
Abstract
Emotional support dialog systems face computational linguistic challenges as they require a deep understanding of explicit utterances and implicit emotional needs. In particular, existing models have shown limitations in effectively capturing subtle emotional contexts, which are essential for providing meaningful emotional support. To address this, we propose Generative Retrieval-Enhanced Emotional Support Conversations (GREEN), an emotional support dialog model using generative retrieval. Inspired by docID, GREEN introduces a Residual Identifier (ResID), enabling the dynamic identification of emotional context and appropriate support strategies from seeker utterances. By approaching emotional support as a context prediction task, our model works to understand both the explicit meaning of utterances and the underlying emotional needs of seekers. GREEN achieves significant improvements over SOTA models on ESConv with over 25% gains in response diversity metrics, 8.3% in content quality (BLEU-4), and 9.8% in strategy prediction accuracy. Our approach integrates generative retrieval with ResID-based context analysis, advancing emotional support dialog systems. For balanced reporting, we note current limitations—ResID stability under quantization/clustering and ambiguity when misidentification occurs—and plan to improve semantic matching and identifier design with broader real-world validation.
Plain Language Summary
Many people face stress, loneliness, and emotional difficulties but cannot always reach professional help when they need it. Emotional support chat systems using artificial intelligence (AI) can provide comfort, encouragement, and practical guidance in such moments. However, most existing AI chat systems struggle to fully understand the deeper meaning of a person’s words and emotions, often producing responses that feel repetitive, vague, or mismatched. Our study introduces GREEN, a new AI framework designed to improve the quality of emotional support conversations. GREEN uses an innovative process called “Response ID” (ResID), which helps the AI recognize both what someone is saying and the hidden feelings or needs behind it. By combining this with knowledge graphs—databases that capture connections between feelings, problems, and solutions—GREEN can suggest more meaningful and supportive replies. We tested GREEN on a widely used dataset of emotional support dialogs and found that it provided more diverse, empathetic, and contextually appropriate responses compared to leading AI systems. In evaluations with human judges, GREEN was rated higher for empathy, clarity, and helpfulness. This research shows that AI can be developed to give more human-like, compassionate support, with potential benefits such as reducing barriers to emotional assistance, providing around-the-clock availability, and complementing traditional therapy. Importantly, we emphasize that AI systems should never replace professional mental health care but can serve as an additional layer of support when immediate comfort is needed.
Introduction
Retrieving semantically aligned responses in dialog systems is a crucial research challenge in both natural language understanding and information retrieval. Retrieval-based dialog systems, such as Dense Passage Retrieval (DPR), typically modify input queries to retrieve relevant responses (Majumder et al., 2021). However, these approaches often fail to effectively capture the conversational context, relying heavily on keyword matching, which leads to inconsistencies in semantic coherence. For example, recent approaches like KEMI (Deng et al., 2023) primarily utilize knowledge graphs to proactively assist seekers but do not sufficiently consider deeper semantic alignment, resulting in a limited understanding of nuanced emotional contexts. Similarly, D2RCU (Xu et al., 2024) employs dynamic demonstration retrieval and cognitive understanding modules; however, it still fundamentally depends on index matching based on embedding similarity. Such index-based matching methods inherently struggle to understand subtle semantic nuances and implicit emotional demands, as they rely on fixed embedding similarity metrics that inadequately capture the complexity of human emotional expressions and intents (Wu et al., 2019). Furthermore, conventional retrieval-based methods mainly focus on retrieving or generating responses without effectively analyzing and structuring the seeker’s utterances, thereby failing to address implicit emotional needs comprehensively (Dziri et al., 2019).
To address these issues, we propose Generative Retrieval-Enhanced Emotional Support Conversations (GREEN), a novel retrieval model that leverages Residual Identifier (ResID) to analyze speaker dialog flow and provide semantically structured retrieval results. Unlike conventional retrieval models, GREEN utilizes ResID-based semantic representations to capture latent linguistic structures in conversations, allowing for a more structured and coherent understanding of the speaker’s input. By learning from the overall dialog context, including the previous utterances and underlying issues, GREEN goes beyond merely understanding individual sentences. Instead, it enables semantically aligned responses that reflect the entire conversational flow. In addition, by integrating Residual Quantized Variational Autoencoder (RQ-VAE) with Sinkhorn-Knopp clustering, GREEN enhances speaker-aware retrieval and analysis. Figure 1 illustrates how GREEN effectively guides a conversation toward empathy by identifying appropriate response strategies. Unlike simple approaches that counter the emotions, GREEN utilizes adaptive knowledge graphs and generative retrieval to address underlying issues. This study empirically validates the effectiveness of ResID-based retrieval in improving retrieval consistency and refining speaker intent analysis. Through this approach, we aim to overcome the limitations of traditional retrieval-based dialog systems and propose a new direction toward semi-structured semantic retrieval in dialog modeling, while Figure 2 details the generative retrieval module that operationalizes this paradigm via ResID generation, semantic-preserving matching with adaptive margins, and codebook balancing.
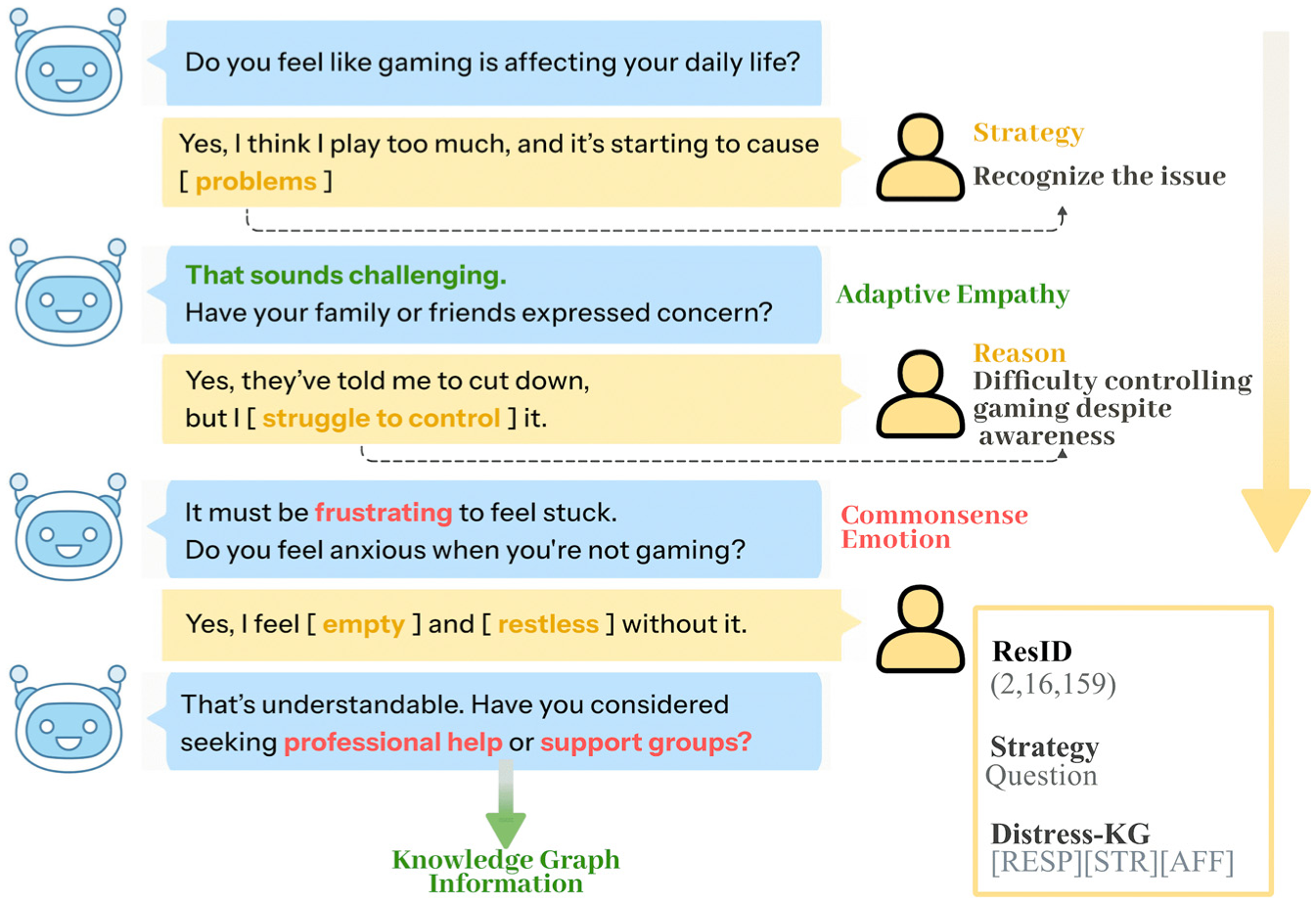
Overview of the GREEN. The model guides emotional support conversations(ESC) by identifying appropriate response strategies via ResID-based generative retrieval and adaptive knowledge graph integration, enabling structured, semantically aligned responses across dialog context.

Detailed architecture of the Generative Retrieval Module in GREEN. The module generates ResID via transformer-based encoding and RQ-VAE codebooks, performs semantic-preserving matching with contrastive learning and adaptive margins, and balances semantic codebooks using a modified Sinkhorn–Knopp procedure to retrieve contextually aligned responses.
Related Works
Generative Retrieval
Generative retrieval is defined as a paradigm that directly generates document identifiers rather than computing similarity scores, enabling semantic-aware retrieval through learned discrete representations (Sun et al., 2024). Generative retrieval was developed to address the limitations of traditional retrieval systems, particularly those relying on index-based methods. Unlike conventional approaches that depend on static indexing and keyword matching, generative retrieval introduces semantic elements into document or ResID. This allows retrieval systems to identify semantically similar content more effectively, enabling a deeper understanding of conversational context and intent. By embedding semantic information directly into ResID, generative retrieval facilitates the discovery of contextually aligned responses, overcoming the rigid constraints of traditional index-based methods (Sun et al., 2024). It is a paradigm that directly generates document identifiers (docID; P. Zhang et al., 2024). DPR advanced retrieval system by computes similarity through high-dimensional embeddings, improving response coherence compared to traditional keyword-based methods (Kwiatkowski et al., 2019). However, DPR suffers from computational complexity and increased storage costs, especially in large-scale datasets. To overcome these limitations, generative retrieval emerged as a novel paradigm that embeds semantic elements into ResID, enabling the retrieval of semantically similar content without relying on static indexing. This approach enhances adaptability and semantic alignment in retrieval tasks. For example, recent studies like GENRET (Sun et al., 2024) and DSI (Tay et al., 2022) have demonstrated the effectiveness of semantic ID-based retrieval in general information retrieval scenarios (Sun et al., 2024). Inspired by these advancements, we propose GREEN, which applies generative retrieval to emotional support conversations(ESC)—a domain where such methods have not yet been explored. By leveraging ResID, GREEN captures the overall dialog flow and latent emotional nuances, allowing for semantically aligned responses tailored to conversational context and emotional needs.
Document ID as an Identifier
With the advent of generative retrieval, the concept of docID has evolved significantly. Early studies introduced docID to improve retrieval systems by embedding semantic elements into identifiers, enabling the discovery of semantically similar content. For example, NOVO utilized n-gram sets to generate multiview identifiers that reflect various aspects of a document, enhancing retrieval accuracy (Y. Li et al., 2023). Similarly, MINDER (Y. Li et al., 2024) combined semantic features with structural information to optimize relationships between documents. These advancements have proven beneficial in recommendation systems, where they effectively capture seeker preferences and address cold-start challenges (Chu et al., 2024).
Inspired by these developments, we propose leveraging ResID in the ESC domain. By embedding semantic and emotional elements into ResID, our approach aims to understand the context of initial conversations more effectively (Liu et al., 2021). While prior work has focused on general information retrieval, applying generative retrieval to ESC scenarios remains unexplored (Sharma et al., 2020). This study bridges that gap by introducing ResID-based retrieval tailored to emotional support dialogs, enabling personalized and contextually relevant responses even in cold-start situations.
Emotional Support Conversation
ESC systems aim to deliver empathetic and contextually appropriate responses to individuals experiencing psychological distress. These systems are essential in addressing mental health challenges as they provide immediate, scalable, and personalized emotional support. Early ESC approaches primarily relied on rule-based or template-based methods, which utilized predefined empathetic expressions. However, these methods exhibited significant limitations in conversational flexibility and personalization, particularly in capturing emotional nuances and adapting to dynamic conversational flows (Yang et al., 2023).
To overcome these challenges, retrieval-based methods such as TF-IDF and BM25 were introduced, enabling response selection from static databases (Zhou & Ren, 2020). While these methods improved response relevance compared to rule-based approaches, their reliance on static indices limited their ability to reflect evolving conversational contexts. DPR further advanced retrieval by leveraging semantic embeddings, enhancing response coherence (Cao et al., 2023). However, DPR faced issues with computational complexity and high storage requirements in large-scale datasets, making it less suitable for real-time ESC scenarios.
Recent advances have attempted to address these limitations through various approaches. Kim et al. (2025) applied reinforcement learning to improve long-term therapeutic outcomes, but their approach still relies on traditional reward mechanisms that may not capture subtle emotional nuances (Kim et al., 2025). Zhao et al. (2024) developed comprehensive evaluation frameworks for large language models in ESC, revealing persistent challenges in maintaining consistent empathetic responses across diverse emotional contexts Zhao et al.; Peng et al. (2023) introduced feedback-aware mechanisms, yet these approaches fundamentally depend on post-hoc corrections rather than proactive contextual understanding (Peng et al., 2023).
Generative models like sequence-to-sequence (Seq2Seq) architectures offered greater flexibility by generating responses dynamically. These models often suffered from overgeneralization, producing vague or insufficiently specific empathetic expressions. Recent advancements have attempted to address these limitations through strategy-aware response generation and multimodal emotional understanding (Cao et al., 2025; Liu et al., 2021; Wang et al., 2023.
Despite these advancements, existing systems still exhibit critical limitations. For example, KEMI (Deng et al., 2023), which integrates a mental health knowledge graph for mixed initiative dialog, struggles with fully capturing dynamic conversational contexts due to its reliance on static retrieval mechanisms. Similarly, D2RCU (Xu et al., 2024) employs dynamic demonstration retrieval but is constrained by embedding-based index matching, which inadequately reflects nuanced emotional states. These fundamental limitations stem from the absence of semantic-aware retrieval mechanisms that can dynamically encode both emotional context and appropriate support strategies within the retrieval process itself.
Furthermore, recent studies have highlighted inherent biases in Large Language Models (LLMs) when applied to ESC tasks (Kang et al., 2024). While LLMs have shown promise in generating empathetic responses, their intrinsic preference biases can hinder their effectiveness in providing domain-specific emotional support. This underscores the need for ESC agents trained exclusively on relevant datasets to mitigate such biases.
To address these gaps, we propose a novel framework that leverages Semantic ID-based retrieval combined with generative retrieval. Unlike existing approaches that apply retrieval and generation as separate processes, our method embeds semantic and emotional elements directly into Response IDs, enabling the retrieval mechanism itself to understand conversational context and emotional dynamics. This enables a deeper understanding of conversational context while addressing cold-start scenarios by effectively capturing the initial emotional state. By applying this methodology within the ESC domain—where generative retrieval has not yet been explored—we aim to enhance both the precision of response selection and the adaptability of generated responses to real-time emotional dynamics (T. Zhang et al., 2024).
Method
We first clarify key terminologies. Generative retrieval refers to a paradigm that directly generates document identifiers rather than computing similarity scores, enabling semantic-aware retrieval through learned discrete representations. ResID denotes discrete semantic codes that encode both emotional context and appropriate support strategies in ESC. Unlike traditional document IDs that primarily capture content similarity, ResIDs dynamically represent the emotional states and support needs expressed in seeker utterances.
The GREEN leverages ResID for query processing. It generates appropriate ResID from input queries and uses them to retrieve the optimal responses. This section presents the architecture of the model and training methodology. GREEN consists of two main components: (1) Generative Retrieval Module and (2) Multi-knowledge Graph Fusion Module. Figure 3 illustrates the complete architecture.

Transformer-based Encoder–Decoder architecture for ResID generation in GREEN. Input query, response, and strategy are encoded; embeddings are quantized via an RQ-VAE semantic codebook into multi-level ResIDs (history, issues, strategy). Semantic-preserving matching is trained with contrastive objectives, and the resulting ResID sequence unifies retrieval and generation for context-aligned response selection.
Generative Retrieval
Response ID Generation
We propose a model that leverages a transformer-based encoder-decoder architecture to transform responses into semantically coherent discrete representations. Unlike conventional ESC models, which rely predominantly on surface-level similarity for retrieval, our approach introduces a mechanism that converts responses into ResID, preserving semantic characteristics and effectively integrating the strengths of both retrieval and generation paradigms. This methodology efficiently captures deep semantic structures typically overlooked in ESC systems and is architected to unify retrieval and generation components seamlessly. We introduce a ResID generation technique for ESC systems that maintains semantic consistency while facilitating efficient response retrieval and generation. RdsIDs serve as compressed encodings of the semantic properties of responses, designed such that semantically similar responses are positioned proximally in the vector space. This approach optimizes semantic associations between query-response pairs and enables responses with equivalent semantic structures to be consistently utilized across diverse contexts.
Formally, ResID is defined as a discrete code sequence
The input data comprises query, response, and strategy, utilizing special tokens ([SEP], [STRATEGY], [RESPONSE]) to delineate the semantic structure of utterances explicitly. Input sequences are processed through a transformer-based Seq2Seq architecture, preserving both syntactic features and the semantic context of the utterances.
The derived embedding vectors

where

with semantic distance D computed using cosine similarity:

In the process of generating ResIDs through Semantic Codebooks, each codebook is designed to capture distinct levels of semantic abstraction. The upper-level codebook encapsulates dialog history, the intermediate level represents the underlying issues, and the lower level encodes strategic approaches.
Semantic-Preserving Matching
The retrieval process focuses on identifying optimal ResIDs while preserving the semantic structure of the query. It extracts semantic representations from the input query
To optimize semantic consistency, we implement semantic contrastive learning, formulated as:


Where ϕ and ψ represent Transformer-based semantic space transformation functions.
We employ adaptive semantic margins to dynamically adjust the contrastive loss margin based on semantic similarity, thereby enhancing the differentiation between semantically similar responses.
Semantic Codebook Balancing
For semantic codebook balancing, we implement a modified Sinkhorn-Knopp algorithm:

Where

This facilitates more nuanced representation of semantically significant patterns in the codebook, as opposed to a uniform distribution.
Through semantic progressive training, we iteratively enhance the semantic expressiveness of the codebook, while semantic commitment loss constrains the embedding space to maintain semantic consistency. This approach captures subtle semantic nuances frequently overlooked in ESC, enabling the generation of contextually appropriate responses. Figure 1 shows the entire process of generative retrieval.
Multi-Knowledge Graph Fusion Module
To generate more consistent and appropriate responses in the emotional support dialog system, this study applies a multi-knowledge fusion decoder. This decoder combines an extended query reflecting the cognitive state and information retrieved from the HEAL graph to ultimately generate a response suitable for an emotional support dialog. To this end, GREEN consists of three main modules: (1) Cognitive Understanding Graph, (2) Distress Management Graph Retrieval, and (3) Multi-Knowledge Fusion Response Generation.
Cognitive Understanding Graph
Understanding the cognitive dimension of distress based on previous conversations is crucial. For this purpose, we use COMET (Bosselut et al., 2019) to enrich queries with multi-perspective insights into the affective state. To capture the cognitive state, we focus on four key relationships—Effect, Intent, Need, and Want—to. The dialog context is consolidated into a single sequence, and the cognitive state is deduced based on this:

where ⊕ represents the concatenation operation and N represents the number of utterances. Encoding is then performed using a dedicated encoder.
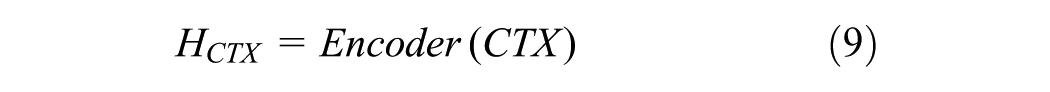
At the same time, the cognitive state is predicted for each cognitive relationship

The predicted cognitive state undergoes additional encoding to generate a final unified representation:

This facilitates the generation of extended queries that reflect cognitive context as opposed to basic keyword-based retrieval.
Distress Management Graph Retrieval
The HEAL (Welivita & Pu, 2022) is used to identify the types of stressors, speaker expectations, reactions, and pain-related feedback in conversations. The HEAL graph includes four main node types: (1) expectation, (2) affective state, (3) stressor, and (4) response. Using the expanded query
Multi-Knowledge Fusion Response Generation
To effectively integrate the retrieved response candidates and the cognitive state, this study applies a multi-knowledge fusion decoder. The decoder is designed to combine the dialog context, retrieved responses, and cognitive state in a balanced manner. To this end, cross-attention is applied to integrate the encoded knowledge sources with the dialog history.
In this process, the affinity score between the historical context (

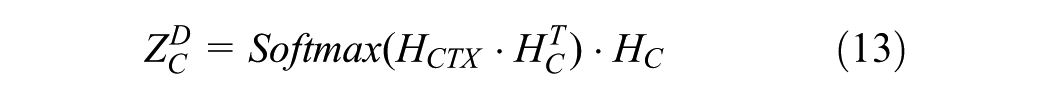
This strengthens the connection between the context of the conversation and the information retrieved and enables more natural response generation.
Finally, a weight-based aggregation strategy is used to combine the two knowledge sources in a balanced manner.

Where
The response generation process is performed using a sequence generation model based on fused knowledge.
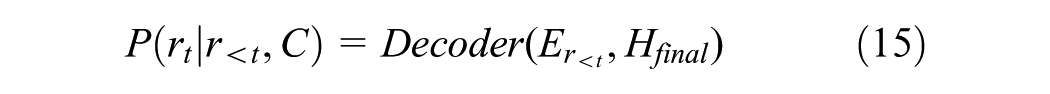
Where
Experimental Setting
In this section, the performance of the proposed GREEN is comprehensively evaluated and validated from multiple perspectives. Comparative analysis with existing baseline models is conducted, and the effectiveness of the model is demonstrated through experimental studies. Additionally, empirical analysis is included to verify the practical applicability in ESC scenarios. Technical details such as experimental setup, hyperparameter configuration, and implementation specifics are described in detail in Supplemental Appendix Implementation Details.
Datasets
We adopt the ESConv (Liu et al., 2021) datasets for evaluation. ESConv contains 38,365 utterances and 1,300 dialogs with eight support strategies. We follow the original dataset splits for training, validation, and testing. ESConv has established itself as the standard benchmark in the ESC field, with recent works including CauESC, hierarchical graph networks, and LLM-based approaches all utilizing this dataset for consistent and comparable evaluation. This widespread adoption ensures that our results are directly comparable to the current state-of-the-art and reflect the accepted evaluation standard in the research community. More details about ESConv are in Supplemental Appendix ESConv.
Metrics
Following established ESC evaluation protocols, we employ standard metrics designed to measure key dimensions of emotional support quality:
Accuracy (ACC) (Hastie et al., 2009) measures balanced performance across ESConv’s eight support strategies (questioning, restatement, reflection of feelings, self-disclosure, affirmation and reassurance, providing suggestions, information, others). This metric is particularly suitable for ESC evaluation as it assesses comprehensive support capabilities without bias toward specific strategies.
Perplexity (PPL) (Chen & Goodman, 1996) measures language modeling performance, with lower values indicating more natural response generation.
BLEU-n (Papineni et al., 2002) & ROUGE-L (Lin, 2004) assess linguistic quality and coherence of generated responses, which directly impact therapeutic effectiveness in emotional support contexts.
Distinct-n (J. Li et al., 2016) is especially important in emotional support, measuring response diversity that indicates personalized support capability rather than generic, template-based responses.
Baselines
BlenderBot-Joint (Liu et al., 2021): Blenderbots is an open-domain chatbot that is fine-tuned with Blended Skill Talk (Smith et al., 2020) to introduce personality, engagingness, and empathy. On this basis, the model is fine-tuned on the ESConv dataset.
KEMI (Deng et al., 2023): It focuses on the proactive aspect of ESC systems, which means ESC systems should provide not only empathy for comfort but also proactively assist in exploring and addressing their problems. To achieve this, knowledge from HEAL is gathered to generate mixed-initiative responses. In addition, KEMI can also be seen as GREEN without adaptive ResID retrieval.
PAL (Cheng et al., 2023): Dynamically models the persona and uses the information from the persona to provide personalized emotional support.
D2RCU (Xu et al., 2024): It introduces two approaches to provide emotional supportive responses. Firstly, dynamic demonstration retrieval with DPR retrieves relevant conversation pairs to provide personalized information. Secondly, Cognitive-Aspect Situation Understanding with COMET (Bosselut et al., 2019) extracts four cognitive relationships from given dialogs, introducing situation-aware information for the model.
Result
Automatic Evaluation
Table 1 Presents the comparison results for each evaluation metric. Our model demonstrates consistent improvements across key metrics that directly impact ESC quality.
Experimental Results on Automatic Evaluation Metrics..

The most significant improvement is observed in response diversity, where GREEN achieves 6.24 and 32.86 for Distinct-1 and Distinct-2, representing 25.6% and 25.4% improvements over the strongest baseline D2RCU (4.97 and 26.21). This enhanced diversity is particularly important in emotional support contexts, as varied responses prevent conversational monotony and demonstrate a nuanced understanding of individual emotional states. High diversity scores indicate the system’s capability to provide personalized support rather than generic, template-based responses.
In strategy prediction accuracy, GREEN achieves 38.8% compared to D2RCU’s 35.32%, representing a 9.8% relative improvement. In clinical contexts, such precision improvements can significantly impact therapeutic outcomes and user trust.
The improvement in BLEU-4 from 2.31 to 2.88 (24.7% increase) indicates enhanced linguistic coherence and more natural response generation. This suggests that GREEN generates emotional support responses that closely align with human language patterns.
Figure 4 illustrates the comparative top-n accuracy of predicted strategies across different models. Our proposed GREEN model consistently outperforms all baseline methods at every accuracy level, demonstrating robust effectiveness in selecting appropriate response strategies. Specifically, GREEN achieves an average improvement of 1.63% compared to the baseline, the closest-performing baseline.

The top-n accuracy of predicted strategies shows that GREEN consistently achieves the best performance.
Furthermore, GREEN shows notably superior performance relative to PAL and MISC, which also use persona and commonsense knowledge, respectively. These results show that GREEN enhances contextual awareness and strategic alignment in ESC.
Ablation Study
We conduct comprehensive ablation studies to systematically analyze the contribution of each component in GREEN. Using the ESConv dataset, we quantitatively evaluate component contributions, with results presented in Table 2.
Relative Performance, Full GREEN = 1.00.

Component Analysis
To verify the effectiveness of the ResID system, we compare against models without ResID. Results show that removing ResID causes ACC to drop from 38.8% to 30.2% (22% decrease), while Distinct-1 significantly decreases from 6.24 to 3.43 (45% reduction). This indicates that ResID-based generative retrieval is crucial for capturing subtle emotional context differences.
Using only generative retrieval (GenRetrieval Only) achieves relative ACC of 0.83 and BLEU-4 of 0.76, demonstrating basic effectiveness but limited performance compared to the full system. Using only MultiKG achieves high ACC (0.91) but significantly reduced diversity (Distinct- 1: 0.67, Distinct-2: 0.71), suggesting the importance of combining knowledge graph information with generative retrieval.
Analysis of Sinkhorn-Knopp constraints shows that unconstrained quantization maintains relatively stable performance (ACC: 0.88, BLEU-4: 0.84), confirming that balanced codebook usage plays an important role in improving retrieval quality.
Codebook Hyperparameters
We systematically analyze the impact of code length on model performance. As shown in Figure 5, optimal performance is achieved at code length 4 with ACC of 38.8% and BLEU-4 of 2.88. In our ResID structure, each code dimension represents different aspects of emotional support: dialog context, emotional state, support strategy, and specific response type. This 4-dimensional representation appropriately captures the complexity of emotional support. Single code (length 1) achieves only 26.1% ACC, showing 26.3% degradation. Code length 2 shows partial improvement (31.3%) but remains limited. Excessive length (8) results in 29.7% performance, confirming overfitting-induced degradation.
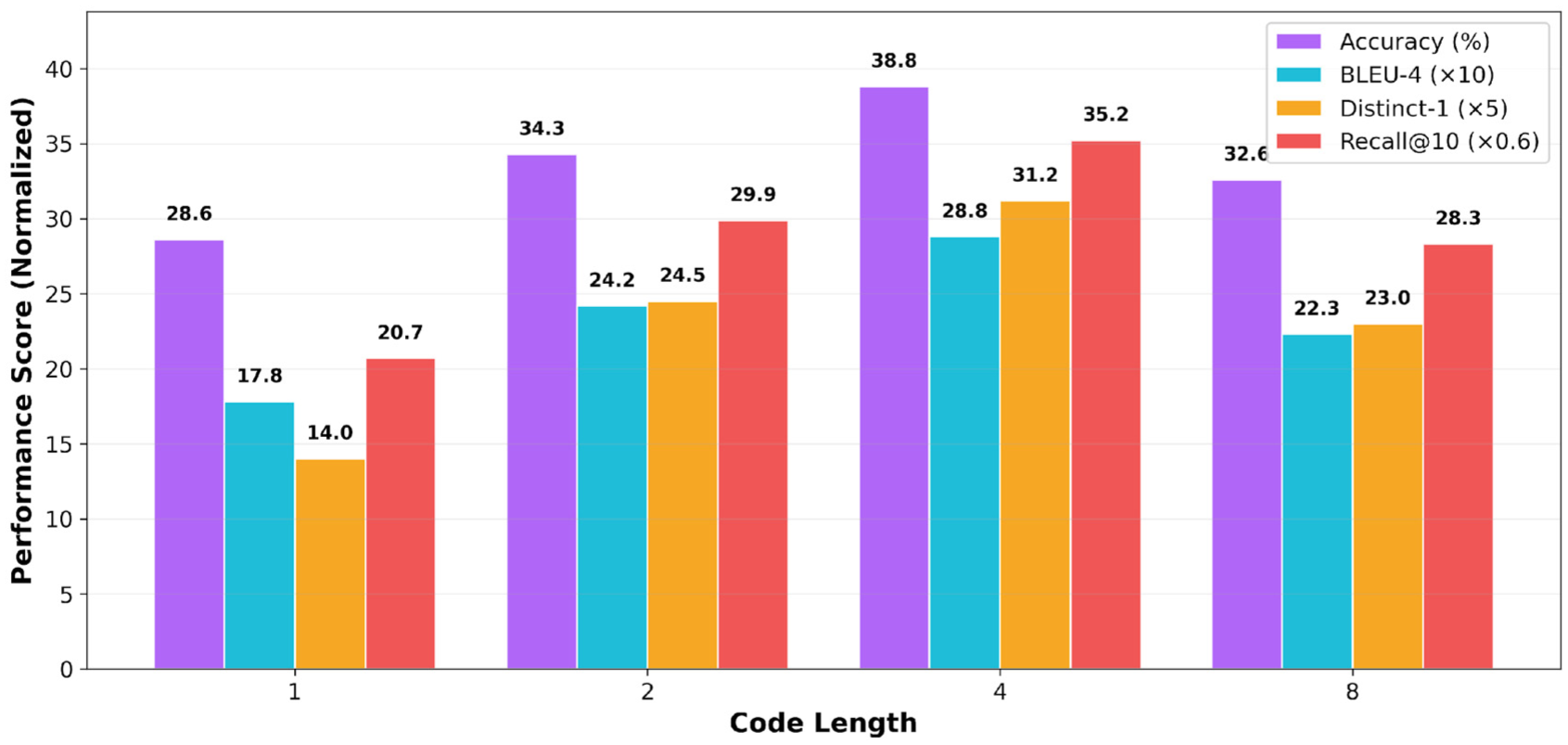
Impact of code length on model performance. Optimal performance is achieved at code length 4 (ACC 38.8%, BLEU-4 2.88), while excessive length causes overfitting.
Additional hyperparameter analysis including codebook size optimization, quantization method comparison, and loss component analysis are provided in Supplemental Appendix Details Ablation Study.
Human Evaluation
We conducted human evaluation following established ethical guidelines for research involving human subjects, with all participants providing informed consent and the right to withdraw at any time. We recruited five volunteers via crowdsourcing, all graduate students specializing in natural language processing with experience in dialog systems, to evaluate and compare our proposed model against the SOTA model. Given the sensitive nature of ESC, evaluators received training on recognizing potentially harmful or inappropriate responses, and clear protocols were established for flagging content that might require human intervention or professional referral.
We randomly sampled 100 dialogs from ESConv and compiled responses. Five annotators with experience in natural language processing and dialog systems evaluated the responses on a 5-point scale (1: Poor, 3: Moderate, 5: Excellent). Furthermore, to compare the responses directly, a pairwise A/B test was applied, during which the annotators were asked to select the best response or mark a tie if both responses were similar in quality.
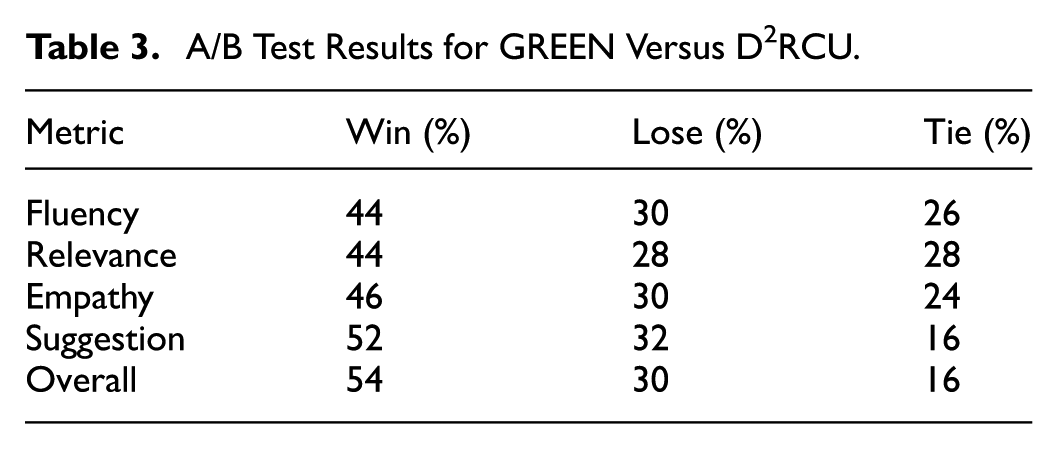
Table 3 presents the evaluation results. Our model significantly outperformed D2RCU, demonstrating its ability to comprehend seeker feelings and provide helpful suggestions. The highest scores in Fluency and Empathy support that our responses were grammatically correct and emotionally resonant, which enhances the coherence and effectiveness of the conversational flow. In the A/B tests, our model surpassed D2RCU in all metrics, with the most significant advantage in Suggestion quality (
A/B Test Results for GREEN Versus D2RCU.
Case Study
To demonstrate GREEN’s effectiveness, we compare responses between GREEN and the baseline model (D2RCU).
Contextual Understanding
In the analyzed case, GREEN accurately identifies the seeker’s core issue of “lack of communication” and directly addresses it in the response. While D2RCU provides general empathetic responses to loneliness, it shows limitations in specific problem recognition. GREEN’s explicit mention of communication difficulties demonstrates that the ResID system effectively identifies key dialog issues.
Personalized Suggestion Generation
GREEN utilizes specific information from dialog history (“children used to call frequently”) to provide tailored suggestions about reaching out to children first. This contrasts with D2RCU’s generic advice about online communities. The 52% win rate in suggestion quality validates this personalized approach.
Balance of Emotional Validation and Practical Solutions
GREEN validates the seeker’s emotions while providing actionable solutions, achieving 46% win rate in empathy and 54% in overall effectiveness. This balanced approach demonstrates comprehensive emotional support capability.
This case analysis empirically shows that GREEN transcends simple keyword matching to deeply understand conversational context and emotional nuances, providing personalized and practical emotional support. Detailed dialog examples are provided in Supplemental Appendix Detail of Case Study.
Conclusion
This work introduces GREEN, a unified generative-retrieval framework that couples retrieval and generation with ResID-based semantic identification, moving beyond embedding-index similarity toward a semi-structured semantic retrieval paradigm that reflects global conversational flow and latent affective needs. Significant gains in response diversity, content fidelity, and contextual alignment demonstrate GREEN’s capacity to capture subtle affective nuances and maintain consistent strategy selection, indicating practical potential to improve personalization, re-engagement, and dialog stability in real-world ESC. Finally, by embedding risk detection and human-in-the-loop escalation, cultural-linguistic sensitivity, explainability, and auditability across the lifecycle, GREEN outlines a path not only to higher metrics but also to a safer and more trustworthy ESC deployment in practice.
Limitation and Future Work
This study has three primary limitations. First, technical constraints in codebook quantization and clustering can lead to inconsistent ResID assignments, which in turn degrade retrieval stability and response consistency; more robust ResID induction and mapping are required. Second, evaluation is limited to ESConv and to English-language data, leaving open questions about generalizability across datasets and cultural-linguistic contexts. Third, current knowledge integration remains narrow in scope, constraining both retrieval precision and cultural appropriateness of responses; deeper coupling with large-scale, culturally-aware knowledge graphs is needed.
Future clinical validation will encompass controlled pilot studies with licensed mental health professionals to evaluate real-world therapeutic outcomes, including pre-post assessments of user emotional well-being, session engagement metrics, and longitudinal follow-up studies to measure sustained emotional improvement. These evaluations will follow established clinical research protocols with IRB approval and comprehensive informed consent procedures, ensuring ethical compliance in human subject research. For cross-cultural adaptation, we plan collaborative partnerships with mental health organizations across different linguistic and cultural contexts (Korean, English, Chinese) to develop culturally sensitive annotation standards an d evaluation rubrics. This includes establishing culture-specific emotional expression taxonomies, validating support strategy effectiveness across different cultural frameworks, and developing adaptive response generation mechanisms that account for cultural nuances in emotional support preferences. Bilingual mental health experts will co-design error classification systems and cultural appropriateness metrics to ensure responsible deployment across diverse populations. Robustness enhancement will involve systematic stress testing under varying conditions, including topic/style shifts, adversarial inputs, and low-resource scenarios, with institutionalized human-in-the-loop routing for high-risk cases. Methodologically, we will extend semantic codebooks to multilingual ResID induction and integrate large-scale, culturally-aware knowledge graphs to optimize retrieval precision and culturally appropriate response generation jointly.
Supplemental Material
sj-docx-1-sgo-10.1177_21582440251395922 – Supplemental material for GREEN: Generative Retrieval-Enhanced Emotional Support Conversations
Supplemental material, sj-docx-1-sgo-10.1177_21582440251395922 for GREEN: Generative Retrieval-Enhanced Emotional Support Conversations by Hayeon Yang, Jiheun Hong, Seongjin Jo, Jooyoung Lim and Hayoung Oh in SAGE Open
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the following funding sources: The Ministry of Science and ICT (MSIT), Korea, under the Graduate School of Metaverse Convergence Support Program (grant number: IITP-2025-RS-2023-00254129), supervised by the Institute for Information & Communications Technology Planning & Evaluation (IITP). The Ministry of Science and ICT (MSIT), Korea, under the Global Scholars Invitation Program (grant number: RS-2024-00459638), also supervised by the IITP. The Sports and Tourism R&D Program through the Korea Creative Content Agency (KOCCA), funded by the Ministry of Culture, Sports and Tourism in 2024, under the project titled “Development of game-based digital therapeutics technology for adolescent mental health (psychological and behavioral control) management” (grant number: RS-2024-00344893). Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No.RS-2025-25442569, AI Star Fellowship Support Program (SungkyunkwanUniv.)). Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No.RS-2025-25443884, Development of Human-Oriented Next-Generation Artificial General Intelligence (AGI) Technology based on EmbodiedVisionary AI Multi-Agents). “Regional Innovation System & Education (RISE)” through the Seoul RISE Center, funded by the Ministry of Education (MOE) and the Seoul Metropolitan Government (2025-RISE-01-018-04). “Regional Innovation System & Education (RISE)” through the Seoul RISE Center, funded by the Ministry of Education (MOE) and the Seoul Metropolitan Government (2025-RISE-01-018-05). This work was supported by KOITA grant funded by MSIT (No.S-2025-1855-000). Industry collaboration with Emotionwave (![]() ).
).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data used in this study (ESConv and other benchmark datasets) are publicly available and can be accessed from the respective repositories referenced in the article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.