
Abstract
Linguistic microaggressions, subtle and often unintentional verbal slights rooted in language bias, remain understudied in multilingual contexts because existing measures capture only overt and generalized forms of language-based discrimination. This study developed and validated the Perceived Linguistic Microaggression Scale (PLMS), a context-sensitive measure capturing subtle, interactional exclusions related to language use. In Stage 1, in-depth semistructured interviews with Mandarin and regional dialect speakers in China generated an initial pool of 15 items grounded in three categories: microassaults (e.g., accent mockery), microinsults (e.g., competence judgments), and microinvalidations (e.g., exclusion from conversations). A panel of experts then refined this pool for redundancy and clarity, resulting in a 10-item instrument. Stage 2 employed exploratory factor analysis (N = 264), revealing a unidimensional structure, indicating that these diverse expressions of linguistic bias cohere as a single underlying construct. Stage 3 used confirmatory factor analysis (N = 267) that supported this single-factor model (CFI = 0.968; TLI = 0.960; RMSEA = 0.07; SRMR = 0.03). The PLMS demonstrated strong internal consistency (α = .78) and measurement invariance across gender, region, and dialect groups. Construct validity was established through significant correlations with psychological outcomes: higher PLMS scores were associated with elevated depression (r = .46, p < .001) and anxiety (r = .26, p < .001), and with lower self-efficacy (r = −.22, p < .001), resilience (r = −.19, p < .001), and life satisfaction (r = −.15, p < .001). These results confirm the PLMS as a reliable, valid tool for assessing everyday linguistic microaggressions. The PLMS equips researchers and practitioners to identify, quantify, and ultimately mitigate the subtle mechanisms that reinforce social hierarchies and undermine inclusion in linguistically diverse communities.
Plain language summary
In multilingual societies, people may experience subtle and sometimes unintentional language-based biases, known as linguistic microaggressions. These include being mocked for an accent, judged as less capable because of how they speak, or left out of conversations when others use a language they don’t understand. To better understand these experiences, our study developed the Perceived Linguistic Microaggression Scale (PLMS), a tool designed to measure such everyday instances of language-related bias. We created the scale in three steps. First, we interviewed 15 speakers of Mandarin and regional dialects to collect real-life examples of linguistic microaggressions. These were grouped into three categories: direct mockery (microassaults), subtle negative judgments (microinsults), and exclusion or dismissal (microinvalidations). Based on these examples, we drafted 15 questions, which were reviewed by experts and refined into a 10-item scale. Next, we tested the scale with two groups of people and found it to be a reliable and consistent way to measure these experiences. People who reported more frequent microaggressions also reported higher levels of depression and anxiety, and lower levels of self-confidence, resilience, and life satisfaction. The PLMS can help researchers, educators, and other professionals identify subtle language-based biases and support efforts to build more inclusive and respectful communication in diverse communities.
Keywords
Introduction
Linguistic microaggressions, subtle, often unintentional verbal or behavioral slights rooted in linguistic bias, are a pervasive yet underexplored dimension of linguistic inequality (Alabi, 2015; Duran & Saenkhum, 2022; Holtgraves, 2023; Tankosić & Dovchin, 2023). These acts may include dismissive remarks about accents, assumptions regarding language proficiency, or the erasure of linguistic identities through exclusionary practices. Unlike overt linguistic discrimination, which is readily identifiable and often contested, linguistic microaggressions are embedded in everyday interactions, making them challenging to detect and address. Despite their subtle nature, these interactions reinforce linguistic hierarchies, perpetuate systemic marginalization, and erode individuals’ sense of belonging, contributing to broader social inequities (Sue et al., 2007, 2009; Sue & Spanierman, 2020).
A growing body of work has documented language-based bias across education, workplaces, and healthcare, revealing its psychological and social consequences (Carlson & McHenry, 2006; Kubota, 2021; Nadal et al., 2014). Although instruments such as the Perceived Language Discrimination Scale (PLDS, Wei et al., 2012) has enhanced the measurement of overt language-related unfairness, they do not adequately capture the subtle, context-dependent enactments of microassaults, microinsults, and microinvalidations characteristic of multilingual settings. This gap underscores the need for a measure that can record the daily, situational expressions of linguistic microaggression. Existing scales lack the precision to distinguish between different forms of microaggressions or to reflect the culturally embedded ways they are experienced. Developing more targeted instruments is therefore essential to reveal how routine language practices sustain broader systems of linguistic marginalization.
Literature Review
Conceptualization of Linguistic Microaggressions
Linguistic microaggressions refer to subtle, often unconscious verbal or behavioral slights that convey derogatory or dismissive messages about an individual’s language use (Holtgraves, 2023). Drawing on Sue et al.’s (2007) taxonomy, originally developed in studies of racial microaggressions, linguistic microaggressions are typically grouped into three categories: microassaults, microinsults, and microinvalidations. Microassaults are the most explicit, involving deliberate forms of exclusion or mockery, such as ridicule of accents or dialects. Microinsults are more indirect, including backhanded compliments or unsolicited corrections that reflect underlying linguistic bias. Microinvalidations, by contrast, occur when a person’s linguistic experiences or challenges are ignored or dismissed. These categories have informed research across race, gender, and language-based inequality (Ahmad et al., 2022; Alabi, 2015; Salami et al., 2021; Takeuchi, 2023), offering a framework for identifying how language use becomes a site of subtle marginalization.
Linguistic microaggressions are not confined to any single domain. Educational studies reveal how teachers’ subtle corrections of non-standard speech patterns can systematically undermine students’ academic engagement and self-perception (Fematt & Ramirez, 2025; Kubota, 2021; Perrucci & Hu, 1995; Steketee et al., 2021). In professional settings, linguistic microaggressions frequently take the form of implicit competence questioning, where employees with non-native accents or dialects face patronizing evaluations of their language skills (Carlson & McHenry, 2006). In healthcare, linguistic microaggressions can create subtle but consequential communication barriers, particularly for speakers of minoritized languages (Kramer et al., 2002; Nadal et al., 2014).
Linguistic Microaggressions in the Chinese Context
China’s sociolinguistic landscape offers a unique context for the examination of linguistic microaggressions. The national promotion of Mandarin, framed as a policy for unification and modernization, has influenced the social positioning of regional dialects. Although this policy does not explicitly aim to marginalize non-Mandarin varieties, it has shaped perceptions and interactions (Gao, 2015). Mandarin is often associated with progress and national identity, whereas regional dialects, such as Cantonese, Wu, and Hokkien, are linked to local identity and cultural heritage (Huang, 2018). This contrast gives rise to implicit stereotypes: speakers of regional dialects may be viewed as less educated or tied to rurality, whereas Mandarin speakers in dialect-dominant regions may be perceived as outsiders or lacking a sense of local connection (Wang & King, 2024).
Building on this context, our previous qualitative research (Zhu & Weng, 2025) examined these dynamics through the lens of Sue et al.’s (2007) taxonomy. Our findings revealed that microassaults frequently took the form of overt mockery, such as when northern Jiangsu accents were disparaged as “rough” or “uncultured” in Suzhou social circles. In dialect-dominant regions, Mandarin speakers experienced explicit ridicule for their pronunciation or inability to understand local speech. Microinsults emerged through more subtle behaviors, particularly in professional settings where competence was routinely judged through a linguistic lens. For examples, one teaching intern in Beijing was removed from classroom duties after students and parents complained about her southern-accented Mandarin, despite her qualifications. Microinvalidations were particularly prevalent in workplace interactions, where non-dialect speakers reported being systematically excluded from conversations conducted in local dialects. Similarly, struggles to learn regional dialects were often minimized, with locals dismissing difficulties by saying, “It’s not hard, just listen carefully.” These findings not only validated Sue et al.’s framework in the Chinese context but also identified culturally specific expressions that informed our scale development.
Psychological Consequences of Linguistic Microaggressions
Linguistic microaggressions are associated with a range of negative psychological outcomes. These subtle yet persistent forms of bias have been consistently linked to heightened symptoms of depression and anxiety (Auguste et al., 2021; Salami et al., 2021), particularly among speakers whose language marks them as outsiders in educational or professional settings. These experiences can erode self-confidence and contribute to persistent emotional strain, as shown in our prior findings (Zhu & Weng, 2025).
Positive psychological resources such as self-efficacy, resilience, and life satisfaction may mitigate some of these effects (Campbell-Sills & Stein, 2007; Schwarzer & Jerusalem, 1995a, 1995b). Self-efficacy supports adaptive coping, while resilience can help reframe negative experiences (Mills et al., 2023; Skinta & Torres-Harding, 2022; Tugade & Fredrickson, 2004). However, repeated exposure to microaggressions can undermine these resources, as seen in studies where dialect speakers reported lower life satisfaction (Adedeji et al., 2022; Diener et al., 1985) in settings where their language use was persistently devalued.
Measurement of Language-Based Bias
Despite growing attention to linguistic microaggressions, few tools have been developed to systematically measure their everyday forms. Most existing instruments were designed to capture broader perceptions of unfair treatment rather than the subtle slights that occur in daily interaction. For example, the Perceived Language Discrimination Scale (PLDS) has been developed to measure broader forms of linguistic discrimination in international student populations (Wei et al., 2012). PLDS asks respondents how often they feel ignored, demeaned, or judged based on language use. While the PLDS reliably captures overt episodes of discrimination, it does not distinguish among different types of microaggressions or reflect how these are shaped by specific linguistic and cultural contexts. This measurement gap highlights the need for instruments that are capable of documenting the nuanced and pervasive effects of linguistic microaggressions (Holtgraves, 2023; Sue & Spanierman, 2020). The development of such measurements is critical to advancing our understanding of how everyday language practices contribute to social inequality.
Research Gaps and Study Objective
Despite linguistic microaggressions having gained increasing scholarly attention, several critical gaps remain. First, most existing research has focused on overt forms of language discrimination or institutional language hierarchies, with less emphasis on the subtle, routine exclusions that occur in everyday interaction (Craft et al., 2020; Holtgraves, 2023). Second, widely used measurement instruments, such as the PLDS (Wei et al., 2012), tend to adopt a generalized approach that does not account for the context-specific nature of microaggressions. Third, the majority of empirical work has been conducted in Western, English-dominant societies (Alabi, 2015; Duran & Saenkhum, 2022; Tankosić & Dovchin, 2023), with limited attention to multilingual contexts like China (Zhu & Weng, 2025), where the coexistence of Mandarin and regional dialects produces distinct patterns of everyday exclusion.
This study aimed to develop and validate the Perceived Linguistic Microaggression Scale (PLMS), a context-sensitive and empirically grounded instrument designed to assess subtle, interactional forms of language-based bias. This study sought to bridge macro-level language policy discourse and micro-level interactional experiences by demonstrating how linguistic inequality is reproduced in everyday encounters. By focusing on context-specific experiences and differentiating types of microaggression, the PLMS contributes a new tool for sociolinguistic research and offers practical relevance for educators, clinicians, and policymakers navigating linguistically diverse environments.
Method
Research Design
The development of the PLMS adhered to a three-step sequential design: item generation, scale development, and scale evaluation. This approach integrated qualitative insights with quantitative psychometric methods to ensure both conceptual grounding and measurement precision (Hinkin, 1995; Netemeyer et al., 2003). Stage 1 built on our previous qualitative interview (Zhu & Weng, 2025) and a Delphi panel to generate and refine items. Stage 2 conducted an exploratory factor analysis (EFA) to determine the scale’s underlying structure. Stage 3 conducted confirmatory factor analysis (CFA) and assessed the scale’s reliability and validity using an independent sample. Ethical approval was obtained from the institutional review board prior to data collection.
Data Collection
In Stage 1, the item development process was informed by our prior qualitative study (Zhu & Weng, 2025), which explored individuals’ lived experiences of linguistic microaggressions in everyday social and institutional contexts across China. Semi-structured interviews elicited narratives of accent-based bias, exclusion from conversation, and other subtle forms of language-based marginalization. Drawing on these interviews, an initial pool of items was generated to reflect recurring themes organized under the categories of microassaults, microinsults, and microinvalidations. A panel of experts in sociolinguistics and psychology reviewed the items for clarity, relevance, and redundancy, providing both qualitative feedback and quantitative ratings to refine the items. Stages 2 and 3 utilized online surveys administered to participants in the EFA and CFA phases, respectively. The surveys included the preliminary scale items alongside demographic questions. Quality control measures were implemented, including attention filters and minimum completion time requirements to ensure data quality. Response rates were 90.2% for Stage 2 and 94.7% for Stage 3.
Participants
Three distinct participant samples were recruited for each phase of the study.
Sample 1 for Item Generation
Fifteen participants (8 females, 7 males; aged 20-39) were selected via purposive sampling to ensure diverse linguistic backgrounds. Eight participants, fluent in their local dialects (e.g., Cantonese, Shanghainese, Hokkien), were from dialect-dominant regions, and seven participants, primarily Mandarin speakers, were from Mandarin-dominant regions (e.g., Beijing, Tianjin, Henan). In addition, 10 participants were from urban areas, and 5 were from rural settings.
Sample 2 for Exploratory Factor Analysis (EFA)
A total of 264 participants were recruited through an online questionnaire. The sample was 67.8% female, with an average age of 23.8 years (SD = 3.9). Participants were geographically diverse: 26.7% from northern China and 73.3% from southern China; 55.7% were urban residents, 21.2% from towns, and 23.1% from rural areas. Linguistic backgrounds included Mandarin (39.0%), Cantonese (12.5%), Sichuan-Chongqing (8.7%), Wu (8.0%), Hokkien (6.4%), Hakka (6.1%), Gan (4.5%), Hui (4.2%), Xiang (3.0%), Guizhou dialects (2.3%), and others (5.3%).
Sample 3 for Confirmatory Factor Analysis (CFA)
A separate sample of 267 participants was recruited online. All had current or past experience studying or working in linguistically diverse regions. The sample was 70.4% female, with a mean age of 24.1 years (SD = 4.2). In terms of geographic origin, 26.2% were from northern China and 73.8% from southern China; 54.3% were urban residents, 21.0% from towns, and 24.7% from rural areas. Their social demographic and dialect backgrounds closely mirrored the EFA sample.
Data Analysis
In Stage 1, the qualitative data were first categorized according to Sue et al.’s (2007) framework of microassaults, microinsults, and microinvalidations. Based on these categories, an initial pool of items was constructed to reflect key experiences described by participants. To refine the item pool, two rounds of expert consultations were conducted using a modified Delphi technique (Younas & Porr, 2018). In each round, 10 experts rated the relevance and clarity of each item on a 4-point scale. We used measures of central tendency (mean) and dispersion (standard deviation) to assess the ratings. Items with a mean score above 2.0 were considered less relevant or clear, and those with standard deviations greater than 1.0 were flagged as lacking expert consensus (Newman et al., 2009). Items not meeting these criteria were revised or removed between rounds.
In Stage 2, Bartlett’s test of sphericity was significant (p < .001), and the Kaiser-Meyer-Olkin (KMO) index was 0.83, indicating sampling adequacy. EFA was performed using principal component analysis with varimax rotation. Factors were retained based on established criteria: eigenvalues exceeding 1.0, items with loadings greater than 0.40, and factors containing at least three items (Hair et al., 2018). Anti-image correlations were examined to ensure sampling adequacy, with all values above the recommended threshold of 0.5, confirming that no items required removal (Osborne, 2014).
In Stage 3, CFA was conducted using structural equation modeling to validate the factor structure derived from the EFA. Fit indices were employed to evaluate the model’s adequacy. The comparative fit index (CFI) and Tucker-Lewis Index (TLI) were utilized, with values exceeding 0.90 indicating good model fit, as suggested by Bentler (1990). In addition, the Root Mean Square Error of Approximation (RMSEA) and Standardized Root Mean Square Residual (SRMR) were analyzed, with values less than 0.08 considered indicative of an acceptable fit (Hu & Bentler, 1999).
The psychometric properties of the PLMS were evaluated through reliability and validity analyses. Internal consistency was examined through Cronbach’s alpha coefficient. Convergent validity was assessed by analyzing the standardized factor loadings of PLMS items. Loadings greater than 0.70 were considered indicative of strong convergence (Hair et al., 2018), reflecting that individual items were highly correlated with their respective latent construct. Discriminant validity was evaluated by examining inter-factor correlations. Low to moderate correlations between factors confirmed the absence of excessive overlap, supporting the scale’s ability to distinguish linguistic microaggressions from other domains. Concurrent validity was tested by examining correlations between PLMS scores and established psychological measures, including both negative (depression, anxiety) and positive (self-efficacy, resilience, life satisfaction) indicators, to assess the scale’s relevance in capturing the psychological impact of linguistic microaggressions.
Measures
To assess concurrent validity, the study incorporated both negative and positive psychological indicators. Negative indicators included depression and anxiety symptoms measured using the 4-item Patient Health Questionnaire (PHQ-4, Kroenke et al., 2009). Positive indicators comprised self-efficacy measured by the 10-item General Self-Efficacy Scale (GSE, Schwarzer & Jerusalem, 1995a), psychological resilience evaluated using the 10-item Connor-Davidson Resilience Scale (CD-RISC-10, Campbell-Sills & Stein, 2007), and life satisfaction assessed with the Satisfaction with Life Scale (SWLS, Diener et al., 1985).
Results
Item Generation
The item generation process produced an initial pool of 15 items grounded in our prior qualitative study (Zhu & Weng, 2025), ensuring that each item reflected lived experiences of linguistic microaggressions in everyday interactions. Drawing on Sue et al.’s (2007) framework, the study identified three core types of microaggressions through thematic analysis: microassaults (e.g., mockery of non-local accents, condescending corrections), microinsults (e.g., negative judgments about competence based on language proficiency, expressions of impatience), and microinvalidations (e.g., exclusion from conversations, dismissal of struggles in learning the local dialect). These categories guided the initial classification of scale items. Table 1 outlines how participant narratives from Zhu and Weng (2025) were used to construct scale items. Each item was directly based on patterns repeatedly described in the interviews, such as being mocked for one’s accent, facing annoyance when struggling to speak a local variety, or being left out of discussions conducted in dialect despite visible misunderstanding.
Development of Initial Item Pool From Qualitative Data.

Note. The qualitative quotes are drawn from our previously published study (Zhu & Weng, 2025), which provides full details on sampling, data collection, coding procedures, and additional examples for each microaggression category.
The expert review process was conducted in two rounds and led to the refinement of the initial 15-item pool. After the first round of feedback, five items were removed due to low relevance (mean > 2.0) and low consensus (SD > 1.0). Two were excluded for describing overt verbal discrimination that exceeded the subtle, ambiguous characteristics typical of microaggressions (e.g., being called a “country bumpkin” or publicly ridiculed for pronunciation). Two additional items were excluded due to vague wording or conceptual redundancy (e.g., the phrase “avoid talking” was considered difficult to interpret consistently across settings). One item was removed due to its broad phrasing, which lacked specificity and subtlety. The remaining 10 items were refined based on second-round feedback, with experts confirming their clarity, contextual specificity, and alignment with the conceptual categories. These items, comprising three microassault, four microinsult, and three microinvalidation indicators, formed the preliminary scale for psychometric testing. Supplemental Appendix Table 1 summarizes expert feedback on the deleted items and the rationale for their exclusion.
Exploratory Factor Analysis (EFA)
The EFA revealed a single factor extracted from the 10-item scale. The scree plot confirmed the one-factor structure (Figure 1). This factor accounted for 63.7% of the total variance, surpassing the commonly accepted threshold of 50% for a valid factor structure (Supplemental Appendix Table 2; Hair et al., 2018). Because only one factor emerged, rotation was unnecessary. All 10 items demonstrated strong factor loadings, ranging from 0.74 to 0.85, with no cross-loadings detected (Supplemental Appendix Table 3). This confirms the unidimensionality of the scale, indicating that all the items align cohesively under the single construct of perceived linguistic microaggressions.

Scree plot of the test of the PLMS.
Confirmatory Factor Analysis (CFA)
The CFA confirmed the unidimensional structure of the PLMS, which was consistent with the findings from the EFA. The model exhibited a good fit, with a chi-square (χ2) value of 112.437 (df = 53), yielding a χ2/df ratio of 2.12. The fit indices further supported the model’s adequacy: The RMSEA was 0.07, and the SRMR was 0.03, both of which are well below the thresholds of 0.08 and 0.05, respectively. In addition, the CFI (0.968) and TLI (0.960) exceeded the widely accepted cutoff of 0.95.
Convergent and Discriminant Validity
The standardized factor loadings for each item of the PLMS (Table 2), which range from 0.67 to 0.82, indicate strong convergent validity (Hair et al., 2018). The interfactor correlations between the items (Table 3), which range from .47 to .69, suggest that although the factors are related, they remain distinct from one another, supporting the scale’s discriminant validity.
Results of the Confirmatory Factor Analysis.

Note.β = standardized factor loading; SE = standard error.
Results of the Descriptive Statistics and Correlation Analysis of the Final Items.
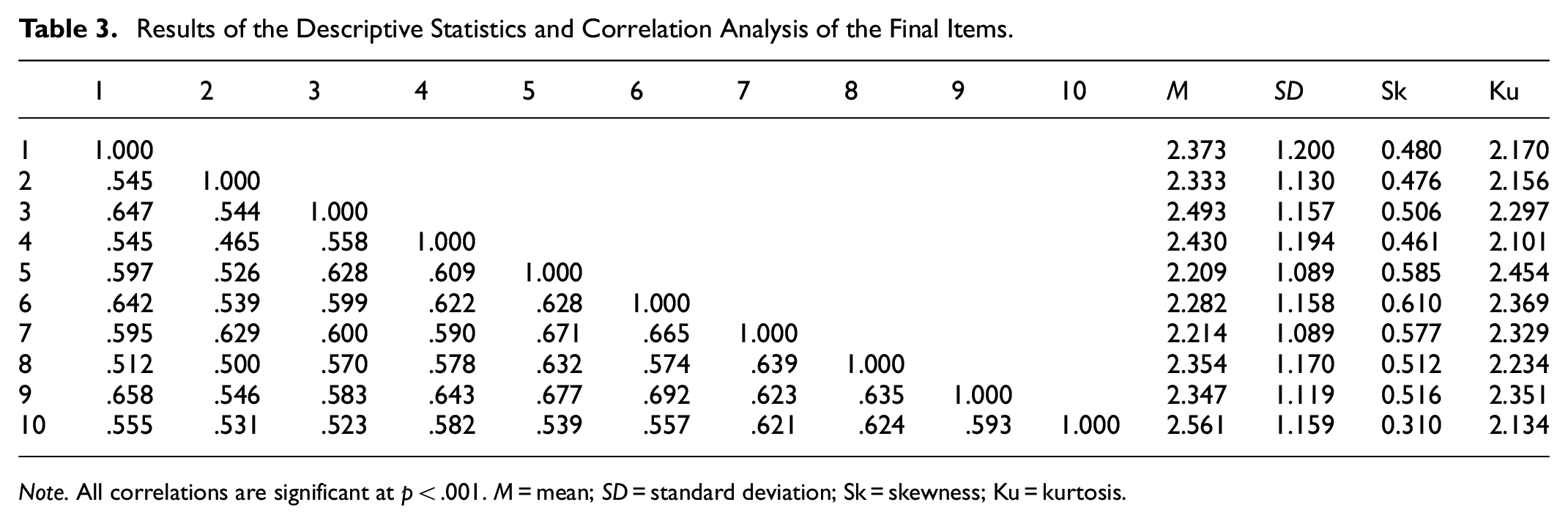
Note. All correlations are significant at p < .001. M = mean; SD = standard deviation; Sk = skewness; Ku = kurtosis.
Concurrent Validity
Correlations between the PLMS and established psychological measures provided evidence of concurrent validity. The PLMS score was significantly positively correlated with depression (r = .46, p < .001) and anxiety (r = .26, p < .001). Negative correlations were observed with general self-efficacy (r = −.22, p < .001), resilience (r = −.19, p < .001), and life satisfaction (r = −.15, p < .05). These results demonstrate that higher levels of perceived linguistic microaggressions are associated with increased psychological distress, reduced self-efficacy, and lower life satisfaction, highlighting the scale’s utility in assessing the psychological effects of linguistic microaggressions.
Reliability
The Cronbach’s α of the PLMS is .78, indicating good internal consistency. Further analysis examined reliability across demographic subgroups, including gender, residence, and dialect spoken. Cronbach’s α values indicated similar reliability across male and female participants, residence (urban, town, rural), and Mandarin-speaking and regional-dialect-speaking participants, demonstrating the scale’s consistent reliability across these subgroups (see Table 4).
Reliability of PLMS Across Subgroups.

Note. PLMS = Perceived Linguistic Microaggression Scale.
Discussion
This study developed and validated the Perceived Linguistic Microaggression Scale (PLMS), demonstrating its strong psychometric properties for assessing subtle forms of linguistic bias. Building on our previous qualitative investigation of dialect-Mandarin interactions in China (Zhu & Weng, 2025), the PLMS captures nuanced behaviors that contribute to linguistic marginalization. Both EFA and CFA results supported a unidimensional structure, indicating that linguistic microaggressions represent a cohesive construct despite their varied manifestations. The PLMS showed high internal consistency and demonstrated measurement invariance across gender, residential, and dialect groups. Validity analyses further revealed that higher PLMS scores were linked to greater symptoms of depression and anxiety as well as lower self-efficacy and life satisfaction.
Our findings extend current understanding by shifting the focus from overt discrimination to everyday linguistic slights that cumulatively reinforce marginalization. Although much of the literature on linguistic discrimination has emphasized overt and structural inequalities (Lippi-Green, 2022; Piller, 2016), the PLMS reveals how micro-level interactions perpetuate exclusion in ways that are often subtle but psychologically impactful. The scale also fills a critical gap in multilingual research, particularly in contexts like China where dialect-Mandarin dynamics produce unique patterns of linguistic marginalization (Wang & King, 2024; Zhu & Weng, 2025).
The unidimensional structure of the PLMS suggests that linguistic microaggressions constitute a cohesive construct. This parallels findings from Wei et al.’s (2012) Perceived Language Discrimination Scale (PLDS), which similarly identified a one-factor model for capturing language-based discrimination. Both linguistic microaggressions and broader language discrimination share a unidimensional nature, emphasizing that these experiences, although varied in manifestation, are underpinned by a singular construct of linguistic exclusion and marginalization. Unlike the PLDS that focus on overt discrimination, the PLMS specifically captures subtle, interactional forms of linguistic exclusion, allowing researchers to examine how everyday language behaviors, such as accent corrections or conversational exclusion, contribute to broader patterns of marginalization.
The associations between PLMS scores and psychological outcomes mirror patterns observed in prior research on discrimination and mental health. Higher levels of perceived linguistic microaggressions were positively associated with depression and anxiety and negatively associated with self-efficacy and life satisfaction, which is consistent with prior research (Jia et al., 2022; Nyqvist et al., 2021; Zhong et al., 2018). These findings are consistent with theoretical frameworks linking microaggressions to psychological distress through cumulative impacts on mental well-being (Nadal et al., 2014; Sue et al., 2007; Tankosić & Dovchin, 2023; Tigadi & Nagata, 2024). Similar patterns were observed in Ahmad et al.’s (2022) study, which highlights how microaggressions in clinical settings exacerbate burnout and reduce job satisfaction, emphasizing the broader psychological consequences across contexts.
Implications
The PLMS represents an important development in sociolinguistic research in that it provides a reliable tool for studying linguistic microaggressions in various contexts. Although this study was conducted in China, the scale’s strong psychometric properties indicate that it could be adapted for use in other multilingual societies. Future comparative research could use the PLMS to explore both shared patterns of linguistic bias and culturally specific forms of microaggressions. Such research would enhance the theoretical understanding of how language contributes to inequality and offer practical insights into promoting linguistic equity. The PLMS thus provides a valuable resource not only for documenting linguistic discrimination but also for facilitating cross-cultural discussions about language-based marginalization and informing policies aimed at reducing such biases.
From a clinical perspective, the PLMS provides a validated framework for mental health professionals to assess and address the psychological impact of linguistic microaggressions. Individuals navigating multilingual environments, such as international students, migrants, or bilingual employees, often experience linguistic biases that exacerbate feelings of marginalization and stress (Carlson & McHenry, 2006; Lee & Rice, 2007; Li et al., 2023; Zhong et al., 2018). The PLMS enables practitioners to identify these experiences systematically, fostering discussions about their emotional and psychological effects. By validating clients’ experiences, clinicians can help mitigate the internalization of linguistic stigma, bolster clients’ self-worth, and help them develop coping strategies that promote resilience. Furthermore, the PLMS can inform culturally responsive therapeutic practices by emphasizing the role of language in identity and well-being.
In educational and professional settings, the PLMS can increase awareness of the often overlooked impact of linguistic microaggressions. Training programs for educators, managers, and policy-makers can use the scale to illustrate how everyday behaviors, such as switching to a dominant language, emphasizing accents, or excluding individuals from conversations, reinforce linguistic hierarchies and perpetuate exclusion. This understanding is essential for the creation of inclusive environments where respect for linguistic diversity is prioritized over conformity. For example, workplace policies that promote multilingualism or reduce reliance on linguistic proficiency as a primary evaluative criterion can encourage greater participation and innovation in diverse teams (Kim & Angouri, 2022; Moody, 2014; Salari et al., 2024).
At the policy level, these findings suggest that measures to address linguistic microaggressions in public institutions, workplaces, and educational systems are needed. Governments and organizations could incorporate tools such as the PLMS into broader equity and diversity initiatives, making linguistic inclusion a central priority. Public awareness campaigns that challenge biases against nonstandard dialects or accents can help reframe these biases as cultural assets rather than deficiencies. By addressing these biases, policies can improve social cohesion and reduce the psychological impact of linguistic marginalization, contributing to a more equitable multilingual society (Sue & Spanierman, 2020; Tankosić & Dovchin, 2023).
Limitations and Future Directions
This study has several limitations that warrant discussion. First, the reliance on self-reported data may have introduced biases, such as social desirability or incomplete self-awareness, that could affect the accuracy of participants’ responses. Self-perceptions of microaggressions are inherently subjective and may not always capture the full scope of these experiences. Second, the use of convenience sampling also introduces potential selection bias. Individuals who are more attuned to or affected by linguistic microaggressions may have been more likely to participate, potentially skewing the results toward higher reported prevalence and psychological impacts. Third, the study’s focus on the Chinese sociolinguistic context limits the scale’s immediate generalizability to other cultural and linguistic settings. Microaggressions may manifest differently across contexts, necessitating cultural and linguistic adaptations for broader applicability. Finally, the cross-sectional design precludes causal interpretations of the relationships observed between linguistic microaggressions and psychological outcomes. Longitudinal data would be needed to clarify the directionality and cumulative effects of these experiences over time.
Future research should address these limitations by adopting more diverse methodologies and refining conceptual approaches. Ethnographic observations, linguistic corpus analyses, and experimental designs could offer more detailed insights into how linguistic microaggressions occur in real-world contexts. Broader and more representative sampling strategies should also be prioritized, with particular attention given to ensuring diversity in linguistic, cultural, and socioeconomic backgrounds. Including underrepresented groups, such as rural dialect speakers or recent migrants, would deepen our understanding of the scope and impact of linguistic microaggressions. Longitudinal studies are essential for understanding the potential long-term effects of linguistic microaggressions on individuals’ mental health, career trajectories, academic outcomes, and social relationships.
The PLMS also opens new opportunities for international research. Adapting the scale to diverse linguistic and cultural contexts will enable comparative studies that examine how microaggressions manifest across different linguistic environments. For example, studying linguistic microaggressions among international students or multilingual workers could highlight shared challenges and context-specific coping strategies. Examining how linguistic biases intersect with factors such as race, gender, socioeconomic status, and migration background would shed light on the compounded effects of discrimination on marginalized populations, providing insights into tailored interventions designed to address these intersecting forms of bias. Future studies should also explore protective factors, such as strong cultural identity or resilience, and test interventions aimed at mitigating the negative effects of linguistic microaggressions.
Conclusion
This study developed and validated the PLMS to assess subtle forms of language-based discrimination. The scale demonstrates strong psychometric properties, including a unidimensional structure and consistent reliability across demographic groups. PLMS scores were significantly related to important psychological outcomes, with higher scores aligned with greater depression and anxiety, and with lower self-efficacy and life satisfaction. While limited by its cross-sectional design and focus on Mandarin-dialect contexts, this research establishes a foundation for future longitudinal studies, cross-cultural adaptations, and practical applications aimed at reducing linguistic bias and fostering inclusion in multilingual settings.
Supplemental Material
sj-docx-1-sgo-10.1177_21582440251361608 – Supplemental material for Development and Validation of the Perceived Linguistic Microaggression Scale
Supplemental material, sj-docx-1-sgo-10.1177_21582440251361608 for Development and Validation of the Perceived Linguistic Microaggression Scale by Lin Zhu and Xue Weng in SAGE Open
Footnotes
Correction (October 2025):
The affiliation of the corresponding author, Xue Weng has been updated in the article.
Ethical Considerations
This research was conducted in line with the principles of the Declaration of Helsinki. Approval was granted by the Institutional Review Board of Beijing Normal University.
Consent to Participate
All research participants provided informed consent before joining the study.
Author Contributions
LZ conceived the study and led the data collection, analysis, and manuscript drafting. XW contributed to the research design and provided feedback during the manuscript review process. Both authors approved the final version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study is funded by Start-Up Fund of Beijing Normal University, Zhuhai (310432104).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Due to confidentiality agreements and to protect the privacy of participants, the data used in this study cannot be made publicly available.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.