
Abstract
Academic discourse is evolving rapidly under the dual pressures of global scientization and local academic capitalism, yet how these systemic forces reshape the stylistic norms of non-Anglophone communities remains underexplored. To address this gap, this study investigates the diachronic evolution of Chinese Foreign Linguistics (CFL) discourse over two decades based on a corpus of 13,658 abstracts from CSSCI-listed journals (2004–2023). We employ a multi-dimensional analysis combining topic modeling, dependency parsing, and sentiment analysis to map the trajectories of research themes, syntactic structures, and evaluative stance. The results reveal a discipline in profound transformation, characterized by three distinct trends: (a) an “Empirical Turn” in thematic foci, transitioning from introspective inquiry to data-driven science; (b) a “Syntactic Rationalization,” evidenced by a universal increase in syntactic complexity to accommodate higher informational density; and (c) an “Evaluative Marketization,” where a general rise in positive sentiment masks a “Promotional Paradox”—applied fields embrace promotional rhetoric to demonstrate relevance, while theoretical core fields retreat into neutrality to signal epistemic integrity. Interpreted through the dual theoretical lenses of Communities of Practice and Activity Theory, these shifts represent a collective renegotiation of the discipline’s joint enterprise toward scientization, while simultaneously creating a stratified activity system. We argue that rhetorical style in this field has evolved into a means of distinction: while elite scholars maintain a stance of confident simplicity, emerging scholars are compelled to adopt complex syntax and promotional evaluation as symbolic passwords to navigate the competitive publication system. These findings highlight the inherent tension between scientific rigor and market visibility in the modern academic ecosystem.
Keywords
Introduction
Academic discourse, as the conventionalized medium of scholarly communication, is not static; it evolves dynamically under shifting sociocultural, institutional, and evaluative pressures (Hyland, 2005). These stylistic transformations encompass not merely what is researched, but how knowledge is encoded, authors are positioned, and audiences are engaged. Recent scholarship has extensively documented these shifts, identifying trends toward greater authorial visibility (Q. Wang & Hu, 2022), increased linguistic positivity (X. Liu & Zhu, 2023), and evolving patterns of lexical density (Zhu et al., 2024) and syntactic complexity (Shen et al., 2023). Such features are linguistic resources through which scholars negotiate the validity of claims and construct academic identities (Kumar et al., 2021). Crucially, this stylistic evolution reflects a growing tension between “informationality”—the need for objective knowledge transmission—and “promotionality”—the pressure to sell research. This tension is increasingly understood within the broader theoretical frameworks of academic capitalism (e.g., Chan et al., 2020; Münch, 2014), where scholars are compelled to market their work to secure funding and recognition in a competitive, metric-driven global academy.
For academic communities in non-Anglophone contexts, this evolution presents unique complexities, requiring a balance between international norms and local linguistic ecosystems. Research in this area is expanding. For instance, Kang and Lee (2025) utilized combinatoric morphemic analysis to investigate formulaic expressions in Korean, highlighting the necessity of methodologies tailored to non-inflectional languages. Similarly, in the context of Pakistan, Missen et al. (2020) revealed how stylistic markers like readability scores diverge significantly across science and social science disciplines, shaped by local developmental trajectories. The field of Chinese Foreign Linguistics (CFL) represents a particularly salient case of this dynamic. While historically shaped by borrowing Western theories (creating a foundational ‘Englishness’), CFL is simultaneously grounded in local rhetorical traditions (“Chineseness”).
Li (2020), for example, demonstrated this by comparing English and Chinese research article abstracts, finding that Chinese abstracts feature distinct rhetorical preferences, such as a lower frequency of ‘Method’ and ‘Product’ moves, reflecting differing epistemological traditions. Furthermore, institutional pressures specific to the Chinese context, such as the non-transparent evaluation systems, have been shown to profoundly influence the output and disciplinary focus of social sciences (K. Chen et al., 2022). While Huang and Li (2023) have offered some insights into micro-level translational mediation in CFL, exploring how “modality shifts” occur when translating Chinese abstracts and how features like a more assertive authorial stance and “run-on” sentences are managed in the process, the diachronic evolution of its core stylistic properties remains largely unexamined.
A primary indicator of disciplinary evolution is the shift in research themes. Understanding how research foci change over time reveals a discipline’s responsiveness to new theories, methodologies, and funding priorities (Gurcan et al., 2022). While bibliometric analyses based on titles and keywords have been effective for mapping macroscopic landscapes (e.g., Bertoglio et al., 2021; Dwivedi & Elluri, 2023), they often fail to capture the nuanced content authors deem central. Abstracts, as concise and obligatory summaries, offer a richer and more direct representation of an article’s core contribution than keywords alone (Hsu et al., 2023). They are meticulously crafted to convey the essence of research and are often the only part read by a wider audience. Despite their significance in indexing content, large-scale diachronic analyses of the thematic evolution embedded within abstracts—particularly in specific national contexts like the CFL community—remain relatively underexplored.
Beyond thematic content, the syntactic architecture of academic writing has garnered considerable attention, with “syntactic complexification” emerging as a notable diachronic trend. Syntactic complexity is a multi-dimensional construct (Shen et al., 2023). It encompasses not only “large-grained” indices like mean length of T-unit, but also “fine-grained” measures focusing on specific phrasal structures, such as the density of nominalizations and embedded clauses (M. Wang & Lowie, 2023). A higher level of syntactic complexity is considered an indicator of advanced proficiency and is closely associated with the precision, density, and formality expected in academic prose (Casal et al., 2021).
Diachronic studies, predominantly focusing on English academic writing in SCI/SSCI journals, have documented a general increase in complexity over time (Lu & Ai, 2015). This trajectory is often theorized to move from a reliance on coordination to subordination, and ultimately to increased phrasal complexity at higher proficiency levels (Norris & Ortega, 2009). However, complexity patterns are highly sensitive to genre and writer background (Biber et al., 2011). Notably, comparisons have revealed distinct strategies: while native English speakers may favor subordination, advanced Chinese writers often demonstrate increased phrasal complexity (M. Wang & Lowie, 2023). Yet, comprehensive diachronic studies examining how these syntactic features have evolved specifically within the Chinese academic context, specifically in Chinese Social Sciences Citation Index (CSSCI) listed CFL journals over an extended period, are less common.
In parallel with thematic and syntactic shifts, the use of evaluative language—particularly “evaluative positivization”—has garnered attention (e.g., L. Chen & Hu, 2020; Q. Wang & Hu, 2023). Evaluative language allows authors to express stance and engage readers (Hyland, 2005), playing a vital role in persuading the community of a study’s validity (Elgendi, 2019). Recent diachronic studies indicate a growing tendency toward positive framing. For example, Yuan and Yao (2022) documented a significant increase in positive sentiment over 25 years, attributing this “linguistic positivity bias” to the competitive nature of publishing. This trend reflects the intensifying tension between informationality and promotionality, a dynamic increasingly understood through the theoretical notion of academic performativity (Brunila & Nehring, 2023). Under these regimes, researchers are compelled to strategically frame their work to enhance its perceived novelty and impact (Vinkers et al., 2015).
This promotional trend may hold particular significance for the humanities and social sciences. These fields often face greater pressure to articulate societal relevance and navigate skepticism regarding their “scientific rigor” (Fecher et al., 2021). In such contexts, the heightened use of positive evaluative language serves as a rhetorical strategy to bolster knowledge claims and engage both specialist and wider audiences. While increasing positivity has been explored in political science (Weidmann et al., 2018) and communication (X. Liu & Zhu, 2023), its specific diachronic manifestation within linguistics research—particularly in the Chinese context where local institutional logic intersects with global market-oriented academic trends—has received less focused attention.
To sum up, this paper investigates three fundamental yet under-explored aspects of this development: thematic evolution, syntactic complexification, and evaluative positivization, as represented by CFL abstracts from the CSSCI-listed journals published between 2004 and 2023. Specifically, this research seeks to answer the following three questions:
How has the thematic landscape of CFL research, as reflected in abstracts from CSSCI-listed journals, evolved between 2004 and 2023, and what are the prominent diachronic shifts in research focus?
In what ways has the syntactic structure of CFL abstracts from CSSCI-listed journals undergone complexification between 2004 and 2023, and are these patterns of syntactic change consistent or varied across different thematic domains?
To what extent does the evaluative expression in CFL abstracts from CSSCI-listed journals demonstrate a trend towards positivization over the 2004 to 2023 period, and how does this trend manifest across different thematic domains?
Methodology
The flowchart (see Figure 1) illustrates the overall research procedures in this study.
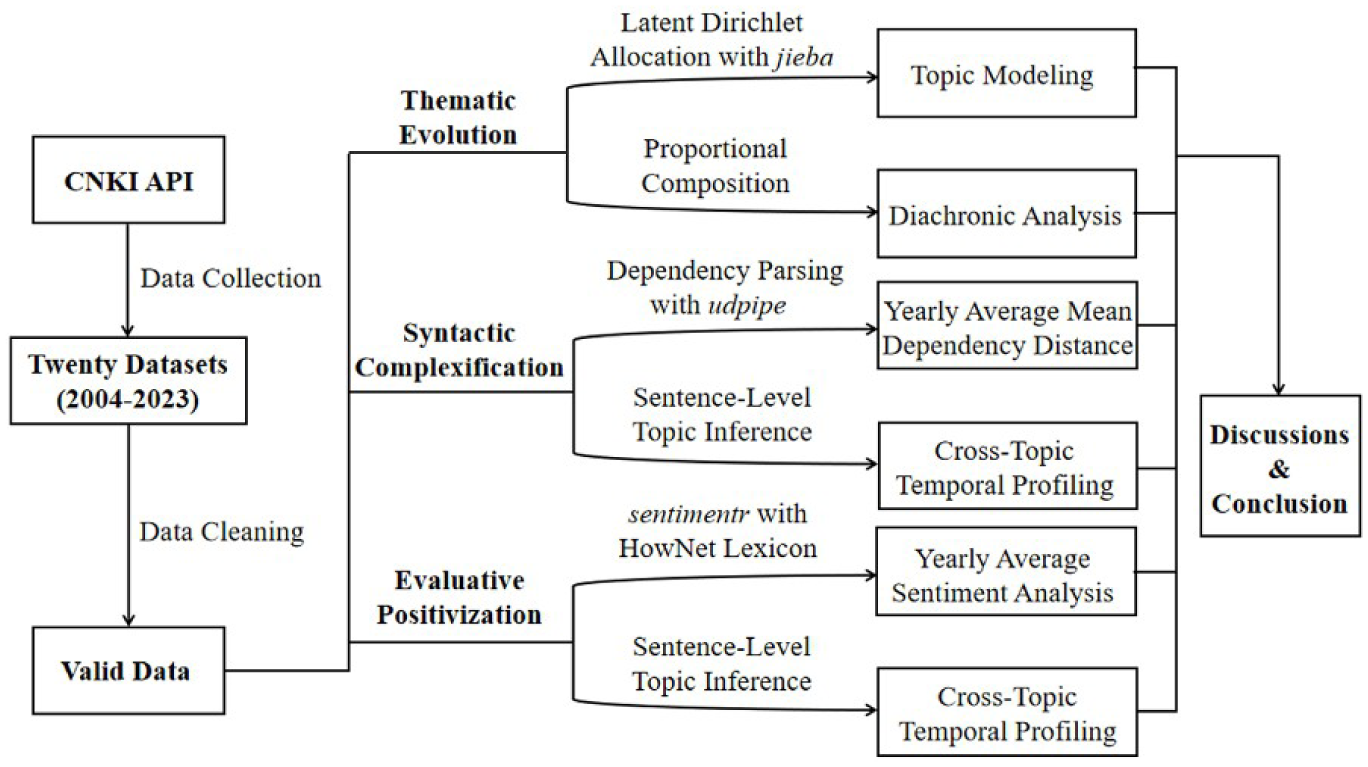
The research workflow diagram.
Data Collection and Pre-Processing
This study analyzes a corpus of 13,658 abstracts published between 2004 and 2023. The data were retrieved via the China National Knowledge Infrastructure (CNKI) API between December 2024 and January 2025. The sample was sourced from eight top-tier (Q1) CSSCI-listed CFL journals, selected based on the 2024 Annual Report for Chinese Academic Journal Impact Factors. These journals include: Foreign Languages in China (中国外语), Foreign Language World (外语界), Foreign Language Education (外语教学), Foreign Language Teaching and Research (外语教学与研究), Foreign Languages and Their Teaching (外语与外语教学), Journal of Foreign Languages (外国语), Modern Foreign Languages (现代外语), and Technology Enhanced Foreign Language Education (外语电化教学).
Data pre-processing was conducted using R (Version 4.2.2). Utilizing the dplyr (Wickham et al., 2023) and tidytext (Silge & Robinson, 2017) packages, we applied a rigorous cleaning pipeline to ensure data quality. The process involved: (a) removing duplicate entries; (b) excluding non-research content, such as book reviews and announcements; (c) retaining only Chinese tokens; and (d) standardizing all text from Traditional to Simplified Chinese. The final valid corpus comprises 2,766,549 words.
Data Analysis: A Multi-Method Approach
All data processing and subsequent analyses detailed in this study were also conducted using R 4.4.2.
Thematic Evolution Analysis
To investigate diachronic shifts in research foci, we employed Latent Dirichlet Allocation (LDA) for unsupervised topic discovery. While neural approaches utilizing Large Language Models (e.g., BERTopic) are increasingly popular, LDA was deliberately selected for this study to ensure methodological rigor in two key aspects: (a) Lexical Precision: Unlike sub-word tokenization in pre-trained models which may fragment specific terminology, LDA allows strict control over tokenization via specialized lexicons, preserving the integrity of academic concepts (L. Yu et al., 2025); (b) Interpretability: As a generative probabilistic model, LDA offers transparent word-topic distributions, facilitating the qualitative scrutiny essential for humanities research (Wu et al., 2025).
Data preprocessing was rigorous and tailored to the linguistic characteristics of the corpus. Chinese word segmentation was performed using the jiebaR package (Qin & Wu, 2019). To enhance segmentation accuracy, particularly for domain-specific terminology relevant to this study, the default dictionary was augmented with two specialized sub-lexicons—“Social Sciences” (社会科学) and “Foreign Language Learning” (外语学习)—derived from the DomainWordsDict compiled by H. Liu (2021). This resource, covering words across more than 68 domains, was instrumental in improving performance in text classification by providing more precise segmentation of academic terms.
Following segmentation, the abstracts for each year were aggregated to form a single “document” representing that year’s scholarly output; this yearly aggregation strategy was chosen to facilitate the identification of broad thematic shifts over time. A Document-Term Matrix (DTM) was subsequently constructed utilizing the tm package (Feinerer et al., 2008). The DTM construction involved four specific preprocessing steps: (a) conversion of the segmented word lists for each year into single string documents; (b) creation of a VCorpus object; (c) comprehensive text cleaning, including the removal of punctuation, numerals, and an iteratively refined list of Chinese stopwords—this list integrated a standard ISO Chinese selection with corpus-specific high-frequency academic terms that offered minimal thematic discrimination; and (d) filtering of the DTM to retain only terms meeting a minimum length criterion (e.g., two or more characters) and the removal of any empty documents to ensure LDA model stability.
The determination of the optimal number of topics (K) was grounded in a rigorous, multi-stage validation framework. Initial quantitative screening via the ldatuning R package (Murzintcev, 2020) suggested a potential range of K = 4 to 10 based on established metrics (see Figure 2 ), including those proposed by Cao et al. (2009), Arun et al. (2010), and Deveaud et al. (2014). To ensure substantive validity, we subsequently conducted a sensitivity analysis on pivotal candidates. Inspection revealed that the K = 6 model conflated distinct sub-fields (e.g., merging Second Language Acquisition with Micro-level Foreign Language Education), whereas K = 8 resulted in excessive fragmentation with high semantic overlap. The K = 7 solution emerged as the optimal configuration, striking a balance between granularity and coherence, evidenced by a favorable perplexity score and a peak Topic Coherence (Cv) of 0.58 (surpassing 0.52 for K = 6 and 0.54 for K = 8), which confirmed the semantic interpretability of the generated topics.

The scree plot.
The final model was trained using the topicmodels R package (Grün & Hornik, 2011) with Gibbs sampling (2,000 iterations, burn-in = 1,000, δ = .01, α = 50/K). To corroborate the algorithmic output with human expert judgment, all four authors independently reviewed representative abstracts for each topic. The inter-rater reliability for topic assignment (Fleiss’ kappa) was calculated at 0.85, indicating high agreement. Following this validation, we extracted the posterior probability (γ) using the posterior() function to map the proportional evolution of the seven identified themes from 2004 to 2023. Visualizations were generated utilizing the ggplot2 R package (Wickham, 2016). To move beyond descriptive observation and strictly test the statistical significance of the evolving research foci, simple linear regression models were fitted to the time-series data. In these models, Year served as the independent variable and the topic’s aggregate posterior probability as the dependent variable.
Syntactic Dependency Analysis
To investigate diachronic changes in the syntactic complexity of CFL abstracts, this study focused on Mean Dependency Distance (MDD) as a primary indicator. Dependency distance, which measures the linear distance between a syntactically dependent word and its head, is widely recognized as a robust correlate of cognitive processing load and syntactic complexity in sentence comprehension and production (e.g., Liang & Sang, 2022; H. Liu et al., 2017). Shorter dependency distances are generally preferred due to working memory constraints, a principle known as Dependency Distance Minimization. This analysis involved two main stages: an overall diachronic analysis of yearly MDD and a more granular cross-topic temporal profiling of MDD. All syntactic parsing and MDD calculations were performed in R using the udpipe package (Straka & Straková, 2017).
To investigate diachronic changes in syntactic complexity, we employed Mean Dependency Distance (MDD) as the primary indicator. Defined as the linear distance between a dependent word and its head, MDD is widely recognized as a robust correlate of cognitive processing load and syntactic complexity (e.g., Liang & Sang, 2022; H. Liu et al., 2017). All syntactic parsing and calculations were performed in R using the udpipe package (Straka & Straková, 2017) with the pre-trained “chinese-gsdsimp” Universal Dependencies model. The analysis began with an overall assessment of annual trends, where the aggregated text for each year was processed using the udpipe_annotate() function to perform tokenization and dependency parsing. The annual MDD was computed by averaging the lengths of all valid dependency arcs, explicitly excluding punctuation marks (where dep_rel = “punct”) to ensure the metric reflected substantive syntactic relations.
To further explore domain-specific syntactic trajectories, we implemented a granular workflow integrating MDD measures with the K = 7 thematic structure. Specifically, abstracts were segmented into individual sentences, and MDD was calculated for each sentence following the procedure above. We then inferred the thematic composition of these sentences using the trained LDA model by constructing a sentence-level Document-Term Matrix aligned with the original vocabulary and utilizing the posterior() function from the topicmodels package to obtain the probability distribution (P(topic|sentence)). A weighted average MDD was subsequently calculated for each topic per year, where each sentence’s MDD was weighted by its posterior probability of belonging to that specific topic. To statistically verify the observed trajectories for both the overall dataset and each thematic domain, simple linear regression models were also employed, treating Year as the independent variable and MDD as the dependent variable.
Evaluative Sentiment Analysis
This study also investigated the diachronic trend of “evaluative positivization”—the tendency toward an increased use of positive evaluative language—to determine whether scholarly sentiment has become increasingly positive from 2004 to 2023, and how these trends diverged across the seven thematic domains. Data processing utilized the jiebaR package for segmentation, alongside dplyr and tidytext. To quantify sentiment, we constructed a customized Chinese sentiment lexicon based on HowNet resources (Dong & Dong, 2006), assigning a score of +1 to positive words and −1 to negative words. The analysis adopted the same sentence-level inference and weighted-average protocol as the syntactic analysis: each sentence’s sentiment score was weighted by its posterior topic probability for each year. Consistent with the previous analyses, simple linear regression models were applied to the time-series data to confirm the presence and directionality of positivization trends across the corpus and within individual topics.
Results
Research Evolution
Table 1 provides a comprehensive overview of the seven identified topics, detailing their descriptive labels and the top 10 characteristic keywords that define their semantic boundaries. The diachronic evolution of these themes is further quantified in Table 2 , which collectively illustrate a profound structural reconfiguration of the field over the two decades.
Results of LDA.

Descriptive Statistics of Research Evolution.

Specifically, as shown in the growth trajectories in Figure 3 , certain topics demonstrated a marked surge in prominence. Topic 1 (Macro-level Foreign Language Education) exhibited a steady upward trajectory, expanding from 9.72% in 2004 to 25.64% in 2023. Linear regression analysis confirms this as a statistically significant growth trend (β = .83, R2 = .78, p < .001), indicating the field’s increasing alignment with national educational strategies. Even more dramatically, Topic 5 (Corpus-based Studies) surged from a marginal 0.84% to a dominant 24.64%, with regression results verifying this as the most rapid expansion in the corpus (β = 1.25, R2 = .82, p < .001).

Visualization of research evolution.
In stark contrast, the data reveals significant declines in other areas. Topic 6 (Pragmatics), formerly the dominant theme in 2004 (31.31%), underwent a continuous contraction to 11.61% (β = −1.04, R2 = .75, p < .001). Similarly, Topic 7 (Micro-level Foreign Language Education) experienced a steep drop from 21.09% to 1.81% (β = −1.01, R2 = .79, p < .001), suggesting a waning interest in classroom-level pedagogy in high-impact journals.
Furthermore, the diachronic analysis uncovers more nuanced, non-linear evolutionary patterns. Topic 2 (Translation Studies) maintained a stable yet fluctuating presence (starting at 22.37%, ending at 22.20%), a trend statistically identified as non-significant (p = .68 > .05). Meanwhile, Topic 3 (Second Language Acquisition) and Topic 4 (General Linguistics) displayed “inverted-U” trajectories. Specifically, Topic 3 rose from 1.62% to a peak of 16.94% in 2016 before receding to 2.31%, resulting in a statistically non-significant linear trend over the full period (p = .61 > .05). Similarly, Topic 4 peaked at 21.51% in 2010 before decreasing to 11.78%, also yielding a statistically insignificant linear outcome (p = .12 > .05).
To explicitly address RQ1 regarding the thematic evolution of the field, these statistical indicators confirm that the CFL landscape has undergone a fundamental structural reconfiguration. The discipline has transitioned from a historical predominance of theoretical and micro-pedagogical inquiries (evidenced by the significant decline in Topics 6 and 7) toward macro-policy oriented and empirically grounded research (evidenced by the significant surge in Topics 1 and 5).
Syntactic Complexification
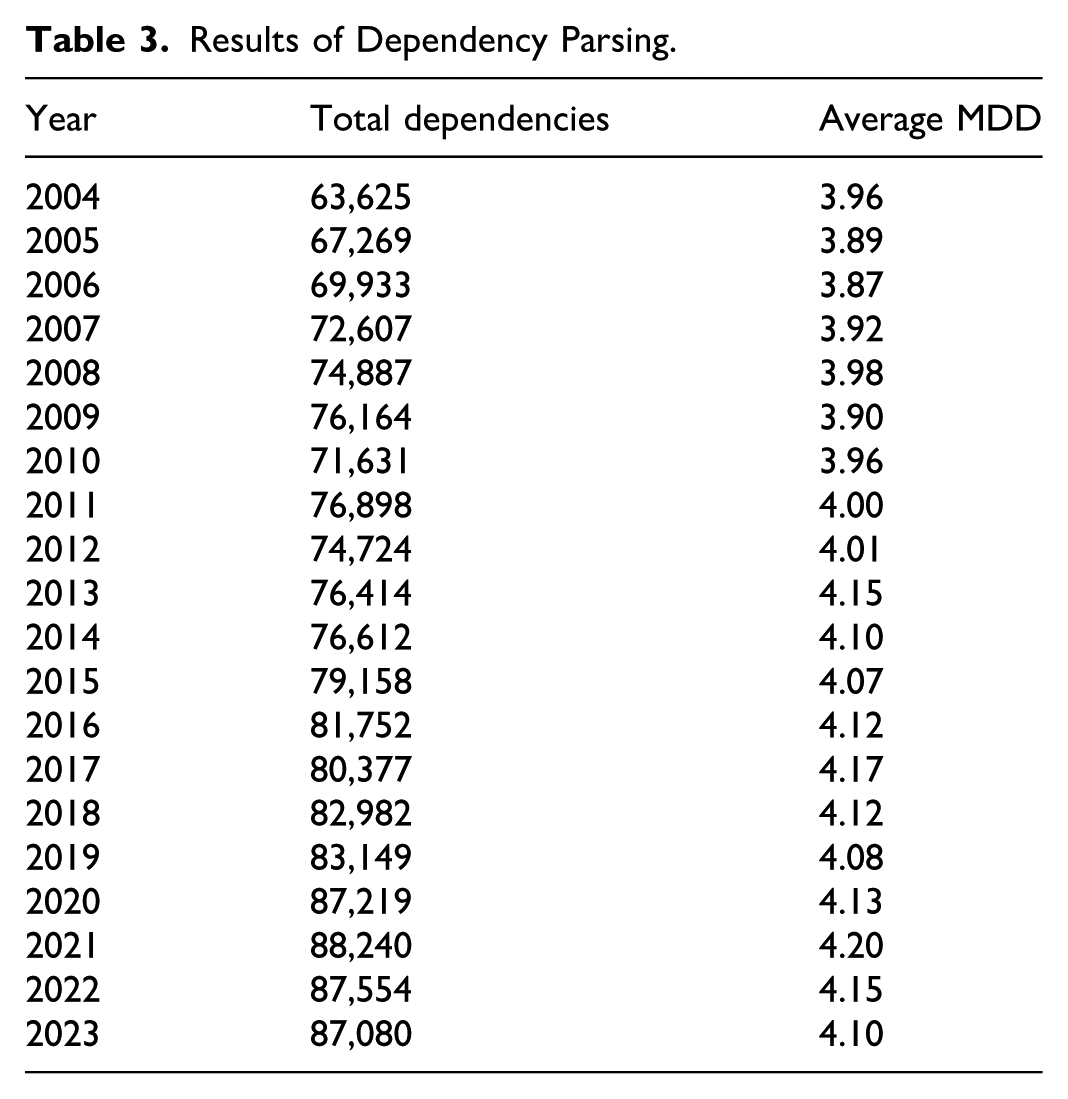
The overall diachronic trend of syntactic complexity is summarized in Table 3 and graphically depicted in Figure 4 . As explicitly indicated by the data, the average MDD followed a general upward trajectory, increasing from 3.96 in 2004 to 4.10 in 2023. Although there were fluctuations—such as a peak of 4.20 in 2021 followed by a slight dip—the final complexity level remained higher than the initial baseline. Crucially, the simple linear regression model fitted to this time series confirms that this overall complexification trend is statistically significant (β = .007, R2 = .65, p = .002 < .01), offering robust empirical evidence that CFL discourse is becoming syntactically more elaborate.
Results of Dependency Parsing.

Visualization of syntactic complexification over 20 years.
To examine domain-specific variations, Figure 5 visualizes the comparative MDD trajectories, supported by the descriptive data in Table 4 . Linear regression analyses of these time series further confirm that the drive toward complexification is pervasive, yielding statistically significant positive trends across all seven domains.

Visualization of cross-topic temporal profiling of MDD.
Results of Yearly Weighted Average MDD.

Specifically, Topic 5 (Corpus-based Studies) exhibited the steepest gradient of complexification, recording the highest growth rate among all domains (β = .008, R2 = .72, p < .001). Closely following this trend, both Topic 1 (Macro-level Foreign Language Education) and Topic 2 (Translation Studies) demonstrated consistent and highly significant increases. Topic 1 showed a robust upward trajectory (β = .006, R2 = .68, p = .002 < .01), which was closely mirrored by the growth observed in Topic 2 (β = .006, R2 = .66, p = .003 < .01).
Significant upward trends were equally evident in the remaining sub-fields. Topic 3 (Second Language Acquisition), despite its fluctuating “inverted-U” pattern in topic prevalence, showed a clear and significant linear increase in syntactic complexity, rising from 3.77 to 3.86 (β = .005, R2 = .45, p = .024 < .05). Similarly, steady increases in syntactic density were observed in Topic 4 (General Linguistics; β = .005, R2 = .52, p = .012 < .05), Topic 6 (Pragmatics; β = .004, R2 = .48, p = .021 < .05), and Topic 7 (Micro-level Foreign Language Education; β = .004, R2 = .42, p = .035 < .05).
To explicitly address RQ2 regarding the diachronic shifts in syntactic complexity, the results provide compelling evidence of a universal drift toward syntactic elaboration. This general complexification—verified by the significant upward trends across all seven thematic domains—suggests that CFL scholars, regardless of their specific sub-disciplinary focus, are increasingly favoring denser, more elaborated sentence structures to package information.
Evaluative Positivization
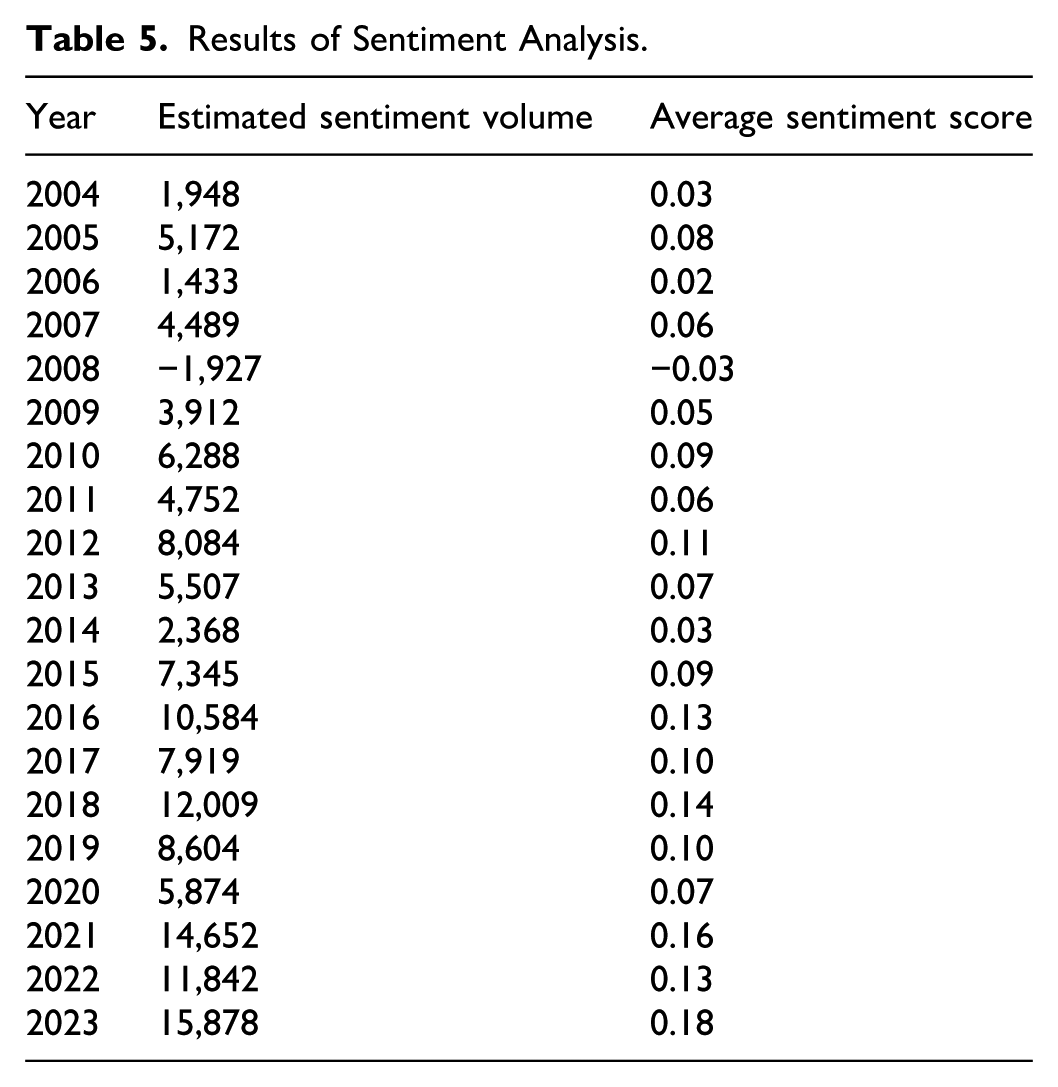
The overall annual trend in evaluative language was first examined. Table 5 presents the estimated sentiment volume and average sentiment scores, while Figure 6 visually tracks the diachronic trajectory. As indicated by the data, the average sentiment score demonstrated a clear trend toward increased positivization over the 20-year period. The score started at 0.03 in 2004, experienced a significant dip to −0.03 in 2008, and then embarked on a sustained rise, ultimately reaching a peak of 0.18 in 2023. Crucially, the simple linear regression model fitted to this time series confirms that this overall positivization trend is statistically significant (β = .008, R2 = .71, p < .001), signifying a strong shift toward more promotional discourse in the corpus.
Results of Sentiment Analysis.

Visualization of evaluative positivization over 20 years.
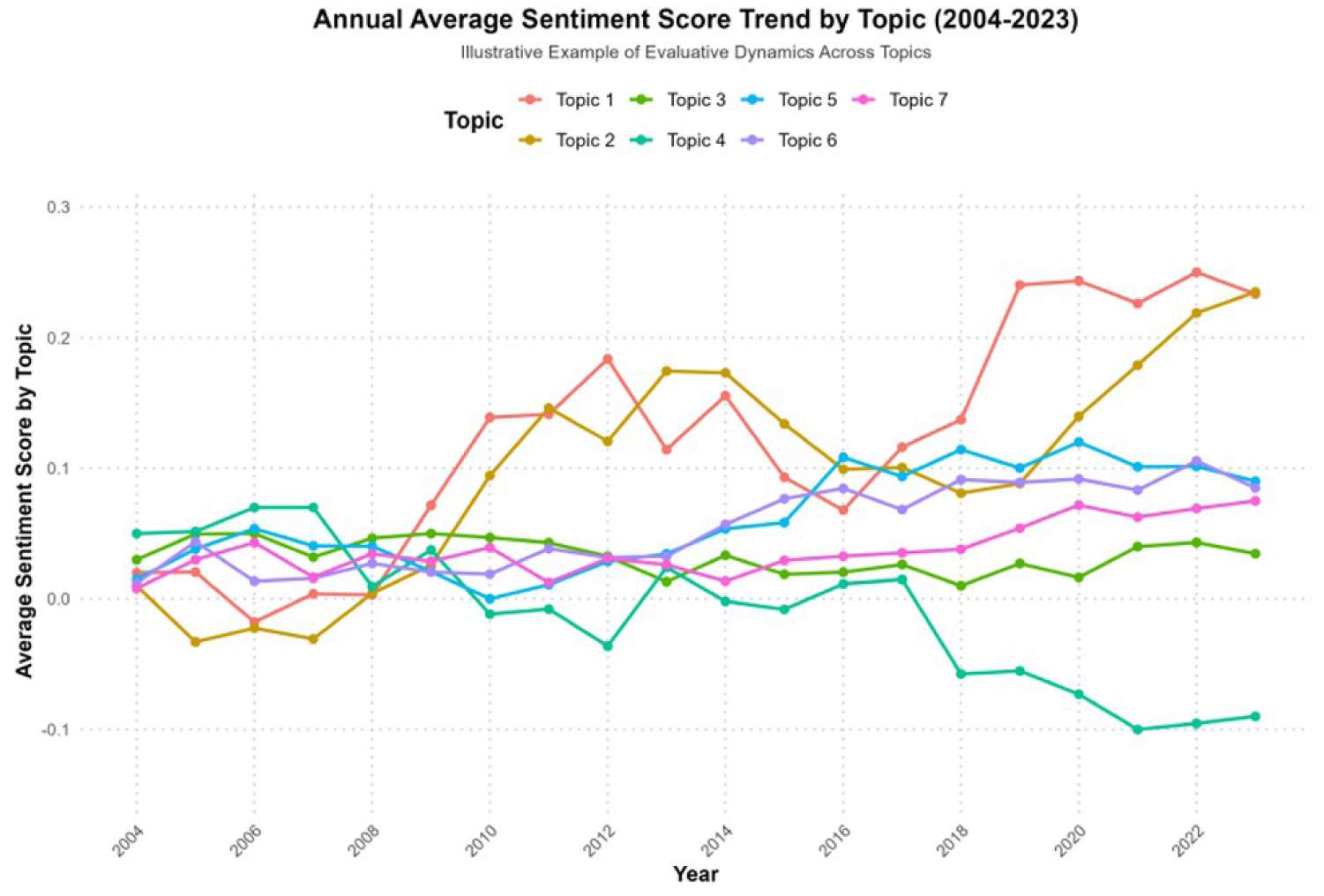
To examine domain-specific variations, Figure 7 visualizes the comparative sentiment profiles, supported by the weighted average data in Table 6 . Linear regression analyses of these time series reveal markedly divergent strategies across the thematic domains, with significant statistical outcomes identified in six out of the seven topics.
Visualization of cross-topic temporal profiling of sentiment score.
Results of Yearly Weighted Average Sentiment Score.

Specifically, Topic 1 (Macro-level Foreign Language Education) and Topic 2 (Translation Studies) emerged as the primary drivers of this positivization trend. Topic 1 showed a substantial surge from 0.02 to 0.23, verified by the strongest statistical growth in the entire corpus (β = .011, R2 = .78, p < .001). This trajectory was closely matched by Topic 2, which rose from 0.01 to 0.23, also demonstrating a highly significant promotional shift (β = .010, R2 = .75, p < .001).
Moderate yet statistically significant increases were observed in the empirical and applied sub-fields. Topic 5 (Corpus-based Studies) exhibited a steady rise in positive sentiment from 0.02 to 0.09 (β = .004, R2 = .55, p = .008 < .01). Similarly, Topic 6 (Pragmatics) showed a consistent upward drift from 0.01 to 0.09 (β = .004, R2 = .52, p = .012 < .05), and Topic 7 (Micro-level Foreign Language Education) increased from 0.01 to 0.08 (β = .003, R2 = .48, p = .025 < .05). These results suggest that while less aggressive than the macro-policy domains, these fields are also gradually adopting more positive evaluative stances.
By comparison, Topic 4 (General Linguistics) displayed a distinct counter-trend toward negativization. This topic began with a positive score of 0.05 in 2004 but progressively declined to −0.09 in 2023. The regression analysis for Topic 4 yielded a significant negative coefficient (β = −.007, R2 = .62, p = .004 < .01), reflecting a unique disciplinary shift toward increased neutrality or critical detachment.
Finally, Topic 3 (Second Language Acquisition) remained the only domain with no significant evolutionary trend. Starting and ending at 0.03 with minor fluctuations, the regression model for Topic 3 confirmed a statistically non-significant outcome (β < .001, R2 = .01, p = .25 > .05), indicating a stable evaluative stance over the two decades.
To explicitly address RQ3 regarding the evolution of evaluative language, the findings unveil a dialectical phenomenon. While the field as a whole is undergoing evaluative positivization—driven by the pressure to articulate societal relevance in applied fields like Language Education (Topics 1 and 7) and Translation (Topic 2)—core theoretical fields like General Linguistics (Topic 4) are resisting this trend, instead reinforcing their scientific rigor through emotional detachment (negativization).
Discussion
The diachronic analyses presented in the preceding section reveal a discipline in flux. The distinct trajectories of thematic reconfiguration, syntactic complexification, and evaluative positivization are not isolated linguistic accidents; rather, they represent a systemic evolution of the academic discourse within the CFL community. To interpret the mechanisms driving these shifts, this section adopts a dual theoretical framework. First, employing Wenger’s (1998) Communities of Practice (CoP) theory, we examine the collective dimension, viewing the observed thematic shifts as a renegotiation of the community’s “joint enterprise” and “shared repertoire.” Subsequently, we utilize Activity Theory (AT; Engeström, 2001) to explore the subjective and systemic perspectives, analyzing how individual scholars navigate the core contradiction between informationality and promotionality under the pressures of academic capitalism. By integrating these perspectives, we illustrate how macro-level disciplinary and global pressures are refracted into micro-level writing practices.
Empirical Turn: Redefining the Joint Enterprise Through Global Scientization
The most fundamental structural change observed in our corpus is the dramatic reconfiguration of research foci, characterized by a decisive transition from theoretical and introspective inquiry to empirical and data-driven investigation. Through the lens of CoP, this empirical turn signifies a profound shift in the community’s joint enterprise—the collectively negotiated understanding of what constitutes valid and valuable knowledge.
The continuous contraction of Topic 6 (Pragmatics) and Topic 7 (Micro-level Foreign Language Education) suggests that the traditional “humanistic” paradigm—often characterized by qualitative discourse analysis or classroom-based pedagogy—is moving from the core to the periphery of the community’s practice. In contrast, the rapid expansion of Topic 5 (Corpus-based Studies) indicates that the community is actively adopting a new shared repertoire of methodological tools. This shift is not merely a change in subject matter; it represents an epistemological reorientation toward “scientization” (Fecher et al., 2021).
This reorientation reflects the CFL community’s active alignment with global paradigms dominant in Anglophone applied linguistics, where evidence-based research has become the gold standard for legitimacy (X. Liu & Zhu, 2023). By embracing corpus linguistics—a methodology capable of processing massive datasets and generating quantifiable patterns—CFL scholars are acquiring the necessary scientific capital to participate in the global academic conversation. The community is, in effect, rewriting its norms of competence: to be a legitimate participant in the high-impact CFL community now increasingly requires the mastery of quantitative tools rather than purely speculative reasoning.
Furthermore, the robust growth of Topic 1 (Macro-level Foreign Language Education) alongside this empirical turn illustrates a unique feature of the Chinese context: a “state-science” alliance. While global scientization drives the methodological shift, national strategic needs drive the thematic focus. The convergence of these two trends suggests that the joint enterprise of CFL has been redefined as a dual pursuit: adopting “hard” scientific methods to address “hard” national concerns. This collective thematic evolution lays the foundation for the stylistic changes observed in syntax and evaluation, as the community’s new enterprise necessitates rhetorical strategies that project both scientific precision and policy relevance.
Syntactic Rationalization: The Dive for Informational Density
The second major stylistic evolution is the universal trend toward syntactic complexification, evidenced by the steady increase in MDD across all seven thematic domains. Through the lens of AT, we argue that this shift represents a structural adaptation to the informationality motivation—specifically, a drive toward “syntactic rationalization” to accommodate the increasing density of scientific knowledge.
This trend mirrors the “densification” phenomenon observed in international Anglophone academic discourse, particularly in the sciences. As Lu and Ai (2015) have noted in their analyses of English journals, academic writing has evolved from an elaborated style (reliant on subordinate clauses) to a compressed style (reliant on phrasal complexity, such as heavy noun phrases and nominalizations). Our findings confirm that CFL scholars are actively synchronizing with this global rhetorical norm. The increase in MDD suggests that authors are packaging more information into fewer linguistic units to achieve the precision and objectivity expected of scientific inquiry.
This interpretation is further supported by the empirical turn in CFL discussed earlier. As research topics shift toward data-driven inquiries (e.g., Topic 5 Corpus-based Studies), the nature of the knowledge being communicated changes. Empirical findings require high-precision descriptions of variables, methodologies, and statistical relationships, which naturally necessitate more complex syntactic structures to encapsulate these logical interdependencies within limited abstract lengths (Zhu et al., 2024). Therefore, the rising syntactic complexity should be viewed not merely as a pedagogical milestone, but as a genre-based strategy: scholars are employing grammatical metaphors and dense phrasal structures to construct an identity of professional expertise and to align their discourse with the science-oriented ethos of the global academic community (Casal et al., 2021; M. Wang & Lowie, 2023).
Evaluative Marketization: The Promotional Paradox
While syntactic rationalization reflects the community’s response to the scientific imperative, the evolution of evaluative language reveals how scholars navigate the market imperative. The overall trend of evaluative positivization suggests that CFL scholars are increasingly adopting a promotional stance, a phenomenon widely documented in global academia as a response to hyper-competition (Yuan & Yao, 2022). Under the pervasive logic of academic capitalism, academic abstracts are no longer mere summaries but sales pitches designed to compete for attention. However, a nuanced inspection of domain-specific trajectories reveals a striking “Promotional Paradox”: the pressure to promote does not yield a uniform increase in positivity; rather, it creates a strategic polarization based on the discipline’s proximity to the market and policy.
For applied and policy-oriented domains, most notably Topic 1 (Macro-level Foreign Language Education) and Topic 2 (Translation Studies), the surge in positive sentiment is strategic and pronounced. These fields are situated at the periphery of the discipline, interfacing directly with societal needs and state policies. Consequently, scholars in these areas face heightened pressure to articulate the societal relevance and practical value of their work (Fecher et al., 2021). In this context, evaluative positivization functions as a necessary rhetorical tool to bridge the gap between academic research and external utility, effectively selling the research by highlighting its robust contributions and successful applications.
In stark contrast, core theoretical fields, specifically Topic 4 (General Linguistics), have resisted this promotional tide, exhibiting a counter-trend toward negativization or critical neutrality. This divergence can be interpreted as a strategy of distinction. For theoretical linguists, whose work is often distanced from immediate market application, legitimacy is derived not from selling points but from scientific rigor and critical detachment. As suggested by Hyland (2005), the avoidance of overt emotion and the use of critical or neutral language serve to construct an identity of objectivity. By rejecting the hype prevalent in applied fields, theoretical scholars reinforce their epistemic integrity, using linguistic restraint to signal the depth and seriousness of their inquiry.
Thus, linguistic positivity in CFL is not a universal mandate but a contested resource. The Promotional Paradox underscores that while the system exerts a general pressure toward marketization, authors’ responses are mediated by their sub-disciplinary identities. Those closer to the market embrace promotionality to enhance visibility, while those at the theoretical core retreat into neutrality to preserve scientific authority.
Subjective Responses to Systemic Stratification: An AT-Based Interpretation
While the quantitative data reveals broad disciplinary trends toward scientization and marketization, a granular qualitative inspection suggests that these pressures are not experienced uniformly. The evolution of CFL discourse appears to be mediated by academic status, creating a stratified landscape of rhetorical strategies. This phenomenon is vividly illustrated by contrasting two abstracts from the 2023 corpus (see Excerpt 1 and Excerpt 2). Both utilize Appraisal Theory to analyze news discourse, yet their stylistic realizations diverge sharply, reflecting the differing accumulation of academic capital by their respective authors.
Excerpt 1: 近年来,黄河流域生态保护和高质量发展已上升为国家战略。与此同时,该主题下的黄河专题新闻报道书写了新时期有关黄河的生态“故事”。构建黄河专题新闻报道中的生态“故事”有利于引导读者了解国家政策,树立正确的黄河生态保护观,并为黄河的生态保护作出自己的贡献。在此背景下,本研究从和谐话语分析的视角出发,借助评价理论中的态度系统,对中新网中的黄河专题新闻报道进行分析,构建了新时期的黄河生态“故事”。
(In recent years, the ecological protection and high-quality development of the Yellow River Basin have been elevated to a national strategy. At the same time, the feature news reports on the Yellow River under this theme described the ecological “story” about the Yellow River in the new period. The construction of the ecological “story” in the feature news reports on the Yellow River is conducive to guide readers to understand national policies, establish a correct view of the ecological protection of the Yellow River, and make their own contribution to the ecological protection of the Yellow River. Based on the attitude system, this article analyzes the feature news reports on the Yellow River in ChinaNews.com from the perspective of harmonious discourse analysis and constructs the ecological “story” of the Yellow River.)
Excerpt 2: 评价是在一定社会框架和意识形态框架下的态度表达,涉及评价来源、评价对象和评价范畴等核心要素。新闻媒体借助语言意义重构世界,建立“媒体现实”。本研究基于评价理论,根据评价范畴与评价对象、评价来源的共选观,提出新闻话语评价研究的组合型式分析框架,探讨媒体如何通过策略性使用媒体作者源和其他声音归属源的积极或消极评价,包括能力性、利益性、安全感、满意感及倾向性等评价参量,建构不同评价对象的新闻立场。本文通过对英国主流媒体“一带一路”新闻报道的个案研究,以实证数据验证了该评价共选分析框架对评价研究的进一步拓展。
(Appraisal conveys attitudes located in particular social and ideological frameworks, in which the core evaluative elements of source and target are involved. The news media has been argued to reproduce the world and reconstruct “media reality” through linguistic representation. On the basis of Appraisal Theory, and according to the perspective of co-selection of evaluative categories with targets and sources, this article proposes a new analytical model of appraisal in news discourse. The study attempts to discuss how the journalistic professionals deploy the authorial voice, i.e. the averral sources, and a variety of non-authorial voices, i.e. attribution sources, which are laden with positive or negative attitudes toward particular targets, including different evaluative parameters of capacity, profitability, security, satisfaction and inclination. The case study focuses on the “Belt and Road Initiative” related news reports in British mainstream media lends empirical support to the feasibility of the newly proposed co-selection framework of evaluation for news discourse.)
The juxtaposition of these examples reveals how authorial identity profoundly influences stylistic choices. The author of Excerpt 1, an established scholar with significant academic capital, adopts a stance of confident simplicity. This position affords the scholar the privilege to be direct and transparent. Their focus is purely on informationality, presenting verifiable findings without the need for elaborate theoretical packaging or dense syntactic structures. In contrast, the authors of Excerpt 2—likely representing non-elite or early-career scholars—face a different set of structural pressures. For them, adopting a highly promotional and theoretically dense style is not merely a preference but a strategic necessity. In a competitive academic market where novelty is a paramount criterion for entry, a straightforward abstract like Excerpt 1 might be perceived by gatekeepers as lacking theoretical depth if submitted by a scholar without established prestige. Consequently, these authors feel compelled to construct complex analytical frameworks and employ abstruse terminology. This performance of promotionality acts as a symbolic password or a demonstration of competence for community membership (Wenger, 1998), designed to signal academic rigor to peer reviewers and thereby gain entry into the scholarly conversation. This stratified response mechanism is visually synthesized in our Activity System model (Figure 8 ).

Activity system model for CFL academic writing based on the fourth-generation AT.
As systematically depicted, the Subject (the author) operates within a tension-filled environment, navigating the core contradiction between the motivation for informationality (acting as a Truth-seeker) and promotionality (acting as a Game-player; L. Chen & Weninger, 2024; Zhao et al., 2023). This internal contradiction is intensified by the bottom-level structural factors: the Rules of commercialization compel authors to “sell” their work rather than merely produce knowledge (Mercelis et al., 2017); the Community is defined by a “highly competitive” atmosphere; and the Division of Labor is characterized by the Matthew Effect, where established scholars already possess visibility and resources (B. Yu & Shu, 2023). These factors collectively create a critical Transformational Gap between the production of a manuscript (Object) and its successful publication (Outcome). To bridge this gap, authors rely on Mediating Artifacts. While standard Writing Tools (e.g., software, databases) are accessible to all, Writing Styles become the contested terrain. Elite scholars (as in Excerpt 1) can bridge the gap relying on their accumulated symbolic capital, allowing them to prioritize linguistic meaning and informational clarity without risking rejection. Conversely, emerging scholars (as in Excerpt 2) face a significantly wider gap. To overcome the high rejection rates driven by hyper-competition, they must lean heavily on sociolinguistic meaning—strategically deploying syntactic complexification and evaluative positivization to market their competence (Yin et al., 2023). Ultimately, this systemic pressure creates a risk scenario depicted in the model where “Bad money drives out good,” as promotional packaging might eventually overshadow substantive informational quality in the race for publication.
Conclusions
Summary and Contributions
This study has provided the first large-scale, diachronic analysis of the stylistic evolution of CFL discourse over the past two decades. By triangulating topic modeling, dependency parsing, and sentiment analysis across 13,658 abstracts, we have mapped a discipline in profound transformation. The findings reveal a clear “Empirical Turn” in research themes (the rise of Topic 5 Corpus-based Studies and Topic 1 Macro-level Foreign Language Education), a universal trend toward “Syntactic Rationalization” (increased complexity), and a “Promotional Paradox” in evaluative stance, where applied fields embrace positivity while theoretical fields retreat into neutrality.
The contribution of this research lies in both methodological and theoretical advancements of the field. Methodologically, it moves beyond small-scale, synchronic snapshots to offer robust, data-driven evidence of long-term evolutionary trends. Theoretically, it challenges the static view of “Chinese academic style,” revealing it instead as a dynamic system evolving under the dual pressures of Global Scientization (the drive for evidence and precision) and Local Academic Capitalism (the drive for visibility and relevance). By establishing the Activity System Model (Figure 8), this study explicates how these macro-level systemic forces are refracted into micro-level rhetorical strategies, creating a stratified landscape of academic writing.
Implications for Theory and Practice
The findings bear significant practical implications for both pedagogical instruction and academic policy. In terms of pedagogy, CFL and LAP (Language for Academic Purposes) instruction must shift from a focus on mere linguistic correctness to critical genre awareness. Instructors should help novice scholars understand why established norms (such as complex syntax) exist—often as markers of informational density and scientific status—while simultaneously warning against the uncritical imitation of promotional hype. Pedagogy should aim to cultivate confident simplicity (as seen in Excerpt 1), teaching students how to balance the need for rigorous packaging with the primary goal of clear, substantive communication.
Concurrently, at the institutional level, the observed Promotional Paradox and the potential risk of “Bad money driving out good” necessitate a critical re-evaluation of gatekeeping practices. Journal editors and reviewers should remain vigilant against the homogenization of academic discourse by valuing diverse rhetorical styles, including the neutral, detached stance typical of theoretical inquiry. Crucially, evaluation criteria must explicitly prioritize substantive contribution over stylistic packaging, ensuring that valid research from non-elite and young scholars is not marginalized simply for lacking the symbolic passwords of complexity and positivity.
Limitations and Future Directions
While this study offers new insights, several limitations must be acknowledged, pointing toward avenues for future research. First, the corpus is restricted to CSSCI-listed (Chinese) journals. While this provides a deep understanding of the local national team, it limits the generalizability of findings regarding the interaction between local and global norms. Future research should conduct comparative analyses with SSCI-listed (international/English) journals to determine the extent to which the observed trends are universal phenomena versus unique local adaptations.
Second, the analysis focuses exclusively on abstracts. Although abstracts are critical selling points, they may not fully capture the stylistic nuances of full-text articles. Future studies could expand the scope to full texts to examine whether the promotional pressure permeates the entire body of the manuscript.
Finally, this study is confined to the discipline of CFL. To fully contextualize these findings within the broader landscape of academic discourse, cross-disciplinary comparisons with other humanities and social sciences (e.g., sociology, psychology, information science) would be valuable to verify whether the scientization and marketization mechanisms identified here are pervasive across the Chinese academy.
Footnotes
Acknowledgements
This paper benefited greatly from a seminar hosted by the Institute of Linguistics and Applied Linguistics, School of Foreign Languages, Peking University, where a previous version was presented. Additionally, this work was also presented at the 2025 High-level Academic Forum for Postgraduate Students of Beijing Foreign Studies University (2025 北京外国语大学研究生高端学术论坛), June 14th 2025. We extend our sincere thanks to the audiences at this event for their insightful questions and feedback.
Ethical Considerations
This study does not involve human participants or their data so no other forms of ethical approval is needed.
Consent to Participate
This study does not involve human participants or their data so no informed consent is needed.
Author Contributions
Hanlin Xu: Conceptualization, Methodology, Software, Writing-original draft. Yuhang Li: Formal analysis, Visualization, Validation. Haonan Li: Data curation, Investigation, Resources. Chenghui Wu: Conceptualization, Writing-review & editing, Supervision, Project administration. All authors have read and agreed to the published version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.*