
Abstract
This article compared three-word move-specific lexical bundles (MLBs) in dissertation abstracts authored by linguistics doctoral students from China and the United States. Two separate corpora were constructed for analysis: (1) The China Linguistics PhD Abstracts Corpus (CLC), consisting of 700 abstracts totaling 613,713 words generated by doctoral students from China specializing in linguistics, and (2) the America Linguistics PhD Abstracts Corpus (ALC), comprising 700 abstracts totaling 247,359 words written by American doctoral students in linguistics. The identification of MLBs was based on log-likelihood values, indicating a notably higher number of instances within a specific move in contrast to the overall corpus. The study then proceeded to compare the structures, functions, and communicative purposes of MLBs in the two corpora. The findings of the analysis are as follows: (1) Chinese students employed a higher percentage of NP- and PP-based MLBs but a lower proportion of VP-based MLBs, and both groups used different words within similar structures; (2) Chinese students employed a higher percentage of research- and participant-oriented MLBs but a lower proportion of text-oriented MLBs, and the two groups used dissimilar MLBs to fulfill similar functions; and (3) the two groups employed distinct MLBs to achieve identical communicative purposes, with Chinese students utilizing MLBs specific to the CLC corpus. These findings highlight the pedagogical significance of MLBs and underscore the importance of corpus linguistics in identifying and teaching essential move-specific vocabulary to second/foreign language learners.
Keywords
Introduction
Formulaic language, as defined by Wray (2002), represents prefabricated, memory-stored sequences of words or elements that are recalled in their entirety during usage, as opposed to being created or deconstructed through grammar. A proficiency in utilizing such language plays a critical role in marking overall language competence (Meunier, 2012). Erman and Warren (2000) highlighted the significant prevalence of formulaic language in both spoken (58.60%) and written (52.30%) English discourse. Research has shown that formulaic language has a positive impact on oral fluency (Yu, 2022) and reading performance (Jiang & Nekrasova, 2007). Appropriate application of formulaic language empowers learners to communicate more fluently, accurately, and diversely, even beyond their current language proficiency level (Yu, 2022).
Lexical bundles (LBs), a form of formulaic language, have received extensive attention in English for Academic Purpose (EAP) contexts. They have been examined in various settings, including university instruction and educational materials (Biber et al., 2004; C. Y. Liu & Chen, 2020), research articles (RAs) or essays authored by L1 and L2 English speakers (Bychkovska & Lee, 2017; Chen & Baker, 2010) as well as across various academic fields (Cortes, 2004; Hyland, 2008a, 2008b). While LBs in abstracts have been predominantly studied in RAs (Kim & Lee, 2021; J. Liu & Lu, 2019), dissertation abstracts (DAs) have received limited research attention (Lu & Deng, 2019). Hyland (2008a) and El-Dakhs (2018) highlight that dissertations and RAs, as separate genres, employ language in unique manners. Given the significant surge in postgraduate students across diverse disciplines in China, with the population of new postgraduate students surpassing 1.2 million in 2022, an increase of over 700,000 in mere 5 years, there is a compelling need for further research on their utilization of LBs in degree paper abstracts, typically written in both English and Chinese.
Additionally, the current literature primarily focuses on comparing frequently used LBs, encompassing all LBs exceeding a predetermined frequency threshold in two corpora. However, there is a notable scarcity of research investigating move-specific lexical bundles (MLBs). These MLBs are defined as LBs that exhibit a significantly higher frequency within a particular rhetorical move compared to the overall corpus of abstracts. Comparative research across nations is even scarcer. Nevertheless, this research is significant because MLBs play a crucial role in composing rhetorical moves that are central to research and instruction on abstract writing. Consequently, the present research aims to compare MLBs in DAs written by linguistics doctoral students from China and the United States. The ultimate goal is to advance our understanding of the teaching and learning aspects associated with this specific genre.
Literature Review
The field of applied linguistics has witnessed a burgeoning curiosity regarding formulaic language. Despite inconsistencies in terminology, scholars generally concur that a substantial portion of natural language consists of formulaic expressions (Schmitt & Carter, 2004). In EAP contexts, the proficiency in discipline-specific patterns serves as an important indicator of belonging to an academic community (Ädel & Erman, 2012; Segalowitz, 2010). For L2 learners, formulaic language holds particular importance as “it reduces the learning burden while maximizing communicative ability” (Ellis, 1994, p. 86) and offers L2 learners readily available sets of linguistic items (Coxhead & Byrd, 2007; Myles, 2004), thus facilitating their utilization of language through “a single mental effort” (Hunston, 2002, p. 174).
LBs are “recurrent expressions, regardless of their idiomaticity, and regardless of their structural status” (Biber et al., 1999, p. 990). They are characterized by “non-idiomaticity, structural incompleteness, and frequency-driven identification” (Bao & Liu, 2022, p. 2). As an illustrative example, characteristics of the lacks idiomaticity, displays structural incompleteness, but is recognized as a LB owing to its high frequency in CLC. The meaning of a LB can be understood by examining its individual components (C. Y. Liu & Chen, 2020). As such, LBs fulfill categorical and pragmatic functions (Biber et al., 2004; Oakey, 2020). The theoretical underpinning of LBs draws upon Sinclair’s (1991) idiom principle, asserting the important role of formulaic language in language expression and comprehension. This principle posits that pre-existing, memorized chunks of language are stored and processed holistically within our mental lexicon, influencing both the comprehension and production of speech. This theoretical standpoint gains further credence from the findings of Biber et al. (1999) and Erman and Warren (2000), which illustrate a significantly higher prevalence of formulaic language in spoken English discourse as opposed to written contexts.
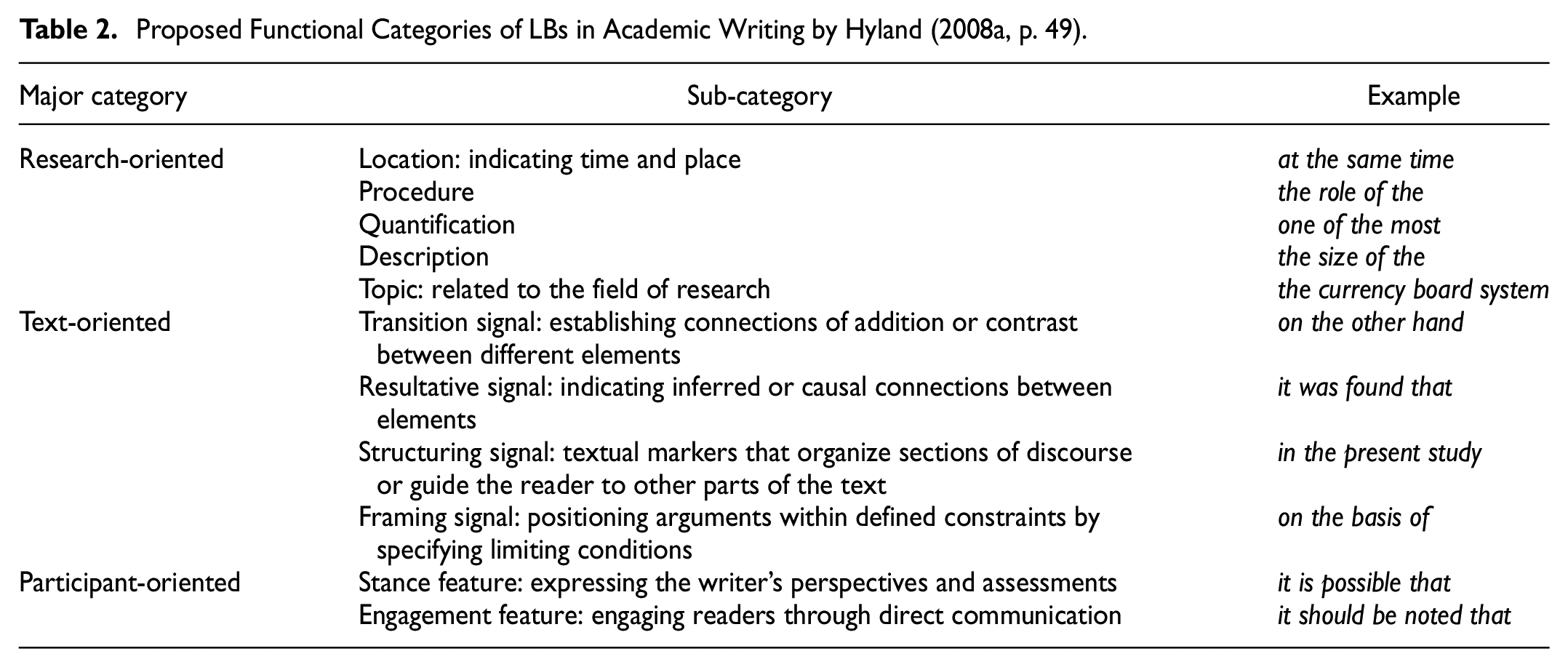
In most studies, established models are employed to classify and examine bundles based on their structural composition, function, and intended communicative objectives. Biber et al. (1999) and Hyland (2008a) introduced significant structural (see Table 1) and functional classifications (see Table 2) for LBs used in academic prose. Additionally, the five-move model (see Table 3) proposed by Swales and Feak (2009) has been used in LB research focused on abstracts to identify their communicative purposes. These models are often adapted (e.g., through the addition, deletion, or promotion of categories) to analyze specific corpus features.
Proposed Structural Categories of LBs in Academic Writing by Biber et al. (1999, pp. 1014–1015).

Proposed Functional Categories of LBs in Academic Writing by Hyland (2008a, p. 49).
Proposed Rhetorical Framework of Abstracts by Swales and Feak (2009, p. 5).

Most research on LBs adopts a comparative approach, examining LBs across two or more corpora beyond a certain frequency threshold. The initial LB research was conducted by Biber et al. (1999), who discovered that LBs in spoken English discourse primarily consisted of clause segments, while those in written discourse were predominantly nominal or prepositional phrases. Subsequently, research has compared LBs across corpora representing diverse registers (Biber, 2006; Huang, 2018), disciplines (Cortes, 2004; C. Y. Liu & Chen, 2020), genres (Gao, 2017; Hyland, 2008a), and groups of writers (Ädel & Erman, 2012; Chen & Baker, 2010).
The majority of LB research within the abstract genre has been concentrated on journal articles (Kim & Lee, 2021; Omidian et al., 2018; Qi & Pan, 2020). However, recognizing that dissertations and RAs constitute “two distinct genres” (El-Dakhs, 2018, p. 58), recent scholarship has begun to investigate LBs in dissertation or thesis abstracts authored by students from China and the United States (Bao & Liu, 2022; Lu & Deng, 2019; Lyu & Gee, 2019), and those by students from different L1 backgrounds (Li et al., 2020). These studies have scrutinized general LBs (Lu & Deng, 2019; Lyu & Gee, 2019), LBs with noteworthy variations in token frequencies across corpora (Bao & Liu, 2022), and sentence-initial LBs (Li et al., 2020). Nonetheless, MLBs, which are LBs characterized by their frequent occurrences within a particular rhetorical move and thus integral to its construction, have been relatively unexplored in existing literature. In our study, MLBs are identified as bundles exhibiting significantly elevated frequencies within a move, as compared to the entire abstract corpus. This is evident when the log-likelihood (LL) value reaches 3.84 or greater, signifying statistical significance at a level of p < .05. Given that instruction in abstract writing is typically move-based (i.e., teaching language patterns from one move to another), understanding how MLBs are utilized by L2 learners and their American counterparts is essential. This understanding could enhance the development of more effective move-based pedagogical strategies, thereby facilitating L2 learners in refining their writing proficiency.
Research Methodology
The conceptual framework for this research paper is based on Sinclair’s (1991) idiom principle. According to this principle, formulaic language comprises fixed forms and functions, treated as holistic units rather than analyzed based on individual word meanings, serving specific communicative purposes. The principle emphasizes the fixed arrangement of words in these patterns, which convey meaning efficiently and provide familiarity and naturalness in language use. Expanding on this groundwork, we utilized Biber et al.’s (1999) taxonomy to analyze MLB structures. Additionally, we employed Hyland’s (2008a) functional taxonomy and Swales and Feak’s (2009) rhetorical move framework to examine the genre-general and -specific functions of MLBs, respectively. This comprehensive approach aimed to provide an in-depth and nuanced understanding of MLB use.
Corpora
We gathered a total of 700 abstracts from linguistics dissertations authored by doctoral students in China (see Table 4). These abstracts were obtained from 13 Chinese universities through two reputable sources, namely the China National Knowledge Infrastructure (CNKI) and the National Library of China. Utilizing the databases’ discipline-based categorization, we accessed the interface dedicated to linguistics, allowing us to view and download the relevant dissertations for further extraction of data. All the universities included in the study were state-authorized to grant PhD degrees and recognized as top-ranking institutions. The timeframe was set between 2000 and 2020, as it covered a significant portion of the genre, aligning with the establishment of numerous doctoral programs during this period. Consequently, the China Linguistics PhD Abstracts Corpus (CLC) was established, comprising 613,713 tokens with an average length of 876.73 (SD = 509.44).
Description of the Corpora.

To establish a parallel comparison with the Chinese universities, we carefully selected 13 high-ranking American universities in the same field, using the QS World University Rankings as our reference point. A total of 700 DAs, written by doctoral students from the institutions, were collected from ProQuest within the same timeframe. This compilation formed the America Linguistics PhD Abstracts Corpus (ALC). In a manner similar to CNKI, ProQuest also employs a categorization system for dissertations based on their respective disciplines. Consequently, we accessed the linguistics section within ProQuest’s database and extracted the abstracts of relevant dissertations for our study. ALC consisted of 247,359 tokens with an average length of 353.37 (SD = 124.63).
Data Analyzing Framework
Identifying Move-Specific Lexical Bundles (MLBs)
The focus of the current study centers on three-word bundles, chosen for their higher frequency in comparison to items with more words (Hyland, 2008a). Furthermore, many previous studies examining LBs in abstracts also focused on three-word LBs (e.g., Azad & Khiabani, 2018; Hu, 2015; Hu & Huang, 2017), and maintaining consistency in the selection of LB length enhances comparability. WordSmith Tools was employed to retrieve LBs that appeared at least 60 times per million words (pmw) within a minimum of 2.00% of the discourses. This percentage entailed 14 abstracts in each corpus.
The selection of a frequency threshold is acknowledged to be “somewhat arbitrary” (Ädel & Erman, 2012, p. 82; Biber, 2006, p. 134; Biber et al., 2004, p. 376; Fattani, 2018, p. 16; Hyland, 2008b, p. 8), and is determined by the necessity to maintain a manageable volume of retrieved items for examination (C. Y. Liu & Chen, 2020; Oakey, 2020). We chose a comparatively low threshold as the distribution of occurrences is a more significant factor in studies centered on short discourses like abstracts. Hyland’s (2008b) 10.00% distribution parameter would have yielded less than 30 LBs from the two corpora. Consequently, a 2.00% distribution threshold was implemented, surpassing the stringency of the parameters set by Lu and Deng (2019) and Omidian et al. (2018). After the collection phase, we merged overlapping LBs to mitigate the influence of frequency biases (Chen & Baker, 2010).
To identify MLBs, we employed the LL and effect size calculator developed by Rayson (2016). This tool allowed us to detect items that exhibited notably greater occurrences within a specific move compared to the overall corpus. Items were classified as MLBs if their LL scores exceeded 3.84.
Categorizing MLBs
In this study, MLBs were categorized based on their structure, function, and communicative purposes. Regarding the structural categorization, we utilized Biber et al.’s (1999) model and made adaptions to make it more pertinent to DAs (see Table 6). In terms of functional categorization, we employed Hyland’s (2008a) categories and expanded them by adding sub-categories including relationship signals, objective signals, inferential signals, causative signals, and other LBs (see Table 10). To enhance objectivity in the classification procedure, a linguistics PhD candidate participated in the task alongside the first author. The inter-coder agreement was assessed using Cohen’s Kappa coefficient, which yielded a value of 0.889, indicating a high level of concurrence according to Landis and Koch (1977). In cases where there was disagreement on the function of specific MLBs, both coders reviewed and discussed the items until a consensus was reached.
In terms of rhetorical moves, we employed Swales and Feak’s (2009) framework and extended it by adding the move of Structure, which specifically outlines the organization of a dissertation. The identification of moves and their communicative purposes was carried out independently, yielding an inter-rater reliability score of 0.813. In cases where there were disagreements regarding the identification of moves, both coders thoroughly reviewed and discussed the items until a consensus was reached.
Analyzing MLBs
To evaluate the utilization of MLBs, we examined them in terms of their structures, functions, and communicative purposes. In the structural analysis, we first compared the distributions of MLBs across CLC and ALC, and then examined the MLBs within each structural category. Similarly, in the functional analysis, we first compared the distribution of MLBs across the two corpora, and then examined the MLBs within each functional category. Finally, in terms of communicative purposes, we conducted a comparison of MLBs that fulfilled identical communicative objectives across the two corpora.
Results
Table 5 shows the identification of a total of 274 LBs within CLC and 195 LBs within ALC. Among these LBs, 87 MLBs were identified in CLC, accounting for 68.25% of the overall LBs in that corpus. Similarly, in ALC, 85 MLBs were identified, constituting 43.59% of the total LBs. It should be noted in CLC, 60 items (21.90%) were found to be specific to more than one rhetorical move, whereas in ALC, eight items (4.10%) exhibited this characteristic. For example, the present study was associated with the move of Goal, Methodology, and Conclusion simultaneously in CLC. Notably, both the type and token frequency of MLBs in CLC constituted a higher percentage of the overall frequency compared to ALC. This suggests that the Chinese students relied more heavily on MLBs in composing their DAs.
Frequencies of LBs and MLBs in the Two Corpora.

Structures of MLBs in the Two Corpora
NP-Based MLBs
Table 6 shows that the NP-based MLBs are more prevalent than PP- and VP-based MLBs in both corpora. However, the Chinese students utilized a higher proportion of NP-based MLBs compared to their American counterparts, with 2.28% more in terms of type and 7.09% more in terms of token. The discrepancy can be attributed to a higher occurrence of noun phrase + of items in ALC (35.29% compared to 28.25% in terms of type), and a greater prevalence of other noun phrase fragment items in CLC (11.86% compared to 4.71% in terms of type).
Structures of MLBs in the Two Corpora.
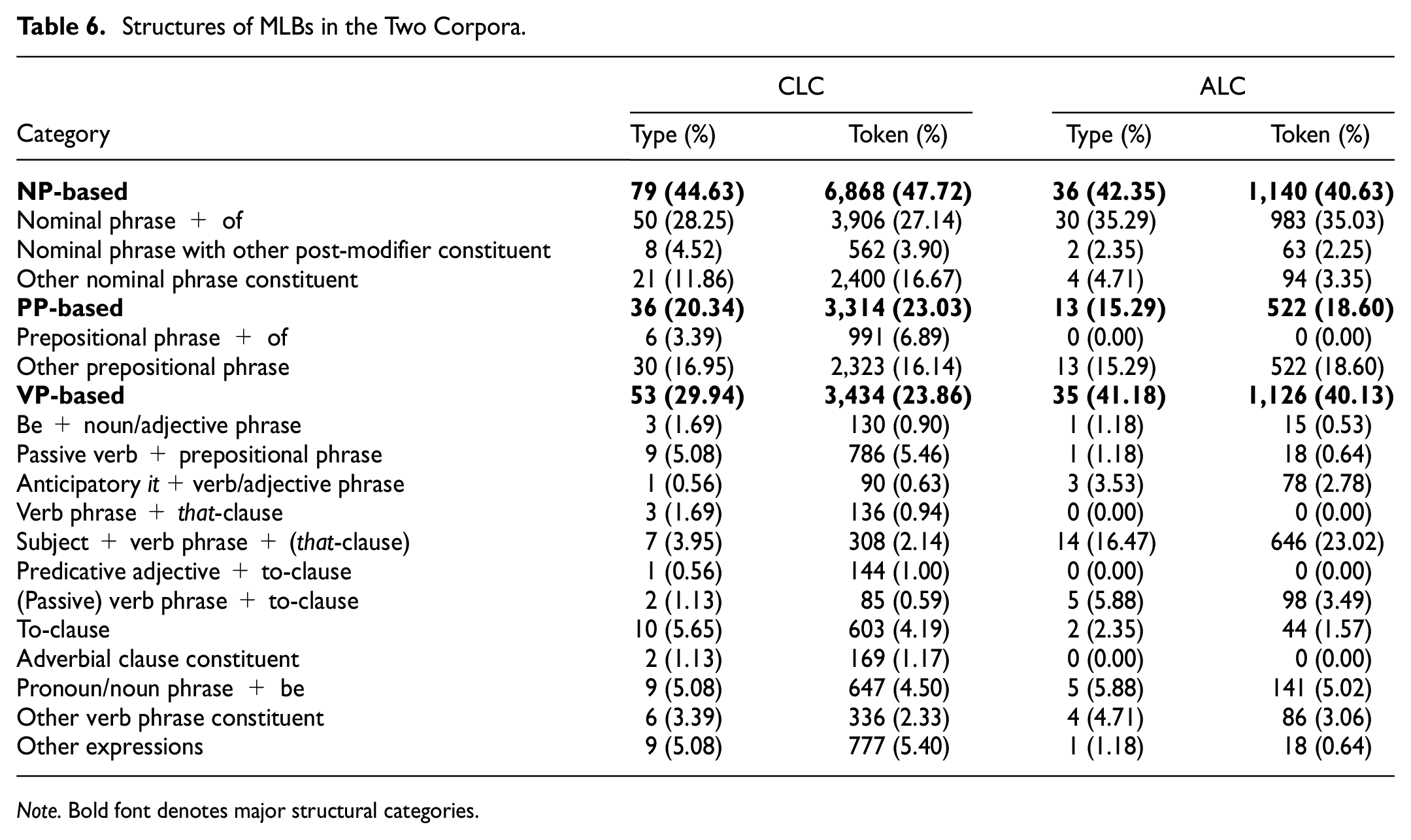
Note. Bold font denotes major structural categories.
An intriguing pattern emerged within the noun phrase + of structure, where the Chinese and American students opted for different nouns to convey similar meanings. As shown in Table 7, the two groups made distinct noun choices in contexts where the nouns were interchangeable, with some choices occurring more frequently in CLC. For example, the meaning of appeared 104 times in CLC compared to 14 times in ALC (LL = 19.41, p < .0001), while the semantics of occurred 38 times in ALC but only 17 times in CLC (LL = 38.29, p < .0001). The frequencies of these noun choices seemed to balance each other out, possibly due to the competing usage of synonyms such as meaning and semantics within the noun phrase + of structure to convey similar and definite contents of DAs. In terms of other noun phrase fragment, both Chinese students and American students employed the pattern the + adjective + noun phrase, but filled the slots with different words, as shown in Table 8. In the adjective slot, CLC items featured previous, present, and current, while ALC items included present, first, and current. In the noun phrase slot, CLC exhibited studies, study, research, and dissertation, while ALC predominantly used study.
Words Filled in Noun Phrase + of Structure in the Two Corpora.

Note. The bold font emphasizes the respective CLC and ALC LBs. The underlined expressions highlight similar contexts of the bundles.
Main Patterns in Other Noun Phrase Fragment Structure in CLC and ALC.

PP-Based MLBs
As indicated in Table 6, the Chinese students employed a slightly higher proportion of PP-based MLBs compared to the American students, approximately 3.00% more. Within the prepositional phrase + of structure, the Chinese students used six MLBs to discuss the conditions that specify their arguments, such as in terms of and on the basis of. However, the American students did not use any items within this structure. In the other prepositional phrase structure, MLBs in both corpora consisted of items following the of/in + definite article + noun pattern. In this pattern, the Chinese students generated more items containing the and research (e.g., of
VP-Based MLBs
Table 6 reveals that the American students used a significantly larger proportion of VP-based MLBs compared to the Chinese students, both in terms of type (41.18%vs. 29.94%) and token (40.13%vs. 23.86%). This difference can be primarily attributed to the more frequent use of LBs within the subject + VP + (that-clause) pattern in ALC. Items within the sub-category accounted for 23.02% of the total MLB tokens in ALC, while only constituting 2.14% in CLC. These items appeared to play a more prominent role in constructing the rhetorical moves in ALC compared to CLC.
As illustrated in Table 9, within the structure of personal pronoun + verb + (that), the Chinese students used we as the subject in one item, whereas the American students employed I as the subject within seven items. Additionally, the Chinese students used the verb find, whereas their American counterparts used various verbs such as show and examine. Similarly, the American students paired results with three verbs such as suggest and indicate, while the Chinese students only used show within the noun phrase + verb + (that) pattern. Regarding the reference to PhD research, the Chinese students used study and dissertation, but the American students predominantly used dissertation, a term specifically associated with doctoral research in the United States.
Major Patterns of MLBs in Subject + VP + (That-Clause) Structure in CLC and ALC.

Note. Bundles with similar subjects were aligned for comparison.
Functions of MLBs in the Two Corpora
Research-Oriented MLBs
CLC exhibited a considerably higher proportion of research-oriented MLBs compared to ALC, with 9.57% more in terms of type and 11.88% more in terms of token (see Table 10). Substantial variations were observed in the sub-categories, particularly in procedure and description items. In the procedure sub-category, both corpora employed MLBs containing passive verbs, such as determined by the, can also be (used), are used to, used in the in CLC, and can be used, be used to, are used to in ALC. These passive verbs were utilized to diminish the authorial voice in discussing research procedures (Ex. 1 and 2). However, the American students also employed I focus on and I examine the to highlight their intellectual engagement in designing research. In contrast, the Chinese students strictly avoided using authorial I and adhered to the conventions of EAP (Ex. 3). Instead, they employed focuses on the and focus on the that primarily followed inanimate nouns. This choice implicitly showcased their efforts in formulating research procedures (Ex. 4).
Functions of MLBs in the Two Corpora.
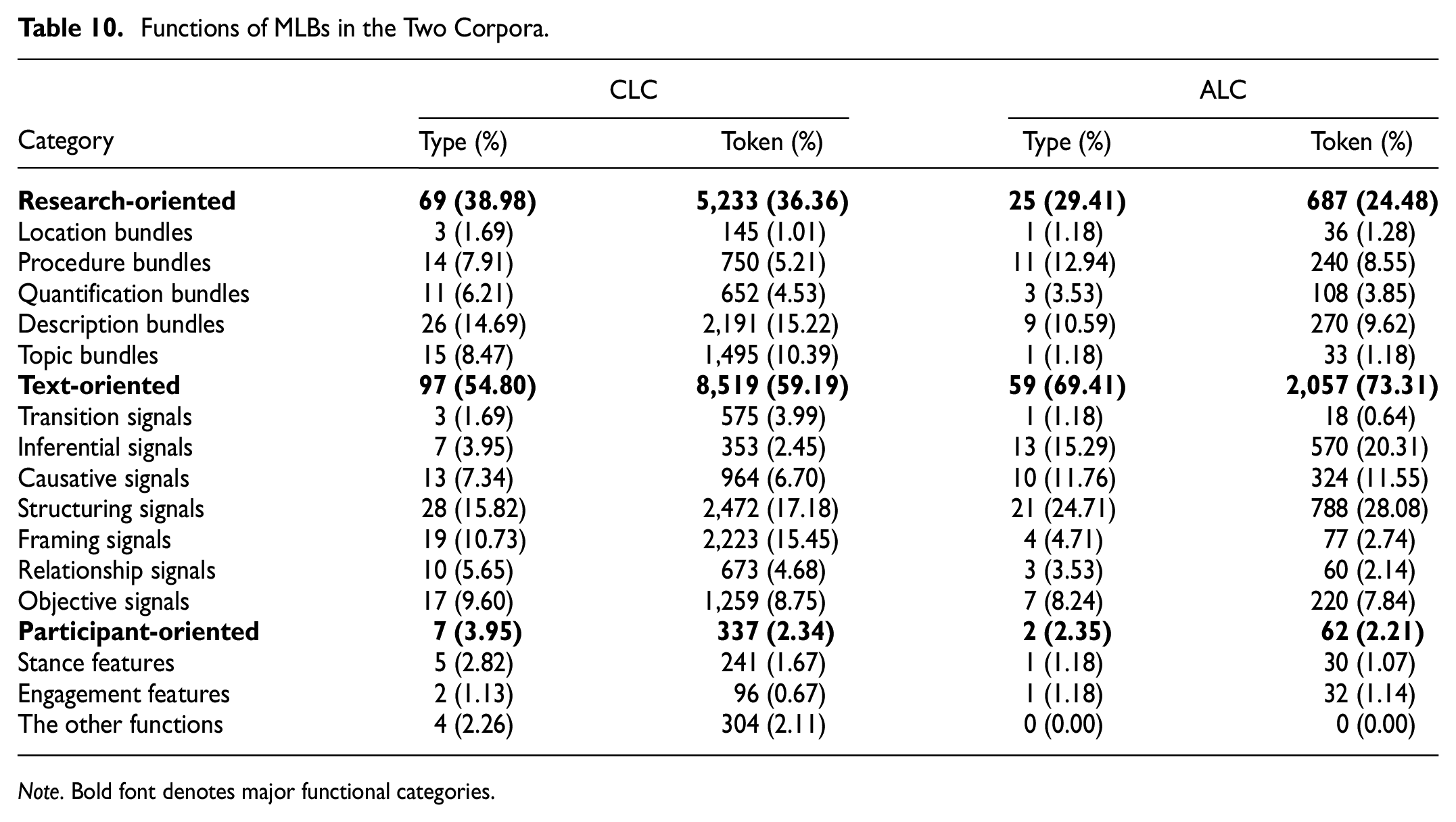
Note. Bold font denotes major functional categories.
Ex. 1. …descriptive analysis and t test Ex. 2. Qualitative and quantitative measures Ex. 3. Ex. 4. The research is characterized by its
We discovered that out of the 35 description MLBs in the two corpora, 30 of them followed the noun phrase + of structure (e.g., the level of), demonstrating a strong consistency between structure and function. The Chinese and American students utilized a total of 17 (e.g., structure, scope, feature) and eight nouns (e.g., semantics, history, property), respectively. Apart from the nouns that denoted similar meanings in both corpora, such as features and properties, many nouns used in CLC did not have move-specific counterparts in ALC. These findings suggest that the Chinese students may use more recurring language or provide more specific descriptions of their PhD research compared to their American counterparts.
Text-Oriented MLBs
This type of MLBs constituted the largest major functional category in both corpora, representing 59.19% and 73.31% of the overall tokens in CLC and ALC, respectively (refer to Table 11). A significantly greater proportion of these MLBs was employed by the American students, who extensively utilized them to structure their texts. In terms of sub-categories, the American students used a notably larger proportion of inferential, causative, and structuring signals, while the students from China relied more significantly on framing signals. These distinctions indicate that the two groups employed bundle functions differently to construct the rhetorical moves in their DAs.
Major Patterns of Move-Specific Inferential Signals in the Two Corpora.

Note. Bundles with similar subjects were aligned for comparison.
We observed a strong consistency between structure and function in inferential signals, which often manifested within subject + VP + (that-clause) as well as (anticipatory it) +VP/AP. This trend was particularly evident in the items from ALC. Table 11 presents seven items from CLC and 10 items from ALC that potentially fell into these two structures, revealing different choices of subjects and verbs. This pattern was also apparent in causative signals, with CLC featuring more items using finding like the findings of, while ALC utilized results like the results of. Furthermore, in structuring signals, CLC exhibited more items employing study (e.g., in this study), while ALC utilized dissertation (e.g., in this dissertation). Notably, they specifically used a greater number of structuring signals in (subject) +VP + (that-clause), especially within this dissertation + presents/investigates/explores/examines, which was rarely found in CLC. Regarding framing signals, the Chinese students employed 19 items (e.g., in terms of, based on a), while their American counterparts just employed four (e.g., is based on, of the data). This discrepancy indicates that the Chinese students paid more attention to carefully specifying the underlying conditions in their arguments within the rhetorical moves.
Participant-Oriented MLBs
Participant-oriented MLBs were relatively scarce, comprising 2.34% and 2.21% of the overall tokens in CLC and ALC, respectively. Both groups utilized only a limited number of MLBs to express their stances and engage their readers. However, there were notable differences in their usage. The Chinese students employed more stance feature items that highlighted the importance of a research field, such as the significance of, the most important, and the importance of. In contrast, the American students predominantly used the importance of. Interestingly, the American students utilized a significantly higher number of tokens for our understanding of (LL = −6.60, p < .05) to engage their readers, while the Chinese students employed the similar LB better understanding of more frequently (LL = 8.04, p < .01). This distinction suggests that the Chinese students tended to avoid personal pronouns, possibly in an attempt to conceal their authorial voice.
Communicative Purposes of MLBs in the Two Corpora
MLBs in the Move of Background
Table 12 shows that CLC displayed a considerably higher amount and wider variety of MLBs within the Background move. Considering that the move in CLC was considerably longer than in ALC (106,482vs. 38,729 running words), the Chinese students provided more extensive content and specific communicative purposes through the use of MLBs. Regarding the expression of research importance, both groups utilized the quantity bundle one of the. However, the Chinese students also employed MLBs such as is not only, the most important, and more and more, which often co-occurred with one of the. It was discovered that 32.63% of the tokens of one of the co-occurred with most important, while this percentage was only 13.05% in the ALC move (compare Ex. 5 and 6). Similarly, 88.89% of the tokens of the CLC item is not only were followed by important in the move (Ex. 7), which was rarely found in ALC.
MLBs in the Move of Background.

Ex. 5. Serving as Ex. 6. The ordering of words is Ex. 7. Second language listening
In introducing previous studies, the Chinese students used more text-oriented LBs, such as in the field and refers to the, indicating their efforts to organize their arguments. They also employed a significant number of items containing the definite article the, which were less prevalent in ALC. Instead of using the study of, the American students frequently utilized the pattern of research on +noun phrase, which had 16 and 18 occurrences in the Background move of CLC and ALC (LL = 8.72, p < .01), respectively. Similarly, noun phrase + research had 39 and 32 occurrences in the Background move of CLC and ALC (LL = 8.51, p < .01), respectively. Moreover, the Chinese students specifically discussed geographical and temporal aspects of research through home and abroad and in recent years. It was observed that 89.19% of the tokens of in recent years and 46.34% of home and abroad in CLC were identified within the Background move, with no similar items identified in the ALC move.
MLBs in the Move of Goal
Table 13 shows that both groups primarily utilized MLBs within structuring signals to refer to their PhD research (e.g., of this dissertation), demonstrating a consistency between structure, function, and purpose. However, the students from China employed a larger quantity of MLBs containing study like in this study. Another interesting finding is that the American students used the determiner this more frequently before the noun denoting their PhD research, while the Chinese students used the present more often, in the Goal move, to refer to the general aspects of their dissertations. A significant difference was also observed in the presentation of their research purposes, which is a key communicative purpose of the Goal move. The students from China predominantly utilized objective signals (e.g., the purpose of), whereas their American counterparts leaned more toward structuring signals (e.g., this dissertation explores), as illustrated in Ex. 8 and Ex.9.
MLBs in the Move of Goal.
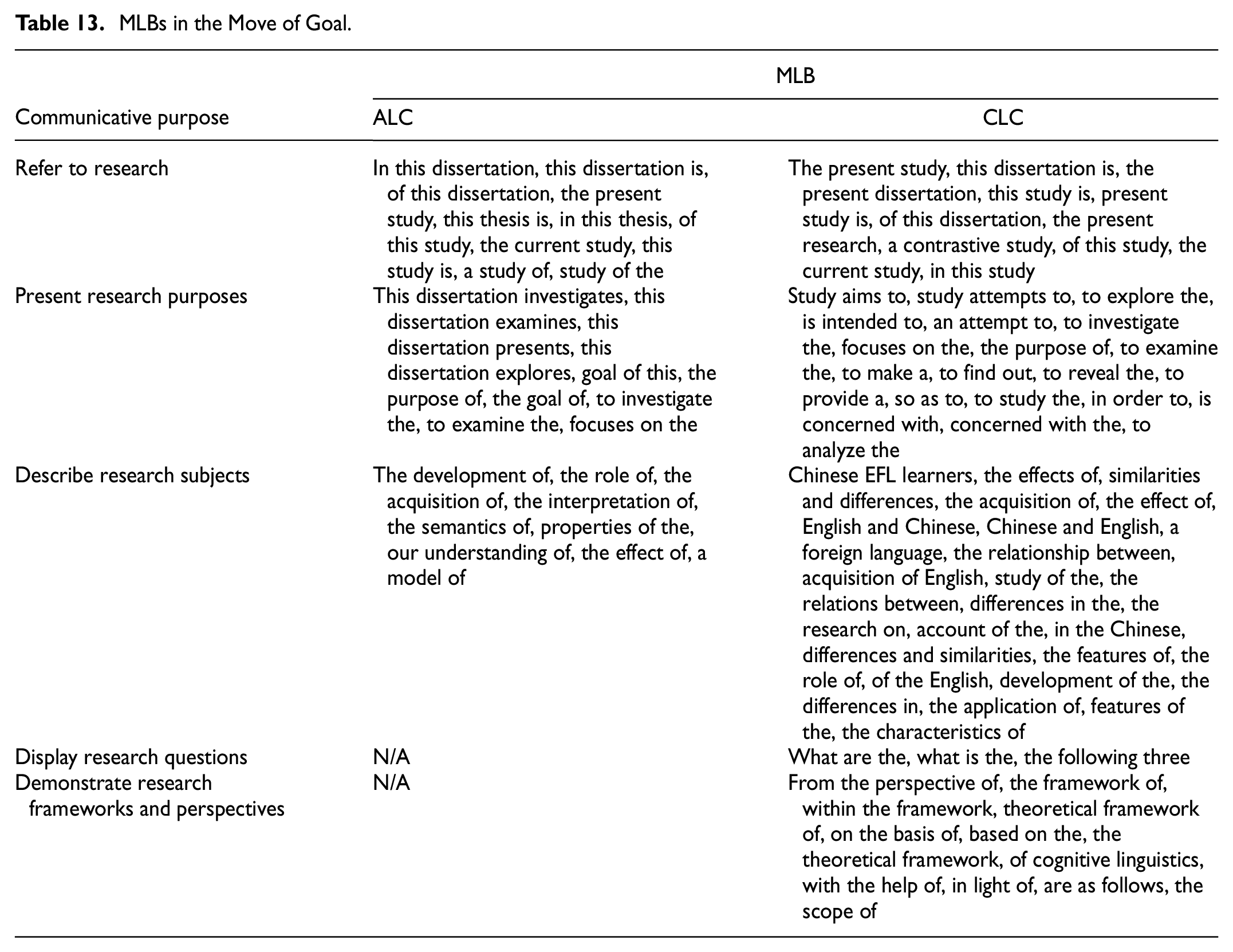
Ex. 8. Ex. 9.
The American students predominantly employed description LBs, while their Chinese counterparts employed a mix of topic, description, as well as relationship LBs, suggesting that the Chinese students provided more content within the Goal move. Additionally, the Chinese students utilized MLBs to present research questions (e.g., what are the) and frameworks (e.g., the framework of), which were not observed in any of the ALC items. In CLC, research questions were frequently posed alongside research aims and often indicated by the following three (Ex. 10). In certain instances, research questions simultaneously served as research purposes. Similarly, the Chinese writers frequently engaged in specific discussions regarding research frameworks (Ex. 11).
Ex. 10. The present research aims to find … by Ex. 11. This research, which is done within
MLBs in the Move of Methodology
When describing the methodology, the Chinese students primarily employed procedure bundles (e.g., qualitative and quantitative) and framing signals (e.g., based on the), whereas their American counterparts predominantly utilized location bundles like the course of. Notably, qualitative and quantitative and quantitative and qualitative appeared only eight occurrences in the move of ALC. The American students were less inclined to discuss the nature of their research methodology. In terms of presenting research subjects, the Chinese students utilized more topic bundles (e.g., native speakers of) and relationship signals (differences and similarities) to consistently remind their readers of the ongoing topics, which was less prominent in ALC. On the other hand, the American students used two procedure bundles containing authorial I (I focus on and I examine the), which were avoided by their Chinese counterparts. Instead, they employed a significantly larger amount of objective signals to illustrate the objectives of research acts (Ex. 12).
Ex. 12. …and independent-samples T tests were conducted
Table 14 reaffirms that the two groups used different terms to refer to their PhD projects, with the Chinese students using study and the American students using dissertation. Additionally, the Chinese students primarily utilized the pattern of in +noun phrase in passive voice sentences, such as in this research (Ex. 13), while the American students predominantly employed the pattern of (PART) of +noun phrase, as seen in of this dissertation (Ex. 14). Similar to the Goal move, the Chinese students specifically employed MLBs to illustrate their research frameworks.
MLBs in the Move of Methodology.

Ex. 13. A contrastive text analysis is adopted in this research… (CLC) Ex. 14. The first half of the dissertation develops a computational model… (ALC)
MLBs in the Move of Result
Table 15 illustrates that the American students employed 13 move-specific inferential signals (e.g., I show that) to indicate the presentation of research results, 12 of which were significantly less utilized by the Chinese students. On the other hand, the Chinese writers employed nine MLBs, with seven being inferential signals, one being a causative marker, as well as one being a structuring marker. These MLBs exhibited a common pattern in CLC (compare Ex. 15 and 16). When presenting results, both groups primarily relied on description bundles. However, the Chinese students used a considerably larger variety of LB types, which contributed to more detailed descriptions. In terms of function, the ALC item is consistent with was more frequently expressed by in line with (Ex. 17 and 18), in accordance with, lend(s) support to, and support(s) in CLC.
MLBs in the Move of Result.

Ex. 15. Ex. 16. Ex. 17. Ex. 18.
MLBs in the Move of Conclusion
Table 16 reveals that the students from China employed more MLBs for each of the eight communicative purposes. In addition to the distinction between dissertation and study, they utilized considerably more structuring signals to connect their findings with the overall research (Ex. 19). Conversely, the American students more frequently used results as the subject without referencing the overall research (Ex. 20). Similarly, there was variation in the utilization of causative signals between CLC and ALC with respect to the distinction between results and findings.
MLBs in the Move of Conclusion.

Ex. 19. Ex. 20. The
To indicate implications, the Chinese students predominantly utilized structuring signals such as in the following and the following aspect, while the American students employed causative signals like implications for the and contributes to the. Ex. 21 and 22 demonstrate that the Chinese students utilized structuring signals followed by ordinal numbers to introduce paragraphs of the report, which typically consisted of one or two sentences in ALC. When describing implications, the Chinese writers specifically employed theoretical and practical before implications. Similarly, they particularly employed the stance LB better understanding of, while using the engagement feature LB our understanding of less frequently compared to the American students (Ex. 23 and 24).
Ex. 21. …the contributions of the present research can be reflected Ex. 22. … Ex. 23. …the present study may provide us with a Ex. 24. …this dissertation advances
MLBs in the Move of Structure
To outline the structures of their dissertations (see Table 17), the Chinese students employed a structuring signal dissertation consists of and the description bundles is divided into and framework of the. No equivalent items were identified in the corresponding move of ALC. Instead, the American students frequently used the construction chapter + NUMBER as a more implicit discourse marker (Ex. 25 and 26).
MLBs in the Move of Structure.

Ex. 25. This Ex. 26. In
When referring to dissertations or chapters, the Chinese students employed structuring signals in the pattern of noun phrase + of the research/dissertation/present study, which connected specific sections to the overall dissertation. Ex. 25 demonstrates how the Chinese students used MLBs such as of the research and the present dissertation to link the contents of a chapter to the entire dissertation. This pattern was infrequently utilized by the American students, as illustrated in Ex. 26. Furthermore, CLC exhibited more structuring signals. Ex. 25 shows their use of three structuring signals in a series of sentences, potentially serving to remind readers of the organization of their dissertation. On the other hand, the American students tended to provide more concise statements, as evident in Ex. 26. Additionally, the Chinese writers described the contents using more topic bundles, a feature rarely observed in ALC.
Discussion
This research identified 177 types with 14,393 tokens of MLBs in CLC, and 85 types with 2,806 tokens in ALC. These findings indicate a higher frequency of MLBs usage in CUS compared to ALC. This observation aligns with previous studies that have reported a significantly greater number of bundles within the EAP writings of L1 Chinese speakers compared to L1 English speakers (Hyland, 2008a; Lyu & Gee, 2019). The higher usage of LBs by the Chinese students may reflect their heavier reliance on prefabricated language due to lower English proficiency (Hyland, 2008a; Paquot & Granger, 2012). This greater reliance on LBs may also stem from the high stakes associated with dissertations, which are widely regarded as the most crucial writing task for PhD students (Hyland, 2008a).
The finding that NP-based MLBs were more prevalent than PP- and VP-based MLBs aligns with previous studies that focused on frequently use LBs (Biber et al. (1999, 2004); Biber & Conrad, 1999). Pan et al. (2016) argued that extensive use of NP-based LBs in academic prose is driven by the need for careful integration of information, which is best achieved through the use of nominal as well as prepositional phrases. Additionally, it was found that spoken discourse exhibited a higher proportion of VP-based LBs compared to NP- and PP-based LBs, which were more prevalent in written discourse (Biber et al., 1999). In line with these findings, our study revealed that the American students employed a larger percentage of VP-based MLBs, indicating a potentially more oral or spoken style of language use. This observation was further supported by the fact that the American students specifically utilized the first-person singular pronoun I in the subject slot of the subject + verb phrase + (that-clause) structure, forming a significant group of MLBs specific to the Result and Methodology moves (e.g., I show that and I focus on). In contrast, the Chinese students strictly avoided authorial I, demonstrating their commitment to adhering to EAP conventions that emphasize objectivity and discourage explicit reference to personal opinions (Arnaudet & Barrett, 1984, p. 73). It is worth noting that while personal pronouns like I are traditionally discouraged in academic writing, there is growing acceptance of the first person viewpoint as a means of presenting one’s perspective and establishing the author’s identity (Hyland, 2001; Ivanic, 1998; Kuo, 1999).
The Chinese students’ tendency to avoid the use of I was subsequently interpreted by Li et al. (2019) as a misinterpretation of rhetorical conventions. Our investigation also unveiled distinctive lexical choices made by the two groups within identical structures to convey analogous meanings in similar contexts (e.g., we find that vs. I show that). In a study undertaken by Li et al. (2019), interviews with Chinese graduate students disclosed that their selection of specific words within the same structures was primarily driven by their familiarity and assurance with the word. Li et al. construed this tendency as indicative of a deficiency in rhetorical confidence. Lu and Deng (2019) also emphasized the partial grasp that Chinese PhD students exhibited concerning certain aspects of English grammar and vocabulary, along with their restricted familiarity with the characteristics of genre-specific LBs. Lyu and Gee (2019) also emphasized the lower English language proficiency of Chinese students when discussing their differing usage of LBs compared to American students. While we concur that there are disparities in the English language proficiencies between Chinese and American students, we contend that when interpreting findings related to DAs, it is crucial to consider the high-stakes nature of these academic texts, as underscored by Hyland (2008a). Given that degree papers serve dual purposes—the demonstration of research findings and the fulfillment of degree requirements—Chinese students are inclined to employ language sequences that instill confidence (Bao & Liu, 2022). In this context, authors are compelled to use LBs that align with the expectations of both dissertation committee members and anonymous reviewers, adhering to their standards of academic writing.
Functionally, our findings revealed that both Chinese and American students predominantly used text- and research-oriented MLBs, while participant-oriented MLBs accounted for a smaller proportion. This aligns with previous studies conducted by Lu and Deng (2019) on DAs, Hyland (2008a) on dissertations, and Lyu and Gee (2019) on thesis abstracts. Hyland (2008a) suggested that the intensive utilization of text-oriented bundles by PhD students reflects their efforts to create more reader-friendly and academically engaging prose. However, our results differ from those of Zheng and Mao’s (2018) study on 230 RA abstracts in applied linguistics, where research-oriented LBs had the highest proportion, followed by text- and participant-oriented LBs. This divergence may be explained by the differences between dissertation and RA abstracts. Moreover, we discovered a higher proportion of research-oriented MLBs and a lower proportion of text-oriented bundles in CLC compared to ALC, which is consistent with the findings of Lu and Deng (2019) on DAs. Further examination of the sub-categories revealed that this difference was mainly driven by the significantly higher proportion of topic bundles and the lower proportion of inferential and causative markers in CLC compared to ALC. In comparison with their American counterparts, the Chinese students more frequently referred to their research topics using MLBs but employed inferential and causative signals less often to present deduction processes. Bao and Liu (2022) underscored the significance and intricacy of DA writing. To manage this complexity, Chinese students, when crafting substantially lengthier texts than their American counterparts, tend to employ a greater number of LBs to meticulously specify argumentative situations. This accounts for the higher prevalence of framing signals observed in CLC as compared to ALC.
Additionally, this research uncovered that they employed distinct MLBs to accomplish identical communicative objectives. This discrepancy could be attributed to the substantially longer discourses within CLC compared to ALC. For example, the Chinese students commonly utilized causative markers like the major findings in combination with structuring markers like are as follows, which usually preceded ordinal numbers (1), (2), (3) and extended to several paragraphs to present their results. Conversely, their American counterparts frequently employed inferential signals like I show that, typically appearing in only a few sentences. Furthermore, this study revealed that the Chinese students used MLBs for specific communicative purposes, such as showcasing research questions (e.g., what are the) and demonstrating research frameworks (e.g., the framework of) within the Goal move. The divergent abstract lengths between the two corpora may be indicative of differing discoursal expectations for the genre in China and the U.S. For instance, many professors in Chinese universities may anticipate the inclusion of research questions in DAs, while this may not be as prevalent among professors in American universities. It is therefore crucial for L2 instructors and learners to recognize that DAs “are a high-stake genre, concerning both research manifestation and degree fulfillment” (Bao & Liu, 2022, p. 10). Although research presentation primarily caters to an international readership, degree fulfillment requires the approval of a dissertation committee, primarily composed of domestic professors.
To illustrate our point, consider this analogy: Two groups of students shop at Walmart stores in Shanghai and New York, respectively. While both stores offer largely similar food categories and brands, local customers make distinct choices based on their differing tastes and intended dishes, whether it be Kung Pao Chicken or a Chicken Burger. Similarly, Chinese students’ English abstracts of dissertations serve dual purposes, akin to preparing Kung Pao Chicken for both Chinese and American diners. Consequently, adaptations to the “recipe” are necessary to make the “dish” palatable to both audiences. From a pedagogical standpoint, we posit that not all MLBs employed by American students hold equal importance for EAP instruction in China. Educators should focus more on MLBs where different word choices are made by the two groups within the same structures to accomplish identical functions as well as communicative objectives (e.g., results show that vs. results indicate that). However, less emphasis should be placed on MLBs that reflect varied discursive expectations of Chinese and American readers (e.g., the use of are as follows by Chinese students specifically to discuss research questions).
Building upon established literature, we assert that the unique application of MLBs by Chinese and American students is influenced by their disparate English proficiency levels, the Chinese students’ compliance with the EAP convention of circumventing authorial I, their predilection for familiar lexical items to navigate the high-stakes genre, their tendency to meticulously outline argumentative situations, and the potential variances in discursive expectations for DAs in China and America. It is noteworthy that the Chinese students involved in this study represent highly advanced L2 English learners, a fact substantiated by their syntactically correct and pragmatically fitting use of MLBs. When scrutinizing the specific MLBs in light of previous literature, the difference in LB usage between these highly competent Chinese learners and their American counterparts should be interpreted less as a reflection of limited understanding of specific facets of the English lexico-grammatical system, as suggested by Lu and Deng (2019) and Lyu and Gee (2019), and more as an indicator of the socio-cultural disparities between the two nations, such as the more conservative culture in China. In conclusion, our study underlines that even highly proficient L2 English learners in China exhibit a distinctive usage of MLBs in comparison to their American peers.
Conclusion and Implications
Upon conducting a comparative analysis of the structures, functions, and communicative purposes of MLBs in CLC and ALC, we have derived the following conclusions:
(1) The Chinese students employed a larger proportion of NP- and PP-based MLBs, while the American students utilized a larger proportion of VP-based MLBs. Additionally, within the same structural patterns, the two groups often used different words to convey similar meanings.
(2) The Chinese students utilized a larger proportion of research- and participant-oriented MLBs, whereas their American counterparts relied more on text-oriented MLBs. Furthermore, the two groups employed different MLBs to fulfill similar functions.
(3) The Chinese students employed MLBs for specific communicative purposes unique to CLC, and the two cohorts of students tended to use distinct MLBs to accomplish identical communicative objectives.
The conclusions derived from this study underscore the importance of MLBs in the composition of rhetorical moves within DAs. Given that instruction on abstract writing is typically move-based, educators can utilize lexical analysis tools to identify and impart knowledge on LBs that exhibit specific recurrences within rhetorical moves. Furthermore, considering that the divergent use of MLBs between the two groups can be ascribed to both unique writing styles and disparate language competencies, it is essential to highlight that the Chinese participants in this study exhibit an advanced level of English language proficiency as a second language. Therefore, we assert that both groups’ frequently employed MLB lists can be effectively utilized as instructional materials. The MLBs identified in CLC hold particular significance for Chinese students who are tasked with composing English abstracts for their dissertations or theses. Meanwhile, the MLBs found in ALC can be beneficial for Chinese students aiming to enhance the native-like quality of their abstract writing. In this regard, we recommend adopting a selective approach to learning, targeting specific MLBs based on individual needs and objectives. It is important for instructors to prioritize MLBs that involve different linguistic choices within the same structure but convey the same meanings, rather than focusing on MLBs related to generic features such as word counts or potential discoursal expectations. In particular, instructors are encouraged to teach Chinese students how to replace first person singular pronouns with nouns denoting their studies or part of them (e.g.,
In conclusion, this study highlights the importance of employing corpus and relevant techniques to recognize and impart essential move-specific lexical items in an L2 learning context. However, there are several limitations in this research that should be acknowledged. Firstly, the study refrained from analyzing MLB’s multifunctionality because of the challenges related to functional categorization’s subjectivity as well as the intricacy of contextual factors. A more focused investigation within a specific context could provide a deeper understanding of the different functions of MLBs. Secondly, the research did not explore the potential longitudinal changes of MLB usage in DAs produced between 2000 and 2020, which could be an interesting area for future studies. Thirdly, the study only examined discourses generated by students in linguistics from China and the United States. Including DAs from students in different disciplines would offer a more comprehensive overview of MLB features. Such studies can contribute to the development of core MLB lists encompassing structures, functions, and communicative purposes, which can be valuable for teaching move-based language and exploring lexical usage relevant to EAP. Furthermore, subsequent research may employ cognitive experiments or interviews to investigate the outcomes and factors related to move-specificity. Exploring the reactions and perception of writers toward various MLBs can assist teachers in developing more effective teaching resources, techniques, and strategies.
Footnotes
Acknowledgements
We would like to thank Professor Shisheng Liu, the editors, and the reviewers for their constructive comments and suggestions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.