
Abstract
This study focused on the development and validation of the guide to investigate Chinese English as a Foreign Language (EFL) undergraduates’ needs in critical thinking (CT) development and AI-enhanced blended learning (BL) in English reading courses. The study examined the intersection of learners’ needs, CT development, and AI-enhanced BL within the context of EFL reading. Based on a recognised theoretical framework, the guide explored learners’ current competencies, desired outcomes, and perceived gaps. Content validity was established through expert review supplemented by a small-scale student pilot, and the results demonstrated strong content validity following rigorous validation procedures. The validated tool provides a systematic means to profile learners’ needs, thereby informing the design of an AI-enhanced blended reading module that supports CT development. Beyond pedagogical applications, the study contributes to understanding how AI-enhanced interventions interact with CT development in non-Western EFL contexts.
Introduction
In recent years, blended learning (BL) has emerged as a flexible and effective instructional approach in higher education, particularly in English as a Foreign Language (EFL) reading classrooms. By integrating adaptive artificial intelligence (AI) tools and multimodal platforms, BL enables learners to engage with diverse texts while developing critical thinking (CT) abilities such as inference, evaluation, and synthesis (Xu & Jumaat, 2025). In Chinese higher education, where reading-intensive curricula prevail, CT is increasingly recognised as a core academic competency (J. Chen et al., 2025; Wei, 2025). Empirical studies suggest that AI-enhanced BL can foster CT, particularly in assumption recognition and reflective reading (Southworth et al., 2023). However, these studies vary in CT dimensions and contexts, and few focus specifically on Chinese EFL undergraduates, highlighting the need for context-specific investigations (Istenič, 2024; Luo, 2025). AI-driven BL platforms have shown potential to improve student engagement and language performance (Cao & Phongsatha, 2025; A. Chen et al., 2025), yet few studies systematically assess learners’ needs prior to implementation, emphasising the importance of needs analysis in context-specific instructional design (Anthony, 2018; Brown, 2016).
Against this backdrop, the development of the Needs Analysis Guide is grounded in McKillip’s (1987) Discrepancy Model, which conceptualises needs analysis in terms of the current state (“what is”), the desired state (“what should be”), and the gap between them (“the discrepancy”), providing a systematic basis for identifying learners’ needs. The guide further draws on established frameworks of CT in EFL contexts (Facione, 1990), emphasising six core skills (interpretation, analysis, evaluation, inference, explanation, and self-regulation) as the theoretical foundation for defining the CT construct and guiding the exploration of students’ CT-related needs. By integrating these theoretical perspectives within an AI-enhanced BL context, the study ensures that the guide’s development is firmly grounded in relevant educational theory and aligned with the study’s objectives.
AI literacy has been broadly defined as the knowledge and skills required to interact effectively with AI systems, including understanding their basic principles, critically evaluating outputs, and engaging with related ethical and social issues (Sánchez-Díaz et al., 2024). In this study, AI literacy is operationalised for EFL learning as students’ knowledge, skills, and attitudes for using AI tools to support learning, including understanding their capabilities and limitations, integrating them into learning tasks, and critically reflecting on AI-generated outputs.
Existing studies often focus on general BL or AI literacy without systematically examining their intersection with CT development in non-Western EFL contexts, and rarely employ rigorously validated instruments to assess learners’ needs (Boelens et al., 2017; Capinding, 2024; Kallio et al., 2016; Ng et al., 2023; Shi, 2025). Moreover, while AI literacy development is documented (Chiu, 2025; Ng et al., 2023; Shi, 2025), its interaction with CT development in EFL reading remains underexplored, leaving an important gap in understanding how AI and cognitive skills intersect in BL environments (Laupichler et al., 2022). Furthermore, many semi-structured interview tools used for needs analysis have limited evidence of content validity, highlighting the necessity of systematic validation to ensure reliable and meaningful qualitative data (Almanasreh et al., 2019; Polit & Beck, 2006; Rhayha & Alaoui-Ismaili, 2024; Romero Jeldres et al., 2023).
Building on these considerations, the present study focused on the development and preliminary validation of a semi-structured interview guide to systematically investigate Chinese EFL undergraduates’ needs in CT development and AI-enhanced BL in reading courses. It is important to note that the study does not report findings from applying the guide to a larger student sample; its primary contribution lies in establishing content validity and usability, with a small pilot study conducted to confirm clarity and comprehensibility. The guide was validated through expert evaluation of item relevance, clarity, and simplicity. Specifically, the study aims (a) to construct a systematic Needs Analysis Guide for eliciting qualitative data on learners’ needs, and (b) to assess its clarity, relevance, simplicity, and alignment with the theoretical framework through expert review. These efforts provide a contextually grounded and empirically informed basis for the future design of an AI-enhanced blended reading module.
Method
Instrument
A semi-structured interview guide was developed based on McKillip’s (1987) Discrepancy Model and Facione’s (1990) six core CT skills. The guide was purposefully constructed for this research and was not adapted from existing instruments. It comprised 16 items organised into five thematic sections: Part A (Background & Current Situation, Q1–4), Part B (Reading & Critical Thinking, Q5–7), Part C (Blended Learning Experience, Q8–10), Part D (AI in English Reading & Critical Thinking, Q11–13), and Part E (Ideal Learning Design & Suggestions, Q14–16). This structure was designed to facilitate a systematic exploration of learners’ current state, ideal state, and perceived gaps in CT development and AI-enhanced blended reading in English courses.
Expert Selection
The selection of experts is critical for ensuring validity, reliability, and credibility in studies involving expert judgement, particularly for content validation. According to Lynn (1986) and Polit and Beck (2006), experts should possess strong academic qualifications (typically a master’s degree or higher), professional expertise, and a deep understanding of the construct being measured, ensuring that their evaluations are both relevant and contextually grounded. Similarly, Oxley et al. (2024) emphasised that experts should be recognised by their peers, have substantial professional or academic experience, and be capable of making independent, unbiased judgements. Okoli and Pawlowski (2004) further highlighted three essential criteria: (a) relevant knowledge of the subject under investigation, (b) availability and willingness to engage in multiple rounds of review, and (c) the ability to provide constructive feedback throughout the validation process.
In line with these recommendations, experts were selected based on academic or professional reputation, relevant research output, and active involvement in English language education and instructional design (Bojke et al., 2021). All selected experts held doctoral degrees and had expertise in one or more of the following areas: AI and educational technology, BL, language testing and evaluation, English language education, critical reading instruction, curriculum design, CT theory, higher education, student development, and mixed-methods research design. Each had more than 5 years of teaching or research experience. A total of nine experts were invited to evaluate the interview guide. All nine experts voluntarily agreed to participate. They were provided with three documents: an informed consent form, the interview guide, and an expert evaluation form. Profiles of the expert panel are presented in Table 1.
Profile of the Expert Panel.

Validation Procedure
Expert validation of the interview guide was conducted first. To establish content validity, a systematic expert review was undertaken, focusing on three key dimensions adapted from Polit and Beck (2006) and Almanasreh et al. (2019): relevance, clarity, and simplicity. Specifically, experts evaluated whether each item (a) reflected the intended construct (relevance), (b) was clearly and unambiguously worded (clarity), and (c) was free from unnecessary complexity or specialised terminology (simplicity). Each expert rated all items independently, without discussion or influence from other panel members, using a 4-point Likert scale: 1 = “not relevant/clear/simple,” 2 = “somewhat relevant/clear/simple,” 3 = “quite relevant/clear/simple,” and 4 = “highly relevant/clear/simple.” Experts were also invited to provide qualitative comments and recommendations for refinement. Qualitative comments were systematically coded using thematic analysis, with NVivo software employed to organise and manage the coding process. Common themes and suggestions were extracted to guide item revisions.
The review process was conducted asynchronously via email or WeChat over 1 week. Items receiving low ratings or substantial feedback were reviewed and modified to ensure clarity, relevance, simplicity, and alignment with the study’s objectives. The systematic application of the Content Validity Index (CVI) ensured that all items met established thresholds for relevance, clarity, and simplicity (Lynn, 1986; Polit & Beck, 2006; Polit et al., 2007). To complement the CVI, inter-rater reliability was assessed using modified Kappa coefficients (k*) based on expert ratings, providing an additional measure of consistency across judgements (Polit et al., 2007).
During the expert review process, interview items were revised based on quantitative and qualitative feedback. All revisions were guided by content validity principles and documented carefully, including the original items, revised items, and rationale for each change. Importantly, the revisions did not alter the constructs under investigation but rather enhanced the interpretability and usability of the interview guide for participants.
Following expert validation, a small-scale student pilot test was conducted with five Chinese EFL undergraduates from Year 2 reading courses to evaluate the clarity, comprehensibility, and usability of the guide. The profile of the student participants in the pilot study are summarised in Table 2.
Profile of the Student Participants.
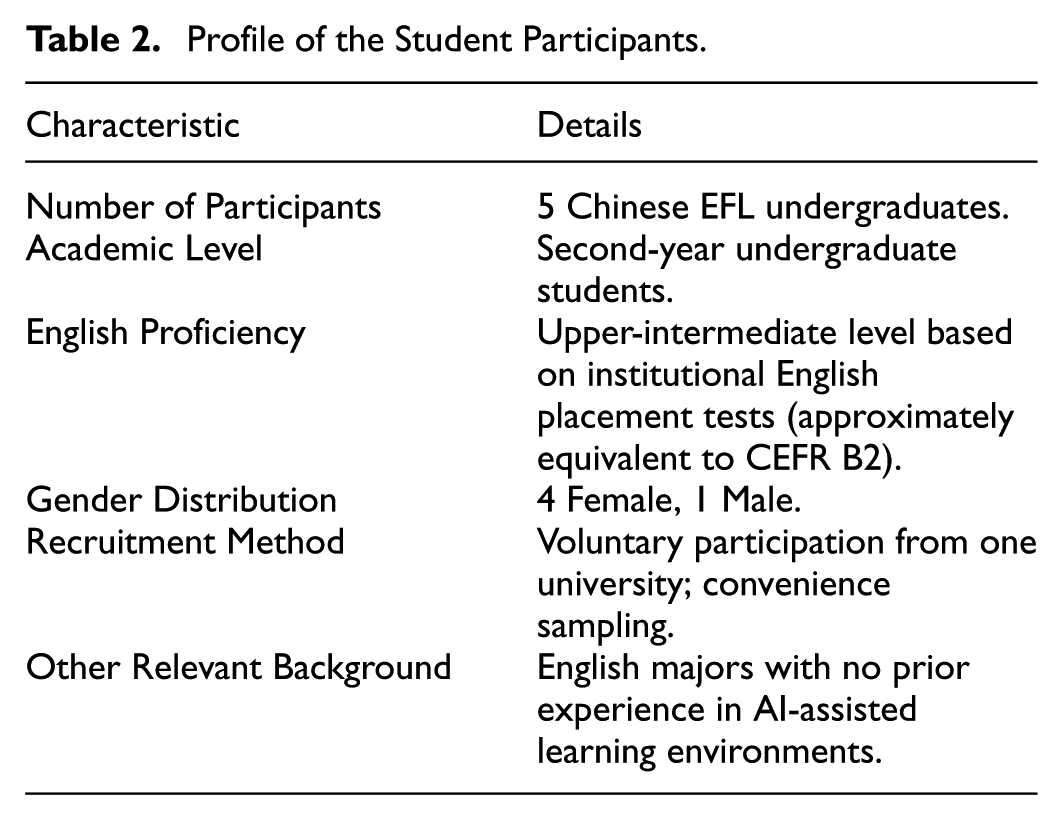
Students completed the semi-structured interview and provided feedback on item wording, scope, and interpretability. Minor revisions were made based on this feedback to enhance clarity and ensure the instrument effectively captured students’ needs in CT development and AI-enhanced BL. At this stage of instrument development, the study focused on establishing content validity through expert review and the small-scale pilot test; construct and criterion validity were not assessed, as these require larger-scale empirical data generated through field implementation. These evaluations are planned for future stages of the overall research project, beyond the scope of the present study. The final version of the guide is presented in Table A1.
Data Analysis
To quantitatively evaluate the content validity of the interview guide, the CVI was applied at both the item and scale levels, following the framework introduced by Lynn (1986) and further developed by Polit and Beck (2006). At the item level, the Item-Level Content Validity Index (I-CVI) was calculated for each item across the three dimensions of relevance, clarity, and simplicity. The I-CVI was defined as the proportion of experts rating an item as either 3 or 4 on the 4-point Likert scale, indicating that it was judged “quite” or “highly” relevant, clear, or simple for the intended construct. Formally:

In the calculation of equation 1, n corresponds to the number of experts who judged the item relevant (ratings of 3 or 4), and N corresponds to the total number of experts consulted. A threshold of 0.78 or higher was regarded as acceptable when five or more experts were involved; items below this level were considered for revision or removal, guided by both quantitative ratings and qualitative feedback.
To further assess the consistency of expert judgements beyond proportional agreement, modified Kappa coefficients (κ*) were calculated for each item across the three dimensions. The k* adjusts for chance agreement and provides a complementary indicator of inter-rater reliability. Following Polit et al. (2007), κ* values of .60 or higher were interpreted as evidence of substantial agreement. The coefficients were computed using the following equations:
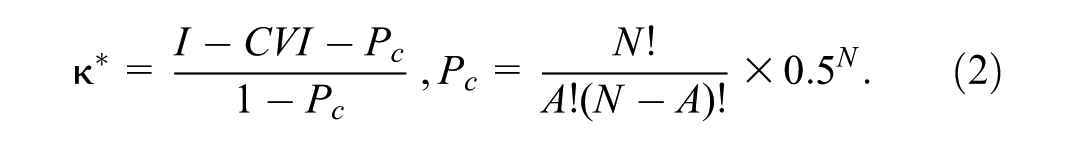
At the scale level, two indices were computed: (a) the Scale-Level Content Validity Index, Average (S-CVI/Ave), obtained by averaging I-CVI values across all items, and (b) the Scale-Level Content Validity Index, Universal Agreement (S-CVI/UA), defined as the proportion of items on which all experts reached full agreement (ratings of 3 or 4). The calculations were as follows:
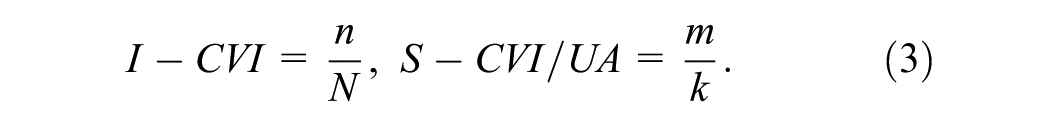
where k is the total number of items and m is the number of items achieving universal agreement. While S-CVI/UA provides the strictest measure of consensus, it has been critiqued as overly conservative, particularly with larger expert panels. For this reason, S-CVI/Ave was treated as the primary indicator, with S-CVI/UA reported as a supplementary measure for transparency. All calculations were conducted manually and cross-checked for accuracy by all researchers. The final version of the interview guide integrated the CVI results, modified Kappa coefficients (k*), and expert qualitative comments, ensuring both strong content validity and practical relevance for subsequent data collection. Additionally, feedback from the pilot study was qualitatively reviewed to identify minor ambiguities or usability issues, and small adjustments were made accordingly before final deployment.
Ethical Considerations
This study involved minimal-risk human participation and adhered to established ethical guidelines for educational research. Several measures were implemented to minimise any potential risks to the expert participants. Only non-sensitive professional background information and discipline-related judgements were collected. No personal identifiers were requested, and all responses were anonymised. The evaluation tasks focused solely on the experts’ professional assessment of the content and did not involve topics that could cause psychological discomfort or social risk.
The potential benefits of the study outweighed these minimal risks. The expert participants contributed to establishing and validating a systematic Needs Analysis Guide for the design of an AI-enhanced blended reading module that aims to foster CT. Their professional judgements helped ensure the clarity, relevance, and practical applicability of the guide, enabling the collection of robust needs-analysis data to inform the subsequent design of the module.
Informed consent was obtained from all participants, including both experts and student participants, prior to data collection. All participants received an information sheet detailing the purpose of the study, the procedures involved, the voluntary nature of participation, the right to withdraw without penalty, and the measures taken to ensure confidentiality. Written informed consent was provided electronically before they completed their respective tasks.
Results
Expert Evaluation Results
Content validation of the semi-structured interview guide was conducted with the involvement of nine experts. Table 3 summarises the I-CVI, S-CVI/Ave, S-CVI/UA, and k* for each item, together with expert comments.
I-CVI, S-CVI/Ave, S-CVI/UA, and k* with Expert Comments Summary.

I-CVI represents the proportion of experts rating an item as 3 or 4. S-CVI/Ave is the mean of I-CVI values across items, and S-CVI/UA reflects the proportion of items achieving universal agreement, where all experts assign a rating of 3 or 4. Acceptable thresholds: I-CVI ≥ 0.78 (for panels of five or more experts); S-CVI/Ave ≥ 0.90 is recommended, while ≥0.80 may be considered acceptable; no universal cut-off exists for S-CVI/UA, which is regarded as a supplementary index (Polit & Beck, 2006; Polit et al., 2007). Modified Kappa coefficients (κ*) adjusts the I-CVI for chance agreement among experts. It is calculated as κ* = (I-CVI−Pc)/(1−Pc), where Pc represents the probability of chance agreement. Following Polit et al. (2007), κ* values of .60 or higher are interpreted as substantial agreement.
The I-CVI values for the 16 items ranged from 0.78 to 1.00, indicating satisfactory item-level content validity. At the scale level, the S-CVI/Ave values were 1.00 (relevance), 0.98 (clarity), and 0.98 (simplicity), all exceeding the recommended threshold of 0.90 (Polit & Beck, 2006). The more stringent S-CVI/UA values were 1.00 (relevance), 0.81(clarity), and 0.88 (simplicity), reflecting the proportion of items that achieved universal agreement among experts. The modified Kappa coefficients (κ*) ranged from .761 to 1.000, indicating substantial to almost perfect agreement across the three dimensions, thereby supporting the reliability and content validity of the expert evaluations. Taken together, these results demonstrated strong overall content validity of the interview guide.
The expert comments of the interview items primarily involved: (a) expanding items into measurable dimensions, (b) refining scope to English reading courses rather than general English learning, (c) simplifying complex or multi-part questions, and (d) adopting neutral or precise wording. These changes ensured that the interview guide more accurately reflected the intended constructs and enhanced its suitability for use in the subsequent needs analysis. Representative revisions are presented in Table 4.
Summary of Representative Item Revisions Based on Expert Feedback.

Student Pilot Feedback
Overall, students found the guide clear and generally understandable. Minor issues were noted, including slightly ambiguous wording in some items (e.g., the term “critical reflection” in one question), questions perceived as broad or overlapping, and suggestions for improving instructions or presentation. Based on this feedback, minor adjustments were made to wording, item sequencing, and instructions.
Discussion
The expert review process and subsequent refinements confirmed the instrument’s strong content validity. Quantitative indices, including the I-CVI, S-CVI/Ave, S-CVI/UA, and κ* values indicated that all items met or exceeded established thresholds for relevance, clarity, and simplicity (Lynn, 1986; Polit & Beck, 2006; Polit et al., 2007). These findings align with prior research validating the usefulness of quantitative content-validity indices for judging item quality (Almanasreh et al., 2019). Feedback from a small pilot study involving five Chinese EFL undergraduates suggested that learners could engage with the items meaningfully, although the small sample size limits generalizability. Taken together, these results demonstrate that the guide is both valid and usable in practice, effectively capturing learners’ current competencies, desired outcomes, and perceived gaps.
Beyond confirming content validity, the results highlight the added value of a mixed evaluation approach. While the quantitative indices provided objective and replicable evidence of item relevance, clarity and simplicity, the expert reviewers’ qualitative comments offered targeted insights for refining item wording, scope, and neutrality. This integration of numerical indices and expert judgement reflects best practices in instrument development and responds to a recognised gap in qualitative research reporting, where systematic validation of interview guides is often overlooked (Almanasreh et al., 2019; Boelens et al., 2017; Kallio et al., 2016; Polit & Beck, 2006).
The organisation of the interview items aligns with McKillip’s (1987) Discrepancy Model, providing a systematic approach to identifying learners’ needs. The revisions primarily improved clarity, sharpened the focus on English reading courses, adopted more neutral wording, and incorporated measurable dimensions such as vocabulary, comprehension, and critical judgement. These revisions preserved the original constructs while improving interpretability and practical relevance. Compared with earlier instruments that lacked course-specific or cognitive skill contextualisation (Boelens et al., 2017; Kallio et al., 2016), the guide demonstrates enhanced specificity and applicability.
The findings deepen theoretical understanding of how CT and AI literacy needs can be systematically articulated in EFL reading contexts. The guide captures learners’ goal-oriented conceptualisations of CT development and AI-enhanced blended learning needs, highlighting the cognitive gap between current and ideal states as a driver for self-regulation. While these insights stem from the theoretical design and limited pilot feedback, they suggest the guide’s potential to elicit meaningful learner perceptions in practice.
In addition, the inclusion of AI-related items was intended to extend existing CT frameworks by highlighting how students’ experiences with AI tools may influence their CT abilities. These items should be considered exploratory, as the pilot study provides only preliminary evidence of their utility. Feedback indicated that students could respond to AI-focused questions without difficulty, supporting practical applicability for future research on the interplay between AI experiences and CT development.
The integration of AI tools into blended reading may shape learners’ cognitive processes by supporting information retrieval, identifying key ideas and argument structures in texts, and providing real-time feedback. These affordances are likely to influence specific CT subskills, particularly Analysis (e.g., identifying relationships and structures), Evaluation (e.g., assessing the credibility and quality of information), and Inference (e.g., drawing reasoned conclusions). At the same time, excessive reliance on AI outputs may lead to cognitive offloading, where learners depend on AI rather than actively engaging in critical reasoning. Although large-scale empirical data from application of the guide are not yet available, this conceptual discussion provides a theoretical framework for understanding the potential interactions between AI literacy and CT in EFL reading and for guiding future research and the design of AI-enhanced instructional interventions.
Practically, the validated interview guide offers a concrete, empirically grounded tool for designing an AI-enhanced blended reading module. It can inform instructional strategies by identifying specific CT skill gaps, although further testing with larger samples is needed before direct implementation. Its emphasis on measurable dimensions and contextual specificity ensures that the guide can support responsive module design rather than generic intervention planning. Pilot feedback confirmed usability, but broader application should be approached cautiously.
Methodologically, the study illustrates the value of combining quantitative indices with expert qualitative judgements in interview guide development, an approach often recommended but not consistently implemented in qualitative research. Robust content validation is essential before examining complex constructs such as CT or AI literacy, as unreliable instruments would compromise theoretical or empirical inferences. Taken together with pilot feedback, the guide provides a validated foundation for future construct- and criterion-related analyses in AI-mediated learning environments, while acknowledging current limitations in sample size and generalizability.
Limitations and Future Directions
Despite the strengths of the study, several limitations should be acknowledged. First, the expert panel, although carefully selected, consisted of nine individuals, which may constrain the generalisability of content validation results. Second, the study focused exclusively on Chinese EFL undergraduates, and its applicability in other linguistic, cultural, or educational contexts remains to be examined. In particular, the cultural and educational specificity of Chinese higher education, including exam-oriented pedagogy, CT expectations, and AI adoption patterns, may limit the direct transferability of some items to other EFL contexts.
Another limitation concerns the AI-related items. Students’ experiences with AI-supported learning, such as perceived usefulness, confidence, or frequency of use, vary widely across regions and institutions. These items may therefore require contextual adaptation before being used in other EFL settings. While the core structure of the guide is transferable, its AI-related components should be localised to align with technological access, institutional policies, and digital literacy norms.
Future research should further evaluate the interview guide through extended qualitative application. This includes examining how well the items function across broader learner groups, assessing the clarity and consistency of responses in different instructional contexts, and gathering additional user feedback to refine items. Given its semi-structured nature, future validation efforts should prioritise usability, response quality, and cross-context applicability. Larger and more diverse expert panels, broader student samples from multiple institutions, and cross-cultural comparisons will help establish the guide’s generalisability and robustness. Subsequent studies could also explore, where appropriate, how learners’ perceived needs relate to learning outcomes using suitable assessment tools.
Finally, the study addresses a gap in both contextual focus and methodological rigour. Existing research often examines general BL or AI literacy without systematically integrating their intersection with CT development in non-Western EFL contexts, and rarely uses carefully developed, content-validated instruments. By providing a theoretically informed, content-validated interview guide, this study demonstrates methodological rigour in content validation and offers practical utility. The instrument can potentially support educators in identifying CT skill gaps, designing AI-enhanced reading modules, and fostering CT in EFL learners, while also informing future research in comparable educational contexts.
Conclusion
This study developed and validated a semi-structured interview guide grounded in McKillip’s (1987) Discrepancy Model, designed to identify learners’ current competencies, ideal goals, and perceived gaps. The results lay a solid foundation for future work aimed at understanding and addressing the CT and AI-enhanced BL needs of Chinese EFL undergraduates.
Content validity was rigorously established through expert review, confirming that the items are relevant, clear, and measurable. Revisions enhanced clarity, scope, and measurability, producing a validated guide that combines methodological rigour with practical applicability. The instrument offers actionable insights for designing an AI-enhanced blended reading module integrating CT and AI literacy, and is readily usable in educational settings.
Despite limitations in expert panel size, cultural specificity, and the preliminary nature of AI-related items, the validated guide provides a methodologically rigorous and contextually grounded tool for designing an AI-enhance blended reading module that foster CT. It bridges theory and practice, supporting evidence-informed, learner-centred interventions. Future research should expand validation across larger, more diverse samples, examine predictive and criterion-related validity, and explore cross-cultural applicability to enhance both theoretical understanding and practical implementation.
Footnotes
Appendix A
Semi-Structured Interview Guide.
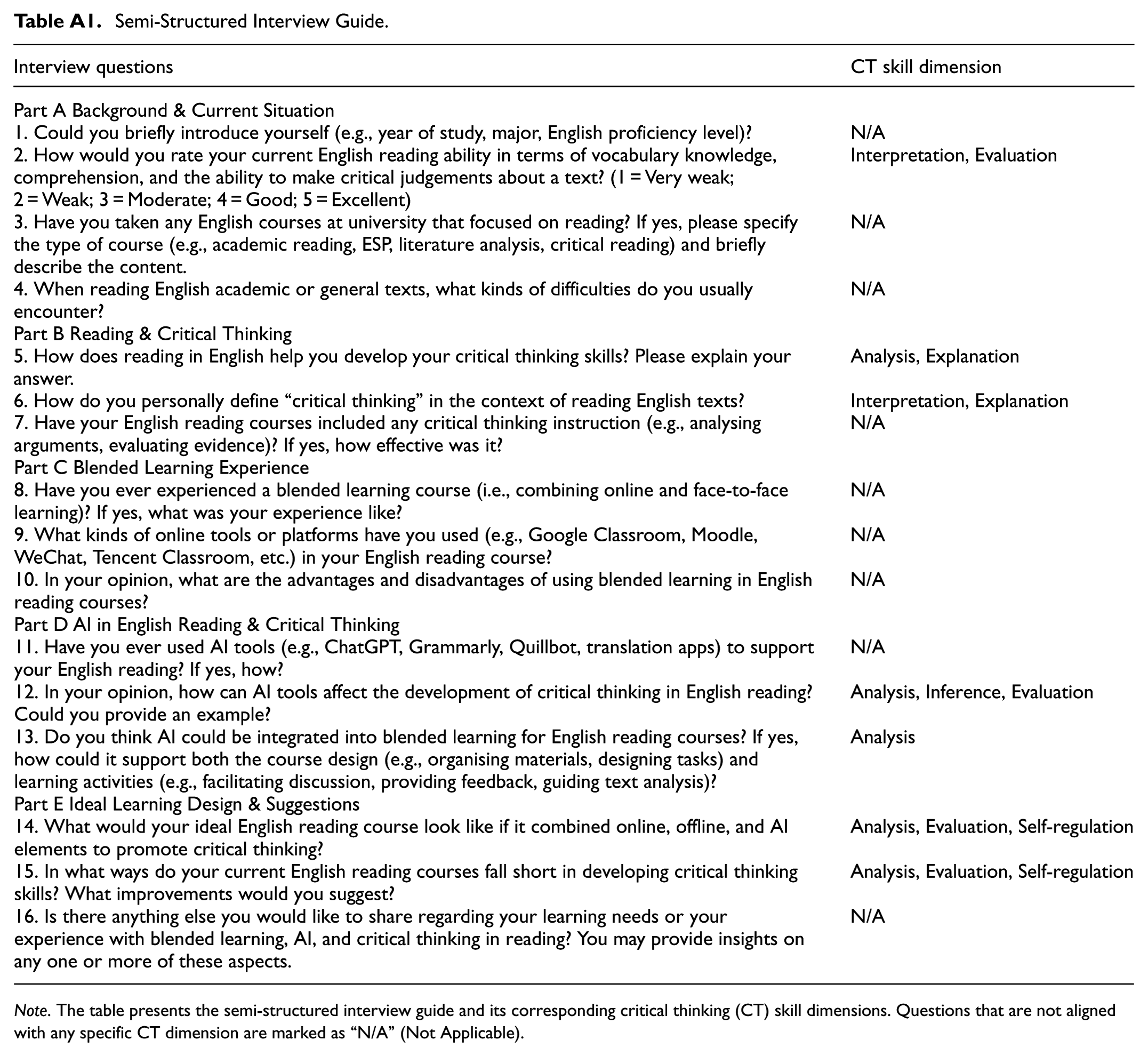
| Interview questions | CT skill dimension |
|---|---|
| Part A Background & Current Situation | |
| 1. Could you briefly introduce yourself (e.g., year of study, major, English proficiency level)? | N/A |
| 2. How would you rate your current English reading ability in terms of vocabulary knowledge, comprehension, and the ability to make critical judgements about a text? (1 = Very weak; 2 = Weak; 3 = Moderate; 4 = Good; 5 = Excellent) | Interpretation, Evaluation |
| 3. Have you taken any English courses at university that focused on reading? If yes, please specify the type of course (e.g., academic reading, ESP, literature analysis, critical reading) and briefly describe the content. | N/A |
| 4. When reading English academic or general texts, what kinds of difficulties do you usually encounter? | N/A |
| Part B Reading & Critical Thinking | |
| 5. How does reading in English help you develop your critical thinking skills? Please explain your answer. | Analysis, Explanation |
| 6. How do you personally define “critical thinking” in the context of reading English texts? | Interpretation, Explanation |
| 7. Have your English reading courses included any critical thinking instruction (e.g., analysing arguments, evaluating evidence)? If yes, how effective was it? | N/A |
| Part C Blended Learning Experience | |
| 8. Have you ever experienced a blended learning course (i.e., combining online and face-to-face learning)? If yes, what was your experience like? | N/A |
| 9. What kinds of online tools or platforms have you used (e.g., Google Classroom, Moodle, WeChat, Tencent Classroom, etc.) in your English reading course? | N/A |
| 10. In your opinion, what are the advantages and disadvantages of using blended learning in English reading courses? | N/A |
| Part D AI in English Reading & Critical Thinking | |
| 11. Have you ever used AI tools (e.g., ChatGPT, Grammarly, Quillbot, translation apps) to support your English reading? If yes, how? | N/A |
| 12. In your opinion, how can AI tools affect the development of critical thinking in English reading? Could you provide an example? | Analysis, Inference, Evaluation |
| 13. Do you think AI could be integrated into blended learning for English reading courses? If yes, how could it support both the course design (e.g., organising materials, designing tasks) and learning activities (e.g., facilitating discussion, providing feedback, guiding text analysis)? | Analysis |
| Part E Ideal Learning Design & Suggestions | |
| 14. What would your ideal English reading course look like if it combined online, offline, and AI elements to promote critical thinking? | Analysis, Evaluation, Self-regulation |
| 15. In what ways do your current English reading courses fall short in developing critical thinking skills? What improvements would you suggest? | Analysis, Evaluation, Self-regulation |
| 16. Is there anything else you would like to share regarding your learning needs or your experience with blended learning, AI, and critical thinking in reading? You may provide insights on any one or more of these aspects. | N/A |
Note. The table presents the semi-structured interview guide and its corresponding critical thinking (CT) skill dimensions. Questions that are not aligned with any specific CT dimension are marked as “N/A” (Not Applicable).
Acknowledgements
The authors sincerely thank the journal editor, the administrator, and the anonymous reviewers for their time and consideration. Special appreciation is also extended to all participants in this study.
Ethical Considerations
This study was conducted in accordance with the principles of the Declaration of Helsinki and adhered to strict ethical standards. Participation was voluntary, anonymous, and confidential. All authors have read and approved the final version of the manuscript for publication.
Consent to Participate
All participants provided written informed consent prior to their participation in the study.
Author Contributions
Anni Yang: was responsible for conceptualisation, data curation, formal analysis, methodology, and data validation, and also took the lead in writing the original draft and in reviewing and editing the manuscript. Nur Ainil Sulaiman: was responsible for methodology and data validation, and contributed to the final reviewing and editing of the manuscript. Nur Syafiqah Yaccob: was responsible for methodology and data validation, and contributed to the final reviewing and editing of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data will be available from the corresponding author upon reasonable request.*