
Abstract
Dependency distance has increasingly become a key measure of interest in cross-linguistic corpus studies from multiple perspectives. Based on a syntactically annotated corpus of 400 PhD dissertation abstracts written by native English (L1) and English as a foreign language (L2) academic writers, the current study investigated the mean dependency distance (MDD) variation across language backgrounds and disciplines, which is followed by a grammatical description based on fine-grained indices related to particular syntactic structures. The findings include: (1) L2 academic writers produce an averagely longer MDD than L1 academic writers because of their heavy use of prepositional phrases; (2) The MDD of the linguistics abstracts is significantly longer than that of the physics & chemistry abstracts because of the relatively higher syntactic complexity of the language of linguistics. The findings suggest that MDD can effectively differentiate academic texts with different language backgrounds and disciplines, that both L1 and L2 academic writers write under the constraint of dependency distance minimization, and that L2 PhD dissertation writers have achieved native-like writing proficiency in extending nominal structures.
Introduction
Earlier assessments and predictions of writing proficiency and its development rely heavily on the quantitative indices of syntactic complexity (e.g., Biber et al., 2016; Crossley, 2020; Crossley & McNamara, 2014; Ferris, 1994; Frase et al., 1998; Grant & Ginther, 2000; Kim & Crossley, 2018; Kyle & Crossley, 2018). These studies have reported scattered results, possibly due to the different indices adopted from multi-dimensions, for example, the mean length of production unit (Hunt, 1965; Larsen-Freeman, 1978; Ortega, 2003; Wolfe-Quintero et al., 1998), the nominal extension (Biber et al., 2011; Lu, 2011; Parkinson & Musgrave, 2014), or multi-dimensional metrics (Ai & Lu, 2013; Lu, 2017; Norris & Ortega, 2009). The indices for syntactic complexity assessment have profiled a development trend from large-grained to fine-grained, from single-dimensional to multi-dimensional. Regardless of the grammatical description supported by more fine-grained and multi-dimensional indices, it becomes more challenging to find a consistent pattern for syntactic complexity assessment (Nasseri, 2021). Against this backdrop, dependency distance has been proposed as a more economical and efficient metric (Liu, 2008).
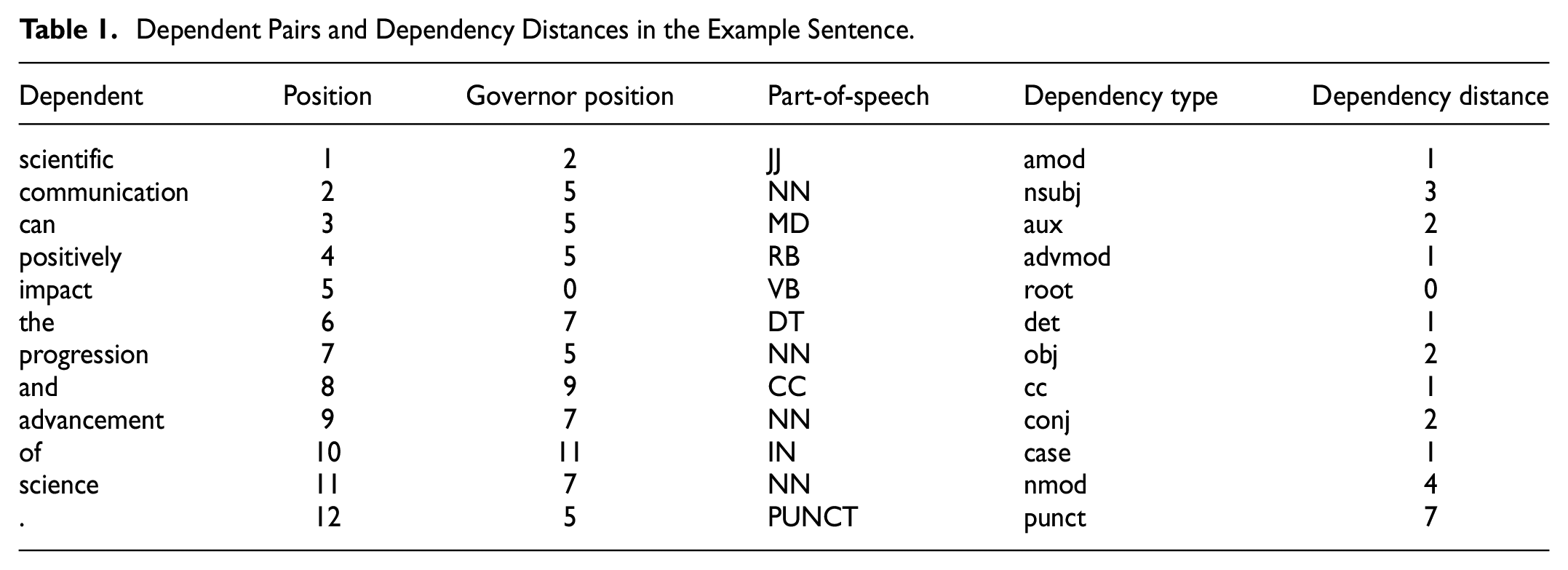
Dependency distance is the linear distance between two word-tokens (the governor and the dependent) within a syntactic dependency relation (Hudson, 2010; Tesnière, 1959). Figure 1 illustrates the dependency structure of an example sentence taken from our self-built corpus.

Dependency analysis of an example sentence.
All the tokens are connected by dependency relations, each arrow representing a dependency pair. The start point of each arrow is the governor, and the endpoint is the dependent. The sentence is visualized as a hierarchical system with the predicate verb as its root. The dependency distance of a dependency pair is the linear distance between the governor and the dependent (Liu, 2007). See Table 1.
Dependent Pairs and Dependency Distances in the Example Sentence.
Some studies (e.g., Chen & Gerdes, 2017; Liu, 2009, 2010; Liu & Xu, 2012) on dependency distance from multi-dimensions conclude that dependency distance and dependency direction are effective indices for language categorization. The typological analysis of 20 languages conducted by Liu (2010), for example, reveals that these languages could be typologically categorized based on dependency distance and dependency direction. Chen and Gerdes (2017) provide further evidence for dependency distance as a valid metric for language categorization using values of directional dependency distance to categorize 43 languages.
Mean dependency distance (MDD) is an essential index for predicting syntactic difficulty and writing proficiency (Jiang & Ouyang, 2017, 2018; Liu et al., 2017; Ouyang et al., 2022). From the perspective of cognition processing, a word can only be removed from the working memory when it encounters the dependent and forms a dependency relation (Ferrer-i-Cancho, 2004; Hudson, 2010; Liu, 2008). Comprehension difficulty will arise from the overloaded working memory caused by the information with long dependency distance. Therefore, the dependency distance of a sentence reflects the difficulty in analyzing a given sentence at the syntactic level. In this respect, the longer the dependency distance, the more words are stored in the working memory, and the more difficulty there is in analyzing the syntactic structure (Gibson, 1998; Hiranuma, 1999; Liu, 2008). According to Jiang and Ouyang (2018), for example, the average MDD of Chinese EFL learners’ essays tends to augment with the increasing scores representing writing proficiency, and the overall MDD is declared the best metric due to its synchronization with the rising writing proficiency levels in narrative writing. It can significantly discriminate all pairs of adjacent proficiency levels (Ouyang et al., 2022).
Dependency Distance Minimization (DDM) refers to the tendency to shorten the dependency distance in human languages (Ferrer-i-Cancho & Liu, 2014; Liu, 2007; Temperley, 2008). Large-scale cross-linguistic studies have confirmed that DDM is a global property of human languages (Futrell et al., 2015; Liu, 2008; Liu et al., 2017). Meanwhile, DDM is not exclusive to L1 language evolution; it can also be used in L2 language acquisition. According to Jiang and Ouyang (2018, p. 187), e.g., “Chinese EFL learners develop their English proficiency under the pressure of DDM.”
One more line of research is devoted to the factors that may affect dependency distance (e.g., Hiranuma, 1999; Oya, 2013; Wang & Liu, 2017; Zhu et al., 2022). According to Hiranuma (1999), for example, more formal texts have longer dependency distances than less formal texts in Japanese. Wang and Liu (2017) report that informative texts have similar or slightly greater MDDs than imaginative texts. This study suggests that dependency distance is genre sensitive and texts in all genres abide by the principle of DDM.
Dependency distance should be more focused on as a metric for syntactic complexity assessment. Over the past decades, research has investigated the syntactic complexity of L2 writers at different proficiency levels by referring to native speakers’ language as unquestioned norms (e.g., Biber et al., 2011; Norris & Ortega, 2009). In this view, language background has been considered as an essential factor affecting language in academic writing. According to Nasseri (2021), the dissertations written by native English PhD students are predominantly phrasal, whereas those written by EFL PhD students exhibit a higher level of subordination. Nevertheless, previous studies do not include whether MDD can effectively distinguish writers of different language backgrounds in terms of syntactic complexity. The hypothesis underlying the research reported in this paper is that EFL academic writers would produce shorter MDD than native English academic writers.
In addition, there is a dearth of research concerning the distinct syntactic features in discipline-specific academic texts (Biber et al., 2013; Casal et al., 2021; Khany & Kafshgar, 2016), and the disciplinary effect on dependency distance has not been effectively explored so far. According to Hyland, particular disciplines are associated with “particular norms, content, nomenclature, bodies of knowledge, sets of conventions and modes of inquiry” (Hyland, 1997, p. 21). Hence, members of a specific discipline always tend to abide by the norms of their communities by producing similar writings in terms of content and language to other texts from the same discipline.
In this view, language in different disciplinary communities may display different syntactic complexities. For example, Khany and Kafshgar (2016) examined the syntactic complexity in the discussion section of research articles, finding that subordinations are more preferred in humanities texts than in physics or life sciences texts. Casal et al. (2021) found significant differences in the use of syntactically complex structures in research articles across different social science disciplines, suggesting that future research can expand on this study by broadening the disciplinary focus beyond social science disciplines. We can hereby work on the second hypothesis that humanities texts are syntactically more complex and have longer MDD than natural sciences texts.
Methodologically, though highly economical and efficient in assessing syntactic complexity, omnibus indices like MDD cannot provide specific information for syntactic structures (Biber et al., 2011). We can predict the syntactic complexity of a text using MDD. However, this reveals little about the types of information/constructions included (e.g., noun phrases, noun modifiers, and subordinated clauses, etc.) or whether writers at a particular proficiency level use a consistent set of structures (Kyle, 2016). This is essential for fully understanding the characteristics of academic texts and the nature of the development of writing proficiency (Biber et al., 2020).
Methodology
Corpus
A self-built corpus was adopted in this research. The corpus consisted of 400 PhD dissertation abstracts from two disciplines: general linguistics (hereinafter referred to as “linguistics”) which can be considered as representative of humanities and physics & chemistry which are representative natural sciences. Within each field, half of the dissertations were selected from the Chinese National Knowledge Infrastructure (CNKI) and the other half from the ProQuest Dissertations & Theses (PQDT). Therefore, there are four sub-corpora included: native English linguistics (47,315 words), native English physics & chemistry (41,757 words), Chinese EFL linguistics (53,433 words), and Chinese EFL physics & chemistry (52,245 words). The PhD dissertations are chosen to prevent MDD from being affected by unprofessional writing proficiency, like excessive grammatical problems or a language articulation and rhetoric shortage (Smalley et al., 2012), because PhD students can be considered as mature and skilled writers in their own disciplinary fields.
The abstract is chosen as the part-genre of analysis in this study for its condensed summary of the content of the dissertation. A concise but comprehensive abstract gives the reader enough information. For space saving, the writers are often forced to impose a word limit on their abstracts. Because of this, abstracts usually involve a very dense, integrated packaging of information (Biber et al., 2011), and thus reflect writing proficiency. Second, the labor-intensive clearing-up of raw texts prevents us from adopting larger data sets. The abstract section chosen as the unit of analysis allows for the inclusion of more texts from varied disciplines into the corpus.
Data Collection
The current study adopts the calculation proposed by Liu (2009) to collect the MDD of each text. The MDD of a sentence can be calculated with the following equation:

where n is the number of words in the sentence, and DDi is the dependency distance of the i-th syntactic link of the sentence. Based on this equation, the MDD of the example sentence in Figure 1 can be computed as:

The second equation calculates the MDD of a text, in which n is the total number of words in the text, and s the total number of sentences. What calls for special attention is that the dependency distances of punctuations and root marks are not included in calculating the MDD.
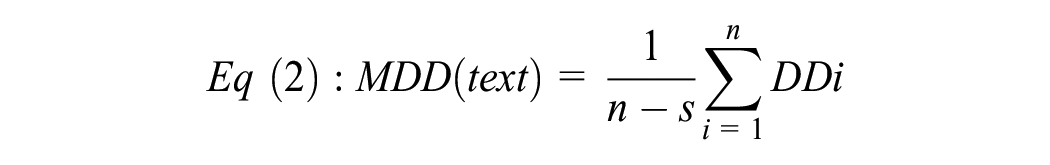
For batch and bulk data collection, a text organizer tool is used to trim irregular layout problems of text materials half-automatically to ensure all specific symbols from the texts are manually extracted and removed. The cleaned texts are processed with Stanford Core NLP parser (3.9.2) (Manning et al., 2014), an open-source probabilistic natural language parsing application, to analyze and annotate the syntactic dependencies of the texts. Specifically, we coded a Python script that can employ the stanfordcorenlp package to annotate the syntactic dependencies and automatically calculate the text MDD. The output is programed into an Excel format for computing the corpus MDD.
To offer a full-scale grammatical description regarding the MDD variation, a syntactic analysis tool based on computational linguistics and natural language processing, TAASSC (tool for the automatic analysis of sophistication and complexity) (Kyle, 2016), is adopted. The tool can be used to automatically extract fine-grained indices related to particular syntactic structures. Also, it allows users to choose the output of indices according to their own research needs. The current study included 31 fine-grained indices of clausal complexity. Additionally, three types of phrasal indices (132 indices in total) are included in the current study. The first type calculates the average number of dependents for each phrase type and for all phrase types. The second type calculates the occurrence of particular dependent types regardless of the type of noun phrase they occur in. The final type calculates the average occurrence of particular dependent types in specific types of noun phrases.
It is worth noting that standard deviations (labeled as “stdev”) are also calculated for some clausal or phrasal indices. These indices provide a measure of variability. Tables 2 and 3 describe the terms and some fine-grained indices from Kyle (2016) for reference in the following-up sections. The results concerning the MDD and syntactic features of the texts will be presented in the following section.
Dependent Types Referred to in the Current Study.

Indices Referred to in the Current Study.
Statistical Analysis
The Shapiro-Wilk test and Q-Q plots indicate that the MDDs follow the normal distribution. The one-way ANOVA test is used to determine whether there are significant differences in the two indices across language backgrounds and disciplines. The post hoc test is further used to examine the efficiency of MDD in differentiating language backgrounds and disciplines. Then, two steps of statistical analysis are employed to test the second hypothesis. First, we conduct Pearson correlation analyses to examine the relations between the MDD and the grammatical indices, aiming to exclude the indices whose correlation coefficient are either non-significant (p ≥ .05) or too small (r < .100). The indices that violate a normal distribution are eliminated, and those that remain are checked for multicollinearity. The index that has multicollinearity with other indices is removed (VIF > 5). We retain the indices that correlate more strongly with MDD (r ≥ .100) (See Kyle & Crossley, 2018). Lastly, we perform stepwise regression analyses to automatically select the most typical grammatical indices that strongly correlate with MDD. In most cases, the indices obtained represent the most frequently occurring syntactic features that correlate with MDD.
Results
MDD Variations Across Language Backgrounds and Disciplines
We first compared the overall MDD distribution regarding language backgrounds and disciplines to offer a global insight into the MDD differences. On the one hand, the Chinese EFL academic writers produce relatively longer MDDs than the native English academic writers. On the other hand, both groups of linguistics abstracts exhibit longer MDDs than the physics & chemistry abstracts. See Figure 2.

MDD across language backgrounds and disciplines.
The one-way ANOVA test confirms the significance of MDD variation (p = .002) as shown in Table 4. By and large, the following-up Post hoc tests shows that MDD could significantly discriminate language backgrounds and disciplines (including the marginally significant differences). See Table 5.
Descriptive Statistics for MDD Variation.

Post hoc Tests on MDD Variation.

The significant differences between the MDDs indicate different syntactic complexities between the academic texts written by the Chinese EFL writers and those written by the native English writers and between the two disciplines. However, how the native English writers utilize particular syntactic structures that differ from the Chinese EFL writers on dependency distance remains unknown. Therefore, a more detailed investigation into the grammatical features closely related to the MDD differences is required.
Syntactic Features of the MDDs Across Language Backgrounds and Disciplines
Before conducting the stepwise regression analysis, we removed those indices that were not significantly correlated with MDD (p < .05 and r ≥ .100). Of the remaining indices, those against normal distribution violation or with multicollinearity (VIF ≥ 5) were also eliminated. The indices that remained were then entered into the stepwise regression analysis.
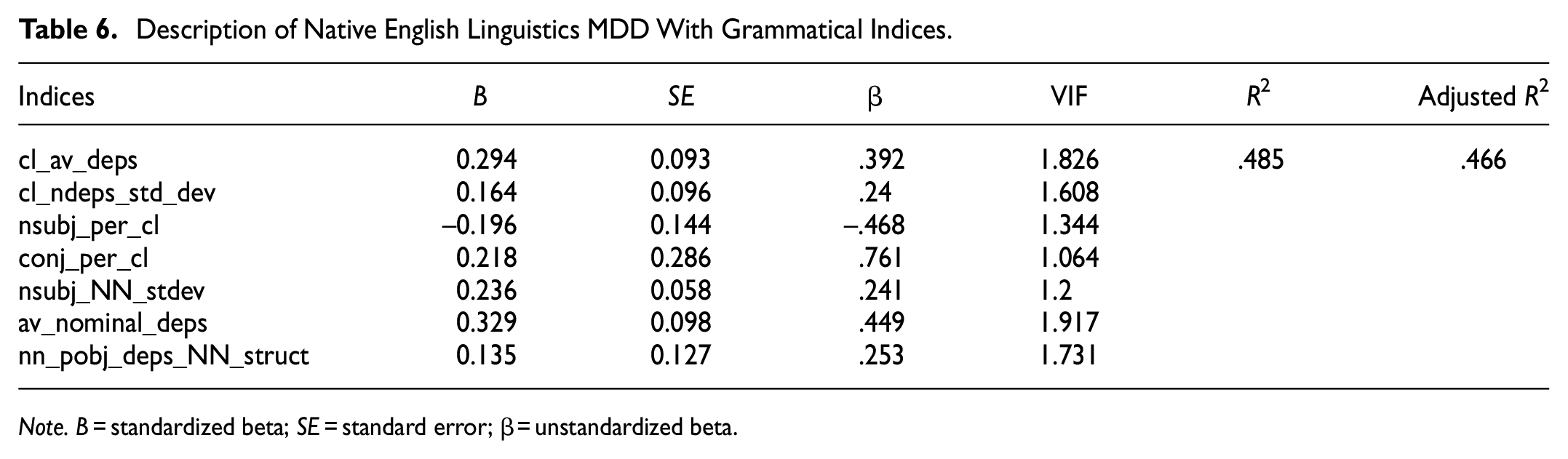
The resulting model regarding the MDD of the native English linguistics abstracts yielded seven significant predictive indices, that is, average number and standard deviation of dependents per clause, nominal subjects per clause, dependents per nominal subject (ignoring direct objects that are pronouns), conjunctions per clause, dependents per noun phrase, and nouns as an object of the prepositional dependent per object of the preposition (ignoring pronouns). The model explained 48.5% (R2 = .485, adjusted R2 = .466) of the variation in the native English linguistics MDD. See Table 6.
Description of Native English Linguistics MDD With Grammatical Indices.
Note. B = standardized beta; SE = standard error; β = unstandardized beta.
The resulting model regarding the MDD of Chinese EFL linguistics abstracts included six indices, that is, standard deviation of dependents per clause, conjunction per clause, dependents per object of the preposition, prepositions per nominal subject (ignoring pronouns), conjunction “and” as a dependent per object of the preposition (ignoring pronouns), and standard deviation of dependents per nominal (ignoring pronouns). The model explained 59.7% (R2 = .597, adjusted R2 = .571) of the variation in the Chinese EFL linguistics MDD. See Table 7.
Description of Chinese EFL Linguistic MDD With Grammatical Indices.
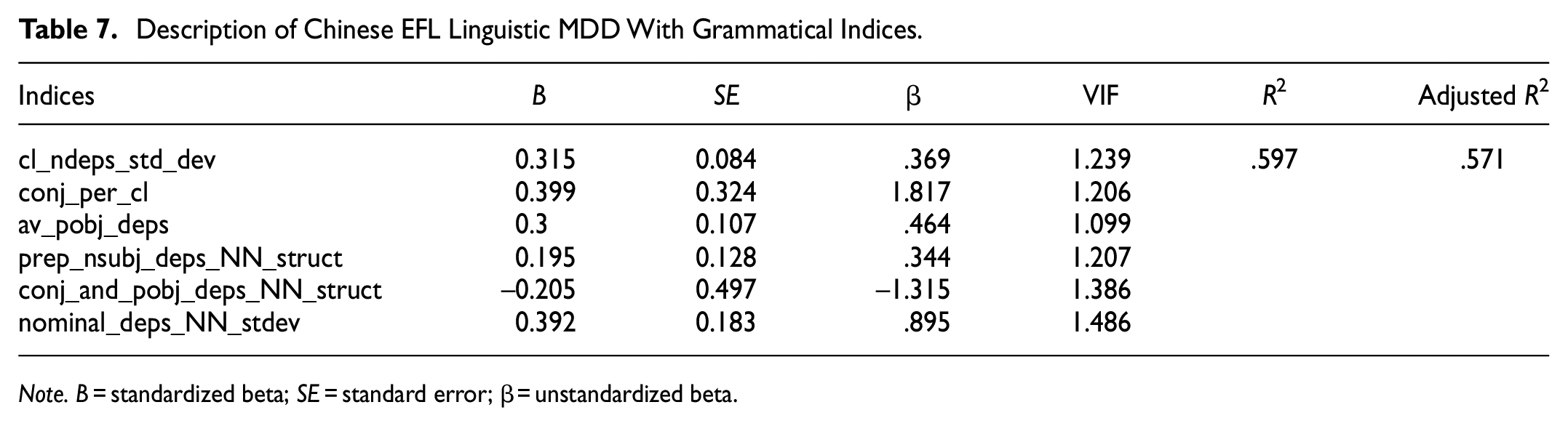
Note. B = standardized beta; SE = standard error; β = unstandardized beta.
The result reveals three larger-grained indices, that is, average number of dependents per clause, prepositions per clause, and dependents per noun phrase, that can describe 36.8% (R2 = .368, adjusted R2 = .348) of the variation in the native English physics & chemistry MDD. See Table 8.
Description of Native English Physics & Chemistry MDD With Grammatical Indices.
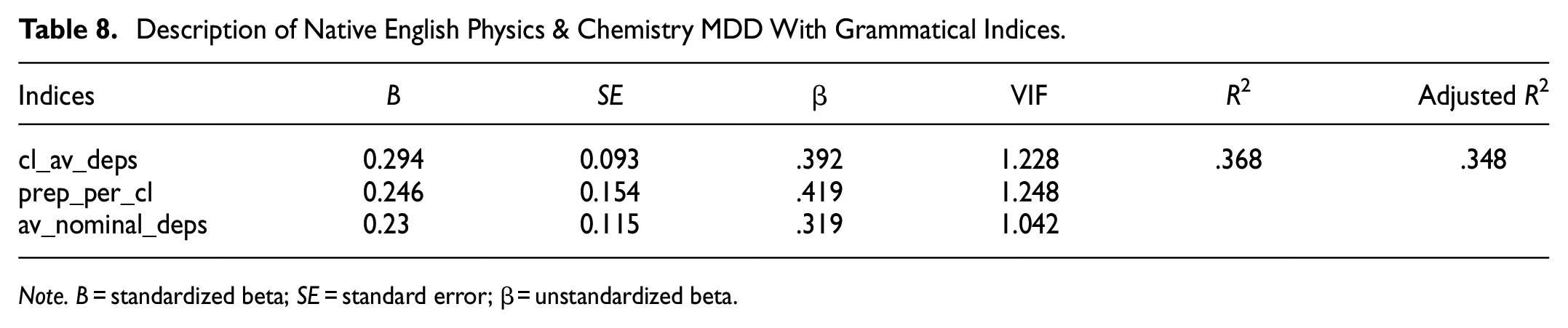
Note. B = standardized beta; SE = standard error; β = unstandardized beta.
Lastly, the resulting model includes five indices, that is, conjunctions per clause, prepositions per nominal (ignoring pronouns), nouns as a direct object dependent per direct object (ignoring pronouns), standard deviation of dependents per clause, and dependents per nominal (no pronouns, standard deviation). The model explained 52.1% (R2 = .521, adjusted R2 = .496) of the variation in the Chinese EFL physics & chemistry MDD. See Table 9.
Description of L2 Physics & Chemistry MDD With Grammatical Indices.

Note. B = standardized beta; SE = standard error; β = unstandardized beta.
Discussion
It is found from the above research that L2 academic writers produce longer MDD than L1 academic writers and that the MDD of the linguistics abstracts is significantly longer than that of the physics & chemistry abstracts. This is partly in agreement with our hypotheses that L2 academic writers would produce shorter MDD than L1 academic writers and that linguistics texts are syntactically more complex and have longer MDD than physics & chemistry texts. This section discusses these research findings. We first provide a grammatical description of the MDDs, and then investigate the MDD differences by comparing the syntactic features between paired groups.
Syntactic Description of MDD
The regression model of native English linguistic abstracts shows that MDD is positively correlated with the number and diversity of dependents in a clause. This indicates that the heavy reliance on finite and non-finite clauses (including subordinations) is a typical writing strategy in native English linguistics abstracts. However, no particular indices regarding subordination appear in the model. The negative correlation between nominal subjects (nominal subjects per clause) and MDD (β = −.468, p = .001) confirms a positive relationship between the prominent inclusion of non-finite clauses (e.g., infinitive and gerund clauses) and MDD. Furthermore, the extension of noun phrases, like pre- and post-modifiers, could be the primary strategy for academic writing since there are three relevant indices retained in the model, that is, standard deviation of dependents per nominal subject, dependent per noun phrase, nouns as an object of the preposition dependent per object of the preposition (ignoring pronouns). In other words, texts with more diversified dependents in noun phrases tend to have longer MDDs. Lastly, it should be noted that coordination also prevails in the texts. For example:
(1) a. I tested the capacity of working memory for object concepts [using an articulatory suppression task to block access to language]non-finite clause as a clausal dependent.
b. The thesis includes three self-contained papers [which show that the conceptual system relies on linguistic or sensorimotor information according to task demands]finite clause as a clausal dependent.
c. The [linguistic-simulation]nn [approach]nsubj [to conceptual representations]prep_nsubj has been investigated for some time.
d. Some of [the effects]nn_pobj1of [imageability]nn_pobj2 found in [the literature]nn_pobj3…
e. This goes contrary to the fact that, in real life, students are exposed to varying listening situations [and]conj expected to perform various listening tasks.
In the Chinese EFL linguistics abstracts, the regression model shows that MDD is positively correlated with the diversity of dependents in a clause, namely, the utilization of finite and non-finite clauses. Besides, four indices directly make clear the writers’ preference for extending nominal structures, that is, dependents per object of the preposition, prepositions per nominal subject (ignoring pronouns), conjunction “and” as a dependent per object of the preposition (ignoring pronouns), and standard deviation dependents per noun phrase (ignoring pronouns), three of which are preposition-related. Prepositional phrases predominantly used as post-modifiers in nominal subjects will inevitably stretch the dependency distance from subject to predicate and increase syntactic complexity and comprehension difficulty (Gibson, 1998). The index of conjunction per clause shows a positive correlation with MDD (β = 1.817), whereas the other (i.e., conjunction “and” as a dependent per object of the preposition (ignoring pronouns) exhibits a negative correlation (β = −1.315). This inconsistency may be due to the different positions the conjunction fills in. For example, the conjunction “and” connecting two predicates or clauses, will bring in new grammatical constituents and lengthen the sentence, which is positively correlated with dependency distance (Jiang & Ouyang, 2018). In contrast, conjunction “and” connecting nominal objects of a prepositional phrase can be considered more of an approach to syntactic structure condensation. In this way, the negative correlation between “and” in prepositional phrases and MDD, though not typical in the native English abstracts, proves that the Chinese EFL academic writers have been fully aware of the significance of nominal extension and structure condensation in academic writing. See example (2) regarding the “prep_nsubj” and “conj_and_poj” indices.
(2) a. Speech [sounds]nsubj [in language]prep_nsubj are traditionally believed to be linearly arranged one after another, but recent gesture-based studies find that this is not always the case.
b. Listening ability assessment is greatly different from assessment of such abilities as in [reading, writing,
Regarding the native English physics & chemistry abstracts, all three indices are positively correlated with MDD. The index of clausal dependents (dependents per clause) confirms non-finite clauses as an effective writing strategy that tends to produce a higher MDD. The clausal preposition (preposition as dependents of predicate per clause) reveals a higher frequency of prepositional phrases of adjuncts of predicates and seemingly occurring more frequently in the passive voice. The number of dependents per noun phrase still suggests that texts with longer MDDs tend to include noun phrases with more dependents. See example (3) regarding “prep_cl.”
(3) a. Systems based on radiative applicators are the most widely used [within the hyperthermic community]prep_cl.
b. Such interactions can be harnessed [in quantum devices]prep_cl to address hard computational problems.
As for the Chinese EFL physics & chemistry abstracts, two indices are closely related to the use of nominal extension, that is, prepositions per nominal (ignoring pronouns) and nouns as a direct object dependent per direct object. In addition, the standard deviation of dependents per clause reveals the wide range of finite and non-finite clauses used in the texts. The standard deviation of dependents per nominal suggests that more dependent types of noun phrases are encouraged due to their positive correlation with MDD. Meanwhile, conjunctions are also frequently used and positively correlated with MDD. See example (4) regarding “prep_all_nominal” and “nn_dobj.”
(4) a. This thesis focuses on the theoretical investigation [of universal and non-universal properties]prep_nominal1 [of ultracold few-atom systems]prep_nominal2.
b. How does it affect the [energy]nn [spectrum]obj of the two-atom system?
MDD Variation Across Language Backgrounds
According to the syntactic description, it is not difficult to note the similarity and nuance between the L1 and L2 abstracts that lead to the MDD difference. First, a diversity of finite and non-finite clauses is frequently used in both L1 and L2 abstracts. In addition, extending noun phrases can be considered as a universally prevalent writing strategy across language backgrounds. However, the shorter MDD produced by L1 writers indicates less syntactic complexity in L1 abstracts. It is worth noting that noun dependents and preposition dependents are the primary means for L2 writers to extend noun phrases since there are more relevant indices in the L2 models. Furthermore, the L2 models account for relatively more considerable MDD variation (59.7% vs. 48.5%; 52.1% vs. 36.8%), indicating higher interpretability and representativeness for the syntactic features of MDD in the L2 abstracts. See example (5):
(5) a. The practice-based definitions [of philology]prep1 produced by this treatment allow critics to emphasize continuities [between philology and the contemporary humanities]prep2 (MDD = 1.94).
b. In recent years, there has been much interest [in the studies]prep1 [on evidentiality]prep2 [in the field]prep3 [of applied linguistics]prep4 (MDD = 2.22).
The dependency structures of the example sentences in (5) are illustrated in Figures 3 and 4.

Dependency analysis of example (5a).

Dependency analysis of example (5b).
Regardless of the nuance in sentence length (20 words in 5a and 19 in 5b), (5b) with more prepositional phrases is syntactically more complex and has longer MDD than (5a).
Overall, the results of the current study support Biber et al.’s (2011) hypothesis that phrasal complexity, particularly the extension of noun phrases, is the most advanced syntactic feature or essential skill for L2 writers to acquire. The value of nominal extension is that a clause can be shifted to a noun phrase functioning as an element in another clause (Halliday, 1989). Therefore, the prevalence of nominal extension reveals that L1 and L2 writers performed their writing proficiency under the pressure of DDM. They attempted to prevent overlength sentences from producing too many complex dependency relations with great spans, keeping the dependency distance within an acceptable range.
Furthermore, the longer MDD produced by the L2 writers may be resulted from more utilization of complex prepositional phrases for higher syntactic complexity, leading to the synchronic growth of MDD (Jiang & Ouyang, 2018). The longer MDD in L2 abstracts also aligns with other studies (e.g., Crossley & McNamara, 2014; Guo et al., 2013; McNamara et al., 2010) that essays with more words preceding the main verb (including nominal subjects) and more modifiers per noun phrase show higher syntactic complexity. Our research found that the L2 writers have reached or even exceeded native-like proficiency in terms of syntactic complexity, corroborating the research of Mancilla et al. (2017).
MDD Variation Across Disciplines
As seen in the regression models, the MDD of linguistic abstracts is significantly longer than that of physics & chemistry abstracts, indicating lower syntactic complexity of the language of physics & chemistry. First, seven indices represent both clausal and phrasal features in the L1 linguistic model. In contrast, no phrasal indices were given from the L1 physics & chemistry model, suggesting that writers of natural sciences tend to use easier-to-understand language. A similar difference can also be found between the L2 texts of different disciplines, as reflected in the number of preposition-related indices, that is, three in the L2 linguistic model and one in the physics & chemistry model.
The shorter MDD and lower syntactic complexity in physics & chemistry abstracts could be related to the author’s intention to provide a clarified description for the audience to comprehend their whole dissertations with great epistemic difficulty. Although prepositional dependents are primarily used as post-modifiers of noun phrases in the L1 linguistics texts, the models show that they mainly function as adjuncts in the physics & chemistry texts. See example (6) and Figure 5.

Dependency analysis of example (6).
(6) The summary of each chapter and findings are mentioned below in order (Chosen from L1 physics & chemistry, MDD = 2).
Writers of natural sciences employ significantly more passive bundles usually followed by a prepositional phrase marking a locative or logical relation (Hyland, 2008), as is reflected in the regression model of L2 physics & chemistry. These bundles function as “directives” (Hyland, 2002) to instruct readers to “perform an action or to see things in the way determined by the writer” (Hyland, 2008, p. 18).
Though different in the use of clausal prepositions, the MDDs of the academic abstracts are positively correlated with two similar grammatical features (dependents per clause, dependents per noun phrase). This similarity proves the common syntactic feature across academic genres, that is, the application of and dependence on nominal extension and hypotactic constructions (Biber et al., 2011). For example.
(7) a. We review relevant aspects of quantum chromodynamics and heavy-ion collisions, [which primarily motivate our work.]finite clause as a clausal dependent. (L1 physics & chemistry)
b. This thesis is motivated by the charge orders and associated symmetry breaking [observed in the enigmatic pseudo gap phase of underdoped cuprates.]non-finite clause as a clausal dependent (L2 physics & chemistry)
c. The [medium]nn [modification]nsubj [of the light vector mesons]prep1 gives insight [on the chiral symmetry restoration]prep2 [ in heavy ion collisions.]prep3 (L2 physics & chemistry)
The disciplinary differences and similarities in MDDs and syntactic features suggest that disciplines can form a cline of syntactic complexity from natural sciences through social sciences to humanities. According to Hyland (2006, p. 240), “disciplines in the humanities rely more on case studies and introspection and claims are accepted or rejected on the strength of argument,” whereas natural sciences “see knowledge as a cumulative development from prior knowledge and accepted on the basis of experimental proof.”
Conclusion
This study investigated the MDD variation caused by language backgrounds and disciplines based on a corpus of 400 PhD dissertation abstracts written by native English and Chinese EFL academic writers. The results reveal significantly different MDDs across backgrounds and disciplines. The stepwise regression analysis indicates that the abstracts authored by L1 and L2 writers show similar syntactic features of academic writing, for example, extended nominal structures with prepositional phrases as modifiers. The frequent use of complex noun phrases supports Biber et al. (2011) that academic writing relies more on phrasal rather than clausal structures. Furthermore, the attempt to condense sentence structure proves the common compliance with the pressure of DDM from both L1 and L2 academic writers. Nevertheless, contrary to our hypothesis, the longer MDD in L2 abstracts suggests higher syntactic complexity due to the emphasis on the use of prepositions in nominal extension. The heavy use of complex noun phrases also reflects the L2 writers’ adherence to academic writing conventions. The cross-discipline MDDs reveal the significant difference between linguistics and physics & chemistry. The longer MDD in linguistics abstracts confirms our hypothesis that linguistics writers employed syntactically complex structures more frequently than physics & chemistry writers. Furthermore, the shorter MDD of physics & chemistry abstracts may be attributed to the writers’ attempts to reduce readers’ comprehension difficulty. Regardless of the different MDDs and discipline-sensitive syntactic features, nominal extension and hypotactic constructions are the shared writing strategies across academic disciplines.
The present study verifies the efficiency and potential of combining dependency distance and fine-grained syntactic measures in the research of writing proficiency. At the same time, this present study can be extended at least in two directions. First, comparisons across more language backgrounds and disciplines should be considered to verify the validity of MDD as an index of syntactic complexity and uncover the syntactic differences. Second, future studies may investigate the MDD of particular syntactic structures as an index of syntactic complexity.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by China National Social Science Fund (21BYY043).
Ethics Statement
This research does not include any content of animal and human studies.