
Abstract
We live in a big data era of unstructured data expressed as natural language (NL) texts. As the volume of text-based information grows, effective methods for encoding and extracting meaningful knowledge from this corpus are of paramount relevance. A challenging task concerns transforming NL texts into structured and semantically rich data. Semantic web technologies have revolutionized how we represent and access structured knowledge. Resource description framework (RDF) triples serve as a fundamental building block for this purpose, enabling the integration of diverse data sources. This investigation examines methods for RDF triple generation and knowledge graphs (KGs) enhancement from NL texts. This study area presents wide-ranging applications encompassing knowledge representation, data integration, NL understanding, and information retrieval. Our systematic literature review addresses the understanding, characterization, and identification of challenges and limitations in existing approaches to RDF triple generation from NL texts and their inclusion into an existing KG. We retrieved, categorized, and analyzed
Introduction
An unprecedented volume of text is generated daily in modern information systems, leading to large data sources from which meaningful knowledge can be derived. In particular, natural language (NL) texts (e.g., web pages, social network posts, and unstructured textual documents) have been generated substantially in the past few years (Kríž et al., 2014).
A great portion of such textual data remains largely unprocessed and untapped (Egger & Gokce, 2022), representing a reservoir of information that could be explored for deriving actionable insights. In this scenario, developing novel methodologies and software tools to convert large volumes of unstructured text into structured, computer-interpretable knowledge is of paramount relevance.
Unlocking the potential of unprocessed NL text can significantly contribute to informed decision-making grounded on knowledge representation. With resource description framework (RDF) (Candan et al., 2001) triples at their core, Semantic Web technologies offer an approach to organizing said information. In this context, knowledge graphs (KGs) (Ehrlinger & Wöß, 2016) play a key role in creating rich and interconnected RDF triples by structuring interlinked data meaningfully (Paulheim, 2017).
KGs serve as invaluable assets across diverse domains, ranging from applications related to improving search engine outcomes (Xiong et al., 2017) to those targeting the enhancement of results of artificial intelligence models and applications (Schneider et al., 2022). Our motivation extends to the critical role KGs play in powering various applications and services (Ji et al., 2022; Zou, 2020). These structured knowledge repositories find applications in diverse fields, including but not limited to information retrieval systems (Arnaout & Elbassuoni, 2018), query and answering questions (Yasunaga et al., 2021), and data integration platforms (Bytyçi et al., 2023; Suchanek & Weikum, 2013a).
The core issue addressed in this investigation is the effective generation of RDF triples from NL texts. This often encompasses tasks regarding entity recognition (Mansouri et al., 2008), relation extraction (Nasar et al., 2021), and challenges in transforming textual information into a structured, semantically rich format. Our study also investigates existing methods in the literature for incorporating generated RDF triples into an existing KG, respecting an underlying ontology (Gruber, 1995).
Studies present distinct approaches for generating RDF triples from NL texts based on natural language processing (NLP) techniques. Some consider rule-based methods like open information extraction (OpenIE) (Dutta et al., 2015) and semantic role labeling (SRL) (Rossanez et al., 2020b) which aim to identify the triple elements (subject, predicate, and object) from textual sentences based on their grammatical structures. More recent research employ transformers (Vaswani et al., 2017) and other types of neural network architectures in identifying and generating RDF triples to generate a KG from scratch.
We investigate additional challenges in enhancing an existing KG with new RDF triples. For instance, KGs require respecting existing intrinsic ontology statements. This often involves identifying already-existing triples and whether they follow such ontology definitions. This integration is even harder when constructing a KG relies on assimilating a fully comprehensive knowledge set at once. KGs are constructed based on the information available at a given moment, making it arduous to capture the entirety of knowledge in a single instantiation comprehensively. The constantly expanding repository of NL texts introduces a dynamic facet to this challenge. Textual data is not stagnant, as new knowledge is continuously generated, thus requiring, a mechanism for KGs to keep pace with this influx of information. In this sense, KGs need to constantly change and evolve automatically or manually to adhere to the evolution of knowledge in the domain they represent (Regino et al., 2021). Information “freshness” and “recency” in KGs of any size or domain is critical to their usefulness (Sendyk et al., 2022).
Existing survey articles on RDF triple generation emphasize the creation of new KGs (Bytyçi et al., 2023; Suchanek & Weikum, 2013a). We found studies describing solutions for similar problems, including transforming table-formatted texts in RDF triples (Auer et al., 2007), transforming relational databases in RDF triples (Thuy et al., 2014), and generating NL texts from RDF triples (Moussallem et al., 2018). Nevertheless, to the best of our knowledge, there is no available systematic literature review that combines research related to RDF triple generation and KG enhancement from NL texts.
This systematic literature review provides insights into how unstructured textual data are transformed into RDF triples and how the produced knowledge is aggregated into existing KGs linked to an underlying ontology. Our specific objectives are:
Investigate studies and techniques that identify relevant parts of NL-produced texts to transform it into RDF triples. Intent and entity discovery, relation extraction, and named entity recognition are examples of such techniques. Investigate techniques that automatically or semi-automatically build RDF triples in a single domain (e.g., biology and medicine) or multi-domain. Investigate methods that link the created triples to an existing set of classes and relations defined by one or more ontologies. Investigate techniques that check the added knowledge’s for consistency, validity, and semantic coherence.
Our study employs a systematic approach organized into three phases: preparation, execution, and reporting. Each phase involves distinct steps, from formulating research questions to categorizing and analyzing relevant articles. Our methodology includes defining research questions, identifying query strings, defining inclusion/exclusion criteria, categorizing studies and methods, generating metadata, description, and analysis of results, and reporting on open challenges in the field.
Our study offer in-depth descriptions of categories, challenges, advancements, and triple-generation trends from NL texts and KG enhancement. We offer researchers and practitioners valuable insights for future investigations. For those entering the study of text-to-triple transformation, this review provides a structured overview, highlighting key considerations in the field. Our study also identifies the varied approaches and methodologies employed in the surveyed articles. Paper search identified
The proposed categorization is a foundation for synthesizing information and discerning common trends, challenges, and advancements within each thematic group. This structured approach may be relevant to researchers, practitioners, and enthusiasts interested in extracting targeted knowledge based on their specific areas of interest. Readers, especially those new to the field, can navigate these categories to understand specific aspects, like technical methodologies, language specificity, and ontology construction. Follows: aside from this introduction, this article has seven other sections. Section 2 formalizes the problem and its components. Section 3 presents the methodology of how we systematically evaluated the state-of-the-art. Section 4 provides quantitative analyses of the retrieved articles. Section 5 categorizes and describes the key relevant articles filtered, and Section 6 discusses relevant aspects of our findings and addresses the research questions. Finally, Section 7 draws conclusion remarks of the article.
This section defines the triple generation problem and highlights its inherent difficulties (Section 2.1), using a motivating example (Section 2.2).
Triple Generation: Formalization and Challenges
This section formalizes the key terms and concepts central to this research. Figure 1 presents the typical pipeline for triple generation and KG enhancement from NL texts.

Typical pipeline for triple generation and KG enhancement based on NL texts. It comprises five elements (set of textual documents, ontology, generated triples, existing KG, and enhanced KG) and two processing components. Boxes
As core elements we have: A shared and formal conceptualization and representation of knowledge (Gruber, 1995). Formally, an ontology A graph-based representation constructed by linking RDF triples according to the structure defined in ontologies. Formally, a KG is a connected directed graph formed by A category or type within the ontology representing a set of entities with common properties. Formally, A characteristic or attribute associated with entities in the ontology. Formally, A statement in the form of a subject-predicate-object, representing a relation between entities in the KG. Formally,
Based on such formalization, the problem of generating RDF triples from NL texts and appending them to an existing KG can be formally defined as follows:
Given a set of NL texts
Common challenging problems faced in triple generation refer to:
Aggregating triples to an existing KG poses additional challenges, such as:
Let us consider the following sentences:
For the first example
<SpaceX, founded_by, Elon Musk> <SpaceX, known_for, space_exploration> <SpaceX, known_for, innovation>
The created triples should be integrated into an existing
For
We list the following challenges for converting
This section describes the methodology for systematically reviewing the literature on triple generation and KG enhancement from NL texts based on Budgen and Bereton (Budgen & Brereton, 2006). Figure 2 presents our methodology with three distinct phases: preparation, execution, and reporting. A series of ordered steps further delineate each of these phases. This phase-based structure provides a comprehensive overview of the entire procedure and highlights our experimental approach’s systematic and controlled nature.

Systematic literature review methodology comprising three main phases: preparation, execution, and reporting. Each phase comprises steps represented by numbers from 1 to 15.
The “Preparation Phase” serves as the initial step, in which we lay the groundwork for our investigation. During this phase, we formulate research questions, identify relevant scientific databases, and establish rigorous inclusion and exclusion criteria (steps 1–6 in Figure 2). The preparation phase seeks to construct a process that guides this systematic literature review article.
We proceed to the “Execution Phase,” in which we pragmatically implement the process discussed in the preparation phase. This phase entails executing a sequence of planned tasks, including database queries, article retrieval, and applying inclusion and exclusion criteria. We synthesize data, categorize results, and perform preliminary analyses (steps 7–11 in Figure 2). The execution phase emphasizes data acquisition and initial assessments.
Finally, the research concludes with the “Reporting Phase.” We gather all our analyses, including bibliometric, quantitative, and qualitative assessments, into a cohesive and structured presentation. This phase is dedicated to synthesizing our findings, the systematic organization of results, and in-depth analytical examinations (steps 13–15 in Figure 2). We discuss our outcomes comprehensively, emphasizing their implications and significance within the context of our survey’s objectives.
Sections 3.1, 3.2, and 3.3 describe each phase and their steps.
Study Definition. Initial Questions to Define the Reasons for Conducting This Study, as well as Its Targets.

Study Definition. Initial Questions to Define the Reasons for Conducting This Study, as well as Its Targets.
RDF = resource description framework.
We would accept any RDF triple generation method (e.g., entity recognition and relation extraction). This choice sought to embrace the diversity of methodologies prevalent in the field, ensuring a comprehensive exploration of the topic. We would not restrict the survey to scientific articles by the type of natural language texts (e.g., news articles, academic papers, and social media posts). This decision allows to capture the breadth of RDF triple generation applications across different textual domains.
The motivation to review the literature on triple generation and KG enhancement derived from the lack of this type of research in the state-of-the-art based on our initial observations of result analyses. Among all the articles found on the subject of generating triples (in this study), only 10% referred to adding these triples to an already existing KG.
Overview of RQs. These Focused Inquiries Form the Basis for Exploring the Surveyed Literature.

RQs = research questions; RDF = resource description framework.
The RQs address the benefits and drawbacks of the surveyed methods, patterns in input texts and generated triples, the most utilized and accurate techniques, the presence of fully automated approaches, applications benefiting from the methodologies; and the exploration of T-Box and A-Box in text-to-triple generation. These research questions not only serve as a guide for our analyses but also function as a means to benchmark the success of our survey.

The query string represents a balance between completeness and specificity. The selection of terms reflects the multifaceted nature of the field, encompassing aspects such as entity recognition, relation extraction, and knowledge representation.
The iterative process of refining and validating the query string in equation (1) involved a continuous dialogue among the research team (authors in this article), ensuring that the queries encapsulate emerging trends and diverse perspectives within the domain. The final set of search terms, detailed in Appendix Table 10, represents a distilled synthesis of our collective understanding.
We assume that these databases contain highly ranked and cited articles relevant to our study. The chosen databases collectively offer a broad spectrum of publications, including conference proceedings and journals, ensuring a sound exploration of the academic landscape.
Inclusion Criteria (IC). Articles Must Present the Characteristics Here Defined to be Included in the Study.

RDF = resource description framework.
Exclusion Criteria (ECs). Articles Wwith Such Characteristics Are Not Included in the Study.

In summary, we included articles that scientifically (IC-01) contribute to the understanding of RDF triple generation from NL texts (IC-02), written in English (IC-03) and that uses RDF specification (IC-04). By setting these standards, we sought to ensure that the articles chosen were not only recent but also provided comprehensive insights into the current state-of-the-art. We excluded articles that are too old (EC-01), duplicates (EC-02), short (EC-03), without abstract (EC-04), not written in English (EC-05), and without further explanation on how generating triples based on text (EC-06).
While reading, we took detailed notes and highlighted key information extracted in the following steps: “Create Categories,” “Generate Metadata,” and “Describe Results.”
We employed a collaborative approach in the review process. To this end, we involved
The rationale behind involving master’s and PhD students in this collaborative review lies in many reasons. First, the students’ academic standing ensures an understanding and critical analysis necessary for interpreting the nuances present in scientific articles. Their familiarity with the Semantic Web and ontologies domain positions them as adept evaluators of the selected articles. Moreover, including these graduate students aligns with a commitment to diversity in perspectives. Drawing on their varied academic backgrounds and research interests within the Semantic Web, those students brought a breadth of insights that enriched our study’s analytical depth. The collaborative approach contributed to a shared understanding of the reviewed literature among the research team, reducing risks associated with using a possible biased categorization.
In addition to the categorization, the students identified valuable aspects of each article’s characteristics, including the availability of the data investigated in the article, the type of evaluation conducted, and an assessment of the solution’s applicability in real-world settings. These insights, derived from the students’ discerning analysis, provided a holistic view of the articles beyond their immediate contributions to RDF triple generation and KG enhancement. After the students categorized the articles, the authors of this study reviewed the provided results, correcting potential erroneous categorizations when necessary.
Categorizing the articles facilitates the synthesis of information and helps identify common themes and trends in the literature. Table 5 presents the proposed 10-category set followed by a brief description.
Categories of the Retrieved Articles and Their Correspondent Description, According to This Study’s Focused Areas.

Categories of the Retrieved Articles and Their Correspondent Description, According to This Study’s Focused Areas.
The categories for organizing the collected articles reflect a diverse landscape of methodologies in the context of RDF triple extraction and KG enhancement from NL texts. We grouped categories that describe similar aspects of the literature to improve comprehension:
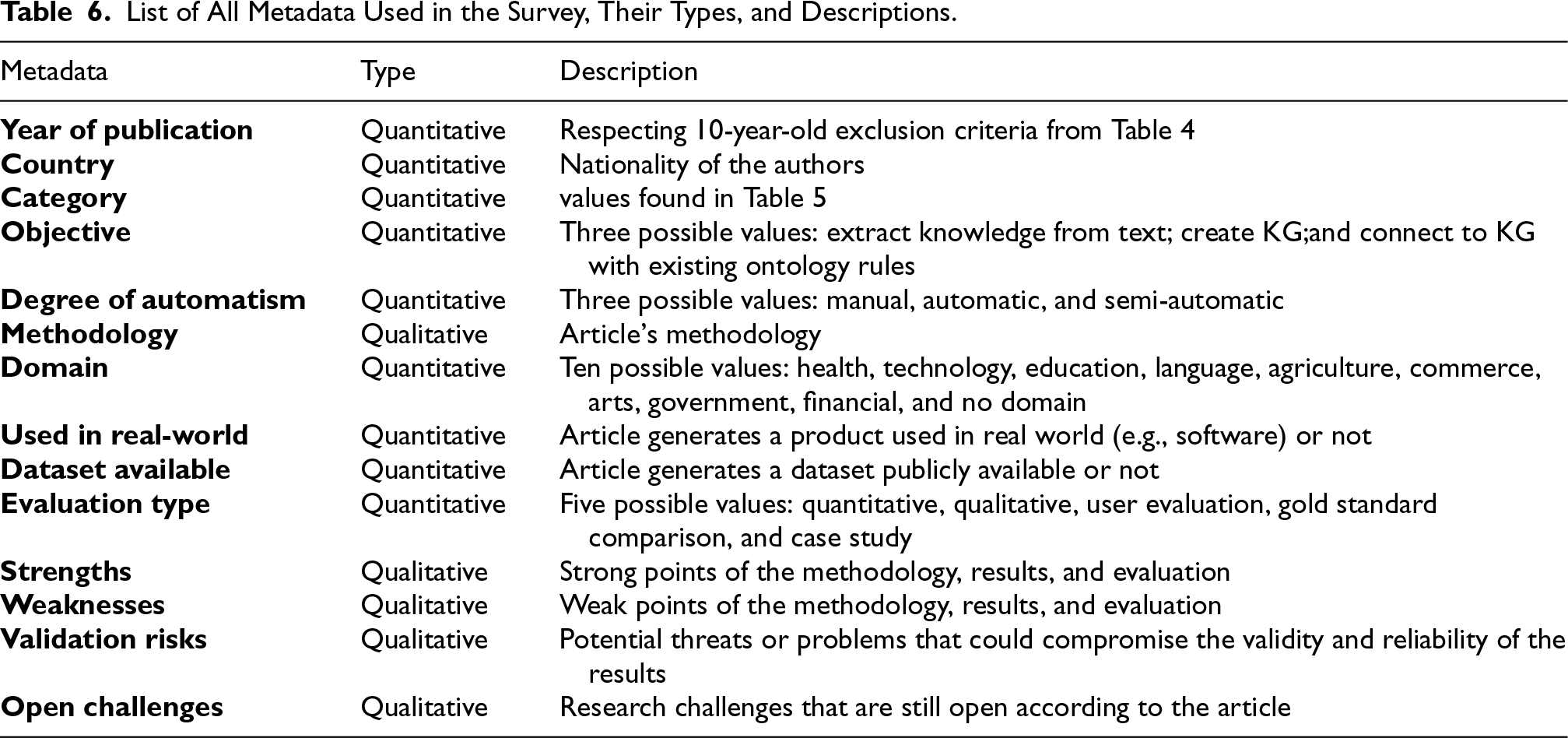
List of All Metadata Used in the Survey, Their Types, and Descriptions.
Following a detailed full-text analysis, we identified a smaller subset of studies that directly addressed our core research focus—namely, the generation of RDF triples from natural language and their integration into existing KGs. Although related to triple generation, most of the initially retrieved articles centered on constructing new KGs rather than updating existing ones. These were therefore not included in the in-depth methodological review presented in Section 5.
Nonetheless, the full collection of articles remains essential to our study. Section 4 presents a broader statistical and quantitative examination of the field, exploring aspects such as publication trends, venues, datasets, evaluation approaches, and the types of natural language inputs considered. This broader analysis provides important context and supports our efforts to understand the field holistically. It also plays a critical role in addressing RQ-05, as many applications are relevant regardless of whether the focus is on building a new KG or updating an existing one. Examining the entire dataset enables us to map out the real-world domains and use cases that drive research in this area, helping to identify gaps and opportunities.
Although several prior surveys have reviewed techniques for generating RDF triples from text (Masoud et al., 2021; Nismi Mol & Santosh Kumar, 2023; Suchanek & Weikum, 2013b), our study occupies a distinct space in the literature. To our knowledge, there has been no focused review examining methods for generating RDF triples that conform to ontological constraints and are suitable for insertion into pre-existing KGs. In this way, our work contributes a unique perspective that advances the understanding of RDF triple generation within this context.
In summary, the broader set of papers forms the foundation for a wide-ranging analysis of the field, while the focused subset enables a more detailed evaluation of approaches directly relevant to knowledge graph updates. These two analytical layers—one broad, one deep—are complementary and offer a well-rounded view of the current research landscape.
Statistical Analysis
This section presents a quantitative analysis of the literature on RDF triple generation based on NL texts. We aim to gain insights into the research landscape in this domain. In this analysis, we used all

Number of articles by publication year. We observe a growing trend in the later years, especially from 2019 to 2022. The numbers related to 2023 are from January to August.

Number of articles by category. Lower number of studies in the multilingual or link creation categories present an opportunity for future research. On the other hand, studies focusing on the A-Box population or English-specific are more common.

Number of articles within the

Number of studies by each type of evaluation. Studies evaluated by quantitative analysis (especially focusing on using gold standards) are more commonly observed in the literature.
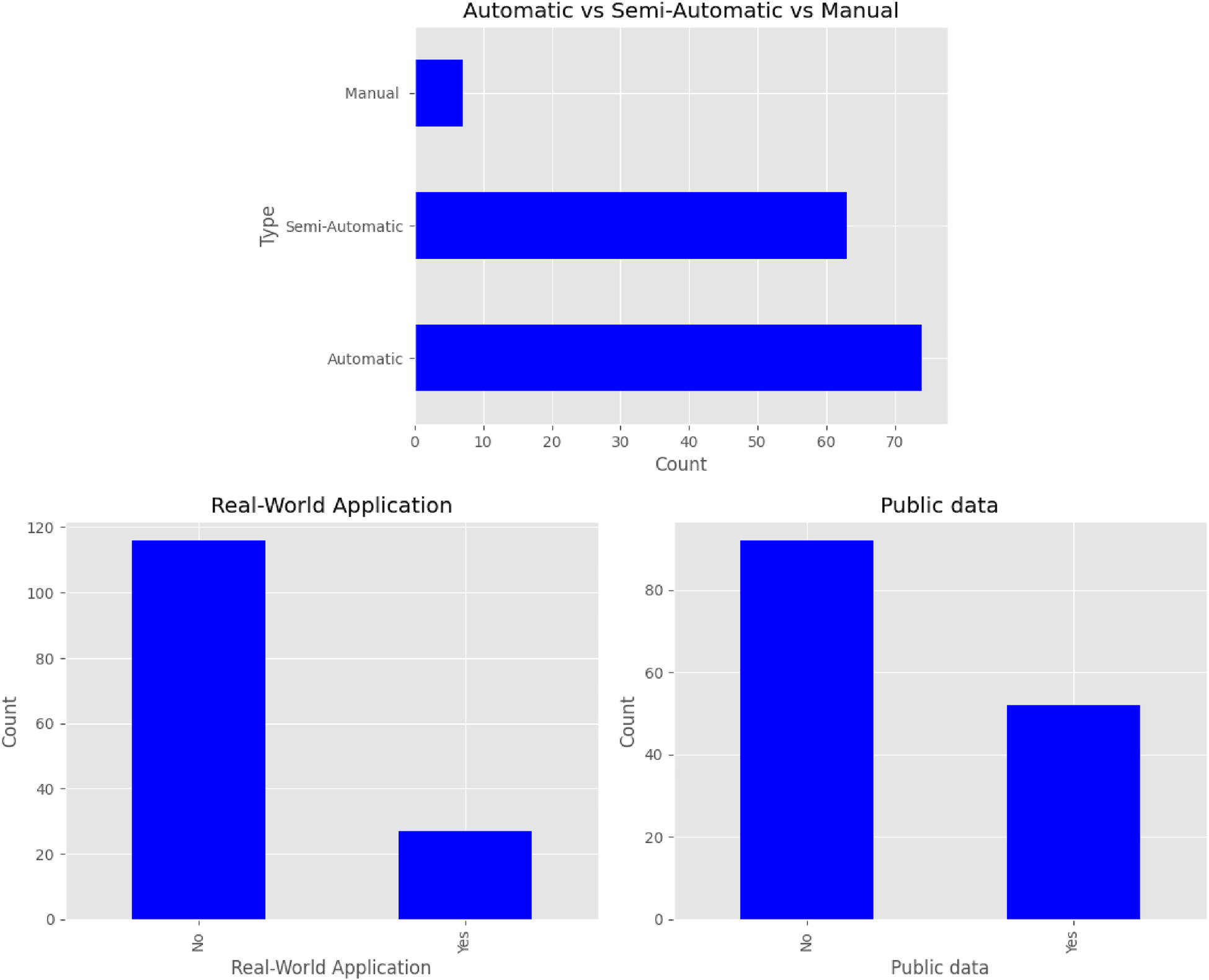
Three plots describing how automatic the solution is, how applicable it is in the real-world settings, and how research data are publicly available. Most studies present a fully automated method, do not relate to a real-world usage scenarios, and do not disclose their data publicly.
Number of Studies Found, According to the Scientific Database. Elsevier Scopus and IEEE Xplore Have Yielded More Relevant Studies.
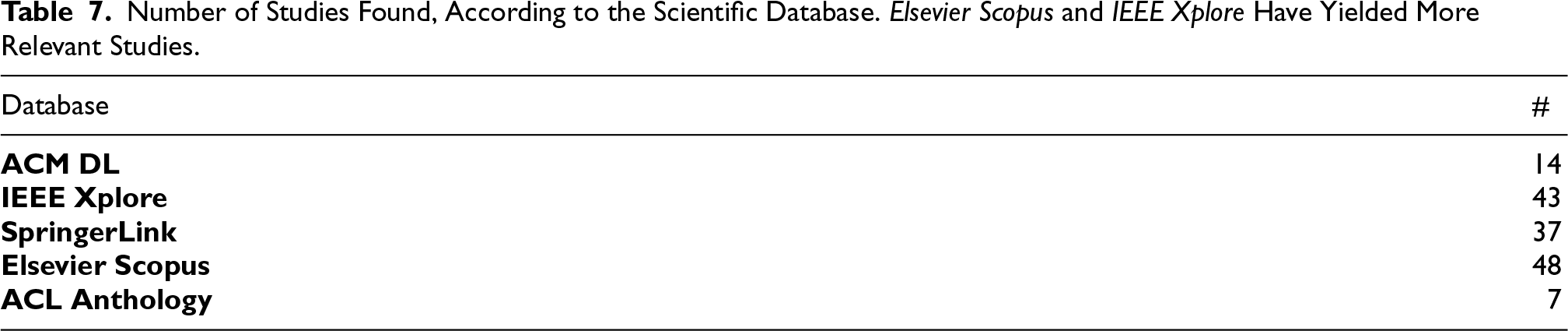
Figure 3 presents the number of articles published annually. One may notice a growing trend, especially considering the 2019–2022 interval. Such a finding helps to ensure the relevance of our work’s subject in recent years. We further analyze and discuss our findings from this analysis in Section 6 (discussion).
Figure 4 presents the number of articles per category. We included a category for survey-related studies, totaling
Additionaly the distribution of articles across categories and evaluation approaches can indicate more mature areas (e.g., A-Box population, generic transformation, and English-specific) or those which require further investigation (e.g., multilingual, link creation, and non-English). In our analysis, each article may belong to one or more categories.
Figure 5 presents the most common domains in which RDF triples are extracted from NL texts for posterior KG enhancement. Most of the studies found target no specific domain. As for studies focusing on specific domains, health is the most frequent, followed by technology, and science & education. We observe a relation between the domain of NL text; the KG produced from these triples, and the application that benefits from this knowledge. Figure 5 contributes to answer
Figure 6 presents the number of articles grouped by the type of evaluation they employ. We identified five distinct types of evaluation, such as quantitative analysis and case studies. This figure highlights the diversity of methodologies used in assessing the proposed solutions.
We investigated the extent to which the solutions are capable of automation which is a fundamental factor in assessing these methods’ scalability and real-world applicability. The first plot in Figure 7 categorizes articles based on how they describe their solutions’ level of “automaticity.” We classify articles into three categories: automatic, semi-automatic, and manual. The level of “automaticity” in the proposed solutions can inform us about how ready for practical deployment they are.
We analyzed studies concerned with real-world applications and discussed data availability. Both of them have implications for the practicality and reproducibility of the research. Identifying how many articles have been applied in real-world scenarios and how many make their data publicly available guide researchers in selecting the most relevant and accessible resources for their work. In the second plot in Figure 7, we explore the practical relevance of the articles by counting how many of them describe applications of proposed methods in real-world settings. In the third plot of Figure 7, we show the number of articles that handled publicly available data. By observing the numbers concerning the automation aspect in Figure 7, we can positively answer
This section categorizes the identified studies related to RDF triple generation from NL texts aiming to enhance KGs. The categorization of articles provides a navigational guide to help understand the area under study. Additionally, this sets the stage for discussions, paving the way for advancements in this domain.
From the
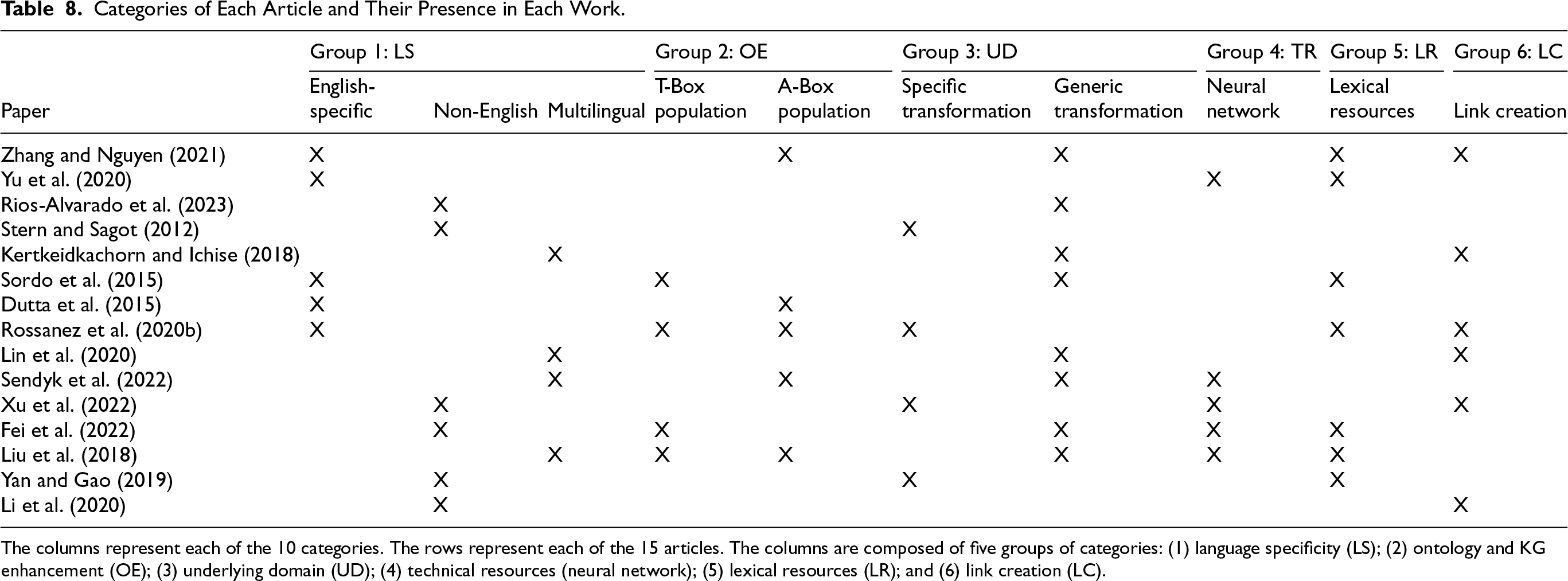
The upcoming sections describe in further detail the categories and the studies that best fit such categories (relying on our procedure conducted for this purpose). Table 8 presents our proposed organization of categories relying on our observations from the analyzed articles. Table 9 describes the learning methods used by each paper to transform text into RDF triples, the evaluation metrics and their respective values.
Categories of Each Article and Their Presence in Each Work.
Categories of Each Article and Their Presence in Each Work.
The columns represent each of the 10 categories. The rows represent each of the 15 articles. The columns are composed of five groups of categories: (1) language specificity (LS); (2) ontology and KG enhancement (OE); (3) underlying domain (UD); (4) technical resources (neural network); (5) lexical resources (LR); and (6) link creation (LC).
We considered the language specificity addressed in the study. More specifically, we considered whether the method applies to English texts (cf. Section 5.1.1), other languages (cf. Section 5.1.2), or even if applicable to texts in multiple languages (cf. Section 5.1.3). Language specificity is represented by the Group 1: LS in Table 8.
Multilingual KGs created over multilingual texts provide a versatile solution by handling multiple languages within a single model, enabling broader language coverage. However, they may face challenges in achieving language-specific precision. Language-specific KGs, while resource-intensive, can offer superior accuracy and depth for individual languages. The choice between multilingual and language-specific depends on the application’s language requirements and the trade-off between broad coverage and language-specific proficiency.
English-Specific
Zhang and Nguyen (2021) focused on generating triples from a text in English. Their primary objective was to create KGs and connect them with ontology classes and properties. The methodology involved text preprocessing, including filtering by English, removal of special words, and capitalization. The following step was done by applying distinct relation and entity extraction methods, including rule-based, OpenNRE, and OpenIE (Fader et al., 2011). The extracted relations were inserted into a graph database, and a software tool was created to explore the results. The specific textual domain is health-related (COVID-19), and although the application has not been used in real-world settings, the dataset is public. The conducted evaluations are quantitative. The solution’s strengths lie in its automation, independence from domain experts, and generalizability. In turn, the solution may yield limited results because it sometimes employs models trained in unrelated domains. Open challenges include using advanced extraction techniques like BERT (Devlin et al., 2019) and connecting to external vocabularies for additional information, such as DBpedia (Auer et al., 2007).
Similarly, Yu et al. (2020) focused on generating triples from texts in English. Their primary objective was establishing connections with classes and properties in an existing ontology. The methodology lies in constructing a network encyclopedia classification system and KG. Domain experts defined the classification system as a KG with concepts and instances. A web crawler algorithm extracted classification information, capturing upper and lower concept relations. Co-occurrence analysis mined implicit associations between concepts, facilitating the extraction of upper and lower relations during KG construction. Their algorithm quantifies co-occurrence probabilities based on the occurrence frequency of classifications, identifying relations if certain conditions are met. Their solution utilized classification data from encyclopedia entries to ensure a reliable and rich KG, showing the interplay between web crawling, co-occurrence analysis, and semantic analysis in constructing a comprehensive classification system. Yu et al. (2020) specifically constructed a KG related to food. Their method was applied in a project using a public dataset. The conducted evaluation was quantitative. The solution’s strengths lie in its comprehensive approach to relation extraction in a domain KG, through various knowledge sources, including structured, semi-structured, and unstructured data. Their method employed a convolutional residual network for extracting lower relations from web texts and stored the resulting KG in Neo4j, 8 showing practical applicability. Concerning their investigation weaknesses, the solution presented dependencies on available knowledge sources, and its effectiveness is contingent on the quality of training data, which is highly sensitive to extraction errors. Risks to the validation included the potential imperfections and errors in the Wikipedia data used for experiments and the necessity for parameter tuning in NLP and semantic analysis algorithms. Open challenges involved developing different relation extraction models for diverse forms of knowledge existence.
Non-English
Rios-Alvarado et al. (2023) investigated triple generation from documents written in Spanish. Their main goal was knowledge extraction from texts, the KG creation, and the connection with classes and properties from an existing ontology. The methodology involved text segmentation using NLP, word tagging, knowledge extraction through lexical analysis, and KG construction. The application domain was technology. Evaluations included quantitative analysis and comparison with a gold standard. The strength of this solution appears in enabling knowledge extraction from Spanish language text, which is not common in the literature. Potential weaknesses included the manual validation of extracted entities using a small sample, which can impact accuracy and reliability. Open challenges included exploring alternative methods for feature extraction and implementing the KG for question-answering applications.
The study by Stern and Sagot work (Stern & Sagot, 2012) belongs to the non-English category as they focused on extracting entities from French texts. The methodology employed NER with the support of well-known databases, such as Wikipedia, 9 Aleda (Sagot & Stern, 2012), and Geonames, 10 specifically tailored for news-related content. The automated process links these entities to ontologies and assigns URIs, subsequently compiling a database containing all identified entities and their occurrences in news articles. The solution’s strengths lie in its reliance on widely acknowledged databases for NER. Their work addressed texts in French exclusively. The investigation publicly evaluated its methodology through quantitative measures and comparison with a Gold Standard, emphasizing transparency in its assessment.
Learning Value and Evaluation Metrics of Each Article.

Learning Value and Evaluation Metrics of Each Article.
The first shows the articles; the second column is the main method used to generate triples from a text; the following four columns present quantitative values: accuracy (ACC), precision (PRE), recall (REC), and F1. The last column shows if the authors perform a qualitative evaluation (QLI). The rows represent the papers. RE stands for relation extraction; NER stands for named entity recognition; OpenIE stands for open information extraction; IM stands for instance matching; SRL stands for semantic role labeling; DP stands for dependency parsing.
Kertkeidkachorn and Ichise (2018) constructed a multilingual framework to map predicates from NL texts to KG triples, named T2KG. The methodology combined rule-based and similarity-based approaches and includes five steps: (1) entity mapping, linking entities in the text to corresponding entities in the KG; (2) coreference resolution, detecting chains of entities and pronouns referring to the same entity; (3) triple extraction, extracting relation triples from the text using open information extraction techniques; (4) triple integration, generating a text triple by combining results from entity mapping, coreference resolution, and triple extraction; and (5) predicate mapping, mapping a predicate of a text triple to a predefined predicate in other KGs. Their solution extracts information from textual documents and aims to integrate it into a KG. The goal was to incorporate new information into preexisting knowledge structures (e.g., ontologies and KGs). The solution applies to various domains. The authors report achieving high precision, recall, and F1 scores, effectively mapping their generated triples to DBpedia’s, and integrating significant new knowledge into the existing KG. The major drawback is the difficulty in mapping complex predicates. Validation risks include potential errors in graph generation depending on the input data. Open challenges involve improving triple extraction accuracy, handling complex predicates, integrating multiple sources of information, and developing effective methods for assessing KG quality, completeness, correctness, and consistency, as well as error identification and correction.
Ontology and KG Enhancement
In this category, we investigate whether the study comprises the triple generation from NL texts either enhances the Ontology that describes an existing KG, that is, populating T-Box (cf. Section 5.2.1), or enhancing the instances portion of the knowledge representation, that is, populating A-Box (cf. Section 5.2.2). The ontology and KG enhancement are represented by Group 2: OE in Table 8.
T-Box Population
Sordo et al. (2015) focused on extracting knowledge from unstructured text sources to generate structured data for music recommendations. The methodology involved identifying relevant entities in texts, extracting meaningful relations between them, and connecting this knowledge to existing ontology classes and properties. The methodology of the knowledge graph construction comprised several key steps, beginning with text input preprocessing, segmenting the input text into sentences, and tokenizing. This work employed NER using DBpedia Spotlight (Mendes et al., 2011) to identify music-related entities, focusing on types like song, band, person, album, and music genre. Simultaneously, dependency parsing (DP) generates trees for sentences, aiming to find relations between multi-word music-related entities. These processes were integrated in a subsequent step, combining NER and DP results by merging nodes in the dependency tree corresponding to recognized entities. The subsequent stages involved relation extraction (RE), in which relations between recognized music-related entities are extracted based on paths in the dependency trees. Empirical rules were introduced to filter out relations irrelevant linguistically. Finally, a graph representation was constructed, encapsulating the music-related entities as nodes and their relations as edges. This graph, composed of five distinct entity types, provided a structured representation of the knowledge extracted from the input text, facilitating a comprehensive understanding of relations within the music domain.
The domain of their work was in the arts, particularly music. The application of their work relates to a real-world project, and the dataset used was publicly available. Evaluations include quantitative and qualitative analyses, user evaluations, and comparisons with a gold standard. The solution’s strengths include using NL for user recommendations, which enhances the user experience, and comparing the extracted knowledge with a gold standard to assess the quality of the relations. Its weaknesses include low recall in extracting relations, potentially leading to the loss of relevant information, and the need for a prior syntactic simplification step to handle potentially noisy relations. Potential validation risks include limited generalization due to a single dataset and the possibility of noisy relations extracted from text variability. Open challenges relates to improving relation extraction system recall and evaluating the method on larger, more diverse datasets for generalization assessment.
A-Box Population
Dutta et al. (2015) generated KGs and connected them to classes and properties of an existing ontology. The methodology involved data clustering before mapping the relations between phrases and clusters. The employed methodology concerns constructing a KG by converting open information extraction (OIE) (Fader et al., 2011) facts into assertions within a target knowledge base (KB). The process involved four key components: instance matching (IM), lookup (LU), clustering (CL), and property mapping (PM) modules. The domain of this work referred to language, and although it was not used in a real-world setting, the dataset is publicly available. Their investigation described an evaluation protocol that includes quantitative assessments and comparisons with a gold standard. One of their solution’s strengths is its focus on simplifying the mapping process for knowledge bases, with clustering being a valuable addition. No weaknesses were identified explicitly, but potential validation risks include dealing with identical phrases that might have different meanings. An open challenge is creating a T-box when certain relations present in OIE do not exist in the target knowledge base.
Underlying Domain
In this category, we considered studies that are either applicable to a specific domain, for example, biomedical (cf. Section 5.3.1), or those which are domain-agnostic (cf. Section 5.3.2). Domain specificity is represented by Group 3: UD in Table 8.
Specific Transformation
Specific transformation refers to methodologies for generating triples for a specific domain. The intersection emphasizes the alignment of domain-specific approaches with ontology construction, highlighting how these methodologies often tailor the generation process to the intricacies of a particular domain.
Rossanez et al. (2020b) presented a specialized method for generating KGs specifically in the biomedical domain. The methodology comprised four main steps: preprocessing, triple extraction, ontology linking, and graph generation. The focus was on extracting knowledge from biomedical texts, connecting it to existing ontologies, and ultimately generating a KG. While the application has not been used in a real-world application, the dataset used is public, and the evaluations included quantitative and qualitative assessments. The strengths of their solution include proposing a semi-automatic method for KG generation and relating it to existing ontologies. The method identifies primary and secondary relations. Validation relies on a ground truth defined by medical experts, albeit not domain specialists. The results show promise, especially regarding the Jaccard coefficient. Weaknesses include the method not being entirely automatic, domain limitations due to the vast internal vocabulary of various medical subfields, and the relatively small number of samples (e.g., articles in the medical domain) evaluated by medical experts. Identified potential validation risks include the involvement of non-specialist medical experts, which might have introduced bias, and the use of abstracts rather than full-text articles, which hinders the assessment of the generalizability of the results. Open challenges included the development of an automatic approach for generating RDF triples more akin to those created by domain specialists, leveraging logical inferences to capture implicit relations in texts, exploring the use of other KGs and ontologies to enrich the main set of triples, comparing knowledge graphs linked to different ontologies using UMLS CUIs (Bodenreider, 2004), and involving more domain-specific experts to establish a baseline for comparison.
Generic Transformation
Generic transformation represents methodologies that generate triples agnostic to a specific domain. This intersection shows how even domain-agnostic approaches often involve ontology construction, showcasing the relevance of aligning the generated triples with a predefined ontology.
Lin et al. (2020) introduced a method that generates triples across various domains. They aimed to extract knowledge from a text by generating KGs and their connection with existing ontology classes and properties. Their methodology included two key stages: knowledge extraction and knowledge linking. The first stage extracts information from documents, including entities and triples. The second stage constructs a graph from this data, and the linkage between entities and predicates is determined using similarity measures. Notably, their study was applied in real projects and leverages public datasets, making it suitable for generalized application. Their evaluation involved quantitative analysis and comparison with a gold standard. Lin et al. (2020) solution’s strengths included the population of incomplete and outdated knowledge bases, extraction and organization of information from unstructured documents, utilization of a semantic graph approach, efficient integration of entities and relations, and effectiveness demonstration compared with other reference techniques. Their study also handled the coherent creation of new entities. However, the proposed method may face limitations in scenarios with very large or complex datasets, and its linking efficacy can depend on the quality of reference KB data. Challenges include dealing with ambiguity and polysemy in extracted information, potential biases in datasets, erroneous input data, and matching failures between entities and relations in reference datasets. Open challenges involve improving entity and relation linking in lengthy and complex documents, adapting the method for different domains and languages, exploring techniques for handling noisy and ambiguous data, and investigating the scalability of the method for larger datasets.
“A Task-Agnostic Machine Learning Framework for Dynamic Knowledge Graphs,” authored by Sendyk et al. (2022), falls under the category of generalized transformations. Their study described the development of a generic framework capable of generating triples in any domain. Their methodology involved a series of steps, including web data extraction, training NLP models based on synthetic data, page classification, sentence segmentation, and graph generation. Notably, the framework was designed for a specific domain, allowing its application across various fields. While their defined process is semi-automatic, incorporating manual classification, the study addressed potential biases by implementing steps to avoid user biases during classification and introducing synthetic data to enhance the available dataset. The solution’s strengths lie in its attempt to mitigate user biases and augment data availability through synthetic data. Challenges include the need for a robust manual classification step and potential risks associated with biased classification and imbalanced base texts. Validation aspects included the framework assessment using quantitative measures and a case study, showing its real-world applicability and emphasizing the need for well-defined manual classification steps in open challenges.
Neural Networks
This category represents methodologies that uses neural network architecture for triple generation.
Transformers (Balabin et al., 2022) are neural network models that rely on the attention mechanism to draw global dependencies between their inputs and outputs. They are often used in text-to-text applications, such as translation. In the literature, several studies employ such models to identify entities and relations from text to build triples.
Graph neural networks (GNNs) (Scarselli et al., 2008) are used in relation extraction tasks and knowledge representation. We found no articles in the literature that describe solutions using GNNs for the complete pipeline of transforming text into triples and adding them to an existing KG.
Xu et al. (2022) described how they used BERT-based and bootstrapping methods to construct a constantly evolving KG in the domain of Traditional Chinese Medicine (TCM). BERT is a transformer-based deep learning model by Google used in various NLP tasks (Devlin et al., 2019). The authors state that the KGs in the TCM domain are static, not fully representing the evolving characteristics of the medicine domain. To overcome this problem, they proposed a methodology that generates a dynamic growth of the proposed KG. It starts by collecting data based on user input keywords and then employs the BERT-CRF (Wu & He, 2019) to identify entities and Bootstrapping to identify relations and obtain structured data. Finally, the structured data was integrated into an existing KG. Bootstrapping is applied to extract the relation between symptoms of diseases and their causes. The entity recognition and relation extraction result is merged into an existing KG. While the method allows the continuous and dynamic growth of the TCM KG through user interactions, its main difficulty lies in merging KGs, especially in handling equivalent entities and term ambiguity. Also, the authors Xu et al. (2022) do not describe how to assess the qualitative aspects of the added information to the KG. Additionally, the methodology was only applicable to English-based knowledge and the TCM domain (Xu et al., 2022).
Fei et al. (2022) relied on few-shot relational triple extraction (RTE) to construct triples. The authors state that traditional triple-construction approaches are not aware of the semantics and coherence of the generated triples. The proposed methodology, perspective-transfer network (PTN), included a multi-perspective approach to constructing a KG. It operates on episodes comprising support and query sets. The framework designed by Fei et al. (2022) used three perspectives: relation, entity, and triple. In the relation perspective, the query detects potential relations by marking entity pairs sentences. A binary classifier predicts if a relation exists among them. If a relation is identified, the entity perspective extracts entity spans in the query, combining relation and entity information into triples. The triple perspective then validates these triples, utilizing labeled query sentences and a binary classifier. Although it does not have a specific domain, the solution can be applied generally. It has not been used in a real project, but the dataset is public, and the evaluations involve quantitative analysis and a comparison with the gold standard. The main strength of their solution (Fei et al., 2022) is the ability to handle a few training examples, which is a common limitation in many NLP tasks. Additionally, their study explore the utilization of an efficient and scalable neural network architecture that can be trained on modern GPUs. Also, the solution is fully automatic and does not require human intervention. As a downside, the solution may be computationally intensive, requiring substantial hardware resources. Its performance can be sensitive to the quality of the input data, mainly affected by annotation errors and data noise (Fei et al., 2022).
Liu et al. (2018) proposed an application named Seq2RDF, which uses the transformer architecture to construct triples. Seq2RDF was one of the first applications of transformers to build KGs, in 2018. The methodology involves applying transformers and generating embeddings for triple generation. It uses DBpedia (Auer et al., 2007) as input to train models, with the encoder processing NL sentences and the decoder producing triples in the <subject, predicate, object> format. Their solution (Liu et al., 2018) is generic and not limited to a single domain. It was applied to a real-world project, but their dataset is public. Evaluations included quantitative analysis and comparison with a gold standard. The authors state that the differential of Seq2RDF is its simplicity and efficiency for generating triples from NL texts. The downside of Seq2RDF remains that it can only generate a single triple per sentence.
Lexical Resources
External lexical resources, such as WordNet (Miller, 1995), PropBank (Kingsbury & Palmer, 2003), or VerbNet (Palmer & Kipper, 2004), have been explored to assist RDF triple generation. Examples of their application include identifying verbs and their parameters in sentences as candidates for subjects or objects. Resources like Yago (Suchanek et al., 2007), BabelNet (Navigli & Ponzetto, 2012), or SpaCy (Honnibal & Montani, 2017), are often employed for identifying named entities in texts. This category emphasizes the reliance on linguistic resources in language-specific contexts, showcasing how the utilization of such resources plays a crucial role in these methodologies.
Yan and Gao (2019) fits this category. Using the Baidu Encyclopedia to aid in the KG construction. Their main objective was to generate KGs and connect them to existing ontology classes and properties, focusing on the domain of biology, specifically water. Their methodology involved information extraction, knowledge fusion, and knowledge processing. Information extraction encompasses extracting entities (concepts), attributes, and relations between entities from the data source, forming the foundation for ontological knowledge representation. After acquiring new knowledge, the following step, called knowledge fusion, integrates this new knowledge to eliminate contradictions and ambiguities. The method was applied in a project and the used dataset is public. The conducted evaluation (Yan & Gao, 2019) was based on a case study. The solution’s strengths lie in customizing the wrapper for extracting entity attributes and values from semi-structured water entry data in the encyclopedia. On the other hand, its weakness lies in the dependence on data sources, as the quality and quantity of data can impact the comprehensiveness of content extraction. The main validation risk is the lack of comparisons with other methods. Open challenges involve expanding the scope of extraction to acquire more knowledge and conducting further research to identify potentially better methods for KG construction in the water domain.
Link Creation
This category focuses on methodologies that create links to existing well-known Linked Open Data (LOD) datasets. LODs often adhere to standardized ontologies and vocabularies, such as RDF and OWL. This adherence ensures consistency and interoperability between different datasets, reducing ambiguity and enhancing the overall quality of information in the KG.
“AliMe KG: Domain Knowledge Graph Construction and Application in E-commerce,” by Li et al. (2020) was categorized under link creation due to its primary focus on connecting newly created triples with other existing datasets. Their proposal involved key components, such as phrase mining, named entity recognition, relation extraction, and knowledge fusion. The authors described a semi-automated process for knowledge acquisition and validation, incorporating human annotation and feedback cycles to enhance KG precision and completeness. Their study (Li et al., 2020) was applied in the e-commerce domain and showcases real-world applications of the AliMe KG in pre-sales conversation scenarios. The evaluation combines both quantitative and qualitative assessments. The solution’s strengths include providing a systematic methodology with semi-automated processes for mining structured knowledge from NL texts applicable to multiple languages and domains. Identified challenges include the significant need for human annotations and feedback cycles, which can be time-consuming and expensive. The solution also relies on external knowledge sources, introducing potential issues of reliability and currency, leading to biases or errors in the KG. Risks to validation involve biases in data sources and potential inaccuracies in external knowledge, impacting the representation and generalization of results. Open challenges include expanding the AliMe KG coverage in the Alibaba e-commerce platform and exploring its application in various domains beyond e-commerce.
Open Challenges
This section describes key findings (cf. Section 6.1) and common themes and revisits our research questions (cf. Section 6.2). We discuss open research challenges and potential paths for future investigations (cf. Section 6.3).
Findings and Limitations
Publication years analysis (Figure 3) reveals a growing trend, especially from 2019 to 2022, which suggests an increasing interest in and importance of the surveyed topic and justifies the relevance of our study. We believe that the numbers for 2023 did not follow this trend because many accepted articles have not yet entered the scientific databases (Table 7). In 2024, data related to 2023 will be better consolidated. Given the increasing adoption of generative models for various NL processing tasks, including those related to KGs, we expect an accelerated growth in the coming years. The increasing adoption of RAG (retrieval augmented generation) (Lewis et al., 2020) indicates that KGs can and should be used with LLMs for information retrieval tasks.
Study categorization served as a venue for understanding the diverse methodologies employed in generating RDF triples from NL texts and enhancing KGs. Each category addresses specific aspects, such as language specificity, ontology and KG enhancement, domain specificity, use of neural networks, lexical resources, and link creation.
Clustering of articles across categories (Figure 4) provides a comprehensive overview of research efforts. These results align with the subset of
Regarding transformation and domain categories (Section 5), we identified the proximity between specific single-domain transformations and generic transformations across multiple domains. WCreating domain-specific KGs can benefit companies, government agencies, or any other entities interested in using specific KGs, given that their maintenance involves domain experts to ensure information consistency and less maintenance. On the other hand, KGs spanning multiple domains may face maintenance and accelerated growth challenges due to the multiplicity of domains and, consequently, the continuous creation of RDF triples. As such, we believe that, for example, creating a specific and local KG about the health sector—the domain with the most articles based on our results (cf. Figure 5)—offers more benefits in terms of creation and maintenance than a domainless KG.
The less represented categories but of great relevance to this research are multilingual and link creation. More solutions should somehow support the creation of links with other ontologies or existing KGs. The rationale is that such solutions would facilitate information reuse, connecting nodes from local KGs with larger and more established KGs. In this sense, they would contribute to the LOD movement, transforming a Web with some disconnected data islands into an interconnected archipelago of data (Regino et al., 2021).
Article distribution based on evaluation types (Figure 6) highlights the methodological diversity in assessing existing proposed solutions. Quantitative methods were widely employed since this type of assessment can use a large set of texts and triples as input, which facilitates adapting the methodology and refactoring tests. With a large dataset, quantitative analysis enables researchers to iteratively adjust their methodologies and improve testing procedures, ensuring a more comprehensive and informed evaluation of proposed solutions.
Figure 7 shows that most of the
Several proposed solutions used a gold standard to evaluate the generated triples. We found no standard used by the
The surveyed articles across various categories exhibit several limitations that provide opportunities for future research and refinement of NL-based KG generation methodologies. First, the challenge of domain specificity. Many studies, particularly those in the specific transformation category, struggle with the adaptability of their approaches to diverse domains. Biomedical applications, for example, present specific requirements that may not be addressed adequately by generic NL-based KG generation methods. Moreover, several articles lack extensive evaluation in real-world scenarios, relying on relatively small datasets or limited case studies. This hinders a comprehensive understanding of the scalability and robustness of the proposed solutions, making it crucial for future work to address this gap by validating solutions in diverse and realistic settings.
Second, while transformer-based approaches present remarkable capabilities, as shown in the neural network category, they are not without limitations. Many studies employing neural network architectures focus on English-centric applications, raising concerns about the generalizability of these methods to non-English languages. Effectiveness of these neural network models can be contingent on the availability of large and high-quality training datasets, limiting their applicability to less-resourced languages. Additionally, the computational intensity associated with neural networks is a common challenge, potentially restricting their deployment in resource-constrained environments. These limitations demand research efforts to enhance the multilingual applicability, dataset diversity, and computational efficiency of transformer-based KG generation methods to foster broader advancements.
Third, Figure 7 indicates that fewer articles explicitly mention real-world applications, suggesting a potential gap between research and practical applications. The availability of publicly accessible data remains limited, impacting the reproducibility and accessibility of the proposed studies.
Answer Summary of RQs
Our literature review enables answering the defined RQs in Table 2. Each RQ was answered throughout this text, which are summarized below:
Promising Research Directions
This section outlines research gaps and promising research directions arising from the analyses and findings described in Sections 4 and 5. We also discuss opportunities identified by us (the authors) and not identified in the reviewed articles in our study.
To the best of our knowledge, no tools exist for adding triples to KG from texts written in NL exclusively for low-resource or low-comprehensive languages. We have found many tools for English Zhang and Nguyen (2021), Yu et al. (2020), Sordo et al. (2015), Dutta et al. (2015), Rossanez et al. (2020b), Spanish Rios-Alvarado et al. (2023), Xu et al. (2022), Fei et al. (2022), French Stern and Sagot (2012), multilingual Kertkeidkachorn and Ichise (2018), Lin et al. (2020), Sendyk et al. (2022), Liu et al. (2018) and other languages with many speakers (Li et al., 2020; Yan & Gao, 2019). Addressing this challenge requires innovative approaches to handle linguistic diversity, improve cross-language generalization, and explore techniques for effective knowledge transfer between languages.
Several studies identified in our systematic literature review reported this challenge. Lin et al. (2020) reported difficulties with both ambiguity and polysemy in noisy data used as input in their method, hidering the process of relation definition between the entities to build the triples. Kertkeidkachorn and Ichise (2018) cited errors that arise with both polysemy and ambiguity, such as low NER accuracy, matching and inconsistent mappings with other KGs. Dutta et al. (2015) discussed errors in their method when dealing with identical phrases. Xu et al. (2022) reported difficulties with equivalent entities in when merging KGs.
An emerging application involves integrating KGs with language models in graph-RAG (retrieval-augmented generation) systems (Dong et al., 2024). In this context, KGs serve as a structured knowledge layer, enhancing the ability of LLMs to generate more accurate and context-aware responses. For instance, in customer support systems, KGs can provide information directly related to a user’s interaction history or the company’s knowledge base, ensuring alignment with verified data.
Conclusion
A considerable portion of textual data remains unprocessed, representing substantial amount of information that holds the potential to provide actionable insights. This is driven by the need to develop novel methodologies and software tools capable of transforming these large volumes of unstructured text into structured, computer-interpretable knowledge. Semantic Web technologies, particularly with the core use of RDF triples and KGs, offer an approach to organize this information. This systematic literature review about studies addressing RDF triple generation from unstructured NL texts sought to enhance existing KGs. We identified the most prominent approaches in the literature for extracting RDF triples from text, especially concerning their inclusion in existing KGs. We provided a comprehensive overview of the domain pointing out the main challenges and the limitations on the current state-of-the-art on such research. Our study systematically surveyed a diverse set of
Footnotes
Acknowledgments
This study was financed by the National Council for Scientific and Technological Development – Brazil (CNPq) process number 140213/2021-0. In addition, this research was partially funded by the São Paulo Research Foundation (FAPESP) (grants #2022/13694-0, #2022/15816-5, and #2024/07716-6). This work was also supported by Nederlandse Organisatie voor Wetenschappelijk Onderzoek [grant number Nwa.1332.20.002]. The authors thank Espaço da Escrita—Pró-Reitoria de Pesquisa—UNICAMP—for the language services provided. The opinions expressed in this work do not necessarily reflect those of the funding agencies.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Notes
Appendix
Table 10 presents all the terms used to query the papers. It is an expanded version of equation (1).
Figure 8 shows the papers submitted by country. Figure 9 highlights the five countries with the highest contribution, namely China, India, the USA, Germany, and Canada.
Considering the institutions, Figure 10 shows the universities that contributed with at least two articles. Of 16 universities, the top five are from China.