
Abstract
This article presents an empirical study investigating the ability of ChatGPT to translate religious texts involved in academic writing. Specifically, religious texts are not easy to translate even for human proficient translators. Three Arabic academic abstracts, religion-oriented, were involved in our study taken from AlQalam Journal which is published in Arabic and English. They have ready translations by the language adviser of the journal. The Arabic abstracts were first translated into English by ChatGPT. We then analyzed and compared ChatGPT translation to the human translation in terms of semantics and syntax. The former is represented by academic inappropriateness, failing to capture religious nuances, redundancy, translation gaps, and englishization, while the latter by first-person pronouns, to-infinitival vs. gerund use, passive versus active voice, full relative clauses, and indefiniteness. The findings revealed that ChatGPT’s performance is still far from human translation, and that ChatGPT translation needs significant human postediting. The study concludes with substantial recommendations for researchers and ChatGPT developers.
Keywords
Introduction
The Neural Networking Algorithms (NNAs) have entered Artificial Intelligence (AI) sphere, leading to outstanding results. AI today creates much fear of what is going to happen in the future due to the fast and vast development of AI tools. It is not certain though, up to now, whether this could be true in the field of translation. NNAs are programmed to work in such a way that gives them the human brain power, which will, if true, be an incredible advancement in AI technology. However, it has been found in the literature that AI translation tools do not understand what is beyond text or the underlying meaning of a text, specifically a text that is embedded within culture such as poetry (Alowedi & Al-Ahdal, 2023), religious texts (Banat & Abu Adla, 2023).
Given the current high expectations about AI, this study first aims to examine whether ChatGPT can capture the Islamic religious nuances in religion-based expressions, beliefs, practices, prayers, and rituals involved in academic writing (Qarabesh et al., 2023). It focuses on such a type of text because it is widely argued that translating culture- and religion-based texts is one of the most difficult translation tasks encountered by human translators (see Katan, 2015; Qarabesh et al., 2023; Shormani, 2020; Sirriyya, 2009). Our second aim is to examine where ChatGPT fails to grasp Islamic nuances involved in academic writing. These nuances are aspects that are beyond actual text or wording. The paucity of studies on such a topic makes this study significant and relevant to the field as it serves to fill this gap. It tackles an important topic in the current hot debate about AI models’ power. It provides AI scientists and developers with valuable insights into how these models including ChatGPT can be developed by training them on massive (internet) data involving academic translation of Islamic rituals, prayers, repertoire, beliefs, traditions, nuances, and peculiarities. It also provides translators with valuable insights, underscoring the value of the postediting process given the fact that translation in AI world becomes a process where the translator’s role is just to postedit AI tools’ output.
This article is set up as follows. The section ChatGPT: Fast and Vast Development lays out the fast and vast development ChatGPT has witnessed. The section Translation and ChatGPT sheds light on how ChatGPT has been developed as a translation tool, spelling out the relationship between religious text, translation, and ChatGPT. The section The Present Study articulates the methodology of the study in terms of the approach employed, the data involved and the methods of analysis followed. The section Conclusion and Recommendations presents the results and discussion of the study. Section 6 concludes the paper and provides recommendations to AI specialists, specifically ChatGPT developers. The section Limitations and Further Research outlines the study limitations and suggestions for further research.
ChatGPT: Fast and Vast Development
AI or machine translation (MT) was first introduced into the field of translation in the 20th century, and its main aim was to replace human translators. It has been developed vastly since then (see e.g., Brown et al., 1993; Denkowski, 2015; Ketpun & Sripetpun, 2016; Tongpoon-Patanasorn & Griffith, 2020). MT started as Rule-based Machine Translation (RMT), Statistical Machine Translation (SMT), and finally Neural Machine Translation (NMT; Koehn et al., 2003; Zhang & Torres-Hostench, 2022; Dwivedi et al., 2023; Cotton et al., 2023). In RMT version, the method Google Translate first adopted was phrase-based method in which a phrase from SL is translated into TL, that is, English. However, this method was not successful, at least at the beginning but it has been improving and many modifications have been introduced into Google Translate’s working mechanism until reaching its present status utilizing NNAs. With the fast and vast developments AI has recently witnessed, these AI models including ChatGPT are expected to translate more accurately and appropriately.
The term ChatGPT is made of “Chat-Generative Pre-Trained Transformer.” ChatGPT is defined as “an intelligent chatting machine developed by OpenAI upon the InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response” (Jiao et al., 2023, p. 1, see also Ouyang et al., 2022). It is an AI model whose functionality depends on internet, meant not only for translation. Rather, it is used for several purposes and in many other fields such as creating content and debugging. OpenAI started developing GPT in 2018 (see e.g., Radford et al., 2019), and launched ChatGPT in 2022, as one of OpenAI’s most influential models of language learning (Dergaa et al., 2023). GPT has been developed in several stages, resulting in several models, namely GPT-2 introduced in 2019, GPT-3 in 2020, and GPT-4 in 2022 (see e.g., Dergaa et al., 2023; Jiao et al., 2023). Massive amounts of internet data have been trained on which enable ChatGPT to generate responses that appear to a great extent similar to human responses and in various and several fields and registers. According to Dergaa et al. (2023, p. 616), OpenAI has launched ChatGPT, “enhancing its ability to handle a wider range of queries and provide more accurate, relevant, and helpful responses to users” (see also van Dis et al., 2023; Dwivedi et al., 2023).
Such improvements of ChatGPT have been noted in several aspects like size of stored and training data, language “abilities,” expanded knowledge base, and higher accuracy and precision, which lead to what ChatGPT is all about today. These developments result in developing conversational AI models including Google’s Bidirectional Encoder Representations (Dergaa et al., 2023, see also Yogesh et al., 2023). Dergaa et al., for instance, argue that ChatGPT can write high quality essays for students, summarizing academic articles and answering “questions well enough to pass medical exams, and generate helpful computer codes”(p. 615). They also argue that ChatGPT can also write academic abstracts even highly qualified scholars do not find different from similar ones prepared by humans.
As for translation, several studies view ChatGPT as a translation tool paralleling other CAT such as Google Translate, Microsoft Translator or any other Internet-based translation models. In this sense, ChatGPT could be defined as an internet-based AI model. Though it was designed for translation purposes, it has been used for several other purposes. It consists of “two deep neural networks, namely the encoder and decoder” (Siu, 2023, p. 2). The former processes the source text and converts it into an internal representation, while the latter generates texts in the target language (TL) based on the prediction of “each subsequent target word” (Siu, 2023, p. 2).
Figure 1 presents the transformers ChatGPT consists of. These are called transformer blocks. From bottom-up, the first is Text and Position Embed. The second is Masked Multi Self Attention, and so on until reaching the Text Prediction and Task Classifier transformers, as is clear in Figure 1.

ChatGPT Architecture.
Translation and ChatGPT
Translation is regarded as a human endeavor through which sciences, ideologies, experiences, knowledge, cultural elements, values, and all human activities are passed down from one generation to another (see Shormani, 2020, 2024). The task of defining translation has spanned over two centuries now, with various scholars offering definitions from different angles. These include linguistic perspectives (Catford, 1965), cultural viewpoints (Katan, 2015; Newmark, 1988; Nida, 1964; Shormani, 2020), and notions of equivalence (Nida, 1964), among other definitions and scholars. A century or so ago, Jakobson (1959, p. 233) defines translation as “an interpretation of verbal signs by means of some other language.”Catford (1965) defines translation as a human activity of much significance today. It has also attracted the interest of linguists, translators, and language teachers alike, and even mathematicians and engineers. In this definition, we notice that translation is important to all fields. Newmark (1988) defines translation more cautiously as rendering the meaning of a source text into the target text as intended by the author of the SL text. In this definition, however, we notice that Newmark is trying to include the author of the original text and his/her intentions.
Today, translation is viewed as more than simply what these theorists have argued for. Translation is considered to be more than brigading the culture gaps; it is a process whereby cultures and peoples (and texts) negotiate (Bassnett, 2014, see also Shormani, 2024). It is also a process where translators help mediate how several types of translation are performed. Translation aims to make peoples and nations get benefits from the experiences of other peoples. It also aims to bridge gaps between peoples worldwide. In this age of globalization, translation becomes a very essential process in several human endeavors such as intercultural communication, business, and trade. Additionally, the human role in translation becomes ever less than before. Translation now enters a new world, a technological world. It is no longer a difficult task. Translation as both process and product has made use of internet and AI models and tools. Several web applications have been developed and used worldwide. To mention just examples, consider Google Translate, Microsoft Translate, WordLingo, Babylon, all types of Computer-assisted translation (CAT) tools, and finally ChatGPT, let alone hundreds (perhaps thousands) of smartphone translation apps. The development translation has witnessed with the help of AI is tremendous. Huge data from any language can be translated in seconds. This is due to the fact that AI outlets like ChatGPT have been trained on massive internet data through artificial algorithmic neurons, which enable these outlets to translate any amount of written texts in seconds, whatever the language is (see e.g., Dergaa et al., 2023).
ChatGPT’s Translation Working Mechanism
Given that ChatGPT is trained on massive internet data, there should be a mechanism in which it works. Details aside, Figures 2 and 3 display ChatGPT’s working mechanism in translation. Figure 2 presents a Template showing a translation sample from Chinese into Romanian.

Translation template.

Translation prompt.
In Figure 2, there are two languages, where translation is from Chinese to Romanian and ChatGPT generates sentences for Chinese ⇔ Romanian. [Ro] represents the sentence in Romanian whereas [Zh] stands for the Chinese sentence.
Consider now Figure 3 which presents ChatGPT translation prompt, viz., input prompt, entered by a human “interlocutor.”
As is clear in Figure 3, there are “role,”“system” and “content.” These determine what ChatGPT is going to do. The “Request” is to “provide” the Target Generated Text [TGT] translation for the following sentence, which will be entered by the “user.” Requests include “Please provide the [TGT] translation for the following sentence step by step” to extract step-by-step translation. (Jiao et al., 2023, p. 7).
Many scholars (see e.g., Hendy et al., 2023; Jiao et al., 2023; Peng et al., 2023) have contended that ChatGPT’s performance is much better than other CAT tools like Google Translate and Microsoft Translator. Thus, ChatGPT’s success or failure might depend on the type of text. For example, ChatGPT might not be that successful in translating texts that are culture-based like proverbs, poetry or religion-based expressions like Islamic greetings, rituals, beliefs, and peculiarities, as in this study.
For these purposes, among others, and for easy access, AI tools such as Machine Translation, Google Translate, start to invade translation trying to replace human translators. Nowadays, translation is seen as a process resulting from Machine-human cooperation/collaboration. As has been stated earlier, AI plays a great role in non-human translation industry. These non-human translation machines have been developing dramatically vastly, specifically with the fast and vast development AI has undergone in recent years. However, AI-based translation tools have succeeded in technical translation, and nonliteral topics, in general. However, considering religious and cultural expressions and texts such as proverbs, idioms and idiomatic expressions, these seem to be difficult for CAT tools, in particular and AI tools like ChatGPT in general.
Translating Religious and Academic Texts
In this section, we briefly sketch translating religious-academic texts. To start with, religious texts have been viewed as not easy to translate, due perhaps to their idiosyncratic and metaphorical nature and differences between religions and cultures, viz. Source Language (SL), and TL cultures. Thus, these expressions are not easy to translate even by human proficient translators. Like culture-based texts, religious texts are also embedded in culture; these texts are heterogeneous in nature, including several religious rituals such as “divinity, jurisprudence, ethics, history, etc. …[and] sanctity” (Sirriyya, 2009, p. 15). For religious texts, there is more than one aspect involved, which is not easy to translate by humans, let alone AI models. Thus, if these texts are not easy to translate by human translators, it is expected that ChatGPT may not capture this very component of religious texts (cf. Charlesworth, 2012, Shormani, 2024).
In translating religious texts, two types of equivalence, viz. Dynamic Equivalence and Formal Equivalence were proposed by Nida and Charles (1969). In the former, the text produced in the TL should be as natural as possible to the SL, and convey both meaning and style. However, the latter aims to convey the “contextual meaning” from the SL to the TL. Nida (1964) considers formal equivalence or correspondence to be a substantial factor for translation to be successful. He believes that structure sometimes is more important than wording. Nida (1964, p. 57) gives us a very interesting example mirroring how this is important in several examples like the noun phrase old man. He opines that “the tolal meaning of the phrase is not signaled by the referential or emotive value of the isolated words old and man, but a part of the meaning is derived from the constructions itself.” He also adds that “the combination of attributive adjective and the noun head also possesses a meaning, namely that the first element qualifies the second. These constructions also include gray house, beautiful fur and tall tree labeling such phrases as a “quantifier-head phrase.” Thus, if such importance was given to just a simple noun phrase, what about complex phrases or sentences, and how syntactic properties are very important in rendering the meaning (see also Shormani, 2024).
As a translation approach, Nida proposes dynamic equivalence for its being capable of reproducing the overall effect and meaning of the source text in the TL (see also Goodwin, 2013). It entails conveying the original text’s intended meaning and effect, rather than relying on a literal or word-for-word (WFW) translation, thus giving naturalness of the TL, both language and culture, to the SL text. However, formal equivalence prioritizes a more literal and WFW translation. The emphasis is on closely mirroring the original text’s structure, syntax, and vocabulary, even if this comes at the expense of naturalness or idiomatic expression in the target language. The goal is to provide a faithful representation of the source text’s linguistic form and maintain its cultural and historical context. These two approaches represent a spectrum of translation strategies with dynamic equivalence emphasizing the target language’s naturalness and readability. However, formal equivalence stresses fidelity to the source text’s linguistic form. Translators often employ a combination of these approaches depending on the specific translation task, target audience, and the purpose of the translation.
As for translating academic texts, there are several studies investigating this topic. We will review five studies here. The first is Kovacs (2019) who argues that translating academic texts is “challenging in several respects, as it is an accurate, standardized, normative language form, the use of which requires thorough knowledge and experience from the part of the translation” (p. 28). Kovacs studies the translator trainees’ awareness of the characteristics of academic texts and how they could encounter these difficulties. She concludes that the trainees committed several serious types of errors, recommending that academic writing and translation require us to raise language skills to the necessary level. She adds that it is also necessary to teach “the characteristics of academic style” of these texts before translating them (p. 28).
The second study was conducted by Kiriman and Kapu (2023), investigating the strategies used by translators in translating academic texts, specifically academic abstracts. It draws on some problems encountered by translators and seeks some solutions. They argue that translating academic texts becomes inevitable in translation industry. Thesis abstracts are usually written in one language and are necessary to be translated into another language in such cases as in Bahasa Indonesia and translating them into English, for instance, or vice versa. They find a number of translation solutions including how to copy structures, change perspectives and density compensation, correspond culturally, and tailor texts.
The third study we will review here was conducted by Shleykina and Junnier (2021), who studied translating authorial presence with reference to first-person pronouns in research article abstracts. They studied cross-linguistic variation in academic discourse and how first-person pronouns are translated in three sub-corpora of academic abstracts. Their analysis was in terms of three factors, namely (a) abstracts written in Russian; (b) English versions of these abstracts, and (c) abstracts written by biologists in English published in the same journals. They conclude that L1 transfer of linguistic code and author agency and presence dominate research sphere.
The fourth study to review here was conducted by Tongpoon-Patanasorn and Griffith (2020). This study is somehow close to ours in subject matter and in using an AI model, viz. Google Translate. They translated 54 Thai thesis abstracts selected from several Humanities and Social Sciences disciplines. They conclude that academic writing requires a different register, a specific language that is used in academic theses, and in academic writing in general. They also found that Google Translate involves several types of errors, the most frequent of which are those pertaining to the use of academic terms, punctuation, capitalization, and fragmentation.
The final study to be reviewed here was conducted by Banat and Abu Adla (2023). The authors conducted a qualitative study to examine GPT-3’s ability to translate religious texts. They found that BERT model’s accuracy was 83%. They also found that in general GPT-3 can produce “understandable translations,” but it cannot capture the cultural nuances. They conclude that ChatGPT needs further development to overcome the cultural as well as religious challenges, recommending further research in this aspect. Based on this account of previous studies, this study strives to answer three major questions:
To what extent can ChatGPT translate Arabic religious texts into English?
Can ChatGPT translate religious concepts found in academic writing?
To what extent does ChatGPT deviate from human translation, and how can this deviation be categorized?
The Present Study
Study Data
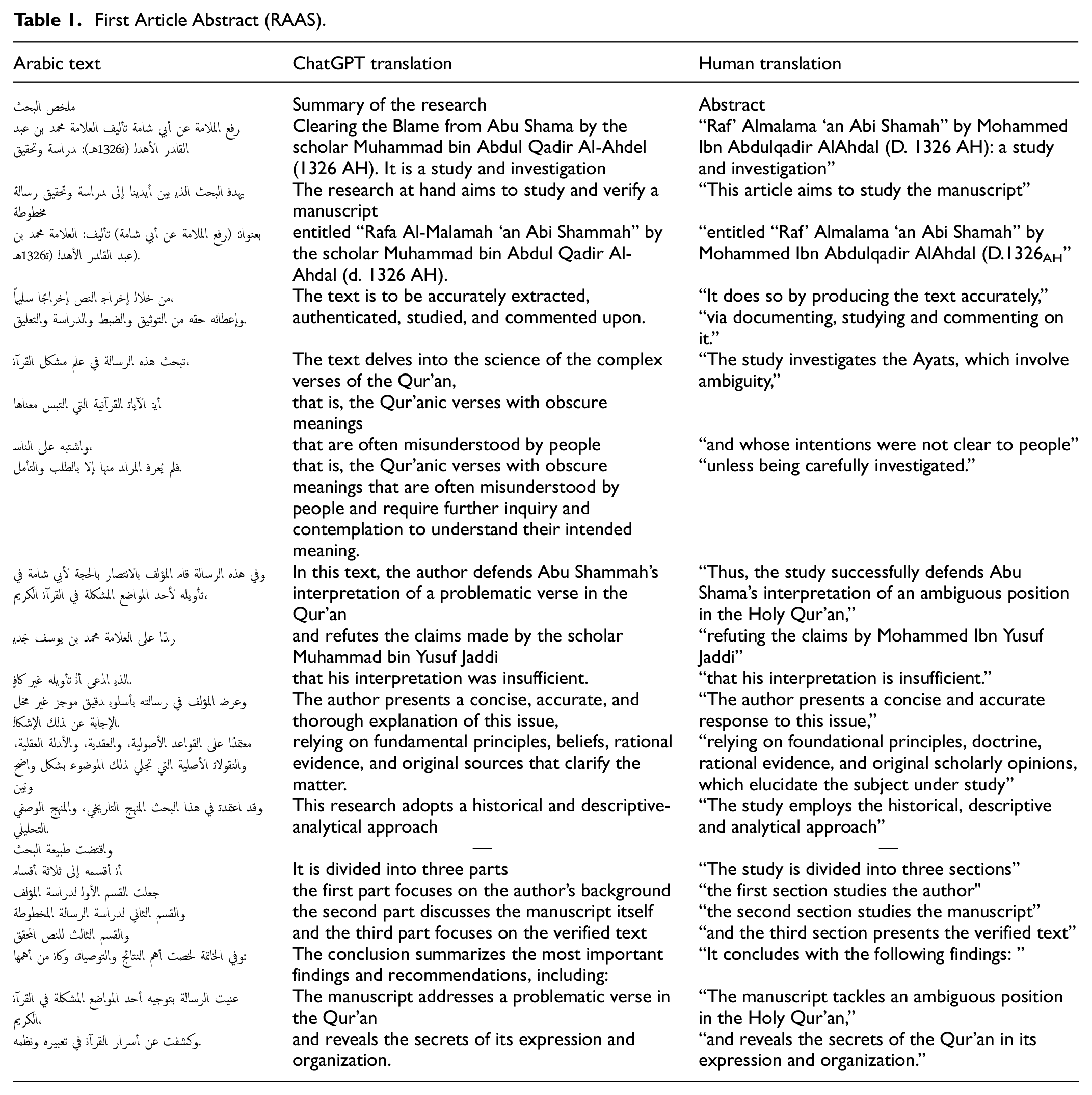
Recall that this study aims to examine to what extent ChatGPT can translate Arabic academic-religious texts into English, and grasp religion- and culture-based concepts in our data. The sample of the study contains three abstracts of religious papers published in Arabic and English by AlQalam Journal:
“‘Raf’ Almalama ‘an Abi Shamah’ by Mohammed Ibn Abdulqadir AlAhdal (D. 1326 AH): a study and investigation” (henceforth, RAAS, see here).
“The Munjiat and Muhlikat and ways of handling them from Surat Al-Hujrat” (henceforth, MAHS, see here).
“Hadiths of pessimism and scholars’ paths in them: a doctrinal study” (henceforth, HPAS, see here).
These three academic abstracts were selected for the following reasons: (i) they are published recently, 2023, (ii) they involve texts deeply rooted in Islamic religiousness, from the Holy Qur’an and Hadith, (iii) they are suitable for micro analysis as involving several linguistic deviations, and (iv) they have ready translations.
Methods of Analysis
This study is qualitative in nature. For the scope and purpose of this study, we employed comparative and analytical methods, adopting micro analysis appropriate for analyzing linguistic data in terms of syntactic and semantic features/properties (cf. Palumbo, 2009). Since the abstracts involved in the study have ready English translations by the language adviser of the journal, they were again translated by ChatGPT, and then checked for syntax and semantic aspects. After the ChatGPT translation, we tabulated both human and ChatGPT translations (see Tables, 1–3), to compare both sets of translations, and then analyze them in terms of semantics and syntax. As for semantics, we focus on issues related semantic deviations where ChatGPT fails to provide faithful semantic renderings. The same procedure was applied with regard to syntactic analysis. These issues among others will be the focus of the section to follow.
First Article Abstract (RAAS).
Second Article Abstract (MAHS).

Third Article Abstract (HPAS).

Results and discussion
In this section, we first present the results we have come up with and then discuss them in details.
Results
The results are first tabulated in terms of Arabic text, ChatGPT translation, and Human translation in the following Tables:
Discussion
As we have alluded to above, our analysis is based on the criteria below:
a. Academic inappropriateness b. Failing to capture religious nuances c. Redundancy d. Translation gaps e. Englishization
a. First-person pronouns b. To-infinitival vs. gerund use c. Passive vs. active voice d. Full relative clauses e. Indefiniteness
Semantics
As for semantics, we consider issues like how much ChatGPT translation deviates from human translation in terms of the criteria outlined in (1) above.
Academic inappropriateness: What we mean by this category is translations that are academically obscure/inappropriate. The first case in point here is translating the phrase “
If we look also at the translation of
Thus, the academic field is a crucial and independent register that needs to be paid much attention by human translators in the postediting process. Academic writing including scientific and research articles is different from any other type of writing. It has its own distinct rules, mechanics and procedures, and ChatGPT failed to grasp this specific register. In this aspect, our study agrees with Tongpoon-Patanasorn and Griffith’s (2020) study, though the AI model is different. While they used Google Translate, we utilized ChatGPT.
Failing to capture religious nuances: The second category is ChatGPT failure to capture religious nuances, sacred expressions, ritual words/phrases. To provide an example, consider how ChatGPT translates the sentence “
The word “
Redundancy: We mean by this category translations that are not precise and concise. This is clear if we consider ChatGPT translation of “
Translation gaps: What we mean by this category is words/phrases/sentences left untranslated by ChatGPT, though translation here cannot be dispensed with. There are several examples of this sort. For example, the Arabic phrase “
Another example is related to what Muslims glorify. For example, Muslims glorify the Qur’an and often (if not always) co-utter the word “Holy” with the “Qur’an” “
Englishization: This category involves positions where translations rendered may not be appropriate, and the best translation of which is to englishize the Arabic terms. We will just give some examples for this category. To begin with, consider the translation of the Arabic title of MAHS: “
Language contact, say, between English and Arabic has resulted in many Arabic religious terms entering the English lexicon such as subhan Allah, Ayat, Surat, Allah, maasha’allah, Hadith, among others, becoming English words/phrase now (see also Shormani, 2024). Yet, ChatGPT fails to capture some religion-based terms, such as “
Syntax
Syntax and linguistics in general are a crucial aspect in translation (see e.g., Catford, 1965; Nida, 1964; Nida & Charles 1969). In this section, we examine whether syntax and syntactic notions are maintained by ChatGPT translation. Syntactically, there are several issues that we want to discuss here regarding the difference between ChatGPT and human translations. However, due to space we will just examine some aspects which have several examples, and to what extent ChatGPT maintains the syntax of the SL, and how it deviates from that of the TL. Thus, our discussion is confined to first-person pronouns, to-infinitival vs. gerund use, full relative clauses, passive vs. active voice and indefiniteness.
First-person pronouns: ChatGPT seems to ignore first-person pronouns. A case in point here is translating “
To-infinitival vs. gerund use: ChatGPT also tends to use to-infinitival constructions more than gerund such as “to objectively interpret them” in translating “
Full relative clauses: A reduced relative clause is a clause whose relative pronoun is not explicitly mentioned, where the relative pronoun which/that and the verb be are elided (see e.g., Shormani, 2013). ChatGPT seems to use full relative clauses, such as translating the Arabic adverbial phrase “
Passive versus active voice: In addition, ChatGPT prefers passive structures rather than active ones. An example of this is translating “
Another example of preferring passive is translating the Arabic terms “
A further example is that ChatGPT translates “
Indefiniteness: ChatGPT seems to favor indefiniteness of the SL text. To give an example, consider “رسالة مخطوطة” which has been translated by ChatGPT as “a manuscript” while human translates it as “the manuscript.” Here, it seems that human considers the context in which this Arabic phrase occurs. A further example that could be taken as favoring indefiniteness by ChatGPT is translating definite nouns as indefinite ones. For example, ChatGPT translates definite nouns such as “وقد
To recapitulate, it seems that ChatGPT rendering deviates considerably from both the syntax and semantics of the SL. We think that the deviations observed in ChatGPT translation may be ascribed to the fact that the training data are still not enough, that is, the training data do not include such Islamic nuances and peculiarities. Hence, ChatGPT fails to transfer the intended meaning and sense. As for syntax, in Abstract 1 the author of the Arabic Abstract intends to express a subtitle, that is, “
Conclusion and Recommendations
As we have seen in the course of this article, most religious concepts, beliefs, rituals, and respected entities were difficult to translate by ChatGPT. A religious expression may have more than one interpretation due to being subject to various interpretations within their respective religious communities. It seems that ChatGPT cannot select the most appropriate interpretation while maintaining a balance between both SL and TL text’s faithfulness and the needs of the target audience. An important aspect of religious texts that should be addressed here is that these texts often deal with abstract and metaphysical concepts that are challenging to express in concrete terms. These are what we may call transcendence and spiritual concepts (Sirriyya, 2009). Thus, translating these concepts accurately while preserving their depth and spiritual significance can be a difficult task for ChatGPT. These findings are in line with those of previous studies (e.g., Banat & Abu Adla, 2023).
Religious texts such as the Bible and the Holy Qur’an involve complex and classical language, idiomatic expressions, and specialized terminology. Translating these texts requires a deep understanding of the original language, its historical context, and cultural/religious nuances. Additionally, religious texts are deeply rooted in specific cultural and historical contexts. They involve using figurative language such as metaphors, religious symbols that may not have direct equivalents in the TL or its culture. Translators are needed to bridge the cultural and historical gaps left in ChatGPT translation to convey the intended meaning accurately. In this line of thought, it should be emphasized that Islamic texts are considered sacred by Muslims and are believed to originate from divine inspiration or revelation.
Another aspect where ChatGPT translation needs postediting concerns academic disciplines. Given the ChatGPT’s flaws concerning the academic aspects such as translating “
Given these problems, we propose that ChatGPT translation needs human translators in what is so called “postediting” (see e.g., de Almeida & O’Brien, 2010; Groves & Schmidtke, 2009; Krings, 2001; O’Brien, 2007, 2012).O’Brien (2012, pp. 197–198), for instance, defines postediting as “the correction of raw machine-translated output by a human translator according to specific guidelines and quality criteria.” In this way, there would be a “complementation” between ChatGPT and Human in translation activity (see also Shormani, 2024). Given the flaws we have observed in this study, human postediting seems essential, enabling ChatGPT to translate religious texts involved in academic writing properly, hence minimalizing nonsense and incorrectness (see also Cotton et al., 2023). Thus, translators are needed to postedit ChatGPT output, reconsidering these issues to transfer both meaning and sense of the religious and cultural nuances of the SL text into the TL.
In addition, developers of ChatGPT may also incorporate into its training data Islamic religious and ritual practices, historical events and cultural aspects in an attempt to conceptualize ChatGPT’s performance. This is due to the fact that Islamic religion-based expressions are not separable from Islamic culture, thus giving ChatGPT enough room to familiarize itself with such data in the training process. ChatGPT developers could collaborate with religion scholars, jurisprudence scholars, interpreters of the Holy Qur’an, or the Bible scholars, providing valuable insights into the religious context, interpretations, and nuances essential for accurate religious translation. Their expertise can help guide the development and evaluation of the AI model’s religious translation “abilities.” Moreover, ChatGPT specialists should ensure that ChatGPT respects the sacredness, sensitivity, and cultural diversity related to religious texts, to avoid generating inappropriate translations. This was noted in our study, in that ChatGPT renders “
Limitations and Further Research
Although the study has come up with interesting findings, it has certain limitations. The first limitation concerns tackling only academic “abstracts” involving religious texts. A broader study could include full articles dealing with religious and academic texts to understand the nature of insufficiency in ChatGPT’s working mechanism and training data so that ChatGPT developers target the deficits in translating religious and academic texts. Another limitation is related to the number of texts and journals: the study involves only three abstracts and one journal. A comprehensive study could include more abstracts/articles and more than one journal to broaden its scope and purpose. This study is also limited to qualitative analysis, that is, qualitatively discussing the difference between ChatGPT and human translations, and the type of postediting required. A more detailed study could involve quantitative analysis as well, providing statistical data of the percentage of the difference between ChatGPT and Human translations and the exact amount of postediting needed. This will help ChatGPT developers pinpoint the areas and, more importantly, the type of data that ChatGPT needs to be trained on at least concerning translating academic and religious texts. A final limitation that could be stated here concerns conducting only micro-level analysis, that is, linguistic analysis, focusing mainly on syntax and semantics. A more elaborated study could involve mezzo- and macro-levels, deeply probing the historical, cultural, and social factors affecting ChatGPT translation.
Footnotes
Acknowledgements
The authors extend their thanks and appreciation to Ongoing Research Funding program (ORF-2025-1252), King Saud University, Riyadh, Saudi. They also thank three SO reviewers for their valuable comments.
Ethical Considerations
The study does not involve human participants.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research article was supported by Ongoing Research Funding program (ORF-2025-1252), King Saud University, Riyadh, Saudi.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.