
Abstract
Supply chain data governance optimization in the context of digital transformation is an emerging topic. The process of data governance optimization involves complex governance subjects and systems. This study aims to clarify the mechanism of supply chain data governance structure and solve the data governance challenges faced by the whole supply chain, in order to promote the sustainable development of supply chain data governance ecosystem and realize the value-added of supply chain. Based on the theory of information ecology, the index system of supply chain data governance ecosystem is constructed. Further, we employed a combined fuzzy decision-making trial and evaluation laboratory (DEMATEL) and Interpretative Structural Models (ISM) method to explore the index prioritization and hierarchical relationships for data governance optimization. The initial weights of the indexes were determined based on the opinions of eight experts in related fields. The results of the DEMATEL analysis identified 16 key indexes for data governance optimization. Futhermore, based on the ISM model, we developed a multi-layer recursive explanatory structural model showing the structural relationships for supply chain data governance optimization and finally proposed the corresponding optimization path. The proposed model provides a more accurate analysis for each governance party of the supply chain when it comes to digital transformation of the supply chain. It provides authorities with a layered progression of supply chain data governance optimization thinking and the actions to be taken at each layer.
Introduction
The new round of technological revolution drives the strong rise of emerging technologies, industrial digitalization has become an important engine of the fourth industrial revolution (Çınar et al., 2020). In recent years, the digital economy has flourished, becoming a pivotal sector propelling global economic growth. According to the latest release of the “Global Digital Economy White Paper (China Academy of Information and Communications Technology, 2024),” in 2023, the aggregate digital economy of five major countries—namely the United States, China, Germany, Japan, and South Korea—totaled $33 trillion, representing 60% of their GDP. This figure reflects an increase of approximately 8 percentage points compared to 2019. Furthermore, the digitalization of industries constitutes 86.8% of the digital economy. In the digital era, the deconstruction and restructuring of the industrial system can catalyze the transformation and upgrading of the supply chain (Kaminski et al., 2017). At the same time, the “digital infrastructure” with industrial Internet as the core has emerged, providing key support for the collaborative innovation of supply chain (Broo et al., 2022). Under the new development pattern, the digital transformation of supply chain has become an inevitable trend of a country’s economic development (Martens & Zscheischler, 2022). Supply chain management is essential to enterprise operations and a central component of digital transformation in the manufacturing industry. Traditional supply chain models and business systems can no longer meet the demands of rapidly changing markets and complex networks. Consequently, digital supply chains have become a primary focus. Integrating the digital economy with manufacturing, digital supply chains rely on the collection, aggregation, and analysis of vast data to enable systematic management in demand forecasting, risk decision-making, information sharing, and collaboration. This process, known as data governance, offers significant advantages over traditional models. As digital transformation continues, more enterprises are prioritizing data governance and optimizing their supply chain management models. However, the supply chain market demand for data capacity and quality is not consistent with the state of the data, so supply chain data governance research is urgent.
Compared with other industries, the traditional manufacturing supply chain has been exposed to many problems that need to be solved under the impact of digital transformation, such as numerous data calibers, obstructed data circulation, unclear data quality and hidden data security, due to the complicated and variable nodes and significant differences in operation modes (Reinartz et al., 2019). However, data governance parties are still facing governance dilemmas such as slow progress, low layer of governance technology and inadequate governance system (Fothergill et al., 2019). At the same time, research on data governance in the supply chain environment is relatively scarce, mostly based on qualitative research on supply chain digital transformation, and has not yet gone into the complexity of supply chain data governance index system. Therefore, it is necessary to explore the underlying logic behind supply chain data governance and clarify the structural mechanism of supply chain data governance. The Fuzzy DEMATEL-ISM model combines the DEMATEL and ISM methods. First, it analyzes the logical relationships among data governance elements to determine the influence of each element on others. Then, it calculates the causality and centrality of each element to assess its importance in the overall governance system. Next, the influencing factors across systems are categorized into different levels, and the core factors and their relationships are analyzed. These will not only help broaden the research ideas of supply chain data governance optimization, but also facilitate the overall process of data governance. Against this background, the aim of this study is to address the below-mentioned objectives.
(1) To find out the composition of indexes for data governance in the supply chain environment.
(2) To clarify the structural system of supply chain data governance optimization.
(3) To propose the corresponding governance optimization paths to improve the effectiveness of data governance.
Furthermore, Supply chain data governance optimization is a dynamic, stable, and sustainable complex cycle system (Hazen et al., 2018). It formed by the interaction of governance subject, governance technology and governance environment with data as the core and the supply chain as the carrier (Li, 2017). Based on this, this paper establishes a multidimensional data governance indicator system in the context of the industrial internet and analyzes it using the fuzzy DEMATEL-ISM model. On one hand, it aims to expand the breadth of the data governance indicator system; on the other hand, by exploring the relationships, hierarchies, causality, and importance of the indicators, it further clarifies the underlying logic of data governance in the industrial internet. This not only provides a theoretical contribution to the digital transformation of the supply chain but also helps enterprises to carry out targeted data governance work, thereby improving the efficiency of data governance.
The remainder of the paper is organized as follows. In Section 2, the literature review is presented followed by Section 3 and its subsections which build a supply chain data governance ecosystem index system based on information ecology theory. Next, Section 4 presents the details of the fuzzy DEMATEL-ISM methodology and the stepwise approach that contains some steps. Thereafter, in Section 5, a multi-layer recursive explanatory structure model for supply chain data governance is proposed to analyze the governance structure in a hierarchical manner, and the data are presented in Tables 1 to 3, Tables A1 to A3 and Figure 3 is a explanation of the structure diagram. Section 6 proposes the corresponding optimization path followed by Section7, which concludes our study.
Comparison Table of Triangular Fuzzy Number.

Ranking of Influence Index of Each Indexes.
First Level Reachable Set and Prior Set.

Literature Review
Data Governance
Data management refers to the guiding principles, organizational structures, implementation policies, systems, and procedures for handling data within an enterprise. It is typically used to guide organizations on how to design and execute data strategies. In contrast, data governance places greater emphasis on overall guidance and control, offering governance principles and standards for data integration, flow, application, evaluation, and other processes. These principles focus on achieving core goals and adapting to different environments in data management.
Data governance is a fundamental issue of economic and social governance in the digital era, and it is also the focus of scholars from all walks of life. Currently, scholars at home and abroad have formed rich research results on data governance at the levels of theoretical exploration (Jiang et al., 2021), model architecture (Bibri et al., 2024), and practical application (Horgan, 2022), and related research perspectives are related to government governance (Mao et al., 2022), smart campus (Roda-Sanchez et al., 2024), artificial intelligence (Janssen et al., 2020), digital health (Islam et al., 2024), and so on.
As an emerging research field, data governance has undergone several stages of development worldwide, and its definition has evolved across different periods, contexts, and practices. Table 4 presents some common definitions of data governance.
Summary of Data Governance Definitions.

Data Governance of Supply Chain
Data management in the supply chain refers to the systematic process of collecting, storing, analyzing, and utilizing the data generated at various stages of the supply chain operations. However, traditional data management still struggles to avoid issues such as data silos, security, and privacy concerns. In contrast to data management, data governance in the supply chain places greater emphasis on holistic guidance and control. It provides governance principles and standards for the integration, circulation, application, and evaluation of data, aiming to achieve a leap forward in the management of supply chain data. So, with the deepening of digital supply chain transformation and upgrading (Nasiri et al., 2020), some scholars gradually turn their attention to the research on data governance based on supply chain environment. The researchers who have constructed a dual-channel supply chain model to analyze the selling price of fresh agricultural products under different decision modes to solve the problem of missing data in the production and marketing process (Modak et al., 2024); The designs and implements a blockchain data sharing market for programmatic supply chain (Lopez & Farooq, 2020); J. Zou et al. (2018) proposed a multi-attribute dynamic access control model for data services to ensure the security of data services in the supply chain.
Although previous studies have addressed data governance in the supply chain by focusing on areas such as data circulation, data deficiency, data sharing, and data security, these perspectives remain fragmented. Most research remains theoretical, with limited quantitative analyses focused on operational decisions in supply chain data governance (Belhadi et al., 2021) or blockchain platform construction (J. Yang et al., 2023). Furthermore, research on the indexes for optimizing supply chain data governance from a systems thinking perspective has been largely neglected. Based on the comprehensive review of the development process of supply chain data governance, data governance, as a new, more comprehensive and efficient data management mode and analysis mode, can effectively help supply chain to achieve a higher level of optimization and performance improvement. However, most scholars focus on the realization of supply chain model selection, supply chain risk decision-making and other goals. Their supply chain indicator system research does not make an overall analysis of upstream and downstream enterprises of the supply chain, relevant participating institutions, so as to find an optimization path for digital transformation of the supply chain.
Fuzzy DEMATEL-ISM
Fuzzy DEMATEL (Fuzzy Decision Making Trial and Evaluation Laboratory) is a method of analyzing system elements by using graph theory and matrix tools. Under the premise of considering fuzzy expression and uncertainty of decision factors, By analyzing the logical relationship and direct influence relationship between the elements in the system, we can judge whether the relationship between the elements is there or not and evaluate its strength and weakness. The characteristic of ISM (Interpretative Structural Modelling) method is to decompose a complex system into several subsystems (elements), and construct the system into a multi-level hierarchical structural model through algebraic operation, which can present the typical analysis method of the association structure between complex elements of the system. However, ISM can only reflect the logical relationship and hierarchical structure among the indicators, and can not determine their causality. As a quantitative method to study the logical relationship of factors in complex systems, DEMATEL method can make up for the defects of ISM method in the analysis of factors in complex systems and has the role of simplifying the internal structure of the system.
In the study of complex systems, Zhou et al. (2008) introduced the integrated DEMATEL-ISM approach to construct system hierarchies. They provided the theoretical foundation and algorithmic model for combining DEMATEL and ISM methods and validated the effectiveness of this integrated approach. Tang et al. (2024) developed a DEMATEL-ISM model to explore the relationships among factors influencing brand competitiveness, resulting in a four-tier hierarchical model that identified key factors at different levels. Similarly, D. Lin et al. (2022) applied the integrated DEMATEL-ISM method to analyze risk factors affecting public hospitals, ranking these factors by importance, thereby identifying key risks impacting patient safety.
In system governance, it is crucial to develop a supply chain data governance ecosystem index from an ecological perspective, focusing on the interaction mechanisms between indicators across different dimensions. By applying the DEMATEL-ISM method, we can determine the importance and influence of governance optimization indicators, identify key factors, and establish their structural levels and categories. This paper constructs a multi-level hierarchical model for optimizing supply chain data governance, reveals its structure, and proposes targeted strategies to enhance governance.
Construction of Index System
Selection of Indexes
Supply chain data governance optimization is in line with the core idea of information ecology theory. It is based on improving the efficiency of supply chain data governance optimization, the data governance subjects establish interdependence (Richey et al., 2016). They form a benign interaction of multiple participants and build a data governance model of shared governance, thus ensuring the continuous circulation, sharing and application of data resources and services relying on technical power in a good governance environment. Therefore, constructing a supply chain data governance ecosystem index system oriented to the constituent elements of information ecology is conducive to expanding the thinking of index selection for supply chain data governance optimization and further promoting theoretical innovation of supply chain data governance optimization research. Based on this, this paper selects indexes of supply chain data governance optimization from four dimensions.
Data governance subjects refer to the organizations or individuals involved in supply chain data governance activities, and these members constitute the value subjects of the supply chain data governance ecosystem. Since these value subjects are primarily interrelated and mutually supportive, they can assume various roles and functions. In addition to providing and using data, they can also transform into data operators and service providers. This is analogous to the diversity of biomes in ecosystems, where different populations are interdependent and interact to form diverse species assemblages.
Data governance technology is an important way to improve data governance capability. Supply chain data can reflect the business status and strategy implementation of manufacturing industry, and play an important role in the value enhancement of supply chain. Therefore, effective data governance technology is a key part of data governance capability.
Data and services are the core drivers of the supply chain data ecosystem and the key embodiment of data governance capabilities. The characteristics of data resources such as variability and instability form the behavior of data acquisition and transmission.
Supply chain data governance environment is mainly divided into two parts: the macro environment, which includes politics, economy, science and technology, humanities, social infrastructure, and manufacturing characteristics and regulations derived from the supply chain environment; and the micro environment, which directly influences supply chain data governance through factors such as supply chain competition, target user markets, financial environments, and other specific scenarios.
Content of the Index System
Data Governance Subjects
Based on relevant stakeholders involved in supply chain data governance and authoritative reports, the data governance entities are categorized into three secondary indexes: government departments, enterprises, and users. These secondary indexes are further broken down into tertiary indexes that influence the optimization of supply chain data governance.
As an external driving force in the data governance process, the government plays a pivotal role in the digital transformation of the manufacturing industry through its participation, promotion, and regulation. The State Council emphasizes that the scientific deployment of digital government policies, innovative governance concepts, and the construction of government information systems are critical supports for advancing the national governance system and modernizing governance capacities (Kaur & Nand, 2021). The government’s willingness to govern data is essential for effectively developing and implementing data governance strategies, and this willingness has a significant positive impact on the outcomes of data governance.
Users, as key value stakeholders in supply chain data governance, play a crucial role in driving the governance process. In recent years, there has been an increased focus on demand chain management, and supply chain reorganization has been centered around meeting user needs. As users’ demand for data usage grows, their participation in both product purchasing and data governance increases, thereby accelerating the data governance process.
Enterprises within the supply chain, including node enterprises, operation service enterprises, and industrial Internet platform companies, are also integral value stakeholders in the governance system. The core competitiveness of these enterprises is a key index for assessing the current status of the supply chain industry and the investment risk of key enterprises. Moreover, the targeted planning of governance objectives in the digital transformation of industrial enterprises is crucial for advancing the governance process.
In view of this, the secondary indexes under the data governance subject dimension are further decomposed into encouraging government policies, government data governance willingness, government service platform construction, supply chain data governance innovation concept, public participation degree, meeting user needs, enterprise core competitiveness, and effective planning of governance objectives.
Data Governance Technologies
The development of governance technology plays a core role in ensuring the optimization of supply chain data governance and is an important basis for realizing the sustainable development of governance ecosystem. It can be further subdivided into two secondary indicators: technology and talent, and infrastructure.
The development of information technology has spurred the urgent demand for governance systems at the technical level, and upstream and downstream entities in the supply chain need governance parties to provide data operation aspects that integrate emerging technologies such as the Internet of Things, artificial intelligence, and blockchain (Bhattacharyya et al., 2021). Therefore, data operation ability is the key factor to judge the optimization efficiency of data governance. Data management talents with high-level operation ability can improve the efficiency of data collection and enhance the ability of independent analysis and data resource mining.
The orderly operation of the information platform can effectively solve problems such as uneven quality and data security risks, so as to improve the efficiency of data governance and optimization. The industrial Internet platform of big data integration and open sharing based on the development of infrastructure and intelligent construction, the higher its perfection, the more it can improve the efficiency of supply chain data governance optimization.
In view of this, technical support for data operation, information department personnel availability, degree of information platform development, and intelligent construction of industrial Internet are selected as the three-level indexes under the technical dimension of data governance.
Data and Services
Data is the core element of the ecological structure of the Industrial Internet. Products, as value carriers, interact with enterprise networks and resource networks through data or data services during their value-added processes (Dubey et al., 2017). These processes reflect industrial entities and integrate product value streams under resource constraints, with data being precisely mapped, transferred, and applied at various stages and levels. As a result, data and services are selected as key indexes for data governance optimization.
Considering the entire life cycle of the data flow process, data governance is divided into several modules, including metadata management, data quality, data standards, data storage and collection, and data security (C. Yang et al., 2022). The level of data security risk is determined by factors such as the amount of false data circulating between the industrial Internet platform and the supply chain, as well as the extent of access to users’ personal privacy data. Supply chain services, as a crucial component of data governance, focus on cost reduction and efficiency improvement by offering data planning, process control, and financing support to the data demand side. However, as data redundancy increases in the service process, the demand for effective data within the supply chain rises. The ease of use and sharing capability of data will, in turn, generate positive feedback, influencing the circulation rate of data across the supply chain network.
In view of this, based on the current status of data governance, the three-level indexes under the data and service dimension are identified as metadata management, data quality, data specification, data storage and collection, data security and risk level, data service and innovation, data ease of use, and data sharing capability.
Data Governance Environment
The internal and external environments within the supply chain data governance ecosystem are interdependent, forming a closed-loop circulation path involving logistics, capital flow, and information flow (R. Lin et al., 2020). Due to the complexity of this ecosystem, the data governance environment is divided into two secondary dimensions: the governance micro-environment and the governance macro-environment.
In the governance micro-environment, the financial demand driven by the cost of data governance motivates the governance subjects to invest financially in the process. This investment, in turn, elevates the importance of professional staffing within the relevant governance organizations. Organizational construction for data governance encompasses elements such as the organizational structure, departmental responsibilities, staffing, job roles, competency requirements, and performance management (Pant et al., 2021). These factors collectively enable the smooth flow of data across various business nodes and information systems, thereby improving the efficiency of data governance both within and between organizations.
In the governance macro-environment, a healthy level of market competition within the supply chain serves as a favorable strategy for value addition, helping enhance the data governance capabilities of supply chain enterprises and facilitating the data governance process. Additionally, supply chain synergy can be achieved by creating a collaborative mechanism among node enterprises through governance strategies, data sharing, and the management of benefits and risks, ultimately improving data governance across the entire supply chain.
In view of this, four three-level indexes are selected in the data governance environment dimension: organization construction level, capital investment, supply chain market competition, and supply chain synergy capability. Based on the above sorting and summarizing of the index dimensions and the subordinate indexes, the supply chain data governance ecosystem index system is constructed as shown in Table 5.
Index System for Supply Chain Data Governance Ecosystem.

Research Methodology
DEMATEL Methodology
Research Method Selection
This study introduces the fuzzy DEMATEL model to determine the importance of each index of supply chain data governance optimization by expert scoring method. We apply fuzzy set theory for initial data processing to reduce the range limitation of data results, and improve the independence of index weights based on the improvement of the data calculation model of direct influence matrix sources. Among them, fuzzy set theory is a mathematical theory that extends the classical set theory and aims to deal with uncertainty and fuzziness. Different from traditional sets, fuzzy sets allow the membership of elements to change in a continuous way, so as to better describe the ambiguity and uncertainty in the real world, which is used to better evaluate data governance indicators in this paper. The above operations can enhance the results of subsequent key index screening and hierarchical analysis studies reliability.
Initial Weight Determination
In order to determine the initial weights of supply chain data governance and construct the original DEMATEL data, this study designed the index importance scoring table for supply chain data governance optimization. 8 experts were contacted for their opinions to determine the importance of the indexes. The experts who participated in the questionnaire survey covered academic professors, industrial Internet industry operators and department heads of supply chain enterprises who studied related topics. At the same time, senior users were invited to participate in the scoring. The questionnaire was distributed and collected online.
To ensure the quality and effectiveness of expert evaluations on supply chain data governance optimization indicators, the following criteria are used for expert selection: (1) Domain expertise, with a deep knowledge of and professional background in manufacturing supply chains; (2) Educational background or work experience, with experts being professors in management science or experienced professionals with over 10 years in manufacturing supply chains; (3) Professional certifications or honors in the field of manufacturing supply chains.
The study uses triangular fuzzy numbers in fuzzy mathematics to reflect the results of experts’ judgments on the importance of indexes, which are easier to obtain ideal solutions from group decisions than traditional methods. The triangular fuzzy numbers refer to the fuzzy numbers on the set of real numbers R with the affiliation function of fuzzy numbers
Data Deblurring Process
In order to reflect the overall influence degree of each index on the governance system and to clarify the specific values of the expert scoring results, the integrated fuzzy values need to be defuzzified. The defuzzification process takes the distribution pattern, shape, and height of the fuzzy numbers into consideration. According to Table 1, the results of the above expert survey scoring table are transformed into triangular fuzzy numbers, and the comprehensive fuzzy value of the degree of influence is obtained based on Equations 1 to 3



Since the CFCS (Converting Fuzzy data into Crisp Scores) method can effectively distinguish two fuzzy numbers with the same exact value (Lina et al., 2021). Therefore, in this study, CFCS method is used for defuzzification, and the combined fuzzy values are regarded as the weight values of indexes for the governance system
Step 1. Fuzzy number normalization.



Step 2. The upper limit value is normalized to the lower limit value.

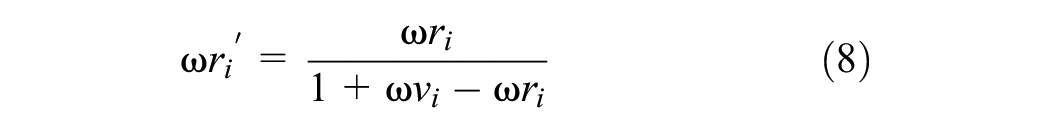
Step 3. Calculate the weight value.

Among them,
Direct Relation Matrix
According to the initial fuzzy weights of indexes for supply chain data governance optimization, the DEMATEL model is introduced to optimize the initial index weights, so as to weaken the subjective determination of data results caused by expert scoring.
In view of the wide scope of supply chain data governance under the industrial Internet, the complexity of the correlation between relevant stakeholders, the interference of the overlapping influence of indexes when experts score, and the difficulty of ensuring the independence of indexes, the study optimizes the data sources based on the original DEMATEL method, and points the experts’ scoring to a single evaluation target, which circumvents the tedious operational problems caused by experts due to the importance of multiple indexes for two-by-two comparison. It also reduces the chance of misjudgment due to the lack of independence among the elements. The direct relation matrix is set as P to characterize the influence of the index
Integrated Relationship Matrix
The direct relation matrix P is normalized according to Equation 10 to obtain the normalization matrix Q.
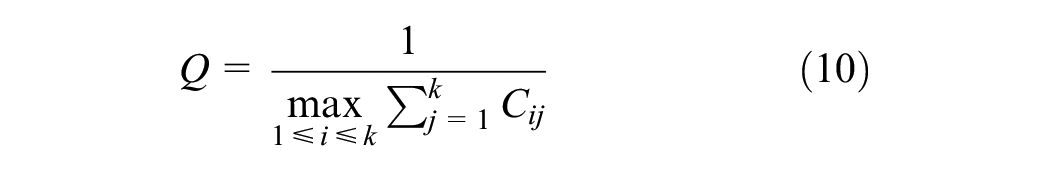
Where, k denotes the number of indexes. In order to represent the degree of direct and indirect influence among the indexes of supply chain data governance, Matlab software is further used to calculate the integrated relationship matrix Z of based on Equation 11 (Table A2). Where I is the unit matrix.

Influence Index Ranking Analysis
After determining the integrated relationship matrix Z, the influence degree of each factor D, the influenced degree R, the centrality degree (D+R), and the reason degree (D-R) are calculated according to Equations 12 to 13, where the influence degree indicates the comprehensive influence degree of each index in the comprehensive influence matrix Z on all other indexes; the influenced degree indicates the comprehensive influence degree of each column of indexes in Z on other indexes; the centrality degree indicates the importance degree of indexes in the whole evaluation system; the reason degree is used to portray the contribution degree of an index to the formation of the evaluation system, that is, the degree of interrelationship between the index and other indexes.


where
Analysis of Main Indexes
Based on the analysis of supply chain data governance ecosystem perspective, the system governance system mainly consists of four indexes: data governance subject, governance technology, governance environment, and data and services. By analyzing the main indexes A and B, the index ranking of index centrality and cause degree is integrated to obtain the mean value of cause degree of A-level indexes (listed in the order of cause degree) as A2, A4, A1, A3, and the centrality degree as A3, A2, A1, A4, respectively. It can be seen that the cause factors of the first-level indexes are data governance technology and data and services; the result elements are data governance subject and data governance environment. The centrality of data governance technology as the cause factor ranks second, indicating that data governance technology dominates the governance system and has a high degree of influence on other indexes. The centrality of data governance environment is in the first place, and because it is the result element, it indicates that data governance environment also plays an important role in the governance system, but it is less stable and vulnerable to other indexes. The data governance subject as the governance subject of the supply chain data governance ecosystem is classified as the result element, which reflects that the current governance situation of the data governance subject is more and more passive, and the governance behavior needs to rely on data governance technology, data and services as support.
According to the comparison of the centrality of B-level indexes, technology and tools, internal environment, users and supply chain services are ranked high, among which the internal environment and users are more influenced, resulting in their centrality ranking among the top, that is, technology and tools and supply chain services are the key factors affecting the governance system, while internal environment and users are in a passive position in the system.
Causal Elements and Centrality Analysis
C-level indexes can more accurately and comprehensively assess the optimization effectiveness of supply chain data governance ecosystem. Based on the positive and negative comparison of C-level indexes, we can find that the supply chain data governance ecosystem index system consists of 13 cause elements and 11 result indexes, and the order of index centrality is C14, C9, C7, C24, C4, C10, C21, C12, C5, C19, C22, C8, C16, C15, C13, C23, etc. Combining the cause elements and centrality, it can be seen that C9, C24, C21, C12, C5, C22, C8, and C16 are the key impact indexes in the governance system, which can directly shape the governance effectiveness fluctuations and have a greater impact on other indexes.
Among them, data operation technical support has the greatest direct impact among all indexes, indicating that data technical support in the process of governance is a key bearing index for the effectiveness of governance optimization, and improving the level of data operation technology of supply chain enterprises and industrial Internet can guarantee the perfection of data governance infrastructure, effectively resist the problems of data circulation, storage, collection, exchange, and sharing to upstream and downstream subjects of supply chain and industrial Internet platform through supply chain. It helps to enhance the intelligent construction of industrial Internet and strengthen the core competitiveness of enterprises, construct a good service and innovation environment for the information platform, and promote the sustainable development of supply chain data governance ecosystem.
Resulting Elements and Centrality Analysis
Combining the result factors and centrality, it can be found that the cause degree of C14, C7, C4, and C6 become negative and their are affected to a greater degree. This suggests that they are vulnerable to fluctuations in the governance system. Although their centrality is high, they are not counted in the screening of key indexes in this study due to the low ranking of the influence degree of the indexes.
C13, C15, and C23 are ranked in the middle in terms of centrality and reason and they are influenced by a greater degree. They are the easiest governance points and also belong to the key indexes. Data governance subjects should focus on these four indexes in the governance process. Therefore, in order to effectively improve the effectiveness of data governance optimization, it is necessary to collaborate with all value subjects in the governance system. Each subject should not only reasonably plan the data governance optimization system and improve data governance organization construction, but also open up the data flow of each business node and information system and enhance the core competitiveness of supply chain node enterprises and industrial Internet enterprises.
Cause-and-Effect Four-Quadrant Diagram Analysis
Based on the data in Table 1, the inter-index causality diagram for supply chain data governance optimization is established by quadrant determination method with centrality as the x-axis and causality as the y-axis, and the values of each index are plotted one by one in the diagram (Figure 1). Among them, since the median indicates the sample distribution based on the middle value, the set of values can be stratified equivalently. Therefore, the median x = 4.41, which corresponds to the centrality of 24 indexes, is added to the graph as the internal auxiliary axis z. The purpose is to visualize the centrality and causality of indexes, so as to visually observe the distribution pattern of indexes and reasonably screen the key indexes.

Four quadrant diagram of cause and effect.
According to the distribution law of indexes in the four quadrants of cause and effect diagram, it can be concluded that C9, C24, C21, C12, C22, C8, C5 in the first quadrant have a centrality greater than 4.41, which belong to the driving indexes with a relatively large degree of influence on the supply chain data governance ecosystem and play a direct driving role in the sustainable development of the governance system; C16, C11, C2, C18, C17, C17 These six indexes have a higher degree of cause although their centrality is lower than 4.41, and they can be used as support indexes for optimizing the governance system and show a stronger indirect driving effect on the governance system. Although C13, C15, and C15 are in the third quadrant, they should be included in the selection of key indexes for the optimization of the supply chain data governance ecosystem because their centrality is close to 4.41 and the absolute value of the cause degree is larger. Based on the aforementioned influence degree analysis, the six indexes in the fourth quadrant were excluded.
In summary, through the comparison and analysis of impact index ranking and cause-effect four-quadrant diagram, 16 key indexes for supply chain data governance ecosystem optimization are finally screened out, namely C1, C2, C5, C8, C9, C11, C12, C13, C15, C16, C17, C18, C21, C22, C23, C24. To further study the structural system of supply chain data governance ecosystem indexes and provide quantitative thinking for the design of optimization paths.
ISM Methodology
Building the Reachable Matrix
Based on the 16 key indexes screened above, the overall impact matrix is established. Given that the comprehensive impact matrix Z obtained by DEMATEL method does not consider the impact of indexes themselves, the comprehensive impact matrix

Where, λ is the threshold value. It is set up with the aim of eliminating less influential indexes, thus simplifying the hierarchical structure of the indexes. To eliminate the subjective dependence of data sources, the study relies on the mean of the combined impact matrix μ with variance
Hierarchy of Indexes
According to the reachability matrix F, the indexes are divided into a hierarchy, and the index reachable set
The first level of supply chain data governance ecosystem indexes includes 5: C1, C13, C17, C15, and C23. After the indexes of the first level are determined, the ranks of the matrix where the indexes of the first level are located are eliminated, and the next level is divided in the same way. Similarly, the eight indexes in the second tier are C2, C5, C8, C11, C12, C16, C18, and C22, and the indexes in the third tier are C9, C21, and C24.
Fuzzy DEMATEL-ISM Model Framework
The fuzzy DEMATEL-ISM model is constructed as follows: First, the fuzzy DEMATEL method determines the initial weight of the supply chain data governance optimization index. The data is processed using fuzzy set theory, and a direct influence matrix is obtained to calculate the comprehensive influence matrix. A causal analysis diagram is created, and key optimization indices are identified. Next, the reachability matrix is derived from the relationship between the comprehensive influence matrix and the identity matrix. The ISM method is then used to structure the optimization index system and build a multi-level hierarchical model. Finally, the DEMATEL-ISM integrated model is employed for comprehensive analysis (Figure 2).

Analytical steps in the DEMATEL-ISM model.
Supply Chain Data Governance Optimization Structure Analysis
Constructing a Multi-Layer Recursive Explanatory Structure Model
According to the hierarchical division of each index, a multi-layer recursive explanation structure model of supply chain data governance ecosystem is established as shown in Figure 3, which divides the data governance optimization structure into three layers, namely, governance surface layer, governance middle layer and governance root layer. The model is characterized by layers advancing and complementing each other to promote supply chain data governance optimization in a systematic and orderly manner and achieve sustainable development of the whole domain of the governance system.
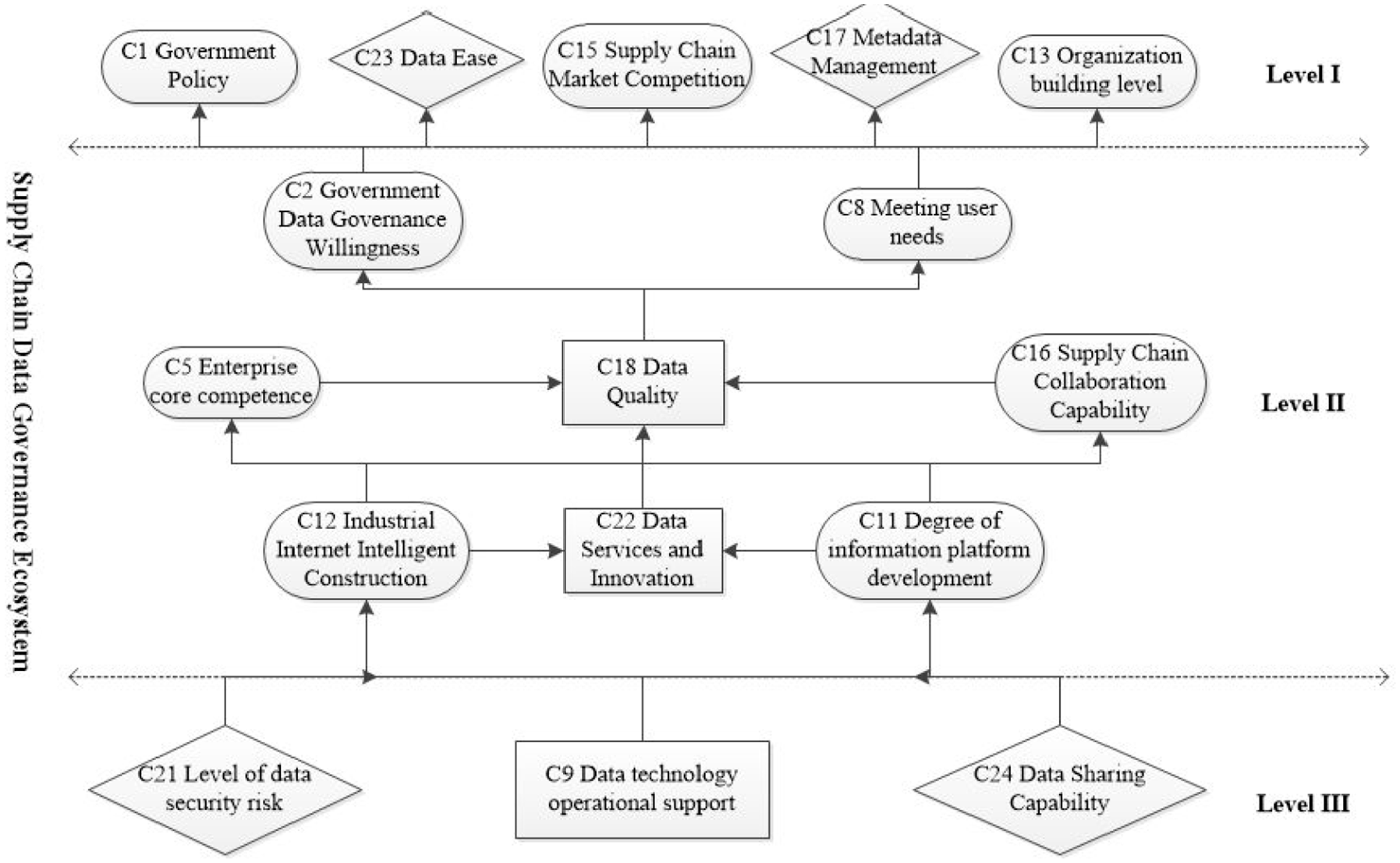
A multi-layer recursive explanatory structure model for supply chain data governance.
The middle layer of data governance plays a transitional role in the sustainable development of the supply chain data governance ecosystem, and its structure is complex, with relatively relaxed control of the middle layer by the governance body and a large governance difficulty factor. Whereas the data governance surface layer can produce direct effect advantages, the data governance root layer starts with the logic of the governance bottom layer to optimize the governance system with maximum intensity. Integrating the data governance surface layer with the root layer structure can efficiently and rapidly achieve sustainable development of the supply chain data governance ecosystem.
Data Governance Optimization Structure Hierarchy Analysis—Take Tianqi Mold as an Example
Case Study of Tianqi Model
The Tianjin Industrial Cloud’s auto mold supply chain centers on Tianjin Auto Mold Co., Ltd. (Tianqi Mold), a leading private listed company in China’s auto mold industry. In January 2013, Tianqi Mold acquired a renowned German mold company, expanding its global presence with key hubs in Germany, the United States, and India, thereby enhancing its international competitiveness. By 2017, Tianqi Mold integrated its internal information system with the Tianjin Industrial Cloud platform, making its manufacturing resources and capabilities accessible to customers.
Currently, the Tianjin Industrial Cloud’s auto mold supply chain revolves around Tianqi Mold, offering cloud-based services to vehicle manufacturers. As a leading example of cloud manufacturing in Tianjin, the digital transformation of the automotive mold supply chain is driven by data governance within the cloud platform. This transformation optimizes the supply chain’s data governance system in alignment with cloud manufacturing business processes.
Data Governance Surface Layer
The surface-level indicators of data governance are the direct elements used to evaluate the data governance process. Effective data utilization and metadata management are fundamental components in improving the efficiency of data governance optimization. Government policies, the organizational structure of corporate data departments, and the competitive environment of the supply chain directly influence the optimization process of supply chain data governance.
Based on this, Tianqi Mold should first optimize the organizational structure of its data department to enhance data processing efficiency and professionalism. Next, it should establish a cloud manufacturing data-sharing mechanism to ensure sufficient communication and utilization of data resources between upstream and downstream enterprises in the automotive supply chain. Additionally, a robust metadata catalog should be created to ensure all data resources are accurately categorized, enabling effective management of all data assets. Furthermore, it is essential to respond to government-established data governance policies and formulate strategies that align with the company’s development goals.
Data Governance Middle Layer
The middle layer of data governance, supported by root layer metrics, influences surface layer metrics and indirectly impacts the entire supply chain’s data governance ecosystem. Data quality, the core of the middle layer, is a key indicator for assessing the success of data governance optimization.
Building an information platform with advanced technologies is essential for the sustainable development of the industrial Internet. This requires integrating technologies like artificial intelligence, the Internet of Things, and cloud computing (Shuangming et al., 2018). Secure and orderly data flow is fundamental to platform intelligence, with data sharing and security enhancing platform development. This fosters collaboration among supply chain enterprises and encourages healthy competition.
Users, as data consumers and stewards, reflect value realization within the supply chain. Encouraging user participation in data governance promotes system sustainability. The government plays a key role in establishing a comprehensive data quality management system. Increasing government support is vital for effective policy implementation and overall supply chain big data planning.
In conclusion, amid the ongoing digital transformation of the supply chain, the data governance middle layer plays an irreplaceable role. Therefore, Tianqi Mold needs to focus on targeted data governance optimization. (1) It should strengthen the data quality monitoring mechanism by collecting real-time, high-quality data to inform planning and risk decision-making. (2) Advanced technologies such as blockchain should be used to ensure data security, safeguarding the integrity of automotive supply chain data. (3) Attention should be given to identifying the actual needs of users and establishing a user feedback mechanism, which will allow for adjustments to the data governance strategy to meet market demands. (4) Tianqi Mold should track government policy trends and adjust its business and strategic layout in a timely manner.
Data Governance Root Cause Layer
The root index of supply chain data governance is the decisive index of supply chain data governance optimization effect. The degree of data security risk, operational support for data technology, and data sharing capabilities have the greatest impact on the sustainability of the governance ecosystem. Advanced data technology can simplify the data service process, reshaping the core competitiveness of each node enterprise in the supply chain. Due to the leakage of personal privacy data in the open and transparent supply chain system, the development of cloud supply chain under the industrial Internet has also exposed the problem of data security crisis. It affects the aggregation and sharing of upstream and downstream data in the supply chain.
In order to make effective improvements at the root level of supply chain data governance, Tianqi mold should first increase investment in data operation technology, introduce advanced data management tools and data sharing platforms, encourage upstream and downstream enterprises in the supply chain to actively carry out data circulation and sharing. In view of data security risks, it is necessary to establish a sound data security management system, and regularly carry out data security assessment and risk analysis within the supply chain to protect the data security of the supply chain.
Path Design
Complete Governance Policies and Improve the Supply Chain Data Security Environment
The security risk problem of supply chain data is the data governance gap in optimizing the governance system, and the government department, as the key node of data storage and circulation, is the key to improving the data security environment of the supply chain. The improvement of risk prevention and privacy protection capabilities can not only ensure the stable operation of the entire supply chain, but also escort the implementation of other optimization links. The government should be aware of security risks, alert to data security risks, and build a scientific and reasonable data security policy system. In addition, enterprises should systematically and comprehensively monitor the security of data, both to prevent external hacker attacks and to prevent improper operation of data by internal personnel, and establish a sound security tracking system while strengthening the underlying design.
Enhance Data Sharing Capability and Increase Effective Data Throughput
Timely, high-quality and comprehensive data resources can stimulate the full release of data value, thus promoting the sustainable development of the supply chain data governance ecosystem. On the one hand, the main body of the supply chain should establish a sound data and information sharing system, emphasizing the value creation and sharing between enterprises with different property rights in the supply chain node. Enterprises should build an information sharing platform, reconstruct data circulation channels, accelerate information sharing among supply chain nodes, and enhance the ease of data use under the premise of considering cost factors. On the other hand, enterprises should integrate advanced blockchain technology, rely on its trustless, transparent and open, decentralized and other excellent features that cannot be matched by other technologies, take user value enhancement as a guide, and establish a blockchain information sharing platform through collaborative innovation mode to ensure the integrity and reliability of data, so as to realize visual perception and regulation of supply chain. Strengthen the core competitiveness of the entire supply chain and promote the orderly development of supply chain data governance.
Enhance Data Technology Support and Pay Attention to Organization Construction and Talent Allocation
Data operation technology support plays a decisive role in the sustainable development of supply chain data governance ecosystem. The main body of supply chain governance should pay attention to the research on the precision technology of big data, improve the data operation ability of each main body of the supply chain, analyze the circulation data of the supply chain through big data technology, provide decision basis for data producers and users. In addition, A special data governance team should be established in the supply chain to classify and manage the data in the industrial Internet, strengthen the training of data-driven professional talents in the industrial Internet, enhance the analysis and problem-solving ability of the governance personnel, and ensure the input of high-end talents in the data governance market.
Accelerate the Construction of Data Governance System to Play a Role According to the Characteristics of Different Supply Chains
According to the different manufacturing fields, the construction of data governance system also needs to change according to the characteristics and needs of different fields. For example, in the automotive field, which has a huge amount of data and high real-time data requirements, the construction of data governance system should pay attention to the data integration within the supply chain, open up the data flow of all links, and encourage data sharing. In the electronics manufacturing industry, where the production process is highly integrated, it is necessary to attach great importance to the accuracy of data in the process of data collection and processing. In the textile industry, where the data utilization rate is relatively low, it is necessary to pay attention to data governance training for employees, especially middle managers, to cultivate their data awareness and ability. In general, with the rapid transformation of supply chain digitalization, different supply chains need to establish a sound data governance system according to their own characteristics and industry characteristics to maximize the effect of data governance.
Build a Supply Chain Data Governance Ecosystem in the Era of Digital Transformation
Ecosystem refers to the unity of living things and the environment in nature. Among them, organisms and the environment interact and restrict each other, and in a certain period of time in a relatively stable state of dynamic equilibrium. In fact, the development and evolution of supply chain data governance is very similar to that of natural ecosystems, and the key idea of data governance is to meet the needs of data fusion among different value subjects. In this process, the main body of the supply chain constantly interacts with external information, and the internal and external environment is interrelated and influence each other, thus forming a complete supply chain data governance operation system. Based on this, the integration of ecosystem and supply chain data governance optimization and the construction of supply chain data governance ecosystem will help select data governance optimization indicators more accurately and systematically, and provide a solid foundation for optimizing governance strategies.
Conclusions and Limitations
In this paper, the causal attributes of supply chain data governance optimization indicators are identified by fuzzy DEMATEL model, and 16 key indicators are selected. On this basis, ISM model is used to further visualize the hierarchy of key indicators, deeply reveal the mechanism of indicators. This study aims to improve the efficiency of supply chain data governance and provide managers with adaptive supply chain data governance optimization strategies. The main conclusions are as follows:
First, surface factors are the most direct factors affecting the efficiency of supply chain data governance. Therefore, administrator taking timely measures on surface indicators can quickly improve the obstacles in the supply chain data governance process and effectively improve the optimization efficiency of data governance in a short period of time.
Second, data sharing capability, data security risks and data technical support are root level factors that will continue to affect other indicators in the supply chain data governance system in the long run. It is necessary for administrator to improve the efficiency of supply chain data governance by continuously improving the three optimization indicators, influencing the middle layer factors, and then acting on the surface factors.
Third, in different levels, the reasons for the high degree of centrality are data operation technical support, data sharing capability, data security risk, industrial Internet intelligent construction, information platform development degree, and data service and innovation, which have greater influence and importance on other optimization indicators in the supply chain data governance system. Mastering the importance of each level of optimization index is conducive to supply chain governance subject to optimize supply chain data governance.
This paper systematically analyzes the optimization indicators of supply chain data governance. However, due to limitations in research conditions and other external factors, several shortcomings exist and require improvement: First, the initial optimization indicators presented in this study were preliminarily determined based on industry research over the past decade, combined with expert opinions. However, the literature review does not comprehensively cover all possible optimization indicators in the field, and some may have been overlooked. Future research should conduct a more thorough literature review and adopt more scientific methods to improve the accuracy of the optimization indicators. Second, the construction of the direct influence matrix has limitations in the selection of expert-rated data samples, which could affect the reliability of the results.
Footnotes
Appendix A
Reachable Matrix (F) for Indexes.

| Indexes | C1 | C2 | C5 | C8 | C9 | C11 | C12 | C13 | C15 | C16 | C17 | C18 | C21 | C22 | C23 | C24 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C5 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| C8 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| C9 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 |
| C11 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C12 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| C13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C16 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| C17 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| C18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| C21 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| C22 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| C23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| C24 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 |
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the National Social Science Fund of China (Grant Number No. 21AGL001).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All data generated or analyzed during this study are included in this published article.