
Abstract
A growing body of learner corpus research underscores the pivotal role of collocational competence in achieving advanced L2 proficiency. Verb–noun collocations have been identified as particularly challenging for L2 learners, largely due to their semantic opacity and combinatorial constraints. However, despite this importance and challenge, relatively little is known about how Turkish learners of English acquire and use verb–noun collocations across different proficiency levels. This study aims to investigate the production of verb-noun collocations by Turkish learners of English across three Common European Framework of Reference for Languages proficiency bands (A1-A2; B1-B2; C1-C2), focusing on their distribution, appropriateness, frequency in the British National Corpus. Also, collocational error types and patterns that persist across proficiency levels have also been examined. The analysis draws on data from the Cambridge Learner Corpus. Salient collocations were identified through frequency-based metrics (t-score and Mutual Information) and cross-referenced with the British National Corpus to assess native-likeness. In addition, collocational errors were manually annotated and classified by type. Findings suggest that Turkish learners of English as a foreign language often struggle with verb-noun collocations and produce incorrect collocations even at advanced level. The frequency of collocations decreases as the proficiency level increases, reflecting Turkish learners’ repetitive use of a limited set of verb–noun combinations at lower proficiency levels. In addition, learners mostly make verb-related (replacement, tense, form) and determiner errors that persist from A1 to C2 level. These results highlight the need for pedagogical interventions that explicitly target collocational development and underscore the value of learner corpus data in informing such approaches.
Plain Language Summary
In English, certain verbs and nouns are commonly used together, such as “make a decision” or “take a risk.” These combinations are called collocations. For people learning English as a foreign language, collocations are important because they make speech and writing sound more natural. However, many learners find them difficult to master. This study looked at how Turkish learners of English use verb–noun collocations, focusing on how their usage changes as they become more advanced. The Turkish subcorpus of the Cambridge Learner Corpus which contains exam scripts written by Turkish EFL learners at different proficiency levels, ranging from beginner (A1–A2) to advanced (C1–C2) was used as data. Learners’ collocation uses were compared to those found in a large database of native English (the British National Corpus) to see how close and distinct learners’ choices were to native usage. The study also examined the kinds of mistakes learners made while producing collocations. The results showed that Turkish learners often use collocations incorrectly, even at higher proficiency levels. While beginners and intermediate learners produced more collocations overall, advanced learners used fewer, perhaps because they avoided using structures they were less confident about. The most common problems involved choosing the wrong verb, using the wrong verb form or tense, or making errors with determiners (e.g., using “do a mistake” instead of “make a mistake”). These errors appeared across all levels. Learners showed little progress with collocations as their overall English improved, partly because they translated word-for-word from Turkish. These mistakes arise both from the complexity and unpredictability of collocations in English and from external factors such as limited exposure to authentic language or differences in educational background. These findings suggest that simply advancing in general language skills does not automatically lead to mastery of collocations.
Keywords
Introduction
The pivotal role of multiword units, including collocations, idioms, and other formulaic sequences, has long been firmly established in both theoretical and empirical accounts of second language acquisition. Scholars have also highlighted the challenges involved in learning these expressions, particularly regarding their frequency, transparency, and native-like use. Since Brown’s (1974) foundational work, this area has continued to attract scholarly attention, as reflected in Granger’s (1998) research on learner corpora, Sinclair’s (1991) idiom principle, and Wray’s (2002) exploration of formulaic language.
Multiword units constitute a core component of lexical competence in L2 learners, serving both a psycholinguistic and communicative function. They facilitate automatic language processing by allowing high-frequency word combinations to be retrieved as unified wholes (Howarth, 1998; Nattinger & DeCarrico, 1992; Wray, 2002), thereby contributing to increased fluency, idiomaticity, and pragmalinguistic appropriateness. As such, they are indispensable not only for efficient real-time processing but also for achieving stylistically appropriate, context-sensitive language production.
The mastery of the idiomatic patterns is frequently cited as a critical threshold distinguishing intermediate learners from advanced users (Thornbury, 2002). Research has demonstrated that the ability to produce native-like multiword combinations, particularly collocations, marks a shift toward more proficient language use, enhancing both accuracy and communicative efficacy (Boers et al., 2006; Wray, 2002).
Among these patterns, verb–noun collocations are of particular interest due to their inherent semantic constraints and limited substitutability, which make them especially difficult for L2 learners to acquire (Nesselhauf, 2005). Verb–noun collocations have been identified as particularly challenging for L2 learners, largely due to their semantic opacity and combinatorial constraints (Peng, 2016). For native speakers, collocations such as break the law, violate the law, and violate someone’s privacy are deeply entrenched in the mental lexicon and accessed holistically (Pawley & Syder, 1983). In contrast, L2 learners, particularly in EFL contexts, often fall back on literal or L1-influenced constructions (e.g., break someone’s privacy), resulting in semantically deviant or stylistically marked output. The acquisition of collocational knowledge not only reduces cognitive load during production but also enables more accurate alignment with native speaker norms in terms of register and stylistic naturalness (Conklin & Schmitt, 2008; Nattinger & DeCarrico, 1992; Wray, 2002).
As Lewis (2000, p. 15) succinctly puts it, “Fluency relies on the internalization of a substantial repository of fixed or semi-fixed prefabricated items, which serve as the basis for any subsequent linguistic innovation or creativity.” Numerous studies have corroborated this view, underscoring collocational competence as one of the primary distinguishing features between native and non-native speaker performance (Aston, 1995; Fillmore, 1979; Kjellmer, 1991). Errors in collocational usage remain one of the most salient markers of non-nativeness, often persisting well beyond the intermediate stages of language development. As Korosadowicz-Strużyńska (1980, p. 115) aptly observes, “errors in the use of word collocations surely add to the foreign flavor in the learner’s speech and writing and, along with faulty pronunciation, they are the strongest markers of “an accent.”
The use of corpora and corpus analysis techniques enable researchers to gather evidence of both accurate and faulty collocations, as well as instances of underuse or overuse by contrasting learner production with established native-speaker norms. Such comparative analyses allow for the identification of overuse, underuse, and misuse patterns, thereby offering a more nuanced understanding of the lexical behaviors that distinguish non-native from native writers.
Verb–noun collocations are widely acknowledged as one of the most challenging aspects of second language acquisition, mainly because of their semantic opacity and strict combinatorial constraints. Mastery of such collocations is crucial for achieving natural and native-like proficiency, yet learners often struggle with their accurate use. Despite this importance and difficulty, research on Turkish learners of English has not sufficiently explored how verb–noun collocations are acquired and used across different proficiency levels. This lack of evidence limits the understanding of the developmental trajectory of collocational competence in this learner group. Addressing this gap, the present study investigates the production of verb–noun collocations by Turkish learners of English at three Common European Framework of Reference for Languages (CEFR) proficiency bands (A1–A2; B1–B2; C1–C2). Specifically, it examines their distribution, appropriateness (native-likeness), frequency in comparison with the British National Corpus (BNC). The most common collocational errors and error patterns that persist across levels have also been investigated. The analysis is based on Turkish subcomponent of the Cambridge Learner Corpus (CLC), which provides a large-scale collection of learner writing.
By comparing the three learner groups, A1-A2; B1-B2; C1-C2, according to Common European Framework of Reference for Languages (CEFR) to one another, the study also aims to uncover developmental patterns in collocational competence. In this regard, the research is guided by the following questions:
What is the frequency distribution of verb-noun collocations across CEFR levels A1-C2?
To what extent do Turkish EFL learners produce appropriate verb-noun collocations in their writing?
How frequent are these collocations in British National Corpus (BNC) across proficiency levels?
What are the most frequent error types associated with these constructions?
Which collocation errors, if any, persist across proficiency levels from A1 to C2??
Review of Literature
Definition of Collocations
The term collocation has been variously defined within the literature, reflecting a continuum between phraseological and statistical traditions. Aisenstadt (1981, p. 53) characterizes collocations as “combinations of two or more words whose components are used in a non-idiomatic way, following certain structural patterns, and restricted in their commutability by grammatical and semantic valency and usage.” This definition underscores the semi-fixed nature of collocations: they are neither entirely free nor wholly fixed, exhibiting a degree of syntagmatic constraint. Similarly, Cowie (1988) distinguish collocations from other multiword units such as idioms, emphasizing their partial transparency and restricted substitutability.
Sinclair (1991) offers a more distributional perspective, defining collocations as “the occurrence of two or more words within a short space of each other in a text” (p. 170). This spatial parameter, or span, typically comprises four words to the left and right of a central lexical item or node, allowing for the identification of statistically salient co-occurrences.
From a methodological standpoint, two broad approaches have predominated. The first, grounded in phraseology, focuses on the semantic and structural properties of multiword combinations, typically categorizing them along a continuum ranging from free combinations to fixed idioms (Nesselhauf, 2005). The second adopts a frequency-driven, statistical framework, wherein collocations are identified based on the strength of association between constituent items, as evidenced through large corpus data (Lee & Shin, 2021; Liu & Afzaal, 2021; Nguyen & Webb, 2016). While the phraseological approach allows for fine-grained semantic analysis, it suffers from subjectivity and labor-intensive validation. In contrast, statistical methods enable large-scale analysis but risk extracting function word sequences with little pedagogical value (e.g., and the, of the) if not filtered appropriately (Nizonkiza, 2017; Szudarski & Carter, 2016).
An increasing number of studies now seek to reconcile these traditions by integrating both frequency-based association measures such as t-score, z-score, and Mutual Information (MI) and native-speaker judgment (Durrant & Schmitt, 2009; Gablasova et al., 2017; Granger & Bestgen, 2014). Despite such methodological advances, the identification and validation of native-like collocations in learner corpora remains a formidable challenge. Phraseological evaluations require subjective and context-sensitive interpretation, while frequency-based assessments demand computationally intensive comparisons against large native-speaker reference corpora.
Moreover, existing literature has disproportionately focused on intermediate and advanced learners, with limited attention paid to beginning-level language users (Siyanova-Chanturia, 2015). Similarly, large-scale, proficiency-stratified learner corpora remain underutilized, despite their potential to shed light on developmental trajectories in collocational competence across CEFR bands.
Present study adopts a phraseological approach to collocations, drawing upon the foundational work of Aisenstadt (1981), Cowie (1981), and Mel’čuk (1998), as well as subsequent scholars operating within this framework (e.g., Gläser, 1998; Howarth, 1998; Nesselhauf, 2005). Within this tradition, collocations are conceptualized as recurrent lexical combinations that are semantically transparent yet characterized by restricted lexical co-occurrence. As Nesselhauf (2005, p. 24) asserts, “collocation is considered the co-occurrence of words at a certain distance,” wherein the relationship between constituents is governed by lexico-grammatical constraints rather than idiomatic opacity.
This study adopts Nesselhauf’s (2005) operational definition of verb–noun collocations, focusing on combinations in which the verb selects a limited range of nouns either due to its semantically specific sense (Criterion 1) or because it fails to combine with all syntactically acceptable noun partners (Criterion 2). Hence, while fully compositional expressions such as read a newspaper do not qualify, combinations like take a picture, where the verb take displays restricted lexical selectivity, are treated as prototypical collocations. Applying these criteria to learner data from the Cambridge Learner Corpus (CLC) ensures the identification of multiword units that exhibit the kinds of substitutability constraints typical of entrenched native-speaker usage. By drawing on Nesselhauf’s (2005) taxonomy, the methodology is anchored in a solid theoretical framework of multiword sequences and is equipped with precise operational criteria for identifying learner errors in collocation choice. This study aims to investigate verb + noun collocations of Turkish EFL learners. In the analysis, all verb–noun combinations were analyzed regardless of the noun’s syntactic role (e.g., object, complement, or adverbial) and irrespective of the presence of any additional clause elements. Also, combinations (not necessarily collocations) such as wage war (VO) and cope with a problem (VPO), combinations such as look out of the window (VA), call sb. a genius (VOC), take sth. into consideration (VOPO) or force teachers to+inf (VO+ to +inf) have also been considered. So, the combinations that have been taken into account in the present study is as follows:
Verb + Object (VO) (e.g., wage war)
Verb + Prepositional Object (VPO) (e.g., cope with a problem)
Verb + Adverbial (VA) (e.g., look out of the window)
Verb + Object + Complement (VOC) (e.g., call someone a genius)
Verb + Object + Prepositional Object (VOPO) (e.g., take something into consideration)
Verb + Prepositional Phrase (VPP) (e.g., go out of control)
(Nesselhauf, 2005, p. 47-48)
Previous Studies on Collocations
In one of the earliest cross-linguistic investigations, Kaszubski (2000) analyzed frequently occurring verbs such as be, have, make, take, do, and get and their collocational patterns across multiple L2 English corpora, including those of Polish, Spanish, and French learners, in addition to a native-speaker corpus. His findings revealed systematic overuse of certain collocations by learners and a corresponding underuse of more idiomatic, native-like combinations, thereby illustrating the tendency of learners to rely on a limited repertoire of collocational structures.
Granger (1998), in her seminal study on the use of -ly intensifier + adjective combinations in academic writing, compared advanced French EFL learners to native English writers. She distinguished between two functional types of intensifiers: maximizers (e.g., absolutely, totally) and boosters (e.g., deeply, highly). While learners exhibited usage rates of maximizers comparable to those of native speakers, their use of boosters was significantly lower. Moreover, when these combinations were subjected to acceptability judgments by both native and non-native informants, the latter group demonstrated a marked insensitivity to collocational salience. Granger concluded that, although advanced learners can produce collocations, they tend to avoid or misuse native-like expressions, resorting instead to atypical or marginal combinations.
In a similar vein, Altenberg and Granger (2001) examined the lexical behavior of the verb make across three corpora: French learners, Swedish learners, and native English speakers. They aimed to identify cross-linguistic differences and native-like norms in collocational usage. While learners overused some collocations constructed with core verbs like be, have, make, etc. or particular amplifiers such as very, completely, highly, strongly, they frequently failed to employ native-like combinations. Learners also produced a notable number of collocational errors even though their grammar and individual word choices were typically accurate.
Nesselhauf (2005), working with the German component of the International Corpus of Learner English (ICLE), conducted one of the most comprehensive studies on verb–noun collocations. Analyzing approximately 2,000 collocational instances in a 154,191-word learner corpus, she reported that nearly one quarter were erroneous, with an additional third considered questionable by expert raters. Importantly, around 50% of the errors were attributed to L1 influence. Intriguingly, the error rate remained unaffected by dictionary consultation or time constraints, suggesting either that learners failed to recognize collocational errors or that reference tools did not provide adequate support. Nesselhauf concludes that the acquisition of collocations remains one of the most persistent challenges for L2 learners, irrespective of their general proficiency.
In another study, Siyanova and Schmitt (2008) first extracted every adjective–noun combination from Russian learners of English and native speakers, then assessed learners’ productive use by counting occurrences of frequent collocations. They also administered psycholinguistic judgment tasks, requiring participants to classify presented collocations as nativelike or atypical and measuring response times. They found that advanced English learners produced a comparable number of adjective–noun collocations to native speakers, with roughly half of these combinations qualifying as frequent collocations in both groups. However, when asked to judge whether presented combinations were nativelike or atypical, learners performed significantly worse than natives. In other words, despite matching native speakers in productive output, advanced learners still struggled to recognize and evaluate collocational patterns accurately, often accepting or producing atypical combinations.
Durrant and Schmitt (2009) compared collocational usage in academic essays written by native and non-native English speakers by analysing premodifier–noun word pairs extracted from a corpus of longer texts from both groups. Using frequency-based statistical measures, specifically t-scores to gauge high-frequency pair strength and Mutual Information (MI) to identify semantically tight but less frequent combinations, the researchers categorized each word pairing according to collocational strength. Results indicated that native writers employed a larger proportion of low-frequency, high-MI collocations, reflecting a broader and more nuanced lexical repertoire, whereas non-native writers relied predominantly on high-frequency collocations with elevated t-scores and underused high-MI pairs. Moreover, non-native writers demonstrated a tendency to repeat a narrow set of favored collocations, suggesting a conservative approach to lexical selection.
Laufer and Waldman (2011), analyzing 759 argumentative essays from the Israeli Learner Corpus of Written English (ILCoWE), undertook a large-scale comparison with the Louvain Corpus of Native English Essays (LOCNESS). Their investigation centered on verb–noun collocations across proficiency levels (basic, intermediate, and advanced), with attention to both quantitative usage and qualitative accuracy. Findings demonstrated a marked underuse of verb–noun collocations among all learner groups relative to the native-speaker baseline. While advanced learners attempted a greater number of collocations, this increase did not correspond to improved accuracy. On the contrary, roughly one-third of collocational attempts were erroneous, and error rates persisted across proficiency levels. Interestingly, advanced learners exhibited higher error rates not because of weaker competence but because of their increased willingness to attempt more collocations, suggesting that the acquisition of collocational accuracy does not necessarily develop in parallel with increased output.
In another study, Gao et al. (2019) investigated the use of verb–noun collocations in the written productions of Chinese EFL learners, drawing on data from the TECCL (Ten-thousand English Composition of Chinese Learners) corpus. The study included compositions from both middle school and university-level students. Collocational instances were manually extracted and subjected to a rigorous validation process incorporating dictionary references, native-speaker judgments, and corpus-based benchmarks. Each collocation was then categorized according to its structural and functional properties. Results revealed an accuracy rate of 79% among middle school learners and 83% among university students, indicating modest gains with increased educational exposure. The most recurrent errors stemmed from the inappropriate selection of either the verb or the noun constituent, with L1 transfer and lexical insufficiency in the L2 identified as primary explanatory factors.
Furhermore, Boone et al. (2023) tested 50 Dutch native speakers learning German on their productive knowledge of 35 target collocations at the end of each academic year using form-recall tasks and mixed-effects logistic regression; predictors included L1–L2 congruency, corpus frequency, association strength (MI), imageability, productive vocabulary size, and a five-month study-abroad stint. Participants’ accuracy rose from about 36% in year 1 to 55% in year 3, with congruent collocations initially almost 12 times more likely to be recalled correctly but showing a shallower learning curve over time, whereas incongruent items, though harder at first, were learned more steeply. Productive vocabulary size modestly boosted acquisition odds, while frequency, MI, imageability, and short-term study abroad had no significant effects.
Likewise, Du et al. (2022) worked on 18,000 EFL essays from the The EF-Cambridge Open Language Database (EFCAMDAT) at three language proficiency. They extracted ‘make/take + noun’ sequences, of which 2,501 were identified as collocations; each collocation’s noun was then annotated for semantic field (USAS), difficulty level (EVP), and orthographic length (LEN). Results of the analyses showed that beginners predominantly used concrete, everyday collocations, while advanced learners favored abstract and social/psychological fields. The findings also indicated that as learners progress, they combine common verbs with semantically richer, more challenging, and longer noun collocates.
In a more recent study, Akbaş and Yükselir (2024) compared adjective–noun combinations in a learner corpus of 341 Turkish EFL essays (TUWE, ~270 K words) against a native-speaker corpus of 325 K words (LOCNESS), focusing on seven high-frequency adjectives (good/bad, positive/negative, important/significant/crucial) and their immediate noun collocates. By comparing these collocations, they found that L2 writers produced a much wider range of adjective–noun strings (742 vs. 191 in L1) but only eight of 57 L2 strings matched conventional L1 usage; the vast majority were unconventional, often reflecting direct L1 transfers.
The reviewed studies converge on the conclusion that collocations represent a persistent area of difficulty for L2 learners, irrespective of their native language, length of instruction, or proficiency level. While learners may demonstrate receptive familiarity with certain collocations, their productive command often remains limited. Research consistently shows that collocational competence develops at a slower pace than vocabulary breadth and that the principal challenge lies not in recognition, but in accurate deployment. Given their centrality to idiomaticity and fluency, collocations merit greater pedagogical focus within the broader trajectory of lexical acquisition in second language learning.
Methodology
Corpus
The present study draws on the Cambridge Learner Corpus (CLC), which constitutes the principal data source for the analysis. The CLC is currently the most extensive annotated corpus of learner English, comprising over 55 million words extracted from more than 200,000 examination scripts compiled by Cambridge University Press and Cambridge English Language Assessment since 1993. These scripts represent learners from 217 countries or territories, covering 148 distinct first-language backgrounds. All essays have been fully transcribed, preserving every learner error, and a substantial proportion of the corpus has been manually annotated using a fine-grained tagging scheme comprising 88 error categories specifically devised for the CLC.
For the purposes of this research, a sub-corpus of texts produced by Turkish learners of English was extracted, thereby enabling quantitative analyses of verb–noun collocations within a richly annotated, large-scale learner corpus. The breakdown of Turkish EFL learner sub-corpora may be seen in Table 1 below.
Breakdown of Turkish EFL Learner Sub-corpora.
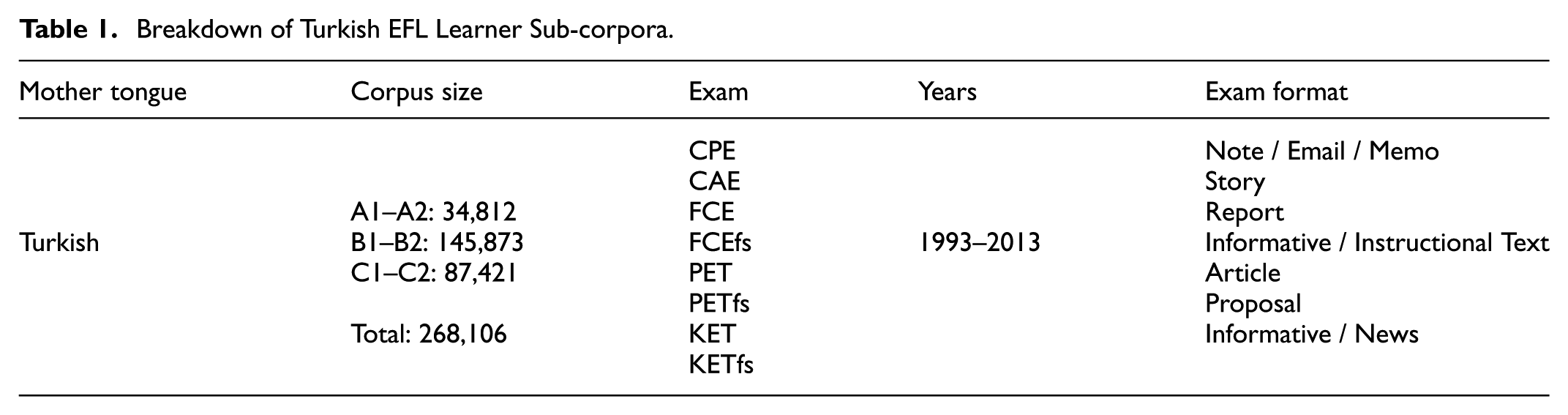
The Turkish sub-corpus of the Cambridge Learner Corpus (CLC) comprises a total of 268,106 words, stratified according to CEFR proficiency levels (Council of Europe, 2001). 34,812 words at A1–A2, 145,873 words at B1–B2, and 87,421 words at C1–C2. All texts were collected between 1993 and 2013 from examination scripts of Turkish EFL learners, encompassing eight different Cambridge English assessments (CPE, CAE, FCE, FCE First Series, PET, PET First Series, KET, and KET First Series). Each script was elicited under standardized test conditions with prompts corresponding to a variety of written task types including notes, emails, memos, stories, reports, informative or instructional texts, articles, proposals, and news-style compositions. This comprehensive dataset allows for a granular examination of verb–noun collocation use across proficiency bands, while controlling for task type and exam context.
SketchEngine: Corpus Management and Analysis Tool
The corpus used in this study, the Cambridge Learner Corpus (CLC), is available in Sketch Engine under a special agreement with Cambridge University Press. All corpus queries and data extraction procedures in the present study were conducted using Sketch Engine, a state-of-the-art corpus management and analysis platform developed by Lexical Computing Ltd. Since its inception in 2003, Sketch Engine has served as a robust tool for the interrogation of large-scale corpora through linguistically-informed search algorithms and customizable query protocols. The system integrates three core components: Manatee, a back-end corpus indexing and database engine; Bonito, a web-based query interface facilitating the execution of complex search strings; and Corpus Architect, a utility for corpus compilation and metadata management.
The Cambridge Learner Corpus (CLC), the primary data source for this study, is accessible via Sketch Engine under a bespoke licensing agreement with Cambridge University Press. All linguistic searches and retrieval operations were performed using Corpus Query Language (CQL), a regular-expression-based syntax enabling highly granular pattern identification within annotated corpora.
Specifically, the Wordlist function was employed to extract the most frequently occurring noun types in the Turkish sub-corpus. Subsequently, the Keywords function was used to isolate verb–noun collocations, based on predefined co-occurrence criteria, which were then subjected to further statistical analysis using association measures described below.
MI Score and T-score
Collocations extraction involved computing association measures to quantify collocational strength. These metrics identify word pairs that occur together with a probability exceeding chance, as described by Manning and Schütze (1999). Each measure compares the observed co-occurrence frequency of a candidate collocation with its expected frequency and distinguish genuine collocations from random co-occurrences. The two most prevalent association measures in lexicography are the t-score and Mutual Information (MI) (Evert, 2004). However, these measures privilege different types of word pairs: t-scores tend to surface very frequent collocations, whereas MI highlights less common combinations whose constituent words rarely appear independently (Stubbs, 1995). For example, high-frequency pairs such as good example, long way, and hard work receive elevated t-scores but modest MI values, while semantically tighter yet infrequent pairs like ultimate arbiter, immortal souls, and tectonic plates exhibit the inverse pattern. To capture both high-frequency and semantically salient collocations, both t-score and MI have been employed in the present study.
In line with established conventions, threshold values of a t-score ≥ 2 and/or an MI score ≥ 3 have been proposed as minimum criteria for identifying collocational relationships (Stubbs, 1995). According to Hunston (2002), an MI score of 3 or above is often taken to indicate a significant collocation threshold. These criteria serve as the baseline for identifying verb–noun pairings as statistically meaningful collocations within the Turkish learner sub-corpus.
Identification of Errors in the Collocations
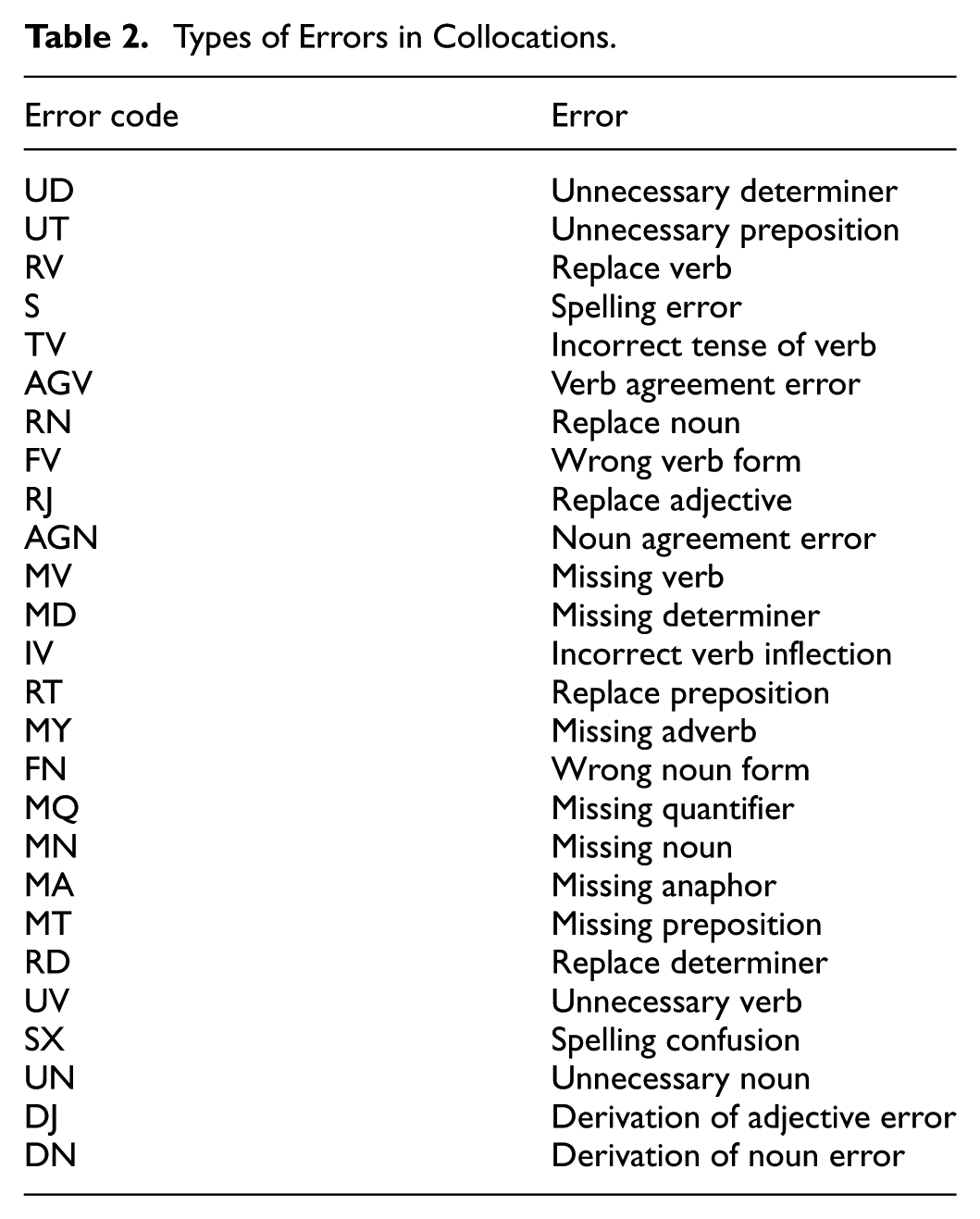
Error identification in the present study draws upon the error-annotation schema developed for the Cambridge Learner Corpus (CLC), a system designed to capture the full spectrum of interlanguage deviations in learner production (Cambridge University Press, 2014). All verb–noun collocational errors were retrieved through corpus queries conducted in Sketch Engine and subsequently classified according to this standardized taxonomy of error codes.
Table 2 provides a comprehensive overview of the error types observed in the dataset. These include both morphosyntactic and lexico-grammatical deviations, encompassing errors in verb selection, tense, agreement, word formation, and determiner/preposition usage, among others. A total of 26 distinct error categories were identified in Turkish EFL learners’ use of verb–noun collocations.
Types of Errors in Collocations.
To illustrate the application of this classification framework, Table 3 presents examples of selected error types extracted from learner scripts. These annotated instances demonstrate the nature of the deviation and the corrected form, highlighting the most salient error categories.
Type of Errors and Examples.

Note. Bold words indicate the errors and corrections.
This typology enables the systematic identification of error patterns in learner collocational usage and facilitates the fine-grained analysis of error persistence across proficiency levels. The annotated corpus thus serves not only as an empirical foundation for learner corpus research but also as a pedagogical resource for understanding recurrent lexico-grammatical difficulties in verb–noun collocations.
Procedure
The analytical procedure consisted of several successive stages aimed at identifying, validating, and categorizing verb–noun collocations produced by Turkish EFL learners across three CEFR-aligned proficiency bands (A1–A2, B1–B2, C1–C2).
As a preliminary step, the Wordlist function of Sketch Engine was employed to extract the most frequently used nouns across the Turkish subcorpus of the Cambridge Learner Corpus (CLC). The top 20 nouns, ranked by relative frequency, are presented in Table 4. These nouns were selected on the premise that their high frequency in learner writing suggests familiarity not only with their meanings but also with their collocational behavior.
The Most Frequent Nouns in Turkish Learner Corpus.

The list of words received consisted of high-frequency words (e.g., friend, people, time, day, house…etc.). Selecting the high frequency nouns was based on the assumption that Turkish EFL learners know not only the meaning of these words but also their usage, including their collocations.
After the noun forms were extracted, the concordances of these nouns were created in the Keywords function of SkethcEngine so that verb-noun combinations could be identified and extracted. Threshold values of a t-score ≥ 2 and/or an MI score ≥ 3 have been utilized as minimum criteria for identifying collocations. In addition, collocations that have a minimum frequency of 5 and occur at least 3 different texts have been selected to enhance validity and mitigate text-dependent idiosyncrasies. Manual post-processing was conducted to eliminate redundant, anomalous, or grammatically implausible pairings.
In the next step, two types of sources were used to determine the degree of acceptability of the combinations that had been extracted from the corpus: dictionaries and British National Corpus (BNC). Two reference dictionaries were consulted to assess the acceptability of the extracted combinations:
The BBI Dictionary of English Word Combinations (Benson et al., 2009)
Longman Collocations Dictionary and Thesaurus (6th Edition).
A similar procedure of verification of collocations was used by Barfield (2007), Nesselhauf (2005), Wang and Shaw (2008) and Laufer and Waldman (2011). After checking the dictionaries, the structures were also consulted to the BNC which contains 100 million words, to determine the frequency band of each collocation. Using the BNC frequency information, we split the collocations into five frequency bands:
Band 0: Not attested in BNC
Band 1–5: Very low frequency
Band 6–20: Low frequency
Band 21–100: Moderate frequency
Band >100: High frequency
All the combinations that did not occur in any of the dictionaries or BNC were categorised as non-attested. Once the entire learner corpus had been examined, each proficiency-level subcorpus was independently analyzed to permit comparison of collocations produced by learners. And lastly, erroneous collocations have been identified, classified and traced according to CEFR levels. Persistent errors from A1 to C2 proficiency level have also been identified.
Findings
RQ1. What Is the Frequency Distribution of Verb–Noun Collocations Across CEFR Levels A1-C2?
The distribution of collocations produced by Turkish EFL learners at three proficiency bands has been provided in the table below. To allow meaningful cross-level comparisons, raw frequencies have been normalized per 100,000 words (Table 5).
The Frequency of Collocations According to Proficiency Bands.

As the normalized frequencies indicate, collocation use diminishes progressively with increasing proficiency. A1–A2 learners produced the highest normalized frequency of verb–noun collocations (7,009 per 100,000 words), followed by B1–B2 learners (4,620), while C1–C2 learners produced the fewest (2,379). This downward trend is notable, as it challenges the commonly held assumption that collocational density increases with proficiency, potentially reflecting greater caution or lexical selectivity among more advanced learners. The reduction observed at higher levels does not indicate weaker collocational competence; rather, advanced learners shift toward more accurate, discourse-level phraseology.
To further illuminate learner performance, the study examined the proportion of correct versus erroneous collocation uses at each level. The results are displayed in Table 6.
Correct and Erroneous Uses of Collocations Across Levels.

The data reveal a gradual decline in collocational error rates with increasing proficiency. While 22.5% of the collocations at A1–A2 were erroneous, this proportion decreased to 20.7% at B1–B2 and further to 15.8% at C1–C2. Despite the relatively small size of the C1–C2 subcorpus, the downward trajectory in error rates appears consistent, supporting the view that collocational accuracy improves over time. Nevertheless, across the entire corpus, approximately one in five collocations (20.2%) was used inaccurately, underscoring the persistent challenge collocations pose for L2 learners.
RQ2. To What Extent Do Turkish EFL Learners Produce Appropriate Verb–Noun Collocations in Their Writing?
Following the identification of correct and erroneous verb–noun collocations, all correct instances were subjected to a validation process using two reference sources: (1) The BBI Dictionary of English Word Combinations and The Longman Collocations Dictionary and Thesaurus, and (2) the British National Corpus. Table 7 summarizes the number of collocations confirmed by these sources.
The Number of Collocations Found in Either One of the Dictionaries or the BNC.

As shown in Table 7, of the 898 collocations deemed correct, 114 (12.7%) could not be found in either the dictionaries or the BNC. The remaining 784 collocations (87.3%) were thus validated as appropriate according to native-like norms. The 114 unconfirmed combinations were further analyzed and are listed in Table 8, categorized by Common European Framework of Reference for Languages level.
Collocations That Do Not Appear in Either of the Dictionaries.

Note. The common phrases across levels have been indicated in bold in the table.
According to the table, the recurrent combination see places appear across all three proficiency bands. Most non-attested combinations reflect literal translations from Turkish (e.g., tell about my house), semantically vague or unidiomatic pairings (e.g., create people), or misuse of otherwise frequent verbs in non-canonical syntactic environments (e.g., film a day). Examples drawn directly from the corpus illustrate these phenomena:
(1) 583052_2 <s> It has been a while since we last saw each other and I have really
(2) 2791133_2 <s>I love designing the houses and
These examples underscore the learners’ tendency to generate semantically comprehensible but pragmatically marked or culturally unnatural combinations, which may not trigger correction in traditional grammar instruction but signal clear collocational deviance to native speakers.
To further evaluate the extent to which Turkish EFL learners use native-like collocations, Table 9 presents verb–noun combinations produced by learners that were not found in the British National Corpus, thus indicating a lack of attestation in standard native-speaker usage.
Collocations That Do Not Appear in the BNC.

Note. The common phrases across levels have been indicated in bold in the table.
Bolded items in the original table reflect collocations recurring across multiple Common European Framework of Reference for Languages levels, suggesting long-term persistence of certain erroneous or non-native-like expressions. Learner data at A1–A2 reveal overgeneralized, literal translations of Turkish phrasal patterns (e.g., bring sb. to house, study for school), while also reflecting dependence on concrete, everyday topics (e.g., love phone, help with sports). Representative corpus examples include:
(3) 2606135_3 <s>You can say that you have to
(4) 2652417_9 <s>My dad can
In both B1–B2 and C1–C2, learners continue to employ non-attested collocations (e.g., afford a computer, cherish the things, benefit life), many of which signal increased lexical ambition but persistent deviation from conventional usage. These are often unidiomatic extensions of otherwise legitimate words and grammatical patterns:
(4) 2606574_2 <s>A TV company came and
(5) 2660091_9 <s>You can
The list of collocations that failed to appear in both the dictionaries and British National Corpus, thus being doubly unattested, is provided in Table 10.
Collocations Absent from Both Dictionaries and BNC.

As can be seen from the table, unique collocations of Turkish EFL learners are observed such as study for school, tell about life, seek free time, learn from the letter, etc. At A1–A2, only five literal transfers (e.g., “Bring phone,”“Help with sports”) appear, reflecting basic L1 interference. In B1–B2, thirteen non-attested sequences (e.g., “Afford a computer,”“Run away from life,”“Learn from the letter”) emerge, indicating that intermediate learners still rely on unidiomatic formulas despite expanding their verb–noun repertoire. By C1–C2, only five items remain (e.g., “Arrange place,”“seek free time”), suggesting some consolidation but persistent non-native patterns at higher proficiency. Some examples from the corpus may be seen below:
(7) 1803337_1 <s>Therefore, I would agree with young people who
(8) 760342_3 but I couldn't find it than I decided to
In the literature, an effective method for assessing native-like collocations in addition to appropriateness involves checking if identical word combinations appear with high frequency of >6 in a native-speaker corpus, BNC; when they do, it is assumed that they constitute native-like collocations. That’s why, instances that appeared with a frequency of 6 and above in the BNC have been considered as native-like collocations, the numbers of which may be seen below (Table 11):
Learner Collocations with a BNC Frequency of >6 and MI >3.

Accordingly, 579 out of 784 validated collocations were found to be both statistically significant and attested at native-like frequency levels in the BNC. This indicates that 73% of the verb–noun combinations used by Turkish EFL learners in this dataset demonstrate native-like qualities, reflecting a considerable degree of lexical competence. Nevertheless, the remaining 27% represent an area of concern in terms of collocational accuracy and idiomaticity.
RQ3. How Frequent Are These Collocations in British National Corpus (BNC) Across Proficiency Levels?
The collocations were checked in the BNC to reveal the frequencies according to five frequency bands: 0 (failed to appear in the BNC), 1–5, 6–20, 21–100, and <100 occurrences. The distribution of these collocations on the basis of their BNC frequencies have been provided below.
As shown in Figure 1, 4.2% of the learner collocations (n = 33) were completely absent from the BNC (Band 0), suggesting non-native or highly idiosyncratic usage. Examples of these collocations include create people, study part-time, learn the time, rest for a week. Some of the examples from the corpus are as follows:
(9) 573337_2 <s>I want to
(10) 766128_3 <s>I told her that I wanted to

Distribution of learner collocations on the basis of their BNC frequency band.
A further 22.1% of collocations fell into the 1–5 frequency range, and 9.1% appeared between 6–20 times in the BNC—both ranges typically considered low-frequency or marginally idiomatic. Examples from this tier include think of people, influence people, kill time, and break into house:
(11) 763548_1 <s> All over the world there are various kinds of music that
Approximately 29.5% of collocations belonged to the 21–100 frequency band, while the largest portion, 35%, consisted of collocations with more than 100 occurrences in the BNC (e.g., go to school, receive a letter, fall in love). These combinations are considered highly entrenched in native-speaker usage and thus represent idiomatic and fluent L2 production.
To gain further insight into developmental progression, the frequency band distribution was also analysed across proficiency levels, as depicted in Figure 2.

Distribution of collocations on the basis of their BNC frequency bands CEFR levels.
Analysis across levels reveals distinct developmental patterns. A1–A2 learners produce relatively few collocations overall, and most are confined to the lowest frequency bands (0–20). Only 37% of their collocations occur in the higher-frequency range (21–100 and >100), while 20% are atypical or absent from native use. Also, B1–B2 learners display greater lexical range and collocational diversity, with substantial representation across all frequency bands. Notably, 45% of their collocations fall into the highest frequency tiers, although 16% remain low-frequency or unattested. As for C1–C2 learners, they exhibit greater reliance on high-frequency collocations (52%), indicating increased convergence with native-like usage. However, a relatively high 23% of their combinations still belong to the lower frequency bands or are unattested, underscoring residual phraseological inaccuracies at advanced levels.
Taken together, these results suggest that collocational appropriacy and idiomaticity improve with proficiency, but learners at all levels, including advanced, continue to produce combinations that fall outside the range of native-speaker norms, meaning that %23 of their uses seems to be infrequent or atypical collocations.
RQ4. What Are the Most Frequent Error Types Assossiated with These Constructions?
Error types in collocational constructions were analyzed according to the Cambridge Learner Corpus error-annotation scheme (Cambridge University Press, 2014). Table 12 presents the most frequently observed error categories at each CEFR proficiency level, with percentage distributions calculated within the total number of erroneous collocations per level.
The Most Frequent Collocational Error Types Across Proficiency Levels.

Across all levels, verb-related errors dominate the learner data. The most prevalent error overall is Incorrect Tense of Verb (TV), followed closely by Replace Verb (RV). These two categories reflect the ongoing challenges learners face in tense selection and verb appropriacy within collocational contexts.
(12) 1094956_8 <s>Dear, I<#TV>
(13) 765190_1 <s>It has been<#RV>taking part|</#RV>
Missing preposition (MT) follows as the third error in A1-A2, and missing determiner (MD) follows it at B1-B2 and C1-C2 levels. In addition, Wrong Verb Form (FV) is observed both at A1-A2 and B1-B2 levels. Samples for these errors from the corpus is as follows:
(14) 2609322_4 <s>I was
(15) 2663836_9 <s>I was wondering if you have time to
In addition, by the intermediate B1–B2 level, FV (Wrong Verb Form) remains common, indicating lingering difficulties with non-finite verb morphology:
(16) 567578_4<s>I do have a few ideas that we can work on<#RP>.|,</#RP>e.g.<#FV>
At C1–C2, after the two verb-related errors, Verb Agreement Error (AGV) and Derivation of Adjective Error (DJ) become notably frequent. This progression indicates that lower-level learners struggle primarily with basic syntactic elements, while advanced learners begin to make more nuanced morphological and agreement errors within collocations. Some errors from the corpus is provided below.
(17) 581647_5 <s>Nevertheless, it<#AGV>
(18) 573511_1 <s> young people are more keen on playing on the computer or watching TV rather than
Such patterns suggest that although advanced learners achieve a higher degree of lexical and syntactic control, residual interlanguage traces still surface in subtle collocational environments. Additional, though less frequent, error types include replace determiner (RD), unneccessary determiner (UD) and replace noun (RN), the examples of which are given below:
(19) 765071_1 <s>I am<#IV>writting|writing</#IV>
(20) 1095003_3 <s>I hope I'll
(21) 2785813_3b <s>You</#MP>would<#UV> be|</#UV>
These instances reinforce the view that collocational errors are multifaceted, influenced not only by lexical choice but also by grammatical concord, derivational morphology, and article/preposition usage. The progression from syntactic to morphological sophistication with rising proficiency is observed from these errors.
RQ5. Which Collocation Errors, If Any, Persist Across Proficiency Levels from A1 to C2??
To explore whether certain collocational errors persist across the developmental continuum of CEFR levels, an error trajectory analysis was conducted. Table 13 presents the error types that occurred consistently across A1, B1, and C1 levels in the Turkish sub-corpus of the Cambridge Learner Corpus.
Persistent errors Across Levels.

According to the Table 13, the data reveal that seven error categories were present across all CEFR levels examined. Among these, verb-related errors, particularly RV (Replace Verb), TV (Incorrect Tense of Verb), and FV (Wrong Verb Form), emerged as systematically persistent problems, regardless of learner proficiency. This pattern suggests a deep-rooted difficulty in verb selection and morphological manipulation, which may be linked to the collocational constraints of English and the transfer of L1 verb semantics.
Additionally, determiner misuse, as reflected in missing determiner and unnecessary determiner, persisted across the corpus. This indicates a continued challenge in article usage and noun phrase construction, commonly observed among speakers of article-less L1s such as Turkish (Ionin et al., 2004). Similarly, Replace Preposition errors reflect ongoing problems in mastering prepositional collocations, where L1 transfer and semantic overgeneralization are likely at play.
Even at advanced proficiency (C1–C2), these error types are not fully resolved, echoing findings from previous learner corpus research (e.g., Granger & Paquot, 2008; Nesselhauf, 2005) that suggest collocational competence develops more slowly than general vocabulary knowledge. This persistence underscores the importance of targeted pedagogical interventions focusing on collocational awareness, especially in the verb and determiner domains.
Discussion
This study examined English verb–noun collocation use in Turkish EFL learners’ written production across CEFR proficiency levels (A1–A2, B1–B2, C1–C2), aiming to identify developmental patterns and recurrent error types. Collocational knowledge is widely acknowledged as a key component of second language proficiency (Wray, 2002). Yet, it remains a persistent challenge for EFL learners, even those at the advanced level learners who have difficulties approximating native speakers’ collocation use, regardless of their language and cultural backgrounds (Granger & Paquot, 2009; Nesselhauf, 2003).
The examination of collocations across A1-C2 level revealed that the number of collocations decreases as the proficiency level increases. This does not concur with Laufer and Waldman’s (2011) and Li et al.’s (2023) studies which both revealed that learners at higher CEFR bands use more verb–noun collocations than lower-level peers. This drop in collocational use may be due to the repetitive use of a limited set of collocations at lower proficiency bands by Turkish EFL learners. The apparent decrease in collocation usage at higher proficiency levels is not an indication of reduced formulaicity, but rather a developmental shift from fixed, textbook-like bi-grams (typical of A1–A2 learners) towards more flexible, structurally complex multi-word units characteristic of C1–C2 production. In other words, advanced learners rely less on memorised two- three-word chunks and more on discourse-level phraseological patterns.
As for the number of the collocational errors across levels, a decrease is observed in the number of errors with a growth in proficiency level. However, this trend may also reflect the overall reduction in collocation use at higher levels. In total, the percentage of errenous collocations is observed to be 20.2%. This seems to be aligned with Nesselhauf’s (2005) study on the German learner corpus, which revealed that a quarter of the collocations were erroneous.This finding also accords with Laufer and Waldman’s (2011) study which revealed that approximately one-third of learners’ collocation attempts were incorrect. Nonetheless, error rates did not diminish with proficiency in their study and advanced learners actually made more errors because they used collocations more frequently. Since the use of collocations by Turkish EFL learners decreases as proficiency level increases, their collocational errors also decline accordingly.
The analysis indicates that a substantial proportion of verb–noun collocations produced by Turkish EFL learners demonstrate a degree of native-likeness. Specifically, 87.3% of the collocations were attested in at least one of the reference dictionaries, and frequency analysis using the BNC showed that 35% of learner collocations occurred more than 100 times, while a further 29.5% appeared between 21 and 100 times. These results suggest that learners are generally capable of producing collocational patterns that align with conventional usage, as evidenced by the finding that 73% of all collocations could be classified as native-like. At the same time, the presence of non-target-like patterns remains notable: 4.2% of learner collocations were entirely absent from the BNC, and 22.1% were extremely infrequent (occurring only 1–5 times). Taken together, these figures indicate that nearly one quarter (27%) of learner collocations diverge from typical native usage. This tendency points to learners’ reliance on unconventional or low-frequency pairings, which may reflect the influence of first language transfer, restricted exposure to authentic input, or an incomplete awareness of the fixed nature of collocational patterns in English.
Additionally, learners’ verb–noun combinations that are not attested in either reference dictionaries or with a frequency threshold >6 in the BNC clearly reflect the cross-linguistic influence from Turkish. Examples such as miss the time, answer the letter, study for school, bring sb. to house, accommodate in house illustrate instances of direct translation or literal transfer from learners' L1. And, most of them may be considered as unique uses such as bring phone, learn from the letter, arrange place, seek free time…etc. The L1 influence is consistent with findings from other learner corpora across diverse language backgrounds including Nesselhauf (2005) who revealed the influence of the learners' native language on the use of collocations in German learners of English corpus. Likewise, Laufer and Waldman (2011) also conclude that there is a persistent L1 interference and high error rates found in their corpus of Hebrew-speaking learners. Similarly, Lee (2016) also reported substantial L1 effects among Korean learners, and Gao et al. (2019) found similar tendencies in a corpus of Chinese EFL learners. Together with the present study, these findings reinforce the view that L1 interference is a cross-linguistic phenomenon affecting collocational competence in second language acquisition, regardless of the learners' first language.
The analysis of frequency bands in the BNC further supports this developmental trajectory, indicating that lower-level learners rely more on infrequent collocations, whereas advanced learners, though producing fewer collocations overall, tend to use a higher proportion of frequent and conventional verb–noun combinations. These trends support Laufer and Waldman’s (2011) finding that intermediate learners often rely on moderately frequent collocations, while advanced learners tend to favor highly frequent, native-like combinations. The results also further support Granger’s (1998) observation that even advanced learners’ underuse idiomatic, high-frequency collocations and sometimes compensate with atypical constructions.
As for the error types across proficiency levels, incorrect tense of verb, and replace verb are the two most frequent error types in collocations produced by Turkish EFL learners. This finding parallels with the findings of Gao et al. (2019), who observed that the most prevalent errors in their Chinese learner corpus stemmed from inappropriate verb selection. This finding is also in line with Can’s (2017) study on verb errors of Turkish EFL learners, revealing the most common verb error categories, which are incorrect tense of verb (TV), wrong verb choice (RV), wrong verb form (FV), missing verb (MV), and verb agreement (AGV) errors.
Following verb errors, missing preposition and missing determiner errors remain most prevalent across levels. A1-A2 and B1-B2 learners exhibit missing prepositions and determiners or wrong verb forms, while C1-C2 learners shift toward missing determiners, verb agreement, and adjective derivation errors, reflecting a move from basic syntactic challenges to more nuanced morphological issues. This pattern underscores that, as learners advance, they transition from fundamental syntactic omissions toward subtler morphological and agreement errors.
In addition to this, verb-related errors (replacement, tense, form) and determiner omissions persist across all CEFR levels, from A1 through C2, indicating that learners continue to struggle with verb usage and article selection in their collocational usage even for advanced learners. This observation aligns with the conclusion of Laufer and Waldman (2011) that collocational errors remain prevalent irrespective of proficiency level. It also echoes Granger and Paquot’s (2009) findings that advanced learners still struggle to approximate native-like collocational usage. This finding is also in line with Akbaş and Yükselir’s (2022) study which also revealed persistent difficulties with collocational awareness of Turkish EFL learners even at intermediate proficiency level. Furthermore, apart from the collocational errors, these verb-related and determiner errors are also among the most frequent error types in the writings of Turkish EFL learners as revealed in Aybek and Can’s (2023) study of errors Turkish EFL learners make in Cambridge ESOL (English for Speakers of Other Languages) exams.
Overall, Turkish EFL learners, like many other L2 learners, often struggle with verb-noun collocations and produce incorrect collocations. The one-fifth of their collocations used is erroneous, a figure consistent with prior corpus-based research. While Turkish learners of English do not show much progress in acquiring collocations with increasing proficiency, their development is hindered by L1 interference and a lack of attention to the fixed nature of collocational phrases in English. The developmental trajectory is hindered by L1 transfer, as learners directly translate Turkish collocational patterns into English, resulting in common mistakes such as using bring smt. instead of give smt. examples. These collocational errors arise from both intralinguistic factors (the complexity, opacity, and unpredictability of verb–noun collocations) and extralinguistic factors (such as the learner's educational background, the genre and context of written production, exposure to authentic input).
Conclusion
This study investigated the developmental trajectory of English verb–noun collocation use among Turkish EFL learners across CEFR levels and revealed that collocation frequency decreases with proficiency. Unlike previous corpus-based studies which reported a steady increase in collocational production at higher levels (Laufer & Waldman, 2011; Li et al., 2023), the present findings suggest a qualitative rather than quantitative development. Lower-level learners relied heavily on a narrow range of repetitive collocations, leading to a high frequency of collocation use, whereas advanced learners shifted toward more flexible and structurally complex multi-word units and discourse-level phraseology. Although overall collocation production was lower at C1–C2, the proportion of native-like combinations was substantially higher, and error rates decreased accordingly. The data also confirm the strong cross-linguistic influence of Turkish on verb selection and argument structure, particularly in low-frequency or unconventional pairings that indicate literal translation from L1.
Despite the reduced quantity of verb–noun collocations at higher proficiency bands, the quality of collocational competence improves, reflecting a gradual move from surface formulaicity toward deeper phraseological competence. Persistent verb-related and determiner-related errors across all levels suggest that collocational mastery remains challenging even at advanced stages. These findings reinforce the view that collocational development is not purely linear and cannot be captured through frequency alone; rather, it involves a shift from memorisation to productive deployment within broader syntactic and discourse frames.
The analysis of error types shows that Turkish learners most frequently struggle with verb-related errors (verb replacement, tense, and form), followed by missing-preposition and missing-determiner errors, which persist across all proficiency bands. At lower levels, errors are predominantly syntactic (e.g., omission of prepositions or determiners), whereas at higher levels they shift toward subtler morphological and lexical-choice issues (e.g., inappropriate verb selection or derivational inaccuracy). This pattern indicates that L1 transfer plays a persistent role in collocational deviance, especially in verb selection and argument structure, and confirms that collocational acquisition develops qualitatively rather than linearly. Pedagogically, the results point to the need for explicit, form–function focused collocation instruction which extends beyond lexical substitution exercises and draws learners’ attention to pattern grammar, phraseological constraints, and cross-linguistic transfer.
Implications
The findings of this study carry significant pedagogical implications for the teaching of English collocations, particularly verb–noun combinations, to Turkish EFL learners. Given the high rate of erroneous and non-native-like collocations across all proficiency levels, explicit instruction in collocations should become a core component of vocabulary and writing pedagogy. Instruction should move beyond incidental exposure and focus systematically on the structure, meaning, and contextual use of frequent verb–noun collocations. In line with previous research (Kjellmer, 1991; Wray, 2002), the results reaffirm that learners often rely on compositional word-by-word strategies rooted in L1, rather than accessing stored multiword units, which impedes fluency and idiomaticity.
To mitigate this, instructional approaches should integrate form-focused activities that evolve in complexity with learner proficiency. At lower levels, learners benefit from guided exposure to formulaic sequences and collocational chunks; whereas at advanced levels, they require contrastive, analytical tasks that raise awareness of subtle semantic and syntactic constraints on collocational usage. Persistent L1 transfer observed in this study further suggests the need for contrastive analysis, especially between Turkish and English collocational patterns, to help learners recognize and avoid direct translation strategies.
Furthermore, the study underscores the importance of Data-Driven Learning (DDL) and corpus-based materials in developing collocational competence. Turkish EFL learners showed difficulty in distinguishing between low- and high-frequency collocations, indicating a lack of exposure to natural language input and insufficient sensitivity to frequency effects. Teachers should therefore incorporate authentic corpus data—such as concordance lines and frequency lists—into classroom activities to promote noticing (Schmidt, 1994) and encourage learners to internalize collocations through contextualized exposure and repetition. Materials should highlight high-frequency verb–noun pairs, illustrate their usage in real-life contexts, and provide ample opportunities for controlled and communicative practice.
Additionally, pedagogical strategies like collocation error analysis, guided rewriting, and native-speaker comparison tasks can foster metalinguistic awareness and help learners self-correct deviant patterns. These activities also serve to reinforce the idea that lexical accuracy in English depends not only on word meaning but also on knowing which words typically co-occur. In conclusion, improving learners’ collocational competence requires intentional, scaffolded, and frequency-informed instruction, supported by tools and resources from corpus linguistics. Such interventions are crucial not only to enhancing learners’ fluency and accuracy but also to fostering the lexical sophistication expected in academic and professional communication.
Limitations and Suggestions
The study relied on the Cambridge Learner Corpus (CLC), which is exam-based data. As such, learners’ performance may reflect test-taking strategies rather than their everyday language use. Also, the CLC includes test-takers of different ages and educational backgrounds, but this information was not always consistently available, which limits the generalizability of the findings.
Furthermore, the study’s methodological decision to focus on high-frequency nouns may have influenced the nature and range of extracted collocations. The analysis was restricted to verb–noun collocations, leaving out other types of collocations (e.g., adjective–noun, verb–preposition) that may also reveal important aspects of learner language. A further limitation concerns the reliance on frequency data from the British National Corpus (BNC), as frequent usage does not necessarily guarantee universal acceptability, and less frequent yet correct collocational patterns may therefore have been disregarded.
Although corpus data provide valuable insights into recurrent errors and usage patterns, they offer limited explanation of the cognitive or conceptual mechanisms underlying learner difficulties. Such challenges may stem from first-language transfer or instructional practices, and therefore often require complementary qualitative or experimental evidence to be fully understood.
Future research could diversify the noun base and include spoken corpora to explore modality-based variation in collocational usage. Future research could also complement exam-based corpora with learner production from classrooms, writing portfolios, or spoken data to capture a fuller picture of collocational use.
In addition, tracking the same group of learners over time would provide clearer insights into developmental patterns and the persistence of collocational errors. Classroom-based studies could test targeted instructional techniques (e.g., data-driven learning, explicit teaching of frequent collocations) to evaluate their effectiveness in reducing persistent errors.
Footnotes
Acknowledgements
The author gratefully acknowledges Prof. Dr. Cem Can for his invaluable feedback and guidance throughout the completion of this paper.
Ethical Considerations
Corpus-based studies rely on pre-existing datasets that were compiled long ago with the necessary legal permissions and informed consent at the time of their creation. As researchers, we analyze these publicly available or previously approved corpora without directly involving human participants in new data collection processes. Therefore, ethical approval is generally not sought for such studies, as the original data compilation had already undergone the necessary ethical considerations.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Raw data, analysis files and categorizations that support the findings of this study are available from the author upon reasonable request.