
Abstract
Generative artificial intelligence is regularly tasked with navigating the complexities of human-to-human interaction, including peer-to-peer mental health support and improving interpersonal emotion regulation within customer service settings. Qualitative findings question whether artificial intelligence deserves a space in this area; however, many recent studies indicate that artificial intelligence may improve human-to-human interaction. In the current study, and across two samples (NGivers = 522; NReceivers = 580; NTotal = 1,102) gathered to detect small effects, we examine a specific use case of generative artificial intelligence in the workplace and whether it can be leveraged to improve prosocial human-to-human messaging above and beyond human-written prompts using a quantitative survey experiment. Specifically, we train and examine the impact of generative artificial intelligence on participants’ perceptions of employee recognition messages in the workplace. We found that participants: (a) believed the trained generative artificial intelligence was in line with Human Resources (HR) industry best practice; and (b) learned from the generative artificial intelligence, believing it would lead them to change their behavior. Generative artificial intelligence messages were more in line with HR industry best practice than human-written messages, and these messages were longer and more positively valenced. Further, after controlling for message length, had more nouns, adjectives, and verbs than human-written messages. Consistencies with the current literature and the place generative artificial intelligence has in human-to-human interaction moving forward are discussed.
Plain Language Summary
This study explored whether ChatGPT can enhance how people write recognition messages to coworkers in the workplace. With data from over 1,100 participants, the researchers compared messages written by humans to those generated or improved by AI. Participants believed the AI messages aligned more closely with Human Resources' best practices. People also reported that they learned from the AI and would change how they write future messages based on its suggestions. These findings suggest that AI may play a valuable role in improving how people communicate support and recognition in professional settings.
Introduction
Artificial intelligence (AI) is regularly tasked with making complex tasks more manageable for humans, including correcting spelling and grammar, automating mundane tasks, generating computer code, and finding intricate patterns in multidimensional data. Given the recent success of OpenAI and other large language models (Vaswani et al., 2017), artificial intelligence is now tasked with writing open-ended social messages requiring intimate knowledge of moral affect at scale (see McCullough, 2002). Large language models are being tasked to navigate conversations predicated on an intimate knowledge of “fuzzy concepts” (or sets; Zadeh, 1965), which have long frustrated humans due to the lack of clear conceptual definitions (e.g., intelligence, empathy, and see Loki’s Wager). For example, recent evidence suggests that AI can enhance written prosocial messages in emotionally complicated settings, including offering empathy to those struggling with mental health concerns (Sharma et al., 2023). In one study from Sharma et al. (2023), untrained peer supporters were recruited from TalkLife, a peer-to-peer support network for mental health concerns, to be assigned to write responses on their own or receive feedback through prompts from a trained AI. Overall, responses generated by the AI were rated equal to or more empathic than the human-only responses 63.60% of the time. Further, peer supporters reported using the service at least once 77.58% of the time, suggestions from the AI were used 83.08% of the time, and 77.70% of participants wanted an AI feedback system to be deployed on TalkLife (Sharma et al., 2023). Indeed, the supporters were perceived as more empathic, used the service regularly, and believed it to be a useful tool.
Though these results are impressive, they are not unique and are becoming more ubiquitous despite ongoing concerns from some providers that “robots [are] incapable of being empathic in a caring relationship” (Doraiswamy et al., 2020, p. 6). Indeed, findings where large language models promote and aid in prosocial human interaction are increasingly common (Henkel et al., 2020; Huang & Rust, 2018). For instance, AI has been leveraged to assist customer service employees in regulating customer emotions (Henkel et al., 2020). This human-AI collaboration has been found to be beneficial. For example, AI has aided employees in regulating customer emotions leading to more positive customer ratings. As a result, employees’ affective well-being was also improved through a reduction in perceived stress (Henkel et al., 2020). In both instances, the AI-coaching is being used to move negative emotional experiences back to baseline (i.e., emotion dysfunction to euthymia; Henkel et al., 2020; Sharma et al., 2023)—a pattern within the psychological sciences that has been identified for decades (Averill, 1980; Fredrickson, 1998). However, the question remains whether AI-coaching can move those in a presumed euthymic state to a state of flourishing, as much of positive psychology argues (e.g., Seligman & Csikszentmihalyi, 2000). These studies highlight the remarkable capabilities of AI in enhancing human emotional experiences and interactions, particularly in terms of empathy and emotional regulation. Building on this foundation, it becomes pertinent to explore how AI can contribute to more advanced aspects of positive psychology, such as gratitude, which goes beyond merely returning to a state of emotional equilibrium.
Expressions of Gratitude as a Starting Point—A Well-Supported Positive Psychology Intervention
Gratitude, a concept deeply rooted in various world religions such as Christianity, Judaism, and Islam, represents a more profound and holistic approach to human well-being. Those who regularly practice gratitude often experience enhanced self-esteem, greater resiliency, and improved quality of relationships (Rashid & Seligman, 2018). Conversely, the absence of gratitude, or ingratitude, is frequently seen as a moral failing with negative implications for both the individual and the wider society including workplace relationships (Amato, 1982; Emmons et al., 2003; McCullough, 2002; McCullough et al., 2002). Gratitude provides a unifying framework for this study. As a central construct in positive psychology and a cornerstone for employee recognition practices, gratitude has often been linked with individual well-being, mental health cost savings, and improved organizational functioning (Lovell et al., 2022, 2023, 2024, 2025).
Gratitude has been expanded on theoretically for decades, and gratitude interventions have become common in the empirical literature and in the business industry (e.g., see Algoe, 2012; Algoe et al., 2020; Emmons et al., 2003; Locklear et al., 2022; McCullough, 2002). In one of the original gratitude intervention studies, participants who recorded five things for which they felt grateful each week for ten weeks rated their life more favorably, reported better health, increased their time spent on exercise, and reported greater well-being compared to the other conditions (Emmons et al., 2003). Other studies have found that delivering gratitude letters to others improved happiness and decreased depressive symptoms to a large degree, but the effects returned to baseline over follow-up (Seligman et al., 2005). The improvements in happiness have been replicated in subsequent studies (Mongrain & Anselmo-Matthews, 2012).
Recent studies have resulted in similar outcomes. For example, participants who focused on written gratitude letters to another individual saw improvements in positive affect compared with written non-directed gratitude (Cregg et al., 2022). More ecologically valid studies (i.e., longitudinal non-treatment focused designs) have started to argue for a reinforcing relationship. Indeed, more positive affect predicts more expressions of gratitude, and more expressions of gratitude predict more positive affect (Snippe et al., 2018). Thus, it is unsurprising that a recent meta-analysis investigating the impact of gratitude interventions on well-being has argued small- to medium-sized effects decreases in depressive (g = −0.23) and anxious (g = −0.55) symptoms (Cregg & Cheavens, 2021).
Given the consistency of the findings, it is unsurprising that some companies have begun to facilitate the development and delivery of gratitude interventions at scale (otherwise known as “recognition” or “employee recognition” within industry). Perhaps unsurprisingly, Human Resources and industry researchers have conducted their own studies to assess the impact of so-called recognition programs (gratitude interventions) on employee well-being measures (Lovell et al., 2022, 2023, 2024, 2025). In addition to taking place within an ecologically-valid setting, these findings differ from those presented above. Instead of focusing on the well-being of the giver of the message, these studies often focus on the receiver's well-being. One such example is the O.C. Tanner Company, who in their annual Global Culture Report, has indicated that recognition that is in line with Human Resources (HR) Industry best practices (i.e., inclusive, relevant, specific, purposeful, meaningful, sincere, and empathic) is associated with feelings of support, feeling valued, and feeling heard (Lovell et al., 2022, 2023, 2024, 2025). Previous reports indicate that recognition that aligns with HR best practices is associated with lower anxiety and stress, higher engagement, more feelings of “purpose,” and greater well-being (Gallup, 2023; Lovell et al., 2022, 2023, 2024, 2025). Thus, employee-to-employee gratitude messaging delivered at scale (i.e., to millions) has the potential to have dramatic impacts on the well-being of both the person who sends the message (e.g., Cregg et al., 2022; Emmons et al, 2003; Seligman et al., 2005; Snippe et al., 2018) as well as the person who receives it (Lovell et al., 2022, 2023, 2024, 2025). First understanding whether the AI-coached messaging is in line with HR best practices compared with human-written messaging would be an initial first step in training an AI-coach aimed at improving prosocial messaging among employees.
Limitations and Gaps in the Current Literature
While strides and innovation are normative in artificial intelligence research, exploratory research in this early stage of development is critical. First, many human-AI collaboration studies attempt to improve relationship processes; however, data is typically gathered from the giver or the receiver (e.g. Khadpe et al. 2020; Sowa et al., 2021). Rarely is data collected from both perspectives (i.e., the giver and the receiver). Positive effects are theoretically assumed to reflect onto the other party, but this isn’t explicitly tested except for a few instances (e.g., Bernard et al., 2023). Second, while understanding the general effects of human-AI collaboration is important, the current literature has yet to explore potential causal mechanisms that may contribute to these effects. Multiple studies have indicated that human-AI collaboration improves (and is associated with more satisfying) written messaging (Henkel et al., 2020; Sharma et al., 2023), and because this messaging is constrained to linguistic features (as opposed to voice tone, facial expressions, or other body language), there should be linguistic differences between the human-written and AI-generated messages. However, we need more information to support this claim.
Research Aims and Hypotheses
Given the current literature, this study has four aims. The first two aims are confirmatory and seek to determine (a) whether participants are satisfied with the AI coaching, and (b) whether participants learn from the coaching and would be willing to revise their message based on the coaching. Given the previous literature, we anticipate participants will indicate that they have learned something from the coaching and would be willing to change their behavior. The third aim of the current study is also confirmatory and aims to examine whether participants believe the material is more in line with industry/HR best practice. Again, given the previous literature, we expect participants will find the messages generated by the AI to be more in line with industry best practices than human-written responses. In the fourth and final exploratory aim of this study, we seek to understand some of the causal mechanisms at play within the messages. Specifically, we aim to examine whether length, sentiment, and part-of-speech differences exist between the AI-generated and human-written messages.
Method
Transparency and Openness: Data Availability Statement
Below, we describe our sampling plan. No data exclusions or manipulations were made to the data. Measures are described below. All code, data, and research materials have been uploaded to the associated OSF webpage for review and reproducibility (https://osf.io/tnbsz/). Data were analyzed using R version 4.3.1 (R Core Team, 2013) and Bayesian analyses were conducted using brms version 2.19.0 (Bürkner, 2017) and BayesianFirstAid version 0.1 (Bååth, 2014). Finally, linguistic elements were extracted using NLTK version 3.6.6 (Loper & Bird, 2002) using Python version 3.11.6 (Van Rossum, 2007).
Power Analysis and Procedure
Preliminary power analyses were conducted before data were gathered, indicating a sample of 504 was needed to detect a small-sized effect (i.e., d = 0.25) with 0.80 power and a 0.05 false-positive rate. To strengthen reliability, we oversampled slightly yielding two independent samples (NGivers = 522; NReceivers = 580). This two-sample design was chosen intentionally to cover both sides of the recognition exchange (i.e., givers and receivers), consistent with our aims and the limitations identified in the previous literature (e.g. Khadpe et al., 2020; Sowa et al., 2021). By collecting independent and samples designed to detect small effects, we ensured adequate coverage of both perspectives.
All participants were recruited from Lucid and directed to take a survey. Lucid is the largest available sample aggregator and facilitates direct-to-respondent sampling through their proprietary marketplace platform (Coppock & McClellan, 2019). We can ensure unique responses are received for our dataset through the marketplace interface. Panel providers individually handle respondent payments, ensuring complete confidentiality. The value of incentives for survey participants ranged from $1.50 to $3.45 USD, and they are often provided as redeemable points for merchandise, gift cards, and cash. The survey was built with Alchemer software (formerly SurveyGizmo).
Both samples were independently gathered in October 2023, the response rate was 83% for the receiver sample and 74% for the giver sample, and both surveys were approximately 20 min long. In the first section of both the giver and receiver survey, participants were given a series of 20 manufactured vignettes that provided the participant with a scenario and asked which of two responses (i.e., one human-written and the other AI-generated) the participant preferred (see Table 1). The human-written responses were written by real humans in real-life settings and received from [The O.C. Tanner Company]—a software-as-a-service employee recognition company. Participants were then directed to answer demographic questions. After this first task, the procedure differed between the two surveys.
Example Vignette (Vignette 1) from the Receiver Sample.

In the second giver survey task, participants read 20 vignettes where they received coaching on a message they “wrote.” Participants then rated whether the coaching aligned with industry best practices, whether they learned something from the coaching, and whether the coaching would lead them to alter the original message.
Participants were also tasked with reading 20 vignettes in the second receiver survey task. However, they were randomly assigned to one of two experimental conditions. In the first condition, participants were randomly assigned to “receive” a message written by a human or a prompt generated by generative AI. Participants then rated whether the message they received aligned with industry best practices.
Prompt Engineering
The generative model was created using OpenAI’s gpt-3.5-turbo model as this model is capable, cost-effective, works well for traditional completions, and generates natural language (OpenAI, 2023). From here, prompt engineering (not fine-tuning) was used to generate the coached responses using recommendations for output customization (see White et al., 2023). Each output request was explicitly mapped to the dimensions of HR best practice (i.e., inclusive, relevant, specific, purposeful, meaningful, sincere, and empathic), with prompts structured in line with definitions provided by the Global Culture Report.
Participants
Participants in both the givers and receivers samples reported being similar ages (MeanGivers = 45.68, SDGivers = 16.89; MeanReceivers = 45.86, SDReceivers = 16.77) with no significant differences between the two samples (p = .86)—this pattern held for income (MedianGivers = $40,000; MedianReceivers = $40,500, p = .80) and hours worked (MedianGivers = 30; MedianReceivers = 30, p = .29). Most participants identified as female (Givers = 49.8%; Receivers = 51.8%), slightly fewer identified as male (Givers = 47.5%; Receivers = 45.0%), and the remaining individuals identified with transgender female (Givers = 0.8%; Receivers = 1.4%), transgender male (Givers = 1.0%; Receivers = 1.2%), or a category not listed (Givers = 1.0%; Receivers = 1.0%). Further, most participants identified as White Non-Hispanic (Givers = 67.8%; Receivers = 66.0%), followed by Black (Givers = 11.9%; Receivers = 12.8%), White Hispanic (Givers = 8.6%; Receivers = 8.5%), Asian (Givers = 2.3%; Receivers = 2.2%), Black Hispanic (Givers = 1.5%; Receivers = 2.1%), American Indian or Alaskan Native (Givers = 1.9%; Receivers = 0.5%), Middle Eastern or North African (Givers = 0.2%; Receivers = 0.9%), Native Hawaiian or Pacific Islander (Givers = 0.4%; Receivers = 0.5%), and the rest of the sample identified as “Other” (Givers = 5.4%; Receivers = 6.5%). Lastly, most participants came from customer service backgrounds (Givers = 13.2%; Receivers = 17.4%), followed by those with backgrounds in information technology (Givers = 10.0%; Receivers = 11.0%). Other backgrounds including general administration, finance, HR, manufacturing, marketing, patient care, product development, sales, shipping, and training. These occupations were represented by less than 10% of the sample.
Measures
Best Recognition Practice
Eight items were used to measure best recognition practices within the giver’s sample, and six items were used to measure best recognition practices within the receiver’s sample—all were on a 1 to 7 Likert-style scale ranging from Strongly Disagree to Strongly Agree. Within the giver’s sample, participants were asked the degree to which they agreed the coaching was helpful, inclusive, relevant, specific, purposeful, meaningful, sincere, and empathic. Within the receivers’ sample, participants were asked the degree to which the message they were randomly assigned to receive was specific, inclusive, purposeful, meaningful, sincere, and empathic.
These constructs have been consistently linked to improved business outcomes with nearly a decade of evidence supporting their utility. For instance, organizations perceived to be inclusive have employees who are 4× more likely to be promoters, 7× more likely to believe senior leaders can achieve organizational goals, and 10× more likely to report thriving at work. When empathy is high, there is a 50% increase in the odds that employees perceive their organization as supportive. Likewise, when purpose is high, organizational innovation is 5× more likely, and the same is true when individuals report their organization as having meaningful work.
Within the receivers’ sample, across all vignettes, a unidimensional factor solution fit the data well (i.e., CFI > 0.95, TLI > 0.95, RMSEA < 0.08, SRMR < 0.08; see Kenny, 2020) even under the stringent assumptions of tau-equivalence (CFI = 0.98, TLI = 0.98, RMSEA = 0.07, 90% CI [0.07, 0.08], SRMR = 0.04) and internal consistency was excellent (α = .93, 95% CI [0.92, 0.93]). These findings justify using a total sum score to compare the treatment (i.e., AI-generated message) and control (i.e., human-written) messages and allowed us to decrease our false-positive rate by conducting one overarching test per vignette.
Participant Learning and Behavior Change
These separate constructs were measured using two items. To measure learning, participants were asked, “Did you learn anything from the coaching?” and could answer “Yes” (coded as 1) or “No” (coded as 0). Similarly, to measure behavioral change, participants were asked, “Given the feedback, would you revise your original e-Card?” participants could answer “Yes” (coded as 1) or “No” (coded as 0).
Linguistic Measurement
In Python version 3.11.6, the total number of words, positively-valenced words, and negatively-valenced words were counted using a natural language toolkit (NLTK; Loper & Bird, 2002). Sentiment was measured using Valence Aware and sEntiment Reasoner (VADER) in Python which assigns a sentient weight to words and punctuation from high negatively-valenced to highly positively-valenced words. This also included a semi-normal transformation. Finally, parts of speech were tagged and counted using the tag library in NTLKIN Python.
Data Analysis
For the first aim of the current study, measures of central tendency (i.e., mean, median, or mode) and spread (i.e., standard deviation) were used to describe the most frequent response after matching the measure to the skew of the respective distribution. In the second and third aims of the current study, Bayesian binomial tests from the BayesianFirstAid package in R were used to compare differences in proportions (e.g., the proportion of individuals who prefer to give/receive messages generated by an AI or written by humans; Bååth, 2014). The Beta (1, 1) prior distribution was used, given it is uninformative and will allow the likelihood to inform the posterior. In this study’s fourth and fifth aim, Bayesian regression from the brms package in R was used to determine whether AI-generated or human-written messages were more in line with HR best practices and whether there were linguistic differences between messages (Bürkner, 2017). Standard brms priors were used, allowing the likelihood (rather than the prior) to inform the posterior. Percentages with 95% highest posterior density intervals (HPDIs) that did not include 50% were considered statistically reliable differences. Similarly, confidence intervals (CIs) that did not include zero were also interpreted as reliable evidence of a difference.
Results
Aim 1: Do Participants Believe the AI Coaching Aligns with HR Best Practice?
Across all measures, the most frequent (and the median) response for a left-skewed distribution was participants “agreed” (6 on a 1 to 7 scale) the coaching was helpful (Mean = 5.44; SD = 1.46), inclusive (Mean = 5.32; SD = 1.48), relevant (Mean = 5.44; SD = 1.44), specific (Mean = 5.47; SD = 1.40), purposeful (Mean = 5.49; SD = 1.39), meaningful (Mean = 5.46; SD = 1.42), sincere (Mean = 5.46; SD = 1.45), and empathic (Mean = 5.35; SD = 1.45).
Aim 2: Are Participants Learning from the AI Coach, and Would it Change Their Behavior?
Overall, 79.0% (95% HPDI [75.6%, 82.5%]) of participants reported learning something from the coaching, and 63.5% (95% HPDI [59.4%, 67.6%]) of participants reported they would revise their original message after receiving the coaching. Even within the poorest rated vignettes, when at the lowest, most participants reported learning something (75.6%, 95% HPDI [71.8%, 79.2%]) and reported they would make revisions to their original message (59.0%, 95% HPDI [55.0%, 63.2%]). Finally, at the highest, 84.2% (95% HPDI [81.1%, 87.4%]) of participants reported learning something from the coaching, and 68.5% (95% HPDI [64.3%, 72.4%]) would revise the original message in response to the coaching.
Aim 3: Do Receivers Perceive the AI-Generated or Human-Written Messages as Being More in Line with HR Best Practices?
Participants in the AI-generated condition rated messages higher (i.e., more in line with HR best practice) than those assigned to receive human-written messages. Seventeen out of 20 vignettes possessed statistically reliable treatment effects (i.e., credible intervals did not include zero). While the effects were not statistically reliable in 3 out of 20 vignettes, the average treatment effect still favored the AI-generated messages in each instance. Averaging across vignettes, the effect was small and statistically reliable (d = 0.34, 95% CI [0.18, 0.49]). The largest statistically reliable treatment effect fell within the medium-sized range (dVignette 34 = 0.67, 95% CI [0.52, 0.82]), whereas the smallest statistically reliable treatment effect was trivial in size (dVignette 31 = 0.18, 95% CI [0.01, 0.34]; see Table 2).
Bayesian Regression Analyses of Real Experiment Determining Whether Message Receivers Perceive the AI-Generated Messages Are More in Line With HR Industry Best Practice Compared With Human-Written Messages.

Note. Cohen’s ds whose 95% credible intervals (CI) did not include zero were assumed to be indicative of an effect. Positive values were indicative of favoring the AI-generated messages whereas negative values were indicative of favoring the human-written messages. In 17/20 instances (and with few exceptions; i.e., 28, 31, 36), participants rated AI-generated messages as falling more in line with HR industry best practices compared to human-written messages. CI = Credible Interval; UB = Upper Bound; LB = Lower Bound.
Aim 4: Are There Length, Sentiment, Parts-of-Speech Differences Between the AI-Generated and Human-Written Messages?
Compared with the human-written messages, the AI-generated messages had more words, more syllables, a greater number of positive words, and the number of negative words did not differ by condition. Overall, sentiment within the AI-generated messages was more positive regardless of the metric used. Regarding parts of speech, there were no differences in the number of prepositions or adverbs between conditions; however, in the AI-generated messages, there were more adjectives, pronouns, nouns, and verbs than in the human-written messages. When controlling for the total number of words in a message, the AI-generated messages still had more syllables, positive words, positive sentiment, adjectives, nouns, and verbs than the human-written messages—pronouns no longer had a reliable effect (see Table 3).
Bayesian Poisson Regression Outcomes of Length, Sentiment, and Part of Speech Differences Between AI-Generated and Human-Written Messages. With the Exception of Negative Words, Prepositions, and Adverbs, All Other Outcomes Positively Favored the AI-Generated Over Human-Written Messages. All Betas Were Left in Their Original Units.
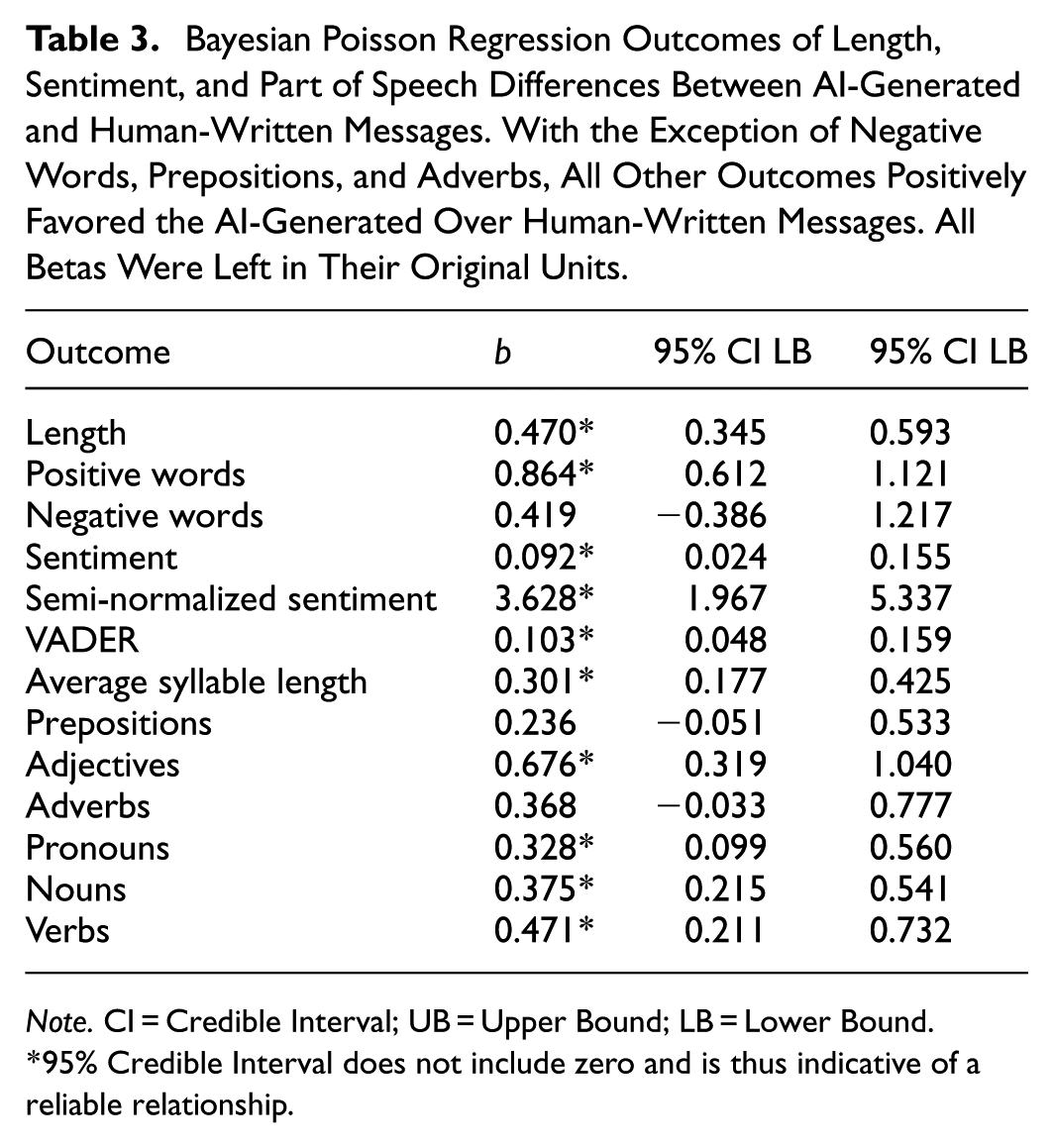
Note. CI = Credible Interval; UB = Upper Bound; LB = Lower Bound.
95% Credible Interval does not include zero and is thus indicative of a reliable relationship.
Discussion
The current study had four aims. The first two aims were confirmatory—do individuals perceive AI-generated messages to be in line with best practice, do participants report learning from the AI coach, and does the coaching result in changes in behavior? We found most participants “agreed” the coaching was in line with HR industry best practices: 79% of participants reported learning something from the coaching, and 63.5% of participants reported they would revise their message in response to the coaching. The third aim was also confirmatory and sought to understand if receivers perceived the AI-generated or human-written messages to be more in line with HR industry best practice (Aim 3). Participants rated AI-generated messages as falling more in line with HR industry best practices than human-written messages.
In the final aim, we sought to explore possible reasons why participants preferred and rated the AI-generated messages higher than the human-written responses by examining language features. Overall, we found the AI-generated messages had higher word counts, greater numbers of syllables and descriptive words, and more positive sentiment than the human-written responses.
Discussion of Study Aims: Consistencies with the Current Literature
Regarding the first two aims, the findings appear largely in line with the current literature. Participants reported the messages were in line with HR industry best practices, that they learned from the coach, and that they would revise their original message in response to the coaching. Though some researchers have been skeptical that generative AI can reliably navigate the complexities of human interaction and produce prosocial human-to-human messaging (e.g., expressions of empathy; Blease et al., 2019), this paper adds to the already robust literature that generative AI can reliably assist humans in navigating the complexities of human-to-human interaction (Henkel et al., 2020; Sharma et al., 2023). Indeed, in a short period of time, researchers from various industries, including mental health, customer service, and now, human resources, have all shown how generative AI can assist humans in peer-to-peer mental health support (Sharma et al., 2023), interpersonal emotion regulation of customer service interactions (Henkel et al., 2020), and generating prosocial messaging consistent with a moral affect (i.e., the current study).
In the third aim, the findings build off what has already been shown in the first two aims. Receivers perceive the AI-generated messages as being more in line with HR industry best practices than the human-written responses (Lovell et al., 2023, 2024). This finding is consistent with Sharma et al. (2023), who found that the AI-generated responses were perceived as more empathic than the messages written just by humans. These findings may make some uncomfortable. Indeed, the humanist might hope for a world in which the giver of a prosocial message might have the perfect and desired impact on the receiver of the same message untainted by an artificial bolstering. However, ChatGPT has been primarily trained by observing human-generated content publicly available online (Schade, 2023). Thus, engineering ChatGPT to engage in prosocial human messaging may allow users to monopolize, tap into, and interface with some of the most positive parts of publicly available human-generated content. Simply put, this engineering enables current users to leverage past human-generated content to improve their own. Thus, AI operates as an important adjunctive coach in this workplace intervention.
In the current study's final aim, we examined differences between AI-generated and human-written messages by examining parts-of-speech. First, we found the AI-generated messages were longer (i.e., had more words), had a greater number of positive words, and had more positive sentiment. Longer messages with more positively valenced words may allow the positive affect to be maintained while the giver writes the messages and the receiver reads it. Second, after controlling for message length, the AI-generated messages had more adjectives, nouns, and verbs than the human-written messages. Though limited by the number of messages analyzed, preventing us from robust word clouds or most frequent word pairings (40 AI-generated and 40 human-written), these initial findings might start the initial recipe for understanding the language of well-received gratitude. For instance, these results might suggest that lengthy messages with positive sentiment that focus on actions (verbs) and describe (adjectives) people (nouns) might be the initial underpinnings of the language of gratitude. However, more research here is required.
Strengths, Limitations, and Future Research Directions
Some strengths of the current study include the study design, the overall positive reception of the AI coach, and the efforts to understand differences between the AI-generated messages over the human-written responses. The study design comprised two samples sufficiently powered to detect small-sized effects, were demographically representative of the general U.S. population, and represented both sides of the interaction (givers and receivers). Next, the data consistently indicated the AI coach had the desired effect throughout each aim. Participants reported the coaching was in line with HR industry best practices, learning from the coach, and that the coaching would change their behavior. Lastly, we examined differences between the AI-generated over the human-written messages. The generated messages were longer, had more syllables, had a greater number of descriptive words, and carried more positive sentiment than the human-written messages.
One limitation of the current study was the hypothetical and lab-like setting in which the data were gathered. Indeed, participants were given a set of 40 standardized vignettes and were asked to place themselves in a manufactured scenario. While this methodological decision lends well to experimental design, it is removed from the more externally valid situation of actually giving and receiving these messages. While we addressed this problem as much as possible by utilizing stimuli that reflect a “real-life” message, it does provide an “unrealistically powerful manipulation” of a pure treatment that does not reflect a typical day-to-day reality of numerous and competing frames of information (Kinder & Palfrey, 1993, p. 27; Sniderman & Theriault, 2004; see also Chong & Druckman, 2012). Thus, generalization may be somewhat limited due to inflated treatment effects (Gaines et al., 2007). However, some recent work does argue that participants often cannot tell the difference between messages written by humans or AI, preferring the messages written by artificial intelligence over the human-generated content, even in high-intensity situations like couple therapy (Hatch et al., 2025).
Another limitation of the current study was the small number of vignettes that were delivered to participants. Though the final aim of this study aimed to start to explore why participants preferred one message over the other, 40 vignettes is hardly enough to form any strong conclusions. Thus, some recommendations for future research include gathering data in more externally valid scenarios (actual givers and receivers) and expand the number of messages written by humans or and an AI coach to robustly begin to understand why participants prefer one message over another. Further, cross-cultural and cross-sector evaluations could be worthwhile as cultural factors may shape how employees perceive AI-driven recognition. Together, these recommendations would allow for prescriptive recommendations to be given directly to HR practitioners.
A Note on Empathy, Other Fuzzy Constructs, and Metaphysics
Debates on whether AI is capable of genuine empathy (or workplace best practice) often hinge on claims that machines lack subjective experience, embodiment, or intentionality. While these are important philosophical concerns, they remain metaphysical and untestable. Following Turing’s (1950) functionalist perspective, we do not attempt to resolve whether AI feels empathy or other fuzzy constructs. Instead, we focus on the pragmatic question: can AI generate outputs that are perceived as empathic in human interactions? Our findings suggest that the functional expression of empathy—how messages are received and experienced—can be achieved through generative AI, regardless of whether the system has inner states.
Conclusion
Generative AI is regularly being tasked with navigating the complexities of human-to-human interaction in a superior way including providing recommendations on peer support for mental health, interpersonal emotion regulation within customer service settings, and improved prosocial human messaging within the workplace. In the current study, using a large sample, experiments, prompt engineering, and generative AI, we found participants (a) believed the AI-coach was in line with HR industry best practice, (b) participants are learning from the AI-coach and it would lead them to change their behavior, (c) receivers believed the AI-generated messages to be more in line with HR industry best practice than human-written messages, and (d) these messages were longer, positively valanced, and after controlling for message length, had a greater number of nouns, adjectives, and verbs than human-written messages.
Footnotes
Ethical Considerations
Our research was produced as part of our work with a private organization in the US. Since our private organization is not federally funded, nor affiliated with any federally funded institution, nor conducting research in conjunction with any federal agency, we are not required to obtain approval from an IRB to complete nor publish this research. According to the updated 2018 Common Rule, “this policy applies to all research involving human subjects conducted, supported, or otherwise subject to regulation by any Federal department or agency that takes appropriate administrative action to make the policy applicable to such research” (2018 Common Rule, 45 C.F.R. § 46.101(a)). Nevertheless, we maintain a robust ethics standard. All researchers within our organization are required to complete PI ethics courses through CITI to meet IRB certification criteria. Additionally, each research protocol is reviewed to ensure compliance with statutory obligations, regardless of our non-requirement to do so. Further, research protocol are continually monitored through completion to ensure compliance with the Belmont Report and principles of sound research design and ethics. Lastly, we maintain an advisory committee that regularly reviews research protocols, as needed, to ensure our research procedures and guidelines meet evolving requirements within the United States, regardless of our non-requirement to comply. With all this said, in our review and in consultation with external IRB reviewers, this study is exempt from IRB review under exemption category 2 (45 C.F.R. § 46.101(b)). During the completion of this research, no qualifying events occurred, or substantive changes made that would change this exemption. Our survey included informed consent. Further, while our survey instrument collected general demographic data in addition to the questions central to our study as presented, no personally identifiable information was collected from respondents. This ensures that this exempted study continues to be minimal risk for research participants. This research was conducted for the O.C. Tanner Institute, and analyzed data was confidential to protect participant identity. Participants also had the option to discontinue the survey at any time.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the O.C. Tanner Company.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: This research was supported by the O.C. Tanner Company (Salt Lake City, UT, USA), which is where the manuscript authors are employed. Publication may lead to the development of products licensed to O.C. Tanner, in which the authors—as employees of the O.C. Tanner Company—may have a business and/or financial interest.