applications, Qwen2.5-1.5B-Instruct is optimal for low or medium-resource settings, while Qwen2.5-0.5B-Instruct provides a pragmatic compromise for more resource-constrained environments. Performance metrics selection: We observed that, for our task, some metrics that were normally used in the English sibling task were not really representative of the results we were obtaining. When selecting metrics, we have to take into account not only the task being evaluated but also the language of the data, given that each language has its own grammatical and vocabulary characteristics that might need specific accommodations.
Conclusions and Future Work
This article presented a study on the performance of resource-efficient models in the Spanish triples-to-text task. First, we created a Spanish dataset for triple-to-text, Spanish WebNLG. This dataset was developed via a semi-supervised process of automatic translation and formatting, followed by a manual revision of triples and potentially problematic verbalizations. Given the availability of both the triples and verbalizations in Spanish, the dataset also presents the potential to be used bidirectionally for generating triples from plain text as well. Second, we developed a study addressing the three main research questions presented in Section 1. Regarding RQ1, "How effectively can resource-efficient LLMs verbalize Spanish triples across different complexity levels?", the results presented in the evaluation show that resource-efficient LLMs are potentially capable of verbalizing triples sets of different size in Spanish, demonstrating their suitability for this task, as the models present competitive results across most lexical and semantic metrics. For RQ2, ‘‘How does task contextualization through examples impact model performance in Spanish triple verbalization?", the study showed that contextualizing the task with examples significantly improved the models’ performance, as we observed a notable improvement from a 0S to a 1S scenario, both in terms of evaluation metrics and processing time. Lastly, for RQ3, ‘‘What are the comparative advantages and limitations of prompt learning versus partial fine-tuning for Spanish triple verbalization?", the study found that partial fine-tuning, specifically using LoRA, generally led to improved performance in both metrics and time efficiency. Even though fine-tuning requires an initial time and resource investment, we see that fine-tuning also translates into a time efficiency improvement that, although modest, makes the overall performance better with fine-tuning compared to prompt learning.
During the multilingual and error analysis, we also observed that Spanish can offer a broader range of valid surface realizations for the same underlying content, supported by richer verbal inflection, gender/number agreement, and more flexible word order. Because of these differences, we cannot always apply the same methods and metrics to both languages. Evaluation must consider linguistic nuances, such as morphology, syntax, and idiomatic expressions, to ensure fair and accurate assessments.
As future work, we plan to explore more concrete modeling strategies for Spanish triple-to-text verbalization, including alternative parameter-efficient fine-tuning methods, improved prompting and constrained decoding, and the end-to-end training of neural architectures on the Spanish WebNLG dataset under a resource-efficiency perspective. On the data side, we aim to conduct a deeper, crowdsourced revision of the corpus that goes beyond low-similarity cases, in order to systematically assess the quality of MT-derived verbalizations, validate cosine-similarity thresholds, and check coherence between triples and texts. We also see importance in extending the benchmark to better reflect the diversity of Spanish by incorporating other Spanish varieties, while continuing to expand the resource to other languages to broaden its linguistic coverage. In parallel, we plan to adapt the dataset towards ontology verbalization for ontology documentation and to investigate how linguistic factors such as morphological richness and syntactic flexibility interact with common automatic metrics and model behavior. Finally, we intend to explore other structured data formats and datasets beyond WebNLG-style triples to further support non-English, resource-efficient NLG in a wider range of scenarios.
Footnotes
Acknowledgments
This work is supported by Grant MALTA PID2024-159504OB-I00, funded by MICIU/AEI/10.13039/501100011033 and by "ERDF/EU". We also want to thank the WebNLG creators and especially the CNRS/LORIA team for their guidance during the planning of the Spanish WebNLG development.
Funding
This work is supported by Grant MALTA PID2024-159504OB-I00, funded by MICIU/AEI/10.13039/501100011033 and by "ERDF/EU".
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Appendix A. Context Learning Prompts
Fine Tuning Spanish Test 2 Full Evaluation Results.

| Metrics | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Triple size | Model | BLEU | METEOR | CHRF++ | Cosine Similarity | BERTScore Precision | BERTScore Recall | BERTScore F1 | Average time per triple set in seconds |
| 1 | Llama-3.2-1B-Instruct | 24.27 | 0.516 | 47.68 | 0.846 | 0.710 | 0.823 | 0.754 | 2.33 |
| Qwen2.5-0.5B-Instruct | 34.91 | 0.623 | 65.43 | 0.894 | 0.882 | 0.889 | 0.884 | 0.47 | |
| Qwen2.5-1.5B-Instruct | 40.23 | 0.668 | 68.89 | 0.909 | 0.894 | 0.903 | 0.897 | 0.56 | |
| Salamandra-2B-Instruct | 32.98 | 0.605 | 64.79 | 0.896 | 0.877 | 0.885 | 0.880 | 0.45 | |
| 2 | Llama-3.2-1B-Instruct | 12.81 | 0.450 | 39.79 | 0.833 | 0.651 | 0.782 | 0.704 | 3.26 |
| Qwen2.5-0.5B-Instruct | 33.14 | 0.639 | 65.49 | 0.910 | 0.872 | 0.876 | 0.873 | 0.77 | |
| Qwen2.5-1.5B-Instruct | 35.63 | 0.663 | 67.55 | 0.921 | 0.879 | 0.883 | 0.879 | 0.95 | |
| Salamandra-2B-Instruct | 28.97 | 0.592 | 62.39 | 0.904 | 0.862 | 0.863 | 0.861 | 0.68 | |
| 3 | Llama-3.2-1B-Instruct | 10.99 | 0.456 | 40.43 | 0.840 | 0.646 | 0.774 | 0.700 | 3.75 |
| Qwen2.5-0.5B-Instruct | 31.87 | 0.626 | 63.98 | 0.907 | 0.857 | 0.862 | 0.858 | 1.06 | |
| Qwen2.5-1.5B-Instruct | 36.11 | 0.656 | 67.12 | 0.921 | 0.870 | 0.873 | 0.870 | 1.24 | |
| Salamandra-2B-Instruct | 27.75 | 0.572 | 60.89 | 0.900 | 0.851 | 0.849 | 0.849 | 0.88 | |
| 4 | Llama-3.2-1B-Instruct | 10.25 | 0.462 | 41.59 | 0.846 | 0.647 | 0.763 | 0.697 | 4.04 |
| Qwen2.5-0.5B-Instruct | 27.78 | 0.572 | 60.78 | 0.891 | 0.841 | 0.845 | 0.842 | 1.36 | |
| Qwen2.5-1.5B-Instruct | 31.42 | 0.614 | 63.81 | 0.911 | 0.857 | 0.858 | 0.857 | 1.58 | |
| Salamandra-2B-Instruct | 24.65 | 0.532 | 58.05 | 0.889 | 0.839 | 0.833 | 0.835 | 1.10 | |
| 5 | Llama-3.2-1B-Instruct | 10.92 | 0.467 | 44.57 | 0.861 | 0.654 | 0.763 | 0.701 | 4.34 |
| Qwen2.5-0.5B-Instruct | 27.07 | 0.560 | 60.25 | 0.893 | 0.837 | 0.837 | 0.836 | 1.64 | |
| Qwen2.5-1.5B-Instruct | 30.56 | 0.607 | 63.57 | 0.918 | 0.854 | 0.853 | 0.853 | 1.94 | |
| Salamandra-2B-Instruct | 24.11 | 0.511 | 56.84 | 0.889 | 0.835 | 0.825 | 0.829 | 1.29 | |
| 6 | Llama-3.2-1B-Instruct | 12.35 | 0.503 | 48.83 | 0.879 | 0.676 | 0.767 | 0.716 | 4.49 |
| Qwen2.5-0.5B-Instruct | 27.70 | 0.560 | 60.48 | 0.890 | 0.834 | 0.833 | 0.833 | 2.00 | |
| Qwen2.5-1.5B-Instruct | 30.78 | 0.591 | 62.96 | 0.919 | 0.850 | 0.848 | 0.848 | 2.28 | |
| Salamandra-2B-Instruct | 24.29 | 0.502 | 56.76 | 0.890 | 0.833 | 0.819 | 0.825 | 1.50 | |
| 7 | Llama-3.2-1B-Instruct | 12.96 | 0.510 | 50.89 | 0.895 | 0.681 | 0.764 | 0.718 | 4.53 |
| Qwen2.5-0.5B-Instruct | 29.75 | 0.561 | 61.65 | 0.894 | 0.825 | 0.824 | 0.824 | 2.31 | |
| Qwen2.5-1.5B-Instruct | 33.87 | 0.587 | 64.44 | 0.923 | 0.846 | 0.839 | 0.842 | 2.62 | |
| Salamandra-2B-Instruct | 22.90 | 0.473 | 55.23 | 0.886 | 0.828 | 0.809 | 0.817 | 1.58 | |
BLEU = Bilingual Evaluation Understudy; METEOR = Metric for Evaluation of Translation with Explicit ORdering; CHRf++ = Character n-gram F-score, extended version.
Fine Tuning English Test 2 Full Evaluation Results.

| Metrics | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Triple size | Model | BLEU | METEOR | CHRF++ | Cosine Similarity | BERTScore Precision | BERTScore Recall | BERTScore F1 | Average time per triple set in seconds |
| 1 | Llama-3.2-1B-Instruct | 56.63 | 0.815 | 81.41 | 0.970 | 0.965 | 0.966 | 0.965 | 0.272 |
| Qwen2.5-0.5B-Instruct | 48.26 | 0.776 | 77.54 | 0.956 | 0.958 | 0.959 | 0.958 | 0.404 | |
| Qwen2.5-1.5B-Instruct | 49.09 | 0.796 | 79.31 | 0.960 | 0.958 | 0.961 | 0.959 | 0.474 | |
| Salamandra-2B-Instruct | 39.73 | 0.735 | 74.34 | 0.940 | 0.945 | 0.950 | 0.947 | 0.431 | |
| 2 | Llama-3.2-1B-Instruct | 43.46 | 0.779 | 76.00 | 0.964 | 0.957 | 0.959 | 0.957 | 0.458 |
| Qwen2.5-0.5B-Instruct | 39.46 | 0.743 | 73.28 | 0.952 | 0.949 | 0.951 | 0.949 | 0.653 | |
| Qwen2.5-1.5B-Instruct | 40.05 | 0.764 | 74.55 | 0.961 | 0.951 | 0.954 | 0.952 | 0.769 | |
| Salamandra-2B-Instruct | 33.04 | 0.703 | 70.28 | 0.938 | 0.938 | 0.943 | 0.940 | 0.680 | |
| 3 | Llama-3.2-1B-Instruct | 38.75 | 0.741 | 72.45 | 0.950 | 0.947 | 0.951 | 0.948 | 0.670 |
| Qwen2.5-0.5B-Instruct | 35.72 | 0.720 | 70.32 | 0.944 | 0.945 | 0.946 | 0.945 | 0.884 | |
| Qwen2.5-1.5B-Instruct | 37.41 | 0.731 | 72.15 | 0.955 | 0.946 | 0.949 | 0.947 | 1.051 | |
| Salamandra-2B-Instruct | 27.66 | 0.649 | 65.95 | 0.933 | 0.932 | 0.935 | 0.933 | 0.879 | |
| 4 | Llama-3.2-1B-Instruct | 35.77 | 0.711 | 70.47 | 0.938 | 0.942 | 0.946 | 0.943 | 0.859 |
| Qwen2.5-0.5B-Instruct | 31.51 | 0.669 | 67.67 | 0.931 | 0.939 | 0.939 | 0.939 | 1.133 | |
| Qwen2.5-1.5B-Instruct | 33.03 | 0.685 | 68.79 | 0.944 | 0.942 | 0.943 | 0.942 | 1.329 | |
| Salamandra-2B-Instruct | 25.37 | 0.621 | 63.74 | 0.920 | 0.926 | 0.928 | 0.926 | 1.105 | |
| 5 | Llama-3.2-1B-Instruct | 34.24 | 0.681 | 69.07 | 0.934 | 0.938 | 0.941 | 0.939 | 1.020 |
| Qwen2.5-0.5B-Instruct | 30.17 | 0.644 | 65.65 | 0.928 | 0.937 | 0.935 | 0.935 | 1.324 | |
| Qwen2.5-1.5B-Instruct | 31.21 | 0.652 | 66.78 | 0.935 | 0.939 | 0.938 | 0.938 | 1.580 | |
| Salamandra-2B-Instruct | 24.01 | 0.570 | 61.09 | 0.906 | 0.924 | 0.924 | 0.923 | 1.309 | |
| 6 | Llama-3.2-1B-Instruct | 32.45 | 0.661 | 67.91 | 0.933 | 0.936 | 0.938 | 0.936 | 1.207 |
| Qwen2.5-0.5B-Instruct | 28.26 | 0.614 | 64.08 | 0.924 | 0.935 | 0.932 | 0.933 | 1.603 | |
| Qwen2.5-1.5B-Instruct | 29.88 | 0.651 | 66.06 | 0.933 | 0.936 | 0.937 | 0.936 | 1.946 | |
| Salamandra-2B-Instruct | 23.18 | 0.565 | 59.81 | 0.900 | 0.923 | 0.920 | 0.921 | 1.538 | |
| 7 | Llama-3.2-1B-Instruct | 35.19 | 0.672 | 69.70 | 0.929 | 0.939 | 0.937 | 0.937 | 1.346 |
| Qwen2.5-0.5B-Instruct | 31.38 | 0.623 | 66.06 | 0.922 | 0.937 | 0.931 | 0.934 | 1.827 | |
| Qwen2.5-1.5B-Instruct | 32.71 | 0.635 | 67.61 | 0.931 | 0.939 | 0.936 | 0.937 | 2.187 | |
| Salamandra-2B-Instruct | 24.87 | 0.543 | 60.05 | 0.892 | 0.925 | 0.918 | 0.921 | 1.759 | |
BLEU = Bilingual Evaluation Understudy; METEOR = Metric for Evaluation of Translation with Explicit ORdering; CHRf++ = Character n-gram F-score, extended version.