
Abstract
Study Design
Comparative study.
Objectives
This study aims to compare Google and GPT-4 in terms of (1) question types, (2) response readability, (3) source quality, and (4) numerical response accuracy for the top 10 most frequently asked questions (FAQs) about anterior cervical discectomy and fusion (ACDF).
Methods
“Anterior cervical discectomy and fusion” was searched on Google and GPT-4 on December 18, 2023. Top 10 FAQs were classified according to the Rothwell system. Source quality was evaluated using JAMA benchmark criteria and readability was assessed using Flesch Reading Ease and Flesch-Kincaid grade level. Differences in JAMA scores, Flesch-Kincaid grade level, Flesch Reading Ease, and word count between platforms were analyzed using Student’s t-tests. Statistical significance was set at the .05 level.
Results
Frequently asked questions from Google were varied, while GPT-4 focused on technical details and indications/management. GPT-4 showed a higher Flesch-Kincaid grade level (12.96 vs 9.28, P = .003), lower Flesch Reading Ease score (37.07 vs 54.85, P = .005), and higher JAMA scores for source quality (3.333 vs 1.800, P = .016). Numerically, 6 out of 10 responses varied between platforms, with GPT-4 providing broader recovery timelines for ACDF.
Conclusions
This study demonstrates GPT-4’s ability to elevate patient education by providing high-quality, diverse information tailored to those with advanced literacy levels. As AI technology evolves, refining these tools for accuracy and user-friendliness remains crucial, catering to patients’ varying literacy levels and information needs in spine surgery.
Keywords
Introduction
ChatGPT, an (artificial intelligence) AI chatbot developed by OpenAI, is used by over 100 million weekly users for its ability to provide insightful answers to various queries. 1 OpenAI released GPT-4 on March 13, 2023, enhancing ChatGPT’s capabilities; it is accessible through a ChatGPT Plus subscription. 2 While both GPT-3.5, the current open-access AI chatbot of ChatGPT, and GPT-4 function on pattern recognition as a means of generating responses, GPT-4 has distinguished itself as a far more accurate and up-to-date source of information for a variety of user queries.3-7 GPT-4 actively pulls information from the Internet search engine Bing and reports sources when formulating responses to users’ questions, which is in stark contrast to the restricted bank of information that GPT-3.5 has access to.8,9 This technological advancement in AI chatbots, especially large language models (LLMs), brings new potential for their use in online patient education. Currently, 89% of U.S. citizens use Google for health-related information before consulting a physician. 10 Google dominates the U.S. search engine market with 88.06% traffic, while Bing and Yahoo hold 6.94% and 2.70%, respectively. 11 As such, Google was utilized as the metric for which the quality of answers provided by GPT-4 would be compared.
Various studies have assessed the quality of online information on different medical conditions. For instance, Wei et al compared Google’s search results with those from GPT-4 for head and neck cancer frequently asked question (FAQs), finding responses by GPT-4 to be less readable. 12 Similarly, Kerbage et al examined GPT-4’s accuracy for gastrointestinal pathologies, noting an 84% accuracy but subpar performance when compared to a physician in broader medical queries. 13 The heterogeneity that exists between Google search results, AI-powered chatbots, and physicians’ expertise introduces a new discussion into the quality of information that patients may encounter online, especially as it pertains to common surgical procedures of the spine. Anterior cervical discectomy and fusion (ACDF) is one of the most common procedures of the cervical spine, accounting for 132 000 surgeries in the United States each year. 14 The indications for ACDF are vast, treating conditions such as cervical myelopathy, radiculopathy, and instability brought upon by disc herniations and other degenerative changes to the cervical spine.15,16 Since ACDF has earned a reputation as a safe, effective treatment for various cervical spine conditions and is often recommended by spine surgeons, analyzing online resources like GPT-4 can offer insights into the quality of information available to those considering or indicated for ACDF.
Previous studies have aimed to assess the quality of answers provided by AI chatbots related to various pathologies and treatment modalities. However, to the best of our knowledge, no studies have analyzed how GPT-4 compares to Google in quality of answers generated regarding a common spinal pathology such as ACDF. This study aims to compare Google and GPT-4 in terms of (1) question types, (2) response readability, (3) source quality, and (4) numerical response accuracy for the top 10 most FAQs about ACDF.
Materials and Methods
Description of Classification Systems for Questions and Websites.
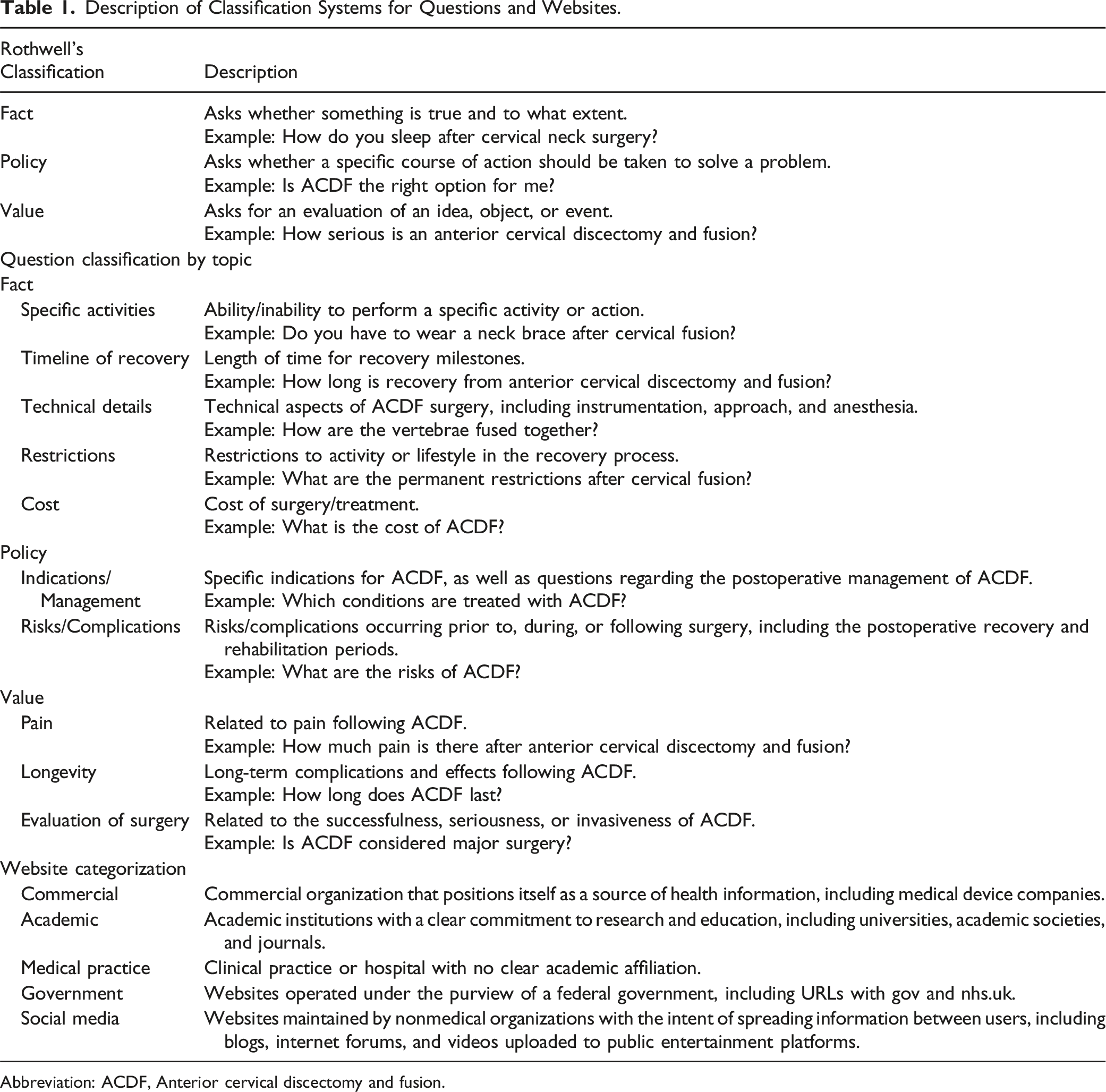
Abbreviation: ACDF, Anterior cervical discectomy and fusion.
Linked websites corresponding to each question were evaluated for quality using the Journal of the American Medical Association (JAMA) benchmark criteria. These criteria, based on authorship, attribution, disclosure, and currency, have been validated in previous studies for assessing website quality.24-28 Two independent reviewers categorized these questions, and any disagreements were resolved by a senior author. The interobserver reliability for this classification was measured using Cohen’s kappa coefficients. Additionally, the top 10 FAQs with numerical responses from the Google search were inputted into GPT-4 for similar numerical outputs.
Comparative analysis of the responses from both platforms included assessments of readability, using the Flesch Reading Ease score and the Flesch-Kincaid grade level, and word count. The Flesch Reading Ease score measures readability on a scale from 0 to 100, utilizing a formula that incorporates average sentence length and average number of syllables per word. Higher scores indicate a higher degree of readability. Flesch Reading Ease scores of 90 to 100 typically indicate articles geared towards an elementary school student, scores of 60 to 70 are geared towards middle school students, and scores of 0 to 30 are geared towards university graduates. The Flesch Reading Ease score is thus inversely correlated with the Flesch-Kincaid Grade Level, with a higher score indicating a lower grade level. The Flesch Reading Ease score inversely correlates with the Flesch-Kincaid grade level.29-31 Plain-text format was used for analyzing shared responses (https://readability-score.com).
Cohen’s kappa coefficient was utilized to assess interobserver reliability using R statistical software (version 4.3.1; R Project for Statistical Computing, Vienna, Austria). Student’s t-tests were used to assess differences in the JAMA benchmark criteria scores, Flesch-Kincaid grade level, Flesch Reading Ease, and word count between GPT-4 and Google responses and website sources. Statistical significance was set at the .05 level.
Results
Frequently Asked Questions in Google Web Search and GPT-4 for ACDF
Top 10 Most Frequently Asked Questions for ACDF.

Abbreviation: ACDF, Anterior cervical discectomy and fusion.
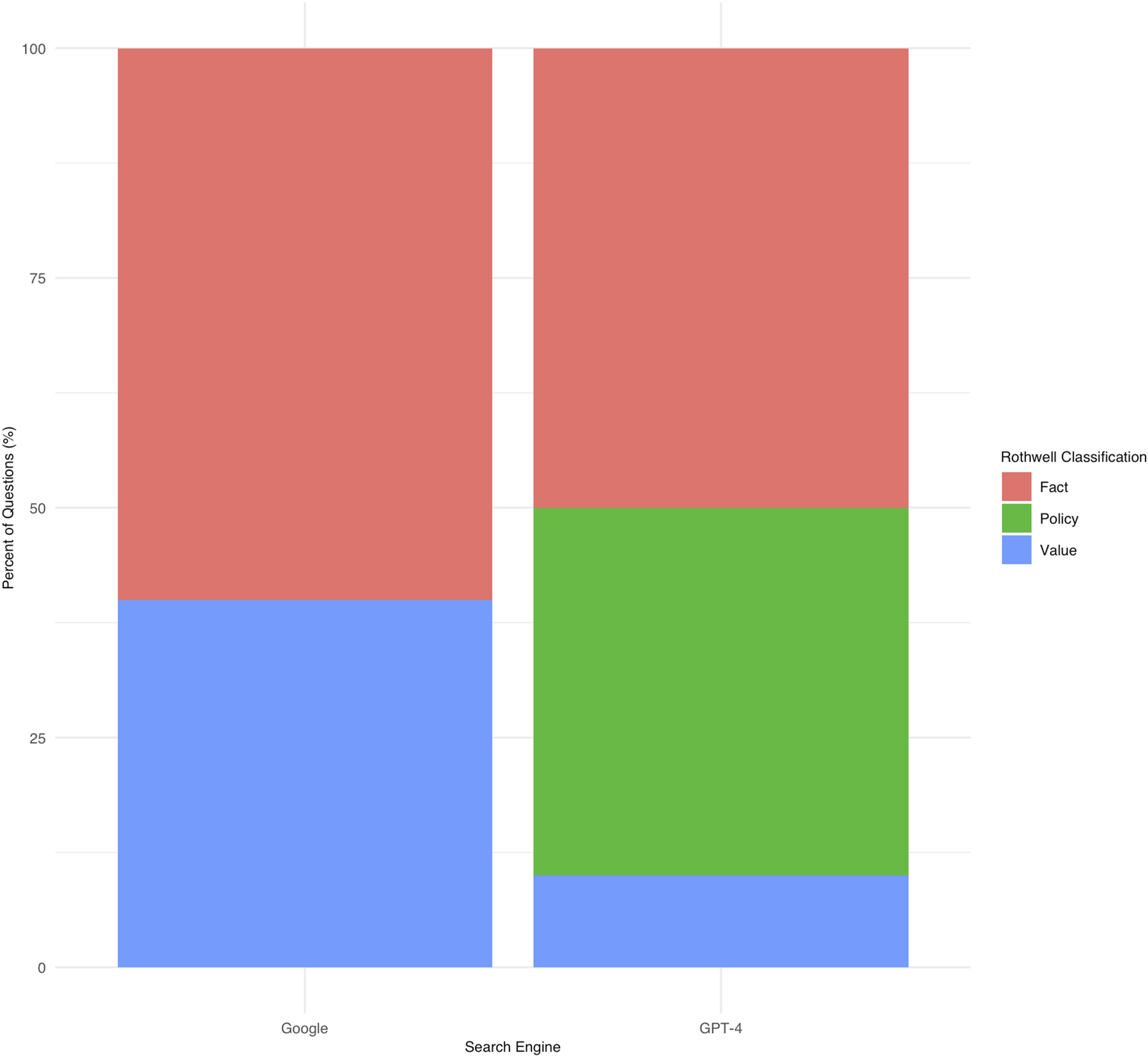
Rothwell’s classification stratified by search engine.
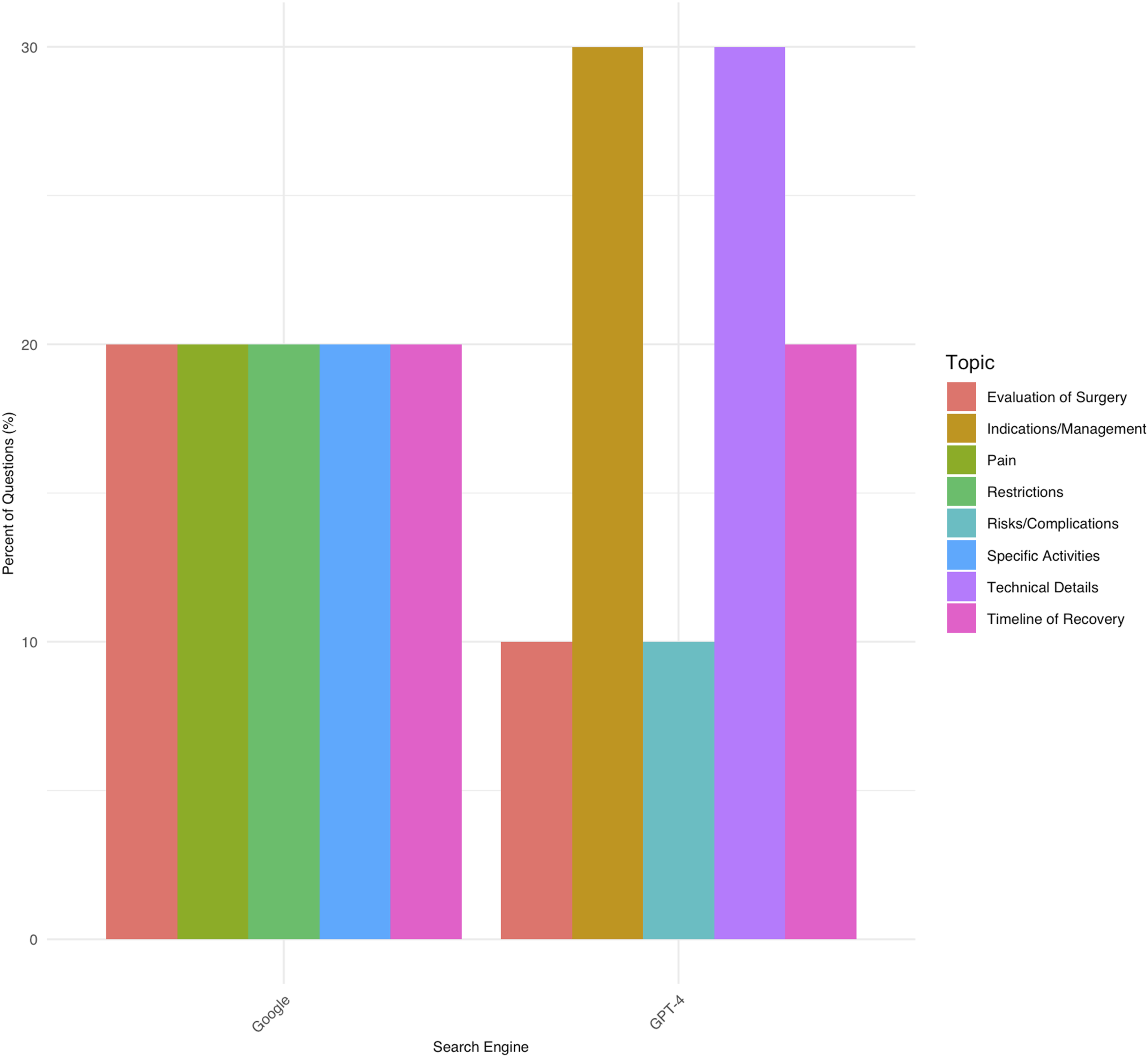
Topic classification stratified by search engine.
Answers to Similarly Asked Questions From Google and GPT-4 for ACDF.

ACDF, Anterior cervical discectomy and fusion.
Comparison of Readability and Source Quality.
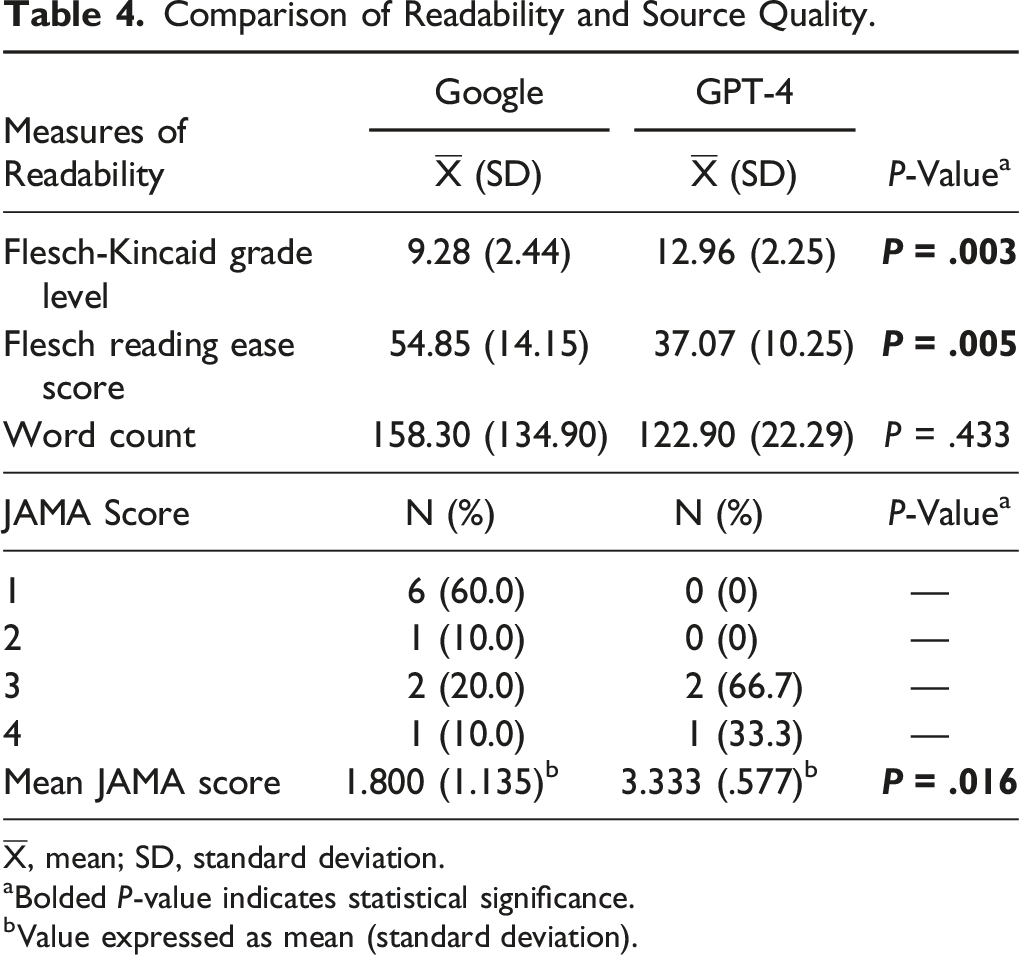
aBolded P-value indicates statistical significance.
bValue expressed as mean (standard deviation).
Source Quality From Which Answers by Google Web Search and GPT-4 for FAQs Regarding ACDF Were Generated
Of the websites provided by Google web search to answer FAQs regarding ACDF, the most common source type was medical practice, accounting for 6 out of 10 unique websites, followed by social media and government, which comprised 3 out of 10 and 1 out of 10 unique websites, respectively. Of the unique websites utilized by GPT-4 to answer FAQs regarding ACDF, 2 out of 3 sources were categorized as social media, and one source was determined to be an academic website. Interobserver reliability for website categorization was .930 (P < .001), suggesting high agreement between observers.
Source quality was further scrutinized through the assignment of JAMA scores. Of the unique websites that Google directed users to for answering FAQs, 6 out of 10 unique sources received a JAMA score of 1 (Table 4). 2 out of the 3 unique sources utilized by GPT-4 received a JAMA score of 3, and the remaining one source received a JAMA score of 4. The mean JAMA scores for sources utilized by Google Web search and GPT-4 to answer FAQs regarding ACDF were determined to be 1.800 and 3.333, respectively. A statistically significant difference (P = .016) between mean JAMA scores of sources utilized by Google and GPT-4 was observed. Interobserver reliability for JAMA score categorization was 1.000 (P < .001), suggesting complete agreement between observers.
Numerical Responses in Google Web Search and GPT-4 for ACDF
Numerical Responses Compared Between Google and GPT-4.

ACDF, Anterior cervical discectomy and fusion.
aQuestions highlighted in bold varied in response.
Discussion
Large language models have been developed to serve a diverse array of functions, including assistance in education, recommendations for medical care, and individual case analysis in surgery.32,33 Despite having fewer parameters than other LLMs, ChatGPT is one of the most studied chatbots in the literature. 34 The purpose of this study was to investigate GPT-4’s ability to provide patients with readable answers and reliable sources to FAQs related to ACDF in comparison to a Google web search conducted on December 18, 2023. While Google had an equal distribution of question topics, technical details and indications/management comprised the majority of FAQs queried through GPT-4. Answers provided by GPT-4 to FAQs were associated with a higher level of source evidence when compared to answers provided by a Google web search. Answers provided by GPT-4 were also associated with a higher Flesch-Kincaid grade level and lower Flesch Reading Ease score, yet similar word count, when compared to Google.
When asked to produce the 10 most FAQs for ACDF, GPT-4 only replicated 1 similar question that was queried through a Google web search. Currently, there is no available literature comparing the ability of GPT-4 to provide the 10 most FAQs related to a given search term to Google. Previous studies, like Dubin et al, found a 25% overlap in FAQs between GPT-3.5 and Google regarding hip and knee arthroplasty. 17 GPT-4’s unique web search capabilities via Bing might contribute to these differences.8,9 Its method of determining FAQs could involve mining data from websites with dedicated FAQ sections, as opposed to querying Bing’s “People Also Ask” feature. Each GPT-4-generated question was linked to a website with a related question, enhancing the reliability of the information. The distinct approach of GPT-4 in generating FAQs, compared to traditional search engines, could influence how patients access and interpret information about ACDF, potentially altering their expectations and understanding of the procedure. This highlights the importance of evaluating the sources and methods of AI-generated medical information to ensure its alignment with evidence-based practices.
GPT-4 cited more reliable web sources than Google, which tended to rely on social media and medical practice websites. This is consistent with prior literature evaluating the most commonly directed websites for FAQs when querying Google for ACDF, whereas GPT-4 utilized sources such as academic and social media websites. 23 The JAMA score of GPT-4’s sources was significantly higher, a novel finding given that earlier ChatGPT models didn’t provide source links, resulting in a JAMA score of zero.35,36 Walker et al also confirmed GPT-4’s ability to match the quality of existing online medical information, as assessed by the Ensuring Quality Information for Patients (EQIP) tool. 37 Additionally, GPT-4’s reduced rate of citation fabrication marks a significant improvement when compared to GPT-3.5, reflecting a critical step forward in the utility of AI for providing trustworthy online health information. 38 This shift towards more reliable and academically credible sources by GPT-4 suggests a notable enhancement in the quality of online health information provided by AI systems. It underscores the potential of AI tools like GPT-4 in supporting spine surgeons by directing patients to more evidence-based and peer-reviewed information, thereby improving patient education and potentially influencing treatment outcomes.
Answers provided by GPT-4 had a higher Flesch-Kincaid grade level and lower Flesch Reading Ease score than answers provided by Google, aligning with earlier observations of GPT-3.5’s collegiate to post-collegiate readability levels.36,39,40 This suggests that GPT-4, like its predecessor, may not be fully accessible to the average American adult, whose health literacy is at or below an eighth-grade level (Flesch-Kincaid grade level 8) as defined by the National Institute of Health (NIH) and American Medical Association (AMA).41,42 However, ChatGPT can be prompted to simplify complex texts, significantly reducing collegiate reading level by an average of 3.3 grades. 43 Despite GPT-4’s answers having a higher reading level, a previous study by Biro et al indicates that exposure to ChatGPT’s technical language responses can improve test scores, particularly among individuals with higher health literacy, and increase trust in the chatbot. 44 The higher reading level of GPT-4’s responses, while potentially limiting accessibility for some, could also be seen as an opportunity to elevate patient understanding and engagement in their healthcare. This suggests the importance of tailoring AI-generated content to the reader’s literacy level, emphasizing the role of spine surgeons in interpreting and contextualizing information for patients to ensure comprehension and informed decision-making.
When comparing Google’s web search responses to those generated by GPT-4 for ACDF-related FAQs requiring numerical responses, 6 out of 10 questions had differing information between the 2 platforms. This finding aligns with a prior study on total joint arthroplasty, which reported that 55% of numerical question responses varied between the platforms. 17 Google’s answers were more concise, while GPT-4 tended to offer a wider range of recovery timelines. For example, in response to “How long is recovery from ACDF?”, Google suggested 8-12 weeks, whereas GPT-4 provided an estimate ranging from a few weeks to 6 months. These variations in response timelines are crucial in the medical context, as they can influence patient expectations and preparedness. The broader spectrum of timelines from GPT-4 might reflect its capability to incorporate a wider array of patient experiences and clinical outcomes, as opposed to the more standardized responses typically found in Google searches. However, more objective questions, like “How long is hospital stay after cervical fusion?”, received consistent responses of 1-2 days from both platforms, indicating a consensus on certain clinical aspects. Overall, these findings suggest that while GPT-4 offers more comprehensive and varied responses, potentially enhancing patient understanding and expectations, it is also important to recognize the value of Google’s concise answers for certain straightforward, objective medical questions. This balance between detailed and straightforward information is essential in providing patients with a well-rounded understanding of their expectations following ACDF.
This study has several limitations. Google’s web search results and GPT-4’s responses, which are dependent on Bing, may vary due to updated content, affecting response accuracy. As a result, our findings might not be reproducible. Despite this limitation, this study provides a starting point for evaluating the capabilities of GPT-4 in answering FAQs relating to ACDF. Additionally, despite using a newly installed Google Chrome browser to avoid personalized results, Google might still have personalized the search outcomes. For GPT-4, user login requirements could introduce biases, as its responses might be influenced by the user’s interaction history. GPT-4 being a paid subscription service, unlike the open-access GPT-3.5, may bias its responses due its limited user base. The search methodology used to query GPT-4 in this study might not fully reflect the natural language of patients. Despite these challenges, this study provides important insights into GPT-4’s capabilities in medical information provision, highlighting the evolving role of AI in healthcare. Future studies should explore methods to prompt GPT-4 to respond in ways that more closely represent patient viewpoints.
Conclusion
AI’s role in patient education is expanding, with GPT-4 showcasing enhanced capabilities and accuracy, though its higher reading level might limit usability for some users. This study demonstrates GPT-4’s potential to complement sources like Google, providing varied, in-depth responses. Yet, it emphasizes the need to balance complex AI content with clear, concise information. As AI integrates further into healthcare, refining these tools for accuracy and accessibility remains essential, meeting the diverse information needs and literacy levels of online medical information seekers.
Footnotes
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Mitchell K. Ng is a paid consultant at Ferghana Partners. For the remaining authors none were declared.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.