
Abstract
Creative problem solving (CPS), a cognitive and affective system, generates innovative solutions. The integration of generative artificial intelligence (AI) tools, such as ChatGPT, with CPS processes has transformed the field, particularly through prompt engineering. Despite the proliferation of generative AI and the prompts that go with it, previous research has only defined their effectiveness and explored their implementation. This study is the first to investigate the influence of prompt elements on CPS performance and the user experience, as measured by user satisfaction and emotional arousal, in interactions with generative AI. We measured five prompt elements: contextual assignment, number of prompts, assigned persona, output format designation, and critical attitude. Data from a ChatGPT prompting contest at a South Korean university were analyzed using mixed-methods to examine the impact of these elements on problem-solving performance and the user experience. The results show that contextual assignments and the number of prompts positively affect CPS performance, whereas assigned personas influence user satisfaction and dissatisfaction. Additionally, the satisfied user group performs CPS at a higher level than that of the dissatisfied group. These findings provide insights into the use of ChatGPT prompts to improve CPS performance and facilitate human–AI collaboration.
Introduction
Since Osborn’s (1963) seminal work, creative problem solving (CPS) has been widely studied as a structured approach for fostering innovative thinking. CPS, a comprehensive cognitive and affective system, deliberately stimulates creative thinking by leveraging natural creative processes, ultimately leading to novel solutions and changes (Puccio et al., 2010). The benefits of CPS have been recognized in the education, industrial, and government sectors, with evidence suggesting that CPS can enhance organizational performance. Recently, workplace emphasis on CPS has intensified in response to the growing complexity and uncertainty in business, locally and globally (World Economic Forum [WEF], 2020).
The rapid adoption of generative artificial intelligence (GAI) tools, particularly large language models (LLMs), such as ChatGPT, has introduced new dynamics into the CPS process (Dwivedi & Banerjee, 2024). These tools are increasingly used for information retrieval to support complex cognitive tasks such as ideation, reflection, and co-construction. They actively assist users in key CPS stages, including idea generation and problem framing, and often engage in iterative interactions to expand creative possibilities (Cress & Kimmerle, 2023; Urban et al., 2024). As GAI becomes a participant in open-ended tasks, it challenges the traditional notion of CPS and provides new opportunities for human–AI collaboration (Memmert & Bittner, 2022). For example, GAI tools are already being adopted in the educational, creative, and research domains, in which CPS-like tasks are performed (Adiguzel et al., 2023; Kasneci et al., 2023; Lo, 2023). Moreover, GAI tools can theoretically support different stages of the CPS process by offering diverse perspectives, generating alternatives, and enabling iterative refinement (Cress & Kimmerle, 2023; Kasneci et al., 2023). Vernon et al. (2016) emphasized the importance of matching appropriate tools to each CPS stage to improve learning outcomes and execution.
Recent research has emphasized the role of prompts in shaping the interaction between users and GAI tools. Prompts do not merely function as instructions to trigger AI responses, but serve as cognitive and affective mediators that articulate user intent and influence the depth and direction of problem-solving (Henrickson & Meroño-Peñuela, 2023; Oppenlaender, 2023; Short & Short, 2023; Wang et al., 2024; Zamfirescu-Pereira et al., 2023). Therefore, prompts may be technically functional and procedurally significant, particularly within the CPS process. Previous studies have suggested guidelines for composing prompts; however, empirical evidence on the effect of prompt characteristics on problem-solving performance is scant (Clayton, 2023; Cook, 2023). Furthermore, existing approaches to prompts are often overly standardized and fail to account for the diversity of user goals and contexts (Gupta et al., 2024; Han & Choi, 2023). Such rigid practices risk simplifying complex user–GAI interactions and limiting the problem-solving potential of users and technology.
To address this gap, this study investigated how specific prompt elements—contextual assignment, number of prompts, assigned persona, output format designation, and critical attitude—affect CPS performance and user experience in problem-solving tasks facilitated by ChatGPT. These elements were selected based on previous studies on structured prompt designs (Clayton, 2023; Cook, 2023; Reynolds & McDonell, 2021; Velásquez-Henao et al., 2023; White et al., 2023). Data were collected from a ChatGPT prompting contest held at a South Korean university in which undergraduate participants engaged in open-ended CPS tasks under time and goal constraints. In this high-engagement, user-driven environment, participants were free to construct, revise, and optimize their prompts in response to the unfolding task requirements.
This research article contributes to the field of human–AI collaboration by offering a focused analysis of prompt engineering within the context of CPS. By examining the influence of prompting strategies on performance and emotional engagement, this paper moves beyond guideline-based approaches and provides insights into the dynamics of user–GAI interaction. The results of this study offer implications for fostering user-centered and context-sensitive CPS practices in GAI environments.
Literature Review and Research Questions
ChatGPT and Prompt Engineering
Effectively leveraging ChatGPT in educational contexts or workplaces depends on the strategic use of prompts (Dai et al., 2023; Reynolds & McDonell, 2021). They are carefully crafted guides that steer the chatbot’s dialogue toward achieving specific objectives and handling complex problem-solving tasks. Prompt engineering, a sophisticated conversational strategy that goes beyond guiding responses (Henrickson & Meroño-Peñuela, 2023; Short & Short, 2023; Wang et al., 2024), establishes a conversational context by setting specific rules and guidelines, influencing how the dialogue unfolds (White et al., 2023). Designing and refining prompts to mirror user intentions accurately is crucial, particularly for improving student engagement and learning outcomes in educational environments and enhancing work performance in workplaces.
Ongoing academic research spanning diverse applications of GAI has highlighted the significance of meticulously developed prompts (Dai et al., 2023; Han et al., 2022; Liu & Chilton, 2022). These range from structured prompts in image generation (Liu & Chilton, 2022) to document categorization improvements (Han et al., 2022), to enhanced reasoning skills via chain-of-thought prompting (Dai et al., 2023). The evolution of this field has led to the development of new methodologies and frameworks that aim to refine interactions with language models and create adaptable prompt patterns for various domains (Lo, 2023; White et al., 2023).
OpenAI has outlined a methodology for optimizing outcomes from ChatGPT, providing specific suggestions for formulating prompts that can serve as criteria for delineating the characteristics of proficient prompts (OpenAI, 2023). Strategies, such as writing clear instructions, providing reference text, and splitting complex tasks into simpler subtasks (OpenAI, 2023), are instructional aids for utilizing ChatGPT and benchmarks for appraising prompts. These strategies highlight specific aspects of prompting—adopting a persona, methodically delineating problem-solving steps (quantifying prompts), and specifying response methodologies such as summarization or enumeration. Ouyang et al. (2022) identified toxicity, bias, and honesty as primary evaluation parameters in a natural language processing experiment using ChatGPT. They suggested that, to be effective, prompts should yield ethical and impartial outcomes. Moreover, providing additional context or background and delineating the conversational scope is imperative when eliciting the desired response by posing queries to ChatGPT . These supplementary elements can be facilitated using prompt formulas and templates. Clayton (2023) introduced the concept of a “power prompt” that amalgamates diverse prompt formulas. Power prompts advocate integrating personas, roles, activities, and methods, judiciously applying suitable methodologies and expertise aligned with the objective, and fostering coherence and synergy to address problems effectively. Furthermore, to enable non-expert users to formulate effective prompts, the behaviors, intuitions, preferences, and capabilities of users should be considered in prompt engineering (Zamfirescu-Pereira et al., 2023).
We selected the following criteria reported in previous studies as suggestions for prompt engineering: query, user activity, and user attitude toward ChatGPT. Queries are formed using contextual or situational information to obtain the desired responses from ChatGPT (Cook, 2023; Gewirtz, 2023). Users can assign ChatGPT a role and request responses based on the assigned personas (Clayton, 2023). Although several studies have indicated that persona settings do not improve ChatGPT results (Y. Chen, Wong, et al., 2023; Gupta et al., 2024), we included persona assignments to verify the extent of their impact. Additionally, users can design formats of output (Clayton, 2023). User activity refers to the number of times a user interacts with ChatGPT. Finally, a user’s attitude toward ChatGPT indicates how critically the user accepts the answers provided by ChatGPT or controls ChatGPT to obtain the desired results (Cook, 2023; Ouyang et al., 2022).
CPS and ChatGPT
CPS involves the effective integration of problem understanding, contextual awareness, critical thinking, domain knowledge, and the application of appropriate processes. Osborn (1963) originally conceptualized the CPS process as comprising three key stages: fact, idea, and solution finding. Isaksen and Treffinger (1985) refined these stages to understanding problems, generating ideas, and planning actions. Subsequent researchers further developed this model (e.g., Puccio et al., 2005). Vernon et al. (2016) reviewed tools applied in different stages of CPS and noted that some positively influence problem definition and ideation. However, they also observed that empirical support for tools related to problem construction and evaluation remains limited, warranting further research.
CPS provides a structured yet flexible framework that emphasizes iterative ideation and the balance between divergent and convergent thinking (Puccio et al., 2005; Vernon et al., 2016), which aligns well with the unfolding of prompt-based interactions with generative AI tools. White et al. (2023) and Oppenlaender (2023) show that prompt engineering shapes the flow of interaction and that iterative experimentation and refinement significantly affect the quality and functionality of GAI outputs. These parallels offer a compelling basis for considering a CPS perspective in examining prompt-based human–AI interactions in this study.
Recently, the CPS domain has entered a new phase with the advent of GAI, particularly LLMs, which are increasingly integrated into creative and educational contexts (Adiguzel et al., 2023; Kasneci et al., 2023). GAI tools assist users in problem solving by providing new ideas and divergent perspectives (Rick et al., 2023). Although the theoretical connection between CPS and GAI is developing, recent research has provided promising insights into their interaction. For example, GAI can perform on par with humans in certain problem-solving contexts (Orrù et al., 2023), and human–AI collaboration often yields more practical and impactful solutions, especially when humans iteratively refine AI-generated ideas (Boussioux et al., 2024; Memmert & Bittner, 2022). Moreover, effective outcomes are achieved through complementary collaboration, in which humans contribute to originality and critical evaluation, whereas GAI provides diverse perspectives and practical alternatives (Urban et al., 2024).
Several studies on education have examined the implementation and impact of GAI on CPS. Students using ChatGPT for programming instruction significantly improve their computational thinking skills (Yilmaz et al., 2023). Tools such as ChatGPT and BingChat enhance reflective thinking and concept comprehension in STEM learning settings (Vasconcelos & Santos, 2023). Thus, GAI significantly affects domains in which complex problem-solving is essential. As these examples show, recent studies have begun to explore how the structure and characteristics of human–AI interactions, particularly prompt design, may influence the quality and outcomes of CPS tasks (Cress & Kimmerle, 2023; Oppenlaender, 2023).
Despite this growing body of research on the interaction between CPS and GAI, a critical gap in the literature remains regarding empirical studies that examine how prompting—the key mechanism shaping human–AI collaboration—influences CPS performance (Cook, 2023; Reynolds & McDonell, 2021; White et al., 2023). To address this gap, this study used ChatGPT as a CPS tool and analyzed the effects of specific prompt elements on CPS performance and user experience. It employed the approach of Mumford et al. (1997), which measures CPS engagement by having participants complete problem-solving tasks. Therefore, we propose the first research question:
RQ1. Which elements of prompting are associated with higher CPS performances?
User Satisfaction and Emotions
Emotions are crucial for understanding the interactions of users with their external environment and involve an intricate combination of contextual factors that induce affective experiences (Dubé & Menon, 2000). Users’ emotional responses have been characterized as psychological phenomena (Thüring & Mahlke, 2007) with two dimensions: valence and arousal (Lang et al., 1993). Valence is the extent to which positive (toward) or negative (away from) emotions are elicited by a stimulus. Arousal is the level of emotional activation induced by a stimulus. These two dimensions are orthogonal, indicating their independence (Lang et al., 1993). This study focused on emotional arousal because previous studies have not explored it sufficiently compared with emotional valence (Zsidó, 2024). As emotions generated during interactions with information systems can affect user satisfaction, they have been widely adopted in assessing information system effectiveness. Moreover, as satisfied users are more likely to continue using these systems (Tsai et al., 2014), several studies have highlighted the importance of satisfaction. It can be defined as the affective and cognitive evaluations users obtain from a pleasant experience of using information systems (Au et al., 2002); we adopted this definition for using ChatGPT in this study.
Prompting with ChatGPT is similar to communication involvement (Muncy & Hunt, 1984), which is associated with user information processing (e.g., information search) and is likely to result in goal-directed behavior (Hoffman & Novak, 1996). A higher level of communication involvement stimulates users to concentrate more on the information presented to them, resulting in satisfaction with their information-seeking activities (Mahmood et al., 2000; Santosa et al., 2005). Similarly, prompting involves a high level of interaction and concentration to seek the appropriate information, leading to our second research question:
RQ2. Which elements of prompting are associated with higher user satisfaction?
In this study, emotional arousal—the degree of feelings activated by a user—was limited to the users’ interactions with ChatGPT. Users assess the appropriateness of the ChatGPT output based on their objectives, which may or may not trigger user emotions. Thus, we arrive at our third research question:
RQ3. Which elements of prompting are associated with higher emotional arousal in users?
Interactions with applications during the search for information and the achievement specific goals are known to affect user satisfaction (Mahmood et al., 2000; Santosa et al., 2005). When searching, users have pleasant experiences and are satisfied when they receive answers that exceed their expectations or results that satisfy their goals. Applying these research results to interactions with ChatGPT, we devised our fourth research question:
RQ4. Does the user group that is satisfied with the prompt outputs exhibit better CPS performance than the dissatisfied group?
Research Methods
Sample and Data Collection
To explore the relationship between prompt engineering and CPS performance, we analyzed the data collected from a ChatGPT prompting contest held at a university in South Korea in May 2023. Participants included students with a diverse range of majors, including engineering (n = 16, 25.8%), software (n = 14, 22.58%), business and economics (n = 12, 19.36%), social sciences (n = 7, 11.29%), humanities (n = 6, 9.67%), natural sciences (n = 3, 4.84%), pharmacy (n = 2, 3.23%), and education (n = 2, 3.23%).
All participants were current students. The distribution of admission years was fairly even: admitted before 2017 (n = 6, 10.17%), in 2018 (n = 11, 18.64%), in 2019 (n = 10, 16.95%), in 2020 (n = 11, 18.64%), in 2021 (n = 6, 10.17%), in 2022 (n = 10, 16.95%), and in 2023 (n = 5, 8.27%). This study included 29 males (49.15%) and 30 females (50.85%). The age groups included teenagers (n = 1; 1.69%), individuals in their thirties (n = 1; 1.69%), and those in their twenties (n = 57; 96.62%). Although the participants had experience using ChatGPT, almost none used it for school assignments. They were tasked with solving problems presented in the competition using ChatGPT. Table 1 lists the two test tasks. Task 1 involved writing a trip report based on information, and Task 2 involved writing a fairy tale that required a unique composition and narration. The participants interacted with ChatGPT to complete tasks within a specified timeframe and submitted a link to the final output without further editing.
Description of the Tasks Provided in the ChatGPT Prompting Contest.

Design of the Research Method
We employed a mixed-methods approach (qualitative and quantitative) that can address exploratory inquiries and validate research objectives, fostering the emergence of new theoretical perspectives (Cheng et al., 2022; Venkatesh et al., 2016). Qualitative analysis ensures effective research that develops an understanding of a phenomenon and constructs propositions (Hua et al., 2020). Conversely, quantitative studies facilitate theoretical testing and causal confirmation (Hua et al., 2020; Venkatesh et al., 2013). Figure 1 illustrates the overall structure and process of this research methodology.

Mixed-Method Approach Employed in This Study.
First, based on text-based qualitative analysis, prompting elements (e.g., number of contextual assignments, prompts, assigned persona, assigned output format, and critical attitude) were refined for clarity. Subsequently, these elements, along with measures of emotional arousal and satisfaction, were systematically coded according to established construct scales. Second, we employed STATA17 to test the research model using hierarchical regression analysis for RQ1, multinomial logistic regression (MNLogit) analysis for RQ2, binomial logistic regression analysis for RQ3, and analysis of variance (ANOVA) for RQ4.
Development of Measurements
The evaluation criteria and corresponding scale were established to analyze quantitatively the prompts collected from the contest, shown in Table 2.
Measurement and Their Criteria.
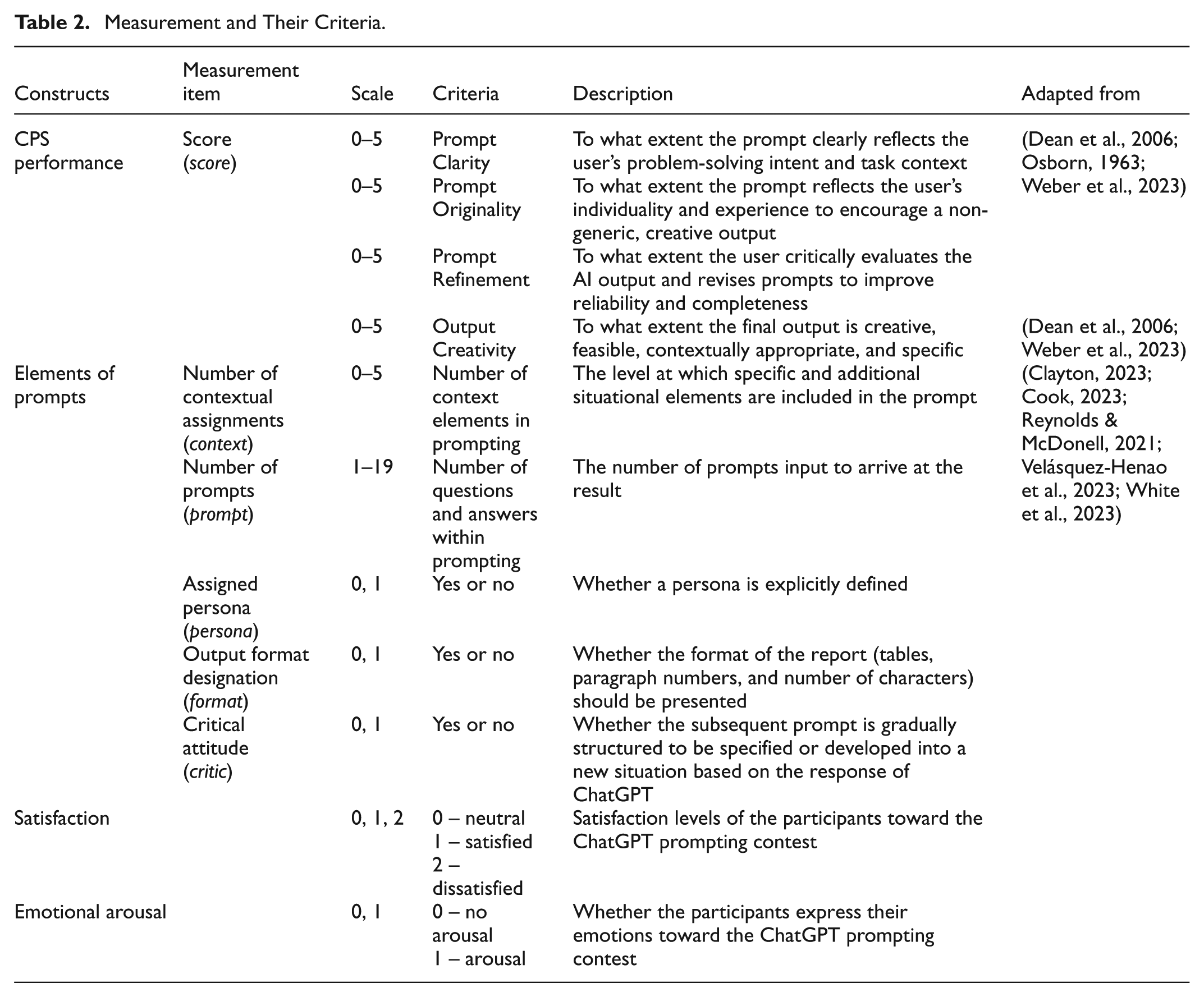
Scores representing the participants’ CPS performance were assessed through contest evaluations conducted by experts in liberal arts education, as recommended by the competition organizers. The evaluation was grounded in three foundational frameworks—the three-step CPS model (Osborn, 1963), the four dimensions of evaluating ideas (novelty, feasibility, relevance, and specificity; Dean et al., 2006), and the experimental framework (Weber et al., 2023)—which analyzed the effects of domain knowledge and prompt engineering strategies on the quality of creative outputs. Based on these foundations, the evaluation rubric included four key criteria—prompt clarity, prompt originality, prompt refinement, and output creativity—each of which corresponds to a critical phase in the CPS process.
Output creativity was designed to capture the final outcome of the process and to assess the creative value of the output qualitatively in terms of originality, feasibility, contextual appropriateness, and specificity (Dean et al., 2006). This criterion was included as a separate dimension to address a key insight from recent research: a well-crafted prompt does not always guarantee creative or valuable output, especially in human–AI collaboration settings (Memmert et al., 2024). In our contest, the participants could not directly revise the AI-generated output; the final results were entirely determined by their prompts. Thus, the output creativity score reflects the participant’s ability to guide and refine the AI behavior and the creative quality of the resulting output. By independently evaluating output creativity (Zhang et al., 2025), the assessment structure acknowledges the complex and sometimes unpredictable relationship between user strategies and AI-generated results. This approach enables a more nuanced interpretation of user–AI interaction throughout the CPS process and offers deeper insight into the CPS process in GAI environments. This expert-based evaluation approach was selected to reflect the contextual and iterative nature of real-world CPS performance, which may not be fully captured by traditional psychometric instruments that focus solely on divergent or convergent thinking. Working with GAI involves recursive and iterative interactions that allow exploring multiple solution paths, necessitating an alternative approach to CPS assessment beyond conventional task-based measures (Marozzo, 2025).
We identified the elements of prompts—“number of contextual assignments (context),”“assigned persona (persona),”“number of prompts (prompt),”“output format designation (format),” and “critical attitude (critic).” The context metric evaluates the extent to which specific scenarios are required to improve outcome quality. For instance, in the case of Task 1, context could entail supplementation with additional information regarding the visited location or specifying relevant local events for inclusion in the itinerary. Moreover, the itinerary specifics, purpose of the visit, and the structure of the report were examined. In Task 2, the evaluation of context involved verifying the direct assignment of the character of the fairy tale, predefinition of the genre, clarity of the background and purpose, and inclusion of a synopsis, encompassing five distinct aspects. Prompt measures the number of prompts entered to produce an outcome; it serves as a quantitative scale for the fine-tuning process through interaction with ChatGPT. Persona evaluates whether the subject of the visit is explicitly defined within the prompts. In Task 1, this choice could result in variations in the scope and level of report-writing based on the role of the participant, such as a graduate student conducting research, an undergraduate attending a general education course, or a guide for foreign tourists. In Task 2, we determined whether roles such as fairy tale writers or counselors should be assigned to ChatGPT. For format, we assessed whether the prompts specified details such as paragraph structure, word count, or table layout. The critic metric examined whether ChatGPT prompts were dynamically adjusted to build on previous responses or restructured to reflect user intentions after evaluating feedback.
Participants shared their feedback on interacting with ChatGPT after completing Task 2. Two researchers, who majored in liberal arts education and participated as judges in the contest, evaluated the participants’ emotions and satisfaction levels regarding the ChatGPT prompts. Emotional arousal was categorized as neutral or emotionally aroused, and satisfaction levels were categorized as positive, negative, or neutral. The experts manually annotated emotional arousal and satisfaction levels because the participants’ feedback included subtle meanings and expressions. The categorizations were finalized after annotating sentiments and satisfaction with the contest feedback.
Analyses and Results
Descriptive Statistics
As indicated in Table 3, the variables persona, format, and critic are 0 or 1 depending on the existence of each feature within the prompt. The variables context, prompt, and score include different ranges of integer values. The prompts with assigned personas (persona) in Task 1 (Mean (M) = 0.34, Standard deviation (SD) = 0.48) were higher than those in Task 2 (M = 0.15, SD = 0.36). By contrast, the prompts for format designation (format) in Task 2 (M = 0.81, SD = 0.39) were higher than those in Task 1 (M = 0.42, SD = 0.50). The critic levels for both Task 1 (M = 0.37, SD = 0.49) and Task 2 (M = 0.31, SD = 0.46) were similar, indicating that the prompting for each task exhibited a similar level of critical attitude. Therefore, we infer that different prompt features can be used to resolve different types of problems while interacting with ChatGPT.
Data Collected from the ChatGPT Prompting Contest.

Obs: Total observations; M: Mean; SD: Standard deviation.
Prompt Engineering and Problem-Solving Performance
Hierarchical regression was implemented to evaluate the prompt factors predicting CPS performance. Tables 4 and 5 show the correlations among the variables and the results of the hierarchical regression for Task 1 (Trip Report), respectively. The variance inflation factor (VIF) values for all variables were below 3, suggesting no multicollinearity (Table 4).
Correlations for Task 1 (Trip report) Variables.

p < 0.1; **p < 0.05; ***p < 0.01.
Results of Hierarchical Regression for Task 1 (Trip report).

p < 0.1; **p < 0.05; ***p < 0.01.
SE: Standard Error.
For the trip report task, prompt characteristics such as context, persona, format, and critic were entered into Model 1, which explained 50.5% of the variance in CPS performance. Both context (β = 1.162; p < 0.01) and critic (β = 2.392; p < 0.01) had positive effects on CPS performance. After entering the number of prompts in Model 2, the total variance explained by the model was 53.6%, with the number of prompts (β = 0.206; p < 0.01) also showing a positive effect on the CPS score. In Model 3, we introduced gender and academic discipline (AcademicBG) as control variables. Their addition did not result in a significant improvement over Model 2.
Tables 6 and 7 show the correlations between the variables and the results of the hierarchical regression for Task 2 (fairy tale writing), respectively. VIF values for all variables were below three, suggesting no multicollinearity.
Correlations for Task 2 (Fairy tale writing) Variables.

p < 0.1; **p < 0.05; ***p < 0.01; VIF: Variance Inflation Factor.
Results of Hierarchical Regression for Task 2.

p < 0.1; **p < 0.05; ***p < 0.01.
For the fairy tale writing task, prompt characteristics such as context, persona, format, and critic were entered into Model 1, which explained 47.3% of the variance in CPS performance. Context (β = 1.190; p < 0.01), persona (β = 1.677; p < 0.1), and critic (β = 2.412; p < 0.01) had positive effects on CPS performance. After entering the number of prompts in Model 2, the explained total variance was 63.7%, with the number of prompts (β = 0.754; p < 0.01) also positively affecting the CPS score. In Model 3, we introduced gender and academic discipline as control variables. Their addition did not result in a significant improvement over Model 2.
In both Task 1 and Task 2, the variables critic, context, and prompt each exhibited a significant positive effect on CPS performance. Therefore, we have an answer for RQ1.
Prompt Engineering and User Satisfaction
We used multinomial logistic regression to examine the influence of five independent variables: context, persona, format, critic, and prompt. The dependent variable was satisfaction, categorized as neutral, satisfied, and dissatisfied. As delineated in Table 8, only persona exhibits a significant effect (β = 16.775; p < 0.01) for the category labeled “satisfied” in the dependent variable satisfaction, denoting a strong positive influence on the likelihood of this satisfaction level. In the category labeled “dissatisfied,”persona again exhibits a positive effect (β = 17.140; p < 0.01). Thus, we have an answer for RQ2. The normal-based 95% confidence intervals for each predictor across both categories offer insight into the precision of the estimate, whose coefficients indicate intervals that do not straddle zero, thereby supporting their significance. Model adequacy was evaluated using the Wald chi-square test, with a statistic of 23.43 (p < 0.01), indicating statistical significance at the conventional level.
Results of MNLogit Analysis for Satisfaction.

Note. Logistic Regression chi2(10) =23.43, Prob > chi2 =0.009, Pseudo R2 = 0.199.
Prompt Engineering and User Emotional Arousal
We performed logistic regression analysis to examine the relationship between a binary emotional outcome of neutral (0) or emotional arousal (1). The predictors included context, persona, format, critic, and prompt. As indicated in Table 9, the normal-based 95% confidence intervals for each predictor suggest a wide range of possible values for the true odds ratios, with none of the intervals excluding the value of one, further reinforcing the lack of statistical significance of the predictors. This observation indicates that statistical evidence is insufficient to conclusively assert the impact of these predictors on emotional arousal. Therefore, the answer to RQ3 is that none of the variables significantly affected the participants’ emotional arousal.
Results of the Logistic Regression Analysis for Emotional Arousal.

Note. Logistic Regression chi2(10) = 4.40, Prob > chi2 = 0.493, Pseudo R2 = 0.054.
User Satisfaction Toward ChatGPT and Problem-Solving Performance
We examined the impact of user satisfaction, categorized into three groups (0: neutral, 1: satisfied, and 2: dissatisfied), on the score. An ANOVA test was used to evaluate the statistical significance of satisfaction levels with CPS performance. Table 10 presents the results, which examined the relationship between score and satisfaction (1: satisfied, 2: dissatisfied).
Analysis of Variance Test for Score and Satisfaction for Task 2 (Fairy Tale Writing).

Bartlett’s equal-variances test: chi2(1) = 0.0949, Prob>chi2 = 0.758.
The observed F-statistic was 3.52 (p = 0.061), which was used to determine whether a significant difference existed in the mean values across the groups defined by satisfaction. The observed variation in score among the different levels of satisfaction was marginally statistically significant. Thus, the ANOVA results suggest that the user group satisfied with the outputs of the prompts exhibited better CPS performance than the dissatisfied group.
Discussion and Implications
Research Observations
This study examined the effects of prompt elements on CPS performance and user experience. Its findings elucidate the interactions between users and ChatGPT and provide clarity on the use of ChatGPT prompts to improve CPS performance. The results indicate that prompts with heightened contextual information are more likely to achieve outputs that align with objectives. The number of contextual assignments significantly affected CPS performance regardless of the task type, which differed notably between trip reports and fairy tale writing tasks. The former requires straightforward and focused strategies, whereas the latter requires unrestricted, innovative thinking. Furthermore, our analysis indicated that the significant effect of the number of prompts on CPS performance was evident regardless of the type of task. In addition, critical attitudes toward ChatGPT responses marginally affected CPS performance. Finally, the assigned personas positively affected user satisfaction and dissatisfaction. The former is consistent with previously reported results; however, the assigned personas were not expected to affect dissatisfaction positively.
This unexpected finding may be explained by the expectation–disconfirmation perspective (Oliver, 1977). Disconfirmation is a psychological state caused by a gap between expectations and perceived performance (Lin et al., 2018). The participants who assigned a persona to a prompt tended to have more specific expectations of ChatGPT’s responses. For instance, when participants choose the persona of a child storywriter, they implicitly expect that the story’s content and tone will be suitable for young readers. If ChatGPT’s output fails to meet these expectations, the participants may feel dissatisfied. This finding was supported by participants’ feedback. For example, those who chose a children’s storybook writer as their persona noted limitations such as “Some parts of the story had repetitive or awkward expressions” and “The mixture of formal and informal tone was uncomfortable.” Consequently, such participants may articulate their discontent and fall into the category of dissatisfied users.
Contrary to expectations, persona assignments and output designations did not affect CPS performance in our study. While earlier studies considered persona settings a key element in prompting (Clayton, 2023; OpenAI, 2023), other research has questioned their practical value, pointing to implementation issues (N. Chen, Wang, et al., 2023; Y. Chen, Wong, et al., 2023) and possible reasoning biases (Gupta et al., 2024). Taken together with previous research, our findings suggest that persona assignments could have a limited effect on CPS performance. Possible explanations can be inferred from the following. First, the primary functions of persona design are representativeness and empathy (Dreamson et al., 2023). For persona assignments to work, users’ needs in areas such as cognition and emotions must be considered. Nevertheless, as ChatGPT does not assume the representativeness of the user or express empathy (Das & Ghoshal, 2023), its ability to enhance CPS performance through the manifestation of empathy is constrained. Second, contextual information is embedded in problem-solving prompts. Therefore, even in the absence of persona assignments, prompts can be construed as inherently embodying personas to a certain extent.
The lack of impact of output designation on CPS performance can be attributed to the clarity of the problem format stipulated by the contest. In the dataset used in this study, the practical task required the creation of trip reports. The structure of the task did not influence the assessment of CPS performance because the prescribed report format was inherently integrated into the task, and most users adhered to the format in their prompts. The creative task inherently specified the genre (fairytale) and word count, causing most users to adhere to this format in their prompts. Therefore, output designation may not function as a distinguishing factor in the evaluation.
Moreover, despite our attempts to incorporate the emotional aspects between users and ChatGPT in this study, we did not obtain a significant response. Users prompting within contextual assignments and those with critical attitudes did not exhibit emotional arousal. Similarly, regardless of the increase in prompt frequency, the users maintained an emotionally neutral state similar to that experienced when conducting a simple task, such as using a calculator. Lee et al. (2019) showed that different routes exist for inducing emotion arousal in human–computer interaction design depending on the design goals, such as sense-making or exploration. Thus, emotional arousal may vary depending on the goal for which the user uses ChatGPT or the user’s perception of ChatGPT. Nevertheless, this inference warrants further research into users’ conceptualizations and relational orientations toward ChatGPT. Furthermore, this study employed only one measurement of emotion from the text analysis. Future studies can adapt multiple components of emotion measurement to analyze emotions in human–computer interactions (Mahlke et al., 2006).
The association between user satisfaction and CPS performance was marginally significant, answering RQ4. Specifically, a significant difference was observed in CPS performance between the satisfied and dissatisfied groups. Thus, user satisfaction in interacting with ChatGPT was positively correlated with CPS performance. However, this association requires further investigation to clarify causality.
Implications
Our study enhanced the understanding of prompt engineering by examining its effects on problem-solving and user satisfaction. Furthermore, our findings contribute significantly to the academic literature. First, the CPS model addresses complex issues through nonlinear processes that include understanding the problem, generating ideas, planning, and execution. As GAI advances rapidly, a review of GAI applicability within the CPS model has become increasingly warranted. Therefore, this study connects CPS with the prompting process to ensure that complex challenges can be effectively addressed. While previous research defined effective prompts and investigated their implementation, this study is the first to assess each prompt element in the context of CPS. Our findings reveal common influential characteristics across task domains, as well as domain-specific effects on CPS performance. Second, our findings suggest that prompt engineering significantly affects CPS performance. A common influential characteristic of prompts exists regardless of the task type. Additionally, this study empirically investigated prompting strategies previously suggested in the literature (Clayton, 2023; Cook, 2023; Liu & Chilton, 2022). Building on this foundation, the study further explored text-based prompting elements that influence CPS.
Third, while previous studies have focused on cognitive evaluations of ChatGPT prompting, we investigated the effects of prompting on problem-solving, satisfaction, and emotional arousal. By examining affective aspects, this study extends prior research that has mostly concentrated on prompting methods to improve learning outcomes or work performance. If more refined data collection and analysis methods are employed to meticulously quantify and analyze the emotional arousal of users engaging in problem-solving via prompts and its impact on satisfaction, the results can contribute to further research on interactions with ChatGPT.
The findings of this study also make a practical contribution to ChatGPT prompting in CPS. First, sufficient contextual information improves the effectiveness of the prompt. We found that the specificity of contextual elements has a positive effect on CPS performance consistently across task types. Therefore, ChatGPT prompts should clearly present the background, objectives, and constraints of the task, guiding the GAI to generate more goal-oriented responses. For example, a prompt such as “Write a field report from the perspective of a university student who participated in a three-day cultural heritage tour in Gyeongju” will likely lead to higher-quality problem-solving outcomes than the simpler instruction, “Write a travel report.” Second, increasing the number of prompt entries is a strategy to enhance user engagement iteratively and refine outputs. A higher number of prompts improved CPS performance—users continuously redefined and elaborated on problems through interactions with ChatGPT. Thus, rather than attempting to derive complete answers from a single query, a conversational approach involving iterative feedback and follow-up prompts is recommended. Finally, a critical attitude toward AI responses reflects the user’s active involvement in the problem-solving process and contributes to performance improvements. When users evaluate and request revisions rather than passively accepting responses, the role of the GAI evolves from a simple information provider to a collaborative problem-solving partner. These prompt strategies encourage users to sustain contextual awareness and adopt a critical perspective throughout the interaction process.
Limitations and Future Research
Certain limitations were observed in this analysis. First, the cross-sectional dataset was collected from a single university, and the initial dataset was small. Furthermore, this study’s contest-based setting may limit its generalizability. Task constraints and performance incentives could have influenced participant behavior, and the self-selected sample may not reflect the broader population. In the future, prompt engineering should be examined by considering a larger dataset in various contexts, and longitudinal research is necessary to capture the prompting dynamics.
Second, although the relationship between emotional arousal and prompting was not confirmed statistically, it was not fully explored. Recent studies have focused on understanding the role of user emotions in the adoption of applications because they often affect user satisfaction and continued usage. The positive valence of emotional responses is associated with user satisfaction, resulting in users’ intent to use products or services (Thüring & Mahlke, 2007). Further research is required to better understand the arousal and valence of emotional responses during the ChatGPT prompting process. This research model should be expanded by incorporating user intentions for future use.
Third, this study employed binary measures for key prompt variables (e.g., persona, format, and critic) and a three-level scale for user satisfaction. Although these simplified measurements facilitated the analysis, they may have overlooked the more nuanced dimensions of prompt design and user experience. Future research could adopt more fine-grained or continuous measures to capture subtle variations. Additionally, it could employ qualitative or mixed-method approaches to better understand how prompt features interact with user perceptions and outcomes.
Fourth, although gender and academic discipline were included as control variables, other potentially influential factors, such as prior experience with ChatGPT, were not considered. Future research should include a broader range of individual variables to enhance explanatory power. Furthermore, while the regression assumed independence among the prompt elements, possible interaction effects were not tested. Exploring these interactions in future studies could better elucidate the joint influence of prompt components on user outcomes.
Conclusions
This study used a mixed-method approach to empirically examine the effects of specific prompt elements in ChatGPT interactions on CPS performance and user experience (satisfaction and emotional arousal). The results show that adding contextual information, using multiple prompts iteratively, and maintaining a critical attitude toward AI responses significantly enhance CPS outcomes. Conversely, assigning personas did not directly improve performance but influenced user experience, specifically user satisfaction. These findings suggest that well-designed prompts should include sufficient context, allow iterative refinement, and encourage users to critically evaluate AI outputs rather than accept them passively. This study contributes new empirical evidence to the field of GAI use in CPS by clarifying which prompt elements influence CPS performance and user satisfaction. By going beyond general prompt guidelines, this study offers a practical understanding of prompt engineering as an active user strategy that shapes the quality of human–AI collaboration.
Footnotes
Author Contributions
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The data that support the findings of this study are available from Chung-Ang University, AI Humanities Research Institute(CAU-AIHRI), but restrictions apply to the availability of these data, which were used under license for the current study and so are not publicly available. The data are, however, available from the authors upon reasonable request and with the permission of CAU-AIHRI.