
Abstract
The rise of the internet has generated a need for fast online translations, which human translators cannot meet. Statistical tools such as Google and Baidu Translate provide automatic translation from one written language to another. This study reports the descriptive comparison of the machine-translation (MT) with human translation (HT), considering the metadiscoursal interactional features. The study uses a parallel corpus consisting of 79 texts translated from Chinese to English by professional human translators and machine translations (Baidu translate & Google translate) and a comparable reference corpus of non-translated English text. The statistical analysis revealed no statistically significant difference between Baidu and Google translate regarding all types of metadiscoursal indicators. However, the findings of this study demonstrate significant disparities in the interactional characteristics of various HT and MT groups. Compared to the metadiscourse features in non-translated English political texts, human translators were found to outperform machine translations in the use of attitude markers. In contrast, the distribution of directives in machine-translated texts is more native-like. In addition, MT and HT have utilized a significantly smaller number of hedges, self-mention, and readers than non-translated texts. Our results indicate that the MT systems, though still calling for further improvement, have shown tremendous growth potential and may complement human translators.
Introduction
Today, the debate over machine translation and human translation is fierce. Machine Translation (MT) has always been a critical application in natural-language processing. It is a very active research area that has attracted significant commercial interest in almost every field. The majority has been driven by the deployment of corpus-based and statistical approaches that can be built in much less time and at a fraction of the cost of traditional, rule-based approaches while producing comparable or superior quality translations. As the quality of machine translation systems has increased substantially over the last decade, assessment has become an increasingly complex—and essential—challenge. Moreover, the systematic use of automated assessment in machine translation implies that automated evaluation closely corresponds with human evaluation and is language agnostic.
Nonetheless, despite recent advancements in machine translation such as cheaper and quicker, confidentiality, and universality, there have been debates over the efficacy of machine translation in contrast to human translations. Ahrenberg (2017) remarks that the primary purpose of MT is to overcome language barriers. However, HT has more ambitious purposes. This paper focuses on the translated texts taking into account the different aspects such as political, coherence, cohesion, and logical expressions embedded within the texts. In doing so, it presents a case study comparing the machine-translated corpus with the human-translated corpus of the same source text. Metadiscourse features are the elements that comprise the writer-reader and speaker-audience interaction in communication. As a result, this study aims to investigate the distributional pattern of metadiscourse features and translator-reader interaction in political texts translated by human translators and machine translators. It also attempts to compare the performance of different machine translation engines.
This study compares machine-translated texts with human translations by employing interactional features of metadiscourse. Metadiscourse relates to how we use language regarding our readers or listeners, depending on our assessment of how best we may assist them in processing and comprehending what we are saying (Hyland, 2018). This is significant because bringing attention to the text in this manner indicates a translator’s knowledge of the reader. The components that build interaction between writer-reader and speaker-audience are metadiscourse characteristics. Consequently, this contrastive parallel corpus-based study investigates how metadiscourse characteristics were employed and distributed in the machine and human translation. Hyland (2004, p. 109) describes metadiscourse as the process of organizing thoughts connected to the linguistic tools that writers employ to create their arguments to meet the expectations and inspire the intended audience. In addition, Afzaal et al. remark that metadiscoursal features are measured as an interpersonal resource available to text producers for the crafting and manifesting discourse or the writer’s standpoint toward their text and readers (Afzaal et al., 2021). Kopple (1985) argues that “writers do not add propositional material, but rather facilitate our audiences in organizing, classifying, interpreting, evaluating, and reacting to such material” (p. 83).
Previously, many researchers have studied metadiscourse in various domains such as academic writing, research articles, abstract writing, and even learners’ corpora. Although, for instance, some experts have maintained the focus on the very center of metadiscourse, that is, the characteristics of textual organization (Bunton, 2014; Mauranen, 1993a, 1993b; Valero-Garcés, 1996) or traces that stand out (Beauvais, 1989), metadiscourse is more perceived as the writer’s craft with language to inject influence in the text to “bracket the discourse organization and the expressive implication of what is being said.” (Schiffrin, 1980, p. 231).
Metadiscourse has made a variety of contributions to text analysis. Text qualities, participant engagement, cross-cultural differences, literary technique, and historical linguistics which have benefited from this work. In addition, it has been found that metadiscourse has a significant role even in informal communication (Schiffrin, 1980), science popularization (Crismore & Farnsworth, 1990), undergraduate textbooks (Hyland, 2004), postgraduate dissertations (Bunton, 2004), and textbooks for school (Crismore & Farnsworth, 1990; Hyland, 1998).
Various language features and attributes have been used to investigate the text’s impact and influence on diverse first-language writing groups (Crismore et al., 1993; Imran et al., 2019; Mauranen, 1993a, 1993b; Valero-Garcés, 1996). Additionally, it has also been found to be present in Early English medical writing, an attribute of good ESL and native speaker student writing; Intaraprawat & Steffensen, 1995), and a crucial component of persuasive and challenging discourse (Intaraprawat & Steffensen, 1995).
Metadiscourse markers were the focus of this study, which did not use automatic evaluation measures but instead relied on the help of a corpus. There are many problems with popular metrics like BLEU. These metrics, for example, are mainly quantitative indicators of quality/provide us with a holistic score rather than specific information about the translation performance. In order to determine whether MT can outperform HT in our context, we must examine parallel translated texts and concentrate on the translation of a specific crucial linguistic category (in this case, MD).
Machine translation systems cannot be improved without evaluating the translated output. Unfortunately, it is widely acknowledged that human judgments of the output are time-consuming and costly. Automated machine translation evaluation metrics have been developed in an effort to free MT developers from the dilemma of evaluating their output in a timely, convenient, and cost-effective manner (Lin & Och, 2004; Papineni et al., 2002; Sudoh et al., 2011). Even though automatic evaluation measures may contain parameters tuned for specific corpora, they may overfit their objective function while scoring unseen corpora less consistently (Huang, Chen et al., 2017; Huang, Geertzen et al., 2017). Human judgments can assess the quality of MT output in terms of adequacy, fidelity, and authenticity (Hovy, 1999), which can be used to improve the MT system. Therefore, our goal is to conduct a corpus-aided assessment of metalinguistic features in MT output and provide valuable information for further improving the MT system by analyzing paralleled translated texts in this study.
Assessment of translation quality is a difficult task involving a wide range of linguistic and extralinguistic factors in academic and professional settings. In addition, language, culture, and technology all come into play when translating. Accordingly, it has been difficult for translators to operationalize and measure the concept of translation quality because of translation’s inherent complexity. Because of this, definitions of translation quality aim to capture these aspects and their interactions in order to develop a system for formally rating translation quality for a specific purpose.
Although Translation Quality and Its Assessment (TQA) is widely acknowledged as a critical topic in the field of translation and localization, the approaches taken by academia and business to define and evaluate translation quality are vastly different. According to Drugan (2013), “theorists and practitioners are unanimous in their belief that there is no one objective way to quantify quality.” Although researchers and academics are increasingly addressing translation quality assurance (TQA), in most industry sectors, it is confined to the application of somewhat arbitrary “one-size-fits-all” error typology models that aim to provide quantitative indicators of quality (Lommel et al., 2017).
However, according to Hyland, the art of metadiscourse is commonly practiced as art by authors to efficiently operate the stream of words in such a way that they generate the desired result of understanding. While adhering to community ethics and customs is a delicate lever that gives writers the freedom to pivot and change their opinion in the text. Most scholars believe metadiscourse has the most critical role in shaping the text and providing meaning. However, the second possibility exists if the linguistic form is regarded as part of metadiscourse. Many challenges stem from how difficult it is to extract metadiscourse from the surrounding context (e.g., Hyland, 2004).
It can be said that there are many overlaps between the metadiscourse categories and classes themselves, making it challenging to describe the metadiscourse markers in the real world accurately. Even though metadiscourse has gained popularity, its boundaries have yet to be defined (Swales, 1990). As a result, it is essential to analyze each key and element of the medtadiscourse individually to fully understand. Authors use metadiscourse tools to convince readers to share their views and ideas, which lead to spread the knowledge in academia. The question arises here is whether machines also use such interactive features to create a reader-writer interaction in the translation or not.
In addition, when it comes to the relationship between propositions and conjunctions, Hyland posits that all external conjunctions transmit real-world entities (propositional substance). In contrast, interior conjunctions communicate metadiscourse (non-propositional matter). However, as Hyland (2004) points out that the propositional matter is linked to the world, and metadiscourse points to the text, text reception does not take precedence over all other aspects of the communication model. This model refers to these dimensions as interactive and interactional because of how they interact. The authors used interactive resources to identify readers’ potential knowledge and educational background to create exciting and engaging work. Language carries the methods writers use to broadcast their beliefs and judgments in the text, and interpersonal functions are a part of those strategies. Writers strive to build a relationship with their audience by adhering to the established discourse community principles. Writing in an interactive discourse setting allows writers to argue over their assertions and emphasize their ideas and presence while interacting with readers.
Because this was a contrastive corpus-based study, compiling a balanced and representative corpus was inevitable (Anthony, 2009). It was determined that Hylands’ interpersonal metadiscourse model distinguishes between interactive metadiscourse and interactional metadiscourse. Interactive metadiscourse is used to decorate textual parts to fulfill the reader’s satisfaction while he is on the journey of reading the text. They decorate textual elements to improve textual coherence and leave the writer’s presence. This study adopted the interactional metadiscourse model to compare the human-translated texts with the machine translation of the same corpus. Five kinds of interactional metadiscourse were studied in this paper: boosters, self-mentions, attitude markers, hedges, and engagement markers. Hedges (perhaps) are applied to reduce the impact of assertiveness and widen the dialogic space, and boosters (demonstrate) are employed to express the writer’s assurances and to close the choices.
Finally, the study is significant because metadiscourse is the commentary on a text made by its producer in speaking or writing and has become one of the most productive ways of modeling interaction (Hyland & Jiang, 2018; Läubli et al., 2020). The study’s outcome provides a broad overview of metadiscourse and its utilization in translation and machine translation in the digital era. It offers direct implications for improving the machine translation system to produce native-like translated output. The study of significance highlights that MT has increased these days. The study is designed to understand why machine translation has not achieved significant status in academic circles and translators.
The evaluation of translated output is somewhat necessary for improving machine translation systems. Unfortunately, it is well recognized that human judgments of the output are incredibly time-consuming and expensive. To rerelease MT developers from the evaluation dilemma, various automatic machine translation evaluation metrics have been developed to achieve rapid, convenient, and economic assessment of MT output (Lin & Och, 2004; Papineni et al., 2002; Sudoh et al., 2011). However, it should be noted that automatic evaluation measures may consist of parameters tuned for particular corpora, which may overfit its objective function while scoring unseen corpora less reliably (Huang, Chen et al., 2017; Huang, Geertzen et al., 2017). On the other hand, human judgments can gage MT output concerning the level of adequacy, fidelity and authenticity (Hovy, 1999), and help develop the MT system. Therefore, we attempt to conduct a corpus-aided assessment of the metadiscourse features in machine-translated output in this work. We expect to provide valuable information to further improve the MT system by scrutinizing the paralleled translated texts. Machine translation is always valuable and has provided ease to humans in the 21st century. But there have been many controversies regarding the quality of machine translations, such as MT does not achieve publication quality.
According to Hyland (1998), metadiscourse is considered one of the major rhetorical strategies that helps achieve an explicit organization of texts and imply the speakers’ attitude. It is used not only according to the writers’ purpose and relationship to the audience but the social context (Hyland, 2018) and “norms of expectations of cultural and professional communities” (Hyland, 1998). Language users (Finnish writers, for instance) with a cultural background favoring implicit rhetorical strategy may use less metadiscourse than the others (such as Anglo-American writers) to guide their audience (Mauranen, 1993a, 1993b). Therefore, the translation of metadiscourse can be challenging for either human or machine translators as it requires more than clues embedded in texts. Herriman (2014) analyzed English and Swedish texts and their translations in the English-Swedish Parallel Corpus. She found an increase in transition markers in the translated texts and decreased level of emphasis by omitting boosters or adding hedges. Previous studies focusing on the usage of metadiscourse in machine-translated texts are somewhat limited. Hence, the objective of this study is to investigate the performance of employing metadiscourse in the target language translated by the MT system. For this study, the following hypotheses have been set.
H1: It is hypothesized that there is a statistical significant difference in metadiscoursal features between different machine translation systems translated texts.
H2: H1: It is hypothesized that there is no significant difference in metadiscoursal features between different machine translation systems translated texts.
To investigate and testify the hypotheses, the following research questions are set;
Is there any significant difference in metadiscoursal features between different machine translation systems translated texts?
Is there any significant difference in metadiscoursal features between machine-translated texts and human-translated texts?
Are there any differences in metadiscoursal features between translated texts (machine and human translated) and non-translated texts, and if so, in which aspects and to which level?
Materials and Methods
Corpus Construction
The corpus of the study is constructed based on the source text, which is the first volume of a published book series entitled Xi Jinping: The Governance of China (Xi Jinping tan zhiguo li zheng  ), which is a collection of political speeches by the current leader of China. It outlines the foreign policies and domestic politics in China. The Governance of China has been considered an encyclopedia that offers insights into the political ideas of the Chinese government. Therefore, significant efforts have been attributed to the translation of this book series. Each volume was translated by a group of “high-caliber, dedicated, very responsible, and efficient (Wang & Zhao, 2013)” translators following highly regulated and comprehensive standard translation procedures (Zappone, 2021). The human-translated English version of The Governance of China was published in 2014 by the Foreign Language Press.
), which is a collection of political speeches by the current leader of China. It outlines the foreign policies and domestic politics in China. The Governance of China has been considered an encyclopedia that offers insights into the political ideas of the Chinese government. Therefore, significant efforts have been attributed to the translation of this book series. Each volume was translated by a group of “high-caliber, dedicated, very responsible, and efficient (Wang & Zhao, 2013)” translators following highly regulated and comprehensive standard translation procedures (Zappone, 2021). The human-translated English version of The Governance of China was published in 2014 by the Foreign Language Press.
Analysis Procedure
Firstly, a subcorpus of human-translated texts was built for our analysis. The Optical Character Recognition (OCR) technology and manual post-correction were applied to convert the human-translated English version of The Governance of China into high-quality editable text. Secondly, Baidu translate (BT) and Google Translate (GT) were employed to generate machine translation texts of the first volume of Xi Jinping: The Governance of China. The two translators have reached a large user base and helped many people with translation work. Thirdly, a reference corpora of non-translated English political texts containing the State of the Union Address (SUA) in the last 31 years was compiled for further comparison. The States of the Union Address by the presidents of the United States has become an ideal counterpart to the Chinese source text, as they both deal with political proposals, achievements, etc. The overall summary of the corpora is given in the following Table 1.
Summary of Corpus Data.

A one-way between-groups Analysis of Variance (ANOVA) was conducted to compare the effect of translation status (i.e., human translation, Google translate, Baidu translate, and non-translated texts) on the application of metadiscourse features (i.e., hedges, boosters, attitude markers, self-mentions, readers, and directives). As the study is based on Hyland’s interactional metadiscourse categories (i.e., hedge, booster, attitude marker, self-mention, reader pronoun, and directive), we used Authorial Voice Analyzer (AVA) developed by Yoon (2021). Yoon (2021) proposes that AVA has been designed to cover a wide range of interactional metadiscourse markers and capture linguistic variability in word sequences through regular expressions. It was reported to achieve a satisfying accuracy rate for quantifying interactional metadiscourse markers (Yoon, 2021). Therefore, the study focuses on the metadiscourse interactional features reflected in MT and HT. We used the expected standard to compare the translated and non-translated texts.
Results and Discussions
The machine-translated, human-translated, and non-translated texts were compared in this contrastive corpus-based study to expose and compare the distributional pattern of metadiscourse traits. Machine translation and translation corpora from Chinese into English were built to achieve this goal. Hyland’s (2014) model of interactive and metadiscourse features were utilized to classify metadiscourse features. The statistical analysis and the corpus reading can reach a wide range of conclusions.
Table 2 presents the descriptive statistics of the six kinds of meta-discourse features employed by each translation subject. Knowing that the source texts vary significantly in length, we have normalized the raw frequencies based on their occurrence per 1,000 words to eliminate the influence of text length.
Descriptive Statistics for Metadiscourse Features by Categories.

Table 3 presents the results of the one-way ANOVA analysis used to compare the effects of translation subjects (i.e., Google translate, Baidu translate, Human translation, and non-translated texts) regarding their metadiscourse features (i.e., hedges, boosters, attitude markers, self-mentions, readers, and directives). Moreover, for a more transparent look, the results are performed with Levene’s test for the assumption of homogeneity of variance and Welch correction when the assumption was violated. The significance cut-off of Bonferroni post hoc tests was adjusted for a comparison of a family of four to avoid Type I error. Eta-squared (η2), the measure of effect size, was reported to represent the percentage of variance, which the independent variables can explain.
ANOVA Results.

p < .001.
Results of the ANOVA test revealed a statistically significant main effect for translation subjects. Significant differences were found in the use of hedges (p < .001, η2 = 0.200), boosters (p < .001, η2 = 0.057), attitude features (p < .001, η2 = 0.073), self-mentions (p < .001, η2 = 0.244), readers (p < .001, η2 = 0.592), directives (p < .001, η2 = 0.047). The amount of variance accounted for by independent variables varies significantly as eta-squared ranges from 0.047 to 0.592, among which predictor exercised the most apparent effect size for the use of readers.
Bonferroni post hoc comparisons were conducted to further clarify the differences among translation subjects. The results are summarized in Table 4. The first comparison is between the machine translation systems, that is, Baidu translate and Google translate. The post hoc testing reported no statistically significant difference between Baidu and Google in translating concerning all kinds of metadiscoursal markers. The second comparison concerns the usage of metadiscourse between machine translations and human translators. It was found that both Google translate (M = 2.88, SD = 2.26) and Baidu translate (M = 2.88, SD = 2.20) have used significantly fewer hedges than human translators (M = 4.05, SD = 2.80). Moreover, either Google translation (M = 13.38, SD = 7.60) or Baidu translation (M = 16.76, SD = 7.81) have utilized significantly less readers than human translators (M = 4.05, SD = 2.80). No significant difference was observed concerning the use of boosters, attitude markers, self-mentions, and directives.
Bonferroni post hoc Comparisons Between Different Translation Subjects.

Note. - no significant difference. P-value adjusted for comparing a family of 4.
p < .05. **p < .01. ***p < .001.
In addition, the third comparison, examining the difference between translated and non-translated texts, has rather yielded mixed results. Firstly, the findings indicated that non-translated texts contained significantly more hedges (M = 6.58, SD = 1.56), self-mentions (M = 12.89, SD = 4.17), and readers (M = 47.26, SD = 5.47) than all kinds of translated texts. Secondly, the use of boosters in Baidu and human translations was significantly more frequent than in non-translated texts. At the same time, no significant difference was found between Google translate and non-translated texts. Thirdly, an interesting result to emerge from the data is that the two machine translation systems used significantly more attitude markers than non-translated texts, while human translators managed to approximate non-translated texts in the use of attitude markers. On the contrary, regarding the use of directives, machine translations employed a similar number of directives as in non-translated texts. In contrast, human translators used a significantly smaller amount than the native speakers of the target language did in non-translated texts.
The following Figure 1 clearly illustrate the different use of metadiscourse in machine-translated, human-translated, and non-translated texts.
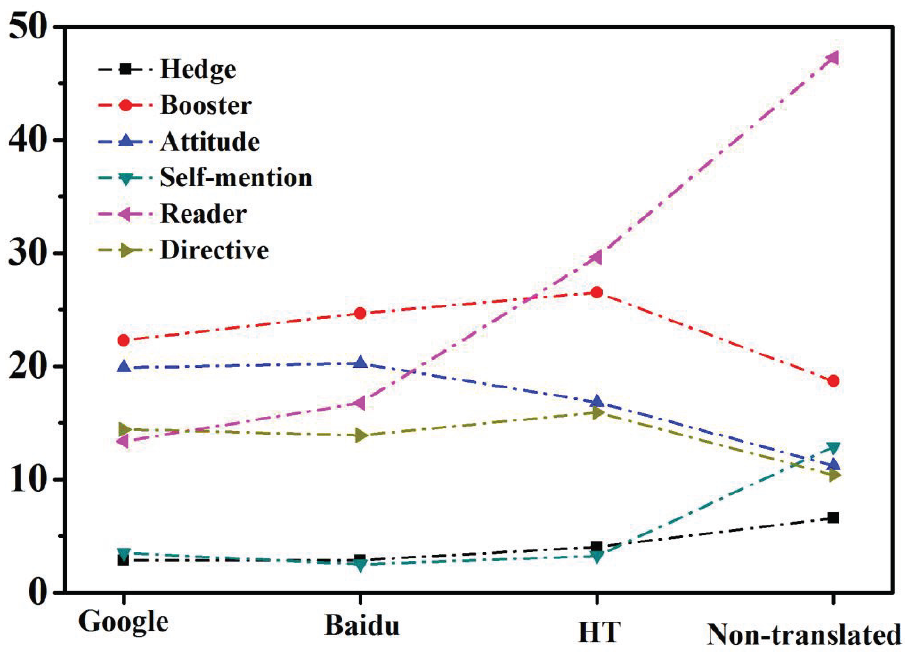
Overall comparison of metadiscourse features between HT and MT.
Discussion
The study investigated the differences between human translations (HT) and machine translations (MT) at the level of metadiscourse features employed in the texts through a corpus-based comparative analysis. Our findings show that the performance of machine translations and human translators vary, which can be debated further to improve both machine and human translations. For example, machine translations were found to have employed a significantly smaller number of hedges, self-mentions, and readers than both human translators and non-translated texts. In addition, human translators surpassed machine translations in the translation of attitude markers. However, machine translations outperformed human translators using directives as no significant differences were found between machine-translated and non-translated texts.
Hedges are one of the most critical metadiscursive resources that reflect the author(s)’ ambivalence by enabling the other voice to be interjected. The author expresses his subjectivity toward the idea by utilizing hedges, which underlines that his comments are more opinions than facts. Alternative voices must be inserted into the text to support this logical reasoning and argumentation. Unfortunately, our findings have shown that the translation of hedges has posed problems for both machine and human translators. The different cross-cultural and cross-linguistic contexts of the source (Chinese in our case) and target language (i.e., English) texts may have caused the problems. Hu and Cao (2011) conducted a quantitative analysis and reported that abstracts in English-medium journals used more hedges than those in Chinese journals. Our results echo Amiryousefi et al. (2019), who found that about 40% of hedges were omitted or altered by translators despite their significance. Sufficient contextual clues and prior cross-linguistic knowledge ought to be further fed into machine translation systems and human translators to help better translate hedges from Chinese to English.
This study shows apparent differences in interactional characteristics across various HT and MT. Compared to other MT, the text translated by humans had more hedges and readers, whereas the text forwarded by MT had a more significant number of boosters, attitude markers, self-mentions, and directives. This could be because translators are developing their position on the proposition of employing more metadiscourse makers to engage in more politeness and express openness to unconventional ideas (Holmes, 1982). To avoid uncertainty and doubt, MT tends to focus more on expressing ideas and arguments in a straightforward style, with less regard for knowledge stance or communicating with the readers. These research findings focus on broadening the classification of East Asian English language learners or those with similar linguistic and cultural values in L2 teaching and research activities.
Many studies have investigated metadiscoursal features in academic writing, L2 acquisition, and L2 writing proficiency. The findings of these studies support the results of noticeable L1 differences support what Odlin and Jarvis (2004) mentioned in their study of influences for L1 speakers. For example, Afzaal et al. (2021) revealed a statistically significant difference in the use of metadiscourse in theses written by Chinese native speakers (CNS) and English native speakers (NS) university students. Hence earlier studies reveal that the genuine aim of most L2 writers/translators is to develop the skill of writing text as like those of their NS colleagues (e.g., Zhou, Busch et al., 2014), which proves the methodological decision of setting essay from NS student as the standard. However, our study is different because it compared incorporating interactional metadiscourse features in MT and HT. This research report, the same as earlier studies (e.g., Hyland & Milton, 1997; Lee & Deakin, 2016), says that L2 translators employ fewer hedging markers when compared to their counterparts at NS but more when compared to MT. Nevertheless, again, this is because they keep straight and uncomplicated affirmations.
On the other hand, this current study also suggests that equal execution of boosters, attitude markers, self-mentions, and directives increases cohesion in the texts. It’s a common trend among all the translators’ groups of L2 that they pay more attention to the need to emphasize and present more about it for writing methods for L2 learners. Further, all the L2 groups are over employing reader pronouns than the NS group can be perceived because of various cultural backgrounds in balance with the respective community, as sole self-projection was taken as impolite and caused rejection (Bloch & Chi, 1995; Shen, 1989). Although so far, the meaning has been extracted in a way that translators over usage of reader pronouns aimed to establish everyday basis between the readers (Hyland, 2001), we also know that extra usage of personal pronouns causes an imbalance in academic writing. Therefore, if instructors come across L2 translators with exceeding use of reader pronouns, they recommend guiding students for its drawbacks, making them compare model essays with their writing.
In academic writing, the voice is extensively recognized. Current empirical consideration has been attached to the problems of what earlier measures contributed to the voice and how to conclude its strength. As stated above, for sure the voice does not originate or converge from the sole source of textual characteristics but rather (Tardy & Matsuda, 2009) present the findings in their study that editor’s group of journals perceive writers’ identities established on the number of traits expressing the use of tentative style and jargon. Many researchers support Hyland’s (2017) text-based voice model to measure the formation of voice ingredients, which are later presented in the following section. As Hyland (2017) mentioned classification of metadiscourse, Wang and Zhao (2013) formed a set of instructional tools for measuring the voice for writing challenging text. With the qualitative methods and factor analysis, for example, thinking aloud and conducting interviews, the instructions were clear to grab the voice from three dimensions: (1) the presence of ideas and clarity in the content; (2) the style of the presentation of ideas; and (3) the same extent the existence of reader and writer” (Wang & Zhao, 2013, p. 201).
The result of thorough measurement for seeking a voice in essay writing has achieved the milestone, as research on the graduated theses carried all types of measures. Such as Morton and Storch (2019) carried out a study in which two separate texts were compared written by PhD students in their first year and the last year of their graduation. These researchers adopted the readers’ perspective and requested five PhD supervisors to assess the writer’s voice delivered in those chosen texts based on Rubric from Tardy (2012). Morton and Storch’s (2019) research the innovation for producing qualitative results by requesting respective supervisors to underline text parts that may have the element of writers’ voice and conduct a follow-up talk.
Finally, it has been observed that language and culture are the vital factors behind the translators’ engagement in metadiscourse; other reasons like discipline, category and translator’s status also appear to relate to the culture in challenging-to-measure ways. For example, strict writing rules seem to hinder the thesis writer in applying a few features from metadiscourse.
Conclusion and Future Work
The study compared human translation and machine-translated texts based on the metadiscourse features, differences between MT and HT can be revealed simply by statistical metrics. However, in this case, the study employed Hyland’s metadiscourse academic writing features to see the difference in interactional metadiscourse in HT and MT. According to metadiscourse, writing catalyzes social interaction between the author and the audience (Thompson, 2001). The study highlights no statistical significance difference in comparing interactive features in HT and MT, such as boosters, attitude markers, self-mentions, and directives.
Hence, the HT and MT corpora have a very distinct structure. Even though both were interactively oriented, there were differences between the English and the Chinese corpus in terms of subcategories of interactive and interactional metadiscourse traits (Tables 3 and 4). Considering the second research question, it can be said that the distribution of interactional metadiscourse features in the HT and MT corpora differed statistically significantly, indicating that the HT corpus contains more hedges and readers than the MT corpus. Consequently, the first and second research questions and null hypotheses were rejected. The study proved statistically different metadiscourse features between translated texts by MT and HT. The study also answered the third question: translated texts contain more hedges and readers than MT corpus, whereas the study did not find any difference between boosters, attitude markers, self-mentions, and directives. Based on the current findings, the study highlights that another topic with a large dataset may be considered to measure the statistical differences between machine-translated and human-translated texts.
The findings of this research could have implications for a variety of stakeholders. First, this paper’s approach and corpus development part may be valuable for researchers who plan to conduct corpus-based investigations. The outcomes of this study will be helpful to language scholars who wish to conduct contrastive studies. Researchers that are interested in genre analysis are the last but not the least of the group to benefit.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project is funded by Education Research Lab, Prince Sultan University, Saudi Arabia.