
Abstract
Study Design
Vignette-based cross-sectional study.
Objective
Generative artificial intelligence (AI) programs such as large language models (LLMs) are reshaping treatment decision-making, yet applications in minimally invasive spine surgery (MISS) are still scarce. This study examines whether OpenAI’s ChatGPT-5 Pro and Google’s Gemini 2.5 Pro reproduce expert management categories from published MISS cases and measures agreement at procedural and binary triage levels.
Methods
We constructed 90 clinical vignettes from published case reports and prompted each LLM to assign 1 or more of ten predefined categories with two-sentence rationales. Agreement with reference was assessed using Jensen–Shannon divergence (JSD), Stuart–Maxwell tests, Cohen’s κ, and McNemar’s test for surgical vs non-surgical triage.
Results
Divergence from reference was small, with Jensen–Shannon divergence 0.115 (ChatGPT-5 Pro) and 0.112 (Gemini 2.5 Pro), and smaller between models at 0.073. Paired multinomial tests found differences from the reference (Stuart–Maxwell χ2(9) = 24.8 and 26.0; P = 0.007 and 0.006) but not between models (14.4; P = 0.108). Case-level agreement was slight for ChatGPT-5 Pro and fair for Gemini 2.5 Pro (κ = 0.146 and 0.245). Collapsing categories to surgical vs non-surgical improved agreement (κ = 0.415 and 0.587 vs reference; 0.692 between models) with no bias in rates (P ≥ 0.401).
Conclusions
LLMs may differentiate between surgical and non-surgical triage, but procedure selection should remain expert-led until systems mature. These findings establish a baseline for integrating LLMs into surgical triage workflows and highlight promise and limitations of generative AI in precision spine care.
Keywords
Introduction
Generative artificial intelligence systems that are based on large language models (LLMs) are rapidly entering clinical workflows. Although LLMs have been benchmarked on diagnostic and referral tasks, no prior work has systematically quantified how they perform when choosing among specific procedural classes within minimally invasive spine surgery (MISS) – a decision domain directly tied to patient outcomes, costs, and risk. In spine surgery, early evaluations have compared LLM responses with guidelines from professional societies for common conditions. For lumbar disc herniation, ChatGPT-3.5/4.0 aligned with North American Spine Society (NASS) recommendations in 52-59% of prompts, while also exhibiting “overconclusive” suggestions and omissions – signals of both utility and risk. 1 Similarly, for lumbar spinal stenosis, ChatGPT’s recommendations were often consistent with guideline-anchored literature but required caution pending formal validation. 2
Beyond clinician-facing guidance, patient-facing studies have shown LLMs can produce clinically appropriate explanations about MISS, but at reading levels exceeding recommended thresholds, with inconsistent performance on intraoperative/technical questions. 3 Benchmarking suggests heterogeneity in strengths among currently available models: in endoscopic lumbar surgery, spine surgeons rated Claude 3.5 Sonnet highest for quality and relevance, while non-medical readers found ChatGPT variants most understandable. 4 A head-to-head comparison with physician experts underscores LLMs’ continued inferiority in complex case analysis, even when knowledge-based performance is respectable. 5
Prior LLM studies in clinical decision support have largely emphasized diagnosis, triage, and referral at a general medicine level, sometimes aided by retrieval-augmented generation (RAG) to mitigate hallucinations. 6 However, a focused, procedural category evaluation in MISS – spanning conservative care, interventional pain, decompression, fusion, lesion/tumor resection, emergency surgery, non-spine referrals, and diagnostics – has been lacking. We address this gap with a vignette-based comparison of 2 contemporary LLMs (ChatGPT-5 Pro and Google Gemini 2.5 Pro) against expert decisions abstracted from published MISS case reports, quantifying agreement both at detailed categories and at a binary (surgical vs non-surgical) triage level.
Methods
Study Design and Power Analysis
We performed a vignette-based evaluation using 90 MISS case reports from peer-reviewed literature (Supplement A). A non-systematic PubMed search was conducted without time restrictions, using key terms such as ‘minimally invasive spine surgery’ and ‘case reports’ to identify both surgical and non-surgical reports. From this general search strategy, 90 cases involving MISS techniques and/or relevant pathologies were selected. From each report, we extracted patient demographics, salient history, examination (including neurologic findings), and imaging summaries to form concise, de-identified vignettes that omitted the actual treatment performed. The treatment recorded in the source report served as the reference category for that vignette. Reference management categories covered ten bins: conservative care; image-guided injections/blocks; pain denervation (e.g., radiofrequency); decompression without fusion; decompression with fusion; cyst/lesion resection (non-neoplastic); tumor/mass resection; emergent decompression (red flag); extraspinal/peripheral nerve surgery; and further diagnostics/referral. The study’s category scheme, prompting template, and quality checks were predefined.
Before data collection, we ran an R-based (v4.5.0) power analysis for our planned paired comparisons using a two-sided McNemar test (Miettinen approximation), with familywise α = 0.05 across k = 2 primary pairwise tests controlled via Bonferroni (per-comparison α′ = 0.025) and target power = 0.80. Assuming discordant proportions p01 = 0.24 (Model A incorrect/Model B correct) and p10 = 0.04 (Model A correct/Model B incorrect) – i.e., a net discordance Δ = |p01 − p10| = 0.20 on the binary endpoint “exact match to the reference treatment bin” – the required sample size was n = 67 vignettes. By enrolling n = 90, our study had approximately 91% power (vs approximately 80% at n = 67) to detect the prespecified net discordance Δ = 0.20 under the same assumptions. Holding the total discordant rate fixed (p01 + p10 = 0.28), the minimum detectable Δ at 80% power improves from ≈ 0.199 to ≈ 0.172. Precision also improves: the expected 95% confidence interval (CI) half-width for Δ tightens from ± 0.117 to ± 0.101 (about 13.7% narrower). On the odds-ratio scale (OR = p01/p10), the expected 95% CI narrows from approximately [1.65, 21.87] to [1.97, 18.31]. Overall, enrolling 90 vignettes enhances power, allows detection of smaller effects, and provides more precise estimates under the same design assumptions.
This study used information solely from published, de-identified case reports and involved no interaction or intervention with living individuals. According to Weill Cornell Medicine (WCM) Human Research Protection Program guidance, case reports and secondary analyses of public or non-identifiable data are generally not human subjects research and do not require institutional review board review under Exemption 4 (secondary research with publicly available or recorded de-identified information) according to 45 CFR 46.104(d) at WCM.
Models and Prompting
We evaluated ChatGPT-5 Pro (OpenAI, San Francisco, CA) and Gemini 2.5 Pro (Google DeepMind, Mountain View, CA) in August 2025. Each model received all 90 vignettes with a standardized instruction to select from ten predefined treatment categories and generate exactly 2 sentences of rationale per case, emphasizing indications and key modifiers, with machine-parsable outputs (i.e., structured so a computer can reliably read and extract the fields without manual review) and quality checks for validity (category list compliance, sentence count, word range, and order of case IDs). The prompt that was used can be found in Supplement B.
Outcomes and Statistical Analysis
Primary analyses compared each model’s distribution over the ten categories with the reference using Jensen–Shannon divergence (JSD; bootstrap mean and 95% CI) as a bounded effect size and the Stuart–Maxwell χ2 test for marginal homogeneity. Secondary analyses assessed case-level exact agreement (Cohen’s κ) for (a) ten-way categories and (b) binary triage (surgical vs nonsurgical), with paired bias evaluated by McNemar’s test. We additionally report inter-LLM agreement for both granular and binary outcomes. The analysis plan and a priori thresholds were specified in the study outline.
Results
Across 90 vignettes spanning degenerative, cystic/lesional, and neoplastic pathologies suitable for MISS, both LLMs produced category assignments with two-sentence rationales per protocol.
Key Agreement and Bias Metrics for LLM Procedural Recommendations vs Expert Reference Across 90 Minimally Invasive Spine Surgery (MISS) Vignettes. Columns show JSD (ten-category mix), Stuart–Maxwell Q with 95% bootstrap CIs (B = 2000), and Holm-adjusted p, Cohen’s κ for ten-category and binary triage, and Δ surgical rate (second − first) with 95% CIs and Holm-adjusted McNemar p
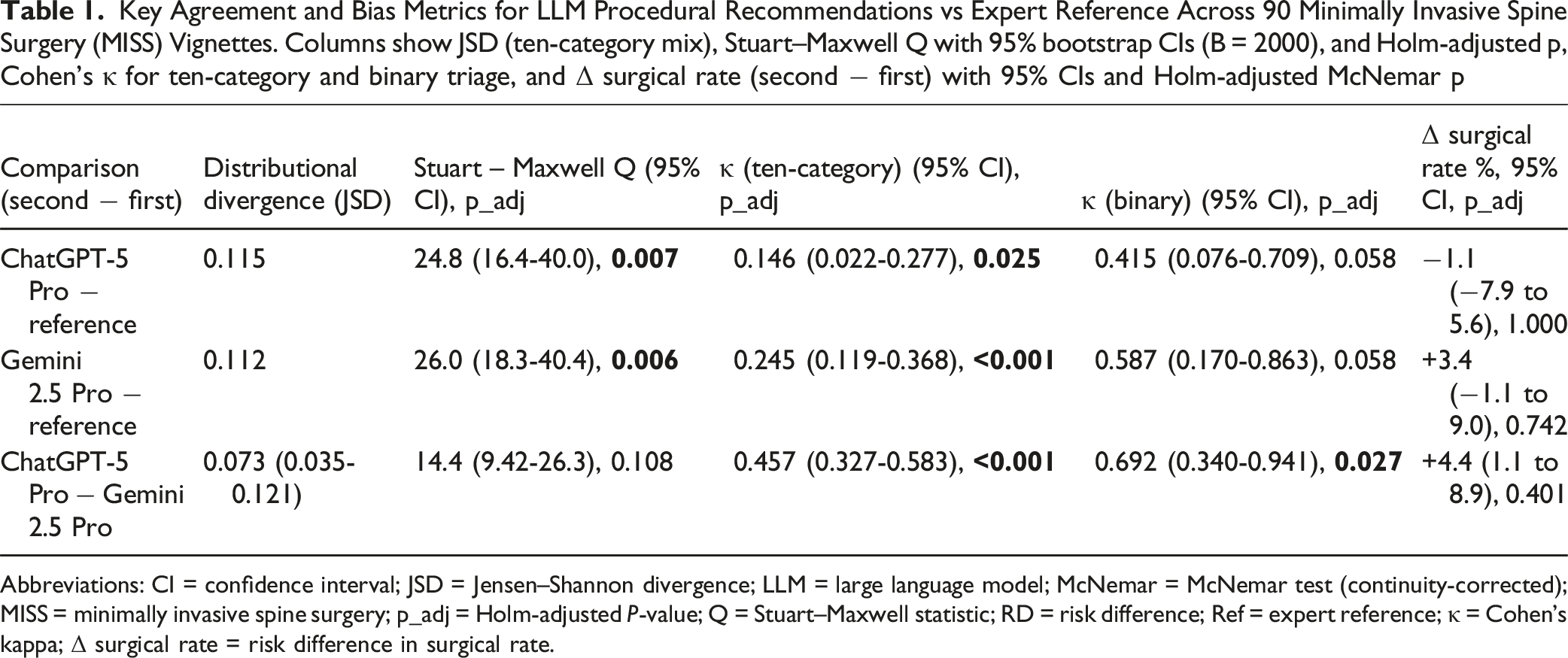
Abbreviations: CI = confidence interval; JSD = Jensen–Shannon divergence; LLM = large language model; McNemar = McNemar test (continuity-corrected); MISS = minimally invasive spine surgery; p_adj = Holm-adjusted P-value; Q = Stuart–Maxwell statistic; RD = risk difference; Ref = expert reference; κ = Cohen’s kappa; Δ surgical rate = risk difference in surgical rate.
Treatment-mix (Ten Categories)
Distributional divergence from the reference was small for both models (Jensen–Shannon divergence, JSD ≈ 0.115 for ChatGPT-5 Pro; ≈ 0.112 for Gemini 2.5 Pro). Inter-LLM divergence was smaller still (JSD = 0.073, 95% CI 0.035-0.121), indicating limited heterogeneity in overall treatment mix (Figure 1). Paired multinomial (Stuart–Maxwell) tests showed significant differences from the reference for each LLM, but not between the LLMs: ChatGPT-5 Pro vs reference χ2(9) = 24.76, Holm-adjusted P = 0.007; Gemini 2.5 Pro vs reference χ2(9) = 25.96, Holm-adjusted P = 0.006; ChatGPT-5 Pro vs Gemini 2.5 Pro χ2(9) = 14.44, Holm-adjusted P = 0.108. To provide a visual representation, bootstrap intervals for the Stuart–Maxwell statistic (Q) were: ChatGPT-5 Pro vs reference Q = 24.8 (95% CI 16.4-40.0); Gemini 2.5 Pro vs reference Q = 26.0 (18.3-40.4); ChatGPT-5 Pro vs Gemini 2.5 Pro Q = 14.4 (9.42-26.3). Category-level net shifts are shown in Figures 2 and 3; here, each dot represents the net change in proportion for that category (second method minus first), and whiskers are 95% CIs. Bounds entirely above/below zero indicate a directionally consistent increase/decrease by the second method; CIs spanning zero are compatible with no consistent shift. Thus, while overall treatment distributions were close to the reference (JSD ≈ 0.11), both LLMs showed statistically significant category-level reallocation vs the reference, with smaller differences between the LLMs themselves. Divergence of Treatment Distributions. Category-level Net Changes from Reference to ChatGPT-5 Pro (Stuart–Maxwell Components). Category-level Net Changes from Reference to Gemini 2.5 Pro (Stuart–Maxwell components).


Case-Level Agreement (Ten Categories)
Exact category agreement (κ) was slight for ChatGPT-5 Pro and fair for Gemini 2.5 Pro relative to the reference: κ = 0.146 (95% CI 0.022-0.277; Holm-adjusted P = 0.025) and κ = 0.245 (95% CI 0.119-0.368; Holm-adjusted P < 0.001), respectively. Inter-LLM agreement was moderate: κ = 0.457 (95% CI 0.327-0.583; Holm-adjusted P < 0.001), indicating the models resembled each other more than they matched the reference at the procedural-category level (Figure 4). In practical terms, Gemini 2.5 Pro’s κ ≈ 0.25 indicates agreement only slightly above chance – roughly a one-in-four beyond-chance alignment with expert procedural selection (observed agreement will be higher, but κ isolates the beyond-chance component); ChatGPT-5 Pro’s κ ≈ 0.15 is lower, and both models’ higher binary κ values suggest triage signal is preserved even when procedure selection diverges. Agreement Across Ten Treatment Categories.
Binary Triage (Surgical vs Non-surgical)
McNemar tests with continuity correction found no detectable bias in overall surgical rates for any pair: ChatGPT-5 Pro vs reference χ2 = 0, Holm P = 1.000; Gemini 2.5 Pro vs reference χ2 = 0.80, Holm P = 0.742; ChatGPT-5 Pro vs Gemini 2.5 Pro χ2 = 2.25, Holm P = 0.401. Corresponding risk-difference (Δ surgical rate) estimates and 95% bootstrap CIs were: ChatGPT-5 Pro vs reference −1.1% (−7.9% to 5.6%); Gemini 2.5 Pro vs reference +3.4% (−1.1% to 9.0%); ChatGPT-5 Pro vs Gemini 2.5 Pro +4.4% (1.1% to 8.9%), as depicted in Figure 5. In the figure, the dot shows the paired second minus first risk difference (RD); CIs that cross 0 are compatible with no directional bias; CIs entirely above or below 0 indicate a consistent increase or decrease in surgical assignment. The reported P-values come from the McNemar test on discordant pairs and are Holm-adjusted; with few discordances and a continuity correction, it is possible for an RD CI to narrowly exclude 0 while the adjusted McNemar P-value remains > 0.05. Matched-pairs odds ratios were: 0.80 (95% CI 0.21-2.98), 4.00 (0.45-35.8), and 9.00 (0.48-167.16), respectively. Although the ChatGPT-vs-Gemini Δ estimate excluded 0, adjusted McNemar tests did not detect bias – consistent with few discordant pairs and continuity correction. Paired Binary Comparison of Risk Difference (Δ Surgical Rate).
Binary Agreement
Collapsing to surgical vs non-surgical increased agreement between each comparison group: κ = 0.415 (95% CI 0.076-0.709; Holm-adjusted P = 0.058) for ChatGPT-5 Pro vs reference; κ = 0.587 (95% CI 0.170-0.863; Holm-adjusted P = 0.058) for Gemini 2.5 Pro vs reference; and κ = 0.692 (95% CI 0.340-0.941; Holm-adjusted P = 0.027) between the LLMs – consistent with preserved triage signal despite disagreement on specific interventions (Figure 6). Κ = 0 reflects chance-level agreement, and κ = 1 is perfect agreement; a lower CI bound above 0 supports agreement beyond chance. Agreement on Surgical vs Non-surgical Decision Making.
Discussion
In a vignette-based assessment of MISS, modern LLMs demonstrated good accuracy in high-level triage decisions (whether to operate or not), but their recommendation for specific treatment procedures varied. As summarized in Figure 7, agreement rises when triaging, while surgical-rate biases remain small and inconsistent, even as procedure-level allocations diverge. The distributional distances from the reference treatment mix were small (JSD ≈ 0.115 for Chat-GPT 5 Pro; JSD ≈ 0.112 for Gemini 2.5 Pro), showing that the overall balance among conservative care, interventional pain, decompression, and fusion was generally acceptable. However, paired Stuart–Maxwell tests and modest case-level κ values indicate that agreement diminishes at the detailed ten-way procedural level, highlighting clinically important misallocations even when triage guidance is correct. The inter-LLM agreement was higher than the agreement between models and the reference at the detailed level, suggesting that these models behave similarly but have not fully grasped the expert subtleties across procedures. In different decision scenarios, such as degenerative lumbar disease, upper-cervical trauma, deformity algorithms, and thoracolumbar trauma, inter-surgeon agreement on the surgical plan generally ranges from κ ≈ 0.4-0.7, indicating moderate consistency agreement.7-10 When surgeons adhere to a well-organized algorithm, their agreement tends to increase. For instance, the minimally invasive spinal deformity surgery (MISDEF2) algorithm showed κ values of 0.82-0.85 over 2 rounds, indicating that standardization can elevate agreement levels beyond the usual moderate range.
11
In our cohort, procedure-level agreement with the expert reference was κ = 0.146 (ChatGPT-5 Pro) and κ = 0.245 (Gemini 2.5 Pro) – below typical inter-surgeon planning ranges (≈ 0.4-0.7); however, binary triage improved to κ = 0.415 and 0.587 vs reference (and κ = 0.692 LLM-to-LLM), overlapping the lower-to-mid human range and reflecting the jump in reliability seen when surgeons use standardized algorithms (e.g., MISDEF2 κ = 0.82-0.85). These findings extend prior spine-specific studies in 3 ways. First, they corroborate guideline-anchored comparisons in lumbar disc herniation (LDH) and lumbar spinal stenosis (LSS): ChatGPT-3.5/4.0 aligned with North American Spine Society (NASS) recommendations for LDH in ∼52-59% of items and often supplied over-conclusive statements when guidelines were noncommittal; similarly, for LSS, responses tracked literature-anchored recommendations but required caution pending validation.
1
Second, they complement patient-facing evaluations by providing clinically acceptable explanations of MISS, with readability levels well above recommended standards, but with inconsistent handling of technical and intraoperative questions.
3
Third, they are consistent with head-to-head assessments in specialty contexts where LLMs’ knowledge formatting can be strong, yet expert clinicians still outperform LLMs on complex case decisions; cross model benchmarking in endoscopic lumbar surgery, for example, found specialists rated Claude 3.5 Sonnet highest for quality and relevance while lay evaluators preferred ChatGPT variants for understandability–highlighting audience-dependent performance and model heterogeneity.
4
Large Language Models (LLMs) in Minimally Invasive Spine Surgery (MISS): Where They Help, Where They Fail.
Why Triage is Better than Procedural Selection
Triage depends on clear, obvious signals like progressive neurologic deficits, red flag symptoms, or refractory radiculopathy, which are detectable even in shorter vignettes. In contrast, selecting the appropriate MISS procedure is more complex and sensitive to modifiers, dependent on factors such as stability, deformity, focal vs multilevel disease, prior surgeries, and subtle radiographic details. Using concise language that mimics real-world clinic notes may increase the likelihood of reasonable but potentially misclassified categories, such as choosing decompression alone vs decompression with fusion. The higher κ value after collapsing the categories into a binary (surgical vs non-surgical) indicates that the primary triage signal remains intact despite potential mismatches in operative choices.
Convergence from Overlapping Pretraining
Although Gemini and ChatGPT differ in architecture and the sharing of proprietary data, both are pretrained on very large, partly overlapping web-scale corpora (such as Common Crawl–style web text) plus curated documents, and are instruction-tuned with broadly similar medical and safety priors. This overlap encourages convergence on high-level decisions when inputs emphasize widely taught signals (e.g., red flag symptoms, progressive neurologic deficit, refractory radiculopathy) that are frequent in guidelines, board review materials, and patient-facing resources. In other words, when the task is to triage, the models are drawn from abundant, consistent patterns learned during pretraining and alignment, so they tend to agree.
By contrast, selecting a specific MISS procedure is sensitive to low-prevalence modifiers – stability, deformity, focal vs multilevel disease, prior surgeries, and subtle radiographic details – that are underrepresented in public web text and often live behind paywalls, imaging findings, or expert judgment. When vignettes use concise, clinical language, these modifiers may be implicit or absent, making it more likely that reasonable but misprioritized recommendations are made (e.g., choosing decompression alone vs decompression with fusion). Accordingly, collapsing categories to a binary endpoint (surgical vs non-surgical) yields a higher κ: the coarse triage signal remains intact and shared across models, whereas fine-grained operative choices diverge because the requisite features are either sparsely represented in pretraining or not text-accessible at all.
Implications for Near-Term Use
The immediate opportunity is guard-railed triage assistance: models can flag likely surgical candidacy and red flags (e.g., cauda equina features) under mandatory clinician oversight. In contrast, unmonitored procedural selection remains risky; here, retrieval-augmented generation (RAG) with indication-aware prompting and structured outputs is a pragmatic path to reduce hallucinations and tether recommendations to guidelines and trials.12-14 Methodologically, future evaluations should report confusion matrices for clinically adjacent classes (e.g., fusion vs decompression only), complement κ with -prevalence robust indices (e.g., Gwet’s AC1), and include distributional effect sizes such as JSD alongside paired multinomial tests (Stuart–Maxwell) to separate “mix” fidelity from case-level allocation accuracy.15-17
Limitations
This study has several limitations. First, contamination of training data between LLMs cannot be entirely ruled out. Since both LLMs are trained on large internet corpora and scholarly content, some source case reports (or similar variants) might be included in the pretraining data, artificially inflating performance through memorization rather than genuine reasoning. To mitigate this, we paraphrased each vignette to minimize lexical overlap and encourage test-time computation rather than retrieval; however, contamination remains a known challenge with current LLMs, and direct verification is often not feasible with closed models.18-20
Additional limitations arise from the vignette abstraction’s inability to fully capture the richness of in-person assessment and may reflect the preferences of the authors or institutions of each underlying case report. Although broad, our ten-category scheme does not encompass all MISS pathways and intraoperative contingencies. We evaluated 2 models in the 2025 timeframe, but their performance may change as the pace of updates in generative artificial intelligence accelerates.
Furthermore, using published case reports as clinical vignettes for testing may introduce unknown selection bias, as they tend to represent unique clinical scenarios, whether in patient presentation or clinical decision-making, rather than the usual norm. However, we attempted to control for this potential factor by increasing our vignette count to 90, above the required 67 from our power analysis. Additionally, abstracting each vignette into concise clinical scenarios likely reduces the subtleties that made each case report unique.
Crucially, our evaluation was text-only: the models did not “see” source imaging studies (e.g., MRI/CT) or operative videos. Multimodal reasoning – especially over dynamic sequences – remains a key limitation for automated surgical decision-making. While a small number of novel LLMs now advertise native video-understanding capabilities (e.g., Google’s Gemini 2.5 Pro via the Gemini API), and some OpenAI models (e.g., ChatGPT-4o via the Realtime API) accept video streams, rigorous, clinically oriented evaluation workflows are still nascent.21-25 A natural extension of this work is to feed representative images and operative videos to multiple models and explicitly elicit rationales for the approach and surgical corridor, benchmarking outputs against expert consensus – and ultimately against outcome data. Building such multimodal benchmarks is a necessary step for artificial intelligence to achieve nuanced, automated surgical decision-making on par with that of a clinical expert.
Lastly, we did not test RAG or tool-use variants that could enhance factual accuracy.12,26 Exploring these variants might offer valuable improvements in ensuring that the information provided is correct and reliable. Future research could focus on integrating such approaches to further develop the system’s capabilities. As LLMs approach clinical deployment, transparent auditing frameworks and human-in-the-loop validation will be essential to ensure safety, accountability, and explainability in procedural decisions.
Conclusions
In 90 MISS vignettes, both LLMs accurately replicated clinicians’ decisions on whether surgery was necessary but differed in choosing the specific procedure. Despite only slight divergence from the reference distribution (JSD ≈ 0.11), the models varied significantly in ten-category assignments and showed only slight to fair agreement with experts at the case level (κ ≈ 0.15 – 0.25). When collapsing categories into surgical vs non-surgical, the agreement improved to moderate levels (κ ≈ 0.42 – 0.59 compared to the reference), with no bias toward “over-“ or “under-surgery”. The models agreed more with each other than with the reference (κ = 0.69, binary). Therefore, near-term deployment should focus on high-level triage under clinician supervision, while procedure selection should remain an expert task until indication-aware, retrieval-based workflows and prospective validation bridge the gap.
Supplemental Material
Supplemental Material - Evaluating Large Language Models for Decision Support in Minimally Invasive Spine Surgery Triage and Procedural Categories
Supplemental Material for Evaluating Large Language Models for Decision Support in Minimally Invasive Spine Surgery Triage and Procedural Categories by Ahmet Kartal, Noel F. Manalil, Chiungwen D. Cheng, Lawrance K. Chung, Harry Gebhard, Michael Greenberg, Roger Härtl, and Galal A. Elsayed in Global Spine Journal
Supplemental Material
Supplemental Material - Evaluating Large Language Models for Decision Support in Minimally Invasive Spine Surgery Triage and Procedural Categories
Supplemental Material for Evaluating Large Language Models for Decision Support in Minimally Invasive Spine Surgery Triage and Procedural Categories by Ahmet Kartal, Noel F. Manalil, Chiungwen D. Cheng, Lawrance K. Chung, Harry Gebhard, Michael Greenberg, Roger Härtl, and Galal A. Elsayed in Global Spine Journal
Footnotes
Ethical Considerations
This project does not constitute human subjects research because it used only published, de-identified case information; therefore, Institutional Review Board (IRB) approval was not required.
Consent to Participate
Patient consent was not required because the study analyzed information abstracted from previously published, de-identified case reports, collected no identifiable data, and involved no contact with human subjects.
Author Contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
We will provide the R programming scripts used to compute Jensen–Shannon divergence, the Stuart–Maxwell test, Cohen’s κ, and McNemar’s test upon reasonable request.
Disclosure of Financial Relationships/Potential Conflicting Interests
Roger Härtl reports consulting relationships with DePuy Synthes, Brainlab, and Aclarion and serves as an advisor to RealSpine. He also has financial relationships with Realists and OnPoint outside the submitted work.
Supplemental Material
Supplemental material for this article is available online
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.