
Abstract
As machine translation (MT) becomes increasingly prevalent in multilingual contexts, growing scholarly attention has been directed toward the latent issue of bias. Such bias not only undermines translation quality and user trust but also reinforces structural inequalities, limiting equitable representation and access. However, existing research remains methodologically fragmented and predominantly technical, often lacking integrative perspectives that bridge disciplinary boundaries. This study employs a bibliometric approach, supplemented by close reading, to systematically review MT bias research published between 2005 and 2024 in the Web of Science Core Collection and Scopus databases, investigating publication patterns, thematic hotspots, and methodological trajectories. The findings reveal that: (1) research in this area has undergone three developmental stages, namely initial exploration, steady accumulation, and rapid growth; (2) technological innovation serves as the core driver, while research themes have diversified, accompanied by increasingly close transnational and cross-sector collaborations; (3) current efforts to address the multi-level challenges of bias in MT, including taxonomy (by source, linguistic form and impacted groups), detection (via benchmark construction and system output evaluation), and mitigation (across data collection, model training, and post-processing stages), exhibit multi-focal and multi-path characteristics. Overall, despite notable advances in theory, methodology, and application, MT bias research still suffers from fragmented standards and weak links to real-world practice, underscoring the need for future work that integrates technical precision with ethical reflection through stronger interdisciplinary collaboration.
Introduction
Machine Translation (MT), a landmark achievement of language technology in the digital intelligence era, has evolved from rule-based and statistical approaches to deep learning-based systems. Its primary objective is to generate fluent and accurate target-language texts, thereby facilitating seamless multilingual communication (Stewart & Mihalcea, 2024). Although originally conceptualized as impartial tools devoid of inherent stance, MT systems inevitably exhibit forms of bias, which is a multifaceted phenomenon rooted in the dynamic interplay between technological design and societal structures. From the technical standpoint, bias manifests in preferential system behaviors, such as making unverified assumptions or non-random selections when faced with semantically ambiguous inputs (Měchura, 2022a). From the sociolinguistic standpoint, bias is evidenced by disproportionate treatment or implicit privileging of certain social groups (Savoldi et al., 2021). In addition to undermining translation quality and eroding user trust, MT bias poses broader social risks by perpetuating structural inequalities and amplifying entrenched social prejudices (Kimera et al., 2024). Against this backdrop, the ethical and social implications of MT systems have become a pressing area of scholarly concern, calling for critical re-examination across disciplinary boundaries.
Although scholarly attention to MT bias has steadily increased, two critical issues still warrant further consideration. First, the considerable variation in methodologies and thematic focuses across numerous case-based studies has led to a fragmented understanding of the issue, while comprehensive reviews that synthesize these dispersed efforts remain scarce. This fragmentation highlights the urgent need to consolidate disparate findings into a cohesive body of knowledge and provide a comprehensive overview of research trends and developmental trajectories. Second, the prevailing emphasis on technical performance optimization and algorithmic debiasing reflects a predominantly techno-centric orientation, sometimes overlooking the broader sociocultural and ethical contexts in which bias is both produced and perpetuated. As scholarly discourse increasingly shifts from instrumental rationality toward ethical rationality, MT bias should no longer be viewed merely as a technical challenge to be quantified and mitigated, but as a critical focal point for interdisciplinary investigation. Effectively addressing the complex and multifaceted nature of MT bias requires transcending disciplinary boundaries and developing integrative frameworks that draw from computer science, linguistics, sociology, and related fields.
To address these challenges, this study adopts a hybrid bibliometric-qualitative approach that combines distant reading and close reading. As studies proliferate, bibliometric methods serve as an effective tool to map publication trends, networks, and themes, revealing those that shape research agendas (Anderson & Lemken, 2023; Antons et al., 2023; Kunisch et al., 2023). Meanwhile, close reading of key documents allows for in-depth engagement with methodological rationales and normative underpinnings, complementing quantitative trends with qualitative insights. This dual strategy is particularly suited to a topic like MT bias, which intersects computational architectures and sociocultural dynamics, and thus demands both breadth and depth of analysis.
Therefore, this paper provides a comprehensive analysis of research on MT bias published between 2005 and 2024. Employing both distant reading and close reading methods, it maps the research landscape and methodological pathways within the field. By integrating large-scale bibliometric mapping with qualitative synthesis, the study offers a longitudinal and interdisciplinary account of how MT bias has been conceptualized, addressed, and debated over time. In doing so, it complements existing reviews by situating computational strategies alongside sociocultural concerns, while also illuminating evolving research trajectories and persistent challenges. Specifically, the study aims to answer the following questions: (1) What are the diachronic trends in MT bias research, and how have scholarly attention and collaboration patterns evolved over the past two decades? (2) How can we systematically synthesize the achievements and ongoing challenges in bias taxonomies, detection methods, and mitigation strategies, and what directions might guide future research?
Methodology
To ensure comprehensive and representative coverage, literature was sourced from two authoritative databases: the Web of Science Core Collection (WoS) and Scopus, covering the period from January 1, 2005, to December 31, 2024. Search strategies were tailored to each database: in WoS, the Core Collection was selected, and the search query TS = (“machine translation”) AND TS = (bias OR discrimination OR prejudice OR fairness) retrieved 214 records; in Scopus, the query TITLE-ABS-KEY (bias OR discrimination OR prejudice OR fairness) AND TITLE-ABS-KEY (machine translation) yielded 439 records. A total of 653 records were initially retrieved from both databases. After retrieval, data standardization was performed using a Java-based program, which included harmonizing citation formats and normalizing author names. Duplicate entries were subsequently removed, resulting in a final corpus of 473 unique and valid documents for analysis.
To systematically examine research patterns and intellectual structures, the 473 documents were subjected to bibliometric analysis. Bibliometric analysis is a quantitative research method for evaluating academic literature, which applies statistical techniques to bibliographic data such as publications, citations, and author collaboration information to uncover trends and patterns in scientific research (Donthu et al., 2021; Passas, 2024; Syahid & Qodir, 2021). In this study, Bibliometric analysis was conducted using the Bibliometrix package (version 4.3.0) in R, with its web-based interface Biblioshiny, providing supplementary visualization functions (Afzaal et al., 2024; Aria & Cuccurullo, 2017). Bibliometrix enabled analyses of authorship, source journals, and thematic clustering, while Biblioshiny facilitated concept structure and network mapping. Furthermore, to enhance visualization and science mapping, VOSviewer (version 1.6.20) and CiteSpace (version 6.3.R1) were also employed. VOSviewer specializes in constructing keyword co-occurrence networks and mapping research collaboration among countries, institutions, and authors (van Eck & Waltman, 2010). CiteSpace integrates burst-detection algorithms and centrality indicators to identify emerging research fronts and paradigm shifts, offering timeline and cluster views for tracking the evolution of knowledge domains (Chen, 2004, 2006). This multifaceted approach enabled a comprehensive and transparent mapping of the field’s intellectual development, including thematic clusters, cooperation patterns, and evolving research trends, as presented in Sections 3 and 4. The main steps of data collection, processing, and bibliometric analysis are illustrated in Figure 1.
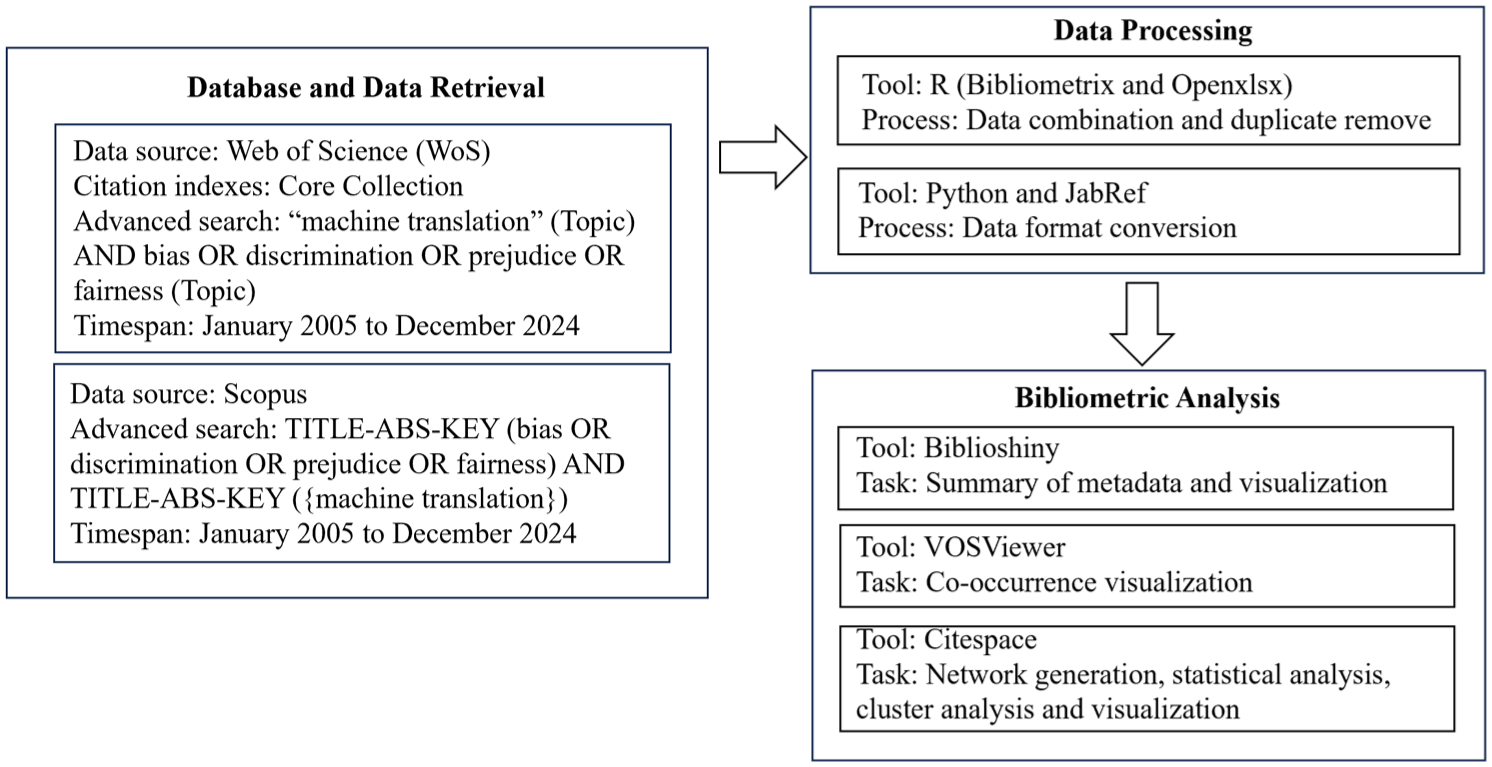
Flowchart of bibliometric analysis.
In addition to this quantitative mapping, close reading was applied to a subset of influential or methodologically distinctive publications. These texts were selected based on their contribution to the taxonomy, detection, or mitigation of bias in MT, with particular attention to how they frame normative concerns such as fairness, harm, and inclusivity. This interpretive strategy was important for capturing the normative dimensions of MT bias research that are often underrepresented in bibliometric outputs. Thus, this study adopts a mixed-methods approach that integrates distant and close reading to align macro-level structural mapping with micro-level conceptual interpretation. This dual-method design also informs the overall structure of the paper: Section 3 and Section 4 present the findings derived from bibliometric analysis, including the publication landscape and thematic clusters; Section 5 draws on close reading to engage more critically with core methodological and ethical debates, organized around three recurring challenges—data imbalance, contextual deficiency, and social sensitivity.
Mapping the MT Bias Literature: Volume, Sources, and Coverage
Volume and Citation
Based on publication volume, the research trajectory on MT bias can be divided into three phases: the Initial Exploratory Period (2005–2015), the Steady Accumulation period (2016–2017), and the Rapid Growth period (2018–2024) (Figure 2).

Trend of annual publications and mean total citations per article.
During the Initial Exploratory Period, the annual publication volume in the field averaged fewer than 10 papers, with some years yielding 1 or 2 publications, indicating the topic’s peripheral status at the time. Nevertheless, this phase also saw high-impact papers; for example, in 2011, despite only 6 publications, the mean total citations per paper reached 57, underscoring the foundational role of early works in establishing the research base. Compared to the first period, the Steady Accumulation Period has seen a modest increase, with annual totals reaching 11 and 10 papers, respectively. Notably, 2016 witnessed the highest average citation frequency of the entire period (52.55), indicating more academic attention during this phase. Following 2018, the field entered the Rapid Growth Period, marked by a pronounced increase in research output. In 2018, the number of publications surpassed 20 for the first time, followed by 28 in 2019, 52 in 2020, and 75 in 2021. Although there was a minor decline in 2022 (63 papers), the upward trajectory resumed in 2023 and 2024, with new records set at 81 and 88 publications, respectively. Meanwhile, the average citation rate remained relatively high, albeit with a slight decrease in 2023 and 2024 (3.47 and 0.55, respectively), which can likely be attributed to the typical citation lag for recent publications.
The changes in publication volume and citation patterns suggest a synergistic growth in both research output and academic impact, indicating that MT bias is gradually evolving from a marginal technical issue to a more independent research domain.
Forms and Platforms
The literature sources encompass 294 distinct types, including journals, conference proceedings, edited materials, and books, reflecting a diverse range of outlets. Figure 3 presents the number and proportion of a total of 473 documents across these publication types.

Distribution of literature source.
First, conference papers (excluding review articles) account for 66.11%, reflecting the highly technical and rapidly evolving nature of research in this field, which is disseminated quickly through conference platforms. The annual meetings of the Association for Computational Linguistics (ACL) contribute the most, with 24 papers, making it the central dissemination platform in this area. The second largest contributor is the series of conferences on Empirical Methods in Natural Language Processing (EMNLP), with 10 papers in 2021, followed by 5 in 2020 and 4 in 2018. Specialized workshops and sub-conferences also play a key role in advancing the topic. For instance, the inaugural Gender-Inclusive Translation Technology Workshop (GITT 2023) contributed 7 papers, while the 2019 Gender Bias in Natural Language Processing (GeBNLP) workshop included 4 papers, reflecting the increasing prominence of gender bias as a subfield in MT research. Additionally, the Chinese Computational Linguistics Conference (CCL 2021) contributed 4 papers, highlighting the growing attention to this issue within the Chinese academic community.
Next, journal articles account for 23.37%, with representative publications including Transactions of the Association for Computational Linguistics, IEEE Access, and Lecture Notes in Computer Science. Although this proportion is lower than that of conference papers, it might indicate that some research has begun to move toward more systematic and theoretical directions. Furthermore, the proportion of review articles is relatively small, with conference reviews accounting for 7.58% and journal reviews for just 1.47%, reflecting the lack of comprehensive reviews and systematic overviews in the field. Moreover, books and editorial materials account for only 1.26 and 0.21% respectively, suggesting that the presence of this topic in book publishing and academic commentary remains relatively limited. In addition, it is notable that in the MT and Natural language processing (NLP) field, top-tier conferences serve as primary venues for high-impact research, with peer-review standards comparable to journals. Their dominance reflects disciplinary norms rather than a methodological artifact, and also underscores the field’s technocentric orientation—especially when contrasted with the journal-centered publishing culture of the humanities disciplines.
The distribution of literature sources reveals two key characteristics of research on MT bias. First, research outputs predominantly rely on relevant platforms, reflecting the field’s emphasis on timeliness and innovation. Second, although technical considerations remain dominant, sociocultural subtopics such as gender bias are developing into independent research branches. These trends suggest that research on MT bias displays a growing tendency toward innovation and interdisciplinarity, with considerable potential for future growth through expansion from conference proceedings to journal publications and more systematic scholarly development.
Institutions and Authors
Research on MT bias is predominantly driven by higher education institutions, though research organizations and technology companies also participate extensively, reflecting a trend toward interdisciplinary and collaborative advancement. Geographically, a global research network has gradually emerged, centered around China, the United States, and Europe. Among the top 25 institutions by publication volume, 19 are universities, such as Peking University, the University of Edinburgh, and Carnegie Mellon University, et cetera. This pattern underscores the sustained investment and strong academic leadership of universities in this field. In addition to academic institutions, organizations such as the Chinese Academy of Sciences, the Bruno Kessler Foundation in Italy, Tencent, Google Inc., IBM, Microsoft, and Microsoft Research Asia have also been highly active, each contributing between six and eight publications (Table 1).
Top 25 Most Relevant Institutions and Number of Articles.

The scholars involved in MT bias research are primarily affiliated with these institutions. A total of 1,188 scholars have been engaged, with only 17.12% of the outcomes being produced independently, while the remainder are collaborative publications. International collaboration accounts for 10.57% of the total output. Highly productive authors are distributed across leading universities, research institutions, and technology companies in Asia, Europe, and North America, reflecting a positive trend in international collaboration within the field. The author collaboration network displays a clear clustering pattern (Figure 4), with certain research teams forming stable partnerships around specific topics. This collaborative framework not only facilitates the practical application of related technologies but also aids in developing bias mitigation solutions that are culturally adaptable and linguistically transferable. Overall, research on MT bias is evolving toward a more balanced distribution of international efforts and strengthened institutional cooperation.

Authorship network visualization map.
Exploring Research Themes: Clusters, Keywords, and Central Topics
To provide a more comprehensive depiction of the thematic distribution and developmental dynamics of research on MT bias, a network visualization map is created to reveal the co-occurrence relationships and clustering structures among various keywords. Figure 5 displays a keyword co-occurrence network generated using VOSviewer. In this visualization, each node represents a frequently occurring keyword within the selected literature corpus. The size of a node reflects the frequency of the term’s appearance, while the distance and thickness of the connecting lines indicate the strength of co-occurrence—that is, how often two keywords appear together in the same publication. Nodes are grouped into color-coded clusters, each representing a distinct thematic community derived from co-occurrence patterns. The spatial proximity of nodes further suggests conceptual or methodological relatedness. This visualization serves to highlight both the central research foci of the field and the structural linkages across technical, social, and methodological domains.

Thematic visualization map.
Among all keywords in the network, “computational linguistics,”“machine translation,”“neural machine translation,”“gender bias,” and “deep learning” stand out with the largest node sizes, indicating that they are the five most frequently occurring terms in the literature. Notably, these high-frequency keywords are also positioned near the center of the network, suggesting their salience in the thematic structure of MT bias research. While the other four terms are closely associated with the technical foundations of the field, “gender bias” intersects with both technological and societal dimensions, connecting strongly with terms related to evaluation practices and ethical concerns, reflecting its dual relevance to both technical performance and value-sensitive design.
In terms of all specific bias types discussed in the literature, gender bias ranks as the most frequently occurring term, which concerns all MT paradigms (Savoldi et al., 2025), indicating its central role in shaping how MT bias is conceptualized, evaluated, and mitigated in empirical studies. This centrality is not only evident in the network structure but also reinforced over time. A timeline analysis using CiteSpace shows that gender bias has remained a central focus since 2008, with Google Translate frequently serving as the primary testing platform. Schiebinger (2014) published an influential article in Nature, highlighting how previous scientific research often overlooked gender issues and emphasizing the inequality perpetuated by the male-default tendency in technologies such as Google Translate. Two years later, Google introduced its first neural network-based MT system—Google Neural Machine Translation (GNMT)—which marked the advent of the neural machine translation (NMT) era and sparked widespread research interest (Wu et al., 2016). Inspired by Schiebinger’s work, subsequent studies increasingly examined bias, frequently using Google Translate as an empirical example. As research in this area grew, Google began acknowledging the issue and implementing countermeasures to reduce bias. In its early versions, Google Translate provided a single translation for gender-ambiguous terms (e.g., when translating the English word “professor” into Italian, the default translation was the masculine form “professore”). However, with growing awareness of gender stereotyping in language (Lindqvist et al., 2019), Google began incorporating gender distinctions in its translations (e.g., “professor” → “professoressa/professore”) (Kuczmarski, 2018). More recently, the company has successfully integrated a gender-rewriting mechanism for short queries in language pairs such as Finnish, Hungarian, Persian, and English, thereby providing both feminine and masculine translation options (Johnson, 2020).
In addition to highlighting keyword centrality, the colors of different clusters reveal several research directions with distinct thematic features. The blue cluster includes “gender bias” along with related keywords such as “quality control,”“post-editing,” and “human evaluation,” reflecting a strong emphasis on detecting and mitigating social bias in MT outputs and aligning system behavior with fairness and user expectations. The green cluster, centered around terms like “machine translation systems,”“zero-shot learning,” and “quality estimation,” addresses methods for training and enhancing these systems. Meanwhile, the yellow cluster features terms like “target language,”“source language,” and “signal encoding,” suggesting that classical translation models and language processing mechanisms remain foundational to bias research in MT. The red cluster combines technical topics such as “machine learning,”“speech recognition,” and “artificial intelligence” with themes often found in the humanities and social sciences, such as “humans” and “bias,” illustrating the interdisciplinary nature of this field. Finally, the purple cluster, represented by terms like “large language models” and “adversarial machine learning,” highlights ongoing exploration of cutting-edge technologies and techniques aimed at mitigating bias through robustness testing and generative architectures.
In sum, the dual orientation of research on MT bias—toward both technical systems and social concerns—is in many ways inherent to its object of study. On the one hand, this field engages deeply with computational domains such as deep learning, system optimization, and quality assessment; on the other hand, it necessarily addresses issues of gender representation, fairness, and ethical accountability embedded in language technologies. However, as evidenced by the co-occurrence network, the overall knowledge structure remains predominantly shaped by computational and engineering priorities. High-frequency and centrally positioned keywords are overwhelmingly technical in nature, whereas concepts and frameworks from the social sciences and humanities remain relatively sparse and peripheral. Although interdisciplinary engagement is beginning to emerge—particularly in areas related to system evaluation and fairness—it has yet to substantively reshape the dominant discourse. The coexistence of classical translation mechanisms and frontier AI-based solutions, as revealed in the clustering structure, points to an evolving methodological landscape. Taken together, these patterns highlight both the expanding scope and the current limitations of MT bias research, underscoring the field’s ongoing effort to integrate technical innovation with critical awareness in pursuit of more equitable and context-sensitive translation technologies.
Addressing Bias in MT: Taxonomy, Detection, and Mitigation
Research on MT bias has developed along three key dimensions: conceptualization (taxonomy), identification (detection), and intervention (mitigation). While each of these areas has attracted growing attention, they are often examined in isolation. This section synthesizes advances across the three dimensions and highlights how they intersect through a set of recurring, cross-cutting challenges.
Specifically, we identify three core challenges that persist throughout the MT bias research landscape: 1) Data imbalance: The disproportionate representation of gender, social groups, and languages in training and evaluation datasets, which underpins both the emergence and persistence of bias; 2) Contextual deficiency: The lack of discourse-level, pragmatic, or sociocultural context in system design and evaluation, which limits the capacity of both detection and mitigation strategies; 3) Social sensitivity: The difficulty of capturing culturally contingent norms, values, and notions of harm, which demands interdisciplinary approaches and user-centered evaluation frameworks.
Using these three challenges as analytical lenses, the following subsections examine how current studies conceptualize, detect, and address bias in MT. Each subsection concludes with a synthesis of key insights and remaining gaps in relation to these shared challenges.
Multi-Perspective Taxonomy of Bias
To lay the conceptual groundwork for understanding bias in MT systems, this section introduces a multi-perspective taxonomy that synthesizes how bias has been categorized in existing research. While prior studies have proposed various classification schemes, a unified typology that captures the multidimensional nature of MT bias remains lacking. We address this gap by organizing the literature around three interrelated perspectives: the source of bias, its linguistic manifestation, and its practical impact on affected communities. These perspectives are not mutually exclusive but serve as heuristic lenses that emphasize different aspects of bias: the first considers what generates bias, the second how it is encoded in language, and the third where and for whom it produces harm. Rather than mapping directly onto the challenges of data imbalance, contextual deficiency, and social sensitivity outlined earlier, these perspectives intersect with them in complex ways. Understanding this interplay reveals how structural, linguistic, and sociocultural dynamics jointly shape both the emergence and the consequences of MT bias.
From the perspective of the bias sources, Friedman and Nissenbaum (1996) proposed a triadic model of bias based on 17 different computer systems in fields such as banking, business, and education. This model has been widely applied and extended in subsequent MT studies, which includes pre-existing bias, technical bias, and emergent bias (ibid). Pre-existing bias arises from inherent imbalances in training data, often influenced by historical or social factors. Examples include racial bias (Merullo et al., 2019), political bias (Fan et al., 2019), and gender bias (Vanmassenhove & Hardmeier, 2018). Technical bias stems from model architecture, such as feature selection, optimization methods, or prediction mechanisms. For instance, studies have shown that label bias in NMT models can lead to overly short translations, thereby degrading model performance (Murray & Chiang, 2018). Emergent bias occurs after the model design has been completed, typically resulting from shifts in societal knowledge, linguistic structure, user profiles, population distribution, or cultural values, which may no longer align with the assumptions made during the model’s original design. These source-level categories frequently intersect with linguistic and user-centered manifestations of bias, especially when outdated social assumptions shape both input data and model output. Together, these patterns show how lexical choice, syntactic structure, and discourse conventions function as critical channels through which bias becomes embedded in MT outputs.
From the perspective of linguistic features, bias can be categorized into lexical, grammatical, and pragmatic dimensions. Lexical bias is often evident in the gendered stereotyping of certain terms, such as professions or identities. For example, Prates et al. (2020) conducted a study using Google Translate to translate job-related sentences into 12 gender-neutral languages and quantified the distribution of pronouns. They found that male-default bias was particularly pronounced in STEM-related professions, which did not align with the gender distribution seen in real-world demographics (ibid). Grammatical bias typically manifests in issues such as subject-object agreement and gender-number concordance. For example, while English does not distinguish between singular and plural forms of the pronoun “you,” languages like French, Spanish, and Chinese do. However, MT systems sometimes fail to properly handle these distinctions when translating between languages that make these distinctions (Měchura, 2022b). Pragmatic bias reflects the model’s inability to grasp politeness, honorifics, or cultural formality, leading to inappropriate translations in cross-cultural communication (Měchura, 2022a). These subtypes reveal how structural features of language contribute to encoding and reinforcing bias in MT outputs.
From the perspective of affected individuals and communities, existing research has predominantly concentrated on three types: gender bias, low-resource language bias, and cultural bias. Gender bias has received sustained attention for reinforcing stereotypes and undermining inclusivity, with evidence across political discourse (Vanmassenhove et al., 2018), occupational translation (Cho et al., 2019), and audiovisual media subtitling (Lardelli & Gromann, 2023). Low-resource language bias emerges when MT systems lack adequate training data for certain languages, resulting in lower translation quality compared to high-resource languages. Only about three percent of languages are well represented in most MT systems (Helm et al., 2023), leaving many others, such as Mongolian or Uyghur, underrepresented due to limited data collection and demographic or geographic constraints (Jia et al., 2021). The scarcity leads not only to systematic errors in translating low-frequency words (Li et al., 2017) and handling distinctive grammatical structures, but also to inequities in dialogue systems (Shen et al., 2024) and cross-lingual information retrieval (CLIR) (Huang et al., 2023), therefore undermining public information access of certain ethnic groups. Cultural bias, meanwhile, arises when MT systems overlook users’ sociocultural contexts, leading to inappropriate or distorted translations of cultural-specific items (CSIs), such as food, music, or idioms (Yao et al., 2024). This bias is particularly visible in domains like film subtitles, where humor and metaphor are distorted (Sharma et al., 2024), in culinary and artistic references that lack clear counterparts (Yao et al., 2024), and in public health materials, where MT systems exaggerate negative sentiment, potentially reinforcing stigma (Ji, 2023). It is important to note that the domains discussed above reflect only a subset of contexts where bias has been empirically observed and documented. In reality, the lived experiences of affected individuals span a wide array of social, professional, and cultural environments. Ultimately, wherever translation mediates unequal access to language or information, bias can shape outcomes in ways that reflect—and sometimes reinforce—existing social divides.
By mapping bias according to source, linguistic form, and application context, the framework underscores both the multifaceted nature of bias and the diverse interpretive priorities across disciplinary boundaries. At the same time, the very process of classification also brings to light critical limitations that recur across dimensions. For instance, skewed data distributions challenge the representativeness of source-level analyses; the absence of discourse or sociocultural cues complicates linguistic-level distinctions; and normative ambiguity across domains often blurs the line between technical error and social harm. However, there is still a lack of consensus on how to systematically classify and prioritize different types of harm across contexts, indicating the absence of unified normative standards in the current taxonomy frameworks. These structural tensions signal the need for more context-aware, ethically grounded approaches to bias detection—an issue further explored in the next section. Taken together, this integrated framework lays a conceptual foundation for the subsequent discussion of bias detection and mitigation, where these intersecting dimensions are frequently addressed in tandem. While the threefold taxonomy is analytical in nature, its value lies in highlighting the interconnected roots of bias. The challenges of data imbalance, contextual deficiency, and social sensitivity often overlap within and across categories, underscoring the need for detection and mitigation strategies that are likewise multidimensional and context-sensitive.
Multidimensional Bias Detection
At its core, bias detection is a normative judgment process that involves identifying which types of bias are harmful, how they manifest, and who they affect (Blodgett et al., 2020). To be effective, detection must extend beyond identifying linguistic distortions in system output; it also requires assessing their broader social consequences—grounded in how users experience, interpret, and are affected by such outputs in real-world settings (Agnew et al., 2024). Yet, most existing studies prioritize computationally tractable approaches—focusing on system predictions and dataset-level imbalances, such as skewed distributions of gendered pronouns (Blodgett et al., 2020; Zhao et al., 2019)—while giving comparatively little attention to how users actually perceive and experience harm, resulting in a notable insufficiency of direct human engagement in MT bias research (Savoldi et al., 2025). This gap is problematic because harm is not merely a product of textual error; it materializes through the sociotechnical environments in which biased translations are produced, interpreted, and acted upon.
First, to help conceptualize such harms, Crawford’s framework of representational harms and allocational harms has become a foundational reference for assessing bias in MT (Crawford, 2017). Representational harms refer to the inaccurate or unfair portrayal of social groups and identities, which can influence public perceptions and value judgments. Allocational harms, on the other hand, arise when system output biases lead to unequal treatment in the distribution of resources or opportunities for specific groups. While Crawford’s distinction between allocational and representational harms remains one of the most widely adopted in NLP and AI ethics due to its conceptual clarity and broad applicability, we acknowledge that more recent frameworks offer expanded or complementary perspectives on harm, such as the U.S. National Institute of Standards and Technology (NIST, 2023)’s multi-level typology (harms to individuals, organizations, or ecosystems) and Dev et al.’s (2022) task-oriented harm typology encompassing five categories—Stereotyping, Disparagement, Dehumanization, Erasure, and Quality of Service (QoS). However, in the body of research reviewed in this paper, Crawford’s twofold model remains the most foundational framework for conceptualizing harm in MT bias studies. This is because it was specifically developed to address bias-related harms and has been explicitly referenced in multiple MT studies as a practical basis for empirical evaluation. Moreover, its dual emphasis on symbolic (representational) and material (allocational) dimensions aligns closely with how harm typically manifests in translation outputs—through both distorted portrayals of social identities and unequal access to linguistic resources or communicative opportunities. As such, we foreground this framework here not to exclude more recent developments, but because it continues to serve as a conceptual foundation upon which more fine-grained taxonomies have been built.
Second, to identify how bias manifests in MT systems, many current studies construct targeted benchmark datasets tailored to specific research purposes. These benchmarks function as controlled testbeds where specific forms of bias—such as gender stereotypes or pronoun mismatches—are systematically triggered, allowing researchers to observe whether MT systems consistently produce biased outputs under comparable conditions. By holding most variables constant and varying only the target attribute (e.g., gender), they help reveal subtle model preferences that may go undetected in general evaluations. For example, Stanovsky et al. (2019) created the WinoMT dataset based on two existing English gender bias test sets (GBET); Rudinger et al. (2018) developed the Winogender dataset, incorporating male, female, and neutral variables; Zhao, Wang, et al. (2018) built the WinoBias contrastive sentence dataset using U.S. Department of Labor data. Additionally, some studies have attempted to incorporate naturally occurring data to improve the real-world applicability of detection efforts. For example, Lardelli et al. (2024) curated and extended dictionaries developed by online communities advocating for gender equity and extracted sentence sets from encyclopedia entries and parliamentary speeches as test samples to evaluate the bias performance of two commercial translation systems and six NMT models. However, the majority of current benchmarks still rely on template-based or contrastive sentence constructions, largely because of the methodological control and comparability they afford. While these designs are analytically useful, they often fail to capture the complex linguistic, cultural, and contextual dynamics that shape bias in real-world communication. Naturally occurring data, by contrast, better reflects the diversity and nuance of actual user interactions, and has been increasingly recognized as essential for evaluating how MT systems perform in socially consequential settings. As such, expanding benchmark construction to include more authentic and user-centered datasets represents a crucial direction for future research.
Just as the inclusion of naturally occurring data can enhance the contextual validity of benchmark evaluations, another critical strategy for addressing the persistent challenges of data imbalance, contextual deficiency, and social sensitivity is the adoption of qualitative methods—an approach notably underrepresented in the body of literature reviewed. While quantitative techniques remain dominant in current MT bias research, primarily focusing on measurable disparities in system output, they often fail to capture the lived experiences of those most affected, which may, in turn, result in an overly narrow conceptualization of what constitutes “harmful bias.” Therefore, it is essential to complement quantitative approaches with qualitative analysis. Qualitative methods prioritize an examination of the pragmatic and value-laden consequences of bias, foregrounding the perspectives of translation users, social groups, and broader cultural contexts. This orientation has fueled a growing trend toward interdisciplinary collaboration, drawing on theoretical frameworks and methodological tools from fields such as translation studies, sociolinguistics, psychology, and sociology. These disciplines provide more nuanced and contextually sensitive lenses for the detection of bias. For instance, crowdsourced evaluations and user surveys facilitate the collection of subjective feedback from diverse populations (Jiménez-Crespo, 2018), thereby enabling a deeper understanding of the acceptability and sensitivity of model outputs in various social environments. Importantly, qualitative inquiry can be effectively integrated with computational approaches. Quality Estimation (QE), for instance, offers a hybrid method that predicts output quality in real-time and can be enhanced through linguistic annotation or cultural sensitivity metrics. When embedded within an interdisciplinary framework, such methods extend the reach of detection pipelines beyond technical performance into the realm of human-centered evaluation. Ultimately, the convergence of automated assessment and human-centered qualitative insight enables bias detection to move beyond narrow technical parameters, fostering a more comprehensive, multidimensional understanding grounded in the realities of social experience.
This section has examined how bias detection builds upon the classificatory foundations laid by taxonomy to engage more directly with the practical challenges of identifying and evaluating bias in MT. While taxonomy offers a conceptual map of bias types and manifestations, detection methods operationalize these categories through benchmark datasets, quality estimation tools, and user-centered evaluations. These approaches have been developed largely in response to three persistent challenges: data imbalance, contextual deficiency, and social sensitivity. Benchmark construction addresses underrepresentation in training data; quality estimation captures discourse-level variation; and interdisciplinary methods aim to reflect culturally specific harms. Nevertheless, current practices often remain confined to isolated metrics or narrowly defined benchmarks, with limited alignment between detection protocols and real-world application contexts. In addition, there is still no unified normative standard for what constitutes harmful bias, leading to inconsistencies in evaluation criteria across studies. Although limitations remain—such as skewed benchmarks and unresolved ethical standards—these efforts represent meaningful progress. Detection thus serves as a bridge between conceptual understanding and practical intervention. By identifying patterns of harm and clarifying evaluative boundaries, it lays the groundwork for mitigation, with subsequent discussion turning to how targeted strategies can address bias across different stages of the MT development pipeline.
Multi-stage Bias Mitigation
To mitigate bias in MT systems, existing research has incorporated various technical strategies across different stages of model development, covering the entire pipeline from data preparation to model inference and evaluation.
Data collection and processing form the foundation of MT model construction, and eliminating embedded bias at this stage can significantly improve model performance. One feasible strategy is enhancing corpus balance. For example, Costa-jussà et al. (2020) used the Gebiotoolkit to construct a gender-balanced corpus from Wikipedia biographies, to improve the system’s fairness and robustness across gender groups. Another promising direction is the use of multimodal corpora; by integrating text with images, speech, and other inputs, models can improve their ability to recognize social identities, cultural symbols, and contextual nuances, thereby reducing bias in the output. This stage urgently calls for interdisciplinary collaboration, drawing on expertise from corpus linguistics, anthropology, and sociology to help curate, construct, and refine corpora, laying a solid foundation for addressing bias in MT. For example, Ding et al. (2024) show that using native image-text pairs in Chinese medical diagnosis tasks helps avoid cultural biases introduced by machine-translated English datasets, thus demonstrating the potential of multimodal data to mitigate language-related representational bias.
During the model design and training phase, a growing array of optimization strategies has been developed across key components such as representation, training, and inference. At the representation level, the hard debiasing method proposed by Bolukbasi et al. (2016) identifies the gender direction within word embedding spaces and reconstructs vector representations to eliminate gender stereotypes. The GN-GloVe algorithm further advances bias mitigation by confining gender information to specific embedding dimensions, thereby enabling more precise control over gender-related bias (Zhao, Zhou, et al., 2018). In addition, research has demonstrated that modeling contextual information by concatenating preceding and following sentences can help reduce gender bias in pronoun translation, indicating a close relationship between contextual richness and the emergence of bias (Basta et al., 2020). At the training stage, domain adaptation leverages data from specific registers or domains to enhance the model’s sensitivity to specialized language and the linguistic practices of particular groups. Empirical evaluations have shown that domain adaptation can outperform traditional corpus-level debiasing approaches in certain scenarios (Tomalin et al., 2021). Adversarial learning strategies, by introducing adversarial objectives during training, encourage models to weaken their dependence on biased features in internal representations, thereby fostering the development of more neutral and unbiased encodings (Jegadeesan, 2020; Ji et al., 2021). At the inference stage, transfer modeling based on high-resource bridge languages enables zero-shot learning, allowing for relatively fair translation outputs for low-resource languages even in the absence of direct training data (Cabrera & Niehues, 2023). Collectively, these approaches illustrate the increasing sophistication and diversity of debiasing strategies throughout the model development pipeline, from representational adjustments and training innovations to advanced inference techniques.
Beyond the training phase, a growing body of research has investigated external interventions aimed at mitigating bias without necessitating model retraining. One promising approach is post-processing, in which system outputs can be adjusted by adapting rule-based or ratio-based methods (Gennaro et al., 2024). Post-editing by human translators also constitutes a critical mechanism for bias intervention, which creates a complementary relationship between automated systems and human intervention. Particularly in sensitive contexts involving gender, culture, or race, human expertise can address deficiencies in the model’s pragmatic reasoning, contextual understanding, and value judgments. Moreover, the integration of real-time feedback mechanisms and user behavior data enables translation systems to dynamically adjust and respond to evolving social norms following deployment, establishing a framework for continuous and adaptive bias governance. Importantly, as several studies have indicated, effective mitigation of bias in MT systems cannot rely solely on technical adjustments. Rather, it benefits from the incorporation of interdisciplinary perspectives—particularly those grounded in linguistics, translation studies, and cultural analysis (Blodgett et al., 2020; Lew, 2024). For example, Lew (2024) highlights the role of human lexicographers in counteracting biases overlooked by automated systems, especially in data-scarce contexts. Similarly, Ciora et al. (2021) show that addressing both overt and covert gender bias in English–Turkish translation pairs requires culturally informed, language-specific methodologies. These studies suggest that more context-aware and culturally responsive mitigation strategies are likely to emerge from closer integration of technical and humanistic approaches—particularly in settings involving linguistic diversity or socio-cultural sensitivity.
This section has outlined a wide array of mitigation strategies deployed across the MT pipeline—from corpus construction and model training to post-processing and feedback integration. These interventions directly respond to the persistent challenges of data imbalance, contextual deficiency, and social sensitivity by improving representational coverage, enhancing discourse-level modeling, and incorporating human-centered judgment. Importantly, mitigation is not a discrete technical step but a cumulative and distributed process that builds on the diagnostic insights generated through bias detection. Each stage of system development and deployment—data, architecture, inference, and evaluation—offers distinct opportunities to reduce harm and promote fairness. As such, effective mitigation requires sustained, multi-actor collaboration that goes beyond technical refinement. Specifically, insights from linguistics, translation studies, and the broader humanities should be integrated not only at the evaluation stage but throughout the development process, informing corpus design, representational modeling, and value-sensitive interpretation. Nonetheless, many current practices remain narrowly scoped, with limited attention to the social factors. In the absence of clear normative guidelines or consensus-based standards, the effectiveness of mitigation efforts often varies across languages, domains, and user populations. Taken together, these efforts point toward a more equitable and context-aware future for MT systems in complex social environments.
Conclusion
As one of the challenges in the development of MT systems, bias continues to challenge the development of MT systems, undermining both the accuracy and reliability of translations while simultaneously prompting critical reflection on ethical standards and social equity. Through a systematic bibliometric analysis, this paper maps the publication patterns, collaboration networks, thematic evolution, and methodological pathways of international research on bias in MT from 2005 to 2024. The results show that research in this area has developed through three stages: initial exploration, steady accumulation, and rapid growth. This trajectory is characterized by a core focus on technological innovation, a gradual expansion into diverse social issues, and increasingly close transnational and cross-sector collaborations.
In addressing the multilayered challenges of bias classification, detection, and mitigation in MT, current research exhibits a landscape characterized by multiple focal points and coexisting methodological pathways. On the one hand, this diversity reflects the inherent complexity of bias as both a technical and sociocultural phenomenon, reflecting the field’s rich capacity for innovation. On the other hand, this diversity also means the existing studies are often fragmented in scope and disconnected in approach. Efforts across taxonomy, detection, and mitigation tend to operate in silos, with few shared standards or cross-cutting frameworks. This lack of coherence is especially evident in the uneven adoption of evaluation criteria and the limited presence of sociocultural or ethical considerations in dominant approaches. These patterns—identified through both bibliometric trends and close reading of selected studies—suggest that while methodological experimentation is flourishing, conceptual integration remains underdeveloped.
In addition, the other aspects that remain in need of improvement, as we have mentioned, include insufficient alignment between methodological frameworks and real-world application contexts, and the still limited consideration of sociocultural dimensions. For instance, naturalistic data sources remain underutilized compared to constructed benchmarks; “human evaluation” appears as a peripheral term in the thematic keyword network; and most studies continue to rely exclusively on computational methods. This is especially concerning given that the problem of bias in MT extends beyond technical shortcomings to encompass deeper questions of language ideology, cultural representation, and social justice. Although MT bias research is inherently situated at the intersection of technological and humanistic concerns—and although some recent studies have begun to emphasize interdisciplinary perspectives—computational approaches continue to dominate the field. Therefore, looking ahead, future research may benefit from closer interdisciplinary collaboration, drawing on theories and methods from the humanities and social sciences—such as linguistics, translation studies, cultural studies, and ethics. Grounding these efforts in real-world contexts could help bridge the gap between technological innovation and social values, thereby contributing to the development of more equitable and culturally responsive MT systems.
As a final note, we recognize the following limitation in our current approach. This review does not include empirical validation of the tools or frameworks it discusses. Given the wide scope of the study, which covers multiple classifications, detection methods, and mitigation strategies, conducting empirical validation would require selecting only a limited subset of systems or issues. This could introduce selection bias or reduce the breadth of the study. Attempting to evaluate all aspects, on the other hand, would not be feasible and might distract from the primary goal of synthesizing existing research. We therefore acknowledge this as a methodological limitation and plan to conduct follow-up studies to empirically assess selected approaches presented in this review.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.