
Abstract
EL1 learners’ receptive morphological words (root, inflected, and derived words) develop on different scales, but whether they develop similarly in EFL learners’ language production is still unknown and deserves an examination. The answer may provide a clue to theoretical controversy about whether language learners’ morphologically defined words are identical in identity and learnability and whether their productive vocabulary grows constantly. This study uses lexical frequency profile analysis to explore the developmental trends of advanced EFL learners’ (n = 299) morphologically defined words in writing across four consecutive semesters. The results indicate that root words are much more significant in both amount and percentage in all four semesters than inflected and derived words, and infected words are much lower than root words but greater than derived words. Over time, the three morphologically defined words go along different development trajectories.
Plain Language Summary
Theoretically, it is at issue whether the differently sourced words (base forms, inflected words, derived words, and compounds) are identical in identity and learnability. Studies of EL1 vocabulary acquisition have shown that children develop such words on different scales over time. The same question applies to EFL learners’ productive vocabulary acquisition. Second language study also concerns whether L2 learners’ vocabulary develops incrementally over time. This study analysed the quantitative information of the base, inflected and derived words in 299 university students’ compositions written in their final-term examinations of four consecutive semesters to see the quantitative relationship and the developmental trends of these three kinds of words. The results indicate that the base words are much more significant in both amount and percentage in all four semesters than the other two kinds of words and that infected words are much lower than root words but greater than derived words. The study also found that the three categories of words go along different trajectories over time. The results may justify the theoretical idea that these three kinds of words have their own identities to a greater degree, and, therefore, language learners learn base forms piecemeal but learn the other two kinds of words following different rules. The study may also suggest that L2 learners’ productive vocabulary does not develop incrementally but fluctuates, with acquisition alternated with attrition, differing from L1 acquisition.
Introduction
Morphological rules are one primary aspect of English grammar: Inflectional rules modify word forms based on their grammatical functions; Derivational rules produce new words of different past-of-speech categories and/or meanings; Compounding rules control the combination of two or more existing words into a new one. These rules constitute speakers’ essential language knowledge for receptive and productive performance (Nation, 1990, 2001). Thus, there are root, inflected, derived, and compound words in a language. Root words do not refer to the bound roots of words but those free roots, that is, base forms, before adding inflectional or derivational morphemes. Inflected words are those base forms plus inflectional morphemes. Derived words are formed by the combination of the base forms with derivational forms. Compound words are formed by conjoining two or more free morphemes.
In theory, the identity of the root, inflected, and derived words (Avram, 2002) is at issue. The “split morphology hypothesis” believes that derived words are independent while inflected words are not. Distributed Morphology, in contrast, believes that both inflected and derived words originate from root words based on rules. The weak lexicalist treats irregularly inflected and derived words as independent words. The strong lexicalist believes that all the inflected and derived words, resourced from root words based on rules, are independent words. Though not unanimously, some cognitive neuroscience studies have also shown that different morphologically defined words (inflection, derivation, and compounding) are not processed in the same way (Leminen et al., 2019). In a word, systematic differences may exist among different morphologically defined words: root, inflected, and derived words.
Some scholars (e.g., Lindqvist et al., 2011; Schmitt, 2010) advocate distinguishing these three categories of words. Intuitively, they differ in learnability or burden exerted on language learners: Learners learn most root words piecemeal since they are most unrelated in form; Inflected words are usually very regularly rule-based forms created by affixation, though those irregular ones may cause incredible difficulty in learning (Laufer, 2002); Derived words are of much lower regularity than inflected words, thus of less learnability, though, regularly derived words should be more learnable than root words. The learners’ ability to decompose a word into its morphemes can facilitate their recognition and subsequent production of such a word (Ward & Chuenjundaeng, 2009). L1 and L2 learners’ acquisition of morphologically defined words has attracted scholars’ attention. However, they are usually studied independently from each other.
There are no independent studies of root words, and studies on the development of inflected words usually focus on morphological complexity/diversity. In the literature on morphological diversity, some traditional measures could function as inflection and derivation measures, for example, Type Token Ratio, Lemma Token Ratio, Family Token Ratio, etc. Their reciprocals indicate the average number of members (type, lemma, or family) in a word used in the text.
Malvern et al. (2004) used 3 versions of the D score to explore 38 Children’s development in oral morphologically defined words (inflectional diversity). They found that from the 18th month on, the three versions of the D value were increasing on a different scale and that children’s morphological knowledge in inflection became more and more diverse.
Miranda-Garicía and Calle-Martín (2005) used the Index of Flexionability, or Allomorphism, of the text in the study, that is, the number of word types divided by the number of word lemmas. Such a measure has a minimum of 1 when the number of lemmas equals that of word types and a maximum approaching three, which presents the performance of the text producer by surveying whether he uses a high, medium, or low number of inflections. Such a measure has an advantage over the D value in that, on the one hand, it avoids the influence of the length of texts, but on the other hand, it also embodies the contribution of text length to the amount of productive vocabulary in a text for the number of both types and lemmas indicates the length of texts. Granger and Wynne (1999) discussed the advantages and disadvantages of three measures—the crude Type/Token Ratio, the Lemma/Token Ratio, and the adjusted Lemma/Token Ratio—as measures of lexical richness and compared them empirically. The Lemma/Token Ratio value variation can show the language speakers’ usage of root and inflected words in their writings.
Clercq and Housen (2019) used three morphological measures (Type/Family Ratio, Inflection Diversity, and Morphological Complexity Index) to study the cross-linguistic differences in morphological complexity between L2 French and English of four proficiency levels. They found that L2 French increased more continuously than L2 English in inflection.
Brezina and Pallotti (2019) used the Morphological Complexity Index (MCI) in two case studies on Italian and English native and non-native speakers’ argumentative written texts. In the first case, they found that morphological complexity varies between native and non-native speakers of Italian and that the MCI correlated strongly to proficiency and other non-lexical measures, and in the second case, morphological complexity is under the influence of speakers’ proficiency and variation of language category; inflection diversity will not increase forever since there is a threshold for some language with a relatively simple inflectional morphology.
In contrast with the corpus-based study of inflected words, productive derivational knowledge of L2 learning has yet to be studied systematically (Leontjev et al., 2022), but usually on some specific derived words.
Schmitt and Zimmerman (2002) examined 106 graduate and undergraduate nonnative-English-speaking students’ use of the noun, verb, adjective, and adverb derivatives for 16 words. They found that they could only know some of them, only incomplete knowledge of these words and typically productive knowledge for 2 or 3 forms. Their study also indicated that the subjects increasingly obtained knowledge of noun and verb derivatives at each of the four stages but not so much of adjectives and adverbs.
Iwaizumi and Webb (2021) compared 21 L1 speakers with 21 L2 learners and 18 L2 undergraduates with 61 L2 graduates in their productive derivatives of 30 headwords. They found that L1 speakers could produce significantly more derivatives than both groups of ESL learners and that L2 graduates performed better than L2 undergraduates.
Ebrahimi (2021) developed a productive test of word parts (derivations) and a corresponding productive test of form-meaning connection to measure 46 Iranian university EFL students’ productive derivational knowledge of the first 100 frequency-level words and found that the subjects did not have extensive derivational knowledge of the same words.
Iwaizumi and Webb (2022) investigated L1 and L2 learners’ productive derivational knowledge with a decontextualized derivative recall test, examining L2 learners’ variation in L2 productive derivational knowledge at different vocabulary levels and the difference between L1 and L2 productive knowledge at different levels and concluded that learners’ L2 productive derivational knowledge could indicate their vocabulary levels in some way.
Studies have yet to deal with the developmental trend of the root, inflected, and derived words in L2 productive vocabulary contrastively. Theoretically, root, inflectional, and derived words differ in their learnability or the learning burden they bring to language learners. Most root words are usually learned item by item since most have no close relationship with each other, no matter their forms, meanings, or other aspects. Inflected words are usually very regular; most are rule-based forms created from root words by adding affixes. However, irregular features such as plurality, gender, and noun cases may cause more difficulty in learning than those without such complexity (Laufer, 2002). Derived words may be of much lower regularity than inflected words, thus less learnable. Compared with root words, regular derived words should have greater learnability. Learners’ ability to decompose a word into its morphemes can facilitate their recognition and subsequent production of such a word (ibid, p. 146). From the perspective of coherence, the language learners’ productive vocabulary development may also manifest in using the derived forms of root words in their language production to avoid repeated use of root words. In the long run, with the maturity of language learners’ morphological awareness, foreign language learners may use more inflected and derived word forms. Such a tendency has appeared in native language learners’ development in the recognition of words. For example, Anglin et al. (1993) showed that children’s acquisition of recognition words (root, inflected, and derived words) grew on different scales, indicating that they develop independently.
This study aims to bridge such a gap through a longitudinal study on the development patterns of Chinese EFL learners’ root, inflected and derived words in writing across four semesters (the fourth semester to the seventh semester) covering the foundational and advanced stages of their university education.
What is the relationship among the amounts and percentages of the root, inflected, and derived words used by EFL learners at the four stages of language learning?
What are the tendencies of the three morphologically defined words expressed in their percentages at the four stages of the EFL learners’ language learning?
Method
Participants
The subjects involved in the study were all students of the same grade (enrolled in 2008) in English at a normal university in China. For a longitudinal study, the study chose only candidates who took all four tests and completed the writing tasks thoroughly in the tests. Therefore, 349 students were available for the study, among whom 20 were males and 329 were females. Additionally, 201 were teacher-oriented students (11 males and 190 females), and 141 were non-teacher-oriented English majors (9 males and 132 females). Their mean age was 19.83 when they enrolled in the university. Before they entered the university, they all had received 6 years of formal classroom-setting EFL education (junior and senior middle school stages) When the language data were collected, all students had stayed at the university for two academic years. After data cleaning, only 299 students remained for study, rejecting those who failed in accomplishing writing tasks.
Procedure
The language data for the study included 1,196 compositions written by 299 Chinese EFL English majors in their end-of-term tests for a series of compulsory courses in 4 consecutive academic semesters. The writing tasks took about 30 to 40 min after students finished their first few test tasks in examination. The first test is the final term exam in the fourth semester for Integrated English 4. The writing task required students to write a composition of at least 200 words on the topic To be a Master or not. The other three tests were the final term exams for their Advanced English course at the ends of the following three consecutive semesters after their Integrated English course. All the writing tasks were the last test task of their test. The writing task for the Advanced English 1 exam required the student to write a composition of at least 200 words to show their opinion on whether the traditional Chinese customs would be weakened and disappear under the influence of Western festivals. The writing task for the Advanced English 2 exam required the student to write a composition of at least 300 words to show their opinion on what kind of education the students want in universities and how they should be educated. The writing task for the Advanced English 3 exam required the student to write a composition of at least 300 words to show their opinions on the suggestion put forth by the author of an essay in their textbook.
Instruments
Range BNC (Heatley et al., 2002), the most critical tool, was used to analyze the frequency and range of vocabulary in language data, which has different versions, mainly with different numbers of or different sources for word lists. The version used in this study (i.e., the 14,000 version) comes with 16 base word lists. The first 14 word lists consist of word families of different frequency levels, arranged from the most frequently used to the least frequently used ones. The 15th list is composed of proper nouns, such as names of people and places, and the last word list consists of most interjections, exclamations, hesitation, procedure, etc., characteristic of oral English.
Each of the first 16 wordlists contains around 1,000 families. The first 14 word lists stand for distinctive frequency bands (levels) of the word families in native English speakers’ language data, and they range from the most frequently used one 1,000 words (named Basewrd 1) to the least frequently used 1,000 words (named Basewrd 14). The frequency levels reflect the frequencies of the words’ occurrence in BNC (British National Corpus).
The analysis implemented with the software outputs the coverage profile of the different frequency level words in a piece of language material. The analysis obtains a profile by counting the words appearing in the processed language data (Edwards & Collins, 2011).
The lexical frequency profile analysis demonstrates the percentage of the words belonging to different base word lists and the percentage of the words not belonging to any base word lists in each text. The study calculated the ratio using two counting units, that is, token and type. The analysis also shows the abstract numbers of tokens, types, and families.
The results in Table 1 suggest that among the total of the words (801 tokens or 348 types) in the analyzed language data, 605 tokens are from the first list (the first 1,000 frequency level in native speakers’ language data), making up 75.53% of 801 tokens, the total of the running words (tokens) of the text (as shown in the bottom line). If calculated with type as a measurement unit, there are 231 types in the text from the first base word list, accounting for 66.38% of the total word types (348 listed in the bottom row). Similarly, the analysis counts the words in the analyzed text as 277 families, among which 181 families belong to the first list (the first 1,000 frequency level), 14 belong to the 15th base word list (the proper nouns), etc. Range BNC will be used in the study to calculate the numbers and percentages of different frequency-level morphologically defined words.
Sample of the Main Part of the Range Analysis.

Data Processing
The implementation of data processing includes the following steps: (1) Cleaning the text files; (2) Extracting information on the amounts of morphologically defined words.
Cleaning the Text Files
The compositions were keyboarded into a computer, stored as an independent text file, and checked to ensure no other characters except those accepted in English, for example, English words. Almost all the words on the “not-in-the-list” word list were misspellings, a small number of temporary compounds, proper nouns, Chinese Pinyin, etc., and they were beyond account. The researcher corrected those misspellings caused by writers’ carelessly omitting the space between two or more normal words, for example, certianlink, betweenwestern. He also split those unambiguous contractions into their components, that is, I’m →I am, I’ll → I will, and eliminated all the surplus spaces.
After cleaning, the language data for each semester comprised 342 compositions by 342 students. The study discarded those text files of a less-than-2-kilobit size to minimize the influence of non-lingual factors, that is, taking too short on writing. After such a treatment, only text files of 299 students’ compositions in each semester remained. So the final language data, which were 72,782 tokens or 2,504 types, of Chinese learners were the timed compositions written by 299 Chinese EFL learners (English majors) in their final-term test of their courses at four consecutive stages: Integrated English 4 (the fourth semester, hence S4), Advanced English 1 (the fifth semester, hence S5), Advanced English 2 (the sixth semester, hence S6), and Advanced English 3 (the seventh semester, hence S7).
The mean length of the texts for S4 is 217.56 tokens, 108.36 types, or 95.66 families; for S5, it is 257.80 tokens, 127.33 types, or 109.91 families, for S6, it is 295.51 tokens, 145.40 types, or 124.46 families, and for S7, it is 287.01 tokens, 137.90 types, or 119.21 families (Table 2).
Statistics for Language Data in the Study (N = 299).

Note. N = Number of compositions; MTnN = Mean length in token number; MTpN = Mean length in type number; MFN = Mean length in family number.
Extracting Morphologically Defined Words
To track the numbers and percentages of the root, inflected, and derived words with Range BNC, 3 base word lists were compiled based on 14 word lists with Range BNC to represent all roots, infected, and derived words, respectively. The 3 base word files were divided into 14 word lists representing the root, derived, and inflected words of different frequency levels, respectively, to see the details of the frequency level of these 3 morphologically defined words.
After the compilation, the word list for root words contains 8,880 types, for derived words 14,878 types, and for inflected words 25,250, being compiled into 3 word lists (representing root, inflected, and derived words, respectively) to the requirement of Range BNC analysis of the language data.
Data Analysis
The study performed a general lexical frequency profile analysis on each text to see the general lexical growth at different stages, that is there is no separation between root, inflected, and derived words. The study used Range BNC with 14 word lists to analyze the text of each composition and obtain the percentage of word tokens, word types, and the number of word families for the words belonging to different frequency levels contained in those base word files.
The study made one-way repeated-measures ANOVA on each data set to see whether there was any significant difference among different stages in the percentages of word types. If the overall ANOVA results showed a significant difference among all the variables involved, pairwise comparisons would show a significant different result.
Results and Discussion
This part shows the results of the three morphologically defined words from a synchronic perspective and a diachronic one.
The Synchronic Quantitative Relationships Among Different Morphologically Defined Words
EFL learners depend mainly on root words for their language production, embodied in the fact that, in all four semesters, Chinese EFL learners use productively much more root words (from 72.98 to 87.30) than both inflected words (from 20.29 to 30.55) and derived word types from (11.66 to 21.09). They also use more inflected words than derived words (though far less than root words). For example, on average, they used 72.98 root words but only 20.29 inflected words and 11.66 derived words at the end of the fourth semester. A similar tendency also occurs in the other three semesters. This tendency follows a formula: Nr > Ni > Nd, where N = number, r = root words, i = inflected words, and d = derived words.
Although the abstract numbers of word types may indicate the tendency, the total number of words in the composition may neutralize them. The study has also calculated the percentages of the other three categories of words in the whole composition to see such a tendency more clearly (Table 4):
Language speakers have used more root words in language production than inflected words, which may be for two reasons. On the one hand, root words are the primary carriers of meaning, while inflected words only express the specific grammatical meanings of root words. Though a root word may have several inflected forms, these inflected forms may not appear in the same context simultaneously with the root words. On the other hand, the variation of the style for language production may influence the number of inflected words. For example, narrative language production may create more opportunities for inflected verbs, while expository language production may give more chances for inflected adjectives and nouns. The language data for the study are argumentative compositions, which may offer the slightest opportunity for narrative statements and thus award fewer chances for the usage of inflected words.
Comparatively, writers used even fewer derived words because derived words tend to be longer and more formal, making them less facilitative to smoother daily communication than the root words. Such a pattern is manifest in the fact that among the first 1,000 most commonly used word types in the British National Corpus (including both root words, inflected words, and derived words), the derived words only account for less than one-tenth (about 90 tokens; estimated based on the rank frequency order of word tokens in written English (not lemmatized) published at: http://ucrel.lancs.ac.uk/bncfreq/flists.html). So, language users try to select easier words for daily production and comprehension.
From the other perspective, we can get a clue from the different proportions of these three categories of morphologically defined words in these compositions to their learning burden assigned to the language learners. It is convincible that these three categories of morphologically defined words award a quite different burden to language learners, that is, of different learnability. Comparatively, the inflected and derived words are created based on the root words. However, the inflected words may be more regular in word formation because there is usually a general rule for most inflected words. Therefore, once the learners have such rules, they can correctly create the most inflected words without teaching them all individually. Things are different from the derived word. Though there are some rules for forming derived words, these rules are primarily applicable within a small scope. Additionally, the relationship between most derived words and the root words they are derived from is much less predictable than between most inflected words and the root words they are inflected from. On most occasions, the mastery of a root word does not necessarily mean the mastery of the related derived words (Lindqvist et al., 2011; Schmitt, 2008) or the other way around.
The Developmental Patterns of Different Morphologically Defined Words
This part focuses on the tendencies of root, inflected, or derived words throughout four different time points (Tables 3 and 4). They show different and even opposite trajectories: Counted in abstract numbers, they all increase from the first stage to the third stage and then decrease at the last stage, while counted in percentage, they all go in a complex path. When counted in abstract numbers, the total number of words of the whole composition has influenced them (Table 2). Therefore, in the following sections, the comparisons are all based on the percentages of words. The root, inflected, and derived words productively used by Chinese EFL learners follow a different pattern (Table 4), which the following sections will analyze.
Mean Total Number of Morphologically Defined Words (N = 299).
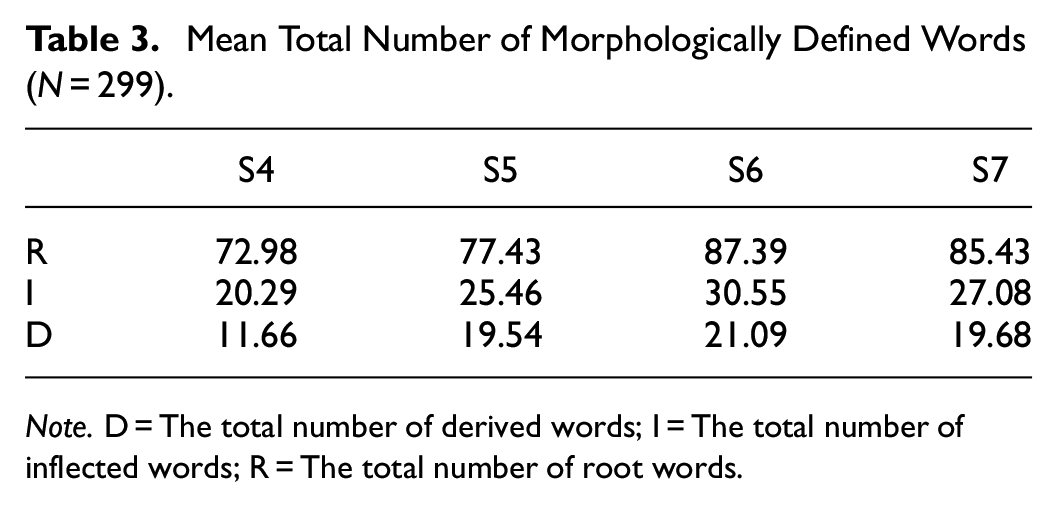
Note. D = The total number of derived words; I = The total number of inflected words; R = The total number of root words.
Total Percentages of Different Morphologically Defined Words (N = 299).

Note. D = the total percentage of derived words; I = the total percentage of inflected words; R = the total percentage of root words.
Root Words
The percentage of EFL learners’ root words (Table 4) decreases sharply from the fourth semester (67.58%) to the fifth semester (60.95%) and then decreases mildly in the sixth semester (60.30%). However, it increases in the seventh semester (62.20%; Figure 1):

Percentage of root words in the four semesters.
The study used repeated-measure ANOVA to see whether there were differences between the four semesters in the percentage of root words. The data met the assumption of independence and normality, and Mauchly’s Test of Sphericity was verified, χ(5) = 4.19, p = .52 (Table 5).
Mauchly’s Test of Sphericity for Root Words.

The overall ANOVA reveals a significant difference between the four semesters in the derived word percentage, F(3, 894) = 219.13, p = .00, partial eta2 = .42 (Table 6).
Tests of Within-subjects Effects.

The results of pairwise comparisons (Table 7) indicate further that the relationship among the four stages in the percentages of root words is as follows: the fifth semester is significantly different from the fourth (p = .00), the sixth semester is significantly different from the fifth (p = .03), and the seventh is significantly different from both the sixth (p = .00) and the fourth (p = .00). It suggests subjects used significantly more derived words in the fifth semester than in the fourth and also significantly more in the sixth semester than in the fifth. However, they used significantly more such words in the seventh semester than in the sixth, though they used significantly fewer root words now than in the fourth.
Pairwise Comparisons for Root Words.

Adjustment for multiple comparisons: Least Significant Difference (equivalent to no adjustments).
The mean difference is significant at the 0.05 level.
Inflected Words
The percentage of EFL learners’ inflected words (Table 4) goes along a contrary path. It increased from the fourth semester (18.62%) through the fifth (19.86%) and to the sixth (20.94%). However, it fell in the seventh semester (19.48%; Figure 2).

Percentage of inflected words in the four semesters.
The study also performed a repeated-measure ANOVA on inflected-word percentages of the four semesters in the square roots (SQR). The data also met the assumption of independence and normality. Mauchly’s Test of Sphericity was verified, χ(5) = 3.36, p = .64 (Table 8).
Mauchly’s Test of Sphericity for Inflected Word Percentage (SQR).
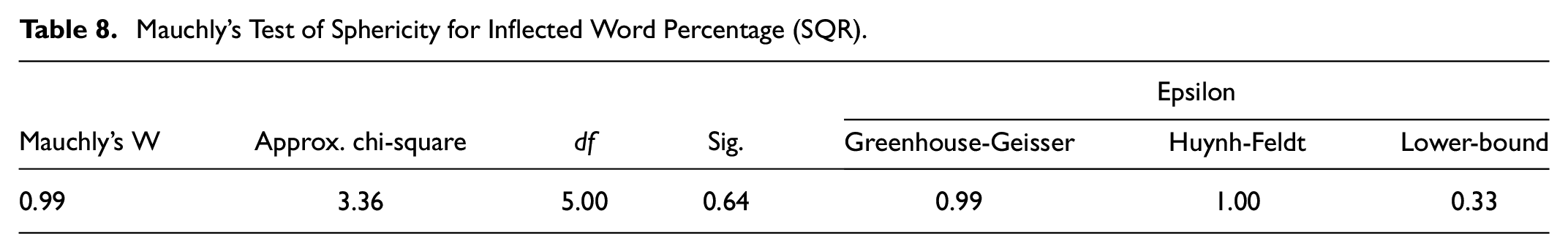
The results (Table 9) show a significant difference between the four semesters in the percentage of the inflected words, F (3, 894) = 24.32, p = .00, partial eta2 = .08.
Tests of Within-subjects Effects for Inflected Words Percentage (SQR).

The results of pairwise comparisons (Table 10) show that among the four semesters, the fifth semester is significantly different from the fourth (p = .00), the sixth semester is significantly different from the fifth (p = .00) and the seventh semester is significantly different from both the sixth (p = .00) and the fourth (p = .00). It indicates subjects used a significantly more significant percentage of inflected words in the fifth semester than in the fourth and, in turn, used significantly more inflected words in the sixth semester than in the fifth. However, they used a significantly smaller percentage of such words in the seventh semester than in the sixth, though still significantly more than in the fourth.
Pairwise Comparisons for Inflected Words (SQR).

Adjustment for multiple comparisons: Least Significant Difference (equivalent to no adjustments).
The mean difference is significant at the 0.05 level.
Derived Words
The descriptive statistics concerning the percentage of EFL learners’ derived words (Table 4) show that it increased sharply from 10.67% in the fourth semester to 15.40% in the fifth semester. However, it decreases weakly to 14.43% in the sixth semester and continuously decreases to 14.26% in the seventh semester (Figure 3):

Percentage of derived words in the four semesters.
The study conducted a repeated-measure ANOVA to assess whether there were differences between the four semesters in the derived word percentages. The data met independence assumption and normality, and Mauchly’s Test of Sphericity was also verified, χ(5) = 4.43, p = .489 (Table 11).
Mauchly’s Test of Sphericity for Derived Words.

The overall ANOVA (Table 12) reveals a significant difference between the four semesters in the percentage of the derived words, F(3, 894) = 176.27, p = .000, partial eta2 = .37.
Tests of Within-subjects Effects for Derived Words.

The pairwise comparisons (Table 13) indicate that the fifth semester is significantly different from the fourth (p = .00) and also that the sixth semester is significantly different from the fifth (p = .00). However, the seventh semester is not significantly different from the sixth (p = .44) but significantly different from the fourth (p = .00). It means subjects used significantly more derived words in the fifth semester than in the fourth, but in the sixth semester, they used significantly fewer such words than in the fifth. They used almost the same percentage of derived words in the sixth and seventh semesters but still significantly more significant than in the fourth.
Pairwise Comparisons for Derived Words.

Adjustment for multiple comparisons: Least Significant Difference (equivalent to no adjustments).
The mean difference is significant at the 0.05 level.
Through the analysis of the three morphologically defined words in Chinese EFL learners’ compositions in four semesters, the study found that at all four stages, there is a similar quantitative relationship among the three categories of morphologically defined words: Root words are much more significant in both amount and percentage than both inflected words and derived words. The inflected words are much lower than root words in both amount and percentage but greater than derived words. Over time, the three morphologically defined words have developed in different tendencies: Root words have a sharp rise in percentage from the first stage to the second, and they are on a slight decrease to the third stage. Though not as abrupt, the tendency for the percentage of root words may still be in the opposite direction since it increases from the first stage through the second to the third stage but falls again to the fourth stage. The percentage of derived words dramatically rises from the first stage to the second and decreases slightly from the third stage to the fourth stage.
Why are the three morphologically defined words generally similar in proportion at all stages?
The fact that the root words covered the most significant part of the produced words in the compositions may be for several aspects. First, most of the root words are the carriers of the primary/core meanings of the whole language, and all the other two are only products derived from the root words through two different processes of transformation: inflection and derivation. Thus, learners usually learn root words in any language and their usages first. Secondly, the root words are short and straightforward, which allows the interlocutors involved in communication to make the least effort. Most importantly, most of the root words are publicly known, which is beneficial to comprehension and production and is undoubtedly facilitative to communication. For this, most language speakers choose usually-used words in communication but avoid using rare words. Naturally, the root words become their preferences.
The fact that the inflected word was more remarkable in quantity than the derived words in the written production of all the groups of speakers may be for the following reasons.
Firstly, it may lie in their differences in formation. Although they are both created based on the root words, they experience two entirely different processes of word transformation: inflection and derivation. Inflection is mostly a rule-based process, that is, a language speaker can apply one rule to form many words beyond those exceptional ones. However, there are seldom such universally effective rules for forming new words—derivation—in English. The derived words, though they are also produced based on the root words, are usually less predictable and less rule-based than the inflected words. The morphological knowledge may contribute a lot to learners’ decoding of the meaning of the derived words and the acquisition of the receptive words (Bellomo, 2009; Schmitt, 1997; Wysocki & Jenkins, 1987). Though there is also a study (Morin, 2003) on its contribution to productive vocabulary acquisition, it is still inconclusive. Language learners must depend on the incomplete rule as cues and their rote memorization of the word forms or meanings to acquire the most derived words.
Second, the inflected words may have derived from two sources: root words and derived words. This study counted only the words formed by inflection as inflected words. In contrast, some infected words were formed by directly appending inflectional morphemes to root words, and some came into being by adding inflectional morphemes to derived words. The two sources contribute to the quantity of the inflected words and raise the probability of their appearing in language production compared to the derived words.
Why do these three morphologically defined words show different developmental trajectories in Chinese EFL learners’ writings across the four stages?
The result does not agree with the conclusion drawn in the study of Anglin et al. (1993). There may be some fundamental differences between this study and theirs, which have the great potential to bring about different results.
Firstly, their study was on the growth of recognition vocabulary, that is, receptive vocabulary, while this study is on productive vocabulary. Productive vocabulary acquisition is generally accepted to be more complex and more challenging to develop than receptive vocabulary in L2 acquisition (Nation, 1990). The number of productive vocabulary is much less than receptive vocabulary, even in one’s native language (Morgan & Oberdeck, 1930), let alone in S/FL (Schmitt, 2008). Therefore, the productive vocabulary usually develops more slowly and is smaller in number than the passive vocabulary, which many empirical studies in different forms and contexts supported (e.g., Fan, 2000; Laufer, 1998; Laufer & Paribakha, 1998; Morgan & Oberdeck, 1930; Waring, 1997; Webb, 2008).
Secondly, their study subjects were a group of L1 Children during their early and middle elementary school years. The students at such a stage may only depend a little on their ability in induction but heavily on rote memorization (MacWhinney, 1975, 1976). Children have a better memory than adult L2 learners, which may constitute an advantage over adult L2 learners in developing productive vocabulary. For example, in psychology, much literature on human memory performance shows the decrement of human recall with age (Craik & McDowd, 1987). In a longitudinal study, Palmberg (1987) showed that the L2 children were slowly accumulating productive vocabulary (recalling words).
Thirdly, they implemented their study by way of a decontextualized test. A decontextualized test exerts a demand on the language learners only of their ability to map meanings onto forms or meaning-form pairing, rarely others. Although it is the initial necessary knowledge for developing productive vocabulary, more is needed for a word to become productive, at least an ultimately productive one. Though it is still not sure to what point we have to master a word and how much knowledge of a word we have to master so that it can be used productively, at least we know that beyond the information of the correct form-meaning correspondence, we should know what function it can play in a sentence and what collocates it can occur within linguistic contexts. It is not strange that the result from the decontextualized test contradicts that from the contextualized test.
Fourthly, they chose words for the test through a systematic sampling from a dictionary, which is the advantage of the decontextualized test over the contextualized test. However, this point cannot make up for its disadvantage. Though the decontextualized test result is of much greater representativeness and reliability than the contextualized test, its low validity destroys itself as a qualified test of productive vocabulary. Examining productive vocabulary through analyzing compositions can expose more information about language learners’ word knowledge, so more researchers prefer to use it in practice. The words correctly used in contextualized tests can also be used correctly by speakers in daily communication. In contrast, those correctly answered in decontextualized tests can never be extrapolated into realistic daily communication as confidently.
Fifthly, their study adopted a forced-response test, while the writing task of this study belongs to the free-response testing. Forced-response or forced-choice testing requires test-takers to choose among given alternatives, which is different from free-response testing, in which test-takers can supply responses constructed by themselves. In a forced-response test, test designers can randomly sample the test words from the target word bank, which is more representative of the target word quantity, and each test item stands for the given amount of the target items, which are the multiples of the test items. So, it is easy to calculate the exact number of language learners’ vocabulary size. In contrast, the decontextualized test requires language learners to supply an answer on their own. The testees can avoid different items but use only relatively solid knowledge items. Therefore, a contextualized test supplies a result different from a decontextualized test.
What facts do the trajectories of the three morphologically defined words suggest?
The study seems to show that from the first stage to the second stage, that is, from the fourth semester to the fifth semester, students’ vocabulary experiences a significant change, which manifests in the remarkable increase in both the percentage of inflected words and that of derived words and also in the sharp decrease in the percentage of root words. This temporal juncture seems to happen in other studies on Chinese EFL majors’ productive vocabulary. For example, the studies by Zhang et al. (2005) indicated a significant difference between the students of grades one and two and those of grades three and four. That is, the students of grades three and four used a significantly more significant percentage of low-frequency words but a lower percentage of high-frequency words, while there was no difference between grades one and two and between grades three and four. Laufer’s (1994) study found such a situation and proposed the “plateau phenomenon.”
However, not all studies arrived at the same conclusion. For example, Wan’s (2010) study suggested a mixed result: the students of different universities did not follow the same way. Most students made continuous progress in their productive vocabulary, while the students from some universities did not make progress but retracted a little. Even Levitzky-Aviad and Laufer (2013) showed that Israeli EFL learners did not make noticeable progress. Some scholars (e.g., Caspi & Lowie, 2013; Larsen-Freeman, 2013) have testified to the instability of the Second language learners’ development and tried to use the Dynamic Systems Theory to describe the second language learners’ development in their target language ability, including vocabulary.
In contrast with the EFL learners, the studies on EL1 students generally show a linearly incremental development. For example, McNamara et al. (2014) reported some indexes of native English speakers’ development in vocabulary, showing that the native EL1 learners were developing in a solidly incremental way, which starkly contrasts with L2 learners’ variability in productive vocabulary usage. Such a result may imply an actual difference between L2 and L1 learners in language ability resulting from their differences in internal and external factors. All L1 learners obtain their language ability through naturalist communication before attending formal classes. Their language input, output and interaction are standard, giving precious opportunities for word learning; contrary to this, most L2 learners are beyond the Critical Period when beginning to learn English and, therefore, learn English in classroom settings. Such a condition seriously weakens their language input and output. The language input L2 learners contact in the classroom teaching or interaction is usually distorted, and they have scarce opportunities for realistic language output and interaction.
Conclusion
Root words increase sharply from the first stage to the second, then decrease weakly to the third stage. However, it increases again in the fourth stage. Compared with the percentage of root words, the tendency, though not as abrupt, may still be in an opposite direction because it increases from the first stage to the second, then to the third stage, and finally, it falls again at the fourth stage. The percentage of derived words increases sharply from the first stage to the second, then decreases weakly in the third and fourth stages.
In summary, the difference between L1 and L2 speakers is that the former constantly develops while the latter is complex, varying with different individuals and situations. L2 learners’ target language learning seems very vulnerable to external factors. Furthermore, these external factors are changeable, so only some factors or a combination of external factors constantly drive the L2 learners to success.
The study implies that theoretically, the language learner’s root, inflected, and derived words may develop independently, as suggested by the theories mentioned above and testified by empirical studies in children’s vocabulary acquisition words (Anglin et al., 1993). Therefore, in language learners’ vocabulary acquisition, teachers should introduce specific learning strategies based on the specificity/idiosyncrasy of different morphologically defined words. Students can depend more on rote memorization in learning root words, but for inflected and derived words, they can learn them by mastering grammatical and derivational rules. The method adopted in this study may be helpful in future studies of different morphologically defined words, whether in studying learners’ development in them or comparing different words.
Finally, this study still has some limitations that deserve further survey. Firstly, compound words, as one of the essential word categories, have yet to be examined in this study due to the difficulty of extraction. Compound words could be more flexible in quantity, formation, and usage. They also contribute a lot to language learners’ vocabulary and may develop quite differently from other categories of words. Secondly, the study analyzed all the different categories of words by calculating the total numbers (percentages) without a distinction of frequency levels. Therefore, future studies can also examine these words based on different frequency levels. Finally, extracting root, inflected, and derived words based on the word lists with Range is not thoroughly clear-cut. That is to say, there may be some derived words listed in the root word list. Therefore, future studies can focus on these words with more accurate word lists.
Footnotes
Acknowledgements
The author would show his gratitude to Minnan Normal University for the support to undertake this study.
Author Contributions
The whole article was written by the author himself.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author was financially supported for the research by Minnan Normal University (L21506/4102)
Ethical Approval
Since this study does not concern any ethical issues, there is no need for ethical approval.
Consent Details
Since the article does not contain any participants’ personal information, there is no need for written informed consent.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.