
Abstract
As a key component of fluent linguistic production, multi-word sequences called lexical bundles are considered an important distinguishing feature of discourse in different registers, genres, and disciplines. They are also an important aspect of empirically correct and proficient language use in a corpus of natural language because they enable writers to establish membership in a specific discourse community. Given the significant role of lexical bundles in academic writing, the comparison of master’s theses, written by L1 English and L2 English master’s students, offers significant insight into the ways in which lexical bundles are utilized, both structurally and functionally. Based on the assumption, we built a 1,282,700-word English corpus of master’s theses to compare the convergent and divergent usage of four-word lexical bundles in the academic texts of L1 English and L1 Chinese of L2-English writers. Findings showed that Chinese students use lexical bundles more frequently but with less variety than L1 English writers. Shared bundles, which exhibit a grammatically compressed discourse style dominated by prepositional phrases, were used by the two groups of writers in different ways and with significantly different frequencies. The analysis of divergent bundles revealed that Chinese writers frequently use clausal bundles while L1 English students employ more phrasal bundles. With regard to students’ ability to write convincingly in various functional categories, the two groups exhibited remarkable differences. Chinese writers also demonstrated some uniqueness of lexical bundles usage and weak awareness of register in the academic writing. The pedagogical implications and further areas of the study are discussed.
Plain language summary
This study examines how multi-word sequences, known as lexical bundles, are used in master’s theses written by both native English speakers and Chinese students studying in English. By analyzing a corpus of 1,282,700 words, we compare how these bundles are employed structurally and functionally. Results indicate that Chinese students use lexical bundles more frequently but with less variety compared to native English writers. Both groups also use shared bundles differently, with Chinese students favoring clausal bundles and native English speakers preferring phrasal ones. These differences highlight distinct writing styles and functional abilities between the two groups, with Chinese writers showing some unique usage patterns and a weaker grasp of academic register. The study discusses implications for teaching academic writing and suggests areas for further research.
Introduction
Lexical bundles are commonly used in written discourse—especially in English language academic writing—as evidenced by numerous corpus-based and corpus-driven analyses of language use (Biber et al., 1999; Hyland & Jiang, 2018; Li & Y. J. Jiang, 2023; Li & F. Jiang, 2023; Siu et al., 2024). Regardless of the context in which lexical bundles are employed, they serve to enhance the meaning and coherence of text and add to the sense of distinctiveness when writing in a specific register such as formal or informal (Hyland, 2008b). The use of lexical bundles also makes it easier for L2 English writers to act as linguistically competent members of an English speaking discourse community (Cortes, 2004; Li, 2025; Wray, 2002). Previous research has confirmed that lexical bundles are important building blocks in academic discourse (Coxhead & Byrd, 2007; Hyland, 2008a), and that competent usage is essential to the accuracy, efficiency, and fluency of English writing in academia (Li & Jiang, 2024; Simpson-Vlach & Ellis, 2010).
The topic of lexical bundles continues to be an expanding area of study due to the increased recognition of these word combinations as an important feature of appropriate and proficient language use in various genres and registers (Biber et al., 1999; Biber & Barbieri, 2007; Cortes, 2004; Hyland, 2008a). Researchers have also investigated the use of lexical bundles across academic disciplines (e.g., Durrant, 2017; Hyland, 2008b; Nekrasova-Beker & Becker, 2020; Reppen & Olson, 2020; Samraj, 2024), between L1 and L2 English writers (e.g., Bao & Liu, 2024; Esfandiari & Barbary, 2017; Öztürk & Köse, 2016; Pan et al., 2016; Pérez-Llantada, 2014). However, only a few studies have examined both L1 and L2 English student writing in the genre of graduate theses or dissertations and using comparable corpora (e.g., Lu & Deng, 2019; Lyu & Gee, 2020). Lu and Deng (2019) compared the use of lexical bundles in English dissertation abstracts by Chinese and L1 English doctoral students in science and technology, Lyu and Gee (2020) investigated thesis abstracts written by L1 Chinese of L2 English and American students in five disciplines. Few studies explored lexical bundles in full texts of Chinese students’ English theses with reference to the L1 English writers’ theses.
The present study differs from previous research in its exploration of the convergent and divergent usage of lexical bundles in English master’s theses written by L1 Chinese of L2 English writers of applied linguistics from Chinese universities and by L1 English writers from American universities. The graduate student genre is chose for it presents some challenges and constraints, and for it is a more high-stakes academic genre than students were faced with during their undergraduate years. The credibility of most graduate student genres may also improve postgraduates’ chances of success in their academic communities. In fact, learning how to use lexical bundles is a difficult process for both L1 and L2 English writers, even as they strive to comply with the linguistic norms of their own discourse communities. Due to their greater heterogeneity, the results of studies conducted with L1 experts and L2 students are not directly comparable in terms of corpus design. In addition, to avoid instances of confounding variables, we chose a single genre (master’s theses), a single academic discipline (applied linguistics), and a single level of expertise (master’s level).
The aim of the study is to investigate the use of lexical bundles in English master’s theses written by L1 Chinese of L2 English and comparable L1 English writers, all of whom are postgraduate students of applied linguistics. To further define the parameters of this investigation, we addressed the following research questions:
RQ 1: What differences are there, if any, in the overall frequency of lexical bundle use in master’s theses written by L1-L2 English academic writers?
RQ 2: Which core lexical bundles are most often used in similar ways by both L1-L2 English academic writers? What kinds of structures and discourse functions do core bundles support? Are there significant differences between the two groups of writers in their use of core lexical bundles?
RQ 3: What lexical bundles are distinctive to L1 Chinese of L2 English and to L1 English writers, respectively? Do these bundles involve unique structure types and discourse functions?
Literature Review
The term “lexical bundle” was coined in the Longman Grammar of Spoken and Written English (LGSWE) (Biber et al., 1999; Chapter 13). Simply stated, they are the most frequently recurring multiword sequences in any given linguistic register, “regardless of their idiomaticity, and regardless of their structural status” (p. 990). The concept of lexical bundles dates back to Salem (1987), who carried out studies analyzing lexical phrases in a corpus of French government documents. Altenberg (1998) was probably the first to employ a frequency-driven approach to identifying recurring word combinations in English (e.g., I am not sure, so I said, because of the). In the London-Lund Corpus of Spoken English, 470 three-word sequences occur more than ten times, totaling over 80% of the text in the corpus. One year later, Biber et al. (1999) extracted commonly used lexical bundles made up of four-to-six-word combinations in different registers and found that four-word bundles comprised the main bundle type. In addition, they found that over 60% of all bundles in academic prose are phrasal fragments, as in noun phrases (e.g., the nature of the) or prepositional phrases (e.g., on the other hand), while, in conversation, approximately 90% of all bundles are clausal fragments comprised of dependent clause fragments (e.g., if you like) and verb phrases (e.g., is going to be).
Since the introduction of ‘lexical bundle’ by Biber et al. (1999), research on the subject has grown into an expanding area of study that explores the linguistic features of different writers or speakers in various registers and genres. For example, Biber et al. (2004) compared the use of lexical bundles in different registers and genres: conversation, university classroom teaching, academic research writing, and university textbooks. Supporting the findings of Biber et al. (1999), their study found that spoken registers include more different lexical bundles and have higher frequencies than written registers. More specifically, university classroom teaching makes greater use of lexical bundles than textbooks, academic prose, or daily conversation. In a follow-up study, Biber and Barbieri (2007) expanded their investigation into a study of written registers such as textbooks, institutional writing, course management, and academic prose, and of spoken registers such as classroom teaching, classroom management, office hours, study groups meetings, and service encounters—that is, in situations that students typically encounter in university life—and found that lexical bundles are more prevalent in spoken registers than in written instructional registers. In contrast to findings in the studies mentioned, lexical bundles are used most frequently in written course management materials.
Another study of interest is Hyland’s (2008a) investigation into the most frequently used four-word lexical bundles across the key academic genres (research articles, master theses, and doctoral dissertations) of a 3.5-million-word corpus. Hyland’s study found that while master’s students make the greatest use of bundles in their theses, expert writers make the least use of bundles in research articles. In addition, some high-frequency bundles in theses and dissertations occurred less frequently in research articles, and others were not even found in articles. These findings are in line with a study by Cortes (2004) which showed considerable variations in frequency, structure, and function across the English language writing of both experts and students. The findings of Cortes are later supported by Wei and Lei (2011), which found that lexical bundles are used more frequently in doctoral dissertations than in research articles. Similarly, Pan and Liu (2019) found that L2 English master’s theses contain more types and tokens of lexical bundles than L2 English research articles. Recently, Shirazizadeh and Amirfazlian (2021) investigated four-word bundles across three genres and found, as did Hyland (2008a), that lexical bundles provide an important means of distinguishing between different genres.
A number of studies have confirmed a wide range of disciplinary variations in the use of lexical bundles. Cortes (2004) compared published research writings in the fields of history and biology, and found significant differences in grammatical structures and discourse functions. The bundles used when writing about history were most commonly noun phrases and prepositional phrases, while those used when writing about biology included a wide range of structures. The most distinctive functional difference across disciplines was the higher frequency in the use of epistemic-impersonal/probable-possible stance bundles in biology. Hyland (2008b) examined four different disciplines and found that texts on the subject of electrical engineering contained the highest number of lexical bundles, followed by business, applied linguistics, and microbiology. Hyland found that soft fields of study tended to employ more prepositional structures and to use more text-oriented bundles and stance bundles, whereas hard fields employed a wide range of passive fragments and focused on research-oriented function.
Durrant (2017) analyzed texts from 24 disciplines, revealing minor differences across disciplines but with a clear distinction between the hard sciences and soft sciences. Reppen and Olson (2020) made a comparison across nine disciplines and reported that 84% of lexical bundles were content- or discipline-specific and occurred in only one or two of the disciplines, and only nine bundles were used in texts pertaining to all of the disciplines. Cross-disciplinary variations in the use of lexical bundles have also been reported by Nesi and Basturkmen (2006), who examined bundle use in four disciplines, and by Nekrasova-Beker and Becker (2020), who compared bundle use in five sub-disciplines of engineering.
Researchers have found differences in the use of bundles by L1 English and L2 English speakers, and also in bundle use between L1 English and L2 English experts. Pérez-Llantada (2014) investigated lexical bundles in three language variables and found that research articles written by L1 Spanish and L2 English experts exhibited a broader repertoire of bundle use as compared to L1 English experts. Pan et al. (2016) found that Chinese experts use bundles more frequently than L1 English experts, that their use by the Chinese group differed significantly from that of the L1 group, both structurally and functionally, and that the Chinese frequently misused some lexical bundles. Similar findings were reported by Pan and Liu (2019), who compared bundle use in research articles by Chinese and L1 English experts, and by Güngör and Uysal (2020) and Ucar (2017), both of whom focused on the academic writing of L1 English and Turkish experts. However, other studies present a different picture. Esfandiari and Barbary (2017) examined lexical bundles used by L1 English and Persian experts in psychology and found that Persian writers use fewer bundles than their English counterparts, with notably different usage in terms of structure and function. Li and F. Jiang (2023) found that Chinese scholars rely more on English lexical bundles than L1 English writers in the published research articles in applied linguistics.
Another strand of research focuses on L1 and L2 differences between experts and students. Öztürk and Köse (2016) found that Turkish postgraduate students used far more bundles as compared to native scholars, and that they frequently overused many lexical bundles (e.g., it can be concluded, it can be said). Moreover, some researchers have focused on ESL (English as a Second Language) writers (e.g., Chen & Baker, 2016; Staples et al., 2013). Staples et al. (2013) examined bundle use across different proficiency levels (low, intermediate, and high) and found that students at lower levels use lexical bundles much more frequently than students at higher levels. However, fewer differences were reported in function across proficiency levels.
Several studies have explored L1 and L2 differences in students’ writing (e.g., essays, master’s theses, and doctoral dissertations) with regard to usage of the often confounding variable of “level of expertise.”Ädel and Erman (2012) found that native English undergraduate students utilize more bundles and more in more varied ways than non-native (L1 Swedish) students. In contrast to Ädel and Erman, Lu and Deng (2019) demonstrated that doctoral dissertation abstracts by Chinese students contained significantly more bundles than those by native students. They also pointed out Chinese students’ incomplete knowledge of English lexico-grammatical system, as well as the effects of transfers of Chinese language features and discourse conventions. Lyu and Gee (2020) investigated the thesis abstracts of Chinese and American master’s students in linguistics, translation, culture, literature, and pedagogy.
Methodology
Corpus Collection
The corpora for the study are English master’s theses of applied linguistics between 2010 and 2020 by L1 English students (MAs-EN) and by L1 Chinese of L2 English students (MAs-CH). The text extraction of L2 English corpus is mainly through random sampling. We randomly selected 100 English master theses in the discipline of foreign linguistics and applied linguistics from 2010 to 2020 from the CNKI master theses database. Each document was read to confirm that the thesis content is concerned about applied linguistics and the writer is native to China. Finally, the first 40 theses were randomly chosen for the corpus by alphabetical sorting.
Random sampling is also used to select the text for L2 English corpus. We randomly selected 100 master theses of Linguistics affiliated with American universities from the ProQuest Dissertations & Theses database from 2010 to 2020. By reading each document, the theses that do not belong to the field of applied linguistics and the author is non-native to English speaking countries were excluded. Using the same method with the Chinese corpus, we randomly selected the top 40 theses for L1 English corpus.
We followed Wood’s (2010) method to ascertain L1 status of the writers. L1 English writers in the study are the students with English first and last names considered native to English-speaking countries and at the same time, affiliated with university in the United Stated. L2 English writers are writers are students affiliated with Chinese university who also has a first and last name considered native to China.
All the texts were all cleaned off the title page, copyright signs, acknowledgments, titles, authors, institutions, abstracts, reference sections, appendices, tables, figures, charts, footers, as well as paragraph breaks and columnar layouts, which are not within the scope of the study. In addition, to avoid potential interference from other authors cited in the texts, the paragraph quotations and cited examples were manually excluded, leaving back only the plain texts produced by the writers. Theses in the MAs-CH subcorpus comprised of 639,322 words whereas those in the MAs-EN subcorpus constituted of 643,378 words.
We adopt the random sampling method to collect the master theses in the same period and the same discipline to ensure the two corpora are representative, comparable, and statistically significant. The two corpora are matched for the number of texts and closely for the total number of words. Therefore, a comparison of the two corpora is taken represent the divergent and convergent usage in the written discourse of L1 English versus L2 English of L1 Chinese master students. Table 1 shows the information of the two corpora, with a slight difference in the size of the corpora.
Constituents of the Two Subcorpora.

Note: MAs-CH: Master’s theses corpus written by L1 Chinese learners of English; MAs-EN: Master’s theses corpus written by L1 English speakers.
Research Instruments
AntConc (3.5.8) was adopted to identify 4-word lexical bundles with different frequencies for the investigation in the study. The tools of Cluster/N-gram, Concordance, Concordance Plot, and File View were frequently employed. SPSS (The Statistical Package for the Social Sciences) program was used to do the statistical work. The Kappa value was employed to assess the inter-coder reliability of classification of lexical bundles with the SPSS, which is discussed in Section “Inter-coder reliability of the classification.” A Chi-square test was also carried out with SPSS to reveal whether any statistically significant differences exist in the texts by Chinese writers and L1 English writers in terms of frequency. In addition, it is also used to examine the statistical significance of certain lexical bundles (i.e., overuse and underuse) between the two groups of writers.
Identification of Lexical Bundles
To identify lexical bundles in the two subcorpora, we adopted three general criteria: cut-off frequency, range, and length. Four-word bundles were chosen because they are the most commonly used bundle length, particularly in academic writing, and also they offer a clearer and wider range of structures and functions than other bundle lengths (Hyland, 2008b). The study set range threshold of at least 10% to exclude instances involving individual writers’ idiosyncrasies and ensure a representative sampling of bundles. To ensure the number of lexical bundles is reasonably manageable, the study adopted the frequency thresholds of 40, 30, and 25 times per million words, with at least 10% text range to extract bundles, respectively. Based on the extracted numbers of lexical bundles and Chen and Baker’s (2016) suggestion of around 100 manageable types, the study set the 30 occurrences per million words.
Using the AntConc (3.5.8) program, we extracted potential four-word bundles from the two subcorpora. The context-dependent bundles and discipline-specific bundles were excluded since they are not the building blocks carrying a distinct discourse function. We also removed lexical bundles that were interrupted by punctuation (e.g., by semicolons, commas, hyphens, dashes, full stops, or slashes)—or by percentages and numbers—because they might lead to frequency information errors due to inconsistencies.
Classification of Lexical Bundles
After identifying the eligible bundles in the two subcorpora, we proceeded to categorize all the bundles according to structure and function. This study follows Hyland and Jiang’s (2018, p. 391) structural taxonomy developed by Biber et al. (1999, p. 1015–1024) for academic prose. This structural classification involves identifying four different types of structural units: noun phrase (NP)-related (e.g., the structure of the, the extent to which), prepositional phrase (PP)-related (e.g., in the context of, on the other hand), verb phrase (VP)-related (e.g., can be seen in, is one of the), and clause-related (e.g., it is important to, we shall have to).
In addition, we adopted the functional taxonomy developed by Hyland (2008a) because it is purposefully designed to facilitate bundle classification in academic writing and is “sufficiently broad to minimize the possibility of overlaps between categories” (p. 49). In accordance with the types of academic texts, we then classified the bundles into three major functional categories: research-oriented, text-oriented, and participant-oriented function. Multi-functional bundles were then classified based on commonly-used concordance functions.
Inter-coder Reliability of the Classification
All the bundles were independently analyzed by two coders according to the taxonomies stated in section “Identification of lexical bundles.” The frequencies of bundles were calculated and inter-coder reliability for each category was assessed in Cohen’s Kappa adopting the SPSS program. Cohen’s Kappa was employed for the inter-coder reliability of bundles classification for it is a chance-corrected method of determining inter-rater reliability, which “takes into account the likelihood that the agreement between coders has occurred by chance” (Cotos et al., 2015, p. 55). The resulting Cohen’ Kappa values range between .883 and .937, shown in Table 2, indicating an excellent reliability level for classification according to Landis et al. (2011).
Inter-rater Reliability of Classification in Cohen’s Kappa.

Resolution of Discrepancies
The controversial or confusing bundles were resolved through negotiation and discussion with the other coder, as Biber et al. (2007) suggest that identifying and discussing discrepancies enhances inter-rater reliability among raters. Another way to strengthen the reliability of the judgement was to consult L1 English experts in reading the concordance lines of the bundles until an acceptable reliability was reached between the coders.
Results and Discussion
General Findings
Table 3 illustrates that, when writing theses in English, Chinese master’s students use more lexical bundle types (CH: 129; EN: 105) and tokens (CH: 2576; EN: 1722) than their L1 English peers and at notably higher bundle density (CH: 0.81; EN: 0.54). This result demonstrates that in academic texts, Chinese students rely more on lexical bundles than their L1 English counterparts. The greater reliance on lexical bundles by L2 English academic writers may be explained that students attempt to write what they perceive to be “academic-like” texts and tend to overuse some expressions (Li & Y. J., Jiang, 2023). The result corroborates with the findings in previous studies (e.g., Lyu & Gee, 2020), in which they revealed that the texts of L2 English students contained a higher number of bundles than those of L1 English students. Lyu and Gee (2020) investigated the use of bundles in the abstracts of English master’s theses in liberal arts between American and Chinese students and found that Chinese students employed a significantly higher number of bundle types and tokens than American students.
Distributions of Four-word Lexical Bundles in MAs-CH and MAs-EN.

We used Type-token ratios (TTR) to identify the lexical diversity or richness of Chinese writers by comparing them to theses by L1 English writers. TTR is commonly used as a measure of lexical variation, based on the ratio of new words (types) to the total number of all words (token), in which the higher the TTR, the greater the diversity of words (Covington & McFall, 2010). As shown in Table 2, master theses by L1 English writers have higher TTR than those written by Chinese writers (EN: 6.10; CH: 5.00). The result demonstrates that L1 English students use bundles more diversely than Chinese writers do in the theses. A possible explanation for lower lexical richness is Chinese students’ overreliance on a limited set of bundles that they are familiar with and confident in using in the writing.
Convergent Usage
Twenty-nine bundles were shared by both groups of academic writers, accounting for 22.5% of all bundles in MAs-CH and 27.6% of those in MAs-EN, as shown in the shared bundles list in Table 4. Major differences are also observed in the frequency of bundles shared between Chinese and L1 English these writers. When counting the bundles that occur more than twice as often in one subcorpus as compared to the other subcorpus, we identified ten different bundles, seven of which were employed more frequently in MAs-CH and three of which in MAs-EN. Among these samples, two bundles (at the same time, on the basis of) were heavily used by Chinese students, accounting for the approximately four to five times greater frequency in MAs-CH than in MAs-EN.
The Use of the Shared Bundles in MAs-CH and MAs-EN.

Note. *significant at p < .05. **significant at p < .01. ***significant at p < .001; The p-value, representing the danger of error, was set at three levels (<.05, <.01, <.001).
Next, we used the SPSS program to perform Chi-square test to assess whether, and to what extent, shared bundles were overused or underused by Chinese student writers as compared to their L1 English counterparts. The findings regarding the use of the shared bundles used by the two groups of writers are reported in Table 4. Results show statistically significant differences in the frequency of 11 bundles (in italic script) at three levels, while the other 18 bundles show no statistical differences.
As shown in Table 4, Chinese writers overuse four bundles (in the use of, in the process of, at the same time, on the basis of) at different levels of significance. It is noteworthy that the bundles at the same time (X2 = 20.344, p ≤ .001), on the basis of (X2 = 17.290, p ≤ .001) are significantly overused by Chinese writers when compared to their L1 English counterparts. Chinese students extremely overuse the English bundles having L1 equivalent in Chinese (e.g., on the basis of, in the process of) or the ones they are familiar and proficient in using with (e.g., at the same time). Considering the number of the bundles, it can be argued that Chinese MA students considerably differed from L1 English MA students in the use of lexical bundles. While they seem to share bundles with their L1 English counterparts, the frequencies of the bundles are significantly different. Chinese students use more varied bundles than L1 English students in a way more repetitive nature.
On the other hand, Chinese writers significantly underuse seven bundles as well as the (−37), in addition to the (−16), at the beginning of (−10), of the present study (−22), the results of the (−17), the end of the (−10), at the end of (−17) at different levels. The latter four bundles also showed high levels of significance (p ≤ .001). Some of the underused bundles (e.g., as well as the, in addition to the) are strongly-associated collocations that are highly salient to L1 English writers. The absence of the highly salient bundles may be “what creates the feeling that non-native writing lacks of ‘idiomaticity’” (Durrant & Schmitt, 2009, p. 175). On the contrary to the dominance of phrasal structures in L1 English academic writing, Chinese writers underused the prepositional phrase bundles (e.g., of the present study) and noun phrase bundles (e.g., the results of the) in their theses. The absence of the phrasal bundles may be EFL learners’ lack of weak awareness of academic written register. Moreover, the underuse of some bundles at high levels of significance in Chinese texts might suggest that some interlanguage stages need to be covered until they attain the native-like usage of the bundles.
Shared bundles are primarily formed using PP (prepositional phrases) with of-phrase fragments (N: 10) (in the use of, in the process of, in the form of, in terms of the, in the field of, at the beginning of, at the end of, on the use of, on the basis of, of the use of) and other PP fragments (N: 8) (at the same time, on the other hand, as well as the, in addition to the, in the present study, in the current study, of the present study, of the current study), representing approximately 62% of all common bundles. NP (noun phrases) with of-phrase fragments (N:6) (the results of the, the purpose of the, the structure of the, the end of the, the use of the, the importance of the) constitute an additional 21%. The structures of the remaining bundles are comprised of copular-be + NP (is one of the), passive verb (can be used to), and clause fragments (the present study is, that the use of). In general, the findings are partly consistent with some previous studies (e.g., Pan & Liu, 2019; Pérez-Llantada, 2014) that the core and shared bundles of L1 and L2 English texts are mostly formed by PP with of-phrase fragment and NP embedding with of-phrase fragment. Pérez-Llantada (2014) found that 60% of the common bundles are NPs with of-phrase fragments and PP +of-phrase fragments. Pan and Liu (2019) reported that more than 90% of the common bundles consisted of NP- and PP-fragments in the two corpora.
Figure 1 plots the functional distribution of the shared bundles. Lexical bundles shared by Chinese and L1 English students perform research-oriented and text-oriented functions, representing circa 62% (N: 18) and 38% (N: 11), respectively. Research-oriented bundles are represented by the subcategories of procedure (e.g., in the use of), location (e.g., at the same time), description (e.g., the structure of the), and quantification (e.g., is one of the). The function of text-oriented bundles is to serve as structuring markers to organize units of discourse (e.g., in the current study), as framing markers to specify limiting conditions in order to situate arguments (e.g., in terms of the), to establish additive links between elements (e.g., on the other hand, in addition to the), and to indicate cause-and-effect relationships (e.g., the results of the).

Functions of shared lexical bundles in MAs-CH and MAs-EN.
Divergent Usage
The study identified 100 bundles specific to Chinese students and 76 bundles distinctive to L1 English students. As shown in Table 5, Chinese writers used more clausal bundles but fewer phrasal fragments than their L1 English counterparts. Compared with L1 English students, Chinese students employ significantly less noun-related (X2 = 10.347, p ≤ .001) and prep-related bundles (X2 = 34.190, p ≤ .000). Chinese writers use significantly more clause-related (X2 = 44.118, p ≤ .000) and verb-related (X2 = 36.076, p ≤ .000) bundles than L1 English writers. This may indicate that the Chinese academic writers have not yet mastered English academic writing in terms of grammatical compression, especially given the high nominalization of academic English.
Main Structural Classification of Distinctive Bundles in MAs-CH and MAs-EN.

Note: Noun-related and prep-related are phrasal structure, verb-related and clause-related are clausal one.
significant at p < .01; ***significant at p < .001.
The subcategory of other NP fragments in NP-related bundles is noteworthy. Chinese writers use statistically significantly (X2 = 8.358, p ≤ .002) more bundles of the subcategory than L1 English writers—nearly twice the number of bundle types and over twice the number of bundle tokens, as shown in Table 6. Chinese students prefer NP with PP fragments (e.g., an important role in) as well as noun and binominal noun phrases (e.g., the similarities and differences). In contrast, L1 English writers mainly used NP embedding relative clauses as post-modifiers (e.g., the extent to which). Chinese students seldom if ever use these types of relative clauses in their academic texts. The less frequent use of NP embedded relative clauses might be due to the influence of typological differences in relative clauses in the Chinese language (i.e., head-last/head-final constructions with pre-modifiers) and the English language (i.e., head-first/head-initial construction with post-modifiers). The structure of a Chinese and English NP is shown in the schemata: Chinese: (determiner/numeral) (associative phrase) (classifier) (pre-modifier) head English: (determiner) (pre-modifier) head (post-modifier)
Other NP Fragments Bundles in MAs-CH and MAs-EN.

The examples below are presented to show the syntactic differences in relative clauses in the Chinese language and the English language. English RRCs follow the head noun that it modifies, whereas Chinese RRCs, left-joined to the head noun, is proceeded by the complementizer de.
(a) nà gè rén mǎ de huà (RRC-de-N)
the painting that the man bought (N-that-RRC)
(b) mǎ huà de nà gè rén (RRC-de-N)
the man who bought the painting (N-that-RRC)
As for VP-related bundles, passive bundles exhibits noteworthy differences between the two groups (X2 = 21.285, p ≤ .000): Chinese students made greater use of passive bundles than their English counterparts: three times the number of bundle types and nearly four times the number of bundle tokens, as shown in Table 7. Rashtchi and Mohammadi (2017) also found passive constructions the most problematic lexical bundles in L2 English writings. One of the important reasons is that English writing instruction and textbooks in China emphasize the use of passive devices to bolster the objectivity of their academic texts (Li & Y. J. Jiang, 2023). Another possible reason is the writers, when constructing academic texts, tend to adopt a conciliatory and non-interventionist stance (Li & Jiang, 2024).
Passive Verb Bundles in MAs-CH and MAs-EN.

As shown in Table 7, master’s students, regardless of their first language, show a preference for “can be+ passive verb” bundles, with a greater number being employed by Chinese students. English students often use three different verbs within a frame: see (can be seen in), find (can be found in), and observe (can be observed in), whereas the verbs collocated in the Chinese list are see (can be seen from), divide (can be divided into), and regard (can be regarded as). The verb see occurred in five different types of passive bundles with 93 tokens in MAs-CH while only one bundle with 19 tokens was found in MAs-EN. The overuse of the verb “see” in passive bundles may be indicative of Chinese students’ lack of knowledge about lexical constructions in academic writing. Both L1 and L2 English students’ essays in Chen and Baker (2016) displayed the similar preference. They found that the verbs collocated in BAWE-CH are explain, regard, and divide, while in BAWE-EN are use, apply, find, see, and use.
We observed yet another statistically significant difference between the two groups in their respective use of “anticipatory-it” clauses (X2 = 19.607, p ≤ .000). As shown in Table 8, master’s theses written by Chinese students have twice the number of bundle types and over three times the number of bundle tokens than those of their English counterparts. However, it does not align with the findings of other studies (e.g., Pan & Liu, 2019) who explored bundle use in research articles by experts and found that native experts employ more “anticipatory-it” bundles than non-native experts. The discrepancy may be that the study focuses on master’s theses while the two studies noted above focused on findings available in various published research articles.
Anticipatory-it Clause Bundles in MAs-CH and MAs-EN.

According to Biber et al. (1999), the two most frequently used frames in English academic writing are as follows: (1) anticipatory-it+ a copula+ a predicative adjective + infinitive-to/conjunctive-that clause (e.g., it is important to), and (2) anticipatory-it+ a copula+ verb in passive voice + infinitive-to/conjunctive- that clause (e.g., it should be noted). Both Chinese and L1 English master’s students used the two frames. However, Chinese students displayed a heavy use of the latter frame (e.g., it can be seen, it is believed that, it is found that, it can be concluded, it can be found). In Pan and Liu (2019), native experts employed four anticipatory-it bundles followed by adjectival phrases (it is clear that, it is important that, it is possible that, it is possible to) while non-native experts only used it is necessary to. This comparison confirms Hewings and Hewings’ (2002) claim that anticipatory-it patterns cause problems for L2 English writers, possibly due to the absence of its counterpart in many languages. Therefore, the less frequent use of these patterns by Chinese students may well be attributed to the absence of counterparts in the Chinese language.
The data analyzed for the study contained more instances of transfer of writing conventions. One of the most striking findings is Chinese writers’ overuse of ‘we’ bundles (e.g., we can see that, we can find that, we can conclude that), the bundles of the type which are not frequent in English academic writing but a translational equivalent of “wǒ mén kě yǐ kàn chū/wǒ mén kě yǐ fā xiàn/wǒ mén kě yǐ dé chū” in Chinese. These phrases are employed to put forward a conclusion or introduce the outcome of reasoning in Chinese academic writing. However, L1 English students do not use the “we” bundles in their theses, and it is not found in the BNC corpus.
The right collocates of “we” in the bundles provide evidence that “can” is a strong collocate in frames constructed by Chinese writers. Chinese learners tend to adopt a more direct style of persuasion with modal verbs in their academic writing. :Can” was the most frequently used positive keyword and “we can+ verb” was the most frequently used frame. Concordance lines reveal that the most frequent collocation in MAs-CH is we can see from, followed by the nouns table, figure, analysis, example, discussion, studies, and database. Most lexical bundles were used to depict data sources rather than to construct a writer’s credibility, indicating students’ lack of familiarity with conventional usage of lexical bundles in English academic writing.
Existential-there structures, a basic and essential part of the English language, is a natural and effective way of introducing new topics into a discussion. The result shows a large number of such bundles (there are still some, there are significant differences, there is no significant, that there is a, that there is no) in the Chinese corpus. Existential-there structures have equivalent forms in most other languages of the world. This may be due to a similar construction in Chinese, (yǒu, there is/are) + NP, in which the existential “yǒu” precedes a VP.
Both students’ excessive use of ‘we’ bundles and ‘there’ bundles could be attributed to the linguistic transfer from Chinese language to English language. It serves as a common compensatory strategy for Chinese student writers in their English academic writing. However, as their linguistic and proficiency imporves, the degree of transfer tend to decrease (Li & F. Jiang, 2023).
As for the various discourse functions of distinctive bundles in each subcorpus, we observed statistically significant differences between MAs-CH and MAs-EN with regard to research-oriented and participant-oriented functions, as shown in Table 9 and Figure 2. Chinese writers use significantly more participant-oriented bundles than L1 English writers, and at high levels of significance (X2 = 99.596, p ≤ .000). In contrast, English students employ significantly more research-oriented bundles than their Chinese counterparts (X2 = 49.996, p ≤ .000). Additionally, almost half of the distinctive bundles in the two copora fall into the category of text-oriented functions, indicating that master’s students, regardless of their native language, focus more keenly on text organization in academic writing.
Functional Classifications of Distinctive Bundles in MAs-CH and MAs-EN.

Note: ***significant at p < .001.
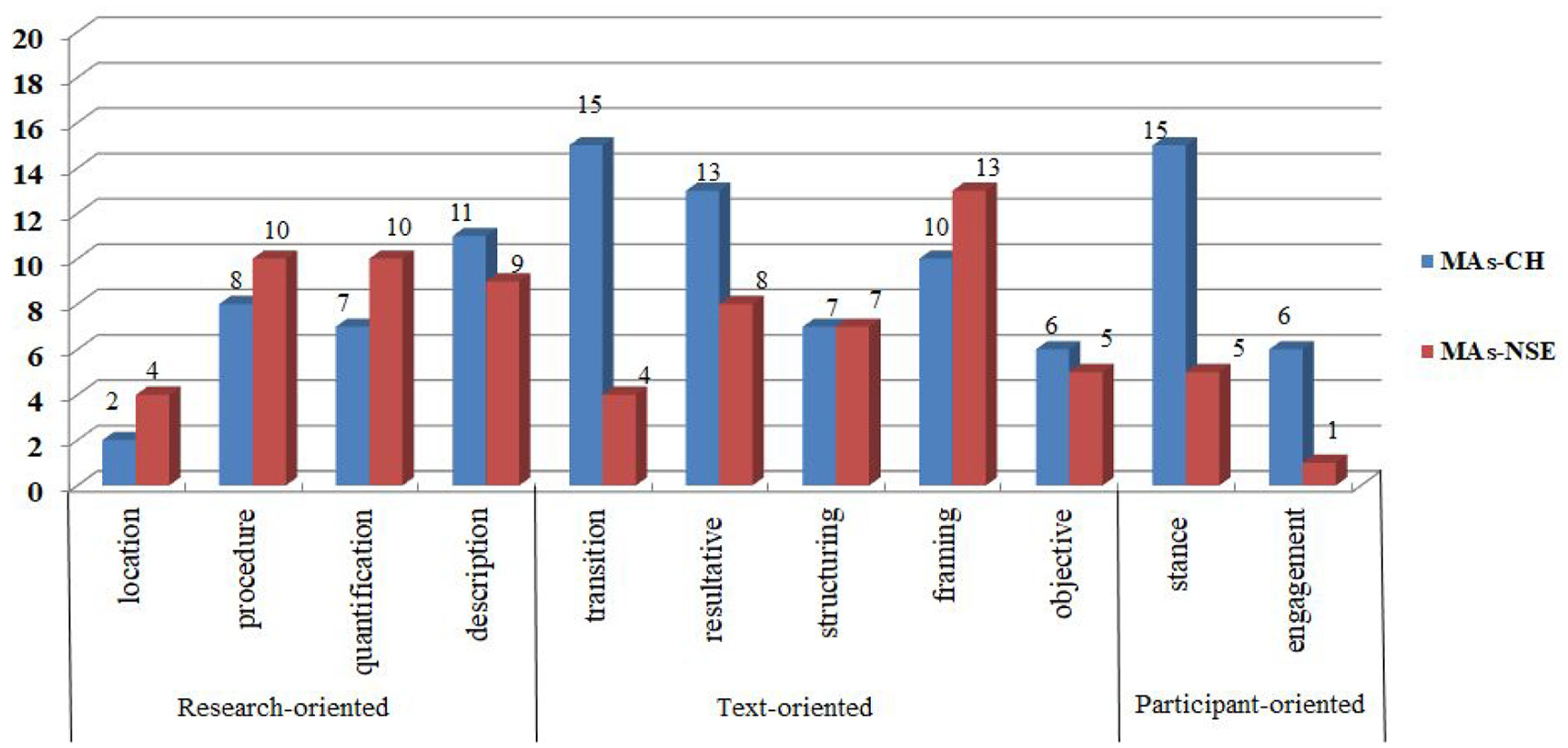
Functions of distinctive bundles in MAs-CH and MAs-EN.
The subcategory of stance in academic writing is especially noteworthy (X2 = 53.679, p ≤ .000). Theses written by Chinese writers contained a significantly greater number of lexical bundles types and bundle tokens—three times the number of bundle types (CH: 15; EN: 5) and nearly five times the number of bundle tokens (CH: 280; EN: 64) than those written by their English counterparts. L1 English students often use stance bundles to indicate the writer’s assessment of importance (it is important to), to convey tentative stance toward propositions (it is possible to), to express degree of certainty (the fact that the), and to show the degree of confidence in specific claims (to be able to).
On the other hand, Chinese writers were shown to exhibit a prominent use of passive linguistic patterns (e.g., can be seen that, can be seen as, can be regarded as) to present their judgements and opinions. In addition, they also used anticipatory-it bundles (e.g., it is necessary to, it is clear that, it is believed that) to indicate an impersonal stance. It is also worth noting that Chinese master’s students frequently used it is necessary to explicitly direct readers’ attention to an important point. However, when examining the concordances in MAs-EN, we found that English students used it is important to often collocated by the verb “note” to indicate pragmatism, as this structure places thematic components at the end of a sentence. The limited use of lexical bundles by Chinese students suggests a restricted awareness of the usage and importance of this function.
The prominent use of engagement bundles reveals a significant difference between the writing of Chinese students and their English counterparts (X2 = 56.767, p ≤ .000). L1 English writers display a strong preference for it should be noted and Chinese students use more ‘we’ bundles, such as we can see that, we can find that, and we can conclude that. It is also worth mentioning how the two groups of writers employed addition bundles. One notable feature of the two subcorpora is the colloquialization in Chinese students’ writing. They tend to use the colloquial lexical markers more typical in speech than in academic writing. For instance, Chinese writers use that is to say, to paraphrase segments of text; in contrast, English writers usually adopt other means (e.g., presenting specific examples) to illustrate the further progression of a previously used proposition. Moreover, while the Chinese students used on the one hand to serve as an additive link between elements in the text, no such cases were found in the texts of their English counterparts. These differences clearly indicate that Chinese writers seldom use bundles in a fully native-like manner, and that they are generally unfamiliar with register conventions.
It is important to stress the extent to which L1 English and Chinese writers employ resultative bundles: Chinese students use a greater number of resultative bundles (esp. inferential markers) than English students. There were 11 different bundles and 132 bundle tokens in MAs-CH and three different bundles and 33 bundle tokens in MAs-EN. The frequent use of inferential bundles in the MAs-CH subcorpus indicates that Chinese students tend to construct a reason-result style of argumentative discourse in their academic writing. Resultative bundles in MAs-CH are more stylistically verbose, as almost all of these bundles are clausal fragments (e.g., it is found that, the results show that, the results showed that, that there is no, there are still some, there is no significant). In contrast, L1 English writers mainly employ phrasal fragments such as the findings of the, results of the analysis, the findings of this, and as a result of. This result reveals that Chinese students seem not to fully follow the norms of English academic writing with their excessive use of clausal structures and passive forms.
Compared to other subcategories, framing is the only one that both Chinese and English students employed in a highly concentrated manner, indicating that both groups of writers tend to “situate arguments by specifying limiting conditions” (Hyland, 2008a, p. 49). Chinese students tend to use more bundle tokens (CH: 247; EN: 199) but fewer bundle types (CH: 10; EN: 13) than their English counterparts. In their theses, both Chinese and English writers used prepositional fragments in bundles such as with regard to the, in the case of, in a way that, in the context of, in the light of, from the perspective of, in accordance with the, in the sense that. Chinese students, on the other hand, tended to use more VP-related bundles (e.g., is based on the) and clause-related bundles (e.g., when it comes to).
Conclusion
The present study contrastively analyzes the use of four-word lexical bundles in English master’s theses written by L1 English and L1 Chinese of L2 English students of applied linguistics in terms of frequency, structure, and function. Findings demonstrate that L1 Chinese students use more bundle types and tokens, but in a less diverse manner than English students. Through their frequent use of such bundles, Chinese writers make great attempts to produce more native-like writing, which also may indicate a lower level of confidence when constructing academic texts. Shared bundle types were also used to perform research-oriented function (procedure, location, description, and quantification) and text-oriented function (structuring, framing, addition, and causative). In addition, we found statistically significant differences in the frequency of shared bundle use between the two groups of writers: Chinese students tend to overuse and underuse specific bundles in their theses.
Findings regarding the use of divergent bundles show a clear distinction between phrasal and clausal bundle use between the two group writers, showing the Chinese students’ lack of grammatical compression, particularly in the nominalization of academic English. The two groups also differed on the bundles functional distribution. Chinese students used significantly more research-oriented but fewer participant-oriented bundles than English students. A closer examination revealed that both Chinese and English writers used bundles differently in some subcategories of text-oriented functions, as well as in their descriptions of research-oriented and participant-oriented functions. In addition, the Chinese writers employed some bundles typical of speech patterns, suggesting a weaker awareness of register conventions. As Leedham (2015) claims, Chinese students are more likely to employ informal expressions across written and spoken registers, which may be explained by the absence of sufficient distinctions between various communicative purposes.
The comparative study may have great implications for pedagogical practices, as the findings provide valuable information for the development of instructional materials on bundle use in academic writing. Contrastive exposure to bundles associated with detailed explanations of the structures and functions that the bundles serve in theses writing could prove pedagogically beneficial. Lexical bundles unique to Chinese students could also be integrated into ESL/EFL curricula to help learners avoid the use of non-native-like or non-academic bundles. Lists of overused and underused bundles could also be useful instruction resources in L2 writing courses, as well in as EAP courses, to enhance learners’ appropriate and stylistic use of lexical bundles in English academic writing. The use of a genre-based approach would also facilitate the transition of student writers of English master’s theses from a conversational style (characterized by clausal fragments) to a scientific style (characterized by phrasal fragments).
It should be noted that the present study suffers from a few limitations. First, the results of the study should be treated with some caution, as are all fields of soft science, because the corpora data cover only one discipline. Lexical bundle use varies across different disciplines and sub-disciplines. Therefore, further research should be conducted using a greater variety of soft science disciplines (e.g., educational sciences or business studies). Second, the present study focused on four-word bundles because they are the most commonly used word length in academic writing. A more detailed exploration of longer bundles (e.g., five-, six-, seven-word) could offer a more complete picture of how this aspect of language is used by Chinese writers.
Footnotes
Ethical Considerations
This article does not contain any studies with human participants performed by any of the authors.
Consent to Participate
This research did not contain any studies involving animals or human participants, nor did take place on any protected areas. There are no human subjects in this article and informed consent is not applicable.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was supported by the Social Science Fund of Shaanxi (No.: 2024K021), Teacher Education Reform and Teacher Development Fund of Xi’an International Studies University (No.: 23JSFZA02), Teaching and Reform Fund of Xi’an International Studies University (No.: 23BZSZ05).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.