
Abstract
Keywords
Introduction
Informed consent is a fundamental ethical requirement in medical research, ensuring that participants have a comprehensive understanding of the risks and benefits associated with their participation. Historical violations in consent related to medical research have shown distrust between minority communities and the clinical research establishment. 1 Clinical researchers must ensure they effectively communicate the implications of participating in medical research in order to ameliorate this distrust. However, the complexity and length of traditional research consent forms can impede comprehension and create barriers to effective communication between researchers and participants. 2 These barriers compromise patient autonomy, pose ethical concerns in research, and can erode trust between patients and researchers. The relationship between ineffective communication and worsened patient care underscores the American Medical Association (AMA) and National Institute of Health (NIH) recommendation that all patient-facing medical information be written at a 6th-grade reading level.3,4
Improved Language learning models present an opportunity to utilize artificial intelligence to optimize research consent forms to be more understandable by enhancing their “readability.” Generative Pre-trained Transformer 3.5, or GPT-3.5, is a Large Language Model that produces humanlike, conversational text passages in response to user input. When prompted, the model generates a statistically-likely text response 3 using a 45 TB dataset of text from the Internet. 5 ChatGPT is a sophisticated language model built upon a neural network structure consisting of sequential layers of attention and prediction. This model is continuously enhanced and refined using a process known as Reinforced Learning from Human Feedback. 6 Through this iterative approach, the model learns and adapts from the guidance provided by human feedback, leading to continuous improvement and enhanced language understanding.
Institutional Review Boards aim to ensure that research consents are cogent yet simple. 7 This study aimed to use ChatGPT to rewrite medical consents for investigative orthopedic procedures, and to compare the readability of the Natural Language Processor-generated research consents to those written by human experts in orthopedic spine, sports, and trauma surgery. We also explored its ability to preserve vital information necessary for adequate informed consent. We hypothesized that ChatGPT could improve the readability of IRB-approved research consent documents.
Methods
This study was conducted at a level one trauma center affiliated with an academic Orthopedic and Sports Medicine Department. Nineteen IRB-approved orthopedic research consents from active, prospective, randomized studies and clinical trials were entered into ChatGPT. The IRB approved all these consent documents before the respective research studies could enroll patients.
A total of 19 consents were analyzed. Each of the consents was broken down into a series of 250-word passages. Sequentially, these passages were then copied into ChatGPT for processing. Preceding each 250-word passage, ChatGPT was prompted with the following:
Help me with my work! I will be feeding you passages of text. You must assist me by making these passages readable at a 6th-grade level. Simplify the text, expanding when necessary, but do not omit crucial detail. Here is the passage:
While ChatGPT purports the ability to have a “conversation” in which the chatbot remembers an initial prompt, in practice, it had to be instructed to simplify each passage individually. Prompting the chatbot only once at the beginning of the conversation without the prompt before each passage caused it to “forget” the initial request over time, leading to nonsensical and unrelated outputs. The “Help me with my work…” prompt was prepended to each passage when submitting inputs to ChatGPT to prevent this.
The resulting ChatGPT-generated outputs were then transferred to a common document to reconstitute a full-length “post-ChatGPT,” consent resulting in 19 post-ChatGPT consents. The 250-word passage length was selected to remain below the resource usage threshold inherent to a ChatGPT query. The 6th-grade reading level, in the ChatGPT prompt, reflects the AMA's recommendation as described in the introduction.
Standard Readability metrics (Figure 1, column 2) were used to evaluate ChatGPT's efficacy in increasing the readability of the original IRB-approved research consents. The metrics reported in Figure 1 have been extensively validated in both linguistic and healthcare literature. The readability scores combine individual textual parameters (Figure 2, column 2) to derive their scores. Readable.com was used to generate these readability metrics. 8
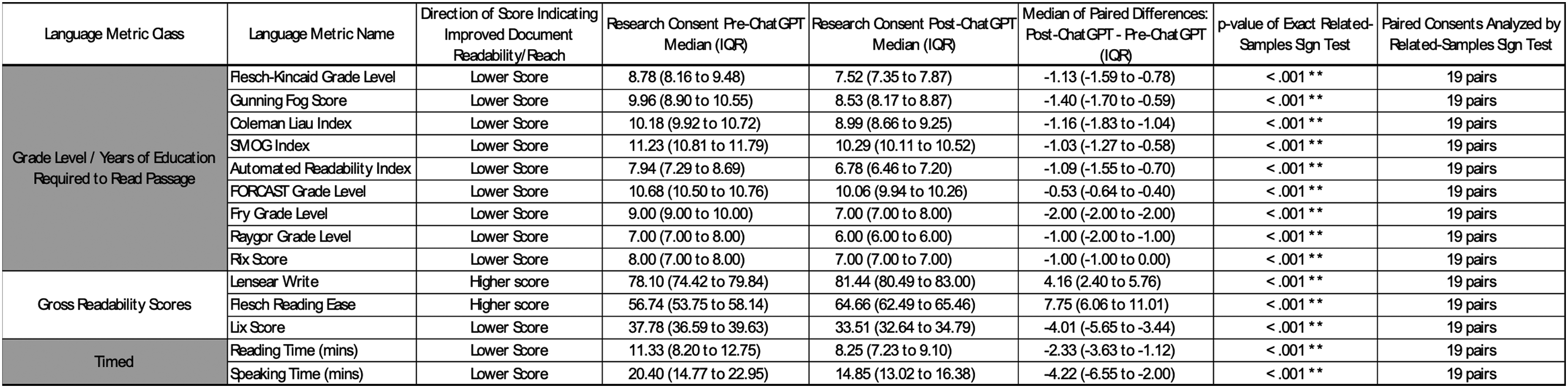
Textual scoring parameters (These scores use differing combinations of the individual textual parameters from Fig. 1 in their derivation) **Denotes a statistically significant p-value (α = 0.05).
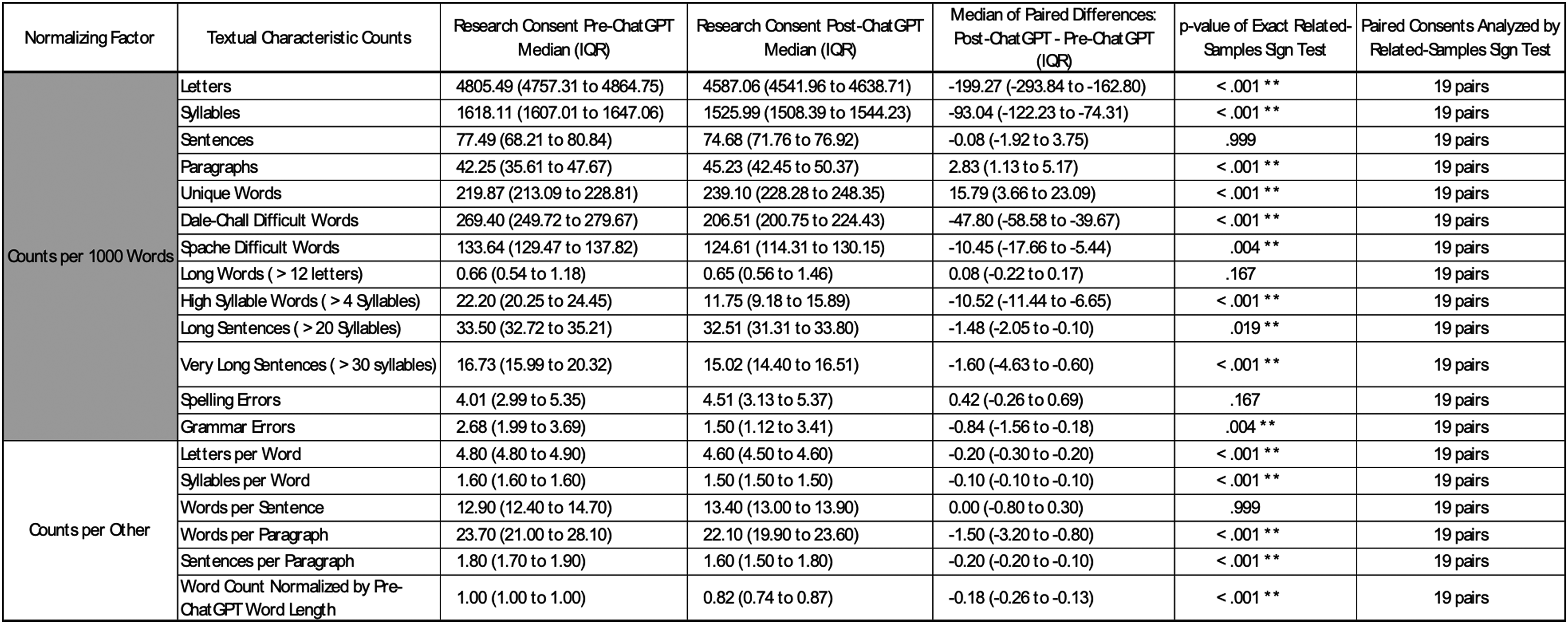
Individual textual parameters. ** Denotes a statistically significant p-value (α = 0.05).
Accuracy and retention of imperative informed consent elements in the post-ChatGPT consents were assessed by an experienced Orthopaedic surgeon who has independently practiced for over 15 years. Type and frequency of errors were recorded.
The pre- and post-ChatGPT readability variables (Figures 1 and 2, column 2) are pairwise variables and were assessed for improved readability using the Exact Sign Test for Paired Samples. This is a nonparametric alternative to the paired samples t-test. The paired samples t-test was not performed because the pairwise pre- and post-ChatGPT differences were not normally distributed using the Shapiro-Wilk's test (p = 0.02). The nonparametric Wilcoxon signed-rank test was not used because the pairwise pre- and post-ChatGPT differences were not symmetrically distributed as analyzed by histogram. The Exact Sign Test for Paired Samples has no distribution requirement and was used; it is less powerful than the other two statistical tests. Sign Test statistics are reported as mean and IQR; the alpha for our study was set to 0.05. 9
Preliminary power analysis indicated 10 paired consents conferred a power of 0.80 in detecting a one-grade level improvement in readability score. Twenty paired consents were initially chosen to double the number needed for the predicted power, but one consent was a duplicate and was therefore removed.
Results
The individual textual parameters (Figure 2) form the foundation for the readability metric calculations (Figure 1). Fifteen of the nineteen variables assessed in Figure 2 had statistically significant median differences between pre-ChatGPT and post-ChatGPT consents. Magnitudes of the effect sizes can be seen in the column titled: “Median of Paired Differences: Post-ChatGPT - Pre-ChatGPT (IQR).” Grossly, these results demonstrate that the post-ChatGPT consents have fewer very long sentences (p < 0.001), less usage of difficult words (p < 0.004), and use shorter words (p < 0.001) that contain fewer syllables (p < 0.001). These results also help to explain the post-ChatGPT consent's 18% median decrease in total words (p < 0.001). The post-ChatGPT consent had no difference in spelling errors (p = 0.167) while achieving fewer grammatical errors (p = 0.004). Post-ChatGPT consents did exhibit more unique words (p < 0.001) and used more paragraphs per 1000 words (p < 0.001), although the latter is best explained by post-ChatGPT consents’ usage of fewer sentences (p < 0.001) and fewer words per paragraph (p < 0.001).
Standard readability metrics are presented in Figure 1. The median differences between pre-ChatGPT and post-ChatGPT were statistically significant for every readability metric (all p < 0.001) and all favored the post-ChatGPT consent as being more readable. All readability scores indicated fewer years of education needed to read the post-ChatGPT consents. Furthermore, ChatGPT generated consents require a less amount of time to read or present. Although the median difference of the 9 Grade Level scores indicated improved readability, only two language metrics, Automated Readability Index and Raygor Grade Level, indicated the post-ChatGPT consent forms could meet the AMA's recommended 6th-grade reading level. Post-ChatGPT consents were assessed for errors (Figure 3). Twelve of 19 post-ChatGPT consents had at least one error. The most frequent error was failing to adequately explain “patient-reported outcome measurements” (7 of 19). The second most frequent error was failing to describe the randomization process (3 of 19) adequately. The most significant error occurred in 1 of 19 consents, where the experimental arm was inadequately explained. None of the post-ChatGPT consents completely omitted a critical informed consent parameter delineated in Figure 3.
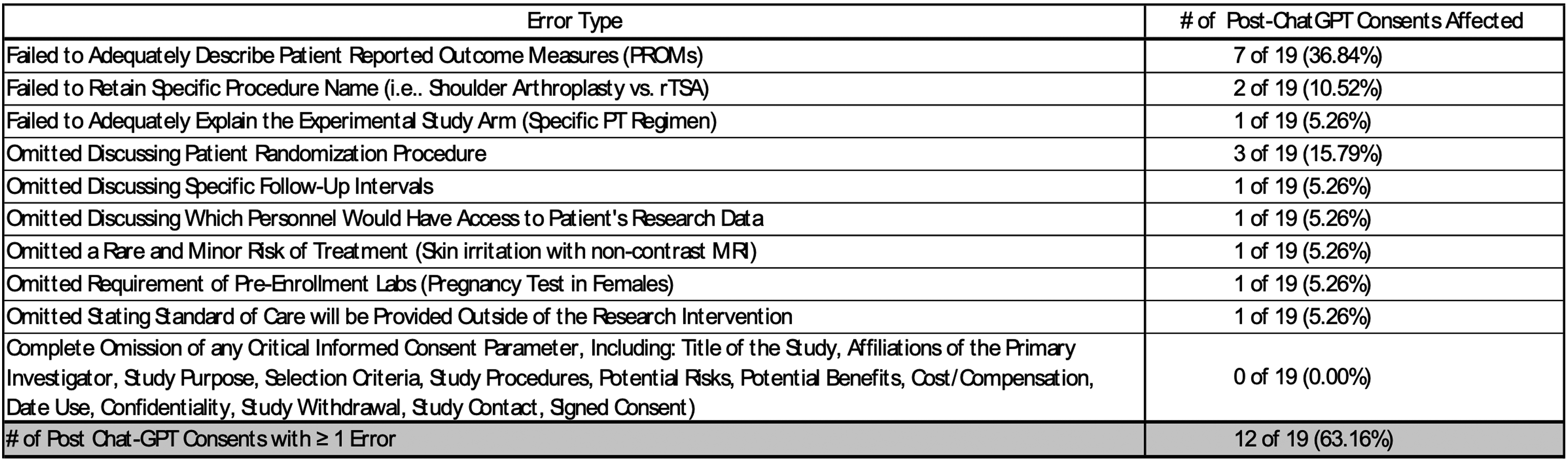
Errors in post-Chat GPT consents (Identified by experienced orthopaedic surgeon with > 15 years independent practice).
Discussion and conclusion
This study demonstrated that Chat-GPT effectively improves the readability of orthopedic research consents. However, these improved scores were still above the AMA's 6th-grade reading level recommendation. In an initial effort to rectify this, ChatGPT was given prompts requesting a “6th-grade reading level” more granularly in terms of the formula used to compute the Flesh-Kinkaid Grade Level score. 10 ChatGPT frequently failed to simplify the passages by any metric when prompted to optimize this score. This is likely due to limitations in arithmetic capabilities inherent to many large language models as a product of their training datasets. 11 As a result, the “Help me with my work…” prompt was used to generate simplified passages. It should be noted that the model has no gestalt understanding of a 6th-grade reading level and is merely producing a statistically-likely output based on patterns inherent to its training dataset.
Current orthopedic practice is highly procedure focused with a large percentage of these procedures being performed in a fast-paced outpatient setting, 12 emphasizing clinical productivity and efficiency. This may cause a discrepancy in the interpretation of research consent between the physician-investigator, research personnel, and the patient. Institutional review boards are tasked with protecting all research subjects and emphasize simplifying the language used in research consent. 13 Used as a standalone tool, ChatGPT produces minimal errors of omission. The error rate in this study supports the use of ChatGPT in a complementary fashion to human clinician/researcher input in writing and reviewing research consents. While the errors identified in this study were predominantly minor in nature, it cannot be assumed that they will consistently remain minor in the future. Consequently, ChatGPT's current role should be seen as a complementary tool alongside a trained clinician or researcher rather than solidifying its position as a standalone substitute.
As OpenAI and its competitors continue to release progressively larger language models for public use, subsequent iterations of this technology should provide an increased ability to generate more readable consent forms in the near future. These models may optimize prompts towards specific grade levels and provide a constellation of “translated” consents based on the individual reading level of each patient in a study. They may also be more receptive to prompt engineering in their ability to generate passages optimized towards specific “readability” characteristics (e.g., “use shorter sentences,” “reduce the average number of syllables per sentence,” “substitute common synonyms without compromising informative value,” etc.).
This study is promising; it demonstrates that a widely available and easy-to-use tool can aid clinicians and research staff in increasing the reach of their orthopedic research consents and likely those of other specialties. 14 Applying language learning models to simplifying consent forms offers numerous benefits in orthopedic research. By prioritizing key information, simplified forms empower patients in the decision-making process, fostering a patient-centered approach. Moreover, they contribute to participant satisfaction and trust, as clear comprehension leads to a sense of value and involvement.
Limitations
This study is not without limitations. Most notably, the readability metrics utilized in this investigation were not specifically formulated for orthopedic clinical research. Therefore, these metrics may penalize a consent form for words or phrases that are verbose or technical but that are necessary for the informed consent process. In the future, a metric explicitly formulated for clinical research would be particularly interesting. An additional limitation of this study is our use of only orthopedic consent forms, limiting the generalizability of these results. Moreover, consent forms for different fields of medicine may be more or less amenable to ChatGPT alterations.
Conclusion
ChatGPT can significantly improve the readability of Orthopedic clinical research consent forms, but these edited consents are not without mistakes and cannot reach the AMA's recommended 6th grade reading level. Therefore, ChatGPT should be used as a tool to supplement the writing and editing process of human researchers.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.