
Abstract
Previous studies on relativization strategies often treat semantic and syntactic gaps in isolation, neglecting their inherent connections. This paper employs a corpus-driven approach from a typological perspective, utilizing cross-linguistic questionnaires for native speakers and large-scale corpus investigations to analyze the characteristics of semantic and syntactic gaps in English and Chinese relative clauses. The findings reveal that while both languages share a double-headed structure, semantic gaps belong to deep structure and syntactic gaps to surface structure. Due to typological differences, Chinese—with its flexible word order and morphological constraints—tends to employ semantic gaps. In contrast, English, constrained by animacy, mood, and other factors, resorts to semantic gaps only in specific contexts, predominantly relying on syntactic gaps. This study not only clarifies differences in relativization between English and Chinese but also provides cross-linguistic and corpus-based support for the theoretical hypothesis of “semantic gap primacy” in English and Chinese, contributing to advancements in linguistic typology.
Plain Language Summary
This study investigates how English and Chinese construct sentences where some words are implied rather than stated, a phenomenon called "gaps." While both languages use these gaps, they do so in very different ways due to their distinct rules. Chinese often relies on word order to imply gaps, making noun phrases like "[wo chi de] shitang" (meaning "the canteen where I eat") feel natural. This approach, called “semantic gaps”, works because Chinese has flexible word order and does not need extra morphological markers to clarify meaning. English, on the other hand, prefers to fill these gaps with visible words like "that" or "who," as in "the book [that I read]." These "syntactic gaps" are more rigid and depend on factors like whether the head noun is a person or thing or accessibility hierarchy. For example, English rarely uses constructions like "that why" except in specific cases, such as explaining the actions. The study compared six languages (Chinese, Vietnamese, Thai, Hmong, Malay, and Indonesian) and analyzed thousands of sentences from English corpora (COCA). Key findings include: (1) Chinese and neighboring languages allow more flexibility in semantic gap usage, while English restricts semantic gaps to certain contexts. (2) In English, semantic gaps like "that which" appear more often in formal writing, whereas spoken English avoids it. (3) Language learners (e.g., Chinese students learning English) often struggle with these patterns, defaulting to simpler structures. This research helps explain why direct translations between languages often fail and offers insights for language teaching and AI tools like translators. Future work could explore how people process these semantic gaps in real time or how they evolve historically.
Keywords
Introduction
Prior research has identified a special relativization strategy in gapless relative clauses across languages: the semantic gap (Collins & Radford, 2015; C. Lee & Lee, 2012; Nikiforidou, 2005; Pan, 2022; Wen, 2020). For example, there are many noun phrases including gapless relative clauses in Chinese, like “[wo (I) chi (eat) de (particle)]GRC shitang (canteen).” The meaning of this noun phrase is “the canteen where I eat.” This invisible and deeper gap governs clause generation and types. This type of special gap allows all syntactic constituents within the relative clause to remain complete, with the head noun typically being a topic or common noun. For example, the common noun can be the head noun like “[wo (I) qianle (have signed) zi (my name) de (particle)]GRC wenjian (document)” in Chinese; the topic can be the head noun like “[Tai-ga (red snapper-nominative) oisii (delicious)]GRC sakana-wa (fish-topic)” (Kuno, 1973, p. 257) in Japanese. While prevalent in East and Southeast Asian languages (e.g., Chinese, Japanese, Korean), semantic gaps also occur in Western languages like English and Greek. Conversely, syntactic gaps—more observable and widely used—are often treated as opposing parameters to semantic gaps.
Semantic Gaps and Syntactic Gaps
Semantic gaps include diverse semantic roles (topic, manner, time, purpose, etc.), whereas syntactic gaps are limited to fixed argument roles (subject, object, etc.). A key distinction lies in recoverability: syntactic gaps allow direct head noun reinstatement (Kou & Yuan, 2017, p. 69; e.g., That book [which I bought]RC→ I bought that book), while semantic gaps require topicalization or prepositions (e.g., The people [where the fast eat the slow]RC→ About those people: the fast eat the slow). Therefore, the key distinction is that there is a gap of the syntactic argument in non-gapless relative clauses. However, all syntactic arguments are complete in gapless relative clauses.
Semantic Concepts and Syntactic Concepts
To better distinguish between syntactic gaps and semantic gaps, it is important to note that all core concepts within relative clauses have undergone diachronic development, and possess typical synchronic features as well as identifiable criteria for judgment.
First, the formal proposal of the concept of “relativization strategy” originated from Keenan and Comrie (1977, p. 64; 1979). Based on 49 languages and using the criterion of “whether a relativization strategy has case marking,” they classified relativization strategies into two major categories: those with case marking and those without. Among these, strategies with case marking include case-marked relative pronouns and personal pronouns, while strategies without case marking include case-less relative pronouns and gaps.
Hawkins (1994, 1999) observed that the gap strategy might be universal, and thus further refined this strategy. He divided the gap strategy into non-subcategorized gaps and subcategorized gaps. Subcategorization can be understood as the ability of words such as verbs and prepositions in a relative clause to define the co-occurrence of the head noun. Their difference lies in the criteria applied—“the former are licensed by phrasal co-occurrence structures, while the latter are activated by lexical co-occurrence structures” (Hawkins, 1999, p. 246). For example, in the noun phrase “[Ø houbeixiang (trunk) huaile (is broken) de (particle)]RC qiche (car),” the verb in the relative clause cannot define the co-occurrence between the head noun “car” and “trunk,” and there is no possessive marker before “trunk.” Therefore, this co-occurrence is licensed by the phrasal structure. In contrast, in the noun phrase “the gift [(that) John likes Ø]RC,” the verb in the relative clause can define the co-occurrence between the head noun “gift” and “likes.” Even if “that” is omitted, the specific syntactic argument being relativized can be clearly identified through words like the verb. This latter type of gap is a prototypical example of syntactic gaps.
Thus, from a typological and syntactic perspective, a syntactic gap is a gap that formally lacks a relativized argument at the superficial structural level. A prominent feature of gapless relative clauses is the absence of syntactic gaps, with only implicit semantic gaps (Pan, 2022, p. 137) controlling the semantic generation and internal semantic content of the relative clause, such as “[wo (I) tiaowu (danced) de (particle)]RC wuban (dance partner).” This paper classifies such gaps as “semantic gaps” because their essential difference from syntactic gaps lies in the fact that the filler of the latter is a fixed and obligatory syntactic argument determined by a subcategorizing verb or preposition. Therefore, from a typological and semantic perspective, a semantic gap is a gap that lacks a relativized argument at the deep semantic level.
Cinque (2020) explained from a typological perspective that the formation of relative clauses is the most fundamental factor leading to variations in relativization strategies. This is because the double-headed relative clause serves as the most primitive structure for generating different types of relative clauses. For example, the noun phrase “[xiaonühai (little girl) zaikan (is watching) dianshi (TV) de (particle)]RC nage (that) dianshi (TV)” (Cinque, 2011, p. 83) is composed of a double-headed relative clause. As double-headed relative clauses can derive various types of relative clauses through syntactic raising or matching, the relative prominence of the internal and external head nouns of these relative clauses changes, resulting in differences in their independence. This leads different relative clauses to adopt distinct relativization strategies. Thus, from a typological perspective, the double-headed structure constitutes the underlying structure of relative clauses.
Second, Haspelmath noted that previous typologists failed to adopt universal semantic concepts when generalizing about relative clauses. He argued that comparative concepts should be defined based on universal semantic concepts, universal formal concepts, and other comparative concepts. Meanwhile, he delineated the comparative concepts of relative clauses and adjectives (2010, pp. 665–672): a relative clause is a clause used to narrow the referential scope of a phrase, where the referent of the phrase fulfills a semantic function. An adjective, by contrast, is a lexical item that expresses descriptive properties and can be used to narrow the referential scope of a noun. Through comparison, Haspelmath identified that the essential difference between relative clauses and adjectives lies in the fact that the former are clauses. Externally, relative clauses are unities of form and meaning. This unity also holds true for their internal structure.
Another factor influencing relativization strategies is the type of relative clause. Relative clauses can be categorized into different types based on various criteria. Generally, a language may simultaneously possess multiple types of relative clauses. According to syntactic criteria (Andrews, 2007), relative clauses can be divided into six categories. These syntactic criteria consist of two aspects. One is whether the head noun is overt. For instance, free relative clauses lack a head noun, but hearers can reconstruct the head noun based on pragmatic, semantic, or other information (e.g., [What you did]RC is good for the environment). The other is the positional pairing pattern between the head noun and the relative clause. For instance, when the head noun is positioned externally to the relative clause, such a relative clause is termed an external relative clause (e.g., “those apples [that I bought]RC”). According to semantic criteria (Benincà & Cinque, 2014), relative clauses can be divided into four categories: restrictive relative clauses, non-restrictive relative clauses, amount/maximalizing relative clauses, and kind-defining relative clauses. The criteria for semantic classification are based on the degree of semantic connection between the head noun and the relative clause. This degree of semantic connection stems from three aspects: whether the deletion of the relative clause affects the hearer’s identification of the referent of the head noun; the semantic type of the head noun; and the semantic type of the relative clause. For example, the deletion of restrictive relative clauses or amount/maximalizing relative clauses affects the hearer’s identification of the head noun, whereas the deletion of non-restrictive relative clauses or kind-defining relative clauses does not. This is because the head noun constitutes given information for the hearer. Appositive clauses are a special subtype of non-restrictive relative clauses. Ding et al. (2024, p. 484) defined appositive clauses as “complete clauses that contain no empty arguments internally, showing no trace co-indexed with the antecedent.” Thus, appositive clauses are indeed typical relative clauses with semantic gaps—they lack syntactic gaps and only contain semantic gaps (e.g., “I heard the news [that we had won the writing competition]RC”).
Therefore, this paper argues that it is highly necessary to distinguish between syntactic gaps and semantic gaps.
This paper hypothesizes that both gap types originate from a double-headed structure (Cinque, 2020) with an irreversible dual-CP (Complement) layer: semantic gaps reside in deep CP, and syntactic gaps in surface CP. Their projection is typologically constrained—English’s morphological richness favors syntactic gaps for marking argument role, while Chinese’s word-order flexibility prefers semantic gaps for the economy principle (e.g., [wo chi de]RC shitang). Existing studies mainly focus on syntactic gaps due to their observable traces, overlooking the semantic gaps’ foundational role. Our work bridges this gap through typology and corpus-driven approaches.
Literature Review
Semantic and syntactic gaps represent the most fundamental manifestations of relativization strategies. The emergence of gap strategies coincides with the deletion of the head noun within the relative clause. Different languages exhibit distinct preferences: some choose syntactic gaps (e.g., Chinese noun phrase “[mai (bought) shu (book) de (particle)]RC nage (that) nanhai (boy)”), while others employ relative pronouns to fill the syntactic gap left by the deleted head (e.g., English noun phrase “that boy [who bought the book]RC”). A critical issue in prior relativization research is the systematic neglect of semantic gaps.
Focus on Syntactic Gaps
Firstly, most studies focus on syntactic gaps (e.g., relative pronouns, resumptive pronouns, island effects), while semantic gaps (e.g., implied arguments, hanging semantic roles) remain severely underexplored. This is particularly evident in regional and typological comparisons. For instance, due to the unique morphological properties of Chinese, relevant studies have been limited to Chinese and its contact languages such as English, Korean, Japanese, Uyghur, and Sanskrit (Cui & An, 2020; Ding & Chen, 2023; Liu & Liu, 2020; Wang & Zhang, 2020; Wu & Peng, 2023; Yu & Ma, 2021; J. Y. Zhang, 2020, Q. H. Zhang, 2023; Y. Q. Zhang & Li, 2019). Language contact does have the effect of simplifying or complicating the structure of relative clauses. Although experimental research has demonstrated that children can rely on semantic cues to process syntactic gaps in Chinese (He & Yang, 2022), the mechanisms underlying semantic gap processing remain unaddressed. At the same time, some studies mention language contact, Sanskrit influence, and nominalization effects can affect the formation of the syntactic gaps and relative pronouns (Muzappar, 2018; Y. J. Zhang & Zhang, 2018; Zou & Hu, 2021), but none systematically analyze the diachronic formation of semantic gaps.
Secondly, prior research has concentrated on uncovering cross-linguistic distribution patterns and influencing factors of syntactic gaps. For example, the choice of English relative pronouns is shaped by both L1 transfer and universal grammar (Fang & Liang, 2019); Spanish resumptive pronouns are influenced by linear distance (Camara, 2018); Maltese relative pronouns are constrained by head noun definiteness (Sadler & Camilleri, 2018); and Chinese syntactic gaps and Russian relative pronouns are affected by animacy, structural information, and semantic plausibility (Kwon et al., 2019; Lyutikova, 2019; Zhou et al., 2018). Additionally, Italian relative pronouns and markers are governed by internal head nouns and case assimilation (Poletto & Sanfelici, 2018; Vatteroni, 2022), while Greek relative pronouns are sensitive to case and word order (Katsika et al., 2022). The deployment of syntactic gaps in Central American languages is subject to regionalization effects (Palancar et al., 2024). What’s more, research on these languages further challenges the stereotype that relative pronouns are a hallmark of European languages (Siegel, 2019, p. 1011), as evidenced by archaic Chinese markers or the relative pronouns “zhe” and “suo” (Zhao & Zhang, 2022), highlighting the dynamic evolution of world languages (Dixon, 1997). This means that relativization strategies also need to undergo the dynamic evolution in languages.
Thirdly, corpus and experimental data in empirical studies can be categorized based on grammatical variable interactions, relativization strategies, L1 background, gender, island effects, etc. Different variables can be combined with each other to explore the influencing factors of relativization strategies. Findings reveal that different grammatical variables, grammaticalization of interrogative pronouns, non-native female researchers, native male researchers, negation structures, island effects, and social class strongly trigger the option of relative and resumptive pronouns (Al-Aqarbeh, 2023, p. 37; Auderset, 2020, pp. 508–509; Calle-Rubio, 2024, p. 43; Diaz-Redondo, 2021, p. 150; Fernandez, 2021, p. 20; S. H. Lee, 2019, pp. 237–238). Conversely, agglutinative languages, L1 diversity, word order, and L2 grammars inhibit relativization strategies and resumptive pronouns (Hu & Zhao, 2023; Kunduz & Montrul, 2022; J. Lee & Lookadoo, 2020; Solaimani et al., 2023). Language variation, colloquialization, and the global spread of English further promote the merger of animate and inanimate relative pronouns, increasing their frequency of use (Akinlotan, 2022, p. 25; Suarez-Gomez & Guijarro-Fuentes, 2024, p. 965). These reveal the methodological value of integrating typology with corpus linguistics, sociolinguistics, and experiments, which can provide the typological theory with more evidence.
Despite their syntactic focus, prior studies have indirectly advanced the understanding of the syntax-semantics interface, transcending traditional syntactic analyses and providing evidence for double-headed structures.
The Syntax-Semantics Interface
Theoretically, research on Japanese and Russian sign language confirms that double-headed structures underpin relativization and the key to relativize in Karachay-Balkar is the syntax-semantics interface (Gurer, 2020; Khristoforova & Kimmelman, 2020; Kitagawa, 2019). Costaouec (2022) further proposes a grammar-centric definition of relativization, which ignores the fact that syntactic and semantic gaps serve identical functions. This definition overlooks dP-generated gaps. But it lays the grammatical groundwork for double-headed structures by emphasizing the importance of the syntactic classes. Different combinations among syntactic classes mean different sizes of modified heads, such as dP and DP, and the size dictates different strategy choices of relativization (Ahmed, 2023; Li & Yin, 2022). In syntactic gaps, even when external heads are deleted, internal heads maintain semantic links to interact with the main clause via semantic strategies, affirming semantics as deep-structure phenomena (J. Lee, 2021). In semantic gaps, researchers also demonstrate the “gapless phenomena” on the surface must be generated from the deep gap (Ma, 2019; Xu & Zhang, 2021). The semantic prominence extends the role of telic features to Chinese semantic gaps, revealing that semantics can decide the syntactic structure of relative clauses (Kou & Yuan, 2019).
Practically, the analysis of syntactic treebanks demonstrates how word order and relativization strategies jointly constrain English recursive depth (Ding & Chen, 2022). Integrating experimental data and relabeling algorithms, researchers have exposed traditional labeling limitations and developed the syntax-semantics interface in relative clauses (L. W. Zhang, 2018). The research from the perspective of cognitive grammar further compares gapless structures in Chinese and English, revealing the cognitive mechanism lies in the fact that Chinese relies on conceptual semantics in gapless relative clauses, which can constitute the baseline and the head invokes an elaboration on the baseline, and English relies on conceptual semantics in main clauses, which can constitute the baseline and the elaboration is based on the semantic relationship between main clauses and gapless relative clauses (Y. Zhang, 2019). Thus, word order and the role of telic features make Chinese produce more gapless relative clauses.
On the whole, the above field remains confined to the further development of syntax-semantics interface, such as lacking the combination of more cross-linguistic and corpus data. Thus, this research proposes the “Semantic Gap Primacy” hypothesis, which is based on Cinque’s double-headed structure (2020, pp. 253–255), examining its typological distribution in Chinese and English based on cross-linguistic and corpus data. This can provide a double-headed structure with more empirical evidence. The research is guided by the following two questions:
Does Chinese exhibit “semantic gap primacy” and is this phenomenon prevalent in neighboring languages? If so, what can explain this phenomenon?
Does English also exhibit “semantic gap primacy”? If so, what governs its distribution patterns?
Future research must transcend syntax-centric paradigms, combining semantics within typological and corpus-based frameworks to fully reveal relativization mechanisms. This approach will not only bridge theoretical gaps but also guide L2 teaching (e.g., the use of implied arguments) and NLP (natural language processing) applications (e.g., machine translation of deep and implied gaps).
Methodology
This section describes the key steps in data collection and processing: data collection and cleaning, questionnaire and tagging design, data processing and analysis, and statistical modeling. Each step is described in detail to ensure methodological rigor.
Data Collection and Cleaning
For RQ (Research Question) 1, the study selected six languages—Chinese, Hmong, Thai, Vietnamese, Malay, and Indonesian—as target languages. The reason is that they belong to SVO (Subject-Verb-Object) word order, which does not require additional markers to form transitive sentences (unlike SOV languages). Data were collected via questionnaires from native speakers of target languages. The sampling frame consisted of native speakers of six SVO languages (Chinese, Hmong, Thai, Vietnamese, Malay, and Indonesian), selected based on their typological proximity and shared syntactic features in relativization strategies. Six participants, consisting of two males and four females, with a mean age of 23 years old, were recruited through purposive sampling at Shanghai International Studies University, with the following criteria.
Inclusion criteria include native proficiency in the target language, enrollment as undergraduate or graduate students, and HSK level 8 certification for non-Chinese speakers. Exclusion criteria include participants with bilingual dominance in a non-target language. This sampling strategy ensured homogeneity in L2 proficiency while capturing typological diversity, reducing confounds from varying language competence.
First, it ensures that they have already acquired a high level of Chinese language proficiency, enabling them to accurately understand and use transitive structures in Chinese, thereby possessing sufficient linguistic knowledge of transitive structures. Second, by applying a unified screening standard for language proficiency, errors in language output caused by differences in language ability can be reduced, ensuring the validity of research data. All native speakers need to write transitive sentences and then relative clauses.
While all participants were from the same university, which may limit geographic representativeness, we mitigated this by ensuring diverse linguistic backgrounds within each language group. Future studies could expand sampling to include community-based participants for greater external validity.
There were two questionnaires, each containing 10 items. Questionnaire 1 aimed to investigate the distribution of semantic roles of NP1 and NP2 in non-compositional transitive sentences, where their relativization can generate semantic gaps (e.g., wo chi shitang → [wo chi de (particle)]RC shitang). While compositional transitive sentences can generate syntactic gaps via the relativization (e.g., nanhai mai shu → [mai shu de (particle)]RC nanhai). This difference arises from the unique morphology of isolating languages, such as Chinese and Hmong. For example, “wo,” “chi,” and “shitang” means “I,” “eat,” and “canteen” respectively, which means isolating languages can form transitive sentences without any prepositions. Thus, “[wo chi de]RC shitang” just relies on semantic links to form a relative clause, which is called a “gapless relative clause.” In Questionnaire 1, native speakers need to write the following three types of non-compositional transitive sentences according to the requirements:
NP1 (prototypical agent) + V + NP2 (non-prototypical patient);
NP1 (non-prototypical agent) + V + NP2 (prototypical patient);
NP1 (non-prototypical agent) + V + NP2 (non-prototypical patient).
Questionnaire 2 aimed to investigate the distribution of semantic roles of NP1 and NP2 in gapless relative clauses based on the above non-compositional transitive sentences. In Questionnaire 2, native speakers of target languages need to write the following three types of gapless relative clauses:
[NP1 (prototypical agent) + V]RC NP2 (non-prototypical patient);
[V + NP2 (prototypical patient)]RC NP1 (non-prototypical agent);
[NP1 (non-prototypical agent) + V]RC NP2 (non-prototypical patient) or
[V + NP2 (non-prototypical patient)]RC NP1(non-prototypical agent).
For RQ 2, data were collected from the COCA corpus and four learner English corpora under BFSU CQPweb using the search query “that+WH-” (e.g., that whose). “that+WH-” structures arise from double-headed structures. The use of unmarked complementizers can convert a wh-marked clause with interrogative mood into a free relative with declarative mood, such as “Webster defines stress as ‘[that which strains or deforms]RC’” (COCA). But the reverse word order “WH-+that” is ungrammatical. This shows that the higher CP layer (that+WH-) constitutes the maximal projection of double-headed structures, confirming the existence of “Semantic Gap Primacy” in English. The data analysis is based on LancsBox with a span of five words to the left and right.
Questionnaire Design
The purpose of the questionnaire design is to collect data on non-compositional transitive structures, relative clause structures, and the semantic roles of arguments across languages. In designing Questionnaire 1, we first listed transitive structures, non-compositional transitive structures, and their example sentences as follows. A prototypical transitive structure follows the grammatical pattern of “NP1 + V + NP2,” where NP1 typically refers to a noun with high animacy capable of initiating an action, V denotes a transitive verb representing the action, and NP2 usually refers to a noun with low animacy capable of undergoing the action, with a classic example being “wo (I) chi (eat) fan (rice).” However, non-compositional transitive structures, which also conform to the “NP1 + V + NP2” pattern, fall into three types (Sun & Wu, 2022). The first type involves NP1 as a high-animacy noun capable of initiating an action, V as a transitive verb representing the action, and NP2 as a low-animacy noun incapable of undergoing the action (e.g., “wo (I) chi (eat) shitang (canteen)”). The second type features NP1 as a low-animacy noun incapable of initiating an action, V as a transitive verb representing the action, and NP2 as a low-animacy noun capable of undergoing the action (e.g., “zhepiandi (this piece of land) zhong (plants) hua (flowers)”); the third type includes both NP1 and NP2 as low-animacy nouns, neither of which can initiate or undergo the action, with V remaining a transitive verb representing the action (e.g., “fan (rice) chi (eat) dawan (big bowl)”).
Second, we designed 10 questions or items about non-compositional structures, grouped into pairs: taking the first pair as an example. The first question required native speakers of target languages to produce non-compositional transitive sentences of the first type, with NP2 restricted to the semantic roles of instrument, location, and purpose, while the second question asked them to annotate the semantic roles of arguments in these sentences, ultimately yielding the following questionnaire data.
For Type 1, the transitive structure is NP1 (e.g., I, they, and personal names) + V (e.g., eat, drink, take an exam, and play) + NP2 (e.g., canteen, big cup, doctoral degree, and place names).
For Type 2, it is NP1 (e.g., small bowl, small knife, land, and food names) + V (e.g., eat, drink, plant, and cut) + NP2 (e.g., wine, flower, vegetable, and food names).
For Type 3, it is NP1 (e.g., small bowl, knife, locations, place names, Chinese food, food names, table, shoes, and water) + V (e.g., eat, drink, cut, study, and put) + NP2 (e.g., big bowl, locations, doctoral degree, culture, and delicacy).
In designing Questionnaire 2, since all native speakers of target languages were familiar with the structure of relative clauses, no additional explanation was provided. Instead, we designed 10 questions or items about noun phrases including relative clauses, again grouped into pairs. Taking the first pair as an example. The first question required native speakers of target languages to produce relative clauses of the first type (referencing Questionnaire 1) with the head noun restricted to NP2 and NP2’s semantic role limited to instrument, location, and purpose, while the second question asked them to annotate the semantic roles of arguments in these relative clauses and head nouns, thereby ensuring the validity of argument annotation.
Data Processing and Analysis
Instead of employing convenience sampling, we conducted exhaustive collection, annotation, and analysis of all results retrieved from the corpus.
To ensure the consistency and repeatability of data annotation, we have developed a detailed coding manual, and the definitions and operationalizations of key variables are as follows.
Gap type includes two categories. Semantic Gap, which refers to a gap in a relative clause that has no direct syntactic argument relationship but has an implicit semantic role (such as location, manner, time, purpose, etc.), and syntactic gap, which means a gap in a relative clause that has a direct syntactic argument relationship (subject, object, etc.). Semantic Role covers agent, patient, instrument, location, purpose, etc. And Relative Clause Type is divided into semantic, non-restrictive, and free relative clauses.
The word “that” which functioned as a determiner needs to be excluded based on POS tagging. The remaining sentences where the word “that” functioned as a complementizer were collected and evaluated by three English researchers, which can make sure “that” served as a complementizer and “WH-” as a relative pronoun. High inter-rater agreement was ensured through cross-validation of data.
To ensure annotation consistency, all annotators followed a detailed guideline that defined the syntactic and functional criteria for identifying complementizers and relative pronouns. Annotators were also trained on a pilot sample of 50 sentences prior to formal annotation. Inter-annotator agreement was quantitatively assessed using Fleiss’ kappa (κ), yielding a score of .83, indicating a high level of consistency. In cases of disagreement, a consensus-based adjudication procedure was implemented: annotations were discussed in a joint session, and a final decision was made based on the syntactic criteria outlined in the guideline.
Statistical Modeling
To quantitatively test the effects of predictor variables—specifically animacy, clause type, mood, register, and tense-aspect—on the binary outcome of relativization strategy choice (e.g., the presence or absence of a “that+WH-” construction), we employed binomial logistic regression modeling. All statistical analyses were conducted using the R programming language (version 4.1.2) with the nnet package (Venables & Ripley, 2002).
Model selection was guided by a principled approach, comparing nested models using likelihood ratio tests (LRTs) and evaluating overall model quality with the Akaike Information Criterion (AIC). The statistical significance of individual fixed effects was assessed using the Wald z-test. To facilitate interpretation, the magnitude of these effects is reported as odds ratios (OR) along with their 95% confidence intervals (CIs).
Results and Analysis
After collecting and processing the questionnaire and corpus data, we established Database 1 and Database 2, respectively. For all questionnaire data, the key finding is as follows.
Cross-Linguistic Distribution of Semantic Gaps (Addressing RQ1)
As shown in Table 1, Chinese, as an isolating language, exhibits the richest variety of semantic links and semantic gaps. However, Type III cannot be relativized because of the absence of a prototypical agent in transitive structures. Thus, the semantic connection between head nouns with low animacy and agentive verbs is weakened, which increases the difficulty of relativization, as exemplified by the ungrammaticality of noun phrase “[du boshi de]RC Shanghai” based on the transitive sentence “Shanghai du (study) boshi (PhD/doctoral degree).” The absence of Type II in Indonesian and Malay is because agentive verbs in agglutinative languages (e.g., “minum (drink)”) require preposition markers, thereby violating the non-compositional transitivity. At the same time, semantic links of Type I in Indonesian and Malay rely on metonymy, while Type III utilizes voice raising and language habits. Malay’s voice system permits the active-passive alternation in transitive sentences without any morphological marking (e.g., “Meja (table) letak (put) utara (north)” means “The table is placed on the north side”). Indonesian, influenced by Dutch, typically requires passive markers (di-/ter-), and usually maintains “patient first” word order in transitive sentences. But when there is no overt agent, tense, and aspect, Indonesian can form non-compositional sentences without passive and additional markers (e.g., “Sepatu (shoes) taruh (put) luar (outside)” means “The shoes are put in the outside”).
Distribution of Gaps in SVO Languages.

Consequently, in Type III, Indonesian only permits patients as NP1 and Malay exhibits more semantic links. Besides, they use the same complementizer “yang” (e.g., Indonesian gapless relative clause “Gelas besar (large glass) [yang (that) saya (I) minum (drink)]RC”). Malay also treats “yang” as a definite article, whereas Indonesian uses it emphatically.
However, isolating languages like Chinese, Vietnamese, Thai, and Hmong can generate more semantic links and gap types due to flexible word order and unique morphology. The examples are as follows.
(3) Zhang San ăn nhàăn. Zhang San eat canteen Zhang San eats in the dining hall. (4) Nhàăn [mà Zhang San ăn]RC Canteen that Zhang San eat The dining hall in which Zhang San eats (5) Chan deum keaw yai, khun deum keaw lek. I drink glass big you drink glass small I drink the large glass, you drink the small glass. (6) Keaw yai [thii chan deum]RC Glass big that I drink The big glass with which I drink something (7) Oʊ ʦʰa wo xo oʊ ʦʰa. Pickled cabbage soup drink pickled soup The pickled soup is preferred part for eating pickled cabbage soup. (8) [Xo oʊ ʦʰa paŋ8]RC oʊ ʦʰa wo Drink pickled soup de pickled cabbage soup The pickled soup in which the (pickled) cabbage soup is the preferred part for eating
Based on the above sentences, the differences are that Vietnamese uses the complementizer “mà” (obligatory with definite heads marked by cái (the)); Thai uses the complementizer “thii” grammaticalized from the locative noun; Hmong’s “paŋ” serves as a particle akin to Chinese “de.”
From the analysis of Table 1, the diversity of semantic gaps in isolating languages arises from their morphology. It further reveals another systematic distribution: instrumental roles dominate across all three types, aligning with Dowty’s (1991, p. 578) semantic role hierarchy (Agent > Instrument > Location > Goal > Patient), where instruments exhibit stronger inferential capacity.
Corpus-Based Distribution of Semantic Gaps (Addressing RQ2)
Existing research has traditionally agreed that complementizers cannot co-occur with relative pronouns, which won’t violate the edge constraint. Relative clauses must contain either a relative pronoun or a relative marker exclusively, thereby viewing syntactic gaps and semantic gaps as mutually exclusive parameters. However, Radford (2018, p. 119) first mentioned six unusual cases in British English variants, exemplified by “that+WH-” constructions such as “This is a country [that whose leadership has been our ally for over 30 years]RC,” which demonstrate the co-occurrence of a complementizer and a marked relative pronoun. In subsequent communications between Radford (2019, p. 38) and Cinque (2020), Cinque analyzed similar structures (e.g., “You need to buy a world class striker [that who you can put in up front]RC”) as containing an empty operator (semantic gap), and labeled the configuration: “a world class striker [SUBP [SUB that] [RELP who [REL ø] you can put up front]].” SUB represents subordinator, P represents phrase, and REL represents relative clause.
Building upon this fact, Cinque (2020, p. 57) advanced the hypothesis that in double-headed structures, the higher CP layer is introduced by a complementizer while the lower CP layer is introduced by a marked relative pronoun, suggesting the existence of a “Semantic Gap Primacy.” This requires a lot of cross-linguistic empirical evidence. The most important point is that this hypothesis has remained unverified in the corpus. This research examines the above hypothesis through the investigation of COCA data, across four influencing factors: animacy (4.2.1), mood and register (4.2.2), tense and aspect (4.2.3), and second language acquisition effects (4.2.4).
Animacy
The search results included 24 examples of “that+whose,” with an actual valid frequency of 15 (370 tokens, 209 types). Among these, one example exhibited rhetorical mood while the remaining 14 examples were in declarative mood. The possessive nouns following “that whose” included both inanimate and animate nouns. Inanimate head nouns (frequency = 11) significantly outnumber animate ones (frequency = 4). And implied head nouns (frequency = 5) occur less than overt head nouns (frequency = 10). For example: (9) Instead, we usually make a type [that whose purpose is to model an aspect of some problem]RC and then later on if we see that the type represents a value with a context and can act like a monad, we give it a Monad instance.
When head nouns were implied, all possessive nouns (frequency = 5) were abstract (i.e., outcome, angle, certainty, characters, time), with no animate examples. When head nouns were overt, nine possessive nouns were abstract (i.e., capital, strength, purpose, survival, image, berths, records, aspect, duration), contrasted with only one animate example (i.e., people). This result reflects the effect of animacy hierarchy and cognitive processing: the lower identifiability of inanimate nouns promotes the explicitness of head nouns, which can add explanation to head nouns, for example, the explanation structure occurs typically with copular rather than agentive verbs. Consequently, inanimate head nouns prefer to occur with “that+whose” than animate head nouns (11 vs. 4). The whole data revealed “that whose” preferentially occurs with inanimate possessive nouns and overt head nouns due to its explanatory function. To statistically validate this pattern, a binomial logistic regression model was fitted with animacy (animate vs. inanimate) as the fixed effect and the log odds of “that whose” occurrence as the response variable.
The model revealed a significant main effect of animacy (β = 2.914, SE = 0.663, p < .001). The odds of “that whose” occurring with an inanimate head noun were approximately 18.43 times higher (OR = 18.43, 95% CI [5.03, 67.56]) than with an animate head noun, confirming a strong animacy-driven selection bias.
Mood and Register
The search result included 3,273 examples of “that+why,” with 165 valid examples (1,737 tokens, 654 types). All valid examples demonstrated declarative, rhetorical, and exclamative moods, with rhetorical mood showing a significant increase (frequency = 81). Its frequency is equivalent to that of the declarative mood. Mood’s label was based on the internal mood in relative clauses. Relative clauses were categorized into three types: free relative clauses (when the head noun was implied), non-restrictive relative clauses (when the head noun occurred with punctuation markers, or when the head/clause had been previously mentioned), and semantic gap relative clauses (when the head noun lacked previous mention). Figures 1 and 2 illustrate the distribution of these mood types across different registers.

Cross-register distribution of mood types in “that why” relative clauses.
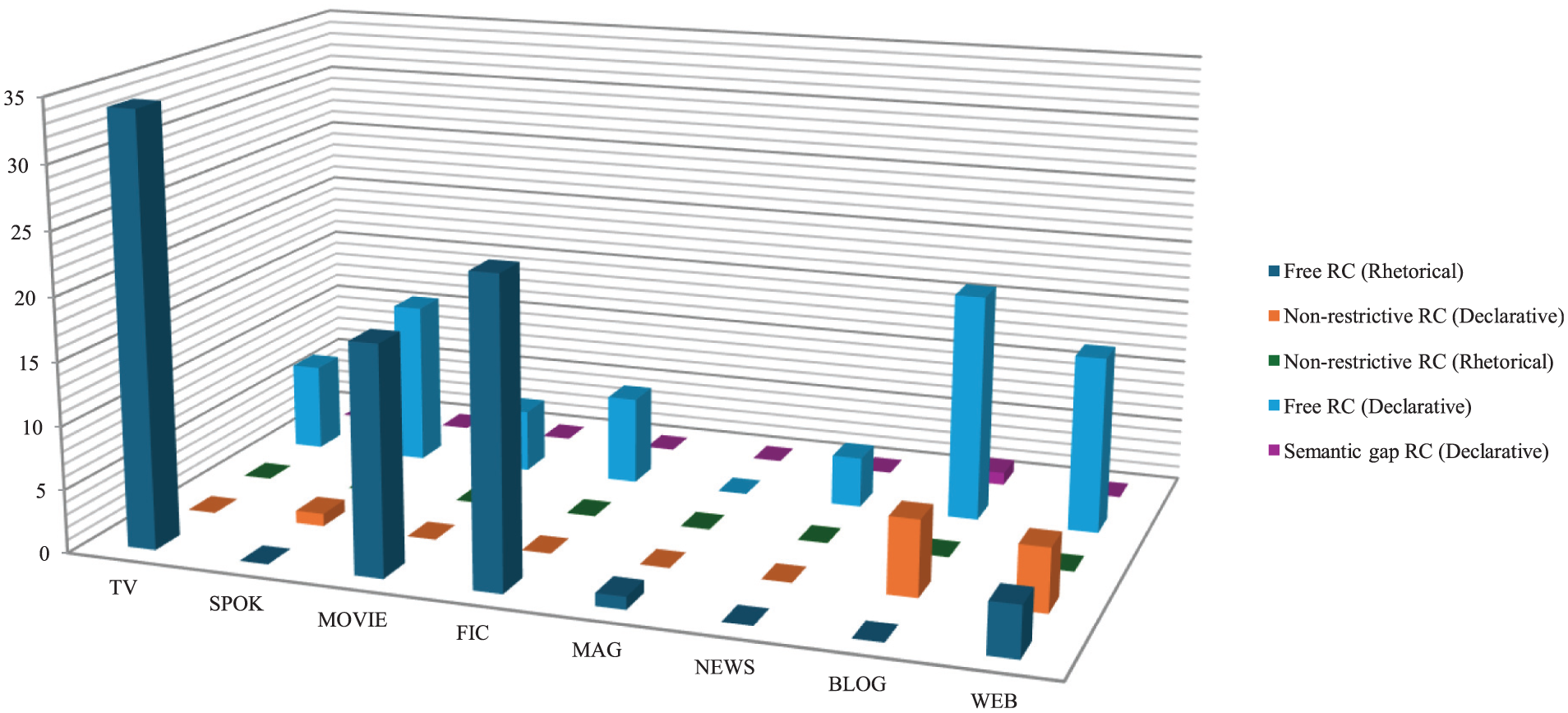
Cross-register distribution of mood types in three types of “that why” relative clauses.
Relative clauses introduced by “that why” primarily function as free relatives or non-restrictive relatives. When the head noun and relative clause represent given information, these types typically are used to question/challenge the hearer. When the head noun represents old information and the relative clause represents new information, they are used to summarize the speaker’s reason. The distribution shows free relatives with rhetorical mood as the most frequent (81 examples), followed by free relatives with declarative mood (68 examples), non-restrictive relatives with declarative mood (12 examples), and semantic gap relatives with declarative mood (1 example).
To examine the influence of mood, a binomial logistic regression was employed, modeling the likelihood of “that why” occurrence. The analysis identified mood as a significant predictor. The odds ratio demonstrated that the likelihood of “that why” being used was dramatically higher with rhetorical mood—specifically, 37.51 times greater (95% CI [17.95, 78.42])—compared to declarative mood. This provides evidence for a robust selection bias governed by mood.
Semantic gap relatives are used to explain newly introduced head nouns, as in: “I explain the reasons [that why the Growing Part of the World seems to be doing so much better than the world economically]RC and offer my view of what its prospects are for the future” (BLOG). Rhetorical mood predominantly occurs in TV, movie, and fiction registers, combining with free relatives to advance the plot’s development and convey the speaker’s skepticism or sarcasm, exemplified by: “[That why you started drinking again]RC?” (MOVIE). Blog and web use “that why” with non-restrictive relatives for explanatory purposes: “Several liberal bosses are controlling the whole media opinions, [that why every media say the same thing except just few]RC” (WEB). In spoken and news registers, “that why” with free relatives are used to summarize the speaker’s actions and viewpoints: “[That why we came out]RC” (SPOK).
The collocation frequency threshold is 5, and both “that whose” and “that why” showed a collocation preference for copular verbs. However, “that why” demonstrated stronger tendencies for implied head nouns and co-occurrence with first and second-person pronouns. The frequency distribution was as follows: you (56), I (23), it (11), you’re (11), we (11), he (10), me (9), him (6), they (6), totaling 143 examples (42.3% of total classes). This reflects their predominant use in interactive contexts (e.g., TV and movie), as exemplified in (10): (10)
In the frequency distribution, copular verbs consistently appeared to the right of “that why,” with “are” (11) and “been” (5) showing 100% right-positioning, while “is” (6) and “was” (3) demonstrated right-positioning rates of 75% and 60% respectively, as in “[That why he is looking]RC” (BLOG). The conjunction “and” (8) typically expressed result-cause relationships (57% left-positioning rate). The pronoun “it” (9) is as referential cohesion to make connections with the above text (81.8% right-positioning rate), as shown in (11): (11) -
Besides, the adverb “so” (10) conveyed the speaker’s dissatisfaction (e.g., “[That why he takes so long]RC?” (TV)), while the verbs “came” (6) and “go” (4) frequently appeared in negative constructions for rhetorical mood (e.g., “[That why you don’t wanna go through with this]RC?” (MOVIE)).
As for “that+where,” the search result included 2,251 examples (54 valid examples; 1,543 tokens; 691 types). The mood distribution shifted significantly, with rhetorical/interrogative examples accounting for only 11% (frequency = 6) versus 49% (48 declarative examples). Figures 3 and 4 present the mood distributions across registers for “that where.”
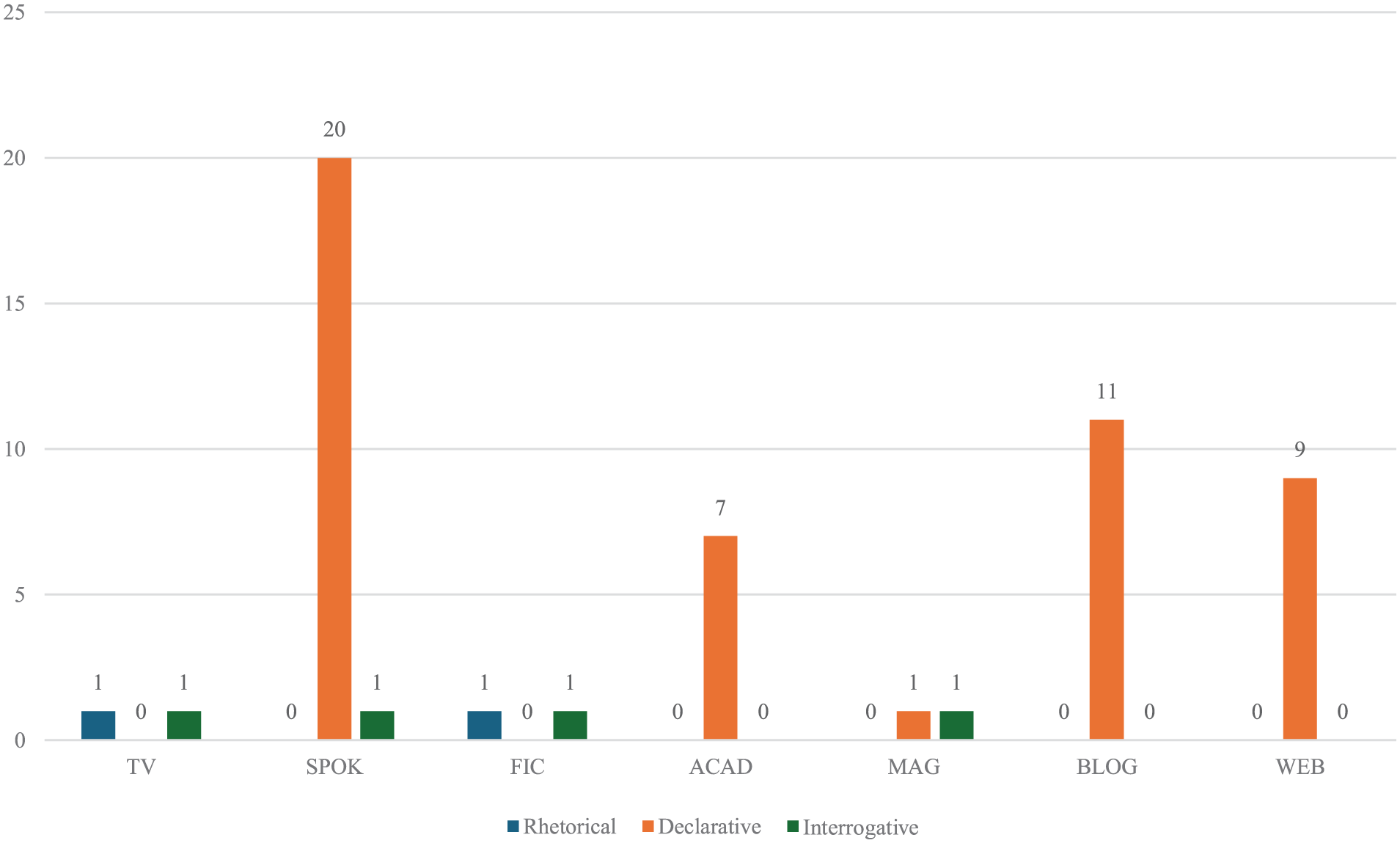
Cross-register distribution of mood types in “that where” relative clauses.

Cross-register distribution of mood types in three types of “that where” relative clauses.
The “that where” distribution demonstrates distinctive characteristics, with semantic gap relatives predominating (76%, 41 examples), particularly in academic registers (ACAD) where they serve explanatory functions. A single interrogative example occurs in spoken discourse: “Mr. Yamauchi, can you direct us to the column [that where you made the numbering mistake]RC?” (SPOK). Free relatives account for 13% (7 examples), while non-restrictive relatives constitute the minority (11%, 6 examples). Non-restrictive relatives primarily appear in written registers (MAG, BLOG, WEB; 5 examples), with only one spoken example. All six examples use declarative mood, serving evidentiary functions in written arguments: “
This mood differentiation arises from functional distinctions: non-restrictive and semantic gap relatives provide explanations (favoring declarative mood), while free relatives in interactive contexts confirm referents (favoring rhetorical and interrogative moods).
But “that who” (776 examples, 35 valid examples; 786 tokens, 370 types) only uses declarative mood, predominantly in spoken registers according to Figure 5. Semantic gap relatives dominate (74.3%, 26 examples), indicating a preference for overt head nouns. Free relatives (4 examples) show a preference for written registers, while semantic gap and non-restrictive relatives (5 examples) prefer spoken registers.
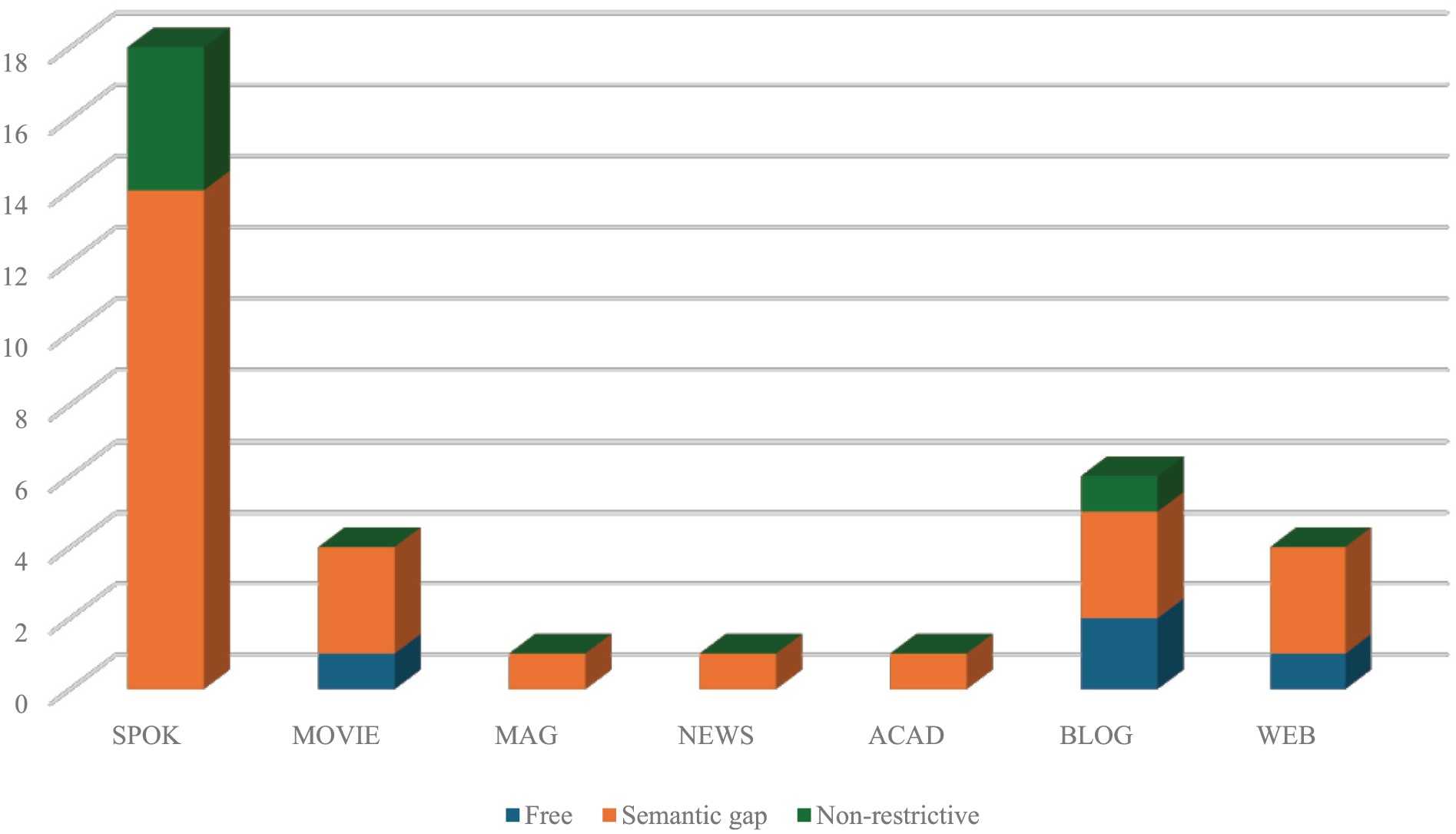
Distribution in three types of “that who” relative clauses.
The “that which” included 9,628 examples (460 valid examples; 15,730 tokens, 4,208 types), with only one rhetorical example. Declarative mood prevails in written registers.
Figure 6 reveals distinct characteristics for “that which”: semantic gap and subject relatives (162 examples) and object relatives (50 examples) total of 212 examples, while in non-restrictive relatives there are 200 subject relatives and 48 object relatives (248 in total), demonstrating the preference of non-restrictive for “that which.” Similarly, “that who” also exhibits a strong preference for subject relative clauses (28 subject relatives examples vs. 3 object relatives examples). This preference is across both “that who” and “that which.” But “that who” prefers to occur with semantic gap relatives (highlighting the explanation for animate head nouns with high identifiability), while “that which” prefers to occur with non-restrictive relatives (adding new information and comments to inanimate head nouns with lower identifiability to advance the development of discourse). The binomial logistic regression analysis revealed a statistically significant main effect of clause type on the occurrence of the “that who” construction (Wald χ2(2) = 12.525, p = .002). Both levels of clause type examined were associated with significantly lower odds of the construction appearing compared to the reference free relatives. Specifically, the odds for semantic gap relatives were reduced by 77.4% (OR = 0.226, 95% CI [0.078, 0.657], p = .006), and for non-restrictive relatives by 80.4% (OR = 0.196, 95% CI [0.061, 0.623], p = .006). No significant effect was found for register.

Distribution of head noun types in two types of “that which” relative clauses.
The most important point is the animacy-driven distribution based on head nouns which manifests in collocations. This is due to the different functions of relative clauses. For “that who,” semantic gap relatives often co-occur with “people” (5 examples, Z = 12.682) and non-restrictive relatives often co-occur with “ones” (3 examples, Z = 9.824). For “that which,” non-restrictive relatives often co-occur with “it” (31 examples, 8 left-positioning), and semantic gap relatives often co-occur with “this” (17 examples, 7 left-positioning).
Examples (12) and (13) illustrate the above contrast: (12) The (13) We see
Tense and Aspect
The search result included 40,723 examples of “that+when,” with 37 valid examples (1,359 tokens, 566 types). The mood distribution showed the dominance of declarative mood (35 examples), while rhetorical mood occurred only twice, both appearing sentence-finally. The relative clause types included both semantic gaps and non-restrictive relatives. To investigate potential and collocational patterns between tense/aspect and “that when,” we labeled the tense/aspect markers on both sides in sentences: the left side representing the matrix clause (containing the head noun) and the right side representing the relative clause. The label aimed to identify systematic correlations between “that when” and tense/aspect, as illustrated in Figure 7.
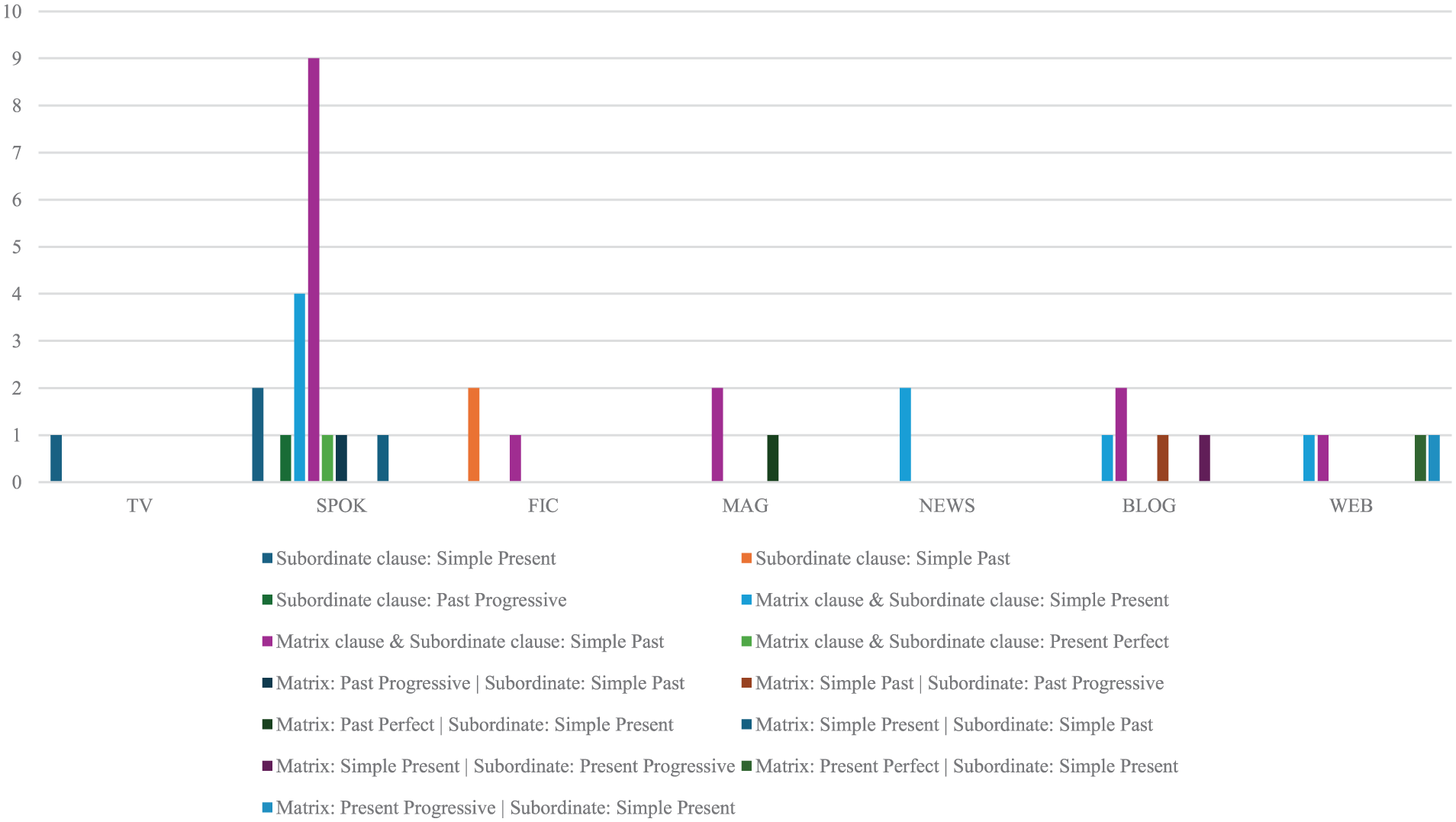
Cross-register distribution of tense/aspect types in “that when” relative clauses.
Figures 7 and 8 reveal 13 kinds of combinations of tense/aspect between matrix clause and relative clause. For tenses, only past and present tenses occur. For aspects, simple (unmarked aspect), progressive, and perfect aspects occur. The most frequent combination shows both matrix and relative clauses are in the simple past tense, followed by the simple present tense. Relative clauses demonstrate a preference for past tense (21 examples, 57%) over present tense (16 examples, 43%). Relative clauses also demonstrate a preference for simple aspect (33 examples, 89%) over progressive aspect (3 examples, 8%) and perfect aspect (1 example, 3%). This combination indicates that matrix and relative clauses prefer to use past tense, with present tense as a secondary option, while generally resisting aspectual markers.

Distribution of tense/aspect types in three types of “that when” relative clauses.
Based on the binomial logistic regression analysis examining the influence of tense and aspect on the occurrence of the “that when” construction, the variable tense and aspect demonstrated a statistically significant overall effect (Wald χ2(12) = 29.62, p = .003). The parameter estimates, with level 13 (Matrix: Simple Past | Subordinate: Past Progressive) as the reference category, revealed several specific and significant effects: level 4 (Matrix clause and Subordinate clause: Simple Present) significantly increased the odds of the “that when” construction (β = 1.969, SE = 0.652, Wald χ2(1) = 9.116, p = .003). The odds ratio was 7.16, indicating that the odds of the construction occurring are approximately 7.2 times higher for this level compared to the reference level (95% CI [2.00, 25.72]).
Three factors govern the above combinations: (1) the type of relative clause; (2) the category of head noun; (3) the construction of matrix clause. For semantic gap relatives (23 examples), the tense in matrix clause highly corresponds with that in relative clauses (61%), that is, simple past (8 examples) and simple present (6 examples). Semantic gap relatives have the greatest tense/aspect diversity (11 combinations), including simple past/present and past progressive in relative clauses (3 examples), simple past in matrix clause and past progressive in relative clause (1 example), past progressive in matrix clause and simple past in relative clause (1 example) and simple present in matrix clause and present progressive in relative clause (1 example), and the above two combinations. Aspect markers in relative clauses depend on head nouns and prepositions, as illustrated by: “ (14) There (15) Clinton interrupted, noting appreciatively that he
Example (14) demonstrates past tense used in spoken discourse is for describing specific past events that won’t happen again, whereas example (15) shows present tense is used in written discourse for describing generic events that are going on.
But for non-restrictive relatives (13 examples), they maintain tense/aspect correspondence as the dominant (10 examples), but it is more balanced in distribution, because of the past tense in the relative clause (7 examples) and the present tense in the relative clause (6 examples). This contrasts with the preference for the past tense in semantic gap relatives (13 past examples, 57%). And the functional differentiation of non-restrictive relatives explains this balanced distribution: past tense in relative clauses serves narrative advancement (“Legend has it that Pynchon was living in Mexico at the time his remarkable debut novel, V, was about to appear in 1963 and [that when he discovered that Time magazine had sent someone down there to photograph the new sensation]RC, ‘he just got on a bus and disappeared’, as one of his associates told me”), while present tense in relative clauses facilitates plot association and opinion expression (“Probably this, that as busy as he’s been with a life of public service for
Second Language Acquisition
Overall, the “that why” dominates in L2 English production, accounting for 84.21% (80 examples, 95 examples in total). This prevalence stems from the economy principle and the head is matrix clause. The distribution across sub-corpora is as follows:
Chinese Learner English Corpus (CLEC) includes two semantic gaps and one non-restrictive relatives introduced by “that why.” iWriteBaby Chinese Learner English Corpus (iWBCLEC) demonstrates significant production differences between different universities. In a regular university, there are 27 semantic gaps, 16 non-restrictive, and 10 free relatives introduced by “that why,” alongside 1 semantic gap relative introduced by “that where” and “that who” examples (6 semantic gap relatives, 2 free relatives). In contrast, students in a key university produce 12 semantic gaps and 2 free relatives introduced by “that why,” with other types (1 semantic gap relative introduced by “that where,” 1 free relative introduced by “that which”).
Ten-thousand English Compositions of Chinese Learners (TECCL) shows another limited production, which includes two non-restrictive, one free, and two semantic gap relatives introduced by “that why”; one free relative introduced by “that which”; one semantic gap relative introduced by “that who.”
The written part of SWECCL 2 (WECCL 2) also has a broad range, including one semantic gap relative introduced by “that whose,” alongside one non-restrictive, two free, and two semantic gap relatives introduced by “that why,” and one semantic gap relative introduced by “that who.”
Another Evidence for Semantic Gap Primacy
The syntactic foundation of this hypothesis rests upon the dual CP layers in double-headed structures. Radford’s analysis positions “that” as a Force Head, transforming the interrogative mood of relative pronouns into the declarative mood, thereby situating “that” within the internal structure of free relative clauses (2018, p. 113). This relativization strategy emerges because unmarked relative pronouns function as weak pronouns capable of passing through a higher complementizer’s specifier to acquire its partial features without violating relativized minimality (Rizzi, 2004). For non-restrictive and free relative clauses, this phenomenon enables their long-distance head’s feature assignment, permitting the non-adjacent relationship between head and relative clause, as evidenced cross-linguistically:
Arabic (arGLOBE Corpus) demonstrates a single example: “أن التي أحبة” (the one who loved me), and “أن” functions as a complementizer and “التي” as a relative pronoun.
Polish (National Corpus of Polish) shows “co którą” (that+WH-) where “co” independently introduces semantic gap relatives or combines with “którą” for non-restrictive relatives, as in the free relatives: “[co którą złapie]RC” (what she catches).
Hungarian (Hungarian National MNSZ2 Corpus) exhibits this strategy: “[
Other Indo-European languages also use this relativization strategy: German (deGLOBE Corpus): “[ Dutch (nlBrown Corpus): “[ Spanish (Spanish News Corpus): “[
These examples uniformly maintain the word order, that is, complementizer-relative pronoun. The cross-linguistic evidence supports the universality of semantic gap primacy in double-headed structures.
This strategy extends to South Caucasian languages, though with altered complementizer positioning (sentence-final), as evidenced in Mingrelian (Danelia & Canava, 1991, p. 204): (16) Ate šara-Ø, [namu šara-s giorgi-Ø ge-Ø-Ɂu DEM.PROX road-NOM which road-DAT Giorgi-NOM PV-IO.3 n-d-u=ni]RC, atena xolo me-Ø-wl-s have.ANIM-EM-S.3SG.PAST=COMP DEM.PROX ADD PV-S.3-go-S.3SG wišo thither
This road, which road Giorgi took/was following, it goes that way, too.
South Caucasian languages use this relativization strategy across free, restrictive, and non-restrictive relative clauses, with complementizers becoming obligatory in non-restrictive relatives.
Conclusion
This research tests the “Semantic Gap Primacy” hypothesis based on cross-linguistic questionnaires and large-scale corpus data, focusing on Chinese and English. The Chinese and English syntactic foundation of this hypothesis lies in the shared and double-headed structures underlying semantic and syntactic gaps. Due to structural and morphological constraints, this double-headed structure manifests as a postposed “complementizer + relative pronoun” in English, while appearing as a proposed “complementizer” in Chinese.
The core issue at the syntax-semantics interface involves “gaps versus fillers” and “matches versus types,” etc. For example, English must use marked relative pronouns to indicate the filling of semantic roles and use complementizers to indicate gap types, such as semantic gaps, because of their rich morphological changes. And, due to many constraints like animacy and mood, English resorts to semantic gaps only in limited contexts. In contrast, Chinese relies on flexible word order—specifically, non-compositional transitive structures—to prompt head noun types and match types. This comparison reveals that English and Chinese employ distinct conceptualization approaches in their relativization strategies. The syntax-semantics interface of the “Semantic Gap Primacy” hypothesis highlights the projection relationship from syntactic structure to semantic interpretation—how syntactic forms influence semantic expressions while semantic requirements constrain syntactic choices.
Research limitations primarily concern the future need for expanded language samples, diachronic data, and multi-dimensional corpora. Future research should integrate psycholinguistic experiments and combine them with more corpus observations to advance the processing mechanism of semantic gaps.
This study has several limitations. The current analysis is primarily based on English-Chinese comparative data, with insufficient diachronic investigation into the evolution of relativization strategies. Furthermore, there is a notable lack of psycholinguistic evidence examining the cognitive mechanisms underlying semantic gaps. Future research should expand the scope to include a wider range of languages and systematically explore the distinctions between semantic and syntactic gaps using corpus-based methods. Employing experimental techniques such as eye-tracking would also help elucidate the real-time processing mechanisms of semantic gaps. Such efforts would contribute to refining the “Semantic Gap Primacy” hypothesis and advancing the theoretical understanding of the syntax-semantics interface.
Footnotes
Acknowledgements
The authors would like to thank the editor and the anonymous reviewers for their insightful comments, which have greatly improved the quality of the manuscript.
Ethical Considerations
The study was approved by the Institutional Review Board of Zhengzhou University.
Consent to Participate
Written informed consent was obtained from all participants included in the study.
Author Contributions
W.W.: Conceptualization, Writing – original draft.
J.G.: Validation, Writing – review & editing.
Q.R.: Writing – original draft.
L.L.: Data curation, Writing – original draft.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Research Project on the High-Quality Development of Foreign Language Education Empowered by Digitalization and Artificial Intelligence (WYJZW-2025-10-0217), Innovation Training Program of Henan Students (S202510459179), Henan Province Philosophy and Social Science Project (2024BYY014), Graduate Education Reform Project of Henan Province (2023SJGLX133Y), and Postgraduate Education Reform and Quality Improvement Project of Henan Province (YJS2024JC09, YJS2025AL15).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All data generated or analyzed during this study are included in this published article.